用C语言实现的——一个支持完整增删查改功能的二叉排序树BST管理系统,通过控制台实现用户与数据结构的交互操作。
一、知识回顾
二叉排序树(Binary Search Tree,BST),又称二叉查找树或二叉搜索树,是一种特殊的二叉树数据结构。
基本性质:
①有序性
对于树中的每个节点,其左子树中所有节点的值都小于该节点的值。
其右子树中所有节点的值都大于该节点的值。
②子树递归性
左子树和右子树也都是二叉排序树。
基本操作的时间复杂度

优点:
高效性:在平衡情况下,查找、插入和删除操作的时间复杂度均为 O(logn),效率较高。
动态性:支持动态插入和删除操作,便于数据的增删改查。
缺点:
最坏情况退化:如果插入的数据是有序的,可能导致树退化为链表,此时时间复杂度变为 O(n)。
额外内存开销:每个节点需要存储左右子节点的指针,增加了内存开销。
应用场景:
动态查找表:适用于需要频繁插入、删除和查找的数据集合。
排序算法:通过中序遍历可以得到一个有序序列。
文件系统:用于文件的快速检索和管理。
二叉排序树的结构和操作使其在需要高效查找和动态更新的场景中具有广泛的应用价值。
二、代码分析
1.二叉树节点结构体定义Node

typedef struct Node 创建了一个新的数据类型 Node,用于表示二叉树中的节点。
int data:用于存储节点的数据或值。
struct Node* left:一个指向该节点左孩子节点的指针。
struct Node* right:一个指向该节点右孩子节点的指针。
2. 创建二叉树节点createNode
函数createNode:
用于创建一个新的二叉树节点。函数接收一个整型参数data,表示节点要存储的数据。
作用:是分配内存、初始化节点并返回节点的指针。
① 使用malloc为新的Node结构体分配内存。如果分配成功,返回一个指向该内存的指针转换为
Node*类型。
② 检查newNode是否为NULL,如果是NULL,说明内存分配失败,打印错误信息并返回NULL。
③ 如果内存分配成功,将data赋值给newNode->data。
④ 将左子节点指针newNode->left和右子节点指针newNode->right初始化为NULL,表明新节点初
始时没有左右子节点。
⑤ 最后返回创建好的新节点指针。
3. 插入操作insert
函数作用:
该函数用于将一个新的数据值插入到二叉排序树中,
同时保持二叉排序树的性质:
对于树中的每个节点,其左子树中所有节点的值都小于该节点的值。
其右子树中所有节点的值都大于该节点的值。
参数说明:
Node* root:指向当前树的根节点的指针。如果树为空,root 为 NULL。
int data:要插入的新数据值。


如果 root 为 NULL,说明当前树为空,因此直接创建一个新节点并返回它作为根节点。这是通过调用 createNode(data) 实现的。

如果 data 小于 root->data,则递归地将数据插入到 root 的左子树中。
如果 data 大于 root->data,则递归地将数据插入到 root 的右子树中。
这样可以确保在插入过程中保持二叉排序树的性质。
最后,函数返回当前树的根节点,以便在递归调用中更新父节点的左或右子节点。
4.查找最小值节点的函数 findMin

通过一个 while 循环持续向左遍历树。只要当前节点的左子节点不为空,就将当前节点更新为它的左子节点。
当循环结束时,当前节点就是树中最左的节点,也就是值最小的节点,直接返回该节点。
二叉排序树中的最小值节点一定是最左的节点,因为每次向左移动都会找到更小的值。所以,通过从根节点开始,不断向左子节点遍历,直到左子节点为 NULL 为止,此时当前节点就是整个树的最小值节点。
5.删除函数delete
删除操作需要处理以下三种情况:
①要删除的节点不存在于树中:直接返回原树。
②要删除的节点存在:
a. 节点没有子节点(叶子节点):直接删除该节点。
b. 节点有一个子节点:用其子节点替换该节点。
c. 节点有两个子节点:用其右子树的最小值节点替换该节点,并递归删除右子树中的这个最小值节点。
参数说明:
Node* root:指向当前树的根节点的指针。
int data:要删除的节点的数据值。

1. 查找要删除的节点:
如果 root 为 NULL,说明树中没有要删除的节点,直接返回 NULL。
如果 data 小于 root->data,递归地在左子树中查找并删除。
如果 data 大于 root->data,递归地在右子树中查找并删除。
2.节点找到后的处理:
情况1:节点没有左子节点:
将右子节点存储在临时变量 temp 中。
释放当前节点的内存。
返回 temp 作为新的子树根节点。
情况2:节点没有右子节点:
将左子节点存储在临时变量 temp 中。
释放当前节点的内存。
返回 temp 作为新的子树根节点。
情况3:节点有两个子节点:
找到右子树中的最小值节点(findMin(root->right))。
将当前节点的数据替换为这个最小值。
递归地删除右子树中的这个最小值节点。
最后返回当前树的根节点,以便在递归调用中更新父节点的左或右子节点。
6. 搜索操作search
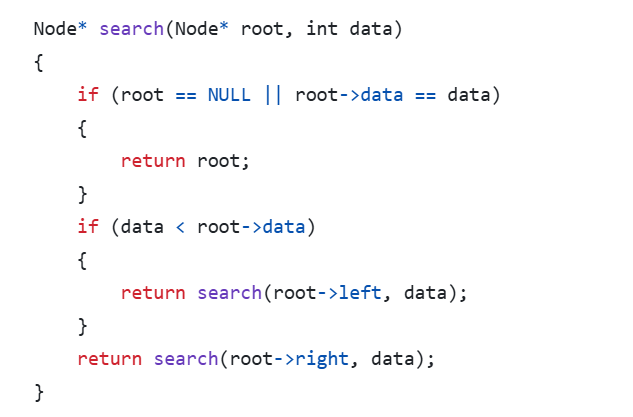
终止条件:
如果当前节点为空(root == NULL),说明查找路径已到达树的尽头,未找到目标值,返回 NULL如果当前节点的值等于目标值(root->data == data),返回当前节点指针。
递归查找:
如果目标值小于当前节点值,递归在左子树中查找。
否则,递归在右子树中查找。
7.先序遍历preOrder

