es 里的Filesystem Cache 理解
文章目录
- 背景
- 问题1,Filesystem Cache 里放的是啥
- 问题2,哪些查询它们会受益于文件系统缓存
- 问题3 查询分析
背景
对于es 优化来说常常看到会有一条结论给,给 JVM Heap 最多不超过物理内存的 50%,且不要超过 31GB(避免压缩指针失效)。剩下的内存尽量留给操作系统做文件系统缓存。es查询重度依赖
Filesystem Cache。
问题1,Filesystem Cache 里放的是啥
文件系统缓存保存的是什么?
文件系统缓存由操作系统管理,而不是 Elasticsearch。
它缓存的是从磁盘读取的文件内容,比如 Lucene 构建的倒排索引文件(segment files)。
这些文件包括:
.fnm (field names)
.tim / .tip (term index and dictionary)
.doc / .pos / .pay (document values, positions, payloads)
.dvd / .dvm (doc values)
等等。
这些数据构成了 Elasticsearch 实现快速全文检索的核心结构 —— 倒排索引(Inverted Index)
问题2,哪些查询它们会受益于文件系统缓存
以下是一些典型的查询类型和场景,它们会受益于文件系统缓存:
🔹1. Term 查询 / Term-level 查询
示例:精确匹配某个字段值
{"query": {"term": {"status": "published"}}
}
解释:
term 查询会查找包含特定 term 的文档。
Lucene 使用 .tim(Term Index) 和 .tip(Term Dictionary) 文件快速定位 term。
如果这些文件已经在文件系统缓存中,则完全不需要磁盘 I/O。
🔹2. Terms 查询
示例:匹配多个枚举值
{"query": {"terms": {"category": ["books", "electronics", "movies"]}}
}
解释:
多个 term 的组合查询。
每个 term 都会在倒排索引中查找对应的文档列表。
只要 .tim, .tip, .doc, .pos 等文件都在缓存中,性能非常高。
🔹3. Range 查询(数值或时间范围)
示例:查询某段时间内的订单
{"query": {"range": {"timestamp": {"gte": "2024-01-01","lt": "2025-01-01"}}}
}
解释:
如果字段是 keyword 或已经构建了 doc values(.dvm, .dvd),Lucene 会利用排序结构进行快速范围扫描。
如果相关 segment 的 .dvd 文件在缓存中,范围查询非常高效。
🔹4. Filter 上下文中的查询(Query in Filter Context)
示例:
{
"query": {"bool": {"filter": [{ "term": { "status": "published" } },{ "range": { "price": { "gte": 100, "lt": 500 } } }]}}
}
解释:
filter 上下文不计算相关度分数,只关心是否匹配。
Lucene 会使用 bitset 来加速 filter 查询,如果索引文件已在缓存中,速度极快。
filter 查询非常适合利用缓存,因为结果可重复使用(适合 cache)。
🔹5. 聚合查询(Aggregations)
示例:按 category 分组统计数量
{"size": 0,"aggs": {"categories": {"terms": { "field": "category.keyword" }}}
}
解释:
聚合操作需要遍历大量文档,读取字段值。
如果字段是 keyword 类型,Lucene 使用全局序号(global ordinals)和 .gob 文件进行处理。
如果这些文件在缓存中,聚合速度非常快,否则会触发大量磁盘读取。
🔹6. Doc value 字段查询
示例:
{"query": {"range": {"price": {"gte": 100,"lt": 500}}}
}
解释:
如果 price 字段开启了 doc_values(默认开启),Lucene 使用 .dvd 和 .dvm 文件来存储列式数据。
这些文件会被操作系统缓存在内存中,所以范围查询、排序、聚合等都非常快。
🔹7. 前缀查询(Prefix Query)
示例:
{"query": {"prefix": {"name": "elasti"}}
}
问题3 查询分析
- 如果_source 是true的话,要先查系统缓存,找到文档ID ,再查磁盘找到原始文件
- 如果返回的是部分字段?
下面我们详细解释每种方式的工作原理。
🔍 一、使用 _source filtering(源过滤)
这是最常见的方法,适用于你只想返回原始文档中的某些字段。
示例:
json
{"_source": {"includes": ["title", "author"]},"query": {"term": {"status": "published"}}
}
工作流程:
Elasticsearch 仍然会从 .source 文件中加载整个原始文档。
然后在内存中进行字段过滤,只保留你需要的字段。
最终只返回这些字段给客户端。
💡 关键点:
即使你只要几个字段,Elasticsearch 仍需要加载完整 _source。
如果 .source 文件不在文件系统缓存中,就会触发磁盘 I/O。
所以:虽然减少了网络传输量,但没有减少磁盘访问。
🔍 二、使用 store: true 的 stored fields(存储字段)
如果你只需要少量字段,并希望快速获取它们而不需要加载整个 _source,可以在 mapping 中为某些字段设置 store: true。
示例 mapping:
json
{"mappings": {"properties": {"title": { "type": "text", "store": true },"author": { "type": "keyword", "store": true },"content": { "type": "text" } // 默认不存储}}
}
查询时:
json
{"stored_fields": ["title", "author"],"source": false,"query": {"term": {"status": "published"}}
}
工作流程:
Elasticsearch 从 Lucene 的 .fdt / .fdx 文件中读取存储字段(stored fields)。
这些文件是独立于 _source 的。
如果这些文件在文件系统缓存中,查询速度非常快。
💡 关键点:
没有加载 _source,所以节省了内存和磁盘 I/O。
更适合“高频访问 + 字段少”的场景。
缺点是:占用更多磁盘空间 ,因为每个字段都单独存储了一份。
🔍 三、使用 docvalue_fields(适合聚合/排序)
对于 keyword 类型或数值类型字段,Lucene 使用 doc values 来支持高效的排序和聚合。
示例:
{"docvalue_fields": ["price", "publish_date"],"source": false,"query": {"term": {"status": "published"}}
}
工作流程:
Elasticsearch 从 .dvd, .dvm 文件中读取字段值。
这些文件也是列式存储,非常适合批量读取。
如果这些文件在缓存中,性能非常高。
💡 关键点:
完全不依赖 _source。
对聚合、排序、范围查询非常有用。
不适合返回大量文本内容(如文章正文)。
相关文章:

es 里的Filesystem Cache 理解
文章目录 背景问题1,Filesystem Cache 里放的是啥问题2,哪些查询它们会受益于文件系统缓存问题3 查询分析 背景 对于es 优化来说常常看到会有一条结论给,给 JVM Heap 最多不超过物理内存的 50%,且不要超过 31GB(避免压…...
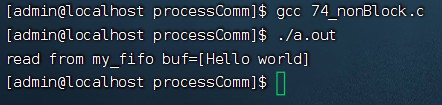
Linux进程10-有名管道概述、创建、读写操作、两个管道进程间通信、读写规律(只读、只写、读写区别)、设置阻塞/非阻塞
目录 1.有名管道 1.1概述 1.2与无名管道的差异 2.有名管道的创建 2.1 直接用shell命令创建有名管道 2.2使用mkfifo函数创建有名管道 3.有名管道读写操作 3.1单次读写 3.2多次读写 4.有名管道进程间通信 4.1回合制通信 4.2父子进程通信 5.有名管道读写规律ÿ…...

精品可编辑PPT | 全面风险管理信息系统项目建设风控一体化标准方案
这份文档是一份全面风险管理信息系统项目建设风控一体化标准方案,涵盖了业务架构、功能方案、系统技术架构设计、项目实施及服务等多个方面的详细内容。方案旨在通过信息化手段提升企业全面风险管理工作水平,促进风险管理落地和内部控制规范化࿰…...
YOLOv8网络结构
YOLOv8的网络结构由输入端(Input)、骨干网络(Backbone)、颈部网络(Neck)和检测头(Head)四部分组成。 YOLOv8的网络结构如下图所示: 在整个系统架构中,图像首先进入输入处理模块,该模块承担着图像预处理与数据增强的双重任务。接着,…...

