Easysearch 时序数据的基于时间范围的合并策略
如果你正在使用 Easysearch 处理日志、监控指标、事件流或其他任何具有时间顺序的数据,那么你一定知道索引的性能和效率至关重要。Easysearch 底层的 Lucene Segment 合并是保持搜索和索引性能的关键后台任务。然而,你是否意识到,默认的合并策略可能并不是处理时序数据的最佳选择?
今天,我们就来介绍 Easysearch 1.12.1 版本起引入的一个重要优化:基于时间范围的合并策略 (TimeRangeMergePolicy) ,它专门为优化时序数据的 Segment 合并而生。
时序数据的合并挑战:默认策略的局限性
Easysearch 默认使用的合并策略(如 TieredMergePolicy)非常智能,它会根据 Segment 的大小、文档删除比例等因素来决定合并哪些 Segment,以平衡查询性能和资源使用。
但在时序数据场景下,这种通用策略可能会遇到一些问题:
- 冷热数据混合: 想象一下,几个月前的旧日志数据(冷数据)可能因为大小合适而被选中,与最近几小时内产生的新数据(热数据)进行合并。这会带来不必要的 I/O 和 CPU 开销,因为冷数据通常访问很少,合并它们对查询性能的提升有限,反而消耗了宝贵的资源。
- 查询性能影响: 合并可能产生覆盖时间跨度非常大的 Segment。当你执行按时间范围过滤的查询时(这在时序场景中非常常见),查询可能需要扫描这些巨大的 Segment,即使其中大部分数据都不在你的目标时间范围内,从而降低查询效率。
解决方案:TimeRangeMergePolicy 登场!
为了解决上述痛点,Easysearch 引入了 TimeRangeMergePolicy。顾名思义,这种策略在做合并决策时,将时间维度纳入了核心考量。
它的核心思想很简单,但非常有效:
- 时间优先: 倾向于合并那些时间上相邻或接近的 Segment。比如,属于同一天或同一小时的 Segment 更有可能被一起合并。
- 保留时间分区: 尽量避免将时间跨度极大的 Segment 合并在一起。这有助于保持数据的“时间局部性”,使得按时间范围查询时能更快地排除不相关的 Segment。
- 优先合并新数据: 通常,新产生的数据(热数据)更新和删除操作更频繁。优先合并包含较新数据的 Segment,有助于更快地回收被删除文档占用的空间,并优化对最新数据的查询性能。
如何为你的时序索引启用 TimeRangeMergePolicy?
启用这个功能非常简单,只需要两步:
- 确认日期字段: 首先,确保你的索引 Mapping 中有一个能准确代表数据时间的字段,通常是日期(
date)或时间戳(date_nanos)类型,例如@timestamp、event_time等。这个字段的值应该反映数据产生的实际时间。 - 更新索引设置: 使用 Index Settings API,为你的索引指定
index.merge.policy.time_range_field参数,并将其值设置为你的时间字段名。
示例:
假设你的时间字段是 timestamp,索引名称是 my-timeseries-index,你可以执行以下请求:
PUT /my-timeseries-index/_settings
{"index": {"merge.policy.time_range_field": "timestamp"}
}
搞定!设置之后,my-timeseries-index 后续的 Segment 合并就会自动采用 TimeRangeMergePolicy 了。
专家提示: 如果你想让所有新创建的时序索引默认就使用这个策略,可以将这个设置添加到你的索引模板 (Index Template) 中。
TimeRangeMergePolicy 的优势
启用时间范围合并策略能带来哪些好处呢?
- 降低合并开销: 显著减少冷热数据的无效合并,节省 I/O 和 CPU 资源。
- 提高资源效率: 更智能的合并有助于更快地回收已删除文档的空间,并可能降低整体计算资源的使用。
- 优化查询性能: 保持 Segment 的时间局部性,对于按时间范围过滤的查询(例如,“查询过去一小时的日志”)可能会有明显的性能提升。
- 对时序数据更友好: 该策略的设计初衷就是为了更好地服务于日志、指标这类严格按时间增长的数据模式。
注意事项
在使用 TimeRangeMergePolicy 时,有几点需要注意:
- 时间字段是关键: 策略的效果高度依赖于你所指定的
time_range_field。如果该字段不存在,或者字段中的时间值混乱、不准确,策略可能无法发挥预期效果,甚至适得其反。 - 并非万能丹: 这个策略最适合具有明确时间序列特征的数据。对于非时序数据(例如,商品信息、用户信息索引),默认的
TieredMergePolicy可能仍然是更好的选择。 - 版本要求: 请确保你的 Easysearch 集群版本至少为 1.12.1。
总结
对于处理大量时序数据的 Easysearch 用户来说,TimeRangeMergePolicy 是一个非常有价值的优化工具。通过感知数据的时间属性,它可以让 Segment 合并操作更加智能和高效,从而降低资源消耗、提升查询性能。如果你的索引符合时序数据的特征,并且正在运行 Easysearch 1.12.1 或更高版本,不妨尝试启用这个策略,看看它能否为你的集群带来改善!
相关文章:

Easysearch 时序数据的基于时间范围的合并策略
如果你正在使用 Easysearch 处理日志、监控指标、事件流或其他任何具有时间顺序的数据,那么你一定知道索引的性能和效率至关重要。Easysearch 底层的 Lucene Segment 合并是保持搜索和索引性能的关键后台任务。然而,你是否意识到,默认的合并策…...

【C++】深入理解 unordered 容器、布隆过滤器与分布式一致性哈希
【C】深入理解 unordered 容器、布隆过滤器与分布式一致性哈希 在日常开发中,无论是数据结构优化、缓存设计,还是分布式架构搭建,unordered_map、布隆过滤器和一致性哈希都是绕不开的关键工具。它们高效、轻量,在性能与扩展性方面…...
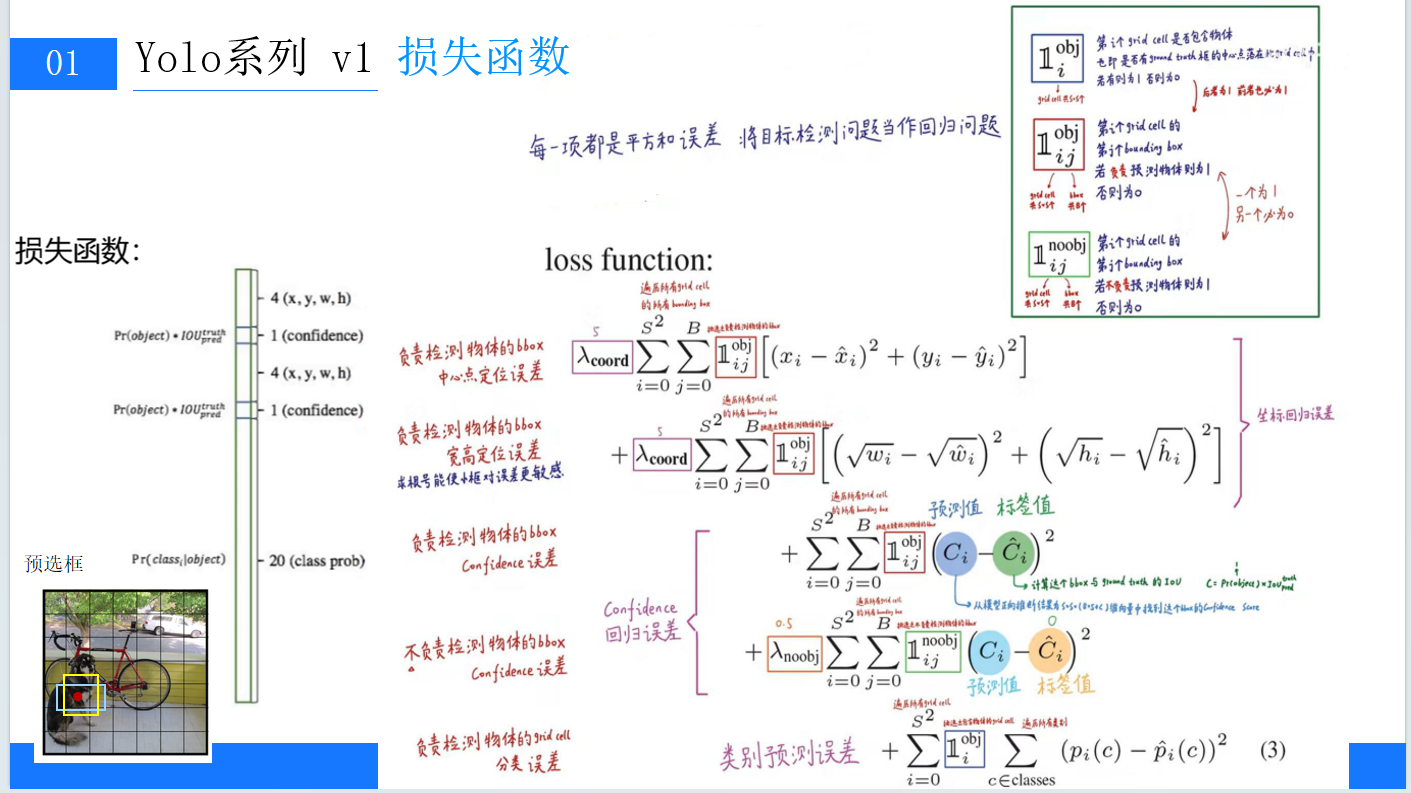
YOLOv1:开启实时目标检测的新篇章
YOLOv1:开启实时目标检测的新篇章 在深度学习目标检测领域,YOLO(You Only Look Once)系列算法无疑占据着重要地位。其中,YOLOv1作为开山之作,以其独特的设计理念和高效的检测速度,为后续的目标…...

