内存、磁盘、CPU区别,Hadoop/Spark与哪个联系密切
1. 内存、磁盘、CPU的区别和作用
1.1 内存(Memory)
- 作用:
- 内存是计算机的短期存储器,用于存储正在运行的程序和数据。
- 它的访问速度非常快,比磁盘快几个数量级。
- 在分布式计算中,内存用于缓存中间结果、存储任务的运行状态等。
- 特点:
- 速度快:访问时间通常是纳秒级。
- 容量有限:内存容量通常比磁盘小得多。
- 易失性:断电后数据会丢失。
- 在Hadoop/Spark中的表现:
- 内存不足时,任务可能会频繁使用磁盘(即“溢写到磁盘”),导致性能下降。
- Spark更依赖内存(内存计算框架),而Hadoop主要依赖磁盘(磁盘计算框架)。
1.2 磁盘(Disk)
- 作用:
- 磁盘是计算机的长期存储器,用于存储持久化的数据。
- 在分布式计算中,磁盘用于存储输入数据、输出数据以及中间结果的溢写。
- 特点:
- 速度慢:访问时间通常是毫秒级,比内存慢很多。
- 容量大:磁盘容量通常比内存大得多。
- 非易失性:断电后数据不会丢失。
- 在Hadoop/Spark中的表现:
- Hadoop的HDFS(Hadoop分布式文件系统)依赖磁盘存储数据。
- 在MapReduce中,中间结果会写入磁盘,导致较高的I/O开销。
- Spark通过尽量减少磁盘I/O(如使用内存缓存)提升性能。
1.3 CPU(中央处理器)
- 作用:
- CPU是计算机的大脑,负责执行程序中的计算任务。
- 在分布式计算中,CPU用于执行数据处理逻辑(如Map、Reduce、Join等操作)。
- 特点:
- 速度快:处理速度通常以GHz为单位。
- 并行性:现代CPU通常有多个核心,可以同时处理多个任务。
- 依赖内存:CPU需要从内存中读取数据进行计算,内存速度会影响CPU效率。
- 在Hadoop/Spark中的表现:
- Hadoop的MapReduce任务需要CPU执行Map和Reduce逻辑。
- Spark的并行计算依赖CPU核心数,任务分区的并行度通常与CPU核心数相关。
2. Hadoop和资源的关系
Hadoop是一个以磁盘为核心的分布式计算框架,主要依赖磁盘和CPU,内存的作用相对较小。以下是Hadoop与内存、磁盘、CPU的具体联系:
2.1 磁盘(Disk)
- 核心依赖:Hadoop的核心组件HDFS(Hadoop Distributed File System)是一个分布式文件系统,所有数据都存储在磁盘上。
- 中间结果存储:
- 在MapReduce中,Map任务的输出结果会写入磁盘,然后由Reduce任务读取。
- 这种磁盘I/O的开销是Hadoop性能的主要瓶颈。
- 数据持久化:
- Hadoop的设计目标是处理大规模数据,因此需要磁盘来存储海量数据。
2.2 内存(Memory)
- 作用有限:
- Hadoop的MapReduce框架设计时假设内存有限,因此中间结果通常直接写入磁盘,而不是缓存到内存中。
- 内存主要用于存储任务的运行状态、缓冲区等。
- 优化点:
- Hadoop可以通过增加内存缓冲区(如
io.sort.mb参数)来减少磁盘I/O。
- Hadoop可以通过增加内存缓冲区(如
2.3 CPU
- 计算核心:
- Hadoop的Map和Reduce任务都需要CPU执行数据处理逻辑。
- Hadoop的并行度受CPU核心数限制,更多的CPU核心可以提高任务的并行度。
- I/O瓶颈:
- 在Hadoop中,CPU通常不是性能瓶颈,磁盘I/O才是主要限制因素。
3. Spark和资源的关系
相比Hadoop,Spark更依赖内存,减少了对磁盘的依赖,因此性能通常比Hadoop更高。
3.1 内存(Memory)
- 核心依赖:
- Spark是一个内存计算框架,尽量将中间结果存储在内存中,减少磁盘I/O。
- Spark的
cache()和persist()功能可以将数据缓存到内存中,提升后续计算的速度。
- 内存不足时的行为:
- 如果内存不足,Spark会将数据溢写到磁盘(如
MEMORY_AND_DISK存储级别),但性能会下降。
- 如果内存不足,Spark会将数据溢写到磁盘(如
3.2 磁盘(Disk)
- 辅助作用:
- Spark尽量减少磁盘I/O,但仍需要磁盘存储输入数据、输出数据以及内存不足时的中间结果。
- 优化点:
- 使用高效的文件格式(如Parquet、ORC)和分区策略可以减少磁盘I/O。
3.3 CPU
- 并行计算:
- Spark的并行度与CPU核心数密切相关,更多的CPU核心可以提高任务的并行度。
- 序列化和反序列化:
- Spark的计算任务需要序列化数据传输到各个Executor,CPU需要处理这些序列化操作。
4. Hadoop和Spark的对比
| 资源类型 | Hadoop 的依赖 | Spark 的依赖 |
|---|---|---|
| 内存 | 依赖较少,主要用于任务状态和缓冲区 | 依赖较多,核心用于缓存中间结果 |
| 磁盘 | 核心依赖,HDFS存储数据,MapReduce中间结果写磁盘 | 辅助依赖,主要用于输入/输出数据和溢写 |
| CPU | 依赖较少,通常受限于磁盘I/O | 依赖较多,任务并行度与CPU核心数相关 |
总结
- Hadoop与磁盘联系最密切,设计时假设内存有限,因此主要依赖磁盘存储数据和中间结果。
- Spark与内存联系最密切,尽量将数据存储在内存中以提高性能,同时减少磁盘I/O。
- CPU在两者中都很重要,但通常不是性能瓶颈,I/O(内存或磁盘)才是主要限制因素。
相关文章:

内存、磁盘、CPU区别,Hadoop/Spark与哪个联系密切
1. 内存、磁盘、CPU的区别和作用 1.1 内存(Memory) 作用: 内存是计算机的短期存储器,用于存储正在运行的程序和数据。它的访问速度非常快,比磁盘快几个数量级。在分布式计算中,内存用于缓存中间结果、存储…...

hz2新建Keyword页面
新建一个single-keywords.php即可,需要筛选项再建taxonomy-knowledge-category.php 参考:https://www.tkwlkj.com/customize-wordpress-category-pages.html WordPress中使用了ACF创建了自定义产品分类products,现在想实现自定义产品分类下的…...
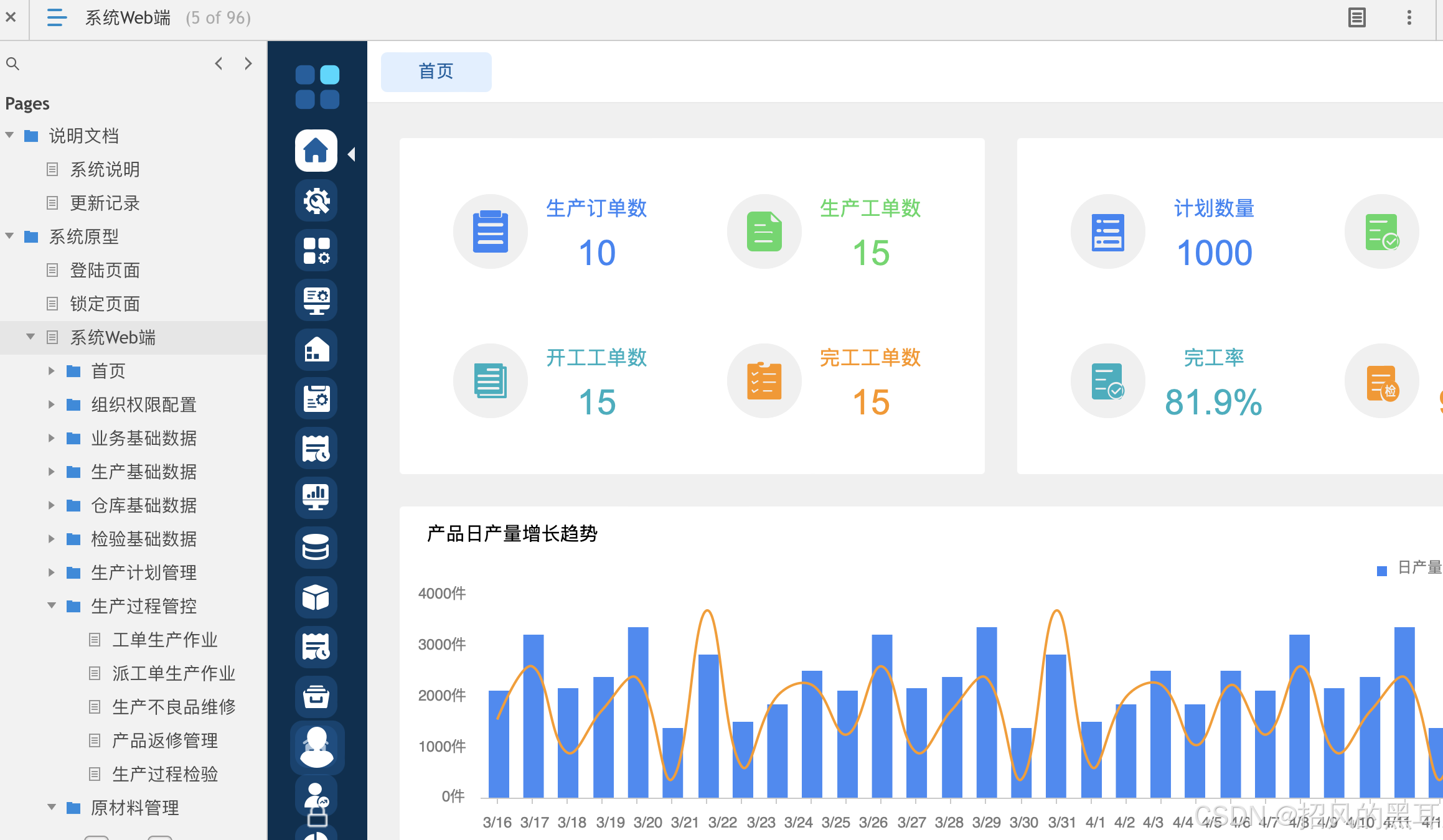
离散制造企业WMS+MES+QMS+条码管理系统高保真原型全解析
在离散型制造企业的生产过程中,库存管理混乱、生产进度不透明、质检流程繁琐等问题常常成为制约企业发展的瓶颈。为了帮助企业实现全流程数字化管控,我们精心打造了一款基于离散型制造企业(涵盖单件生产、批量生产、混合生产模式)…...

【并发编程基石】CAS无锁算法详解:原理、实现与应用场景
