多样本整合Banksy空间聚类分析(Visium HD, Xenium, CosMx)
在空间数据分析中,传统的单细胞聚类算法,例如Seurat和Scanpy中的lovain和leiden等聚类算法,通常在处理空间数据时忽略了空间信息。然而,由于细胞状态受其周围细胞的影响,将转录组数据与细胞的空间信息结合起来进行聚类分析,有助于揭示细胞在组织中的分布和相互作用。之前我们介绍了Banksy的python版本代码使用(针对单个样本)。我们知道BANKSY是一种空间组学数据的聚类方法,通过将每个细胞的特征(基因表达)与其空间近邻特征的平均值以及邻域特征梯度相结合来进行聚类,这样就结合了细胞分子邻域特征,增强了空间结构识别。
Visium HD数据分析之空间聚类算法Banksy
这里我们介绍下针对有多个样本情况下,从一个包含多个样本细胞的Anndata对象开始,先对多样本空间坐标进行错位处理(Staggering,解决多个样本合并时坐标重叠问题),然后怎样构建空间最近邻图,再降维和harmony去批次,最后整合起来进行聚类。
1. 未经坐标偏移的两个样本空间坐标(原始)
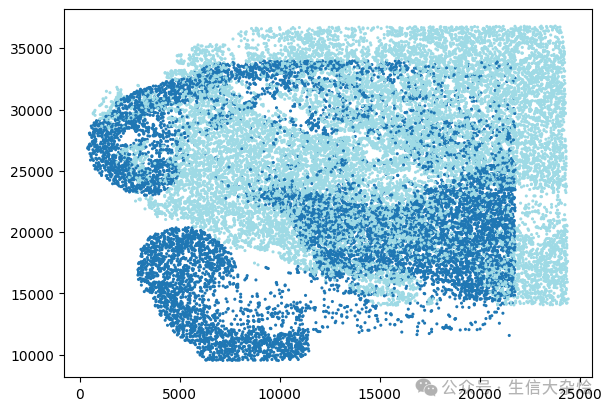
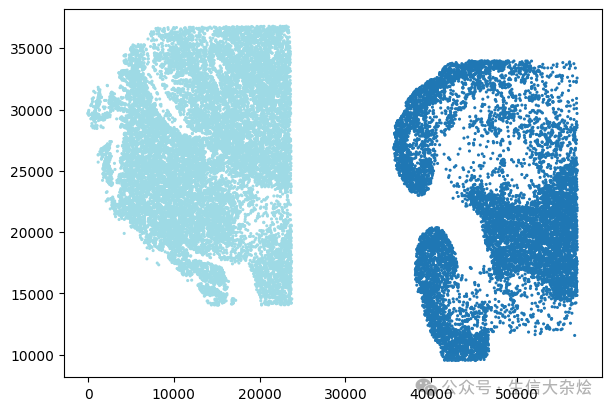
2. Stagger the spatial coordinates across the samples, so that spots from different samples do not overlap (sample specific treatment)
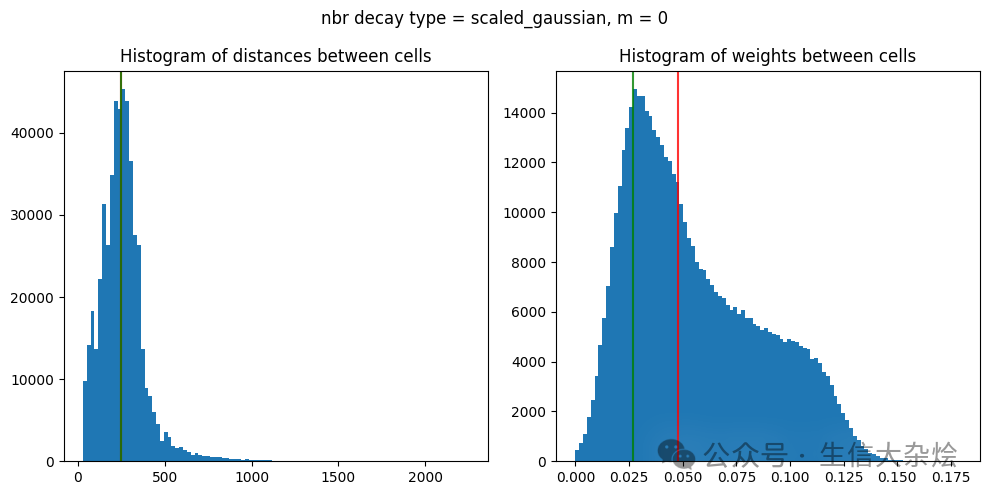
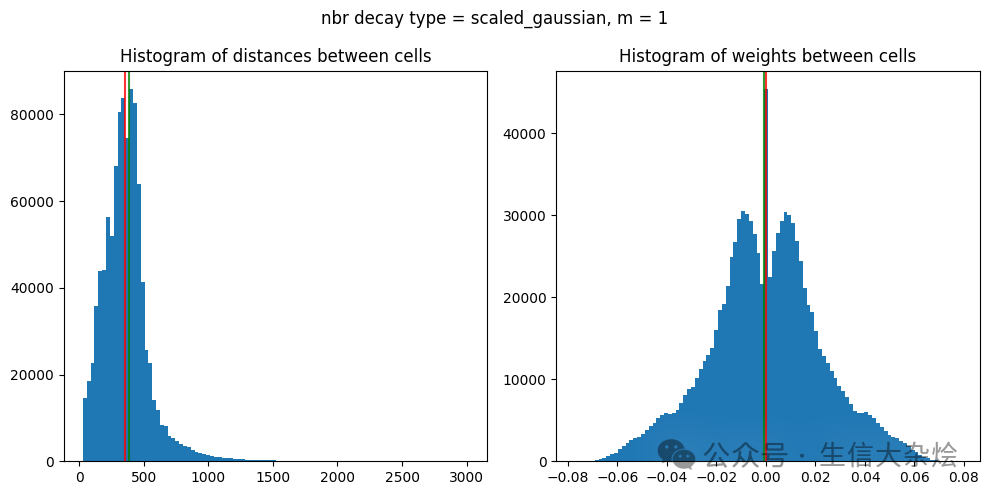
3. Calculate Banksy matrix
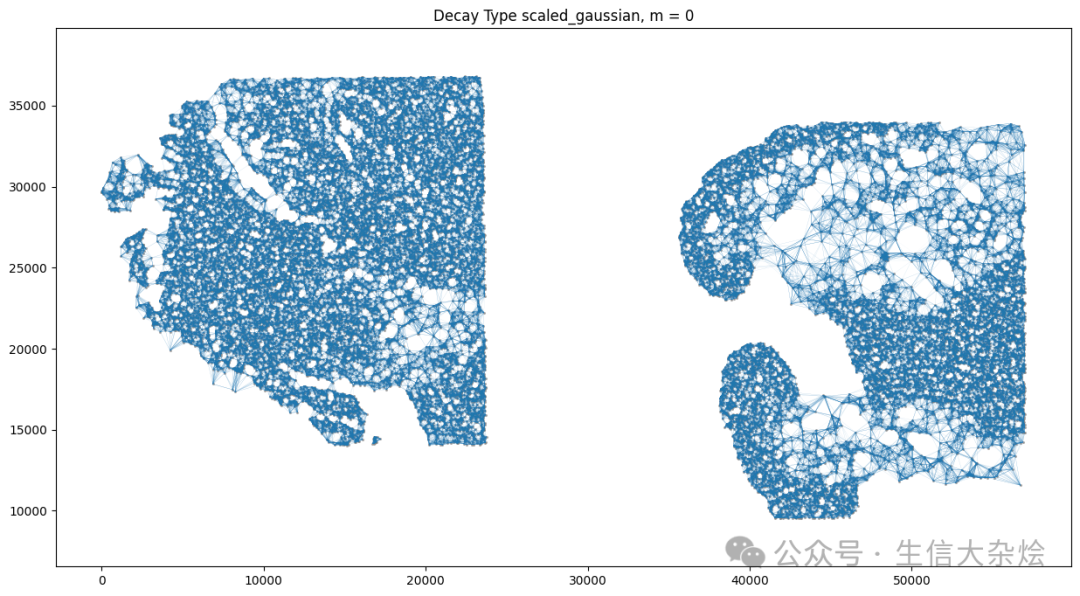
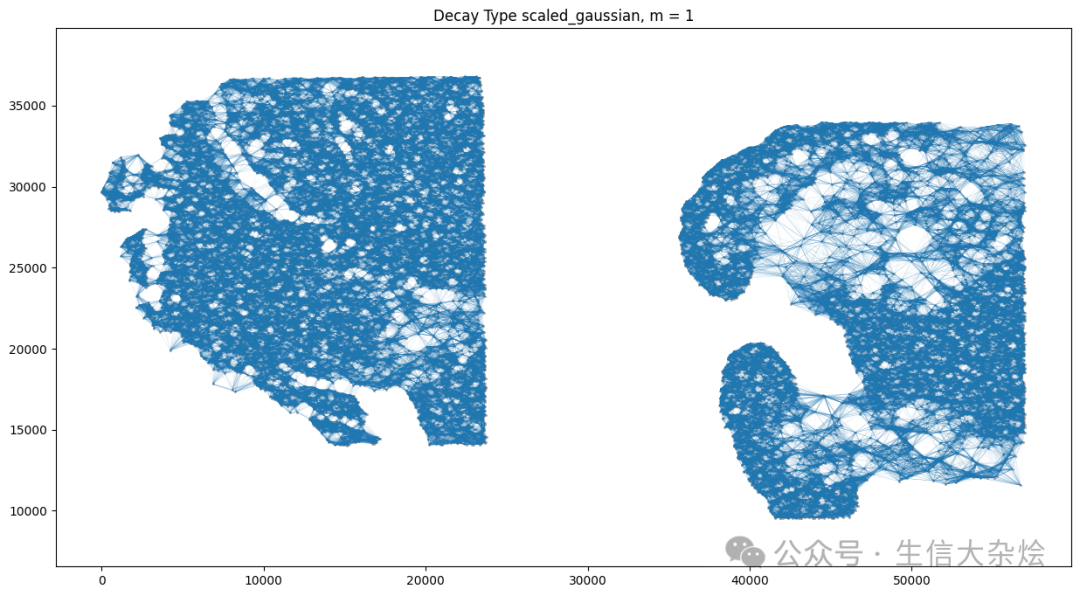
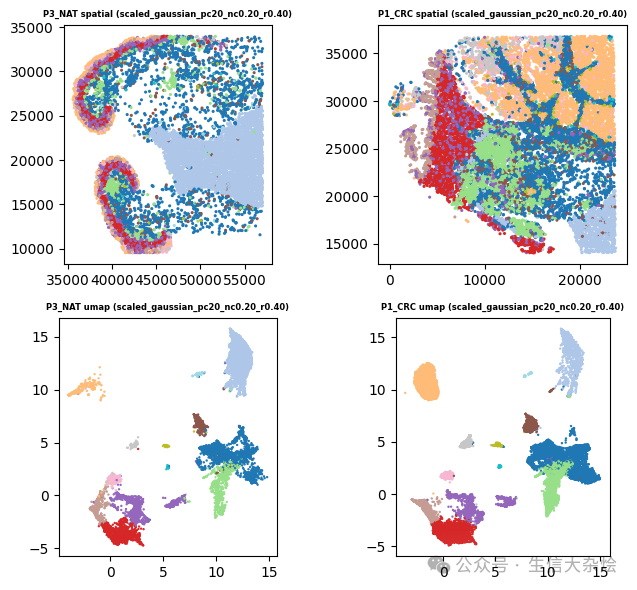
4. 多样本Banksy后空间及UMAP结果
代码实现:
分析环境加载
import osimport umapimport randomimport numpy as npimport pandas as pdimport scanpy as scfrom harmony import harmonizefrom banksy.initialize_banksy import initialize_banksyfrom banksy.embed_banksy import generate_banksy_matrixfrom banksy.main import concatenate_allfrom banksy_utils.umap_pca import pca_umapfrom banksy.cluster_methods import run_Leiden_partitionimport matplotlib.pyplot as pltimport warningswarnings.filterwarnings("ignore")plt.style.use('default')plt.rcParams['figure.facecolor'] = 'white'seeds = [0]random.seed(seeds[0])np.random.seed(seeds[0])
多样本数据读取及预处理