Spring Boot 整合 Redis 实战
一、整合准备:环境与依赖 1. 技术栈说明 Spring Boot 版本:3.1.2(兼容 Java 17) Redis 服务器:Redis 7.0(本地部署或 Docker 容器) Maven 依赖: <dependency><…...

Spring事务失效的全面剖析
文章目录 1. Spring事务基础1.1 什么是Spring事务1.2 Spring事务的实现原理1.3 `@Transactional`注解的主要属性1.4 使用Spring事务的简单示例2. Spring事务失效的常见场景及解决方案2.1 方法不是public的问题描述问题示例解决方案技术原理解释2.2 自调用问题(同一个类中的方法…...

Pytorch张量和损失函数
文章目录 张量张量类型张量例子使用概率分布创建张量正态分布创建张量 (torch.normal)正态分布创建张量示例标准正态分布创建张量标准正态分布创建张量示例均匀分布创建张量均匀分布创建张量示例 激活函数常见激活函数 损失函数(Pytorch API)L1范数损失函数均方误差损失函数交叉…...
ConcurrentHashMap发送)
消息~组件(群聊类型)ConcurrentHashMap发送
为什么选择ConcurrentHashMap? 在开发聊天应用时,我们需要存储和管理大量的聊天消息数据,这些数据会被多个线程频繁访问和修改。比如,当多个用户同时发送消息时,服务端需要同时处理这些消息的存储和查询。如果用普通的…...
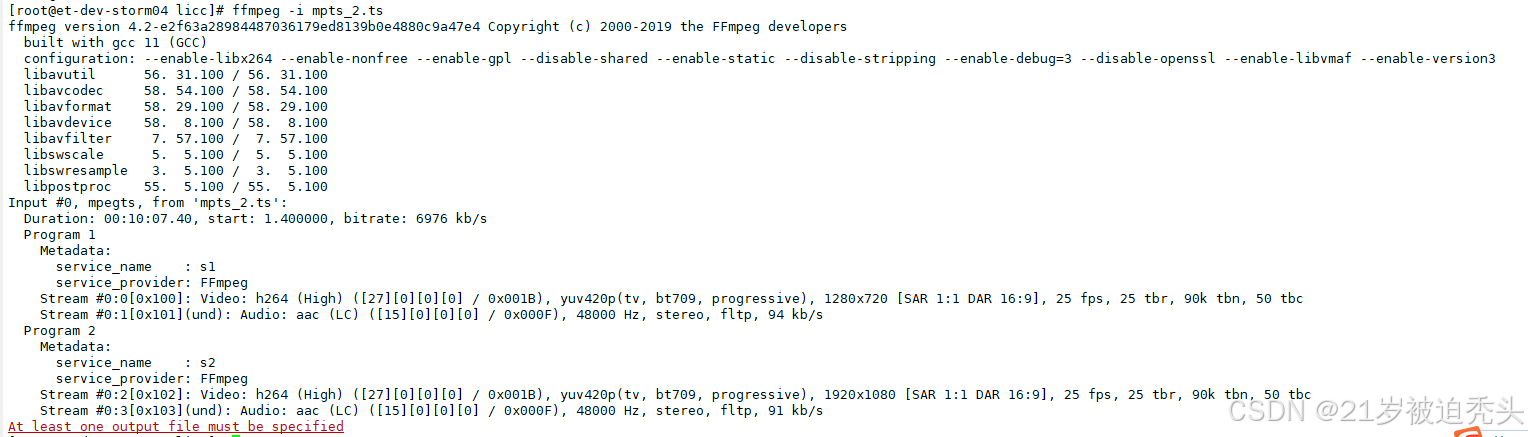
FFmpeg多路节目流复用为一路包含多个节目的输出流
在音视频处理领域,将多个独立的节目流(如不同频道的音视频内容)合并为一个包含多个节目的输出流是常见需求。FFmpeg 作为功能强大的多媒体处理工具,提供了灵活的流复用能力,本文将通过具体案例解析如何使用 FFmpeg 实现…...
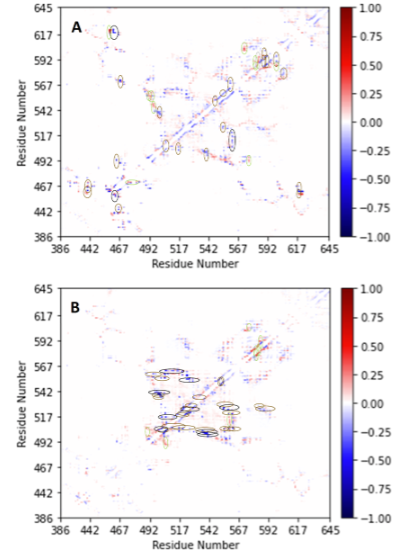
分子动力学模拟揭示点突变对 hCFTR NBD1结构域热稳定性的影响
囊性纤维化(CF) 作为一种严重的常染色体隐性遗传疾病,全球约有 10 万名患者深受其害。它会累及人体多个器官,如肺部、胰腺等,严重影响患者的生活质量和寿命。CF 的 “罪魁祸首” 是 CFTR 氯离子通道的突变,…...

