LeetCode 513 找树左下角的值 LeetCode 112 路径总和 LeetCode106 从中序与后序遍历序列构造二叉树
LeetCode 513 找树左下角的值
迭代法——层序遍历
思路:对树进行层序遍历操作,层序遍历完后,输出树最后一层的第一个节点。
# Definition for a binary tree node.
# class TreeNode(object):
# def __init__(self, val=0, left=None, right=None):
# self.val = val
# self.left = left
# self.right = right
class Solution(object):def findBottomLeftValue(self, root):""":type root: Optional[TreeNode]:rtype: int"""### Version 1 : 层序遍历,遍历每一层后取出最后一层的第一个元素。result = []queue = deque([root])while queue:level = []size = len(queue)while size:cur = queue.popleft()if cur.left:queue.append(cur.left)if cur.right:queue.append(cur.right)level.append(cur.val)size -= 1result.append(level)return result[-1][0] 递归法
思路:
- 由于是记录底层最左侧节点的值,因此我们需要去获取遍历时的深度,深度最深的时候才去考虑是否是最左侧节点的值。
- 由于是获取最左侧节点的值,因此只要遍历顺序是左先于右,这样的话在深度最深的时候,由于遍历顺序是左先,因此第一个遍历到的节点一定是底层最左侧节点(前中后序遍历中左都是在右之前,因此三种遍历方式都可以,另外本题对于中不需要处理,所以中其实就是无代码)
关键:
- 遍历后记得回溯,因为你遍历是在遍历下一层的,当你遍历完下一层后,需要回退到上一层中去遍历另外一边。如下图所示:你在遍历完3之后需要回退到1,才能继续去遍历1的右子树。没有回溯的话就会一直卡在左边(因为左边优先遍历)。同理遍历完右边后也需要回退。
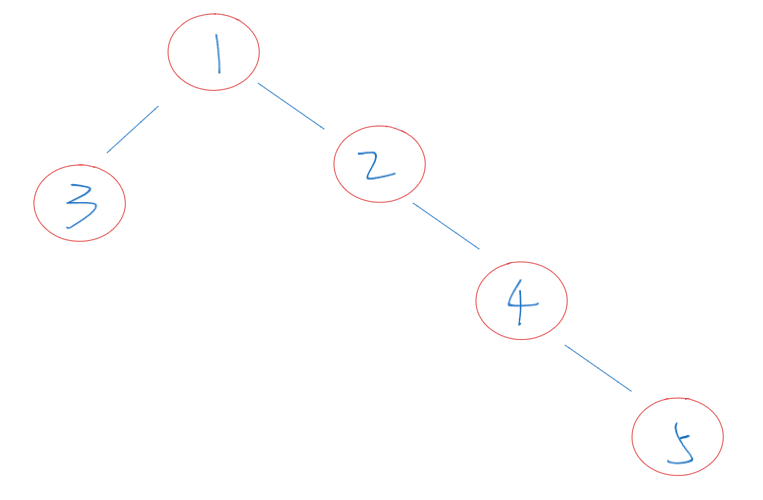
- 由于需要在遍历的过程中去比较是否到达深度最深的地方,因此需要通过一个全局变量用于记录已遍历过的最大深度的信息。当遍历到叶子节点时,就需要判断当前是否是最大深度了,如果是则更新最大深度的值,反之。
# Definition for a binary tree node.
# class TreeNode(object):
# def __init__(self, val=0, left=None, right=None):
# self.val = val
# self.left = left
# self.right = right
class Solution(object):def findBottomLeftValue(self, root):""":type root: Optional[TreeNode]:rtype: int"""#### 递归法:底层最左边节点的值,其深度一定是最大的。#### 前中后序遍历都可以,因为都是左遍历在右遍历之前。self.max_depth = float('-inf') ### 全局变量,存储最大深度self.result = 0 ### 全局变量,存储底层最左侧节点的值self.search_DepLeft(root, 1)return self.resultdef search_DepLeft(self, root, depth):### 递归逻辑:记录当前遍历节点的深度,遍历顺序需要满足左一定在右之前。这样的话,深度最大时,一个遍历到的元素就是底层的最左侧节点。### 关键:如何对max_depth初始化,且在下一次递归时,max_depth的值是上一层节点的值。这样的话max_depth是一个全局变量,其初始化不应该在递归函数内设置if not root.left and not root.right: ### 终止条件 —— 到叶子节点if depth > self.max_depth: ### 到达叶子节点后,需要判断深度是否是最底层self.max_depth = depthself.result = root.val ### 由于左遍历在右遍历之前,因此深度最大时遍历到的第一个节点一定是底层的最左侧节点return if root.left: ### 有左叶子节点的话depth += 1 ### 更新遍历左叶子节点时候的深度self.search_DepLeft(root.left, depth)depth -= 1 ### 遍历完后,需要回溯,不然的话就会一直停留在左子树。if root.right:depth += 1self.search_DepLeft(root.right, depth)depth -= 1LeetCode 112 路径总和
思路:(前中后序遍历都可以,这里是前序遍历)
- 定义一个全局变量记录,根节点逐渐向下遍历过程中的和,到达根节点的时候,判断当前路径是否成立。
- 如果不成立的话,需要对子递归函数进行回溯操作。
手撕Code:
# Definition for a binary tree node.
# class TreeNode(object):
# def __init__(self, val=0, left=None, right=None):
# self.val = val
# self.left = left
# self.right = right
class Solution(object):def hasPathSum(self, root, targetSum):""":type root: Optional[TreeNode]:type targetSum: int:rtype: bool"""### 根节点到叶子节点的路径, 这个做过。