数据提取之BeautifulSoup4快速使用
文章目录
- 一、前言
- 二、概述
- 2.1 安装
- 2.2 初始化
- 2.3 对象类型
- 三、遍历文档树
- 3.1 子节点
- 3.2 父节点
- 3.3 兄弟节点
- 3.4 前后节点
- 3.5 节点内容
- 3.5.1 文本内容
- 3.5.2 属性值
- 3.5.3 标签删除
- 四、搜索文档树
- 4.1 find_all
- 4.2 find
- 4.3 CSS选择器
- 4.4 更多
一、前言
官方文档:https://beautifulsoup.readthedocs.io/zh-cn/v4.4.0/
参考文档:https://cuiqingcai.com/1319.html
在线编辑器:https://www.w3cschool.cn/tryrun/runcode?lang=python3
二、概述
2.1 安装
BeautifulSoup4是一个HTML/XML的解释器,可以用来提取HTML/XML数据。
安装:pip install beautifulsoup4 -i https://pypi.tuna.tsinghua.edu.cn/simple
常用导入方式:
from bs4 import BeautifulSoup
2.2 初始化
在BeautifulSoup4 中,解析器(Parser)决定了如何将 HTML/XML 内容转换为文档树对象。
BS4支持的解析器有html.parse(Python内置)、lxml、和html5lib等
| 解析器 | 速度 | 依赖库 | 容错性 | 支持文档类型 | 安装方式 |
|---|---|---|---|---|---|
html.parser | 中等 | 内置 | 一般 | HTML | Python 自带 |
lxml | 快 | lxml | 较好 | HTML/XML | pip install lxml |
html5lib | 慢 | html5lib | 强 | HTML5 | pip install html5lib |
lxml-xml | 快 | lxml | 严格 | XML | pip install lxml |
初始化对象时解析器推荐使用lxml;其中html为要解析的文档,features为使用的解析器类型
soup = BeautifulSoup(html, features="lxml") # lxml解析器
# soup = BeautifulSoup(html, features="html.parser") html.parser解析器
了解大概的使用过程:
from bs4 import BeautifulSouphtml = """
<html><head><title>The Dormouse's story</title></head>
<body>
<p class="title" name="dromouse"><b>The Dormouse's story</b></p>
<p class="story">Once upon a time there were three little sisters; and their names were
<a href="http://example.com/elsie" class="sister" id="link1">Elsie</a>,
<a href="http://example.com/lacie" class="sister" id="link2">Lacie</a> and
<a href="http://example.com/tillie" class="sister" id="link3">Tillie</a>;
and they lived at the bottom of a well.</p>
<p class="story">...</p>
"""# 创建 Beautiful Soup 对象
soup = BeautifulSoup(html, features="lxml")# 美化输出
print(soup.prettify())
soup.prettify可以格式化内容,运行结果为:
<html><head><title>The Dormouse's story</title></head><body><p class="title" name="dromouse"><b>The Dormouse's story</b></p><p class="story">Once upon a time there were three little sisters; and their names were<a class="sister" href="http://example.com/elsie" id="link1">Elsie</a>,<a class="sister" href="http://example.com/lacie" id="link2">Lacie</a>and<a class="sister" href="http://example.com/tillie" id="link3">Tillie</a>;
and they lived at the bottom of a well.</p><p class="story">...</p></body>
</html>
2.3 对象类型
BeautifulSoup将复杂HTML文档转换成一个复杂的树形结构,每个节点都是Python对象,所有对象可以归纳为4种: Tag , NavigableString , BeautifulSoup , Comment:
Tag:标签对象,可获取属性和文本,与XML或HTML中的标签相同
soup = BeautifulSoup('<b class="boldest">Extremely bold</b>','lxml')
tag = soup.b
print(tag) # <b class="boldest">Extremely bold</b>
print(type(tag)) # <class 'bs4.element.Tag'>
Tag有两个重要的属性:name和attrs,以上面的代码为例
print(tag.name) # b
print(tag.attrs) # {'class': ['boldest']}
如果要获取某个属性,可以这么写
print(tag['class']) # ['boldest']
# 或者
print(tag.get('class')) # ['boldest']
NavigableString:标签内的文本对象,如果要获取标签的内容,可以这么写:
print(tag.string) # Extremely bold
print(tag.text) # Extremely bold
BeautifulSoup:整个文档的根对象,有一个特殊的name属性
print(soup.name) # [document]
Comment:特殊的NavigableString对象,用来处理注释内容
markup = "<b><!--Hey, buddy. Want to buy a used parser?--></b>"
soup = BeautifulSoup(markup,'lxml')
tag = soup.b
comment = tag.string
print(comment) # Hey, buddy. Want to buy a used parser?
如果直接使用.string来输出,就判断不出它是否是注释,因此还需要类型判断,可使用isinstance()函数或者使用type()来判断
from bs4 import Comment
if type(tag.string)==Comment:# isinstance(tag,Comment)print("发现注释:",tag.string)# 发现注释: Hey, buddy. Want to buy a used parser?
三、遍历文档树
BeautifulSoup 将文档解析为一个树形结构(DOM 树),每个节点(标签、文本、注释等)都是树的一部分。遍历文档树即通过节点关系(上下级、同级)访问和操作这些节点。
3.1 子节点
(1)直接子节点:
tag.contents返回子节点列表,包含换行符等文本节点
html = '''
<div><p>段落1</p><p>段落2</p>
</div>
'''
div = soup.div
print(div.contents)
# ['\n', <p>段落1</p>, '\n', <p>段落2</p>, '\n']
tag.children返回子节点的生成器
div = soup.div
print(div.children)
# <list_iterator object at 0x7f9738f4eda0>
(2)递归子节点:tag.descendants递归遍历所有子孙节点
div = soup.div
print(div.descendants)
# <generator object descendants at 0x7f92da3d2a40>
3.2 父节点
直接父节点:tag.parent
p = soup.find('p')
print(p.parent.name) # div
递归父节点:tag.parents
for parent in p.parents:print(parent.name)

