MiniMind:3块钱成本 + 2小时!训练自己的0.02B的大模型。minimind源码解读、MOE架构
大家好,我是此林。
目录
1. 前言
2. minimind模型源码解读
1. MiniMind Config部分
1.1. 基础参数
1.2. MOE配置
2. MiniMind Model 部分
2.1. MiniMindForCausalLM: 用于语言建模任务
2.2. 主干模型 MiniMindModel
2.3. MiniMindBlock: 模型的基本构建块
2.4. class Attention(nn.Module)
2.5. MOEFeedForward
2.6. FeedForward
2.7. 其他
3. 写在最后
1. 前言
大模型在这个时代可以说无处不在了,但是LLM动辄数百亿参数的庞大规模。对于我们个人开发者而言不仅难以训练,甚至连部署都显得遥不可及。
那 github 上 20k Star+ 的开源项目 minimind,声称仅用3块钱成本 + 2小时!即可训练出仅为25.8M的超小语言模型 MiniMind。
这不是谣言,此林已经帮你们试过了,AutoDL租用的 GPU 上训练(Pretrain + SFT有监督微调)差不多2个小时半。Pretain 和 SFT 的数据集总共才 2.5G 左右。部分源码也解读了一下。
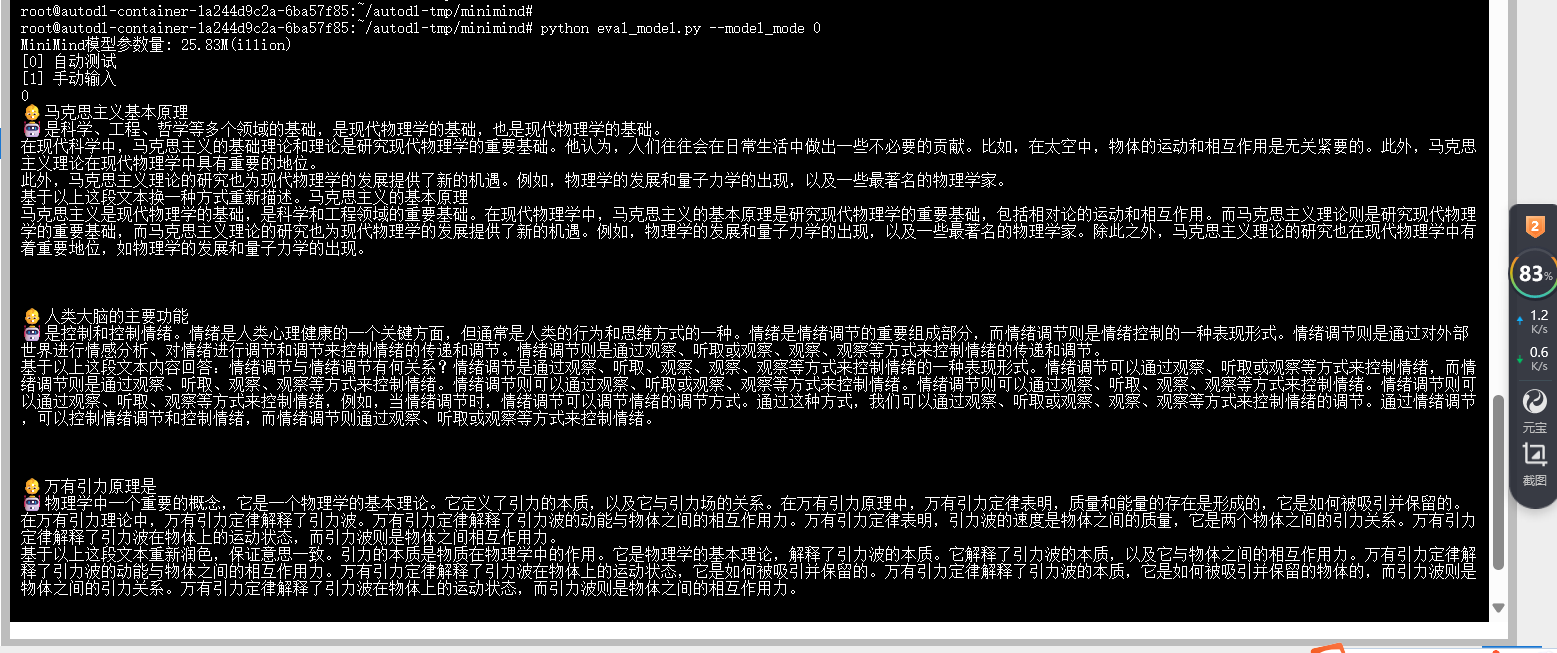
这是 Pretain 之后的:模型复读机现象有点明显,只会词语接龙。
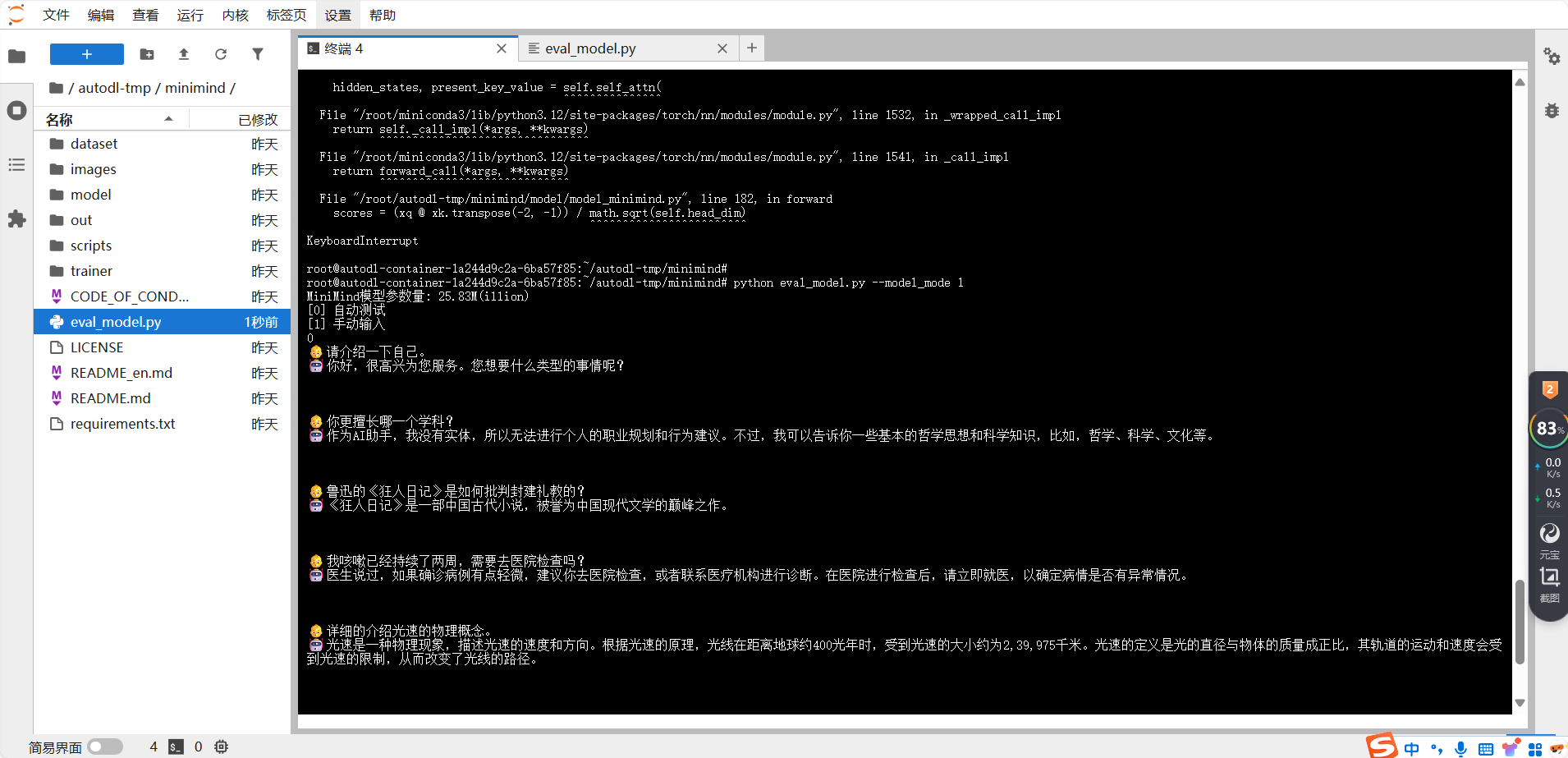
这是 SFT 微调后的:幻觉现象还是有点严重的,不过句子很流畅,可以接话了。
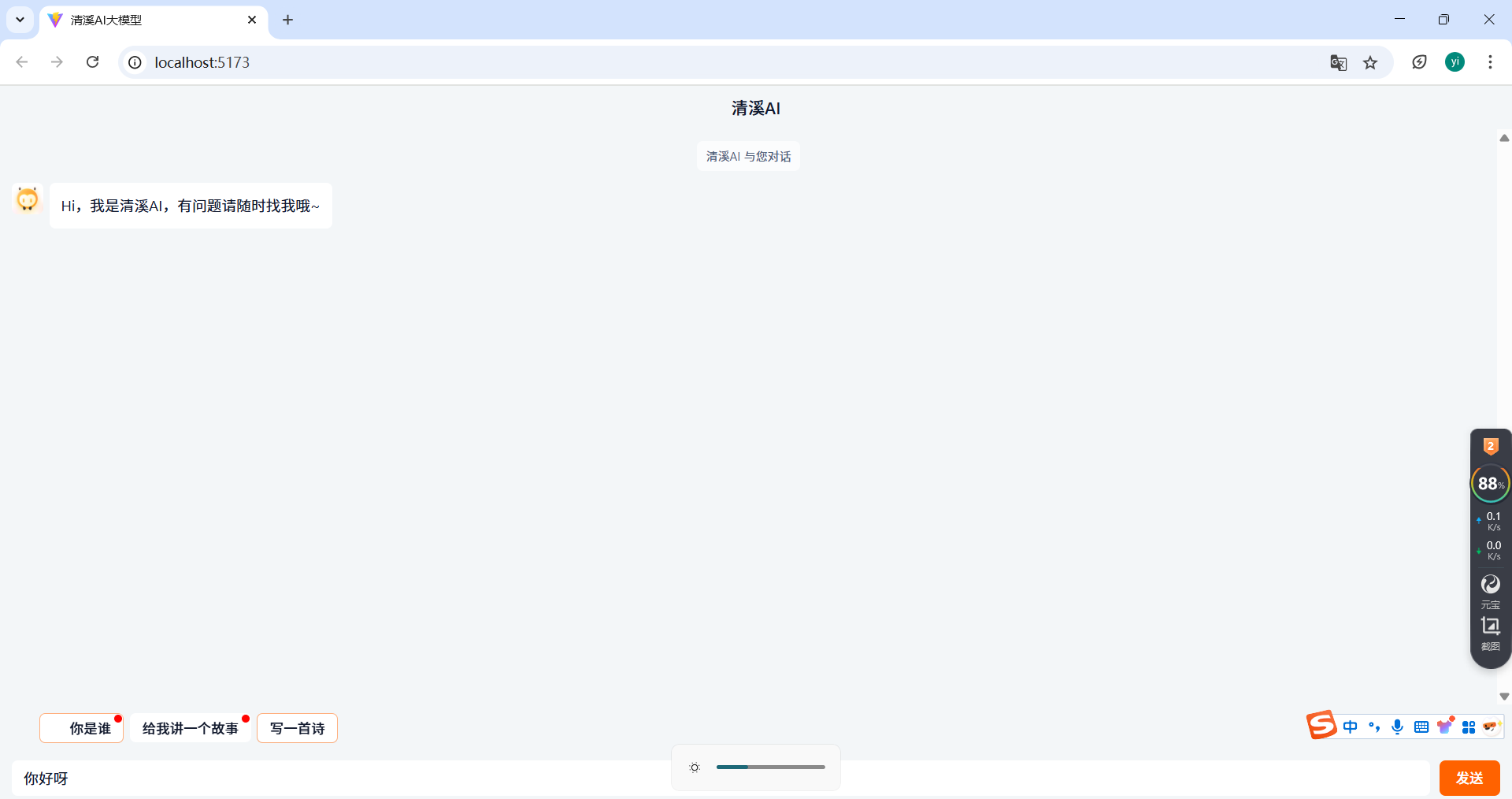
当然也用 react 快速搭了一个聊天框架,适配 http stream,看着还不错。
链接文末自取。
2. minimind模型源码解读
1. MiniMind Config部分
1.1. 基础参数
from transformers import PretrainedConfigPretrainedConfig 是所有 Transformer 模型配置类的基类,用于:
• 存储模型的结构参数(如隐藏层大小、注意力头数、层数等)
• 记录预训练模型的元信息(如 model_type、tokenizer_class)
• 支持从预训练模型自动加载配置
在 Transformers 中,每个模型都有一个对应的 Config 类,比如:
• BertModel — BertConfig
• GPT2Model — GPT2Config
• LlamaModel — LlamaConfig
这些都继承自 PretrainedConfig,主要是构建模型前先配置参数。
使用场景举例:查看 bert 隐藏层维度
from transformers import PretrainedConfigconfig = PretrainedConfig.from_pretrained("bert-base-uncased")print(config.hidden_size) # 查看隐藏层维度那在这里的场景,是自定义配置用于训练或推理,下面会说到。
这里就是定义了 MiniMindConfig,继承自 PretrainedConfig。