但这道题不需要返回整条path,而是返回path的值之和是否等于targetSum### 现在是在上述基础上,计算根节点到叶子节点的路径上的值,判断该值是否等于targetSumself.sum = 0 ## 记录当前遍历的path值的总和if not root:return Falseresult = self.search_Path(root, targetSum)return resultdef search_Path(self, root, targetSum):self.sum += root.val# print("path_self.sum, root.val", self.sum, root.val)if not root.left and not root.right: ###终止条件if self.sum == targetSum:return Trueif root.left:if self.search_Path(root.left, targetSum):return True# self.search_Path(root.left, targetSum)self.sum -= root.left.val if root.right:if self.search_Path(root.right, targetSum):return True# self.search_Path(root.right, targetSum)self.sum -= root.right.valreturn False ### 完全遍历后,没有输出True就输出return错误地方分析:
- 递归思路可以实现逐渐查找并回溯。但下面代码这样编写有问题,即当self.search_Path(root.left, targetSum)搜到叶子节点时,发现路径之和==targetSum时,此时会return True,但这也仅代表这个递归函数返回True,后续没有显式返回子递归的结果,因此最终输出的会是Null。(子递归返回了值,但未传递返回值,从而结果被更上一层的递归也覆盖掉了)
- 为什么要加这个判断,比如你目前的主递归函数是递归根节点的左节点,随后子递归是逐渐往下遍历,那当子递归输出为True时,就已经告诉了目前左子树存在一条路径,使得根节点到左子树的一个叶子节点的值等于targetSum,那你此时就需要就子递归的输出直接return给根节点的左节点函数,那主递归函数在收到True时,此时就明确了左子树存在一条路径之和符合题目要求的情况。
if root.left:self.search_Path(root.left, targetSum)self.sum -= root.left.val if root.right:self.search_Path(root.right, targetSum)self.sum -= root.right.valLeetCode 113 路径总和 II
注意:
- 浅拷贝和深拷贝的问题。
- self.result.append(self.path) ### 这里存的是self.path的指针,并没有存储当targetSum的数组元素。这个指针会始终指向这块数组的内存位置,如果存储的是指针的话,最终result的内容只会是该内存块中最后的元素,在这道题中,最后result.append的只会是5,因为在遍历完并回溯完后,最终数组只有根节点元素。
- self.result.append(self.path[:]) ### 这里是深拷贝,即在内存中重新开辟一块空间来copy此时符合条件的路径的数组,result存储的是这个新的数组。
# Definition for a binary tree node.
# class TreeNode(object):
# def __init__(self, val=0, left=None, right=None):
# self.val = val
# self.left = left
# self.right = right
class Solution(object):def pathSum(self, root, targetSum):""":type root: Optional[TreeNode]:type targetSum: int:rtype: List[List[int]]"""self.sum = 0self.result = []self.path = []self.search_Path(root, self.path, targetSum, self.result)return self.resultdef search_Path(self, root, path, targetSum, result):if not root:returnself.sum += root.valself.path.append(root.val)if not root.left and not root.right:if self.sum == targetSum:self.result.append(self.path[:])# self.result.append(self.path) ### 这里存的是self.path的指针,并没有存储当targetSum的数组元素。这个指针会始终指向这块数组的内存位置,如果存储的是指针的话,最终result的内容只会是该内存块中最后的元素,在这道题中,最后result.append的只会是5,因为在遍历完并回溯完后,最终数组只有根节点元素。return else:return if root.left:self.search_Path(root.left, self.path, targetSum, self.result)self.sum -= root.left.valpath.pop()if root.right:self.search_Path(root.right, self.path, targetSum, self.result)self.sum -= root.right.valpath.pop() LeetCode106 从中序与后序遍历序列构造二叉树
中序遍历:左中右
后序遍历:左右中
根据中序遍历和后序遍历的规则,我可以得出以下特性来构造二叉树:
- 后序遍历的最后一个节点一定是根节点,因此我们可以根据这个根节点,去中序遍历中将左子树和右子树给区分开来。
- 中序遍历和后序遍历起始都是左,在中序遍历中根据根节点将左子树和右子树区分开来后,我们可以根据中序遍历左子树元素的个数,在后序遍历中获得左子树的后序遍历数组,其余的就是右子树的后序遍历数组。
根据上述特性后,我们可以就可以确定了这颗树的根节点、左子树的中序遍历和后序遍历数组、右子树的中序和后序遍历数组。那分别对左右子树的中序和后序数组进行递归操作,又可以根据相同的特性获得唯一左子树和右子树。
如下面例子:
| 9 | 3 | 15 | 20 | 7 |
| 9 | 15 | 7 | 20 | 3 |
