多线程爬虫语言选择与实现
之前文中有人提到:想要一个简单易用、能快速实现多线程爬虫的方案,而且目标是小网站,基本可以确定对反爬虫措施要求不高,这些就比较简单了。
以往我肯定要考虑常见的编程语言中哪些适合爬虫。Python、JavaScript(Node.js)、Go、Java这些应该都是候选。因为需要省事,所以可能更倾向于语法简单、库丰富的语言。
Python的话,有requests和Scrapy框架,还有aiohttp做异步。多线程的话,Python的threading模块可能因为GIL限制效率,但如果是IO密集型任务,比如网络请求,多线程还是有效的。不过异步可能更好,比如asyncio,但用户明确说多线程,可能需要用concurrent.futures的ThreadPoolExecutor。Python的优点是库多,代码简洁,适合小项目,省时间。
针对多线程爬取小网站的需求,推荐以下语言和方案,按优先级排序:
1. Python(首选)
-
优势:
- 生态完善:
requests/aiohttp+BeautifulSoup/parsel组合开箱即用。 - 快速开发:代码简洁,20 行内即可实现多线程爬虫。
- 线程池简化:
concurrent.futures.ThreadPoolExecutor两行代码实现线程池。 - Scrapy 框架:内置异步引擎,无需手动管理线程,适合规则化爬取。
- 生态完善:
-
代码示例(极简线程池):
import requests from concurrent.futures import ThreadPoolExecutordef fetch(url):return requests.get(url).texturls = ["http://example.com/page1", ...] with ThreadPoolExecutor(max_workers=10) as executor:results = list(executor.map(fetch, urls))
2. Go(高性能场景)
-
优势:
- 原生并发:
goroutine+channel轻松管理百万级并发。 - 编译高效:二进制部署,资源占用低。
- 标准库强大:
net/http+goquery满足基础需求。
- 原生并发:
-
适合场景:需要高频请求或未来扩展至大规模爬虫。
-
代码片段:
package main import ("net/http"; "sync") func fetch(url string, wg *sync.WaitGroup) {defer wg.Done()http.Get(url) // 实际需处理响应 } func main() {var wg sync.WaitGroupurls := []string{"http://example.com/1", ...}for _, u := range urls {wg.Add(1)go fetch(u, &wg)}wg.Wait() }
3. Node.js(适合异步I/O)
- 优势:
- 事件循环:非阻塞IO天然适合高并发请求。
- 语法灵活:
axios+cheerio类似前端开发体验。
- 注意点:回调需用
Promise.all或worker_threads实现真并行。
避坑建议:
- 频率控制:即使小网站也需添加延迟(如
time.sleep(1)),避免触发封禁。 - 错误处理:务必捕获异常,网络爬虫需处理超时、重试逻辑。
- 合规性:检查
robots.txt,避免敏感数据抓取。
总结:
- 追求 极速开发 → 选Python(脚本级开发速度)。
- 需要 高性能/资源控制 → 选Go(协程开销极低)。
- 前端背景想复用JS技能 → Node.js(但注意线程模型差异)。
现在我以 Python 为例,手把手教你写一个多线程爬虫,10分钟即可跑通,适合新手快速上手。
目标:多线程爬取豆瓣电影Top250的标题和评分
网址:
https://movie.douban.com/top250
第一步:安装依赖
pip install requests parsel concurrent-log-handler # 核心库:请求 + 解析 + 线程池
第二步:完整代码
import requests
from parsel import Selector
from concurrent.futures import ThreadPoolExecutor