3.3 兄弟节点
同级节点(前后相邻):tag.next_sibling/tag.previous_sibling
p1 = soup.find('p')
p2 = p1.next_sibling
print(p2)
可以看到上述输出结果为空,这是因为它包含了换行符等文本节点,因此还需要再.next_sibling
p2 = p1.next_sibling.next_sibling
print(p2) # <p>段落2</p>
所有同级节点:tag.next_siblings/tag.previous_siblings
for sibling in p1.next_siblings:if sibling.name == 'p':print(sibling.text) # 段落2
3.4 前后节点
next_element/previous_element:返回当前节点的文档顺序中的下一个/前一个元素(无论层级)
html = '''
<div><p>Hello <b>World</b></p>
</div>
'''
p_tag = soup.p
print(p_tag.next_element) # 输出: "Hello"(第一个子文本节点)
print(p_tag.b.next_element) # 输出: "World"(<b>标签的子文本节点)
print(p_tag.next_element.next_element) # 输出: <b>World</b>
next_elements/previous_elements则是遍历所有前后节点
3.5 节点内容
3.5.1 文本内容
(1)单标签文本:
tag.string返回标签内的直接文本,注意仅当标签内无子标签时有效
html = '''
<div><p>段落1</p><p>段落2</p>
</div>
'''
p1 = soup.find('p')
print(p1.string) # 段落1
可以发现当标签内有多个子标签,输出时会显示None
div = soup.find('div')
print(div.string) # None
tag.text/tag.get_text()返回标签内所有子标签的文本合并结果,包含嵌套内容
div = soup.find('div')
print(div.text) # "\n段落1\n段落2\n"
tag.get_text(separator='',strip=True)合并文本并清理空白
div = soup.find('div')
text = div.get_text(separator=' ', strip=True)
print(text) # 输出: "段落1 段落2"
(2)多文本节点处理:
tag.strings:返回标签内所有文本节点,包含换行符等
for text in div.strings:print(repr(text)) # 输出: '\n', '段落1', '\n', '段落2', '\n'
tag.stripped_strings返回去除空白后的文本节点
for text in div.stripped_strings:print(text) # 输出: "段落1", "段落2"
3.5.2 属性值
(1)直接获取属性
tag['属性名']来获取,若属性不存在会抛出KeyError
html = '''
<a href="https://example.com" class="link">示例链接</a>
'''
a = soup.a
print(a['href']) # https://example.com
tag.get('属性名',默认值)安全获取属性,避免异常
value = a.get('id', 'default-id')
print(value) # default-id
根据结果,可以发现如果id不存在,会返回default-id
(2)获取所有属性:tag.attrs返回字典,包含标签所有属性
print(a.attrs)
# {'href': 'https://example.com', 'class': ['link']}
3.5.3 标签删除
tag.decompose()彻底销毁标签及其子节点,从内存中移除,无法恢复
html = '''
<div class="ad"><p>广告内容</p>
</div>
<p>正文内容</p>
'''
soup = BeautifulSoup(html, 'lxml')
ad_div = soup.find('div', class_='ad')
ad_div.decompose() # 彻底删除广告div
print(soup.prettify())
# 输出: <p>正文内容</p>
tag.extract()将标签从文档树中分离出来,返回被删除的标签对象
script_tag = soup.find('script')
removed_script = script_tag.extract() # 移除脚本但保留对象
print("被移除的脚本:", removed_script.text)
四、搜索文档树
4.1 find_all
find_all返回所有匹配的列表,否则返回空列表;函数格式:find_all(self, name=None, attrs={}, recursive=True, text=None, limit=None,**kwargs)
