大规模预训练范式(Large-scale Pre-training)
大规模预训练指在巨量无标注数据上,通过自监督学习训练大参数量的基础模型,使其具备通用的表征与推理能力。其重要作用如下:
一 跨任务泛化
单一模型可在微调后处理多种NLP(自然语言处理)、CV(计算机视觉)任务。
1.1大规模预训练模型的核心目标
在大量无标签文本上学习语言的通用模式,形成高维语义向量空间。
实现方法:
(1)词汇层面:通过词嵌入(如WordPiece)捕捉词汇间关系(如语义、句法相似性)。
(2)上下文层面:利用Transformer的自注意力机制建模长距离依赖关系。
(3)知识层面:通过跨领域数据隐式存储常识和领域知识(如时间序列、因果关系)。
1.2模型架构的适应性
(1)Transformer的灵活性:通过自注意力机制和层级堆叠(低层捕捉语法,高层捕捉语义和逻辑)
(2)任务适配能力:通过调整顶层结构(如添加分类头、序列标注层、生成解码器),同一模型可适配不同任务.
1.3 参数迁移与微调策略
(1)参数高效迁移:作为任务无关的高质量初始化,覆盖95%以上的模型参数。
(2)微调时更新:仅调整顶层结构和小部分底层参数即可(如最后3-4层)。(实验表明:底层参数对通用特征敏感,高层参数更需适应任务特性)
大规模预训练模型通过通用表示学习和灵活架构设计,实现了从训练数据到下游任务的高效迁移。微调的本质是通过局部参数调整,将通用知识映射到具体任务空间。
二 上下文学习
无需参数更新,仅通过Prompt(提示)即可适配新任务(如GPT-3)。
其本质是为模型输入结构化引导信息,通过特定模板或指示,激发表征空间中预存的通用知识,使其能够在不更新参数的情况下适应新任务。
核心价值:
(1)无需微调:Zero-shot/Few-Shot场景下快速部署。
(2)人机对齐:通过自然语言直观引导模型行为
(3)知识蒸馏:将复杂任务简化为预训练已知的模式
| 方法 | 数据需求 | 模型改动 | 应用场景 |
|---|---|---|---|
| 全量微调 | 数千-百万样本 | 调整全部参数 | 专一任务 |
| Prompt | 0-数十样本 | 仅修改输入 | 多任务快速切换 |
2.1Prompt基本结构
prompt_template = """
任务指令:{instruction} #指令:明确任务类型
输入内容:{input} #输入:待处理的实际内容
示例参考:{examples} #示例:少量示范
模型回答:
"""
2.2 Prompt类型对比
| 类型 | 示例 | 适用场景 |
|---|---|---|
| 完形填空式 | “中国的首都是[MASK]。” | 知识推理(如BERT) |
| 指令驱动式 | “请将以下英文翻译为中文:{text}” | 文本生成(如GPT系列) |
| 思维链(CoT) | “问题:X。逐步推理过程:首先…因此答案是…” | 复杂推理任务 |
| 元模板式 | “假设你是一名律师,请回答:…” | 角色设定类任务 |
2.3Prompt设计方法论
2.3.1人工设计准则
(1)词汇兼容性:使用模型预训练时常见的表达(如“翻译”、“总结”)
(2)逻辑连贯性:示例与任务保持严格一致性(避免歧义)
(3)位置敏感性:关键指令放开头(因Transformer对前128词关注度更高)
Bad vs Good Prompt对比:
# Bad(模糊指令)
"处理这段文本:{text}"# Good(明确指向)
"请对以下中文评论进行情感分析(正向/负向),输出结果:
评论:{text}
情感标签:"
2.3.2 自动生成技术
(1)AutoPrompt:通过梯度搜索找到使目标标签概率最大化的词序列。
(其中 ⊕\oplus⊕ 表示提示连接操作)
(2)Prompt Tuning:训练可学习的软提示向量(Soft Prompt)
# 示例代码:软提示嵌入
soft_prompt = nn.Parameter(torch.randn(10, hidden_dim)) # 10个可学习向量
inputs = torch.cat([soft_prompt, text_embeddings], dim=1)
2.3.3实际应用案例
多语言翻译:Prompt设计
prompt = """
将英文翻译为中文:
Example 1:
Input: "Hello, how are you?" → Output: "你好,最近怎么样?"
Example 2:
Input: "The quick brown fox jumps over the lazy dog" → Output: "敏捷的棕色狐狸跳过了懒狗"
现在翻译:
Input: "Large-scale pretraining requires massive computing resources."
Output:
"""Prompt技术通过语义空间导航激活模型的隐式知识,已成为大规模预训练模型的核心交互范式。未来将向多模态、自动化、可解释方向发展,同时需解决提示注入攻击、评估量化等挑战。
三 数据效率
相比传统监督学习,微调所需标注数据减少90%以上,其本质源于通用知识预存储与参数高效迁移机制的结合。
其核心逻辑为:
知识压缩:预训练阶段将海量无标注数据的信息压缩至模型参数中。
知识检索:微调通过轻量级参数调整,激活与任务相关的知识子集。
3.1知识预存储:预训练阶段的隐含知识泛化
3.1.1通用语义表征学习
