【类拷贝文件的运用】
常用示例
当我们面临将文本文件分成最大大小块的时,我们可能会尝试编写如下代码:
public class TestSplit {private static final long maxFileSizeBytes = 10 * 1024 * 1024; // 默认10MBpublic void split(Path inputFile, Path outputDir) throws IOException {if (!Files.exists(inputFile)) {throw new IOException("输入文件不存在: " + inputFile);}if (Files.size(inputFile) == 0) {throw new IOException("输入文件为空: " + inputFile);}Files.createDirectories(outputDir);try (BufferedReader reader = Files.newBufferedReader(inputFile)) {int fileIndex = 0;long currentSize = 0;BufferedWriter writer = null;try {writer = newWriter(outputDir, fileIndex++);String line;while ((line = reader.readLine()) != null) {byte[] lineBytes = (line + System.lineSeparator()).getBytes();if (currentSize + lineBytes.length > maxFileSizeBytes) {if (writer != null) {writer.close();}writer = newWriter(outputDir, fileIndex++);currentSize = 0;}writer.write(line);writer.newLine();currentSize += lineBytes.length;}} finally {if (writer != null) {writer.close();}}}}private BufferedWriter newWriter(Path dir, int index) throws IOException {Path filePath = dir.resolve("part_" + index + ".txt");return Files.newBufferedWriter(filePath);}public static void main(String[] args) {String inputFilePath = "C:\Users\fei\Desktop\testTwo.txt";String outputDirPath = "C:\Users\fei\Desktop\testTwo";TestSplit splitter = new TestSplit();try {long startTime = System.currentTimeMillis();splitter.split(Paths.get(inputFilePath), Paths.get(outputDirPath));long endTime = System.currentTimeMillis();long duration = endTime - startTime;System.out.println("文件拆分完成!");System.out.printf("总耗时:%d 毫秒%n", duration);} catch (IOException e) {System.out.println("文件拆分过程中发生错误:" + e.getMessage());}}
}
效率分析
此代码在技术上是可以的,但是将大文件拆分为多个块的效率非常低。具体如下
- 它执行许多堆分配 (行),导致创建和丢弃大量临时对象 (字符串、字节数组) 。
- 还有一个不太明显的问题,它将数据复制到多个缓冲区,并在用户和内核模式之间执行上下文切换。
代码详细分析
BufferedReader: BufferedReader 的 BufferedReader 中:
- 在底层
FileReader或InputStreamReader上调用read() - 数据从内核空间→用户空间缓冲区复制。
- 然后解析为 Java 字符串(堆分配)。
getBytes() : getBytes() 的
- 将
String转换为新的byte[]→更多的堆分配。
BufferedWriter: BufferedWriter 的 BufferedWriter 中:
- 从用户空间获取 byte/char 数据。
- 调用
write()这又涉及将用户空间复制到内核空间→。 - 最终刷新到磁盘。
因此,数据在内核和用户空间之间来回移动多次,并产生额外的堆改动。除了垃圾收集压力外,它还具有以下后果:
- 内存带宽浪费在缓冲区之间进行复制。
- 磁盘到磁盘传输的 CPU 利用率较高。
- 操作系统本可直接处理批量拷贝(通过DMA或优化I/O),但Java代码通过引入用户空间逻辑拦截了这种高效性。
方案
那么,我们如何避免上述问题呢?
答案是尽可能使用 zero copy,即尽可能避免离开 kernel 空间。这可以通过使用 FileChannel 方法 long transferTo(long position, long count, WritableByteChannel target) 在 java 中完成。它直接是磁盘到磁盘的传输,还会利用作系统的一些 IO 优化。
有问题就是所描述的方法对字节块进行作,可能会破坏行的完整性。为了解决这个问题,我们需要一种策略来确保即使通过移动字节段处理文件时,行也保持完整
没有上述的问题就很容易,只需为每个块调用
transferTo,将position递增为position = position + maxFileSize,直到无法传输更多数据。
为了保持行的完整性,我们需要确定每个字节块中最后一个完整行的结尾。为此,我们首先查找 chunk 的预期末尾,然后向后扫描以找到前面的换行符。这将为我们提供 chunk 的准确字节计数,确保包含最后的、不间断的行。这将是执行缓冲区分配和复制的代码的唯一部分,并且由于这些作应该最小,因此预计性能影响可以忽略不计。
private static final int LINE_ENDING_SEARCH_WINDOW = 8 * 1024;
private long maxSizePerFileInBytes;
private Path outputDirectory;
private Path tempDir;
private void split(Path fileToSplit) throws IOException {try (RandomAccessFile raf = new RandomAccessFile(fileToSplit.toFile(), "r");FileChannel inputChannel = raf.getChannel()) {
long fileSize = raf.length();long position = 0;int fileCounter = 1;
while (position < fileSize) {// Calculate end position (try to get close to max size)long targetEndPosition = Math.min(position + maxSizePerFileInBytes, fileSize);
