DeepSeek基于注意力模型的可控图像生成
DeepSeek大模型高性能核心技术与多模态融合开发 - 商品搜索 - 京东
图像的加噪与模型训练
在扩散模型的训练过程中,首先需要对输入的信号进行加噪处理,经典的加噪过程是在图像进行向量化处理后在其中添加正态分布,而正态分布的值也是与时间步相关的。这样逐步向图像中添加噪声,直到图像变得完全噪声化。
import torch T = 1000 # Diffusion过程的总步数 # 前向diffusion计算参数
# (T,) 生成一个线性间隔的tensor,用于计算每一步的噪声水平
betas = torch.linspace(0.0001, 0.02, T)
alphas = 1 - betas # (T,) 计算每一步的保留率
# alpha_t累乘 (T,),计算每一步累积的保留率
alphas_cumprod = torch.cumprod(alphas, dim=-1)
# alpha_t-1累乘(T,),为计算方差做准备
alphas_cumprod_prev = torch.cat((torch.tensor([1.0]), alphas_cumprod[:-1]), dim=-1)
# denoise用的方差(T,),计算每一步的去噪方差
variance = (1 - alphas) * (1 - alphas_cumprod_prev) / (1 - alphas_cumprod) # 执行前向加噪
def forward_add_noise(x, t): # batch_x: (batch,channel,height,width), batch_t: (batch_size,) noise = torch.randn_like(x) # 为每幅图片生成第t步的高斯噪声 (batch,channel,height,width) # 根据当前步数t,获取对应的累积保留率,并调整其形状以匹配输入x的形状 batch_alphas_cumprod = alphas_cumprod[t].view(x.size(0), 1, 1, 1) # 基于公式直接生成第t步加噪后的图片 x = torch.sqrt(batch_alphas_cumprod) * x + torch.sqrt(1 - batch_alphas_cumprod) * noise return x, noise # 返回加噪后的图片和生成的噪声
上面这段代码首先定义了扩散模型的前向过程中需要的参数,包括每一步的噪声水平betas、保留率alphas、累积保留率alphas_cumprod以及用于去噪的方差variance。然后定义了一个函数forward_add_noise,该函数接受一个图像x和步数t作为输入。根据扩散模型的前向过程,向图像中添加噪声,并返回加噪后的图像和生成的噪声。
读者可以采用以下代码尝试完成为图像添加噪声的演示:
import matplotlib.pyplot as plt
from dataset import MNISTdataset=MNIST()
# 两幅图片拼batch, (2,1,48,48)
x=torch.stack((dataset[0][0],dataset[1][0]),dim=0) # 原图
plt.figure(figsize=(10,10))
plt.subplot(1,2,1)
plt.imshow(x[0].permute(1,2,0))
plt.subplot(1,2,2)
plt.imshow(x[1].permute(1,2,0))
plt.show()# 随机时间步
t=torch.randint(0,T,size=(x.size(0),))
print('t:',t)# 加噪
x=x*2-1 # [0,1]像素值调整到[-1,1]之间,以便与高斯噪声值范围匹配
x,noise=forward_add_noise(x,t)
print('x:',x.size())
print('noise:',noise.size())# 加噪图
plt.figure(figsize=(10,10))
plt.subplot(1,2,1)
plt.imshow(((x[0]+1)/2).permute(1,2,0))
plt.subplot(1,2,2)
plt.imshow(((x[0]+1)/2).permute(1,2,0))
plt.show()
运行结果如图9-13所示。
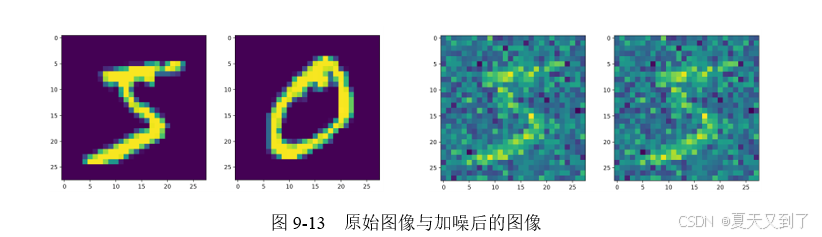
在此基础上,我们可以完成对Dit模型的训练,代码如下:
from torch.utils.data import DataLoader # 导入PyTorch的数据加载工具
from dataset import MNIST # 从dataset模块导入MNIST数据集类
from diffusion import forward_add_noise # 从diffusion模块导入forward_add_noise函数,用于向图像添加噪声
import torch # 导入PyTorch库
from torch import nn # 从PyTorch导入nn模块,包含构建神经网络所需的工具
import os # 导入os模块,用于处理文件和目录路径
from dit import DiT # 从dit模块导入DiT模型
# 判断是否有可用的CUDA设备,如果有则使用GPU,否则使用CPU
DEVICE='cuda' if torch.cuda.is_available() else 'cpu' dataset=MNIST() # 实例化MNIST数据集对象 T = 1000 # 设置扩散过程中的总时间步数
model=DiT(img_size=28,patch_size=4,channel=1,emb_size=64,label_num=10,dit_num=3,head=4).to(DEVICE) # 实例化DiT模型并移至指定设备
#model.load_state_dict(torch.load('./saver/model.pth')) # 可选:加载预训练模型参数 # 使用Adam优化器,学习率设置为0.001
optimzer=torch.optim.Adam(model.parameters(),lr=1e-3)
loss_fn=nn.L1Loss() # 使用L1损失函数(即绝对值误差均值) '''训练模型'''
EPOCH=300 # 设置训练的总轮次
