python 上海新闻爬虫, 东方网 + 澎湃新闻
1. 起因, 目的:
- 继续做新闻爬虫。我之前写过。
- 此文先记录2个新闻来源。
- 后面打算进行过滤,比如只选出某一个类型新闻。
2. 先看效果
过滤出某种类型的新闻,然后生成 html 页面,而且,自动打开这个页面。
比如科技犯罪类的新闻。

3. 过程:
代码 1 ,爬取东方网
- 很久之前写过,代码还能用。
- 这里虽然是复制一下,也是为了自己方便。
import os
import csv
import time
import requests"""
# home: https://sh.eastday.com/
# 1. 标题, url, 来源,时间
"""headers = {'Accept-Language': 'zh-CN,zh;q=0.9,en;q=0.8','User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/136.0.0.0 Safari/537.36'
}def get_data(pages):file_name = '5.8.400.csv' # 400个标题。has_file = os.path.exists(file_name)# 打开文件,写入模式with open(file_name, 'a', newline='', encoding='utf-8') as file:# 创建一个csv.DictWriter对象,用于写入字典数据columns = ['title', 'url', 'time','source']writer = csv.DictWriter(file, fieldnames=columns)# 写入表头if not has_file:writer.writeheader()# 爬取数据. 默认是 20页,每页20条。 每天大概有400个新闻。for i in range(pages):print(f"正在爬取第{i+1} / {pages}页数据")time.sleep(0.5)url = f"https://apin.eastday.com/apiplus/special/specialnewslistbyurl?specialUrl=1632798465040016&skipCount={i * 20}&limitCount=20"resp = requests.get(url, headers=headers)if resp.status_code!= 200:print(f"请求失败:{resp.status_code}")breakret = resp.json()junk = ret['data']['list']for x in junk:item = dict()# print(x)item["time"] = x["time"]item['title'] = x["title"]item["url"] = x["url"]item["source"] = x["infoSource"]# 写入数据writer.writerow(item)# print(item)get_data(pages=20)
代码 2 , 爬取, 澎湃新闻
- 也是很简单。
import os
import csv
import time
import requests
from datetime import datetime, timedelta# 请求头
headers = {'Accept-Language': 'zh-CN,zh;q=0.9,en;q=0.8','User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/136.0.0.0 Safari/537.36','Content-Type': 'application/json', # 响应头要求 Content-Type'Referer': 'https://www.thepaper.cn/', # 引荐来源,遵循 strict-origin-when-cross-origin'Origin': 'https://www.thepaper.cn' # 跨域请求需要 Origin
}def get_thepaper_data(file_name='peng_pai_400.csv', max_pages=100, channel_id='-8'):"""爬取澎湃新闻数据,保存到 CSV 文件参数:file_name: 输出 CSV 文件名max_pages: 最大爬取页数channel_id: 新闻频道 ID"""# 检查文件是否存在has_file = os.path.exists(file_name)# 打开 CSV 文件,追加模式with open(file_name, 'a', newline='', encoding='utf-8') as file:columns = ['title', 'url', 'time', 'source']writer = csv.DictWriter(file, fieldnames=columns)if not has_file:writer.writeheader()# 计算 startTime(当前时间戳)current_time = int(time.time() * 1000) # 当前毫秒时间戳start_time = current_time # 使用此时此刻的时间# 爬取数据for page in range(1, max_pages + 1):time.sleep(0.5) # 请求间隔payload = {'channelId': channel_id,'excludeContIds': [], # 留空,需根据实际需求调整'province': '','pageSize': 20,'startTime': start_time,'pageNum': page}url = 'https://api.thepaper.cn/contentapi/nodeCont/getByChannelId'resp = requests.post(url, headers=headers, json=payload, timeout=10)if resp.status_code != 200:print(f"请求失败:{url}, 状态码: {resp.status_code}, 页码: {page}")breakret = resp.json()# print(f"页面 {page} 响应:{ret}")news_list = ret['data']['list']for item in news_list:# print(item)news = {}news['title'] = item.get('name', '')news['url'] = f"https://www.thepaper.cn/newsDetail_forward_{item.get('originalContId', '')}"news['time'] = item.get('pubTimeLong', '')news['source'] = item.get('authorInfo', {}).get('sname', '澎湃新闻')# 转换时间格式(如果 API 返回时间戳)news['time'] = datetime.fromtimestamp(news['time'] / 1000).strftime('%Y-%m-%d %H:%M:%S')# 直接写入,不去重writer.writerow(news)print(f"保存新闻:{news}")if __name__ == "__main__":get_thepaper_data(file_name='peng_pai_400.csv', max_pages=20, channel_id='-8')4. 结论 + todo
1 数据来源,还需要增加。可选项:
- 上观新闻 shobserver.com 与解放日报关联,报道上海本地案件。
- 新浪新闻 news.sina.com.cn 全国性新闻,包含科技犯罪。
- 腾讯新闻 news.qq.com 聚合多种来源,覆盖广泛。
- 聚合。 提取出自己感兴趣的新闻,比如,科技犯罪。
希望对大家有帮助。
相关文章:
python 上海新闻爬虫, 东方网 + 澎湃新闻
1. 起因, 目的: 继续做新闻爬虫。我之前写过。此文先记录2个新闻来源。后面打算进行过滤,比如只选出某一个类型新闻。 2. 先看效果 过滤出某种类型的新闻,然后生成 html 页面,而且,自动打开这个页面。 比如科技犯罪…...

