Westlake-Omni 情感端音频生成式输出模型
简述
github地址在
GitHub - xinchen-ai/Westlake-OmniContribute to xinchen-ai/Westlake-Omni development by creating an account on GitHub.![]() https://github.com/xinchen-ai/Westlake-Omni
https://github.com/xinchen-ai/Westlake-Omni
Westlake-Omni 是由西湖心辰(xinchen-ai)开发的一个开源中文情感端到端语音交互大模型,托管在 Hugging Face 平台 , Hugging Face地址
https://huggingface.co/xinchen-ai/Westlake-Omni![]() https://huggingface.co/xinchen-ai/Westlake-Omni它旨在通过统一的文本和语音模态处理,实现低延迟、高质量的中文情感语音交互。该模型亮点是
https://huggingface.co/xinchen-ai/Westlake-Omni它旨在通过统一的文本和语音模态处理,实现低延迟、高质量的中文情感语音交互。该模型亮点是
Trained on a high-quality Chinese emotional speech dataset, enabling native emotional speech interaction in Chinese. 在高质量的中文情感语音数据集上训练,使其能够实现原生的中文情感语音交互。
应用场景
- 智能助手:在手机或智能家居设备中提供情感化的语音交互。
- 客户服务:作为自动客服,处理咨询和投诉,提供 24/7 服务。
- 教育辅助:支持语言学习和课程辅导,生成情感化的教学语音。
- 医疗咨询:提供语音交互的健康指导,增强患者体验。
- 娱乐与新闻:生成情感化的游戏对话或新闻播报。
1 Westlake-Omni 模型概述
Westlake-Omni 是一个多模态大语言模型,专注于中文情感语音交互。其核心特点包括:
- 统一模态处理:通过离散表示法(discrete representations),将语音和文本模态统一处理,简化跨模态交互。
- 低延迟交互:支持实时语音输入和输出,生成文本和语音响应几乎无延迟。
- 情感表达:在高质量中文情感语音数据集上训练,能够理解和生成具有情感色彩的语音,增强交互的人性化。
- 开源特性:模型代码和权重在 GitHub(https://github.com/xinchen-ai/Westlake-Omni)和 Hugging Face 上公开,支持社区进一步开发和优化。
2. 模型原理与架构
Westlake-Omni 的核心在于其多模态架构,能够同时处理语音和文本输入,并生成相应的文本和情感语音输出。以下从原理和架构层面逐步讲解。
2.1 统一模态处理:离散表示法
Westlake-Omni 采用离散表示法(discrete representations)来统一文本和语音模态的处理。传统多模态模型通常需要独立的语音识别(ASR)、文本处理(NLP)和语音合成(TTS)模块,而 Westlake-Omni 通过将语音和文本转化为统一的离散 token 表示,简化了模态间的转换和处理流程。
- 离散表示的原理:
- 语音信号(如 WAV 文件)通过编码器(可能是 Whisper 或 Wave2Vec 类似的预训练模型)转换为离散的语音 token。
- 文本输入直接通过分词器(tokenizer)转换为文本 token。
- 这些 token 在模型内部被统一编码为嵌入向量(embeddings),进入相同的 transformer 架构处理。
- 输出端,模型可以生成文本 token 或语音 token,并通过解码器转换为自然语言或语音。
- 优势:
- 统一表示减少了模态转换的复杂性,提高了计算效率。
- 支持端到端的训练和推理,降低延迟。
- 便于扩展到其他模态。
2.2 模型架构
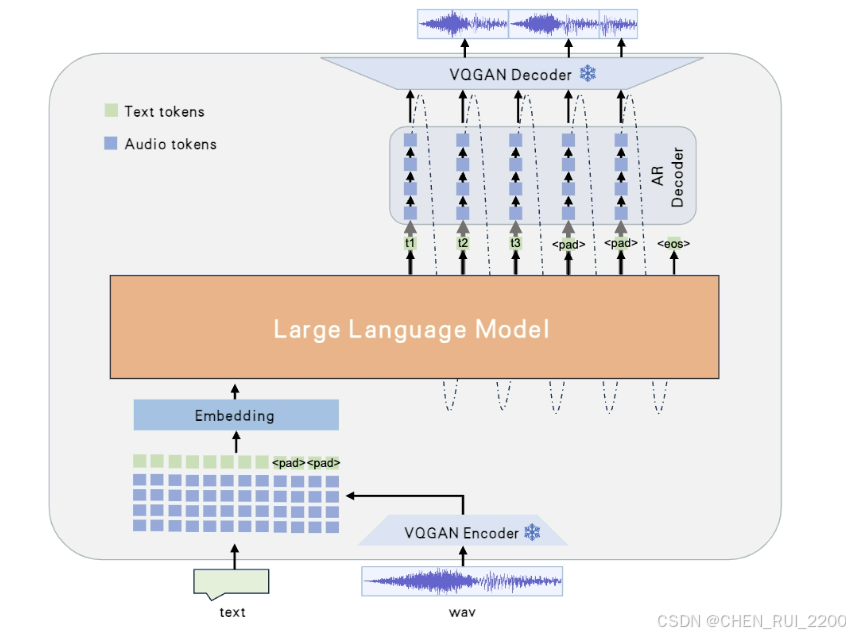
Westlake-Omni 的架构可以分为以下几个关键组件(以下为文字描述的结构,建议参考 GitHub 仓库中的架构图):
- 输入编码器:
- 语音编码器:将原始音频(例如 WAV 文件)编码为离散 token,可能基于 Whisper 或类似的语音预训练模型。
- 文本分词器:将输入文本(例如“最近心情不好,能聊聊吗?”)分词为 token,生成嵌入向量。
- 统一嵌入层:将语音和文本 token 映射到一个共享的嵌入空间,形成统一的输入表示。
- Transformer 核心:
- 基于 Transformer 的多层架构,包含自注意力(self-attention)和前馈神经网络(FFN)。
- 支持多模态输入的上下文建模,能够捕捉语音中的情感线索和文本中的语义信息。
- 可能采用因果注意力(causal attention)机制,确保实时生成(即生成当前 token 时不依赖未来 token)。
- 情感建模模块:
- 专门设计的情感理解和生成模块,用于分析语音输入中的情感色彩(如语调、语速)并在输出中注入相应的情感。
- 可能通过额外的注意力机制或嵌入层,在生成语音时控制情感表达(如高兴、悲伤、平静)。
- 输出解码器:
- 文本解码器:将 Transformer 的输出 token 转换为自然语言文本。
- 语音解码器:将 token 转换为语音波形,可能基于预训练的 TTS 模型(如 Tacotron 或 VITS)。
- 支持同时生成文本和语音,实现“边思考边说话”的效果。
- 低延迟优化:
- 采用流式处理(streaming processing),将输入音频分块(chunked input)处理,减少初始延迟。
- 输出端通过增量生成(incremental generation),实时产生语音和文本。
2.3 模型代码
FireflyArchitecture 模型
FireflyArchitecture 是一个专门为音频处理设计的神经网络模型,主要用于将输入音频(如语音)转换为高质量的音频输出,典型应用包括文本转语音(TTS)或语音转换。它的工作流程可以概括为以下几个步骤:
- 音频预处理:将原始音频波形转换为梅尔频谱图(Mel-Spectrogram),这是一种模仿人类听觉的频率表示形式。
- 特征编码:将梅尔频谱图编码为高层次的特征表示(latent representation)。
- 特征量化:通过量化和下采样,将特征压缩为离散的 token 表示,减少数据量并便于处理。
- 音频生成:将量化的特征解码为高质量的音频波形。
模型由以下四个核心组件组成:
- LogMelSpectrogram:将原始音频转换为梅尔频谱图。
- ConvNeXtEncoder:对梅尔频谱图进行编码,提取高层次特征。
- DownsampleFiniteScalarQuantize:对特征进行量化和下采样,生成离散表示。
- HiFiGANGenerator:将量化后的特征解码为音频波形。
1. LogMelSpectrogram(梅尔频谱图转换)
作用:将原始音频波形(时域信号)转换为梅尔频谱图,这是一种基于频率的表示形式,更适合人类听觉感知和后续处理。
通俗解释:
- 想象音频波形是一条上下波动的曲线,记录了声音的振幅随时间变化。直接处理这种波形很复杂,因为它包含大量数据。
- LogMelSpectrogram 就像一个“音频分析仪”,它把波形分解成不同频率的成分(类似乐谱中的音高),然后按照人类耳朵对频率的敏感度(梅尔尺度)重新组织这些信息。
- 最终输出的是一个二维图像(梅尔频谱图),横轴是时间,纵轴是频率,亮度表示强度。
实现细节:
- 输入:原始音频波形(1D 张量,形状为 [batch_size, 1, time_steps])。
- 处理步骤:
- 短时傅里叶变换(STFT):通过 torch.stft 将音频分成小段(帧),计算每段的频率成分,生成线性频谱图。
- 参数:n_fft=2048(傅里叶变换点数)、win_length=2048(窗口长度)、hop_length=512(帧间步长)。
- 使用汉宁窗(Hann Window)平滑信号,减少频谱泄漏。
- 梅尔尺度转换:通过梅尔滤波器组(torchaudio.functional.melscale_fbanks)将线性频谱图转换为梅尔频谱图。
- 参数:n_mels=160(梅尔滤波器数量)、sample_rate=44100(采样率)、f_min=0.0(最低频率)、f_max=22050(最高频率)。
- 对数压缩:对梅尔频谱图应用对数操作(torch.log),将幅度压缩到更适合神经网络处理的范围。
- 短时傅里叶变换(STFT):通过 torch.stft 将音频分成小段(帧),计算每段的频率成分,生成线性频谱图。
- 输出:梅尔频谱图(形状为 [batch_size, n_mels, time_frames]),其中 time_frames = time_steps // hop_length。