根节点 → 左子树 → 右子树”的顺序访问节点
空树判断:函数首先检查传入的根节点是否为空(if (root != NULL))。如果根节点为空,说明树为空或已遍历到叶子节点的子节点,此时直接返回,不再进行后续操作。
访问根节点:如果根节点不为空,先打印当前根节点的数据(printf("%d ", root->data))。
递归遍历左子树:然后递归调用 preOrder 函数,传入根节点的左子节点(preOrder(root->left)),对左子树进行先序遍历。
递归遍历右子树:最后递归调用 preOrder 函数,传入根节点的右子节点(preOrder(root->right)),对右子树进行先序遍历。
8.中序遍历inOeder

中序遍历的顺序是“左子树 → 根节点 → 右子树”,在二叉排序树中,这种遍历方式可以按升序输出所有节点的值。
空树判断:函数先检查传入的根节点是否为空(if (root != NULL))。如果为空,直接返回,结束当前递归调用。
递归左子树:如果根节点不为空,先递归调用 inOrder 遍历左子树(inOrder(root->left))。
访问根节点:遍历完左子树后,打印当前根节点的值(printf("%d ", root->data))。
递归右子树:最后递归调用 inOrder 遍历右子树(inOrder(root->right))。
9.后续遍历posOeder

后序遍历的顺序是“左子树 → 右子树 → 根节点”,常用于确保在处理父节点之前先处理所有的子节点。
空树判断:函数先检查传入的根节点是否为 NULL(if (root != NULL))。如果为空,直接返回,结束当前递归调用。
递归左子树:如果根节点不为空,先递归调用 postOrder 遍历左子树(postOrder(root->left))。
递归右子树:然后递归调用 postOrder 遍历右子树(postOrder(root->right))。
访问根节点:最后打印当前根节点的值(printf("%d ", root->data))。
10.二叉树的层次遍历levelOrder

空树判断:函数开始时检查根节点是否为 NULL,如果是空树则直接返回。
队列初始化:使用一个数组 queue 作为队列来辅助遍历。队列的前端和后端分别由 front 和 rear 索引表示。
根节点入队:
queue[rear++] = root;
将根节点添加到队列中。rear++ 表示先将根节点存入队列位置 rear,然后 rear 自增1。
这一步将根节点作为层次遍历的起始点。
遍历循环:当队列不为空时,持续执行以下操作:
Node* current = queue[front++];
从队列的前端取出一个节点,赋值给指针变量 current。
front++ 表示先取出位置 front 的节点,然后 front 自增1,指向下一个待处理的节点。
节点出队:从队列前端取出一个节点(current),并打印其数据。
子节点入队:如果当前节点有左子节点,则将左子节点添加到队列的末尾。同样地,如果有右子节点,也将其添加到队列末尾。
if (current->left != NULL)
检查当前节点是否有左子节点。如果左子节点不为空,则执行下列代码。
queue[rear++] = current->left;
将当前节点的左子节点添加到队列的末尾。
rear++ 表示先存入左子节点,然后 rear 自增1。
if (current->right != NULL)
检查当前节点是否有右子节点。如果右子节点不为空,则执行下列代码。
queue[rear++] = current->right;
将当前节点的右子节点添加到队列的末尾。
rear++ 表示先存入右子节点,然后 rear 自增1。
循环终止:当队列为空时,树的所有节点都已被访问,遍历完成。
优点:
广度优先顺序:按照从左到右、从上到下的顺序访问节点,这在某些应用场景(如查找最短路径)中非常有用。
非递归实现:使用队列实现,避免了递归可能带来的栈溢出问题。
缺点与限制:
内存占用:需要额外的队列空间来存储待访问的节点,这可能导致更高的内存使用。
实现复杂性:相较于递归实现的先序、中序、后序遍历,层次遍历的代码相对复杂,需要管理队列的前端和后端。
11.释放空间函数

①:void freeTree(Node* root)
定义了一个名为 freeTree 的函数,用于释放以 root 为根节点的二叉树所占用的内存。
②:if (root == NULL) return;
检查当前节点是否为空。如果节点为空,直接返回,因为没有内存需要释放。
这是递归函数的终止条件,防止对空指针进行操作。
③:freeTree(root->left);
递归调用 freeTree 函数,释放当前节点的左子树所占用的内存。
这一步确保在释放当前节点之前,其左子树的所有节点都被释放。
④:freeTree(root->right);
递归调用 freeTree 函数,释放当前节点的右子树所占用的内存。
这一步确保在释放当前节点之前,其右子树的所有节点都被释放。
⑤:free(root);
使用 free 函数释放当前节点所占用的内存。
这是实际释放内存的操作,必须在左右子树都被释放之后执行,以确保所有子节点的内存都已被正确释放。
12.循环输入部分
实现了二叉排序树的初始化阶段,允许用户批量插入节点,直到用户输入特定值(-1)为止。