BATCH_SIZE=300 # 设置每个批次的大小 if __name__ == '__main__': from tqdm import tqdm # 导入tqdm库,用于在训练过程中显示进度条 dataloader=DataLoader(dataset,batch_size=BATCH_SIZE,shuffle=True,num_workers=10,persistent_workers=True) # 创建数据加载器 iter_count=0 for epoch in range(EPOCH): # 遍历每个训练轮次 pbar = tqdm(dataloader, total=len(dataloader)) # 初始化进度条 for imgs,labels in pbar: # 遍历每个批次的数据 x=imgs*2-1 # 将图像的像素范围从[0,1]转换到[-1,1],与噪声高斯分布的范围对应 t=torch.randint(0,T,(imgs.size(0),)) # 为每幅图片生成一个随机的t时刻 y=labels # 向图像添加噪声,返回加噪后的图像和添加的噪声x,noise=forward_add_noise(x,t) # 模型预测添加的噪声pred_noise=model(x.to(DEVICE),t.to(DEVICE),y.to(DEVICE)) # 计算预测噪声和实际噪声之间的L1损失loss=loss_fn(pred_noise,noise.to(DEVICE)) optimzer.zero_grad() # 清除之前的梯度 loss.backward() # 反向传播,计算梯度 optimzer.step() # 更新模型参数 # 更新进度条描述pbar.set_description(f"epoch:{epoch + 1}, train_loss:{loss.item():.5f}") if epoch % 20 == 0: # 每20轮保存一次模型 torch.save(model.state_dict(),'./saver/model.pth') print("base diffusion saved")
读者自行查看代码运行结果。
基于注意力模型的可控图像生成
DiT模型的可控图像生成是在我们训练的基础上,逐渐对正态分布的噪声图像进行按步骤的脱噪过程。这一过程不仅要求模型具备精准的噪声预测能力,还需确保脱噪步骤的细腻与连贯,从而最终实现从纯粹噪声到目标图像的华丽蜕变。
完整的可控图像生成代码如下:
import torch from dit import DiT
import matplotlib.pyplot as plt
# 导入diffusion模块中的所有内容,这通常包含一些与扩散模型相关的预定义变量和函数
from diffusion import * # 设置设备为GPU或CPU
DEVICE = 'cuda' if torch.cuda.is_available() else 'cpu'
DEVICE = "cpu" # 强制使用CPU T = 1000 # 扩散步骤的总数 def backward_denoise(model,x,y): steps=[x.clone(),] # 初始化步骤列表,包含初始噪声图像 global alphas,alphas_cumprod,variance # 这些是从diffusion模块导入的全局变量 x=x.to(DEVICE) # 将输入x移动到指定的设备 alphas=alphas.to(DEVICE) alphas_cumprod=alphas_cumprod.to(DEVICE) variance=variance.to(DEVICE) y=y.to(DEVICE) # 将标签y移动到指定的设备 model.eval() # 设置模型为评估模式 with torch.no_grad(): # 在不计算梯度的情况下运行,节省内存和计算资源 for time in range(T-1,-1,-1): # 从T-1到0逆序迭代 t=torch.full((x.size(0),),time).to(DEVICE) # 创建一个包含当前时间步的tensor # 预测x_t时刻的噪声 noise=model(x,t,y) # 生成t-1时刻的图像 shape=(x.size(0),1,1,1) mean=1/torch.sqrt(alphas[t].view(*shape))* \ ( x- (1-alphas[t].view(*shape))/torch.sqrt(1-alphas_cumprod[t].view(*shape))*noise ) if time!=0: x=mean+ \ torch.randn_like(x)* \ torch.sqrt(variance[t].view(*shape)) else: x=mean x=torch.clamp(x, -1.0, 1.0).detach() # 确保x的值在[-1,1]之间,并分离计算图 steps.append(x) return steps # 初始化DiT模型
model=DiT(img_size=28,patch_size=4,channel=1,emb_size=64,label_num=10,dit_num=3,head=4).to(DEVICE)
model.load_state_dict(torch.load('./saver/model.pth')) # 加载模型权重 # 生成噪声图
batch_size=10
x=torch.randn(size=(batch_size,1,28,28)) # 生成随机噪声图像
y=torch.arange(start=0,end=10,dtype=torch.long) # 生成标签 # 逐步去噪得到原图
steps=backward_denoise(model,x,y) # 绘制数量
num_imgs=20 # 绘制还原过程
plt.figure(figsize=(15,15))
for b in range(batch_size): for i in range(0,num_imgs): idx=int(T/num_imgs)*(i+1) # 计算要绘制的步骤索引 # 像素值还原到[0,1] final_img=(steps[idx][b].to('cpu')+1)/2 # tensor转回PIL图 final_img=final_img.permute(1,2,0) # 调整通道顺序以匹配图像格式 plt.subplot(batch_size,num_imgs,b*num_imgs+i+1)plt.imshow(final_img)
plt.show() # 显示图像
上面的代码展示了使用DiT进行图像去噪的完整过程。首先,它导入了必要的库和模块,包括PyTorch、DiT模型、matplotlib绘图模块,以及从diffusion模块导入的一些预定义变量和函数,这些通常与扩散模型相关。然后,代码设置了计算设备为CPU(尽管提供了检测GPU可用性的选项),并定义了扩散步骤的总数。
backward_denoise函数是实现图像去噪的核心。它接受一个DiT模型、一批噪声图像以及对应的标签作为输入。在这个函数内部,它首先将输入移动到指定的计算设备,然后将模型设置为评估模式,并开始一个不计算梯度的循环,从最后一个扩散步骤开始逆向迭代至第一步。在每一步中,它使用模型预测当前步骤的噪声,然后根据扩散模型的公式计算上一步的图像。这个过程一直持续到生成原始图像。
接下来,代码初始化了DiT模型,并加载了预训练的权重。然后,它生成了一批随机噪声图像和对应的标签,并使用backward_denoise函数对这些噪声图像进行去噪,逐步还原出原始图像。运行结果如图9-14所示。

