从代码学习深度学习 - 单发多框检测(SSD)PyTorch版
文章目录
- 前言
- 工具函数
- 数据处理工具 (`utils_for_data.py`)
- 训练工具 (`utils_for_train.py`)
- 检测相关工具 (`utils_for_detection.py`)
- 可视化工具 (`utils_for_huitu.py`)
- 模型
- 类别预测层
- 边界框预测层
- 连接多尺度预测
- 高和宽减半块
- 基础网络块
- 完整的模型
- 训练模型
- 读取数据集和初始化
- 定义损失函数和评价函数
- 训练模型
- 预测目标
- 图像预处理
- 执行预测和后处理
- 可视化结果
- 总结
前言
大家好!欢迎来到“从代码学习深度学习”系列博客。目标检测是计算机视觉领域的核心任务之一,旨在识别图像或视频中特定类别的对象实例,并确定它们的位置和范围。近年来,深度学习技术极大地推动了目标检测的发展,涌现出许多优秀的算法,如 R-CNN 系列、YOLO 系列以及我们今天要重点介绍的单发多框检测(Single Shot MultiBox Detector, SSD)。
SSD 是一种流行的单阶段目标检测器,以其在速度和精度之间的良好平衡而闻名。与两阶段检测器(如 Faster R-CNN)先生成区域提议再进行分类和回归不同,SSD 直接在不同尺度的特征图上预测边界框和类别,从而实现了更快的检测速度。
本篇博客旨在通过一个具体的 PyTorch 实现(基于香蕉检测数据集),带领大家深入理解 SSD 的核心原理和代码实现细节。我们将逐步剖析模型结构、损失函数、训练过程以及预测可视化等关键环节,真正做到“从代码中学习”。
完整代码:下载链接
在深入 SSD 模型之前,我们先引入一些在整个项目中会用到的工具函数,它们主要负责数据处理、模型训练辅助以及结果可视化。
工具函数
在实现和训练 SSD 模型以及可视化结果的过程中,我们会用到一些辅助函数。这些函数分散在不同的工具文件中。
数据处理工具 (utils_for_data.py)
这部分代码负责读取和加载香蕉检测数据集。read_data_bananas 函数读取图像和对应的 CSV 标签文件,并将它们转换成 PyTorch 张量。BananasDataset 类继承了 torch.utils.data.Dataset,方便我们构建数据加载器。load_data_bananas 函数则利用 BananasDataset 创建了训练和验证数据的数据加载器(DataLoader)。
# --- START OF FILE utils_for_data.py ---import os
import pandas as pd
import torch
import torchvisiondef read_data_bananas(is_train=True):"""读取香蕉检测数据集中的图像和标签参数:is_train (bool): 是否读取训练集数据,True表示读取训练集,False表示读取验证集返回:tuple: (images, targets)- images: 图像列表,每个元素是一个形状为[C, H, W]的张量- targets: 标注信息张量,形状为[N, 1, 5],每行包含[类别, 左上角x, 左上角y, 右下角x, 右下角y]"""# 设置数据目录路径data_dir = 'banana-detection'# 根据is_train确定使用训练集还是验证集路径subset_name = 'bananas_train' if is_train else 'bananas_val'# 构建标签CSV文件的完整路径# csv_fname: 字符串,表示CSV文件的完整路径csv_fname = os.path.join(data_dir, subset_name, 'label.csv')# 读取CSV文件到pandas DataFrame# csv_data: DataFrame,包含图像名称和对应的标注信息csv_data = pd.read_csv(csv_fname)# 将img_name列设置为索引,便于后续访问# csv_data: DataFrame,索引为图像名称,列为标注信息csv_data = csv_data.set_index('img_name')# 初始化存储图像和标注的列表# images: 列表,用于存储读取的图像张量# targets: 列表,用于存储对应的标注信息images, targets = [], []# 遍历DataFrame中的每一行,读取图像和对应的标注信息for img_name, target in csv_data.iterrows():# 读取图像并添加到images列表中# img_name: 字符串,图像文件名# 读取的图像: 张量,形状为[C, H, W],C是通道数,H是高度,W是宽度images.append(torchvision.io.read_image(os.path.join(data_dir, subset_name, 'images', f'{img_name}')))# 添加标注信息到targets列表中# target: Series,包含类别和边界框坐标信息# list(target): 列表,形状为[5],包含[类别, 左上角x, 左上角y, 右下角x, 右下角y]targets.append(list(target))# 将targets列表转换为张量,并添加一个维度,然后将值归一化到0-1范围# torch.tensor(targets): 张量,形状为[N, 5],N是样本数量# torch.tensor(targets).unsqueeze(1): 张量,形状为[N, 1, 5]# 最终返回的targets: 张量,形状为[N, 1, 5],值范围在0-1之间targets_tensor = torch.tensor(targets).unsqueeze(1) / 256return images, targets_tensorclass BananasDataset(torch.utils.data.Dataset):"""一个用于加载香蕉检测数据集的自定义数据集类继承自torch.utils.data.Dataset基类,实现了必要的__init__、__getitem__和__len__方法用于提供数据加载器(DataLoader)访问数据集的接口"""def __init__(self, is_train):"""初始化香蕉检测数据集参数:is_train (bool): 是否加载训练集数据,True表示加载训练集,False表示加载验证集属性:self.features: 列表,包含所有图像张量,每个张量形状为[C, H, W]self.labels: 张量,形状为[N, 1, 5],其中N是样本数量,1是类别数量每个样本包含[类别, 左上角x, 左上角y, 右下角x, 右下角y]"""# 调用read_data_bananas函数读取数据集# self.features: 列表,包含N个形状为[C, H, W]的图像张量# self.labels: 张量,形状为[N, 1, 5]self.features, self.labels = read_data_bananas(is_train)# 打印读取的数据集信息dataset_type = '训练样本' if is_train else '验证样本'print(f'读取了 {len(self.features)} 个{dataset_type}')def __getitem__(self, idx):"""获取指定索引的样本参数:idx (int): 样本索引返回:tuple: (feature, label)- feature: 张量,形状为[C, H, W],图像数据,已转换为float类型- label: 张量,形状为[1, 5],对应的标注信息"""# 返回索引为idx的特征和标签对# self.features[idx]: 张量,形状为[C, H, W]# self.features[idx].float(): 将图像张量转换为float类型,形状不变,仍为[C, H, W]# self.labels[idx]: 张量,形状为[1, 5],包含一个目标的类别和边界框信息return (self.features[idx].float(), self.labels[idx])def __len__(self):"""获取数据集中样本的数量返回:int: 数据集中的样本数量"""# 返回数据集中的样本数量# len(self.features): int,表示数据集中图像的总数return len(self.features)def load_data_bananas(batch_size):"""加载香蕉检测数据集,并创建数据加载器参数:batch_size (int): 批量大小,指定每次加载的样本数量返回:tuple: (train_iter, val_iter)- train_iter: 训练数据加载器,每次返回batch_size个训练样本每个批次包含:- 特征张量,形状为[batch_size, C, H, W]- 标签张量,形状为[batch_size, 1, 5]- val_iter: 验证数据加载器,每次返回batch_size个验证样本批次格式与train_iter相同"""# 创建训练集数据加载器# BananasDataset(is_train=True): 实例化训练集数据集对象# batch_size: 每个批次的样本数量# shuffle=True: 打乱数据顺序,增强模型的泛化能力# train_iter的每个批次包含:# - 特征张量,形状为[batch_size, C, H, W],C是通道数,H是高度,W是宽度# - 标签张量,形状为[batch_size, 1, 5],每行包含[类别, 左上角x, 左上角y, 右下角x, 右下角y]train_iter = torch.utils.data.DataLoader(BananasDataset(is_train=True),batch_size=batch_size,shuffle=True)# 创建验证集数据加载器# BananasDataset(is_train=False): 实例化验证集数据集对象# batch_size: 每个批次的样本数量# shuffle默认为False: 不打乱验证数据的顺序,保持一致性# val_iter的每个批次包含:# - 特征张量,形状为[batch_size, C, H, W]# - 标签张量,形状为[batch_size, 1, 5]val_iter = torch.utils.data.DataLoader(BananasDataset(is_train=False),batch_size=batch_size)return train_iter, val_iter
# --- END OF FILE utils_for_data.py ---
训练工具 (utils_for_train.py)
这部分包含通用的训练辅助类。Timer 类用于记录和计算代码块的执行时间。Accumulator 类则方便我们在训练过程中累加损失、准确率等多个指标。try_gpu 函数尝试获取可用的 GPU 设备,否则回退到 CPU。
# --- START OF FILE utils_for_train.py ---import torch
import math # 导入math包,用于计算指数
from torch import nn
import time
import numpy as np # 导入numpy 用于cumsum计算class Timer:"""记录多次运行时间"""def __init__(self):"""Defined in :numref:`subsec_linear_model`"""self.times = []self.start()def start(self):"""启动计时器"""self.tik = time.time()def stop(self):"""停止计时器并将时间记录在列表中"""self.times.append(time.time() - self.tik)return self.times[-1]def avg(self):"""返回平均时间"""return sum(self.times) / len(self.times)def sum(self):"""返回时间总和"""return sum(self.times)def cumsum(self):"""返回累计时间"""return np.array(self.times).cumsum().tolist()class Accumulator:"""在 n 个变量上累加"""def __init__(self, n):"""初始化 Accumulator 类输入:n: 需要累加的变量数量 # 输入参数:变量数量输出:无返回值 # 方法无显式返回值"""self.data = [0.0] * n # 初始化一个长度为 n 的浮点数列表,初始值为 0.0def add(self, *args):"""向累加器中添加多个值输入:*args: 可变数量的数值,用于累加 # 输入参数:可变参数,表示要累加的值输出:无返回值 # 方法无显式返回值"""self.data = [a + float(b) for a, b in zip(self.data, args)] # 将输入值累加到对应位置的数据上def reset(self):"""重置累加器中的所有值为 0输入:无 # 方法无输入参数输出:无返回值 # 方法无显式返回值"""self.data = [0.0] * len(self.data) # 重置数据列表,所有值设为 0.0def __getitem__(self, idx):"""获取指定索引处的值输入:idx: 索引值 # 输入参数:要访问的数据索引输出:float: 指定索引处的值 # 返回指定位置的累加值"""return self.data[idx] # 返回指定索引处的数据值def try_gpu(i=0):"""如果存在,则返回gpu(i),否则返回cpu()Args:i (int, optional): GPU设备的编号,默认为0,表示尝试使用第0号GPUReturns:torch.device: 返回可用的设备对象,如果指定编号的GPU可用则返回GPU,否则返回CPU"""# 检查系统中可用的GPU数量是否大于等于i+1if torch.cuda.device_count() >= i + 1:# 如果条件满足,返回指定编号i的GPU设备return torch.device(f'cuda:{i}')# 如果没有足够的GPU设备,返回CPU设备return torch.device('cpu')# --- END OF FILE utils_for_train.py ---
检测相关工具 (utils_for_detection.py)
这是 SSD 实现的核心工具集。包含了以下关键功能:
- 边界框表示转换:
box_corner_to_center和box_center_to_corner用于在 (左上角, 右下角) 和 (中心点, 宽高) 两种坐标表示法之间转换。 - 锚框生成:
multibox_prior根据输入的特征图、尺寸比例 (sizes) 和宽高比 (ratios) 生成大量的锚框。 - IoU 计算:
box_iou计算两组边界框之间的交并比 (Intersection over Union),这是目标检测中的基本度量。 - 锚框分配:
assign_anchor_to_bbox将真实边界框 (ground truth) 分配给最匹配的锚框。 - 偏移量计算:
offset_boxes计算预测边界框相对于锚框的偏移量(中心点坐标和宽高),这是回归任务的目标。offset_inverse则根据锚框和预测的偏移量反算出预测的边界框坐标。 - 目标生成:
multibox_target是关键函数,它整合了锚框分配和偏移量计算,为每个锚框生成对应的类别标签和边界框回归目标。 - 非极大值抑制 (NMS):
nms用于在预测阶段去除高度重叠的冗余检测框,保留置信度最高的框。 - 多框检测:
multibox_detection结合类别概率预测、边界框偏移量预测、锚框以及 NMS,生成最终的检测结果。 - 可视化辅助:
bbox_to_rect将边界框转换为 Matplotlib 绘图格式,show_bboxes则用于在图像上绘制边界框和标签。