关于SIS/DCS点检周期
在中国化工行业,近几年在设备维护上有个挺有意思的现象,即SIS和DCS这两个系统的点检周期问题,隔三差五就被管理层会议讨论,可以说是企业管理层关注的重要方向与关心要素。 与一般工业行业中设备运维不同,SIS与DCS的点…...

python-pyqt6框架工具开发总结
菜单栏 工具栏 状态栏 QTreeView 用于展示树形结构数据(模-视图框架),文件系统,组织结构 通常与QAbstractItemModel的子类(如QStandardItemModel或自动义模型) 展开/折叠 控制节点的显示状态,展开时显示子节点,折叠时隐藏子节点 s…...

Docker Volumes
Docker Volumes 是 Docker 提供的一种机制,用于持久化存储容器数据。与容器的生命周期不同,Volumes 可以独立存在,即使容器被删除,数据仍然保留。以下是关于 Docker Volumes 的详细说明: 1. 为什么需要 Volumes&#…...
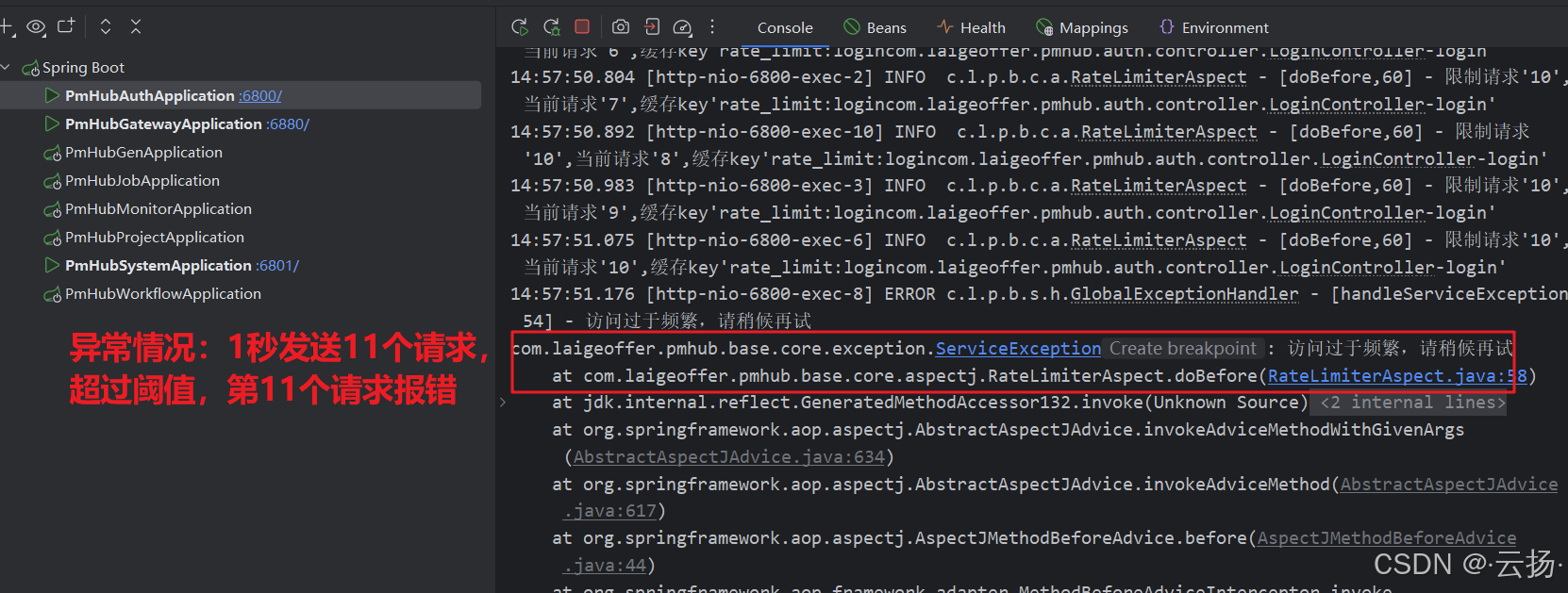
【PmHub后端篇】PmHub中基于Redis加Lua脚本的计数器算法限流实现
1 限流的重要性 在高并发系统中,保护系统稳定运行的关键技术有缓存、降级和限流。 缓存通过在内存中存储常用数据,减少对数据库的访问,提升系统响应速度,如浏览器缓存、CDN缓存等多种应用层面。降级则是在系统压力过大或部分服务…...

FPGA实战项目2———多协议通信控制器
