Scrapyd 详解:分布式爬虫部署与管理利器
Scrapyd 是 Scrapy 官方提供的爬虫部署与管理平台,支持分布式爬虫部署、定时任务调度、远程管理爬虫等功能。本文将深入讲解 Scrapyd 的核心功能、安装配置、爬虫部署流程、API 接口使用,以及如何结合 Scrapy-Redis 实现分布式爬虫管理。通过本文,读者可以掌握 Scrapyd 的使用方法,并构建高效的爬虫自动化管理方案。
1. 引言
在 Scrapy 爬虫开发中,手动运行爬虫效率较低,尤其是在分布式爬取时,如何高效管理多个爬虫任务成为一大挑战。Scrapyd 作为 Scrapy 官方推荐的爬虫部署工具,提供了 批量部署、远程管理、定时任务调度 等功能,适用于企业级爬虫管理。
2. Scrapyd 核心功能

(1)爬虫部署
- 通过
scrapyd-deploy命令上传爬虫代码到 Scrapyd 服务器。 - 支持多环境部署(开发、测试、生产)。
(2)爬虫管理
- 启动、停止、暂停、恢复爬虫任务。
- 查看爬虫运行状态(
running、pending、finished)。
(3)任务调度
- 支持
cron表达式定时执行爬虫任务。 - 可配置任务优先级。
(4)日志管理
- 自动记录爬虫运行日志,便于调试和监控。
(5)分布式支持
- 结合 Scrapy-Redis 实现分布式爬虫管理。
3. Scrapyd 安装与配置
(1)安装 Scrapyd
pip install scrapyd
安装后,可直接运行:
scrapyd
默认监听 http://localhost:6800。
(2)配置 Scrapyd
修改 scrapyd.conf(通常位于 ~/.config/scrapy/scrapyd.conf):
[scrapyd]
eggs_dir = eggs
logs_dir = logs
items_dir = items
jobs_to_keep = 100
dbs_dir = dbs
max_proc = 4
max_proc_per_cpu = 4
finished_to_keep = 100
poll_interval = 5.0
bind_address = 0.0.0.0
http_port = 6800
(3)安装客户端工具
pip install scrapyd-client
该工具提供 scrapyd-deploy 命令,用于上传爬虫到 Scrapyd 服务器。
4. 爬虫部署流程
(1)项目打包
在 Scrapy 项目目录下执行:
python setup.py sdist
生成 .tar.gz 文件。
(2)上传爬虫
使用 scrapyd-deploy 部署:
scrapyd-deploy <target-name> -p <project-name>
<target-name> 是 Scrapyd 服务器名称(可在 scrapy.cfg 中配置),<project-name> 是 Scrapy 项目名称。
示例:
# 编辑 scrapy.cfg
[deploy:scrapyd-server]
url = http://localhost:6800/
project = my_scrapy_project# 部署
scrapyd-deploy scrapyd-server -p my_scrapy_project
(3)查看可用爬虫
访问 http://localhost:6800/listspiders.json?project=my_scrapy_project,获取爬虫列表。
(4)启动爬虫
curl http://localhost:6800/schedule.json -d project=my_scrapy_project -d spider=my_spider
5. API 接口使用
Scrapyd 提供 RESTful API,适用于自动化管理:
(1)常用 API
| API | 说明 | 示例 |
|---|---|---|
GET /listprojects.json | 列出所有项目 | curl http://localhost:6800/listprojects.json |
GET /listspiders.json?project=my_project | 列出项目下的爬虫 | curl http://localhost:6800/listspiders.json?project=my_project |
POST /schedule.json | 启动爬虫 | curl http://localhost:6800/schedule.json -d project=my_project -d spider=my_spider |
POST /cancel.json | 取消爬虫任务 | curl http://localhost:6800/cancel.json -d project=my_project -d job=my_job_id |
(2)Python 客户端调用示例
import requests# 启动爬虫
url = "http://localhost:6800/schedule.json"
data = {"project": "my_project","spider": "my_spider"
}
response = requests.post(url, data=data)
print(response.json())# 取消爬虫
cancel_url = "http://localhost:6800/cancel.json"
cancel_data = {"project": "my_project","job": "my_job_id"
}
cancel_response = requests.post(cancel_url, data=cancel_data)
print(cancel_response.json())
6. 分布式爬虫管理(结合 Scrapy-Redis)
Scrapyd 支持 Scrapy-Redis 的分布式爬虫管理:
-
安装 Scrapy-Redis
pip install scrapy-redis -
修改
settings.pySCHEDULER = "scrapy_redis.scheduler.Scheduler" DUPEFILTER_CLASS = "scrapy_redis.dupefilter.RFPDupeFilter" REDIS_URL = "redis://localhost:6379/0" -
部署到 Scrapyd
同普通 Scrapy 项目一样部署即可。 -
多台机器协作
- 所有爬虫节点指向同一个 Redis 实例。
- 通过 Scrapyd API 控制爬虫任务。
7. 总结
Scrapyd 是 Scrapy 爬虫管理的强大工具,适用于:
- 单机爬虫管理:方便启动、停止、监控爬虫。
- 分布式爬虫管理:结合 Scrapy-Redis 实现多机协作。
- 自动化运维:通过 API 实现定时任务、批量部署。
实践建议:
- 使用
scrapy.cfg配置多个 Scrapyd 服务器,实现多环境部署。 - 结合 Jenkins 或 Airflow 实现定时爬虫调度。
- 利用 Scrapyd 的日志功能优化爬虫性能。
Scrapyd 让爬虫管理更高效,是构建大规模爬虫系统的关键工具!
