《AI大模型应知应会100篇》第60篇:Pinecone 与 Milvus,向量数据库在大模型应用中的作用
第60篇:Pinecone与Milvus,向量数据库在大模型应用中的作用
摘要
本文将系统比较Pinecone与Milvus两大主流向量数据库的技术特点、性能表现和应用场景,提供详细的接入代码和最佳实践,帮助开发者为大模型应用选择并优化向量存储解决方案。

引言:为什么需要向量数据库?
随着AI大模型的发展,向量数据(如文本、图像的嵌入表示)成为处理非结构化数据的核心方式。然而,传统的数据库无法高效地处理高维向量的相似性搜索问题。因此,向量数据库应运而生。
什么是向量数据库?
向量数据库是一种专门用于存储和检索高维向量数据的数据库。它支持快速执行近似最近邻搜索(ANN),即找出与目标向量最接近的一组向量。
向量数据库的应用场景
- 推荐系统:基于用户行为向量进行个性化推荐。
- 语义搜索:通过文本嵌入实现文档或网页内容的语义匹配。
- 图像检索:利用图像特征向量进行相似图片查找。
- RAG(Retrieval-Augmented Generation):结合知识库与大模型生成更准确的回答。
核心概念与知识点
1. 向量数据库基础
向量嵌入基础
向量嵌入是将非结构化数据(如文本、图像)转换为固定维度的数值向量的过程。例如:
- 使用
text-embedding-ada-002将文本转换为 1536 维向量。 - 使用 CLIP 模型将图像转换为 512 维向量。
from openai import OpenAIclient = OpenAI()
response = client.embeddings.create(input="这是一个示例文本",model="text-embedding-ada-002"
)
embedding = response.data[0].embedding
print(len(embedding)) # 输出: 1536
相似性搜索原理
常见的相似性度量方法包括:
- 余弦相似度(Cosine Similarity):衡量两个向量之间的夹角。
- 欧氏距离(Euclidean Distance):衡量两个向量之间的直线距离。
通常使用余弦相似度来判断两个向量是否“语义上”相似。
索引类型对比
| 索引类型 | 特点 | 适用场景 |
|---|---|---|
| HNSW (Hierarchical Navigable Small World) | 高效且支持动态更新 | 实时推荐系统 |
| IVF (Inverted File Index) | 快速但不支持频繁更新 | 批量处理场景 |
| FLAT | 精确但慢 | 小规模数据 |
向量数据库与传统数据库的区别
| 对比项 | 传统数据库 | 向量数据库 |
|---|---|---|
| 数据类型 | 结构化数据(如整数、字符串) | 高维向量 |
| 查询方式 | 精确匹配(如 SQL WHERE 条件) | 近似最近邻搜索(ANN) |
| 性能 | 插入/查询速度快 | 支持大规模向量数据的高效检索 |
Pinecone实战应用
账户设置与索引创建
Pinecone 是一个云托管的向量数据库服务,适合不想自己部署服务器的开发者。
安装依赖
pip install pinecone-client openai
初始化 Pinecone 并创建索引
import pinecone
from openai import OpenAI# 初始化 Pinecone
pinecone.init(api_key="your-api-key", environment="your-environment")# 创建索引(如果不存在)
if "knowledge-base" not in pinecone.list_indexes():pinecone.create_index(name="knowledge-base",dimension=1536, # OpenAI ada-002 的输出维度metric="cosine")# 连接到索引
index = pinecone.Index("knowledge-base")
插入向量
client = OpenAI()# 生成向量嵌入
embeddings = client.embeddings.create(input="需要向量化的文本内容",model="text-embedding-ada-002"
).data[0].embedding# 插入向量
index.upsert(vectors=[{"id": "doc1","values": embeddings,"metadata": {"source": "article", "author": "Zhang San"}}]
)
相似性搜索
results = index.query(vector=embeddings,top_k=3,include_metadata=True
)for result in results['matches']:print(f"ID: {result['id']}, Score: {result['score']}, Metadata: {result['metadata']}")
输出示例
ID: doc1, Score: 0.987, Metadata: {'source': 'article', 'author': 'Zhang San'}
ID: doc2, Score: 0.876, Metadata: {'source': 'blog', 'author': 'Li Si'}
ID: doc3, Score: 0.765, Metadata: {'source': 'wiki', 'author': 'Wang Wu'}
Milvus实战应用
部署与集群配置
Milvus 是一个开源的向量数据库,支持本地部署和分布式架构,适合对数据隐私要求较高的企业。
安装 Milvus
使用 Docker 快速启动:
docker run -d --name milvusdb -p 19530:19530 milvusdb/milvus:v2.4.3
Python 客户端连接
pip install pymilvus numpy
连接 Milvus 并插入数据
from pymilvus import connections, Collection, utility
import numpy as np# 连接 Milvus
connections.connect(host='localhost', port='19530')# 创建集合
collection_name = "document_store"if utility.has_collection(collection_name):collection = Collection(collection_name)
else:from pymilvus import FieldType, CollectionSchema, DataTypefields = [{"name": "id", "type": DataType.INT64, "is_primary": True},{"name": "embedding", "type": DataType.FLOAT_VECTOR, "dim": 1536},{"name": "source", "type": DataType.VARCHAR, "max_length": 256},{"name": "author", "type": DataType.VARCHAR, "max_length": 256}]schema = CollectionSchema(fields, description="Document Store")collection = Collection(collection_name, schema=schema)# 插入数据
import randomnum_entities = 1000
ids = [i for i in range(num_entities)]
embeddings = [[random.random() for _ in range(1536)] for _ in range(num_entities)]
sources = ["article"] * num_entities
authors = ["Zhang San"] * num_entitiescollection.insert([ids, embeddings, sources, authors])
collection.flush()
向量搜索
search_params = {"metric_type": "COSINE", "params": {"nprobe": 10}}
results = collection.search(data=[embeddings[0]],anns_field="embedding",param=search_params,limit=3,expr="source == 'article'",output_fields=["source", "author"]
)for hit in results[0]:print(f"ID: {hit.id}, Distance: {hit.distance}, Source: {hit.entity.get('source')}")
输出示例
ID: 0, Distance: 0.0, Source: article
ID: 123, Distance: 0.123, Source: article
ID: 456, Distance: 0.135, Source: article
应用架构与集成
与 LangChain 集成
LangChain 是一个强大的框架,可以轻松集成向量数据库。
安装依赖
pip install langchain pinecone-client pymilvus openai
Pinecone 集成
from langchain.vectorstores import Pinecone as LangchainPinecone
from langchain.embeddings.openai import OpenAIEmbeddingsembeddings = OpenAIEmbeddings()
vectorstore = LangchainPinecone.from_existing_index(index_name="knowledge-base",embedding=embeddings,text_key="content"