首先,我们可以知道根节点为3。知道根节点为3之后,就可以明确知道在中序遍历数组3左边是左子树,3右边是右子树。根据中序遍历中左子树的元素个数就可以确定在后序遍历中的左子树后序遍历数组,这里是都为9。其余的就是右子树的内容,那对其余的进行分析,可以知道右子树中序遍历数组为 [15, 20, 7],后序遍历数组为[15, 7, 20]。执行相同的操作,就可以确定唯一的右子树。最后整棵树为如下:
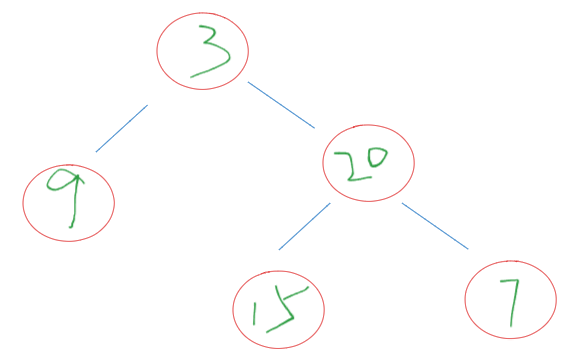
代码思路:
- 判断后序数组是否为None,如果是,则证明为空树
- 判断后序数组长度是否为1,如果是,则证明则有根节点
- 如果后序数组大于1,则首先获得这颗树的根节点。
- 根据根节点的值,去中序遍历数组中找到等于该值的元素下标,在这个下标之前的子数组就是左子树的中序遍历数组,之后的就是右子树中序遍历的子数组。
- 根据左子树的中序遍历数组的个数,我们可以从后序遍历数组中获得左子树的后序遍历数组。其余的,除了最后一个节点之外的元素,就是右子树后序遍历的子数组。
- 根据左,右子树的中序遍历和后序遍历子数组,进行递归操作,来唯一确定左右子树。
手撕Code:
# Definition for a binary tree node.
# class TreeNode(object):
# def __init__(self, val=0, left=None, right=None):
# self.val = val
# self.left = left
# self.right = right
class Solution(object):def buildTree(self, inorder, postorder):""":type inorder: List[int]:type postorder: List[int]:rtype: Optional[TreeNode]"""if len(postorder) == 0: ## 空树return None### 只有根结点的情况,以下也能进行判断root_val = postorder[-1]root = TreeNode(val=root_val)SEP = inorder.index(root_val) ### 获得切割点的indexleft_inorder = inorder[:SEP]right_inorder = inorder[SEP+1:]#### 区间是左闭右开,数组[A:B] 等于 A到B-1位置的子数组left_postorder = postorder[0:len(left_inorder)]right_postorder = postorder[len(left_inorder):len(postorder)-1]root_left = self.buildTree(left_inorder, left_postorder)root_right = self.buildTree(right_inorder, right_postorder)root.left = root_left ### 将构造好的左右子树连接到根节点中root.right = root_rightreturn root- 注意再获得左右子树后,要将根节点的左右指针进行赋值。
- 注意区间是左闭右开还是左闭右闭
LeetCode 105 从前序与中序遍历序列构造二叉树
中序遍历:左中右
前序遍历:中左右
根据中序遍历和前序遍历的规则,我可以得出以下特性来构造二叉树:
- 前序遍历的第一个节点一定是根节点,因此我们可以根据这个根节点,去中序遍历中将左子树和右子树给区分开来。
- 中序遍历和前序遍历结尾都是右,在中序遍历中根据根节点将左子树和右子树区分开来后,我们可以根据中序遍历右子树元素的个数,在前序遍历中获得右子树的前序遍历数组,其余的就是左子树的前序遍历数组。
手撕Code:
# Definition for a binary tree node.
# class TreeNode(object):
# def __init__(self, val=0, left=None, right=None):
# self.val = val
# self.left = left
# self.right = right
class Solution(object):def buildTree(self, preorder, inorder):""":type preorder: List[int]:type inorder: List[int]:rtype: Optional[TreeNode]"""### preorder: 中左右### inorder : 左中右if len(preorder) == 0: ##空树return Noneroot_val = preorder[0]root = TreeNode(val=root_val) ##根节点SEP = inorder.index(root_val)left_inorder = inorder[:SEP] ### 区间是左闭右开left_preorder = preorder[1:len(left_inorder)+1]right_preorder = preorder[len(left_inorder)+1:]right_inorder = inorder[SEP+1:]left_tree = self.buildTree(left_preorder, left_inorder)right_tree = self.buildTree(right_preorder, right_inorder)root.left = left_treeroot.right = right_treereturn root 总结
中序遍历 + 前序/后序遍历 可以 确定一个唯一的二叉树。必须有中序遍历的存在。
而前序遍历+后序遍历无法确认。
前序遍历:中左右
后序遍历:左右中
根据前序遍历和后序遍历的特性,我们只能唯一确定根节点,但无法从前序遍历和后序遍历划分出左右。例子如下:
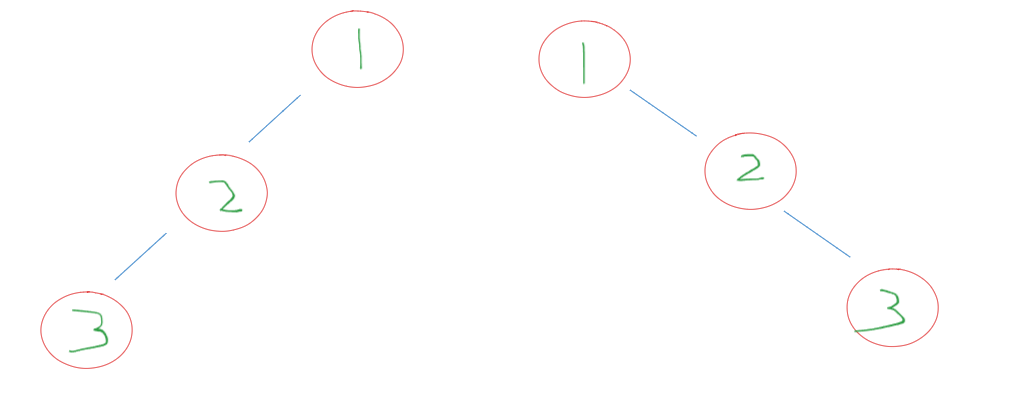
上面这两颗树的前序遍历都为[ 1, 2, 3] ,后序遍历为[3, 2, 1]
相关文章:
LeetCode 513 找树左下角的值 LeetCode 112 路径总和 LeetCode106 从中序与后序遍历序列构造二叉树
LeetCode 513 找树左下角的值 迭代法——层序遍历 思路:对树进行层序遍历操作,层序遍历完后,输出树最后一层的第一个节点。 # Definition for a binary tree node. # class TreeNode(object): # def __init__(self, val0, leftNone, r…...

