基于VeRL源码深度拆解字节Seed的DAPO

1. 背景与现状:从PPO到GRPO的技术演进
1.1 PPO算法的基础与局限
Proximal Policy Optimization(PPO)作为当前强化学习领域的主流算法,通过重要性采样比率剪裁机制将策略更新限制在先前策略的近端区域内,构建了稳定的策略优化框架。其核心目标函数可表示为:
J P P O ( θ ) = E [ min ( r t ( θ ) A ^ t , clip ( r t ( θ ) , 1 − ε , 1 + ε ) A ^ t ) ] \mathcal{J}_{PPO}(\theta)=E\left[\min\left(r_t(\theta)\hat{A}_t,\operatorname{clip}(r_t(\theta),1-\varepsilon,1+\varepsilon)\hat{A}_t\right)\right] JPPO(θ)=E[min(rt(θ)A^t,clip(rt(θ),1−ε,1+ε)A^t)]
其中 r t ( θ ) = π θ ( a t ∣ s t ) / π θ o l d ( a t ∣ s t ) r_t(\theta)=\pi_\theta(a_t|s_t)/\pi_{\theta_{old}}(a_t|s_t) rt(θ)=πθ(at∣st)/πθold(at∣st)为重要性采样比率。这种对称式剪裁机制虽然保证了训练稳定性,但在处理复杂推理任务时逐渐暴露出三个关键问题:
- 探索能力受限:默认的对称剪裁区间(如 ε = 0.2 \varepsilon=0.2 ε=0.2)对低概率token的采样提升形成压制。例如当初始概率 π θ o l d ( a t ) = 0.01 \pi_{\theta_{old}}(a_t)=0.01 πθold(at)=0.01时,新策略概率最大可提升至 0.012 0.012 0.012,而高概率token(如0.9)却可提升至 1.08 1.08 1.08,这种不对称限制导致模型过早收敛到某种局部最优。
- 长序列优化失效:在需要多步推理的数学证明、代码生成等场景中,传统PPO的样本级损失计算方式(先对每个样本的token损失取平均,再对样本间取平均)导致长序列的有效梯度信号被稀释。
- 奖励噪声敏感:基于规则的奖励机制(如最终答案正确性)在长推理场景中面临严重的延迟奖励问题。特别是在响应长度达到16k+token的复杂数学题场景下,很多正确推理过程因中途截断被错误标记为负奖励。
1.2 GRPO的改进与瓶颈
Group Relative Policy Optimization(GRPO)通过群体相对优势估计和显式KL惩罚项对PPO进行了重要改进:
A ^ i , t = R i − m e a n ( { R i } ) s t d ( { R i } ) \hat{A}_{i,t}=\frac{R_i-mean(\{R_i\})}{std(\{R_i\})} A^i,t=std({Ri})Ri−mean({Ri})
J G R P O = E [ ∑ min ( r i , t A ^ i , t , c l i p ( r i , t , 1 − ε , 1 + ε ) A ^ i , t ) − β D K L ] \mathcal{J}_{GRPO}=E\left[\sum\min(r_{i,t}\hat{A}_{i,t},clip(r_{i,t},1-\varepsilon,1+\varepsilon)\hat{A}_{i,t})-\beta D_{KL}\right] JGRPO=E[∑min(ri,tA^i,t,clip(ri,t,1−ε,1+ε)A^i,t)−βDKL]
虽然GRPO在数学推理任务上取得了突破,但在实际工业级应用中仍面临三大挑战:

- 熵崩溃现象:如图2b所示,PPO/GRPO策略熵会有一个骤降的过程,导致采样多样性丧失。在AIME测试集上,模型效果也随着训练进行而逐渐收敛不变。上述现象证明,如PPO或者GRPO等算法严重限制复杂推理路径的探索。
- 梯度稀释效应:当某一批次中存在部分全正确或全错误的样本组时,优势函数计算结果趋近于零。零优势导致策略更新没有梯度,从而降低了样本效率。实验证明,训练过程中准确性等于1的样本数量会持续增加,这意味着每批中的有效提示数量不断减少,这可能导致梯度方差增大,并削弱模型训练中的梯度信号。
- 长度失控风险:在未施加长度约束的情况下,模型响应长度呈现指数级增长趋势。默认情况下,我们对截断样本施加惩罚性奖励,这种方法可能会在训练过程中引入噪声,因为一个合理的推理过程可能仅仅因为过长而受到惩罚。这种惩罚可能会让模型对其推理过程的有效性产生混淆。
2. DAPO的核心创新:突破大规模RL训练瓶颈
DAPO,即Decoupled Clip and Dynamic sAmpling Policy Optimization,解耦裁剪与动态采样的策略优化算法。在这一节中,将结合代码来讲解DAPO的核心创新。
在讨论核心创新之前,原文中先讨论了KL散度损失。KL正则化机制的核心功能在于平衡在线学习策略与固定参考策略之间的策略偏移。在RLHF框架中,训练的核心诉求是在保持预训练模型基准特性的前提下优化模型响应。但当处理长链思维推理任务时,模型输出分布可能发生显著漂移,此时继续施加分布约束反而会阻碍模型性能提升。基于此认知,DAPO算法框架选择移除KL loss。
2.1 解耦剪裁机制(Clip-Higher)
DAPO通过非对称剪裁区间设计重构了策略优化边界:
clip ( r i , t , 1 − ε l o w , 1 + ε h i g h ) \operatorname{clip}(r_{i,t},1-\varepsilon_{low},1+\varepsilon_{high}) clip(ri,t,1−εlow,1+εhigh)
其中 ε l o w = 0.2 \varepsilon_{low}=0.2 εlow=0.2, ε h i g h = 0.28 \varepsilon_{high}=0.28 εhigh=0.28。这种设计在保持策略更新稳定性的同时,显著提升了低概率token的探索空间:
- 概率提升上限解禁:对于初始概率为0.01的token,最大可提升至 0.01 ∗ ( 1 + 0.28 ) = 0.0128 0.01*(1+0.28)=0.0128 0.01∗(1+0.28)=0.0128,相比标准PPO提升28%。对应配置:
actor_rollout_ref:actor:clip_ratio_low: 0.2clip_ratio_high: 0.28
无论是PPO还是GRPO,默认的裁剪上下限都是0.2。作者在原文中声称,传统GRPO的对称剪裁范围(如ε=0.2)限制低概率token的探索,导致策略快速收敛(熵崩溃)。作者提出的解决办法是,将剪裁范围解耦为ε_low(抑制高概率token)和ε_high(放宽低概率token限制),允许低概率token有更大提升空间,增加生成多样性。
具体来说,在配置文件中,clip_ratio_high从0.2提高至0.28。
2.2 动态采样策略(Dynamic Sampling)
data:gen_batch_size: 256train_batch_size: 64
algorithm:filter_groups:enable: Truemetric: acc # score / seq_reward / seq_final_reward / ...max_num_gen_batches: 10 # Non-positive values mean no upper limit
DAPO中第二个关键改进点是动态采样。原文中说,当所有样本奖励相同(如全正确/全错误),梯度信号消失(Zero Advantage)。作者提出的解决方案为,预采样时过滤掉奖励为0或1的样本,仅保留有效梯度样本填充批次。
我一开始理解的是,如果某个大小为64的batch中有5个prompt不满足要求,则对这5个重新采样,或者对64个都重新采样,直到满足要求。
但显然,上面的想法是错误的。核心代码如下:
prompt_bsz = self.config.data.train_batch_size # 原始的batch_size,这里为64
if num_prompt_in_batch < prompt_bsz: # num_prompt_in_batch为统计出来的std不为0的group数量print(f'{num_prompt_in_batch=} < {prompt_bsz=}')num_gen_batches += 1 # 继续采样一次max_num_gen_batches = self.config.algorithm.filter_groups.max_num_gen_batchesif max_num_gen_batches <= 0 or num_gen_batches < max_num_gen_batches:# 没有达到最大采样上限,这里需要取下一个批次print(f'{num_gen_batches=} < {max_num_gen_batches=}. Keep generating...')continueelse:# 已经达到采样次数上限了,但是还是没有满足要求,此时会报错raise ValueError(f'{num_gen_batches=} >= {max_num_gen_batches=}. Generated too many. Please check your data.')
else:# Align the batchtraj_bsz = self.config.data.train_batch_size * self.config.actor_rollout_ref.rollout.nbatch = batch[:traj_bsz]
代码逻辑解析:
# 外层循环从dataloader获取prompt batch
for batch_dict in self.train_dataloader:# 每次生成全新的gen_batch(包含新的prompt集合)gen_batch = new_batch.pop(...)gen_batch_output = self.actor_rollout_wg.generate_sequences(gen_batch)# 动态过滤逻辑if self.config.algorithm.filter_groups.enable:# 计算当前gen_batch的有效promptkept_prompt_uids = [...] num_prompt_in_batch += len(kept_prompt_uids)# 如果有效prompt不足,继续生成新的gen_batchif num_prompt_in_batch < self.config.data.train_batch_size:continue # 跳回外层循环,获取下一个batch_dict
假设存在以下场景:
- 初始batch:包含64个prompt,每个生成8个response
- 过滤结果:其中5个prompt的response标准差为0(被过滤),剩余59个有效
- 保留有效prompt:将59个有效prompt加入累积池
- 检查数量:num_prompt_in_batch = 59 < train_batch_size(假设为64)
- 触发重新生成:通过continue语句跳回外层循环,从self.train_dataloader获取下一个batch_dict
- 处理新batch:对新batch中的prompt(可能是全新的64个)重复生成和过滤流程
- 累积结果:将新batch的有效prompt加入累积池,直到总数≥train_batch_size
- 上述过程最多持续max_num_gen_batches次,如果连续max_num_gen_batches次都没有凑够64个有效样本,那说明数据很有问题了,直接报错即可。
设计特点
- 全量更新:每个gen_batch来自数据加载器的独立prompt集合,而非针对特定prompt重新采样
- 增量累积:有效prompt会跨多个gen_batch累积,直到满足train_batch_size
2.3 灵活的损失聚合模式
示例配置如下:
actor_rollout_ref:actor:loss_agg_mode: "token-mean" # / "seq-mean-token-sum" / "seq-mean-token-mean"# NOTE: "token-mean" is the default behavior
将loss_agg_mode设置为token-mean将意味着小批量中将计算所有序列的所有标记的(策略梯度)损失。
2.4 长度惩罚
DAPO对过长的生成进行了惩罚,相关示例配置如下:
data:max_response_length: 20480 # 16384 + 4096
reward_model:overlong_buffer: enable: Truelen: 4096penalty_factor: 1.0
原文中的公式如下:
R length ( y ) = { 0 , ∣ y ∣ ≤ L max − L cache ( L max − L cache ) − ∣ y ∣ L cache , L max − L cache < ∣ y ∣ ≤ L max − 1 , L max < ∣ y ∣ R_{\text{length}}(y) = \begin{cases} 0, & |y| \leq L_{\text{max}} - L_{\text{cache}} \\ \frac{(L_{\text{max}} - L_{\text{cache}}) - |y|}{L_{\text{cache}}}, & L_{\text{max}} - L_{\text{cache}} < |y| \leq L_{\text{max}} \\ -1, & L_{\text{max}} < |y| \end{cases} Rlength(y)=⎩ ⎨ ⎧0,Lcache(Lmax−Lcache)−∣y∣,−1,∣y∣≤Lmax−LcacheLmax−Lcache<∣y∣≤LmaxLmax<∣y∣
具体来说,当response长度超过预设的最大长度时,定义一个惩罚区间,在这个区间内长度越长收到的惩罚越大。根据上述公式,首先会预设一个最大长度 L m a x L_{max} Lmax,即max_response_length;然后预设一个惩罚区间长度 L c a c h e L_{cache} Lcache,即overlong_buffer.len;接着:
- 如果回复长度小于max_response_length - overlong_buffer.len,那么没有额外奖励也没有额外惩罚
- 如果回复长度大于max_response_length - overlong_buffer.len但又小于预设的最大长度max_response_length,则施加一个软惩罚机制,回复越长,额外添加的reward越小。
- 如果回复长度大于了预设的最大长度,则额外奖励为-1,即惩罚。
相关代码如下:
if self.overlong_buffer_cfg.enable:overlong_buffer_len = self.overlong_buffer_cfg.len # 惩罚区间长度expected_len = self.max_resp_len - overlong_buffer_len # L_max - L_cacheexceed_len = valid_response_length - expected_len # 超出的长度overlong_penalty_factor = self.overlong_buffer_cfg.penalty_factoroverlong_reward = min(-exceed_len / overlong_buffer_len * overlong_penalty_factor, 0)reward += overlong_reward
3. 实验
在实验中,DAPO成功将 Qwen-32B Base模型训练成一个强大的推理模型。在AIME 2024测试集上,DAPO展现出显著优势:

此外,根据图1

DAPO将Qwen2.5-32B模型在AIME上的准确率从接近 0% 提升至 50%,并且这一提升仅使用了 DeepSeek-R1-Zero-Qwen-32B所需训练步数的 50%。
相关文章:
基于VeRL源码深度拆解字节Seed的DAPO
1. 背景与现状:从PPO到GRPO的技术演进 1.1 PPO算法的基础与局限 Proximal Policy Optimization(PPO)作为当前强化学习领域的主流算法,通过重要性采样比率剪裁机制将策略更新限制在先前策略的近端区域内,构建了稳定的…...

zst-2001 历年真题 软件工程
软件工程 - 第1题 b 软件工程 - 第2题 c 软件工程 - 第3题 c 软件工程 - 第4题 b 软件工程 - 第5题 b 软件工程 - 第6题 0.未完成:未执行未得到目标。1.已执行:输入-输出实现支持2.已管理:过程制度化,项目遵…...

WSL 安装 Debian 12 后,Linux 如何安装 redis ?
在 WSL 的 Debian 12 上安装 Redis 的步骤如下: 1. 更新系统包列表 sudo apt update && sudo apt upgrade -y2. 安装 Redis sudo apt install redis-server -y3. 启动 Redis 服务 sudo systemctl start redis4. 设置开机自启 sudo systemctl enable red…...

在Ubuntu系统下编译OpenCV 4.8源码
编译OpenCV 4.8源码可以为你提供更高的灵活性和优化性能,适合特定的需求。以下是详细的步骤,指导你在Ubuntu系统上编译和安装OpenCV 4.8。 1. 安装必要的依赖 首先,确保你的系统已经安装了所有必要的依赖项。 sudo apt update sudo apt in…...

Arduino快速入门
Arduino快速入门指南 一、硬件准备 选择开发板: 推荐使用 Arduino UNO(兼容性强,适合初学者),其他常见型号包括NANO(体积小)、Mega(接口更多)。准备基础元件:…...

基于WSL用MSVC编译ffmpeg7.1
在windows平台编译FFmpeg,网上的大部分资料都是推荐用msys2mingw进行编译。在win10平台,我们可以采用另一种方式,即wslmsvc 实现window平台的ffmpeg编译。 下面将以vs2022ubuntu22.04 为例,介绍此方法 0、前期准备 安装vs2022 &…...
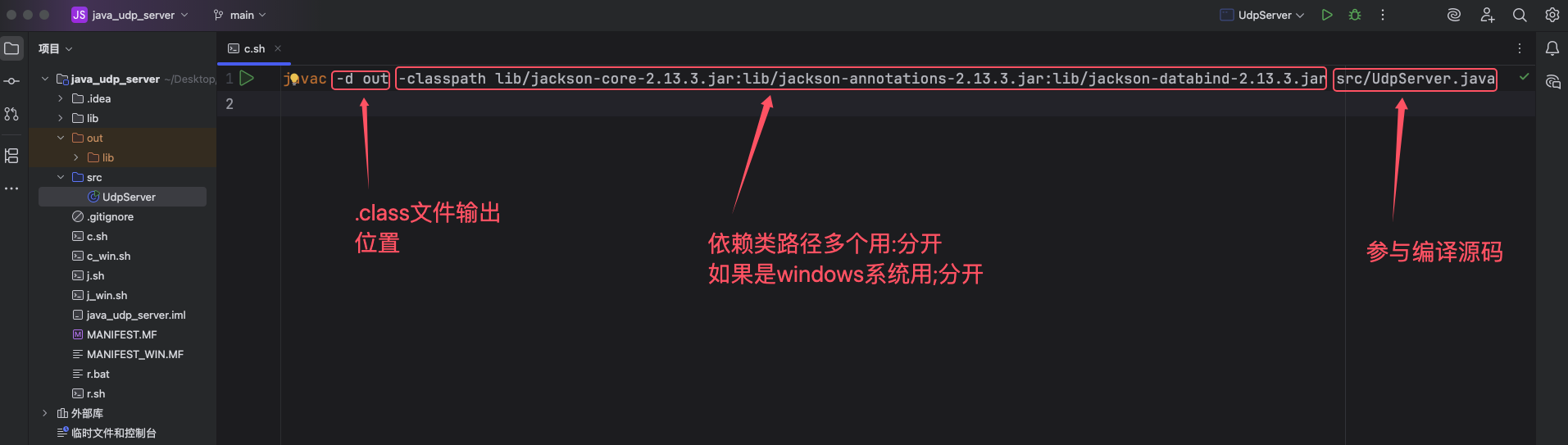
java命令行打包class为jar并运行
1.创建无包名类: 2.添加依赖jackson 3.引用依赖包 4.命令编译class文件 生成命令: javac -d out -classpath lib/jackson-core-2.13.3.jar:lib/jackson-annotations-2.13.3.jar:lib/jackson-databind-2.13.3.jar src/UdpServer.java 编译生成class文件如下 <...
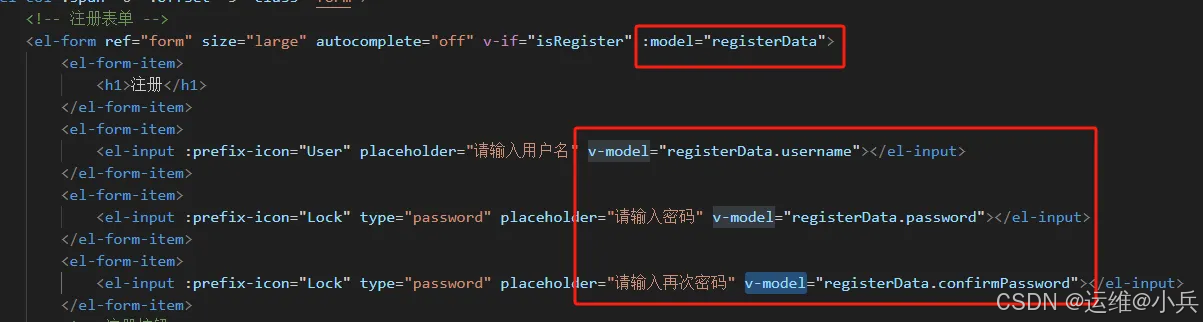
vue注册用户使用v-model实现数据双向绑定
定义数据模型 Login.vue //定义数据模型 const registerData ref({username: ,password: ,confirmPassword: })使用 v-model 实现数据模型的key与注册表单中的元素之间的双向绑定 <!-- 注册表单 --><el-form ref"form" size"large" autocompl…...

