NCCL N卡通信机制
转自我的博客:https://shar-pen.github.io/2025/05/05/torch-distributed-series/nccl_communication/
from IPython.display import Image
import logging
import torch
import torch.distributed as dist
pytorch 分布式相关api
torch.distributed.init_process_group(),初始化进程组,必须先用这条命令才能使用torch.distrubuted相关操作。torch.distributed.get_rank(),可以获得当前进程的 rank;torch.distributed.get_world_size(),可以获得进程组的进程数量。torch.distributed.barrier(),同步进程组内的所有进程,阻塞所有进程直到所有进程都执行到操作。
节点获取信息
def main():dist.init_process_group("nccl")rank = dist.get_rank()world_size = dist.get_world_size()logging.info(f'world size: {world_size}, rank: {rank}')dist.destroy_process_group()
命令: torchrun --nproc_per_node 2 torch_nccl_test.py
输出结果为
INFO:root:world size: 2, rank: 0
INFO:root:world size: 2, rank: 1
scatter
Image(url='https://i-blog.csdnimg.cn/img_convert/3aa3584628cb0526c8b0e9d02b15d876.png', width=400)
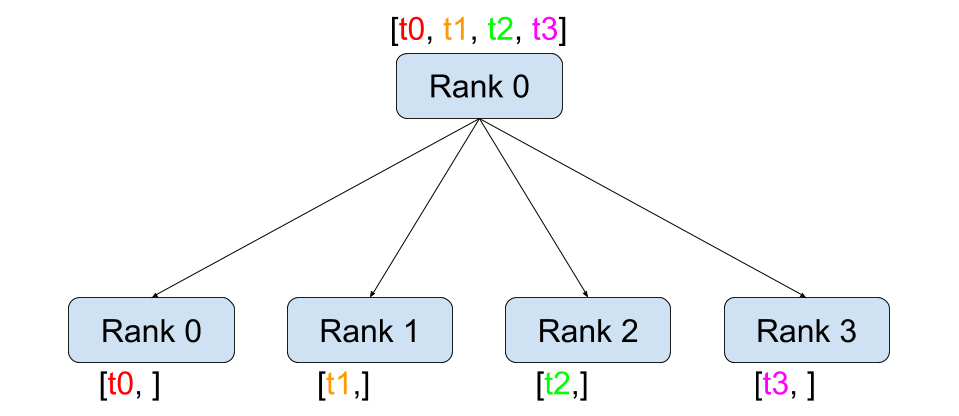
def dist_scatter():dist.barrier()rank = dist.get_rank()world_size = dist.get_world_size()if rank == 0:logging.info(f"rank: {rank} is scattering data")tensor = torch.zeros(world_size)before_tensor = tensor.clone()if dist.get_rank() == 0:# Assumes world_size of 2.# Only tensors, all of which must be the same size.t_ones = torch.ones(world_size)t_fives = torch.ones(world_size) * 5# [[1, 1], [5, 5]]scatter_list = [t_ones, t_fives]else:scatter_list = Nonedist.scatter(tensor, scatter_list, src=0)logging.info(f"scatter, rank: {rank}, before scatter: {repr(before_tensor)} after scatter: {repr(tensor)}")dist.barrier()
scatter 的用法就是从某个节点把数据分散到所有节点,包括自己。scatter_list 本身两个数组,在指定 src=0 (source)(由 rank 0 来分散数据)时,scatter_list数据被分别发送给 rank 0 和 rank 1,最终赋值到 tensor 上。
INFO:root:rank: 0 is scattering data
INFO:root:scatter, rank: 1, before scatter: tensor([0., 0.], device='cuda:1') after scatter: tensor([5., 5.], device='cuda:1')
INFO:root:scatter, rank: 0, before scatter: tensor([0., 0.], device='cuda:0') after scatter: tensor([1., 1.], device='cuda:0')
gather
Image(url='https://i-blog.csdnimg.cn/img_convert/7e8670a3b7cdc7848394514ef1da090a.png', width=400)
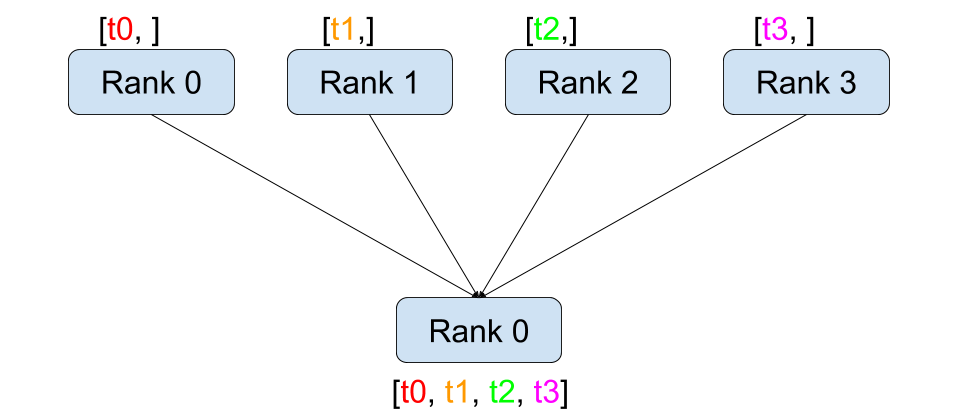
def dist_gather():dist.barrier()rank = dist.get_rank()world_size = dist.get_world_size()tensor = torch.tensor([rank], dtype=torch.float32)before_tensor = tensor.clone()gather_list = [torch.zeros(1) for _ in range(world_size)] if rank == 0 else Nonedist.gather(tensor, gather_list, dst=0)logging.info(f"gather, rank: {rank}, before gather: {repr(before_tensor)} after gather: {repr(gather_list)}")dist.barrier()
gather 的作用是 scatter 相反作用的,让所有 rank 上的 tensor 收集到 rank 为 dst (destination) 的卡上
INFO:root:gather, rank: 0, before gather: tensor([0.], device='cuda:0') after gather: [tensor([0.], device='cuda:0'), tensor([1.], device='cuda:0')]