(1)预训练数据覆盖性:模型在万亿级跨领域文本(网页、书籍、代码)中学习,涵盖词汇、语法、逻辑关系、常识和领域知识,形成高度抽象的通用语义空间。
(2)数学视角:预训练通过语言建模损失(如MLM、自回归预测),强制模型编码文本的条件概率分布:
这种优化使得隐藏层表示 成为与任务无关的“语言特征蒸馏器”。
3.1.2知识的参数化存储
参数冗余设计:大模型(如175B参数的GPT-3)通过过参数化架构,将多样化知识分布在神经网络的多个层级。例如:
浅层网络:捕捉语法结构(如句法树)
中层网络:编码语义角色(如主谓宾关系)
深层网络:存储逻辑推理模式(如因果关系、类比联想)
3.2参数高效迁移:微调阶段的关键技术机制
3.2.1参数冻结策略
| 策略 | 可调参数占比 | 典型应用场景 |
|---|---|---|
| 全量微调 | 100% | 数据充足(>10,000样本) |
| 部分层微调 | 5%-20% | 中小规模数据(100-1k样本) |
| 适配器/软提示 | 0.5%-3% | 极小样本(<100样本) |
科学依据:底层参数承载通用特征(词嵌入、句法分析),高层参数更侧重任务适配(如情感极性分类),因此仅微调最后3-4层即可适配大多数任务。
3.2.2 梯度更新约束
通过低秩适应(LoRA)等技术减少梯度更新维度:
其中秩r通常设为8-64,使参数更新量仅为原模型的0.01%级别。
LoRA的核心思想:在微调时,冻结原始模型参数,仅通过低秩分解的增量矩阵来适应下游任务。
数学表达:
对于预训练权重矩阵 ,LoRA将其更新量约束为低秩矩阵:
微调后的权重为:
其中:
:低秩的维度(通常设为8-64)
:缩放系数(控制增量幅度)
LoRA的工作原理
实现步骤:
(1)冻结原参数:保持预训练权重 W 不变,避免灾难性遗忘
(2)引入可训练低秩矩阵:向模型插入旁路矩阵 B 和 A,梯度仅更新这两个小矩阵
(3)前向传播合并:在计算时动态叠加 ,不影响推理速度
技术原理:
(1)过参数化假设:大规模神经网络中存在大量冗余参数,真正有效更新存在于低维子空间
(2)秩的物理意义:秩 r 约束了模型变化的自由度,实验表明 r=8 足以覆盖大多数任务需求
import torch
import torch.nn as nnclass LoRALayer(nn.Module):def __init__(self, in_dim, out_dim, rank=8):super().__init__()self.rank = rank# 原始权重(冻结)self.W = nn.Parameter(torch.randn(out_dim, in_dim), requires_grad=False)# LoRA旁路参数self.B = nn.Parameter(torch.zeros(out_dim, rank))self.A = nn.Parameter(torch.zeros(rank, in_dim))def forward(self, x):# 前向计算:Wx + (B A^T)x = (W + B A^T)xreturn x @ (self.W + (self.B @ self.A)).T# 使用示例:替换Transformer的FFN层
class TransformerFFNWithLoRA(nn.Module):def __init__(self, d_model, d_ff, rank=8):super().__init__()self.fc1 = LoRALayer(d_model, d_ff, rank)self.fc2 = LoRALayer(d_ff, d_model, rank)
3.2.3任务相似性补偿
当下游任务与预训练任务的语义空间重叠度较高时(如情感分析 vs 预训练的文本理解),模型只需微调任务专属特征,而非重建整个语义体系。
量化指标:任务相似性 S 的计算公式:
当 S>0.7 时,仅需1%的标注数据即可达到全量训练90%的性能。
3.2.4与传统监督学习的对比机制
| 维度 | 传统监督学习 | 预训练+微调 | 效率差异来源 |
|---|---|---|---|
| 初始化状态 | 随机初始化的白板模型 | 携带语言结构和知识的“专家”模型 | 预训练模型具备任务无关的强先验 |
| 数据依赖 | 需覆盖所有可能的特征组合 | 仅需补充任务特有的特征差异 | 通过知识蒸馏避免从头学习 |
| 参数更新量 | 全参数空间搜索 | 局部子空间优化(<10%参数) | 维数灾难(Curse of Dimensionality)的缓解 |
| 过拟合风险 | 高(需正则化、早停等强干预) | 低(通用表征提供正则化效果) | 隐式正则化提升小数据泛化能力 |
四 基础架构对比
| 架构类型 | 代表模型 | 预训练目标 | 典型应用领域 |
|---|---|---|---|
| 自回归型 | GPT系列 | 语言建模(从左到右) | 文本生成、问答 |
| 自编码型 | BERT | 掩码语言模型 | 文本分类、实体识别 |
| 混合架构 | T5 | 文本到文本转换 | 翻译、摘要生成 |
| 多模态融合 | CLIP、GPT-4 | 图文对齐损失 | 跨模态检索、生成 |
相关文章:
大规模预训练范式(Large-scale Pre-training)
大规模预训练指在巨量无标注数据上,通过自监督学习训练大参数量的基础模型,使其具备通用的表征与推理能力。其重要作用如下: 一 跨任务泛化 单一模型可在微调后处理多种NLP(自然语言处理)、CV(计算机视觉…...

