1、Kafka与消息队列核心原理详解
消息队列(Message Queue, MQ)作为现代分布式系统的基础组件,极大提升了系统的解耦、异步处理和削峰能力。本文以Kafka为例,系统梳理消息队列的核心原理、架构细节及实际应用。
Kafka 基础架构及术语关系图
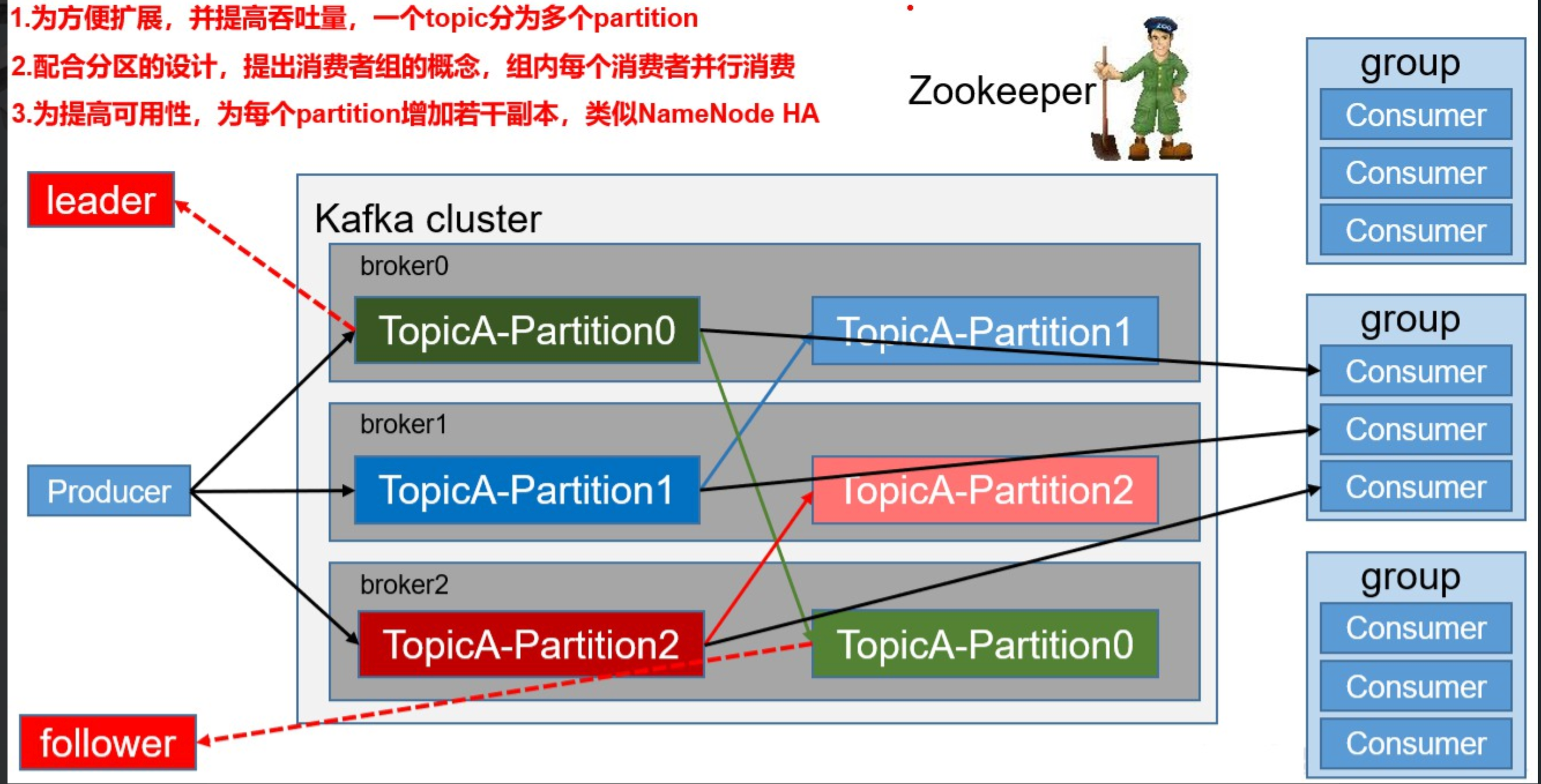
术语简要说明
- Producer:消息生产者,负责发送消息到 Topic。
- Broker:Kafka 实例,每台服务器可有一个或多个 Broker,负责存储和转发消息。
- Topic:消息主题,逻辑分类,数据以 Topic 组织。
- Partition:Topic 的分区,提升并发和吞吐量,每个分区的数据互不重复。
- Replication:分区副本,提升容错性,分为 Leader 和 Follower。
- Message:每条发送的消息主体。
- Consumer:消息消费者,负责消费 Topic 中的数据。
- Consumer Group:消费者组,组内消费者协作消费分区数据,提升吞吐量。
- Zookeeper:Kafka 集群依赖 Zookeeper 存储元信息,保证系统可用性。
为什么需要消息队列?
在分布式系统中,服务之间往往需要解耦、异步和高效通信。以快递和便利店的类比,消息队列就像"中转站",让生产者和消费者解耦:
- 解耦:生产者和消费者无需直接通信,通过队列中转,降低系统耦合度,便于独立扩展和维护。
- 异步:生产者无需等待消费者处理完毕,提升整体响应速度和系统吞吐量。
- 削峰填谷:高峰期消息先入队,消费者按能力慢慢处理,平滑流量压力,防止系统被突发流量压垮。
- 容错与可靠性:消息队列可持久化消息,防止数据丢失,提升系统健壮性。
消息队列的两种通信模式
- 点对点模式(P2P):
- 每条消息只被一个消费者消费。
- 适合任务分发、工作队列等场景。
- 消息有明确的发送者和接收者,消费后即被移除。
- 发布/订阅模式(Pub/Sub):
- 一条消息可被多个订阅者消费。
- 适合广播、通知、日志收集等场景。
- 生产者将消息发布到主题,所有订阅该主题的消费者都能收到消息。
Kafka简介
核心概念与机制
- Segment(段文件):分区的物理存储单元,便于管理和查找。
- Offset:消息在分区内的唯一编号,消费者通过offset定位消费进度。
- 副本机制:每个分区可配置多个副本(Replica),提升数据可靠性和高可用性。
- Leader-Follower:每个分区有一个Leader,负责读写请求,Follower同步Leader数据。
消息存储与高效查找
Kafka 在数据持久化方面采用了高效的顺序写入机制。Producer 将数据写入 Kafka 后,Kafka 会将数据直接顺序写入磁盘,避免了随机写入的低效问题。Kafka 启动时会单独开辟一块磁盘空间用于顺序写入,这也是其高并发高吞吐的关键。
Partition 结构
每个 Topic 可以分为一个或多个 Partition。Partition 在服务器上的表现形式就是一个个文件夹,每个 Partition 文件夹下包含多组 segment 文件。每组 segment 文件又包含 .index 文件、.log 文件、.timeindex 文件(早期版本中没有)。
.log文件:实际存储消息(message)的地方。.index和.timeindex文件:为索引文件,用于高效检索消息。
如:
- 一个 Partition 可能有三组 segment 文件,每个 log 文件的大小相同,但存储的 message 数量可能不同(因每条 message 大小不一)。
- 文件命名以该 segment 最小 offset 命名,如
000.index存储 offset 为 0~368795 的消息。 - Kafka 通过分段(segment)+ 索引的方式,实现高效查找。
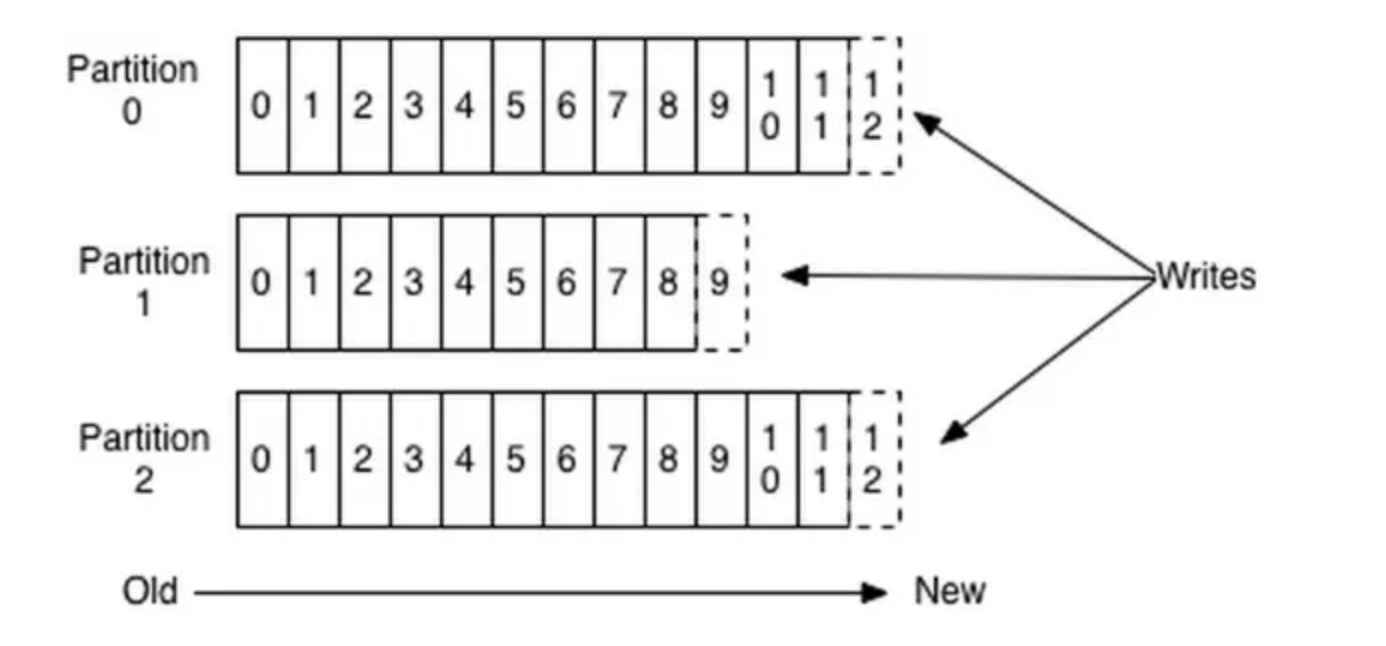
Message 结构
每条消息(message)在 log 文件中的结构主要包括:
- offset:8 字节有序 id,唯一标识消息在 partition 内的位置。
- 消息大小:4 字节,描述消息体的大小。
- 消息体:实际存放的数据(通常已压缩),大小不定。
存储策略
Kafka 无论消息是否被消费,都会保存所有消息。对于旧数据,Kafka 提供两种删除策略:
- 基于时间:如默认 168 小时(7 天)后自动删除。
- 基于大小:如默认 1GB,超出后删除最早的数据。
需要注意:Kafka 读取特定消息的时间复杂度为 O(1),删除过期文件并不会提升查找性能。
- 消息即使被消费也不会立即删除,便于多消费者组独立消费。
- 这种分段+索引+顺序写入的设计,是 Kafka 能够兼顾高吞吐与高效检索的核心。
消费机制与消费组
消息存储在 log 文件后,消费者即可进行消费。与生产消息类似,消费者在拉取消息时也是直接向分区的 leader 拉取数据。
Kafka 支持多个消费者组成一个消费者组(Consumer Group),每个组有唯一的 group id。组内的每个消费者可以消费同一 topic 下不同分区的数据,但同一分区的数据不会被组内多个消费者重复消费。
- 当消费者组内的消费者数量小于分区数量时,部分消费者会消费多个分区的数据,导致这些消费者的负载较重。
- 当消费者数量多于分区数量时,多出来的消费者不会分配到任何分区,不参与消费。
- 实际应用中,建议消费者组的 consumer 数量与 partition 数量一致,以充分利用并发能力。
offset 查找与高效检索
Kafka 通过 segment + offset + 稀疏索引 + 二分查找 + 顺序查找等机制,实现高效的数据定位。查找某个 offset 的消息流程如下:
- 先定位 offset 所在的 segment 文件(利用二分法查找)。
- 打开该 segment 的 .index 文件,查找小于或等于目标 offset 的最大相对 offset 条目,获取其物理偏移量。
- 从该物理位置开始顺序扫描 log 文件,直到找到目标 offset 的消息。
这种机制依赖 offset 的有序性和稀疏索引,极大提升了查找效率。
offset 管理
每个消费者需要记录自己消费到的位置(offset)。
- 早期 Kafka 版本将 offset 存储在 Zookeeper 中,易导致重复消费且性能有限。
- 新版本中,offset 已直接存储在 Kafka 集群的
__consumer_offsets这个特殊 topic 中,支持断点续传和高效管理。
应用场景
- 日志收集与分析:集中采集应用日志,实时分析与监控。
- 流式数据处理:与Spark、Flink等流处理框架集成,实现实时大数据分析。
- 消息驱动架构:微服务间异步通信,解耦业务模块。
- 事件溯源与审计:持久化事件流,便于追踪和回溯。
优缺点分析
优点:
- 高吞吐、低延迟,适合大规模数据流转。
- 分布式架构,易于横向扩展。
- 支持消息持久化和多副本,数据可靠性高。
- 灵活的消费模型,适应多种业务场景。
缺点:
- 依赖Zookeeper(或KRaft),运维复杂度较高。
- 消息顺序只在分区内保证,跨分区无序。
- 不适合极端低延迟、强事务场景。
总结
消息队列通过解耦、异步和削峰,极大提升了系统的弹性和可维护性。Kafka作为业界主流消息中间件,凭借高吞吐、分布式和高可用特性,成为大规模数据流转的首选。理解其原理和架构,有助于更好地设计和优化分布式系统。
相关文章:
1、Kafka与消息队列核心原理详解
消息队列(Message Queue, MQ)作为现代分布式系统的基础组件,极大提升了系统的解耦、异步处理和削峰能力。本文以Kafka为例,系统梳理消息队列的核心原理、架构细节及实际应用。 Kafka 基础架构及术语关系图 术语简要说明 Produce…...
免费公共DNS服务器推荐
当自动获取的DNS或本地运营商的DNS出现问题,可能导致软件无法连接服务器。此时,手动修改电脑的DNS设置或许能解决问题。许多用户觉得电脑上网速度慢、游戏卡顿,归咎于DNS问题。确实,我们可以自行设置一个DNS来改善网络体验。不少用…...