INFO:root:gather, rank: 1, before gather: tensor([1.], device='cuda:1') after gather: None
broadcast
Image(url='https://i-blog.csdnimg.cn/img_convert/525847c9d4b48933cb231204a2d13e0e.png', width=400)
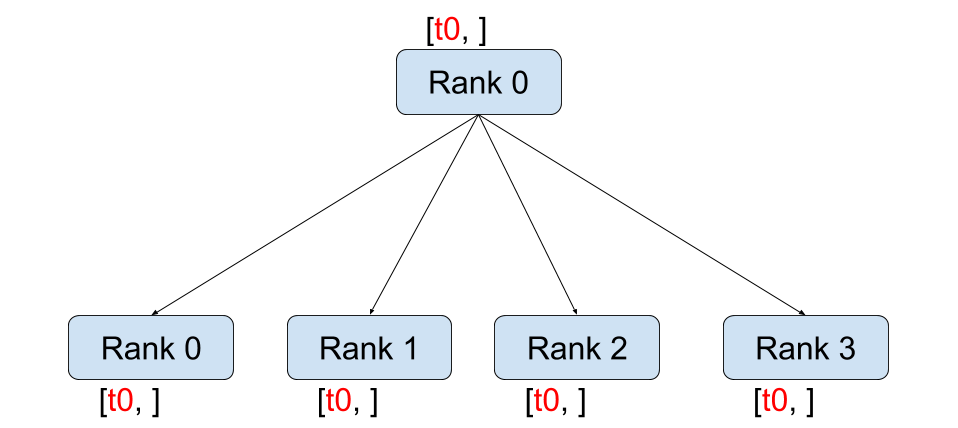
def dist_broadcast():dist.barrier()rank = dist.get_rank()world_size = dist.get_world_size()src_rank = 0tensor = torch.tensor(rank)before_tensor = tensor.clone()dist.broadcast(tensor, src=src_rank)logging.info(f"broadcast, rank: {rank}, before broadcast tensor: {repr(before_tensor)} after broadcast tensor: {repr(tensor)}")dist.barrier()
broadcast 的作用就是把 rank 为 src_rank 的 tensor 广播到其他 rank 上。
INFO:root:broadcast, rank: 1, before broadcast tensor: tensor(1, device='cuda:1') after broadcast tensor: tensor(0, device='cuda:1')
INFO:root:broadcast, rank: 2, before broadcast tensor: tensor(2, device='cuda:2') after broadcast tensor: tensor(0, device='cuda:2')
INFO:root:broadcast, rank: 3, before broadcast tensor: tensor(3, device='cuda:3') after broadcast tensor: tensor(0, device='cuda:3')
INFO:root:broadcast, rank: 0, before broadcast tensor: tensor(0, device='cuda:0') after broadcast tensor: tensor(0, device='cuda:0')
reduce
Image(url='https://i-blog.csdnimg.cn/img_convert/a9ef6dbfcf0761f7fb20154c4db4d3f2.png', width=400)
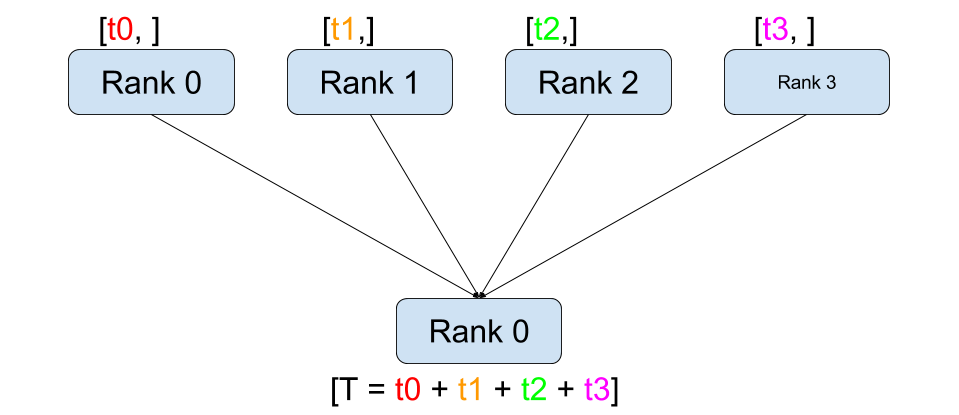
from torch.distributed import ReduceOpdef dist_reduce():dist.barrier()rank = dist.get_rank()world_size = dist.get_world_size()tensor = torch.tensor([rank], dtype=torch.float32)before_tensor = tensor.clone()dist.reduce(tensor, op=ReduceOp.SUM, dst=0)logging.info(f"reduce, rank: {rank}, before reduce: {repr(before_tensor)} after reduce: {repr(tensor)}")dist.barrier()
reduce 的作用和 gather 类似,都是把所有卡上数据集合到某个卡上,但不会组合为 list,会直接对这些数据进行结合式的计算。
INFO:root:reduce, rank: 1, before reduce: tensor([1.], device='cuda:1') after reduce: tensor([1.], device='cuda:1')
INFO:root:reduce, rank: 0, before reduce: tensor([0.], device='cuda:0') after reduce: tensor([6.], device='cuda:0')
INFO:root:reduce, rank: 2, before reduce: tensor([2.], device='cuda:2') after reduce: tensor([2.], device='cuda:2')
INFO:root:reduce, rank: 3, before reduce: tensor([3.], device='cuda:3') after reduce: tensor([3.], device='cuda:3')
rank 0 上的 tensor 值为 0+1+2+3 = 6
all-reduce
Image(url='https://i-blog.csdnimg.cn/img_convert/8172236b90e6b20b75b2428bb4376adc.png', width=400)
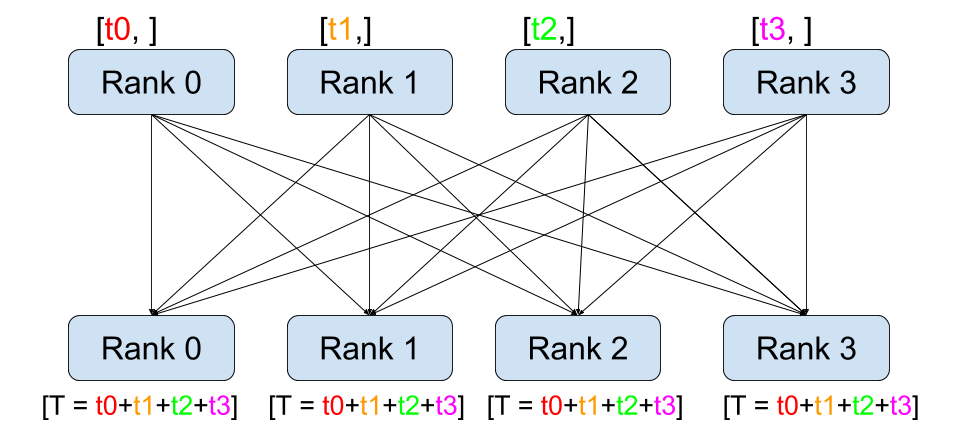
def dist_allreduce():print_rank_0("all_reduce:")dist.barrier()rank = dist.get_rank()# world_size = torch.distributed.get_world_size()tensor = torch.tensor([rank], dtype=torch.float32)input_tensor = tensor.clone()dist.all_reduce(tensor)logging.info(f"all_reduce, rank: {rank}, before allreduce tensor: {repr(input_tensor)}, after allreduce tensor: {repr(tensor)}")dist.barrier()