1. 多协议通信控制器模块 (multi_protocol_controller) 简要介绍 这是整个设计的顶层模块,承担着整合各个子模块的重要任务,是整个系统的核心枢纽。它负责协调 UART、SPI、I2C 等不同通信协议模块以及 DMA 模块的工作,同时处理不同时钟域之间的信号交互,确保各个模块能够…...
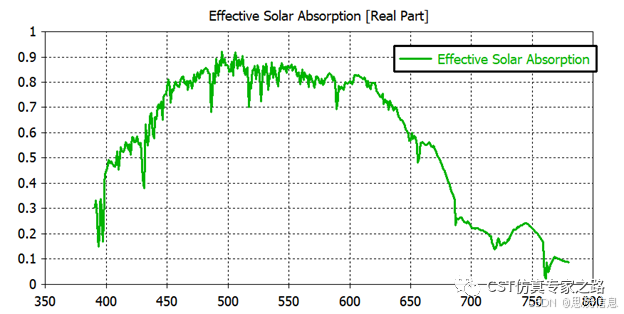
CST软件仿真案例——太阳能薄膜频谱吸收率
CST软件中的太阳能薄膜的功率吸收可用光频电磁波在介质材料中的损耗来计算。本案例计算非晶硅的功率吸收,然后考虑真实太阳频谱,计算有效吸收频谱。 用太阳能单元模板,时域求解器: 材料库提取四个材料,非晶硅…...
)
多线程进阶核心知识详解(通俗版)
Java多线程进阶详解 一、锁策略:如何高效管理资源竞争 在多线程环境中,锁是协调资源访问的核心机制。不同的锁策略适用于不同的场景,理解它们的差异能帮助优化程序性能。 1. 乐观锁 vs 悲观锁 悲观锁: 核心思想:假设…...

大模型中的KV Cache
1. KV Cache的定义与核心原理 KV Cache(Key-Value Cache)是一种在Transformer架构的大模型推理阶段使用的优化技术,通过缓存自注意力机制中的键(Key)和值(Value)矩阵,避免重复计算&…...

FHQ平衡树
FHQ平衡树 大致是这样的题目: 您需要动态地维护一个可重集合 M M M,并且提供以下操作: 向 M M M 中插入一个数 x x x。从 M M M 中删除一个数 x x x(若有多个相同的数,应只删除一个)。查询 M M M 中…...