// If we're not at the end of the file, find the last line ending before max sizelong endPosition = targetEndPosition;if (endPosition < fileSize) {endPosition = findLastLineEndBeforePosition(raf, position, targetEndPosition);}
long chunkSize = endPosition - position;var outputFilePath = tempDir.resolve("_part" + fileCounter);try (FileOutputStream fos = new FileOutputStream(outputFilePath.toFile());FileChannel outputChannel = fos.getChannel()) {inputChannel.transferTo(position, chunkSize, outputChannel);}
position = endPosition;fileCounter++;}
}
}
private long findLastLineEndBeforePosition(RandomAccessFile raf, long startPosition, long maxPosition)throws IOException {long originalPosition = raf.getFilePointer();
try {int bufferSize = LINE_ENDING_SEARCH_WINDOW;long chunkSize = maxPosition - startPosition;
if (chunkSize < bufferSize) {bufferSize = (int) chunkSize;}
byte[] buffer = new byte[bufferSize];long searchPos = maxPosition;
while (searchPos > startPosition) {long distanceToStart = searchPos - startPosition;int bytesToRead = (int) Math.min(bufferSize, distanceToStart);
long readStartPos = searchPos - bytesToRead;raf.seek(readStartPos);
int bytesRead = raf.read(buffer, 0, bytesToRead);if (bytesRead <= 0)break;
// Search backwards through the buffer for newlinefor (int i = bytesRead - 1; i >= 0; i--) {if (buffer[i] == '\n') {return readStartPos + i + 1;}}
searchPos -= bytesRead;}
throw new IllegalArgumentException("File " + fileToSplit + " cannot be split. No newline found within the limits.");} finally {raf.seek(originalPosition);}
}
findLastLineEndBeforePosition 方法具有某些限制。具体来说,它仅适用于类 Unix 系统 (\n),非常长的行可能会导致大量向后读取迭代,并且包含超过 maxSizePerFileInBytes 的行的文件无法拆分。但是,它非常适合拆分访问日志文件等场景,这些场景通常具有短行和大量条目。
性能分析
理论上,我们zero copy拆分文件应该【常用方式】更快,现在是时候衡量它能有多快了。为此,我为这两个实现运行了一些基准测试,这些是结果。
Benchmark Mode Cnt Score Error Units
FileSplitterBenchmark.splitFile avgt 15 1179.429 ± 54.271 ms/op
FileSplitterBenchmark.splitFile:·gc.alloc.rate avgt 15 1349.613 ± 60.903 MB/sec
FileSplitterBenchmark.splitFile:·gc.alloc.rate.norm avgt 15 1694927403.481 ± 6060.581 B/op
FileSplitterBenchmark.splitFile:·gc.count avgt 15 718.000 counts
FileSplitterBenchmark.splitFile:·gc.time avgt 15 317.000 ms
FileSplitterBenchmark.splitFileZeroCopy avgt 15 77.352 ± 1.339 ms/op
FileSplitterBenchmark.splitFileZeroCopy:·gc.alloc.rate avgt 15 23.759 ± 0.465 MB/sec
FileSplitterBenchmark.splitFileZeroCopy:·gc.alloc.rate.norm avgt 15 2555608.877 ± 8644.153 B/op
FileSplitterBenchmark.splitFileZeroCopy:·gc.count avgt 15 10.000 counts
FileSplitterBenchmark.splitFileZeroCopy:·gc.time avgt 15 5.000 ms
以下是用于上述结果的基准测试代码和文件大小。
int maxSizePerFileInBytes = 1024 * 1024 // 1 MB chunks
public void setup() throws Exception {inputFile = Paths.get("/tmp/large_input.txt");outputDir = Paths.get("/tmp/split_output");// Create a large file for benchmarking if it doesn't existif (!Files.exists(inputFile)) {try (BufferedWriter writer = Files.newBufferedWriter(inputFile)) {for (int i = 0; i < 10_000_000; i++) {writer.write("This is line number " + i);writer.newLine();}}}
}
public void splitFile() throws Exception {splitter.split(inputFile, outputDir);
}
public void splitFileZeroCopy() throws Exception {zeroCopySplitter.split(inputFile);
}
zeroCopy表现出相当大的加速,仅用了 77 毫秒,而对于这种特定情况,【常用方式】需要 1179 毫秒。在处理大量数据或许多文件时,这种性能优势可能至关重要。
结论
高效拆分大型文本文件需要系统级性能考虑,而不仅仅是逻辑。虽然基本方法突出了内存作过多的问题,但重新设计的解决方案利用零拷贝技术并保持行完整性,可以显著提高性能。
这证明了系统感知编程和理解 I/O 机制在创建更快、更节省资源的工具来处理大型文本数据(如日志或数据集)方面的影响。
相关文章:

【类拷贝文件的运用】
常用示例 当我们面临将文本文件分成最大大小块的时,我们可能会尝试编写如下代码: public class TestSplit {private static final long maxFileSizeBytes 10 * 1024 * 1024; // 默认10MBpublic void split(Path inputFile, Path outputDir) throws IOException {…...

从 AGI 到具身智能体:解构 AI 核心概念与演化路径全景20250509
🤖 从 AGI 到具身智能体:解构 AI 核心概念与演化路径全景 作者:AI 应用实践者 在过去的几年中,AI 领域飞速发展,从简单的文本生成模型演进为今天具备复杂推理、感知能力的“智能体”系统。本文将从核心概念出发&#x…...
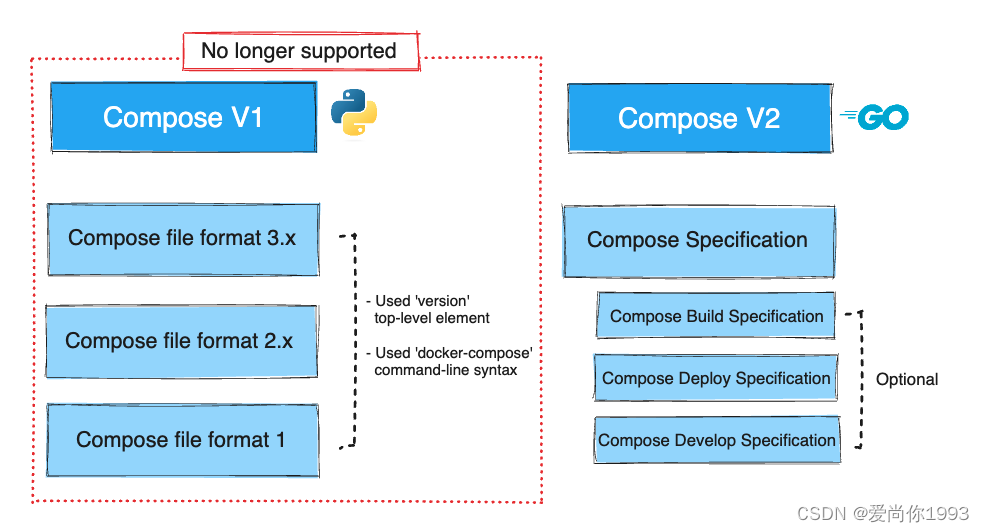
Docker Compose 的历史和发展
这张图表展示了Docker Compose从V1到V2的演变过程,并解释了不同版本的Compose文件格式及其支持情况。以下是对图表的详细讲解: Compose V1 No longer supported: Compose V1已经不再支持。Compose file format 3.x: 使用了版本3.x的Compose文件格式。 …...