相关文章:
Scrapyd 详解:分布式爬虫部署与管理利器
Scrapyd 是 Scrapy 官方提供的爬虫部署与管理平台,支持分布式爬虫部署、定时任务调度、远程管理爬虫等功能。本文将深入讲解 Scrapyd 的核心功能、安装配置、爬虫部署流程、API 接口使用,以及如何结合 Scrapy-Redis 实现分布式爬虫管理。通过本文&#x…...

ai之pdf解析rapidOCR 的两种底层依赖PaddlePaddle 和ONNXRuntime
rapidocr_onnxruntime 与 rapidocr(通常指 rapidocr_paddle 或其他后端实现)的核心区别及使用推荐: 一、核心区别 特性rapidocr_onnxruntimerapidocr(以 rapidocr_paddle 为例)后端引擎基于 ONNXRuntime 推理框架&…...
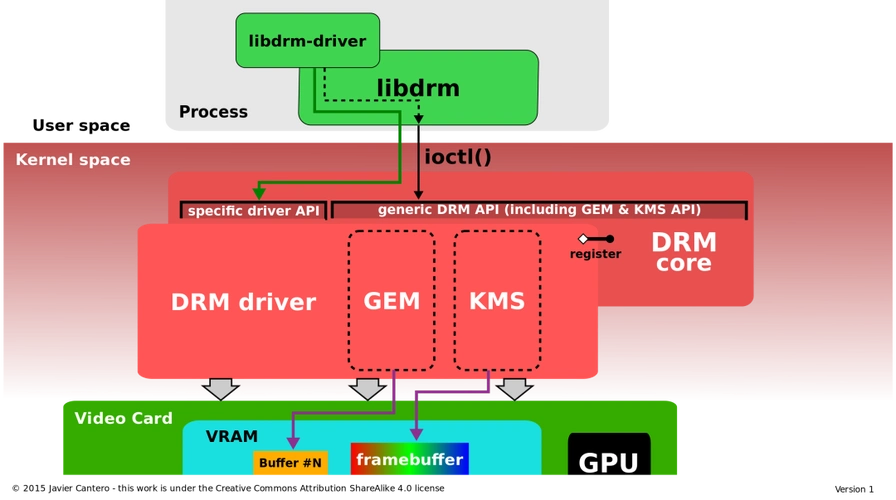
驱动开发硬核特训 · 专题篇:Vivante GPU 与 DRM 图形显示体系全解析(i.MX8MP 平台实战)
视频教程请关注 B 站:“嵌入式Jerry”。 一、背景导读:GPU 与 DRM 到底谁负责“显示”? 在嵌入式 Linux 图形系统中,“画面怎么显示出来”的问题,表面看似简单,实则涉及多个内核子系统与用户态组件的协同&…...

C——猜数字游戏
前面我们已经学习了C语言常见概念,数据类型和变量以及分置于循环的内容,现在我们可以将这些内容结合起来写一个有趣的小游戏。下面正式开始我们今天的主题——猜数字游戏的实现。 猜数字游戏的要求: 1.电脑自动生成1~100的随机数。 2.玩家…...

C/C++实践(三)深入理解 C++ 三大特性之一:封装
一、封装的概念与核心思想 封装(Encencapsulation)是 C 面向对象编程(OOP)的三大核心特性之一,其本质是将数据(成员变量)和对数据的操作(成员函数)捆绑在一个逻辑单元&a…...

Filecoin存储管理:如何停止Lotus向特定存储路径写入新扇区数据
Filecoin存储管理:如何停止Lotus向特定存储路径写入新扇区数据 引言背景问题场景解决方案步骤1:修改sectorstore.json文件步骤2:重新加载存储配置步骤3:验证更改 技术原理替代方案最佳实践结论 引言 在Filecoin挖矿过程中&#x…...
