Pytorch张量和损失函数
文章目录
- 张量
- 张量类型
- 张量例子
- 使用概率分布创建张量
- 正态分布创建张量 (torch.normal)
- 正态分布创建张量示例
- 标准正态分布创建张量
- 标准正态分布创建张量示例
- 均匀分布创建张量
- 均匀分布创建张量示例
- 激活函数
- 常见激活函数
- 损失函数(Pytorch API)
- L1范数损失函数
- 均方误差损失函数
- 交叉熵损失函数
- 余弦相似度损失
- 计算两个向量的余弦相似度
- 计算两个矩阵的余弦相似度(逐行计算)
- 计算两个 batch 数据的余弦相似度
张量
张量类型
- 张量是一个多维数组,它的每个方向都被称为模(Mode)。张量的阶数就是它的维数,一阶张量就是向量,二阶张量就是矩阵,三界以上的张量统称为高阶张量。
- Tensor是Pytorch的基本数据结构,在使用时表示为
torch.Tensor形式。主要属性包括以下内容(前四个属性与数据相关,后四个属性与梯度求导相关):- data:被包装的张量。
- dtype:张量的数据类型。
- shape:张量的形状/维度。
- device:张量所在的设备,加速计算的关键(CPU、GPU)
- grad:data的梯度
- grad_fn:创建张量的Function(自动求导的关键)
- requires_grad:指示是否需要计算梯度
- is_leaf:指示是否为叶子节点
torch.dtype是表示torch.Tensor数据类型的对象,PyTorch支持以下9种数据类型:
| 数据类型 | dtype表示 | CPU张量类型 | GPU张量类型 |
|---|---|---|---|
| 32位浮点数 | torch.float32 或 torch.float | torch.FloatTensor | torch.cuda.FloatTensor |
| 64位浮点数 | torch.float64 或 torch.double | torch.DoubleTensor | torch.cuda.DoubleTensor |
| 16位浮点数 | torch.float16 或 torch.half | torch.HalfTensor | torch.cuda.HalfTensor |
| 8位无符号整数 | torch.uint8 | torch.ByteTensor | torch.cuda.ByteTensor |
| 8位有符号整数 | torch.int8 | torch.CharTensor | torch.cuda.CharTensor |
| 16位有符号整数 | torch.int16 或 torch.short | torch.ShortTensor | torch.cuda.ShortTensor |
| 32位有符号整数 | torch.int32 或 torch.int | torch.IntTensor | torch.cuda.IntTensor |
| 64位有符号整数 | torch.int64 或 torch.long | torch.LongTensor | torch.cuda.LongTensor |
| 布尔型 | torch.bool | torch.BoolTensor | torch.cuda.BoolTensor |
- 浮点类型默认使用
torch.float32 - 整数类型默认使用
torch.int64 - 布尔类型用于存储True/False值
- GPU张量类型需在CUDA环境下使用
张量例子
import torch
import numpy as np
# 1. 创建Tensor
x = torch.tensor([[1, 2], [3, 4.]]) # 自动推断为float32类型
print("Tensor x:\n", x)
y=torch.tensor(np.ones((3,3)))
print("Tensor y:\n", y)
Tensor x:tensor([[1., 2.],[3., 4.]])
Tensor y:tensor([[1., 1., 1.],[1., 1., 1.],[1., 1., 1.]], dtype=torch.float64)
# 2. 查看Tensor属性
print("\nTensor属性:")
print("data:", x.data) # 被包装的张量
print("dtype:", x.dtype) # 数据类型 torch.float32
print("shape:", x.shape) # 形状/维度 torch.Size([2, 2])
print("device:", x.device) # 所在设备 cpu
print("requires_grad:", x.requires_grad) # 是否需要计算梯度 False
print("is_leaf:", x.is_leaf) # 是否为叶子节点 True
Tensor属性:
data: tensor([[1., 2.],[3., 4.]])
dtype: torch.float32
shape: torch.Size([2, 2])
device: cpu
requires_grad: False
is_leaf: True
# 3. 设置requires_grad=True以跟踪计算
x = torch.tensor([[1., 2], [3, 4]], device='cpu', requires_grad=True)
print("\n设置requires_grad=True后的x:", x)
设置requires_grad=True后的x: tensor([[1., 2.],[3., 4.]], requires_grad=True)
# 4. 进行一些计算操作
y = x + 2
z = y * y * 3
out = z.mean()print("\n计算过程:")
print("y = x + 2:\n", y)
print("z = y * y * 3:\n", z)
print("out = z.mean():", out)
计算过程:
y = x + 2:tensor([[3., 4.],[5., 6.]], grad_fn=<AddBackward0>)
z = y * y * 3:tensor([[ 27., 48.],[ 75., 108.]], grad_fn=<MulBackward0>)
out = z.mean(): tensor(64.5000, grad_fn=<MeanBackward0>)
# 5. 反向传播计算梯度
out.backward()
print("\n梯度计算:")
print("x.grad:\n", x.grad) # d(out)/dx
梯度计算:
x.grad:tensor([[4.5000, 6.0000],[7.5000, 9.0000]])
# 6. 查看grad_fn
print("\n梯度函数:")
print("y.grad_fn:", y.grad_fn) # <AddBackward0>
print("z.grad_fn:", z.grad_fn) # <MulBackward0>
print("out.grad_fn:", out.grad_fn) # <MeanBackward0>
梯度函数:
y.grad_fn: <AddBackward0 object at 0x0000025AD0B28670>
z.grad_fn: <MulBackward0 object at 0x0000025AD0B919A0>
out.grad_fn: <MeanBackward0 object at 0x0000025AD0B28670>
# 7. 设备管理
if torch.cuda.is_available():device = torch.device("cuda")x_cuda = x.to(device)print("\nGPU Tensor:")print("x_cuda device:", x_cuda.device)
else:print("\nCUDA不可用")
GPU Tensor:
x_cuda device: cuda:0