POST请求 、响应、requests库高级用法
常见请求方式POST请求 代码如下 import requestsdata {name:germey,age:25} r requests.post("https://www.httpbin.org/post",datadata) print(r.text) 如果请求方式为POST方式,运行结果如下: {"args": {}, "data"…...

React 第三十八节 Router 中useRoutes 的使用详解及注意事项
前言 useRoutes 是 React Router v6 引入的一个钩子函数,允许通过 JavaScript 对象(而非传统的 JSX 语法)定义路由配置。这种方式更适合复杂路由结构,且代码更简洁易维护。 一、基础使用 1.1、useRoutes路由配置对象 useRoute…...

ApplicationEventPublisher 深度解析:Spring 事件驱动模型的核心
ApplicationEventPublisher 是 Spring 框架中 事件驱动编程模型 的核心接口,用于实现 观察者模式(Observer Pattern)。它允许 Bean 之间通过 发布-订阅机制 进行松耦合通信,适用于解耦业务逻辑、实现异步处理等场景。 1. Applicat…...
【统计以空格隔开的字符串数量】2021-11-26
缘由一提标准的大一oj提木-编程语言-CSDN问答 void 统计以空格隔开的字符串数量() {//缘由https://ask.csdn.net/questions/7580109?spm1005.2025.3001.5141int n 0, x 0, g 0, k 1;string s "";cin >> n;getchar();while (n--){getline(cin, s);while …...

