python打卡day22@浙大疏锦行
复习日
仔细回顾一下之前21天的内容,没跟上进度的同学补一下进度。
作业:
自行学习参考如何使用kaggle平台,写下使用注意点,并对下述比赛提交代码
一、数据预处理
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
import seaborn as sns
import warnings
from sklearn.model_selection import train_test_split
warnings.filterwarnings("ignore")
plt.rcParams['font.sans-serif'] = ['SimHei']
plt.rcParams['axes.unicode_minus'] = False
data = pd.read_csv('./day22/train.csv')
print(data.info())
print(data.isnull().sum())
for i in data.columns:if data[i].isnull().sum() > 0:if pd.api.types.is_numeric_dtype(data[i]):median_val = data[i].median()data[i].fillna(median_val, inplace=True)print(f"用中位数 {median_val} 填补列:{i}")else:zhongshu = data[i].mode()[0]data[i].fillna(zhongshu, inplace=True)print(f"用众数{zhongshu} 填补列:{i}")data = data.drop(columns=['Name','Ticket', 'Cabin'])
print(data.info())
print(data.isnull().sum())data = pd.get_dummies(data, columns=['Embarked'])
data2 = pd.read_csv('./day22/train.csv')
list_final = []
for i in data.columns:if i not in data2.columns:list_final.append(i)
for i in list_final:data[i] = data[i].astype(int) sex_mapping = {'male': 1,'female': 0,
}
data['Sex'] = data['Sex'].map(sex_mapping)
print(data.info())
print(data.isnull().sum())二、利用随机森林模型进行训练和验证
from sklearn.model_selection import train_test_splitX = data.drop(['Survived'], axis=1)
y = data['Survived']
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
print(X_train.shape, X_test.shape, y_train.shape, y_test.shape) # (1382, 6) (346, 6) (1382,) (346,)import numpy as np
from sklearn.ensemble import RandomForestClassifier
from sklearn.model_selection import StratifiedKFold, cross_validate
from sklearn.metrics import make_scorer, accuracy_score, precision_score, recall_score, f1_score, confusion_matrix, classification_report
import time
import warnings
warnings.filterwarnings("ignore")
warnings.filterwarnings("ignore")
print("--- 1. 默认参数随机森林 (训练集 -> 测试集) ---")
import time
start_time = time.time()
rf_model = RandomForestClassifier(random_state=42)
rf_model.fit(X_train, y_train)
rf_pred = rf_model.predict(X_test)
end_time = time.time()print(f"训练与预测耗时: {end_time - start_time:.4f} 秒")
print("\n默认随机森林 在测试集上的分类报告:")
print(classification_report(y_test, rf_pred))
print("默认随机森林 在测试集上的混淆矩阵:")
print(confusion_matrix(y_test, rf_pred))from imblearn.over_sampling import SMOTE
smote = SMOTE(random_state=42)
X_train_smote, y_train_smote = smote.fit_resample(X_train, y_train)print("SMOTE过采样后训练集的形状:", X_train_smote.shape, y_train_smote.shape)print("--- 2. 带权重随机森林 + 交叉验证 (在训练集上进行) ---")counts = np.bincount(y_train)
minority_label = np.argmin(counts)
majority_label = np.argmax(counts)
print(f"训练集中各类别数量: {counts}")
print(f"少数类标签: {minority_label}, 多数类标签: {majority_label}")rf_model_weighted = RandomForestClassifier(random_state=42,class_weight='balanced' # class_weight={minority_label: 10, majority_label: 1} cv_strategy = StratifiedKFold(n_splits=5, shuffle=True, random_state=42)
scoring = {'accuracy': 'accuracy','precision_minority': make_scorer(precision_score, average='macro', zero_division=0),'recall_minority': make_scorer(recall_score, average='macro'),'f1_minority': make_scorer(f1_score, average='macro')
}
print(f"开始进行 {cv_strategy.get_n_splits()} 折交叉验证...")
start_time_cv = time.time()cv_results = cross_validate(estimator=rf_model_weighted,X=X_train_smote,y=y_train_smote,cv=cv_strategy,scoring=scoring,n_jobs=-1, return_train_score=False
)end_time_cv = time.time()
print(f"交叉验证耗时: {end_time_cv - start_time_cv:.4f} 秒")print("\n带权重随机森林 交叉验证平均性能 (基于训练集划分):")
for metric_name, scores in cv_results.items():if metric_name.startswith('test_'): clean_metric_name = metric_name.split('test_')[1]print(f" 平均 {clean_metric_name}: {np.mean(scores):.4f} (+/- {np.std(scores):.4f})")print("-" * 50)print("--- 3. 训练最终的带权重模型 (整个训练集) 并在测试集上评估 ---")
start_time_final = time.time()
rf_model_weighted_final = RandomForestClassifier(random_state=42,class_weight='balanced'
)
rf_model_weighted_final.fit(X_train_smote, y_train_smote)
rf_pred_weighted = rf_model_weighted_final.predict(X_test)
end_time_final = time.time()print(f"最终带权重模型训练与预测耗时: {end_time_final - start_time_final:.4f} 秒")
print("\n带权重随机森林 在测试集上的分类报告:")
print(classification_report(y_test, rf_pred_weighted))
print("带权重随机森林 在测试集上的混淆矩阵:")
print(confusion_matrix(y_test, rf_pred_weighted))
print("-" * 50)print("性能对比 (测试集上的少数类召回率 Recall):")
recall_default = recall_score(y_test, rf_pred, average='macro')
recall_weighted = recall_score(y_test, rf_pred_weighted, average='macro')
print(f" 默认模型: {recall_default:.4f}")
print(f" 带权重模型: {recall_weighted:.4f}")三、导入测试集并对数据测试
test_data = pd.read_csv('./day22/test.csv')
for i in test_data.columns:if test_data[i].isnull().sum() > 0:if pd.api.types.is_numeric_dtype(test_data[i]):median_val = test_data[i].median()test_data[i].fillna(median_val, inplace=True)print(f"用中位数 {median_val} 填补列:{i}")else:zhongshu = test_data[i].mode()[0]test_data[i].fillna(zhongshu, inplace=True)print(f"用众数{zhongshu} 填补列:{i}")test_data = test_data.drop(columns=['Name','Ticket', 'Cabin'])test_data = pd.get_dummies(test_data, columns=['Embarked'])
data2 = pd.read_csv('./day22/test.csv')
list_final = []
for i in test_data.columns:if i not in data2.columns:list_final.append(i)
for i in list_final:test_data[i] = test_data[i].astype(int) sex_mapping = {'male': 1,'female': 0,
}
test_data['Sex'] = test_data['Sex'].map(sex_mapping)
print(test_data.info())
print(test_data.isnull().sum())rf_pred_weighted = rf_model_weighted_final.predict(test_data) output = pd.DataFrame({'PassengerId': test_data['PassengerId'],'Survived': rf_pred_weighted
})output.to_csv('titanic_predictions.csv', index=False)相关文章:

python打卡day22@浙大疏锦行
复习日 仔细回顾一下之前21天的内容,没跟上进度的同学补一下进度。 作业: 自行学习参考如何使用kaggle平台,写下使用注意点,并对下述比赛提交代码 一、数据预处理 import pandas as pd import numpy as np import matplo…...

C#游戏开发中的注意事项
目录 一、性能优化:提升游戏运行效率 1. 避免不必要的循环和迭代 2. 减少字符串拼接 3. 利用Unity的生命周期函数 4. 使用对象池(Object Pooling) 二、内存管理:避免内存泄漏和资源浪费 1. 及时释放非托管资源 2. 避免空引用异常 3. 合理使用引用类型和值类型 4. …...
Spring Boot项目(Vue3+ElementPlus+Axios+MyBatisPlus+Spring Boot前后端分离)
下载地址: 前端:https://download.csdn.net/download/2401_83418369/90811402 后端:https://download.csdn.net/download/2401_83418369/90811405 一、前端vue部分的搭建 这里直接看另一期刊的搭建Vue前端工程部分 前端vue后端ssm项目_v…...
Spyglass:在batch/shell模式下运行目标的顶层是什么?
相关阅读 Spyglasshttps://blog.csdn.net/weixin_45791458/category_12828934.html?spm1001.2014.3001.5482 除了可以在图形用户界面(GUI)中运行目标外,使用Batch模式或Shell模式也可以运行目标,如下面的命令所示。 % spyglass -project test.prj -ba…...