基于Flink的用户画像 OLAP 实时数仓统计分析
1.基于Flink的用户画像 OLAP 实时数仓统计分析 数据源是来自业务系统的T日数据,利用kakfa进行同步 拼接多个事实表形成大宽表,优化多流Join方式,抽取主键和外键形成主外键前置层,抽取外键和其余内容形成融合层,将4次事…...

React Native踩坑实录:解决NativeBase Radio组件在Android上的兼容性问题
React Native踩坑实录:解决NativeBase Radio组件在Android上的兼容性问题 问题背景 在最近的React Native项目开发中,我们的应用在iOS设备上运行良好,但当部署到Android设备时,进入语言设置和隐私设置页面后应用崩溃。我们遇到了…...

iptables实现DDos
最近有客户要定制路由器的默认防火墙等级,然后涉及到了DDos规则,对比客户提供的规则发现我们现有的规则存在明显的错误,在此记录一下如何使用iptables防护DDoS攻击 直接贴一下规则 #开启TCP SYN Cookies 机制 sysctl -w net.ipv4.tcp_synco…...
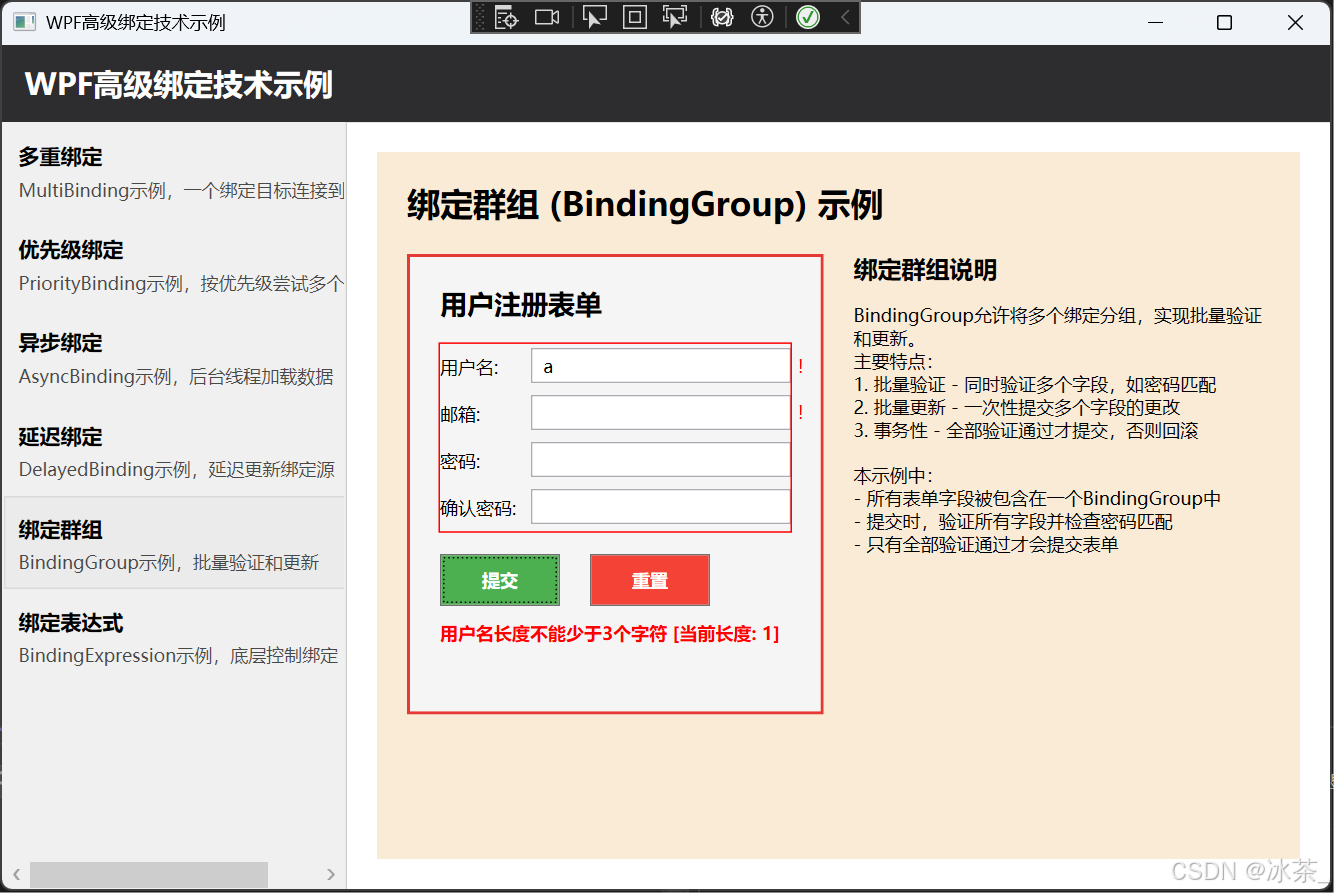
WPF之高级绑定技术
文章目录 引言多重绑定(MultiBinding)基本概念实现自定义IMultiValueConverterMultiBinding在XAML中的应用示例使用StringFormat简化MultiBinding 优先级绑定(PriorityBinding)基本概念PriorityBinding示例实现PriorityBinding的后…...
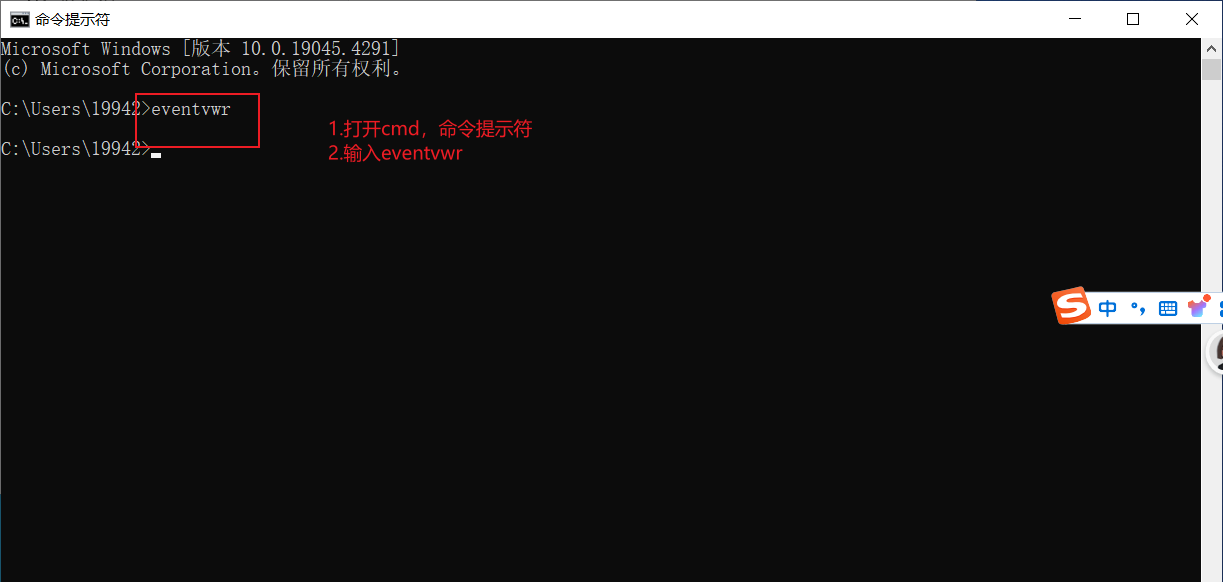
调出事件查看器界面的4种方法
方法1. 方法2. 方法3. 方法4....
使用vite重构vue-cli的vue3项目
一、修改依赖 首先修改 package.json,修改启动方式与相应依赖 移除vue-cli并下载vite相关依赖,注意一些peerDependency如fast-glob需要手动下载 # 移除 vue-cli 相关依赖 npm remove vue/cli-plugin-babel vue/cli-plugin-eslint vue/cli-plugin-rout…...

