015枚举之滑动窗口——算法备赛
滑动窗口
最大子数组和
题目描述
给你一个整数数组 nums ,请你找出一个具有最大和的连续子数组(子数组最少包含一个元素),返回其最大和。
原题链接
思路分析
见代码注解
代码
int maxSubArray(vector<int>& nums) {int numsSize=nums.size();int max=nums[0];int m=0;for(int i=1;i<numsSize;i++){m+=nums[i-1]; //m记录前面区间窗口区间的总和if(m<0){m=0; //当区间总和小于0时放弃不用,m置为0}if(m+nums[i]>max){max=m+nums[i]; //更新max值。}}return max; //如果数组值都为非正数,则最大值为某个元素}
子数组操作后的最大频数
问题描述
给你一个长度为 n 的数组 nums ,同时给你一个整数 k 。
你可以对 nums 执行以下操作 一次 :
- 选择一个子数组
nums[i..j],其中0 <= i <= j <= n - 1。 - 选择一个整数
x并将nums[i..j]中 所有 元素都增加x。
请你返回执行以上操作以后数组中 k 的 最大 频数。
子数组 是一个数组中一段连续 非空 的元素序列。
提示:
1 <= n == nums.length <= 10^51 <= nums[i] <= 501 <= k <= 50
原题链接
思路分析
记数组中k的频数为cnt,可以肯定答案最小不会小于cnt(将数组中所有元素加0得到)
将子数组中所有元素都加x,为最大化答案,最优策略就是将子数组中频数最大的那个元素变为k(如果使对答案贡献为负数,那就不能操作该子数组)。
定义m_max[i]记录将元素i全变为k对答案的贡献,maxn为所有m_max[i]的最大值,最后的答案就是cnt+maxn。
具体实现时,再定义一个数组m,m[i]记录将最后枚举到的i的下标为操作的子数组的右边界且将i都变为k的对答案的最大贡献,枚举到nums[i],当nums[i]==k时,将前面统计到的所有的大于0的m[j]都减1,因为后面再枚举到j时,前面有一个k,对答案的贡献要减1,贡献本身就是0了就没必要再减了。
本题思路和上题最大子数组和的思路有点像。m[i]记录的是前缀和(遇到i加一,遇到k减1),m_max[i]记录的是i对应的最大子数组和。
代码
int maxFrequency(vector<int>& nums, int k) {int ans=0,cnt=0,n=nums.size();vector<int>m(51); vector<int>m_max(51); //m_max[i]记录将元素i全变为k对答案的贡献int maxn=0;for(int i=0;i<n;i++){int t=nums[i];if(t==k){ cnt++; //记录k的个数for(int j=1;j<=50;j++) if(m[j]>0) m[j]--;}else m[t]++;m_max[t]=max(m[t],m_max[t]); maxn=max(maxn,m_max[t]);}return cnt+maxn;}
滑动窗口最大值
问题描述
给你一个整数数组 nums,有一个大小为 k 的滑动窗口从数组的最左侧移动到数组的最右侧。你只可以看到在滑动窗口内的 k 个数字。滑动窗口每次只向右移动一位。
返回 滑动窗口中的最大值 数组,数组每个元素记录了滑动窗口每个阶段的最大值。
原题链接
思路分析
这题是滑动窗口的经典题。
定义一个单调队列(双端队列实现),队头维护的是窗口的最大值,每次滑动将当前枚举到的新元素nums[i]尾插入队列,在插入前将影响单调的元素从尾部移除。
细节:当从队头取出元素时,有些元素可能已过期(不满足当前窗口大小为k),需要从头部移除,因为需要判断元素是否过期,这知道元素的下标,所以单调队列应该存储下标值。
代码
vector<int> maxSlidingWindow(vector<int>& nums, int k) {vector<int> arr;deque<int>q;for(int i=0;i<nums.size();i++){while(!q.empty()&&nums[q.back()]<nums[i]) q.pop_back();q.push_back(i);if(i>=k-1){while(q.front()<=i-k) q.pop_front();arr.push_back(nums[q.front()]);}}return arr;}
子矩阵
蓝桥杯2023年省赛题
问题描述
给定一个n*m的矩阵。设矩阵的价值为所有数中最大值与最小值的乘积。求给定的所有大小为a*b的子矩阵的价值的和。
答案很大,请输出答案对998244353的结果。
数据规模:
1<=a<=n<=10001<=b<=m<=10001<=aij<=1^9
原题链接
思路分析
本题是滑动窗口最值的二维版本,请先回顾上题。
首先考虑暴力法,枚举每个子矩阵,总复杂度接近O(n*m*a*b),是个天文数字,肯定不允许。从数据规模来看需要设计一个O(n*m)的算法。
类似求一维的固定长度的子数组的最值,本题是求二维的固定长宽的子矩阵的最值。
参考滑动窗口最大值,先预处理数据,将原矩阵的每一行看作一维数组,对每一行求滑窗最值,定义maxn[i][j]表示第i行第j个长度为b的滑动窗口的最大值,同理定义minn[i][j]表示第i行第j个长度为b的滑动窗口的最小值。
再在maxn和minn的基础上求滑动窗口的最大值和最小值,滑动窗口的大小为a,这样通过横向再纵向扫描的方式求解。
以求2*3子矩阵最大值为例,图解:

代码中多次求解滑窗最值,可以定义getMin()和getMax()来快速求解。
时间复杂度:单次求解滑窗最值是线性的时间复杂度,求解minn,maxn的复杂度为O(n*m),再在minn和maxn基础上求解滑窗最值的时间复杂度为O(n*c)(c为minn和maxn的列宽即m-b),总时间复杂度为O(n*m+n*c)比O(n*m*a*b)好多了。
代码
#include<bits/stdc++.h>
using namespace std;
typedef long long ll;
int n, m, a, b;
const int mod = 998244353;
vector<vector<int>>nums; //存储原数组
vector<vector<int>>maxn; //maxn[i][j]存储第i行第j个滑动窗口的最大值
vector<vector<int>>minn; //maxn[i][j]存储第i行第j个滑动窗口的最小值
void getMin(vector<int>& tar, vector<int>& mats, int k) { //求解滑动窗口最小值的子问题deque<int>dq;for (int i = 0; i < mats.size(); i++) {while (!dq.empty() && mats[dq.back()] > mats[i]) dq.pop_back();dq.push_back(i);if (i >= k - 1) {while (dq.front() <= i - k) dq.pop_front();tar.push_back(mats[dq.front()]);}}
}
void getMax(vector<int>& tar, vector<int>&mats, int k) { //求解滑动窗口最大值的子问题deque<int>dq;for (int i = 0; i < mats.size(); i++) {while (!dq.empty() && mats[dq.back()] < mats[i]) dq.pop_back();dq.push_back(i);if (i >= k - 1) {while (dq.front() <= i - k) dq.pop_front();tar.push_back(mats[dq.front()]);}}
}
void init() {cin >> n >> m >> a >> b;nums = vector<vector<int>>(n, vector<int>(m));minn.resize(n);maxn.resize(n);for (int i = 0; i < n; i++) {for (int j = 0; j < m; j++) {cin >> nums[i][j];}}
}
int solve() {ll ans = 0;for (int i = 0; i < n; i++) getMax(maxn[i], nums[i], b);for (int i = 0; i < n; i++) getMin(minn[i], nums[i], b);int cols = maxn[0].size();vector<int>sMax, sMin; //子矩阵的最大最小值vector<int>temp(n);for (int j = 0; j < cols; j++) {for (int i = 0; i < n; i++) temp[i] = maxn[i][j];sMax.clear(); //容器清空,达到复用的目的,节省空间getMax(sMax, temp, a);for (int i = 0; i < n; i++) temp[i] = minn[i][j]; //同上sMin.clear();getMin(sMin, temp, a);for (int i = 0; i < sMin.size(); i++) {ans = (ans + ((ll)sMax[i] * sMin[i]) % mod) % mod;}}return ans;
}
int main() {ios::sync_with_stdio(0);cin.tie(0); cout.tie(0);init();cout << solve();return 0;
}
最小区间
问题描述
你有 k 个 非递减排列 的整数列表。找到一个 最小 区间,使得 k 个列表中的每个列表至少有一个数包含在其中。
我们定义如果 b-a < d-c 或者在 b-a == d-c 时 a < c,则区间 [a,b] 比 [c,d] 小。
原题链接
思路分析
首先将列表中元素(额外记录所在区间)装进一个集合count中并按升序排好序,定义一个左边界left,右边界right,先正向遍历右边界,直到所有列表中的元素都至少出现一次,然后正向遍历左边界直到存在一个列表的元素没出现,将当前满足要求的区间[nums[left],nums[right]]与历史最优值比较并更新历史最优值。
从小到大遍历右边界寻找最大的左边界,确保计算了每个可能更新历史最值的答案。
代码
vector<int> smallestRange(vector<vector<int>>& nums) {vector<pair<int, int>> count;int k = nums.size();for(int i = 0; i < k; ++i){for(auto num : nums[i])count.push_back({num, i});}sort(count.begin(), count.end()); //基本有序的排序,时间复杂度为O(nk)int ans_left = 0, ans_right = INT_MAX; //历史最优值vector<int> map(k); //map[i]统计第i个列表在当前区间出现了多少次int kinds = 0; //统计有多少个列表的至少一个元素出现for(int left = 0, right = 0; right < count.size(); ++right){if(!map[count[right].second]++) kinds++; //在自增之前判断是否为0while(kinds == k){if(count[right].first - count[left].first < ans_right - ans_left){ //更新历史最值ans_right = count[right].first;ans_left = count[left].first;}if(--map[count[left++].second] == 0) kinds--; //自减之后判断是否为0}}return {ans_left, ans_right};}
时间复杂度O(nk)
最小覆盖子串
问题描述
给你一个字符串 s 、一个字符串 t 。返回 s 中涵盖 t 所有字符的最小子串。如果 s 中不存在涵盖 t 所有字符的子串,则返回空字符串 "" 。
原题链接
注意:
- 对于
t中重复字符,我们寻找的子字符串中该字符数量必须不少于t中该字符数量。 - 如果
s中存在这样的子串,我们保证它是唯一的答案。
思路分析
首先考虑一下暴力一点的方法
定义l,r [l,r]表示当前遍历到的区间窗口
定义一个字符表table储存区间内的字符的频数,当区间中的t中的某字符的频数都达标时,在不破坏达标条件的前提下逐渐向右移动左边界l
此时的r-l+1是以r为右边界的最小达标子串,每遍历一次r更新历史最小长度值和起始左边界。
上述思路,每遍历到一个r就需要去table中挨个检查每个字符的频数是否达标,又要多一层循环,能不能优化一些呢?
我们可以先对table预处理,让t中的字符对应的频数的负数存进table,表示t中对应字符需要补充的数量
在后面正式右边界遍历时一共需要补充tLen(t字符串的长度)个目标字符。
每次只需在O(1)的时间复杂度下判断tLen是否等于0即可判断区间内目标字符频数是否达标。
右边界每遍历到一个字符,对应字符频数+1,
频数+1之前判断该字符对应的频数是否为负数(表示该字符需要补充),是负数则tLen-1表示已补充一个目标字符,
当tLen减为0时,表示目标字符全部补充完(即窗口区间中t对应的字符数都达标),此时便在不破坏达标条件的前提下逐渐向右移动左边界(对应的字符频数大于0则减1且右移l,)。
当tlen减为0时,由于移动左右边界都不破坏达标条件,table存储的每个字符频数始终大于等于0,tLen便一直为0了(待补充目标字符数为0)。
代码
int table[26]={0};int start=-1;int leng=INT_MAX;string minWindow(string s, string t) {for (int i = 0; i < t.length(); i++) { //存储字符表table[t[i]-'A']--;}for (int l = 0, r = 0,debt=t.length(); r < s.length(); r++) { //枚举右边界if ((table[s[r]-'A']++)< 0) debt--; //debt减到0后不会再减if (debt == 0) {while (table[s[l]-'A'] > 0) table[s[l++]-'A']--; //table[i]最减到0后不会再减if (r - l + 1 < leng) {leng = r - l + 1; //更新最小长度start = l; //更新起始索引}}}return start == -1 ? "" : s.substr(start, leng);}
数据流的中位数
问题描述
中位数是有序整数列表中的中间值。如果列表的大小是偶数,则没有中间值,中位数是两个中间值的平均值。
- 例如
arr = [2,3,4]的中位数是3。 - 例如
arr = [2,3]的中位数是(2 + 3) / 2 = 2.5。
实现 MedianFinder 类:
MedianFinder()初始化MedianFinder对象。void addNum(int num)将数据流中的整数num添加到数据结构中。double findMedian()返回到目前为止所有元素的中位数。与实际答案相差10-5以内的答案将被接受。
原题链接
思路分析
定义一个升序的优先队列(大根堆)queMin,队列中的所有元素都小于等于当前集合的中位数。
定义一个降序序的优先队列(小根堆)queMax,队列中的所有元素都大于当前集合的中位数。
每往集合添加一个数x
- 若x小于等于queMin堆顶或queMin为空,则将x添加进queMin,添加完后,判断queMin的大小大于queMax的大小+1(此时小于等于中位数的个数过多),则将queMin的堆顶元素移动到queMax