# 8. 数据类型转换
x_int = x.int()
print("\n数据类型转换:")
print("x_int dtype:", x_int.dtype) # torch.int32
数据类型转换:
x_int dtype: torch.int32
使用概率分布创建张量
正态分布创建张量 (torch.normal)
- 通过
torch.normal()函数从给定参数的离散正态分布中抽取随机数创建张量。
torch.normal(mean, std, size=None, out=None)
mean(Tensor/float): 正态分布的均值(支持标量或张量)std(Tensor/float): 正态分布的标准差(支持标量或张量)size(tuple): 输出张量的形状(仅当mean/std为标量时必需)out(Tensor): 可选输出张量
- 均值和标准差均为标量
- 均值为张量,标准差为标量
- 均值为标量,标准差为张量
- 均值和标准差均为张量(需同形状)
正态分布创建张量示例
import torch# 模式1:标量均值和标准差
normal_tensor1 = torch.normal(mean=0.0, std=1.0, size=(2,2))
print("标量参数:\n", normal_tensor1)# 模式2:张量均值 + 标量标准差
mean_tensor = torch.arange(1, 5, dtype=torch.float)
normal_tensor2 = torch.normal(mean=mean_tensor, std=1.0)
print("\n张量均值:\n", normal_tensor2)# 模式4:张量均值 + 张量标准差
std_tensor = torch.linspace(0.1, 0.4, steps=4)
normal_tensor3 = torch.normal(mean=mean_tensor, std=std_tensor)
print("\n双张量参数:\n", normal_tensor3)
标量参数:tensor([[-1.5585, 0.2315],[-1.5771, -0.0783]])张量均值:tensor([0.9710, 1.2523, 3.6285, 4.2808])双张量参数:tensor([1.0566, 2.1025, 3.1653, 3.3020])
标准正态分布创建张量
- torch.randn
torch.randn(*size, out=None, dtype=None, layout=torch.strided, device=None, requires_grad=False)
-
size(tuple): 定义张量形状的整数序列 -
dtype(torch.dtype): 指定数据类型(如torch.float32) -
device(torch.device): 指定设备(‘cpu’或’cuda’) -
requires_grad(bool): 是否启用梯度计算 -
torch.randn_like
torch.randn_like(input, dtype=None, layout=None, device=None, requires_grad=False)
input(Tensor): 参考张量(复制其形状)
标准正态分布创建张量示例
# 基础用法
randn_tensor = torch.randn(3, 4, dtype=torch.float64)
print("标准正态张量:\n", randn_tensor)# 类似张量创建
base_tensor = torch.empty(2, 3)
randn_like_tensor = torch.randn_like(base_tensor)
print("\n类似形状创建:\n", randn_like_tensor)# GPU张量创建(需CUDA环境)
if torch.cuda.is_available():gpu_tensor = torch.randn(3, 3, device='cuda')print("\nGPU张量:", gpu_tensor.device)
标准正态张量:tensor([[-0.3266, -0.9314, 0.1892, -0.3418],[ 0.4397, -1.2986, -0.7380, -0.6443],[ 0.7485, 0.4076, -0.6021, -0.9000]], dtype=torch.float64)类似形状创建:tensor([[-0.8994, 0.5934, -1.3246],[-0.1019, 0.8172, -1.3164]])GPU张量: cuda:0
均匀分布创建张量
- torch.rand:生成[0,1)区间内的均匀分布
torch.rand(*size, out=None, dtype=None, layout=torch.strided, device=None,requires_grad=False) → Tensor
- torch.rand_like
torch.rand_like(input, dtype=None, layout=None, device=None, requires_grad=False)
均匀分布创建张量示例
# 基础均匀分布
uniform_tensor = torch.rand(2, 2)
print("均匀分布张量:\n", uniform_tensor)# 指定范围的均匀分布(需线性变换)
a, b = 5, 10
scaled_tensor = a + (b - a) * torch.rand(3, 3)
print("\n[5,10)区间张量:\n", scaled_tensor)# 整数均匀分布(需结合random.randint)
int_tensor = torch.randint(low=0, high=10, size=(4,))
print("\n整数均匀分布:\n", int_tensor)
均匀分布张量:tensor([[0.4809, 0.6847],[0.9278, 0.9965]])[5,10)区间张量:tensor([[8.6137, 5.9940, 7.2302],[5.1680, 7.0532, 5.9403],[8.3315, 6.1549, 8.5181]])整数均匀分布:tensor([8, 5, 9, 6])
激活函数
- 激活函数是指在神经网络的神经元上运行的函数,其负责将神经元的输入映射到输出端。
常见激活函数
- 参看深度学习系统学习系列【5】之深度学习基础
损失函数(Pytorch API)
- 在监督学习中,损失函数表示样本真实值与模型预测值之间的偏差,其值通常用于衡量模型的性能。现有的监督学习算法不仅使用了损失函数,而且求解不同应用场景的算法会使用不同的损失函数。即使在相同场景下,不同的损失函数度量同一样本的性能时也存在差异。
- 损失函数的选用是否合理直接决定着监督学习算法预测性能的优劣。
- 在PyTorch中,损失函数通过
torch.nn包实现调用。
L1范数损失函数
- L1范数损失即L1LoSS,原理就是取预测值和真实值的绝对误差的平均数,计算模型预测输出output和目标target之差的绝对值,可选择返回同维度的张量或者标量。
l o s s ( x , y ) = 1 N ∑ i = 1 N ∣ x − y ∣ loss(x,y)=\frac{1}{N}\sum_{i=1}^{N}|x-y| loss(x,y)=N1i=1∑N∣x−y∣
torch.nn.L1Loss (size_average=None, reduce=None, reduction='mean')
size_average:为True时,返回的loss为平均值;为False时,返回的loss为各样本的loss值之和。reduce:返回值是否为标量,默认为True。
import torch
import torch.nn as nn
loss=nn.L1Loss(eduction='mean')
input=torch.tensor([1.0,2.0,3.0,4.0])
target=torch.tensor([4.0,5.0,6.0,7.0])