OSCP备战-kioptrixvm3详细解法
探测IP arp-scan -l 得出目标IP:192.168.155.165 也可以使用 netdiscover -i eth0 -r 192.168.155.0/24 也可以使用 nmap -sN 192.168.155.0/24 --min-rate 1000 修改hosts文件 找到IP后,通过之前读取README.txt了解到,我们需要编辑host…...

客服系统重构详细计划
# 客服系统重构详细计划 ## 第一阶段:系统分析与准备工作 ### 1. 代码审查和分析 (1-2周) - 全面分析现有代码结构 - 识别代码中的问题和瓶颈 - 理解当前系统的业务逻辑 - 确定可重用的组件 - 制作系统功能清单 ### 2. 技术栈升级准备 (1周) - 升级PHP版本到7…...

《从零构建大模型》PDF下载(中文版、英文版)
内容简介 本书是关于如何从零开始构建大模型的指南,由畅销书作家塞巴斯蒂安• 拉施卡撰写,通过清晰的文字、图表和实例,逐步指导读者创建自己的大模型。在本书中,读者将学习如何规划和编写大模型的各个组成部分、为大模型训练准备…...

视频编解码学习六之视频采集和存储
视频采集的核心原理是用光学元件(如摄像头)将光信号转换为电信号进行传输和存储。 摄像头的主要功能是将光学图像转换为电信号(模拟或数字),核心流程如下: 1. 光学成像 镜头组:聚焦光线到感光…...
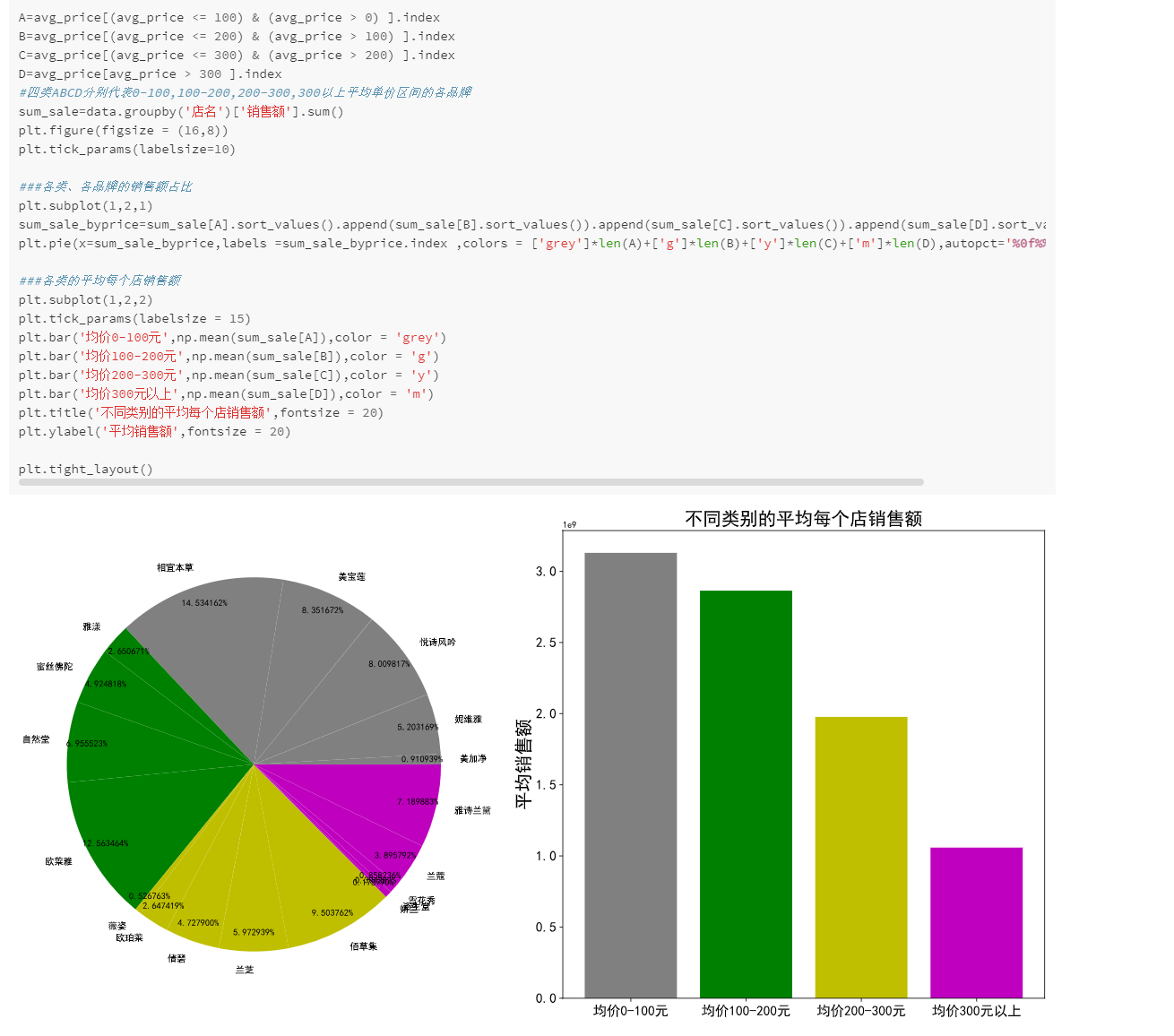
大数据应用开发和项目实战-电商双11美妆数据分析
数据初步了解 (head出现,意味着只出现前5行,如果只出现后面几行就是tail) info shape describe 数据清洗 重复值处理 这个重复值是否去掉要看实际情况,比如说:昨天卖了5瓶七喜,今天卖了5瓶七…...
》阅读笔记:p18-p31)
《算法导论(第4版)》阅读笔记:p18-p31
《算法导论(第4版)》学习第 11 天,p18-p31 总结,总计 4 页。 一、技术总结 1. Fourier transform(傅里叶变换) In mathematics, the Fourier transform (FT) is an integral transform that takes a function as input then outputs another function…...