import time# 伪装浏览器 + 全局Headers
HEADERS = {"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/124.0.0.0 Safari/537.36"
}def scrape_page(url):"""爬取单个页面"""try:response = requests.get(url, headers=HEADERS, timeout=5)response.raise_for_status() # 自动识别HTTP错误(如404)return response.textexcept Exception as e:print(f"请求失败: {url} | 错误: {e}")return Nonedef parse_data(html):"""解析页面数据"""selector = Selector(html)movies = []for item in selector.css(".item"):title = item.css(".title::text").get()rating = item.css(".rating_num::text").get()movies.append({"title": title, "rating": rating})return moviesdef worker(page):"""线程任务函数:处理单页"""url = f"https://movie.douban.com/top250?start={(page-1)*25}"html = scrape_page(url)if html:movies = parse_data(html)print(f"第{page}页爬取完成,共{len(movies)}部电影")return moviesreturn []def main():# 创建线程池(限制为5线程,避免封IP)with ThreadPoolExecutor(max_workers=5) as executor:# 提交25页任务(豆瓣Top250共10页,这里测试用3页)futures = [executor.submit(worker, page) for page in range(1, 4)]# 等待所有任务完成并合并结果all_movies = []for future in futures:all_movies.extend(future.result())time.sleep(1) # 每页间隔1秒,降低被封风险# 打印结果print("\n===== 爬取结果 =====")for movie in all_movies:print(f"《{movie['title']}》 评分:{movie['rating']}")if __name__ == "__main__":main()
第三步:逐行解释
- 伪装浏览器:通过
HEADERS模拟Chrome浏览器,绕过基础反爬。 - 线程池控制:
ThreadPoolExecutor自动管理线程,max_workers=5限制并发数。 - 任务分发:通过
executor.submit提交页码(1~3页)到线程池。 - 间隔防封:每处理完一页后强制等待1秒(
time.sleep(1))。 - 异常处理:
scrape_page中捕获超时、HTTP错误等,避免程序崩溃。
运行效果
第1页爬取完成,共25部电影
第2页爬取完成,共25部电影
第3页爬取完成,共25部电影===== 爬取结果 =====
《肖申克的救赎》 评分:9.7
《霸王别姬》 评分:9.6
《阿甘正传》 评分:9.5
...
(共75条数据)
升级方向(根据需求扩展)
- 代理IP:在
requests.get中添加proxies参数应对封IP。 - 异步加速:改用
aiohttp+asyncio实现更高并发。 - 存储数据:添加
with open('movies.json', 'w')保存结果。 - 动态页面:若遇到JavaScript渲染,换用
selenium或playwright。
为什么选Python?
- 代码量少:25行核心逻辑完成多线程爬虫。
- 调试方便:直接打印中间结果,无需编译。
- 生态丰富:遇到验证码、登录等复杂场景有现成库(如
pytesseract)。
最后适合不适合就得结合自己的项目,尝试跑起来看看吧!遇到问题随时调整线程数和间隔时间即可~
相关文章:

多线程爬虫语言选择与实现
之前文中有人提到:想要一个简单易用、能快速实现多线程爬虫的方案,而且目标是小网站,基本可以确定对反爬虫措施要求不高,这些就比较简单了。 以往我肯定要考虑常见的编程语言中哪些适合爬虫。Python、JavaScript(Node…...
【数据结构】——双向链表
一、链表的分类 我们前面学习了单链表,其是我们链表中的其中一种,我们前面的单链表其实全称是单向无头不循环链表,我们的链表从三个维度进行分类,一共分为八种。 1、单向和双向 可以看到第一个链表,其只能找到其后一个…...

AI助力:零基础开启编程之旅
一、代码调试 三步解决BUG 1. 错误信息翻译 指令模板: 错误诊断模式我遇到【编程语言】报错“粘贴报错信息“ 请: 用小白能懂的话解释问题本质标注可能引发该错误的三个场景给出最可能的修复方案和其他备选方案 2. 上下文分析 进阶指令 结合上下文代…...
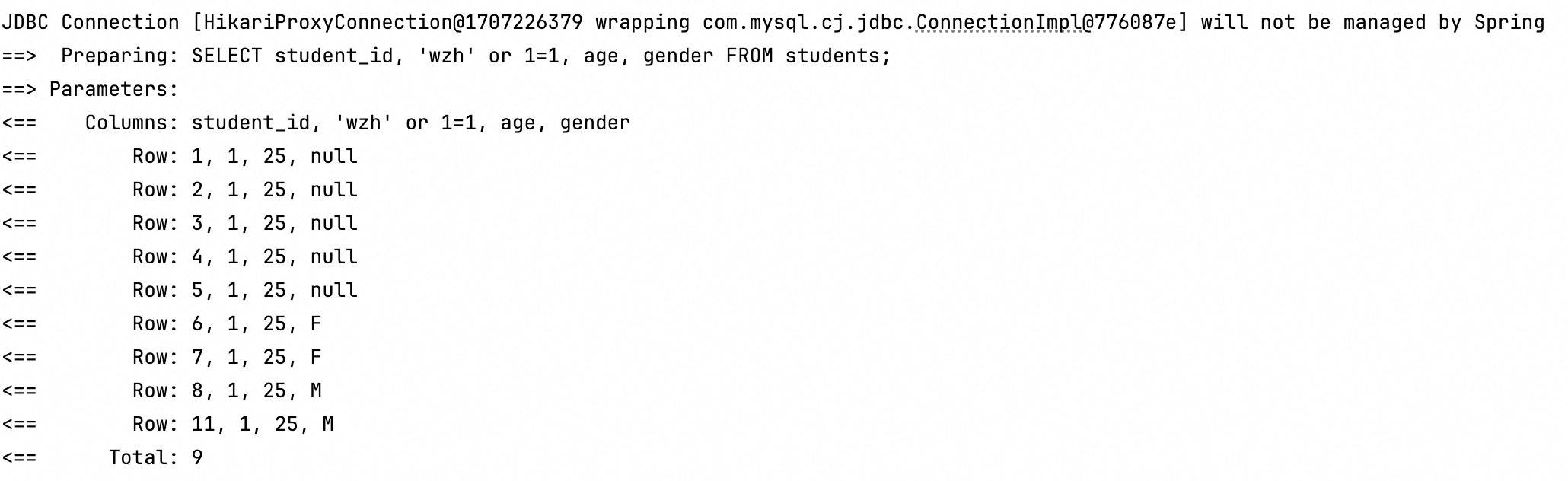
mybatis中${}和#{}的区别
先测试,再说结论 userService.selectStudentByClssIds(10000, "wzh or 11");List<StudentEntity> selectStudentByClssIds(Param("stuId") int stuId, Param("field") String field);<select id"selectStudentByClssI…...

【计算机组成原理】第二部分 存储器--分类、层次结构
文章目录 分类&层次结构0x01 分类按存储介质分类按存取方式分类按在计算机中的作用分类 0x02 层次结构 分类&层次结构 0x01 分类 按存储介质分类 半导体存储器磁表面存储器磁芯存储器光盘存储器 按存取方式分类 存取时间与物理地址无关(随机访问&#…...
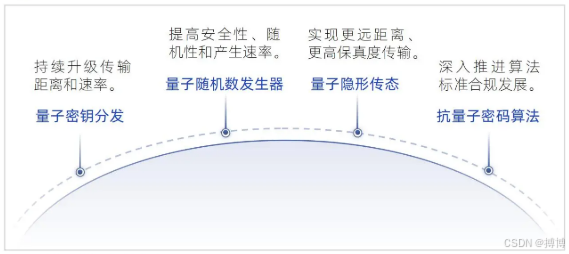
抗量子计算攻击的数据安全体系构建:从理论突破到工程实践
在“端 - 边 - 云”三级智能协同理论中,端 - 边、边 - 云之间要进行数据传输,网络的安全尤为重要,为了实现系统总体的安全可控,将构建安全网络。 可先了解我的前文:“端 - 边 - 云”三级智能协同平台的理论建构与技术实…...