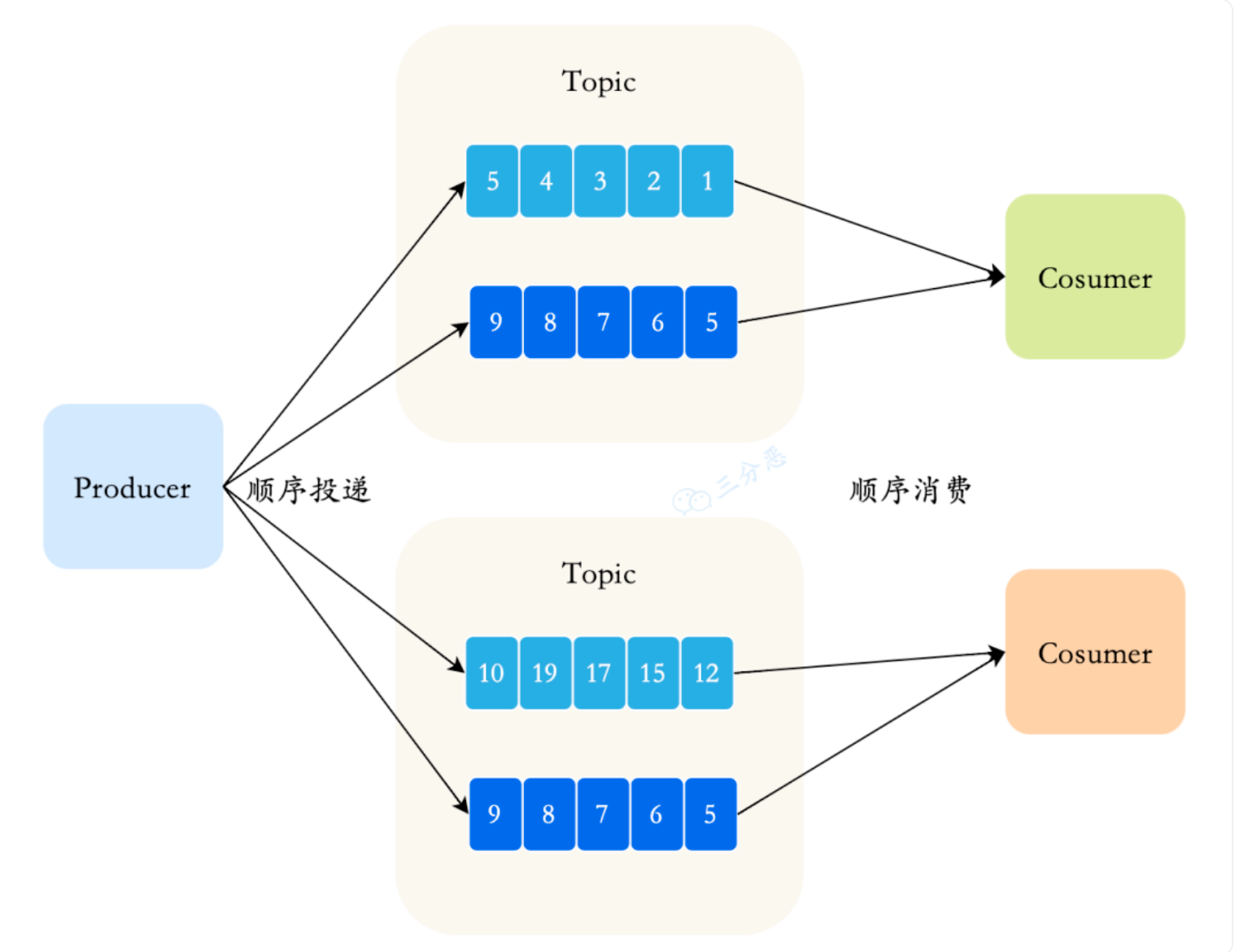
1、RocketMQ 核心架构拆解
1. 为什么要使用消息队列? 消息队列(MQ)是分布式系统中不可或缺的中间件,主要解决系统间的解耦、异步和削峰填谷问题。 解耦:生产者和消费者通过消息队列通信,彼此无需直接依赖,极大提升系统灵…...
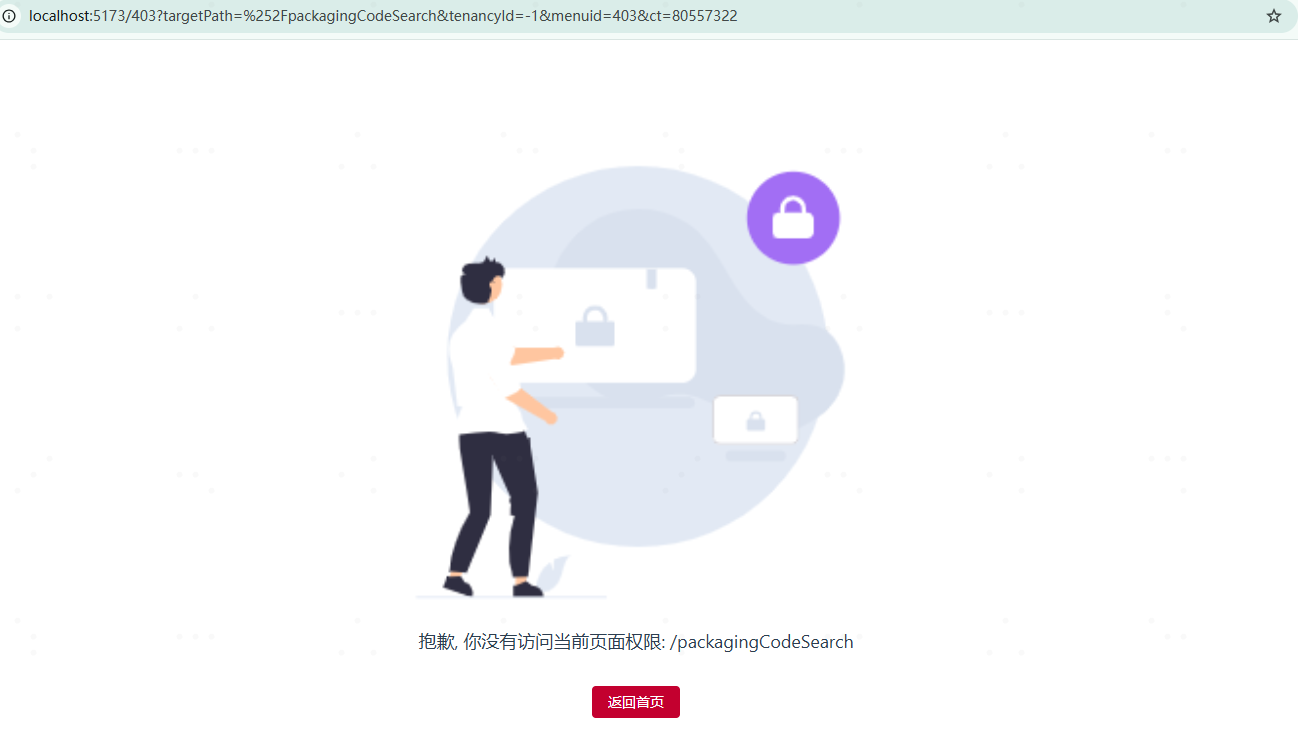
vue3 element-plus 输入框回车跳转页面问题处理
问题描述: 当页面搜索条件只有一个的情况下,输入框不管有没有值,回车后会跳转页面 解决办法,给表单添加 submit.prevent <el-form ref"ruleForm" :model"search" label-width"120px" class&qu…...

常见WEB漏洞----暴力破解
什么是暴力破解 暴力破解 (Brue Force) 是一种攻击方法 (穷举法),简称为“爆破”,黑客通过反复猜解和实验,旨在以暴力手段登入、访问目标主机获取服务,破坏系统安全,其属于 ATT&CK技术中的一种,常利用…...

快速入门深度学习系列(2)----损失函数、逻辑回归、向量化
针对深度学习入门新手目标不明确 知识体系杂乱的问题 拟开启快速入门深度学习系列文章的创作 旨在帮助大家快速的入门深度学习 写在前面: 本系列按照吴恩达系列课程顺序发布(说明一下为什么不直接看原笔记 因为内容太多 没有大量时间去阅读 所有作者需要一次梳理…...

[超详细,推荐!!!]前端性能优化策略详解