all_reduce 相当于 reduce + broadcast,all 体现在所有 rank 都要执行所有操作,可以视为 reduce + broadcast,实际应该是所有 rank 都执行 reduce。
INFO:root:all_reduce, rank: 0, before allreduce tensor: tensor([0.], device='cuda:0'), after allreduce tensor: tensor([6.], device='cuda:0')
INFO:root:all_reduce, rank: 2, before allreduce tensor: tensor([2.], device='cuda:2'), after allreduce tensor: tensor([6.], device='cuda:2')
INFO:root:all_reduce, rank: 1, before allreduce tensor: tensor([1.], device='cuda:1'), after allreduce tensor: tensor([6.], device='cuda:1')
INFO:root:all_reduce, rank: 3, before allreduce tensor: tensor([3.], device='cuda:3'), after allreduce tensor: tensor([6.], device='cuda:3')
all gather
Image(url='https://i-blog.csdnimg.cn/img_convert/4a48977cd9545f897942a4a4ef1175ac.png', width=400)
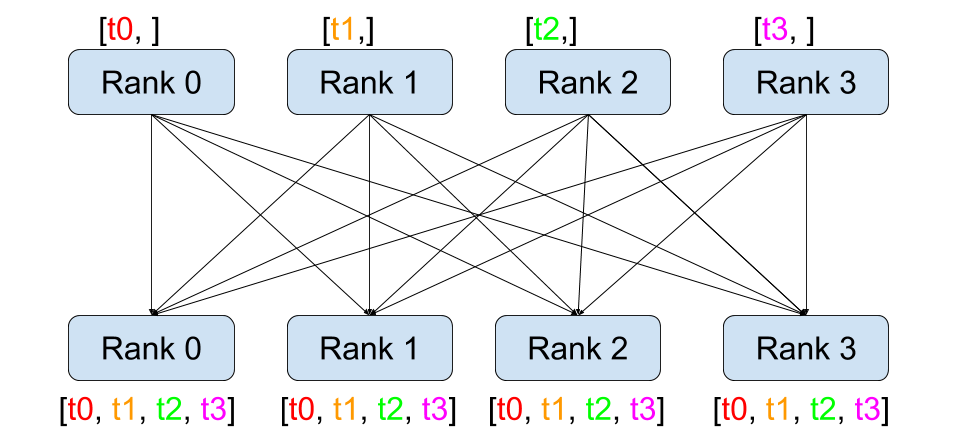
def dist_allgather():dist.barrier()rank = dist.get_rank()world_size = dist.get_world_size()input_tensor = torch.tensor(rank)tensor_list = [torch.zeros(1, dtype=torch.int64) for _ in range(world_size)]dist.all_gather(tensor_list, input_tensor)logging.info(f"allgather, rank: {rank}, input_tensor: {repr(input_tensor)}, output tensor_list: {tensor_list}")dist.barrier()
all_gather 也是类似所有 rank 执行 gather
INFO:root:allgather, rank: 0, input_tensor: tensor(0, device='cuda:0'), output tensor_list: [tensor([0], device='cuda:0'), tensor([1], device='cuda:0')]
INFO:root:allgather, rank: 1, input_tensor: tensor(1, device='cuda:1'), output tensor_list: [tensor([0], device='cuda:1'), tensor([1], device='cuda:1')]
reduce-scatter
Image(url='https://i-blog.csdnimg.cn/img_convert/66ea136cfe7f3e7394fd0b056fd9d949.png', width=400)
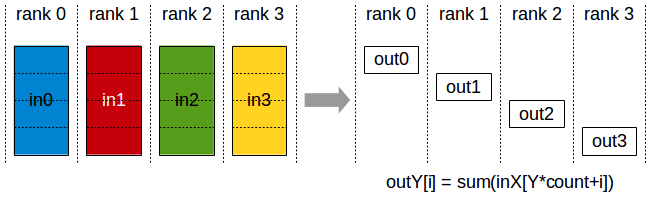
def dist_reducescatter():dist.barrier()rank = dist.get_rank()world_size = dist.get_world_size()output = torch.empty(1, dtype=torch.int64)input_list = [torch.tensor(rank*2+1), torch.tensor(rank*2+2)]dist.reduce_scatter(output, input_list, op=ReduceOp.SUM)dist.barrier()logging.info(f"reduce_scatter, rank: {rank}, input_list: {input_list}, tensor: {repr(output)}")dist.barrier()
reduce_scatter 是每个 rank 上都有完整的数据,但 reduce 后再 scatter 到所有 rank 上。
INFO:root:reduce_scatter, rank: 0, input_list: [tensor(1, device='cuda:0'), tensor(2, device='cuda:0')], tensor: tensor([4], device='cuda:0')
INFO:root:reduce_scatter, rank: 1, input_list: [tensor(3, device='cuda:1'), tensor(4, device='cuda:1')], tensor: tensor([6], device='cuda:1')
rank 0 上是 [1,2], rank 1 上是 [3,4], 执行 reduce 效果是 [4,6], 再加上 scatter 效果变成了 rank 0 上是 4, rank 1 上是 6。
相关文章:
NCCL N卡通信机制
转自我的博客:https://shar-pen.github.io/2025/05/05/torch-distributed-series/nccl_communication/ from IPython.display import Image import logging import torch import torch.distributed as distpytorch 分布式相关api torch.distributed.init_process_…...