数组对象 按照对象中的某个字段排序
在JavaScript中,可以使用数组的sort()方法按照对象中的某个字段对数组进行排序。 按照对象中的某个字段对数组进行排序: 基本排序方法 升序排序 const array [{ name: John, age: 25 },{ name: Jane, age: 21 },{ name: Bob, age: 30 } ];// 按照age字…...
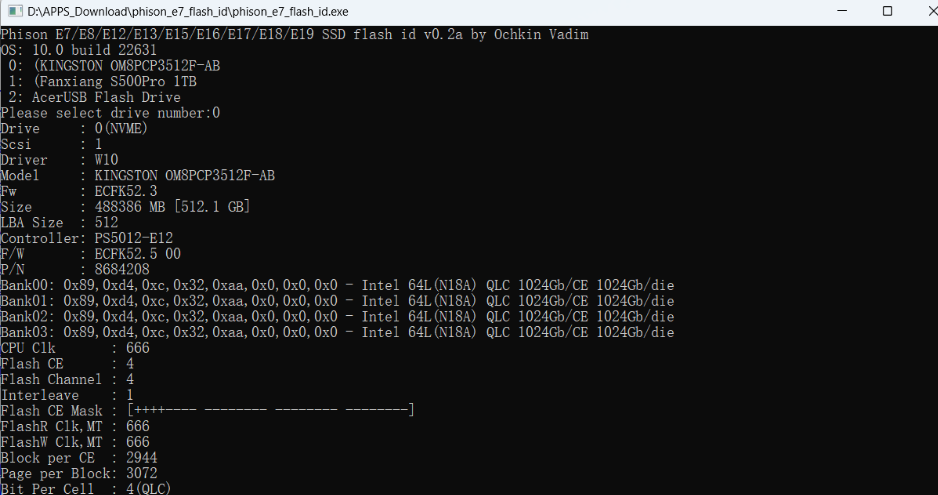
笔记本电脑升级实战手册【扩展篇1】:flash id查询硬盘颗粒
文章目录 前言:一、硬盘颗粒介绍1、MLC(Multi-Level Cell)2、TLC(Triple-Level Cell)3、QLC(Quad-Level Cell) 二、硬盘与主控1、主控介绍2、主流主控厂家 三 、硬盘颗粒查询使用flash id工具查…...
AutoDL租用服务器教程
在跑ai模型的时候,容易遇到算力不够的情况。此时便需要租用服务器。autodl是个较为便宜的服务器租用平台,h20仅需七点几元每小时。下面是简单的介绍。 打开网站AutoDL算力云 | 弹性、好用、省钱。租GPU就上AutoDL,并登录账号 登录后ÿ…...

四、STM32 HAL库API完全指南:从功能分类到实战示例
STM32 HAL库API完全指南:从功能分类到实战示例 一、HAL库API的总体架构 STM32 HAL库(Hardware Abstraction Layer)作为STMicroelectronics推出的统一驱动框架,提供了覆盖所有STM32外设的标准化API。HAL库的API设计遵循严格的分层…...

MySQL全量、增量备份与恢复
目录 数据备份 一、数据备份类型 二、常见备份方法 扩展:GTID与XtraBackup 一、GTID(全局事务标识符) 1. 定义与核心作用 2. GTID在备份恢复中的意义 3. GTID配置与启用 二、XtraBackup的意义与核心价值 1. 定…...

fastboot 如何只刷system.img 分区
在 fastboot 模式下只刷入 system.img 分区,可以按照以下步骤操作: 1. 确保设备已进入 Fastboot 模式 连接设备到电脑,并确保已进入 Fastboot/Bootloader 模式:adb reboot bootloader或手动进入(通常为 电源键 音量…...

连接词化归律详解
1. 连接词化归律的基本概念 连接词化归律(也称为归结原理)是数理逻辑中用于简化逻辑表达式的重要方法,它允许我们将复杂的逻辑表达式转化为更简单的等价形式,特别是转化为合取范式(CNF)或析取范式(DNF)。 核心思想 连接词化归律基于一系列逻辑等价关系…...

《构建社交应用用户激励引擎:React Native与Flutter实战解析》
React Native凭借其与JavaScript和React的紧密联系,为开发者提供了一个熟悉且灵活的开发环境。在构建用户等级体系时,它能够充分利用现有的前端开发知识和工具。通过将用户在社交应用中的各种行为进行量化,比如发布动态的数量、点赞评论的次数…...

goner/otel 在Gone框架接入OpenTelemetry
文章目录 背景与意义快速上手:五步集成 OpenTelemetry运行效果展示代码详解与实践目录结构说明组件加载(module.load.go)业务组件示例(your_component.go)程序入口(main.go) 进阶用法与最佳实践…...
杨校老师项目之基于SSM与JSP的鲜花销售系统-【成品设计含文档】
基于SSMJSP鲜花商城系统 随着电子商务的快速发展,鲜花在线销售已成为一种重要的消费模式。本文设计并实现了一个基于JSP技术的鲜花销售管理系统,采用B/S架构,使用SSM框架进行开发,并结合Maven进行项目依赖管理。系统分为前台用户模…...