学习记录,部分内容版权归妙码学院 1.优化内容包括那些 其实前端的优化,整体粗略概括下来,白话之: 打开速度怎么变快再次打开速度怎么变快操作怎么才顺滑动画怎么保证流畅 2.性能优化 2.1首屏加载优化 在了解优化方法和策略之…...
数据提取之BeautifulSoup4快速使用
文章目录 一、前言二、概述2.1 安装2.2 初始化2.3 对象类型 三、遍历文档树3.1 子节点3.2 父节点3.3 兄弟节点3.4 前后节点3.5 节点内容3.5.1 文本内容3.5.2 属性值3.5.3 标签删除 四、搜索文档树4.1 find_all4.2 find4.3 CSS选择器4.4 更多 一、前言 官方文档:http…...
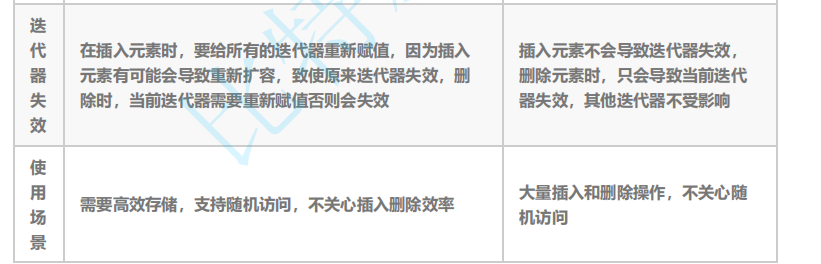
list类的详细讲解
【本节目标】 1. list的介绍及使用 2. list的深度剖析及模拟实现 3. list与vector的对比 1. list的介绍及使用 1.1 list的介绍 1. list 是可以在常数范围内在任意位置进行插入和删除的序列式容器,并且该容器可以前后双向迭代。 2. list 的底层是双向链表结构&a…...
Linux系统下安装mongodb
1. 配置MongoDB的yum仓库 创建仓库文件 sudo vi /etc/yum.repos.d/mongodb-org.repo添加仓库配置 根据系统版本选择配置(以下示例为CentOS 7和CentOS 9的配置): CentOS 7(安装MongoDB 5.0/4.2等旧版本): In…...