- 关键特性:
- 支持动态采样率调整(通过重采样)。
- 可选择返回线性频谱图(return_linear=True)用于调试或多任务训练。
- 使用反射填充(reflect 模式)处理音频边界,避免边缘失真。
def forward(self, x: Tensor, return_linear: bool = False, sample_rate: int = None) -> Tensor:if sample_rate is not None and sample_rate != self.sample_rate:x = F.resample(x, orig_freq=sample_rate, new_freq=self.sample_rate)linear = self.spectrogram(x) # 线性频谱图x = self.apply_mel_scale(linear) # 梅尔频谱图x = self.compress(x) # 对数压缩if return_linear:return x, self.compress(linear)return x- 梅尔频谱图比原始波形更紧凑,减少了数据量,便于神经网络处理。
- 梅尔尺度模拟了人类听觉对高低频的非线性感知,使得模型更擅长处理语音相关任务。
2. ConvNeXtEncoder(特征编码器)
作用:对梅尔频谱图进行编码,提取高层次的特征表示,用于后续量化和解码。
通俗解释:
- 梅尔频谱图就像一张描述声音的“图像”,但它仍然包含很多冗余信息。ConvNeXtEncoder 就像一个“特征提取器”,它分析这张图像,提炼出最重要的模式和结构(比如语音的音调、节奏、语义)。
- 它使用了一种现代化的卷积网络结构(ConvNeXt),通过多层处理逐步将梅尔频谱图压缩为更抽象的特征表示。
实现细节:
- 输入:梅尔频谱图(形状为 [batch_size, n_mels=160, time_frames])。
- 结构:
- 下采样层(downsample_layers):
- 初始层(stem):通过 FishConvNet(1D 卷积)将输入通道从 n_mels=160 转换为第一个维度 dims[0]=128,并应用层归一化(LayerNorm)。
- 后续下采样层:通过 1x1 卷积和层归一化,将通道数逐步增加(dims=[128, 256, 384, 512]),压缩时间维度。
- 阶段(stages):
- 包含多个 ConvNeXtBlock,每个块是一个残差结构,结合深度卷积(depthwise conv)、层归一化、MLP(多层感知机)和随机 DropPath(随机深度,增强泛化能力)。
- 每个阶段有不同数量的块(depths=[3, 3, 9, 3]),对应不同的通道数(dims)。
- 归一化:最后通过层归一化(LayerNorm)稳定输出。
- 下采样层(downsample_layers):
- 输出:高层次特征表示(形状为 [batch_size, dims[-1]=512, reduced_time_frames]),时间维度因下采样而减少。
- 关键特性:
- 使用 ConvNeXtBlock,结合深度卷积和 MLP,提升特征提取能力。
- 支持随机深度(drop_path_rate=0.2),防止过拟合。
- 初始化权重采用截断正态分布(trunc_normal_),确保训练稳定性。
def forward(self, x: torch.Tensor) -> torch.Tensor:for i in range(len(self.downsample_layers)):x = self.downsample_layers[i](x)x = self.stages[i](x)return self.norm(x)- ConvNeXtEncoder 提取了音频的语义和结构信息,为后续量化提供了高质量的特征。
- 其现代化的卷积设计(ConvNeXt)比传统卷积网络更高效,适合处理复杂音频数据。
3. DownsampleFiniteScalarQuantize(特征量化和下采样)
作用:将编码后的特征量化为离散的 token 表示,并通过下采样减少时间维度,压缩数据量。
通俗解释:
- 编码后的特征就像一本厚厚的书,包含很多细节,但我们只需要一个简短的“摘要”。DownsampleFiniteScalarQuantize 就像一个“压缩机”,它把特征简化为一组数字(token),就像把一首歌压缩成几个关键音符。
- 它还通过下采样减少时间分辨率,降低计算量。
实现细节:
- 输入:编码后的特征(形状为 [batch_size, dim=512, time_frames])。
- 结构:
- 下采样(downsample):
- 通过一系列 FishConvNet 和 ConvNeXtBlock,将时间维度按 downsample_factor=[2, 2] 缩减(总缩减因子为 4)。
- 通道数根据 downsample_dims 调整,保持信息完整性。
- 量化(residual_fsq):
- 使用 GroupedResidualFSQ(分组残差有限标量量化),将特征量化为离散的索引(indices)。
- 参数:n_codebooks=1(量化器数量)、n_groups=8(分组数)、levels=[8, 5, 5, 5](量化级别,约 2^10 个可能值)。
- 上采样(upsample):
- 在解码时,通过 FishTransConvNet 和 ConvNeXtBlock,将量化后的特征恢复到原始时间分辨率。
- 下采样(downsample):
- 输出:
- 编码:量化索引(形状为 [batch_size, n_groups * n_codebooks, reduced_time_frames])。
- 解码:恢复的特征(形状为 [batch_size, dim=512, original_time_frames])。
- 关键特性:
- 向量量化(FSQ)减少了存储和计算需求,适合实时应用。
- 分组残差量化提高了量化精度。
- 下采样和上采样确保时间维度的可逆性。
def encode(self, z):z = self.downsample(z)_, indices = self.residual_fsq(z.mT)indices = rearrange(indices, "g b l r -> b (g r) l")return indicesdef decode(self, indices: torch.Tensor):indices = rearrange(indices, "b (g r) l -> g b l r", g=self.residual_fsq.groups)z_q = self.residual_fsq.get_output_from_indices(indices)z_q = self.upsample(z_q.mT)return z_q4. HiFiGANGenerator(音频生成器)
作用:将量化后的特征解码为高质量的音频波形。
通俗解释:
- 量化后的特征就像一个简化的“乐谱”,HiFiGANGenerator 是一个“音乐家”,它根据这个乐谱重新演奏出一首完整的歌曲(音频波形)。
- 它使用了一种高效的生成器结构(HiFi-GAN),通过上采样和残差块生成逼真的音频。
实现细节:
- 输入:量化后恢复的特征(形状为 [batch_size, dim=512, time_frames])。
- 结构:
- 预卷积(conv_pre):
- 通过 FishConvNet 将输入通道从 num_mels=512 转换为初始通道 upsample_initial_channel=512。
- 上采样层(ups):
- 通过 FishTransConvNet,将时间维度按 upsample_rates=[8, 8, 2, 2, 2] 上采样(总因子为 512,匹配 hop_length)。
- 通道数逐步减半(512 → 256 → 128 → 64 → 32)。
- 残差块(resblocks):
- 使用 ParallelBlock,包含多个 ResBlock1,每个块有不同核大小(resblock_kernel_sizes=[3, 7, 11])和膨胀率(resblock_dilation_sizes)。
- 并行处理不同核大小的特征,增强多样性。
- 后处理:
- 通过 SiLU 激活(activation_post)和 FishConvNet(conv_post)生成最终波形。
- 使用 tanh 激活将输出限制在 [-1, 1],匹配音频波形范围。
- 预卷积(conv_pre):
- 输出:音频波形(形状为 [batch_size, 1, time_steps]),时间步数为 time_frames * hop_length。
- 关键特性:
- HiFi-GAN 结构以高保真音频生成著称,广泛用于 TTS。
- 权重归一化(weight_norm)提高训练稳定性。
- 支持梯度检查点(checkpoint),降低内存占用。