springboot集成langchain4j实现票务助手实战
前言 看此篇的前置知识为langchain4j整合springboot,以及springboot集成langchain4j记忆对话。 Function-Calls介绍 langchain4j 中的 Function Calls(函数调用)是一种让大语言模型(LLM)与外部工具(如 A…...
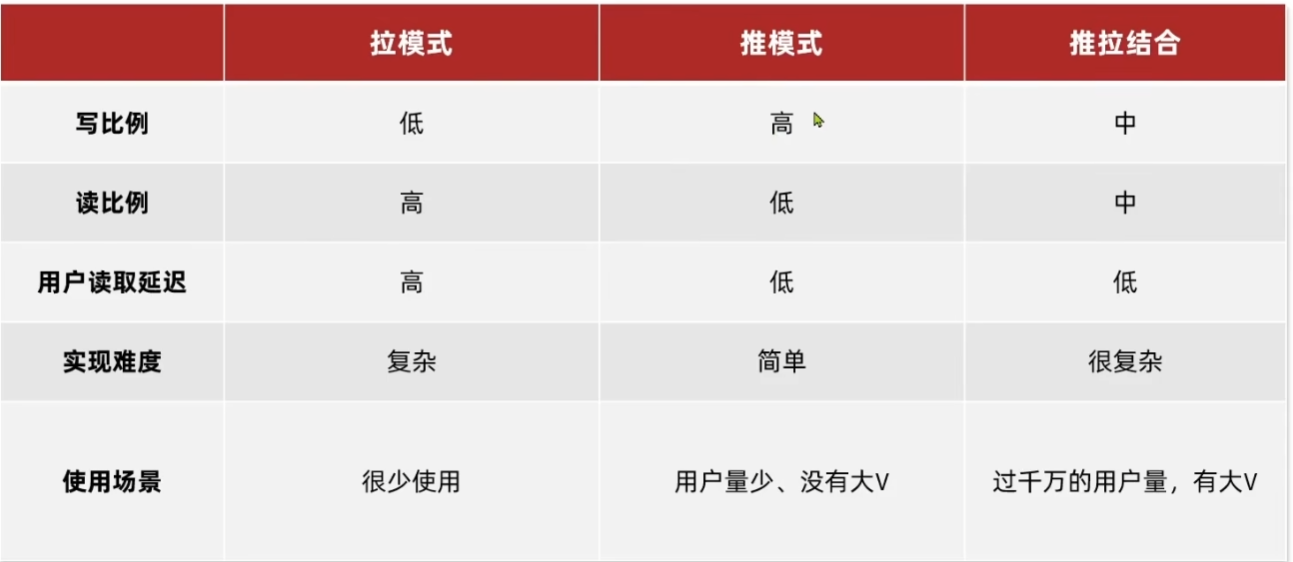
Feed流推送之订阅推送
分类 feed流分为TimeLine和智能排序,前者不对内容进行过滤,一般根据发布的时间来进行排序,一般用于好友动态或者推送关注的人的消息,而后者一般有着复杂的算法,可以根据算法智能地向目标用户推送内容,例如…...
wordpress自学笔记 第四节 商城菜单的添加和修改美化
wordpress自学笔记 摘自 超详细WordPress搭建独立站商城教程-第四节 商城菜单的添加和修改美化,2025 WordPress搭建独立站商城#WordPress建站教程https://www.bilibili.com/video/BV1UwwgeuEkK?spm_id_from333.788.videopod.sections&vd_sourcea0af3bbc6b6d…...
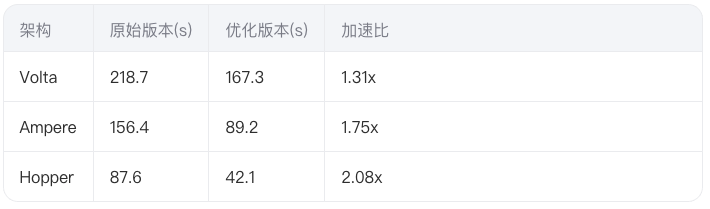
GPU L2 Cache一致性协议对科学计算的影响研究
点击 “AladdinEdu,同学们用得起的【H卡】算力平台”,H卡级别算力,按量计费,灵活弹性,顶级配置,学生专属优惠。 一、GPU缓存层级革命:从Volta到Hopper的演进图谱 1.1 架构级缓存策略对比 Vo…...

