vLLM中paged attention算子分析
简要分析vLLM中PA的代码架构和v1与v2的区别
vLLM版本:0.8.4
整体结构分析
首先从torch_bindings.cpp入手分析:
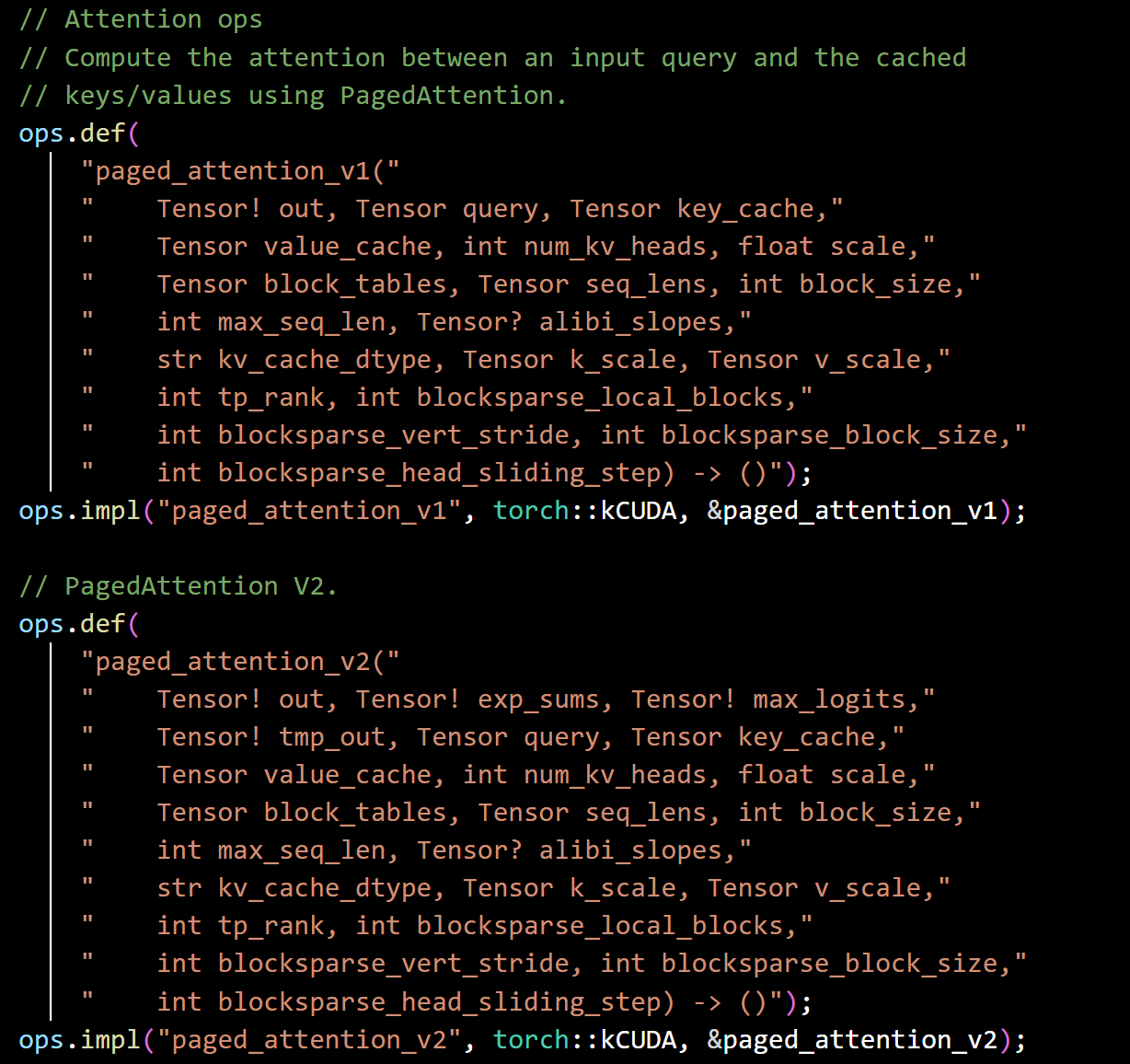
这里可以看到vLLM向pytorch中注册了两个PA算子:v1和v2
其中paged_attention_v1和paged_attention_v2分别实现在csrc/attention/paged_attention_v1.cu以及csrc/attention/paged_attention_v2.cu中:
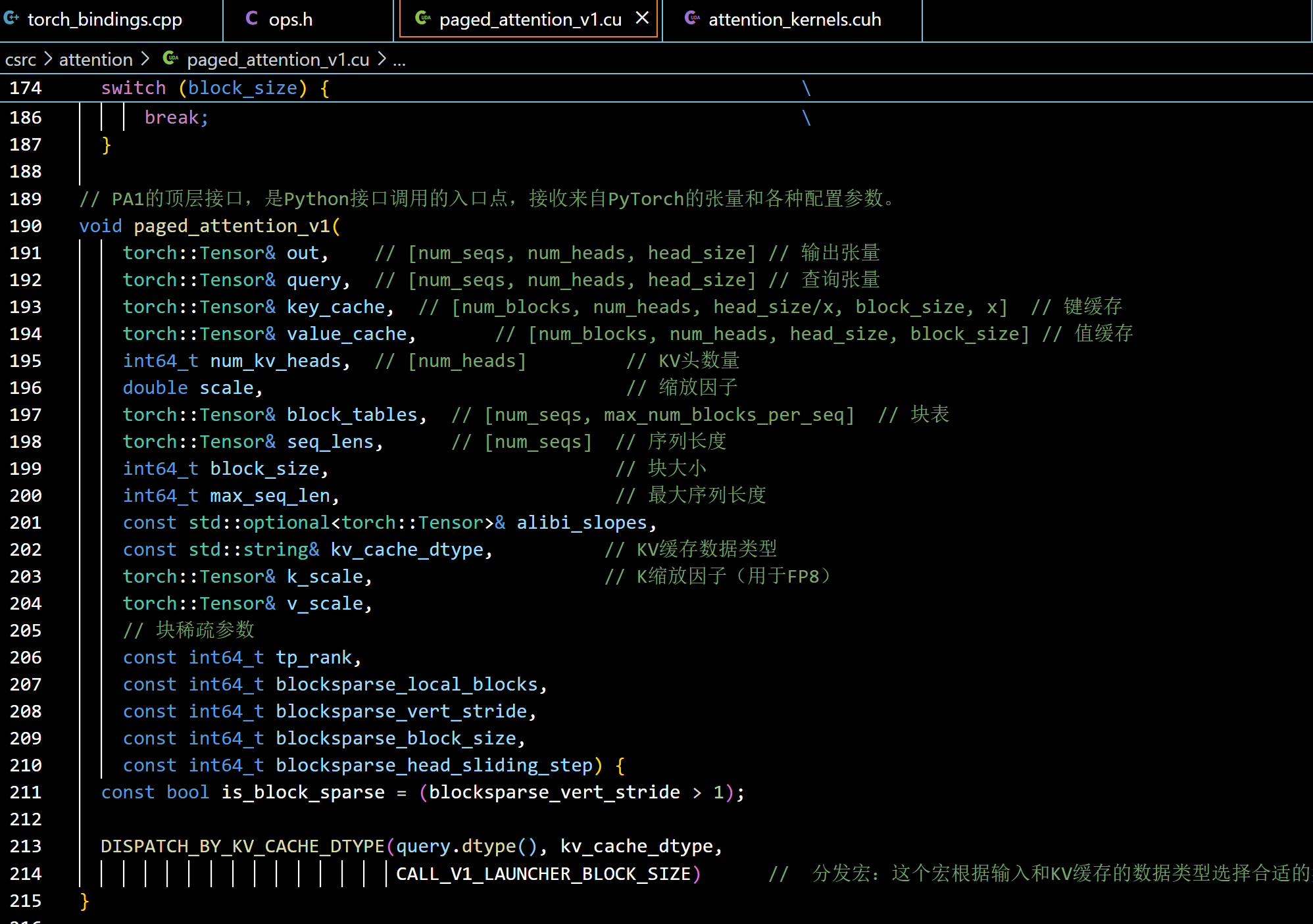
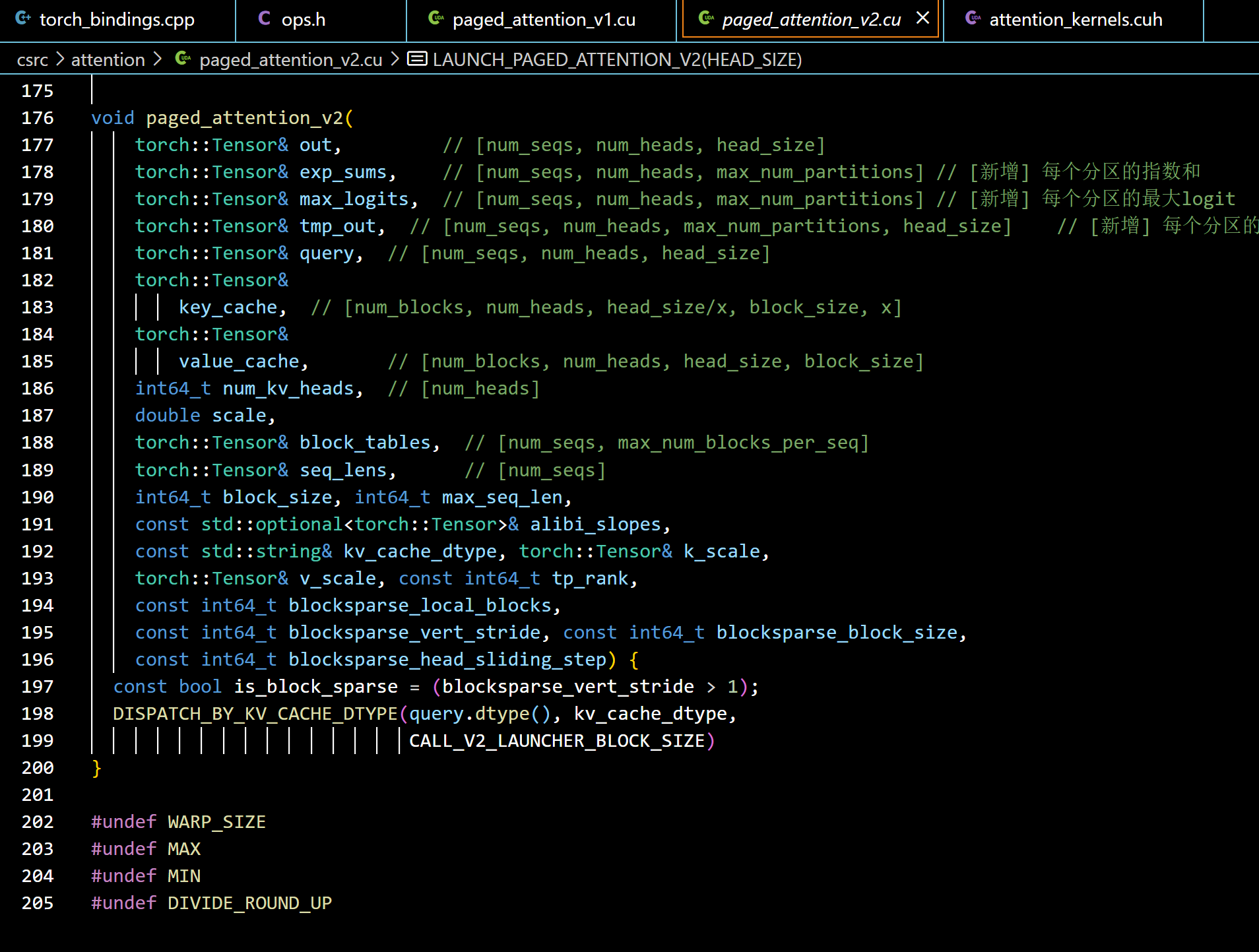
paged_attention_v1和paged_attention_v2都是PA实现的顶层接口,是Python接口调用的入口点,接收来自PyTorch的张量和各种配置参数。
根据csrc/attention/paged_attention_v1.cu中的代码逻辑,我们可以知道vLLM使用了多层分发机制来实现灵活的算子调用,以csrc/attention/paged_attention_v1.cu中的paged_attention_v1为例,分发层级为:
paged_attention_v1:
-> DISPATCH_BY_KV_CACHE_DTYPE
-> CALL_V1_LAUNCHER_BLOCK_SIZE
-> CALL_V1_LAUNCHER_SPARSITY
-> CALL_V1_LAUNCHER
-> paged_attention_v1_launcher
-> LAUNCH_PAGED_ATTENTION_V1
-> paged_attention_v1_kernel (csrc/attention/attention_kernels.cuh实现)
-> paged_attention_kernel(csrc/attention/attention_kernels.cuh实现)
可知paged_attention_kernel是具体的PA算子,csrc/attention/attention_kernels.cuh的代码主要包含以下几个函数:

paged_attention_v1_kernel和paged_attention_v2_kernel分别是v1和v2对paged_attention_kernel的封装,功能是类似的。
v1与v2的具体区别
总体上:
- v1版本提供了直接、无分区的注意力计算,适用于中短序列,实现简单,内核启动开销低。
- v2版本引入了分区计算和归约合并的两阶段处理,解决了长序列的共享内存限制问题,提高了GPU利用率。
函数参数
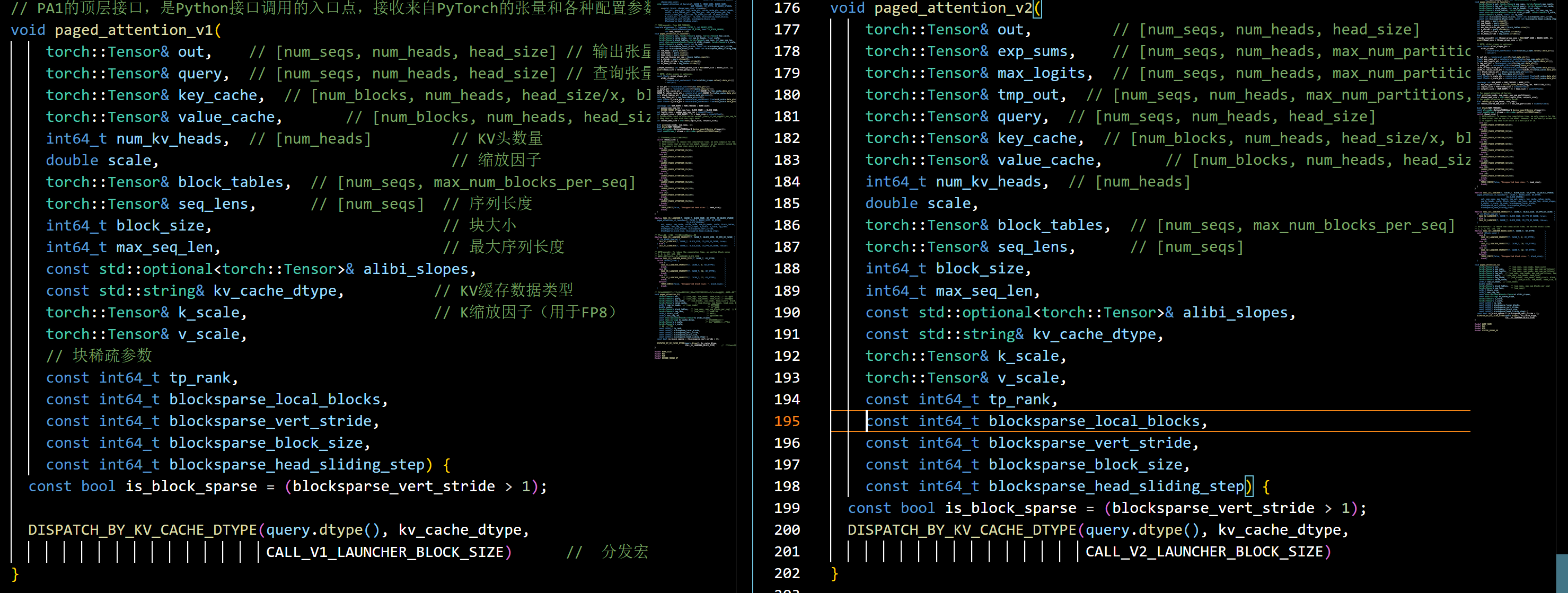
paged_attention_v1和paged_attention_v2参数对比可以发现,v2版本新增了三个参数:exp_sums,max_logits,tmp_out,他们是用于分区注意力计算。
这三个参数的维度包含了max_num_partitions,表示序列被划分的最大分区数。
分区计算策略
v2版本引入了固定大小的分区(默认512个token),将长序列分割成多个分区并行处理。
// v1版本 - 整体处理序列
dim3 grid(num_heads, num_seqs, 1); // 注意z维度为1// v2版本 - 分区处理序列
int max_num_partitions = DIVIDE_ROUND_UP(max_seq_len, PARTITION_SIZE);// 默认分区大小PARTITION_SIZE = 512
dim3 grid(num_heads, num_seqs, max_num_partitions); // z维度为分区数
v2两阶段计算
#define LAUNCH_PAGED_ATTENTION_V2(HEAD_SIZE) \vllm::paged_attention_v2_kernel<T, CACHE_T, HEAD_SIZE, BLOCK_SIZE, \NUM_THREADS, KV_DTYPE, IS_BLOCK_SPARSE, \PARTITION_SIZE> \<<<grid, block, shared_mem_size, stream>>>( \exp_sums_ptr, max_logits_ptr, tmp_out_ptr, query_ptr, key_cache_ptr, \value_cache_ptr, num_kv_heads, scale, block_tables_ptr, \seq_lens_ptr, max_num_blocks_per_seq, alibi_slopes_ptr, q_stride, \kv_block_stride, kv_head_stride, k_scale_ptr, v_scale_ptr, tp_rank, \blocksparse_local_blocks, blocksparse_vert_stride, \blocksparse_block_size, blocksparse_head_sliding_step); \vllm::paged_attention_v2_reduce_kernel<T, HEAD_SIZE, NUM_THREADS, \PARTITION_SIZE> \<<<reduce_grid, block, reduce_shared_mem_size, stream>>>( \out_ptr, exp_sums_ptr, max_logits_ptr, tmp_out_ptr, seq_lens_ptr, \max_num_partitions);
相对于v1,v2包含两阶段计算,分别是:
// 第一阶段:分区计算
vllm::paged_attention_v2_kernel<<< ... >>>(/* 参数 */);// 第二阶段:合并结果
vllm::paged_attention_v2_reduce_kernel<<< ... >>>(/* 参数 */);
而v1版本只需一个核函数:
vllm::paged_attention_v1_kernel<<< ... >>>(/* 参数 */);
共享内存的使用上
// v1版本 - 需要为整个序列分配共享内存
int padded_max_seq_len = DIVIDE_ROUND_UP(max_seq_len, BLOCK_SIZE) * BLOCK_SIZE;
int logits_size = padded_max_seq_len * sizeof(float);// v2版本 - 只需为一个分区分配共享内存
int logits_size = PARTITION_SIZE * sizeof(float);
v2版本显著减少了每个线程块需要的共享内存大小.
v2版本的规约
v2版本在paged_attention_v2_reduce_kernel中实现了复杂的跨分区归约。
// 计算全局最大logit
max_logit = fmaxf(max_logit, VLLM_SHFL_XOR_SYNC(max_logit, mask));// 计算重新缩放的指数和
float rescaled_exp_sum = exp_sums_ptr[i] * expf(l - max_logit);// 聚合分区结果
float acc = 0.0f;
for (int j = 0; j < num_partitions; ++j) {acc += to_float(tmp_out_ptr[j * HEAD_SIZE + i]) * shared_exp_sums[j] * inv_global_exp_sum;
}
若有错误,欢迎指正!
相关文章:
vLLM中paged attention算子分析
简要分析vLLM中PA的代码架构和v1与v2的区别 vLLM版本:0.8.4 整体结构分析 首先从torch_bindings.cpp入手分析: 这里可以看到vLLM向pytorch中注册了两个PA算子:v1和v2 其中paged_attention_v1和paged_attention_v2分别实现在csrc/attentio…...
多样本整合Banksy空间聚类分析(Visium HD, Xenium, CosMx)
在空间数据分析中,传统的单细胞聚类算法,例如Seurat和Scanpy中的lovain和leiden等聚类算法,通常在处理空间数据时忽略了空间信息。然而,由于细胞状态受其周围细胞的影响,将转录组数据与细胞的空间信息结合起来进行聚类…...

