语音合成之十三 中文文本归一化在现代语音合成系统中的应用与实践
中文文本归一化在现代语音合成系统中的应用与实践
- 引言
- 理解中文文本归一化(TN)
- 3 主流LLM驱动的TTS系统及其对中文文本归一化的需求分析
- A. SparkTTS(基于Qwen2.5)与文本归一化
- B. CosyVoice(基于Qwen)与文本归一化
- 4. Python库与代码实例
- A. 基础与通用库
- B. 综合性中文文本归一化工具包
- C. 专用转换库
- D. 综合归一化流程概念示例
- 建议与未来展望
引言
语音合成(Text-to-Speech, TTS)技术,旨在将文本信息转化为自然流畅的人类语音,已成为人机交互、内容播报和辅助技术等领域的核心组成部分 。近年来,大型语言模型(LLM)的崛起为TTS领域带来了革命性的进步,使得合成语音在自然度、表现力和个性化方面达到了前所未有的高度 。然而,高质量的语音合成始于对输入文本的精确理解和规范化处理。
中文文本因其语言特性,如缺乏显式词边界、多音字、以及数字、日期、特殊符号等非标准词(Non-Standard Words, NSW)的复杂表述方式,对TTS系统的前端处理提出了严峻挑战 。文本归一化(Text Normalization, TN),作为TTS系统前端的关键环节,其任务是将书面文本转换为标准化的、可供后续声学模型直接处理的口语化文本形式 。
理解中文文本归一化(TN)
中文文本归一化是将原始文本中包含的非标准词语(NSW)转换为TTS系统能够直接处理和正确发音的标准书面语或口语化表达的过程 。这一过程对于提升合成语音的质量至关重要。
-
A. 中文文本归一化的核心作用与重要性
- 提升发音准确性:原始中文文本常含有数字、日期、缩写、特殊符号等,若不加处理直接送入TTS后端,极易产生发音错误或不自然的韵律。例如,数字“123”应读作“一百二十三”,而非“一二三”或逐字发音 。文本归一化通过将这些NSW转换为规范的汉字表达,确保TTS系统能准确发声。
- 增强语音自然度:日常书面语中存在的缩写、非正式表达以及特定格式(如网址、邮件地址)需要被转换为更符合口语习惯的形式,从而使合成语音听起来更自然、更像人类讲话 。
- 消除歧义,提高可理解性:某些NSW,如特定格式的数字串或未经解释的缩写,可能存在多种解读方式,导致听者困惑。文本归一化致力于消除这些歧义,生成清晰、单一的口语化表达 。例如,“2023/5/11”应明确转换为“二零二三年五月十一日”或“两千零二十三年五月十一日”,避免按符号逐字朗读 。
- 作为TTS前端处理的基石:文本归一化是TTS系统前端处理流程中的初始且关键的一步,其输出质量直接影响后续的词性标注、韵律预测、声学模型处理等环节 。一个鲁棒的TN模块为整个TTS流程的顺畅运行和高质量输出奠定了坚实基础。在一些系统中,如Nuance Vocalizer,TN相关的代码甚至占到核心应用代码的20%以上,这足以说明其复杂性和重要性 。
-
B. 中文文本归一化的主要挑战
中文文本归一化面临的挑战主要源于中文语言的特性和NSW的多样性:- NSW形式多样复杂:数字(整数、小数、分数、百分比)、日期与时间(多种格式)、货币金额、度量单位、电话号码、网址、邮箱地址、数学符号、以及各种中英文缩写等,其书面形式与口语表达差异巨大,难以用简单规则完全覆盖 。
- 上下文歧义性:同一NSW在不同上下文中可能有不同的读法。例如,数字串“110”在“110米”中读作“一百一十”,在报警电话场景中则读作“幺幺零” 。这种歧义的解决高度依赖上下文语境信息。
- 口语表达的地域差异与习惯:对于某些NSW,如数字“二”和“两”的使用,不同地区或语境下有不同的口语习惯。
新词新语的涌现:网络时代不断产生新的缩写、表达方式,TN系统需要具备一定的扩展性和适应性。
-
C. 中文文本归一化流程与关键处理对象
典型的中文文本归一化流程通常包含预处理、非标准词识别与转换、后处理三个主要阶段 。- 预处理(Pre-processing):
- 字符宽度转换:将全角字符(如IPHONE,123)转换为半角字符(IPHONE, 123),以统一字符编码表示 。
- Unicode标准化:使用如NFKC(Normalization Form Compatibility Composition)等形式对Unicode文本进行标准化,确保字符表示的一致性,例如合并组合字符、转换兼容字符 。
- 繁简转换:根据TTS系统目标音库的语言,将输入文本统一转换为简体中文或繁体中文 。
- 无效字符或噪音去除:移除文本中不影响语义的控制字符、特定表情符号或预定义的黑名单词汇(如口头禅“呃”)。
- 非标准词(NSW)识别与转换:这是TN的核心环节,针对不同类型的NSW应用特定的转换规则。
- 数字(Numbers):
- 基数词:如“465”转换为“四百六十五”,“6.42”转换为“六点四二” 。
- 分数:“1/5”转换为“五分之一” 。
- 百分比:“6.3%”转换为“百分之六点三” 。
- 数字序列:电话号码、邮政编码、房间号等,如“12306”转换为“幺二三零六” 。这需要区分是作为数值还是序列来读。
- 特殊处理:如“二”和“两”的区分,通常在百、千、万等单位前或特定语境下使用“两”。
- 日期(Dates):
- 多种格式(“2002/01/28”,“2002-01-28”,“2002.01.28”)统一转换为规范读法,如“二零零二年一月二十八日” 。
- 年份的读法,如“2002年”可读作“二零零二年”或“两千零二年”。
- 时间(Time):
- “12:00”转换为“十二点”,“5:02”转换为“五点零二分”,“5:35:36”转换为“五点三十五分三十六秒” 。
- 处理am/pm标记,如“8:00 a.m.”转换为“早上八点” 。
- 货币(Money):
- “¥13.5”转换为“十三点五元”,“$13.5”转换为“十三点五美元” 。需要识别货币符号并转换为对应货币单位。
- 度量单位(Measure):
- “25kg”转换为“二十五千克”,“38°C”转换为“三十八摄氏度”,“10km/h”转换为“每小时十公里” 。单位符号需要展开为完整的中文名称。
- 数学表达式(Math):
- “78:96”(比分)转换为“七十八比九十六”,“-2”转换为“负二”,“±2”转换为“正负二” 。
- 缩写与特殊词(Abbreviations & Whitelist):
- 英文缩写如“CEO”可能读作字母序列“C E O”或根据约定俗成的中文对应词(如果存在)。
- 特定组合如“O2O”可能转换为“O to O” 。
- 通过白名单机制处理特定机构名、品牌名或其他专有名词的固定读法。
- 儿化音处理(Erhua):根据需求移除或保留儿化音,如“这地儿”可转换为“这地” 。
- 预处理(Pre-processing):
- 后处理(Post-processing):
- 标点符号处理:移除不影响韵律的标点,或将特定标点转换为停顿标记。例如,句末标点(如“!”、“。”)通常保留以指导韵律,而某些中间标点可能被移除或替换 。
- OOV(Out-Of-Vocabulary)标记:对于无法识别或转换的字符(如罕见字、非目标语言字符),进行标记,如“我们안녕”转换为“我们안녕” 。
- 文本格式整理:去除转换过程中可能产生的多余空格等。
中文文本归一化的复杂性在于,它不仅仅是简单的字符串替换,而是需要结合语言学知识、上下文信息,有时甚至需要机器学习模型来解决歧义问题 。一个设计良好的TN系统能够显著提升TTS的最终效果。
3 主流LLM驱动的TTS系统及其对中文文本归一化的需求分析
基于LLM的TTS模型如SparkTTS和CosyVoice,凭借其强大的文本理解和生成能力,在语音合成领域取得了显著进展。然而,这些模型在处理原始中文文本时,对文本归一化的依赖程度和处理方式各有侧重。
A. SparkTTS(基于Qwen2.5)与文本归一化
SparkTTS是一个基于Qwen2.5 LLM的高效文本转语音模型 。它通过BiCodec将语音分解为语义标记和全局说话人属性标记,并利用Qwen2.5进行建模 。
尽管SparkTTS基于Qwen2.5,但其公开的资料(包括论文摘要和GitHub)并未详细说明其内置的中文文本归一化具体规则和覆盖范围 。虽然LLM可能隐式处理一些简单的NSW,但对于复杂的中文特有现象(如“幺”的读法、特定的日期和金额格式转换),其鲁棒性从测试结果来看并不理想,而归一化之后的文本则具有较好的处理效果。
因此对于SparkTTS,尽管其依赖的Qwen2.5 LLM具有强大的文本处理能力,但为了确保在各种复杂中文输入下的语音合成准确性和自然度,进行显式的中文文本归一化预处理仍然是推荐的做法。依赖LLM自身隐式处理所有NSW可能存在风险,特别是在对发音准确性要求极高的场景。一个外部的、规则明确的TN模块可以作为重要的保障。
B. CosyVoice(基于Qwen)与文本归一化