# --- START OF FILE utils_for_detection.py ---import torch
import matplotlib.pyplot as plt
torch.set_printoptions(2) # 精简输出精度def box_corner_to_center(boxes):"""将边界框从(左上角,右下角)表示法转换为(中心点,宽度,高度)表示法该函数接收以(x1, y1, x2, y2)格式表示的边界框张量,其中:- (x1, y1):表示边界框左上角的坐标- (x2, y2):表示边界框右下角的坐标然后将其转换为(cx, cy, w, h)格式,其中:- (cx, cy):表示边界框中心点的坐标- w:表示边界框的宽度- h:表示边界框的高度参数:boxes (torch.Tensor): 形状为(N, 4)的张量,包含N个边界框的左上角和右下角坐标返回:torch.Tensor: 形状为(N, 4)的张量,包含N个边界框的中心点坐标、宽度和高度"""# 分别提取所有边界框的左上角和右下角坐标x1, y1, x2, y2 = boxes[:, 0], boxes[:, 1], boxes[:, 2], boxes[:, 3]# 计算中心点坐标cx = (x1 + x2) / 2 # 中心点x坐标 = (左边界x + 右边界x) / 2cy = (y1 + y2) / 2 # 中心点y坐标 = (上边界y + 下边界y) / 2# 计算宽度和高度w = x2 - x1 # 宽度 = 右边界x - 左边界xh = y2 - y1 # 高度 = 下边界y - 上边界y# 将计算得到的中心点坐标、宽度和高度堆叠成新的张量boxes = torch.stack((cx, cy, w, h), axis=-1)return boxesdef box_center_to_corner(boxes):"""将边界框从(中心点,宽度,高度)表示法转换为(左上角,右下角)表示法该函数接收以(cx, cy, w, h)格式表示的边界框张量,其中:- (cx, cy):表示边界框中心点的坐标- w:表示边界框的宽度- h:表示边界框的高度然后将其转换为(x1, y1, x2, y2)格式,其中:- (x1, y1):表示边界框左上角的坐标- (x2, y2):表示边界框右下角的坐标参数:boxes (torch.Tensor): 形状为(N, 4)的张量,包含N个边界框的中心点坐标、宽度和高度返回:torch.Tensor: 形状为(N, 4)的张量,包含N个边界框的左上角和右下角坐标"""# 分别提取所有边界框的中心点坐标、宽度和高度cx, cy, w, h = boxes[:, 0], boxes[:, 1], boxes[:, 2], boxes[:, 3]# 计算左上角坐标x1 = cx - 0.5 * w # 左边界x = 中心点x - 宽度/2y1 = cy - 0.5 * h # 上边界y = 中心点y - 高度/2# 计算右下角坐标x2 = cx + 0.5 * w # 右边界x = 中心点x + 宽度/2y2 = cy + 0.5 * h # 下边界y = 中心点y + 高度/2# 将计算得到的左上角和右下角坐标堆叠成新的张量boxes = torch.stack((x1, y1, x2, y2), axis=-1)return boxesdef multibox_prior(data, sizes, ratios):"""生成以每个像素为中心具有不同形状的锚框参数:data:输入图像张量,维度为(批量大小, 通道数, 高度, 宽度)sizes:锚框缩放比列表,元素个数为num_sizes,每个元素∈(0,1]ratios:锚框宽高比列表,元素个数为num_ratios,每个元素>0返回:输出张量,维度为(1, 像素总数*每像素锚框数, 4),表示所有锚框的坐标"""# 获取输入数据的高度和宽度# in_height, in_width: 标量in_height, in_width = data.shape[-2:]# 获取设备信息以及尺寸和比例的数量# device: 字符串; num_sizes, num_ratios: 标量device, num_sizes, num_ratios = data.device, len(sizes), len(ratios)# 计算每个像素点产生的锚框数量 = 尺寸数 + 宽高比数 - 1# boxes_per_pixel: 标量boxes_per_pixel = (num_sizes + num_ratios - 1)# 将尺寸和比例转换为张量# size_tensor: 维度为(num_sizes,)# ratio_tensor: 维度为(num_ratios,)size_tensor = torch.tensor(sizes, device=device)ratio_tensor = torch.tensor(ratios, device=device)# 为了将锚点移动到像素的中心,需要设置偏移量# 因为一个像素的高为1且宽为1,我们选择偏移中心0.5# offset_h, offset_w: 标量offset_h, offset_w = 0.5, 0.5# 计算高度和宽度方向上的步长(归一化)# steps_h, steps_w: 标量steps_h = 1.0 / in_height # 在y轴上缩放步长steps_w = 1.0 / in_width # 在x轴上缩放步长# 生成锚框的所有中心点# center_h: 维度为(in_height,)# center_w: 维度为(in_width,)center_h = (torch.arange(in_height, device=device) + offset_h) * steps_hcenter_w = (torch.arange(in_width, device=device) + offset_w) * steps_w# 使用meshgrid生成网格坐标# shift_y, shift_x: 维度均为(in_height, in_width)shift_y, shift_x = torch.meshgrid(center_h, center_w, indexing='ij')# 将坐标展平为一维# shift_y, shift_x: 展平后维度均为(in_height*in_width,)shift_y, shift_x = shift_y.reshape(-1), shift_x.reshape(-1)# 生成"boxes_per_pixel"个高和宽,# 之后用于创建锚框的四角坐标(xmin,ymin,xmax,ymax)# 计算锚框宽度:先计算尺寸与第一个比例的组合,再计算第一个尺寸与其余比例的组合# w: 维度为(num_sizes + num_ratios - 1,)w = torch.cat((size_tensor * torch.sqrt(ratio_tensor[0]),sizes[0] * torch.sqrt(ratio_tensor[1:])))\* in_height / in_width # 处理矩形输入,调整宽度# 计算锚框高度:对应于宽度的计算方式# h: 维度为(num_sizes + num_ratios - 1,)h = torch.cat((size_tensor / torch.sqrt(ratio_tensor[0]),sizes[0] / torch.sqrt(ratio_tensor[1:]</相关文章:
PyTorch版)
从代码学习深度学习 - 单发多框检测(SSD)PyTorch版
文章目录 前言工具函数数据处理工具 (`utils_for_data.py`)训练工具 (`utils_for_train.py`)检测相关工具 (`utils_for_detection.py`)可视化工具 (`utils_for_huitu.py`)模型类别预测层边界框预测层连接多尺度预测高和宽减半块基础网络块完整的模型训练模型读取数据集和初始化…...
机器视觉的平板电脑屏幕组件覆膜应用
在现代智能制造业中,平板电脑屏幕组件覆膜工序是确保产品外观和功能完整性的重要环节。随着技术的进步,传统的覆膜方式已经无法满足高速度、高精度的生产需求。而MasterAlign视觉系统的出现,将传统覆膜工艺转变为智能化、自动化的生产流程。在…...