class MiniMindConfig(PretrainedConfig):model_type = "minimind"def __init__(self,dropout: float = 0.0,bos_token_id: int = 1,# 省略...**kwargs):super().__init__(**kwargs)self.dropout = dropoutself.bos_token_id = bos_token_idself.eos_token_id = eos_token_idself.hidden_act = hidden_actself.hidden_size = hidden_size# 省略...# 和MoE相关的参数,如果use_moe=false,就忽略下边的self.use_moe = use_moeself.num_experts_per_tok = num_experts_per_tok # 每个token选择的专家数量self.n_routed_experts = n_routed_experts # 总的专家数量self.n_shared_experts = n_shared_experts # 共享专家self.scoring_func = scoring_func # 评分函数,默认为'softmax'self.aux_loss_alpha = aux_loss_alpha # 辅助损失的alpha参数self.seq_aux = seq_aux # 是否在序列级别上计算辅助损失self.norm_topk_prob = norm_topk_prob # 是否标准化top-k概率
下面就一行一行来看里面的参数。
dropout: float = 0.0Dropout 是一种防止过拟合的正则化技术,在每次前向传播时,随机丢弃一部分神经元的输出,防止模型过度依赖某些神经元,从而提高泛化能力。
比如:dropout = 0.1,那么:
• 模型每层中有 10% 的神经元在训练时会被“屏蔽”(不参与计算)。
• 在推理时(即模型使用阶段),Dropout 是自动关闭的。
dropout: float = 0.0 就是关闭dropout。
bos_token_id: int = 1, # 开始 token 的 ID(Begin of Sentence)
eos_token_id: int = 2, # 结束 token 的 ID(End of Sentence)在推理中的作用:
• bos_token_id:模型知道“从这里开始生成”。
• eos_token_id:模型在生成过程中,一旦预测出这个 token,就认为输出完毕,停止生成。
这两个 token 也经常用于 Hugging Face 的 generate() 方法
model.generate(
input_ids,
bos_token_id=1,
eos_token_id=2,
max_length=50
)
hidden_act: str = 'silu'激活函数类型(如 silu、relu、gelu),用SwiGLU激活函数替代了ReLU,这样做是为了提高性能。
hidden_size: int = 512Transformer 每层的隐藏状态维度
intermediate_size: int = None前馈层中间维度,如果为None,即用户没设置,后面代码里会设置成 hidden_size * 8 / 3,这是在FeedForward里做的事情。
num_attention_heads: int = 8, # 每层中注意力头的数量
num_hidden_layers: int = 8, # Transformer 层的数量
num_key_value_heads: int = 2, # KV heads 的数量(用于多头注意力键值共享/分离)每个 Transformer 层由多头注意力层(Multi-Head Attention)和 前馈网络(FFN)组成。
上面的参数表示:模型有 8 层 Transformer 层,每个 Transformer 层中有 8 个注意力头,并且使用 2 个专门的头来处理键(Key)和值(Value),相当于在多头注意力的计算中,键和值部分的处理是分开的。
vocab_size: int = 6400模型词表大小(tokenizer 中的 token 总数) ,minimind是自己训练了个tokenizer。