adata = sc.read_h5ad('/data/VisiumHD/CRC_demo/adata_raw.h5ad')# 这里只是为了快速演示,所以抽了百分之十细胞进行后续分析sc.pp.sample(adata, 0.1)adata.var["mt"] = adata.var_names.str.startswith("MT-")adata.var["ribo"] = adata.var_names.str.startswith(("RPS", "RPL"))sc.pp.calculate_qc_metrics(adata, qc_vars=["mt", "ribo"], inplace=True, log1p=True)sc.pp.filter_cells(adata, min_counts=30)sc.pp.filter_genes(adata, min_cells=10)adata = adata[adata.obs['pct_counts_mt']<20, :]# Normalizeadata.layers["counts"] = adata.X.copy()sc.pp.normalize_total(adata)
Stagger the spatial coordinates across the samples, so that spots from different samples do not overlap (sample specific treatment)
adata.obs['x_pixel'] = adata.obsm['spatial'][:, 0]adata.obs['y_pixel'] = adata.obsm['spatial'][:, 1]# 为每个样本生成颜色unique_samples = adata.obs['sample'].unique()colors = plt.cm.tab20(np.linspace(0, 1, len(unique_samples)))color_dict = {sample: colors[i] for i, sample in enumerate(unique_samples)}sample_colors = [color_dict[s] for s in adata.obs['sample']]# 绘制散点图fig = plt.figure(figsize=(6, 4), constrained_layout=True)scatter = plt.scatter(x=adata.obs['x_pixel'],y=adata.obs['y_pixel'],c=sample_colors,alpha=1,s=1.5)# Staggeringcoords_df = pd.DataFrame(adata.obs[['x_pixel', 'y_pixel', 'sample']])coords_df['x_pixel'] = coords_df.groupby('sample')['x_pixel'].transform(lambda x: x - x.min())global_max_x = max(coords_df['x_pixel']) * 1.5#Turn samples into factorscoords_df['sample_no'] = pd.Categorical(coords_df['sample']).codes#Update x coordinatescoords_df['x_pixel'] = coords_df['x_pixel'] + coords_df['sample_no'] * global_max_x#Update staggered coords to AnnData objectadata.obs['x_pixel'] = coords_df['x_pixel']adata.obs['y_pixel'] = coords_df['y_pixel']# AFTER staggering the spatial coordinatesfig = plt.figure(figsize=(6, 4), constrained_layout=True)scatter = plt.scatter(x=adata.obs['x_pixel'],y=adata.obs['y_pixel'],c=sample_colors,alpha=1,s=1.5)