更换内存条会影响电脑的IP地址吗?——全面解析
在日常电脑维护和升级过程中,许多用户都会遇到需要更换内存条的情况。与此同时,不少用户也担心硬件更换是否会影响电脑的网络配置,特别是IP地址的设置。本文将详细探讨更换内存条与IP地址之间的关系,帮助读者理解这两者之间的本质…...
)
SQLite数据库加密(Java语言、python语言)
1. 背景与需求 SQLite 是一种轻量级的关系型数据库,广泛应用于嵌入式设备、移动应用、桌面应用等场景。为了保护数据的隐私与安全,SQLite 提供了加密功能(通过 SQLCipher 扩展)。在 Java 中,可以使用 sqlite-jdbc 驱动与 SQLCipher 集成来实现 SQLite 数据库的加密。 本…...

RISC-V入门资料
以下是获取 RISC-V 相关资料的权威渠道和推荐资源,涵盖技术文档、开发工具、社区支持等: 1. 官方资料 RISC-V 国际基金会官网 https://riscv.org 核心文档:ISA 规范(包括基础指令集(RV32I/RV64I)、扩展指令…...

C++访问权限控制符
访问权限控制符 在C中,访问权限控制符是用来限制类或结构体成员(例如:变量、函数等)的访问级别的。C提供了三种访问权限级别: Public 访问权限: 公共成员可以在任何地方被访问,包括类的内部、…...
VMware安装CentOS Stream10
文章目录 安装下载iso文件vmware安装CentOS Stream创建新虚拟机安装CentOS Stream10 安装 下载iso文件 官方地址:跳转链接 vmware安装CentOS Stream 创建新虚拟机 参考以下步骤 安装CentOS Stream10 指定ISO文件 开启虚拟机选择Install CentOS Stream 10 鼠…...