Alpha3DCS公差分析系统_国产替代的3D精度管控方案-SNK施努卡
随着智能制造发展规划的深入推进,工业软件国产化替代已上升为国家战略。在公差分析这一细分领域,长期被国外软件垄断的局面正被打破。 苏州施努卡自主研发的Alpha3DCS,凭借完全自主知识产权和军工级安全标准,成为国内实现三维公差…...
ABB电机控制和保护单元与Profibus DP主站转Modbus TCP网关快速通讯案例
ABB电机控制和保护单元与Profibus DP主站转Modbus TCP网关快速通讯案例 在现代工业自动化系统中,设备之间的互联互通至关重要。Profibus DP和Modbus TCP是两种常见的通信协议,分别应用于不同的场景。为了实现这两种协议的相互转换,Profibus …...

深入理解 Java 适配器模式:架构设计中的接口转换艺术
一、适配器模式的核心概念与设计思想 在软件开发的演进过程中,我们经常会遇到这样的场景:系统需要整合一个现有的类,但其接口与系统所需的接口不兼容。此时,适配器模式(Adapter Pattern)就成为解决接口不匹…...

skopeo工具详解
Skopeo 是一个功能强大的命令行工具,用于操作容器镜像及镜像仓库,支持多种容器镜像格式(如 Docker、OCI),能够在不下载完整镜像的情况下直接与远程仓库交互。以下是其主要功能、使用场景及操作指南: 一、核…...

vue 中的ref
vue 中的ref vue 中的ref 1. ref ** 的基本作用** 在 Vue 中,ref 是用来获取 DOM 元素或者组件实例的一种方式。对于 <el-form> 组件,通过 ref 可以获取到该表单组件的实例,进而调用表单组件提供的各种方法和访问其属性。 …...