output=loss(input,target)
print(output) # tensor(3.)
- 两个输入类型必须一致,
reduction是损失函数一个参数,有三个值:'none’返回的是一个向量(batch_size),'sum’返回的是和,'mean’返回的是均值。
均方误差损失函数
- 均方误差损失即MSELoss,计算公式是预测值和真实值之间的平方和的平均数,计算模型预测输出output和目标target之差的平方,可选返回同维度的张量或者标量。
l o s s ( x , y ) = 1 N ∑ i = 1 N ∣ x − y ∣ 2 loss(x,y)=\frac{1}{N}\sum_{i=1}^{N}|x-y|^2 loss(x,y)=N1i=1∑N∣x−y∣2
torch.nn.MSELoss(reduce=True,size average=True,reduction='mean')
- reduce:返回值是否为标量,默认为True。
- size_average:当reduce=True时有效。为True时,返回的loss为平均值;为False时,返回的loss为各样本的loss值之和。
import torch
import torch.nn as nn
loss=nn.MSELoss(reduction='mean')
input=torch.tensor([1.0,2.0,3.0,4.0])
target=torch.tensor([4.0,5.0,6.0,7.0])
output=loss(input,target)
print(output) # tensor(9.)
交叉熵损失函数
- 交叉熵损失(Cross Entropy Loss)函数结合了nn.LogSoftmax()和nn.NLLLoss()两个函数,在做分类训练的时候非常有用。
- 交叉熵的概念,它用来判定实际输出与期望输出的接近程度。也就是说,用它来衡量网络的输出与标签的差异,利用这种差异通过反向传播来更新网络参数。交叉熵主要刻画的是实际输出概率与期望输出概率的距离,也就是交叉熵的值越小,两个概率分布就越接近,假设概率分布p为期望输出,概率分布q为实际输出,计算公式如下:
H ( p , q ) = − ∑ x p ( x ) × l o g q ( x ) H(p, q)=-\sum_x p(x) \times logq(x) H(p,q)=−x∑p(x)×logq(x)
torch.nn.CrossEntropyLoss(weight=None, size_average=None,ignore_index=-100,reduce=None,reduction='mean')
- weight(tensor):n个元素的一维张量,分别代表n类权重,如果训练样本很不均衡的话,则非常有用,默认值为None。
- size_average:当reduce=True时有效。为True时,返回的loss为平均值;为False时,返回的loss为各样本的loss值之和。
- ignore_index:忽略某一类别,不计算其loss,并且在采用size_average时,不会计算那一类的loss值。
- reduce:返回值是否为标量,默认为True。
import torch.nn as nn
entroy=nn.CrossEntropyLoss(reduction='mean')
input=torch.tensor([[-0.011,-0.022,-0.033,-0.044]])
target=torch.tensor([0])
output=entroy(input,target)
print(output)
余弦相似度损失
- 余弦相似度损失(Cosine SimilarityLoss)通常用于度量两个向量的相似性,可以通过最大化这个相似度来进行优化。
l o s s ( x , y ) = { l − c o s ( x 1 , x 2 ) , y = 1 m a x ( 0 , c o s ( x 1 , x 2 ) − m a r g i n ) , y = − 1 \begin{array} { r } { \mathrm { l o s s } ( x , y ) = \left\{ \begin{array} { l l } { \mathrm { l } - \mathrm { c o s } ( x _ { 1 } , x _ { 2 } ) , \quad } & { y = 1 } \\ { \mathrm { m a x } ( 0 , \mathrm { c o s } ( x _ { 1 } , x _ { 2 } ) - \mathrm { m a r g i n } ) , \quad } & { y = - 1 } \end{array} \right. } \end{array} loss(x,y)={l−cos(x1,x2),max(0,cos(x1,x2)−margin),y=1y=−1 torch.nn.functional.cosine_similarity是 PyTorch 提供的用于计算两个张量之间 余弦相似度(Cosine Similarity) 的函数。余弦相似度衡量的是两个向量在方向上的相似程度,取值范围为[-1, 1],值越大表示方向越相似。
torch.nn.functional.cosine_similarity(x1, x2, dim=1, eps=1e-8)
| 参数 | 类型 | 说明 |
|---|---|---|
x1 | Tensor | 第一个输入张量 |
x2 | Tensor | 第二个输入张量 |
dim | int | 计算相似度的维度,默认 dim=1表示对每个样本计算特征向量的相似度。 |
eps | float | 防止除零的小数值,默认 1e-8 防止分母为零(当某个向量的 L2 范数为 0 时) |
常见用途
- 文本/图像相似度计算(如对比学习、检索任务)。
- 损失函数设计(如
1 - cosine_similarity用于最小化方向差异)。 - 特征匹配(如计算两个嵌入向量的相似度)。
计算两个向量的余弦相似度
- 输入要求:
x1和x2必须具有 相同的形状(shape)。如果输入是 1D 张量(向量),需要先unsqueeze(0)变成 2D(矩阵)才能计算。例如:
import torch
import torch.nn.functional as Fa = torch.tensor([1.0, 2.0, 3.0])
b = torch.tensor([4.0, 5.0, 6.0])# 需要 unsqueeze(0) 变成 2D
similarity = F.cosine_similarity(a.unsqueeze(0), b.unsqueeze(0), dim=1)
print(similarity) # 输出:tensor([0.9746])
计算两个矩阵的余弦相似度(逐行计算)
import torch
import torch.nn.functional as F
x1 = torch.tensor([[1.0, 2.0], [3.0, 4.0]])
x2 = torch.tensor([[5.0, 6.0], [7.0, 8.0]])similarity = F.cosine_similarity(x1, x2, dim=1)
print(similarity) # 输出:tensor([0.9689, 0.9974])
计算两个 batch 数据的余弦相似度
import torch
import torch.nn.functional as F
batch_a = torch.tensor([[1.0, 2.0, 3.0], [4.0, 5.0, 6.0]])
batch_b = torch.tensor([[4.0, 5.0, 6.0], [7.0, 8.0, 9.0]])similarity = F.cosine_similarity(batch_a, batch_b, dim=1)
print(similarity) # 输出:tensor([0.9746, 0.9989])
相关文章:

Pytorch张量和损失函数
文章目录 张量张量类型张量例子使用概率分布创建张量正态分布创建张量 (torch.normal)正态分布创建张量示例标准正态分布创建张量标准正态分布创建张量示例均匀分布创建张量均匀分布创建张量示例 激活函数常见激活函数 损失函数(Pytorch API)L1范数损失函数均方误差损失函数交叉…...
ConcurrentHashMap发送)
消息~组件(群聊类型)ConcurrentHashMap发送
为什么选择ConcurrentHashMap? 在开发聊天应用时,我们需要存储和管理大量的聊天消息数据,这些数据会被多个线程频繁访问和修改。比如,当多个用户同时发送消息时,服务端需要同时处理这些消息的存储和查询。如果用普通的…...
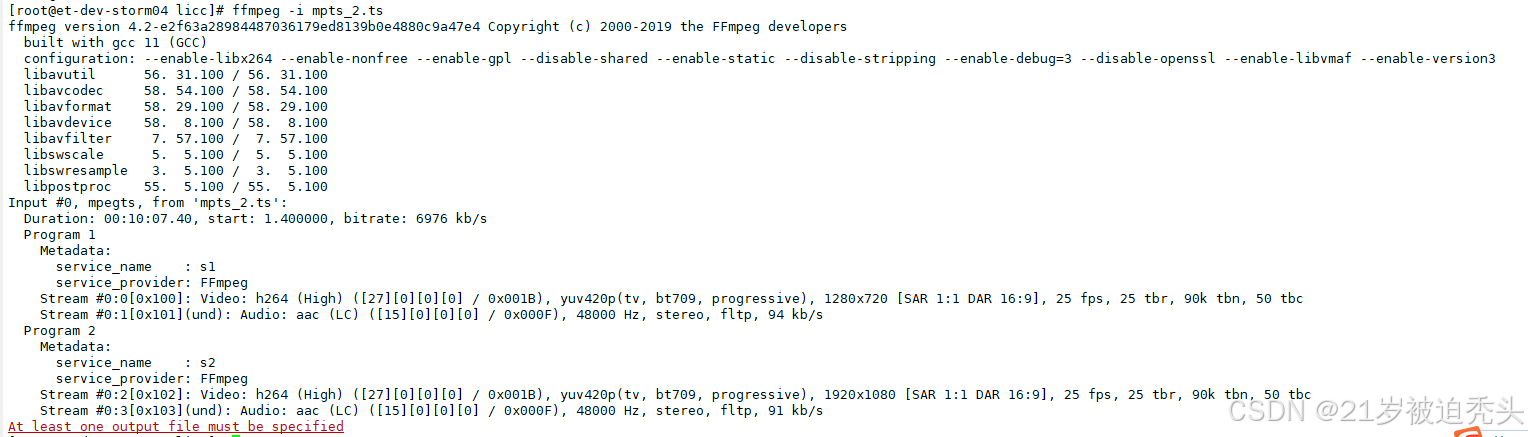
FFmpeg多路节目流复用为一路包含多个节目的输出流
在音视频处理领域,将多个独立的节目流(如不同频道的音视频内容)合并为一个包含多个节目的输出流是常见需求。FFmpeg 作为功能强大的多媒体处理工具,提供了灵活的流复用能力,本文将通过具体案例解析如何使用 FFmpeg 实现…...
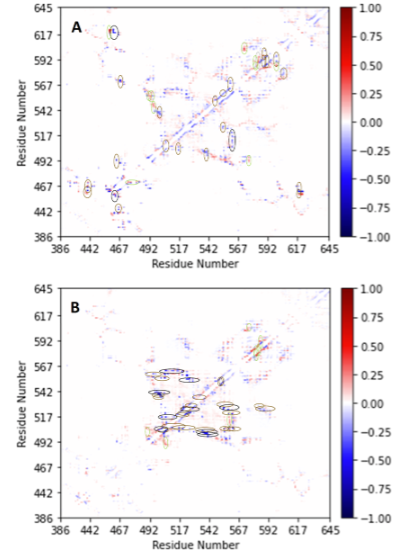
分子动力学模拟揭示点突变对 hCFTR NBD1结构域热稳定性的影响
囊性纤维化(CF) 作为一种严重的常染色体隐性遗传疾病,全球约有 10 万名患者深受其害。它会累及人体多个器官,如肺部、胰腺等,严重影响患者的生活质量和寿命。CF 的 “罪魁祸首” 是 CFTR 氯离子通道的突变,…...