没有Mac,我是怎么上传IPA到App Store的?
没有Mac,我是怎么上传IPA到App Store的? 最近赶一个小项目上线,写的是一个Flutter做的App。安卓版本一晚上搞定,iOS上架却差点把人整崩。 不是我技术菜,是实在太麻烦了。最关键的,是我这台Windows笔电根本…...

微服务架构中如何保证服务间通讯的安全
在微服务架构中,保证服务间通信的安全至关重要。服务间的通信通常是通过HTTP、gRPC、消息队列等方式实现的,而这些通信链路可能面临多种安全风险。为了应对这些风险,可以采取多种措施来保证通信安全。 常见的服务间通信风险 1.数据泄露:在服务间通信过程中,敏感数据可能会…...

2025-05-11 项目绩效域记忆逻辑管理
好的,我们可以用一个故事来帮助记忆这些规划绩效域的要素,同时通过逻辑关系来串联它们。以下是一个故事化的版本: 《项目管理的奇幻之旅》 在一个遥远的王国里,有一个勇敢的项目经理名叫小K。小K被国王赋予了一个艰巨的任务&…...
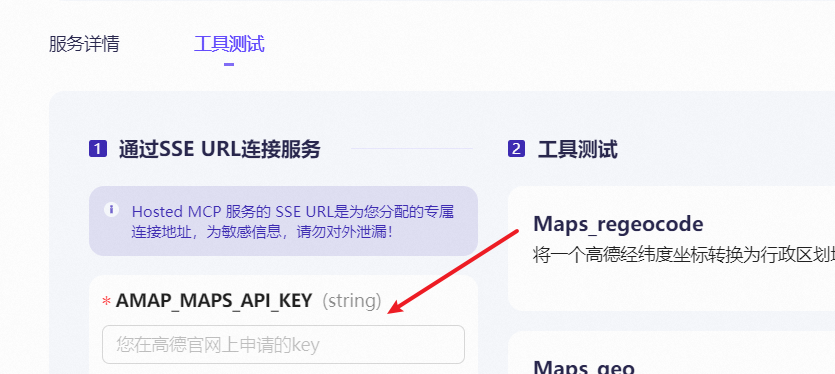
工具篇-Cherry Studio之MCP使用
一、添加MCP 打开Cherry Studio,如果没有可以到官网下载:Cherry Studio 官方网站 - 全能的AI助手 按上面步骤打开同步服务器 1、先去注册ModelScope,申请令牌 2、再打开MCP广场,找到高德MCP 选择工具测试,这里有个高德的api key需要申请 打开如下地址高德开放平…...

DeepSeek“智”造:解锁旅游行业新玩法
目录 一、DeepSeek 简介1.1 DeepSeek 技术原理1.2 DeepSeek 在 AI 领域地位 二、DeepSeek 在旅游攻略生成的应用2.1 生成流程展示2.2 优势分析2.3 实际案例剖析 三、DeepSeek 助力旅游宣传文案创作3.1 文案创作模式3.2 效果评估3.3 创意亮点挖掘 四、DeepSeek 优化游客咨询服务…...

LOJ 6346 线段树:关于时间 Solution
Description 给定序列 a ( a 1 , a 2 , ⋯ , a n ) a(a_1,a_2,\cdots,a_n) a(a1,a2,⋯,an),另有一个存储三元组的列表 L L L. 有 m m m 个操作分两种: add ( l , r , k ) \operatorname{add}(l,r,k) add(l,r,k):将 ( l , r , …...

java 多核,多线程,分布式 并发编程的现状 :从本身的jdk ,到 spring ,到其它第三方。
Java 在多核、多线程和高性能编程领域提供了丰富的现成框架和工具,既有标准库中的并发组件,也有第三方框架。以下是一些关键框架及其应用场景的总结:便于后面我们站在巨人的肩膀上,继续前行 一、Java 标准库中的多线程框架 Execut…...