ARMV8 RK3399 u-boot TPL启动流程分析 --crt0.S
上一篇介绍到start.S 最后一个指令是跳转到_main, 接下来分析 __main 都做了什么 arch/arm/lib/crt0.S __main 注释写的很详细,主要分为5步 1. 准备board_init_f的运行环境 2. 跳转到board_init_f 3. 设置broad_init_f 申请的stack 和 GD 4. 完整u-boot 执行re…...

从 JIT 即时编译一直讲到CGI|FastGGI|WSGI|ASGI四种协议的实现细节
背景 我一度理解错了这个东西,之前没有AI的时候,也没深究过,还觉得PHP8支持了常驻内存的运行的错误理解,时至今日再来看这个就很清晰了。 另外,早几年对以上4个协议,我也没搞懂,时至今日&…...

Vue.js 页面切换空白与刷新 404 问题深度解析
在使用 Vue.js 开发单页应用 (SPA) 的过程中,开发者经常会遇到两个常见问题:页面切换时出现短暂的空白屏幕,以及刷新页面时返回 404 错误。这两个问题不仅影响用户体验,还可能阻碍项目的正常上线。本文将深入探讨这两个问题的成因…...

CSS3 遮罩
在网页设计中,我们经常需要实现一些特殊的视觉效果来增强用户体验。CSS3 遮罩(mask)允许我们通过控制元素的可见区域来创建各种精美的视觉效果。本文将带你全面了解 CSS3 遮罩的功能和应用。 什么是 CSS3 遮罩? CSS3 遮罩是一种…...