第1-2行:提示信息

第3-4行:输入循环
第5-6行:提示输入数值

提示用户输入一个整数值。
使用 scanf 函数读取用户输入的整数值,并将结果存储在 data 变量中,返回值存储在 scanResult 中,用于检查输入是否有效。
第7-12行:处理无效输入

如果 scanf 返回值不是1,说明输入不是有效的整数。
使用 getchar() 清空输入缓冲区,直到遇到换行符 \n。
提示用户输入错误,并使用 continue 跳过本次循环的剩余部分,重新开始循环。
第22行:插入节点

调用 insert 函数,将用户输入的 data 插入到二叉排序树中。
更新 root 指针,以反映树结构的变化。
第24-25行:清理输入缓冲区
![]()
在退出循环后,再次清空输入缓冲区,确保后续输入操作不会受到之前输入的影响。
12. 调试演示:
=== 二叉排序树初始化 ===
请输入要插入的数值(输入-1结束):
输入数值: 50
输入数值: 30
输入数值: 70
输入数值: 20
输入数值: 40
输入数值: -1
初始化完成,进入操作菜单...
二叉排序树操作菜单:
1. 插入节点
2. 删除节点
...(后续操作正常)
三、完整代码
#include <stdio.h>
#include <stdlib.h>typedef struct Node
{int data;struct Node* left;struct Node* right;
} Node;Node* createNode(int data)
{Node* newNode = (Node*)malloc(sizeof(Node));if (newNode == NULL) {printf("内存分配错误\n");return NULL;}newNode->data = data;newNode->left = newNode->right = NULL;return newNode;
}Node* insert(Node* root, int data)
{if (root == NULL){return createNode(data);}if (data < root->data){root->left = insert(root->left, data);}else if (data > root->data) {root->right = insert(root->right, data);}return root;
}Node* findMin(Node* root)
{while (root->left != NULL) {root = root->left;}return root;
}Node* delete(Node* root, int data)
{if (root == NULL) return root;if (data < root->data){root->left = delete(root->left, data);}else if (data > root->data) {root->right = delete(root->right, data);}else{// 节点找到if (root->left == NULL) {Node* temp = root->right;free(root);return temp;}else if (root->right == NULL) {Node* temp = root->left;free(root);return temp;}// 有两个子节点的情况Node* temp = findMin(root->right);root->data = temp->data;root->right = delete(root->right, temp->data);}return root;
}Node* search(Node* root, int data)
{if (root == NULL || root->data == data) {return root;}if (data < root->data) {return search(root->left, data);}return search(root->right, data);
}void preOrder(Node* root)
{if (root != NULL){printf("%d ", root->data);preOrder(root->left);preOrder(root->right);}
}void inOrder(Node* root)
{if (root != NULL) {inOrder(root->left);printf("%d ", root->data);inOrder(root->right);}
}void postOrder(Node* root)
{if (root != NULL){postOrder(root->left);postOrder(root->right);printf("%d ", root->data);}
}void levelOrder(Node* root)
{if (root == NULL) return;Node* queue[100];int front = 0, rear = 0;queue[rear++] = root;while (front < rear){Node* current = queue[front++];printf("%d ", current->data);if (current->left != NULL){queue[rear++] = current->left;}if (current->right != NULL) {queue[rear++] = current->right;}}
}void freeTree(Node* root)
{if (root == NULL)return;freeTree(root->left);freeTree(root->right);free(root);
}void displayMenu()
{printf("\n\n二叉排序树操作菜单:");printf("\n1. 插入节点");printf("\n2. 删除节点");printf("\n3. 查找节点");printf("\n4. 前序遍历");printf("\n5. 中序遍历");printf("\n6. 后序遍历");printf("\n7. 层次遍历");printf("\n8. 退出系统");printf("\n请输入您的选择:");
}int main()
{Node* root = NULL;int choice, data;// 初始批量插入阶段printf("=== 二叉排序树初始化 ===\n");printf("请输入要插入的数值(输入-1结束):\n");while (1){printf("输入数值: ");int scanResult = scanf("%d", &data);// 处理无效输入if (scanResult != 1) {while (getchar() != '\n'); // 清空输入缓冲区printf("输入错误,请重新输入!\n");continue;}// 结束条件判断if (data == -1) {printf("初始化完成,进入操作菜单...\n\n");break;}root = insert(root, data);}// 清理输入缓冲区while (getchar() != '\n');while (1) {displayMenu();scanf_s("%d", &choice);switch (choice){case 1:printf("请输入要插入的数值:");scanf_s("%d", &data);root = insert(root, data);break;case 2:printf("请输入要删除的数值:");scanf_s("%d", &data);if (search(root, data) == NULL) {printf("数值 %d 不存在于树中\n", data);}else {root = delete(root, data);printf("数值 %d 已成功删除\n", data);}break;case 3:printf("请输入要查找的数值:");scanf_s("%d", &data);if (search(root, data) != NULL){printf("数值 %d 存在于树中\n", data);}else {printf("数值 %d 不存在于树中\n", data);}break;case 4:printf("前序遍历结果:");preOrder(root);break;case 5:printf("中序遍历结果:");inOrder(root);break;case 6:printf("后序遍历结果:");postOrder(root);break;case 7:printf("层次遍历结果:");levelOrder(root);break;case 8:printf("正在退出程序...\n");freeTree(root); // 释放内存exit(0);default:printf("无效选项,请重新输入!\n");}}return 0;
}该程序实现了以下功能:
1.交互式二叉排序树管理
支持通过控制台进行动态操作,提供清晰的中文菜单界面
2.初始化批量建树
启动时支持连续输入多个数值构建初始树结构,输入 -1 结束初始化
3.核心操作功能
插入新节点
删除指定数值节点
查找数值是否存在
四种遍历方式:前序、中序、后序、层次遍历
4.内存管理
退出时自动释放整棵树内存
包含输入错误处理机制
5.数据展示
实时显示操作结果(成功/失败提示)
每次遍历操作后立即输出遍历序列
程序本质是一个支持完整增删查改功能的二叉排序树管理系统,通过控制台实现用户与数据结构的交互操作。
相关文章:
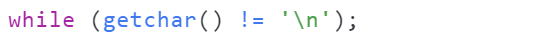
用C语言实现的——一个支持完整增删查改功能的二叉排序树BST管理系统,通过控制台实现用户与数据结构的交互操作。
一、知识回顾 二叉排序树(Binary Search Tree,BST),又称二叉查找树或二叉搜索树,是一种特殊的二叉树数据结构。 基本性质: ①有序性 对于树中的每个节点,其左子树中所有节点的值都小于该节点的…...

