基于C++的多线程网络爬虫设计与实现(CURL + 线程池)
在当今大数据时代,网络爬虫作为数据采集的重要工具,其性能直接决定了数据获取的效率。传统的单线程爬虫在面对海量网页时往往力不从心,而多线程技术可以充分利用现代多核CPU的计算能力,显著提升爬取效率。本文将详细介绍如何使用C++结合libcurl和线程池技术构建一个高性能的多线程网络爬虫。

一、技术选型与架构设计
1.1 核心技术组件
我们选择以下技术构建爬虫系统:
-
libcurl:一个强大且高效的跨平台网络传输库,支持HTTP、HTTPS、FTP等多种协议
-
C++11线程库:提供标准的线程管理接口,保证代码的可移植性
-
生产者-消费者模型:通过任务队列实现线程间的高效协作
1.2 系统架构
爬虫系统主要由三个核心模块组成:
-
URL管理器:负责URL的存储、去重和分发
-
线程池:管理多个工作线程,执行实际的网页抓取任务
-
网络请求模块:基于libcurl实现HTTP请求和响应处理
┌─────────────┐ ┌─────────────┐ ┌─────────────┐
│ URL管理器 │───>│ 任务队列 │───>│ 线程池 │
└─────────────┘ └─────────────┘ └─────────────┘↑ ││ ↓┌─────────────┐ ┌─────────────┐│ 新URL发现 │<───│ 网页解析器 │└─────────────┘ └─────────────┘二、核心实现详解
2.1 线程安全的任务队列
在多线程环境下,共享数据的同步访问是必须解决的问题。我们实现了一个线程安全的队列模板类:
template <typename T>
class ThreadSafeQueue {
public:void push(const T& value) {std::lock_guard<std::mutex> lock(mutex_);queue_.push(value);cond_.notify_one(); // 通知等待的消费者线程}bool try_pop(T& value) {std::lock_guard<std::mutex> lock(mutex_);if (queue_.empty()) {return false;}value = queue_.front();queue_.pop();return true;}// ... 其他成员函数
private:mutable std::mutex mutex_;std::queue<T> queue_;std::condition_variable cond_;
};该实现具有以下特点:
-
使用互斥锁(mutex)保证队列操作的原子性
-
通过条件变量(condition variable)实现高效的通知机制
-
提供非阻塞的try_pop接口,避免线程不必要的等待
2.2 线程池实现
线程池是爬虫系统的核心,负责管理工作线程的生命周期和任务分配:
class ThreadPool {
public:ThreadPool(size_t num_threads, ThreadSafeQueue<std::string>& task_queue): task_queue_(task_queue), stop_(false) {for (size_t i = 0; i < num_threads; ++i) {workers_.emplace_back([this] {while (true) {std::string url;if (!task_queue_.try_pop(url)) {if (stop_) return; // 线程池停止时退出std::this_thread::yield();continue;}fetchUrl(url); // 执行实际爬取任务}});}}~ThreadPool() {stop_ = true; // 设置停止标志for (auto& worker : workers_) {if (worker.joinable()) worker.join();}}private:void fetchUrl(const std::string& url) {// libcurl请求实现...}std::vector<std::thread> workers_;ThreadSafeQueue<std::string>& task_queue_;std::atomic<bool> stop_;
};线程池的关键设计考虑:
-
工作线程数量通常设置为CPU核心数的1-2倍
-
使用原子布尔变量实现优雅的线程停止机制
-
当队列为空时,线程通过yield()让出CPU,减少资源占用
2.3 libcurl网络请求
我们封装了libcurl的HTTP请求功能:
void fetchUrl(const std::string& url) {CURL* curl = curl_easy_init();if (!curl) {std::cerr << "Failed to initialize CURL for URL: " << url << std::endl;return;}std::string response;curl_easy_setopt(curl, CURLOPT_URL, url.c_str());curl_easy_setopt(curl, CURLOPT_WRITEFUNCTION, WriteCallback);curl_easy_setopt(curl, CURLOPT_WRITEDATA, &response);curl_easy_setopt(curl, CURLOPT_FOLLOWLOCATION, 1L); // 跟随重定向curl_easy_setopt(curl, CURLOPT_TIMEOUT, 10L); // 10秒超时CURLcode res = curl_easy_perform(curl);if (res != CURLE_OK) {std::cerr << "CURL failed for URL: " << url << " - Error: " << curl_easy_strerror(res) << std::endl;} else {long http_code = 0;curl_easy_getinfo(curl, CURLINFO_RESPONSE_CODE, &http_code);std::cout << "URL: " << url << "\nStatus: " << http_code << "\nResponse length: " << response.size() << " bytes\n\n";}curl_easy_cleanup(curl);