Go-GJSON 组件,解锁 JSON 读取新姿势
现在的通义灵码不但全面支持 Qwen3,还支持配置自己的 MCP 工具,还没体验过的小伙伴,马上配置起来啦~ https://click.aliyun.com/m/1000403618/ 在 Go 语言开发领域,json 数据处理是极为常见的任务。Go 标准库提供了 encoding/jso…...
:LeetCode 56. 合并区间(Merge Intervals)详解)
Java详解LeetCode 热题 100(14):LeetCode 56. 合并区间(Merge Intervals)详解
文章目录 1. 题目描述2. 理解题目3. 解法一:排序 + 一次遍历法3.1 思路3.2 Java代码实现3.3 代码详解3.4 复杂度分析3.5 适用场景4. 解法二:双指针法4.1 思路4.2 Java代码实现4.3 代码详解4.4 复杂度分析4.5 与解法一的比较5. 解法三:TreeMap法5.1 思路5.2 Java代码实现5.3 …...

将Docker镜像变为可执行文件?体验docker2exe带来的便捷!
在现代软件开发中,容器化技术极大地改变了应用程序部署和管理的方式。Docker,作为领先的容器化平台,已经成为开发者不可或缺的工具。然而,对于不熟悉Docker的用户来说,接触和运行Docker镜像可能会是一个复杂的过程。为了解决这一问题,docker2exe项目应运而生。它提供了一…...

ev_loop_fork函数
libev监视器介绍:libev监视器用法-CSDN博客 libev loop对象介绍:loop对象-CSDN博客 libev ev_loop_fork函数介绍:ev_loop_fork函数-CSDN博客 libev API吐血整理:https://download.csdn.net/download/qq_39466755/90794251?spm1001.2014.3…...
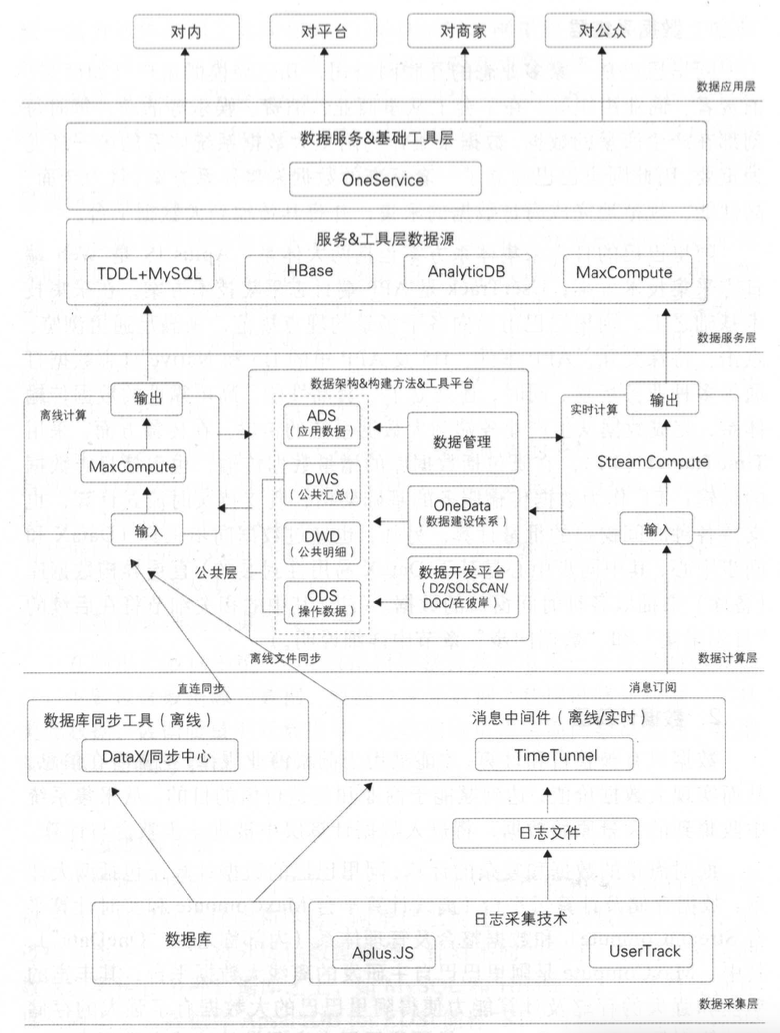
数据治理域——数据治理体系建设
摘要 本文主要介绍了数据治理系统的建设。数据治理对企业至关重要,其动因包括应对数据爆炸增长、提升内部管理效率、支撑复杂业务需求、加强风险防控与合规管理以及实现数字化转型战略。其核心目的是提升数据质量、统一数据标准、优化数据资产管理、支撑业务发展和…...