排队论基础一:马尔可夫排队模型
排队论基础一:马尔可夫排队模型 介绍基本概念状态概率分布平均队列人数与平均排队人数平均停留时间与平均等待时间Little公式(Little Law)生灭过程生灭过程排队系统(马尔可夫排队模型)状态平衡方程介绍 最近写论文需要,学了一下排队过程模型。其实这些内容本科的时候我都…...
论文阅读笔记——ROBOGROUND: Robotic Manipulation with Grounded Vision-Language Priors
RoboGround 论文 一类中间表征是语言指令,但对于空间位置描述过于模糊(“把杯子放桌上”但不知道放桌上哪里);另一类是目标图像或点流,但是开销大;由此 GeoDEX 提出一种兼具二者的掩码。 相比于 GR-1&#…...
:架构风格总结)
系统架构设计(四):架构风格总结
黑板 概念 黑板体系架构是一种用于求解复杂问题的软件架构风格,尤其适合知识密集型、推理驱动、数据不确定性大的场景。 它模拟了人类专家协同解决问题的方式,通过一个共享的“黑板”协同多个模块(专家)逐步构建解决方案。 组…...
『 测试 』测试基础
文章目录 1. 调试与测试的区别2. 开发过程中的需求3. 开发模型3.1 软件的生命周期3.2 瀑布模型3.2.1 瀑布模型的特点/缺点 3.3 螺旋模型3.3.1 螺旋模型的特点/缺点 3.4 增量模型与迭代模型3.5 敏捷模型3.5.1 Scrum模型3.5.2 敏捷模型中的测试 4 测试模型4.1 V模型4.2 W模型(双V…...

robomaster机甲大师--电调电机
文章目录 C620电调ID设置速率 电调发送报文电调接收报文cubemx程序初始化发送接收 C620电调 ID设置 速率 1Mbps 电调发送报文 发送的数据为控制电机的输出电流,需要将can数据帧的ID设置为0x200 电调接收报文 机械角度:电机的0到360度映射到0到几千转…...

汽车诊断简介
历史 20世纪80年代,由于美国西海岸严重的雾霾问题,CARB(加州空气资源委员会)通过了一项法律,要求对机动车辆进行车载监测诊断。这推动了OBD-I的引入,并在1990年代被OBD II取代。与此同时,欧洲也…...

少儿编程机构用的教务系统
在编程教育行业快速发展的今天,培训机构面临着学员管理复杂、课程体系专业性强、教学效果难以量化等独特挑战。爱耕云教务系统针对编程培训机构的特殊需求,提供了一套全方位的数字化解决方案,帮助机构实现高效运营和教学质量提升。 为什么编…...

优化理赔数据同步机制:从4小时延迟降至15分钟
优化理赔数据同步机制:从4小时延迟降至15分钟 1. 分析当前同步瓶颈 首先诊断当前同步延迟原因: -- 检查主从复制状态(在主库执行) SHOW MASTER STATUS; SHOW SLAVE HOSTS;-- 在从库执行检查复制延迟 SHOW SLAVE STATUS\G -- 关…...