httpclient请求出现403
问题 httpclient请求对方服务器报403,用postman是可以的 解决方案: request.setHeader( “User-Agent” ,“Mozilla/5.0 (Windows NT 6.1; Win64; x64; rv:50.0) Gecko/20100101 Firefox/50.0” ); // 设置请求头 原因: 因为没有设置为浏览器形式&#…...
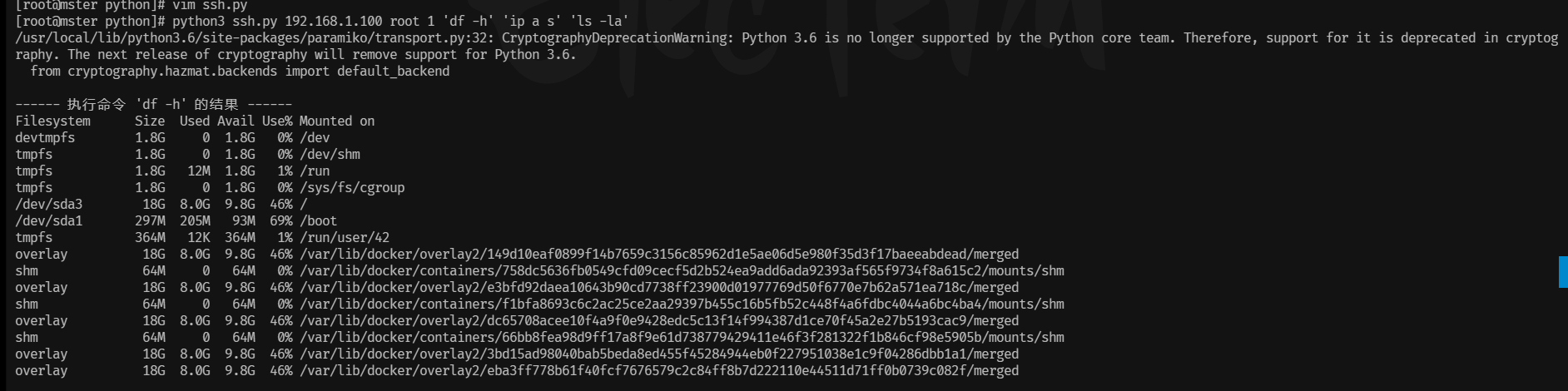
Python 运维脚本
1、备份文件 import os import shutil# 定义配置文件目录和备份目录的路径 config_dir "/root/python/to/config/files/" backup_dir "/root/python/to/backup/"# 遍历配置文件目录中的所有文件 for filename in os.listdir(config_dir):# 如果文件名以…...

MySQL数据库常见面试题之三大范式
写在前面 此文章大部分不会引用最原始的概念,采用说人话的方式。 面试题:三大范式是什么?目的是什么?必须遵循吗? 假设有一张表(学号,姓名,课程,老师) 是…...
大模型项目:普通蓝牙音响接入DeepSeek,解锁语音交互新玩法
本文附带视频讲解 【代码宇宙019】技术方案:蓝牙音响接入DeepSeek,解锁语音交互新玩法_哔哩哔哩_bilibili 目录 效果演示 核心逻辑 技术实现 大模型对话(技术: LangChain4j 接入 DeepSeek) 语音识别(…...