ES常识7:ES8.X集群允许4个 master 节点吗
在 Elasticsearch(ES)中,4 个 Master 节点的集群可以运行,但存在稳定性风险,且不符合官方推荐的最佳实践。以下从选举机制、故障容错、资源消耗三个维度详细分析: 一、4 个 Master 节点的可行性࿱…...

onGAU:简化的生成式 AI UI界面,一个非常简单的 AI 图像生成器 UI 界面,使用 Dear PyGui 和 Diffusers 构建。
一、软件介绍 文末提供程序和源码下载 onGAU:简化的生成式 AI UI界面开源程序,一个非常简单的 AI 图像生成器 UI 界面,使用 Dear PyGui 和 Diffusers 构建。 二、Installation 安装 文末下载后解压缩 Run install.py with python to setup…...
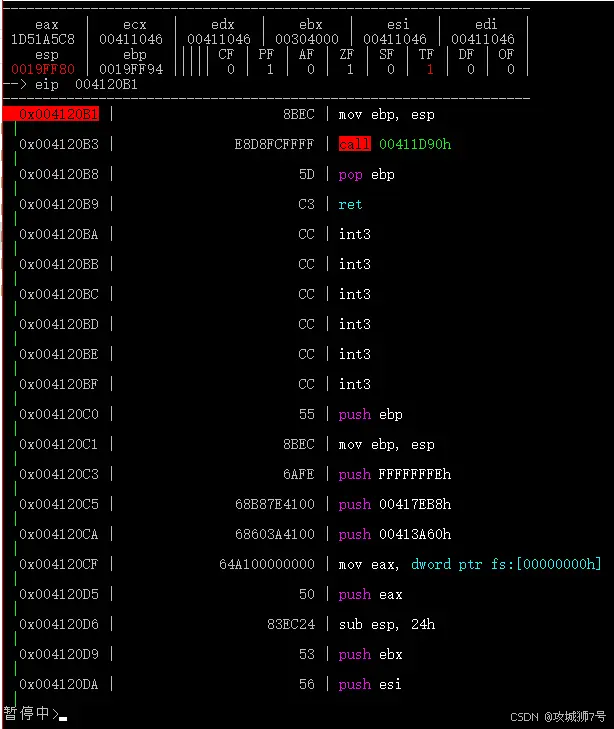
【第52节】Windows编程必学之从零手写C++调试器下篇(仿ollydbg)
目录 一、引言 二、调试器核心功能设计与实现 三、断点功能 四、高级功能 五、附加功能 六、开发环境与实现概要 七、项目展示及完整代码参考 八、总结 一、引言 在软件开发领域,调试器是开发者不可或缺的工具。它不仅能帮助定位代码中的逻辑错误࿰…...

uni-app学习笔记五--vue3插值表达式的使用
vue3快速上手导航:简介 | Vue.js 模板语法 插值表达式 最基本的数据绑定形式是文本插值,它使用的是“Mustache”语法 (即双大括号): <span>Message: {{ msg }}</span> 双大括号标签会被替换为相应组件实例中 msg 属性的值。同…...
C++类与对象(二):六个默认构造函数(一)
在学C语言时,实现栈和队列时容易忘记初始化和销毁,就会造成内存泄漏。而在C的类中我们忘记写初始化和销毁函数时,编译器会自动生成构造函数和析构函数,对应的初始化和在对象生命周期结束时清理资源。那是什么是默认构造函数呢&…...
操作的一个函数 flip())
OpenCV CUDA 模块中在 GPU 上对图像或矩阵进行 翻转(镜像)操作的一个函数 flip()
操作系统:ubuntu22.04 OpenCV版本:OpenCV4.9 IDE:Visual Studio Code 编程语言:C11 算法描述 cv::cuda::flip 是 OpenCV 的 CUDA 模块中的一个函数,用于在 GPU 上对图像或矩阵进行 翻转(镜像)操作。它类似…...