ResNet残差神经网络的模型结构定义(pytorch实现)
ResNet残差神经网络的模型结构定义(pytorch实现) ResNet‑34 ResNet‑34的实现思路。核心在于: 定义残差块(BasicBlock)用 _make_layer 方法堆叠多个残差块按照 ResNet‑34 的通道和层数配置来搭建网络 import torch…...
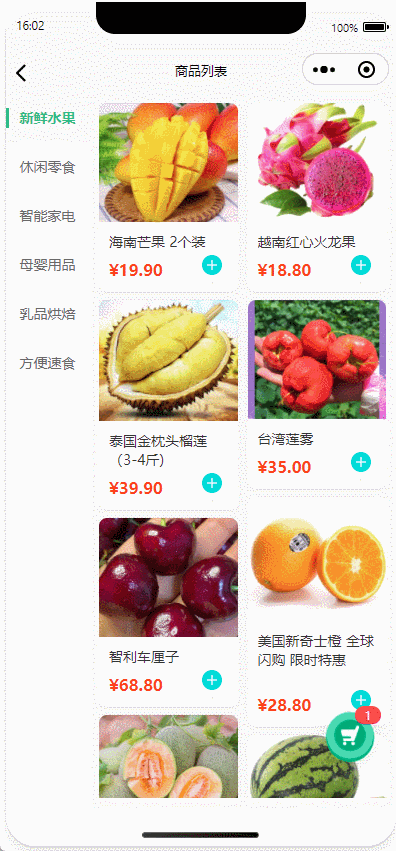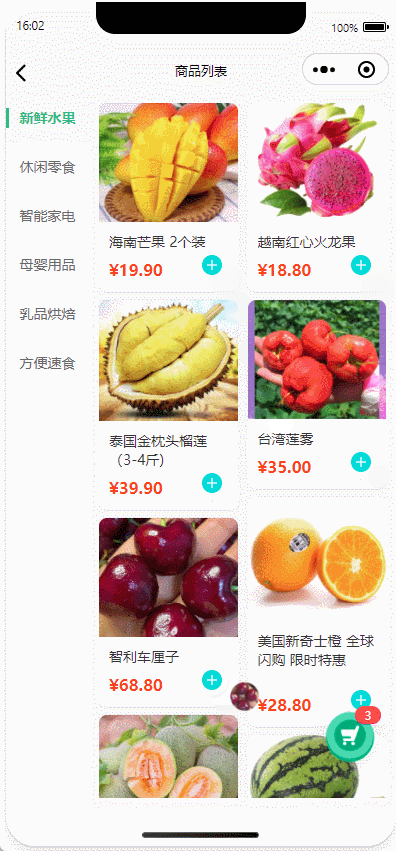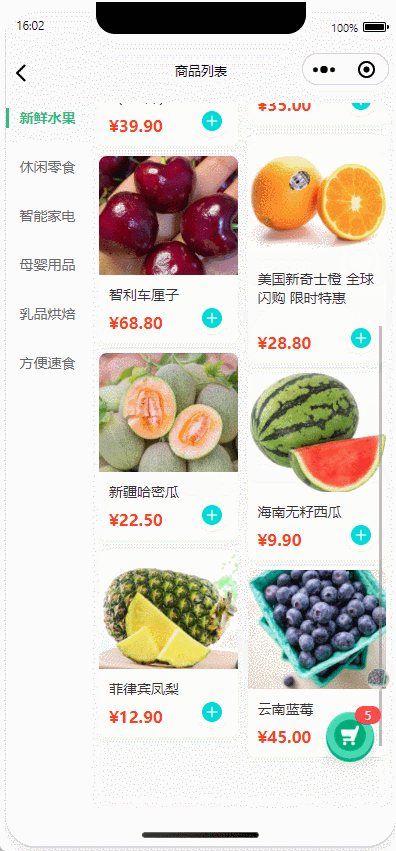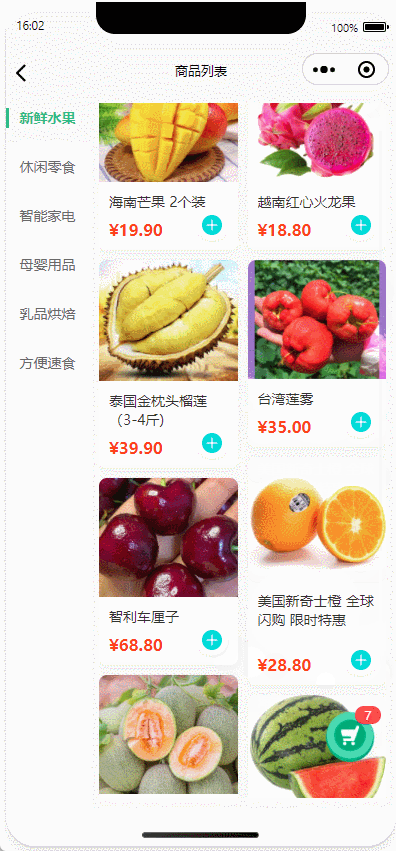
uniapp|商品列表加入购物车实现抛物线动画效果、上下左右抛入、多端兼容(H5、APP、微信小程序)