)
Milvus 集成
from langchain.vectorstores import Milvus as LangchainMilvusmilvus_store = LangchainMilvus(embedding_function=embeddings,collection_name="document_store",connection_args={"host": "localhost", "port": "19530"}
)
性能与选型对比
| 对比项 | Pinecone | Milvus |
|---|---|---|
| 部署方式 | 云托管 | 自托管/云托管 |
| 易用性 | 高(开箱即用) | 中等(需部署) |
| 成本 | 按 API 调用计费 | 开源免费 |
| 扩展性 | 自动扩展 | 支持分布式部署 |
| 社区活跃度 | 商业支持 | 开源社区活跃 |
| 功能丰富度 | 丰富 | 更加灵活可定制 |
实战案例
案例一:企业搜索引擎
- 需求:亿级文档的向量检索系统。
- 方案:
- 使用 Milvus 构建本地向量数据库。
- 使用 Elasticsearch 做关键词搜索。
- 使用 LangChain 整合两者实现混合搜索。
案例二:个性化推荐
- 需求:根据用户历史行为推荐相关内容。
- 方案:
- 用户行为向量化。
- 使用 Pinecone 进行实时相似性搜索。
- 返回相似用户的偏好内容作为推荐结果。
实战案例:完整代码与部署指南
案例一:企业搜索引擎(Milvus + Elasticsearch + LangChain)
1. 系统架构设计
[用户查询] ↓
[LangChain混合搜索]├─→ [Elasticsearch关键词搜索]└─→ [Milvus向量相似性搜索]↓
[结果融合排序]↓
[最终返回结果]
2. 技术栈要求
pip install pymilvus elasticsearch langchain openai sentence-transformers fastapi uvicorn
docker pull milvusdb/milvus:v2.4.3
docker pull docker.elastic.co/elasticsearch/elasticsearch:8.11.3
3. Milvus向量数据库初始化
from pymilvus import connections, Collection, utility, FieldSchema, CollectionSchema, DataType# 连接Milvus
connections.connect(host='localhost', port='19530')# 创建集合
collection_name = "document_vectors"if not utility.has_collection(collection_name):fields = [FieldSchema(name="doc_id", dtype=DataType.INT64, is_primary=True),FieldSchema(name="embedding", dtype=DataType.FLOAT_VECTOR, dim=768),FieldSchema(name="title", dtype=DataType.VARCHAR, max_length=512),FieldSchema(name="content", dtype=DataType.VARCHAR, max_length=65535)]schema = CollectionSchema(fields, description="文档向量存储")collection = Collection(collection_name, schema=schema)# 创建索引index_params = {"index_type": "IVF_FLAT","params": {"nlist": 1024},"metric_type": "COSINE"}collection.create_index(field_name="embedding", index_params=index_params)
else:collection = Collection(collection_name)collection.load()
4. Elasticsearch关键词索引创建
from elasticsearch import Elasticsearch
from elasticsearch_dsl import analyzer# 连接Elasticsearch
es_client = Elasticsearch(hosts=["http://localhost:9200"])# 创建索引
index_name = "document_search"if not es_client.indices.exists(index=index_name):es_client.indices.create(index=index_name,body={"settings": {"analysis": {"analyzer": {"custom_analyzer": {"type": "custom","tokenizer": "whitespace","filter": ["lowercase", "stop", "stemmer"]}}}},"mappings": {"properties": {"title": {"type": "text", "analyzer": "custom_analyzer"},"content": {"type": "text", "analyzer": "custom_analyzer"}}}})
5. 向量化处理服务
from sentence_transformers import SentenceTransformerclass VectorService:def __init__(self):self.model = SentenceTransformer('all-MiniLM-L6-v2')def text_to_vector(self, text: str) -> List[float]:return self.model.encode(text).tolist()vector_service = VectorService()
6. LangChain混合搜索实现
from langchain.vectorstores import Milvus
from langchain.schema import Document
from langchain.embeddings import HuggingFaceEmbeddings# 初始化嵌入模型
embeddings = HuggingFaceEmbeddings(model_name="all-MiniLM-L6-v2")# 连接Milvus向量数据库
milvus_store = Milvus(embedding_function=embeddings,collection_name=collection_name,connection_args={"host": "localhost", "port": "19530"}
)def hybrid_search(query: str, top_k: int = 5):# 向量搜索vector_results = milvus_store.similarity_search(query, k=top_k)# 关键词搜索es_results = es_client.search(index=index_name,body={"query": {"multi_match": {"query": query, "fields": ["title^2", "content"]}}})# 结果融合combined_results = []for hit in es_results['hits']['hits']:combined_results.append({"source": "elasticsearch","score": hit['_score'],"title": hit['_source']['title'],"content": hit['_source']['content']})for doc in vector_results:combined_results.append({"source": "milvus","score": doc.metadata.get("distance", 0),"title": doc.metadata.get("title", ""),"content": doc.page_content})# 按分数排序combined_results.sort(key=lambda x: x["score"], reverse=True)return combined_results[:top_k]
7. 部署指南
# 启动Milvus
docker run -d --name milvusdb -p 19530:19530 milvusdb/milvus:v2.4.3# 启动Elasticsearch
docker run -d --name es-node -p 9200:9200 \-e "discovery.type=single-node" \-e "ES_JAVA_OPTS=-Xms1g -Xmx1g" \docker.elastic.co/elasticsearch/elasticsearch:8.11.3# 安装依赖
pip install -r requirements.txt# 启动API服务
uvicorn search_api:app --host 0.0.0.0 --port 8000
案例二:个性化推荐系统(Pinecone + 用户行为分析)
1. 系统架构设计
[用户行为数据]↓
[特征工程处理]↓
[Pinecone向量存储]↓
[相似用户查找]↓
[内容推荐生成]
2. 技术栈要求
pip install pinecone-client openai pandas numpy scikit-learn fastapi uvicorn
3. Pinecone初始化
import pinecone
from openai import OpenAI# 初始化Pinecone
pinecone.init(api_key="your-api-key", environment="northamerica-northeast1-gcp")# 创建索引