CosyVoice是另一个基于LLM(如Qwen)的先进TTS系统,支持多语言和零样本语音克隆,并特别强调了流式合成能力 。 SparkTTS仅开源了低采样率的模型和其推理代码,而CosyVoice的开源较为详细,涵盖了各种模型、数据集一集训练的代码,是推荐入手的模型。
“原始文本输入”与BPE分词器:CosyVoice 2的一个特点是直接使用“原始文本”作为输入,并通过一个基于BPE(Byte Pair Encoding)的分词器进行处理 。这种方式旨在简化数据预处理流程,使模型能够以端到端的方式学习词汇在不同上下文中的发音。
集成的文本归一化选项:CosyVoice在其GitHub仓库中明确提到了文本归一化处理。它提供了两种选项:
WeTextProcessing:默认使用的文本归一化工具,如果ttsfrd未安装 。WeTextProcessing是一个功能较全面的中文TN工具包 。
ttsfrd:一个可选的文本归一化包,据称可能提供更好的TN性能 。其规则基于Zhiyang Zhou的工作,涵盖了多种中文NSW类型 。
frontend.py中的处理逻辑:CosyVoice的frontend.py代码(如中部分展示)清晰地显示了在文本送入模型前,会根据配置选择ttsfrd或WeTextProcessing(通过self.zh_tn_model.normalize(text))对中文文本进行归一化处理。
结论:对于CosyVoice,中文文本归一化是其系统设计中明确考虑并集成的一环。用户可以选择使用其默认的WeTextProcessing或配置性能可能更优的ttsfrd。这意味着CosyVoice认识到,即使采用了先进的LLM和端到端学习策略,一个专门的中文TN模块对于处理复杂中文输入、保证合成质量仍然是必要的。
4. Python库与代码实例
为了在Python环境中实现中文文本归一化,开发者可以利用一系列开源库。这些库功能各异,有的专注于基础的字符处理,有的提供全面的NSW规则,有的则针对特定类型的转换。
A. 基础与通用库
unicodedata(Python标准库)
- 功能: 提供对Unicode字符数据库的访问,常用于字符属性检查和Unicode文本的标准化(如NFC, NFD, NFKC, NFKD形式的转换)。对于中文TN,NFKC范式特别有用,它可以将全角字符转换为半角,并处理一些兼容字符,有助于文本的初步清理和统一。
- 安装: Python内置,无需额外安装。
- 用途: 文本预处理阶段,进行字符层面的规范化,特别是全角到半角的转换。
代码示例:
Pythonimport unicodedatatext_full_width = "IPHONE手机,价格:1234元,ABC"
# 使用NFKC进行归一化,全角数字和字母会转为半角
normalized_text_nfkc = unicodedata.normalize('NFKC', text_full_width)print(f"原始文本: {text_full_width}")
print(f"NFKC 归一化后: {normalized_text_nfkc}")
# 预期输出: IPHONE手机,价格:1234元,ABC
相关集成: 阿里云LLM文本标准化组件使用ftfy.fix_text(text, normalization=‘NFKC’),其核心也依赖unicodedata的原理 。
-
OpenCC-Python(或opencc-python-reimplemented, OpenCC)- 功能: 提供高质量的中文简繁体转换,支持词汇级别转换、异体字转换以及中国大陆、台湾、香港等地区的用词习惯转换 。
- 安装: pip install opencc-python-reimplemented 或 pip install opencc 。后者是官方维护的更新版本。
- 用途: 根据TTS系统的目标音库(简体或繁体)统一输入文本的字符集。
代码示例 (使用 opencc):
import unicodedatatext_full_width = "IPHONE手机,价格:1234元,ABC"
# 使用NFKC进行归一化,全角数字和字母会转为半角
normalized_text_nfkc = unicodedata.normalize('NFKC', text_full_width)print(f"原始文本: {text_full_width}")
print(f"NFKC 归一化后: {normalized_text_nfkc}")
# 预期输出: IPHONE手机,价格:1234元,ABC
- 相关集成: 阿里云LLM文本标准化组件使用opencc包进行繁简转换 。
B. 综合性中文文本归一化工具包
- WeTextProcessing
- 功能: 一个面向生产环境的中文文本归一化(TN)与反归一化(ITN)工具包,提供了针对多种NSW的详细规则,并包含预处理和后处理流程 。
- 安装:
pip install WeTextProcessing。通常需要通过conda安装其依赖pynini:conda install -c conda-forge pynini。
中文TN主要特性: - 数字归一化:基数、分数、百分比。
- 日期和时间归一化。
- 货币和度量单位归一化。
- 数字序列(如电话号码)归一化。
- 儿化音去除选项。
- 字符宽度转换(全角到半角)。
- 标点符号处理规则。
- 通过白名单/黑名单进行自定义处理 。
from tn.chinese.normalizer import Normalizer as ZhNormalizer# 假设WeTextProcessing已正确安装,并且规则文件可访问
# 初始化中文归一化器,例如,选择去除儿化音
# 在实际使用中,cache_dir可能需要指向WeTextProcessing规则编译后的缓存路径
# overwrite_cache=True 会强制重新编译规则,首次运行时或规则更新后使用
try:zh_tn_model = ZhNormalizer(remove_erhua=True, overwrite_cache=False)
except Exception as e:print(f"初始化ZhNormalizer失败,请确保pynini和相关规则已正确配置: {e}")print("尝试不使用缓存 (可能较慢,且需要规则源文件):")# zh_tn_model = ZhNormalizer(remove_erhua=True, overwrite_cache=True, cache_dir=None) # 示例raise etext_to_normalize = "总量的1/5以上,价格是¥13.5,今天是2022/01/28,我儿子喜欢这地儿。电话是13800138000。"
normalized_text = zh_tn_model.normalize(text_to_normalize)print(f"原始文本: {text_to_normalize}")
print(f"WeTextProcessing 归一化后: {normalized_text}")
# 预期输出 [8]:
# 总量的五分之一以上,价格是十三点五元,今天是二零零二年一月二十八日,我儿子喜欢这地。电话是幺三八零零幺三八零零零。
- 相关集成: CosyVoice默认使用WeTextProcessing进行文本归一化 。
- NVIDIA NeMo-text-processing
-
功能: 基于加权有限状态转换器(WFST)的文本归一化和反归一化工具,支持包括中文(zh)在内的多种语言 。
-
安装:
pip install nemo_text_processing或从源码安装。依赖pynini,推荐通过conda安装:conda install -c conda-forge pynini==2.1.5(版本号可能需根据NeMo版本调整) 。 -
中文TN主要特性: 支持中文的TN和ITN 。WFST基础使其在模式匹配方面非常强大和高效。可以利用缓存的编译语法文件(.far)来加速处理 。
-
代码示例 (Python调用方式): NeMo的TN功能主要通过normalize.py脚本或其内部的Normalizer类来使用。以下是一个概念性的Python调用示例,具体API参数和用法请参考NeMo官方文档。
-
相关资料: NeMo提供了详细的WFST教程,解释了如何构建和使用语法 。中文的特定语法规则文件(.tsv或Python定义的规则)位于NeMo-text-processing/nemo_text_processing/text_normalization/zh/目录下,例如cardinal.py用于处理基数词 。
C. 专用转换库
num2chinese / ChineseNumberUtils
- 功能: 专注于阿拉伯数字与中文数字字符之间的相互转换 。ChineseNumberUtils支持简繁体、大写数字,并能处理较大的数值范围和“二/两”的用法。