什么是静态住宅IP?为什么静态住宅IP能提高注册通过率?
在全球最大的电商平台亚马逊上,竞争异常激烈,每一位卖家都渴望顺利通过平台的审核并成功开设店铺。在这个过程中,选择合适的IP地址成为了一个容易被忽视但至关重要的因素。静态住宅IP作为一种特殊的网络地址类型,对于提升亚马逊卖…...

数据库审计如何维护数据完整性:7 种工具和技术
在当今的数字环境中,数据库审计是维护数据完整性的一个重要方面。本文探讨了专业人员用来确保数据库系统安全性和可靠性的基本工具和技术。通过专家的独到见解,读者将发现用于监控活动、实施访问控制以及利用区块链等尖端技术进行防篡改审计的行之有效的…...

langchain 接入国内搜索api——百度AI搜索
为什么使用百度AI搜索 学习langchain的过程中,遇到使用search api的时候,发现langchain官方文档中支持的搜索工具大多是国外的,例如google search或bing search,收费不说,很多还连接不上(工具 | LangChain…...

0基础 | L298N电机驱动模块 | 使用指南
引言 在嵌入式系统开发中,电机驱动是一个常见且重要的功能。L298N是一款高电压、大电流电机驱动芯片,广泛应用于各种电机控制场景,如直流电机的正反转、调速,以及步进电机的驱动等。本文将详细介绍如何使用51单片机来控制L298N电…...

【金仓数据库征文】金仓数据库:创新驱动,引领数据库行业新未来
一、引言 在数字化转型的时代洪流中,数据已跃升为企业的核心资产,宛如企业运营与发展的 “数字命脉”。从企业日常运营的精细化管理,到战略决策的高瞻远瞩制定;从客户关系管理的深度耕耘,到供应链优化的全面协同&…...
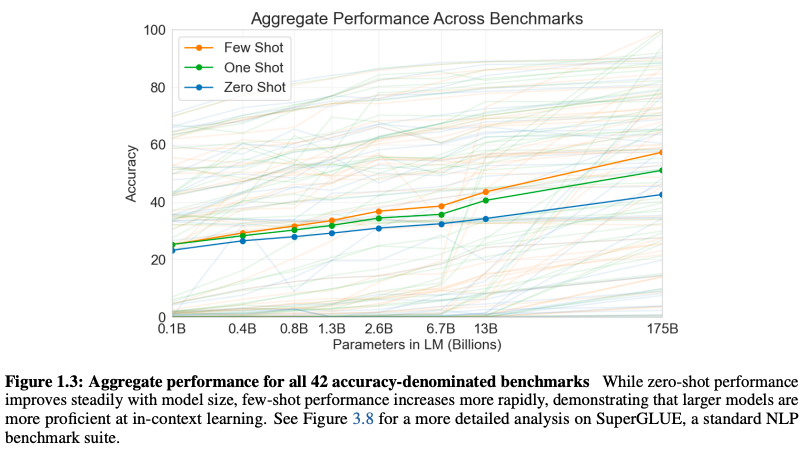
大模型系列(五)--- GPT3: Language Models are Few-Shot Learners
论文链接: Language Models are Few-Shot Learners 点评: GPT3把参数规模扩大到1750亿,且在少样本场景下性能优异。对于所有任务,GPT-3均未进行任何梯度更新或微调,仅通过纯文本交互形式接收任务描述和少量示例。然而&…...
Qt QCheckBox 使用
1.开发背景 Qt QCheckBox 是勾选组件,具体使用方法可以参考 Qt 官方文档,这里只是记录使用过程中常用的方法示例和遇到的一些问题。 2.开发需求 QCheckBox 使用和踩坑 3.开发环境 Window10 Qt5.12.2 QtCreator4.8.2 4.功能简介 4.1 简单接口 QChec…...