}libcurl的配置选项非常丰富,可以根据需要调整:
-
CURLOPT_CONNECTTIMEOUT:连接超时时间
-
CURLOPT_USERAGENT:设置用户代理
-
CURLOPT_COOKIEFILE/CURLOPT_COOKIEJAR:Cookie管理
-
CURLOPT_PROXY:设置代理服务器
三、性能优化策略
3.1 连接复用
libcurl支持连接复用,可以显著减少TCP握手开销:
// 全局初始化时创建共享接口
CURLSH* share = curl_share_init();
curl_share_setopt(share, CURLSHOPT_SHARE, CURL_LOCK_DATA_DNS);// 在每个easy handle上设置共享接口
curl_easy_setopt(curl, CURLOPT_SHARE, share);3.2 异步I/O与多路复用
对于更高性能的场景,可以考虑使用libcurl的multi接口实现异步I/O:
CURLM* multi_handle = curl_multi_init();// 添加多个easy handle
curl_multi_add_handle(multi_handle, easy1);
curl_multi_add_handle(multi_handle, easy2);// 执行多路复用循环
int running_handles;
do {curl_multi_perform(multi_handle, &running_handles);curl_multi_wait(multi_handle, NULL, 0, 1000, NULL);
} while (running_handles);3.3 智能任务调度
实现优先级队列支持重要URL优先抓取:
class PriorityTaskQueue {
public:void push(int priority, const std::string& url) {std::lock_guard<std::mutex> lock(mutex_);queue_.emplace(priority, url);cond_.notify_one();}bool try_pop(std::string& url) {std::lock_guard<std::mutex> lock(mutex_);if (queue_.empty()) return false;url = queue_.top().second;queue_.pop();return true;}private:using Item = std::pair<int, std::string>;struct Compare {bool operator()(const Item& a, const Item& b) {return a.first < b.first; // 优先级高的先出队}};std::priority_queue<Item, std::vector<Item>, Compare> queue_;// ... 其他成员
};四、扩展功能实现
4.1 URL去重
使用布隆过滤器实现高效去重:
#include <bloom_filter.hpp>class UrlDeduplicator {
public:bool hasSeen(const std::string& url) {std::lock_guard<std::mutex> lock(mutex_);if (filter_.contains(url)) {return true;}filter_.insert(url);return false;}private:bloom_filter filter_;mutable std::mutex mutex_;
};4.2 速率限制
实现请求速率控制:
class RateLimiter {
public:RateLimiter(int max_requests, std::chrono::milliseconds interval): max_requests_(max_requests), interval_(interval) {}void acquire() {std::unique_lock<std::mutex> lock(mutex_);auto now = Clock::now();// 移除过期的请求记录while (!timestamps_.empty() && now - timestamps_.front() > interval_) {timestamps_.pop();}// 如果达到限制,等待if (timestamps_.size() >= max_requests_) {auto wait_time = interval_ - (now - timestamps_.front());cond_.wait_for(lock, wait_time);now = Clock::now(); // 更新now,因为可能已经等待timestamps_.pop(); // 移除最旧的记录}timestamps_.push(now);}private:using Clock = std::chrono::steady_clock;std::queue<Clock::time_point> timestamps_;int max_requests_;std::chrono::milliseconds interval_;std::mutex mutex_;std::condition_variable cond_;