[Java实战]Spring Boot 整合 Freemarker (十一)
[Java实战]Spring Boot 整合 Freemarker (十一) 引言 Apache FreeMarker 作为一款高性能的模板引擎,凭借其简洁语法、卓越性能和灵活扩展性,在 Java Web 开发中占据重要地位。结合 Spring Boot 的自动化配置能力,开发者能快速构建动态页面、…...

LeetCode 高频题实战:如何优雅地序列化和反序列化字符串数组?
文章目录 摘要描述题解答案题解代码分析编码方法解码方法 示例测试及结果时间复杂度空间复杂度总结 摘要 在分布式系统中,数据的序列化与反序列化是常见的需求,尤其是在网络传输、数据存储等场景中。LeetCode 第 271 题“字符串的编码与解码”要求我们设…...

为什么拆分高低字节而不直接存入数组
您的代码片段是在将一个16位值()拆分为高字节和低字节:IR_RF_Signal.length temp_low IR_RF_Signal.length & 0xFF; temp_high IR_RF_Signal.length >> 8; 虽然我在 PX4-Autopilot 仓库中没有找到这段确切的代码,…...

python打卡day22@浙大疏锦行
复习日 仔细回顾一下之前21天的内容,没跟上进度的同学补一下进度。 作业: 自行学习参考如何使用kaggle平台,写下使用注意点,并对下述比赛提交代码 一、数据预处理 import pandas as pd import numpy as np import matplo…...