| 参数 | 描述 |
|---|---|
name | 可以传入字符串(完整匹配)、正则,列表(任意匹配),用来匹配tag的name属性 |
keyword | 搜索属性,可以传入字符串、正则表达式、列表、True |
text | 搜索内容,例如soup.find_all(text='b') |
attrs | 属性 |
recursive | 默认递归搜索子孙节点 |
limit | 限制返回结果数量 |
参数详解
name参数:可以查找所有名字为name的tag,字符串对象会被自动忽略。
# 字符串(完整匹配)
soup.find_all('b')# 正则表达式
soup.find_all(re.compile("^b"))# 列表(任意匹配)
soup.find_all(['b','a'])
keyword参数:如果一个指定名字的参数不是搜索内置的参数名,搜索时会把该参数当作指定名字tag的属性来搜索。
# 精确搜索
soup.find_all(id='p1')
soup.find_all('a', href='https://example.com')# 模糊匹配(正则表达式)
soup.find_all('a', href=re.compile(r'example'))# 传入True,匹配任何值
soup.find_all(id=True)
attrs参数:
# 查找class为"btn"且data-type为"submit"的按钮
buttons = soup.find_all(attrs={'class': 'btn', 'data-type': 'submit'})#
soup.find_all(attrs={"class": ["btn", "primary"]})
text参数:匹配标签及其子标签所有文本组合,等效于tag.get_text()
# 正则表达式
soup.find_all(text=re.compile(r'段落'))# 字符串
soup.find_all(text='段落1')
string参数:匹配标签内的直接文本,不含子标签,如果有子标签则返回None
# 字符串
soup.find_all(string='段落1')# 正则表达式
soup.find_all(string=re.compile(r'重要'))
recursive参数:默认递归搜索子孙节点
# 仅查找<div>的直接子<p>标签(忽略嵌套的p)
direct_p = soup.div.find_all('p', recursive=False)
limit参数:限制返回结果数量
# 最多返回2个<p>标签
first_two_p = soup.find_all('p', limit=2)
class_参数:按照CSS类名搜索,由于class在python中是保留字,因此通过添加下横线的方式来区分。接受过滤器、字符串、正则表达式、方法、True。
# 字符串
soup.find_all("a", class_="sister")# 正则表达式
soup.find_all(class_=re.compile("itl"))# 过滤器
def has_six_characters(css_class):return css_class is not None and len(css_class) == 6soup.find_all(class_=has_six_characters)# 匹配多个类名
soup.find_all(class_=['btn', 'active'])
注意,class_参数默认按空格分隔的多个类名中的任意一个匹配,例如class_='btn primary' 无法匹配 <div class="btn primary">,推荐使用attrs参数
soup.find_all(attrs={'class': ['btn', 'primary']})
4.2 find
find函数与findall函数一样用法,区别在于find返回一个对象,如果没有则返回None,而findall返回列表。
其他函数:
find_parents和find_parent用来搜索当前节点的父节点
find_next_siblings和find_next_sibling搜索当前节点后面的兄弟节点
find_previous_siblings和find_previous_sibling搜索当前节点前面的兄弟节点
find_all_next和find_next返回符合条件的节点
find_all_previous和find_previous返回符合条件的节点
4.3 CSS选择器
具体:https://www.w3school.com.cn/css/css_selector_type.asp
使用select方法,返回的是列表
| 选择器 | 描述 |
|---|---|
| 标签选择器 | 例如soup.select('title') |
| 类选择器 | 例如soup.select('.sister') |
| id选择器 | 例如soup.select('#title') |
| 层级选择器 | 例如soup.select('p title') |