};4.3 HTML解析与链接提取
集成HTML解析库提取新链接:
#include <gumbo.h>void extractLinks(const std::string& html, std::vector<std::string>& links) {GumboOutput* output = gumbo_parse(html.c_str());extractLinksFromNode(output->root, links);gumbo_destroy_output(&kGumboDefaultOptions, output);
}void extractLinksFromNode(GumboNode* node, std::vector<std::string>& links) {if (node->type != GUMBO_NODE_ELEMENT) return;if (node->v.element.tag == GUMBO_TAG_A) {GumboAttribute* href = gumbo_get_attribute(&node->v.element.attributes, "href");if (href) {links.push_back(href->value);}}// 递归处理子节点GumboVector* children = &node->v.element.children;for (unsigned int i = 0; i < children->length; ++i) {extractLinksFromNode(static_cast<GumboNode*>(children->data[i]), links);}
}五、工程实践建议
5.1 错误处理与日志
实现完善的错误处理和日志系统:
class Logger {
public:enum Level { DEBUG, INFO, WARNING, ERROR };static Logger& instance() {static Logger logger;return logger;}void log(Level level, const std::string& message) {std::lock_guard<std::mutex> lock(mutex_);std::time_t now = std::time(nullptr);std::cout << std::put_time(std::localtime(&now), "%F %T") << " ["<< levelToString(level) << "] " << message << std::endl;}private:std::string levelToString(Level level) {static const char* levels[] = {"DEBUG", "INFO", "WARNING", "ERROR"};return levels[level];}std::mutex mutex_;
};#define LOG_DEBUG(msg) Logger::instance().log(Logger::DEBUG, msg)
#define LOG_ERROR(msg) Logger::instance().log(Logger::ERROR, msg)5.2 配置管理
从配置文件加载爬虫参数:
# config.ini
[network]
timeout = 10
user_agent = Mozilla/5.0
max_redirects = 5[thread_pool]
thread_count = 8
queue_size = 1000[rate_limit]
requests_per_second = 5使用INI解析库读取配置:
#include <inih/INIReader.h>class Config {
public:static Config& instance() {static Config config("config.ini");return config;}int getThreadCount() { return reader.GetInteger("thread_pool", "thread_count", 4); }// ... 其他配置项private:Config(const std::string& filename) : reader(filename) {}INIReader reader;
};总结与展望
本文详细介绍了如何使用C++构建一个高性能的多线程网络爬虫。通过结合libcurl和线程池技术,我们实现了一个可扩展的爬虫框架,并讨论了多种性能优化和功能扩展方案。
未来可能的改进方向包括:
-
分布式爬虫:将爬虫扩展到多机协作,使用消息队列(如RabbitMQ)协调工作
-
JavaScript渲染:集成Headless Chrome或PhantomJS处理动态网页
-
机器学习:应用机器学习算法智能调度爬取优先级
-
反反爬虫:实现更复杂的反检测机制
-
可视化监控:开发Web界面实时监控爬虫状态
网络爬虫技术是一个广阔的领域,希望本文能为读者提供一个扎实的起点,帮助构建自己的高性能爬虫系统。
相关文章:
基于C++的多线程网络爬虫设计与实现(CURL + 线程池)
在当今大数据时代,网络爬虫作为数据采集的重要工具,其性能直接决定了数据获取的效率。传统的单线程爬虫在面对海量网页时往往力不从心,而多线程技术可以充分利用现代多核CPU的计算能力,显著提升爬取效率。本文将详细介绍如何使用C…...

