Android学习总结之kotlin协程面试篇
一、协程基础概念与原理类真题
真题 1:协程是线程吗?为什么说它是轻量级的?(字节跳动 / 美团)
解答:
- 本质区别:
线程是操作系统调度的最小单位(内核态),协程是用户态的轻量级执行单元,由协程库(如kotlinx.coroutines)管理。 - 轻量级核心优势:
- 内存占用极小:每个线程默认分配 1MB 栈内存,协程共享宿主线程栈,单个协程仅需几十字节(如
Continuation对象)。 - 无内核态切换:协程切换在用户态通过
Continuation实现,避免线程切换的上下文开销(寄存器保存 / 恢复)。 - 超高并发能力:单线程可运行上万协程,而线程受限于系统资源(如 Android 手机通常仅支持几百个线程)。
- 内存占用极小:每个线程默认分配 1MB 栈内存,协程共享宿主线程栈,单个协程仅需几十字节(如
代码佐证:
// 启动 10万协程(内存无明显波动)
CoroutineScope().launch {repeat(100_000) { launch { delay(1000) } }
}
真题 2:挂起函数的本质是什么?为什么不能在普通函数中调用?(阿里 / 腾讯)
解答:
- 编译期转换(CPS 模式):
挂起函数(suspend)被编译器转换为接收Continuation参数的函数,通过状态机保存执行现场。
示例:suspend fun fetchData(): String { /* 耗时操作 */ }
编译后等价于:fun fetchData(continuation: Continuation<String>): Any? {// 保存当前局部变量,挂起时通过 continuation.resume() 恢复 } - 调用限制:
挂起函数依赖Continuation上下文,只能在协程体内或其他挂起函数中调用,避免脱离协程调度机制导致的状态丢失。
反例:
fun normalFunction() {fetchData() // 报错!必须在协程或另一个挂起函数中调用
}
二、调度器与线程切换类真题
真题 3:Dispatchers.IO 和 Dispatchers.Default 有什么区别?如何选择?
解答:
| 调度器 | 底层线程池 | 适用场景 | 最佳实践 |
|---|---|---|---|
| Dispatchers.IO | 共享的 IO 优化线程池 | 磁盘读写、网络请求(IO 密集型) | 耗时 IO 操作(如 Retrofit、文件读取) |
| Dispatchers.Default | 共享的 CPU 密集型线程池 | 计算任务(JSON 解析、数据排序) | CPU 耗时操作(避免阻塞 IO 线程) |
核心区别:
Dispatchers.IO会复用线程,适合处理耗时但不占用 CPU 的操作(如等待网络响应时线程可处理其他任务)。Dispatchers.Default限制线程数量(默认 CPU 核心数 × 2),避免 CPU 密集型任务占用过多资源。
错误案例:
// 错误:在 IO 调度器执行 CPU 密集型任务(浪费线程池资源)
withContext(Dispatchers.IO) { complexCalculation() } // 正确:CPU 任务用 Default,IO 任务用 IO
launch(Dispatchers.Default) { complexCalculation() }
launch(Dispatchers.IO) { networkRequest() }
真题 4:withContext 如何实现线程切换?原理是什么?
解答:
- 实现原理:
withContext(newContext)创建新的协程上下文,通过CoroutineDispatcher.dispatch将协程派发到目标线程。
关键步骤:- 保存当前协程状态(局部变量、挂起点)到
Continuation对象。 - 调度器(如
Dispatchers.Main)将Continuation提交到目标线程(如主线程 Looper)。 - 目标线程恢复协程执行,继续后续逻辑(如 UI 更新)。
- 保存当前协程状态(局部变量、挂起点)到
源码视角(简化版):
suspend fun <T> withContext(context: CoroutineContext, block: suspend CoroutineScope.() -> T): T {val oldContext = currentCoroutineContext()val newContext = oldContext + contextreturn newContext[ContinuationInterceptor]!!.interceptContinuation { cont ->// 调度 cont 到新线程}.invokeCancellable(block)
}
三、作用域与生命周期管理类真题
真题 5:为什么不推荐使用 GlobalScope?如何避免协程泄漏?(字节跳动 / 百度)
解答:
- GlobalScope 风险:
作用域生命周期与进程绑定,启动的协程不会随组件(如 Activity)销毁而取消,导致内存泄漏(如协程中持有 Activity 引用)。
正确做法:
- 绑定组件生命周期:
- Activity/Fragment 使用
lifecycleScope(AndroidX 库提供,自动随组件销毁取消)。 - ViewModel 使用
viewModelScope(随 ViewModel 销毁取消)。
// Activity 中安全启动协程 lifecycleScope.launch(Dispatchers.IO) {val data = fetchData()withContext(Dispatchers.Main) { uiUpdate(data) } } - Activity/Fragment 使用
- 自定义作用域时手动管理:
// 手动创建作用域,确保调用 cancel() val myScope = CoroutineScope(Job() + Dispatchers.IO) // 取消所有子协程 myScope.cancel()
反例对比:
// 危险!Activity 销毁后协程仍运行
GlobalScope.launch { delay(10_000)activity?.showToast("泄漏!") // NPE 风险
}
真题 6:协程的结构化并发是什么?有什么优势?(美团 / 京东)
解答:
-
定义:协程必须在作用域(
CoroutineScope)内启动,子协程自动继承父作用域的生命周期,父作用域取消时所有子协程同步取消。 -
核心优势:
- 避免泄漏:无需手动管理每个协程的取消,作用域销毁时统一清理。
- 异常传播:父协程捕获异常时,子协程自动取消(如
launch中未处理的异常会终止整个作用域)。
示例:
CoroutineScope().launch { // 父协程launch { // 子协程 1error("崩溃") // 未处理异常,父协程及所有子协程取消}launch { // 子协程 2delay(1000) // 提前被取消}
}
四、协程构建器与高级特性类真题
真题 7:launch 和 async 有什么区别?如何获取 async 的返回值?
解答:
| 构建器 | 阻塞当前线程 | 返回值类型 | 主要用途 | 获取结果方式 |
|---|---|---|---|---|