kuka, fanuc, abb机器人和移动相机的标定
基础知识 : 一, 9点标定之固定相机标定: 图1: 固定位置相机拍照 因为相机和机器人的基坐标系是固定的, 所以在海康威视相机的9点标定功能栏中, 填上海康使用“圆查找”捕捉到的坐标值, 再将机器人显示的工具坐标系在基坐标系的实时位置pos_act值填入物理坐标X, Y中即可 图2:…...

Android Framework学习四:init进程实现
文章目录 init流程简介init源码执行顺序执行顺序 init进程的具体工作事项挂载文件系统设置 SELinuxSecondStageMaininit.rc启动zygote和serviceManager进程的重要性serviceManager工作原理 Framework学习之系列文章 init流程简介 下面图片主要围绕 Android 系统中init进程的运…...

Linux计划任务与进程
at 命令使用方法 at 命令可在指定时间执行任务,适用于一次性任务调度。以下是基本用法: 安装 atd 服务(如未安装) # Debian/Ubuntu sudo apt-get install at# CentOS/RHEL sudo yum install at启动服务 sudo systemctl start atd…...
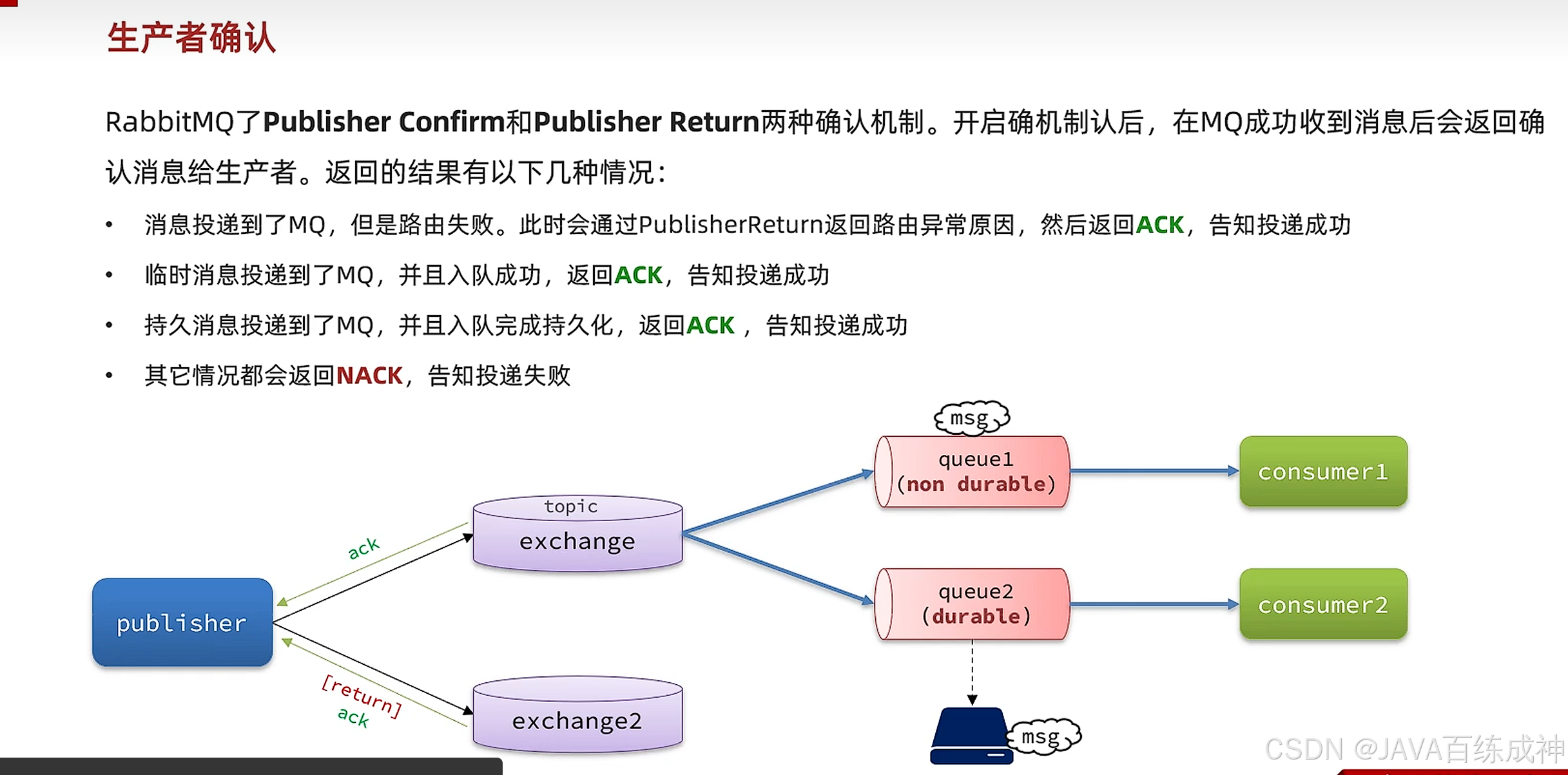
Java引用RabbitMQ快速入门
这里写目录 Java发送消息给MQ消费者接收消息实现一个队列绑定多个消费者消息推送限制 Fanout交换机路由的作用Direct交换机使用案例 Topic交换机声明队列和交换机的方式MQ消息转换器业务改造生产者可靠性设置重连 系统可靠性 Java发送消息给MQ public void testSendMessage() t…...