Android11.0 framework第三方无源码APP读写断电后数据丢失问题解决
1.前言 在11.0中rom定制化开发中,在某些产品开发中,在某些情况下在App用FileOutputStream读写完毕后,突然断电 会出现写完的数据丢失的问题,接下来就需要分析下关于使用FileOutputStream读写数据的相关流程,来实现相关 功能 2.framework第三方无源码APP读写断电后数据丢…...

国产大模型「五强争霸」:决战AGI,谁主沉浮?
引言 中国AI大模型市场正经历一场史无前例的洗牌!曾经“百模混战”的局面已落幕,字节、阿里、阶跃星辰、智谱和DeepSeek五大巨头强势崛起,形成“基模五强”新格局。这场竞争不仅是技术实力的较量,更是资源、人才与生态的全面博弈。…...

【Python 基础语法】
Python 基础语法是编程的基石,以下从核心要素到实用技巧进行系统梳理: 一、代码结构规范 缩进规则 使用4个空格缩进(PEP 8标准)缩进定义代码块(如函数、循环、条件语句) def greet(name):if name: # 正确缩…...
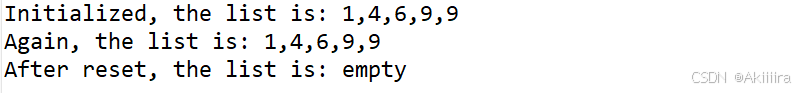
【日撸 Java 三百行】Day 11(顺序表(一))
目录 Day 11:顺序表(一) 一、关于顺序表 二、关于面向对象 三、代码模块分析 1. 顺序表的属性 2. 顺序表的方法 四、代码及测试 拓展: 小结 Day 11:顺序表(一) Task: 在《数…...

path环境变量满了如何处理,分割 PATH 到 Path1 和 Path2
要正确设置 Path1 的值,你需要将现有的 PATH 环境变量 中的部分路径复制到 Path1 和 Path2 中。以下是详细步骤: 步骤 1:获取当前 PATH 的值 打开环境变量窗口: 按 Win R,输入 sysdm.cpl,点击 确定。在 系…...

软考 系统架构设计师系列知识点之杂项集萃(55)
接前一篇文章:软考 系统架构设计师系列知识点之杂项集萃(54) 第89题 某软件公司欲开发一个Windows平台上的公告板系统。在明确用户需求后,该公司的架构师决定采用Command模式实现该系统的界面显示部分,并设计UML类图如…...

保持Word中插入图片的清晰度
大家有没有遇到这个问题,原本绘制的高清晰度图片,插入word后就变模糊了。先说原因,word默认启动了自动压缩图片功能,分享一下如何关闭这项功能,保持Word中插入图片的清晰度。 ①在Word文档中,点击左上角的…...

Web应用开发指南
一、引言 随着互联网的迅猛发展,Web应用已深度融入日常生活的各个方面。为满足用户对性能、交互与可维护性的日益增长的需求,开发者需要一整套高效、系统化的解决方案。在此背景下,前端框架应运而生。不同于仅提供UI组件的工具库,…...

贝叶斯算法
贝叶斯算法是一类基于贝叶斯定理的机器学习算法,它们在分类任务中表现出色,尤其在处理具有不确定性和 probabilistic 关系的数据时具有独特优势。本文将深入探讨贝叶斯算法的核心原理、主要类型以及实际应用案例,带你领略贝叶斯算法在概率推理…...

Linux复习笔记(三) 网络服务配置(web)
遇到的问题,都有解决方案,希望我的博客能为你提供一点帮助。 二、网络服务配置 2.3 web服务配置 2.3.1通信基础:HTTP协议与C/S架构(了解) HTTP协议的核心作用 Web服务基于HTTP/HTTPS协议实现客户端ÿ…...
springboot旅游小程序-计算机毕业设计源码76696
目 录 摘要 1 绪论 1.1研究背景与意义 1.2研究现状 1.3论文结构与章节安排 2 基于微信小程序旅游网站系统分析 2.1 可行性分析 2.1.1 技术可行性分析 2.1.2 经济可行性分析 2.1.3 法律可行性分析 2.2 系统功能分析 2.2.1 功能性分析 2.2.2 非功能性分析 2.3 系统…...
uniapp自定义导航栏搭配插槽
<uni-nav-bar dark :fixed"true" shadow background-color"#007AFF" left-icon"left" left-text"返回" clickLeft"back"><view class"nav-bar-title">{{ navBarTitle }}</view><block v-slo…...
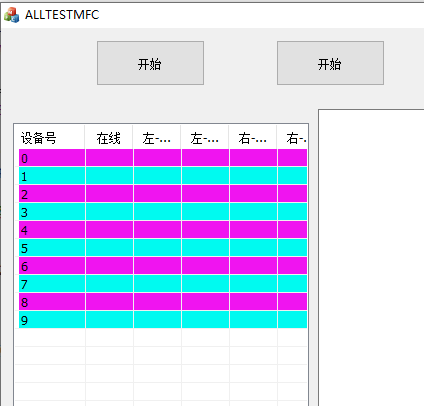
MFC listctrl修改背景颜色
在 MFC 中修改 ListCtrl 控件的行背景颜色,需要通过自绘(Owner-Draw)机制实现。以下是详细的实现方法: 方法一:通过自绘(Owner-Draw)实现 步骤 1:启用自绘属性 在对话框设计器中选…...

