数据分析2
五、文件
CSV
Comma-Separated Value,逗号分割值。CSV文件以纯文本形式存储表格数据(数字和文本)。
CSV记录间以某种换行符分隔,每条记录由字段组成,字段间以其他字符或字符串分割,最常用逗号或制表符。
CSV文件第一行为表头,数据之间用逗号分割。
读取
import csv
import sys
input_file = 'D:/pythoncode/aiSelf/supplier_data.csv'
output_file = 'D:/pythoncode/aiSelf/supplier_data2.csv'
with open(input_file, 'r', newline='') as filereader:with open(output_file, 'w', newline='') as filewriter:header = filereader.readline()header = header.strip()header_list = header.split(',')print(header_list)filewriter.write(','.join(map(str, header_list))+'\n')for row in filereader:row = row.strip()row_list = row.split(',')print(row_list)filewriter.write(','.join(map(str, row_list))+'\n')筛选特定行
import csv
import sys
input_file = 'D:/pythoncode/aiSelf/supplier_data.csv'
output_file = 'D:/pythoncode/aiSelf/supplier_data2.csv'
with open(input_file, 'r', newline='') as csv_in_file:with open(output_file, 'w', newline='') as csv_out_file:filereader = csv.reader(csv_in_file)filewriter = csv.writer(csv_out_file)header = next(filereader)filewriter.writerow(header)for row_list in filereader:year = int(str(row_list[0]).strip())cost = int(str(row_list[-1]).strip('$').replace(',',''))if year > 2020 and cost < 5000:filewriter.writerow(row_list)
筛选特定行
import csv
import sys
import re
input_file = 'D:/pythoncode/aiSelf/supplier_data.csv'
output_file = 'D:/pythoncode/aiSelf/supplier_data3.csv'
pattern = re.compile(r'(a2.*)')
with open(input_file, 'r', newline='', encoding='utf-8') as csv_in_file:with open(output_file, 'w', newline='', encoding='utf-8') as csv_out_file:filereader = csv.reader(csv_in_file)filewriter = csv.writer(csv_out_file)header = next(filereader)filewriter.writerow(header)for row_list in filereader:invoice_number = row_list[2]if pattern.search(invoice_number):filewriter.writerow(row_list)统计文件数与文件中行列数
import csv
import glob
import os
import string
import sys
pa = 'D:/pythoncode/aiSelf'
file_counter = 0
for input_file in glob.glob(os.path.join(pa,'p11*')):row_counter = 1with open(input_file,'r',newline='',encoding='utf-8') as csvfile:filereader = csv.reader(csvfile)header = next(filereader)for row in filereader:row_counter += 1print('{0:s}:\t{1:d} rows \t {2:d} columns'.format(\os.path.basename(input_file),row_counter,len(header)))file_counter += 1
print('文件数量:{0:d}'.format(file_counter))
CSV文件数据统计
import csv
import glob
import os
import string
import sys
input_path = 'D:/pythoncode/aiSelf'
output_path = 'D:/pythoncode/aiSelf/output.txt'
output_header_list = ['file_name','total_sales','average_sales']
csv_out_file = open(output_path, 'a', newline='')
filewriter = csv.writer(csv_out_file)
filewriter.writerow(output_header_list)
for input_file in glob.glob(os.path.join(input_path, 'instruments*.csv')):with open(input_file, 'r', newline='', encoding='utf-8') as csv_in_file:filereader = csv.reader(csv_in_file)output_list = []output_list.append(os.path.basename(input_file))header = next(filereader)total_sales = 0.0number_of_sales = 0.0for row in filereader:sale_amount = row[4]total_sales += float(str(sale_amount).strip('$').replace(',',''))number_of_sales += 1.0average_sales = '{0:.2f}'.format(total_sales/number_of_sales)output_list.append(total_sales)output_list.append(average_sales)filewriter.writerow(output_list)
csv_out_file.close()
Excel文件
Python处理Excel需导入xlrd和xlwt两个扩展包。
查看工作簿信息
import sys
from xlrd import open_workbook
input_file = 'D:/pythoncode/aiSelf/instruments_1.xls'
workbook = open_workbook(input_file)
print('工作簿数量:',workbook.nsheets)
for worksheet in workbook.sheets():print('工作簿名字:', worksheet.name, '\tRows:', worksheet.nrows, '\tColumns:', worksheet.ncols)
筛选满足一定条件的行
import sys
from datetime import date
from xlrd import open_workbook, xldate_as_tuple
from xlwt import Workbook
input_file = 'D:/pythoncode/aiSelf/instruments_2.xls'
output_file = 'D:/pythoncode/aiSelf/p128shujufenxi356.xls'
output_workbook = Workbook()
output_worksheet = output_workbook.add_sheet('Sheet1')
sale_amount_column_index = 3