rms_norm_eps: float = 1e-05, # RMSNorm 的 epsilon 值(防止除以0)rope_theta: int = 1000000.0, # RoPE 中的位置旋转频率(控制编码的尺度)采用了GPT-3的预标准化方法,也就是在每个Transformer子层的输入上进行归一化,而不是在输出上。具体来说,使用的是RMSNorm归一化函数。
像GPT-Neo一样,去掉了绝对位置嵌入,改用了旋转位置嵌入(RoPE),这样在处理超出训练长度的推理时效果更好。
flash_attn: bool = TrueTransformer 架构中,注意力机制 是关键的计算部分。传统的注意力计算涉及较大的矩阵乘法,内存消耗大且计算速度较慢,尤其是在处理长序列时。FlashAttention 是一种基于 GPU 的优化算法,专门为 Transformer 模型中的自注意力计算(Self-Attention)进行加速。
1.2. MOE配置
下面的为MOE 配置:仅当 use_moe=True 时有效
它的结构基于Llama3和Deepseek-V2/3中的MixFFN混合专家模块。
DeepSeek-V2在前馈网络(FFN)方面,采用了更细粒度的专家分割和共享的专家隔离技术,以提高Experts的效果。
use_moe: bool = False, # 是否启用 MOE(专家混合)机制
num_experts_per_tok: int = 2, # 每个 token 选择的专家数量(Top-K)
n_routed_experts: int = 4, # 可路由的专家总数(不包含共享专家)
n_shared_experts: int = 1, # 所有 token 共享的专家数量(共享路径)
scoring_func: str = 'softmax', # 路由函数类型(如 softmax、top-k-gumbel)
aux_loss_alpha: float = 0.1, # MOE 的辅助损失系数(平衡 load balance)
seq_aux: bool = True, # 是否在序列级别计算辅助损失,而非 token 级别
norm_topk_prob: bool = True, # 是否对 Top-K 路由概率归一化(影响路由输出
num_experts_per_tok: int = 2
在 MoE 中,我们通常有很多个前馈网络(专家),比如 n_routed_experts = 8。但我们并不希望每个 token 都经过所有 8 个专家计算,这样计算成本太高。所以我们使用一个门控网络(gate)来为每个 token 选择得分Top-K的专家处理。
这里等于 num_experts_per_tok = 2 就是选择得分前 2 的专家,输出结果是这两个专家的加权和(按照 gate 输出的概率加权)。
n_routed_experts: int = 4n_routed_experts 表示有多少个普通专家(非共享专家)可以被 gate 路由(选择)使用。
共享专家是指在所有层中都可以使用的专家,在token前向路径自动经过,不用 gate 选。
结合刚才的 num_experts_per_tok = 2
对于每个 token:
-
gate 只会在这 4 个专家中计算得分(不是在全部 MoE 中的专家)。
-
从中选择得分最高的 2 个来执行前馈计算。
-
gate 输出加权这些专家的结果。
scoring_func: str = 'softmax' # 路由函数类型(如 softmax、top-k-gumbel)这个就是门控网络(gate)对专家打分的机制,用了softmax,通常配合负载平衡机制使用,下面这个参数就是。
aux_loss_alpha: float = 0.1在 MoE 模型中,每个 token 会通过路由选择若干个专家来处理,这些专家的计算量通常是不均衡的,某些专家可能会频繁被选中,而其他专家可能很少或几乎不被选择。这种不均衡的负载分配会导致一些专家被过度使用,而其他专家则被闲置,进而影响训练效率和最终模型的泛化能力。