基于大模型的原发性醛固酮增多症全流程预测与诊疗方案研究
目录 一、引言 1.1 研究背景与意义 1.2 国内外研究现状 1.3 研究目的与方法 二、原发性醛固酮增多症概述 2.1 疾病定义与发病机制 2.2 临床表现与诊断标准 2.3 流行病学特征 三、大模型预测原理与技术 3.1 大模型简介 3.2 预测原理与算法 3.3 数据收集与预处理 四…...
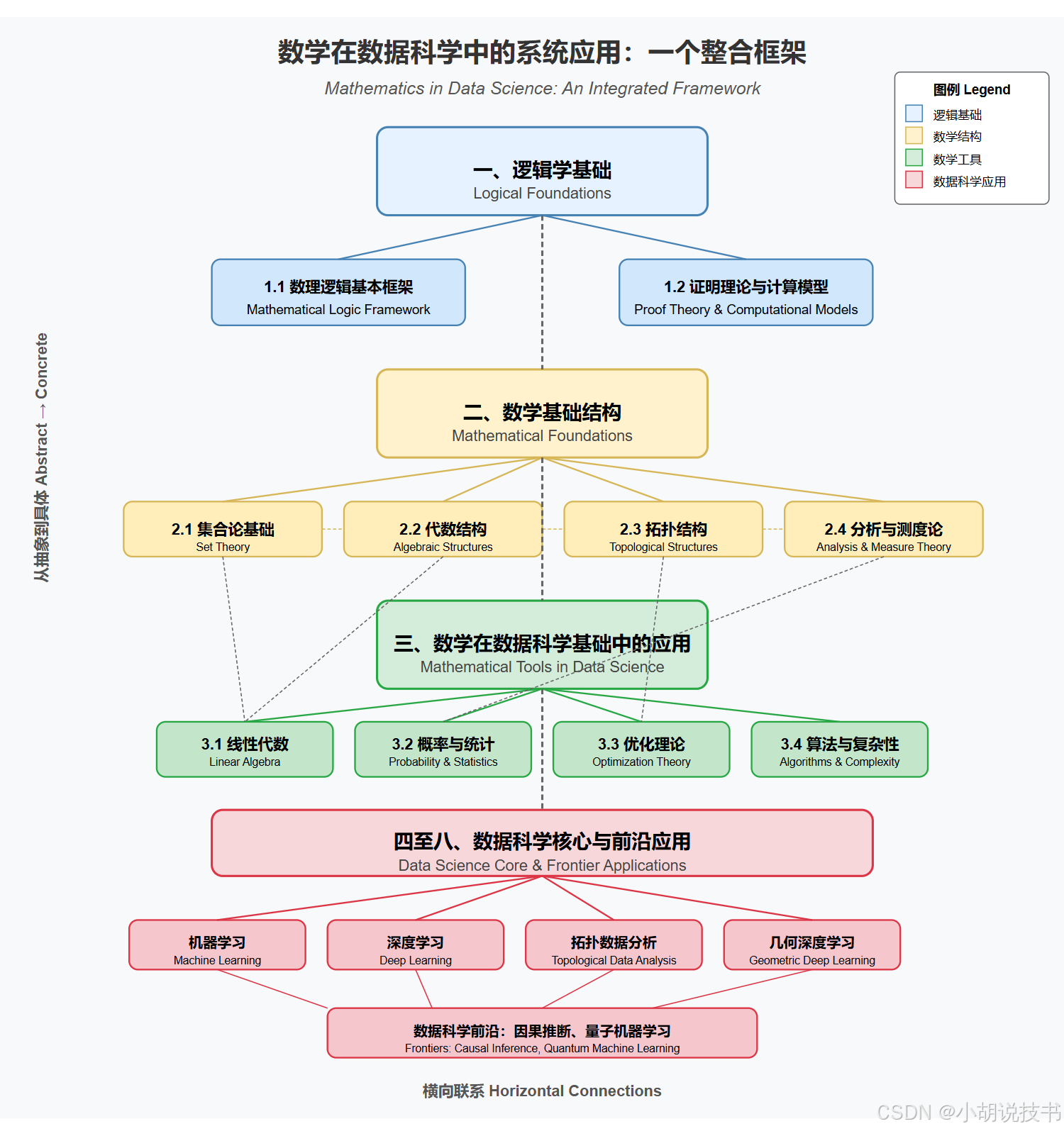
从逻辑学视角探索数学在数据科学中的系统应用:一个整合框架
声明:一家之言,看个乐子就行。 图表采用了两个维度组织知识结构: 垂直维度:从上到下展示了知识的抽象到具体的演进过程,分为四个主要层级: 逻辑学基础 - 包括数理逻辑框架和证明理论数学基础结构 - 涵盖…...
Matplotlib 完全指南:从入门到精通
前言 Matplotlib 是 Python 中最基础、最强大的数据可视化库之一。无论你是数据分析师、数据科学家还是研究人员,掌握 Matplotlib 都是必不可少的技能。本文将带你从零开始学习 Matplotlib,帮助你掌握各种图表的绘制方法和高级技巧。 目录 Matplotli…...
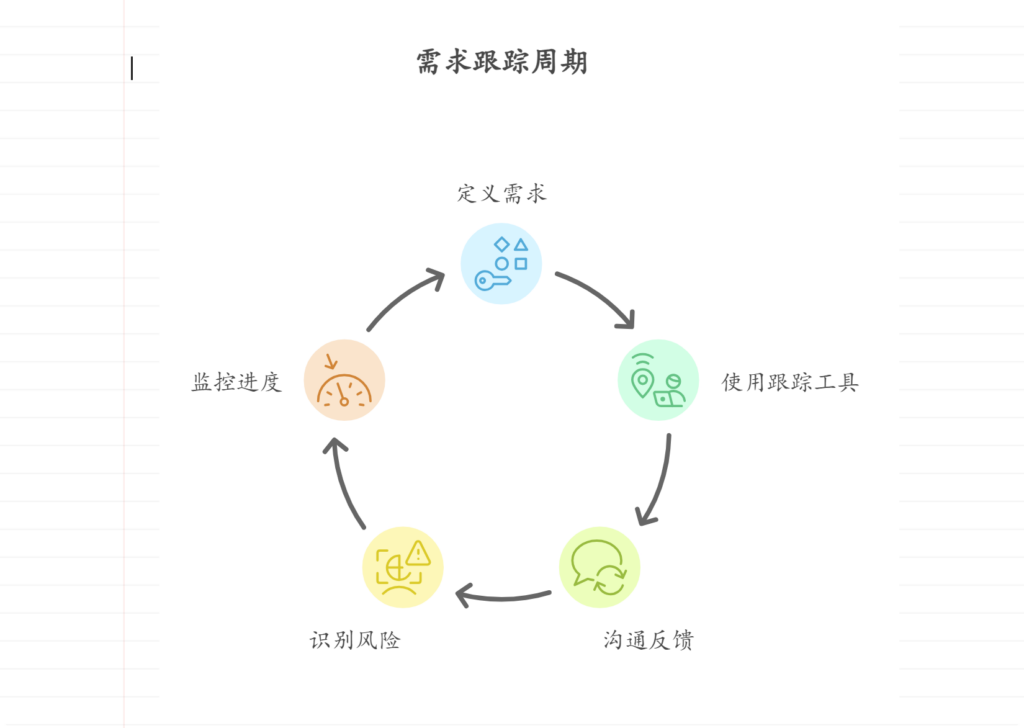