图9-14 基于DiT模型的可控图像生成
可见,我们使用生成代码绘制了去噪过程的图像,展示了从完全噪声的图像逐步还原为清晰图像的过程。通过调整通道顺序和像素值范围,它将tensor格式的图像转换为适合绘制的格式,并使用matplotlib库的subplot函数在一个大图中展示了所有步骤的图像。

相关文章:
DeepSeek基于注意力模型的可控图像生成
DeepSeek大模型高性能核心技术与多模态融合开发 - 商品搜索 - 京东 图像的加噪与模型训练 在扩散模型的训练过程中,首先需要对输入的信号进行加噪处理,经典的加噪过程是在图像进行向量化处理后在其中添加正态分布,而正态分布的值也是与时间…...
“端 - 边 - 云”三级智能协同平台的理论建构与技术实现
摘要 随着低空经济与智能制造的深度融合,传统集中式云计算架构在实时性、隐私保护和资源效率上的瓶颈日益凸显。本文提出“端 - 边 - 云”三级智能协同平台架构,以“时空 - 资源 - 服务”三维协同理论为核心,构建覆盖终端感知、边缘计算、云端…...

AI时代,如何实现人机共舞?
在科技飞速发展的当下,人工智能(AI)已不再是科幻作品中的遥远想象,而是深入渗透到我们生活与工作的方方面面。从智能手机中的语音助手,到金融领域的风险预测模型;从医疗影像的智能诊断,到工业生…...

component :is是什么?
问: component :is是什么? 是组件? 那我们是不是就不需要自己创建组件了?还是什么意思?component :is和什么功能是类似的,同时和类似功能相比对什么时候用component :is…...

2025 3D工业相机选型及推荐
3D工业相机是专门为工业应用设计的三维视觉采集设备,能够获取物体的三维空间信息,在智能制造、质量检测、机器人引导等领域有广泛应用。 一、主要类型 1.结构光3D相机 通过投射特定光斑或条纹图案并分析变形来重建三维形状 典型代表:双目结构…...
OceanBase 在业务监控系统中的应用实践
本文作者来自于一家总部在宁波的新能源上市公司,公司业务包括光伏新能源产品的研发与产销。 作为年产值达百亿的企业,监控系统是不可或缺的IT管理体系之一,对于确保业务连续性及预警风险非常重要。2022年,公司选择把Zabbix作为企业…...

每日Prompt:品牌化键盘键帽
提示词 一个超逼真的3D渲染图,展示了四个机械键盘键帽,排列成紧密的2x2网格,所有键帽相互接触。从等轴测角度观察。一个键帽是透明的,上面用红色印刷着“{just}”字样。另外三个键帽采用颜色:{黑色、紫色和白色}。一个…...

RabbitMQ发布订阅模式深度解析与实践指南
目录 RabbitMQ发布订阅模式深度解析与实践指南1. 发布订阅模式核心原理1.1 消息分发模型1.2 核心组件对比 2. 交换机类型详解2.1 交换机类型矩阵2.2 消息生命周期 3. 案例分析与实现案例1:基础广播消息系统案例2:分级日志处理系统案例3:分布式…...
超声波传感器模块
欢迎来到 破晓的历程的 博客 ⛺️不负时光,不负己✈️ 文章目录 1.HC-SR04介绍2.HC-SR04原理介绍2.1原理概述3.2原理详解 4驱动代码编写4.1写前思考4.2硬件连线 5.总结hcsr04.hhcsr04.c 1.HC-SR04介绍 超声波传感器有很多种类的型号:HC-SR04、UC-025、…...
LeetCode 513 找树左下角的值 LeetCode 112 路径总和 LeetCode106 从中序与后序遍历序列构造二叉树
LeetCode 513 找树左下角的值 迭代法——层序遍历 思路:对树进行层序遍历操作,层序遍历完后,输出树最后一层的第一个节点。 # Definition for a binary tree node. # class TreeNode(object): # def __init__(self, val0, leftNone, r…...

Docker常见问题全攻略:从安装到优化
常见Docker安装问题及解决方案 系统兼容性问题排查安装过程中权限不足的解决方法网络配置问题导致安装失败的修复 系统兼容性问题排查 Docker在安装过程中可能会遇到系统兼容性问题,尤其是在较旧的操作系统或特定硬件架构上。确保操作系统版本符合Docker的最低要…...

『大模型笔记』Langchain作者Harrison Chase专访:环境智能体与全新智能体收件箱
Langchain作者Harrison Chase专访:环境智能体与全新智能体收件箱 文章目录 摘要访谈内容什么环境智能体为什么要探索环境智能体怎么让人类能更方便地和环境智能体互动参考文献摘要 LangChain 的 CEO Harrison Chase 提出了_“环境智能体”(Ambient Agents)的概念,这是一种…...