def forward(self, x):x = self.conv_pre(x)for i in range(self.num_upsamples):x = F.silu(x, inplace=True)x = self.ups[i](x)x = self.resblocks[i](x)x = self.activation_post(x)x = self.conv_post(x)x = torch.tanh(x)return x- HiFiGANGenerator 确保生成的音频具有高保真度,接近人类语音。
- 其上采样和残差设计平衡了质量和效率,适合实时应用。
3 结构示意图
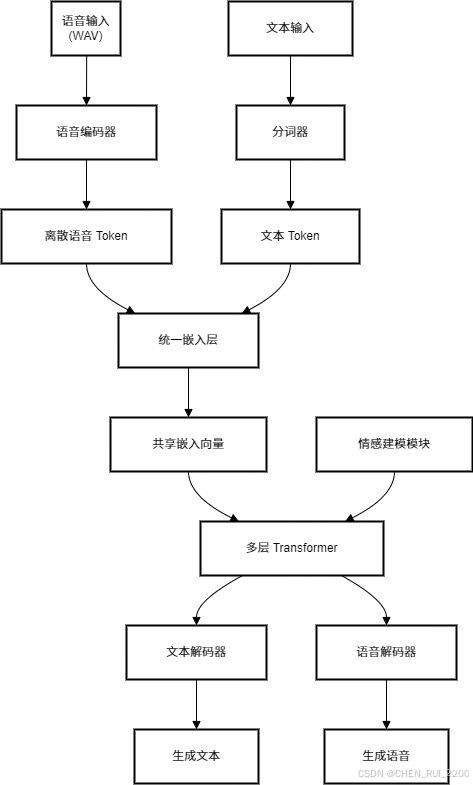
Westlake-Omni 的低延迟特性是其一大亮点,依赖以下技术:
- 流式输入处理:语音输入被分块处理,每收到一小段音频即可开始编码和生成响应,无需等待完整输入。
- 增量生成:模型在生成 token 时逐个输出,而不是一次性生成完整序列,适合实时对话。
- 高效推理:通过优化 Transformer 架构(如减少注意力计算复杂度)和硬件加速(如 GPU),确保快速响应。
3.1 情感理解与表达
Westlake-Omni 在高质量中文情感语音数据集上训练,具备以下能力:
- 情感理解:通过分析语音的音高、语速、音量等特征,识别用户的情感状态(如悲伤、兴奋)。
- 情感生成:在生成语音时,调整输出的语调和节奏,匹配目标情感。例如,回应“心情不好”时,生成带有安慰语气的语音。
- 上下文保持:通过 Transformer 的长上下文建模能力,维持对话的连贯性和情感一致性。
3.2 数据流与整体工作流程
FireflyArchitecture 的整体工作流程如下:
def encode(self, audios, audio_lengths):mels = self.spec_transform(audios)mel_lengths = audio_lengths // self.spec_transform.hop_lengthmel_masks = sequence_mask(mel_lengths, mels.shape[2])mels = mels * mel_masks[:, None, :].float()encoded_features = self.backbone(mels) * mel_masks[:, None, :].float()feature_lengths = mel_lengths // self.downsample_factorreturn self.quantizer.encode(encoded_features), feature_lengthsdef decode(self, indices, feature_lengths):z = self.quantizer.decode(indices) * mel_masks[:, None, :].float()x = self.head(z) * audio_masks[:, None, :].float()return x, audio_lengths- 输入:原始音频波形([batch_size, 1, time_steps])和对应的长度(audio_lengths)。
- 梅尔频谱图转换:
- 通过 LogMelSpectrogram 将音频转换为梅尔频谱图([batch_size, n_mels, time_frames])。
- 使用掩码(sequence_mask)处理变长序列。
- 编码:
- ConvNeXtEncoder 将梅尔频谱图编码为高层次特征([batch_size, dim, reduced_time_frames])。
- DownsampleFiniteScalarQuantize 量化为离散索引([batch_size, n_groups * n_codebooks, further_reduced_time_frames])。
- 解码:
- DownsampleFiniteScalarQuantize 将索引解码为特征([batch_size, dim, time_frames])。
- HiFiGANGenerator 将特征转换为音频波形([batch_size, 1, time_steps])。
3.3 优势与局限性
优势
- 端到端设计:从语音输入到语音输出全程由单一模型处理,减少模块间误差。
- 低延迟:流式处理和增量生成适合实时交互。
- 情感能力:在中文情感语音交互方面表现出色,增强用户体验。
- 开源:公开代码和模型权重,便于社区优化和定制。
局限性
- 数据集依赖:模型性能依赖于中文情感语音数据集的质量和多样性,可能在非中文或特定方言场景下表现不佳。
- 计算资源:实时推理需要 GPU 支持,对硬件要求较高。
- 模态扩展:目前专注于语音和文本,尚未支持图像或视频输入,功能相对单一。
- 开源文档:官方文档可能不够详细,需参考代码深入理解。
与其他模型的对比
与 Qwen2.5-Omni()和 Mini-Omni()等模型相比,Westlake-Omni 的特点如下:
- 与 Qwen2.5-Omni 的对比:
- 相似点:两者均为端到端多模态模型,支持文本和语音交互。
- 不同点:Qwen2.5-Omni 支持更多模态(包括图像和视频),而 Westlake-Omni 专注于中文情感语音,延迟更低,情感表达更强。
- 架构差异:Qwen2.5-Omni 采用 Thinker-Talker 架构,而 Westlake-Omni 强调离散表示的统一处理。
- 与 Mini-Omni 的对比:
- 相似点:两者均为开源,专注于实时语音交互。
- 不同点:Mini-Omni 使用 Qwen2 作为语言骨干,规模较小,而 Westlake-Omni 更专注于中文情感场景,数据集更定制化。
使用页面测试
输入文本:
因为无法播放音频,我截取控制台输出
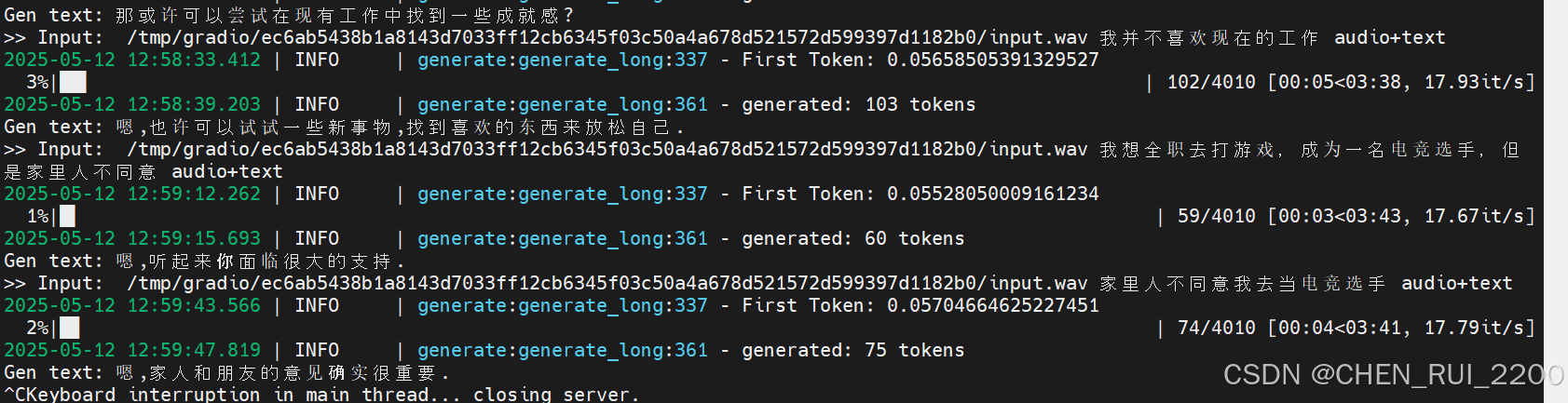
>> Input: /tmp/gradio/ec6ab5438b1a8143d7033ff12cb6345f03c50a4a678d521572d599397d1182b0/input.wav 我并不喜欢现在的工作 audio+text
2025-05-12 12:58:33.412 | INFO | generate:generate_long:337 - First Token: 0.05658505391329527
3%|██▍ | 102/4010 [00:05<03:38, 17.93it/s]
2025-05-12 12:58:39.203 | INFO | generate:generate_long:361 - generated: 103 tokens
Gen text: 嗯,也许可以试试一些新事物,找到喜欢的东西来放松自己.
>> Input: /tmp/gradio/ec6ab5438b1a8143d7033ff12cb6345f03c50a4a678d521572d599397d1182b0/input.wav 我想全职去打游戏,成为一名电竞选手,但是家里人不同意 audio+text
2025-05-12 12:59:12.262 | INFO | generate:generate_long:337 - First Token: 0.05528050009161234
1%|█▍ | 59/4010 [00:03<03:43, 17.67it/s]
2025-05-12 12:59:15.693 | INFO | generate:generate_long:361 - generated: 60 tokens
Gen text: 嗯,听起来你面临很大的支持.
>> Input: /tmp/gradio/ec6ab5438b1a8143d7033ff12cb6345f03c50a4a678d521572d599397d1182b0/input.wav 家里人不同意我去当电竞选手 audio+text
2025-05-12 12:59:43.566 | INFO | generate:generate_long:337 - First Token: 0.05704664625227451
2%|█▊ | 74/4010 [00:04<03:41, 17.79it/s]
2025-05-12 12:59:47.819 | INFO | generate:generate_long:361 - generated: 75 tokens
Gen text: 嗯,家人和朋友的意见确实很重要.
相关文章:
Westlake-Omni 情感端音频生成式输出模型
简述 github地址在 GitHub - xinchen-ai/Westlake-OmniContribute to xinchen-ai/Westlake-Omni development by creating an account on GitHub.https://github.com/xinchen-ai/Westlake-Omni Westlake-Omni 是由西湖心辰(xinchen-ai)开发的一个开源…...