关于SIS/DCS点检周期
在中国化工行业,近几年在设备维护上有个挺有意思的现象,即SIS和DCS这两个系统的点检周期问题,隔三差五就被管理层会议讨论,可以说是企业管理层关注的重要方向与关心要素。 与一般工业行业中设备运维不同,SIS与DCS的点…...

python-pyqt6框架工具开发总结
菜单栏 工具栏 状态栏 QTreeView 用于展示树形结构数据(模-视图框架),文件系统,组织结构 通常与QAbstractItemModel的子类(如QStandardItemModel或自动义模型) 展开/折叠 控制节点的显示状态,展开时显示子节点,折叠时隐藏子节点 s…...

Docker Volumes
Docker Volumes 是 Docker 提供的一种机制,用于持久化存储容器数据。与容器的生命周期不同,Volumes 可以独立存在,即使容器被删除,数据仍然保留。以下是关于 Docker Volumes 的详细说明: 1. 为什么需要 Volumes&#…...
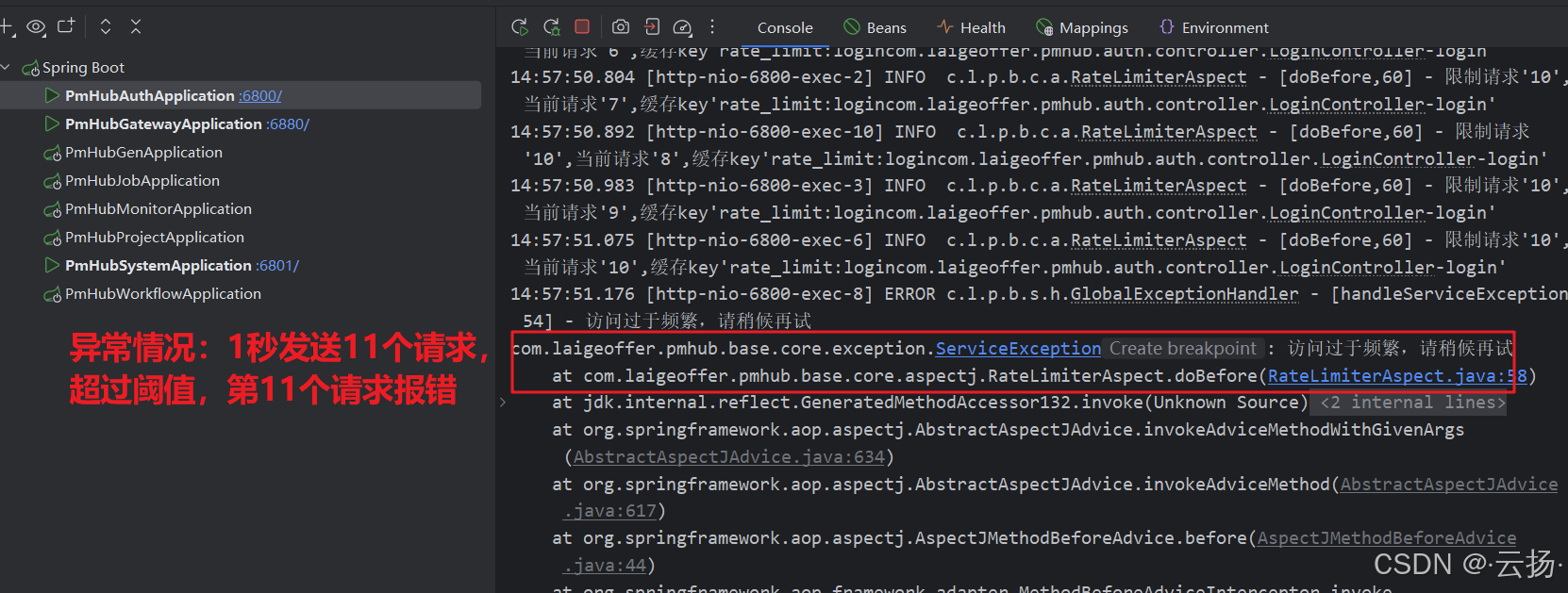
【PmHub后端篇】PmHub中基于Redis加Lua脚本的计数器算法限流实现
1 限流的重要性 在高并发系统中,保护系统稳定运行的关键技术有缓存、降级和限流。 缓存通过在内存中存储常用数据,减少对数据库的访问,提升系统响应速度,如浏览器缓存、CDN缓存等多种应用层面。降级则是在系统压力过大或部分服务…...

FPGA实战项目2———多协议通信控制器
1. 多协议通信控制器模块 (multi_protocol_controller) 简要介绍 这是整个设计的顶层模块,承担着整合各个子模块的重要任务,是整个系统的核心枢纽。它负责协调 UART、SPI、I2C 等不同通信协议模块以及 DMA 模块的工作,同时处理不同时钟域之间的信号交互,确保各个模块能够…...
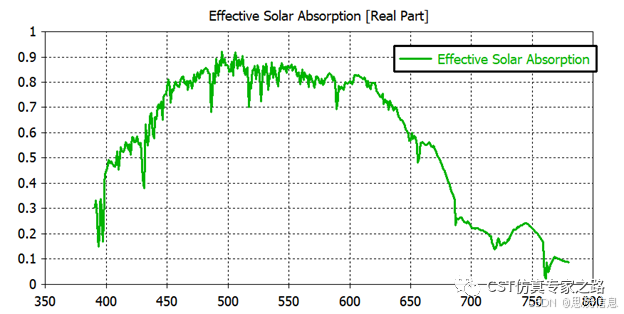
CST软件仿真案例——太阳能薄膜频谱吸收率
CST软件中的太阳能薄膜的功率吸收可用光频电磁波在介质材料中的损耗来计算。本案例计算非晶硅的功率吸收,然后考虑真实太阳频谱,计算有效吸收频谱。 用太阳能单元模板,时域求解器: 材料库提取四个材料,非晶硅…...
)
多线程进阶核心知识详解(通俗版)
Java多线程进阶详解 一、锁策略:如何高效管理资源竞争 在多线程环境中,锁是协调资源访问的核心机制。不同的锁策略适用于不同的场景,理解它们的差异能帮助优化程序性能。 1. 乐观锁 vs 悲观锁 悲观锁: 核心思想:假设…...