C++中类中const知识应用详解
下面将从**const 成员**、const 成员函数、const 对象、mutable、constexpr 等方面,逐一详解 C 类中常见的 const 用法及注意事项,并配合示例。 一、const 数据成员 必须在初始化列表中初始化 class A {const int x; // const 成员 public:A(int v) :…...
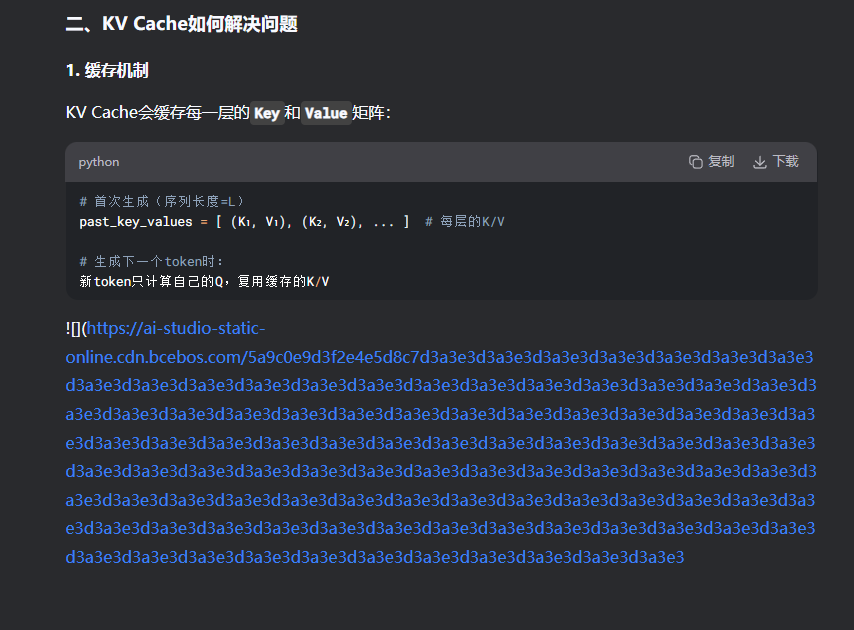
【速写】KV-cache与解码的再探讨(以束搜索实现为例)
文章目录 1 Beam Search 解码算法实现2 实现带KV Cache的Beam Search解码3 关于在带kv-cache的情况下的use_cache参数 1 Beam Search 解码算法实现 下面是一个使用PyTorch实现的beam search解码算法: 几个小细节: 束搜索可以加入length_penalty&#…...
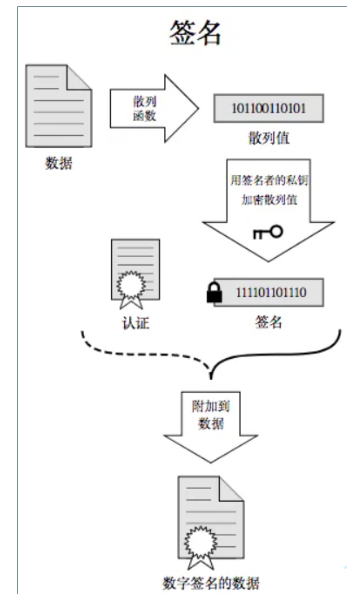
(网络)应用层协议-HTTPS
1.HTTPS是什么? HTTPS是应用层的一种协议,是在HTTP的基础上进行了加密层的处理。 HTTP协议的内容都是按照文本的形式进行传输的,所以呢就很容易被别人知道传输的是什么。 我们在了解了TCP/IP之后是知道我们的数据在传输的过程中是通过路由器进…...

vue3: pdf.js 3.4.120 using javascript
npm install pdfjs-dist3.4.120 项目结构: pdfjsViewer.vue <template><div><div v-if"loading" class"flex justify-center items-center py-8"><div class"animate-spin rounded-full h-12 w-12 border-b-2 borde…...