一、什么是CAS? CAS(Compare-And-Swap) 是现代并发编程的核心算法之一,它通过处理器指令级的原子操作实现线程安全,无需传统锁机制。其核心逻辑可以用一个公式表示: CAS(V, E, N) {if (V E) { // 比较当…...
Java学习-5.8(总结,springboot))
(自用)Java学习-5.8(总结,springboot)
一、MySQL 数据库 表关系 一对一、一对多、多对多关系设计外键约束与级联操作 DML 操作 INSERT INTO table VALUES(...) DELETE FROM table WHERE... UPDATE table SET colval WHERE...DQL 查询 基础查询:SELECT * FROM table WHERE...聚合函数:COUNT()…...

GOOSE 协议中MAC配置
在 GOOSE(Generic Object Oriented Substation Event)协议中,主站(Publisher)发送的 MAC 地址不需要与从站(Listener)的 MAC 地址一致,其通信机制与 MAC 地址的匹配逻辑取决于 GOOSE…...

机器学习之决策树与决策森林:机器学习中的强大工具
机器学习之决策树与决策森林:机器学习中的强大工具 摘要:本文深入探讨决策树和决策森林在机器学习中的应用优势及其适用场景。决策树凭借其易于配置、原生处理多种数据类型、鲁棒性及可解释性等特点,在小数据集和表格数据处理方面表现卓越。…...