大模型中的KV Cache
1. KV Cache的定义与核心原理 KV Cache(Key-Value Cache)是一种在Transformer架构的大模型推理阶段使用的优化技术,通过缓存自注意力机制中的键(Key)和值(Value)矩阵,避免重复计算&…...

FHQ平衡树
FHQ平衡树 大致是这样的题目: 您需要动态地维护一个可重集合 M M M,并且提供以下操作: 向 M M M 中插入一个数 x x x。从 M M M 中删除一个数 x x x(若有多个相同的数,应只删除一个)。查询 M M M 中…...

力扣算法---总结篇
5.13 数组总结 数组是存放在连续内存空间上的相同类型数据的集合。 数组可以方便的通过下标索引的方式获取到下标对应的数据。 正是因为数组在内存空间的地址是连续的,所以我们在删除或者增添元素的时候,就难免要移动其他元素的地址。 数组的元素是不…...
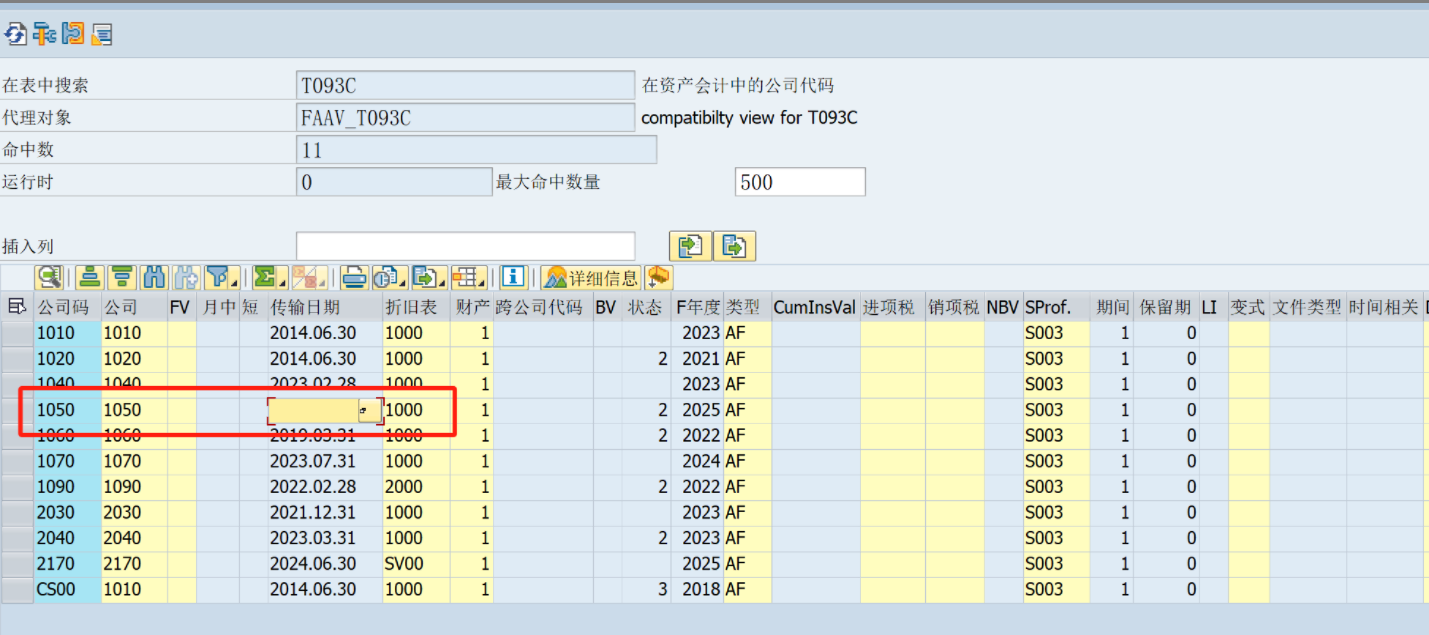
ABAP+旧数据接管的会计年度未确定
导资产主数据时,报错旧数据接管的会计年度未确定 是因为程序里面使用了下列函数AISCO_CALCULATE_FIRST_DAY,输入公司代码,获取会计年度,这个数据是在后台表T093C表中取数的,通过SE16N可以看到后台表数据没有数…...
)
Java【10_1】用户注册登录(面向过程与面向对象)
测试题 1、基于文本界面实现登录注册的需求(要求可以满足多个用户的注册和登录) 通过工具去完成 公共类: public class User { private int id;//用户编号 private int username;//用户名 private int password;//密码 private String name;//真…...

养生:打造健康生活的全方位策略
在生活节奏不断加快的当下,养生已成为提升生活质量、维护身心平衡的重要方式。从饮食、运动到睡眠,再到心态调节,各个方面的养生之道共同构建起健康生活的坚实基础。以下为您详细介绍养生的关键要点,助您拥抱健康生活。 饮食养生…...