Kafka集群加入新Broker节点会发生什么
Kafka集群加入新Broker节点会发生什么 当向现有的Kafka集群添加新的Broker节点时,会触发一系列自动和手动的过程。以下是详细的流程和影响: 自动发生的流程 集群发现与注册 新Broker启动时会向ZooKeeper注册自己加入集群的/brokers/ids路径下其他Broke…...
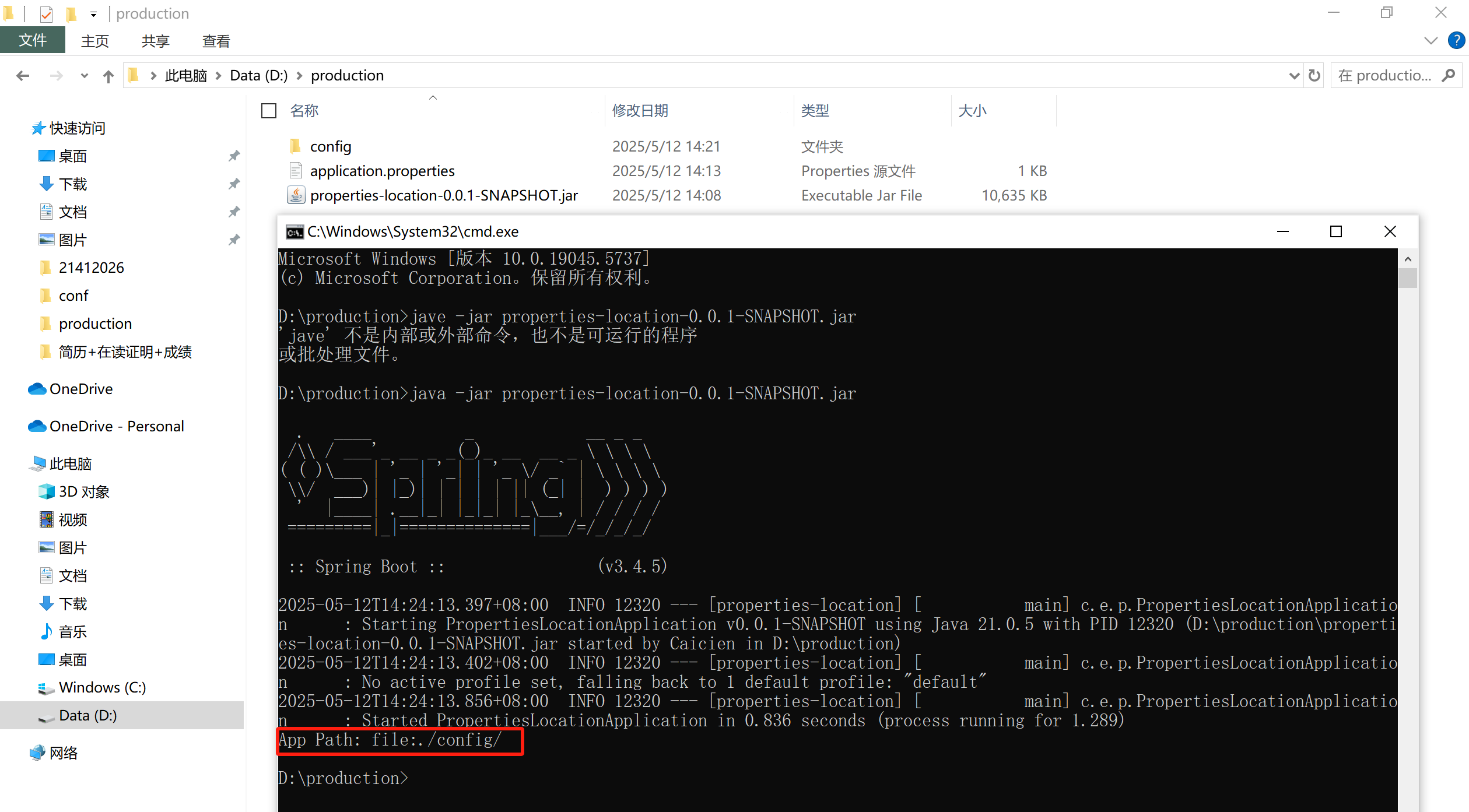
SpringBoot的外部化配置
一、什么是外部化配置 外部化配置是指把应用程序中各种可配置的参数、属性等信息,从代码内部提取出来,放置在外部的配置文件、数据库或配置中心等地方(比如使用.properties、.yml 或.xml 等格式的文件)进行管理。提高应用程序的可…...