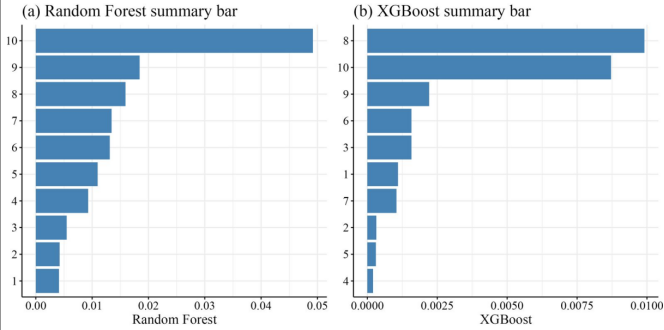
用R语言+随机森林玩转遥感空间预测-基于R语言机器学习遥感数据处理与模型空间预测技术及实际项目案例分析
遥感数据具有高维度、非线性及空间异质性等特点,传统分析方法往往难以充分挖掘其信息价值。机器学习技术的引入为遥感数据处理与模型预测提供了新的解决方案,其中随机森林(Random Forest)以其优异的性能和灵活性成为研究者的首选工…...

【许可证】Open Source Licenses
长期更新 扩展:shield.io装饰 开源许可证(Open Source Licenses)有很多种,每种都有不同的授权和限制,适用于不同目的。 默认的ISC🟰MIT License是否可商用是否要求开源衍生项目是否必须署名是否有专利授权…...
Spring Boot 文件上传实现详解
在项目开发过程中,文件上传是极为常见的功能需求。对于熟悉 Spring MVC 文件上传操作的开发者而言,Spring Boot 中的文件上传与之原理基本相通,只是在依赖管理和配置方式上更为简化。接下来,将详细阐述 Spring Boot 项目中文件上传…...
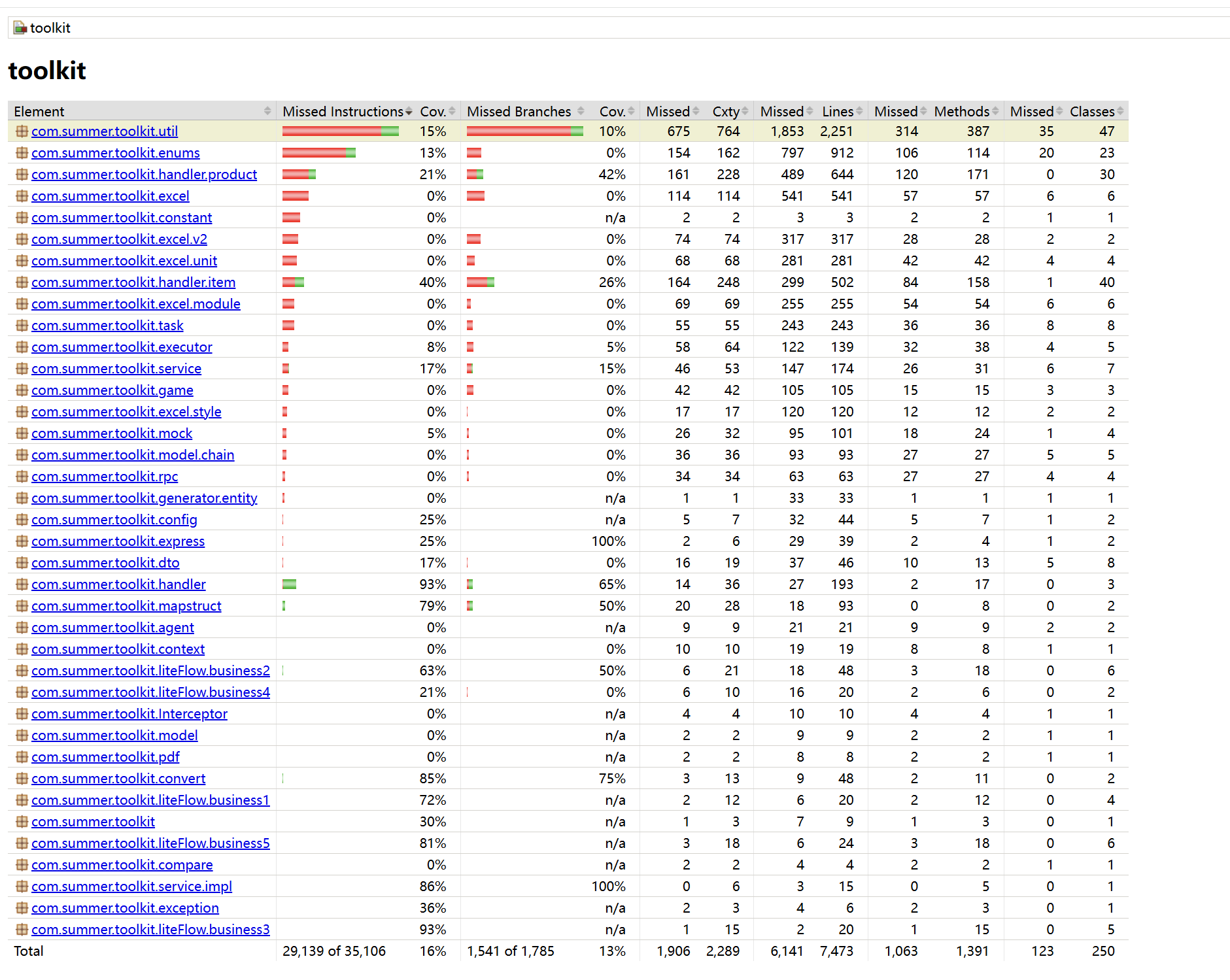
查看单元测试覆盖率
文章目录 1、POM文件配置2、编写单元测试3、执行单元测试4、查看单元测试覆盖率 1、POM文件配置 pom文件配置jacoco插件 <!-- 生成JaCoCo覆盖率数据插件 --> <plugin><groupId>org.jacoco</groupId><artifactId>jacoco-maven-plugin</artif…...