Android学习之响应式编程
本篇基于DeepSeek 搜索结果修改。 一、响应式编程基础认知 1.1 为什么需要响应式编程? 在传统的Android开发中,我们经常会遇到以下痛点: // 传统方式处理数据变化 button.setOnClickListener {// 触发网络请求fetchDataFromNetwork { res…...

如何使用极狐GitLab 软件包仓库功能托管 helm chart?
极狐GitLab 是 GitLab 在中国的发行版,关于中文参考文档和资料有: 极狐GitLab 中文文档极狐GitLab 中文论坛极狐GitLab 官网 软件包库中的 Helm charts (BASIC ALL) WARNING:Helm chart 库正在开发中,由于功能有限,尚未准备好用…...

中国古代史4
东汉 公元25年,刘秀建立东汉,定都洛阳,史称光武中兴 白马寺:汉明帝时期建立,是佛教传入中国后兴建的第一座官办寺院,有中国佛教的“祖庭”和“释源”之称,距今1900多年历史 班超—西域都护—投…...
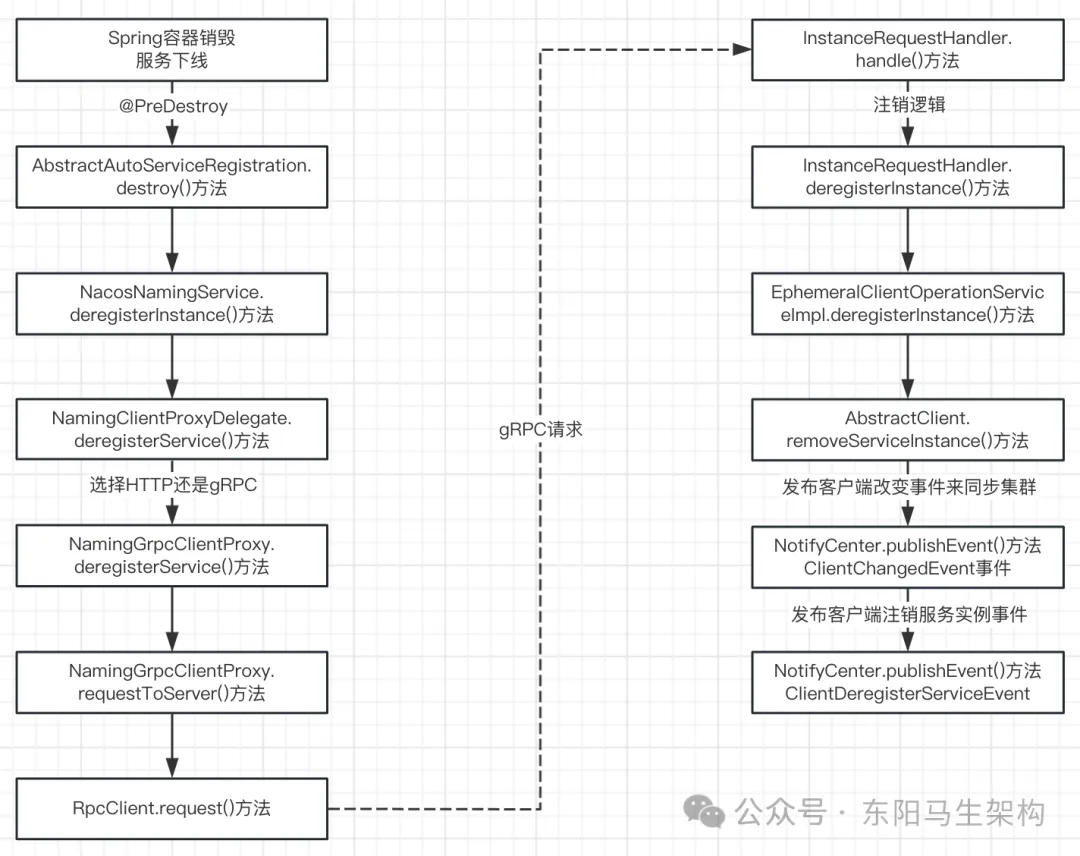
Nacos源码—8.Nacos升级gRPC分析六
大纲 7.服务端对服务实例进行健康检查 8.服务下线如何注销注册表和客户端等信息 9.事件驱动架构源码分析 一.处理ClientChangedEvent事件 也就是同步数据到集群节点: public class DistroClientDataProcessor extends SmartSubscriber implements DistroDataSt…...