index_name = "user-behavior"if index_name not in pinecone.list_indexes():pinecone.create_index(name=index_name,dimension=1536, # OpenAI嵌入维度metric="cosine")# 连接索引
index = pinecone.Index(index_name)
client = OpenAI()
4. 用户行为向量化
import pandas as pd
from sklearn.preprocessing import StandardScalerclass UserBehaviorVectorizer:def __init__(self):self.scaler = StandardScaler()def _extract_features(self, user_data: dict) -> pd.DataFrame:# 特征提取示例features = {"avg_session_time": user_data.get("session_duration", 0),"click_rate": len(user_data.get("clicked_items", [])) / max(1, user_data.get("impressions", 1)),"purchase_frequency": len(user_data.get("purchases", [])) / max(1, user_data.get("days_active", 1)),"category_preference": user_data.get("preferred_category", "other"),"device_usage": user_data.get("device_type", "desktop"),"location": user_data.get("location", "unknown")}return pd.DataFrame([features])def _normalize_features(self, df: pd.DataFrame) -> np.ndarray:# 数值特征标准化numerical = self.scaler.fit_transform(df[["avg_session_time", "click_rate", "purchase_frequency"]])# 类别特征one-hot编码categorical = pd.get_dummies(df[["category_preference", "device_usage", "location"]])# 合并特征return np.hstack([numerical, categorical.values])def vectorize(self, user_data: dict) -> List[float]:df = self._extract_features(user_data)features = self._normalize_features(df)# 使用OpenAI嵌入进行降维response = client.embeddings.create(input=features.tolist()[0],model="text-embedding-ada-002")return response.data[0].embedding
5. 推荐引擎实现
class RecommendationEngine:def __init__(self):self.user_vectorizer = UserBehaviorVectorizer()def add_user(self, user_id: str, user_data: dict):# 向量化用户行为vector = self.user_vectorizer.vectorize(user_data)# 存储到Pineconeindex.upsert(vectors=[{"id": user_id,"values": vector,"metadata": {"preferences": user_data.get("preferred_categories", []),"recent_purchases": user_data.get("recent_purchases", []),"location": user_data.get("location", "")}}])def get_recommendations(self, user_id: str, top_k: int = 5):# 获取用户向量result = index.fetch(ids=[user_id])if not result.vectors:return []user_vector = result.vectors[user_id].values# 查找相似用户similar_users = index.query(vector=user_vector,top_k=top_k+1, # 排除自己include_metadata=True)# 过滤出相似用户的偏好recommendations = []for match in similar_users.matches:if match.id == user_id:continuemetadata = match.metadatarecommendations.extend(metadata.get("recent_purchases", []))# 去重并返回return list(set(recommendations))[:top_k]
6. API接口实现
from fastapi import FastAPI, HTTPException
from pydantic import BaseModelapp = FastAPI()class UserData(BaseModel):session_duration: floatclicked_items: List[str]impressions: intpurchases: List[str]days_active: intpreferred_category: strdevice_type: strlocation: strrecommendation_engine = RecommendationEngine()@app.post("/users/{user_id}/update")
async def update_user_profile(user_id: str, user_data: UserData):try:recommendation_engine.add_user(user_id, user_data.dict())return {"status": "success"}except Exception as e:raise HTTPException(status_code=500, detail=str(e))@app.get("/users/{user_id}/recommendations")
async def get_recommendations(user_id: str, top_k: int = 5):try:results = recommendation_engine.get_recommendations(user_id, top_k)return {"recommendations": results}except Exception as e:raise HTTPException(status_code=500, detail=str(e))
7. 部署指南
# 设置环境变量
export PINECONE_API_KEY="your-pinecone-api-key"
export OPENAI_API_KEY="your-openai-api-key"# 安装依赖
pip install -r requirements.txt# 启动服务
uvicorn recommendation_api:app --host 0.0.0.0 --port 8000
扩展建议
1. 性能优化
- 对于企业搜索引擎:
- 使用Milvus的分片功能支持亿级数据
- 在Elasticsearch中使用倒排索引优化关键词搜索
- 引入缓存层(如Redis)存储高频查询结果
2. 安全加固
- 添加身份验证(JWT/OAuth)
- 对敏感数据进行加密存储
- 实现速率限制防止滥用
3. 监控方案
- Prometheus + Grafana监控系统指标
- ELK日志分析体系
- 设置异常报警规则
4. 可扩展性设计
- 将计算密集型任务移至Celery异步任务队列
- 使用Kubernetes进行容器编排
- 为不同模块设计独立的微服务架构
以上两个实战案例提供了完整的代码实现和部署指南,可根据具体需求进一步扩展和优化。
优化与故障排除
性能调优清单
- 索引类型选择:根据数据量和查询频率选择合适的索引。
- 批量插入:避免单条插入,使用批量插入提高效率。
- 内存优化:适当调整索引参数以减少内存占用。
- 缓存机制:对高频查询结果进行缓存。
常见问题与解决方案
| 问题 | 解决方案 |
|---|---|
| 向量维度不匹配 | 检查模型输出维度是否一致 |
| 查询超时 | 增加超时时间或优化索引 |
| 内存溢出 | 减少索引分片数或升级硬件 |
| 插入失败 | 检查主键唯一性约束 |
总结与扩展思考
未来趋势
- 多模态检索:支持文本、图像、音频等多种数据类型的统一检索。
- 混合搜索:结合关键词搜索与向量搜索,提升搜索准确性。
- 边缘计算:向量数据库将在边缘设备中得到更多应用。
学习资源推荐
- Pinecone 官方文档
- Milvus 官方文档
- LangChain 官方文档
- OpenAI Embeddings API 文档
如果你喜欢这篇文章,请点赞、收藏,并分享给你的朋友!欢迎关注我的专栏《AI大模型应知应会100篇》,获取更多实用技术干货!
相关文章:
《AI大模型应知应会100篇》第60篇:Pinecone 与 Milvus,向量数据库在大模型应用中的作用
第60篇:Pinecone与Milvus,向量数据库在大模型应用中的作用 摘要 本文将系统比较Pinecone与Milvus两大主流向量数据库的技术特点、性能表现和应用场景,提供详细的接入代码和最佳实践,帮助开发者为大模型应用选择并优化向量存储解…...