Docker常见问题全攻略:从安装到优化
常见Docker安装问题及解决方案 系统兼容性问题排查安装过程中权限不足的解决方法网络配置问题导致安装失败的修复 系统兼容性问题排查 Docker在安装过程中可能会遇到系统兼容性问题,尤其是在较旧的操作系统或特定硬件架构上。确保操作系统版本符合Docker的最低要…...

『大模型笔记』Langchain作者Harrison Chase专访:环境智能体与全新智能体收件箱
Langchain作者Harrison Chase专访:环境智能体与全新智能体收件箱 文章目录 摘要访谈内容什么环境智能体为什么要探索环境智能体怎么让人类能更方便地和环境智能体互动参考文献摘要 LangChain 的 CEO Harrison Chase 提出了_“环境智能体”(Ambient Agents)的概念,这是一种…...

Kafka集群加入新Broker节点会发生什么
Kafka集群加入新Broker节点会发生什么 当向现有的Kafka集群添加新的Broker节点时,会触发一系列自动和手动的过程。以下是详细的流程和影响: 自动发生的流程 集群发现与注册 新Broker启动时会向ZooKeeper注册自己加入集群的/brokers/ids路径下其他Broke…...
SpringBoot的外部化配置
一、什么是外部化配置 外部化配置是指把应用程序中各种可配置的参数、属性等信息,从代码内部提取出来,放置在外部的配置文件、数据库或配置中心等地方(比如使用.properties、.yml 或.xml 等格式的文件)进行管理。提高应用程序的可…...

3.5 统计初步
本章系统阐述统计推断理论基础,涵盖大数定律、抽样分布、参数估计与假设检验等核心内容。以下从六个核心考点系统梳理知识体系: 考点一:大数定律与中心极限定理 1. 大数定律 切比雪夫不等式: 设随机变量 X X X 的数学期望 E (…...
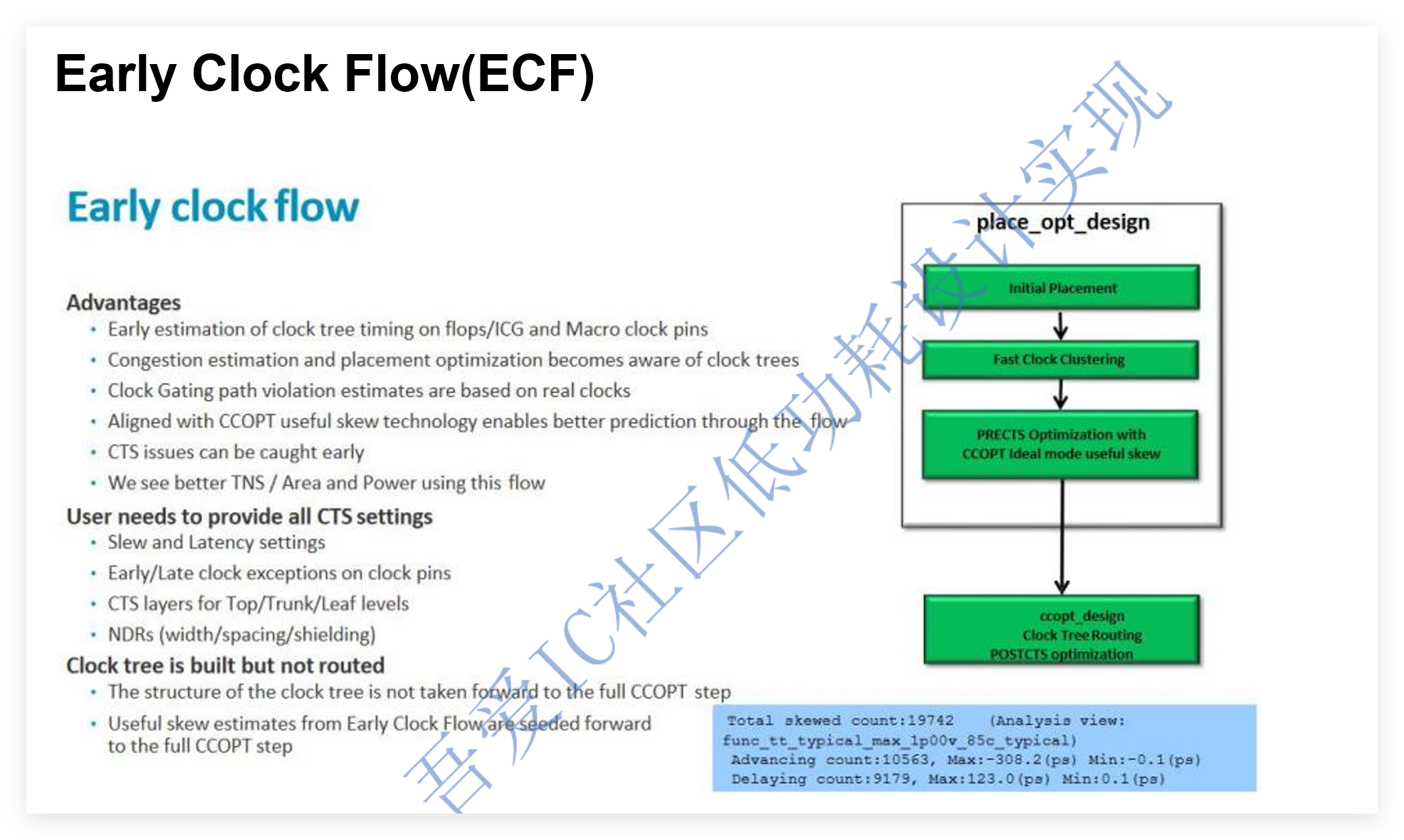
数字IC后端实现教程 | Early Clock Flow和Useful skew完全不是一个东西
数字后端零基础入门系列 | Innovus零基础LAB学习Day10 Q: Early clock flow和useful skew都是做短某段路径,这两个有什么区别呢,既然这样还用useful skew是不是有点多余了? Useful Skew技术 在不使用useful skew技术,第一级FF到第二级FF的…...
)
.Net HttpClient 管理客户端(初始化与生命周期管理)
HttpClient 初始化与生命周期管理 HttpClient 旨在实例化一次,并在应用程序的整个生命周期内重复使用。 为实现复用,HttpClient类库默认使用连接池和请求管道,可以手动管理(连接池、配置管道、使用Polly); 结合IoC容器、工厂模式(提供了IHt…...