3.5 统计初步
本章系统阐述统计推断理论基础,涵盖大数定律、抽样分布、参数估计与假设检验等核心内容。以下从六个核心考点系统梳理知识体系: 考点一:大数定律与中心极限定理 1. 大数定律 切比雪夫不等式: 设随机变量 X X X 的数学期望 E (…...
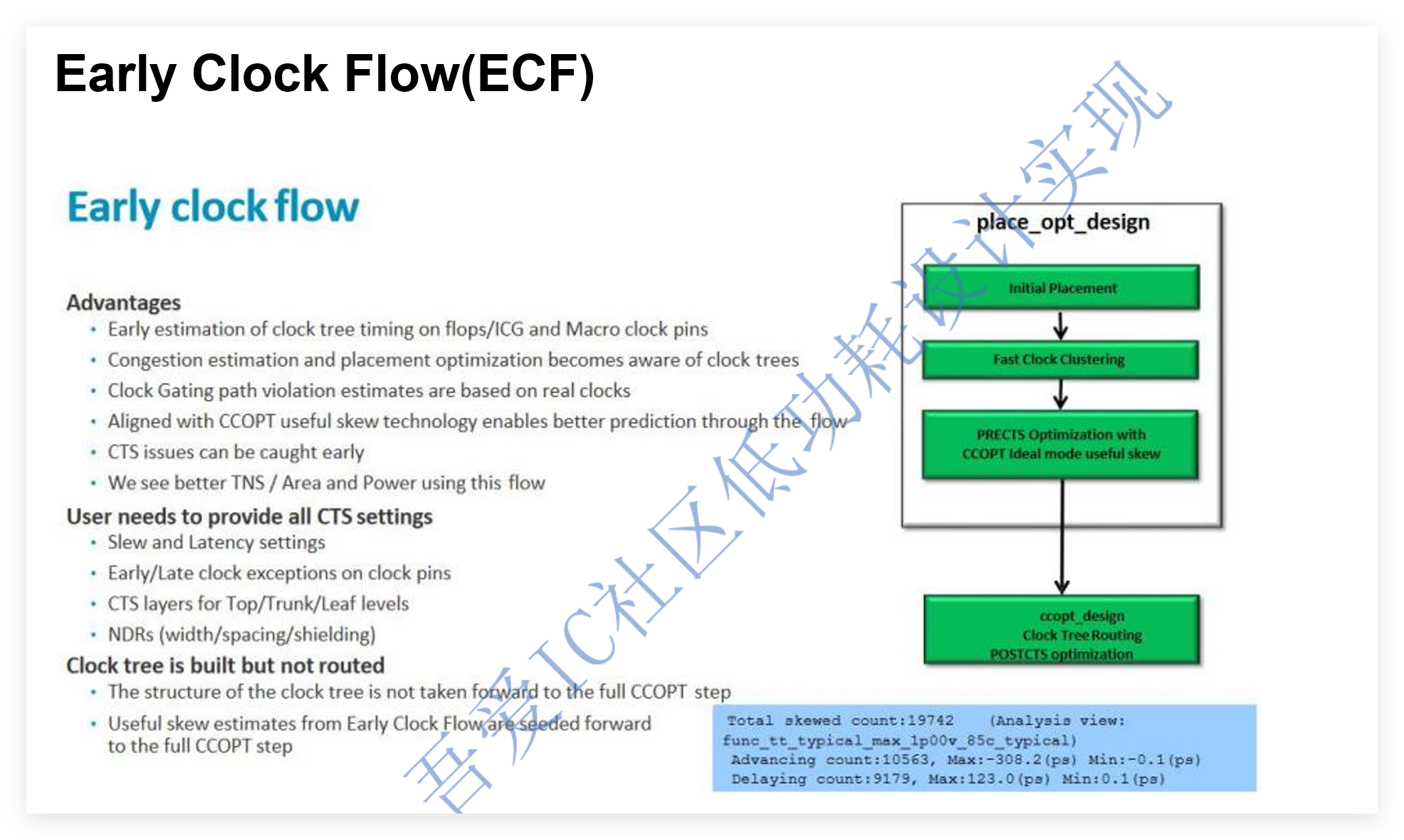
数字IC后端实现教程 | Early Clock Flow和Useful skew完全不是一个东西
数字后端零基础入门系列 | Innovus零基础LAB学习Day10 Q: Early clock flow和useful skew都是做短某段路径,这两个有什么区别呢,既然这样还用useful skew是不是有点多余了? Useful Skew技术 在不使用useful skew技术,第一级FF到第二级FF的…...
)
.Net HttpClient 管理客户端(初始化与生命周期管理)
HttpClient 初始化与生命周期管理 HttpClient 旨在实例化一次,并在应用程序的整个生命周期内重复使用。 为实现复用,HttpClient类库默认使用连接池和请求管道,可以手动管理(连接池、配置管道、使用Polly); 结合IoC容器、工厂模式(提供了IHt…...

【Docker】Docker环境下快速部署Ollama与Open-WebUI:详细指南
Docker环境下快速部署Ollama与Open-WebUI:详细指南 在本篇文章中,我们将深入探讨如何在Docker中高效部署 Ollama 和 Open-WebUI,并解决在实际使用中常见的问题,确保你的模型服务稳定高效地运行。 一、Ollama 和 Open-WebUI 快速部…...