- 安装:
pip install num2chinese或pip install ChineseNumberUtils。 - 用途: 在TN流程中专门处理数字字符串的转换,可以作为更大型TN系统的一个组件,或者在对数字格式有特殊要求时使用。
- 代码示例 :
from cnc import convert# 阿拉伯数字转中文
number1 = 578.5
chinese_numeral_s = convert.number2chinese(number1, language="S") # 简体
chinese_numeral_t_big = convert.number2chinese(number1, language="T", bigNumber=True) # 繁体大写print(f"数字: {number1}")
print(f"简体中文数字: {chinese_numeral_s}") # 预期: 五百七十八点五
print(f"繁体大写中文数字: {chinese_numeral_t_big}") # 预期: 伍佰柒拾捌點伍# 中文转阿拉伯数字
chinese_text1 = "两千零一十二"
arabic_number1 = convert.chinese2number(chinese_text1)
chinese_text2 = "贰佰零贰" # 大写简体
arabic_number2 = convert.chinese2number(chinese_text2)print(f"中文文本: {chinese_text1} => 阿拉伯数字: {arabic_number1}") # 预期: 2012
print(f"中文文本: {chinese_text2} => 阿拉伯数字: {arabic_number2}") # 预期: 202
ttsfrd
- 功能: 作为CosyVoice中的一个可选中文TN模块,据称能提供更好的性能 。其规则基于Zhiyang Zhou的工作,涵盖了基数词、日期、数字、分数、金额、百分比、电话等NSW的归一化 。
- 安装: 通常通过CosyVoice项目提供的.whl文件进行安装 。
- 用途: 主要集成在CosyVoice系统内部。其frontend.py中通过self.frd.do_voicegen_frd(text)调用 。独立使用的API细节在现有资料中尚不完全清晰,但其核心能力是针对中文NSW的规则化处理。
- 代码示例 (概念性,基于CosyVoice内部调用):
# 概念性代码,ttsfrd的直接API调用需查阅其具体实现或文档
# class TTSFRD_Handler:
# def __init__(self):
# # 此处进行ttsfrd相关初始化
# # self.frd = ttsfrd.Frontend() # 假设的初始化方式
# pass# def normalize_text(self, chinese_text: str) -> str:
# # normalized_data = self.frd.do_voicegen_frd(chinese_text) # 调用核心处理
# # sentences_data = json.loads(normalized_data)["sentences"]
# # return "".join([item["text"] for item in sentences_data])
# return "示例:ttsfrd处理后的文本" # 占位符# handler = TTSFRD_Handler()
# text = "价格12块5,日期86年8月18日"
# normalized = handler.normalize_text(text)
# print(f"ttsfrd 归一化后 (概念): {normalized}")
- whisper-normalizer
- 功能: 实现了OpenAI Whisper模型中使用的文本归一化算法,主要包含BasicTextNormalizer和EnglishTextNormalizer 。
- 对中文的适用性: 文档明确提示,“在母语中使用BasicTextNormalizer可能不是一个好主意”,并且指出其在印地语等资源较少的语言中可能存在问题 。这意味着直接将其用于中文TN可能效果不佳,除非针对中文进行大量的规则定制和适配。其主要设计目标是为ASR评估提供一致的文本处理,而非专门为中文TTS的口语化转换。
- 代码示例 (通用,非中文优化):
from whisper_normalizer.basic import BasicTextNormalizer# BasicTextNormalizer主要进行一些通用清理,如小写化、移除特定标点等
# 对中文的NSW处理能力有限
normalizer = BasicTextNormalizer()
text = "这是 一段CHINESE文本,包含123。"
normalized_text = normalizer(text)print(f"原始文本: {text}")
print(f"Whisper BasicTextNormalizer 后: {normalized_text}")
# 预期输出 (可能只是小写化和一些符号处理): 这是 一段chinese文本,包含123。
D. 综合归一化流程概念示例
在实际应用中,通常需要组合使用这些库来实现一个鲁棒的中文文本归一化流程。以下是一个概念性的Python函数,展示了如何将多个工具串联起来:
import unicodedata
import opencc # 假设使用官方 opencc 包
from tn.chinese.normalizer import Normalizer as WeTextProcessingNormalizer # 假设 WeTextProcessing 已安装且路径配置正确
from cnc import convert as num_converter # 假设 ChineseNumberUtils 已安装# 初始化转换器 (一次性)
oc_converter = None
try:oc_converter = opencc.OpenCC('t2s.json') # 示例:繁体到简体
except Exception as e:print(f"OpenCC 初始化失败: {e}")wetext_normalizer = None
try:# 实际使用时,请确保 pynini 及 WeTextProcessing 的规则文件路径正确# cache_dir 指向编译好的.far 文件目录,若为 None 或路径无效,可能尝试从源规则编译wetext_normalizer = WeTextProcessingNormalizer(remove_erhua=True, overwrite_cache=False)
except Exception as e:print(f"WeTextProcessing Normalizer 初始化失败: {e}")def comprehensive_chinese_tn_pipeline(text: str) -> str:print(f"原始输入: {text}")# 步骤 1: Unicode 归一化 (例如 NFKC)try:text = unicodedata.normalize('NFKC', text)print(f"Unicode NFKC 归一化后: {text}")except Exception as e:print(f"Unicode 归一化失败: {e}")# 根据策略决定是否继续或抛出异常# 步骤 2: 繁简转换 (按需选择,此处示例为繁转简)if oc_converter:try:text = oc_converter.convert(text)print(f"OpenCC 繁转简后: {text}")except Exception as e:print(f"OpenCC 转换失败: {e}")else:print("OpenCC 未初始化,跳过繁简转换。")# 步骤 3: 使用综合性工具包进行NSW归一化 (如 WeTextProcessing)if wetext_normalizer:try:text = wetext_normalizer.normalize(text)print(f"WeTextProcessing 归一化后: {text}")except Exception as e:print(f"WeTextProcessing 处理失败: {e}")else:print("WeTextProcessing Normalizer 未初始化,跳过NSW归一化。")# 步骤 4: (可选) 针对特定需求,使用专用库进行补充处理# 例如,如果WeTextProcessing对某种数字格式处理不符合预期,可以在此用 ChineseNumberUtils 等进行修正# 此处仅为示例,实际中需要判断是否必要# if "特定未处理模式" in text:# text = custom_specific_normalization(text, num_converter)# print(f"特定规则补充处理后: {text}")# 步骤 5: 最终清理 (例如,去除可能由多步处理引入的多余空格)text = " ".join(text.split())print(f"最终清理后: {text}")return text# 示例调用