互联网大厂Java求职面试:云原生与AI融合下的系统设计挑战-2
互联网大厂Java求职面试:云原生与AI融合下的系统设计挑战-2 第一轮提问:云原生架构选型与微服务治理 面试官(技术总监):郑薪苦,我们先从一个基础问题开始。你了解Spring Cloud和Kubernetes在微服务架构中…...
基于Dify实现对Excel的数据分析
在dify部署完成后,大家就可以基于此进行各种应用场景建设,目前dify支持聊天助手(包括对话工作流)、工作流、agent等模式的场景建设,我们在日常工作中经常会遇到各种各样的数据清洗、格式转换处理、数据统计成图等数据分…...
资产月报怎么填?资产月报填报指南
资产月报是企业对固定资产进行定期检查和管理的重要工具,它能够帮助管理者了解资产的使用情况、维护状况和财务状况,从而为资产的优化配置和决策提供依据。填写资产月报时,除了填报内容外,还需要注意格式的规范性和数据的准确性。…...

MIT XV6 - 1.3 Lab: Xv6 and Unix utilities - primes
接上文 MIT XV6 - 1.2 Lab: Xv6 and Unix utilities - pingpong primes 继续实验,实验介绍和要求如下 (原文链接 译文链接) : Write a concurrent prime sieve program for xv6 using pipes and the design illustrated in the picture halfway down this page and…...

Android学习总结之kotlin协程面试篇
一、协程基础概念与原理类真题 真题 1:协程是线程吗?为什么说它是轻量级的?(字节跳动 / 美团) 解答: 本质区别: 线程是操作系统调度的最小单位(内核态),协…...
从前端视角看网络协议的演进
别再让才华被埋没,别再让github 项目蒙尘!github star 请点击 GitHub 在线专业服务直通车GitHub赋能精灵 - 艾米莉,立即加入这场席卷全球开发者的星光革命!若你有快速提升github Star github 加星数的需求,访问taimili…...
Docker中运行的Chrome崩溃问题解决
问题 各位看官是否在 Docker 容器中的 Linux 桌面环境(如Xfce)上启动Chrome ,遇到了令人沮丧的频繁崩溃问题?尤其是在打开包含图片、视频的网页,或者进行一些稍复杂的操作时,窗口突然消失?如果…...

【沉浸式求职学习day36】【初识Maven】
沉浸式求职学习 Maven1. Maven项目架构管理工具2.下载安装Maven3.利用Tomcat和Maven进入一个网站 Maven 为什么要学习这个技术? 在Java Web开发中,需要使用大量的jar包,我们手动去导入,这种操作很麻烦,PASS!…...

ES面试题系列「一」
1、Elasticsearch 是什么?它与传统数据库有什么区别? 答案:Elasticsearch 是一个基于 Lucene 的分布式、开源的搜索和分析引擎,主要用于处理大量的文本数据,提供快速的搜索和分析功能。与传统数据库相比,E…...

【音视频工具】MP4BOX使用
这里写目录标题 使用介绍 使用 下面这个网站直接使用: MP4Box.js - JavaScript MP4 Reader/Fragmenter (gpac.github.io) 介绍 MMP4Box 是 GPAC 项目开发的一款命令行工具,专门用于处理 MP4 格式多媒体文件,也可操作 AVI、MPG、TS 等格…...
Linux中常见开发工具简单介绍
目录 apt/yum 介绍 常用命令 install remove list vim 介绍 常用模式 命令模式 插入模式 批量操作 底行模式 模式替换图 vim的配置文件 gcc/g 介绍 处理过程 预处理 编译 汇编 链接 库 静态库 动态库(共享库) make/Makefile …...