Java SolonMCP 实现 MCP 实践全解析:SSE 与 STDIO 通信模式详解
一、MCP简介 MCP(Model Context Protocol,模型上下文协议)是由Anthropic公司于2024年推出的开放标准,旨在统一AI模型与外部数据源、工具之间的通信方式。MCP提供了一套规范化的接口,使大语言模型(LLM&…...
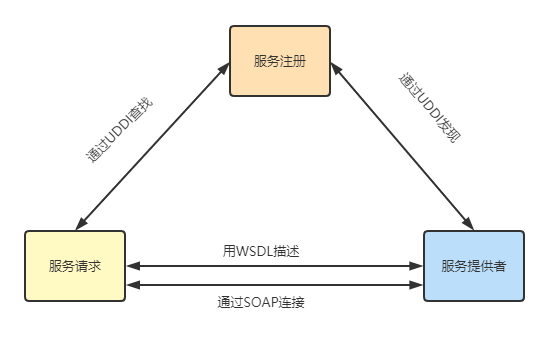
系统架构-面向服务架构(SOA)
概述 服务指的是系统对外提供的功能集 从应用的角度定义,可以认为SOA是一种应用框架,将日常业务划分为单独的业务功能和流程(即服务),SOA使用户可以构建、部署和整合这些服务。 从软件的基本原理定义,SO…...
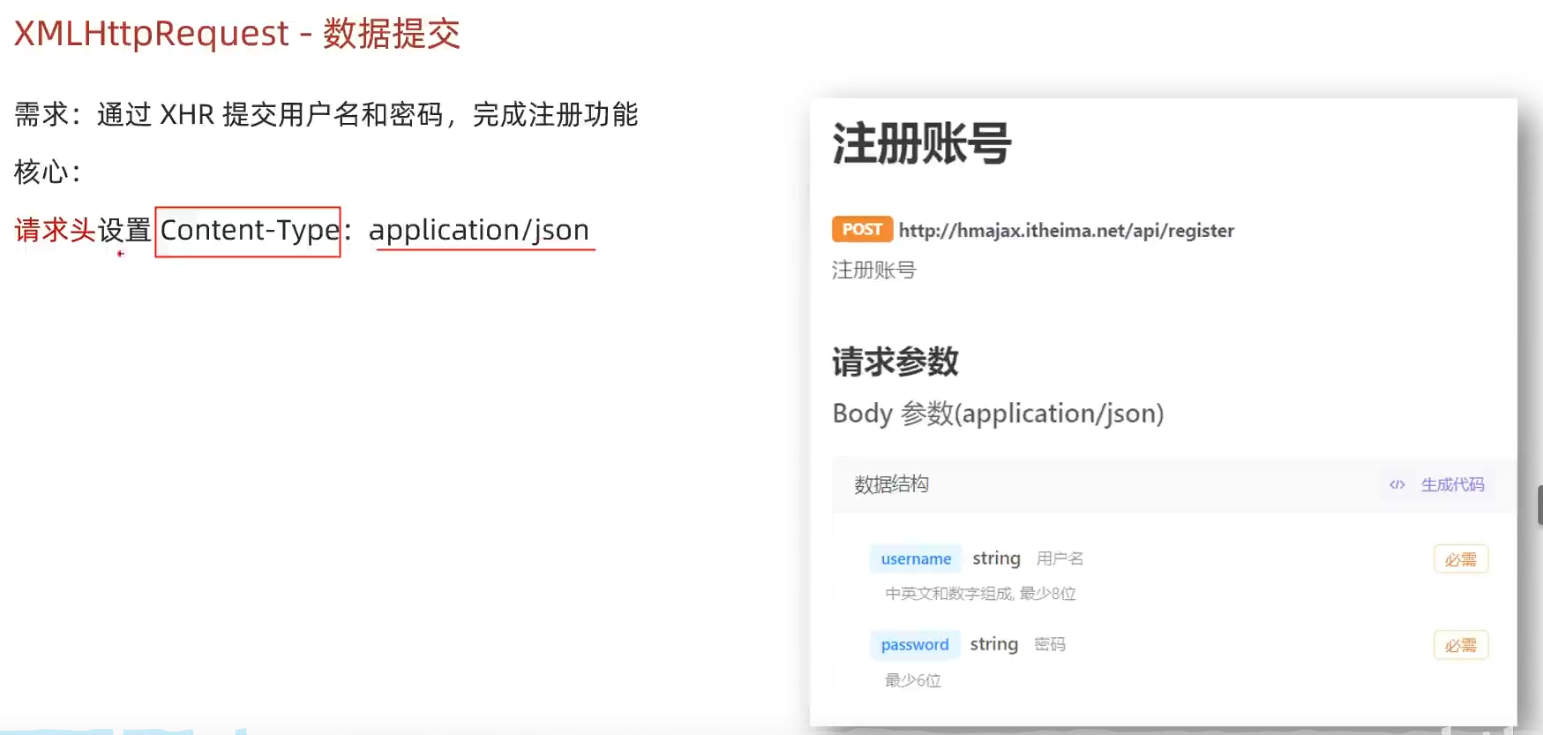
AJAX原理
AJAX使用XHR 对象和服务器进行数据交互 XHR <p class"my-p"></p><script>const xhr new XMLHttpRequest()xhr.open(GET,http://hmajax.itheima.net/api/province)xhr.addEventListener(loadend,()>{// console.log(xhr.response)const data …...