以uniapp框架为基础,详细解析商品列表加入购物车抛物线动画的实现方案。通过动态获取商品点击位置与购物车坐标,结合CSS过渡动画模拟抛物线轨迹,实现从商品图到购物车图标的动态效果。 目录 核心实现原理坐标动态计算抛物线轨迹模拟动画元素控制代码实现详解模板层设计脚本…...
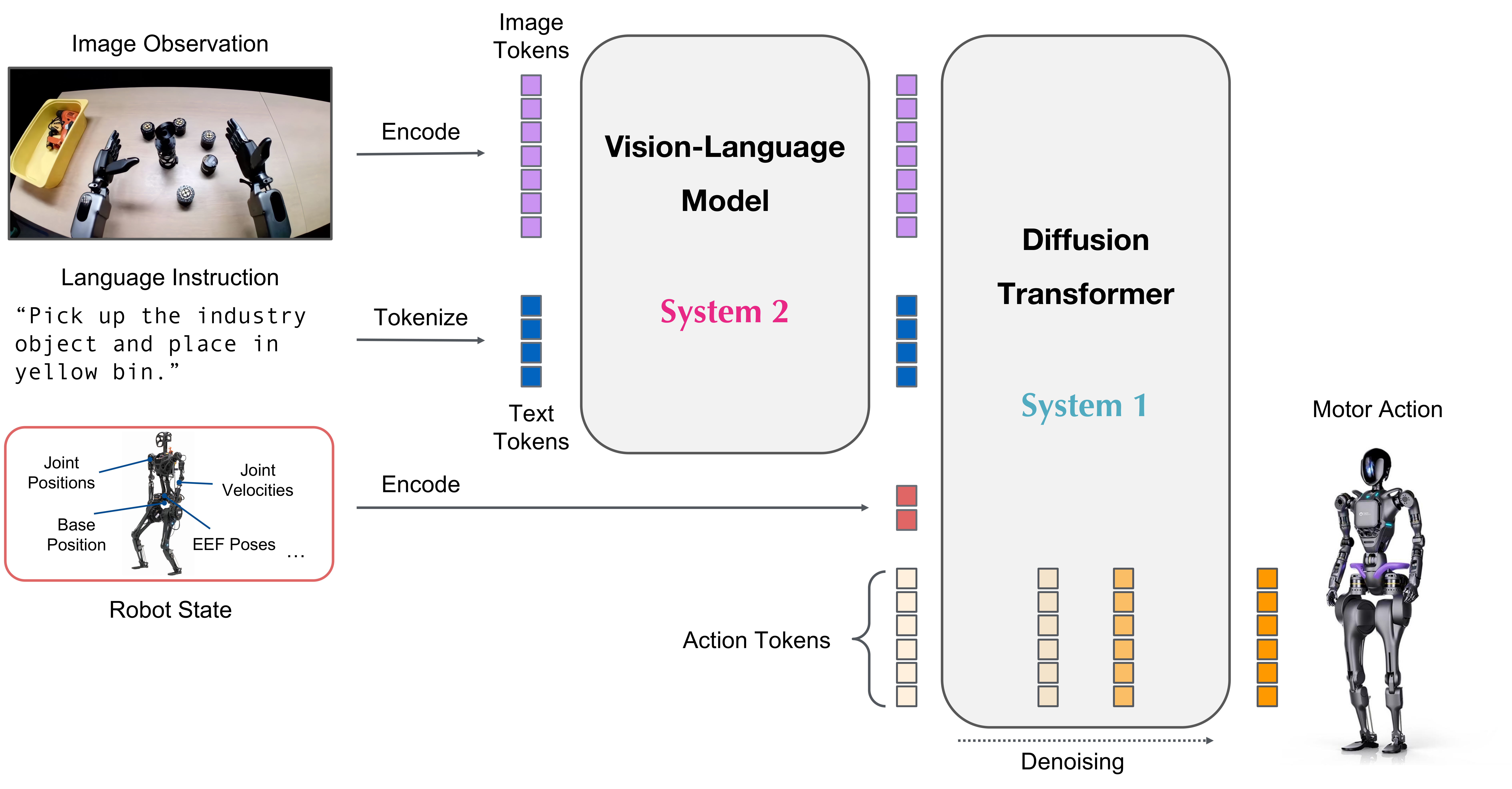
谈AI/OT 的融合
过去的十几年间,工业界讨论最多的话题之一就是IT/OT 融合,现在,我们不仅要实现IT/OT 的融合,更要面向AI/OT 的融合。看起来不太靠谱,却留给我们无限的想象空间。OT 领域的专家们不要再当“九斤老太”,指责这…...
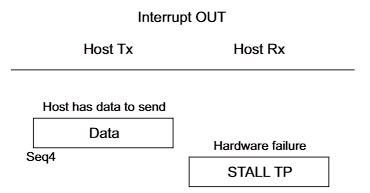
USB传输模式
USB有四种传输模式: 控制传输, 中断传输, 同步传输, 批量传输 1. 中断传输 中断传输一般用于小批量, 非连续的传输. 对实时性要求较高. 常见的使用此传输模式的设备有: 鼠标, 键盘等. 要注意的是, 这里的 “中断” 和我们常见的中断概念有差异. Linux中的中断是设备主动发起的…...