【Docker】Docker环境下快速部署Ollama与Open-WebUI:详细指南
Docker环境下快速部署Ollama与Open-WebUI:详细指南 在本篇文章中,我们将深入探讨如何在Docker中高效部署 Ollama 和 Open-WebUI,并解决在实际使用中常见的问题,确保你的模型服务稳定高效地运行。 一、Ollama 和 Open-WebUI 快速部…...

MySQL OCP试题解析(3)
试题如图所示: 一、解析 正确选项:D)The backup can be impacted when DDL operations run during the backup(备份期间运行的 DDL 操作可能影响备份) 1. 关键知识点解析: 题目中的命令 mysqlbackup 使用了…...
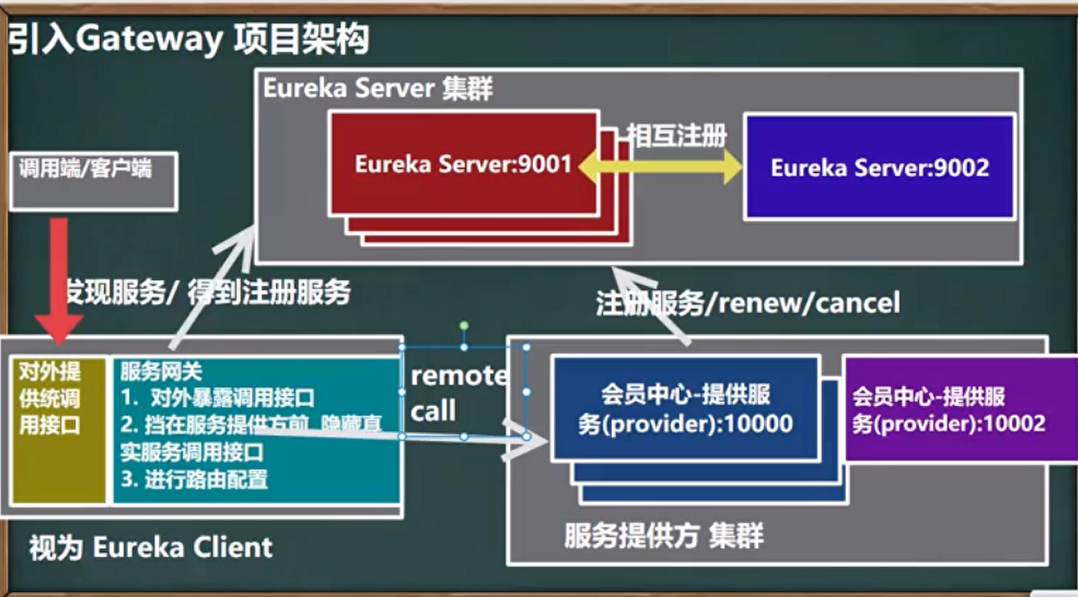
SpringCloud之Gateway基础认识-服务网关
0、Gateway基本知识 Gateway 是在 Spring 生态系统之上构建的 API 网关服务,基于 Spring ,Spring Boot 和 Project Reactor 等技术。 Gateway 旨在提供一种简单而有效的方式来对 API 进行路由,以及提供一些强大的过滤器功能,例如…...

ubuntu----100,常用命令2
目录 文件与目录管理系统信息与管理用户与权限管理网络配置与管理软件包管理打包与压缩系统服务与任务调度硬件信息查看系统操作高级工具开发相关其他实用命令 在 Ubuntu 系统中,掌握常用命令可以大幅提升操作效率。以下是一些常用的命令,涵盖了文件管理…...
CMOS VLSI Design)
数字ic后端设计从入门到精通4(含fusion compiler, tcl教学)CMOS VLSI Design
Layout Design Rules 一、什么是 Layout Design Rules? 布局设计规则是一套用于指导芯片物理设计的几何约束条件,确保设计可以在特定制造工艺下被正确制造。这些规则通常由代工厂(foundry)提供,规定了最小线宽、间距、…...