MySQL OCP试题解析(3)
试题如图所示: 一、解析 正确选项:D)The backup can be impacted when DDL operations run during the backup(备份期间运行的 DDL 操作可能影响备份) 1. 关键知识点解析: 题目中的命令 mysqlbackup 使用了…...
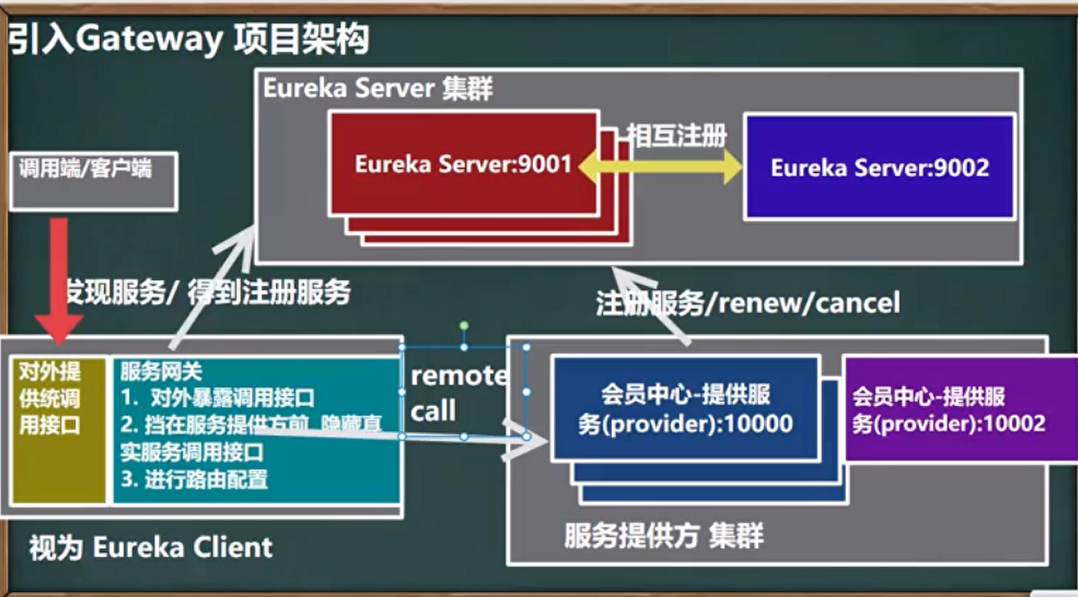
SpringCloud之Gateway基础认识-服务网关
0、Gateway基本知识 Gateway 是在 Spring 生态系统之上构建的 API 网关服务,基于 Spring ,Spring Boot 和 Project Reactor 等技术。 Gateway 旨在提供一种简单而有效的方式来对 API 进行路由,以及提供一些强大的过滤器功能,例如…...

ubuntu----100,常用命令2
目录 文件与目录管理系统信息与管理用户与权限管理网络配置与管理软件包管理打包与压缩系统服务与任务调度硬件信息查看系统操作高级工具开发相关其他实用命令 在 Ubuntu 系统中,掌握常用命令可以大幅提升操作效率。以下是一些常用的命令,涵盖了文件管理…...
CMOS VLSI Design)
数字ic后端设计从入门到精通4(含fusion compiler, tcl教学)CMOS VLSI Design
Layout Design Rules 一、什么是 Layout Design Rules? 布局设计规则是一套用于指导芯片物理设计的几何约束条件,确保设计可以在特定制造工艺下被正确制造。这些规则通常由代工厂(foundry)提供,规定了最小线宽、间距、…...