Egg.js知识框架
一、Egg.js 核心概念 1. Egg.js 简介 基于 Koa 的企业级 Node.js 框架(阿里开源) 约定优于配置(Convention over Configuration) 插件化架构,内置多进程管理、日志、安全等能力 适合中大型企业应用,提供…...
随手记录5
一些顶级思维: 顶级思维 1、永远不要自卑。 也永远不要感觉自己比别人差,这个人有没有钱,有多少钱,其实跟你都没有关系。有很多人就是那个奴性太强,看到比自己优秀的人,甚至一些装逼的人,这…...
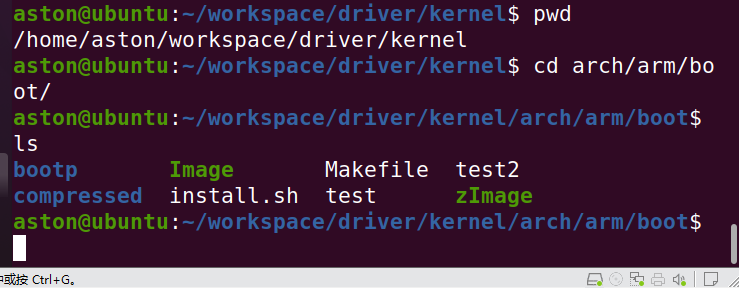
Linux驱动:驱动编译流程了解
要求 1、开发板中的linux的zImage必须是自己编译的 2、内核源码树,其实就是一个经过了配置编译之后的内核源码。 3、nfs挂载的rootfs,主机ubuntu中必须搭建一个nfs服务器。 内核源码树 解压 tar -jxvf x210kernel.tar.bz2 编译 make x210ii_qt_defconfigmakeCan’t use ‘…...
使用 Flowise 构建基于私有知识库的智能客服 Agent(图文教程)
使用 Flowise 构建基于私有知识库的智能客服 Agent(图文教程) 在构建 AI 客服时,常见的需求是让机器人基于企业自身的知识文档,提供准确可靠的答案。本文将手把手教你如何使用 Flowise + 向量数据库(如 Pinecone),构建一个结合 RAG(Retrieval-Augmented Generation)检…...