Subset to 2000 HVGs and Running BANKSY (with AGF)
sc.pp.highly_variable_genes(adata, n_top_genes=2000, flavor='seurat_v3', layer='counts', batch_key="sample")adata = adata[:, adata.var['highly_variable']]## banksy parameters ##nbr_weight_decay = 'scaled_gaussian'k_geom = 18resolutions = [0.40] # clustering resolution for UMAPpca_dims = [20] # Dimensionality in which PCA reduces tolambda_list = [0.2] # list of lambda parametersm = 1c_map = 'tab20' # specify color map# Include spatial coordinates informationcoord_keys = ('x_pixel', 'y_pixel', 'coord_xy')x_coord, y_coord, xy_coord = coord_keys[0], coord_keys[1], coord_keys[2]raw_y, raw_x = adata.obs[y_coord], adata.obs[x_coord]adata.obsm[xy_coord] = np.vstack((adata.obs[x_coord].values, adata.obs[y_coord].values)).T### run banksy ###banksy_dict = initialize_banksy(adata,coord_keys,k_geom,nbr_weight_decay=nbr_weight_decay,max_m=m,plt_edge_hist= True,plt_nbr_weights= True,plt_agf_angles=False,plt_theta=False)banksy_dict, banksy_matrix = generate_banksy_matrix(adata,banksy_dict,lambda_list,max_m=m)banksy_dict["nonspatial"] = {# Here we simply append the nonspatial matrix (adata.X) to obtain the nonspatial clustering results0.0: {"adata": concatenate_all([adata.X], 0, adata=adata), }}print(banksy_dict['nonspatial'][0.0]['adata'])
Dimensionality Reduction and Harmony
相关文章:
多样本整合Banksy空间聚类分析(Visium HD, Xenium, CosMx)
在空间数据分析中,传统的单细胞聚类算法,例如Seurat和Scanpy中的lovain和leiden等聚类算法,通常在处理空间数据时忽略了空间信息。然而,由于细胞状态受其周围细胞的影响,将转录组数据与细胞的空间信息结合起来进行聚类…...