基于Vue3.0的高德地图api教程005:实现绘制线并编辑功能
文章目录 6、绘制多段线6.1 绘制多段线6.1.1 开启绘制功能6.1.2 双击完成绘制6.1.3 保存到数据库6.2 修改多段线6.2.1 点击线,进入编辑模式6.2.2 编辑线6.3 完整代码6、绘制多段线 6.1 绘制多段线 6.1.1 开启绘制功能 实现代码: const changeSwitchDrawPolyline = ()=>…...

SpringBoot 自动装配原理 自定义一个 starter
目录 1、pom.xml 文件1.1、parent 模块1.1.1、资源文件1.1.1.1、resources 标签说明1.1.1.2、从 Maven 视角:资源处理全流程 1.1.2、插件 1.2、dependencies 模块 2、启动器3、主程序3.1、SpringBootApplication 注解3.2、SpringBootConfiguration 注解3.2.1、Con…...
【C++进阶篇】多态
深入探索C多态:静态与动态绑定的奥秘 一. 多态1.1 定义1.2 多态定义及实现1.2.1 多态构成条件1.2.1.1 实现多态两个必要条件1.2.1.2 虚函数1.2.1.3 虚函数的重写/覆盖1.2.1.4 协变1.2.1.5 析构函数重写1.2.1.6 override和final关键字1.2.1.7 重载/重写/隐藏的对⽐ 1…...

Redis 基础详解:从入门到精通
在当今互联网应用开发领域,数据存储与处理的性能和效率至关重要。Redis(Remote Dictionary Server)作为一款开源的、基于内存的键值存储系统,凭借其出色的性能和丰富的功能,被广泛应用于数据库、缓存、消息中间件等场景…...

Android Studio的jks文件
在 Android Studio 中,.jks 文件是 Java KeyStore(Java 密钥库)文件的一种,用于存储和管理用于签署 Android 应用程序的数字证书和私钥。 一、.jks 文件的作用 在 Android 开发中,.jks 文件主要用于: 应用…...

互联网大厂Java面试实战:从Spring Boot到微服务的技术问答与解析
💪🏻 1. Python基础专栏,基础知识一网打尽,9.9元买不了吃亏,买不了上当。 Python从入门到精通 😁 2. 毕业设计专栏,毕业季咱们不慌忙,几百款毕业设计等你选。 ❤️ 3. Python爬虫专栏…...

《AI大模型应知应会100篇》第60篇:Pinecone 与 Milvus,向量数据库在大模型应用中的作用
第60篇:Pinecone与Milvus,向量数据库在大模型应用中的作用 摘要 本文将系统比较Pinecone与Milvus两大主流向量数据库的技术特点、性能表现和应用场景,提供详细的接入代码和最佳实践,帮助开发者为大模型应用选择并优化向量存储解…...

HDFS客户端操作
一、命令行工具操作 HDFS 命令行工具基于 hdfs dfs 命令,语法类似 Linux 文件操作。 1. 文件操作 bash # 创建目录 hdfs dfs -mkdir /test# 递归创建多级目录 hdfs dfs -mkdir -p /test/data/logs# 上传本地文件到 HDFS hdfs dfs -put local_file.txt /test/# 从…...