launch | 否 | Job(无返回值) | 启动无需结果的异步任务 | 通过 Job.cancel() |
async | 否 | Deferred<T> | 启动需要返回值的异步任务 | deferred.await() |
使用场景:
// 并行获取两个数据(耗时 1s)
val deferred1 = async { fetchUser() }
val deferred2 = async { fetchOrder() }
val result = deferred1.await() + deferred2.await() // 合并结果
注意:async 默认以 CoroutineStart.DEFAULT 启动(立即调度),可通过 start = CoroutineStart.LAZY 延迟启动:
val lazyDeferred = async(start = CoroutineStart.LAZY) { heavyTask() }
// 按需启动
if (needData) lazyDeferred.start()
真题 8:如何处理协程中的异常?CoroutineExceptionHandler 如何使用?
解答:
- 三种异常处理方式:
- try-catch 块:捕获当前协程内的异常(不影响其他子协程)。
launch {try {riskyOperation()} catch (e: Exception) {logError(e)} } - 作用域异常处理器:通过
CoroutineScope构造函数传入CoroutineExceptionHandler。val scope = CoroutineScope(CoroutineExceptionHandler { _, e -> handleGlobalError(e) // 处理所有未捕获异常 }) - 全局异常处理(不推荐):通过
CoroutineExceptionHandler绑定到Dispatchers.Main。
- try-catch 块:捕获当前协程内的异常(不影响其他子协程)。
关键区别:
try-catch仅捕获当前协程块内的异常。CoroutineExceptionHandler捕获作用域内所有未处理异常,并终止整个作用域(包括子协程)。
一、Android 实战类真题
真题 1:如何在 Android 中安全地使用协程更新 UI?
解答:
- 线程安全原则:
Android UI 操作必须在主线程执行,协程通过withContext(Dispatchers.Main)切换到主线程。
示例代码:lifecycleScope.launch(Dispatchers.IO) {val data = fetchDataFromNetwork() // IO 线程withContext(Dispatchers.Main) {textView.text = data // 安全更新 UI} } - 原理:
Dispatchers.Main封装了主线程的Looper,通过Handler将 UI 操作提交到主线程消息队列,避免直接阻塞主线程。 - 关键策略:
- 显式切换主线程:耗时操作(如网络请求、数据库查询)在非主线程调度器(
Dispatchers.IO/Default)执行,完成后通过withContext(Dispatchers.Main)切回主线程更新 UI。 - 避免隐性线程风险:协程默认继承调用者线程,若在非主线程启动协程且未指定调度器,直接操作 UI 会导致崩溃。务必通过
launch(Dispatchers.IO)或withContext明确线程分工。
- 显式切换主线程:耗时操作(如网络请求、数据库查询)在非主线程调度器(
错误案例:
// 危险!在非主线程直接更新 UI(导致崩溃)
launch { textView.text = "错误" } // 未指定调度器,默认使用调用者线程(可能非主线程)
真题 2:协程如何与 Retrofit 结合实现网络请求?
解答:
- Retrofit 适配协程:
使用 Retrofit 2.6+ 的suspend函数支持,直接返回Response或Result。
接口定义:interface ApiService {@GET("users")suspend fun getUsers(): Response<List<User>> } - 协程调用:
viewModelScope.launch(Dispatchers.IO) {try {val response = apiService.getUsers()withContext(Dispatchers.Main) {if (response.isSuccessful) {usersLiveData.value = response.body()} else {showError(response.errorBody())}}} catch (e: Exception) {withContext(Dispatchers.Main) { showError(e) }} } - 优势:
避免回调嵌套,代码简洁;自动处理线程切换,保证主线程安全。 - 消除回调地狱:Retrofit 支持
suspend函数后,网络请求可直接以同步写法实现异步逻辑,无需嵌套回调。 - 生命周期安全:在 ViewModel 或组件作用域(
viewModelScope/lifecycleScope)内启动协程,框架自动管理协程与组件的生命周期绑定,避免泄漏。 - 最佳实践:
将网络 / 数据库操作封装为挂起函数,在协程体内通过调度器切换线程,最终通过LiveData或StateFlow通知 UI 层,形成「异步处理 - 线程切换 - 响应式更新」的完整链路。
真题 3:如何在 Room 数据库中使用协程?
解答:
- Room 适配协程:
在 DAO 中定义suspend函数,Room 自动生成协程适配代码。
DAO 示例:@Dao interface UserDao {@Query("SELECT * FROM users")suspend fun getUsers(): List<User> } - 协程调用:
viewModelScope.launch(Dispatchers.IO) {val users = userDao.getUsers()withContext(Dispatchers.Main) {usersLiveData.value = users} } - 性能优化:
使用Flow实现响应式数据更新(需结合flowOn(Dispatchers.IO)切换线程)。@Dao interface UserDao {@Query("SELECT * FROM users")fun getUsersFlow(): Flow<List<User>> // 自动适配协程 }
二、性能优化类真题
真题 4:如何优化协程中的分页加载?
解答:
- 分页加载策略:
- 按需加载:滑动到列表底部时触发下一页请求。
- 并行加载:使用
async并行获取多个页面数据(如预加载下一页)。
示例代码:
private fun loadNextPage(page: Int) {viewModelScope.launch(Dispatchers.IO) {val deferred = async { apiService.getPage(page) }val data = deferred.await()withContext(Dispatchers.Main) { updateUI(data) }} } - 避免重复请求:
使用StateFlow或LiveData跟踪加载状态,防止多次触发同一页请求。 - 使用 Flow 响应式编程:
Flow是协程的数据流处理工具,可通过flowOn切换线程,collect收集数据,天然支持背压(Backpressure),适合处理列表分页加载、实时消息同步等场景。例如:- 分页加载时,滑动到列表底部触发
flow.emit(nextPageData),自动切换到 IO 线程请求数据,主线程更新 UI。 - 结合
StateFlow/SharedFlow实现数据的可观察性,替代传统的LiveData回调,代码更简洁且线程安全。
- 分页加载时,滑动到列表底部触发
- 并行预加载:对已知的后续操作(如下一页数据),用
async并行启动协程,利用等待当前结果的时间预加载数据,减少用户等待时间。
真题 5:如何处理协程中的内存泄漏?
解答:
- 结构化并发原则:
协程必须绑定到组件生命周期(如lifecycleScope/viewModelScope),避免使用GlobalScope。
正确做法:// Activity 中使用 lifecycleScope lifecycleScope.launch { /* 协程任务 */ }// ViewModel 中使用 viewModelScope viewModelScope.launch { /* 协程任务 */ } - 上下文管理:
单例中避免持有 Activity 上下文,优先使用 Application 上下文。
反例:// 危险!单例持有 Activity 上下文导致泄漏 class BadSingleton(private val context: Context) {init { /* 初始化操作 */ } }
正例:class GoodSingleton(private val context: Context) {private val appContext = context.applicationContext // 使用 Application 上下文 }
真题 6:如何优化协程的启动性能?
解答:
- 按任务类型选择调度器:
- IO 密集型任务(网络 / 磁盘):用
Dispatchers.IO,其内部线程池会复用线程,避免频繁创建开销(如网络请求等待时线程可处理其他任务)。 - CPU 密集型任务(数据解析 / 计算):用
Dispatchers.Default,其线程数限制为 CPU 核心数 × 2,防止过度占用 CPU 资源。 - UI 操作:必须用
Dispatchers.Main,通过主线程Looper安全更新界面。
- IO 密集型任务(网络 / 磁盘):用
- 减少上下文切换:避免在协程体内频繁调用
withContext切换线程,尽量在同一调度器内完成相关操作(如先在 IO 线程读取文件,再在同线程解析数据,最后切回主线程)。
- 延迟启动(LAZY 模式):
使用async(start = CoroutineStart.LAZY)延迟执行耗时操作,减少初始化开销。val lazyDeferred = async(start = CoroutineStart.LAZY) { loadHeavyData() } // 按需启动 if (needData) lazyDeferred.start() - 复用线程池:
避免频繁创建新线程,使用Dispatchers.IO或自定义线程池。
自定义线程池:val ioDispatcher = Executors.newFixedThreadPool(4).asCoroutineDispatcher() // 使用 ioDispatcher 启动协程 CoroutineScope(ioDispatcher).launch { /* 任务 */ } - 减少上下文切换:
在协程体内尽可能完成同一线程的任务,避免频繁调用withContext。
三、高级实战与性能优化真题
真题 7:如何实现协程与 LiveData 的高效结合?(阿里 / 字节跳动)
解答:
- LiveData 包装协程结果:
使用LiveData的postValue或setValue在主线程更新数据。
示例代码:class UserViewModel : ViewModel() {private val _users = MutableLiveData<List<User>>()val users: LiveData<List<User>> = _usersfun fetchUsers() {viewModelScope.launch(Dispatchers.IO) {val data = apiService.getUsers()_users.postValue(data) // 非主线程调用 postValue}} } - 结合 Flow:
使用flow发射数据流,通过flowOn切换线程,collect到LiveData。class UserViewModel : ViewModel() {val usersFlow = flow {emit(apiService.getUsers())}.flowOn(Dispatchers.IO)fun observeUsers(owner: LifecycleOwner, observer: Observer<List<User>>) {usersFlow.launchIn(viewModelScope).collect {_users.postValue(it)}} }
真题 8:如何处理协程中的耗时操作导致的 ANR?
解答:
- 避免阻塞主线程:
耗时操作(如文件读写、网络请求)必须在非主线程执行。
错误案例:// 危险!在主线程执行耗时操作(导致 ANR) runBlocking {delay(10_000) // 阻塞主线程 10 秒 }
正确做法:viewModelScope.launch(Dispatchers.IO) {delay(10_000) // IO 线程执行耗时操作withContext(Dispatchers.Main) { /* 更新 UI */ } } - 超时控制:
使用withTimeout限制协程执行时间,防止长时间阻塞。viewModelScope.launch(Dispatchers.IO) {try {withTimeout(5_000) { // 超时时间 5 秒val data = apiService.getUsers()}} catch (e: TimeoutCancellationException) {withContext(Dispatchers.Main) { showTimeoutError() }} }
- 严格分离主线程任务:任何耗时超过 16ms(60fps 要求)的操作必须在非主线程调度器执行,通过
launch(Dispatchers.IO)或withContext明确切换。 - 设置超时控制:使用
withTimeout限制协程执行时间,避免因网络延迟、数据异常等导致的长时间阻塞。例如:withTimeout(5000) { /* 网络请求或复杂计算 */ }
超时后协程自动取消,防止主线程因等待结果而卡顿。 - 避免阻塞式 API:协程中优先使用挂起函数(如
Retrofit的suspend方法),而非阻塞式的execute()或get(),确保任务以非阻塞方式挂起,释放线程资源。
相关文章:

Android学习总结之kotlin协程面试篇
一、协程基础概念与原理类真题 真题 1:协程是线程吗?为什么说它是轻量级的?(字节跳动 / 美团) 解答: 本质区别: 线程是操作系统调度的最小单位(内核态),协…...
从前端视角看网络协议的演进
别再让才华被埋没,别再让github 项目蒙尘!github star 请点击 GitHub 在线专业服务直通车GitHub赋能精灵 - 艾米莉,立即加入这场席卷全球开发者的星光革命!若你有快速提升github Star github 加星数的需求,访问taimili…...
Docker中运行的Chrome崩溃问题解决
问题 各位看官是否在 Docker 容器中的 Linux 桌面环境(如Xfce)上启动Chrome ,遇到了令人沮丧的频繁崩溃问题?尤其是在打开包含图片、视频的网页,或者进行一些稍复杂的操作时,窗口突然消失?如果…...

【沉浸式求职学习day36】【初识Maven】
沉浸式求职学习 Maven1. Maven项目架构管理工具2.下载安装Maven3.利用Tomcat和Maven进入一个网站 Maven 为什么要学习这个技术? 在Java Web开发中,需要使用大量的jar包,我们手动去导入,这种操作很麻烦,PASS!…...

ES面试题系列「一」
1、Elasticsearch 是什么?它与传统数据库有什么区别? 答案:Elasticsearch 是一个基于 Lucene 的分布式、开源的搜索和分析引擎,主要用于处理大量的文本数据,提供快速的搜索和分析功能。与传统数据库相比,E…...