win10 局域网内聊天
在 Windows 10 的局域网 中,如果你想实现 多个用户之间的聊天功能,可以选择以下几种方案,取决于你需要的是: • ✅ 命令行纯文字聊天(如 Linux talk) • ✅ 图形界面聊天室 • ✅ 局域网广播消息 • ✅ 多人…...
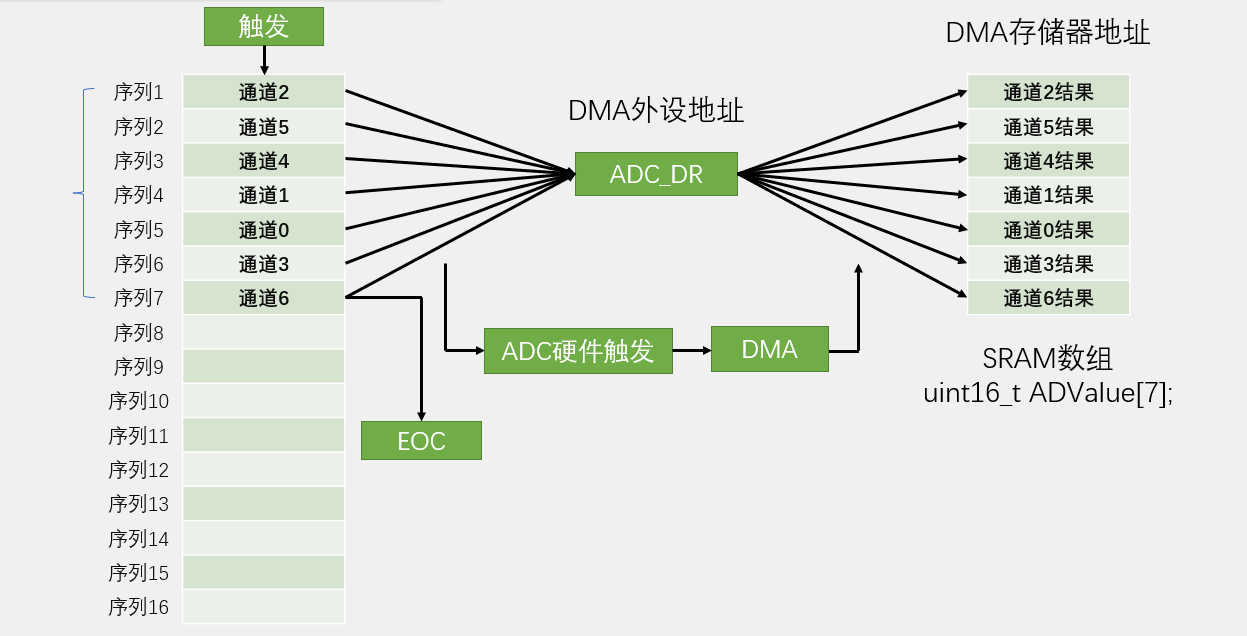
STM32-DMA数据转运(8)
目录 一、简介 二、存储器映像 三、DMA框图编辑 四、DMA基本结构 五、两个数据转运的实例 一、简介 直接存储器存取简称DMA(Direct Memory Access),它是一个数据转运小助手,主要用来协助CPU,完成数据转运的工作…...
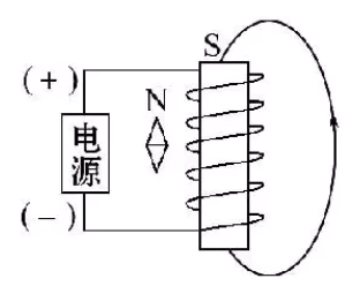
电机控制储备知识学习(一) 电机驱动的本质分析以及与磁相关的使用场景
目录 电机控制储备知识学习(一)一、电机驱动的本质分析以及与磁相关的使用场景1)电机为什么能够旋转2)电磁原理的学习重要性 二、电磁学理论知识1)磁场基础知识2)反电动势的公式推导 附学习参考网址欢迎大家…...
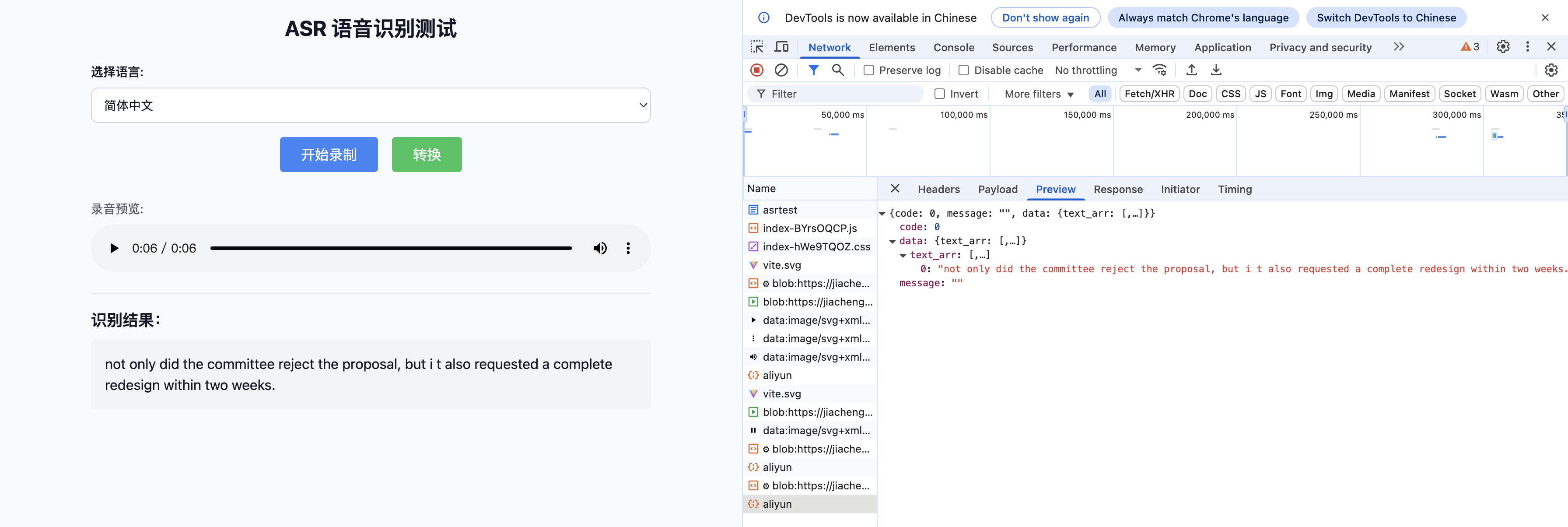
使用 React 实现语音识别并转换功能
在现代 Web 开发中,语音识别技术的应用越来越广泛。它为用户提供了更加便捷、自然的交互方式,例如语音输入、语音指令等。本文将介绍如何使用 React 实现一个简单的语音识别并转换的功能。 功能概述 我们要实现的功能是一个语音识别测试页面࿰…...
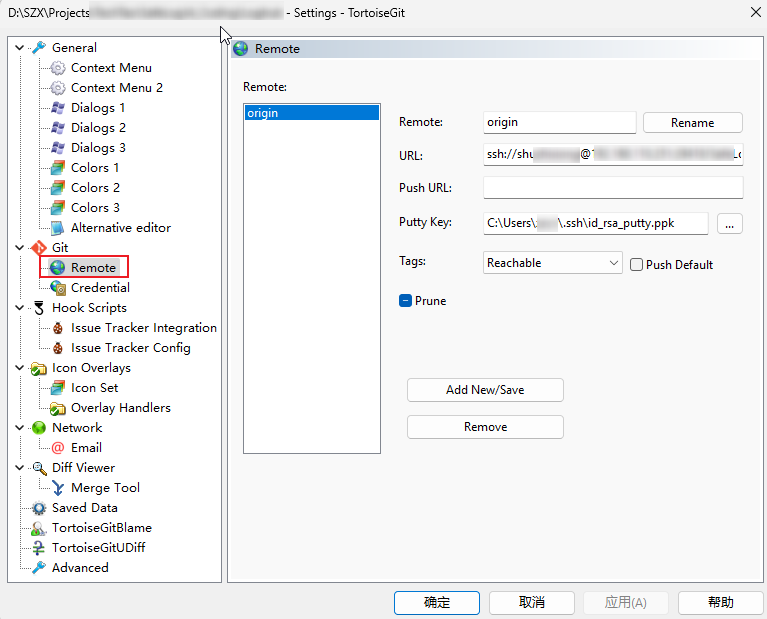
[Git]ssh下用Tortoisegit每次提交都要输密码
问题描述 ssh模式下,用小乌龟提交代码,即使在git服务端存储了公钥,仍然要每次输入密码。 原因分析 小乌龟需要额外配置自己的密钥,才能免除每次输密码。 解决方案 1.配置好ssh密钥 具体方法参考我前一篇文章: […...