RabbitMQ ③-Spring使用RabbitMQ
Spring使用RabbitMQ 创建 Spring 项目后,引入依赖: <!-- https://mvnrepository.com/artifact/org.springframework.boot/spring-boot-starter-amqp --> <dependency><groupId>org.springframework.boot</groupId><artifac…...

测试文章标题01
模型上下文协议(Model Context Protocol, MCP)深度解析 一、MCP的核心概念 模型上下文协议(Model Context Protocol, MCP)是一种用于规范机器学习模型与外部环境交互的标准化框架。其核心目标是通过定义统一的接口和数据格式&am…...
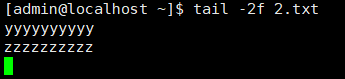
linux中常用的命令(四)
目录 1-cat查看文件内容 2-more命令 3-less命令 4-head命令 5-tail命令 1-cat查看文件内容 cat中的一些操作 -b : 列出行号(不含空白行)-E : 将结尾的断行以 $ 的形式展示出来-n : 列出行号(含空白行)-T : 将 tab 键 以 ^I 显示…...
)
2025年阿里云大数据ACP高级工程师认证模拟试题(附答案解析)
这篇文章的内容是阿里云大数据ACP高级工程师认证考试的模拟试题。 所有模拟试题由AI自动生成,主要为了练习和巩固知识,并非所谓的 “题库”,考试中如果出现同样试题那真是纯属巧合。 1、下列关于MaxCompute的描述中,错误的是&am…...