| 属性选择器 | 例如soup.select('a[href="http://baidu.com"]') |
| 组合选择器 | 例如soup.select('div.class1.class2') |
| 获取文本内容 | get_text(),例如soup.select('title')[0].get_text() |
| 获取属性 | get('属性名'),例如soup.select('title')[0].get('href') |
标签选择器
# 选择所有 <a> 标签
links = soup.select('a')
类选择器
# 选择 class 包含 "btn" 的标签
buttons = soup.select('.btn')# 选择同时包含多个类的标签(注意用`.`连接)
multi_class = soup.select('.btn.primary') # class="btn primary"
ID选择器
# 选择 id 为 "header" 的标签
header = soup.select('#header')
属性选择器:
# 精确匹配属性
soup.select('a[href="https://example.com"]')# 属性包含特定值
soup.select('a[href*="example"]') # href包含"example"# 属性以特定值开头
soup.select('a[href^="https"]') # href以"https"开头# 属性以特定值结尾
soup.select('a[href$=".pdf"]') # href以".pdf"结尾
层级选择器:
# 直接子元素
# 选择 <div> 下的直接子元素 <p>
soup.select('div > p')# 后代元素
# 选择 <div> 内的所有 <a>(不限层级)
soup.select('div a')# 相邻兄弟元素
# 选择紧跟在 <h2> 后的第一个 <p>
soup.select('h2 + p')# 后续所有兄弟元素
# 选择 <h2> 之后的所有 <p>
soup.select('h2 ~ p')
组合选择器
# 并集选择
# 选择所有 <h1> 和 <h2>
soup.select('h1, h2')# 复合条件
# 选择 class 为 "menu" 的 <ul> 下的 <li>
soup.select('ul.menu > li')# 选择 id 为 "content" 的 <div> 中所有含 data-id 属性的 <p>
soup.select('div#content p[data-id]')
伪类:BeautifulSoup 的 CSS 选择器不支持浏览器式伪类(如 :hover),但支持以下功能:
:contains(text),例如soup.select('a:contains("点击这里")')- 属性存在判断,例如
soup.select('a[target]')
在浏览器中,可通过开发者工具快速定位要查找的元素
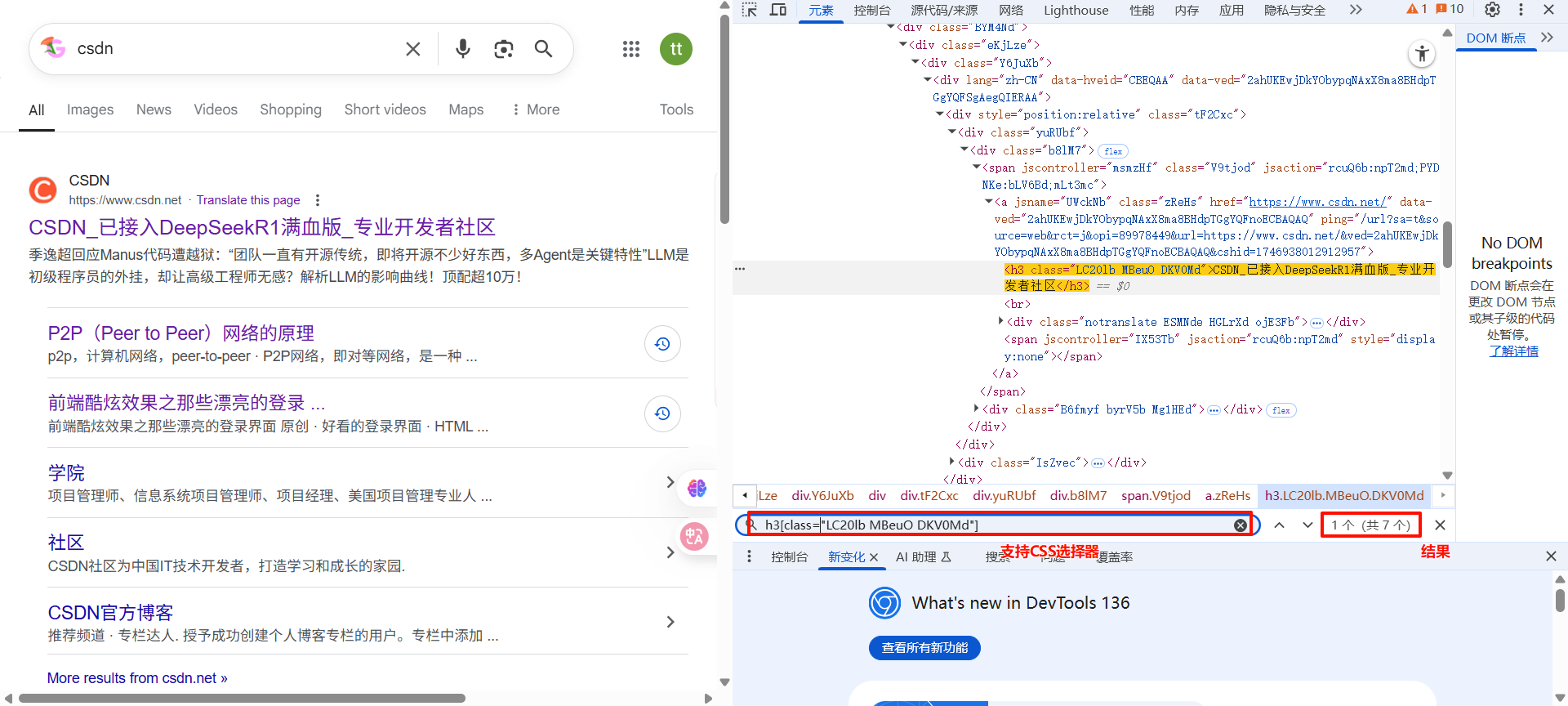
4.4 更多
自定义过滤函数
# 查找有id且class包含"box"的标签
def complex_filter(tag):return tag.has_attr('id') and 'box' in tag.get('class', [])matching_tags = soup.find_all(complex_filter)
链式调用
# 先找到<div>,再在其中找所有<p>
div = soup.find('div', class_='content')
paragraphs = div.find_all('p')
组合条件
# 查找所有<p>标签且class不为"hidden"
visible_ps = soup.find_all('p', class_=lambda x: x != 'hidden')
相关文章:
数据提取之BeautifulSoup4快速使用
文章目录 一、前言二、概述2.1 安装2.2 初始化2.3 对象类型 三、遍历文档树3.1 子节点3.2 父节点3.3 兄弟节点3.4 前后节点3.5 节点内容3.5.1 文本内容3.5.2 属性值3.5.3 标签删除 四、搜索文档树4.1 find_all4.2 find4.3 CSS选择器4.4 更多 一、前言 官方文档:http…...
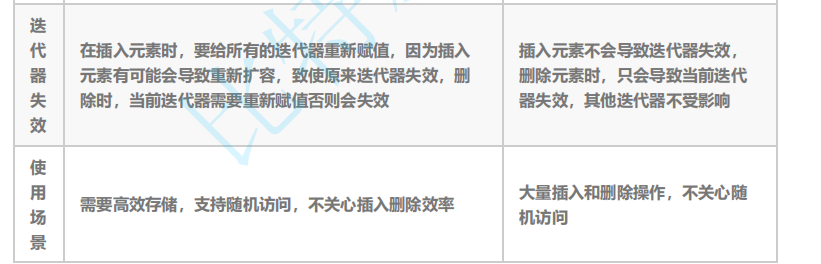
list类的详细讲解
【本节目标】 1. list的介绍及使用 2. list的深度剖析及模拟实现 3. list与vector的对比 1. list的介绍及使用 1.1 list的介绍 1. list 是可以在常数范围内在任意位置进行插入和删除的序列式容器,并且该容器可以前后双向迭代。 2. list 的底层是双向链表结构&a…...
Linux系统下安装mongodb
1. 配置MongoDB的yum仓库 创建仓库文件 sudo vi /etc/yum.repos.d/mongodb-org.repo添加仓库配置 根据系统版本选择配置(以下示例为CentOS 7和CentOS 9的配置): CentOS 7(安装MongoDB 5.0/4.2等旧版本): In…...