Paddle Serving|部署一个自己的OCR识别服务器
前言 之前使用C部署了自己的OCR识别服务器,Socket网络传输部分是自己写的,回过头来一看,自己犯傻了,PaddleOCR本来就有自己的OCR服务器项目,叫PaddleServing,这里记录一下部署过程。 1 下载依赖环境 1.1 …...
Web开发—Vue工程化
文章目录 前言 Vue工程化 一、介绍 二、环境准备 1.介绍create-vue 2.NodeJS安装 3.npm介绍 三,Vue项目创建 四,项目结构 五,启动项目 六,Vue项目开发流程 七,API风格 前言 Vue工程化 前面我们在介绍Vue的时候&#…...
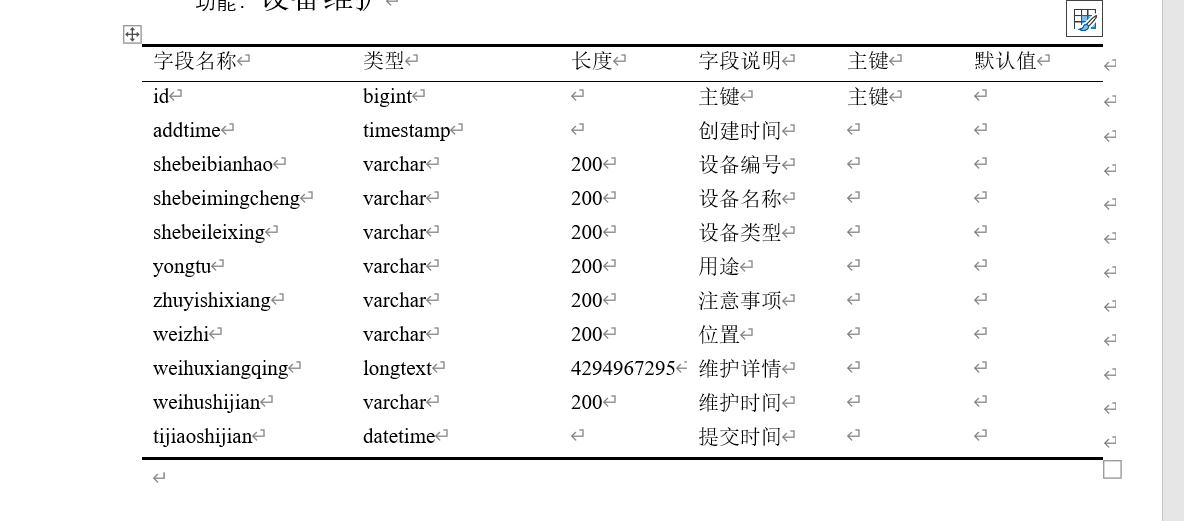
Word如何制作三线表格
1.需求 将像这样的表格整理成论文中需要的三线表格。 2.直观流程 选中表格 --> 表格属性中的边框与底纹B --> 在设置中选择无(重置表格)–> 确定 --> 选择第一行(其实是将第一行看成独立表格了,为了设置中线&…...

毫米波雷达点云SLAM系统
毫米波雷达点云SLAM系统 基于毫米波雷达点云数据的三维SLAM(同步定位与建图)系统,用于狭窄环境如室内和地下隧道的三维建图。 项目概述 本项目实现了一个完整的SLAM系统,利用毫米波雷达采集的点云数据进行实时定位和环境三维重建。系统特别针对狭窄空…...

5 从众效应
引言 有一个成语叫做三人成虎,意思是说,有三个人谎报市上有老虎,听者就信以为真。这种人在社会群体中,容易不加分析地接受大多数人认同的观点或行为的心理倾向,被称为从众效应。 从众效应(Bandwagon Effec…...

【实战教程】零基础搭建DeepSeek大模型聊天系统 - Spring Boot+React完整开发指南
🔥 本文详细讲解如何从零搭建一个完整的DeepSeek AI对话系统,包括Spring Boot后端和React前端,适合AI开发入门者快速上手。即使你是编程萌新,也能轻松搭建自己的AI助手! 📚博主匠心之作,强推专栏…...
用C语言实现的——一个支持完整增删查改功能的二叉排序树BST管理系统,通过控制台实现用户与数据结构的交互操作。
一、知识回顾 二叉排序树(Binary Search Tree,BST),又称二叉查找树或二叉搜索树,是一种特殊的二叉树数据结构。 基本性质: ①有序性 对于树中的每个节点,其左子树中所有节点的值都小于该节点的…...