C++:公有,保护及私有继承
从已有的类派生出新的类,而派生类继承了原有类的特征被称为类继承。下面按照访问权限分别介绍公有继承,私有继承与保护继承。 公有继承 使用公有继承,基类的公有成员将成为派生类的公有成员(派生类对象可直接调用方法)…...

ElasticSearch聚合操作案例
1、根据color分组统计销售数量 只执行聚合分组,不做复杂的聚合统计。在ES中最基础的聚合为terms,相当于 SQL中的count。 在ES中默认为分组数据做排序,使用的是doc_count数据执行降序排列。可以使用 _key元数据,根据分组后的字段数…...
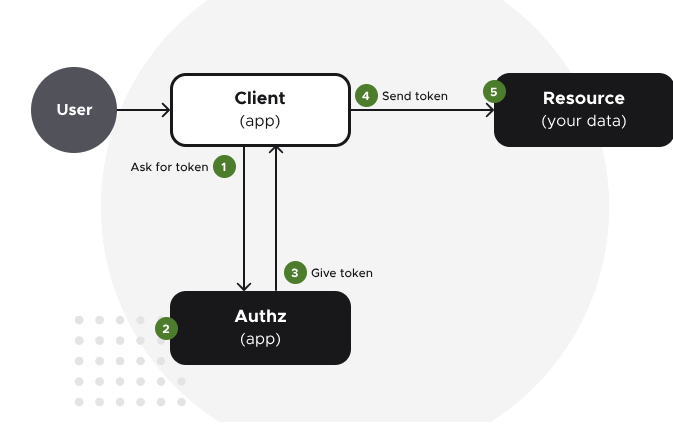
使用 OAuth 2.0 保护 REST API
使用 OAuth 2.0 保护 REST API 使用 OAuth 2.0 保护 REST API1.1 不安全的api1.2 安全默认值安全默认值Spring Security 默认值 需要对所有请求进行身份验证Servlet、过滤器和调度程序安全优势 使用所有请求的安全标头进行响应缓存标头 严格传输安全标头内容类型选项需要对所有…...