力扣算法---总结篇
5.13 数组总结 数组是存放在连续内存空间上的相同类型数据的集合。 数组可以方便的通过下标索引的方式获取到下标对应的数据。 正是因为数组在内存空间的地址是连续的,所以我们在删除或者增添元素的时候,就难免要移动其他元素的地址。 数组的元素是不…...
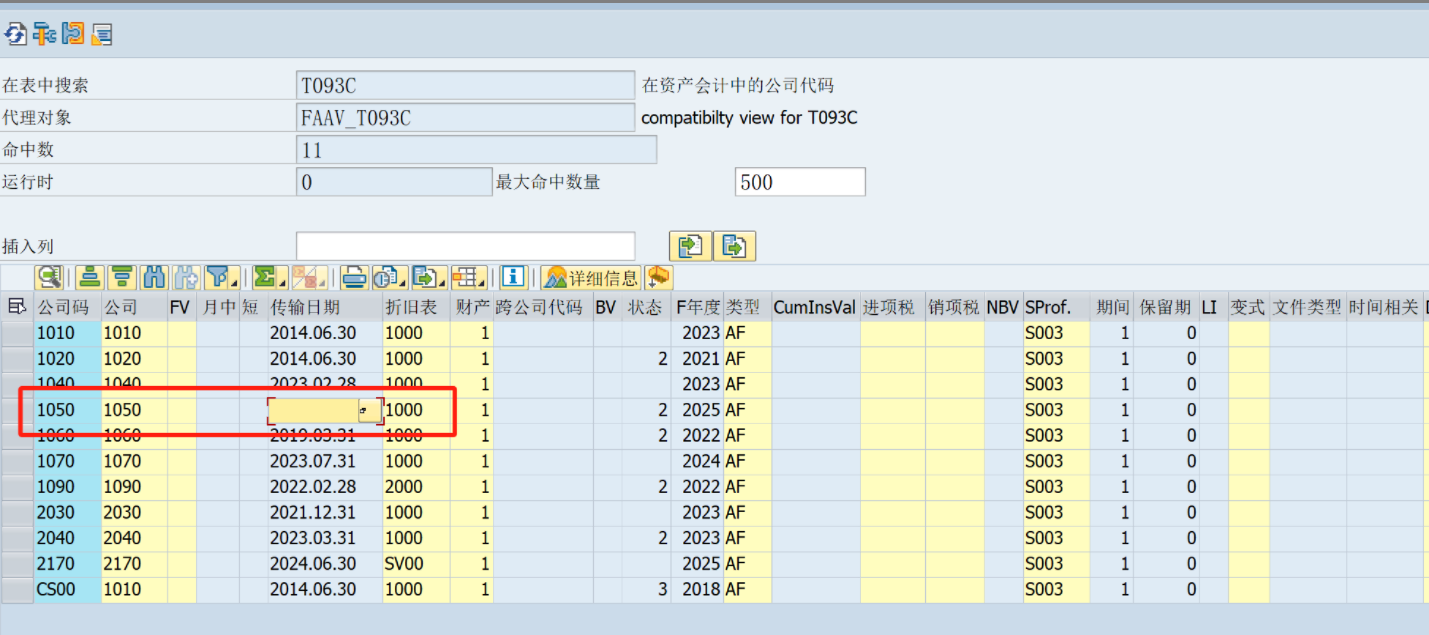
ABAP+旧数据接管的会计年度未确定
导资产主数据时,报错旧数据接管的会计年度未确定 是因为程序里面使用了下列函数AISCO_CALCULATE_FIRST_DAY,输入公司代码,获取会计年度,这个数据是在后台表T093C表中取数的,通过SE16N可以看到后台表数据没有数…...
)
Java【10_1】用户注册登录(面向过程与面向对象)
测试题 1、基于文本界面实现登录注册的需求(要求可以满足多个用户的注册和登录) 通过工具去完成 公共类: public class User { private int id;//用户编号 private int username;//用户名 private int password;//密码 private String name;//真…...

养生:打造健康生活的全方位策略
在生活节奏不断加快的当下,养生已成为提升生活质量、维护身心平衡的重要方式。从饮食、运动到睡眠,再到心态调节,各个方面的养生之道共同构建起健康生活的坚实基础。以下为您详细介绍养生的关键要点,助您拥抱健康生活。 饮食养生…...