排队论基础一:马尔可夫排队模型
排队论基础一:马尔可夫排队模型 介绍基本概念状态概率分布平均队列人数与平均排队人数平均停留时间与平均等待时间Little公式(Little Law)生灭过程生灭过程排队系统(马尔可夫排队模型)状态平衡方程介绍 最近写论文需要,学了一下排队过程模型。其实这些内容本科的时候我都…...
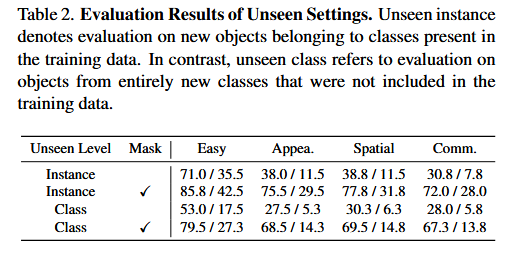
论文阅读笔记——ROBOGROUND: Robotic Manipulation with Grounded Vision-Language Priors
RoboGround 论文 一类中间表征是语言指令,但对于空间位置描述过于模糊(“把杯子放桌上”但不知道放桌上哪里);另一类是目标图像或点流,但是开销大;由此 GeoDEX 提出一种兼具二者的掩码。 相比于 GR-1&#…...
:架构风格总结)
系统架构设计(四):架构风格总结
黑板 概念 黑板体系架构是一种用于求解复杂问题的软件架构风格,尤其适合知识密集型、推理驱动、数据不确定性大的场景。 它模拟了人类专家协同解决问题的方式,通过一个共享的“黑板”协同多个模块(专家)逐步构建解决方案。 组…...
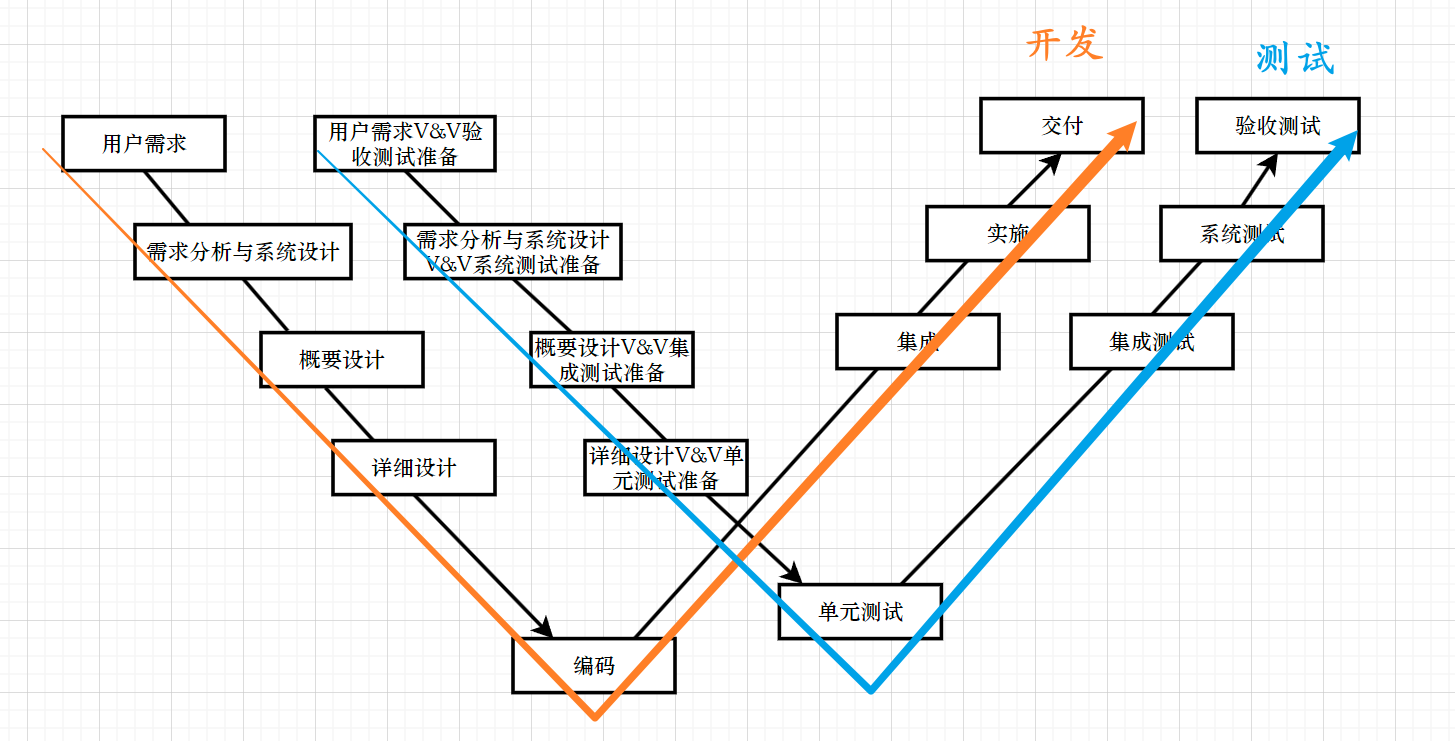
『 测试 』测试基础
文章目录 1. 调试与测试的区别2. 开发过程中的需求3. 开发模型3.1 软件的生命周期3.2 瀑布模型3.2.1 瀑布模型的特点/缺点 3.3 螺旋模型3.3.1 螺旋模型的特点/缺点 3.4 增量模型与迭代模型3.5 敏捷模型3.5.1 Scrum模型3.5.2 敏捷模型中的测试 4 测试模型4.1 V模型4.2 W模型(双V…...

robomaster机甲大师--电调电机
文章目录 C620电调ID设置速率 电调发送报文电调接收报文cubemx程序初始化发送接收 C620电调 ID设置 速率 1Mbps 电调发送报文 发送的数据为控制电机的输出电流,需要将can数据帧的ID设置为0x200 电调接收报文 机械角度:电机的0到360度映射到0到几千转…...

汽车诊断简介
历史 20世纪80年代,由于美国西海岸严重的雾霾问题,CARB(加州空气资源委员会)通过了一项法律,要求对机动车辆进行车载监测诊断。这推动了OBD-I的引入,并在1990年代被OBD II取代。与此同时,欧洲也…...

少儿编程机构用的教务系统
在编程教育行业快速发展的今天,培训机构面临着学员管理复杂、课程体系专业性强、教学效果难以量化等独特挑战。爱耕云教务系统针对编程培训机构的特殊需求,提供了一套全方位的数字化解决方案,帮助机构实现高效运营和教学质量提升。 为什么编…...