解决下拉框数据提交后回显名称不对
问题背景描述 页面组件使用 antd 的 Select 组件,下拉框的 options 数据是动态获取的,基本就是有value 和 label 属性的对象数组。 提交数据后,我们有一个保存草稿的操作,支持返回或者刷新页面,浏览其他页面之后通过其…...
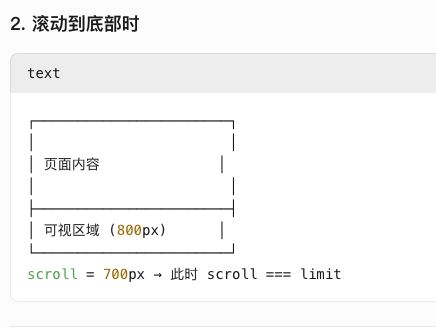
lenis滑动插件的笔记
官网 lenis - npm 方法一:基础判断(推荐) 通过 Lenis 自带的 scroll 和 limit 属性直接判断: const lenis new Lenis()// 滚动事件监听 lenis.on(scroll, ({ scroll, limit }) > {const distanceToBottom limit - scroll…...

基于Python的高效批量处理Splunk Session ID并写入MySQL的解决方案
已经用Python实现对Splunk通过session id获取查询数据,现在要实现Python批量数据获取,通过一个列表中的大量Session ID,快速高效地获取一个数据表,考虑异常处理,多线程和异步操作以提高性能,同时将数据表写…...
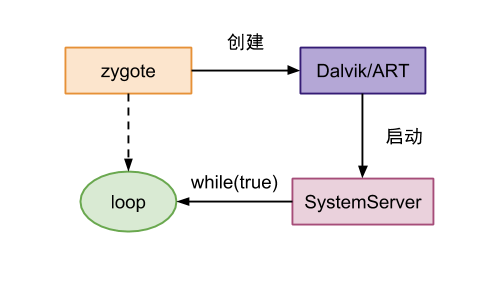
Android Framework
Android 分区 /boot:存放引导程序,包括内核和内存操作程序。/system:相当于电脑 C 盘,存放 Android 系统及系统应用。/recovery:恢复分区,可以进入该分区进行系统恢复。/data:用户数据区&#…...

JVM对象分配与程序崩溃排查
一、new 对象在 JVM 中的过程 在 JVM 中通过 new 关键字创建对象时,会经历以下步骤: 内存分配 对象的内存分配在 堆(Heap) 中,优先在 新生代(Young Generation) 的 Eden 区 分配。分配方式取决…...
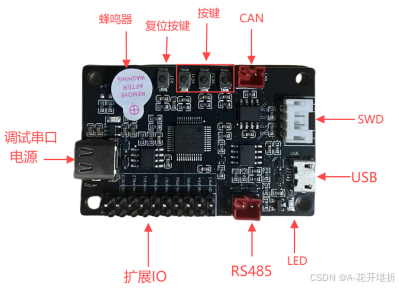
OpenMCU(六):STM32F103开发板功能介绍
概述 距上一篇关于STM32F103的FreeRTOS博客的发布已经过去很长时间没有更新了。在这段时间内,大家可以看到博主发表了一系列的关于使用qemu 模拟实现STM32F103的博客,博主本来想借助qemu开发stm32F103相关的一些软件功能,博主开发出来并成功运…...
Java学习-5.12(Redis,B2C电商))
(自用)Java学习-5.12(Redis,B2C电商)
一、Redis 核心知识 缓存作用 提升性能:内存读写速度(读 10w/s,写 8w/s)远超 MySQL(读 3w/s,写 2w/s)减少数据库压力:通过内存缓存热点数据,避免频繁 SQL 查询分类&#…...