kuka, fanuc, abb机器人和移动相机的标定
基础知识 : 一, 9点标定之固定相机标定: 图1: 固定位置相机拍照 因为相机和机器人的基坐标系是固定的, 所以在海康威视相机的9点标定功能栏中, 填上海康使用“圆查找”捕捉到的坐标值, 再将机器人显示的工具坐标系在基坐标系的实时位置pos_act值填入物理坐标X, Y中即可 图2:…...

Android Framework学习四:init进程实现
文章目录 init流程简介init源码执行顺序执行顺序 init进程的具体工作事项挂载文件系统设置 SELinuxSecondStageMaininit.rc启动zygote和serviceManager进程的重要性serviceManager工作原理 Framework学习之系列文章 init流程简介 下面图片主要围绕 Android 系统中init进程的运…...

Linux计划任务与进程
at 命令使用方法 at 命令可在指定时间执行任务,适用于一次性任务调度。以下是基本用法: 安装 atd 服务(如未安装) # Debian/Ubuntu sudo apt-get install at# CentOS/RHEL sudo yum install at启动服务 sudo systemctl start atd…...
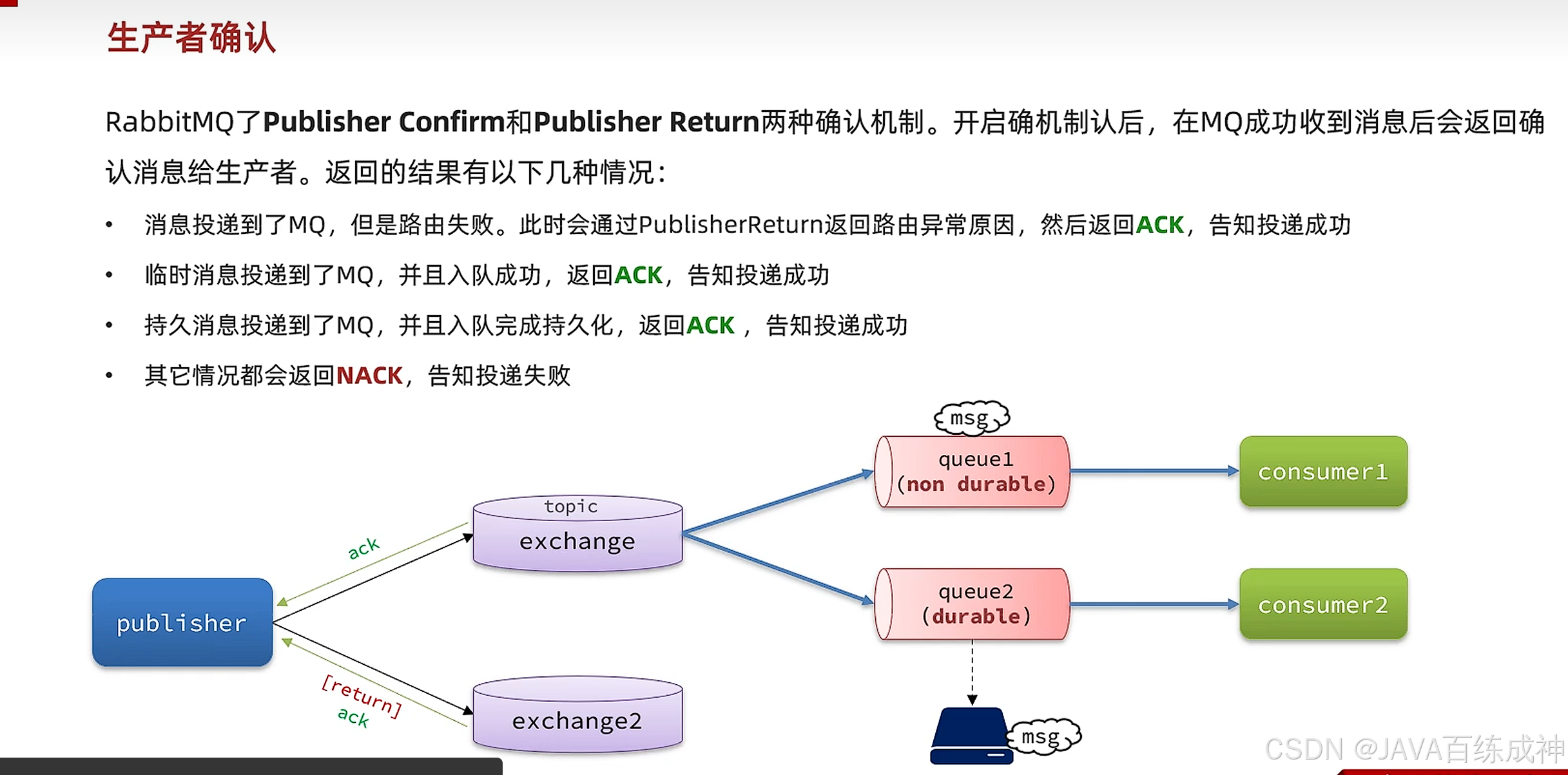
Java引用RabbitMQ快速入门
这里写目录 Java发送消息给MQ消费者接收消息实现一个队列绑定多个消费者消息推送限制 Fanout交换机路由的作用Direct交换机使用案例 Topic交换机声明队列和交换机的方式MQ消息转换器业务改造生产者可靠性设置重连 系统可靠性 Java发送消息给MQ public void testSendMessage() t…...
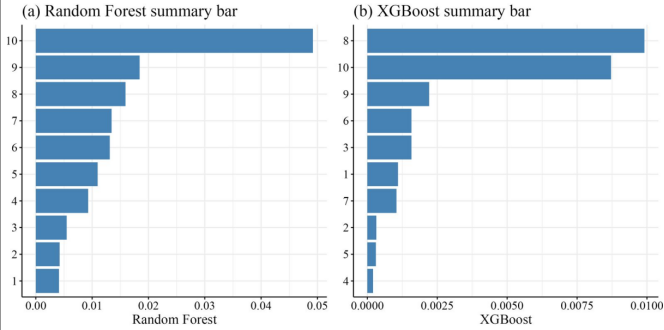
用R语言+随机森林玩转遥感空间预测-基于R语言机器学习遥感数据处理与模型空间预测技术及实际项目案例分析
遥感数据具有高维度、非线性及空间异质性等特点,传统分析方法往往难以充分挖掘其信息价值。机器学习技术的引入为遥感数据处理与模型预测提供了新的解决方案,其中随机森林(Random Forest)以其优异的性能和灵活性成为研究者的首选工…...