C/C++复习--C语言隐式类型转换
目录 什么是隐式类型转换?整型提升 规则与示例符号位扩展的底层逻辑 算术转换 类型层次与转换规则混合类型运算的陷阱 隐式转换的实际应用与问题 代码示例分析常见错误与避免方法 总结与最佳实践 1. 什么是隐式类型转换? 隐式类型转换是C语言在编译阶段…...
 与 Timestamp() 深度解析)
Pandas 时间处理利器:to_datetime() 与 Timestamp() 深度解析
Pandas 时间处理利器:to_datetime() 与 Timestamp() 深度解析 在数据分析和处理中,时间序列数据扮演着至关重要的角色。Pandas 库凭借其强大的时间序列处理能力,成为 Python 数据分析领域的佼佼者。其中,to_datetime() 函数和 Ti…...
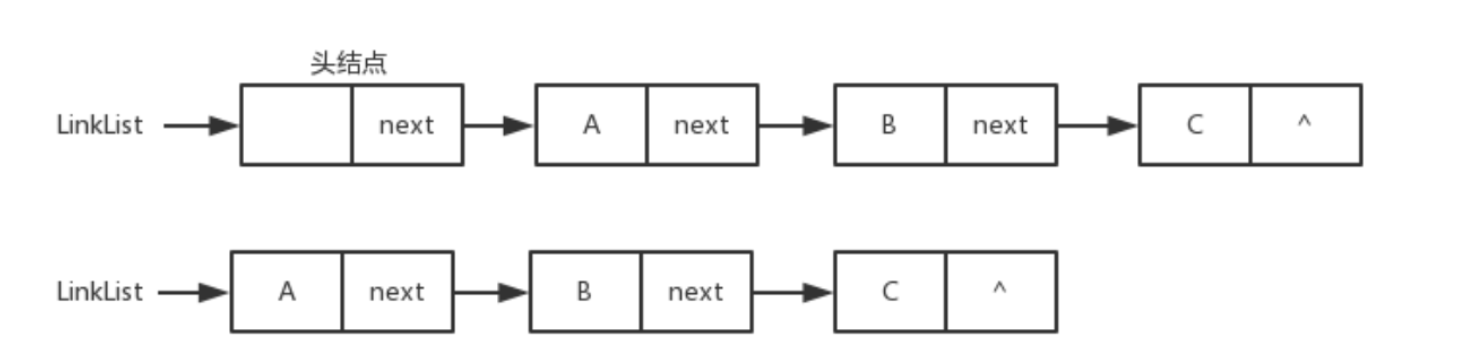
单链表设计与实现
01. 单链表简介 在数据结构中,单链表的实现可以分为 带头结点 和 不带头结点 两种方式,这里我们讨论第二种方式。 头结点:链表第一个节点不存实际数据,仅作为辅助节点指向首元节点(第一个数据节点)。头指…...

JDS-算法开发工程师-第9批
单选题 print(fn.__default__) 哪一个不是自适应学习率的优化算法 (选项:Adagrad,RMSprop,Adam,Momentum,动量法在梯度下降的基础上,加入了“惯性”概念,通过累积历史的梯度更新来加速收敛&…...

Git标签删除脚本解析与实践:轻松管理本地与远程标签
Git 标签删除脚本解析与实践:轻松管理本地与远程标签 在 Git 版本控制系统中,标签常用于标记重要的版本节点,方便追溯和管理项目的不同阶段。随着项目的推进,一些旧标签可能不再需要,此时就需要对它们进行清理。本文将通过一个完整的脚本,详细介绍如何删除本地和远程的 …...

Python中,async和with结合使用,有什么好处?
在Python的异步编程中,async和with的结合使用(即async with)为开发者提供了一种优雅且高效的资源管理模式。这种组合不仅简化了异步代码的编写,还显著提升了程序的健壮性和可维护性。以下是其核心优势及典型应用场景的分析&#x…...
springboot生成二维码到海报模板上
springboot生成二维码到海报模板上 QRCodeController package com.ruoyi.web.controller.app;import com.google.zxing.WriterException; import com.ruoyi.app.domain.Opportunity; import com.ruoyi.app.tool.QRCodeGenerator; import com.ruoyi.common.core.page.TableDat…...

SEO长尾关键词布局优化法则
内容概要 在SEO优化体系中,长尾关键词的精准布局是突破流量瓶颈的关键路径。相较于竞争激烈的核心词,长尾词凭借其高转化率和低竞争特性,成为内容矩阵流量裂变的核心驱动力。本节将系统梳理长尾关键词布局的核心逻辑框架,涵盖从需…...

python:trimesh 用于 STL 文件解析和 3D 操作
python:trimesh 是一个用于处理三维模型的库,支持多种格式的导入导出,比如STL、OBJ等,还包含网格操作、几何计算等功能。 Python Trimesh 库使用指南 安装依赖库 pip install trimesh Downloading trimesh-4.6.8-py3-none-any.w…...

应急响应基础模拟靶机-security2
PS:杰克创建的流量包(result.pcap)在root目录下,请根据已有信息进行分析 1、首个攻击者扫描端口使用的工具是? 2、后个攻击者使用的漏洞扫描工具是? 3、攻击者上传webshell的绝对路径及User-agent是什么? 4、攻击者反弹shell的…...

ROS 2 FishBot PID控制电机代码
#include <Arduino.h> #include <Wire.h> #include <MPU6050_light.h> #include <Esp32McpwmMotor.h> #include <Esp32PcntEncoder.h>Esp32McpwmMotor motor; // 创建一个名为motor的对象,用于控制电机 Esp32PcntEncoder enco…...