Spark目前支持的部署模式。
一、本地模式(Local Mode) 特点: 在单台机器上运行,无需集群。主要用于开发、测试和调试。所有组件(Driver、Executor)在同一个 JVM 中运行。 启动命令: bash spark-submit --master local[*]…...
想实现一个基于MCP的pptx生成系统架构图【初版实现】
技术栈:Python + MCP协议 + python-pptx + FastMCP 核心创新点:通过MCP协议实现PPTX元素的动态化生成与标准化模板管理 当前还是个半成品,后续持续更新。 主要先介绍一下思路。 一、MCP协议与系统设计原理 1.1 为什么选择MCP? 标准化工具调用:通过MCP将PPTX元素生成逻辑封…...
PyTorch Lightning实战 - 训练 MNIST 数据集
MNIST with PyTorch Lightning 利用 PyTorch Lightning 训练 MNIST 数据。验证梯度范数、学习率、优化器对训练的影响。 pip show lightning Version: 2.5.1.post0Fast dev run DATASET_DIR"/repos/datasets" python mnist_pl.py --output_grad_norm --fast_dev_run…...
力扣2094题解
记录: 2025.5.12 题目: 思路: 暴力遍历。 解题步骤: 1.统计数字出现次数:使用数组cnt来记录输入数组中每个数字的出现次数。 2.生成三位偶数:通过循环从100开始,每次递增2,生成…...
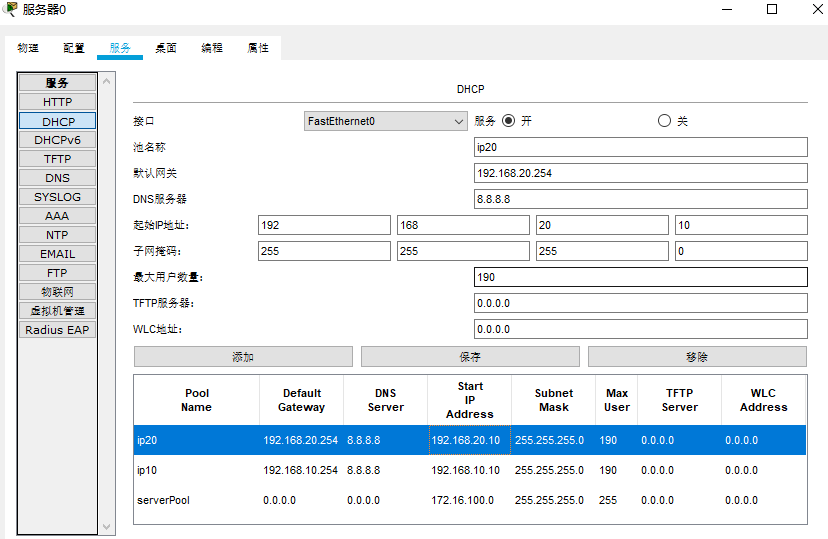
DHCP自动分配IP
DHCP自动分配IP 练习1 路由器 Router>en Router#conf t Router(config)#ip dhcp pool ip10 //创建DHCP地址池 Router(dhcp-config)#network 192.168.20.0 255.255.255.0 // 配置网络地址和子网掩码 Router(dhcp-config)#default-router 192.168.20.254 //配置默认网关 Rou…...
【CF】Day57——Codeforces Round 955 (Div. 2, with prizes from NEAR!) BCD
B. Collatz Conjecture 题目: 思路: 简单模拟 很简单的模拟,我们只需要快速的找到下一个离 x 最近的 y 的倍数即可(要大于 x) 这里我们可以这样写 add y - (x % y),这样就知道如果 x 要变成 y 的倍数还要…...
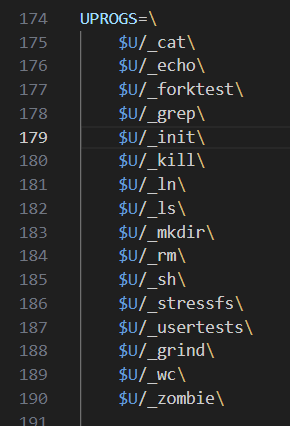
(done) 补充:xv6 的一个用户程序 init 是怎么启动的 ?它如何启动第一个 bash ?
先看 main.c 从函数名来看,比较相关的就 userinit() 和 scheduler() #include "types.h" #include "param.h" #include "memlayout.h" #include "riscv.h" #include "defs.h"volatile static int started 0;//…...

Nginx部署前端项目深度解析
在部署Vue前端项目时,Nginx的高效配置直接影响用户体验和性能表现。以下从7个关键维度深度解析部署方案,并提供专业级配置策略: 一、项目构建与基础部署 生产构建 npm run build -- --modern # 现代模式构建生成dist/目录包含:…...