C#游戏开发中的注意事项
目录 一、性能优化:提升游戏运行效率 1. 避免不必要的循环和迭代 2. 减少字符串拼接 3. 利用Unity的生命周期函数 4. 使用对象池(Object Pooling) 二、内存管理:避免内存泄漏和资源浪费 1. 及时释放非托管资源 2. 避免空引用异常 3. 合理使用引用类型和值类型 4. …...
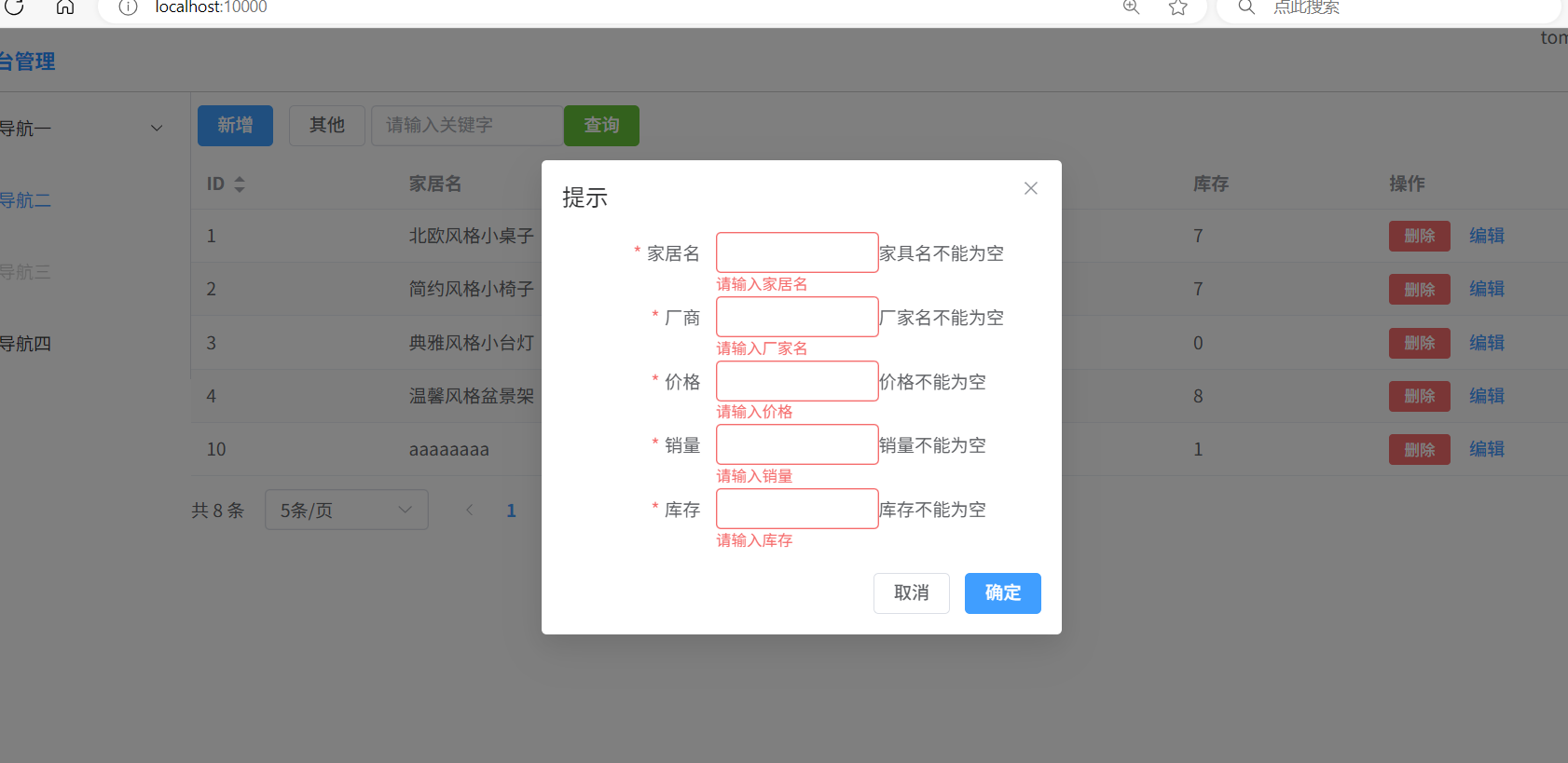
Spring Boot项目(Vue3+ElementPlus+Axios+MyBatisPlus+Spring Boot前后端分离)
下载地址: 前端:https://download.csdn.net/download/2401_83418369/90811402 后端:https://download.csdn.net/download/2401_83418369/90811405 一、前端vue部分的搭建 这里直接看另一期刊的搭建Vue前端工程部分 前端vue后端ssm项目_v…...
Spyglass:在batch/shell模式下运行目标的顶层是什么?
相关阅读 Spyglasshttps://blog.csdn.net/weixin_45791458/category_12828934.html?spm1001.2014.3001.5482 除了可以在图形用户界面(GUI)中运行目标外,使用Batch模式或Shell模式也可以运行目标,如下面的命令所示。 % spyglass -project test.prj -ba…...

没有Mac,我是怎么上传IPA到App Store的?
没有Mac,我是怎么上传IPA到App Store的? 最近赶一个小项目上线,写的是一个Flutter做的App。安卓版本一晚上搞定,iOS上架却差点把人整崩。 不是我技术菜,是实在太麻烦了。最关键的,是我这台Windows笔电根本…...