【FAQ】HarmonyOS SDK 闭源开放能力 — PDF Kit
1.问题描述: 预览PDF文件,文档上所描述的loadDocument接口,可以返回文件的状态,并无法实现PDF的预览,是否有能预览PDF相关接口? 解决方案: 1、执行loadDocument进行加载PDF文件后,…...
的翻转概率)
二元随机响应(Binary Randomized Response, RR)的翻转概率
随机响应(Randomized Response)机制 ✅ 回答核心: p 1 1 e ε 才是「翻转概率」 \boxed{p \frac{1}{1 e^{\varepsilon}}} \quad \text{才是「翻转概率」} p1eε1才是「翻转概率」 而: q e ε 1 e ε 是「保留真实值」…...

hive两个表不同数据类型字段关联引发的数据倾斜
不同数据类型引发的Hive数据倾斜解决方案 #### 一、原因分析 当两个表的关联字段存在数据类型不一致时(如int vs string、bigint vs decimal),Hive会触发隐式类型转换引发以下问题: Key值的精度损失:若关联字…...
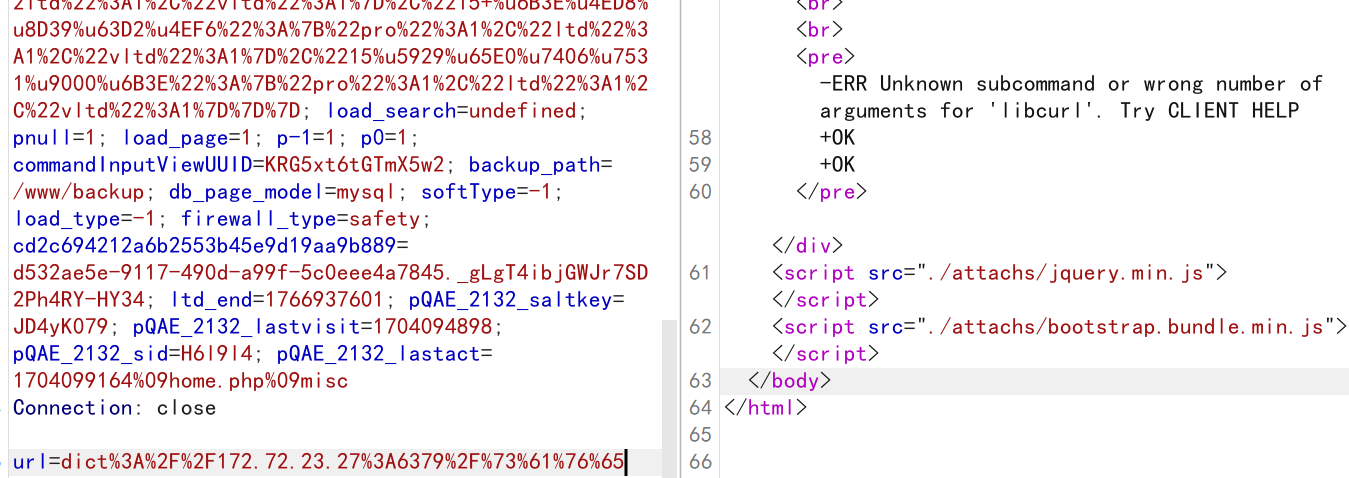
利用SSRF击穿内网!kali靶机实验
目录 1. 靶场拓扑图 2. 判断SSRF的存在 3. SSRF获取本地信息 3.1. SSRF常用协议 3.2. 使用file协议 4. 172.150.23.1/24探测端口 5. 172.150.23.22 - 代码注入 6. 172.150.23.23 SQL注入 7. 172.150.23.24 命令执行 7.1. 实验步骤 8. 172.150.23.27:6379 Redis未授权…...
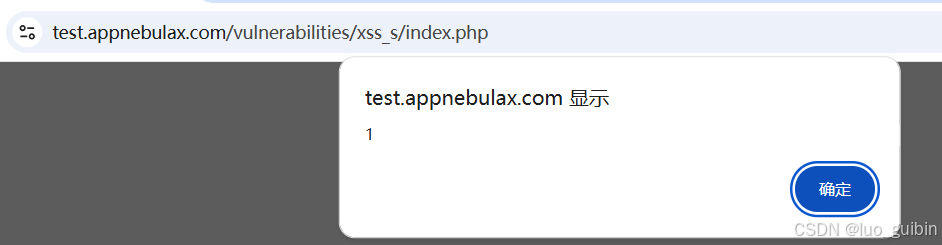
DVWA在线靶场-xss部分
目录 1. xxs(dom) 1.1 low 1.2 medium 1.3 high 1.4 impossible 2. xss(reflected) 反射型 2.1 low 2.2 medium 2.3 high 2.4 impossible 3. xss(stored)存储型 --留言板 3.1 low 3.2 medium 3.3 high 3.…...
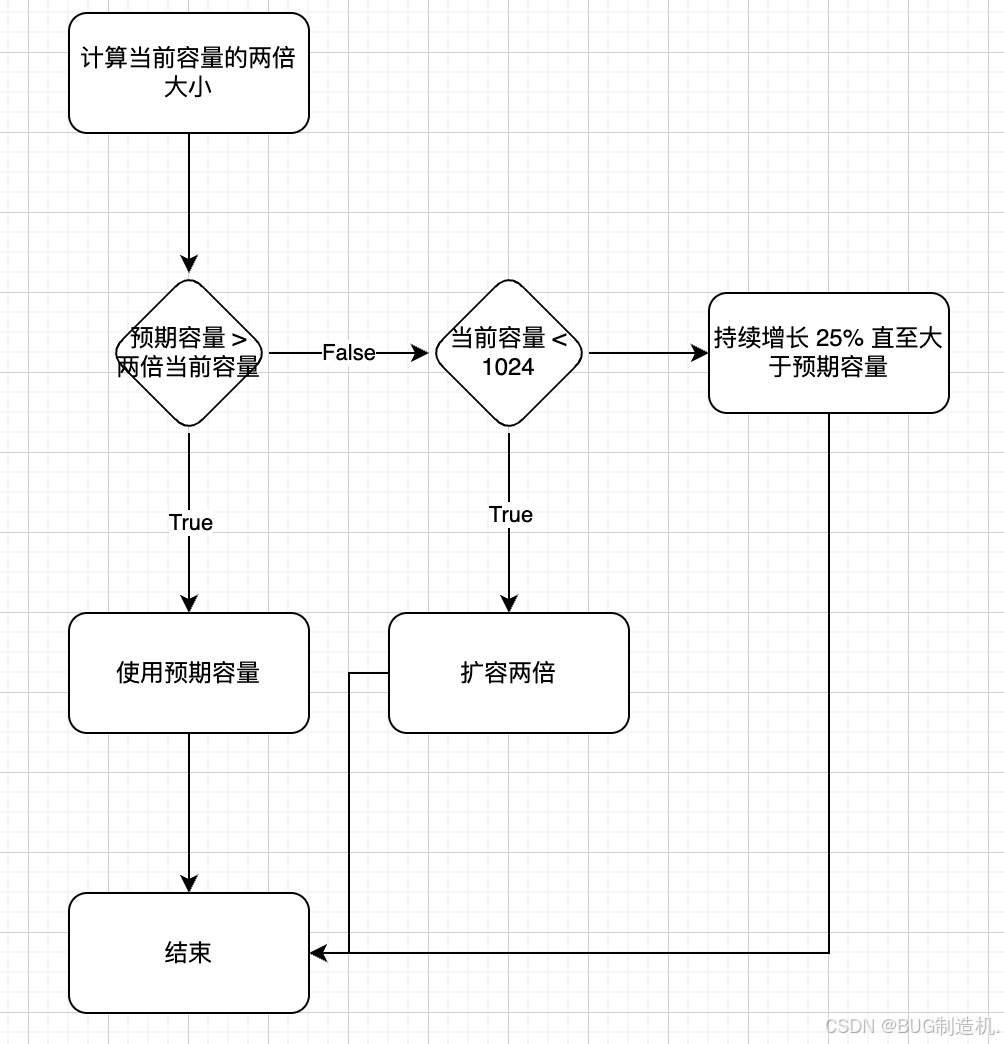
Go 语言 slice(切片) 的使用
序言 在许多开发语言中,动态数组是必不可少的一个组成部分。在实际的开发中很少会使用到数组,因为对于数组的大小大多数情况下我们是不能事先就确定好的,所以他不够灵活。动态数组通过提供自动扩容的机制,极大地提升了开发效率。这…...

Android Exoplayer 实现多个音视频文件混合播放以及音轨切换
在之前的文章ExoPlayer中常见MediaSource子类的区别和使用场景中介绍了Exoplayer中各种子MediaSource的使用场景,这篇我们着重详细介绍下实现多路流混合播放的用法。常见的使用场景有:视频文件电影字幕、正片视频广告视频、背景视频背景音乐等。 初始化…...

深入浅出:Java 中的动态类加载与编译技术
1. 引言 Java 的动态性是其强大功能之一,允许开发者在运行时加载和编译类,从而构建灵活、可扩展的应用程序。动态类加载和编译在许多高级场景中至关重要,例如插件系统、动态代理、框架开发(如 Spring)和代码生成工具。Java 提供了两大核心机制来实现这一目标: 自定义 Cl…...

js常用的数组遍历方式
以下是一个完整的示例,将包含图片、文字和数字的数组渲染到 HTML 页面,使用 多种遍历方式 实现不同的渲染效果: 1. 准备数据(数组) const items [{ id: 1, name: "苹果", price: 5.99, image: "h…...

【网络编程】五、三次握手 四次挥手
文章目录 Ⅰ. 三次握手Ⅱ. 建立连接后的通信Ⅲ. 四次挥手 Ⅰ. 三次握手 1、首先双方都是处于未通信的状态,也就是关闭状态 CLOSE。 2、因为服务端是为了服务客户端的,所以它会提前调用 listen() 函数进行对客户端请求的监听。 3、接着客户端就…...

【类拷贝文件的运用】
常用示例 当我们面临将文本文件分成最大大小块的时,我们可能会尝试编写如下代码: public class TestSplit {private static final long maxFileSizeBytes 10 * 1024 * 1024; // 默认10MBpublic void split(Path inputFile, Path outputDir) throws IOException {…...