【Redis】谈谈Redis的设计
Redis(Remote Dictionary Service)是一个高性能的内存键值数据库,其设计核心是速度、简单性和灵活性。以下从架构、数据结构、持久化、网络模型等方面解析 Redis 的设计实现原理: 1. 核心设计思想 内存优先:数据主要存…...
详解:标准流、文件流和字符串流)
【C++】流(Stream)详解:标准流、文件流和字符串流
【C】流(Stream)详解:标准流、文件流和字符串流 在C编程中,流(Stream)是一个非常重要的概念,它为我们提供了统一的数据输入输出接口。本文将详细介绍C中的三种主要流类型:标准流、文件流和字符串流。 一、标准流(Standard Strea…...
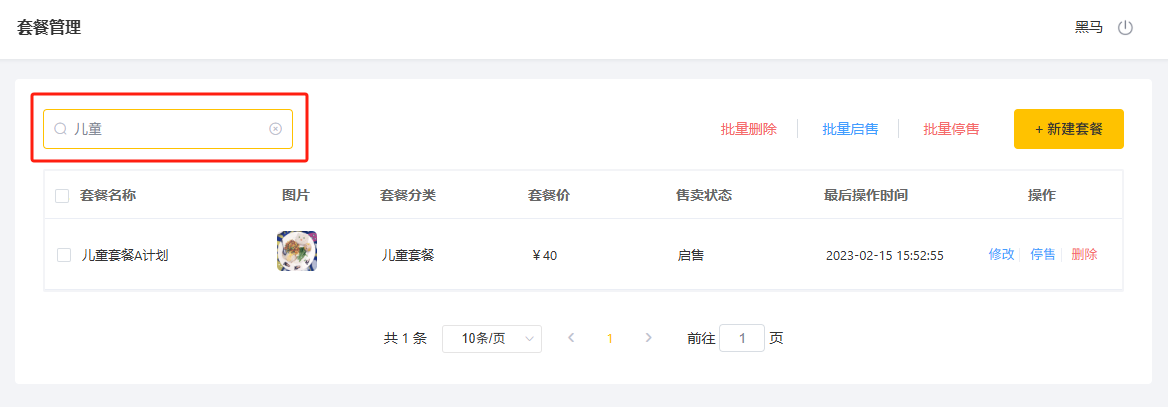
基于 Spring Boot 瑞吉外卖系统开发(十三)
基于 Spring Boot 瑞吉外卖系统开发(十三) 查询套餐 在查询套餐信息时包含套餐的分类名,分类名称在category表中,因此这里需要进行两表关联查询。 自定义SQL如下: select s.* ,c.name as category_name from setmeal…...
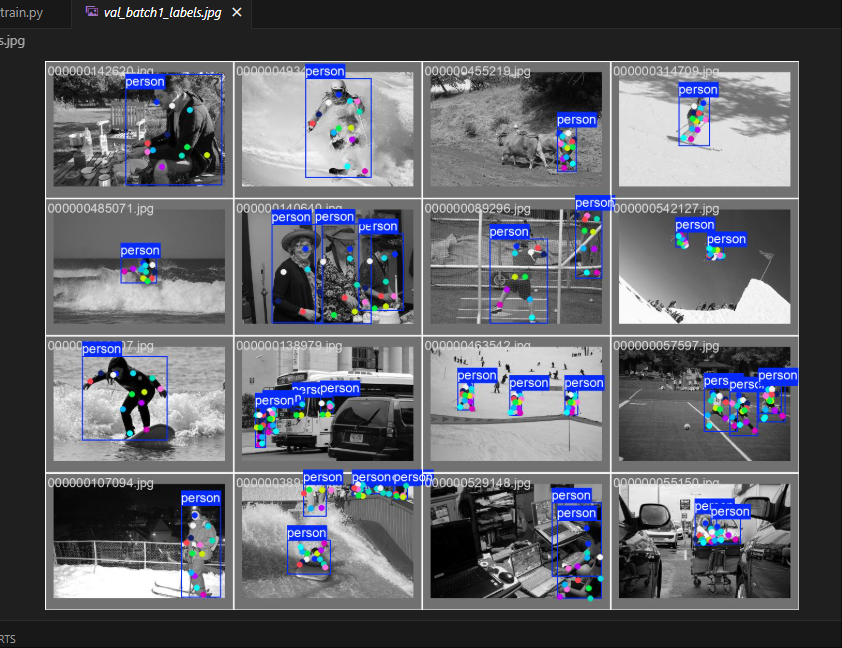
POSE识别 神经网络
Pose 识别模型介绍 Pose 识别是计算机视觉领域的一个重要研究方向,其目标是从图像或视频中检测出人体的关键点位置,从而估计出人体的姿态。这项技术在许多领域都有广泛的应用,如动作捕捉、人机交互、体育分析、安防监控等。 Pose 识别模型的…...