[Java][Leetcode simple]26. 删除有序数组中的重复项
思路 第一个元素不动从第二个元素开始:只要跟上一个元素不一样就放入数组中 public int removeDuplicates(int[] nums) {int cnt1;for(int i 1; i < nums.length; i) {if(nums[i] ! nums[i-1]) {nums[cnt] nums[i];}}return cnt;}...

招行数字金融挑战赛数据分析赛带赛题二
赛题描述:根据提供的脱敏资讯新闻数据,选手需要对提供的训练集进行特征工程,构建资讯分类模型,对与测试集进行准确的新闻分类。 最终得分:0.8120。十二点关榜没看到排名,估算100? 训练集很小&am…...
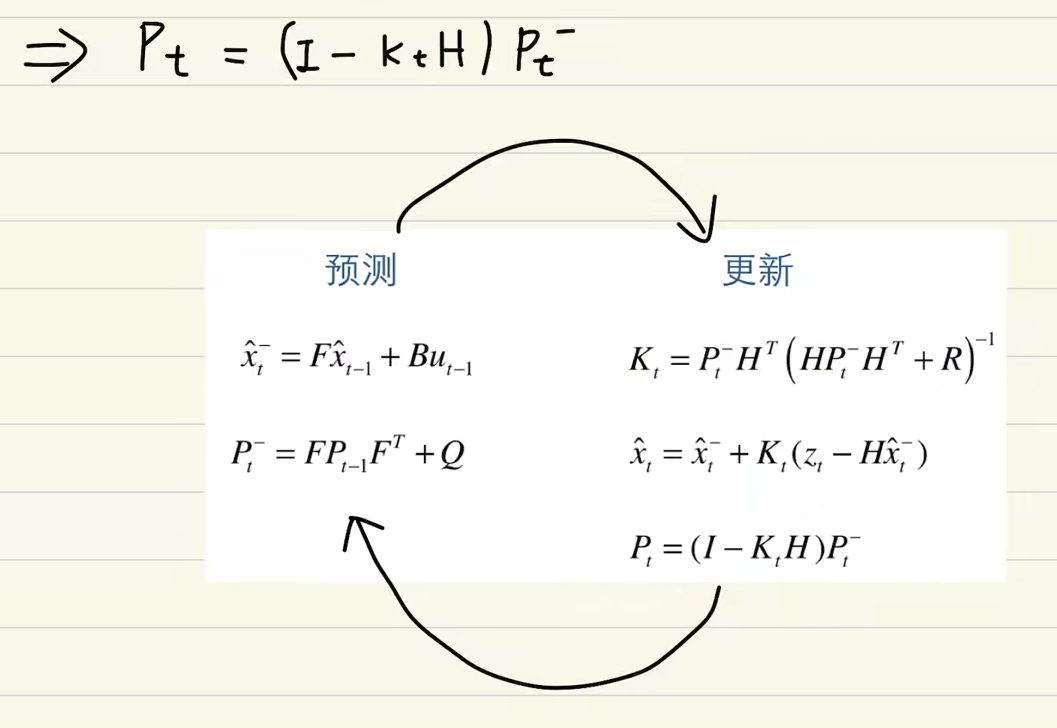
卡尔曼滤波算法(C语言)
此处感谢华南虎和互联网的众多大佬的无偿分享。 入门常识 先简单了解以下概念:叠加性,齐次性。 用大白话讲,叠加性:多个输入对输出有影响。齐次性:输入放大多少倍,输出也跟着放大多少倍 卡尔曼滤波符合这…...
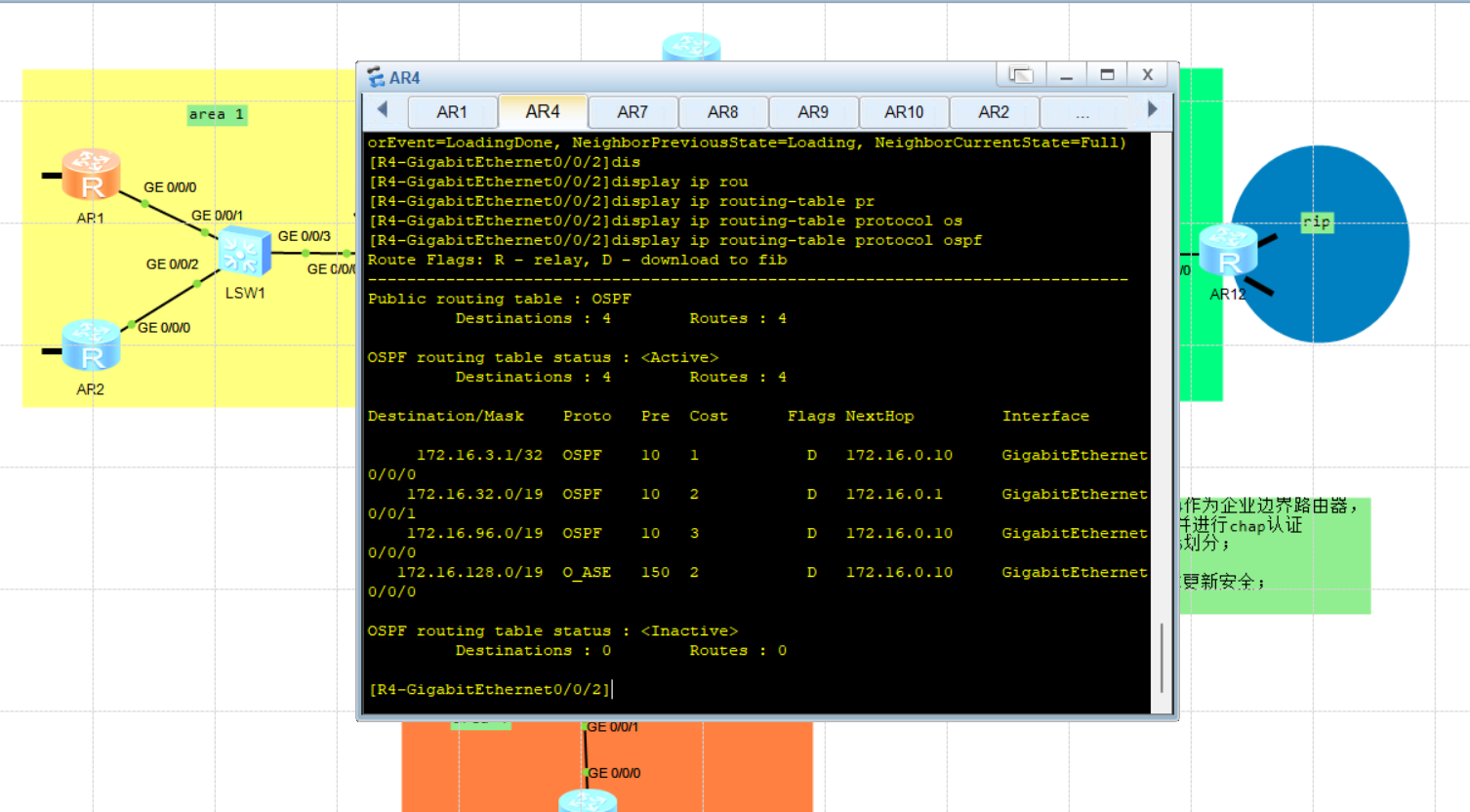
ENSP-OSPF综合实验
AR4中通过ospf获取的其他区域路由信息,并且通过路由汇总后简化路由信息 实现全网通,以及单向重发布,以及通过缺省双向访问, 通过stub简化过滤四类五类lsa,简化ospf路由信息 通过nssa简化ospf信息 区域汇总简化R4路由信…...
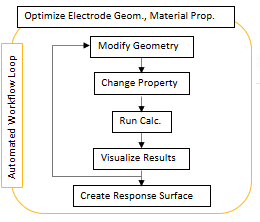
电池单元和电极性能
电芯设计中的挑战 对于电池制造商来说,提高电池能量和功率密度至关重要。在高功率密度和长循环寿命之间取得平衡是电池设计中的关键挑战,通常需要仔细优化材料、电极结构和热管理系统。另一个关键挑战是通过优化重量体积比来降低电池单元的总体成本。 工…...