【音视频工具】MP4BOX使用
这里写目录标题 使用介绍 使用 下面这个网站直接使用: MP4Box.js - JavaScript MP4 Reader/Fragmenter (gpac.github.io) 介绍 MMP4Box 是 GPAC 项目开发的一款命令行工具,专门用于处理 MP4 格式多媒体文件,也可操作 AVI、MPG、TS 等格…...
Linux中常见开发工具简单介绍
目录 apt/yum 介绍 常用命令 install remove list vim 介绍 常用模式 命令模式 插入模式 批量操作 底行模式 模式替换图 vim的配置文件 gcc/g 介绍 处理过程 预处理 编译 汇编 链接 库 静态库 动态库(共享库) make/Makefile …...

laravel 使用异步队列,context带的上下文造成反序列化出问题
2025年5月8日17:03:44 如果你是单个应用,异步递交任务,是在应用内部使用,一般不会发生这样的问题 但是现在app项目是 app是一个应用,admin是一个应用,app吧为了接口性能吧异步任务丢给admin去执行,如果两个…...
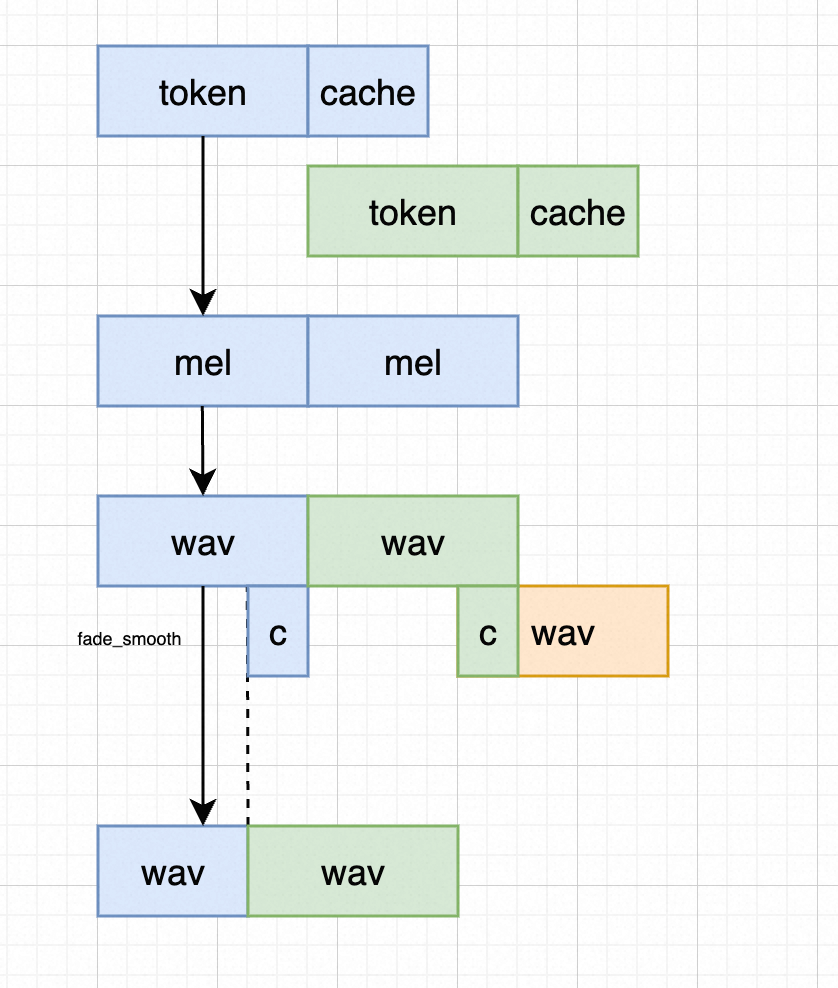
flow-matching 之学习matcha-tts cosyvoice
文章目录 matcha 实现cosyvoice 实现chunk_fmchunk_maskcache_attn stream token2wav 关于flow-matching 很好的原理性解释文章, 值得仔细读,多读几遍,关于文章Flow Straight and Fast: Learning to Generate and Transfer Data with Rectifi…...