CSS3 基础知识、原理及与CSS的区别
CSS3 基础知识、原理及与CSS的区别 CSS3 基础知识 CSS3 是 Cascading Style Sheets 的第3个版本,是CSS技术的升级版本,于1999年开始制订,2001年5月23日W3C完成了CSS3的工作草案。 CSS3 主要模块 选择器:更强大的元素选择方式盒…...

电能质量扰动信号信号通过hilbert变换得到瞬时频率
利用Hilbert变换从电能质量扰动信号中提取瞬时频率、瞬时幅值、Hilbert谱和边际谱的详细步骤及MATLAB代码实现。该流程适用于电压暂降、暂升、谐波、闪变等扰动分析。 1. Hilbert变换与特征提取流程 1.1 基本步骤 信号预处理:滤波去噪(如小波去噪&…...
)
Linux工作台文件操作命令全流程解析(高级篇之awk精讲)
全文目录 1 工具介绍2 核心优势3 命令格式3.1 命令格式说明3.2 组成部分详解3.2.1 选项3.2.2 模式3.2.3 动作3.2.4 输入文件 4 使用说明4.1 常用示例4.2 awk 编程解析4.2.1 基础说明4.2.2 编程进阶 4.3 温馨提示 5 内置变量6 参考文献 写在前面 前面一篇《Linux工作台文件操作命…...
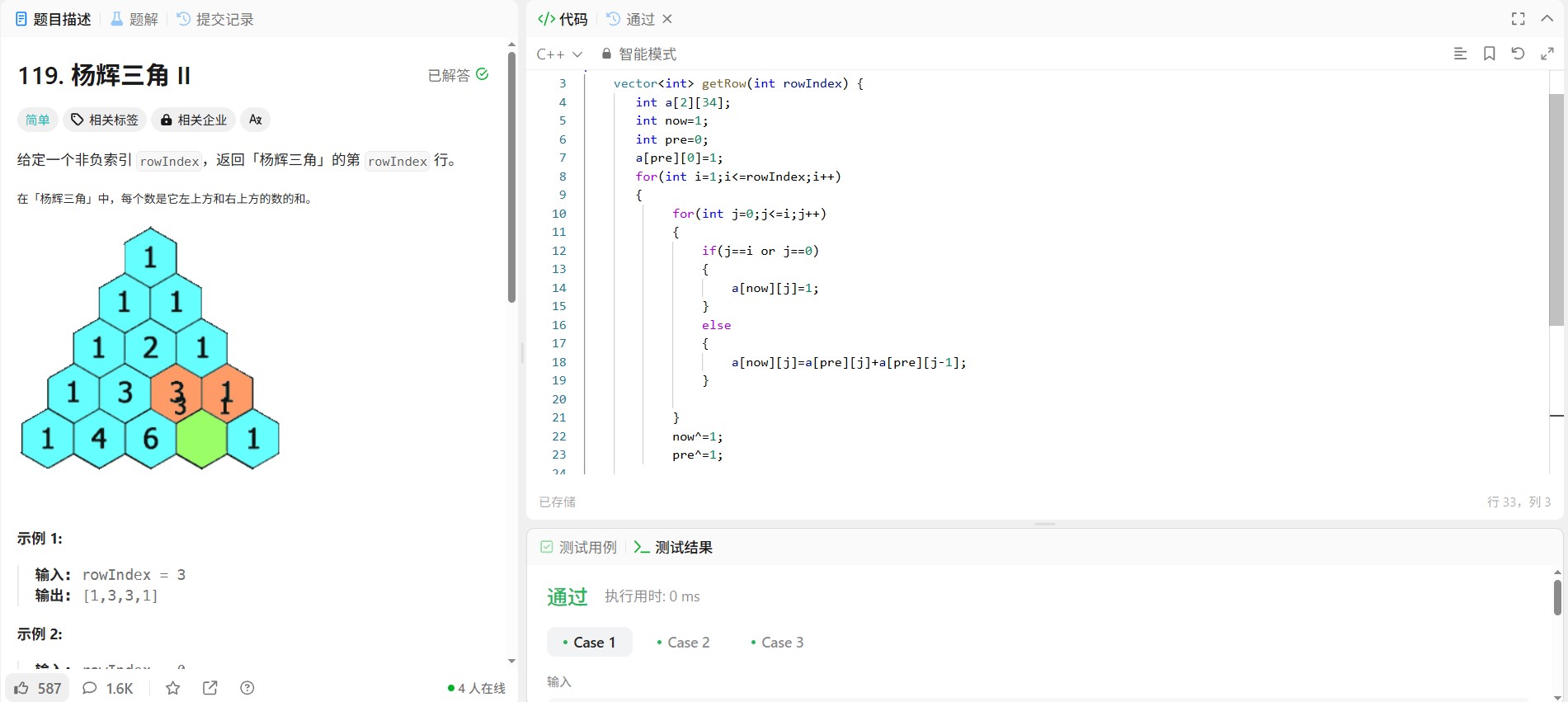
力扣119题:杨辉三角II(滚动数组)
小学生一枚,自学信奥中,没参加培训机构,所以命名不规范、代码不优美是在所难免的,欢迎指正。 标签: 杨辉三角、滚动数组 语言: C 题目: 给定一个非负索引 rowIndex,返回「杨辉三角…...
)
c++:算法(Algorithms)
目录 常用 STL 算法 1️⃣ std::sort(排序) 2️⃣ std::find(查找等于某值的元素) 3️⃣ std::count(统计出现次数) 4️⃣ std::next(获取迭代器的下一个位置) 5️⃣ .erase(…...