with open_workbook(input_file) as workbook:worksheet = workbook.sheet_by_name('instruments_2')data = []header = worksheet.row_values(0)data.append(header)for row_index in range(1, worksheet.nrows):row_list = []sale_amount = worksheet.cell_value(row_index,sale_amount_column_index)if sale_amount > 1500.0 and sale_amount < 4500.0:for column_index in range(worksheet.ncols):cell_value = worksheet.cell_value(row_index,column_index)cell_type = worksheet.cell_type(row_index,column_index)if cell_type == 3:date_cell = xldate_as_tuple(cell_value, workbook.datemode)date_cell = date(*date_cell[0:3]).strftime('%Y/%m/%d')row_list.append(date_cell)else:row_list.append(cell_value)if row_list:data.append(row_list)for list_index, output_list in enumerate(data):for element_index, element in enumerate(output_list):output_worksheet.write(list_index, element_index, element)
output_workbook.save(output_file)一组工作表的处理
import sys
from datetime import date
from xlrd import open_workbook, xldate_as_tuple
from xlwt import Workbook
input_file = 'D:/pythoncode/aiSelf/instruments_2.xls'
output_file = 'D:/pythoncode/aiSelf/p129shujufenxi357.xls'
output_workbook = Workbook()
output_worksheet = output_workbook.add_sheet('Sheet1')
my_sheets = [0,1]
threshold = 3000.0
sales_column_index = 3
first_worksheet = True
with open_workbook(input_file) as workbook:data = []for sheet_index in range(workbook.nsheets):if sheet_index in my_sheets:worksheet = workbook.sheet_by_index(sheet_index)if first_worksheet:header_row = worksheet.row_values(0)data.append(header_row)first_worksheet = Falsefor row_index in range(1,worksheet.nrows):row_list = []sale_amount = worksheet.cell_value(row_index, sales_column_index)if sale_amount > threshold:for column_index in range(worksheet.ncols):cell_value = worksheet.cell_value(row_index, column_index)cell_type = worksheet.cell_type(row_index, column_index)if cell_type == 3:date_cell = xldate_as_tuple(cell_value, workbook.datemode)date_cell = date(*date_cell[0:3].strftime('%Y%m%d'))row_list.append(date_cell)else:row_list.append(cell_value)if row_list:data.append(row_list)for list_index, output_list in enumerate(data):for element_index, element in enumerate(output_list):output_worksheet.write(list_index, element_index, element)
output_workbook.save(output_file)多个工作簿的处理
六、Python标准库
数据处理的Numpy、Pandas和数据可视化的Matplotlib详见数据分析1。
datetime模块
| 常用类 | 说明 |
| date | 日期类。包括year、month、day属性 |
| time | 时间类。包括hour、minute、second、microsecond属性 |
| datetime | 时间日期类。 |
| timedelta | 时间间隔类。表示两个date、time、datetime实例之间的时间间隔 |
| tzinfo | 时区类。 |
from datetime import date
date类
date类包含对日期数据进行操作和格式化的方法。
格式化日期
| 方法 | 功能 |
| isoformat() | 返回符合ISO8601标准的YYYY-MM-DD |
| isocalender() | 返回包括三个值的元组,年份year,本年的第几周week number,weekday周一为1,周日为7 |
| isoweekday() | 返回ISO标准日期所在的星期几,周一为1,周日为7 |
| weekday() | 返回指定日期星期几,周一为0,周日为6 |
日期比较方法
| 方法 | 功能 |
| x.__eq__(y) | x是否等于y |
| x.__lt__(y) | x是否小于y |
| x.__le__(y) | x是否小于等于y |
| x.__gt__(y) | x是否大于y |
| x.__ge__(y) | x是否大于等于y |
| x.__ne__(y) | x是否不等于y |
计算日期差
| 方法 | 功能 |
| x.__sub__(y) | 计算x和y两个日期的差 |
| x.__rsub__(y) | 计算y和x两个日期的差 |
其他
| 方法 | 功能 |
| today() | 获取当前日期 |
| fromtimestamp() | 将时间戳转换为日期 |
datetime类
可以看作date类和time类的综合。它有一些专有方法。
| 方法 | 功能 |
| now() | 返回当前日期和时间 |
| date() | 返回当前日期和时间的日期部分 |
| time() | 返回当前日期和时间的时间部分 |
| combine(date对象,time对象) | 将date对象和time对象合并为datetime对象 |
时间转化与格式设置
时间对象转化为字符串用isoformat()方法。
字符串转化为时间对象用strptime()方法。
time对象
| 格式控制字符 | 说明 |
| %H | 24小时制小时数0-23 |
| %I | 12小时制小时数01-12 |
| %M | 分钟数00-59 |
| %S | 秒数00-59 |
| %p | 设置显示AM上午,PM下午 |
date对象和datetime对象
| 格式控制字符 | 说明 |
| %Y | 四位数年份0001-9999 |
| %y | 两位数年份01-99 |
| %m | 月份01-12 |
| %d | 日期01-31 |
from datetime import date
date1 = date(2025,5,1)
print(date1)
print(date1.year)
print(date1.month)
print(date1.day)from datetime import date
from datetime import datetime
date2 = date.today()
print(date2.strftime("%Y-%m-%d"))
datetime3 = datetime.now()
print(datetime3.strftime("%Y-%m-%d %H:%M:%S %p"))