HDFS客户端操作
一、命令行工具操作 HDFS 命令行工具基于 hdfs dfs 命令,语法类似 Linux 文件操作。 1. 文件操作 bash # 创建目录 hdfs dfs -mkdir /test# 递归创建多级目录 hdfs dfs -mkdir -p /test/data/logs# 上传本地文件到 HDFS hdfs dfs -put local_file.txt /test/# 从…...

MySQL--视图详解
介绍 视图(View)是一种虚拟存在的表。视图中的数据并不在数据库中实际存在,行和列数据来自定义视图的查询中使用的表(称为基表),并且是在使用视图时动态生成的。 简而言之:视图只保存了查询的…...

Java学习手册:客户端负载均衡
一、客户端负载均衡的概念 客户端负载均衡是指在客户端应用程序中,根据一定的算法和策略,将请求分发到多个服务实例上。与服务端负载均衡不同,客户端负载均衡不需要通过专门的负载均衡设备或服务,而是直接在客户端进行请求的分发…...
Docker私有仓库实战:官方registry镜像实战应用
抱歉抱歉,离职后反而更忙了,拖了好久,从4月拖到现在,在学习企业级方案Harbor之前,我们先学习下官方方案registry,话不多说,详情见下文。 注意:下文省略了基本认证 TLS加密ÿ…...

LeetCode 373 查找和最小的 K 对数字题解
LeetCode 373 查找和最小的 K 对数字题解 题目描述 给定两个以升序排列的整数数组 nums1 和 nums2,以及一个整数 k。定义一对值 (u,v),其中第一个元素来自 nums1,第二个元素来自 nums2。请找到和最小的 k 个数对。 解题思路 最小堆优化法…...

WebSocket集成方案对比
WebSocket集成方案对比与实战 架构选型全景图 #mermaid-svg-BEuyOkkoP6cFygI0 {font-family:"trebuchet ms",verdana,arial,sans-serif;font-size:16px;fill:#333;}#mermaid-svg-BEuyOkkoP6cFygI0 .error-icon{fill:#552222;}#mermaid-svg-BEuyOkkoP6cFygI0 .er…...

深入理解 Istio v1.25.2
要深入理解 Istio 的最新版本(截至 2025 年 5 月,最新版本为 1.25.2,发布Iweb:1⁊)源码,我们可以通过分析其核心组件和代码结构来加深对 Istio 的理解。以下是对 Istio 源码的解读,结合其架构和功能&#x…...

使用conda导致无法找到libpython动态库
最近在用 AFL 的时候编译完成后遇到如下的报错: afl-fuzz: error while loading shared libraries: libpython3.9.so.1.0: cannot open shared object file: No such file or directory然后发现是因为编译时用的Python环境是通过miniconda构建的虚拟环境࿰…...
Redis+Caffeine构建高性能二级缓存
大家好,我是摘星。今天为大家带来的是RedisCaffeine构建高性能二级缓存,废话不多说直接开始~ 目录 二级缓存架构的技术背景 1. 基础缓存架构 2. 架构演进动因 3. 二级缓存解决方案 为什么选择本地缓存? 1. 极速访问 2. 减少网络IO 3…...
 添加自定义 SQL 片段)
MyBatis-Plus使用 wrapper.apply() 添加自定义 SQL 片段
在 MyBatis-Plus 中,wrapper.apply() 方法允许你在构建查询条件时插入任意的 SQL 片段。这对于实现一些复杂的查询需求特别有用,比如添加子查询、使用数据库特定函数等; 示例 1: 基本应用 import com.baomidou.mybatisplus.core.conditions…...
【计算机网络】NAT技术、内网穿透与代理服务器全解析:原理、应用及实践
📚 博主的专栏 🐧 Linux | 🖥️ C | 📊 数据结构 | 💡C 算法 | 🅒 C 语言 | 🌐 计算机网络 上篇文章:以太网、MAC地址、MTU与ARP协议 下篇文章:五种IO模型与阻…...
Python训练打卡Day21
常见的降维算法: # 先运行预处理阶段的代码 import pandas as pd import pandas as pd #用于数据处理和分析,可处理表格数据。 import numpy as np #用于数值计算,提供了高效的数组操作。 import matplotlib.pyplot as plt #用于绘…...
一、开始——1. 介绍)
【大模型MCP协议】MCP官方文档(Model Context Protocol)一、开始——1. 介绍
https://modelcontextprotocol.io/tutorials/building-mcp-with-llms 文章目录 介绍为什么选择MCP?总体架构 开始使用快速入门示例 教程探索MCP贡献支持和反馈探索 MCP贡献代码支持与反馈 介绍 开始使用模型上下文协议(MCP) C# SDK已发布&…...

三大告警方案解析:从日志监控到流处理的演进之路
引言:告警系统的核心挑战与演进逻辑 在分布式系统中,实时告警是实现业务稳定性的第一道防线。随着系统复杂度提升,告警机制从简单的日志匹配逐步演进到流式处理的秒级响应。本文将基于三大主流方案(日志告警、离线统计、实时流…...
node .js 启动基于express框架的后端服务报错解决
问题: node .js 用npm start 启动基于express框架的后端服务报错如下: /c/Program Files/nodejs/npm: line 65: 26880 Segmentation fault "$NODE_EXE" "$NPM_CLI_JS" "$" 原因分析: 遇到 /c/Program F…...

互联网大厂Java求职面试实战:Spring Boot与微服务场景深度解析
💪🏻 1. Python基础专栏,基础知识一网打尽,9.9元买不了吃亏,买不了上当。 Python从入门到精通 😁 2. 毕业设计专栏,毕业季咱们不慌忙,几百款毕业设计等你选。 ❤️ 3. Python爬虫专栏…...

并发笔记-信号量(四)
文章目录 背景与动机31.1 信号量:定义 (Semaphores: A Definition)31.2 二元信号量 (用作锁) (Binary Semaphores - Locks)31.3 用于排序的信号量 (Semaphores For Ordering)31.4 生产者/消费者问题 (The Producer/Consumer (Bounded Buffer) Problem)31.5 读写锁 (…...