【许可证】Open Source Licenses
长期更新 扩展:shield.io装饰 开源许可证(Open Source Licenses)有很多种,每种都有不同的授权和限制,适用于不同目的。 默认的ISC🟰MIT License是否可商用是否要求开源衍生项目是否必须署名是否有专利授权…...
Spring Boot 文件上传实现详解
在项目开发过程中,文件上传是极为常见的功能需求。对于熟悉 Spring MVC 文件上传操作的开发者而言,Spring Boot 中的文件上传与之原理基本相通,只是在依赖管理和配置方式上更为简化。接下来,将详细阐述 Spring Boot 项目中文件上传…...
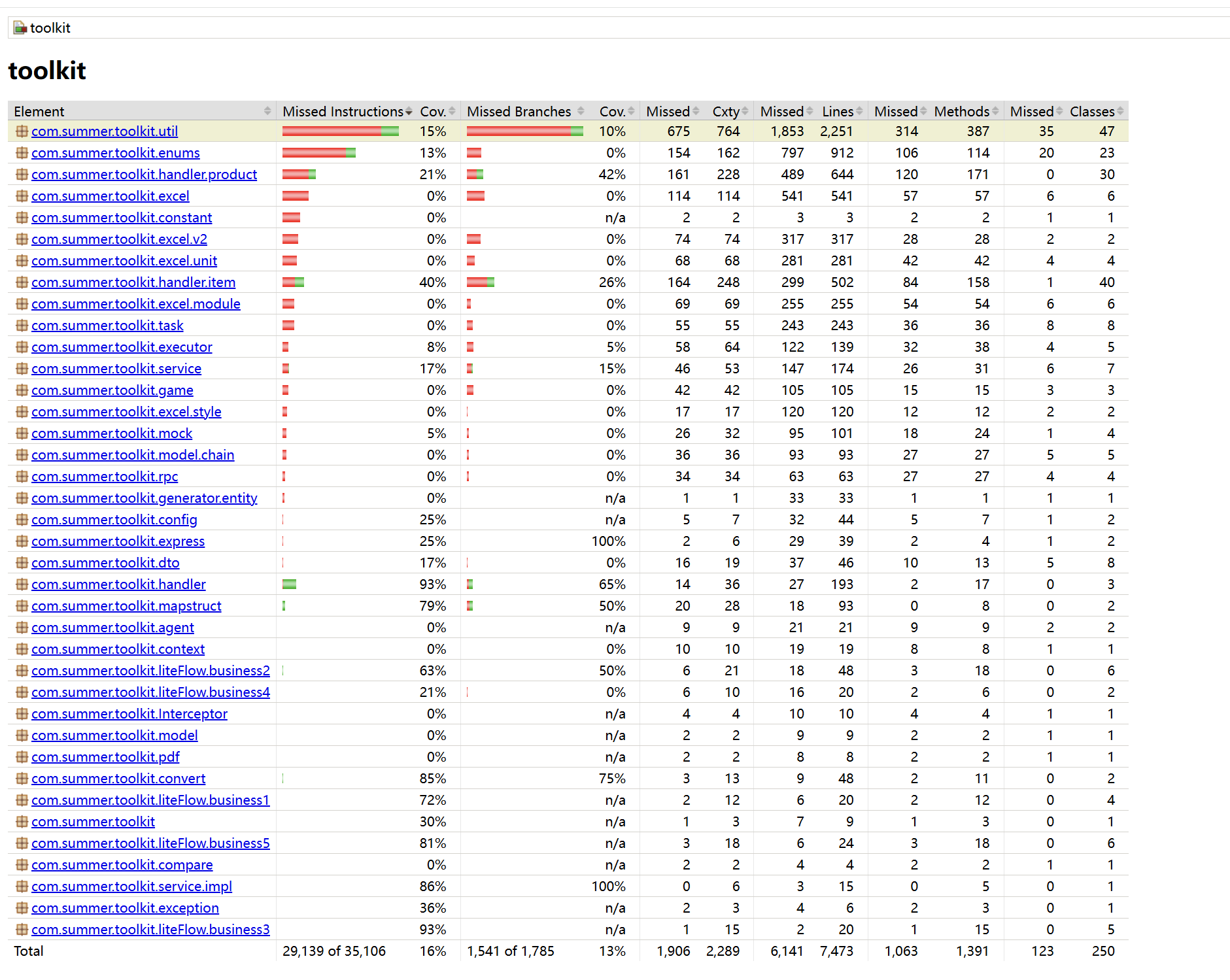
查看单元测试覆盖率
文章目录 1、POM文件配置2、编写单元测试3、执行单元测试4、查看单元测试覆盖率 1、POM文件配置 pom文件配置jacoco插件 <!-- 生成JaCoCo覆盖率数据插件 --> <plugin><groupId>org.jacoco</groupId><artifactId>jacoco-maven-plugin</artif…...
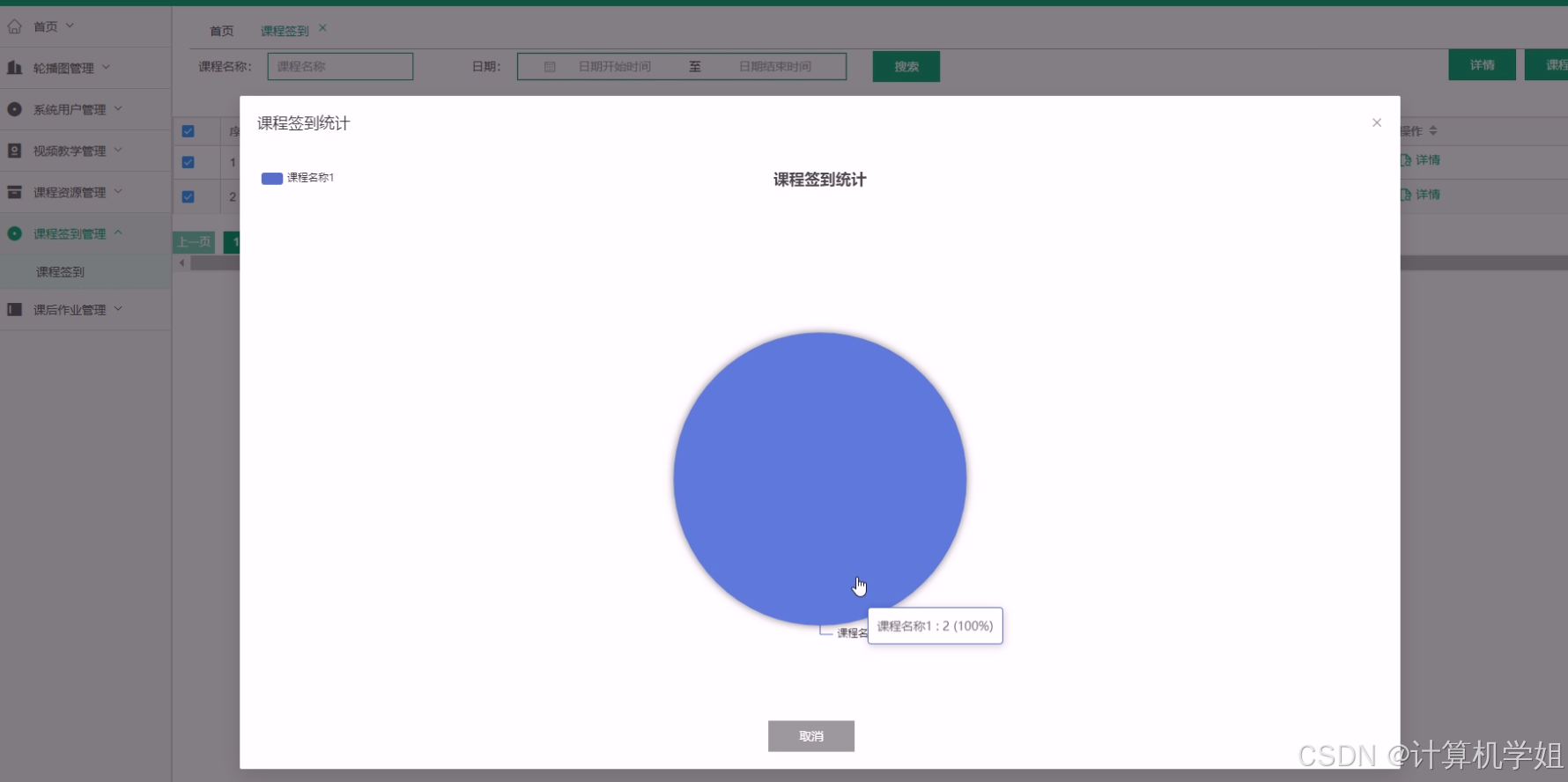
基于SpringBoot的在线教育管理系统
作者:计算机学姐 开发技术:SpringBoot、SSM、Vue、MySQL、JSP、ElementUI、Python、小程序等,“文末源码”。 专栏推荐:前后端分离项目源码、SpringBoot项目源码、Vue项目源码、SSM项目源码、微信小程序源码 精品专栏:…...