C++:公有,保护及私有继承
从已有的类派生出新的类,而派生类继承了原有类的特征被称为类继承。下面按照访问权限分别介绍公有继承,私有继承与保护继承。 公有继承 使用公有继承,基类的公有成员将成为派生类的公有成员(派生类对象可直接调用方法)…...

ElasticSearch聚合操作案例
1、根据color分组统计销售数量 只执行聚合分组,不做复杂的聚合统计。在ES中最基础的聚合为terms,相当于 SQL中的count。 在ES中默认为分组数据做排序,使用的是doc_count数据执行降序排列。可以使用 _key元数据,根据分组后的字段数…...
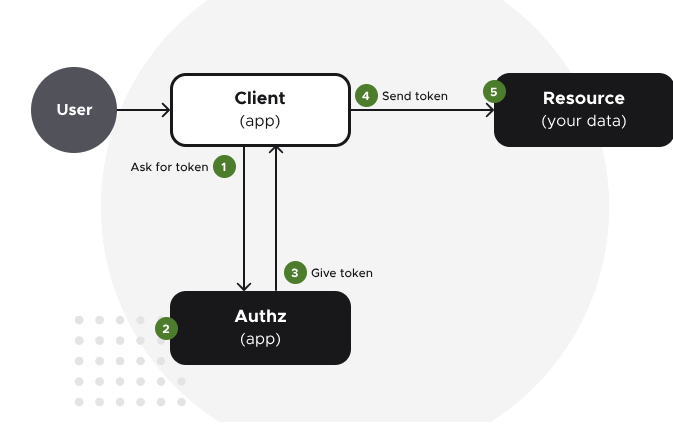
使用 OAuth 2.0 保护 REST API
使用 OAuth 2.0 保护 REST API 使用 OAuth 2.0 保护 REST API1.1 不安全的api1.2 安全默认值安全默认值Spring Security 默认值 需要对所有请求进行身份验证Servlet、过滤器和调度程序安全优势 使用所有请求的安全标头进行响应缓存标头 严格传输安全标头内容类型选项需要对所有…...