math模块
数学常量:
| math.pi | 3.14159.. |
| math.e | 2.718.. |
| math.inf | 浮点正无穷大 |
| math.nan | 浮点非数字NaN值 |
数学函数:
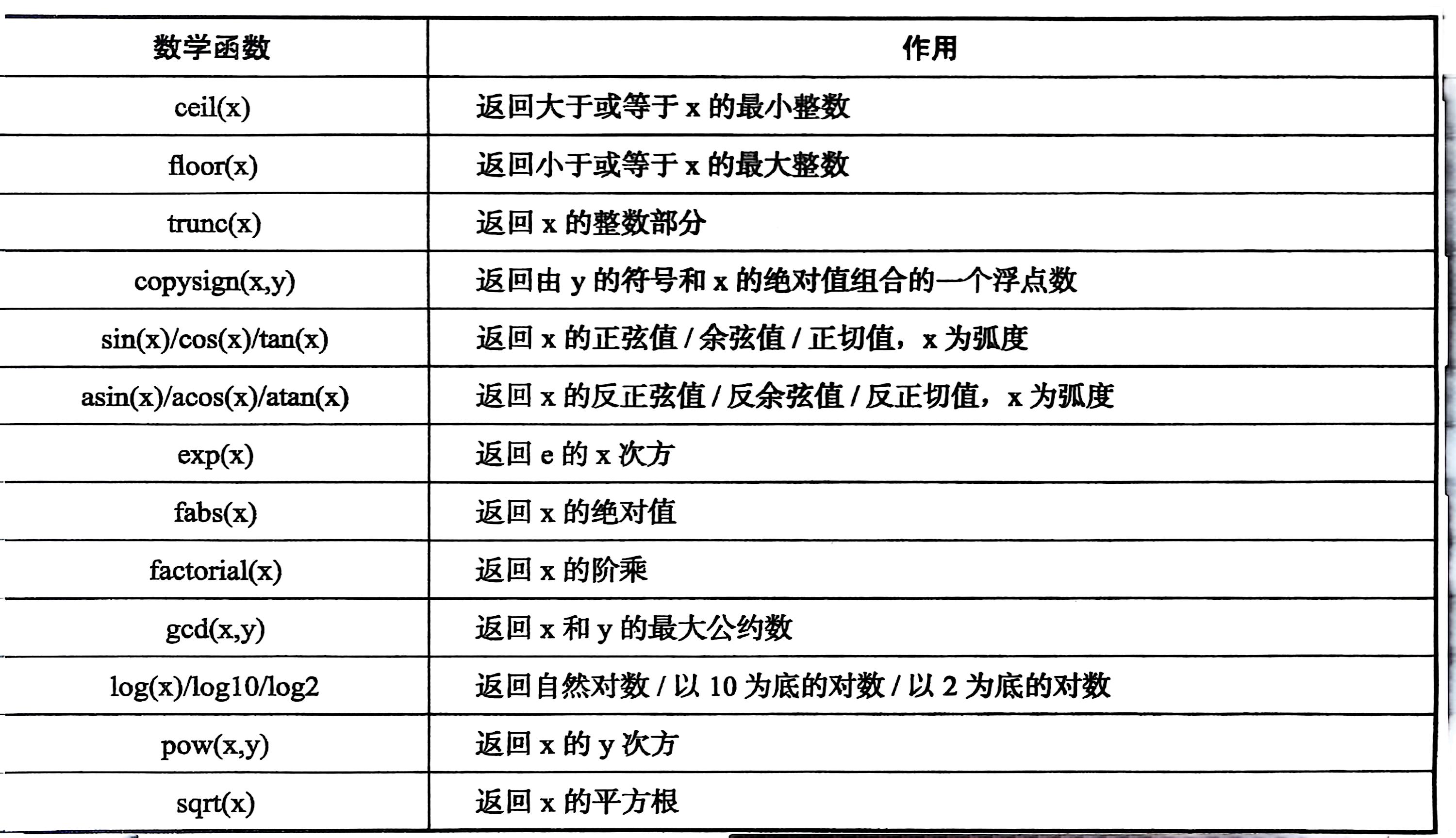
import math
print(math.ceil(3.5))
print(math.floor(3.5))
print(math.trunc(3.5))
print(math.log(math.e))random模块
import random
print('输出各种随机数')
print(random.random())
print(random.uniform(10,100))
print(random.randint(10,100))
print(random.randrange(10,100))
print(random.randrange(4,100,4))
print('返回序列中随机元素')
print(random.choice('wolf is very handsome'))
print(random.choice(['wolf', 'is', 'very', 'handsome']))
print(random.choice(('wolf', 'is', 'very', 'handsome')))
print('改变List中元素顺序')
list = ['wolf', 'is', 'very', 'handsome']
random.shuffle(list)
print(list)
print('随机种子')
random.seed(1)
print(random.random())
print(random.uniform(10,100))
print(random.randint(10,100))
print(random.randrange(10,100))
print(random.randrange(4,100,4))
如果指定种子,会使每次随机的结果相同
os模块
| os.name | 判断正在使用的平台 |
| os.environ | 查看系统环境变量 |
| os.listdir() | 指定所有目录中所有的文件名称和目录名称 |
| os.remove() | 删除指定文件 |
| os.rmdir() | 删除指定目录 |
| os.mkdir() | 创建目录 |
| os.path.isdir() | 判断指定对象是否为目录 |
| os.path.isfile() | 判断指定对象是否为文件 |
import os
if os.name == 'nt':print('当前使用windows')
if os.name == 'posix':print('当前使用Linux')print('系统使用环境变量为', os.environ)
print(os.environ['HOMEPATH'])path = '/pythoncode/'
for i in os.listdir(path):print(i)os.remove('D:/pythoncode/analyse/text804.txt')
print('文件删除完毕')# os.removedirs('文件名')
# os.mkdir('一层的路径')
# os.path.isdir()用来判定对象是否为目录
# os.path.isfile()用来判定指定对象是否为文件
七、正则表达式
元字符
元字符是预先定义好的特殊字符,是用来描述其他字符的。
主要元字符
| \ | 转义符,表示转义 |
| . | 表示任意一个字符 |
| + | 表示重复1次或多次 |
| * | 表示重复0次或多次 |
| ? | 表示重复0次或1次 |
| | | 选择符号,或 |
| {} | 定义量词 |
| [] | 定义字符类 |
| () | 定义分组 |
| ^ | 表示取反,或匹配一行的开始 |
| $ | 匹配一行的结束 |
预定义字符
用于转义
| \n | 匹配换行符 |
| \r | 匹配回车符 |
| \f | 匹配一个换页符 |
| \t | 匹配一个水平制表符 |
| \v | 匹配一个垂直制表符 |
| \s | 匹配一个空格符,等价于[\t\n\r\f\v] |
| \S | 匹配一个非空格符,等价于[^\s] |
| \d | 匹配一个数字字符,等价于[0-9] |
| \D | 匹配一个非数字字符,等价于[^0-9] |
| \b | 匹配单词的开始或结束,单词的分布符为空格、标点符号或换行 |
| \w | 匹配任意语言的字符、数字或下划线等内容。若正则表达式标志设置为ASCII,则只匹配[a-zA-Z0-9] |
| \W | 等价于[^\w] |
例如匹配一个8位数字的电话号码,可以使用
\d\d\d\d\d\d\d\d
该方法还是比较繁琐的,可以使用下面这个正则表达式代替。
\d{8}
标记开始与结束
$结束,^开始
\w+@163.com$ 以163.com结尾
^\w+@163.com 以163.com开头
匹配一组字符
正则表达式中可以用字符类定义一组字符,其中任意一个字符出现在输入字符串中即匹配成功。需注意,每次只能匹配一个字符。