- 否则,将x添加进queMax,添加完后,判断queMax的大小大于queMin的大小(此时大于中位数的个数过多),则将queMax的堆顶元素移动到queMin
返回当前集合的中位数,若queMin的大小大于queMax,则返回queMin的堆顶元素,否则返回queMin堆顶元素和queMax堆顶元素的平均值。
代码
class MedianFinder {
public:priority_queue<int>queMin; //升序,队头为最大值priority_queue<int,vector<int>,greater<int>>queMax; //降序,队头为最小值MedianFinder() {}void addNum(int num) {if (queMin.empty() || num <= queMin.top()) {queMin.push(num);if (queMax.size() + 1 < queMin.size()) {queMax.push(queMin.top()); //将小于等于中位数队列中的最大值移动到大于中位数队列queMin.pop();}} else {queMax.push(num);if (queMax.size() > queMin.size()) {queMin.push(queMax.top()); //将大于中位数队列中的最小值移动到小于等于中位数队列queMax.pop();}}}double findMedian() {if(queMin.size()>queMax.size()) return queMin.top();return ((double)queMin.top()+(double)queMax.top())/2;}
};
滑动窗口中位数
问题描述
中位数是有序序列最中间的那个数。如果序列的长度是偶数,则没有最中间的数;此时中位数是最中间的两个数的平均数。
例如:
[2,3,4],中位数是3[2,3],中位数是(2 + 3) / 2 = 2.5
给你一个数组 nums,有一个长度为 k 的窗口从最左端滑动到最右端。窗口中有 k 个数,每次窗口向右移动 1 位。你的任务是找出每次窗口移动后得到的新窗口中元素的中位数,并输出由它们组成的数组。
原题链接
思路分析
我们首先思考一下完成本题需要做哪些事情:
-
初始时,我们需要将数组 nums 中的前 k 个元素放入一个滑动窗口,并且求出它们的中位数;
-
随后滑动窗口会向右进行移动。每一次移动后,会将一个新的元素放入滑动窗口,并且将一个旧的元素移出滑动窗口,最后再求出它们的中位数。
因此,我们需要设计一个「数据结构」,用来维护滑动窗口,并且需要提供如下的三个接口:
-
insert(num):将一个数 num 加入数据结构;
-
erase(num):将一个数 num 移出数据结构;
-
getMedian():返回当前数据结构中所有数的中位数。
使用两个优先队列(堆)维护所有的元素,第一个优先队列 small 是一个大根堆,它负责维护所有元素中较小的那一半;第二个优先队列 large 是一个小根堆,它负责维护所有元素中较大的那一半。(参考上一题)
延迟删除
对于insert添加元素来说比较简单,然而对于 erase(num) 而言,设计起来就不是那么容易了,因为我们知道,优先队列是不支持移出非堆顶元素这一操作的,因此我们可以考虑使用「延迟删除」的技巧
当我们需要移出优先队列中的某个元素时,我们只将这个删除操作「记录」下来,而不去真的删除这个元素。当这个元素出现在 small 或者 large 的堆顶时,我们再去将其移出对应的优先队列。
「延迟删除」使用到的辅助数据结构一般为哈希表 delayed,其中的每个键值对 (num,freq),表示元素 num 还需要被删除 freq 次。
我们首先设计一个辅助函数 prune(heap),它的作用很简单,就是对 heap 这个优先队列(small 或者 large 之一),不断地弹出其需要被删除的堆顶元素,并且减少 delayed 中对应项的值。在 prune(heap) 完成之后,我们就可以保证 heap 的堆顶元素是不需要被「延迟删除」的。
在 prune(heap) 的基础上设计另一个辅助函数 makeBalance(),它的作用即为调整 small 和 large 中的元素个数,使得二者的元素个数满足要求,即small.size()-large.size()的值为0或1。调整策略如下:
-
如果 small 和 large 中的元素个数满足要求,则不进行任何操作;
-
如果 small 比 large 的元素个数多了 2 个,那么我们我们将 small 的堆顶元素放入 large。此时 small 的对应元素可能是需要删除的,因此我们调用 prune(small);
-
如果 small 比 large 的元素个数少了 1 个,那么我们将 large 的堆顶元素放入 small。此时 large 的对应的元素可能是需要删除的,因此我们调用 prune(large)。
此时,我们在原先 insert(num) 的设计的最后加上一步 makeBalance() 调整两个优先队列大小即可。
对于erase(num)还需进一步思考:
-
如果 num 与 small 和 large 的堆顶元素都不相同,那么 num 是需要被「延迟删除」的,我们将其在哈希表中的值增加 1;
-
否则,例如 num 与 small 的堆顶元素相同,那么该元素是可以理解被删除的。虽然我们没有实现「立即删除」这个辅助函数,但只要我们将 num 在哈希表中的值增加 1,并且调用「延迟删除」的辅助函数 prune(small),那么就相当于实现了「立即删除」的功能。
无论是「立即删除」还是「延迟删除」,其中一个优先队列中的元素个数(这里指的是当前包含的个数,实际大小扣除延迟删除的个数)都发生了变化(减少了 1),因此我们还需要用 makeBalance() 调整元素的个数。
此时,所有的接口都已经设计完成了。由于 insert(num) 和 erase(num) 的最后一步都是 makeBalance(),而 makeBalance() 的最后一步是 prune(heap),因此我们就保证了任意操作完成之后,small 和 large 的堆顶元素都是不需要被「延迟删除」的,且两个堆的元素个数符合要求。
具体实现的细节相对较多,读者可以参考下面的代码和注释进一步理解。
代码
class DualHeap {
private:// 大根堆,维护较小的一半元素priority_queue<int> small;// 小根堆,维护较大的一半元素priority_queue<int, vector<int>, greater<int>> large;// 哈希表,记录「延迟删除」的元素,key 为元素,value 为需要删除的次数unordered_map<int, int> delayed;int k;// small 和 large 当前包含的元素个数,扣除被「延迟删除」的元素int smallSize, largeSize;public:DualHeap(int _k): k(_k), smallSize(0), largeSize(0) {}private:// 不断地弹出 heap 的堆顶元素,并且更新哈希表template<typename T> //标记为模版函数void prune(T& heap) {while (!heap.empty()) {int num = heap.top();if (delayed.count(num)) {--delayed[num];if (!delayed[num]) { //延迟删除数减为0,不需要再删除delayed.erase(num);}heap.pop();}else {break;}}}// 调整 small 和 large 中的元素个数,使得二者的元素个数满足要求//即 small.size()-large.size()的值为0或1void makeBalance() {if (smallSize > largeSize + 1) {// small 比 large 元素多 2 个large.push(small.top());small.pop();--smallSize;++largeSize;// small 堆顶元素被移除,堆顶元素变化,需要进行 pruneprune(small);}else if (smallSize < largeSize) {// large 比 small 元素多 1 个small.push(large.top());large.pop();++smallSize;--largeSize;// large 堆顶元素被移除,堆顶元素变化,需要进行 pruneprune(large);}}public:void insert(int num) {if (small.empty() || num <= small.top()) {small.push(num);++smallSize;}else {large.push(num);++largeSize;}makeBalance();}void erase(int num) {++delayed[num];if (num <= small.top()) {--smallSize;if (num == small.top()) {prune(small);}}else {--largeSize;if (num == large.top()) {prune(large);}}makeBalance();}double getMedian() {return k & 1 ? small.top() : ((double)small.top() + large.top()) / 2;}
};class Solution {
public:vector<double> medianSlidingWindow(vector<int>& nums, int k) {DualHeap dh(k);for (int i = 0; i < k; ++i) {dh.insert(nums[i]);}vector<double> ans = {dh.getMedian()};for (int i = k; i < nums.size(); ++i) {dh.insert(nums[i]);dh.erase(nums[i - k]);ans.push_back(dh.getMedian());}return ans;}
};
相关文章:
015枚举之滑动窗口——算法备赛
滑动窗口 最大子数组和 题目描述 给你一个整数数组 nums ,请你找出一个具有最大和的连续子数组(子数组最少包含一个元素),返回其最大和。 原题链接 思路分析 见代码注解 代码 int maxSubArray(vector<int>& num…...