解决下拉框数据提交后回显名称不对
问题背景描述 页面组件使用 antd 的 Select 组件,下拉框的 options 数据是动态获取的,基本就是有value 和 label 属性的对象数组。 提交数据后,我们有一个保存草稿的操作,支持返回或者刷新页面,浏览其他页面之后通过其…...
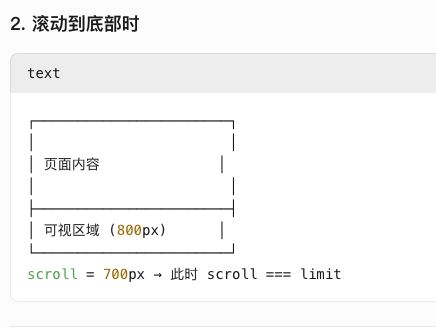
lenis滑动插件的笔记
官网 lenis - npm 方法一:基础判断(推荐) 通过 Lenis 自带的 scroll 和 limit 属性直接判断: const lenis new Lenis()// 滚动事件监听 lenis.on(scroll, ({ scroll, limit }) > {const distanceToBottom limit - scroll…...

基于Python的高效批量处理Splunk Session ID并写入MySQL的解决方案
已经用Python实现对Splunk通过session id获取查询数据,现在要实现Python批量数据获取,通过一个列表中的大量Session ID,快速高效地获取一个数据表,考虑异常处理,多线程和异步操作以提高性能,同时将数据表写…...
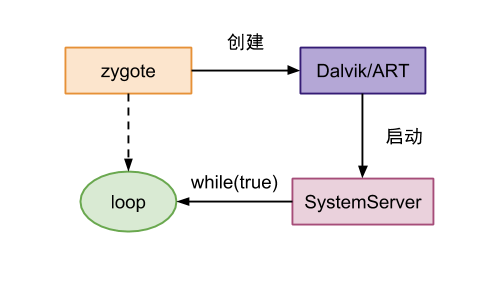
Android Framework
Android 分区 /boot:存放引导程序,包括内核和内存操作程序。/system:相当于电脑 C 盘,存放 Android 系统及系统应用。/recovery:恢复分区,可以进入该分区进行系统恢复。/data:用户数据区&#…...

JVM对象分配与程序崩溃排查
一、new 对象在 JVM 中的过程 在 JVM 中通过 new 关键字创建对象时,会经历以下步骤: 内存分配 对象的内存分配在 堆(Heap) 中,优先在 新生代(Young Generation) 的 Eden 区 分配。分配方式取决…...
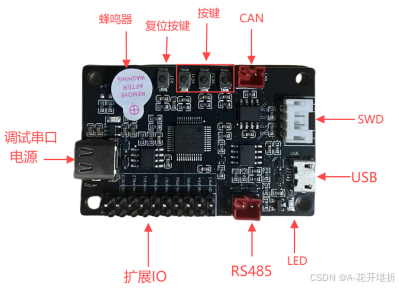
OpenMCU(六):STM32F103开发板功能介绍
概述 距上一篇关于STM32F103的FreeRTOS博客的发布已经过去很长时间没有更新了。在这段时间内,大家可以看到博主发表了一系列的关于使用qemu 模拟实现STM32F103的博客,博主本来想借助qemu开发stm32F103相关的一些软件功能,博主开发出来并成功运…...
Java学习-5.12(Redis,B2C电商))
(自用)Java学习-5.12(Redis,B2C电商)
一、Redis 核心知识 缓存作用 提升性能:内存读写速度(读 10w/s,写 8w/s)远超 MySQL(读 3w/s,写 2w/s)减少数据库压力:通过内存缓存热点数据,避免频繁 SQL 查询分类&#…...