视频编解码学习三之显示器续
一、现在主流的显示器是LCD显示器吗? 是的,现在主流的显示器仍然是 LCD(液晶显示器,Liquid Crystal Display),但它已经细分为多种技术类型,并和其他显示技术(如OLED)形成…...
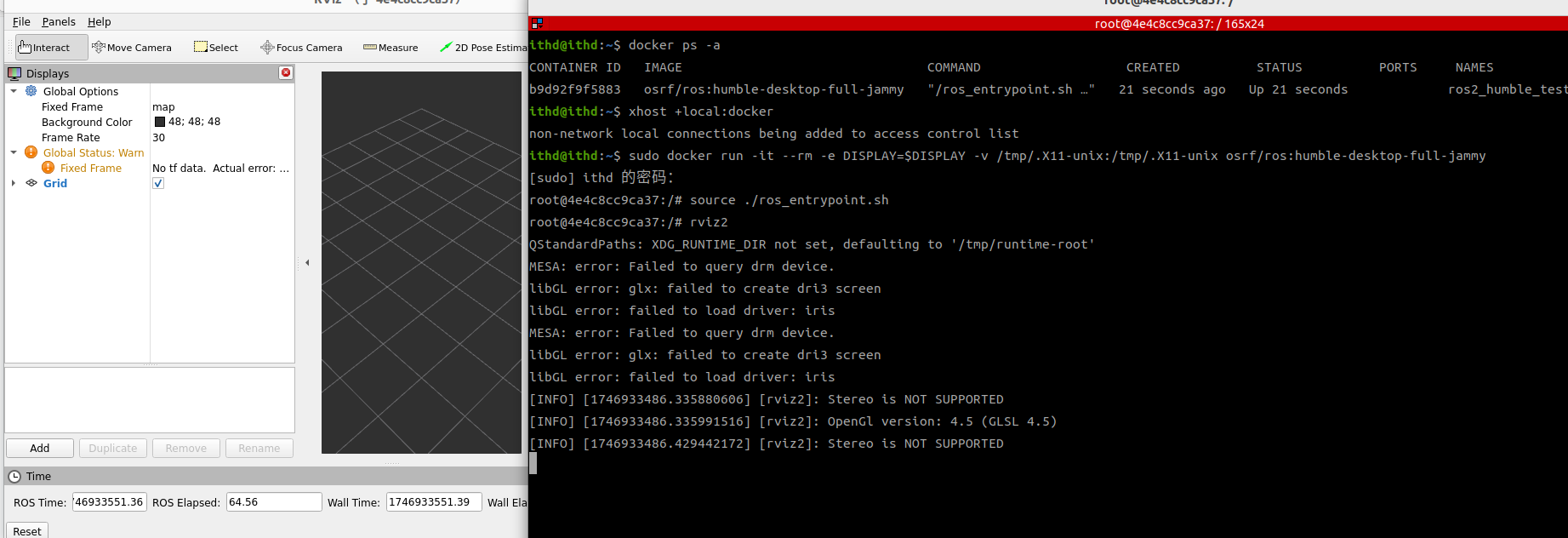
ubuntu22.04在 Docker容器中安装 ROS2-Humble
22.04 安装 docker 容器并实现rviz功能 1 docker pull命令拉取包含ROS-Humble的镜像: docker pull osrf/ros:humble-desktop-full-jammy docker images验证该镜像是否拉取成功。 使用镜像osrf/ros:humble-desktop-full-jammy创建并运行容器 sudo docker run -it…...
【JavaWeb+后端常用部件】
回顾内容看: 一、获取请求参数的方法 参考:[JavaWeb]——获取请求参数的方式(全面!!!)_java 获取请求参数-CSDN博客 Json格式的Body加备注RequestBody{id}动态路径加备注PathVariableid?&name?直接接收就好 i…...

Redis 重回开源怀抱:开源精神的回归与未来展望
在开源软件的广袤天地里,Redis 一直是备受瞩目的明星项目。近期,Redis 宣布重新回归开源,这一消息犹如一颗石子投入平静的湖面,在技术社区激起层层涟漪。今天,就让我们深入了解 Redis 这一重大转变背后的故事、意义以及…...

弹窗表单的使用,基于element-ui二次封装
el-dialog-form 介绍 基于element-ui封装的弹窗式表单组件 示例 git地址 https://gitee.com/chenfency/el-dialog-form.git 更新日志 2021-8-12 版本1.0.0 2021-8-17 优化组件,兼容element原组件所有Attributes及Events 2021-9-9 新增tip提示 安装教程 npm install …...

Unity打包安卓失败 Build failure 解决方法
【Unity】打包安卓失败 Build failure 的解决方法_com.android.build.gradle.internal.res.linkapplicat-CSDN博客 unity在打包时设置手机屏幕横屏竖屏的方法_unity打包默认横屏-CSDN博客...