软件设计师-错题笔记-软件工程基础知识
1. 解析: A:体系结构设计是概要设计的重要内容,它关注系统整体的架构,包括系统由哪些子系统组成、子系统之间的关系等 B:数据库设计在概要设计阶段会涉及数据库的逻辑结构设计等内容,如确定数据库的表结…...
)
Redis协议与异步方式(二)
目录 1.redis pipeline 2.redis 事务 2.1 MULTI 2.2 EXEC 2.3 DISCARD 2.4 WATCH 3.lua 脚本 调用方式 4.ACID 特性分析 5.发布订阅 原理 命令 6.异步连接 思想 代码 1.redis pipeline 通过一次发送多次请求命令,为了减少网络传输时间。 注意:p…...

使用 Java 反射打印和操作类信息
Java 反射是 Java 语言的强大特性,允许开发者在运行时动态检查和操作类、字段、方法和构造函数等信息。通过 java.lang.Class 和 java.lang.reflect 包,反射 API 提供了类似 JDK 工具 javap 的功能,用于打印类的详细信息,或实现动态方法调用和字段访问。反射广泛应用于框架…...
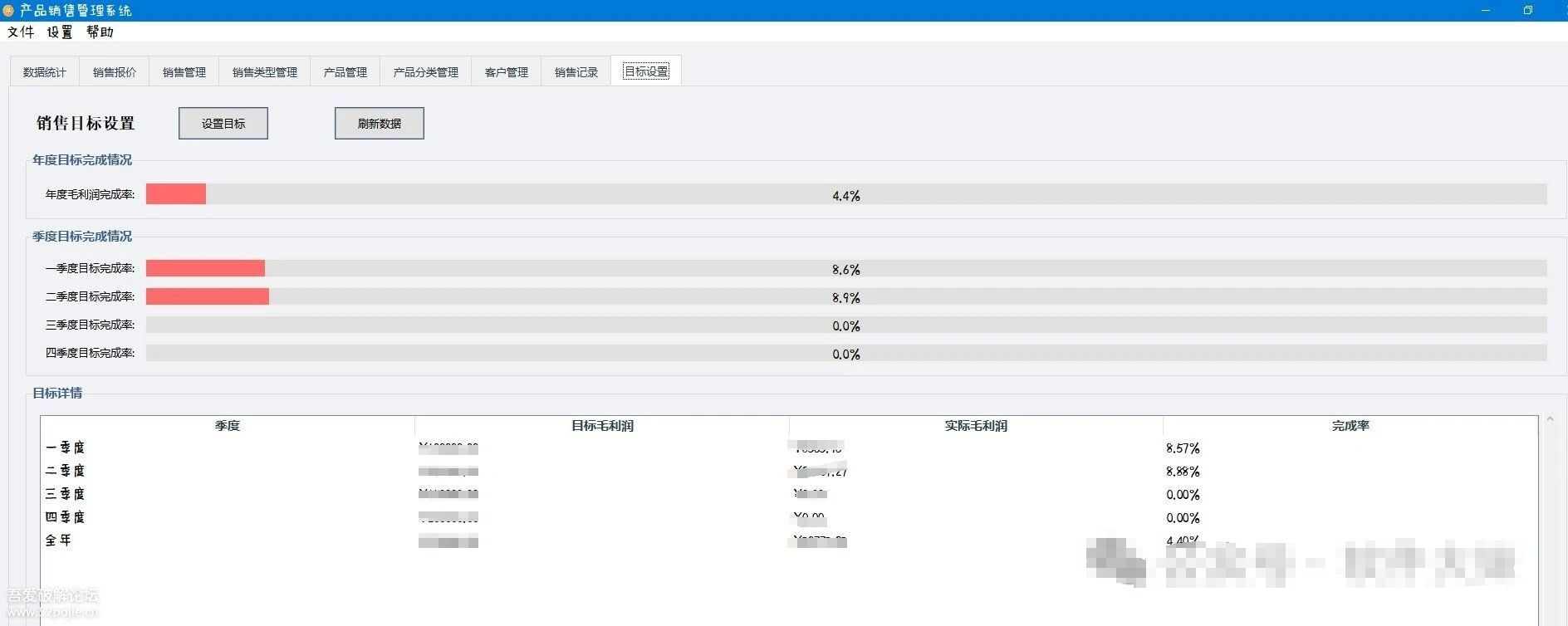
销售管理系统使用全攻略:从基础配置到数据分析
如果你是一名刚接手公司销售管理系统的销售经理,你会深刻体会到一个好工具的重要性。如果老板突然要查看季度销售数据时,就不用手忙脚乱地翻找各种Excel表格。 今天就来分享我的经验,希望能帮助到同样需要快速上手的朋友。 系统基础配置指南 …...