定义一组字符
需要中括号[]基本元字符
想要匹配python和Python
[pP]ython
对一组字符取反
^取反
想要匹配不是阿拉伯数字
[^1234567890]
使用区间简化一组字符的定义
-
想要匹配不是阿拉伯数字
[^0-9]
所有英文字母和数字
[A-Za-z0-9]
下面这个正则表达式是0-3和6-8,不是0-36
[0-36-8]
使用量词多次匹配
元字符只能匹配显示一次字符或字符串,想要匹配多次字符或字符串,应使用量词
常用量词
| ? | 出现0次或1次 |
| * | 出现0次或多次 |
| + | 出现1次或多次 |
| {n} | 出现n次 |
| {n,m} | 至少出现n次,但不超过m次 |
| {n,} | 至少出现n次 |
匹配八位数字的电话号码,不要再用8个\d了
\d{8}
颜色有color和colour
colou?r
贪婪和非贪婪匹配
关于重复的操作,需要注意正则表达式默认使用贪婪匹配方式。
贪婪匹配是只要符合条件就会尽可能多的匹配。
转换成非贪婪匹配只要在量词后加上?
\d{5,9}
\d{5,9}?
分组
在前面的例子中,量词只能重复显示一个字符,如果想让一个字符串作为整体使用量词对其进行重复匹配,可以使用圆括号(),分组。
(123){3}匹配123123123
123{3}只会对字符3重复匹配
使用re模块处理正则表达式
Python的re模块具有正则表达式的匹配功能。使用re模块前先导入
import rePython正则表达式的语法
Python中的正则表达式是作为模式字符串使用的,也就是两侧加单引号。
例如[^a-zA-Z]应写为
'[^a-zA-Z]'部分特殊含义字母应使用反斜杠\
或在模式字符串前加上大小写字母R或r,表示原生字符串
例如\bd\w*\b应写为
r'\bd\w*\b'
# 或
'\\bd\w*\\b'匹配字符串
re模块中的match()方法、search()方法、findall()方法用于字符串匹配
match()方法从字符串开始位置匹配,在开始位置匹配成功返回Match对象,否则返回None。
re.match(pattern模式字符串, string要匹配的字符串, [flags]可选可不选标志位用于控制匹配方式如是否区分字母大小写等)
import re
mystr = ['streetwolf', 'silverwolf', 'Streetsheep', 'streetcat', 'StreetMouse', 'streetfish']
p = r'street\w+'
for i in range(len(mystr)):m = re.match(p, mystr[i], re.I)if m:print(mystr[i], '开始位置', m.start(), ',结束位置', m.end(), ',跨度', m.span(), ',匹配内容', m.string)else:print(mystr[i], '不匹配')with open('telephonenumber.txt', 'r', encoding='utf-8') as f:lst = f.readlines()
number = 0for i in range(len(lst)):p = re.match(r'17[01]\d{8}|000',lst[i])if p:number = number + 1
print(number)search()方法可以在整个字符串中查找,并返回第一个匹配内容,若找到一个则匹配对象,否则匹配None。
re.search(pattern模式字符串, string要匹配的字符串, [flags]可选可不选标志位用于控制匹配方式如是否区分字母大小写等)
findall()方法用于在整个字符串中搜索所有符合正则表达式的字符串,匹配成功以列表形式返回,否则返回空列表。
re.findall(pattern模式字符串, string要匹配的字符串, [flags]可选可不选标志位用于控制匹配方式如是否区分字母大小写等)
替换字符串
sub()方法实现字符串替换
re.sub(pattern模式字符串,repl替换的字符串,string原始字符串,count模式匹配后替换的最大次数默认0替换所有匹配,flags表示位控制匹配方式)
分割字符串
split()方法分割字符串,返回列表,与字符串对象的split()方法类似
re.split(pattern,string,[maxsplit]最大拆分次数,[flags])
相关文章:
数据分析2
五、文件 CSV Comma-Separated Value,逗号分割值。CSV文件以纯文本形式存储表格数据(数字和文本)。 CSV记录间以某种换行符分隔,每条记录由字段组成,字段间以其他字符或字符串分割,最常用逗号或制表符。…...
实战项目5(08)
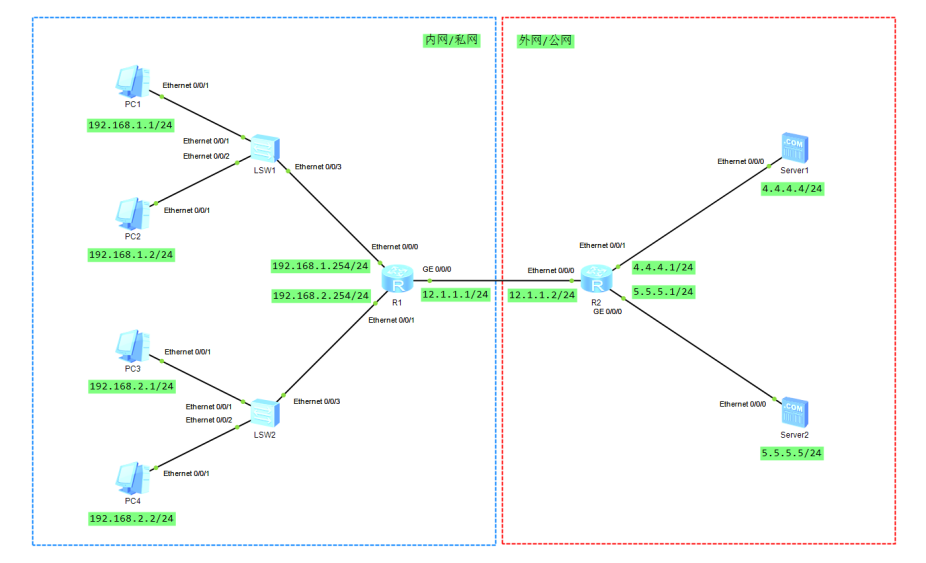
目录 任务场景一 【r1配置】 【r2配置】 【r3配置】 任务场景二 【r1配置】 【r2配置】 任务场景一 按照下图完成网络拓扑搭建和配置 任务要求: 通过在路由器R1、R2和R3上配置静态路由,实现网络中各终端PC能够正常…...