Kotlin跨平台Compose Multiplatform实战指南
Kotlin Multiplatform(KMP)结合 Compose Multiplatform 正在成为跨平台开发的热门选择,它允许开发者用一套代码构建 Android、iOS、桌面(Windows/macOS/Linux)和 Web 应用。以下是一个实战指南,涵盖核心概念…...
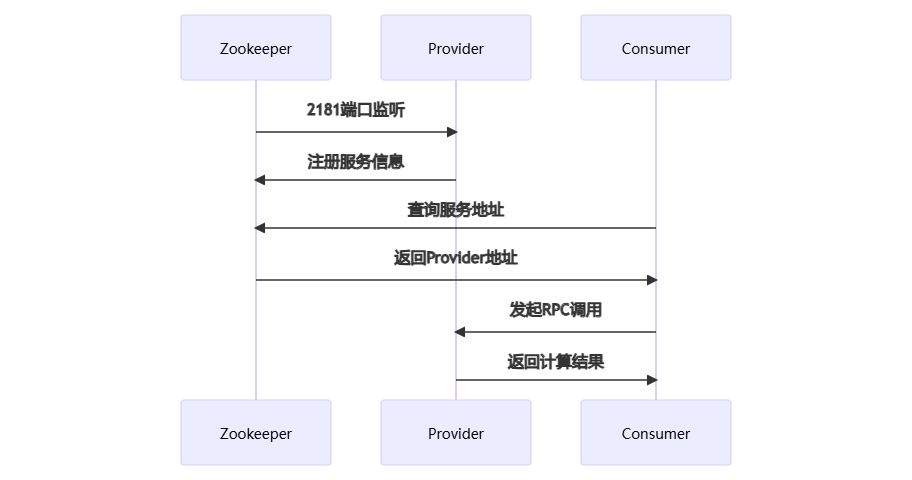
SpringBoot+Dubbo+Zookeeper实现分布式系统步骤
SpringBootDubboZookeeper实现分布式系统 一、分布式系统通俗解释二、环境准备(详细版)1. 软件版本2. 安装Zookeeper(单机模式) 三、完整项目结构(带详细注释)四、手把手代码实现步骤1:创建父工…...

一个极简单的 VUE3 + Element-Plus 查询表单展开收起功能组件
在管理系统页面开发时,会遇到一个简单又令人头痛的问题,那就是:搜索页面太多,搜索表单项内容太多。对于过多的内容,往往采取折叠的形式,仅展示部分内容,需要时展开查看全部。 如果在程序设计时…...

es 里的Filesystem Cache 理解
文章目录 背景问题1,Filesystem Cache 里放的是啥问题2,哪些查询它们会受益于文件系统缓存问题3 查询分析 背景 对于es 优化来说常常看到会有一条结论给,给 JVM Heap 最多不超过物理内存的 50%,且不要超过 31GB(避免压…...
Linux进程10-有名管道概述、创建、读写操作、两个管道进程间通信、读写规律(只读、只写、读写区别)、设置阻塞/非阻塞
目录 1.有名管道 1.1概述 1.2与无名管道的差异 2.有名管道的创建 2.1 直接用shell命令创建有名管道 2.2使用mkfifo函数创建有名管道 3.有名管道读写操作 3.1单次读写 3.2多次读写 4.有名管道进程间通信 4.1回合制通信 4.2父子进程通信 5.有名管道读写规律ÿ…...

精品可编辑PPT | 全面风险管理信息系统项目建设风控一体化标准方案
这份文档是一份全面风险管理信息系统项目建设风控一体化标准方案,涵盖了业务架构、功能方案、系统技术架构设计、项目实施及服务等多个方面的详细内容。方案旨在通过信息化手段提升企业全面风险管理工作水平,促进风险管理落地和内部控制规范化࿰…...
YOLOv8网络结构
YOLOv8的网络结构由输入端(Input)、骨干网络(Backbone)、颈部网络(Neck)和检测头(Head)四部分组成。 YOLOv8的网络结构如下图所示: 在整个系统架构中,图像首先进入输入处理模块,该模块承担着图像预处理与数据增强的双重任务。接着,…...