SQL 索引优化指南:原理、知识点与实践案例
SQL 索引优化指南:原理、知识点与实践案例 索引的基本原理 索引是数据库中用于加速数据检索的数据结构,类似于书籍的目录。它通过创建额外的数据结构来存储部分数据,使得查询可以快速定位到所需数据而不必扫描整个表。 索引的工作原理 B-…...

centos服务器,疑似感染phishing家族钓鱼软件的检查
如果怀疑 CentOS 服务器感染了 Phishing 家族钓鱼软件,需要立即进行全面检查并采取相应措施。以下是详细的检查和处理步骤: 1. 立即隔离服务器 如果可能,将服务器从网络中隔离,以防止进一步传播或数据泄露。如果无法完全隔离&…...
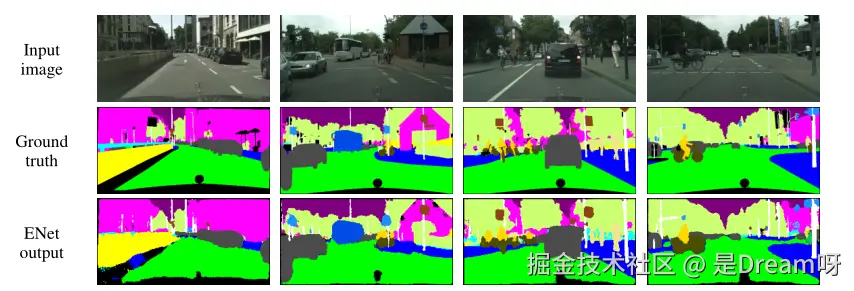
新型深度神经网络架构:ENet模型
语义分割技术能够为图像中的每个像素分配一个类别标签,这对于理解图像内容和在复杂场景中找到目标对象至关重要。在自动驾驶和增强现实等应用中,实时性是一个硬性要求,因此设计能够快速运行的卷积神经网络非常关键。 尽管深度卷积神经网络&am…...
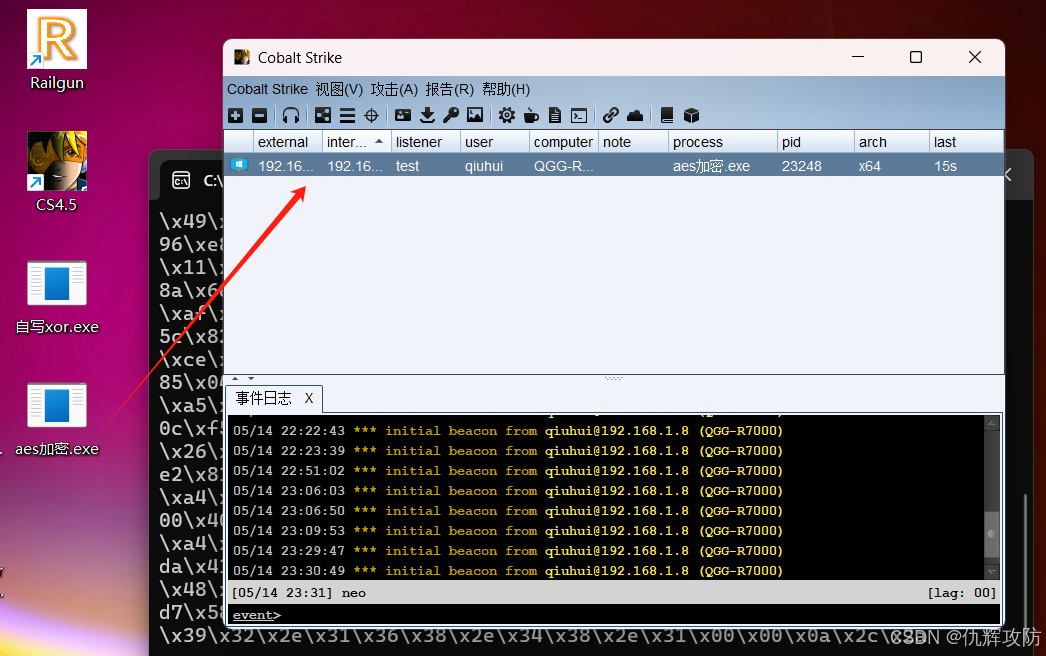
【免杀】C2免杀技术(三)shellcode加密
前言 shellcode加密是shellcode混淆的一种手段。shellcode混淆手段有多种:加密(编码)、偏移量混淆、UUID混淆、IPv4混淆、MAC混淆等。 随着杀毒软件的不断进化,其检测方式早已超越传统的静态特征分析。现代杀软往往会在受控的虚…...