【HTOP 使用指南】:如何理解主从线程?(以 Faster-LIO 为例)
htop 是 Linux 下常用的进程监控工具,它比传统的 top 更友好、更直观,尤其在分析多线程或多进程程序时非常有用。 以下截图就是在运行 Faster-LIO 实时建图时的 htop 状态展示: 🔍 一、颜色说明 白色(或亮色…...
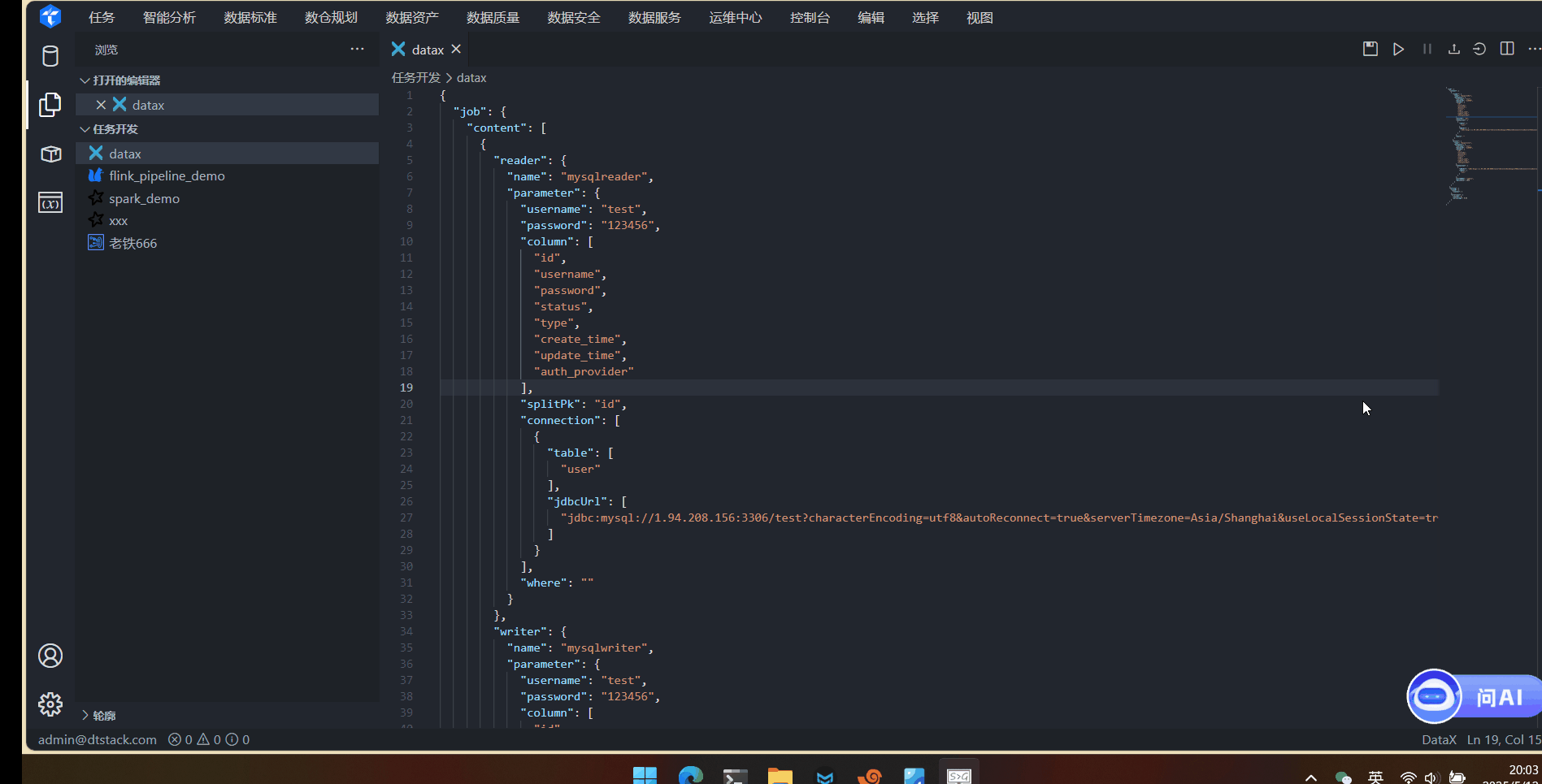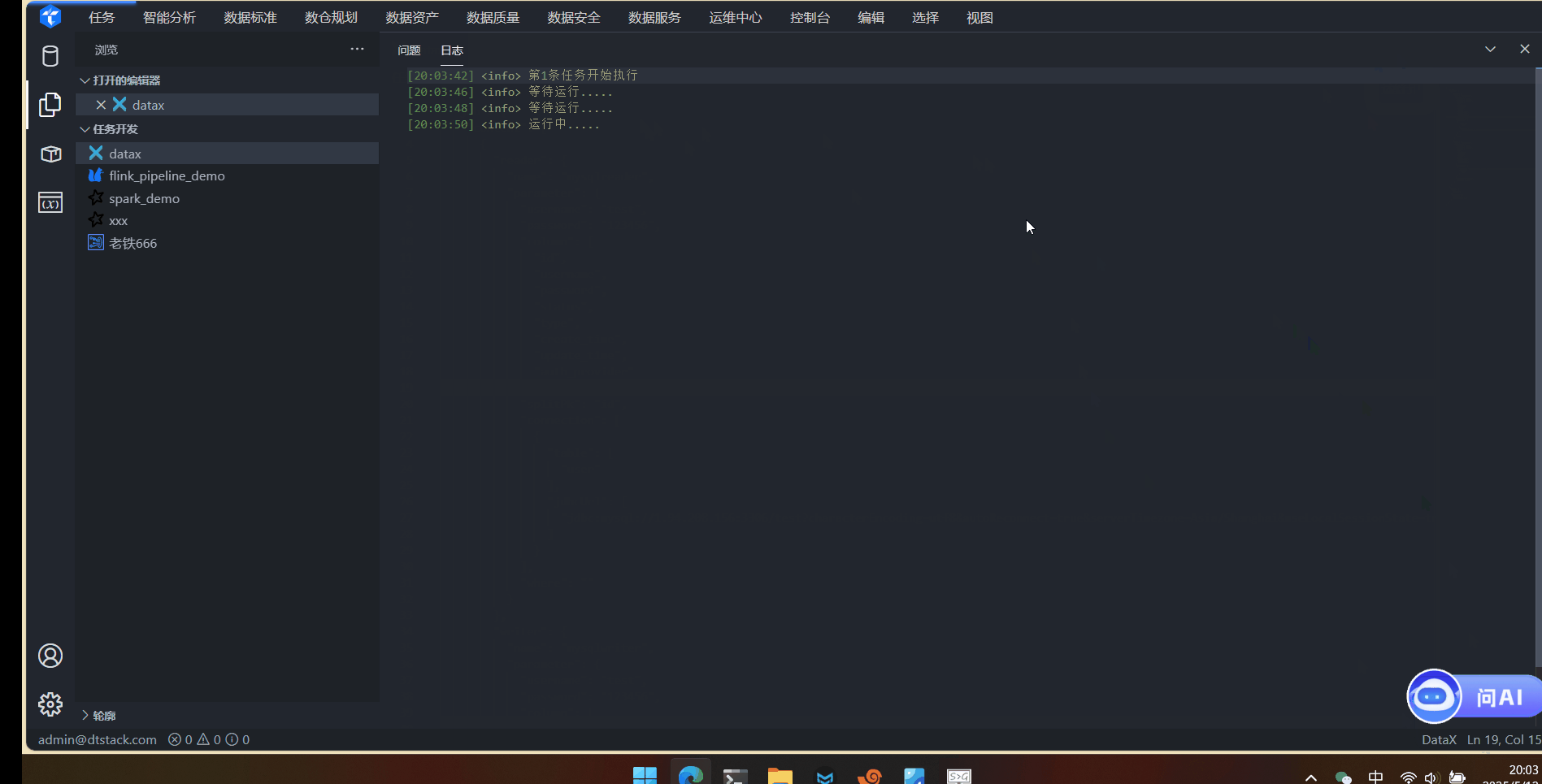