raw_text_example = "臺北的氣溫是25°C,價格是NT$100元,佔總數的1/2。電話是02-27376666。"
if __name__ == '__main__':# 确保在主模块执行时进行初始化和调用,避免多进程问题# (上面初始化部分已移至全局,实际应用中需考虑初始化时机)if not oc_converter or not wetext_normalizer:print("错误:一个或多个核心归一化组件未能成功初始化。请检查依赖和配置。")else:normalized_for_tts = comprehensive_chinese_tn_pipeline(raw_text_example)print(f"\n最终送往TTS的文本: {normalized_for_tts}")# 预期输出 (概念性,实际输出依赖各库的具体实现和规则):# 台北的气温是25摄氏度,价格是新台币100元,占总数的二分之一。电话是零二二七三七六六六六。这个流程展示了多层次处理的思想:从基础的字符层面标准化,到简繁统一,再到复杂的NSW处理,最后进行清理。实际应用中,每一步的选择和顺序可能需要根据具体需求和所用库的特性进行调整和优化。重要的是,没有一个单一的库能够完美解决所有中文TN问题,组合使用往往是必要的。
表1: 主要Python中文文本归一化库对比
| 库名称 | 主要功能 | 中文TN关键特性 | 安装方式 (pip) | 主要依赖 | 理想使用场景 |
|---|---|---|---|---|---|
| unicodedata | Unicode字符数据库访问与标准化 | 全角转半角 (NFKC),字符属性查询 | Python内置 | 无 | 文本预处理,字符层面一致性处理 |
| opencc-python / OpenCC | 中文简繁体转换 | 支持简繁、地区词汇(大陆、台湾、香港)转换 | opencc 或 opencc-python-reimplemented | OpenCC核心库 (通常随包提供) | 统一输入文本的简繁体 |
| WeTextProcessing | 中文TN与ITN | 数字、日期、时间、货币、度量衡、序列号归一化;儿化音处理;字符宽度转换;标点规则;白名单 | WeTextProcessing | pynini (通常需conda安装) | 作为TTS系统主要的中文TN引擎,处理各类NSW |
| NVIDIA NeMo-text-processing | 多语言TN与ITN (基于WFST) | 支持中文TN/ITN;WFST规则驱动;可缓存语法 | nemo_text_processing | pynini (通常需conda安装), PyTorch(可选) | 需要高性能、基于WFST的TN方案,特别是在NVIDIA生态中 |
| ChineseNumberUtils | 中文数字与阿拉伯数字互转 | 支持大数、小数、简繁体、大写数字、“二/两”区分 | ChineseNumberUtils | 无 | 专门处理数字与中文数字字符的转换,或作为大型TN系统的补充 |
| ttsfrd | 中文TN (CosyVoice选用) | 基于规则的NSW处理(数字、日期、金额等) | 通过CosyVoice提供的.whl文件安装 | pynini (通过ttsfrd_dependency.whl) | 主要用于CosyVoice系统,或希望使用其特定规则集的场景 |
| whisper-normalizer | OpenAI Whisper的文本归一化算法实现 | 基础文本清理,英文归一化。对中文NSW处理能力有限,不推荐直接用于复杂中文TN | whisper-normalizer | 无 | ASR评估时的文本标准化,不适合作为中文TTS的主要TN工具 |
这个表格为开发者选择合适的Python库提供了清晰的对比和参考。选择时应综合考虑项目需求、输入文本的复杂程度、对特定NSW处理的精细度要求以及系统环境的依赖。通常,一个稳健的中文TN方案会结合unicodedata进行预处理,OpenCC进行简繁转换,再选用WeTextProcessing或NeMo-text-processing作为主要的NSW处理引擎,并可能辅以ChineseNumberUtils等专用库处理特定细节。
建议与未来展望
为LLM驱动的TTS系统实现高效且准确的中文文本归一化,需要周全的策略和对可用工具的深入理解。同时,该领域仍在不断发展,展现出一些值得关注的趋势。中文文本归一化在LLM驱动的TTS中的最佳实践
- 坚持显式归一化优先:尽管LLM具备一定的语言理解能力,但不应完全依赖其隐式处理复杂的中文NSW。一个明确的、前置的TN流程能显著提升系统的鲁棒性、可预测性和最终语音的准确性。对于规则明确的转换(如特定数字读法、日期格式),显式规则通常比LLM的概率性生成更为可靠。
- 采用分层处理策略:构建一个多层次的TN流程。首先进行基础的Unicode标准化(如使用unicodedata进行NFKC转换)和必要的简繁转换(使用OpenCC)。随后,应用一个综合性的中文TN工具包(如WeTextProcessing或NVIDIA NeMo-text-processing)来处理常见的NSW。最后,可以针对特定领域或未覆盖的边缘情况,补充自定义规则或专用库(如ChineseNumberUtils)。
- 重视上下文消歧:中文NSW的歧义性是一大挑战(例如,“110”的读法)。对于这类情况,需要利用上下文信息。这可以通过设计更精细的规则(如在WFST中编码上下文约束)或训练专门的机器学习/LLM组件来辅助判断 。例如,Llama在TTS前端的研究中就包含了同形异义词消歧任务 。
- 进行严格和全面的测试:建立一个覆盖各类中文NSW(数字、日期、时间、金额、度量、地址、电话、缩写等)、不同格式、以及潜在歧义和边缘案例的测试集。不仅要评估TN模块的文本输出,更要结合TTS系统评估最终合成语音的准确性和自然度。
- 确保规则和模型的可维护性:如果TN流程中包含基于规则的组件(如WFST或正则表达式),务必确保这些规则有良好的文档、易于理解和修改。对于基于机器学习或LLM的TN组件,应建立完善的数据管理、模型训练和版本控制流程。
- 考虑用户自定义和白名单机制:对于特定行业应用或用户群体,可能存在独特的术语、缩写或读法偏好。提供白名单功能(如WeTextProcessing 和NeMo 所支持的)允许用户自定义归一化行为,能显著提升系统的适应性和用户满意度。
中文文本归一化技术,尤其是在LLM的背景下,正朝着更智能、更融合的方向发展:
- LLM与TN的更紧密融合:未来的TTS系统可能会看到LLM更深入地参与到TN过程中,不仅仅是接收已归一化的文本。LLM有望在理解上下文的基础上,更智能地指导NSW的读法选择,甚至参与到部分归一化任务中,如更复杂的歧义消解和风格化朗读(例如,将“100元”根据上下文读作“一百块”或“一百元”)。
- 端到端归一化的潜力与挑战:虽然完全依赖LLM进行端到端的隐式归一化(即从原始文本直接到声学特征,中间不经过明确的文本转换步骤)在理论上可行,并且LLM能从大规模(文本,语音)数据中学习一些常见模式,但对于低频、复杂或有严格发音规则的中文NSW,其鲁棒性和准确性仍是巨大挑战。确定性的规则在这些场景下仍具有不可替代的优势。
- 上下文感知能力的增强:LLM的上下文理解能力将持续赋能TN。例如,对于数字“一”在电话号码中读“幺”,在序数词中读“一”,LLM可以凭借其对篇章级上下文的把握,更准确地指导这些发音选择。
- 零样本/少样本适应性:借助LLM强大的泛化能力,未来TN系统有望在少量甚至无需特定领域样本的情况下,快速适应新领域、新词汇或特定用户群体的归一化需求。
- 中文TN基准的标准化与完善:目前,相较于英文(如Google Text Normalization dataset ),公开的、大规模、高质量的中文TN评测基准相对缺乏。未来有望出现更完善的中文TN数据集和评测标准,以推动该领域技术的发展和客观比较。
- 混合模型成为主流:纯规则系统在处理灵活性和上下文感知方面有局限,而纯LLM系统在确定性和细粒度控制方面可能不足。因此,结合规则(如WFST)的确定性、高效性与LLM的上下文理解、泛化能力的混合模型,很可能成为未来中文TN的主流解决方案。这种混合系统能够利用规则处理明确的、模式化的NSW,同时利用LLM处理更复杂、更依赖上下文的归一化任务和歧义消解。
相关文章:

语音合成之十三 中文文本归一化在现代语音合成系统中的应用与实践
中文文本归一化在现代语音合成系统中的应用与实践 引言理解中文文本归一化(TN)3 主流LLM驱动的TTS系统及其对中文文本归一化的需求分析A. SparkTTS(基于Qwen2.5)与文本归一化B. CosyVoice(基于Qwen)与文本归…...
前端性能指标及优化策略——从加载、渲染和交互阶段分别解读详解并以Webpack+Vue项目为例进行解读
按照加载阶段、渲染阶段和交互阶段三个维度进行系统性阐述: 在现代 Web 开发中,性能不再是锦上添花,而是决定用户体验与业务成败的关键因素。为了全面监控与优化网页性能,我们可以将性能指标划分为加载阶段、渲染阶段、和交互阶段…...

RDD实现单词计数
Scala(Spark Shell)方法 如果你在 spark-shell(Scala 环境)中运行: 1. 启动 Spark Shell spark-shell (确保 Spark 已安装,PATH 配置正确) 2. 执行单词统计 // 1. 读取文件&am…...
Java快速上手之实验七
1.编写鼠标事件响应程序MouseEventDemo.java,当鼠标进入和离开窗口时给出相应显示,当按下、弹起时显示当前鼠标的坐标值。 2.编写鼠标事件响应程序MouseMotionEventDemo.java,当鼠标在窗口内移动时显示鼠标的坐标值。 …...