CSS结构性伪类、UI伪类与动态伪类全解析:从文档结构到交互状态的精准选择
一、结构性伪类选择器:文档树中的位置导航器 结构性伪类选择器是CSS中基于元素在HTML文档树中的层级关系、位置索引或结构特征进行匹配的一类选择器。它们无需依赖具体的类名或ID,仅通过文档结构即可精准定位元素,是实现响应式布局和复杂文档…...
.NET MAUI 基础知识
文章目录 什么是 .NET MAUI?MAUI的核心特点与Xamarin.Forms的区别 开发环境搭建安装Visual Studio 2022安装必要组件配置Android开发环境配置iOS开发环境验证安装 创建第一个MAUI应用创建新项目MAUI项目结构解析理解关键文件运行应用程序简单修改示例使用热重载 MAU…...
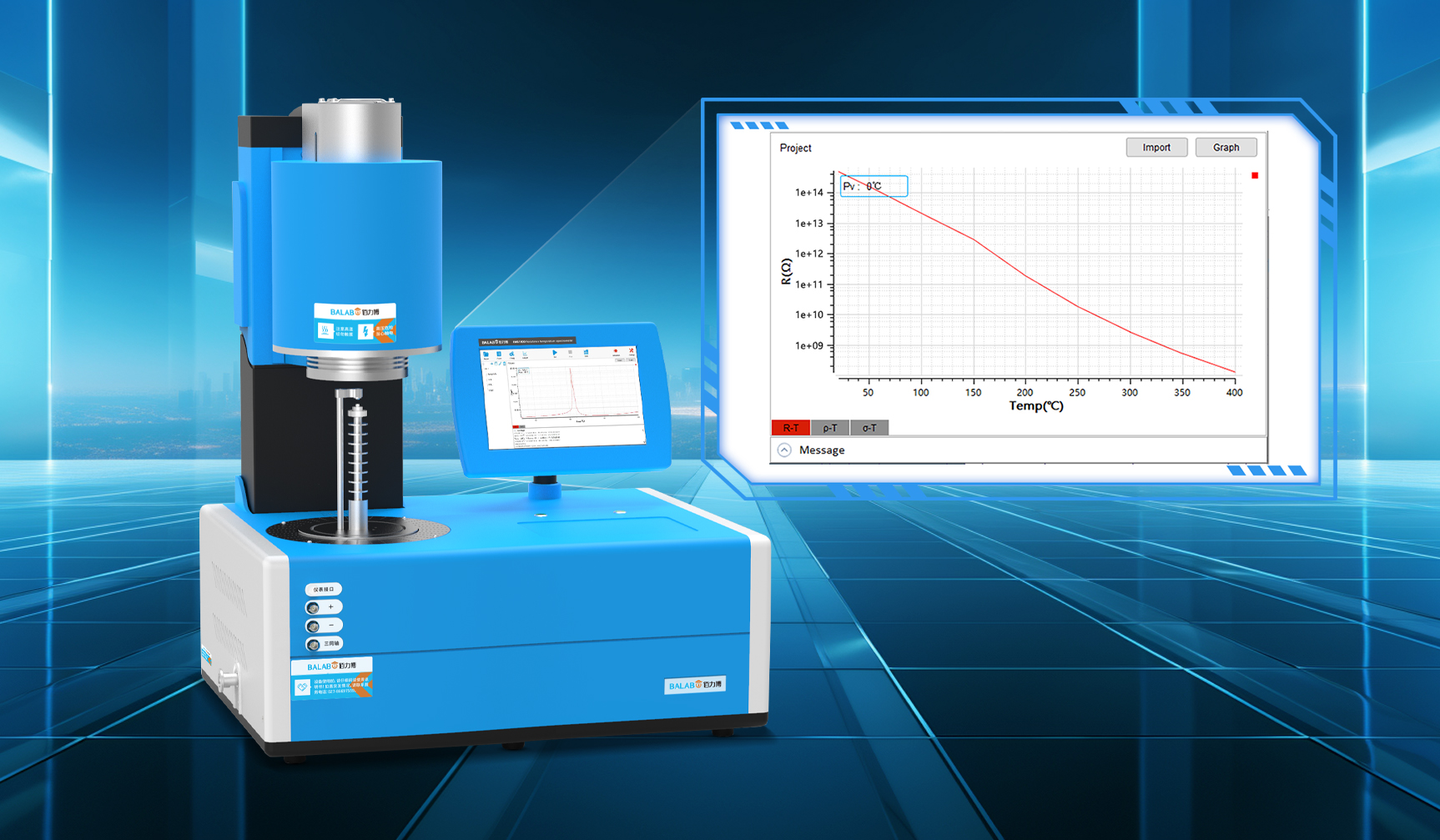
佰力博科技与您探讨表面电阻的测试方法及应用领域
表面电阻测试是一种用于测量材料表面电阻值的技术,广泛应用于评估材料的导电性能、静电防护性能以及绝缘性能。 1、表面电阻的测试测试方法: 表面电阻测试通常采用平行电极法、同心圆电极法和四探针法等方法进行。其中,平行电极法通过在试样…...
鹅厂面试数学题
题目 一个圆上随机取三个点,求这三个点构成锐角三角形的概率。 解答 根据圆周角定理,此题目等价为:一条线段长度为1的线段随机取两个点分成三段,任意一段长度均不大于1/2的概率。记前两段的长度为,则第三段的长度为…...