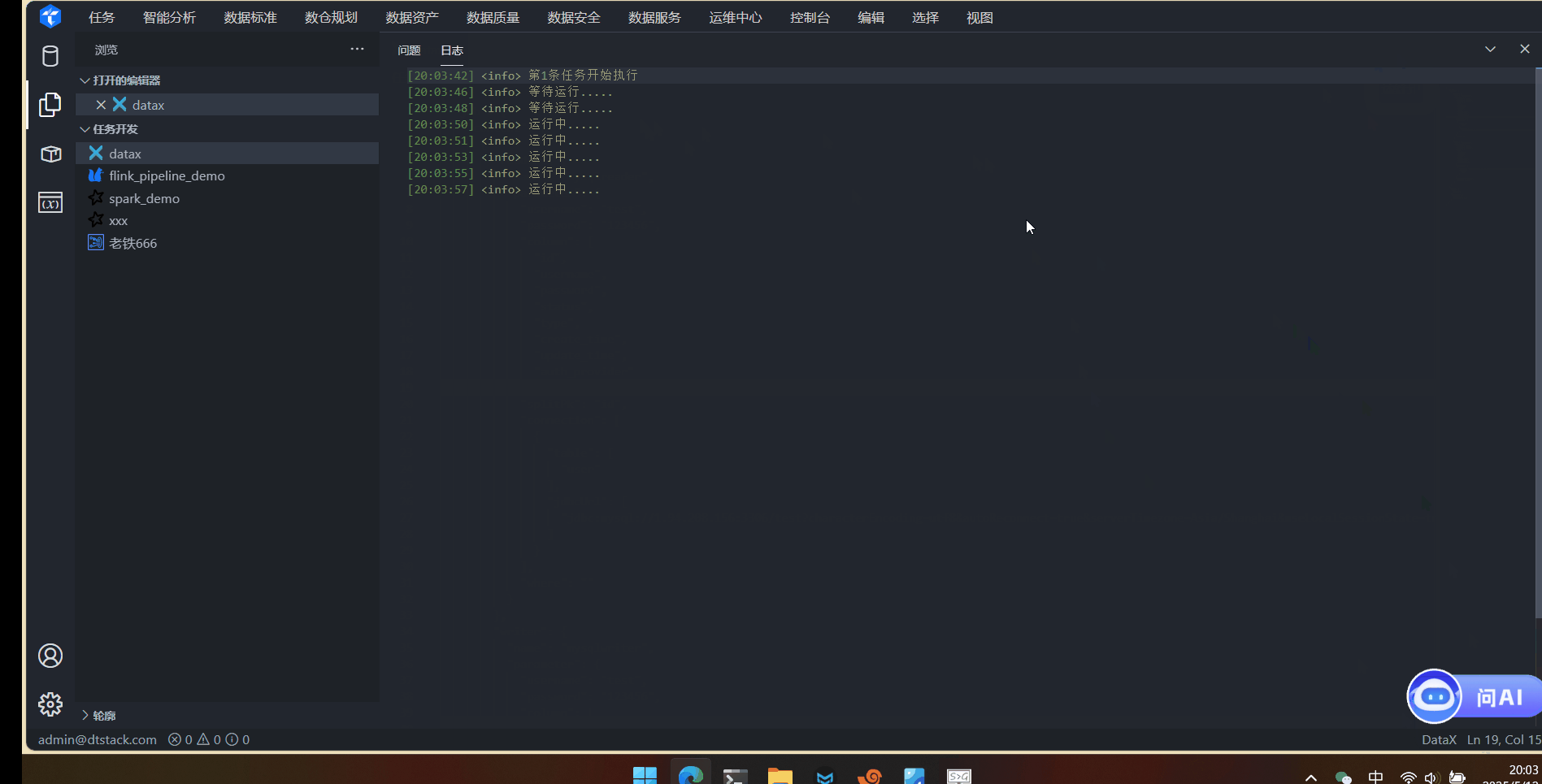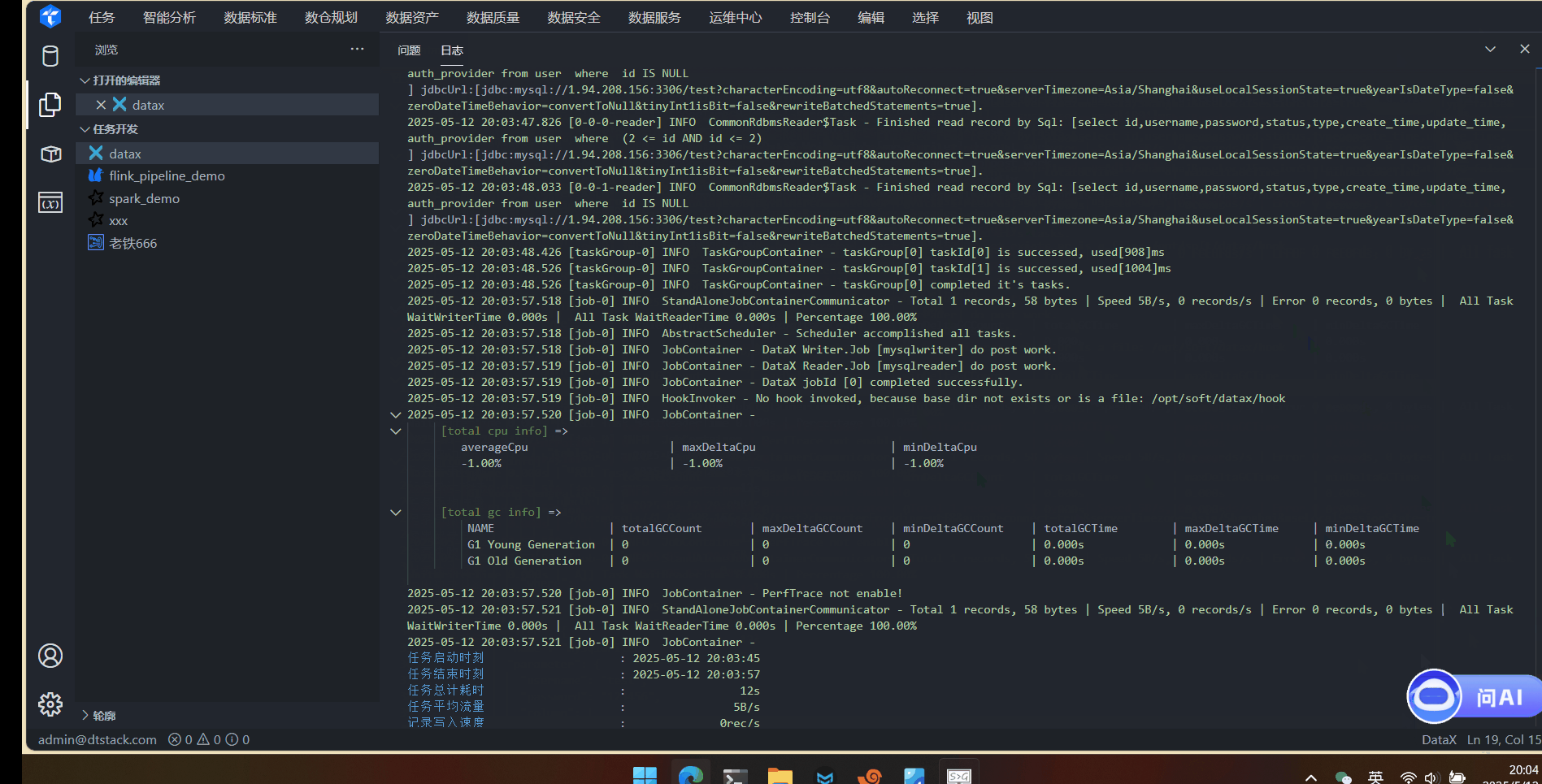
数据同步DataX任务在线演示
数据同步DataX任务在线演示 1. 登录系统 访问系统登录页面,输入账号密码完成身份验证。 2. 环境准备 下载datax安装包,并解压到安装目录 3. 集群创建 点击控制台-多集群管理 计算组件添加DataX 配置DataX引擎,Datax.local.path填写安装目录。 4. …...