基于SpringBoot的在线教育管理系统
作者:计算机学姐 开发技术:SpringBoot、SSM、Vue、MySQL、JSP、ElementUI、Python、小程序等,“文末源码”。 专栏推荐:前后端分离项目源码、SpringBoot项目源码、Vue项目源码、SSM项目源码、微信小程序源码 精品专栏:…...

交叉编译 opencv-4.10
编译说明 opencv 下包含很多模块,各个模块的作用可以参考Opencv—模块概览. 嵌入式考虑有限存储等因素会对模块进行裁剪,我这里主要保留图像拼接(stitching)图片编解码(imgcodecs)与特征点匹配(…...
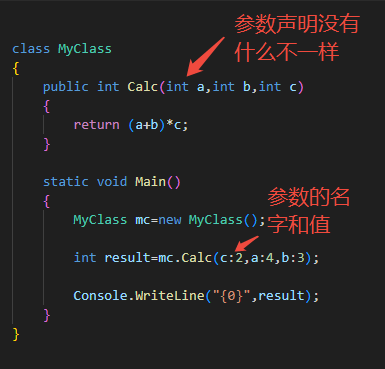
C# 方法(方法重载)
本章内容: 方法的结构 方法体内部的代码执行 局部变量 局部常量 控制流 方法调用 返回值 返回语句和void方法 局部函数 参数 值参数 引用参数 引用类型作为值参数和引用参数 输出参数 参数数组 参数类型总结 方法重载 命名参数 可选参数 栈帧 递归 方法重载 一个类中可以有多个…...
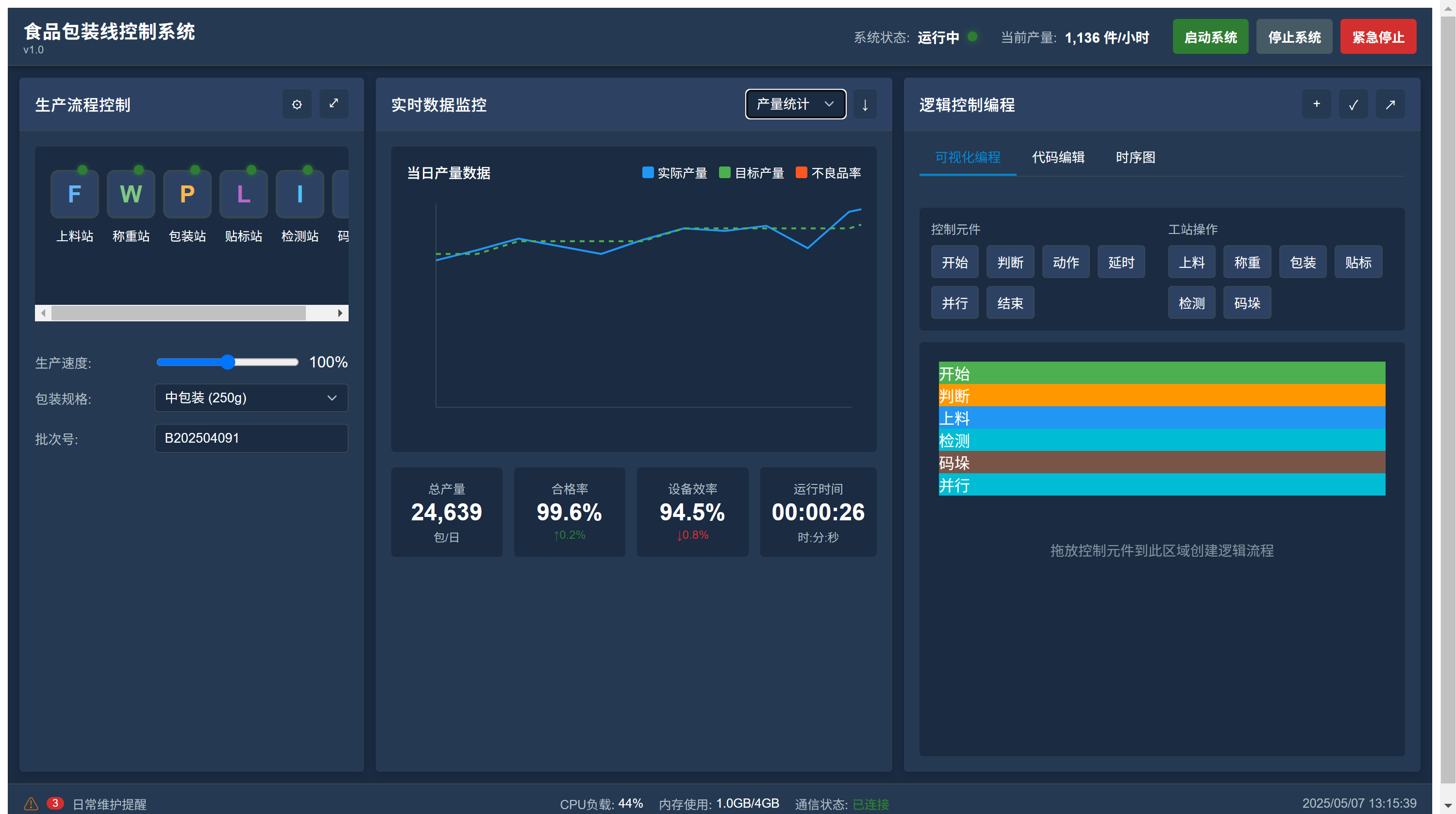
3、食品包装控制系统 - /自动化与控制组件/food-packaging-control
76个工业组件库示例汇总 食品包装线控制系统 这是一个用于食品包装线控制系统的自定义组件,提供了食品包装生产线的可视化监控与控制界面。组件采用工业风格设计,包含生产流程控制、实时数据监控和逻辑编程三个主要功能区域。 功能特点 工业风格UI设…...