正则表达式: 从基础到进阶的语法指南
正则表达式语法详解 前言一、基础概念二、基础元字符2.1 字符匹配2.2 字符类2.3 预定义字符类 三、重复匹配3.1 贪婪与非贪婪匹配3.2 精确重复匹配 四、边界匹配4.1 行首与行尾匹配4.2 单词边界匹配 五、分组与引用5.1 分组5.2 反向引用5.3 命名分组 六、逻辑运算符6.1 或运算 …...
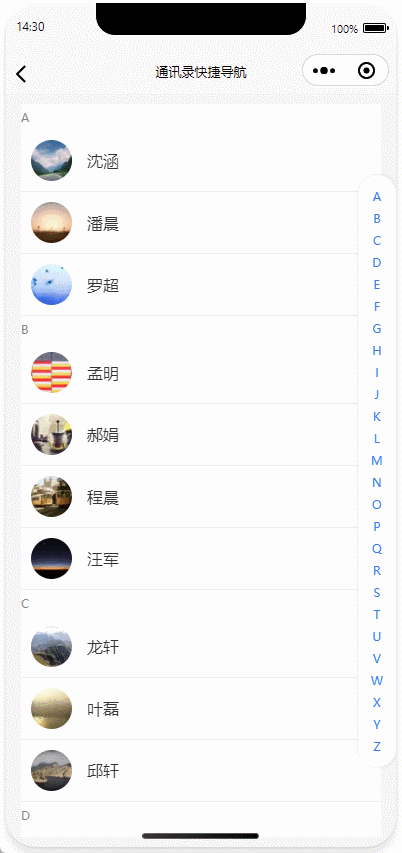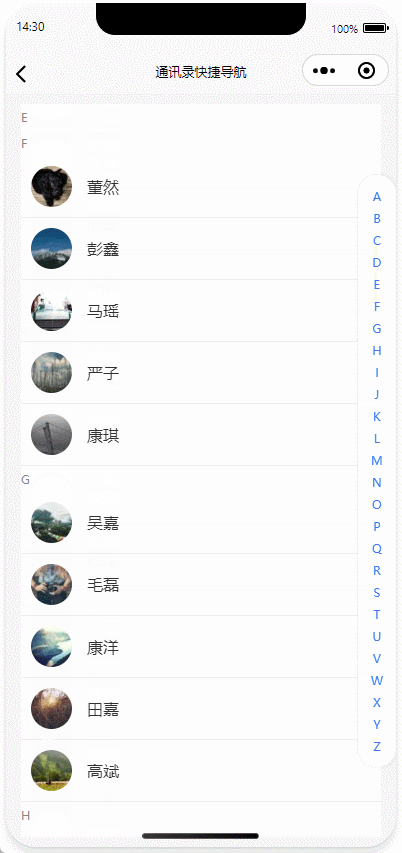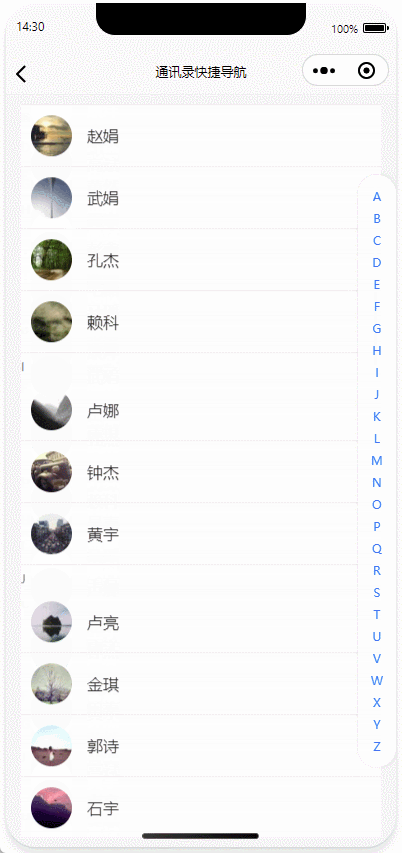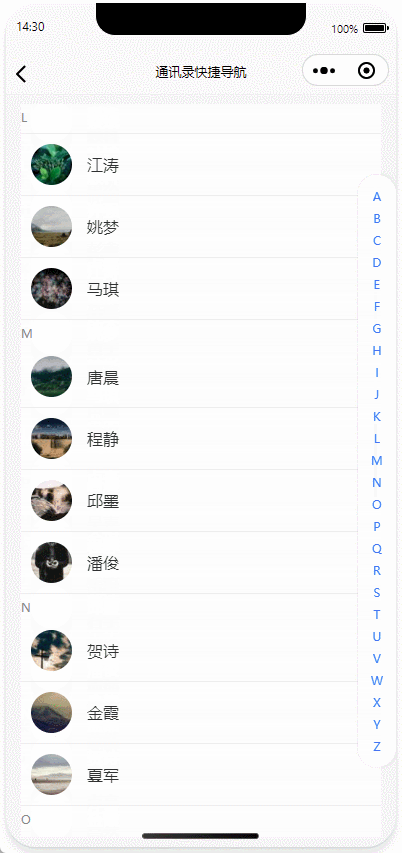
uniapp|实现手机通讯录、首字母快捷导航功能、多端兼容(H5、微信小程序、APP)
基于uniapp实现带首字母快捷导航的通讯录功能,通过拼音转换库实现汉字姓名首字母提取与分类,结合uniapp的scroll-view组件与pageScrollTo API完成滚动定位交互,并引入uni-indexed-list插件优化索引栏性能。 目录 核心功能实现动态索引栏生成联系人列表渲染滚动定位联动性…...
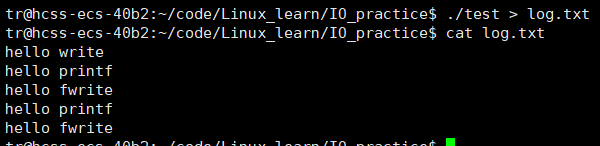
【Linux】基础IO(二)
📝前言: 上篇文章我们对Linux的基础IO有了一定的了解,这篇文章我们来讲讲IO更底层的东西: 重定向及其原理感受file_operation文件缓冲区 🎬个人简介:努力学习ing 📋个人专栏:Linux…...