Flink + Kafka 数据血缘追踪与审计机制实战
一、引言 在实时数据系统中,“我的数据从哪来?去往何处?” 是业务方最关心的问题之一。 尤其在以下场景下: 📉 金融风控:模型出现预警,需回溯数据源链路。 🧾 合规审计:监管要求提供数据全流程路径。 🛠 运维排查:Kafka Topic 数据乱序或错发后快速定位来源。 …...
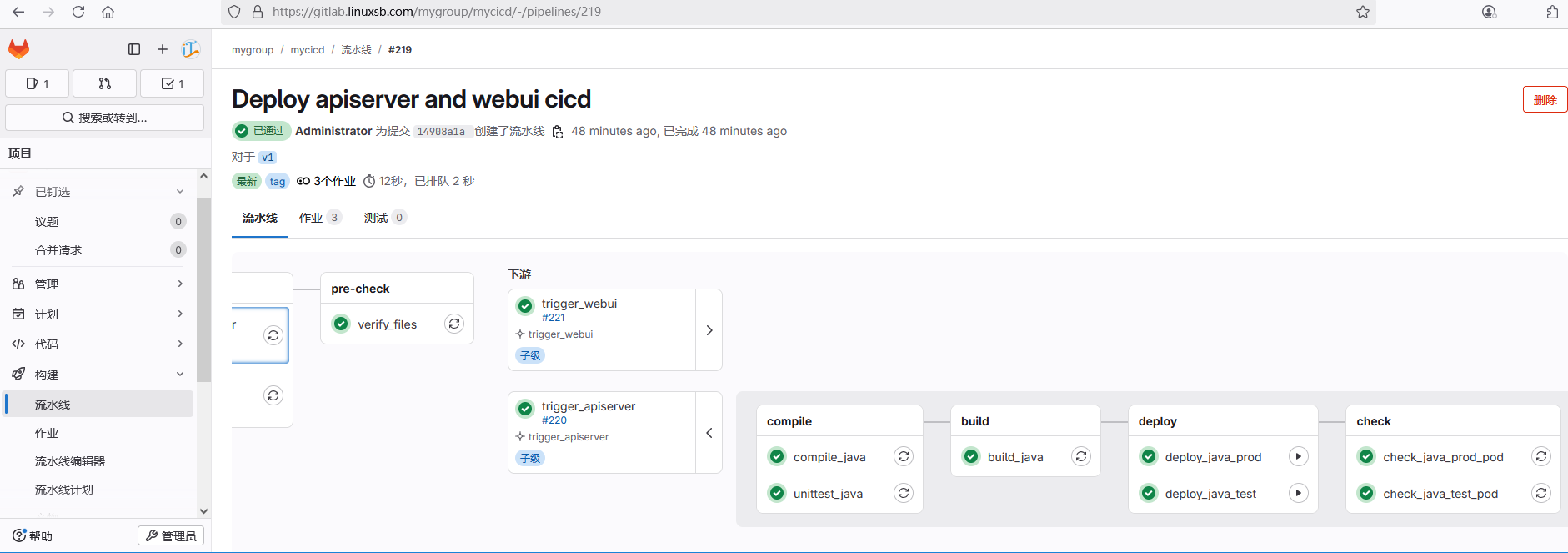
实践005-Gitlab CICD全项目整合
文章目录 环境准备环境准备集成Kubernetes Gitlab CICD项目整合项目整合整合设计 后端Java项目部署后端Java项目静态检查后端Java项目镜像构建创建Java项目部署文件创建完整流水线 前端webui项目部署前端webui项目镜像构建创建webui项目部署文件创建完整流水线 构建父子类型流水…...

懒人美食帮SpringBoot订餐系统开发实现
概述 快速构建一个订餐系统,今天,我们将通过”懒人美食帮”这个基于SpringBoot的订餐系统项目,为大家详细解析从用户登录到多角色权限管理的完整实现方案。本教程特别适合想要学习企业级应用开发的初学者。 主要内容 1. 用户系统设计与实现…...

css animation 动画属性
animation // 要绑定的关键帧规则名称 animation-name: slidein;// 定义动画完成一个周期所需的时间,秒或毫秒 animation-duration: 3s;// 定义动画速度曲线 animation-timing-function: ease;// 定义动画开始前的延迟时间 animation-delay: 1s;// 定义动画播放次数…...
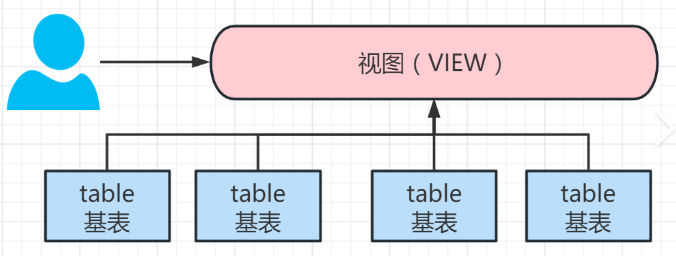
MySQL 从入门到精通(六):视图全面详解 —— 虚拟表的灵活运用
在数据库开发中,我们经常需要重复执行复杂的多表查询,或是需要限制用户只能访问特定数据。这时候,MySQL 的 视图(View)就能大显身手。作为一种 “虚拟表”,视图不存储实际数据,却能基于 SQL 查询…...

手机隐私数据彻底删除工具:回收或弃用手机前防数据恢复
软件介绍 有这样一款由吾爱网友chenwangjun 原创开发的数据处理软件,名为 AndroidDiskClear。它的核心功能十分强大,能够将你手机里已经删除的各类文件,像图片、普通文件、文字信息等彻底清除干净,有效杜绝数据恢复类软件的二次恢…...
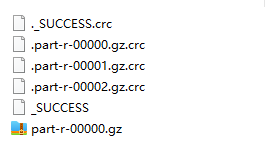
数据压缩实现案例
在driver中修改代码 package com.root.mapreduce.compress; import java.io.IOException; import org.apache.hadoop.conf.Configuration; import org.apache.hadoop.fs.Path; import org.apache.hadoop.io.IntWritable; import org.apache.hadoop.io.Text; import org.apache.…...