3、ubantu系统docker常用命令
1、自助查看docker命令 1.1、查看所有命令 docker 客户端非常简单,可以直接输入 docker 命令来查看到 Docker 客户端的所有命令选项。 angqiangwangqiang:~$ dockerUsage: docker [OPTIONS] COMMANDA self-sufficient runtime for containersCommon Commands:ru…...

【Linux】shell内置命令fg,bg和jobs
Shell 内置命令 fg(foreground 的缩写)。它用于将后台挂起的任务恢复到前台运行。 例如: 假设你运行了一个耗时的 SVN 操作(如 svn update 或 svn checkout)。按下 CtrlZ 将该进程挂起到后台。输入 fg…...

Java GUI开发全攻略:Swing、JavaFX与AWT
Swing 界面开发 Swing 是 Java 中用于创建图形用户界面(GUI)的库。它提供了丰富的组件,如按钮、文本框、标签等。 import javax.swing.*; import java.awt.event.ActionEvent; import java.awt.event.ActionListener;public class SwingExa…...
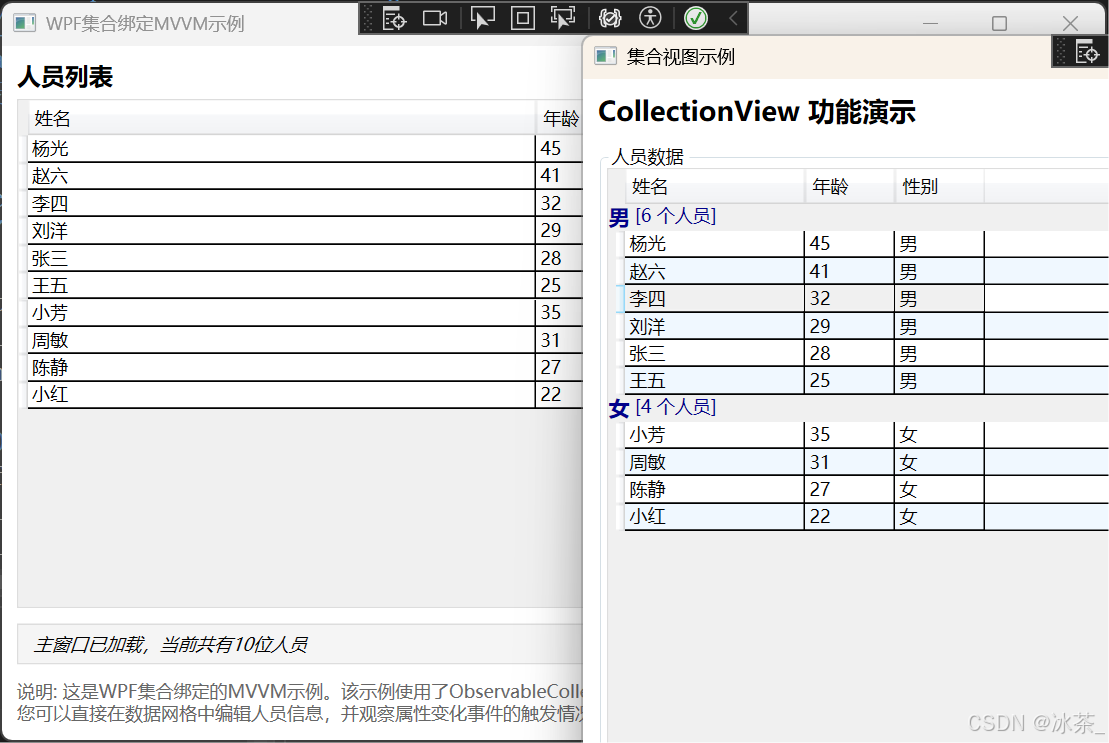
WPF之集合绑定深入
文章目录 引言ObservableCollection<T>基础什么是ObservableCollectionObservableCollection的工作原理基本用法示例ObservableCollection与MVVM模式ObservableCollection的局限性 INotifyCollectionChanged接口深入接口定义与作用NotifyCollectionChangedEventArgs详解自…...