贪吃蛇游戏排行榜模块开发总结:从数据到视觉的实现
一、项目背景与成果概览 在完成贪吃蛇游戏核心玩法后,本次开发重点聚焦于排行榜系统的实现。该系统具备以下核心特性: 🌐 双数据源支持:本地存储(localStorage)与远程API自由切换 🕒 时间维度统计:日榜/周榜/月榜/全时段数据筛选 🎮 模式区分:闯关模式(关卡进度…...

pytorch 数据预处理和常用工具
文章目录 NumPyNumpy数据结构安装和使用NumPy Matplotlib的安装和导入安装和导入Matplotlib绘制基础图画折线图散点图柱状图图例 数据清洗据清洗的作用Pandas进行数据清洗Pandas数据结构Series 数据结构DataFrame数据结构 Pandas数据清洗常用代码 特征工程主成分分析线性判别分…...

如何界定合法收集数据?
首席数据官高鹏律师团队 在当今数字化时代,数据的价值日益凸显,而合法收集数据成为了企业、机构以及各类组织必须严守的关键准则。作为律师,深入理解并准确界定合法收集数据的范畴,对于保障各方权益、维护法律秩序至关重要。 一…...

企业对数据集成工具的需求及 ETL 工具工作原理详解
当下,数据已然成为企业运营发展过程中的关键生产要素,其重要性不言而喻。 海量的数据分散在企业的各类系统、平台以及不同的业务部门之中,企业要充分挖掘这些数据背后所蕴含的巨大价值,实现数据驱动的精准决策,数据集…...

内核深入学习3——分析ARM32和ARM64体系架构下的Linux内存区域示意图与页表的建立流程
内核深入学习3——ARM32/ARM64在Linux内核中的实现(2) 今天我们来讨论的是一个硬核的内容,也是一个老生常谈的话题——那就是分析ARM32和ARM64体系架构下的Linux内存区域示意图的内容。对于ARM64的部分,我们早就知道一个基本的…...

MapReduce基本介绍
核心思想 分而治之:将大规模的数据处理任务分解成多个可以并行处理的子任务,然后将这些子任务分配到不同的计算节点上进行处理,最后将各个子任务的处理结果合并起来,得到最终的结果。 工作流程 Map 阶段: 输入数据被…...
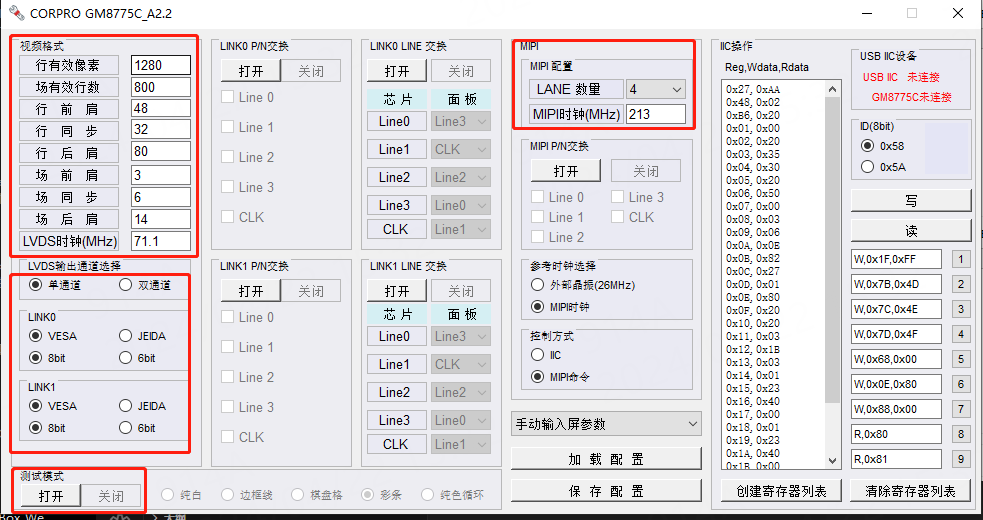
屏幕与触摸调试
本章配套视频介绍: 《28-屏幕与触摸设置》 【鲁班猫】28-屏幕与触摸设置_哔哩哔哩_bilibili LubanCat-RK3588系列板卡都支持mipi屏以及hdmi显示屏的显示。 19.1. 旋转触摸屏 参考文章 触摸校准 参考文章 旋转触摸方向 配置触摸旋转方向 1 2 # 1.查看触摸输入设备 xinput…...
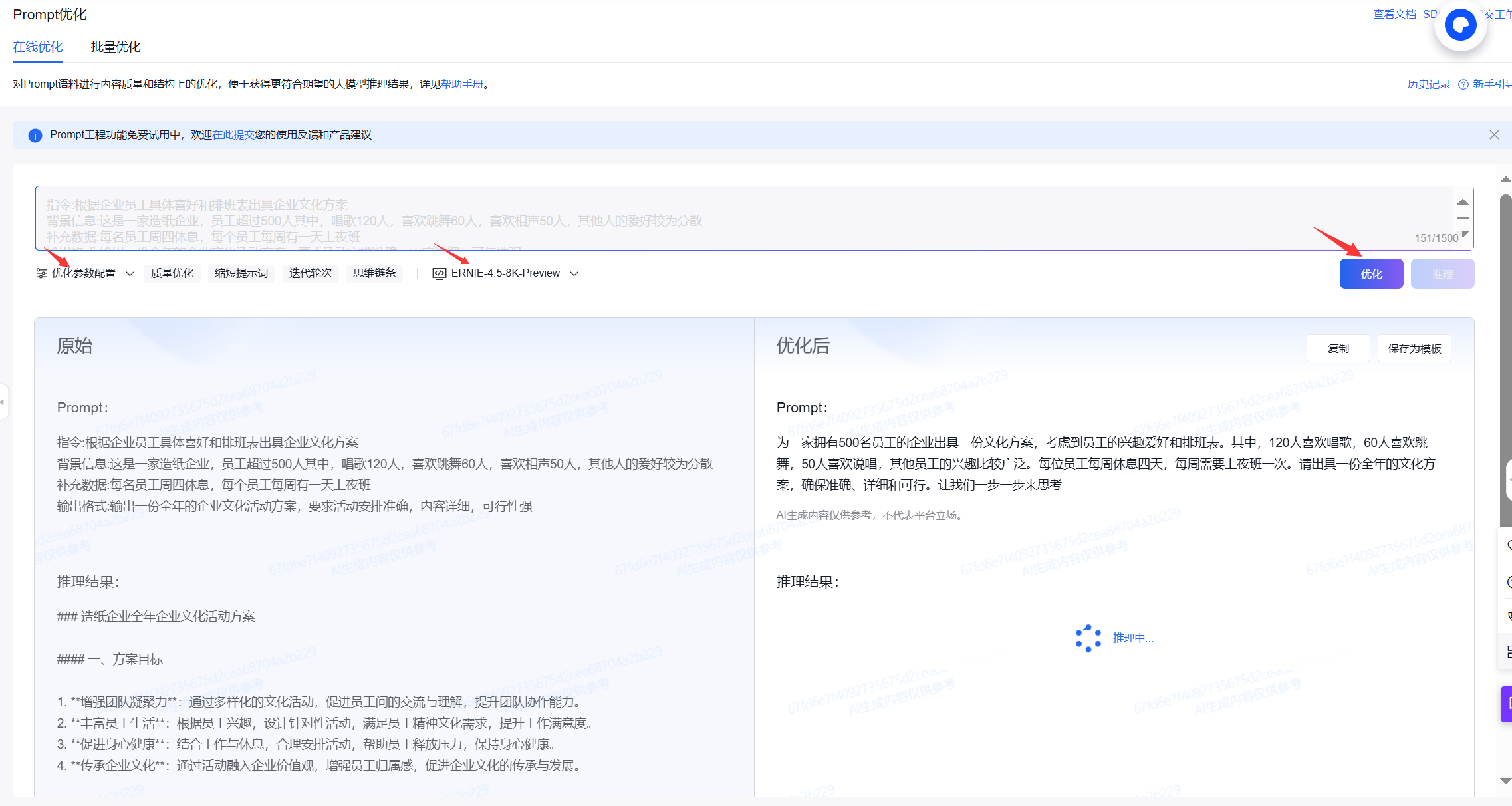
使用 百度云大模型平台 做 【提示词优化】
1. 百度云大模型平台 百度智能云千帆大模型平台  平台功能:演示了阿里云大模型的百炼平台,该平台提供Prompt工程功能,支持在线创建和优化Prompt模板模板类型:平台提供多种预制模板,同时也支持用户自定义…...