Bash 字符串语法糖详解
Bash 作为 Linux 和 Unix 系统中最常用的 Shell 之一,其字符串处理能力是脚本开发者的核心技能之一。为了让字符串操作更高效、更直观,Bash 提供了丰富的语法糖(syntactic sugar)。这些语法糖通过简洁的语法形式,隐藏了…...
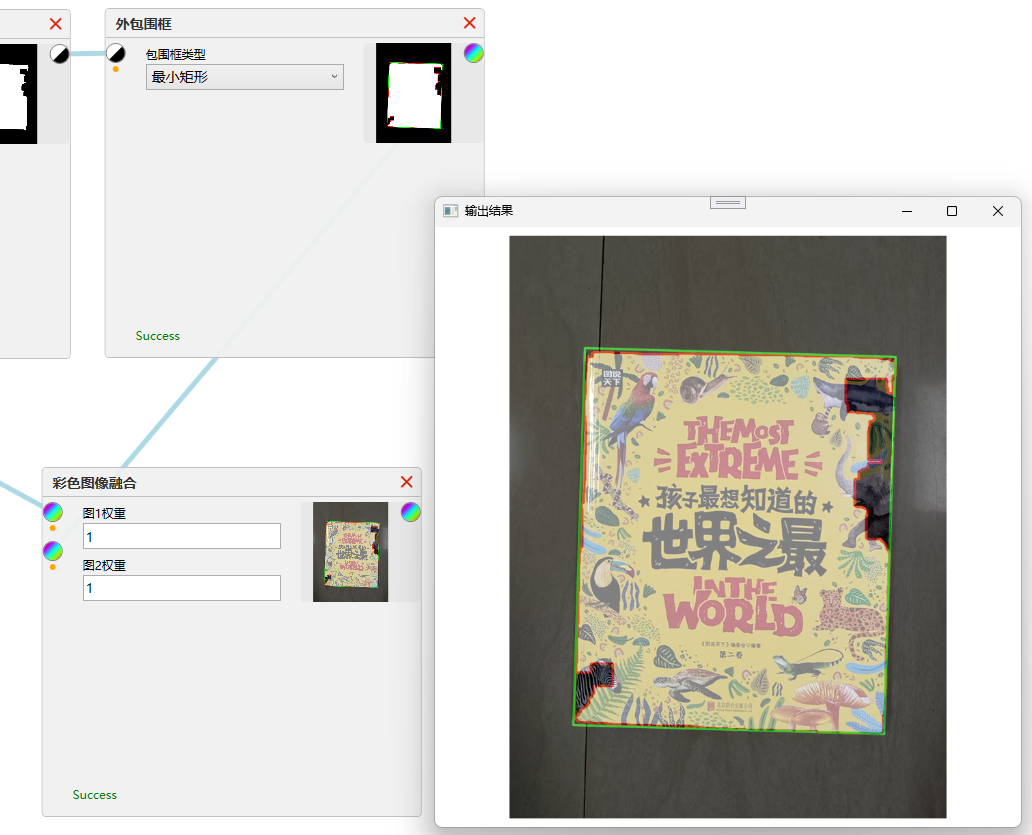
OpenCV定位地板上的书
任务目标是将下面的图片中的书本找出来: 使用到的技术包括:转灰度图、提取颜色分量、二值化、形态学、轮廓提取等。 我们尝试先把图片转为灰度图,然后二值化,看看效果: 可以看到,二值化后,书的…...

C++ string初始化、string赋值操作、string拼接操作
以下介绍了string的六种定义方式,还有很多,这个只是简单举例 #include<iostream>using namespace std;int main() {//1 无参构造string s1;cout << s1 << endl;//2 初始化构造string s2 ({h, h, l, l, o});cout << s2 <<…...

linux动态占用cpu脚本、根据阈值增加占用或取消占用cpu的脚本、自动检测占用脚本状态、3脚本联合套用。
文章目录 说明流程占用脚本1.0版本使用测试占用脚本2.0版本使用测试测试脚本使用测试检测脚本使用测试脚本说明书启动说明停止说明内存占用cpu内存成品任务测试说明 cpu占用实现的功能整体流程 1、先获取当前实际使用率2、设置一个最低阈值30%,一个最高阈值80%、一个需要增加的…...