微服务架构中如何保证服务间通讯的安全
在微服务架构中,保证服务间通信的安全至关重要。服务间的通信通常是通过HTTP、gRPC、消息队列等方式实现的,而这些通信链路可能面临多种安全风险。为了应对这些风险,可以采取多种措施来保证通信安全。 常见的服务间通信风险 1.数据泄露:在服务间通信过程中,敏感数据可能会…...

2025-05-11 项目绩效域记忆逻辑管理
好的,我们可以用一个故事来帮助记忆这些规划绩效域的要素,同时通过逻辑关系来串联它们。以下是一个故事化的版本: 《项目管理的奇幻之旅》 在一个遥远的王国里,有一个勇敢的项目经理名叫小K。小K被国王赋予了一个艰巨的任务&…...
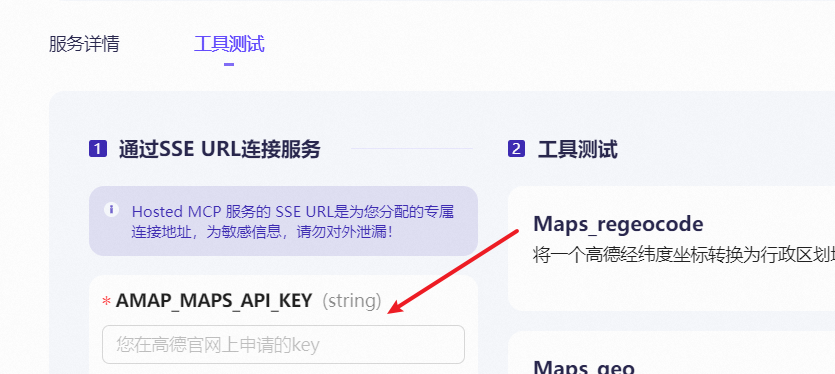
工具篇-Cherry Studio之MCP使用
一、添加MCP 打开Cherry Studio,如果没有可以到官网下载:Cherry Studio 官方网站 - 全能的AI助手 按上面步骤打开同步服务器 1、先去注册ModelScope,申请令牌 2、再打开MCP广场,找到高德MCP 选择工具测试,这里有个高德的api key需要申请 打开如下地址高德开放平…...

DeepSeek“智”造:解锁旅游行业新玩法
目录 一、DeepSeek 简介1.1 DeepSeek 技术原理1.2 DeepSeek 在 AI 领域地位 二、DeepSeek 在旅游攻略生成的应用2.1 生成流程展示2.2 优势分析2.3 实际案例剖析 三、DeepSeek 助力旅游宣传文案创作3.1 文案创作模式3.2 效果评估3.3 创意亮点挖掘 四、DeepSeek 优化游客咨询服务…...

LOJ 6346 线段树:关于时间 Solution
Description 给定序列 a ( a 1 , a 2 , ⋯ , a n ) a(a_1,a_2,\cdots,a_n) a(a1,a2,⋯,an),另有一个存储三元组的列表 L L L. 有 m m m 个操作分两种: add ( l , r , k ) \operatorname{add}(l,r,k) add(l,r,k):将 ( l , r , …...

java 多核,多线程,分布式 并发编程的现状 :从本身的jdk ,到 spring ,到其它第三方。
Java 在多核、多线程和高性能编程领域提供了丰富的现成框架和工具,既有标准库中的并发组件,也有第三方框架。以下是一些关键框架及其应用场景的总结:便于后面我们站在巨人的肩膀上,继续前行 一、Java 标准库中的多线程框架 Execut…...