GO语言-导入自定义包
文章目录 1. 项目目录结构2. 创建自定义包3. 初始化模块4. 导入自定义包5. 相对路径导入 在Go语言中导入自定义包需要遵循一定的目录结构和导入规则。以下是详细指南(包含两种方式): 1. 项目目录结构 方法1:适用于Go 1.11 &#…...

java基础-package关键字、MVC、import关键字
1.package关键字: (1)为了更好管理类,提供包的概念 (2)声明类或接口所属的包,声明在源文件首行 (3)包,属于标识符,用小写字母表示 ࿰…...
[6-2] 定时器定时中断定时器外部时钟 江协科技学习笔记(41个知识点)
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 V 30 31 32 33 34 35 36 37 38 39 40 41...

第五节:对象与原型链:JavaScript 的“类”与“继承”
📌 第五节:对象与原型链:JavaScript 的“类”与“继承” 目标:理解对象创建、原型继承、this 绑定,掌握类语法与原型设计模式,实现模块化组件开发。 一、对象基础:数据的“容器” 1. 对象字面…...
)
本地的ip实现https访问-OpenSSL安装+ssl正式的生成(Windows 系统)
1.下载OpenSSL软件 网站地址:Win32/Win64 OpenSSL Installer for Windows - Shining Light Productions 安装: 一直点击下一步就可以了 2.设置环境变量 在开始菜单右键「此电脑」→「属性」→「高级系统设置」→「环境变量」 在Path 中添加一个: xxxx\OpenSSL-…...

Spring Boot + MyBatis-Plus 高并发读写分离实战
引言 在高并发场景下,单一数据库实例往往成为性能瓶颈。数据库读写分离通过将读操作和写操作分配到不同的数据库实例,有效缓解主库压力,提升系统吞吐量。MyBatis-Plus 作为一款强大的持久层框架,结合 Spring Boot 能够轻松实现读…...
)
HarmonyOS 【诗韵悠然】AI古诗词赏析APP开发实战从零到一系列(二、项目准备与后台服务搭建)
在开发一款面向HarmonyOS平台的应用程序——【诗韵悠然】AI古诗词赏析APP时,选择了流行Go语言作为后端开发语言,并使用了go-zero微服务框架来搭建服务接口。本文将详细介绍项目准备和后台服务搭建的过程,帮助大家更好地理解和掌握go-zero框架…...
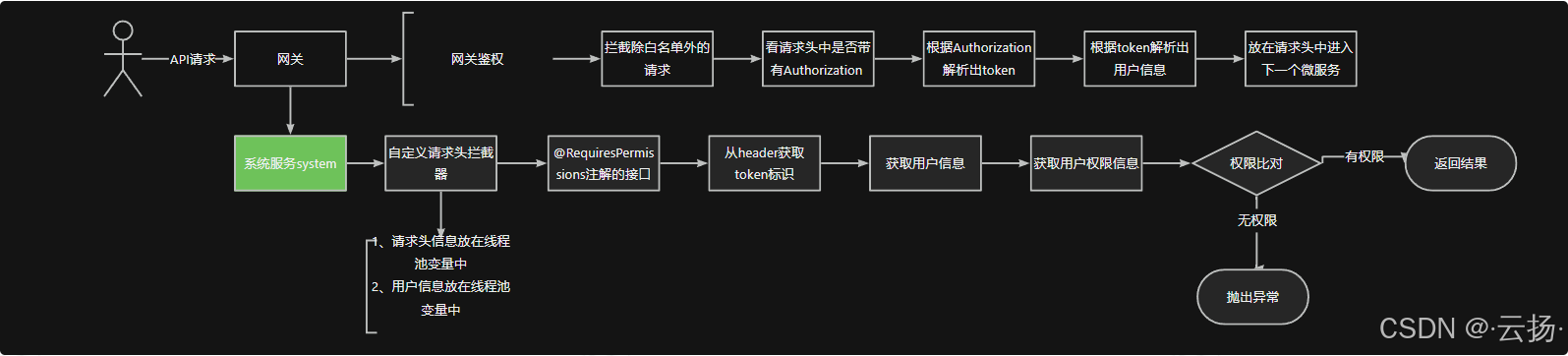
【PmHub后端篇】PmHub中基于自定义注解和AOP的服务接口鉴权与内部认证实现
1 引言 在现代软件开发中,尤其是在微服务架构下,服务接口的鉴权和内部认证是保障系统安全的重要环节。本文将详细介绍PmHub中如何利用自定义注解和AOP(面向切面编程)实现服务接口的鉴权和内部认证,所涉及的技术知识点…...
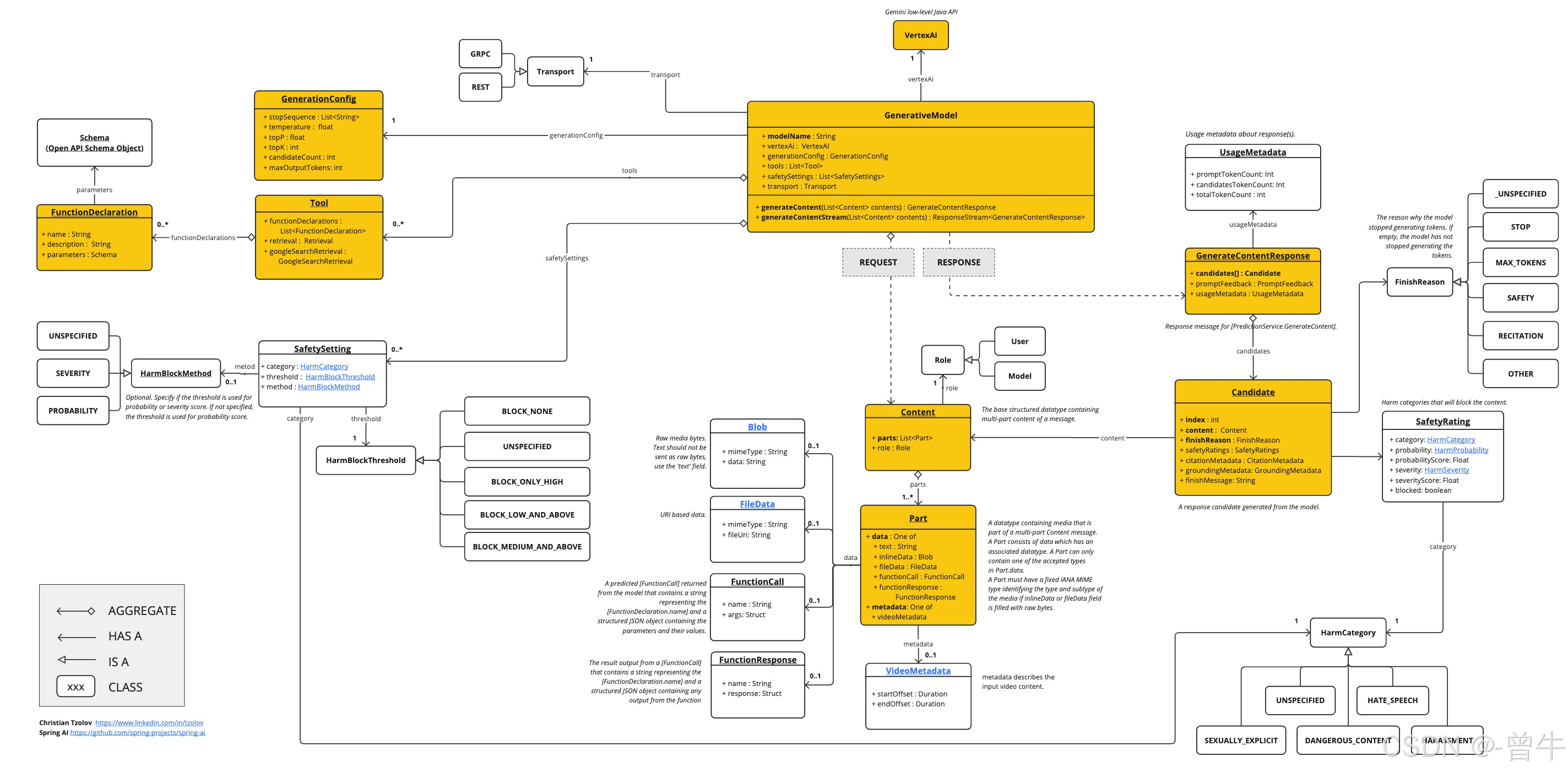
多模态AI新纪元:Vertex AI Gemini与Spring AI深度集成实践
企业级AI集成进阶:Spring AI与Vertex AI Gemini的配置与调优实战 一、前沿技术:多模态模型的企业级配置范式 在生成式AI技术快速迭代的当下,企业级应用对模型配置的精细化需求日益增长。Vertex AI Gemini作为Google推出的多模态大模型&…...