Tomcat的`context.xml`配置详解!
全文目录: 开篇语前言一、context.xml 文件的基本结构二、常见的 context.xml 配置项1. **数据源(DataSource)配置**示例: 2. **日志配置**示例: 3. **设置环境变量(Environment Variables)**示…...

MapReduce 的工作原理
MapReduce 是一种分布式计算框架,用于处理和生成大规模数据集。它将任务分为两个主要阶段:Map 阶段和 Reduce 阶段。开发人员可以使用存储在 HDFS 中的数据,编写 Hadoop 的 MapReduce 任务,从而实现并行处理1。 MapReduce 的工作…...
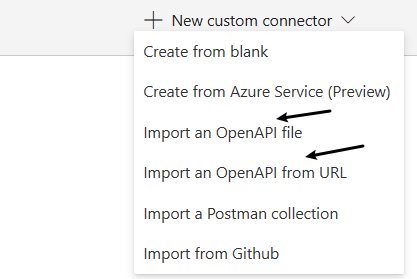
.NET10 - 尝试一下Open Api的一些新特性
1.简单介绍 .NET9中Open Api有了很大的变化,在默认的Asp.NET Core Web Api项目中,已经移除了Swashbuckle.AspNetCore package,同时progrom中也变更为 builder.Servers.AddOpenApi() builder.Services.MapOpenApi() 2025年微软将发布…...

RabbitMQ 工作模式
RabbitMQ 一共有 7 中工作模式,可以先去官网上了解一下(一下截图均来自官网):RabbitMQ 官网 Simple P:生产者,要发送消息的程序;C:消费者,消息的接受者;hell…...

基于C++的多线程网络爬虫设计与实现(CURL + 线程池)
在当今大数据时代,网络爬虫作为数据采集的重要工具,其性能直接决定了数据获取的效率。传统的单线程爬虫在面对海量网页时往往力不从心,而多线程技术可以充分利用现代多核CPU的计算能力,显著提升爬取效率。本文将详细介绍如何使用C…...

Android11.0 framework第三方无源码APP读写断电后数据丢失问题解决
1.前言 在11.0中rom定制化开发中,在某些产品开发中,在某些情况下在App用FileOutputStream读写完毕后,突然断电 会出现写完的数据丢失的问题,接下来就需要分析下关于使用FileOutputStream读写数据的相关流程,来实现相关 功能 2.framework第三方无源码APP读写断电后数据丢…...

国产大模型「五强争霸」:决战AGI,谁主沉浮?
引言 中国AI大模型市场正经历一场史无前例的洗牌!曾经“百模混战”的局面已落幕,字节、阿里、阶跃星辰、智谱和DeepSeek五大巨头强势崛起,形成“基模五强”新格局。这场竞争不仅是技术实力的较量,更是资源、人才与生态的全面博弈。…...

【Python 基础语法】
Python 基础语法是编程的基石,以下从核心要素到实用技巧进行系统梳理: 一、代码结构规范 缩进规则 使用4个空格缩进(PEP 8标准)缩进定义代码块(如函数、循环、条件语句) def greet(name):if name: # 正确缩…...
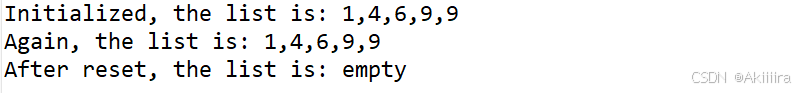
【日撸 Java 三百行】Day 11(顺序表(一))
目录 Day 11:顺序表(一) 一、关于顺序表 二、关于面向对象 三、代码模块分析 1. 顺序表的属性 2. 顺序表的方法 四、代码及测试 拓展: 小结 Day 11:顺序表(一) Task: 在《数…...

path环境变量满了如何处理,分割 PATH 到 Path1 和 Path2
要正确设置 Path1 的值,你需要将现有的 PATH 环境变量 中的部分路径复制到 Path1 和 Path2 中。以下是详细步骤: 步骤 1:获取当前 PATH 的值 打开环境变量窗口: 按 Win R,输入 sysdm.cpl,点击 确定。在 系…...