httpclient请求出现403
问题 httpclient请求对方服务器报403,用postman是可以的 解决方案: request.setHeader( “User-Agent” ,“Mozilla/5.0 (Windows NT 6.1; Win64; x64; rv:50.0) Gecko/20100101 Firefox/50.0” ); // 设置请求头 原因: 因为没有设置为浏览器形式&#…...
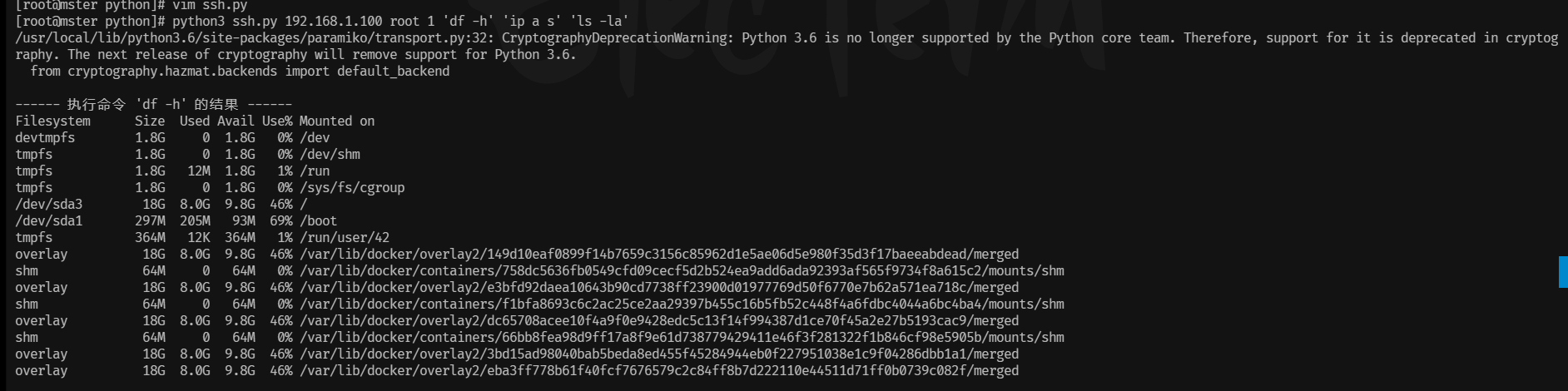
Python 运维脚本
1、备份文件 import os import shutil# 定义配置文件目录和备份目录的路径 config_dir "/root/python/to/config/files/" backup_dir "/root/python/to/backup/"# 遍历配置文件目录中的所有文件 for filename in os.listdir(config_dir):# 如果文件名以…...