面试中常问的设计模式及其简洁定义
🎯 一、面试中常问的设计模式及其简洁定义 模式名常被问到解释(简洁)单例模式✅ 高频保证一个类只有一个实例,并提供全局访问点。工厂模式✅ 高频创建对象的接口由子类决定,屏蔽了对象创建逻辑。抽象工厂模式✅提供多…...
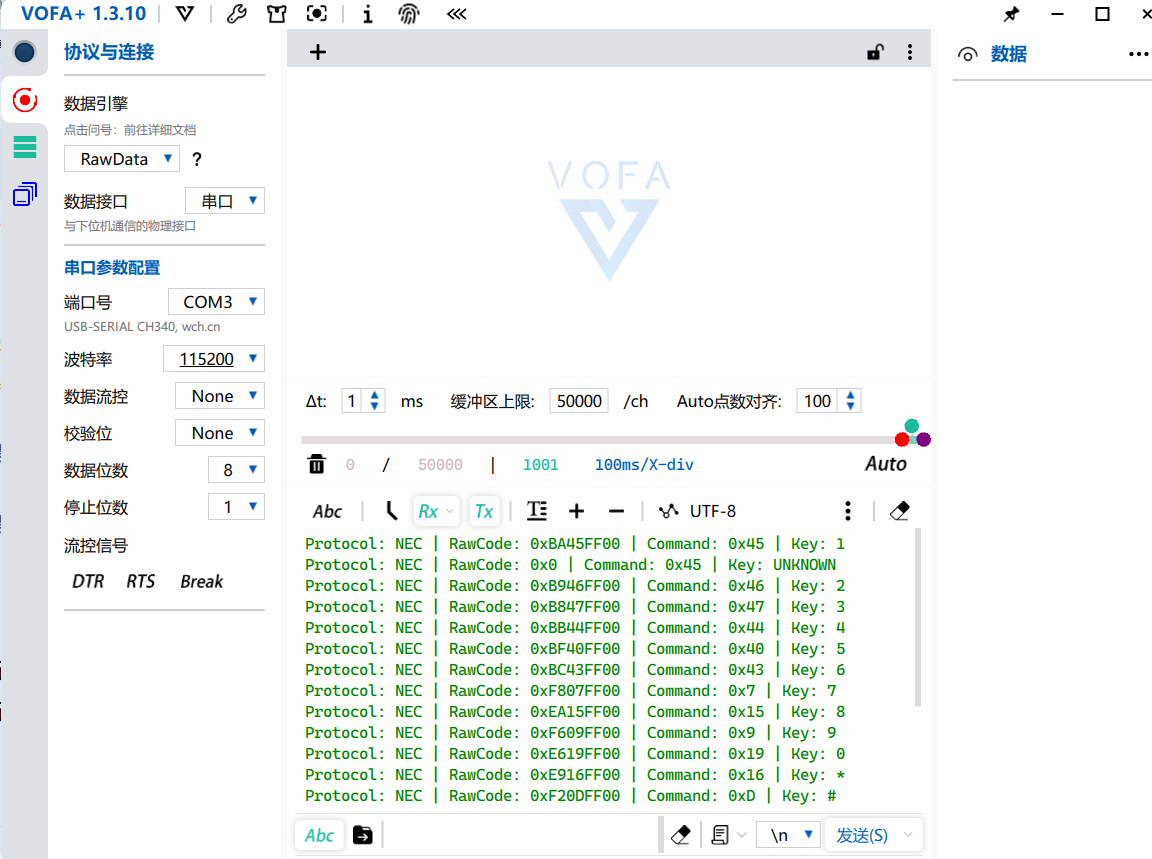
基于VSCode+PlatformIO环境的ESP8266的HX1838红外模块
以下是针对ESP8266开发板的红外遥控解码系统开发教程,基于VSCodePlatformIO环境编写 一、概述 本实验通过ESP8266开发板实现: 红外遥控信号解码自定义按键功能映射串口监控输出基础设备控制(LED) 硬件组成: NodeMC…...
Linux中的防火墙
什么是防火墙 windows防火墙的设置 linux防火墙设置命令 什么是防火墙? 防火墙是一种网络安全设备,它能够: 监控和过滤进出网络的流量 阻止不安全的连接 保护计算机和网络免受未授权访问 创建一个安全边界 简单来说,防火…...
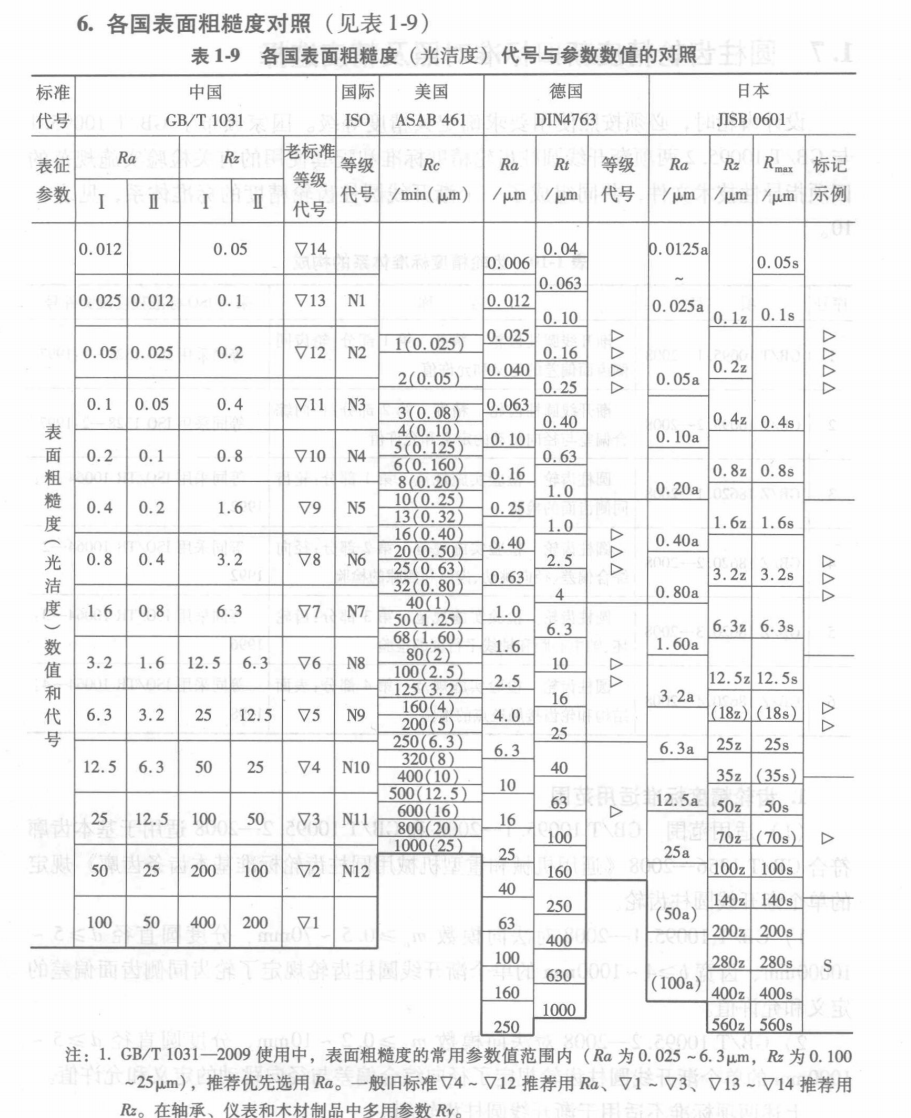
补补表面粗糙度的相关知识(一)
表面粗糙度,或简称粗糙度,是指表面不光滑的特性。这个在机械加工行业内可以说是绝绝的必备知识之一,但往往也是最容易被忽略的,因为往往天天接触的反而不怎么关心,或者没有真正的去认真学习掌握。对于像我一样…...
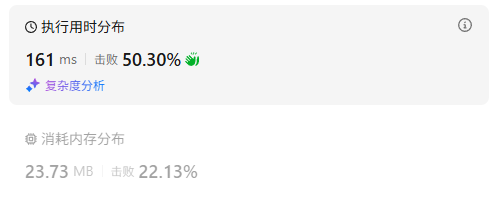
力扣刷题Day 46:搜索二维矩阵 II(240)
1.题目描述 2.思路 方法1:分别找到搜索矩阵的右、下边界,然后从[0][0]位置开始遍历这部分矩阵搜索目标值。 方法2:学习Krahets佬的思路,从搜索矩阵的左下角开始遍历,matrix[i][j] > target时消去第i行,…...