LeetCode 每日一题 3341. 到达最后一个房间的最少时间 I + II
3341. 到达最后一个房间的最少时间 I II 有一个地窖,地窖中有 n x m 个房间,它们呈网格状排布。 给你一个大小为 n x m 的二维数组 moveTime ,其中 moveTime[i][j] 表示在这个时刻 以后 你才可以 开始 往这个房间 移动 。你在时刻 t 0 时从…...
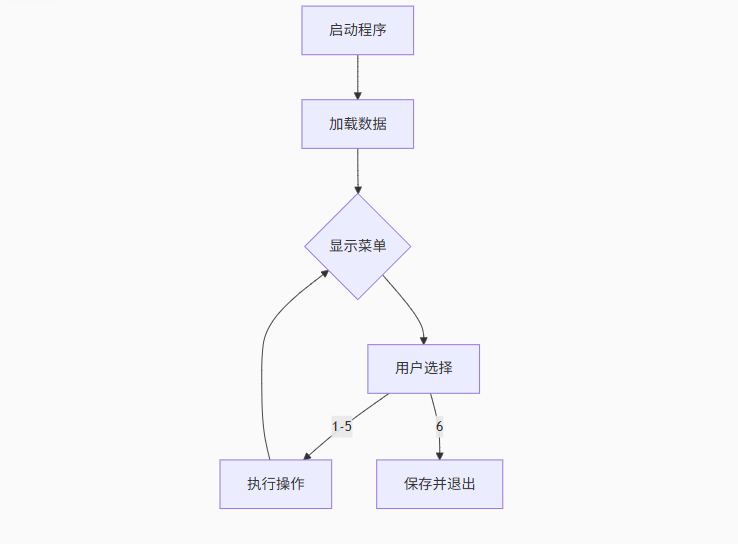
(C语言)超市管理系统(测试2版)(指针)(数据结构)(清屏操作)
目录 前言: 源代码: product.h product.c fileio.h fileio.c main.c 代码解析: 一、程序结构概述 二、product.c 函数详解 1. 初始化商品列表 Init_products 2. 添加商品 add_product 3. 显示商品 display_products 4. 修改商品 mo…...

什么是虚拟同步发电机
虚拟同步发电机(Virtual Synchronous Generator, VSG) 是一种基于电力电子技术的先进控制策略,通过模拟传统同步发电机的机电特性和动态行为,使逆变器或储能系统能够像传统发电机一样为电网提供惯性支撑、频率调节和电压稳定性支持…...

Python字符串全面指南:从基础到高级
文章目录 Python字符串全面指南:从基础到高级1. 字符串基础概念2. 字符串的基本操作2.1 字符串拼接2.2 字符串索引和切片 3. 字符串常用方法3.1 大小写转换3.2 字符串查找和替换3.3 字符串分割和连接3.4 字符串格式化3.5 字符串验证 4. 字符串的不可变性5. 字符串编…...

基于大模型的TIA诊疗全流程智能决策系统技术方案
目录 一、多模态数据融合与预处理系统1.1 数据接入模块1.2 数据预处理伪代码二、TIA智能预测模型系统2.1 模型训练流程2.2 混合模型架构伪代码三、术中智能监测系统3.1 实时监测流程3.2 实时预测伪代码四、智能诊疗决策系统4.1 手术方案推荐流程4.2 麻醉方案生成伪代码五、预后…...
编译openssl源码
openssl版本 1.1.1c windows 安装环境 perl 先安装perl,生成makefile需要 https://strawberryperl.com/releases.html nasm nasm 也是生成makefile需要 https://www.nasm.us/ 安装完perl输入一下nasm,看看能不能找到,找不到的话需要配…...

CMake入门与实践:现代C++项目的构建利器
文章目录 CMake入门与实践:现代C项目的构建利器引言什么是CMake?快速入门:从Hello World开始1. 安装CMake2. 最小项目示例3. 构建项目 核心概念详解1. 项目结构组织2. 常用指令3. 变量与条件控制 进阶技巧1. 多目录项目管理2. 集成第三方库3.…...

OpenCV实现数字水印的相关函数和示例代码
OpenCV计算机视觉开发实践:基于Qt C - 商品搜索 - 京东 实现数字水印的相关函数 用OpenCV来实现数字水印功能,需要使用一些位操作函数,我们需要先了解一下这些函数。 1. bitwise_and函数 bitwise_and函数是OpenCV中的位运算函数之一&…...
计算模块)
BMS工具箱用来执行贝叶斯模型平均(BMA)计算模块
贝叶斯模型平均(Bayesian Model Averaging,BMA)是一种用于处理模型不确定性的统计方法,通过结合多个模型的预测结果来提高预测的准确性和鲁棒性。在 MATLAB 中,可以使用专门的工具箱(如 BMS 工具箱…...
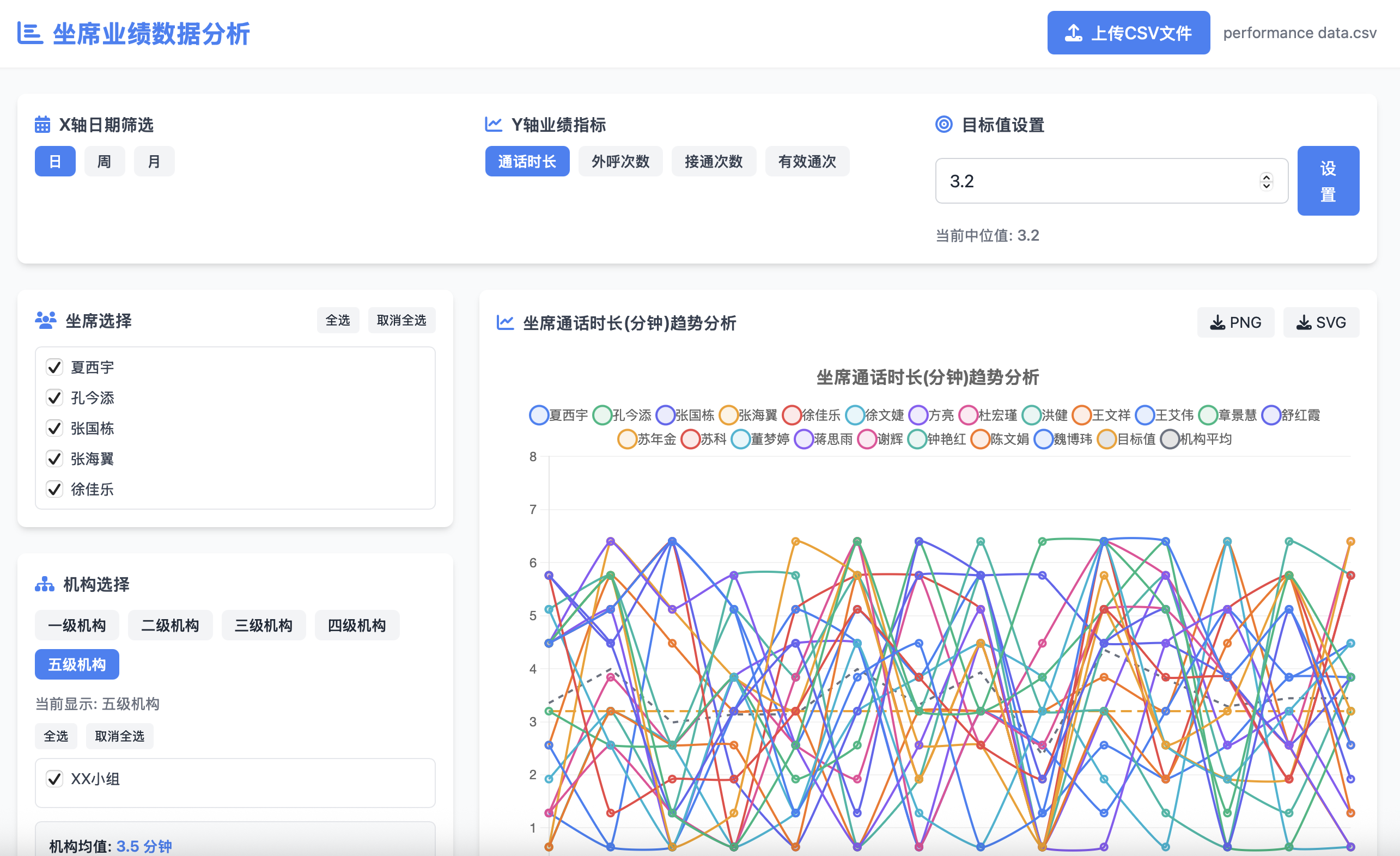
坐席业绩数据分析
豆包提示词: 使用papaparse.js,chart.js,tailwindcss和font-awesome,生成一个可以交互的简洁且可以运行的HTML代码,不要输出无关内容。 具体要求如下: 1、按坐席姓名输出业绩折线图。 2、系统导航区域&…...