MySQL数据库常见面试题之三大范式
写在前面 此文章大部分不会引用最原始的概念,采用说人话的方式。 面试题:三大范式是什么?目的是什么?必须遵循吗? 假设有一张表(学号,姓名,课程,老师) 是…...
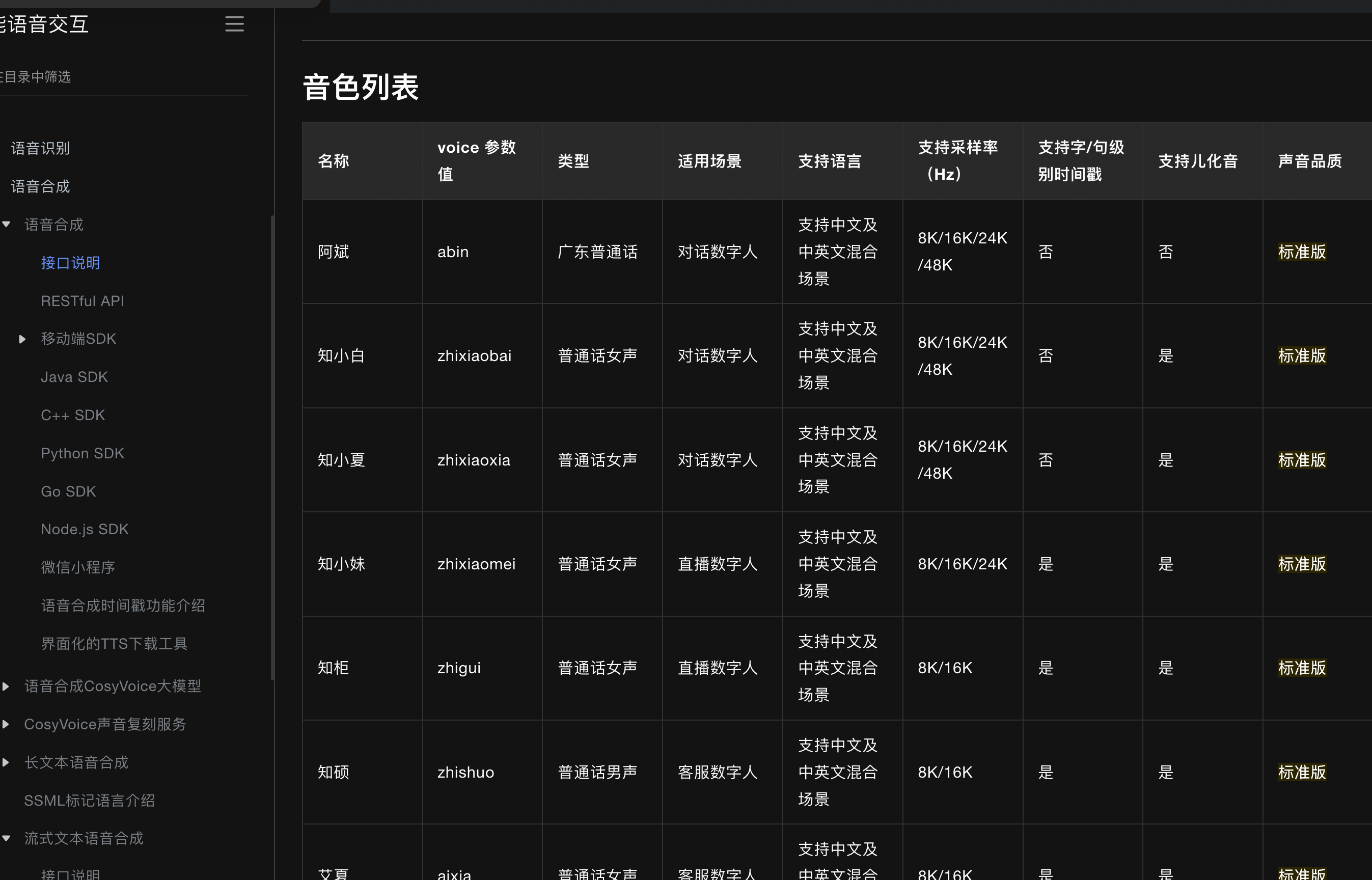
大模型项目:普通蓝牙音响接入DeepSeek,解锁语音交互新玩法
本文附带视频讲解 【代码宇宙019】技术方案:蓝牙音响接入DeepSeek,解锁语音交互新玩法_哔哩哔哩_bilibili 目录 效果演示 核心逻辑 技术实现 大模型对话(技术: LangChain4j 接入 DeepSeek) 语音识别(…...

C/C++复习--C语言隐式类型转换
目录 什么是隐式类型转换?整型提升 规则与示例符号位扩展的底层逻辑 算术转换 类型层次与转换规则混合类型运算的陷阱 隐式转换的实际应用与问题 代码示例分析常见错误与避免方法 总结与最佳实践 1. 什么是隐式类型转换? 隐式类型转换是C语言在编译阶段…...
 与 Timestamp() 深度解析)
Pandas 时间处理利器:to_datetime() 与 Timestamp() 深度解析
Pandas 时间处理利器:to_datetime() 与 Timestamp() 深度解析 在数据分析和处理中,时间序列数据扮演着至关重要的角色。Pandas 库凭借其强大的时间序列处理能力,成为 Python 数据分析领域的佼佼者。其中,to_datetime() 函数和 Ti…...
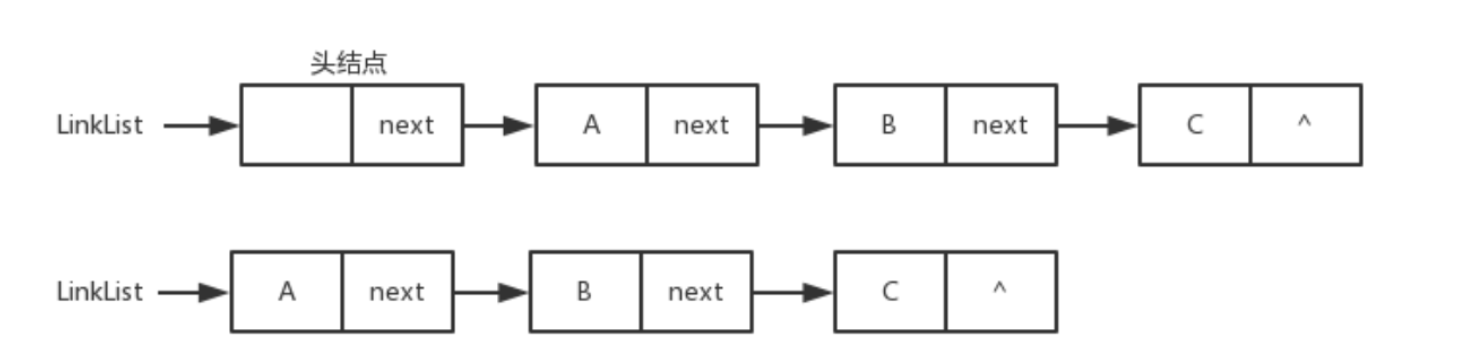
单链表设计与实现
01. 单链表简介 在数据结构中,单链表的实现可以分为 带头结点 和 不带头结点 两种方式,这里我们讨论第二种方式。 头结点:链表第一个节点不存实际数据,仅作为辅助节点指向首元节点(第一个数据节点)。头指…...