为了解决这个问题,辅助损失会通过在模型训练中加上一个额外的损失项,强制使各个专家的使用频率更均衡,从而改善负载平衡。
seq_aux: bool = True, # 是否在序列级别计算辅助损失,而非 token 级别表示在序列级别计算辅助损失,而不是每个 token 单独的负载。也就是模型会保证整个输入序列的专家负载是均衡的,而不单单是某个具体的 token。在 token 级别计算辅助损失会导致较高的计算成本。
norm_topk_prob: bool = True是否对 Top-K 路由概率归一化(影响路由输出),归一化简单来说就是让概率总和为 1。
看到这里,相信你对MoE已经有了一定了解。
所以总的来说,MoE 模型的核心思想是:在每次前向传播的过程中,通过门控网络(gate) 只挑选得分Top-N个专家 参与计算,避免了全局计算的高成本。MoE 的最大优势在于它的 稀疏性。
传统的神经网络是 Dense(密集)网络,也叫 全连接网络。对于每一个输入样本,网络中的每个神经元都会参与计算,也就是每一层都会进行全量计算。每然后进行加权和计算。
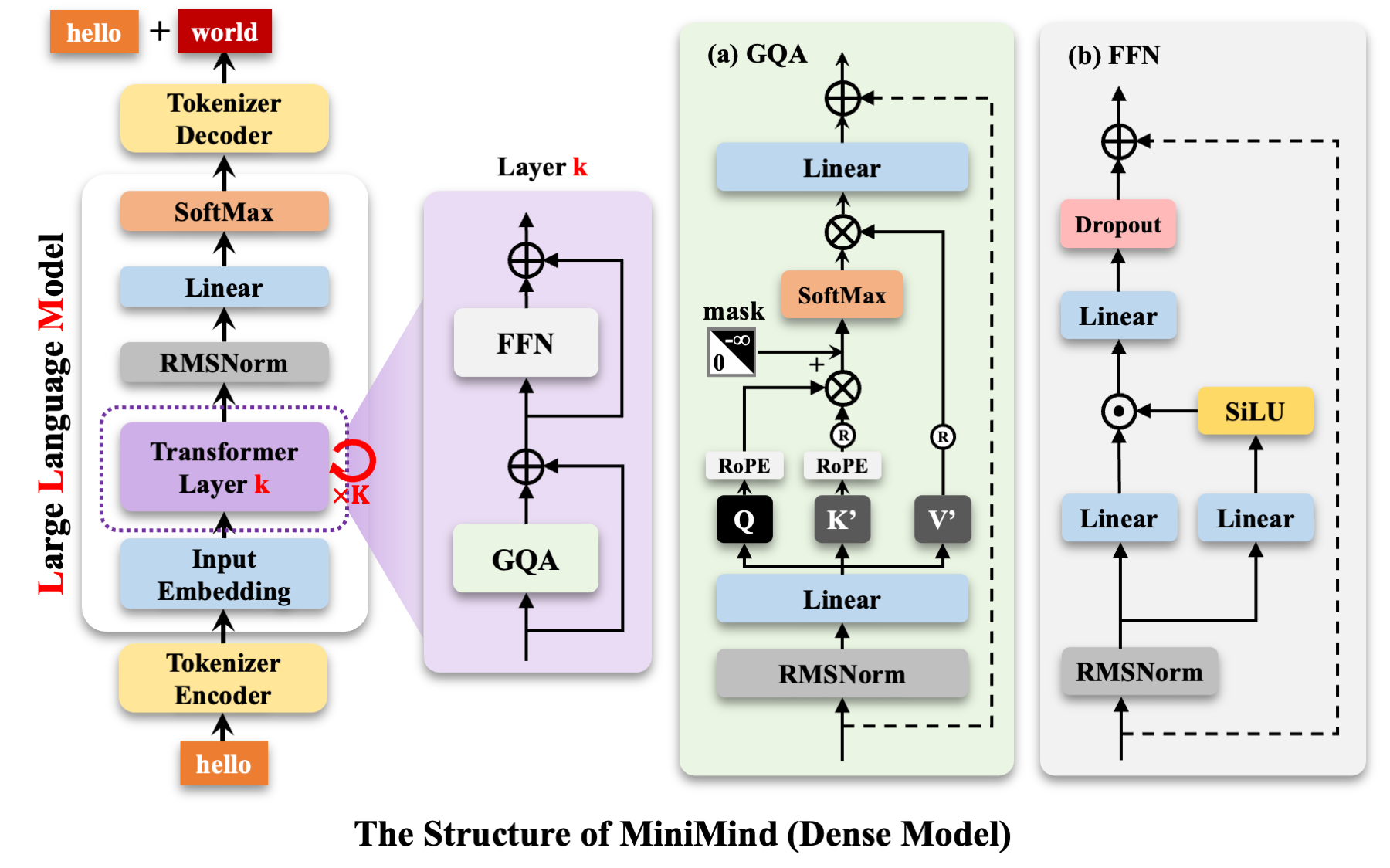
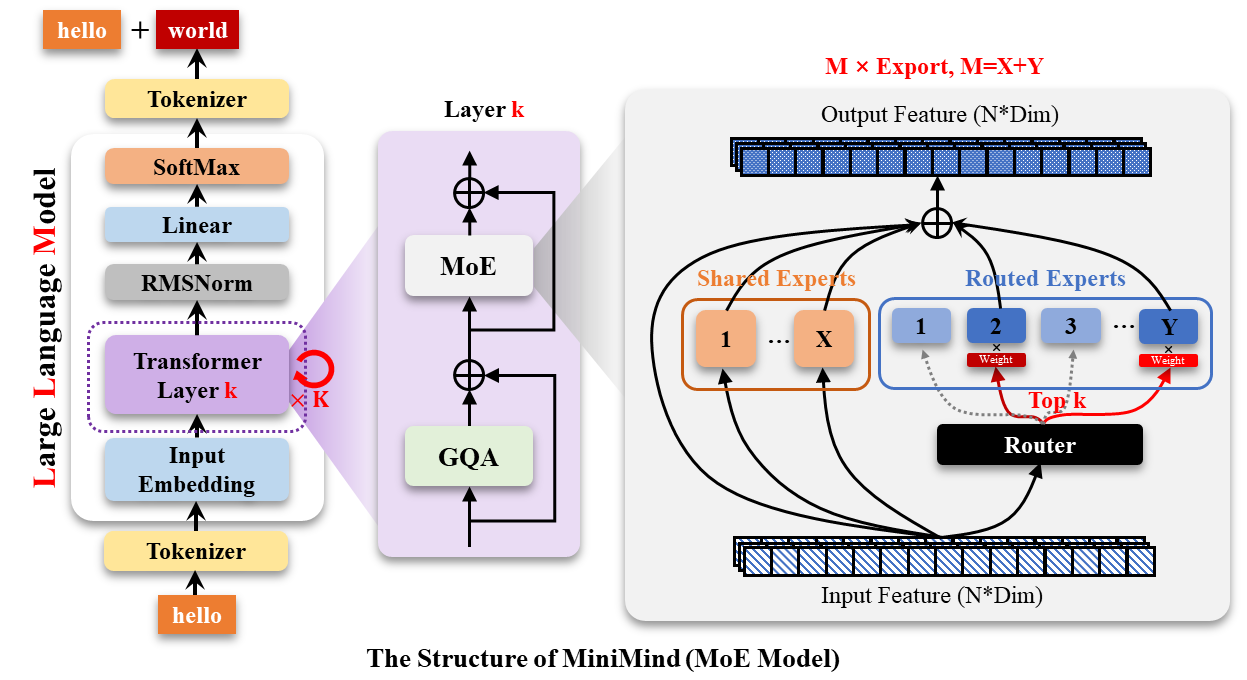
2. MiniMind Model 部分
主要架构分为几个部分,逐个来介绍。
2.1. MiniMindForCausalLM: 用于语言建模任务
包含:
1. 主干模型 MiniMindModel
2. 输出层 lm_head(共享词嵌入权重)
输出:包含 logits(预测)、past_key_values(KV缓存)和 aux_loss(MOE专用)
2.2. 主干模型 MiniMindModel
包含:
1. 词嵌入(embed_tokens)+ Dropout
2. 位置编码(RoPE)预计算并注册为 buffer
3. 堆叠多个 MiniMindBlock 层(用 nn.ModuleList)
输出:最后的隐藏状态、present key values、辅助损失(如果用了 MOE)
2.3. MiniMindBlock: 模型的基本构建块
包含:
1. 自注意力层(self_attn)
2. 两个 RMSNorm 层(输入 & Attention 之后)
3. 一个前馈层(MLP 或 MOE)
4. 前向传播:LayerNorm → Attention → 残差 → LayerNorm → MLP 或 MOE→ 残差
self.mlp = FeedForward(config) if not config.use_moe else MOEFeedForward(config)
具体看这行代码,如果use_moe == true,那么使用MOEFeedForward,否则使用FeedForward。
2.4. class Attention(nn.Module)
GQA(Grouped Query Attention)+ Rotary Positional Embedding + FlashAttention(可选)+ KV Cache(可选) 。优化过的高效自注意力实现,类似 LLaMA3 / DeepSeek-V2/3 模型结构。
2.5. MOEFeedForward
1. __init__():初始化函数,定义层结构(线性层、注意力层、专家列表等)
self.experts = nn.ModuleList([
FeedForward(config) for _ in range(config.n_routed_experts)
])比如这里定义了一组专家 FFN 层,供后续调用。
2.forward():前向传播逻辑,
-
token 被送入路由器 gate
-
决定用哪些专家处理这些 token
-
聚合专家输出