软考 系统架构设计师系列知识点之杂项集萃(55)
接前一篇文章:软考 系统架构设计师系列知识点之杂项集萃(54) 第89题 某软件公司欲开发一个Windows平台上的公告板系统。在明确用户需求后,该公司的架构师决定采用Command模式实现该系统的界面显示部分,并设计UML类图如…...

保持Word中插入图片的清晰度
大家有没有遇到这个问题,原本绘制的高清晰度图片,插入word后就变模糊了。先说原因,word默认启动了自动压缩图片功能,分享一下如何关闭这项功能,保持Word中插入图片的清晰度。 ①在Word文档中,点击左上角的…...

Web应用开发指南
一、引言 随着互联网的迅猛发展,Web应用已深度融入日常生活的各个方面。为满足用户对性能、交互与可维护性的日益增长的需求,开发者需要一整套高效、系统化的解决方案。在此背景下,前端框架应运而生。不同于仅提供UI组件的工具库,…...

贝叶斯算法
贝叶斯算法是一类基于贝叶斯定理的机器学习算法,它们在分类任务中表现出色,尤其在处理具有不确定性和 probabilistic 关系的数据时具有独特优势。本文将深入探讨贝叶斯算法的核心原理、主要类型以及实际应用案例,带你领略贝叶斯算法在概率推理…...

Linux复习笔记(三) 网络服务配置(web)
遇到的问题,都有解决方案,希望我的博客能为你提供一点帮助。 二、网络服务配置 2.3 web服务配置 2.3.1通信基础:HTTP协议与C/S架构(了解) HTTP协议的核心作用 Web服务基于HTTP/HTTPS协议实现客户端ÿ…...
springboot旅游小程序-计算机毕业设计源码76696
目 录 摘要 1 绪论 1.1研究背景与意义 1.2研究现状 1.3论文结构与章节安排 2 基于微信小程序旅游网站系统分析 2.1 可行性分析 2.1.1 技术可行性分析 2.1.2 经济可行性分析 2.1.3 法律可行性分析 2.2 系统功能分析 2.2.1 功能性分析 2.2.2 非功能性分析 2.3 系统…...
uniapp自定义导航栏搭配插槽
<uni-nav-bar dark :fixed"true" shadow background-color"#007AFF" left-icon"left" left-text"返回" clickLeft"back"><view class"nav-bar-title">{{ navBarTitle }}</view><block v-slo…...
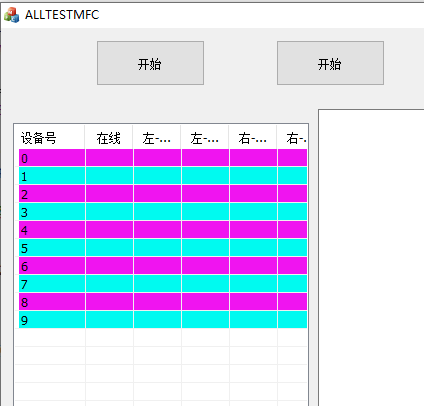
MFC listctrl修改背景颜色
在 MFC 中修改 ListCtrl 控件的行背景颜色,需要通过自绘(Owner-Draw)机制实现。以下是详细的实现方法: 方法一:通过自绘(Owner-Draw)实现 步骤 1:启用自绘属性 在对话框设计器中选…...

Kotlin跨平台Compose Multiplatform实战指南
Kotlin Multiplatform(KMP)结合 Compose Multiplatform 正在成为跨平台开发的热门选择,它允许开发者用一套代码构建 Android、iOS、桌面(Windows/macOS/Linux)和 Web 应用。以下是一个实战指南,涵盖核心概念…...