python实战项目69:基于Python爬虫的链家二手房数据采集方法研究
python实战项目69:链家二手房数据采集 一、项目需求1.1 房地产数据价值1.2 传统数据获取局限性1.3 技术可行性二、数据采集流程2.1 需求分析2.2 网页结构分析2.3 请求发送与反爬策略2.4 数据解析2.5 数据存储三、结论与展望四、完整代码一、项目需求 本文针对房地产数据分析需…...

xml与注解的区别
功能xml配置注解定义bean bean标签 id属性 class属性 Component Controller Service Repository ComponentScan 设置依赖注入 setter注入(set方法) 构造器注入(构造方法) Autowired Qualifier Value 配置第三方bean bean标签 静…...
FlySecAgent:——MCP全自动AI Agent的实战利器
最近,出于对人工智能在网络安全领域应用潜力的浓厚兴趣,我利用闲暇时间进行了深入研究,并成功开发了一款小型轻量化的AI Agent安全客户端FlySecAgent。 什么是 FlySecAgent? 这是一个基于大语言模型和MCP(Model-Contr…...

利用flask设计接口
Flask 接口设计详尽指南(整合知识库优化版) 目录 基础概念与安装接口设计规范核心功能实现高级特性扩展错误处理与调试部署与优化完整示例 基础概念与安装 安装 Flask pip install Flask项目结构建议 my_flask_api/ ├── app.py # 主…...
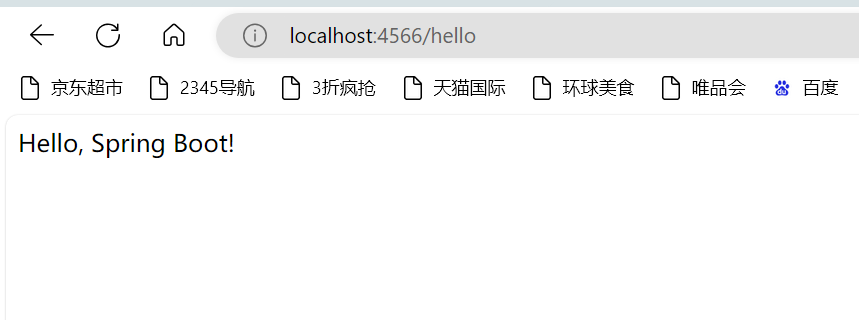
ideal创建Springboot项目(Maven,yml)
以下是使用 IntelliJ IDEA 创建基于 Maven 的 Spring Boot 项目并使用 YAML 配置文件的详细步骤: 一、创建 Spring Boot 项目 启动项目创建向导 打开 IntelliJ IDEA,点击“File”->“New”->“Project”。 在弹出的“New Project”窗口中&#…...
Pycharm(十九)深度学习
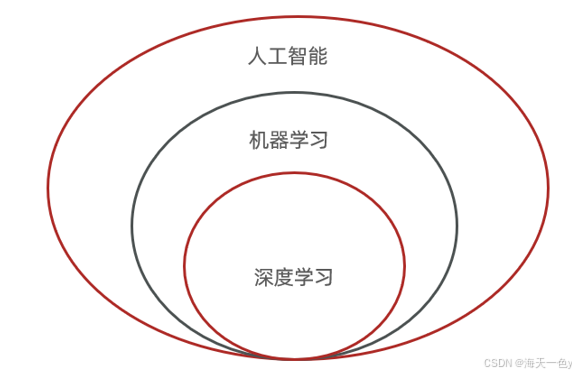
一、深度学习概述 1.1 什么是深度学习 深度学习是机器学习中的一种特殊方法,它使用称为神经网络的复杂结构,特别是“深层”的神经网络,来学习和做出预测。深度学习特别适合处理大规模和高维度的数据,如图像、声音和文本。深度学习、机器学习和人工智能之间的关系如下图所…...

XSS 攻击:深入剖析“暗藏在网页中的脚本“与防御之道
XSS (Cross-Site Scripting),即跨站脚本攻击,是 Web 安全领域中最常见也最具危害性的漏洞之一。攻击者通过巧妙的手段将恶意的 JavaScript、HTML 或其他脚本代码注入到正常的 Web 页面中。当其他用户浏览这些被注入了恶意脚本的页面时,这些脚…...

Scrapyd 详解:分布式爬虫部署与管理利器
Scrapyd 是 Scrapy 官方提供的爬虫部署与管理平台,支持分布式爬虫部署、定时任务调度、远程管理爬虫等功能。本文将深入讲解 Scrapyd 的核心功能、安装配置、爬虫部署流程、API 接口使用,以及如何结合 Scrapy-Redis 实现分布式爬虫管理。通过本文&#x…...