贪吃蛇游戏排行榜模块开发总结:从数据到视觉的实现
一、项目背景与成果概览 在完成贪吃蛇游戏核心玩法后,本次开发重点聚焦于排行榜系统的实现。该系统具备以下核心特性: 🌐 双数据源支持:本地存储(localStorage)与远程API自由切换 🕒 时间维度统计:日榜/周榜/月榜/全时段数据筛选 🎮 模式区分:闯关模式(关卡进度…...

pytorch 数据预处理和常用工具
文章目录 NumPyNumpy数据结构安装和使用NumPy Matplotlib的安装和导入安装和导入Matplotlib绘制基础图画折线图散点图柱状图图例 数据清洗据清洗的作用Pandas进行数据清洗Pandas数据结构Series 数据结构DataFrame数据结构 Pandas数据清洗常用代码 特征工程主成分分析线性判别分…...

如何界定合法收集数据?
首席数据官高鹏律师团队 在当今数字化时代,数据的价值日益凸显,而合法收集数据成为了企业、机构以及各类组织必须严守的关键准则。作为律师,深入理解并准确界定合法收集数据的范畴,对于保障各方权益、维护法律秩序至关重要。 一…...

企业对数据集成工具的需求及 ETL 工具工作原理详解
当下,数据已然成为企业运营发展过程中的关键生产要素,其重要性不言而喻。 海量的数据分散在企业的各类系统、平台以及不同的业务部门之中,企业要充分挖掘这些数据背后所蕴含的巨大价值,实现数据驱动的精准决策,数据集…...

内核深入学习3——分析ARM32和ARM64体系架构下的Linux内存区域示意图与页表的建立流程
内核深入学习3——ARM32/ARM64在Linux内核中的实现(2) 今天我们来讨论的是一个硬核的内容,也是一个老生常谈的话题——那就是分析ARM32和ARM64体系架构下的Linux内存区域示意图的内容。对于ARM64的部分,我们早就知道一个基本的…...