国产大模型 “五强争霸”,决战 AGI
中国 AI 大模型市场正经历一场史无前例的洗牌!曾经 “百模混战” 的局面已落幕,字节、阿里、阶跃星辰、智谱和 DeepSeek 五大巨头强势崛起,形成 “基模五强” 新格局。这场竞争不仅是技术实力的较量,更是资源、人才与生态的全面博…...
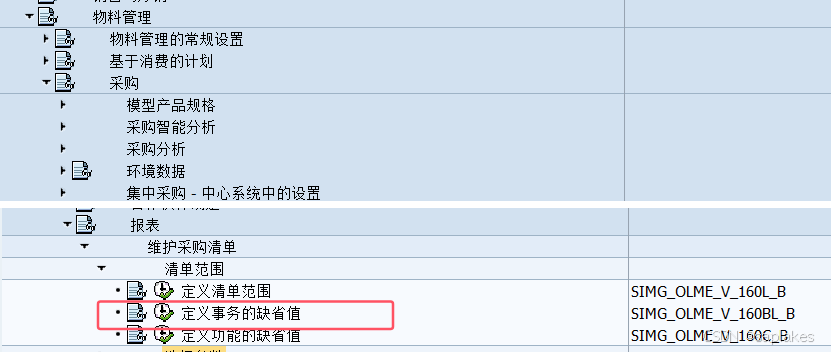
怎样将MM模块常用报表设置为ALV默认格式(MB52、MB5B、ME2M、ME1M等)
【SAP系统研究】 对SAP系统中的报表,最方便的格式就是ALV了,可排序、可导出,非常友好。 但有些常见报表却不是默认ALV界面的,譬如MB52: 是不是有点别扭?但其实是可以后台配置进行调整的。 现将一些常用报表修改为默认ALV的方法进行总结,便于大家使用。 一、MB52、MB5…...

Spark 集群配置、启动与监控指南
Spark 集群的配置和启动需要几个关键步骤。以下是完整的操作流程,包含配置修改、集群启动、任务提交和常见错误排查方法。 1. 修改 Spark 配置文件 首先需要编辑 Spark 配置文件,设置集群参数: bash # 进入 Spark 配置目录 cd $SPARK_HOM…...

前端面试每日三题 - Day 34
这是我为准备前端/全栈开发工程师面试整理的第34天每日三题练习: ✅ 题目1:WebGPU图形编程实战指南 核心概念 // WebGPU初始化流程 const adapter await navigator.gpu.requestAdapter(); const device await adapter.requestDevice();// 渲染管线配…...