Rspack:字节跳动自研 Web 构建工具-基于 Rust打造高性能前端工具链
字节跳动开源了一款采用 Rust 开发的前端模块打包工具:Rspack(读音为 /ɑrspk/)。 据介绍,Rspack 是一个基于 Rust 的高性能构建引擎,具备与 Webpack 生态系统的互操作性,可以被 Webpack 项目低成本集成&a…...

深度解析LLM参数:Top-K、Top-p和温度如何影响输出随机性?
许多大模型具有推理参数,用于控制输出的“随机性”。常见的几个是 Top-K、Top-p,以及温度。 Top-p: 含义:Kernel sampling threshold. Used to determine the randomness of the results. The higher the value, the stronger t…...
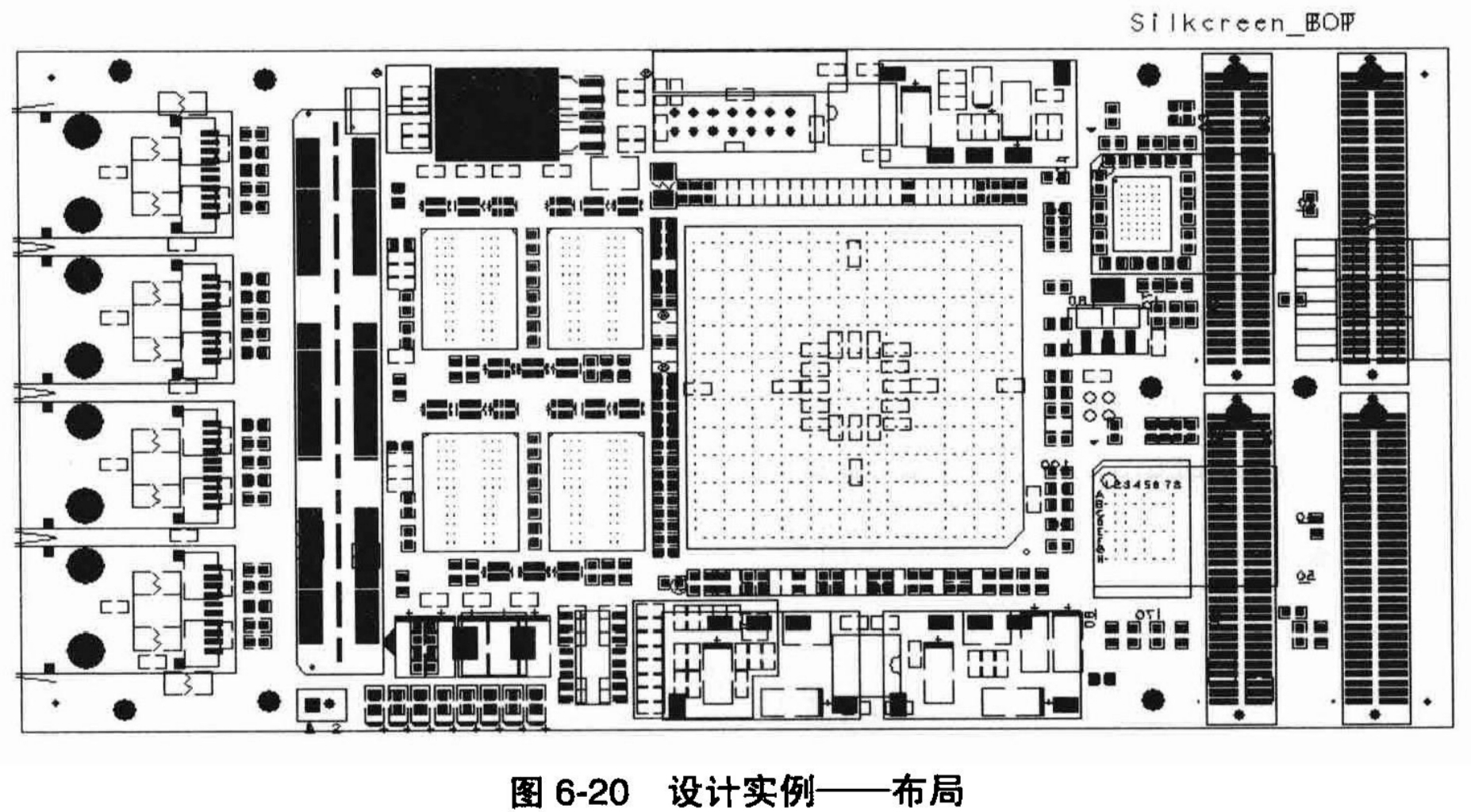
高速系统设计实例设计分析
在上几章的内容中,我们从纯粹高速信号的理论分析,到 Cadence 工具的具体使用都做了详细的讲解和介绍。相信读者通过前面章节的学习,已经对高速系统的设计理念及 Cadence 相应的设计流程和工具有了一个基本的认识。但是,对于高速电…...
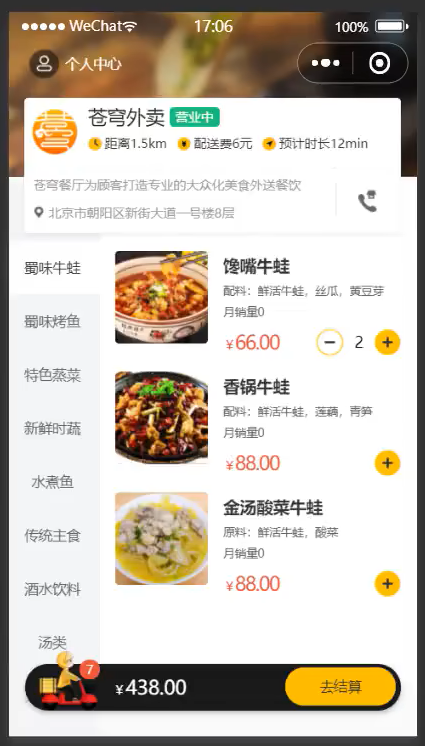
查看购物车
一.查看购物车 查看购物车使用get请求。我们要查看当前用户的购物车,就要获取当前用户的userId字段进行条件查询。因为在用户登录时就已经将userId封装在token中了,因此我们只需要解析token获取userId即可,不需要前端再传入参数了。 Control…...