数组对象 按照对象中的某个字段排序
在JavaScript中,可以使用数组的sort()方法按照对象中的某个字段对数组进行排序。 按照对象中的某个字段对数组进行排序: 基本排序方法 升序排序 const array [{ name: John, age: 25 },{ name: Jane, age: 21 },{ name: Bob, age: 30 } ];// 按照age字…...
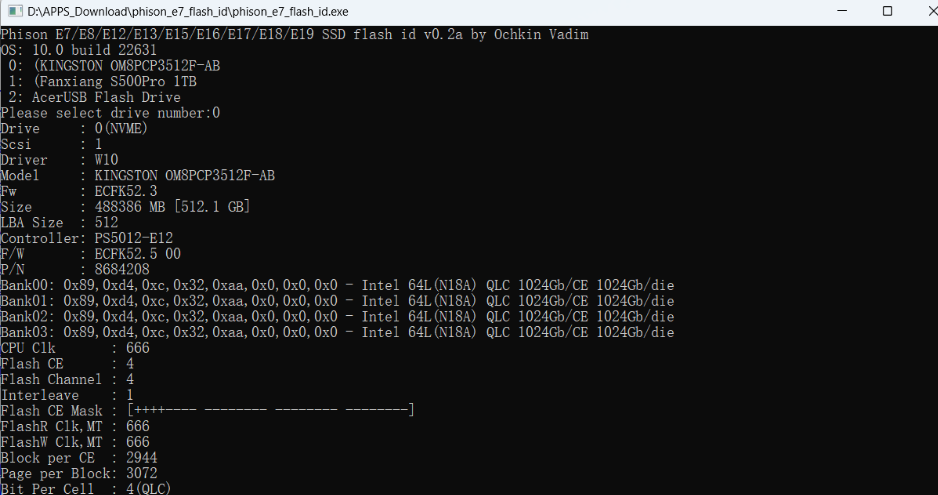
笔记本电脑升级实战手册【扩展篇1】:flash id查询硬盘颗粒
文章目录 前言:一、硬盘颗粒介绍1、MLC(Multi-Level Cell)2、TLC(Triple-Level Cell)3、QLC(Quad-Level Cell) 二、硬盘与主控1、主控介绍2、主流主控厂家 三 、硬盘颗粒查询使用flash id工具查…...
AutoDL租用服务器教程
在跑ai模型的时候,容易遇到算力不够的情况。此时便需要租用服务器。autodl是个较为便宜的服务器租用平台,h20仅需七点几元每小时。下面是简单的介绍。 打开网站AutoDL算力云 | 弹性、好用、省钱。租GPU就上AutoDL,并登录账号 登录后ÿ…...

四、STM32 HAL库API完全指南:从功能分类到实战示例
STM32 HAL库API完全指南:从功能分类到实战示例 一、HAL库API的总体架构 STM32 HAL库(Hardware Abstraction Layer)作为STMicroelectronics推出的统一驱动框架,提供了覆盖所有STM32外设的标准化API。HAL库的API设计遵循严格的分层…...

MySQL全量、增量备份与恢复
目录 数据备份 一、数据备份类型 二、常见备份方法 扩展:GTID与XtraBackup 一、GTID(全局事务标识符) 1. 定义与核心作用 2. GTID在备份恢复中的意义 3. GTID配置与启用 二、XtraBackup的意义与核心价值 1. 定…...

fastboot 如何只刷system.img 分区
在 fastboot 模式下只刷入 system.img 分区,可以按照以下步骤操作: 1. 确保设备已进入 Fastboot 模式 连接设备到电脑,并确保已进入 Fastboot/Bootloader 模式:adb reboot bootloader或手动进入(通常为 电源键 音量…...

连接词化归律详解
1. 连接词化归律的基本概念 连接词化归律(也称为归结原理)是数理逻辑中用于简化逻辑表达式的重要方法,它允许我们将复杂的逻辑表达式转化为更简单的等价形式,特别是转化为合取范式(CNF)或析取范式(DNF)。 核心思想 连接词化归律基于一系列逻辑等价关系…...

《构建社交应用用户激励引擎:React Native与Flutter实战解析》
React Native凭借其与JavaScript和React的紧密联系,为开发者提供了一个熟悉且灵活的开发环境。在构建用户等级体系时,它能够充分利用现有的前端开发知识和工具。通过将用户在社交应用中的各种行为进行量化,比如发布动态的数量、点赞评论的次数…...

goner/otel 在Gone框架接入OpenTelemetry
文章目录 背景与意义快速上手:五步集成 OpenTelemetry运行效果展示代码详解与实践目录结构说明组件加载(module.load.go)业务组件示例(your_component.go)程序入口(main.go) 进阶用法与最佳实践…...