交叉编译 opencv-4.10
编译说明 opencv 下包含很多模块,各个模块的作用可以参考Opencv—模块概览. 嵌入式考虑有限存储等因素会对模块进行裁剪,我这里主要保留图像拼接(stitching)图片编解码(imgcodecs)与特征点匹配(…...
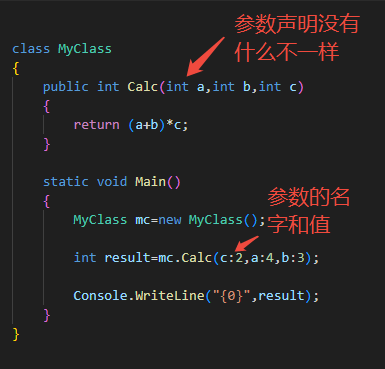
C# 方法(方法重载)
本章内容: 方法的结构 方法体内部的代码执行 局部变量 局部常量 控制流 方法调用 返回值 返回语句和void方法 局部函数 参数 值参数 引用参数 引用类型作为值参数和引用参数 输出参数 参数数组 参数类型总结 方法重载 命名参数 可选参数 栈帧 递归 方法重载 一个类中可以有多个…...
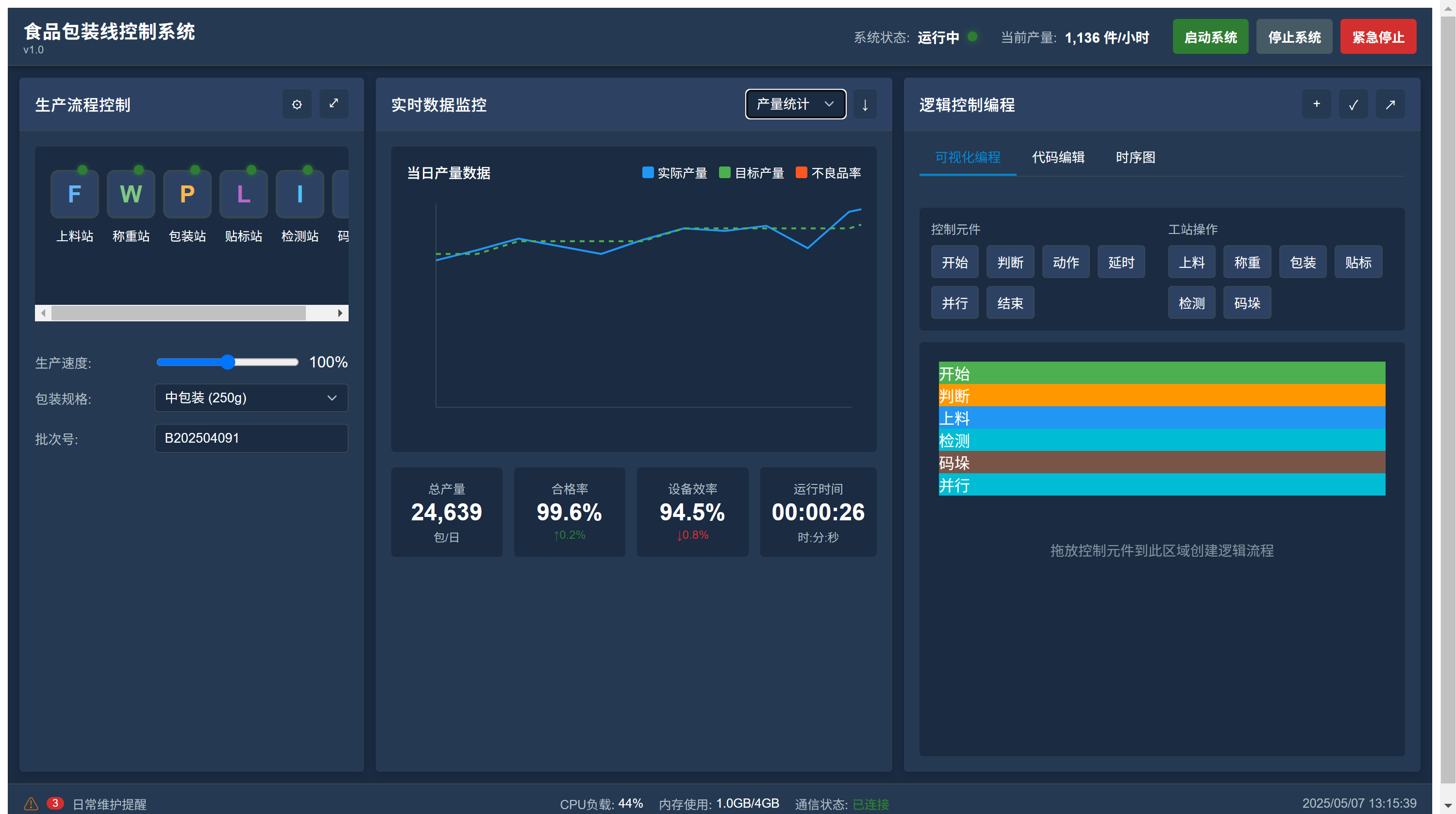
3、食品包装控制系统 - /自动化与控制组件/food-packaging-control
76个工业组件库示例汇总 食品包装线控制系统 这是一个用于食品包装线控制系统的自定义组件,提供了食品包装生产线的可视化监控与控制界面。组件采用工业风格设计,包含生产流程控制、实时数据监控和逻辑编程三个主要功能区域。 功能特点 工业风格UI设…...
初始图形学(7)
上一章完成了相机类的实现,对之前所学的内容进行了封装与整理,现在要学习新的内容。 抗锯齿 我们放大之前渲染的图片,往往会发现我们渲染的图像边缘有尖锐的"阶梯"性质。这种阶梯状被称为"锯齿"。当真实的相机拍照时&a…...
)
Linux NVIDIA 显卡驱动安装指南(适用于 RHEL/CentOS)
📌 一、禁用 Nouveau 开源驱动 NVIDIA 闭源驱动与开源的 nouveau 驱动冲突,需先禁用: if [ ! -f /etc/modprobe.d/blacklist-nouveau.conf ]; thenecho -e "blacklist nouveau\noptions nouveau modeset0" | sudo tee /etc/modpr…...
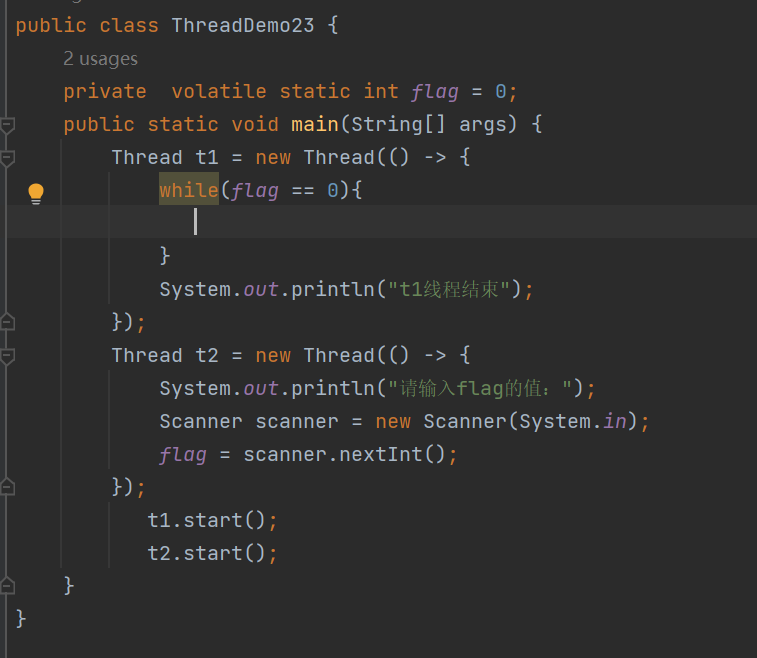
线程的一些事(2)
在java中,线程的终止,是一种“软性”操作,必须要对应的线程配合,才能把终止落实下去 然而,系统原生的api其实还提供了,强制终止线程的操作,无论线程执行到哪,都能强行把这个线程干掉…...