SpringBoot异步处理@Async深度解析:从基础到高阶实战
一、异步编程基础概念 1.1 同步 vs 异步 特性同步异步执行方式顺序执行,阻塞调用非阻塞,调用后立即返回线程使用单线程完成所有任务多线程并行处理响应性较差,需等待前任务完成较好,可立即响应新请求复杂度简单直观较复杂&#…...

【生存技能】ubuntu 24.04 如何pip install
目录 原因解决方案说明关于忽略系统路径 在接手一个新项目需要安装python库时弹出了以下提示: 原因 这个报错是因为在ubuntu中尝试直接使用 pip 安装 Python 包到系统环境中,ubuntu 系统 出于稳定性考虑禁止了这种操作 这里的kali是因为这台机器的用户起名叫kali…...
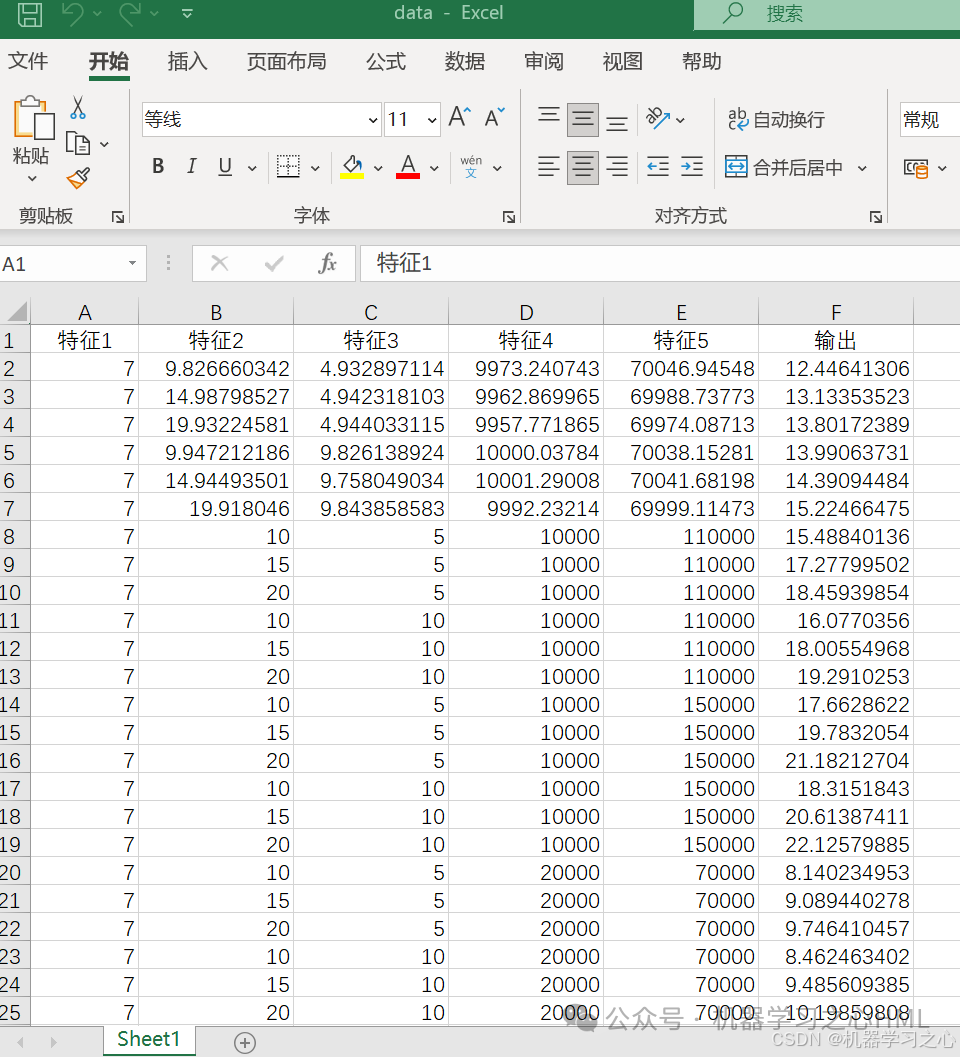
SHAP分析!Transformer-GRU组合模型SHAP分析,模型可解释不在发愁!
SHAP分析!Transformer-GRU组合模型SHAP分析,模型可解释不在发愁! 目录 SHAP分析!Transformer-GRU组合模型SHAP分析,模型可解释不在发愁!效果一览基本介绍程序设计参考资料 效果一览 基本介绍 基于SHAP分析…...