如何有效追踪需求的实现情况
有效追踪需求实现情况,需要清晰的需求定义、高效的需求跟踪工具、持续的沟通反馈机制,其中高效的需求跟踪工具尤为关键。 使用需求跟踪工具能确保需求实现进度可视化、提高团队协作效率,并帮助识别和管理潜在风险。例如,使用专业的…...
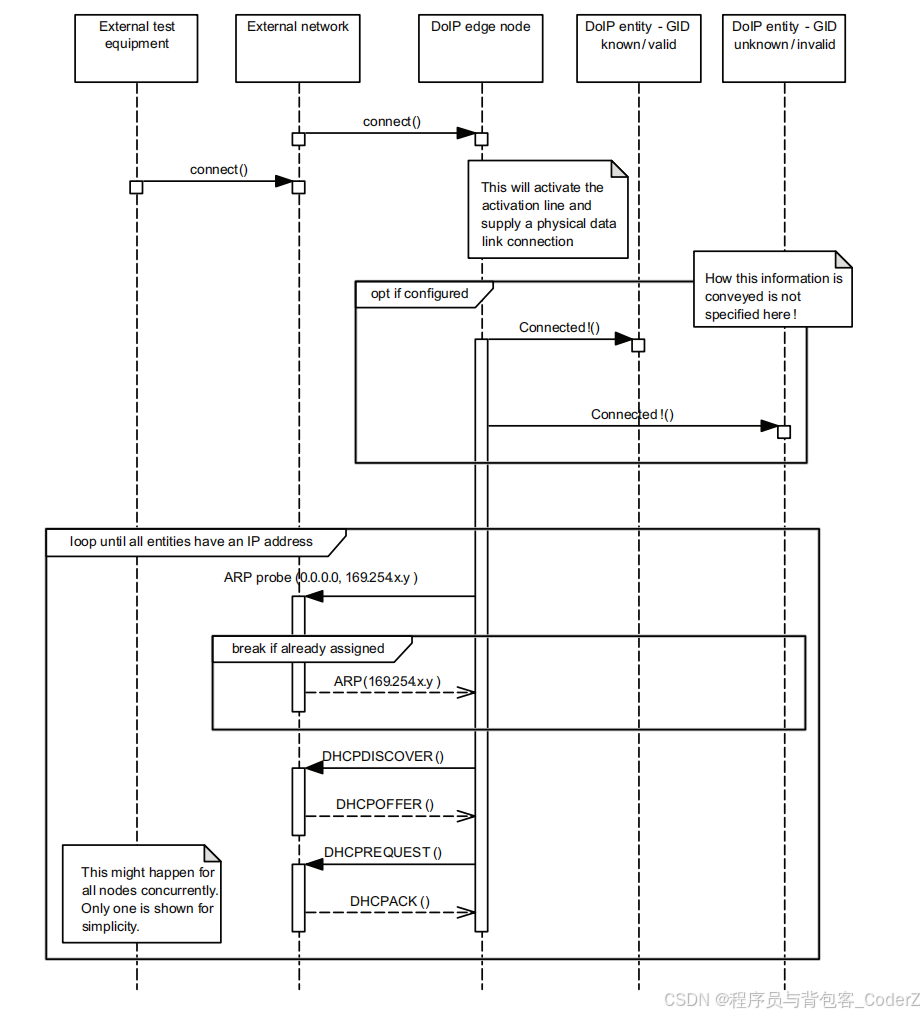
自动驾驶技术栈——DoIP通信协议
一、DoIP协议简介 DoIP,英文全称是Diagnostic communication over Internet Protocol,是一种基于因特网的诊断通信协议。 DoIP协议基于TCP/IP等网络协议实现了车辆电子控制单元(ECU)与诊断应用程序之间的通信,常用于汽车行业的远程诊断、远…...
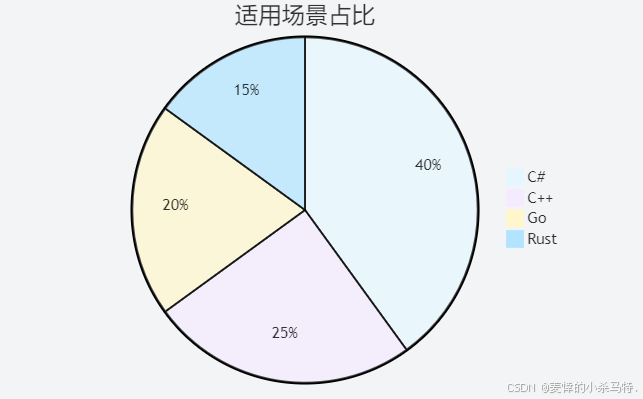
C++ 与 Go、Rust、C#:基于实践场景的语言特性对比
目录 编辑 一、语法特性对比 1.1 变量声明与数据类型 1.2 函数与控制流 1.3 面向对象特性 二、性能表现对比编辑 2.1 基准测试数据 在计算密集型任务(如 10⁷ 次加法运算)中: 在内存分配测试(10⁵ 次对象创建…...