win10 局域网内聊天
在 Windows 10 的局域网 中,如果你想实现 多个用户之间的聊天功能,可以选择以下几种方案,取决于你需要的是: • ✅ 命令行纯文字聊天(如 Linux talk) • ✅ 图形界面聊天室 • ✅ 局域网广播消息 • ✅ 多人…...
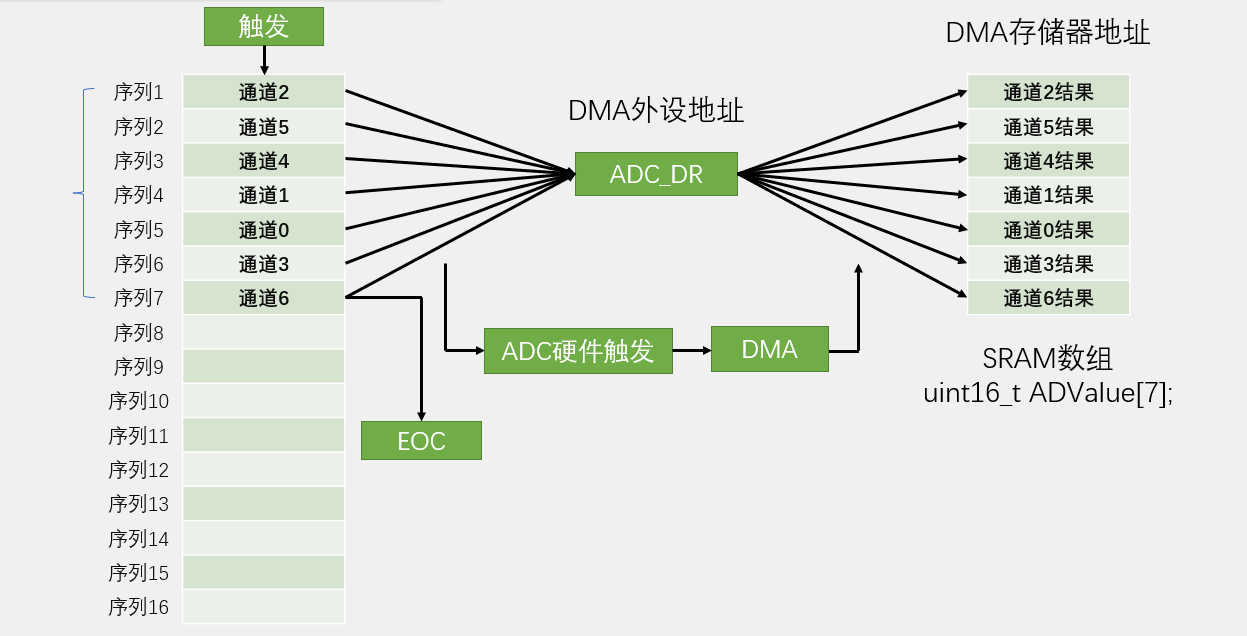
STM32-DMA数据转运(8)
目录 一、简介 二、存储器映像 三、DMA框图编辑 四、DMA基本结构 五、两个数据转运的实例 一、简介 直接存储器存取简称DMA(Direct Memory Access),它是一个数据转运小助手,主要用来协助CPU,完成数据转运的工作…...
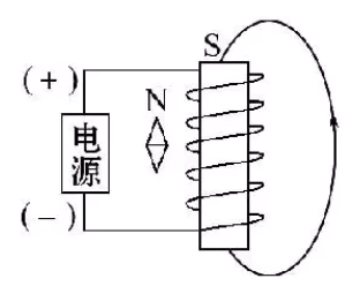
电机控制储备知识学习(一) 电机驱动的本质分析以及与磁相关的使用场景
目录 电机控制储备知识学习(一)一、电机驱动的本质分析以及与磁相关的使用场景1)电机为什么能够旋转2)电磁原理的学习重要性 二、电磁学理论知识1)磁场基础知识2)反电动势的公式推导 附学习参考网址欢迎大家…...
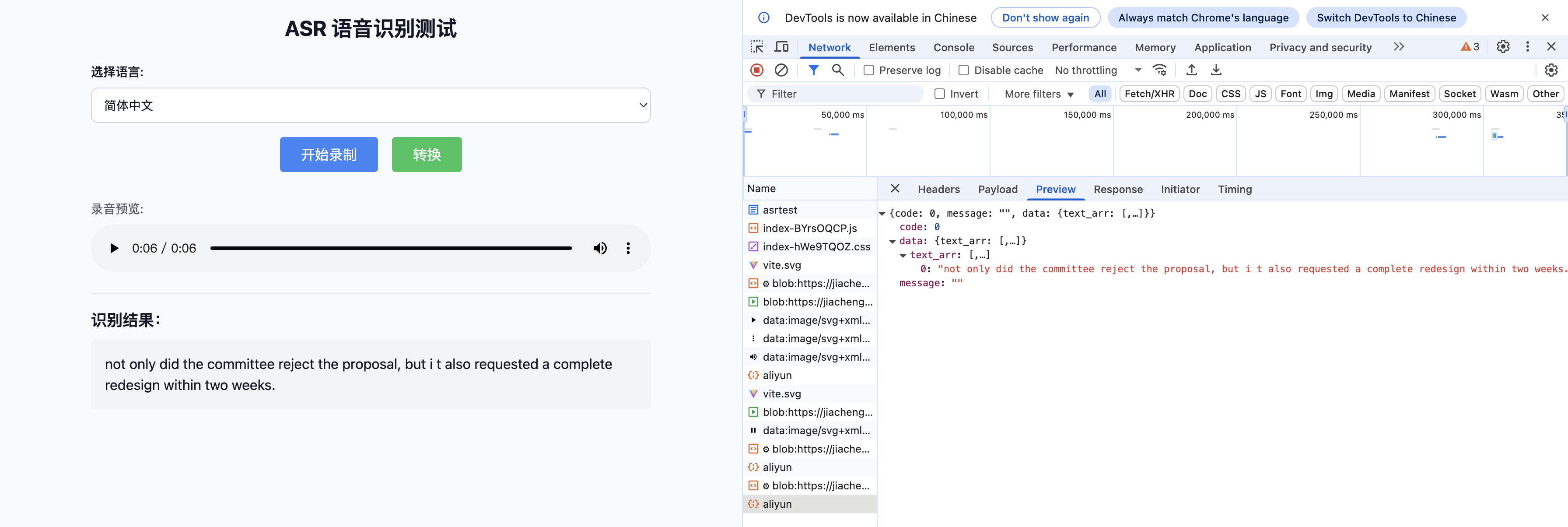
使用 React 实现语音识别并转换功能
在现代 Web 开发中,语音识别技术的应用越来越广泛。它为用户提供了更加便捷、自然的交互方式,例如语音输入、语音指令等。本文将介绍如何使用 React 实现一个简单的语音识别并转换的功能。 功能概述 我们要实现的功能是一个语音识别测试页面࿰…...
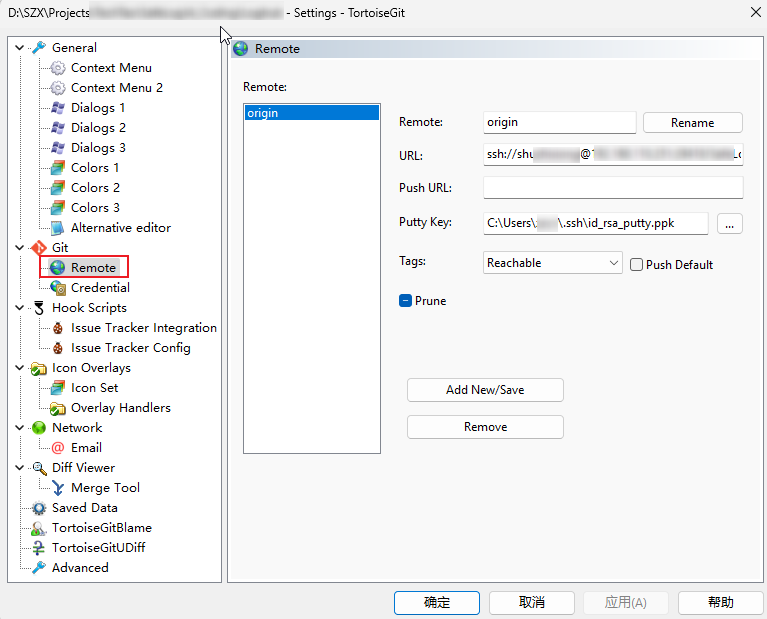
[Git]ssh下用Tortoisegit每次提交都要输密码
问题描述 ssh模式下,用小乌龟提交代码,即使在git服务端存储了公钥,仍然要每次输入密码。 原因分析 小乌龟需要额外配置自己的密钥,才能免除每次输密码。 解决方案 1.配置好ssh密钥 具体方法参考我前一篇文章: […...