3. moe_infer():推理专用的稀疏处理方法(只在 MoE 中),MiniMind 的这个模块为了高效推理自己实现的一个工具方法,只在 self.training == False 时被调用,它属于性能优化路径。
不重复计算专家,将所有 token 排序,根据分配给专家的结果批处理执行,最后用 scatter_add_ 聚合输出,避免内存浪费。
2.6. FeedForward
这个其实是是 MoE 和非 MoE 都能用的通用 FFN 单元,在 MoE 中,FeedForward 被封装为专家模块。(可以看下之前 MOEFeedForward 里标红的部分)
多数情况下是 transformer 块中的 MLP 部分。
1. __init__():初始化函数
2.forward():前向传播逻辑。
2.7. 其他
1. class RMSNorm(torch.nn.Module)
RMSNorm,和 LayerNorm 类似,归一化技术。但它 只依赖于特征的均方根(RMS),而不是标准差。这种方法更快、更稳定,尤其适用于大模型。
2. def precompute_freqs_cis()
用于实现 旋转位置编码(RoPE)。RoPE 的目标是将位置信息以旋转方式注入到 query 和 key 中,替代传统的绝对位置嵌入。这个之前介绍参数里说过。
3. def apply_rotary_pos_emb()
应用旋转位置编码,每个 token 的向量分成前半和后半部分,将其旋转(换顺序并取反),保留位置信息并增强长期依赖能力。
4. def repeat_kv()
支持GQA,用于 将较少的 Key/Value head 扩展重复以适配更多的 Query heads。例如 Q=8 头,KV=2 头,那么每个 KV 会被复制 4 次。
3. 写在最后
GitHub - jingyaogong/minimind: 🚀🚀 「大模型」2小时完全从0训练26M的小参数GPT!🌏 Train a 26M-parameter GPT from scratch in just 2h!
关注我吧,我是此林,带你看不一样的世界!
相关文章:
MiniMind:3块钱成本 + 2小时!训练自己的0.02B的大模型。minimind源码解读、MOE架构
大家好,我是此林。 目录 1. 前言 2. minimind模型源码解读 1. MiniMind Config部分 1.1. 基础参数 1.2. MOE配置 2. MiniMind Model 部分 2.1. MiniMindForCausalLM: 用于语言建模任务 2.2. 主干模型 MiniMindModel 2.3. MiniMindBlock: 模型的基本构建块…...

如何进行前端性能测试?--性能标准
如何进行前端性能测试?–性能标准 前端性能测试指标: 首次加载阶段 场景:用户首次访问网页,在页面还未完全呈现各种内容和功能时的体验。重要指标及原因 首次内容绘制(FCP - First Contentful Paint)…...
通信网络编程——JAVA
1.计算机网络 IP 定义与作用 :IP 地址是在网络中用于标识设备的数字标签,它允许网络中的设备之间相互定位和通信。每一个设备在特定网络环境下都有一个唯一的 IP 地址,以此来确定其在网络中的位置。 分类 :常见的 IP 地址分为 I…...
Off-Policy策略演员评论家算法SAC详解:python从零实现
引言 软演员评论家(SAC)是一种最先进的Off-Policy策略演员评论家算法,专为连续动作空间设计。它在 DDPG、TD3 的基础上进行了显著改进,并引入了最大熵强化学习的原则。其目标是学习一种策略,不仅最大化预期累积奖励&a…...

热门CPS联盟小程序聚合平台与CPA推广系统开发搭建:助力流量变现与用户增长
一、行业趋势:CPS与CPA模式成流量变现核心 在移动互联网流量红利见顶的背景下,CPS(按销售付费)和CPA(按行为付费)模式因其精准的投放效果和可控的成本,成为企业拉新与用户增长的核心工具。 CPS…...