C++八股——函数对象
文章目录 一、仿函数二、Lambda表达式三、bind四、function 一、仿函数 仿函数:重载了操作符()的类,也叫函数对象 特征:可以有状态,通过类的成员变量来存储;(有状态的函数对象称之为闭包) 样…...
可视化图解算法36: 序列化二叉树-I(二叉树序列化与反序列化)
1. 题目 描述 请实现两个函数,分别用来序列化和反序列化二叉树,不对序列化之后的字符串进行约束,但要求能够根据序列化之后的字符串重新构造出一棵与原二叉树相同的树。 二叉树的序列化(Serialize)是指:把一棵二叉树按照某种遍…...

Vivado FPGA 开发 | 创建工程 / 仿真 / 烧录
注:本文为 “Vivado FPGA 开发 | 创建工程 / 仿真 / 烧录” 相关文章合辑。 略作重排,未整理去重。 如有内容异常,请看原文。 Vivado 开发流程(手把手教学实例)(FPGA) 不完美先生 于 2018-04-…...
)
每日算法刷题 Day3 5.11:leetcode数组2道题,用时1h(有点慢)
5.LC 零矩阵(中等) 面试题 01.08. 零矩阵 - 力扣(LeetCode) 思想: 法一: 利用两个集合分别储存要清0的行和列索引 另外两种原地优化空间的做法暂时不是目前刷题目标,故不考虑 代码 c: class Solution { public:void setZeroes(vector&l…...
Javascript:数组和函数
数组 创建数组 使用new创建 let arrnew array(数组大小); 直接赋值创建 let Arr2[];let Arr3[1,A,"HELLLO"]; 这里JS的数组里面的元素属性可以各不相同 演示代码 <script>let Arr1new Array(5);let Arr2[];let Arr3[1,A,"HELLLO"];console.…...
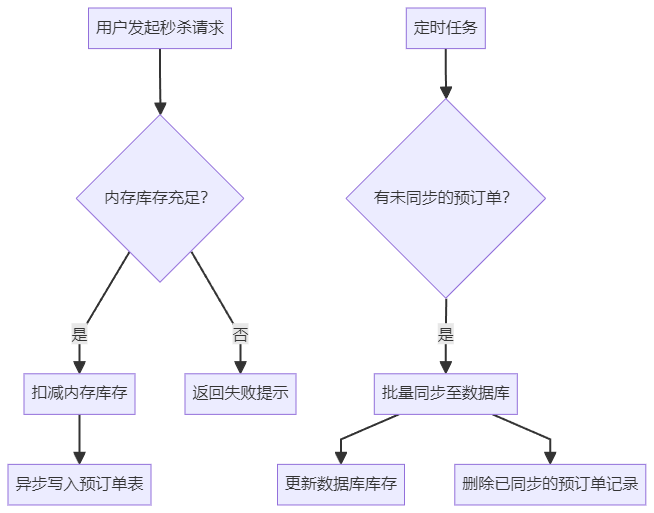
无锁秒杀系统设计:基于Java的高效实现
引言 在电商促销活动中,秒杀场景是非常常见的。为了确保高并发下的数据一致性、性能以及用户体验,本文将介绍几种不依赖 Redis 实现的无锁秒杀方案,并提供简化后的 Java 代码示例和架构图。 一、基于数据库乐观锁机制 ✅ 实现思路…...
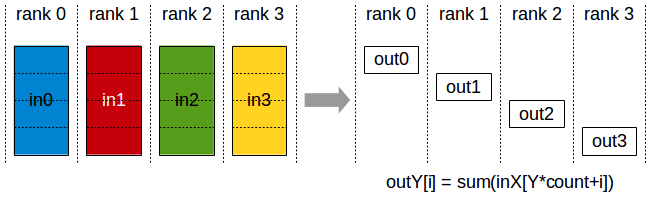
NCCL N卡通信机制
转自我的博客:https://shar-pen.github.io/2025/05/05/torch-distributed-series/nccl_communication/ from IPython.display import Image import logging import torch import torch.distributed as distpytorch 分布式相关api torch.distributed.init_process_…...