从 AGI 到具身智能体:解构 AI 核心概念与演化路径全景20250509
🤖 从 AGI 到具身智能体:解构 AI 核心概念与演化路径全景 作者:AI 应用实践者 在过去的几年中,AI 领域飞速发展,从简单的文本生成模型演进为今天具备复杂推理、感知能力的“智能体”系统。本文将从核心概念出发&#x…...
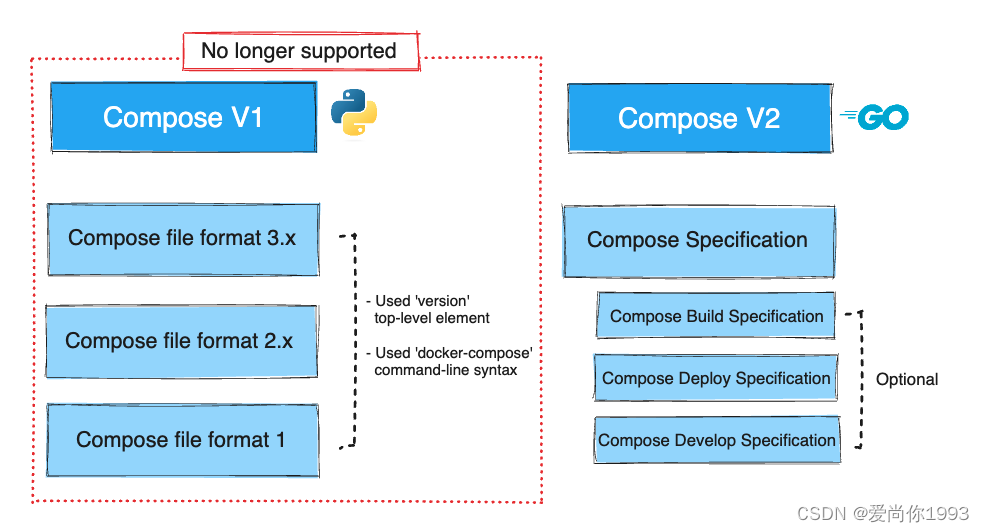
Docker Compose 的历史和发展
这张图表展示了Docker Compose从V1到V2的演变过程,并解释了不同版本的Compose文件格式及其支持情况。以下是对图表的详细讲解: Compose V1 No longer supported: Compose V1已经不再支持。Compose file format 3.x: 使用了版本3.x的Compose文件格式。 …...

ARMV8 RK3399 u-boot TPL启动流程分析 --crt0.S
上一篇介绍到start.S 最后一个指令是跳转到_main, 接下来分析 __main 都做了什么 arch/arm/lib/crt0.S __main 注释写的很详细,主要分为5步 1. 准备board_init_f的运行环境 2. 跳转到board_init_f 3. 设置broad_init_f 申请的stack 和 GD 4. 完整u-boot 执行re…...

从 JIT 即时编译一直讲到CGI|FastGGI|WSGI|ASGI四种协议的实现细节
背景 我一度理解错了这个东西,之前没有AI的时候,也没深究过,还觉得PHP8支持了常驻内存的运行的错误理解,时至今日再来看这个就很清晰了。 另外,早几年对以上4个协议,我也没搞懂,时至今日&…...

Vue.js 页面切换空白与刷新 404 问题深度解析
在使用 Vue.js 开发单页应用 (SPA) 的过程中,开发者经常会遇到两个常见问题:页面切换时出现短暂的空白屏幕,以及刷新页面时返回 404 错误。这两个问题不仅影响用户体验,还可能阻碍项目的正常上线。本文将深入探讨这两个问题的成因…...

CSS3 遮罩
在网页设计中,我们经常需要实现一些特殊的视觉效果来增强用户体验。CSS3 遮罩(mask)允许我们通过控制元素的可见区域来创建各种精美的视觉效果。本文将带你全面了解 CSS3 遮罩的功能和应用。 什么是 CSS3 遮罩? CSS3 遮罩是一种…...