Kubernetes 集群部署应用
部署 Nginx 应用 命令行的方式 1. 创建 deployment 控制器的 pod # --imagenginx:这个会从 docker.io 中拉取,这个网站拉不下来 # kubectl create deployment mynginx --imagenginx# 使用国内镜像源拉取 kubectl create deployment mynginx --imaged…...

Spark 处理过程转换:算子与行动算子详解
在大数据处理领域,Apache Spark 凭借其强大的分布式计算能力脱颖而出,成为处理海量数据的利器。而 Spark 的核心处理过程,主要通过转换算子和行动算子来实现。本文将深入探讨 Spark 中的转换算子和行动算子,帮助读者更好地理解和应…...
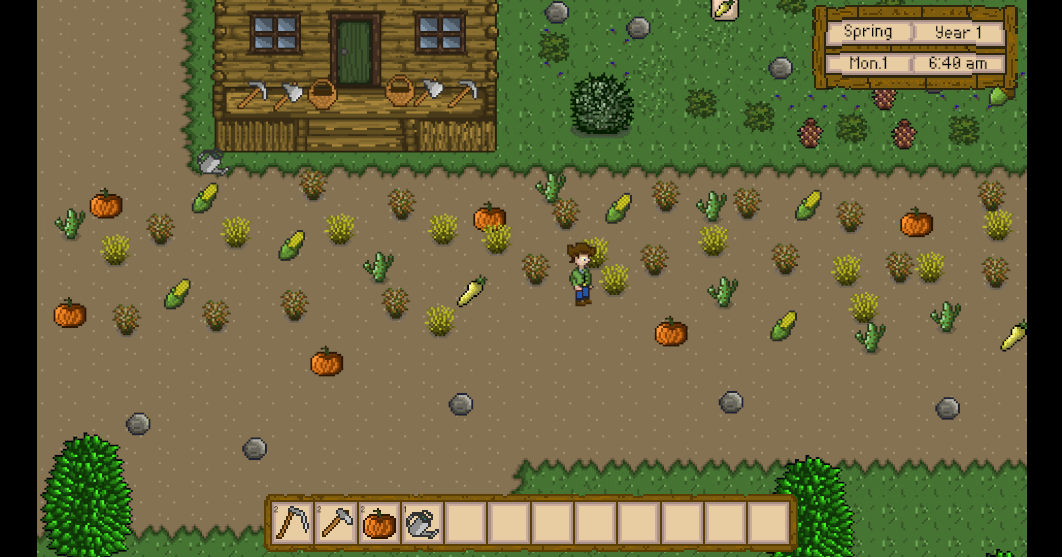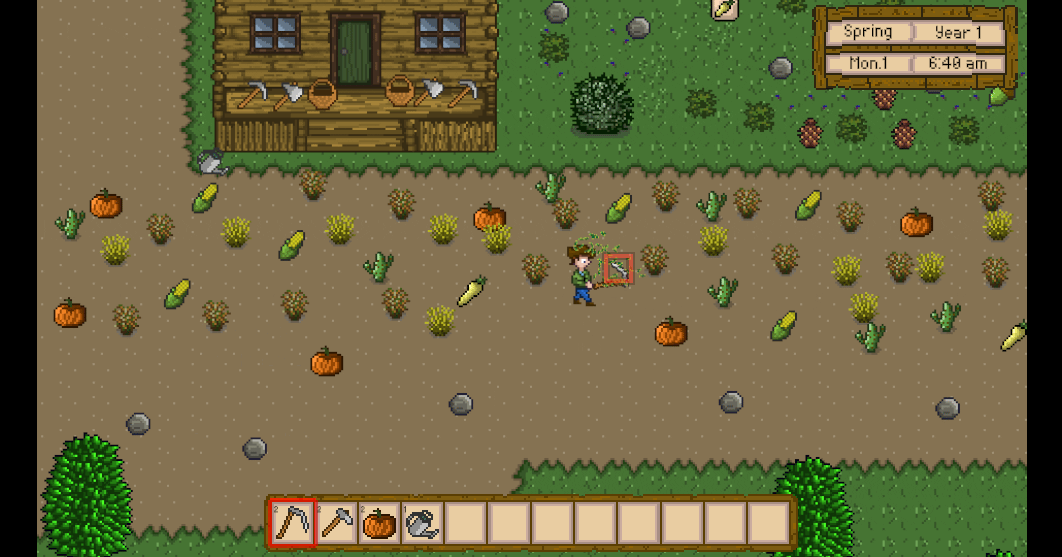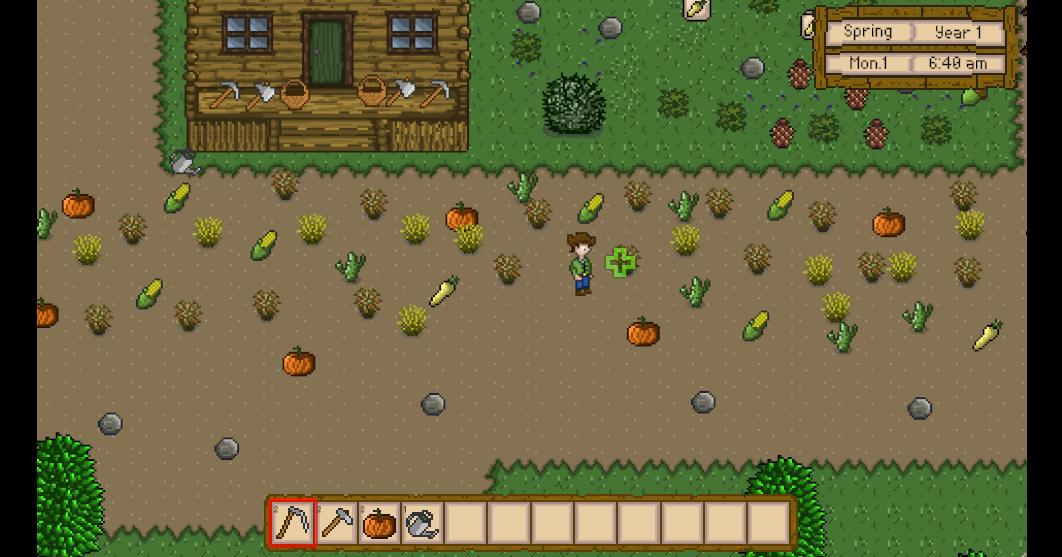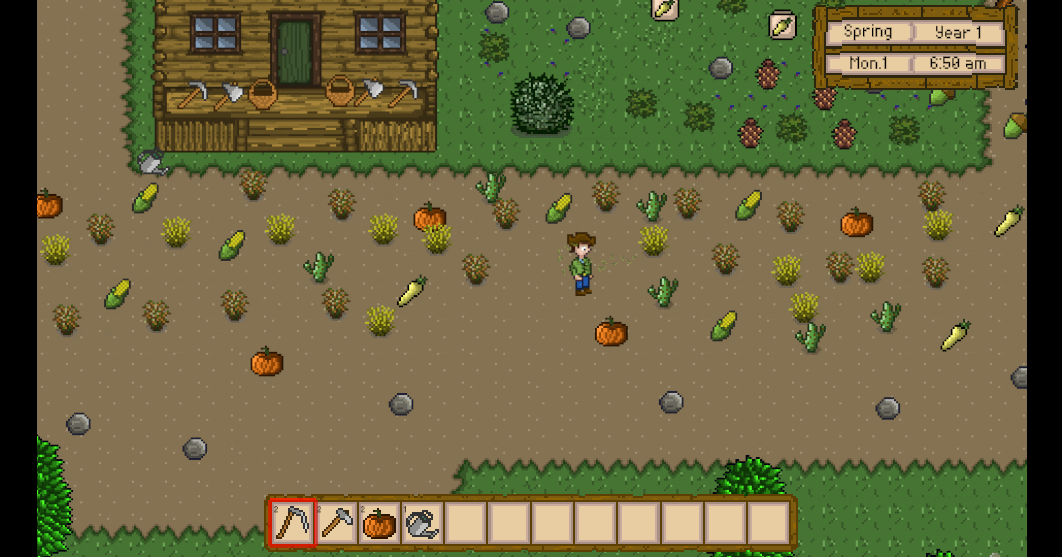
Unity3D仿星露谷物语开发42之粒子系统
1、目标 使用例子系统,实现割草后草掉落的特效。 通过PoolManager获取特效预制体,通过VFXManager来触发特效。 2、配置例子特效 在Hierarchy -> PersistentScene下创建新物体命名为Reaping。 给该物体添加Particle System组件。 配置例子系统参数…...

python 上海新闻爬虫, 东方网 + 澎湃新闻
1. 起因, 目的: 继续做新闻爬虫。我之前写过。此文先记录2个新闻来源。后面打算进行过滤,比如只选出某一个类型新闻。 2. 先看效果 过滤出某种类型的新闻,然后生成 html 页面,而且,自动打开这个页面。 比如科技犯罪…...