MapReduce基本介绍
核心思想 分而治之:将大规模的数据处理任务分解成多个可以并行处理的子任务,然后将这些子任务分配到不同的计算节点上进行处理,最后将各个子任务的处理结果合并起来,得到最终的结果。 工作流程 Map 阶段: 输入数据被…...
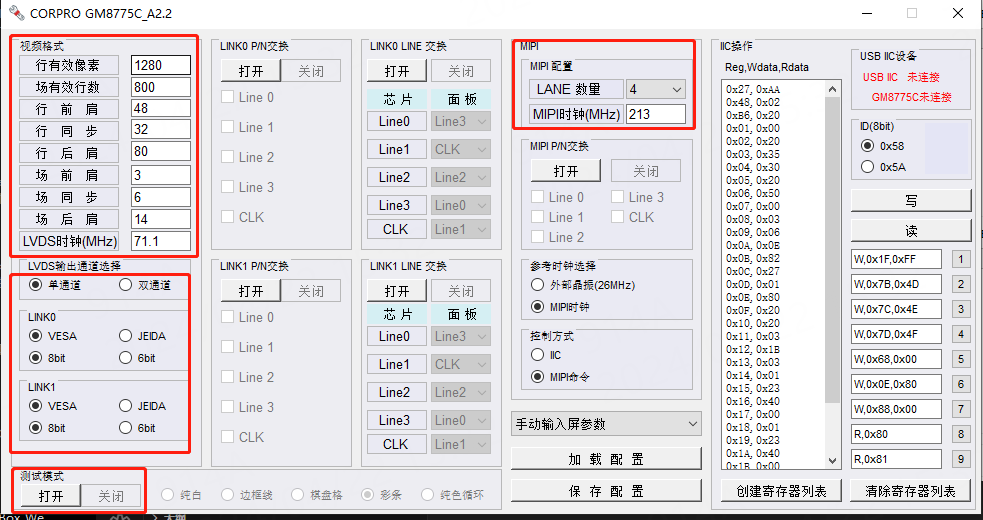
屏幕与触摸调试
本章配套视频介绍: 《28-屏幕与触摸设置》 【鲁班猫】28-屏幕与触摸设置_哔哩哔哩_bilibili LubanCat-RK3588系列板卡都支持mipi屏以及hdmi显示屏的显示。 19.1. 旋转触摸屏 参考文章 触摸校准 参考文章 旋转触摸方向 配置触摸旋转方向 1 2 # 1.查看触摸输入设备 xinput…...
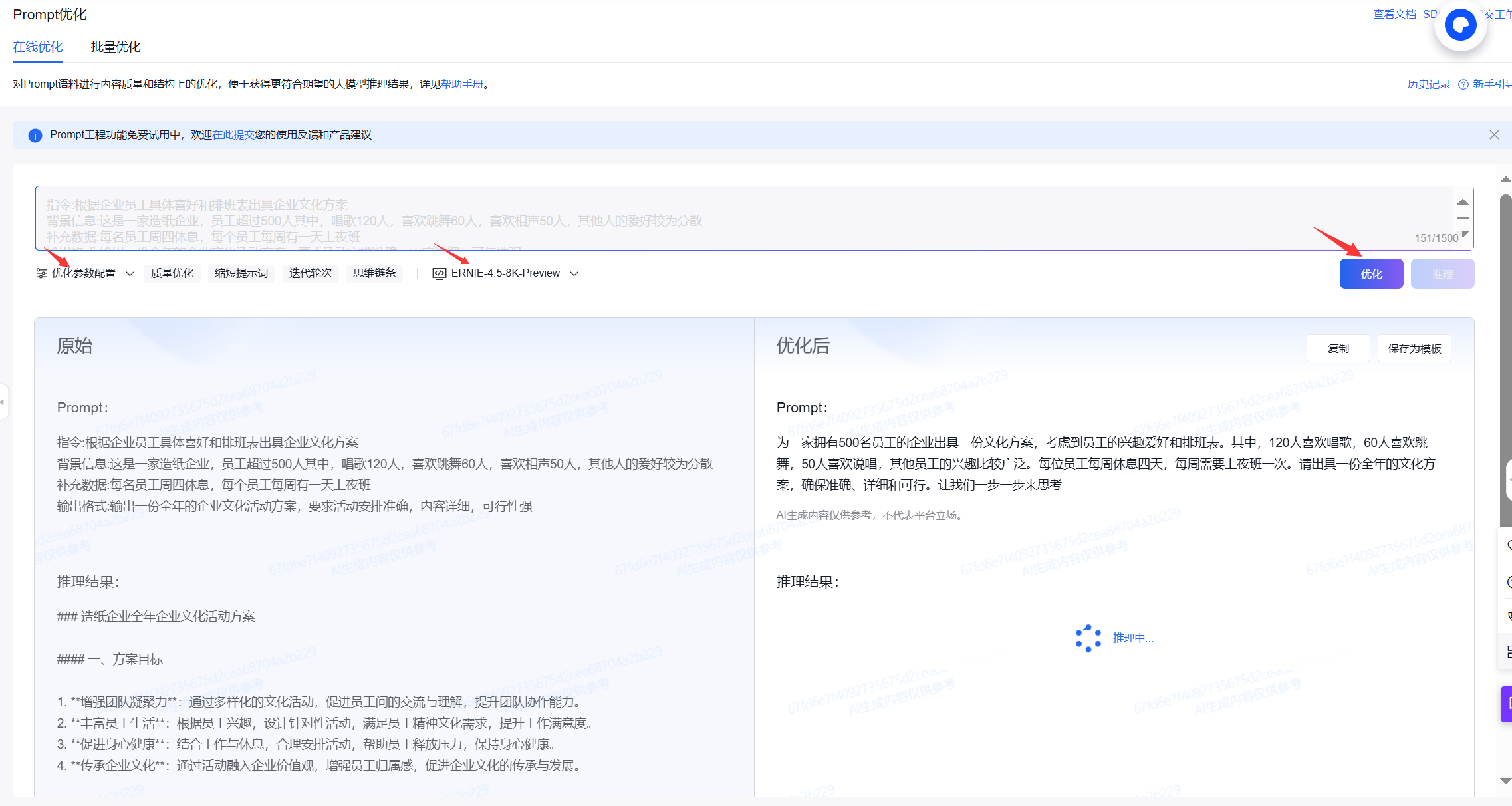
使用 百度云大模型平台 做 【提示词优化】
1. 百度云大模型平台 百度智能云千帆大模型平台  平台功能:演示了阿里云大模型的百炼平台,该平台提供Prompt工程功能,支持在线创建和优化Prompt模板模板类型:平台提供多种预制模板,同时也支持用户自定义…...