Tcp 通信简单demo思路
Server 端 -------------------------- 初始化部分 ------------------------------- 1.创建监听套接字: 使用socket(协议家族,套接字的类型,0) 套接字类型有 SOCK_STREAM:表示面向连接的套接字(Tcp协议)&…...
)
MySQL 8.0安装(压缩包方式)
MySQL 8.0安装(压缩包方式) 下载安装包并解压 下载 https://dev.mysql.com/downloads/mysql/可关注“后端码匠”回复“MySQL8”关键字获取 解压(我解压到D:\dev\mysql-8.4.5-winx64目录下) 创建mysql服务 注意,这步之前一定要保证自己电…...

常见标签语言的对比
XML、JSON 和 YAML 是常见的数据序列化格式 相同点 结构化数据表示 三者均支持嵌套结构,能描述复杂的数据层级关系(如对象、数组、键值对)。跨平台兼容性 均为纯文本格式,可被多种编程语言解析,适用于跨系统数据交换…...

知名人工智能AI培训公开课内训课程培训师培训老师专家咨询顾问唐兴通AI在金融零售制造业医药服务业创新实践应用
AI赋能未来工作:引爆效率与价值创造的实战营 AI驱动的工作革命:从效率提升到价值共创 培训时长: 本课程不仅是AI工具的操作指南,更是面向未来的工作方式升级罗盘。旨在帮助学员系统掌握AI(特别是生成式AI/大语言模型…...
Qt Creator 配置 Android 编译环境
Qt Creator 配置 Android 编译环境 环境配置流程下载JDK修改Qt Creator默认android配置文件修改sdk_definitions.json配置修改的内容 Qt Creator配置 异常处理删除提示占用编译报错连接安卓机调试APP闪退 环境 Qt Creator 版本 qtcreator-16.0.1Win10 嗯, Qt这个开发环境有点难…...

智能手表蓝牙 GATT 通讯协议文档
以下是一份适用于智能手表的 蓝牙 GATT 通讯协议文档,适用于 BLE 5.0 及以上标准,兼容 iOS / Android 平台: 智能手表蓝牙 GATT 通讯协议文档 文档版本:V1.0 编写日期:2025年xx月xx日 产品型号:Aurora Wat…...

AWS EC2源代码安装valkey命令行客户端
sudo yum -y install openssl-devel gcc wget https://github.com/valkey-io/valkey/archive/refs/tags/8.1.1.tar.gz tar xvzf 8.1.1.tar.gz cd valkey-8.1.1/ make distclean make valkey-cli BUILD_TLSyes参考 Connecting to nodes...
RT-THREAD RTC组件中Alarm功能驱动完善
使用Rt-Thread的目的为了更快的搭载工程,使用Rt-Thread丰富的组件和第三方包资源,解耦硬件,在更换芯片时可以移植应用层代码。你是要RTT的目的什么呢? 文章项目背景 以STM32L475RCT6为例 RTC使用的为LSE外部低速32 .756k Hz 的…...

MySQL解决主从复制的报错问题
MySQL 8.4 非 GTID 模式部分数据库主从复制指南 在进行MySQL 8.4非GTID模式下部分数据库主从复制时,以下是详细的操作步骤以及对应的执行位置说明,还有报错处理方法介绍: 操作步骤 1. 备份主库指定数据库(db1、db2)…...