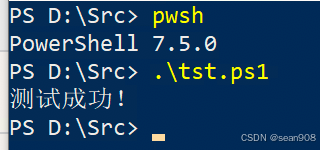
PowerShell 脚本中文乱码处理
问题描述 脚本带中文,执行时命令行窗口会显示出乱码 示例 Write-Host "测试成功!"解决方法 问了DeepSeek,让确认是不是 UTF8 无 BOM 格式 事实证明方向对了 但是确认信息有偏差 改成 UTF8 with BOM 使用任意支持修改编码的文本…...

语音合成之十三 中文文本归一化在现代语音合成系统中的应用与实践
中文文本归一化在现代语音合成系统中的应用与实践 引言理解中文文本归一化(TN)3 主流LLM驱动的TTS系统及其对中文文本归一化的需求分析A. SparkTTS(基于Qwen2.5)与文本归一化B. CosyVoice(基于Qwen)与文本归…...
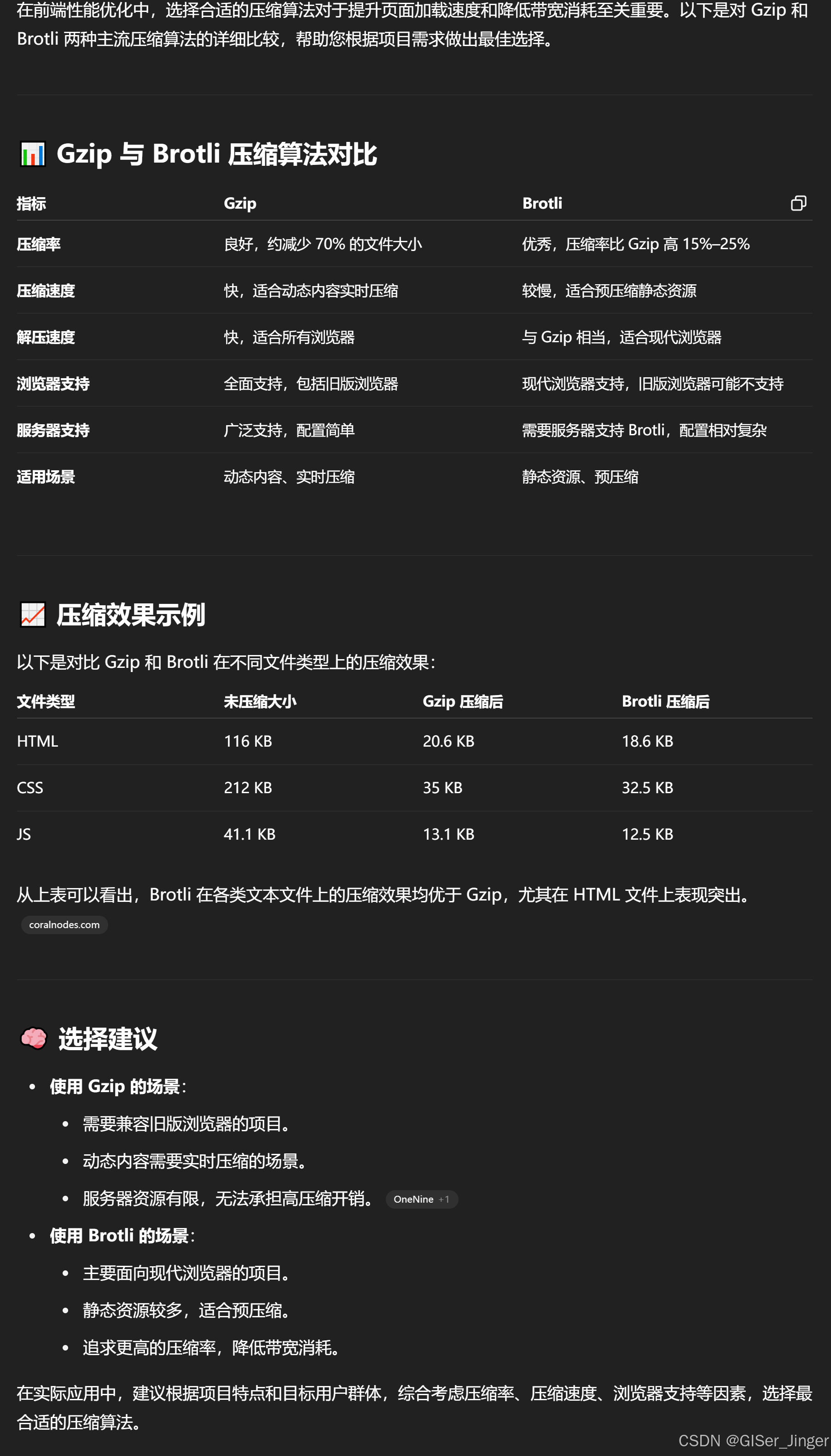
前端性能指标及优化策略——从加载、渲染和交互阶段分别解读详解并以Webpack+Vue项目为例进行解读
按照加载阶段、渲染阶段和交互阶段三个维度进行系统性阐述: 在现代 Web 开发中,性能不再是锦上添花,而是决定用户体验与业务成败的关键因素。为了全面监控与优化网页性能,我们可以将性能指标划分为加载阶段、渲染阶段、和交互阶段…...