ResNet残差神经网络的模型结构定义(pytorch实现)
ResNet残差神经网络的模型结构定义(pytorch实现) ResNet‑34 ResNet‑34的实现思路。核心在于: 定义残差块(BasicBlock)用 _make_layer 方法堆叠多个残差块按照 ResNet‑34 的通道和层数配置来搭建网络 import torch…...
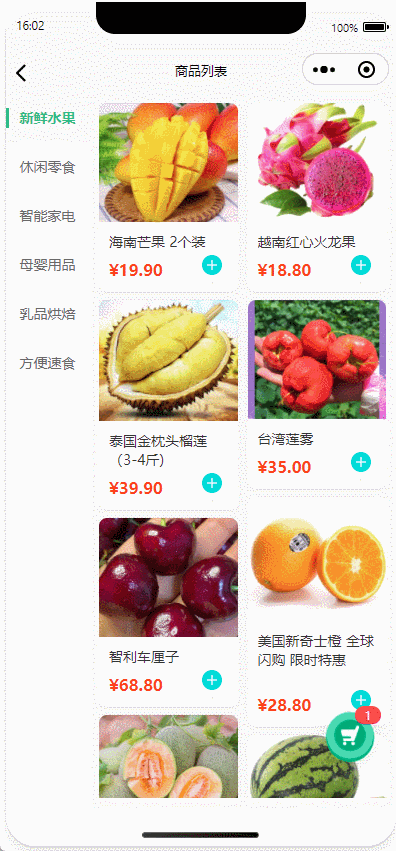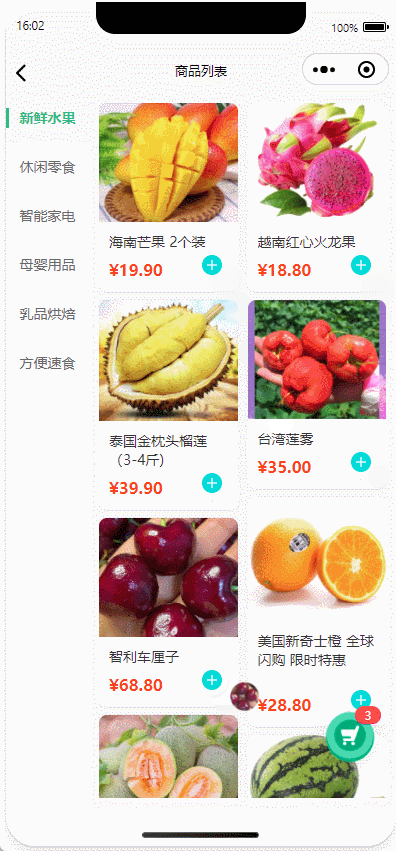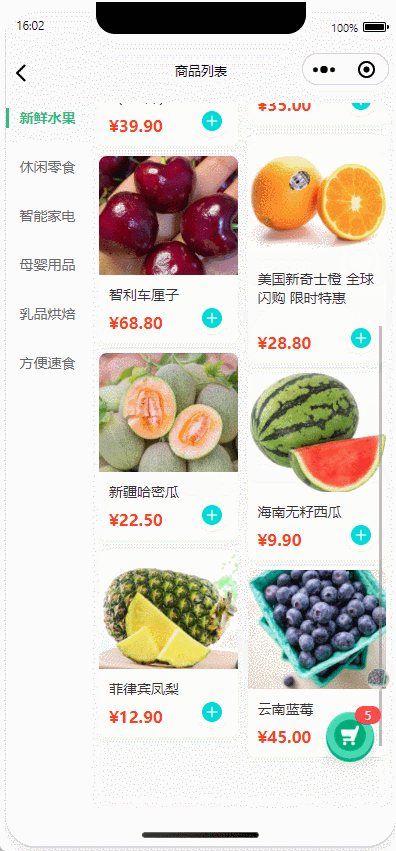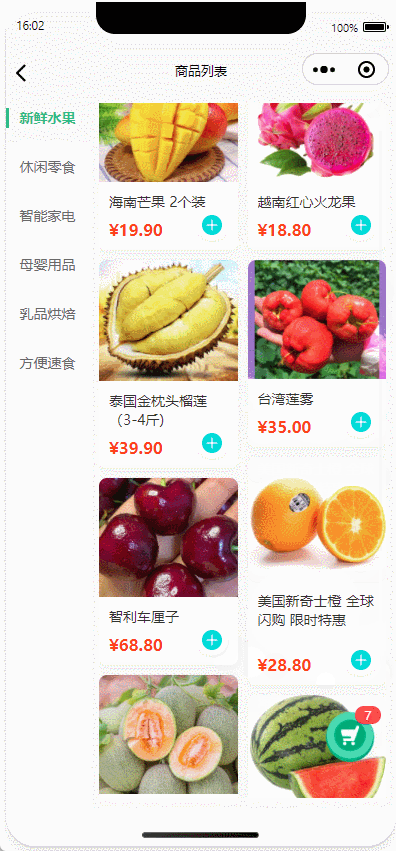
uniapp|商品列表加入购物车实现抛物线动画效果、上下左右抛入、多端兼容(H5、APP、微信小程序)
以uniapp框架为基础,详细解析商品列表加入购物车抛物线动画的实现方案。通过动态获取商品点击位置与购物车坐标,结合CSS过渡动画模拟抛物线轨迹,实现从商品图到购物车图标的动态效果。 目录 核心实现原理坐标动态计算抛物线轨迹模拟动画元素控制代码实现详解模板层设计脚本…...
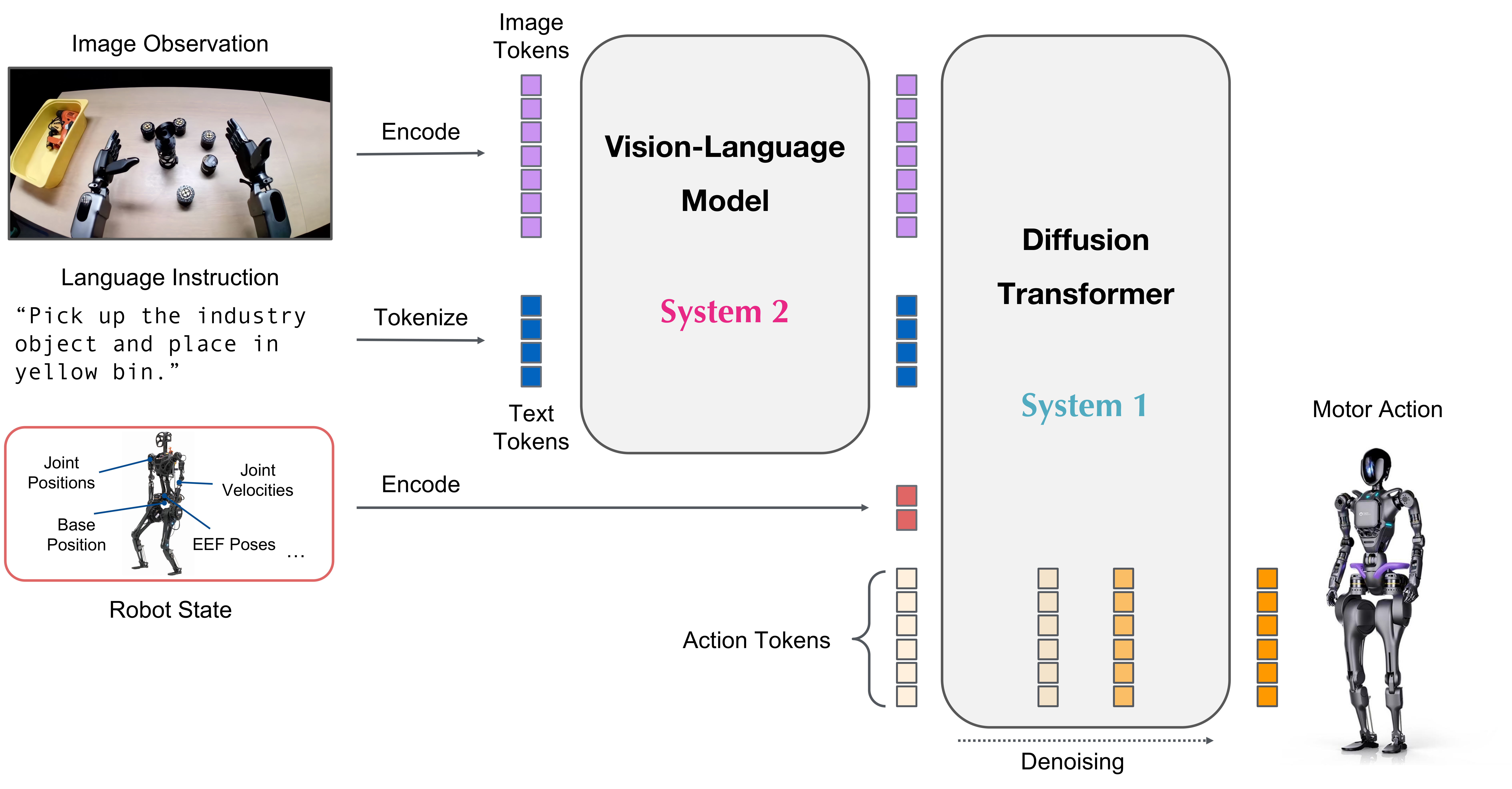
谈AI/OT 的融合
过去的十几年间,工业界讨论最多的话题之一就是IT/OT 融合,现在,我们不仅要实现IT/OT 的融合,更要面向AI/OT 的融合。看起来不太靠谱,却留给我们无限的想象空间。OT 领域的专家们不要再当“九斤老太”,指责这…...
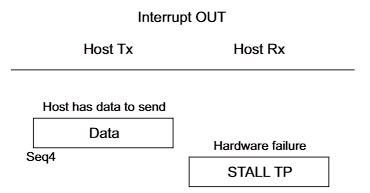
USB传输模式
USB有四种传输模式: 控制传输, 中断传输, 同步传输, 批量传输 1. 中断传输 中断传输一般用于小批量, 非连续的传输. 对实时性要求较高. 常见的使用此传输模式的设备有: 鼠标, 键盘等. 要注意的是, 这里的 “中断” 和我们常见的中断概念有差异. Linux中的中断是设备主动发起的…...