MySQL--视图详解
介绍 视图(View)是一种虚拟存在的表。视图中的数据并不在数据库中实际存在,行和列数据来自定义视图的查询中使用的表(称为基表),并且是在使用视图时动态生成的。 简而言之:视图只保存了查询的…...

Java学习手册:客户端负载均衡
一、客户端负载均衡的概念 客户端负载均衡是指在客户端应用程序中,根据一定的算法和策略,将请求分发到多个服务实例上。与服务端负载均衡不同,客户端负载均衡不需要通过专门的负载均衡设备或服务,而是直接在客户端进行请求的分发…...
Docker私有仓库实战:官方registry镜像实战应用
抱歉抱歉,离职后反而更忙了,拖了好久,从4月拖到现在,在学习企业级方案Harbor之前,我们先学习下官方方案registry,话不多说,详情见下文。 注意:下文省略了基本认证 TLS加密ÿ…...

LeetCode 373 查找和最小的 K 对数字题解
LeetCode 373 查找和最小的 K 对数字题解 题目描述 给定两个以升序排列的整数数组 nums1 和 nums2,以及一个整数 k。定义一对值 (u,v),其中第一个元素来自 nums1,第二个元素来自 nums2。请找到和最小的 k 个数对。 解题思路 最小堆优化法…...

WebSocket集成方案对比
WebSocket集成方案对比与实战 架构选型全景图 #mermaid-svg-BEuyOkkoP6cFygI0 {font-family:"trebuchet ms",verdana,arial,sans-serif;font-size:16px;fill:#333;}#mermaid-svg-BEuyOkkoP6cFygI0 .error-icon{fill:#552222;}#mermaid-svg-BEuyOkkoP6cFygI0 .er…...

深入理解 Istio v1.25.2
要深入理解 Istio 的最新版本(截至 2025 年 5 月,最新版本为 1.25.2,发布Iweb:1⁊)源码,我们可以通过分析其核心组件和代码结构来加深对 Istio 的理解。以下是对 Istio 源码的解读,结合其架构和功能&#x…...