如何查看项目是否支持最新 Android 16K Page Size 一文汇总
前几天刚聊过 《Google 开始正式强制 Android 适配 16 K Page Size》 之后,被问到最多的问题是「怎么查看项目是否支持 16K Page Size」 ?其实有很多直接的方式,但是最难的是当你的项目有很多依赖时,怎么知道这个「不支持的动态库…...
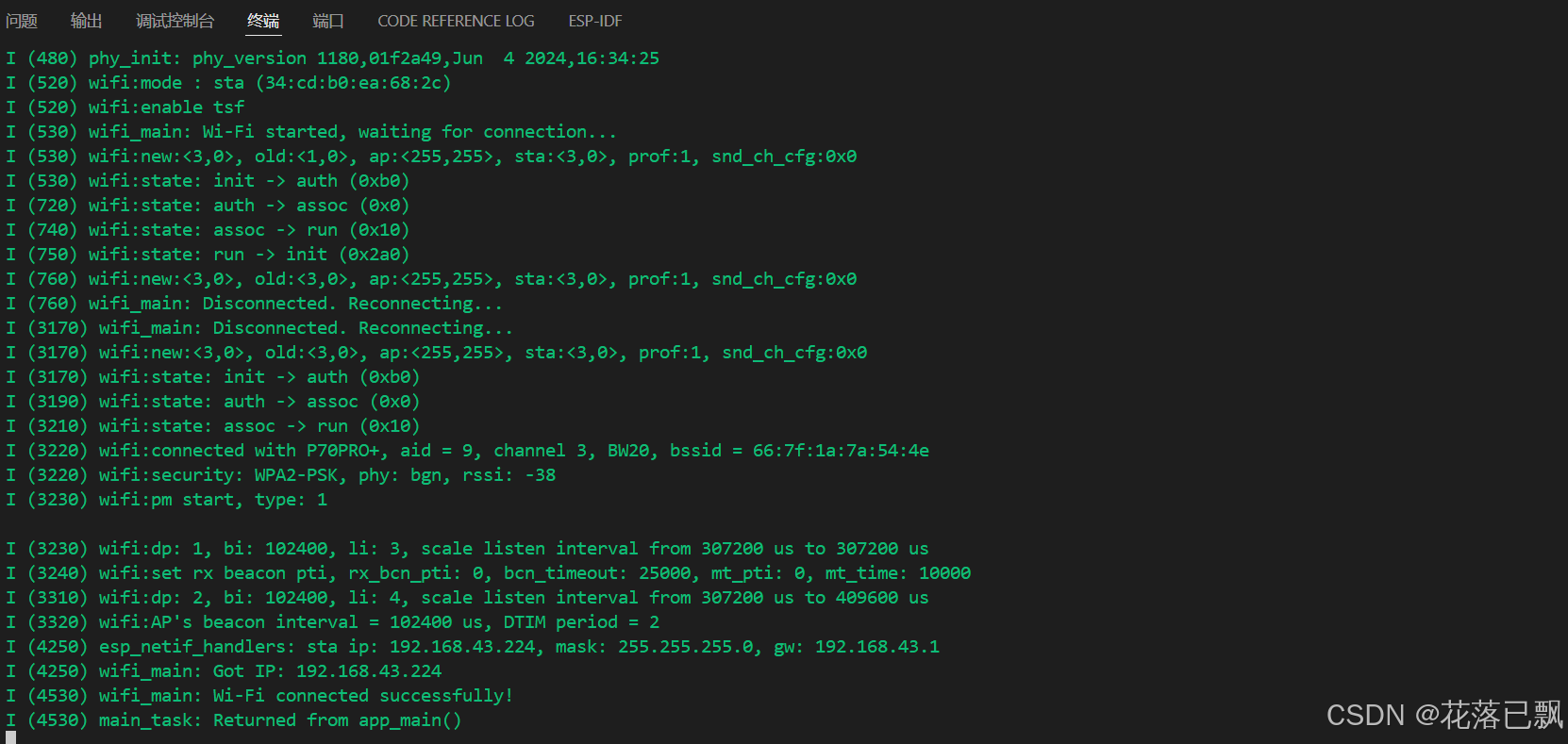
ESP32C3连接wifi
文章目录 🔧 一、ESP32-C3 连接 Wi-Fi 的基本原理(STA 模式)✅ 二、完整代码 注释讲解(适配 ESP32-C3)📌 三、几个关键点解释🔚 四、小结 🔧 一、ESP32-C3 连接 Wi-Fi 的基本原理&a…...
)
HTTP方法和状态码(Status Code)
HTTP方法 HTTP方法(也称HTTP动词)主要用于定义对资源的操作类型。根据HTTP/1.1规范(RFC 7231)以及后续扩展,常用的HTTP方法有以下几种: GET:请求获取指定资源的表示形式。POST:向指…...