大语言模型RLHF训练框架全景解析:OpenRLHF、verl、LLaMA-Factory与SWIFT深度对比
引言 随着大语言模型(LLM)参数规模突破千亿级,基于人类反馈的强化学习(RLHF)成为提升模型对齐能力的关键技术。OpenRLHF、verl、LLaMA-Factory和SWIFT作为开源社区的四大标杆框架,分别通过分布式架构、混合…...

开源AI数字人分身克隆小程序源码系统深度剖析:从搭建到应用
在人工智能与小程序生态深度融合的当下,开源 AI 数字人分身克隆小程序源码成为开发者的热门工具。从搭建基础环境到实现实际应用,这一过程涉及多项技术与复杂流程。本文将带您深入剖析开源 AI 数字人分身克隆小程序源码,揭开其从搭建到应用的…...
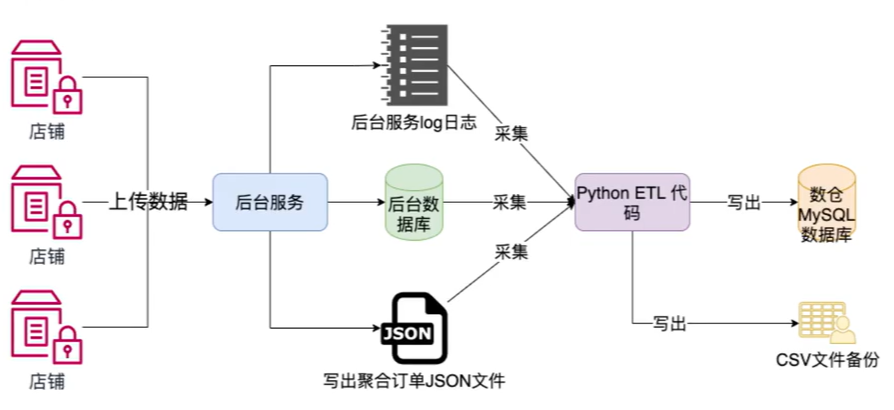
ETL背景介绍_1:数据孤岛仓库的介绍
1 ETL介绍 1.1 数据孤岛 随着企业内客户数据大量的涌现,单个数据库已不再足够。为了储存这些数据,公司通常会建立多个业务部门组织的数据库来保存数据。比如,随着数据量的增长,公司通常可能会构建数十个独立运行的业务数据库&am…...
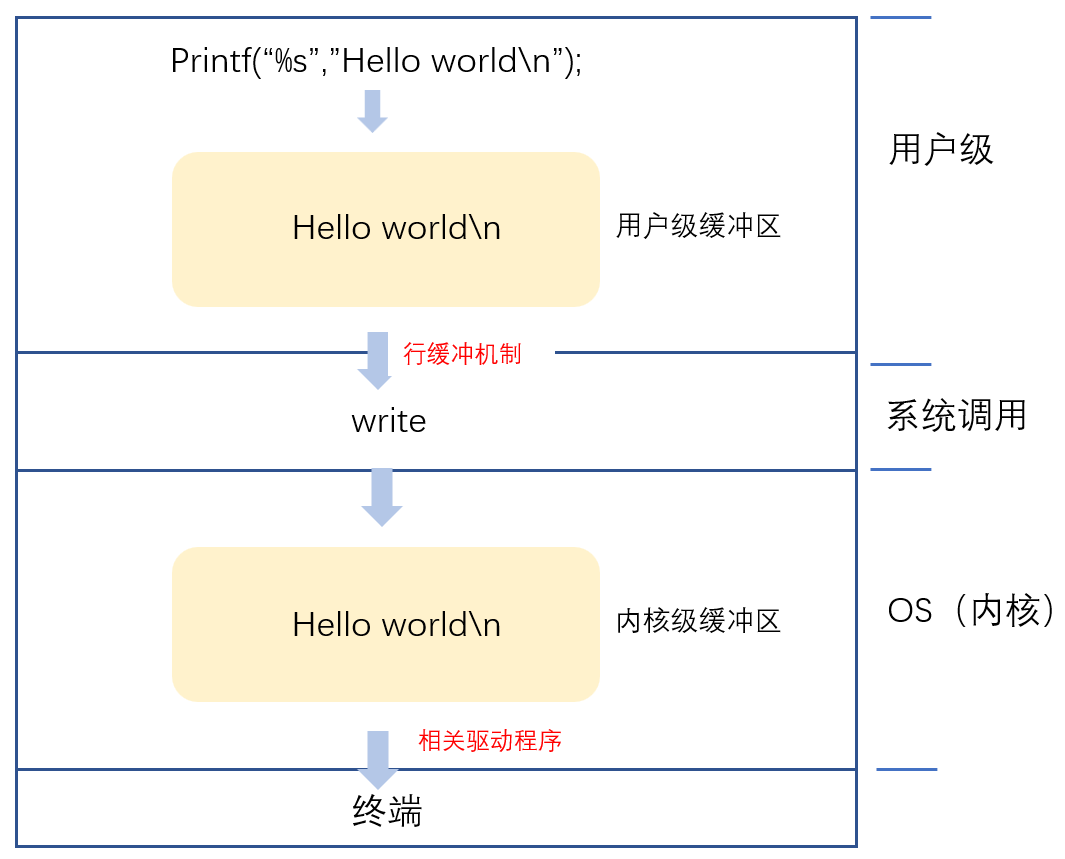
Linux系统:虚拟文件系统与文件缓冲区(语言级内核级)
本节重点 初步理解一切皆文件理解文件缓冲区的分类用户级文件缓冲区与内核级文件缓冲区用户级文件缓冲区的刷新机制两级缓冲区的分层协作 一、虚拟文件系统 1.1 理解“一切皆文件” 我们都知道操作系统访问不同的外部设备(显示器、磁盘、键盘、鼠标、网卡&#…...