大疆无人机(全系列,包括mini)拉流至电脑,实现直播
参考视频 【保姆级教程】大疆无人机rtmp推流直播教程_哔哩哔哩_bilibili VLC使用教程: VLC工具使用指南-CSDN博客 目录 实现效果: 电脑端 编辑 编辑 无人机端 VLC拉流 分析 实现效果: (实验机型:大疆mini4kRC-N2遥控器、大…...

uniapp-商城-54-后台 新增商品(页面布局)
后台页面中还存在商品信息的添加和修改等。接下来我们逐步进行分析和展开。包含页面布局和数据库逻辑等等。 1、整体效果 样式效果如下,依然采用了表单形式来完成和商家信息差不多,但在商品属性上多做了一些弹窗等界面,样式和功能点表多。 …...

深入浅出MySQL 8.0:新特性与最佳实践
MySQL作为开源关系型数据库的佼佼者,近年来持续更新迭代,尤其是在8.0版本中引入了一系列令人兴奋的新特性。本文将介绍一些MySQL 8.0的关键新功能,并提供最佳实践,旨在帮助开发人员和DBA更好地利用这一强大的数据库管理系统。 一…...

JIT+Opcache如何配置才能达到性能最优
首先打开php.ini文件,进行配置 1、OPcache配置 ; 启用OPcache opcache.enable1; CLI环境下启用OPcache(按需配置) opcache.enable_cli0; 预加载脚本(PHP 7.4,加速常用类) ; opcache.preload/path/to/prel…...
python开发经验)
(2)python开发经验
文章目录 1 pyside6加载ui文件2 使用pyinstaller打包 更多精彩内容👉内容导航 👈👉Qt开发 👈👉python开发 👈 1 pyside6加载ui文件 方法1: 直接加载ui文件 from PySide6.QtWidgets import QAp…...