如何查看项目是否支持最新 Android 16K Page Size 一文汇总
前几天刚聊过 《Google 开始正式强制 Android 适配 16 K Page Size》 之后,被问到最多的问题是「怎么查看项目是否支持 16K Page Size」 ?其实有很多直接的方式,但是最难的是当你的项目有很多依赖时,怎么知道这个「不支持的动态库…...
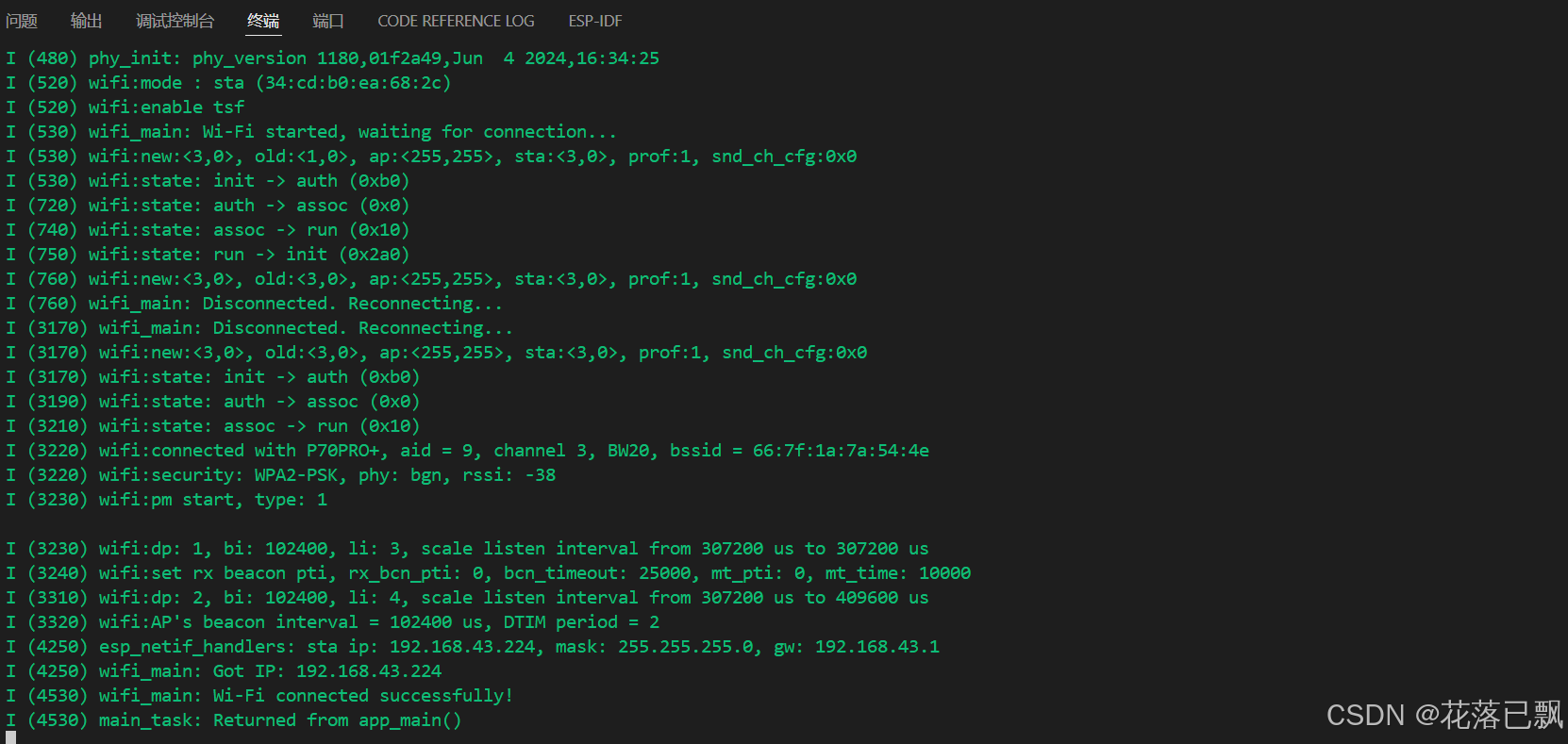
ESP32C3连接wifi
文章目录 🔧 一、ESP32-C3 连接 Wi-Fi 的基本原理(STA 模式)✅ 二、完整代码 注释讲解(适配 ESP32-C3)📌 三、几个关键点解释🔚 四、小结 🔧 一、ESP32-C3 连接 Wi-Fi 的基本原理&a…...
)
HTTP方法和状态码(Status Code)
HTTP方法 HTTP方法(也称HTTP动词)主要用于定义对资源的操作类型。根据HTTP/1.1规范(RFC 7231)以及后续扩展,常用的HTTP方法有以下几种: GET:请求获取指定资源的表示形式。POST:向指…...