机器学习中分类模型的常用评价指标
评价指标是针对模型性能优劣的一个定量指标。 一种评价指标只能反映模型一部分性能,如果选择的评价指标不合理,那么可能会得出错误的结论,故而应该针对具体的数据、模型选取不同的的评价指标。 本文将详细介绍机器学习分类任务的常用评价指…...

# YOLOv3:基于 PyTorch 的目标检测模型实现
YOLOv3:基于 PyTorch 的目标检测模型实现 引言 YOLOv3(You Only Look Once)是一种流行的单阶段目标检测算法,它能够直接在输入图像上预测边界框和类别概率。YOLOv3 的优势在于其高效性和准确性,使其在实时目标检测任…...

MySQL的Docker版本,部署在ubantu系统
前言 MySQL的Docker版本,部署在ubantu系统,出现问题: 1.执行一个SQL,只有错误编码,没有错误提示信息,主要影响排查SQL运行问题; 2.这个问题,并不影响实际的MySQL运行,如…...

Mac QT水平布局和垂直布局
首先上代码 #include "mainwindow.h" #include "ui_mainwindow.h" #include <QPushButton> #include<QVBoxLayout>//垂直布局 #include<QHBoxLayout>//水平布局头文件 MainWindow::MainWindow(QWidget *parent): QMainWindow(parent), …...

服务器制造业中,L2、L6、L10等表示什么意思
在服务器制造业中,L2、L6、L10等是用于描述服务器生产流程集成度的分级体系,从基础零件到完整机架系统共分为L1-L12共12个等级。不同等级对应不同的生产环节和交付形态,以下是核心级别的具体含义: L2(Level 2…...

回答 | 图形数据库neo4j社区版可以应用小型企业嘛?
刚在知乎上看到了一个提问,挺有意思,于是乎,贴到这里再简聊一二。 转自知乎提问 当然可以,不过成本问题不容小觑。另外还有性能上的考量。 就在最近,米国国家航空航天局——NASA因为人力成本问题,摒弃了使…...

Linux操作系统从入门到实战(二)手把手教你安装VMware17pro与CentOS 9 stream,实现Vim配置,并配置C++环境
Linux操作系统从入门到实战(二)手把手教你安装VMware17pro与CentOS 9.0 stream,实现Vim配置,并编译C文件 前言一、安装VMware17pro二、安装CentOS9.02.1 为什么选择CentOS9,与CentOS7对比2.1 官网下载CentOS9.02.2 国内…...

软考架构师考试-UML图总结
考点 选择题 2-4分 案例分析0~1题和面向对象结合考察,前几年固定一题。近3次考试没有出现。但还是有可能考。 UML图概述 1.用例图:描述系统功能需求和用户(参与者)与系统之间的交互关系,聚焦于“做什么”。 2.类图&…...

后端系统做国际化改造,生成多语言包
要将你当前系统中的 中文文案提取并翻译为英文语言包,建议采用 自动扫描 翻译辅助 语言包生成 的方式,流程如下: ✅ 一、目标总结 提取:扫描后端 C# 和 Java 代码中的 中文字符串 翻译:将中文自动翻译为英文&#x…...