用ffmpeg压缩视频参数建议
注意:代码中的斜杠\可以删除 一、基础压缩命令(画质优先) libx265推荐配置 ffmpeg -i input.mp4 -c:v libx265 -crf 25 -preset medium -c:a aac -b:a 128k output.mp4-crf:建议25-28(值越小画质越高) -preset:平…...
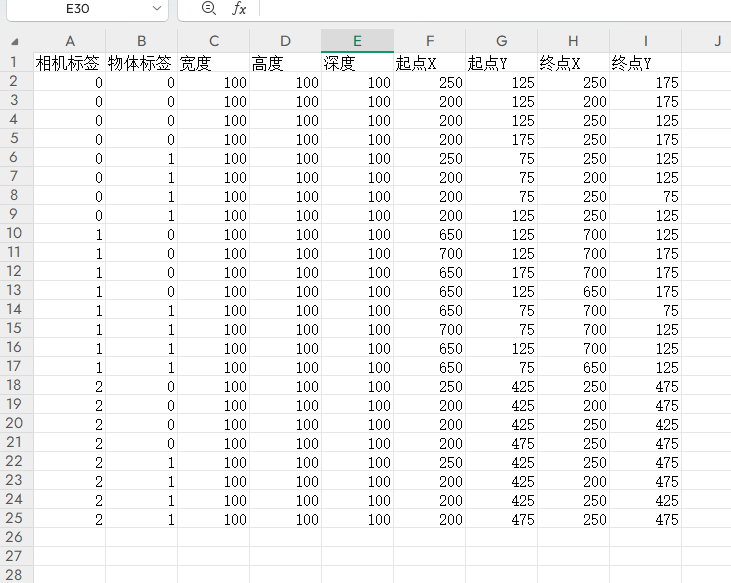
输入顶点坐标输出立方体长宽高的神经网络 Snipaste贴图软件安装
写一个神经网络,我输入立方体投影线段的三视图坐标,输出分类和长宽高 放这了明天接着搞 -------------------------------------------- 开搞 然而我的数据是这样的 winget install Snipaste f1启动,双击贴图隐藏 用右边4个数据做输入…...

用python清除PDF文件中的水印(Adobe Acrobat 无法删除)
学校老师发的资料,有时候会带水印,有点强迫症的都想给它去掉。用Adobe Acrobat试了下,检测不到水印,无法删除!分析发现原来这类PDF文件是用word编辑的,其中的水印是加在了页眉中! 自己动手想办法…...

kotlin 数据类
一 kotlin数据类与java普通类区别 Kotlin 的 data class 与 Java 中的普通类(POJO)相比,确实大大减少了样板代码(boilerplate),但它的优势不止于自动生成 getter/setter、copy()、equals()、toString()&am…...
)
豆瓣电影Top250数据工程实践:从爬虫到智能存储的技术演进(含完整代码)
目录 引言:当豆瓣榜单遇见大数据技术 项目文档 1.1 选题背景 1.2 项目目标 2. 项目概述 2.1 系统架构设计 2.2 技术选型 2.3 项目环境搭建 2.3.1 基础环境准备 2.3.2 爬虫环境配置 2.3.3 Docker安装ES连接Kibana 安装IK插件 2.3.4 vscode依赖服务安装 3. 核心模…...

把Excel数据文件导入到Oracle数据库
数据管理和分析的领域,将Excel中的数据导入到Oracle数据库是一个常见的需求,无论是为了利用Oracle强大的数据处理能力,还是为了实现数据的集中存储和管理,这一过程都需要一定的步骤和技巧,本文将详细介绍如何从Excel导…...