数据可视化:艺术与科学的交汇点,如何让数据“开口说话”?
数据可视化:艺术与科学的交汇点,如何让数据“开口说话”? 数据可视化,是科技与艺术的结合,是让冰冷的数字变得生动有趣的桥梁。它既是科学——讲究准确性、逻辑性、数据处理的严谨性;又是艺术——强调美感…...
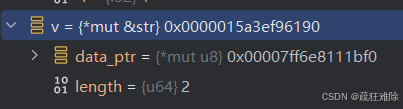
使用lldb看看Rust的HashMap
目录 前言 正文 读取桶的状态 获取键值对 键值对的指针地址 此时,读取数据 读取索引4的键值对 多添加几个键值对 使用i32作为键,&str作为值 使用i32作为键,String作为值 前言 前面使用ldb看了看不同的类型,这篇再使用…...
——版本体系)
Oracle版本、补丁及升级(12)——版本体系
12.1. 版本体系 Oracle作为最流行的一款关系数据库软件产品,其拥有自己一套成熟的版本管理体系。具体版本体系以12c为分界线,前后版本体系分别不同。 12.1.1. 12c之前版本 12c之前的Oracle,版本共有5位阿拉伯数字组成,其中的每位数字,都有各自的含义,具…...

2025最新免费视频号下载工具!支持Win/Mac,一键解析原画质+封面
软件介绍 适用于Windows 2025 最新5月蝴蝶视频号下载工具,免费使用,无广告且免费,支持对原视频和封面进行解析下载,亲测可用,现在很多工具都失效了,难得的几款下载视频号工具,大家且用且珍…...

在 Ubuntu 中配置 Samba 实现「特定用户可写,其他用户只读」的共享目录
需求目标 所有认证用户可访问 Samba 共享目录 /path/to/home;**仅特定用户(如 developer)**拥有写权限;其他用户仅允许读取;禁止匿名访问。 配置步骤 1. 设置文件系统权限 将目录 /home3/guest 的所有权设为 develo…...
Newton GPU 机器人仿真器入门教程(零)— NVIDIA、DeepMind、Disney 联合推出
系列文章目录 目录 系列文章目录 前言 一、快速入门 1.1 实时渲染 1.2 USD 渲染 1.3 示例:创建一个粒子链 二、重要概念 三、API 参考 3.1 求解器 3.1.1 XPBD 求解器 3.1.2 VBD 求解器 3.1.3 MuJoCo 求解器 3.2 关节控制模式 四、Newton 集成 4.1 Is…...

《零基础学机器学习》学习大纲
《零基础学机器学习》学习大纲 《零基础学机器学习》采用对话体的形式,通过人物对话和故事讲解机器学习知识,使内容生动有趣、通俗易懂,降低了学习门槛,豆瓣高分9.1分,作者权威。 接下来的数篇文章,我将用…...

CSS 基础知识分享:从入门到注意事项
什么是CSS? CSS是用于描述HTML或XML文档呈现方式的语言。它控制网页的布局、颜色、字体等视觉表现,让内容与表现分离。 通俗的说,html是骨头,那么css就是他的画皮。 基本语法 CSS规则由两部分组成:选择器和声明块。…...

深入浅出理解JavaScript原型与原型链
先让我们结合生活案例理解原型原型链相关概念,想象一下一个大家庭,有很多成员。 1. 原型 (Prototype) - 家族的共同特征或技能模板 概念对应: 家族中代代相传的共同特征、习惯、或者家族里独有的某个手艺或知识。例子: 假设你们家族的成员普遍都有高个子、善于烹饪一道祖传菜…...

重操旧业,做起了OnlineTool.cc在线工具站
最近闲来无事,做了个在线工具站。 工具不多,起码有:当前IP查询,QRCode二维码生成,图片压缩,JSON格式化,简体繁体转换,等。 使用Astro框架React,Caddy,目前是…...

vue 中的数据代理
在 Vue 中,数据代理(Data Proxy) 是 Vue 实现 MVVM 模式 的关键技术之一。Vue 使用数据代理让你可以通过 this.message 访问 data.message,而不需要写 this.data.message —— 这大大简化了模板和逻辑代码。 我们来深入理解它的本…...

ubuntu安装Go SDK
# 下载最新版 Go 安装包(以 1.21.5 为例) wget https://golang.google.cn/dl/go1.21.5.linux-amd64.tar.gz # 解压到系统目录(需要 root 权限) sudo tar -C /usr/local -xzf go1.21.5.linux-amd64.tar.gz # 使用 Go 官方安装脚本…...