使用conda导致无法找到libpython动态库
最近在用 AFL 的时候编译完成后遇到如下的报错: afl-fuzz: error while loading shared libraries: libpython3.9.so.1.0: cannot open shared object file: No such file or directory然后发现是因为编译时用的Python环境是通过miniconda构建的虚拟环境࿰…...
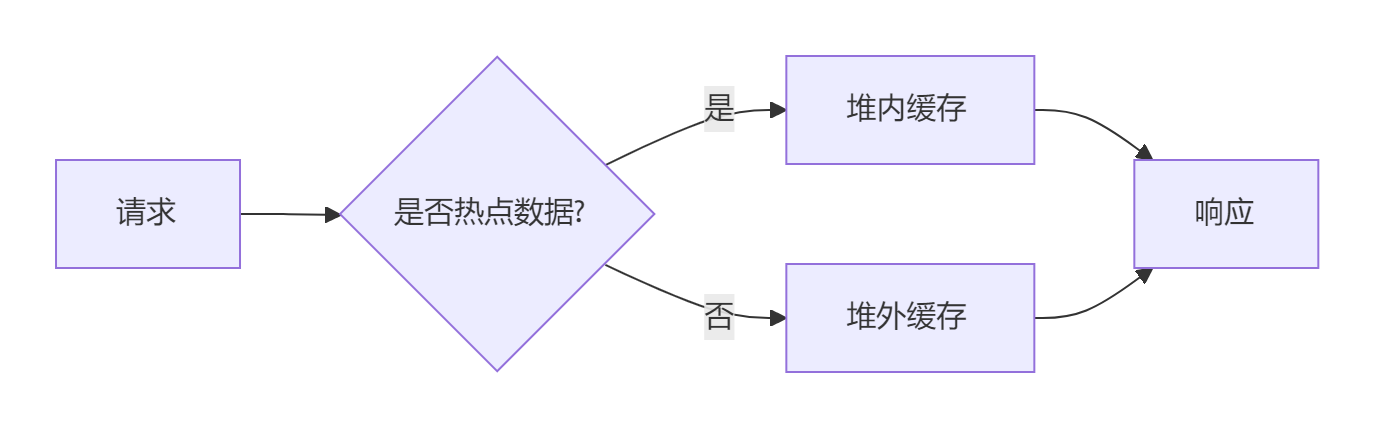
Redis+Caffeine构建高性能二级缓存
大家好,我是摘星。今天为大家带来的是RedisCaffeine构建高性能二级缓存,废话不多说直接开始~ 目录 二级缓存架构的技术背景 1. 基础缓存架构 2. 架构演进动因 3. 二级缓存解决方案 为什么选择本地缓存? 1. 极速访问 2. 减少网络IO 3…...
 添加自定义 SQL 片段)
MyBatis-Plus使用 wrapper.apply() 添加自定义 SQL 片段
在 MyBatis-Plus 中,wrapper.apply() 方法允许你在构建查询条件时插入任意的 SQL 片段。这对于实现一些复杂的查询需求特别有用,比如添加子查询、使用数据库特定函数等; 示例 1: 基本应用 import com.baomidou.mybatisplus.core.conditions…...
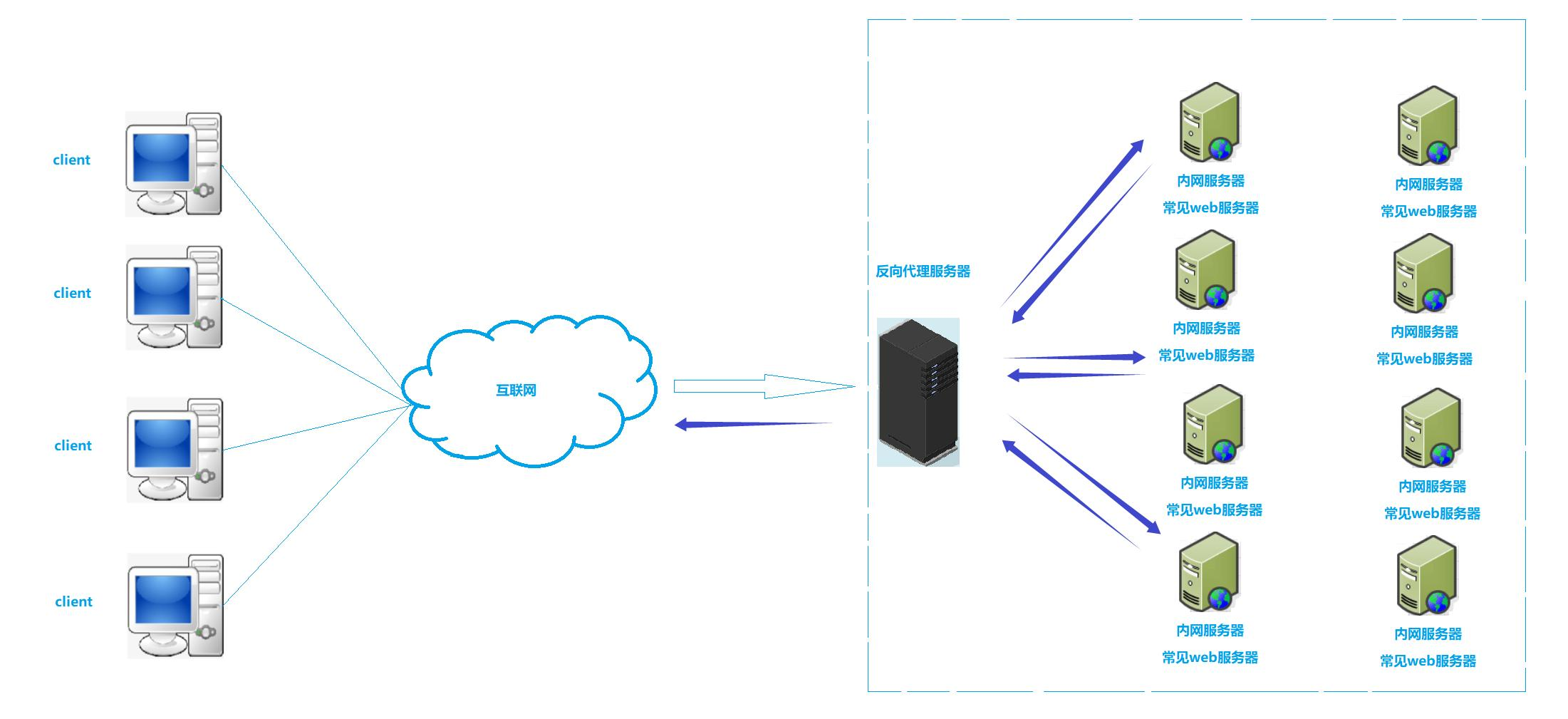
【计算机网络】NAT技术、内网穿透与代理服务器全解析:原理、应用及实践
📚 博主的专栏 🐧 Linux | 🖥️ C | 📊 数据结构 | 💡C 算法 | 🅒 C 语言 | 🌐 计算机网络 上篇文章:以太网、MAC地址、MTU与ARP协议 下篇文章:五种IO模型与阻…...