智能体的典型应用:自动驾驶、智能客服、智能制造、游戏AI与数字人技术
本文为《React Agent:从零开始构建 AI 智能体》专栏系列文章。 专栏地址:https://blog.csdn.net/suiyingy/category_12933485.html。项目地址:https://gitee.com/fgai/react-agent(含完整代码示例与实战源)。完整介绍…...

【技巧】使用UV创建python项目的开发环境
回到目录 【技巧】使用UV创建python项目的开发环境 0. 为什么用UV 下载速度快、虚拟环境、多版本python支持、清晰的依赖关系 1. 安装基础软件 1.1. 安装python 下载地址:https://www.python.org/downloads/windows/ 1.2. 安装UV > pip install uv -i ht…...

什么是时序数据库?
2025年5月13日,周二清晨 时序数据库(Time Series Database,TSDB)是一种专门用于高效存储、管理和分析时间序列数据的数据库系统。时间序列数据是指按时间顺序记录的数据点,通常包含时间戳和对应的数值或事件࿰…...

react父组件往孙子组件传值Context API
步骤: 创建一个 Context 在父组件中用 Provider 提供值 在孙子组件中用 useContext 消费值 // 创建 Context const MyContext React.createContext();// 父组件 const Parent () > {const value "Hello from parent";return (<MyContext.Provid…...

2025年第十六届蓝桥杯大赛软件赛C/C++大学B组题解
第十六届蓝桥杯大赛软件赛C/C大学B组题解 试题A: 移动距离 问题描述 小明初始在二维平面的原点,他想前往坐标(233,666)。在移动过程中,他只能采用以下两种移动方式,并且这两种移动方式可以交替、不限次数地使用: 水平向右移动…...

国联股份卫多多与七腾机器人签署战略合作协议
5月13日,七腾机器人有限公司(以下简称“七腾机器人”)市场部总经理孙永刚、销售经理吕娟一行到访国联股份卫多多,同卫多多/纸多多副总裁、产发部总经理段任飞,卫多多机器人产业链总经理郭碧波展开深入交流,…...
)
python学习笔记七(文件)
文章目录 Python 文件操作与异常处理全面指南一、文件基本知识1. 文件类型2. 文件操作基本步骤 二、文件操作1. 打开文件2. 读取文件内容3. 写入文件4. 关闭文件5. 使用with语句(推荐) 三、CSV文件操作1. 使用csv模块2. 读取CSV文件3. 写入CSV文件 四、异…...
WebGL 开发的前沿探索:开启 3D 网页的新时代
你是否曾好奇,为何如今网页上能呈现出如同游戏般逼真的 3D 场景?这一切都要归功于 WebGL。它看似神秘,却悄然改变着我们浏览网页的体验。以往,网页内容大多局限于二维平面,可 WebGL 打破了这一限制。它究竟凭借什么&am…...

高防服务器部署实战:从IP隐匿到协议混淆
1. IP隐匿方案设计 传统高防服务器常因源站IP暴露遭针对性攻击,群联通过三层架构实现深度隐藏: 流量入口层:域名解析至动态CNAME节点(如ai-protect.example.com)。智能调度层:AI模型分配清洗节点…...
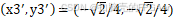
激光雷达定位算法在FPGA中的实现——section3 Matlab实现和校验
1、校验section2的计算方法是否正确 以section1里面的图示 举个例子: 1.1 手动计算...

AI+可视化:数据呈现的未来形态
当AI生成的图表开始自动“美化”数据,当动态可视化报告能像人类一样“讲故事”,当你的眼球运动直接决定数据呈现方式——数据可视化的未来形态,正在撕裂传统认知。某车企用AI生成的3D可视化方案,让设计师集体失业;某医…...