[Java实战]Spring Boot 整合 Freemarker (十一)
[Java实战]Spring Boot 整合 Freemarker (十一) 引言 Apache FreeMarker 作为一款高性能的模板引擎,凭借其简洁语法、卓越性能和灵活扩展性,在 Java Web 开发中占据重要地位。结合 Spring Boot 的自动化配置能力,开发者能快速构建动态页面、…...

LeetCode 高频题实战:如何优雅地序列化和反序列化字符串数组?
文章目录 摘要描述题解答案题解代码分析编码方法解码方法 示例测试及结果时间复杂度空间复杂度总结 摘要 在分布式系统中,数据的序列化与反序列化是常见的需求,尤其是在网络传输、数据存储等场景中。LeetCode 第 271 题“字符串的编码与解码”要求我们设…...

为什么拆分高低字节而不直接存入数组
您的代码片段是在将一个16位值()拆分为高字节和低字节:IR_RF_Signal.length temp_low IR_RF_Signal.length & 0xFF; temp_high IR_RF_Signal.length >> 8; 虽然我在 PX4-Autopilot 仓库中没有找到这段确切的代码,…...

python打卡day22@浙大疏锦行
复习日 仔细回顾一下之前21天的内容,没跟上进度的同学补一下进度。 作业: 自行学习参考如何使用kaggle平台,写下使用注意点,并对下述比赛提交代码 一、数据预处理 import pandas as pd import numpy as np import matplo…...

C#游戏开发中的注意事项
目录 一、性能优化:提升游戏运行效率 1. 避免不必要的循环和迭代 2. 减少字符串拼接 3. 利用Unity的生命周期函数 4. 使用对象池(Object Pooling) 二、内存管理:避免内存泄漏和资源浪费 1. 及时释放非托管资源 2. 避免空引用异常 3. 合理使用引用类型和值类型 4. …...
Spring Boot项目(Vue3+ElementPlus+Axios+MyBatisPlus+Spring Boot前后端分离)
下载地址: 前端:https://download.csdn.net/download/2401_83418369/90811402 后端:https://download.csdn.net/download/2401_83418369/90811405 一、前端vue部分的搭建 这里直接看另一期刊的搭建Vue前端工程部分 前端vue后端ssm项目_v…...
Spyglass:在batch/shell模式下运行目标的顶层是什么?
相关阅读 Spyglasshttps://blog.csdn.net/weixin_45791458/category_12828934.html?spm1001.2014.3001.5482 除了可以在图形用户界面(GUI)中运行目标外,使用Batch模式或Shell模式也可以运行目标,如下面的命令所示。 % spyglass -project test.prj -ba…...

没有Mac,我是怎么上传IPA到App Store的?
没有Mac,我是怎么上传IPA到App Store的? 最近赶一个小项目上线,写的是一个Flutter做的App。安卓版本一晚上搞定,iOS上架却差点把人整崩。 不是我技术菜,是实在太麻烦了。最关键的,是我这台Windows笔电根本…...

微服务架构中如何保证服务间通讯的安全
在微服务架构中,保证服务间通信的安全至关重要。服务间的通信通常是通过HTTP、gRPC、消息队列等方式实现的,而这些通信链路可能面临多种安全风险。为了应对这些风险,可以采取多种措施来保证通信安全。 常见的服务间通信风险 1.数据泄露:在服务间通信过程中,敏感数据可能会…...

2025-05-11 项目绩效域记忆逻辑管理
好的,我们可以用一个故事来帮助记忆这些规划绩效域的要素,同时通过逻辑关系来串联它们。以下是一个故事化的版本: 《项目管理的奇幻之旅》 在一个遥远的王国里,有一个勇敢的项目经理名叫小K。小K被国王赋予了一个艰巨的任务&…...
工具篇-Cherry Studio之MCP使用
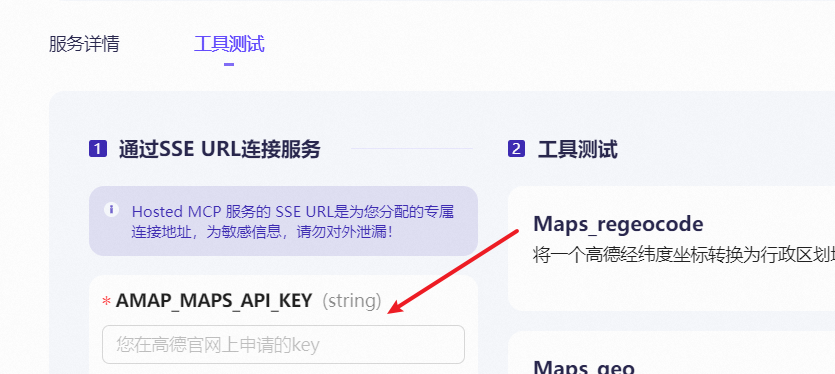
一、添加MCP 打开Cherry Studio,如果没有可以到官网下载:Cherry Studio 官方网站 - 全能的AI助手 按上面步骤打开同步服务器 1、先去注册ModelScope,申请令牌 2、再打开MCP广场,找到高德MCP 选择工具测试,这里有个高德的api key需要申请 打开如下地址高德开放平…...

DeepSeek“智”造:解锁旅游行业新玩法
目录 一、DeepSeek 简介1.1 DeepSeek 技术原理1.2 DeepSeek 在 AI 领域地位 二、DeepSeek 在旅游攻略生成的应用2.1 生成流程展示2.2 优势分析2.3 实际案例剖析 三、DeepSeek 助力旅游宣传文案创作3.1 文案创作模式3.2 效果评估3.3 创意亮点挖掘 四、DeepSeek 优化游客咨询服务…...