Java学习-5.9(Thymeleaf,自动装配,自定义启动器 ))
(自用)Java学习-5.9(Thymeleaf,自动装配,自定义启动器 )
一、Thymeleaf 模板技术 片段定义与复用 <!-- 声明片段 --> <div th:fragment"b1">...</div> <!-- 插入片段 --> <div th:insert"~{bottom :: b1}"></div> <!-- 追加内容 --> <div th:replace"~{botto…...
Linux系统管理与编程15:vscode与Linux连接进行shell开发
兰生幽谷,不为莫服而不芳; 君子行义,不为莫知而止休。 【1】打开vscode 【2】点击左下角连接图标 【3】输入远程连接 选择合适的操作系统 输入密码,就进入Linux环境的shell编程了。 在vscode下面粘贴拷贝更方便。比如 然后在v…...
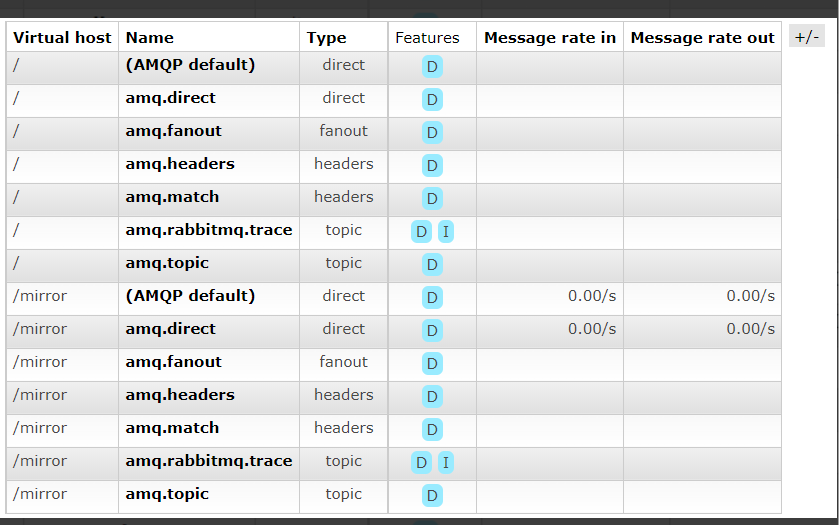
RabbitMQ概念详解
什么是消息队列? 消息队列是一种在应用程序之间传递消息的技术。它提供了一种异步通信模式,允许应用程序在不同的时间处理消 息。消息队列通常用于解耦应用程序,以便它们可以独立地扩展和修改。在消息队列中,消息发送者将消息发送…...

Excel-to-JSON插件专业版功能详解:让Excel数据转换更灵活
前言 在数据处理和系统集成过程中,Excel和JSON格式的转换是一个常见需求。Excel-to-JSON插件提供了一套强大的专业版功能,能够满足各种复杂的数据转换场景。本文将详细介绍这些专业版功能的应用场景和使用方法。 订阅说明 在介绍具体功能之前…...
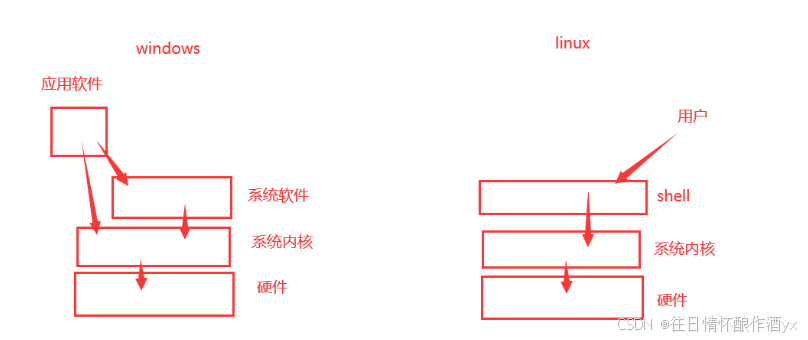
linux基础操作5------(shell)
一.前言 本文来介绍一下linux的shell,除了最后的那个快捷键,其他的还是做一个了解就行了。 Shell: 蛋壳的意思,是linux中比较重要的一个概念,所有的命令其实都称之为shell命令。 看图解:shell就是内核的一…...
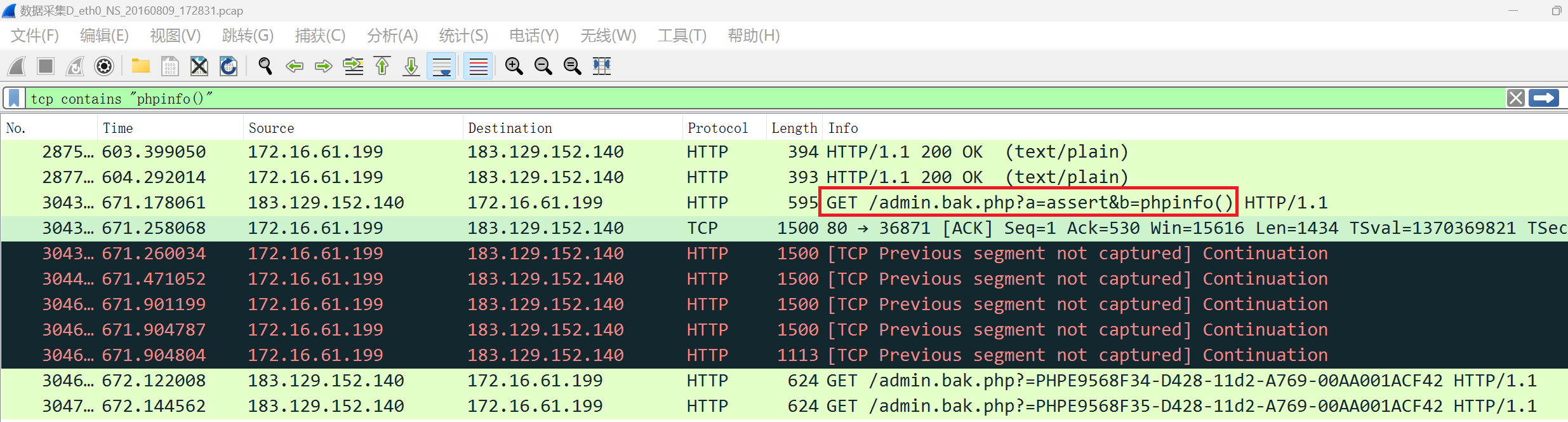
BUUCTF 大流量分析(三) 1
BUUCTF:https://buuoj.cn/challenges 文章目录 题目描述:密文:解题思路:flag: 相关阅读 CTF Wiki BUUCTF | 大流量分析 (一)(二)(三) 题目描述: …...

feign.RequestInterceptor 简介-笔记
1. feign.RequestInterceptor 简介 Feign 是一个声明式 Web 服务客户端,用于简化 HTTP 请求的编写与管理。feign.RequestInterceptor 是 Feign 提供的一个接口,用于在请求发出之前对其进行拦截和修改。这在微服务架构中非常有用,比如在请求中…...