Alpha3DCS公差分析系统_国产替代的3D精度管控方案-SNK施努卡
随着智能制造发展规划的深入推进,工业软件国产化替代已上升为国家战略。在公差分析这一细分领域,长期被国外软件垄断的局面正被打破。 苏州施努卡自主研发的Alpha3DCS,凭借完全自主知识产权和军工级安全标准,成为国内实现三维公差…...
ABB电机控制和保护单元与Profibus DP主站转Modbus TCP网关快速通讯案例
ABB电机控制和保护单元与Profibus DP主站转Modbus TCP网关快速通讯案例 在现代工业自动化系统中,设备之间的互联互通至关重要。Profibus DP和Modbus TCP是两种常见的通信协议,分别应用于不同的场景。为了实现这两种协议的相互转换,Profibus …...

深入理解 Java 适配器模式:架构设计中的接口转换艺术
一、适配器模式的核心概念与设计思想 在软件开发的演进过程中,我们经常会遇到这样的场景:系统需要整合一个现有的类,但其接口与系统所需的接口不兼容。此时,适配器模式(Adapter Pattern)就成为解决接口不匹…...

skopeo工具详解
Skopeo 是一个功能强大的命令行工具,用于操作容器镜像及镜像仓库,支持多种容器镜像格式(如 Docker、OCI),能够在不下载完整镜像的情况下直接与远程仓库交互。以下是其主要功能、使用场景及操作指南: 一、核…...

vue 中的ref
vue 中的ref vue 中的ref 1. ref ** 的基本作用** 在 Vue 中,ref 是用来获取 DOM 元素或者组件实例的一种方式。对于 <el-form> 组件,通过 ref 可以获取到该表单组件的实例,进而调用表单组件提供的各种方法和访问其属性。 …...

什么是静态住宅IP?为什么静态住宅IP能提高注册通过率?
在全球最大的电商平台亚马逊上,竞争异常激烈,每一位卖家都渴望顺利通过平台的审核并成功开设店铺。在这个过程中,选择合适的IP地址成为了一个容易被忽视但至关重要的因素。静态住宅IP作为一种特殊的网络地址类型,对于提升亚马逊卖…...

数据库审计如何维护数据完整性:7 种工具和技术
在当今的数字环境中,数据库审计是维护数据完整性的一个重要方面。本文探讨了专业人员用来确保数据库系统安全性和可靠性的基本工具和技术。通过专家的独到见解,读者将发现用于监控活动、实施访问控制以及利用区块链等尖端技术进行防篡改审计的行之有效的…...

langchain 接入国内搜索api——百度AI搜索
为什么使用百度AI搜索 学习langchain的过程中,遇到使用search api的时候,发现langchain官方文档中支持的搜索工具大多是国外的,例如google search或bing search,收费不说,很多还连接不上(工具 | LangChain…...

0基础 | L298N电机驱动模块 | 使用指南
引言 在嵌入式系统开发中,电机驱动是一个常见且重要的功能。L298N是一款高电压、大电流电机驱动芯片,广泛应用于各种电机控制场景,如直流电机的正反转、调速,以及步进电机的驱动等。本文将详细介绍如何使用51单片机来控制L298N电…...

【金仓数据库征文】金仓数据库:创新驱动,引领数据库行业新未来
一、引言 在数字化转型的时代洪流中,数据已跃升为企业的核心资产,宛如企业运营与发展的 “数字命脉”。从企业日常运营的精细化管理,到战略决策的高瞻远瞩制定;从客户关系管理的深度耕耘,到供应链优化的全面协同&…...
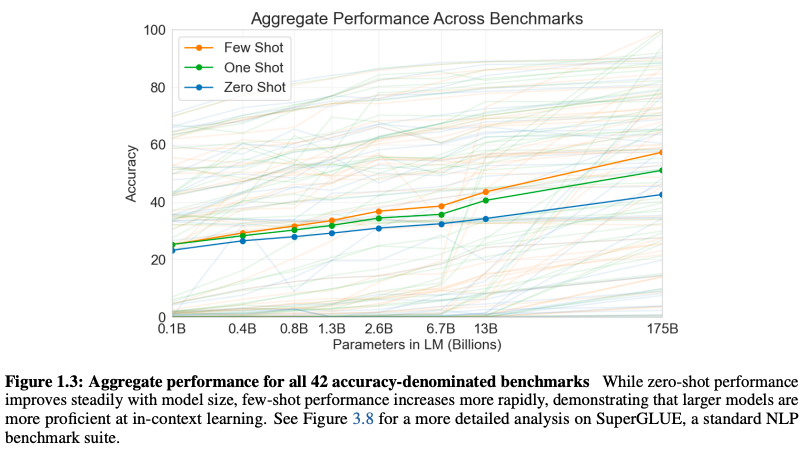
大模型系列(五)--- GPT3: Language Models are Few-Shot Learners
论文链接: Language Models are Few-Shot Learners 点评: GPT3把参数规模扩大到1750亿,且在少样本场景下性能优异。对于所有任务,GPT-3均未进行任何梯度更新或微调,仅通过纯文本交互形式接收任务描述和少量示例。然而&…...
Qt QCheckBox 使用
1.开发背景 Qt QCheckBox 是勾选组件,具体使用方法可以参考 Qt 官方文档,这里只是记录使用过程中常用的方法示例和遇到的一些问题。 2.开发需求 QCheckBox 使用和踩坑 3.开发环境 Window10 Qt5.12.2 QtCreator4.8.2 4.功能简介 4.1 简单接口 QChec…...