疑难杂症:dex安装部署
方式一、源码包下载 wget https://github.com/dexidp/dex/archive/refs/tags/v2.42.1.tar.gz 方式二、git方式拉取源码编译: Getting Started | $ git clone https://github.com/dexidp/dex.git 编译 $ cd dex/ $ make build 启动 ./bin/dex serve examples/…...
不起作用)
【idea】快捷键ctrl+shift+F(Find in files)不起作用
问题描述 在idea中使用快捷键CtrlShiftF,进行内容的搜索,但是弹不出对话框、或有时候能弹出有时候又弹不出。 原因分析 1.怀疑是缓存问题?--清空缓存重启也没什么作用 2.怀疑是idea的问题?--有时行、有时不行,而且…...
开发工具分享: Web前端编码常用的在线编译器
1.OneCompiler 工具网址:https://onecompiler.com/ OneCompiler支持60多种编程语言,在全球有超过1280万用户,让开发者可以轻易实现代码的编写、运行和共享。 OneCompiler的线上调试功能完全免费,对编程语言的覆盖也很全&#x…...

EnumUtils:你的枚举“变形金刚“——让枚举操作不再手工作业
各位枚举操控师们好!今天要介绍的是Apache Commons Lang3中的EnumUtils工具类。这个工具就像枚举界的"瑞士军刀",能让你的枚举操作从石器时代直接跃迁到星际文明! 一、为什么需要EnumUtils? 手动操作枚举就像…...
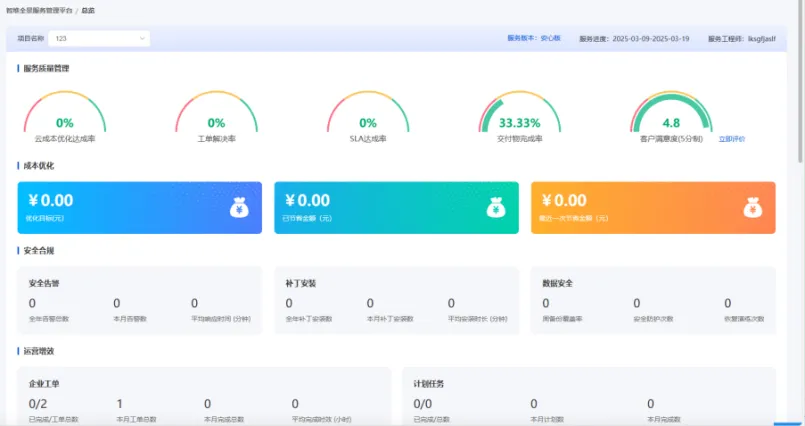
智启未来:新一代云MSP管理服务助力企业实现云成本管理和持续优化
在数字化转型浪潮下,企业纷纷寻求更高效、更经济的运营方式。随着云计算技术的深入应用,云成本优化已成为企业普遍关注的核心议题。 过去,传统云运维服务往往依赖于人力外包,缺乏系统性、规范性的管理,难以有效降低云…...
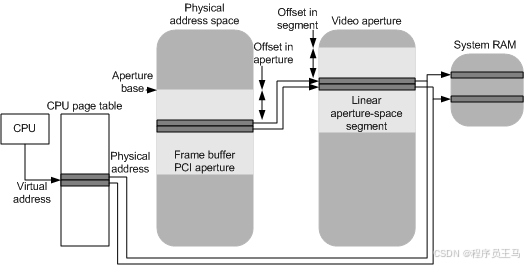
window 显示驱动开发-将虚拟地址映射到内存段(二)
在将虚拟地址映射到段的一部分之前,视频内存管理器调用显示微型端口驱动程序的 DxgkDdiAcquireSwizzlingRange 函数,以便驱动程序可以设置用于访问可能重排的分配位的光圈。 驱动程序既不能将偏移量更改为访问分配的 PCI 光圈,也不能更改分配…...