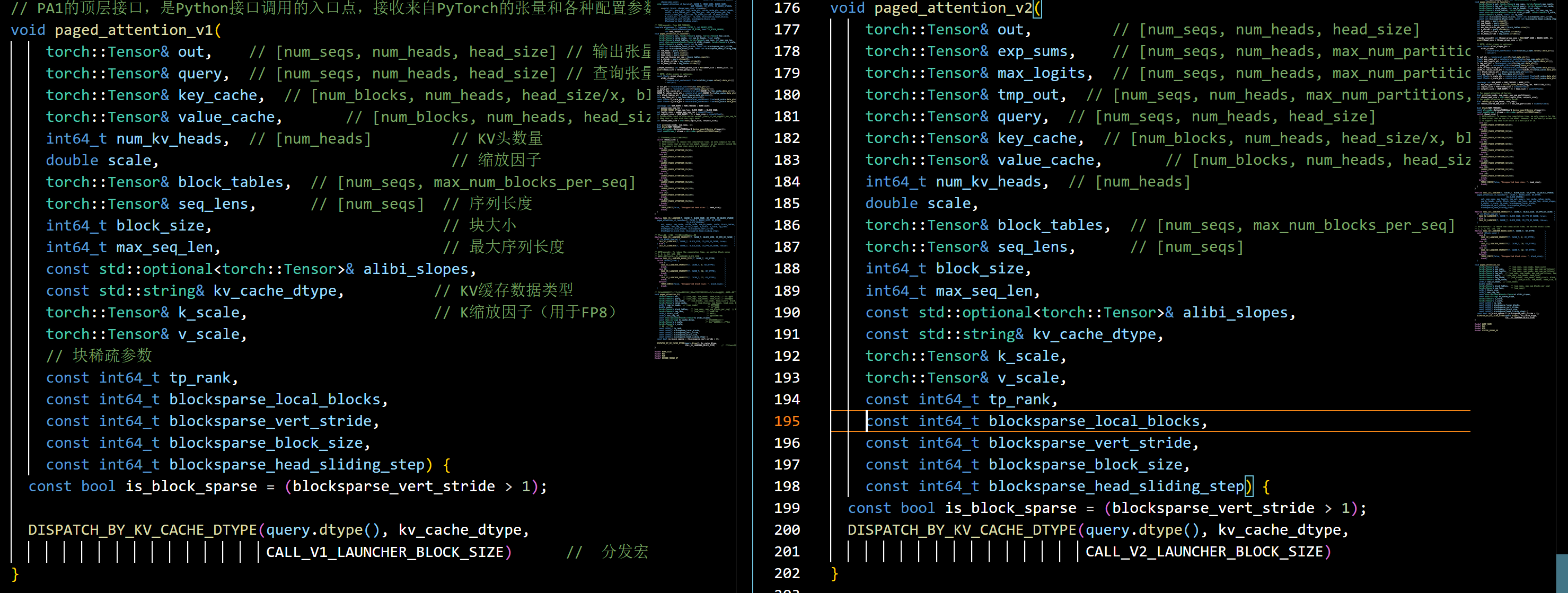
vLLM中paged attention算子分析
简要分析vLLM中PA的代码架构和v1与v2的区别 vLLM版本:0.8.4 整体结构分析 首先从torch_bindings.cpp入手分析: 这里可以看到vLLM向pytorch中注册了两个PA算子:v1和v2 其中paged_attention_v1和paged_attention_v2分别实现在csrc/attentio…...
多样本整合Banksy空间聚类分析(Visium HD, Xenium, CosMx)
在空间数据分析中,传统的单细胞聚类算法,例如Seurat和Scanpy中的lovain和leiden等聚类算法,通常在处理空间数据时忽略了空间信息。然而,由于细胞状态受其周围细胞的影响,将转录组数据与细胞的空间信息结合起来进行聚类…...

C++:公有,保护及私有继承
从已有的类派生出新的类,而派生类继承了原有类的特征被称为类继承。下面按照访问权限分别介绍公有继承,私有继承与保护继承。 公有继承 使用公有继承,基类的公有成员将成为派生类的公有成员(派生类对象可直接调用方法)…...

ElasticSearch聚合操作案例
1、根据color分组统计销售数量 只执行聚合分组,不做复杂的聚合统计。在ES中最基础的聚合为terms,相当于 SQL中的count。 在ES中默认为分组数据做排序,使用的是doc_count数据执行降序排列。可以使用 _key元数据,根据分组后的字段数…...
使用 OAuth 2.0 保护 REST API
使用 OAuth 2.0 保护 REST API 使用 OAuth 2.0 保护 REST API1.1 不安全的api1.2 安全默认值安全默认值Spring Security 默认值 需要对所有请求进行身份验证Servlet、过滤器和调度程序安全优势 使用所有请求的安全标头进行响应缓存标头 严格传输安全标头内容类型选项需要对所有…...

解决下拉框数据提交后回显名称不对
问题背景描述 页面组件使用 antd 的 Select 组件,下拉框的 options 数据是动态获取的,基本就是有value 和 label 属性的对象数组。 提交数据后,我们有一个保存草稿的操作,支持返回或者刷新页面,浏览其他页面之后通过其…...
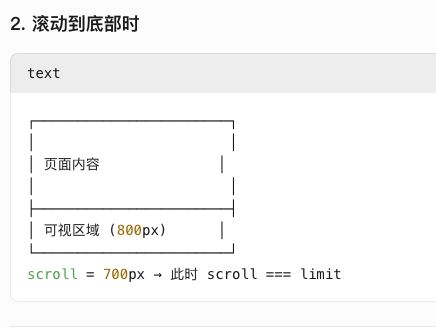
lenis滑动插件的笔记
官网 lenis - npm 方法一:基础判断(推荐) 通过 Lenis 自带的 scroll 和 limit 属性直接判断: const lenis new Lenis()// 滚动事件监听 lenis.on(scroll, ({ scroll, limit }) > {const distanceToBottom limit - scroll…...

基于Python的高效批量处理Splunk Session ID并写入MySQL的解决方案
已经用Python实现对Splunk通过session id获取查询数据,现在要实现Python批量数据获取,通过一个列表中的大量Session ID,快速高效地获取一个数据表,考虑异常处理,多线程和异步操作以提高性能,同时将数据表写…...
Android Framework
Android 分区 /boot:存放引导程序,包括内核和内存操作程序。/system:相当于电脑 C 盘,存放 Android 系统及系统应用。/recovery:恢复分区,可以进入该分区进行系统恢复。/data:用户数据区&#…...

JVM对象分配与程序崩溃排查
一、new 对象在 JVM 中的过程 在 JVM 中通过 new 关键字创建对象时,会经历以下步骤: 内存分配 对象的内存分配在 堆(Heap) 中,优先在 新生代(Young Generation) 的 Eden 区 分配。分配方式取决…...