JDS-算法开发工程师-第9批
单选题 print(fn.__default__) 哪一个不是自适应学习率的优化算法 (选项:Adagrad,RMSprop,Adam,Momentum,动量法在梯度下降的基础上,加入了“惯性”概念,通过累积历史的梯度更新来加速收敛&…...

Git标签删除脚本解析与实践:轻松管理本地与远程标签
Git 标签删除脚本解析与实践:轻松管理本地与远程标签 在 Git 版本控制系统中,标签常用于标记重要的版本节点,方便追溯和管理项目的不同阶段。随着项目的推进,一些旧标签可能不再需要,此时就需要对它们进行清理。本文将通过一个完整的脚本,详细介绍如何删除本地和远程的 …...

Python中,async和with结合使用,有什么好处?
在Python的异步编程中,async和with的结合使用(即async with)为开发者提供了一种优雅且高效的资源管理模式。这种组合不仅简化了异步代码的编写,还显著提升了程序的健壮性和可维护性。以下是其核心优势及典型应用场景的分析&#x…...
springboot生成二维码到海报模板上
springboot生成二维码到海报模板上 QRCodeController package com.ruoyi.web.controller.app;import com.google.zxing.WriterException; import com.ruoyi.app.domain.Opportunity; import com.ruoyi.app.tool.QRCodeGenerator; import com.ruoyi.common.core.page.TableDat…...

SEO长尾关键词布局优化法则
内容概要 在SEO优化体系中,长尾关键词的精准布局是突破流量瓶颈的关键路径。相较于竞争激烈的核心词,长尾词凭借其高转化率和低竞争特性,成为内容矩阵流量裂变的核心驱动力。本节将系统梳理长尾关键词布局的核心逻辑框架,涵盖从需…...

python:trimesh 用于 STL 文件解析和 3D 操作
python:trimesh 是一个用于处理三维模型的库,支持多种格式的导入导出,比如STL、OBJ等,还包含网格操作、几何计算等功能。 Python Trimesh 库使用指南 安装依赖库 pip install trimesh Downloading trimesh-4.6.8-py3-none-any.w…...

应急响应基础模拟靶机-security2
PS:杰克创建的流量包(result.pcap)在root目录下,请根据已有信息进行分析 1、首个攻击者扫描端口使用的工具是? 2、后个攻击者使用的漏洞扫描工具是? 3、攻击者上传webshell的绝对路径及User-agent是什么? 4、攻击者反弹shell的…...

ROS 2 FishBot PID控制电机代码
#include <Arduino.h> #include <Wire.h> #include <MPU6050_light.h> #include <Esp32McpwmMotor.h> #include <Esp32PcntEncoder.h>Esp32McpwmMotor motor; // 创建一个名为motor的对象,用于控制电机 Esp32PcntEncoder enco…...