laravel 使用异步队列,context带的上下文造成反序列化出问题
2025年5月8日17:03:44 如果你是单个应用,异步递交任务,是在应用内部使用,一般不会发生这样的问题 但是现在app项目是 app是一个应用,admin是一个应用,app吧为了接口性能吧异步任务丢给admin去执行,如果两个…...
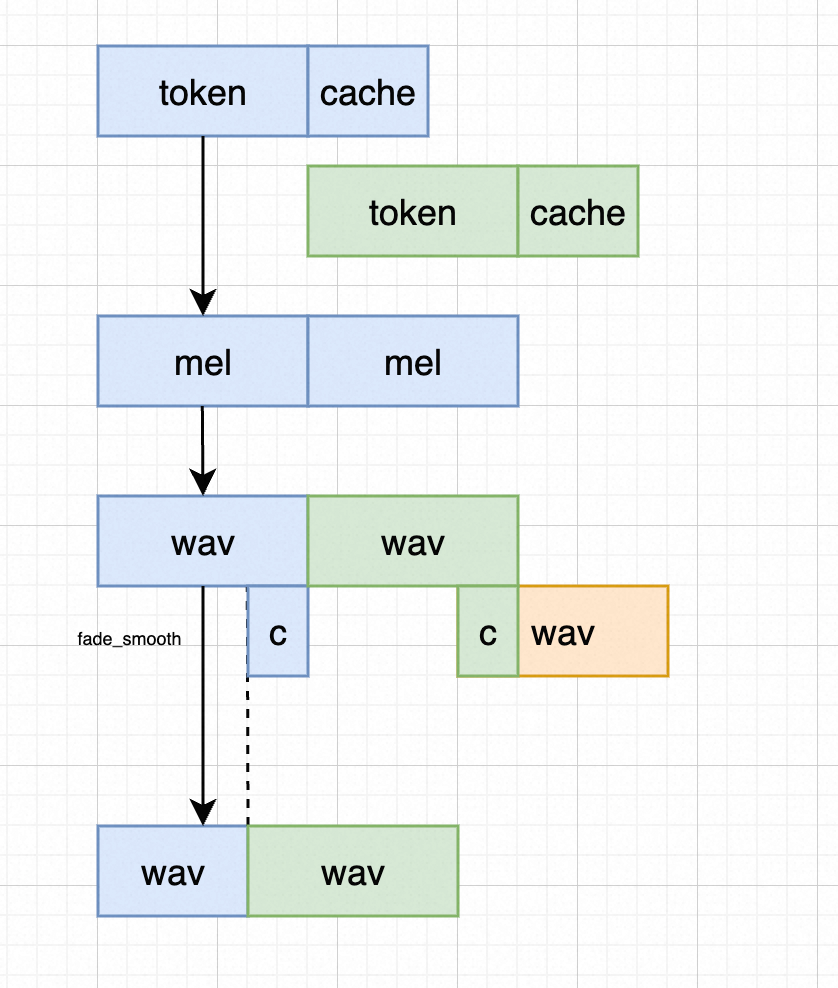
flow-matching 之学习matcha-tts cosyvoice
文章目录 matcha 实现cosyvoice 实现chunk_fmchunk_maskcache_attn stream token2wav 关于flow-matching 很好的原理性解释文章, 值得仔细读,多读几遍,关于文章Flow Straight and Fast: Learning to Generate and Transfer Data with Rectifi…...