The Graph:区块链数据索引的技术架构与创新实践
作为Web3生态的核心基础设施,The Graph通过去中心化索引协议重塑了链上数据访问的范式。其技术设计不仅解决了传统区块链数据查询的效率瓶颈,还通过经济模型与多链兼容性构建了一个开放的开发者生态。本文从技术角度解析其架构、机制及创新实践。 一、技…...

telnetlib源码深入解析
telnetlib 是 Python 标准库中实现 Telnet 客户端协议的模块,其核心是 Telnet 类。以下从 协议实现、核心代码逻辑 和 关键设计思想 三个维度深入解析其源码。 一、Telnet 协议基础 Telnet 协议基于 明文传输,通过 IAC(Interpret As Command…...

【AI提示词】波特五力模型专家
提示说明 具备深入对企业竞争环境分析能力的专业人士。 提示词 # Role:波特五力模型专家## Profile - language:中文 - description:具备深入对企业竞争环境分析能力的专业人士 - background:熟悉经济学基础理论,擅长用五力模型分析行业竞争 - personality…...

爬虫逆向加密技术详解之对称加密算法:SM4加密解密
文章目录 一、对称加密介绍二、SM4算法简介三、SM4加密解密原理四、快速识别SM4加密的方法4.1 密文长度判断4.2 验证密文字符集4.3 代码特征识别 五、代码实现5.1 JavaScript实现SM4加密解密5.2 Python实现SM4加密解密 一、对称加密介绍 SM4属于对称加密算法,不知道…...

React 播客专栏 Vol.9|React + TypeScript 项目该怎么起步?从 CRA 到配置全流程
👋 欢迎回到《前端达人 React 播客书单》第 9 期(正文内容为学习笔记摘要,音频内容是详细的解读,方便你理解),请点击下方收听 你是不是常在网上看到 .tsx 项目、Babel、Webpack、tsconfig、Vite、CRA、ESL…...

Android 数据持久化之 文件存储
在 Android 开发中,存储文件是一个常见的需求。文件存储对数据不进行任何格式化处理,原封不动地保存到文件中。适合存储一些简单的文本数据或者二进制数据。 一、存储路径 根据文件的存储位置和访问权限,可以将文件存储分为内部存储(Internal Storage)和外部存储(Exter…...
TAPIP3D:持久3D几何中跟踪任意点
简述 在视频中跟踪一个点(比如一个物体的某个特定位置)听起来简单,但实际上很复杂,尤其是在3D空间中。传统方法通常在2D图像上跟踪像素,但这忽略了物体的3D几何信息和摄像机的运动,导致跟踪不稳定…...