WebpackVite总结篇与进阶
模块化 Webpack Webpack 入口entry 分离app和第三方库入口 这是什么? 这是告诉 webpack 我们想要配置 2 个单独的入口点(例如上面的示例)。 为什么? 这样你就可以在 vendor.js 中存入未做修改的必要 library 或文件࿰…...

【python】基础知识点100问
以下是Python基础语法知识的30条要点整理,涵盖数据类型、函数、控制结构等核心内容,结合最新资料归纳总结: 基础30问 一、函数特性 函数多返回值 支持用逗号分隔返回多个值,自动打包为元组,接收时可解包到多个变量 def func(): return 1, "a" x, y = func()匿…...

uniapp 百家云直播插件打包失败
打包错误日志 Android自有证书 打包失败 错误日志: https://app.liuyingyong.cn/build/errorLog/cf41a610-effe-11ef-88db-05262d4c3e5d原因:需要导入插件依赖 依赖地址:https://ext.dcloud.net.cn/plugin?id16289 百家云直播插件地址 直播插…...
SpringBoot--springboot简述及快速入门
spring Boot是spring提供的一个子项目,用于快速构建spring应用程序 传统方式: 在众多子项目中,spring framework项目为核心子项目,提供了核心的功能,其他的子项目都需要依赖于spring framework,在我们实际…...
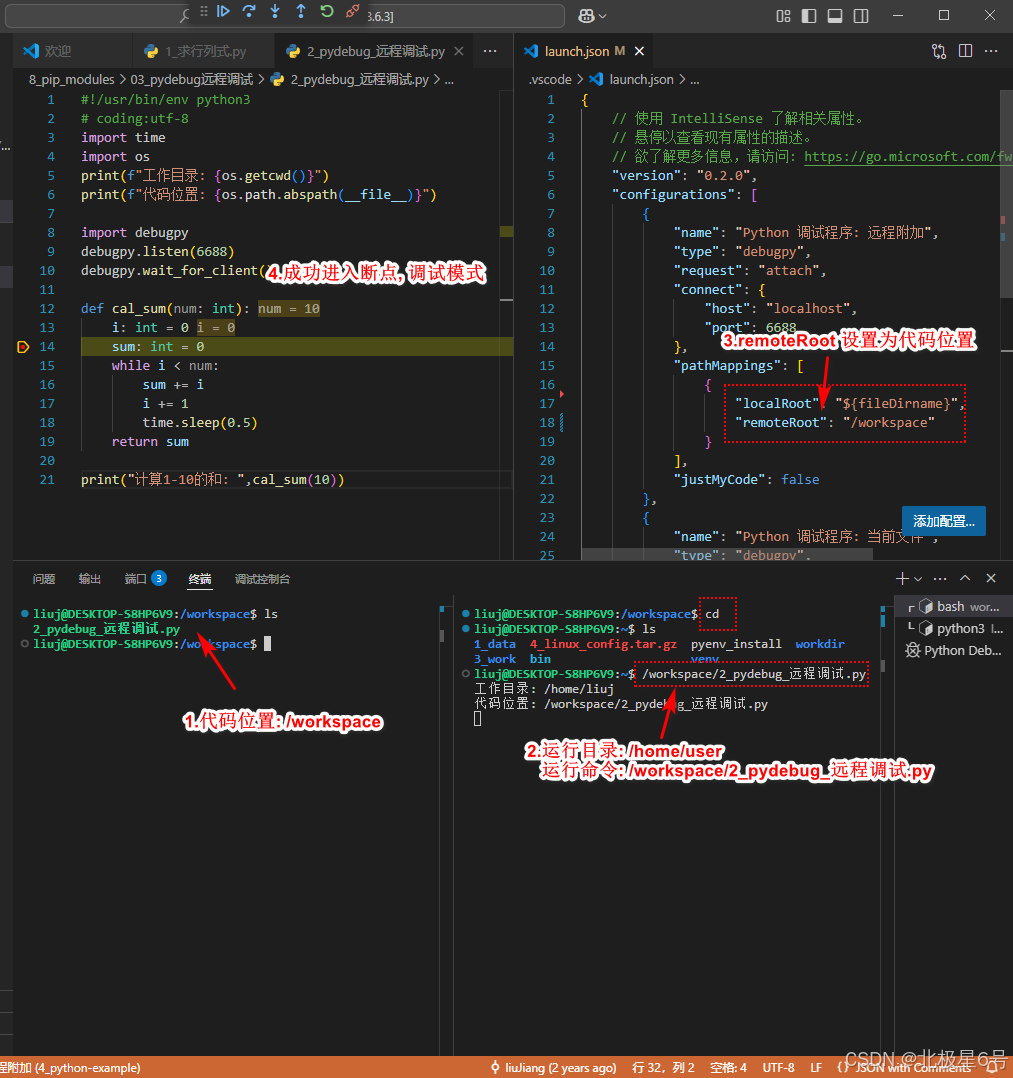
vscode_python远程调试_pathMappings配置说明
1.使用说明 vscode python 远程调试pathMappings 配置 launch.json "pathMappings": [{"localRoot": "本地代码目录","remoteRoot": "远程代码目录" # 注意不是运行目录, 是远程代码的目录}],2.测试验证 测试目的: 远程代…...