RDD实现单词计数
Scala(Spark Shell)方法 如果你在 spark-shell(Scala 环境)中运行: 1. 启动 Spark Shell spark-shell (确保 Spark 已安装,PATH 配置正确) 2. 执行单词统计 // 1. 读取文件&am…...
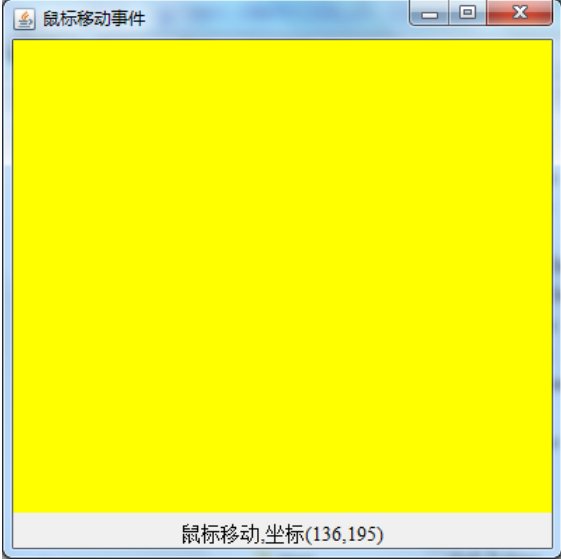
Java快速上手之实验七
1.编写鼠标事件响应程序MouseEventDemo.java,当鼠标进入和离开窗口时给出相应显示,当按下、弹起时显示当前鼠标的坐标值。 2.编写鼠标事件响应程序MouseMotionEventDemo.java,当鼠标在窗口内移动时显示鼠标的坐标值。 …...

C++八股——函数对象
文章目录 一、仿函数二、Lambda表达式三、bind四、function 一、仿函数 仿函数:重载了操作符()的类,也叫函数对象 特征:可以有状态,通过类的成员变量来存储;(有状态的函数对象称之为闭包) 样…...
可视化图解算法36: 序列化二叉树-I(二叉树序列化与反序列化)
1. 题目 描述 请实现两个函数,分别用来序列化和反序列化二叉树,不对序列化之后的字符串进行约束,但要求能够根据序列化之后的字符串重新构造出一棵与原二叉树相同的树。 二叉树的序列化(Serialize)是指:把一棵二叉树按照某种遍…...

Vivado FPGA 开发 | 创建工程 / 仿真 / 烧录
注:本文为 “Vivado FPGA 开发 | 创建工程 / 仿真 / 烧录” 相关文章合辑。 略作重排,未整理去重。 如有内容异常,请看原文。 Vivado 开发流程(手把手教学实例)(FPGA) 不完美先生 于 2018-04-…...
)
每日算法刷题 Day3 5.11:leetcode数组2道题,用时1h(有点慢)
5.LC 零矩阵(中等) 面试题 01.08. 零矩阵 - 力扣(LeetCode) 思想: 法一: 利用两个集合分别储存要清0的行和列索引 另外两种原地优化空间的做法暂时不是目前刷题目标,故不考虑 代码 c: class Solution { public:void setZeroes(vector&l…...