PyTorch API 6 - 编译、fft、fx、函数转换、调试、符号追踪
文章目录 torch.compiler延伸阅读 torch.fft快速傅里叶变换辅助函数 torch.func什么是可组合的函数变换?为什么需要可组合的函数变换?延伸阅读 torch.futurestorch.fx概述编写转换函数图结构快速入门图操作直接操作计算图使用 replace_pattern() 进行子图…...
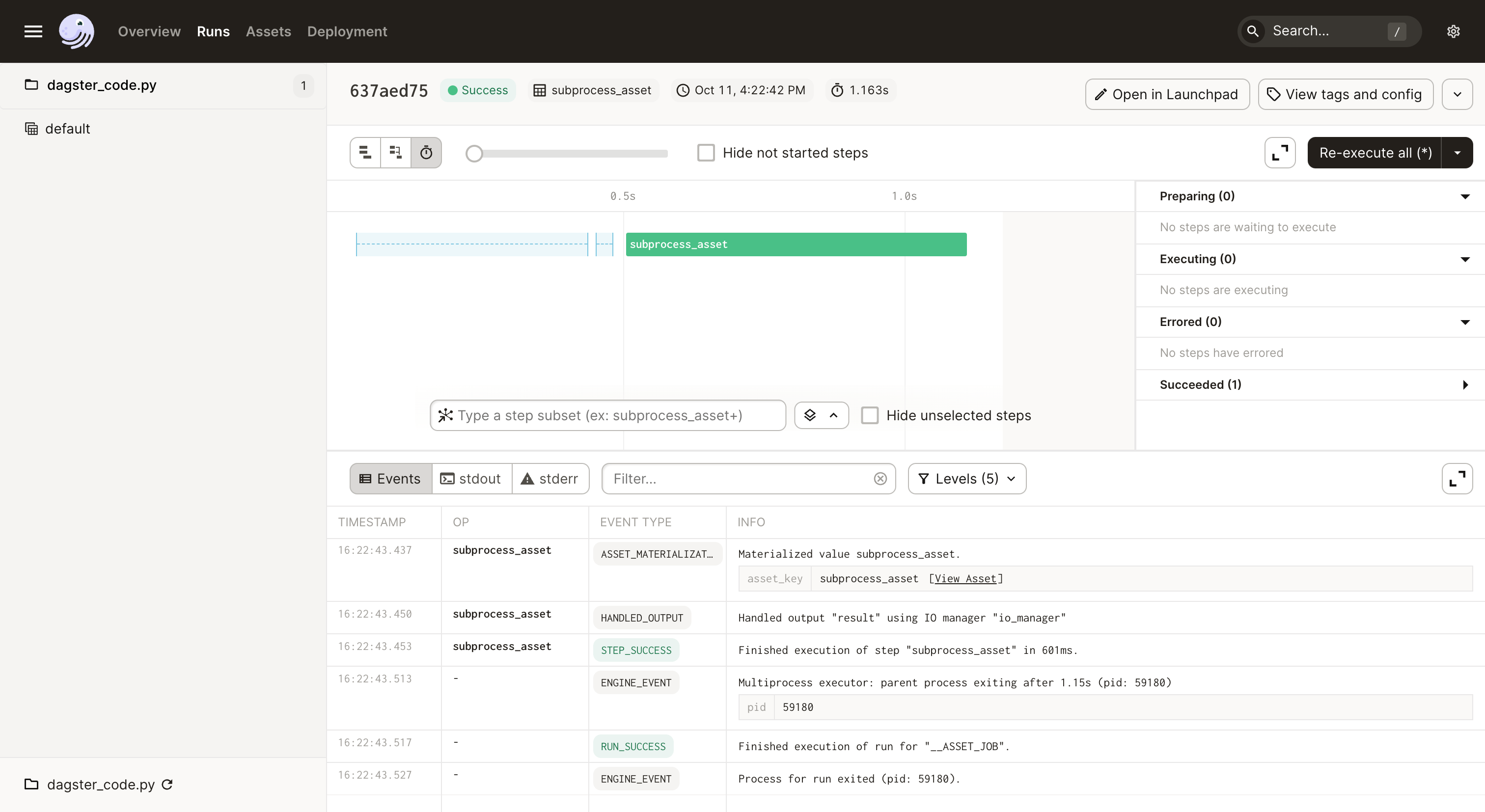
Dagster Pipes系列-1:调用外部Python脚本
本文是"Dagster Pipes教程"的第一部分,介绍如何通过Dagster资产调用外部Python脚本并集成到数据管道中。首先,创建Dagster资产subprocess_asset,利用PipesSubprocessClient资源执行外部脚本external_code.py,实现跨进程…...

python shutil 指定文件夹打包文件为 zip 压缩包
python shutil 指定文件夹打包文件为 zip 压缩包,具体代码如下: import shutil# 指定要打包的文件夹路径 src_doc ./test# 指定输出的压缩包文件名(不包含扩展名) output_filename testfromat_ zip# 打包并压缩文件夹为 ZIP …...