视频编解码学习三之显示器续
一、现在主流的显示器是LCD显示器吗? 是的,现在主流的显示器仍然是 LCD(液晶显示器,Liquid Crystal Display),但它已经细分为多种技术类型,并和其他显示技术(如OLED)形成…...
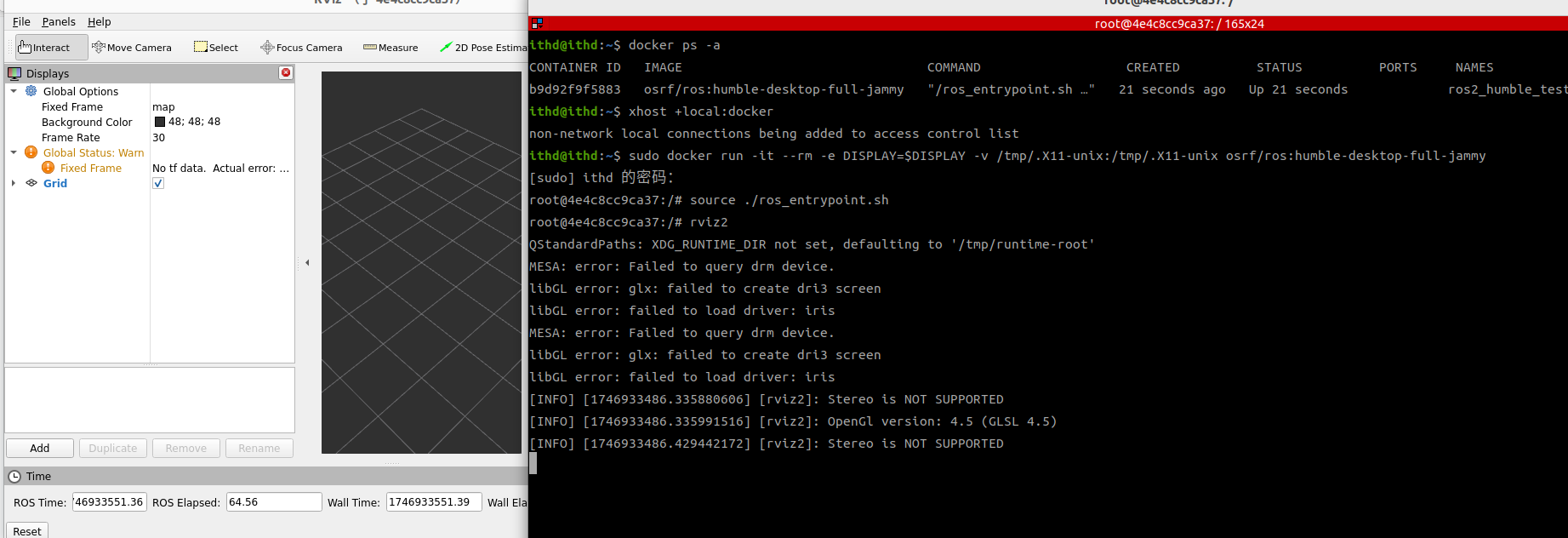
ubuntu22.04在 Docker容器中安装 ROS2-Humble
22.04 安装 docker 容器并实现rviz功能 1 docker pull命令拉取包含ROS-Humble的镜像: docker pull osrf/ros:humble-desktop-full-jammy docker images验证该镜像是否拉取成功。 使用镜像osrf/ros:humble-desktop-full-jammy创建并运行容器 sudo docker run -it…...
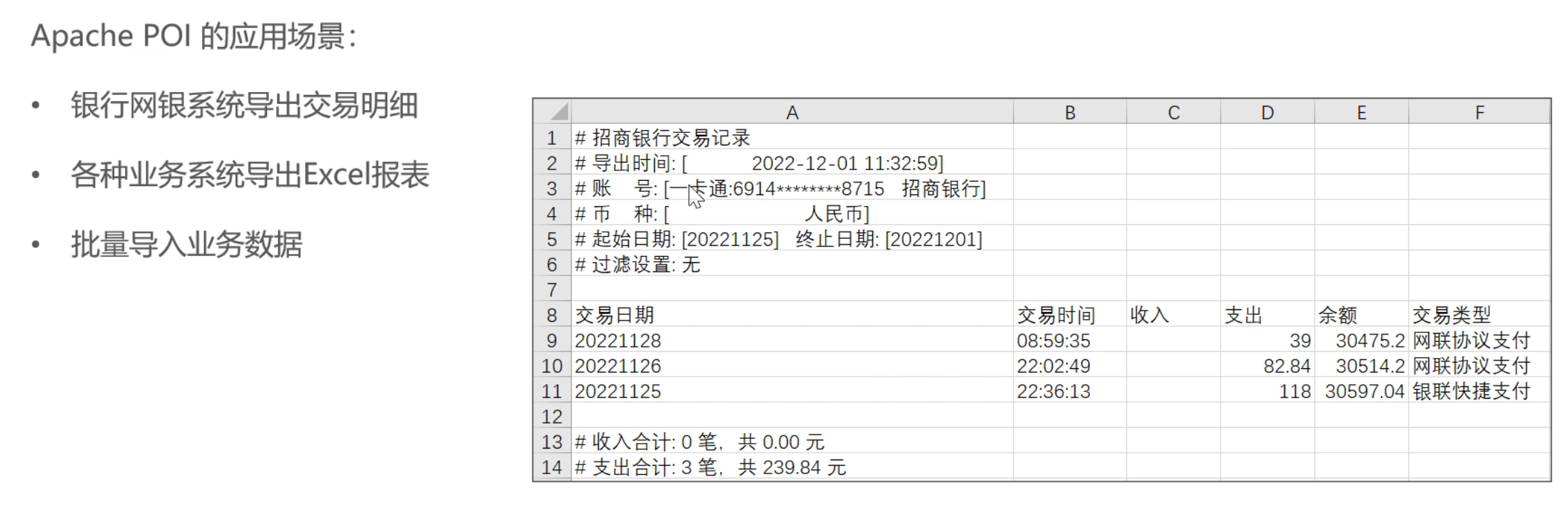
【JavaWeb+后端常用部件】
回顾内容看: 一、获取请求参数的方法 参考:[JavaWeb]——获取请求参数的方式(全面!!!)_java 获取请求参数-CSDN博客 Json格式的Body加备注RequestBody{id}动态路径加备注PathVariableid?&name?直接接收就好 i…...

Redis 重回开源怀抱:开源精神的回归与未来展望
在开源软件的广袤天地里,Redis 一直是备受瞩目的明星项目。近期,Redis 宣布重新回归开源,这一消息犹如一颗石子投入平静的湖面,在技术社区激起层层涟漪。今天,就让我们深入了解 Redis 这一重大转变背后的故事、意义以及…...