遨游5G-A防爆手机:赋能工业通信更快、更安全
在工业数字化转型与5G-A商用进程加速的双重驱动下,中国防爆手机市场正迎来历史性发展机遇。作为“危、急、特”场景通信解决方案服务商,遨游通讯深刻洞察到:当5G-A网络以超高速率、海量连接和毫秒级时延重塑行业生态时,防爆手机这…...
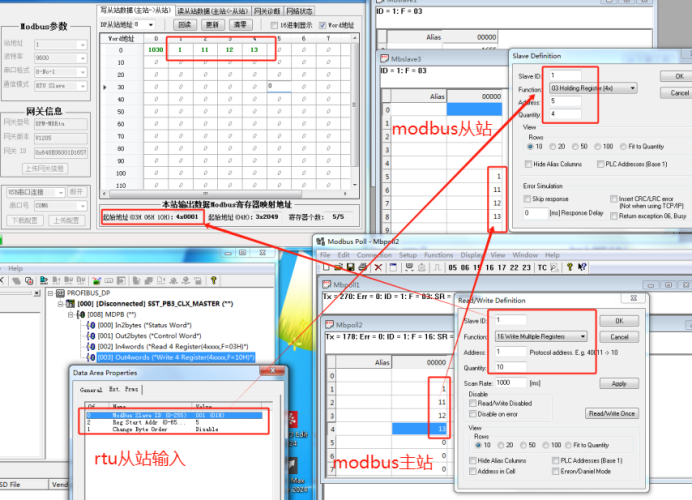
Profibus DP主站与Modbus RTU/TCP网关与海仕达变频器轻松实现数据交互
Profibus DP主站与Modbus RTU/TCP网关与海仕达变频器轻松实现数据交互 Profibus DP主站转Modbus RTU/TCP(XD-MDPBm20)网关在Profibus总线侧实现主站功能,在Modbus串口侧实现从站功能。可将ProfibusDP协议的设备(如:海…...

C++八股——智能指针
文章目录 1. 背景2. 原理与使用2.1 auto_ptr2.2 unique_ptr2.3 shared_ptr2.4 weak_ptr2.5 定制删除器 1. 背景 智能指针不是指针,是一个管理指针的类,用来存储指向动态分配对象的指针,负责自动释放动态分配的对象,防止堆内存泄漏…...

「华为」人形机器人赛道投资首秀!
温馨提示:运营团队2025年最新原创报告(共210页) —— 正文: 近日,【华为】完成具身智能赛道投资首秀,继续加码人形机器人赛道布局。 2025年3月31日,具身智能机器人头部创企【千寻智能&#x…...