C 语言_常见排序算法全解析
排序算法是计算机科学中的基础内容,本文将介绍 C 语言中几种常见的排序算法,包括实现代码、时间复杂度分析、适用场景和详细解析。 一、冒泡排序(Bubble Sort) 基本思想:重复遍历数组,比较相邻元素,将较大元素交换到右侧。 代码实现: void bubbleSort(int arr[], i…...

IJCAI 2025 | 高德首个原生3D生成基座大模型「G3PT」重塑3D生成的未来
国际人工智能联合会议(IJCAI)是人工智能领域最古老、最具权威性的学术会议之一,自1969年首次举办以来,至今已有近六十年的历史。它见证了人工智能从萌芽到蓬勃发展的全过程,是全球人工智能研究者、学者、工程师和行业专…...

Samtec助力电视广播行业
【摘要前言】 现代广播电视技术最有趣的方面之一就是界限的模糊。过去,音频和视频是通过射频电缆传输的模拟技术采集的,而现在,数字世界已经取代了模拟技术。物理胶片和磁带已让位于数字存储设备和流媒体。 在这个过程中,连接器…...
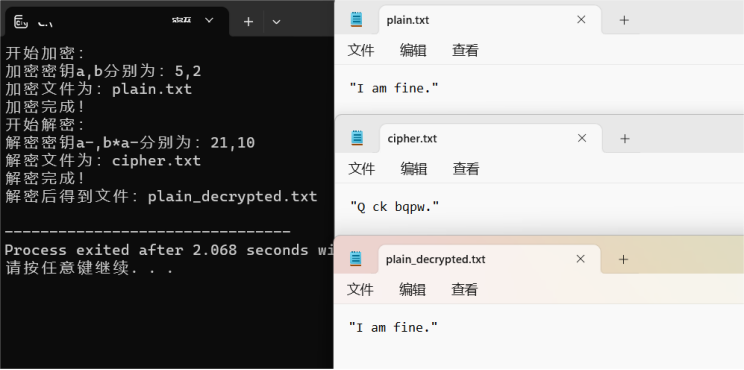
密码学--仿射密码
一、实验目的 1、通过实现简单的古典密码算法,理解密码学的相关概念 2、理解明文、密文、加密密钥、解密密钥、加密算法、解密算法、流密码与分组密码等。 二、实验内容 1、题目内容描述 ①随机生成加密密钥,并验证密钥的可行性 ②从plain文件读入待…...

生成式图像水印研究综述
生成式图像水印研究综述 一、引言二、生成式图像水印研究背景三、生成式图像水印算法研究进展3.1 基于流模型的方案3.2 基于生成对抗网络的方案3.3 基于扩散模型的方案3.3.1 修改图像数据3.3.2 调整生成模型3.3.3 修改隐变量空间四、算法的性能与评价指标五、常用数据集六、本章…...