Docker 中的 DNS 解析机制
在 Docker 容器化环境中,网络连接是至关重要的,而 DNS(Domain Name System,域名系统)解析则是网络通信的基础。容器需要能够解析内部服务名称以及外部域名,以便与其他容器或外部世界进行交互。理解 Docker 如何处理 DNS 请求,可以帮助我们更好地配置和排查网络问题。 D…...

数字化工厂中央控制室驾驶舱系统 API接口文档
数字化工厂中央控制室驾驶舱系统 API接口文档 本文档详细描述了数字化工厂中央控制室驾驶舱系统的API接口规范,包括中端服务提供的数据接口和算法接口。 1. 通用规范 1.1 基础URL 后端服务: http://localhost:8000中端服务数据API: http://localhost:8001中端服…...

如何更改默认字体:ONLYOFFICE 协作空间、桌面编辑器、文档测试示例
在处理办公文件时,字体对提升用户体验至关重要。本文将逐步指导您如何在 ONLYOFFICE 协作空间、桌面应用及文档测试示例中自定义默认字体,以满足个性化需求,更好地掌控文档样式。 关于 ONLYOFFICE ONLYOFFICE 是一个国际开源项目,…...
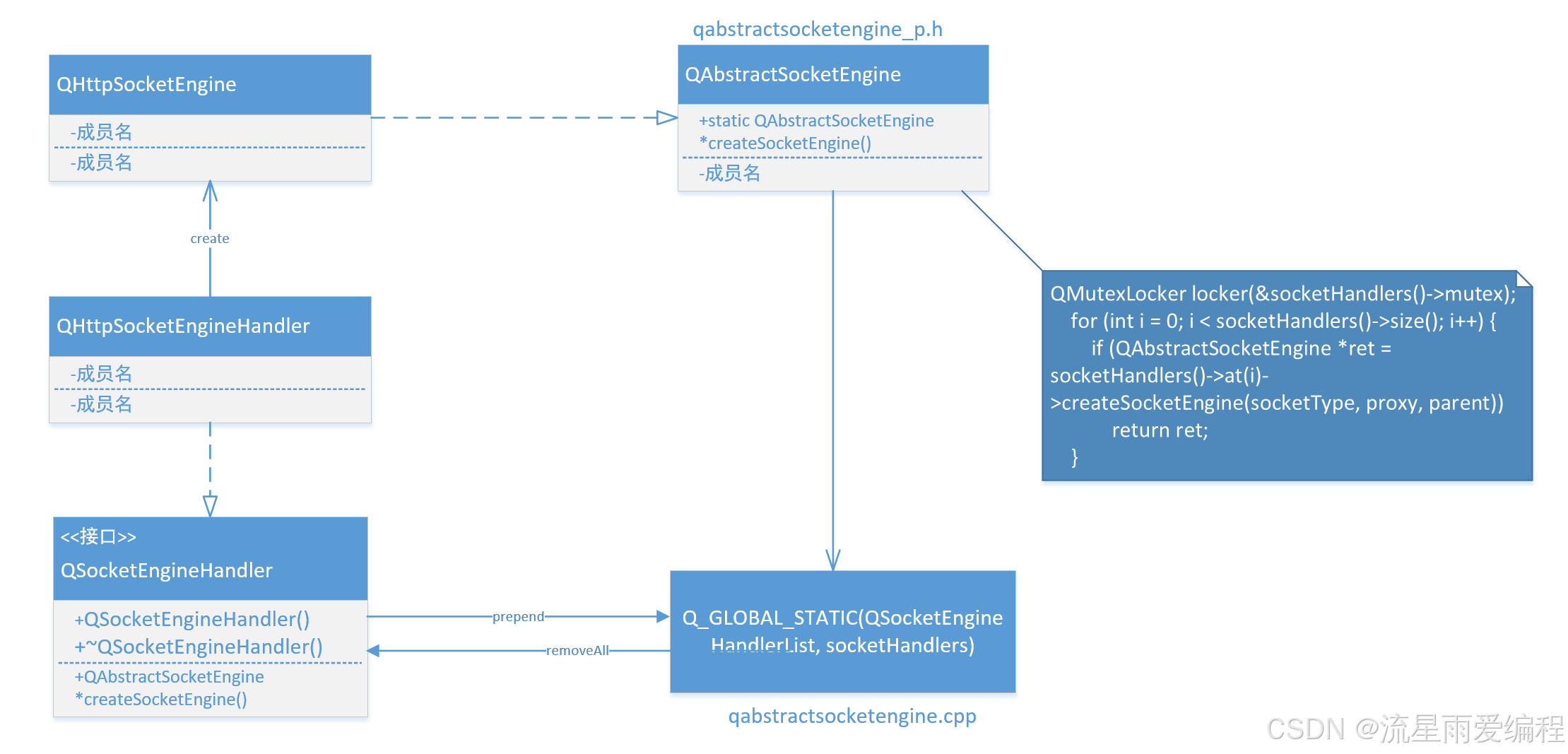
设计模式之工厂模式(二):实际案例
设计模式之工厂模式(一) 在阅读Qt网络部分源码时候,发现在某处运用了工厂模式,而且编程技巧也用的好,于是就想分享出来,供大家参考,理解的不对的地方请多多指点。 以下是我整理出来的类图: 关键说明&#x…...

基于VeRL源码深度拆解字节Seed的DAPO
1. 背景与现状:从PPO到GRPO的技术演进 1.1 PPO算法的基础与局限 Proximal Policy Optimization(PPO)作为当前强化学习领域的主流算法,通过重要性采样比率剪裁机制将策略更新限制在先前策略的近端区域内,构建了稳定的…...

zst-2001 历年真题 软件工程
软件工程 - 第1题 b 软件工程 - 第2题 c 软件工程 - 第3题 c 软件工程 - 第4题 b 软件工程 - 第5题 b 软件工程 - 第6题 0.未完成:未执行未得到目标。1.已执行:输入-输出实现支持2.已管理:过程制度化,项目遵…...