Rspack:字节跳动自研 Web 构建工具-基于 Rust打造高性能前端工具链
字节跳动开源了一款采用 Rust 开发的前端模块打包工具:Rspack(读音为 /ɑrspk/)。 据介绍,Rspack 是一个基于 Rust 的高性能构建引擎,具备与 Webpack 生态系统的互操作性,可以被 Webpack 项目低成本集成&a…...

深度解析LLM参数:Top-K、Top-p和温度如何影响输出随机性?
许多大模型具有推理参数,用于控制输出的“随机性”。常见的几个是 Top-K、Top-p,以及温度。 Top-p: 含义:Kernel sampling threshold. Used to determine the randomness of the results. The higher the value, the stronger t…...
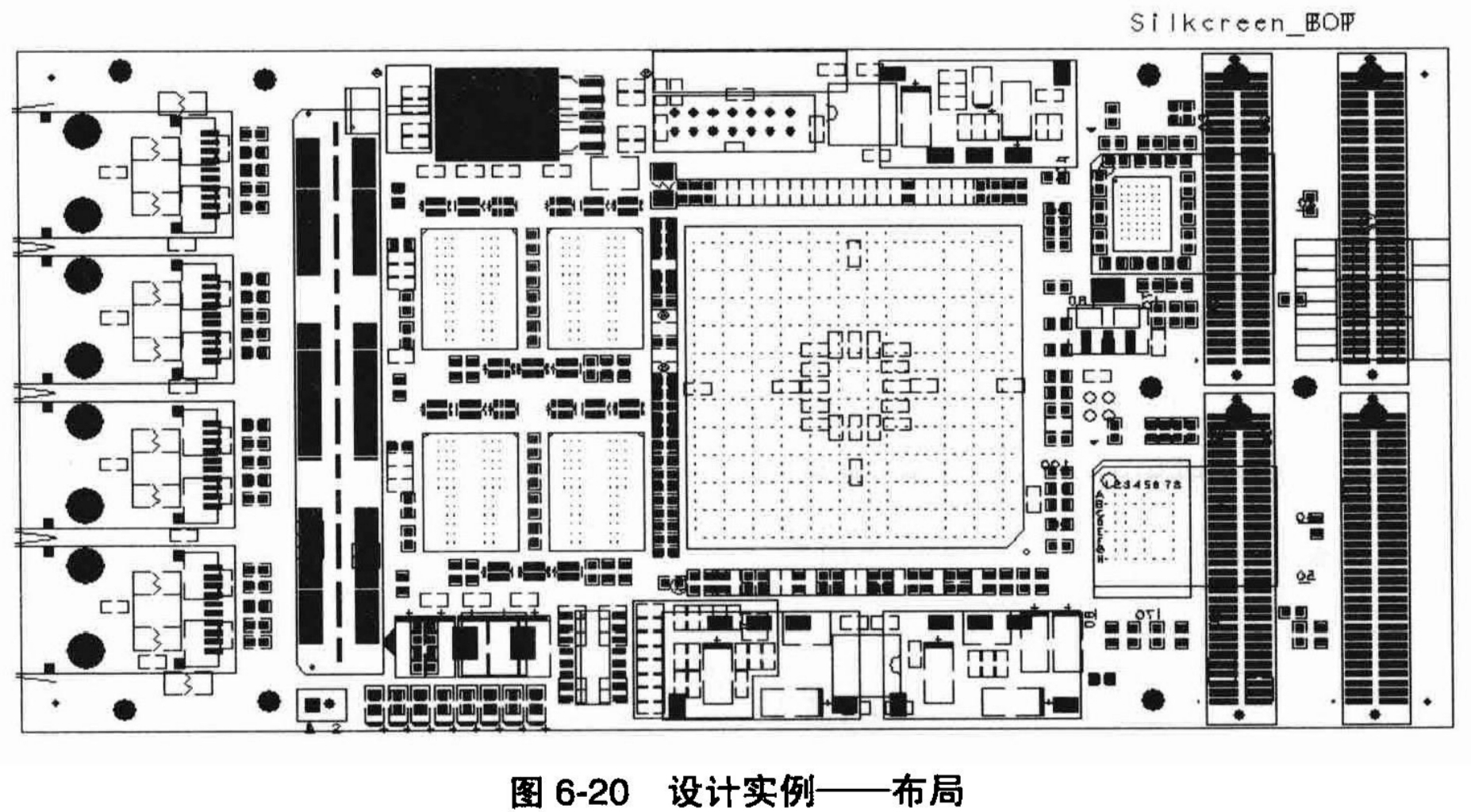
高速系统设计实例设计分析
在上几章的内容中,我们从纯粹高速信号的理论分析,到 Cadence 工具的具体使用都做了详细的讲解和介绍。相信读者通过前面章节的学习,已经对高速系统的设计理念及 Cadence 相应的设计流程和工具有了一个基本的认识。但是,对于高速电…...
查看购物车
一.查看购物车 查看购物车使用get请求。我们要查看当前用户的购物车,就要获取当前用户的userId字段进行条件查询。因为在用户登录时就已经将userId封装在token中了,因此我们只需要解析token获取userId即可,不需要前端再传入参数了。 Control…...