Java SolonMCP 实现 MCP 实践全解析:SSE 与 STDIO 通信模式详解
一、MCP简介 MCP(Model Context Protocol,模型上下文协议)是由Anthropic公司于2024年推出的开放标准,旨在统一AI模型与外部数据源、工具之间的通信方式。MCP提供了一套规范化的接口,使大语言模型(LLM&…...
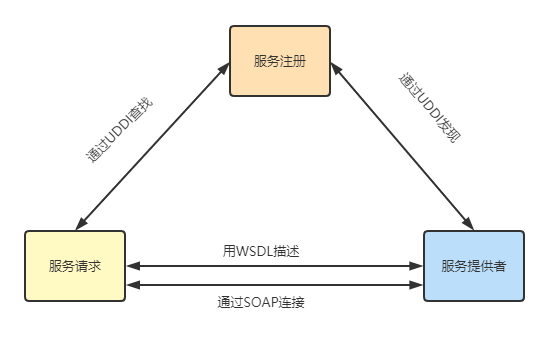
系统架构-面向服务架构(SOA)
概述 服务指的是系统对外提供的功能集 从应用的角度定义,可以认为SOA是一种应用框架,将日常业务划分为单独的业务功能和流程(即服务),SOA使用户可以构建、部署和整合这些服务。 从软件的基本原理定义,SO…...
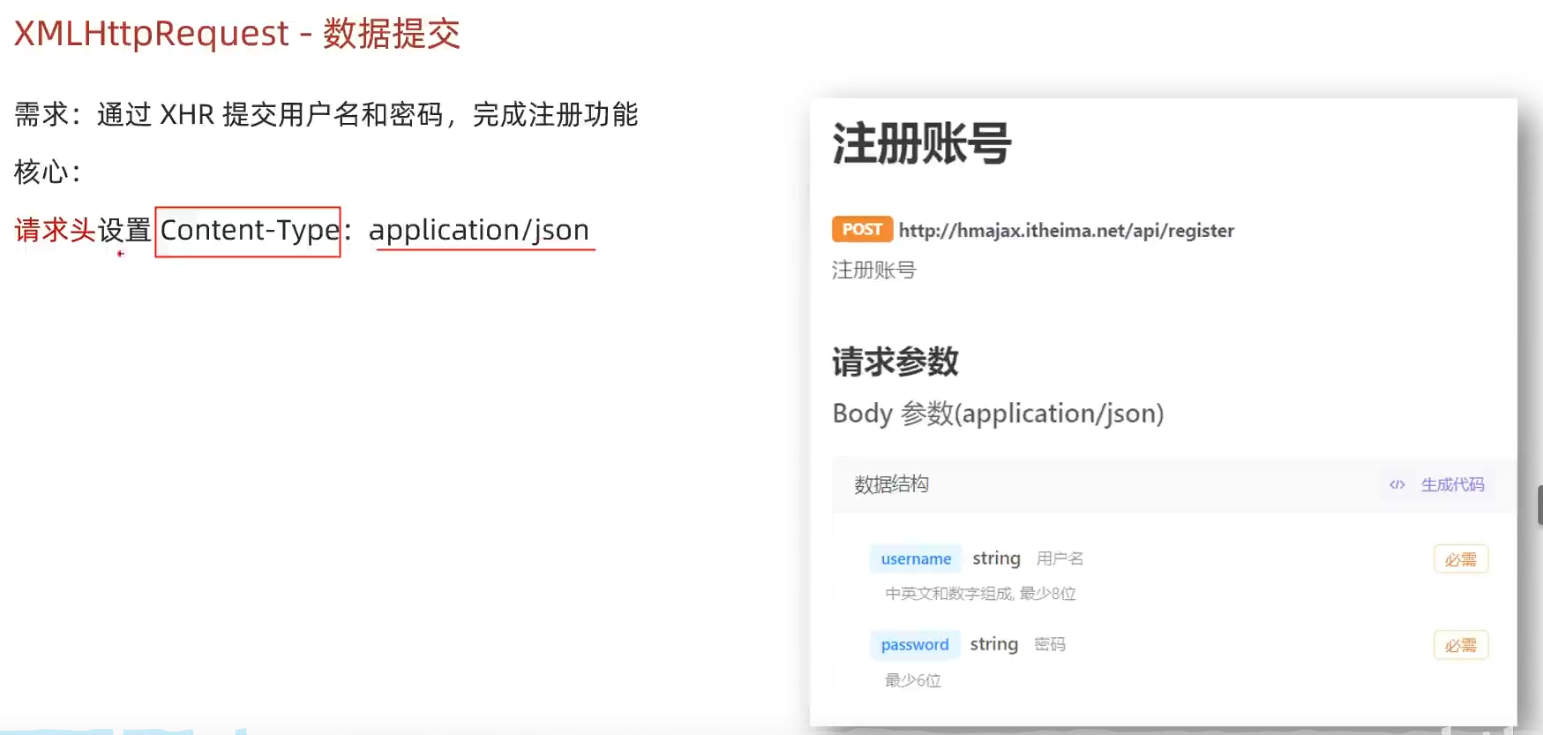
AJAX原理
AJAX使用XHR 对象和服务器进行数据交互 XHR <p class"my-p"></p><script>const xhr new XMLHttpRequest()xhr.open(GET,http://hmajax.itheima.net/api/province)xhr.addEventListener(loadend,()>{// console.log(xhr.response)const data …...

Paddle Serving|部署一个自己的OCR识别服务器
前言 之前使用C部署了自己的OCR识别服务器,Socket网络传输部分是自己写的,回过头来一看,自己犯傻了,PaddleOCR本来就有自己的OCR服务器项目,叫PaddleServing,这里记录一下部署过程。 1 下载依赖环境 1.1 …...
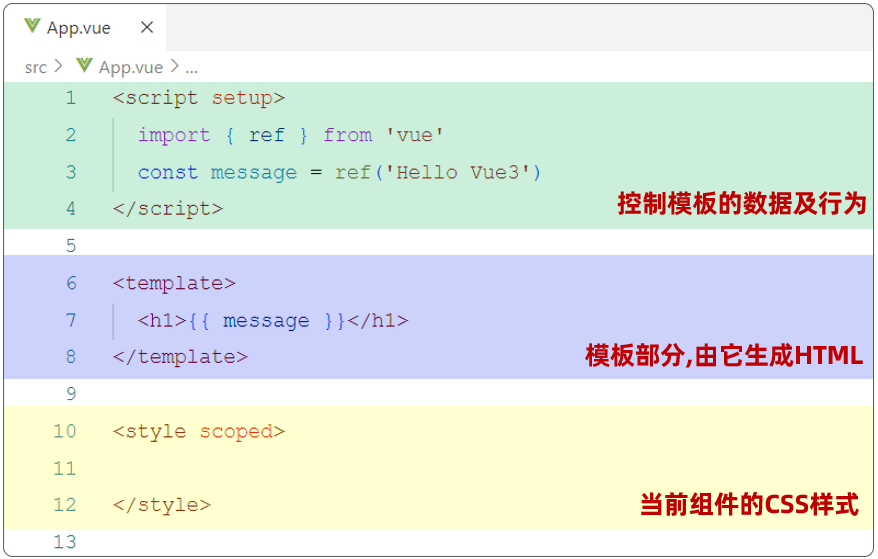
Web开发—Vue工程化
文章目录 前言 Vue工程化 一、介绍 二、环境准备 1.介绍create-vue 2.NodeJS安装 3.npm介绍 三,Vue项目创建 四,项目结构 五,启动项目 六,Vue项目开发流程 七,API风格 前言 Vue工程化 前面我们在介绍Vue的时候&#…...
Word如何制作三线表格
1.需求 将像这样的表格整理成论文中需要的三线表格。 2.直观流程 选中表格 --> 表格属性中的边框与底纹B --> 在设置中选择无(重置表格)–> 确定 --> 选择第一行(其实是将第一行看成独立表格了,为了设置中线&…...

毫米波雷达点云SLAM系统
毫米波雷达点云SLAM系统 基于毫米波雷达点云数据的三维SLAM(同步定位与建图)系统,用于狭窄环境如室内和地下隧道的三维建图。 项目概述 本项目实现了一个完整的SLAM系统,利用毫米波雷达采集的点云数据进行实时定位和环境三维重建。系统特别针对狭窄空…...