C++:构造函数
构造函数是类的六个默认成员函数之一,这里的默认是指我们不写,编译器会自己生成的。 构造函数其目的是初始化对象,不是开空间。 其特征如下: 1.函数名与类名相同 2.没有返回值,意思是不用在函数前面写void。 3.对…...
【文心智能体】使用文心一言来给智能体设计一段稳定调用工作流的提示词
🌹欢迎来到《小5讲堂》🌹 🌹这是《文心智能体》系列文章,每篇文章将以博主理解的角度展开讲解。🌹 🌹温馨提示:博主能力有限,理解水平有限,若有不对之处望指正࿰…...
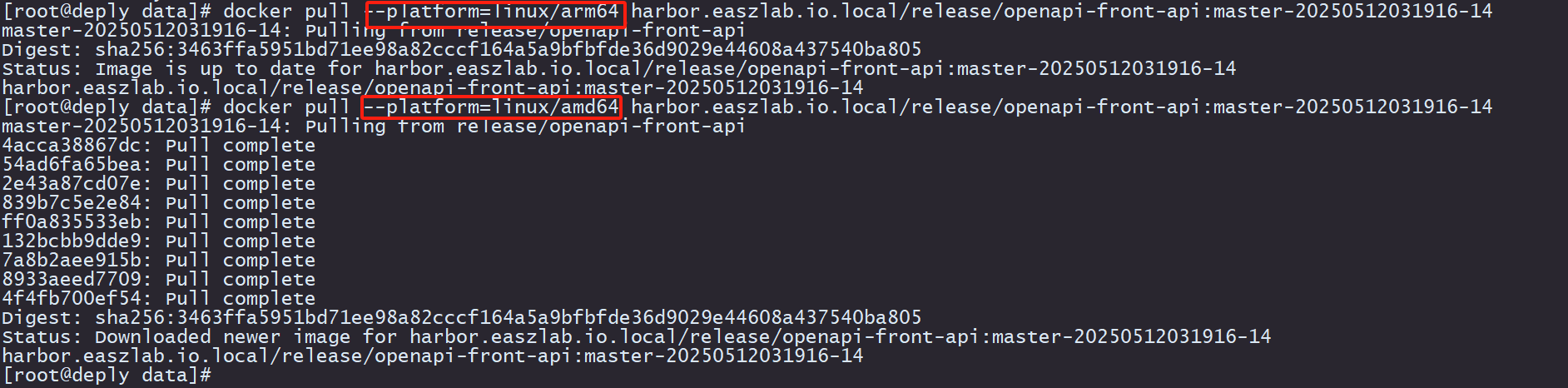
K8S中构建双架构镜像-从零到成功
背景介绍 公司一个客户的项目使用的全信创的环境,服务器采用arm64的机器,而我们的应用全部是amd64的,于是需要对现在公司流水线进行arm64版本的同步镜像生成。本文介绍从最开始到最终生成双架构的全部过程,以及其中使用的相关配置…...

pth的模型格式怎么变成SafeTensors了?
文章目录 背景传统模型格式的安全隐患效率与资源瓶颈跨框架兼容性限制Hugging Face 的解决方案:SafeTensors行业与社区的推动SafeTensors 的意义总结 背景 最近要找一些适合embedding的模型,在huggingface模型库上看到一些排名比较靠前的,准…...

iOS safari和android chrome开启网页调试与检查器的方法
手机开启远程调试教程(适用于 Chrome / Safari) 前端移动端调试指南|适用 iPhone 和 Android|WebDebugX 出品 本教程将详细介绍如何在 iPhone 和 Android 手机上开启网页检查器,配合 WebDebugX 实现远程调试。教程包含…...

c语言第一个小游戏:贪吃蛇小游戏03
我们为贪吃蛇的节点设置为一个结构体,构成贪吃蛇的身子的话我们使用链表,链表的每一个节点是一个结构体 显示贪吃蛇身子的一个节点 我们这边node就表示一个蛇的身体 就是一小节 输出结果如下 显示贪吃蛇完整身子 效果如下 代码实现 这个hasSnakeNode(…...
大规模预训练范式(Large-scale Pre-training)
大规模预训练指在巨量无标注数据上,通过自监督学习训练大参数量的基础模型,使其具备通用的表征与推理能力。其重要作用如下: 一 跨任务泛化 单一模型可在微调后处理多种NLP(自然语言处理)、CV(计算机视觉…...

基于Flink的用户画像 OLAP 实时数仓统计分析
1.基于Flink的用户画像 OLAP 实时数仓统计分析 数据源是来自业务系统的T日数据,利用kakfa进行同步 拼接多个事实表形成大宽表,优化多流Join方式,抽取主键和外键形成主外键前置层,抽取外键和其余内容形成融合层,将4次事…...