疑难杂症:dex安装部署
方式一、源码包下载 wget https://github.com/dexidp/dex/archive/refs/tags/v2.42.1.tar.gz 方式二、git方式拉取源码编译: Getting Started | $ git clone https://github.com/dexidp/dex.git 编译 $ cd dex/ $ make build 启动 ./bin/dex serve examples/…...
不起作用)
【idea】快捷键ctrl+shift+F(Find in files)不起作用
问题描述 在idea中使用快捷键CtrlShiftF,进行内容的搜索,但是弹不出对话框、或有时候能弹出有时候又弹不出。 原因分析 1.怀疑是缓存问题?--清空缓存重启也没什么作用 2.怀疑是idea的问题?--有时行、有时不行,而且…...
开发工具分享: Web前端编码常用的在线编译器
1.OneCompiler 工具网址:https://onecompiler.com/ OneCompiler支持60多种编程语言,在全球有超过1280万用户,让开发者可以轻易实现代码的编写、运行和共享。 OneCompiler的线上调试功能完全免费,对编程语言的覆盖也很全&#x…...

EnumUtils:你的枚举“变形金刚“——让枚举操作不再手工作业
各位枚举操控师们好!今天要介绍的是Apache Commons Lang3中的EnumUtils工具类。这个工具就像枚举界的"瑞士军刀",能让你的枚举操作从石器时代直接跃迁到星际文明! 一、为什么需要EnumUtils? 手动操作枚举就像…...
智启未来:新一代云MSP管理服务助力企业实现云成本管理和持续优化
在数字化转型浪潮下,企业纷纷寻求更高效、更经济的运营方式。随着云计算技术的深入应用,云成本优化已成为企业普遍关注的核心议题。 过去,传统云运维服务往往依赖于人力外包,缺乏系统性、规范性的管理,难以有效降低云…...
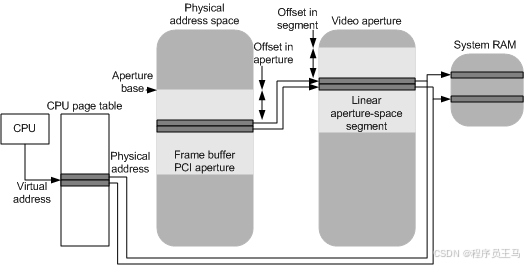
window 显示驱动开发-将虚拟地址映射到内存段(二)
在将虚拟地址映射到段的一部分之前,视频内存管理器调用显示微型端口驱动程序的 DxgkDdiAcquireSwizzlingRange 函数,以便驱动程序可以设置用于访问可能重排的分配位的光圈。 驱动程序既不能将偏移量更改为访问分配的 PCI 光圈,也不能更改分配…...