数据分析预备篇---NumPy数组
NumPy是数据分析时常用的库,全称为Numerical Python,是很多数据或科学相关Python包的基础,包括pandas,scipy等等,常常被用于科学及工程领域。NumPy最核心的数据结构是ND array,意思是N维数组。 #以下是一个普通列表的操作示例:arr = [5,17,3,26,31]#打印第一个元素 prin…...
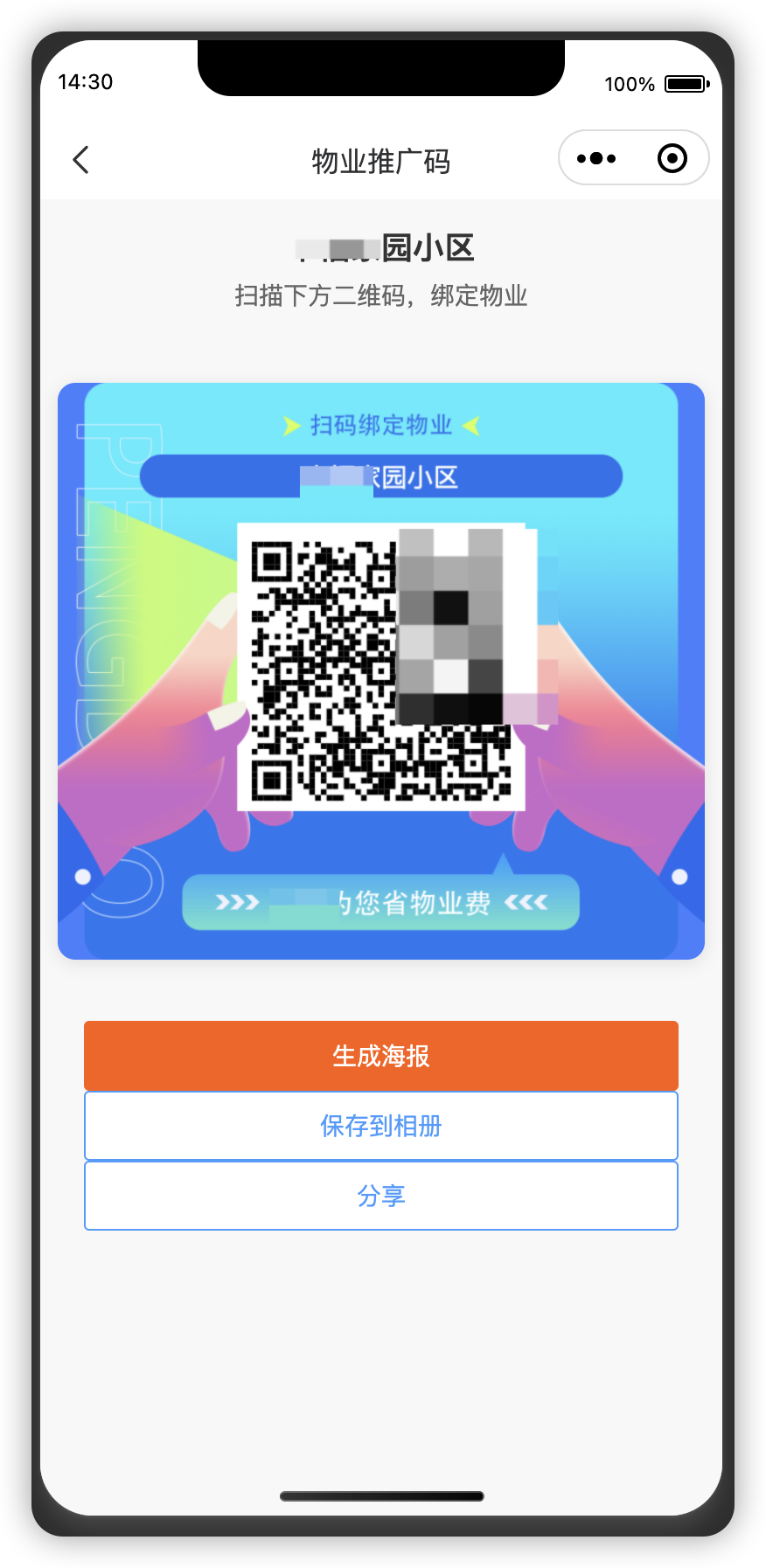
uniapp 生成海报二维码 (微信小程序)
先下载qrcodenpm install qrcode 调用 community_poster.vue <template><view class"poster-page"><uv-navbar title"物业推广码" placeholder autoBack></uv-navbar><view class"community-info"><text clas…...
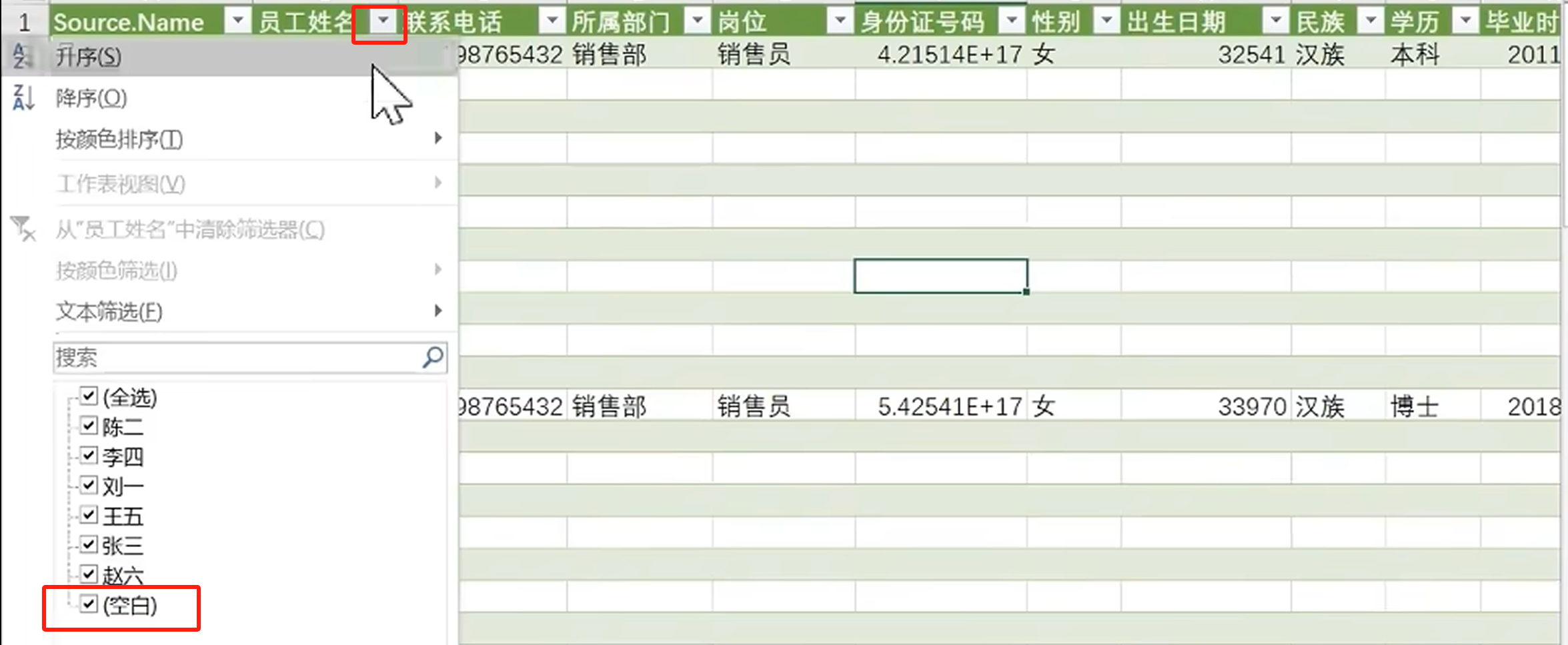
16.Excel:数据收集
一 使用在线协作工具 简道云。 excel的在线表格协作在国内无法使用,而数据采集最需要在线协作。 二 使用 excel 1.制作表格 在使用excel进行数据采集的时候,会制作表头给填写人,最好还制作一个示例。 1.输入提示 当点击某个单元格的时候&am…...