比亚迪固态电池突破:王传福的技术哲学与产业重构|创客匠人热点评述
合肥某车间凌晨两点依然灯火通明,工程师正在调试的银白色设备,即将颠覆整个电动车行业 —— 比亚迪全固态电池产线的曝光,标志着中国新能源汽车产业正式迈入 “技术定义市场” 的新纪元。 一、技术突破的底层逻辑 比亚迪全固态电池的核心竞…...
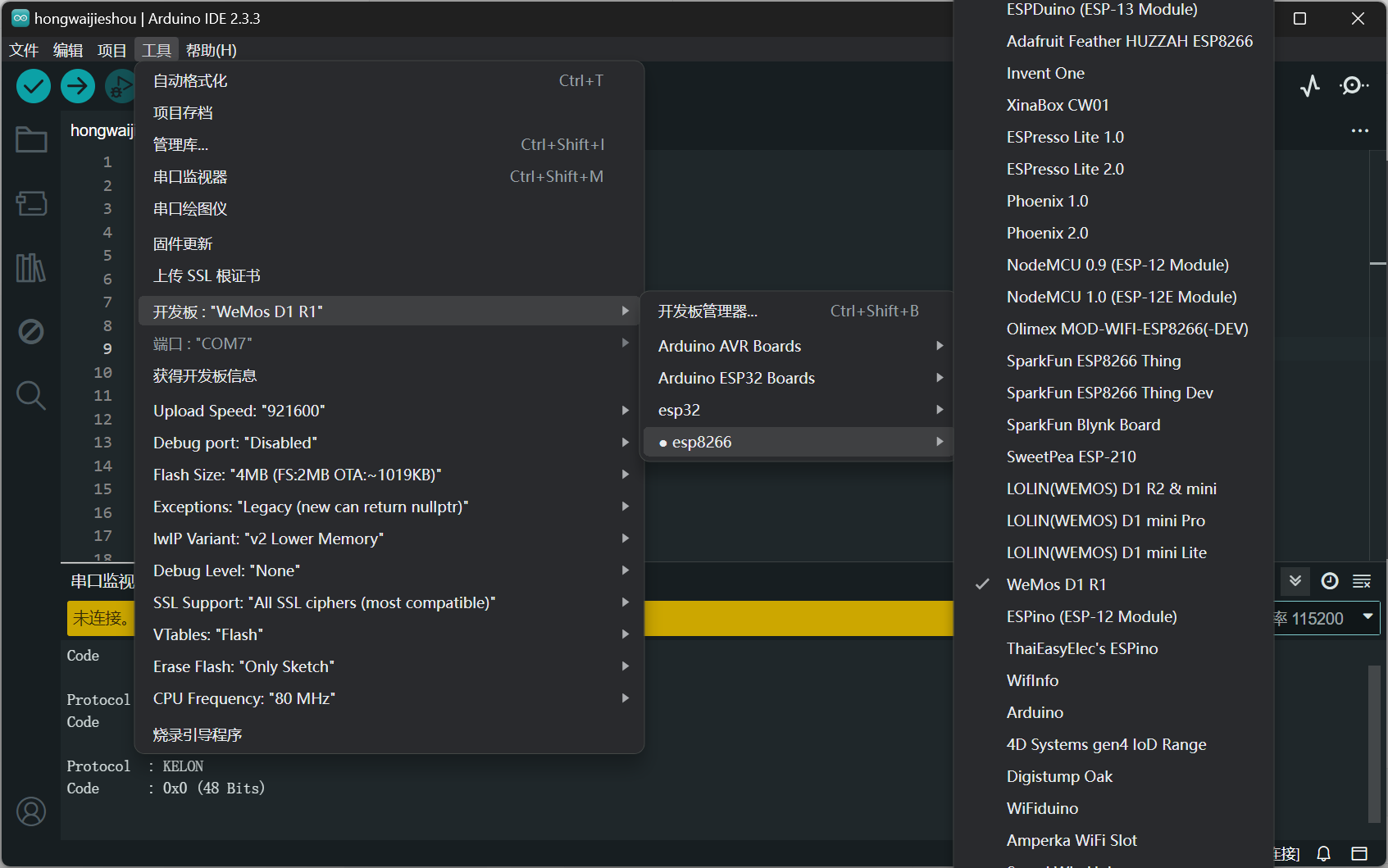
Arduino使用红外收发模块
目录 Arduino UNO连接红外发射模块: Arduino D1连接红外接收模块: 有一个Arduini UNO板子和一个Arduino D1板子,我想通过红外发射模块和红外接收模块让他们进行通信。 先看结果: Arduino UNO连接红外发射模块: 发射模…...

【强化学习】强化学习算法 - 马尔可夫决策过程
马尔可夫决策过程 (Markov Decision Process, MDP) 1. MDP 原理介绍 马尔可夫决策过程 (MDP) 是强化学习 (Reinforcement Learning, RL) 中用于对序贯决策 (Sequential Decision Making) 问题进行数学建模的标准框架。它描述了一个智能体 (Agent) 与环境 (Environment) 交互的…...
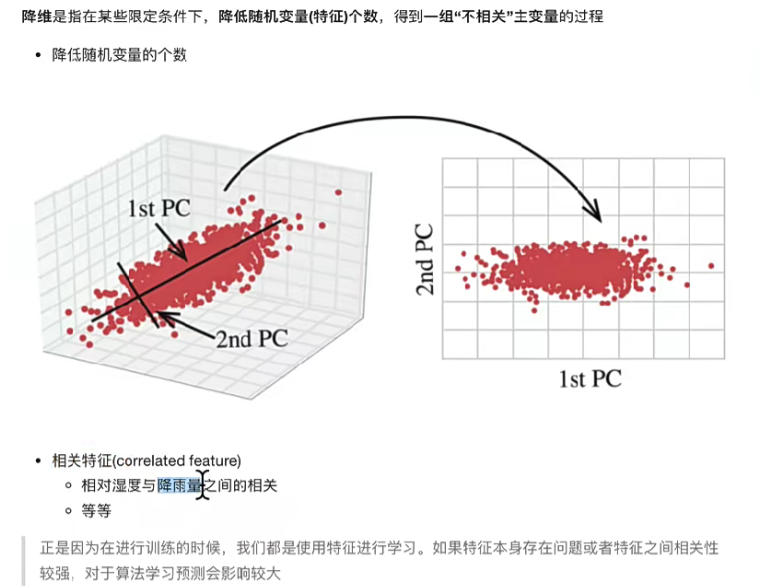
机器学习 Day16 聚类算法 ,数据降维
聚类算法 1.简介 1.1 聚类概念 无监督学习:聚类是一种无监督学习算法,不需要预先标记的训练数据 相似性分组:根据样本之间的相似性自动将样本归到不同类别 相似度度量:常用欧式距离作为相似度计算方法 1.2 聚类vs分类 聚类&…...

开源Heygem本地跑AI数字人视频教程
图文教程: 点击跳转 视频教程 资料包下载 点击下载:...

软件测试——面试八股文(入门篇)
今天给大家分享软件测试面试题入门篇,看看大家能答对几题 一、 请你说一说测试用例的边界 参考回答: 边界值分析法就是对输入或输出的边界值进行测试的一种黑盒测试方法。通常边界值分析法是作为对等价类划分法的补充,这种情况下ÿ…...

Yolov8的详解与实战-深度学习目标检测
Yolov8的详解与实战- 文章目录 摘要 模型详解 C2F模块 Loss head部分 模型实战 训练COCO数据集 下载数据集 COCO转yolo格式数据集(适用V4,V5,V6,V7,V8) 配置yolov8环境 训练 测试 训练自定义数据集 Labelme…...