弹窗表单的使用,基于element-ui二次封装
el-dialog-form 介绍 基于element-ui封装的弹窗式表单组件 示例 git地址 https://gitee.com/chenfency/el-dialog-form.git 更新日志 2021-8-12 版本1.0.0 2021-8-17 优化组件,兼容element原组件所有Attributes及Events 2021-9-9 新增tip提示 安装教程 npm install …...

Unity打包安卓失败 Build failure 解决方法
【Unity】打包安卓失败 Build failure 的解决方法_com.android.build.gradle.internal.res.linkapplicat-CSDN博客 unity在打包时设置手机屏幕横屏竖屏的方法_unity打包默认横屏-CSDN博客...

Flink + Kafka 数据血缘追踪与审计机制实战
一、引言 在实时数据系统中,“我的数据从哪来?去往何处?” 是业务方最关心的问题之一。 尤其在以下场景下: 📉 金融风控:模型出现预警,需回溯数据源链路。 🧾 合规审计:监管要求提供数据全流程路径。 🛠 运维排查:Kafka Topic 数据乱序或错发后快速定位来源。 …...
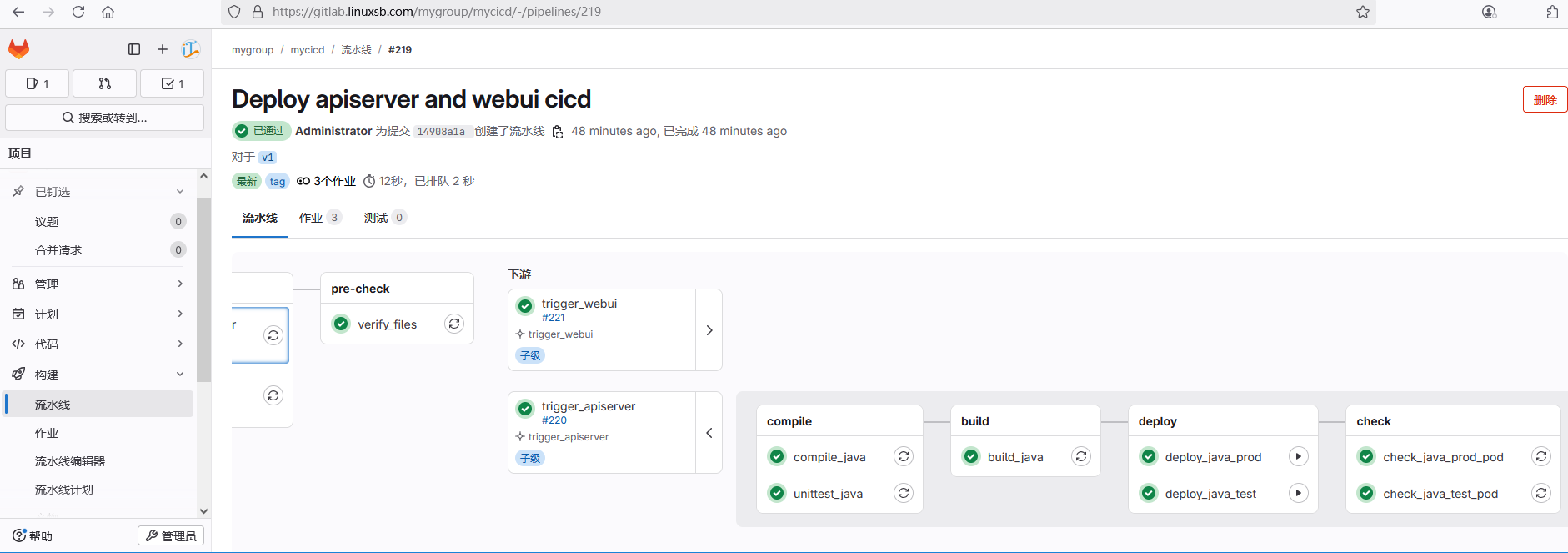
实践005-Gitlab CICD全项目整合
文章目录 环境准备环境准备集成Kubernetes Gitlab CICD项目整合项目整合整合设计 后端Java项目部署后端Java项目静态检查后端Java项目镜像构建创建Java项目部署文件创建完整流水线 前端webui项目部署前端webui项目镜像构建创建webui项目部署文件创建完整流水线 构建父子类型流水…...

懒人美食帮SpringBoot订餐系统开发实现
概述 快速构建一个订餐系统,今天,我们将通过”懒人美食帮”这个基于SpringBoot的订餐系统项目,为大家详细解析从用户登录到多角色权限管理的完整实现方案。本教程特别适合想要学习企业级应用开发的初学者。 主要内容 1. 用户系统设计与实现…...

css animation 动画属性
animation // 要绑定的关键帧规则名称 animation-name: slidein;// 定义动画完成一个周期所需的时间,秒或毫秒 animation-duration: 3s;// 定义动画速度曲线 animation-timing-function: ease;// 定义动画开始前的延迟时间 animation-delay: 1s;// 定义动画播放次数…...