初始图形学(7)
上一章完成了相机类的实现,对之前所学的内容进行了封装与整理,现在要学习新的内容。 抗锯齿 我们放大之前渲染的图片,往往会发现我们渲染的图像边缘有尖锐的"阶梯"性质。这种阶梯状被称为"锯齿"。当真实的相机拍照时&a…...
)
Linux NVIDIA 显卡驱动安装指南(适用于 RHEL/CentOS)
📌 一、禁用 Nouveau 开源驱动 NVIDIA 闭源驱动与开源的 nouveau 驱动冲突,需先禁用: if [ ! -f /etc/modprobe.d/blacklist-nouveau.conf ]; thenecho -e "blacklist nouveau\noptions nouveau modeset0" | sudo tee /etc/modpr…...
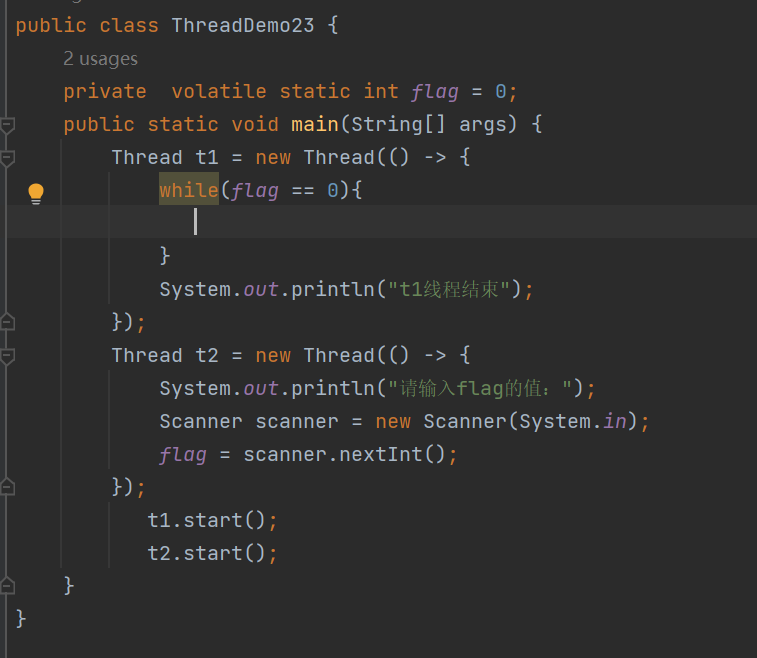
线程的一些事(2)
在java中,线程的终止,是一种“软性”操作,必须要对应的线程配合,才能把终止落实下去 然而,系统原生的api其实还提供了,强制终止线程的操作,无论线程执行到哪,都能强行把这个线程干掉…...

数据可视化:艺术与科学的交汇点,如何让数据“开口说话”?
数据可视化:艺术与科学的交汇点,如何让数据“开口说话”? 数据可视化,是科技与艺术的结合,是让冰冷的数字变得生动有趣的桥梁。它既是科学——讲究准确性、逻辑性、数据处理的严谨性;又是艺术——强调美感…...