C++:构造函数
构造函数是类的六个默认成员函数之一,这里的默认是指我们不写,编译器会自己生成的。 构造函数其目的是初始化对象,不是开空间。 其特征如下: 1.函数名与类名相同 2.没有返回值,意思是不用在函数前面写void。 3.对…...
【文心智能体】使用文心一言来给智能体设计一段稳定调用工作流的提示词
🌹欢迎来到《小5讲堂》🌹 🌹这是《文心智能体》系列文章,每篇文章将以博主理解的角度展开讲解。🌹 🌹温馨提示:博主能力有限,理解水平有限,若有不对之处望指正࿰…...
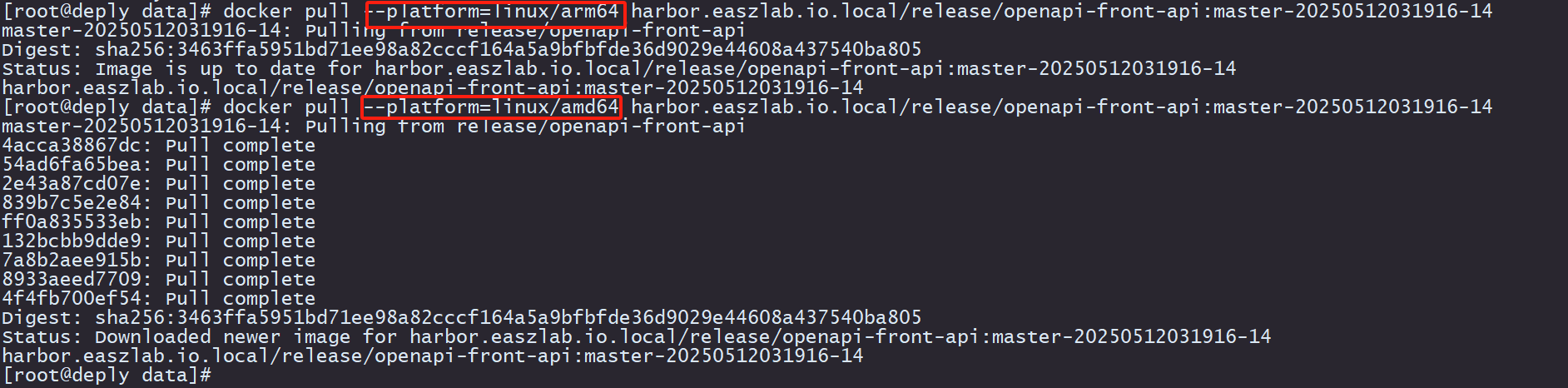
K8S中构建双架构镜像-从零到成功
背景介绍 公司一个客户的项目使用的全信创的环境,服务器采用arm64的机器,而我们的应用全部是amd64的,于是需要对现在公司流水线进行arm64版本的同步镜像生成。本文介绍从最开始到最终生成双架构的全部过程,以及其中使用的相关配置…...

pth的模型格式怎么变成SafeTensors了?
文章目录 背景传统模型格式的安全隐患效率与资源瓶颈跨框架兼容性限制Hugging Face 的解决方案:SafeTensors行业与社区的推动SafeTensors 的意义总结 背景 最近要找一些适合embedding的模型,在huggingface模型库上看到一些排名比较靠前的,准…...

iOS safari和android chrome开启网页调试与检查器的方法
手机开启远程调试教程(适用于 Chrome / Safari) 前端移动端调试指南|适用 iPhone 和 Android|WebDebugX 出品 本教程将详细介绍如何在 iPhone 和 Android 手机上开启网页检查器,配合 WebDebugX 实现远程调试。教程包含…...

c语言第一个小游戏:贪吃蛇小游戏03
我们为贪吃蛇的节点设置为一个结构体,构成贪吃蛇的身子的话我们使用链表,链表的每一个节点是一个结构体 显示贪吃蛇身子的一个节点 我们这边node就表示一个蛇的身体 就是一小节 输出结果如下 显示贪吃蛇完整身子 效果如下 代码实现 这个hasSnakeNode(…...
大规模预训练范式(Large-scale Pre-training)
大规模预训练指在巨量无标注数据上,通过自监督学习训练大参数量的基础模型,使其具备通用的表征与推理能力。其重要作用如下: 一 跨任务泛化 单一模型可在微调后处理多种NLP(自然语言处理)、CV(计算机视觉…...

基于Flink的用户画像 OLAP 实时数仓统计分析
1.基于Flink的用户画像 OLAP 实时数仓统计分析 数据源是来自业务系统的T日数据,利用kakfa进行同步 拼接多个事实表形成大宽表,优化多流Join方式,抽取主键和外键形成主外键前置层,抽取外键和其余内容形成融合层,将4次事…...

React Native踩坑实录:解决NativeBase Radio组件在Android上的兼容性问题
React Native踩坑实录:解决NativeBase Radio组件在Android上的兼容性问题 问题背景 在最近的React Native项目开发中,我们的应用在iOS设备上运行良好,但当部署到Android设备时,进入语言设置和隐私设置页面后应用崩溃。我们遇到了…...