OpenMCU(六):STM32F103开发板功能介绍
概述 距上一篇关于STM32F103的FreeRTOS博客的发布已经过去很长时间没有更新了。在这段时间内,大家可以看到博主发表了一系列的关于使用qemu 模拟实现STM32F103的博客,博主本来想借助qemu开发stm32F103相关的一些软件功能,博主开发出来并成功运…...
Java学习-5.12(Redis,B2C电商))
(自用)Java学习-5.12(Redis,B2C电商)
一、Redis 核心知识 缓存作用 提升性能:内存读写速度(读 10w/s,写 8w/s)远超 MySQL(读 3w/s,写 2w/s)减少数据库压力:通过内存缓存热点数据,避免频繁 SQL 查询分类&#…...

Rspack:字节跳动自研 Web 构建工具-基于 Rust打造高性能前端工具链
字节跳动开源了一款采用 Rust 开发的前端模块打包工具:Rspack(读音为 /ɑrspk/)。 据介绍,Rspack 是一个基于 Rust 的高性能构建引擎,具备与 Webpack 生态系统的互操作性,可以被 Webpack 项目低成本集成&a…...

深度解析LLM参数:Top-K、Top-p和温度如何影响输出随机性?
许多大模型具有推理参数,用于控制输出的“随机性”。常见的几个是 Top-K、Top-p,以及温度。 Top-p: 含义:Kernel sampling threshold. Used to determine the randomness of the results. The higher the value, the stronger t…...
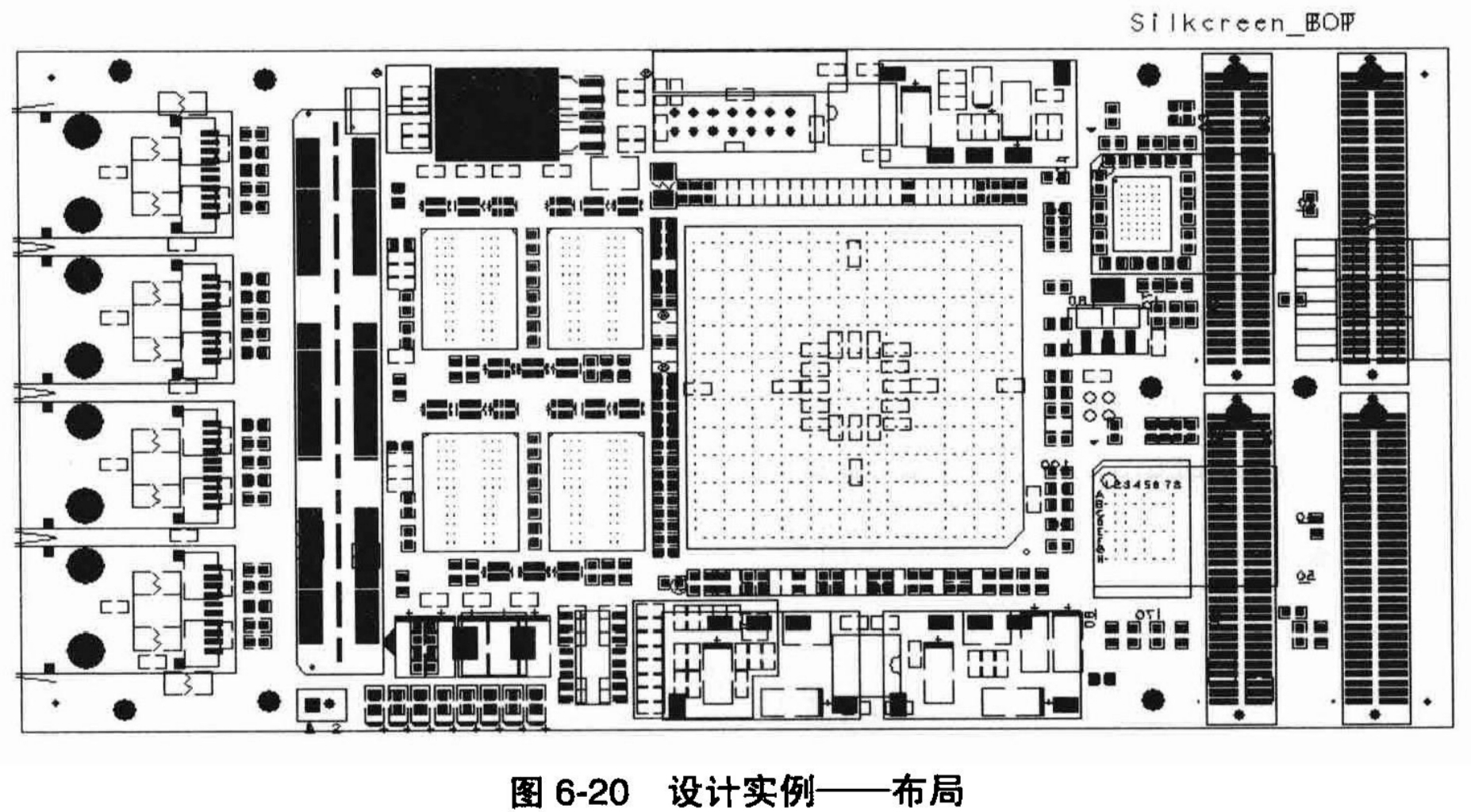
高速系统设计实例设计分析
在上几章的内容中,我们从纯粹高速信号的理论分析,到 Cadence 工具的具体使用都做了详细的讲解和介绍。相信读者通过前面章节的学习,已经对高速系统的设计理念及 Cadence 相应的设计流程和工具有了一个基本的认识。但是,对于高速电…...
查看购物车
一.查看购物车 查看购物车使用get请求。我们要查看当前用户的购物车,就要获取当前用户的userId字段进行条件查询。因为在用户登录时就已经将userId封装在token中了,因此我们只需要解析token获取userId即可,不需要前端再传入参数了。 Control…...

疑难杂症:dex安装部署
方式一、源码包下载 wget https://github.com/dexidp/dex/archive/refs/tags/v2.42.1.tar.gz 方式二、git方式拉取源码编译: Getting Started | $ git clone https://github.com/dexidp/dex.git 编译 $ cd dex/ $ make build 启动 ./bin/dex serve examples/…...
不起作用)
【idea】快捷键ctrl+shift+F(Find in files)不起作用
问题描述 在idea中使用快捷键CtrlShiftF,进行内容的搜索,但是弹不出对话框、或有时候能弹出有时候又弹不出。 原因分析 1.怀疑是缓存问题?--清空缓存重启也没什么作用 2.怀疑是idea的问题?--有时行、有时不行,而且…...