FlashInfer - 介绍 LLM服务加速库 地基的一块石头
FlashInfer - 介绍 LLM服务加速库 地基的一块石头
flyfish
大型语言模型服务中的注意力机制
大型语言模型服务(LLM Serving)迅速成为重要的工作负载。Transformer中的算子效率——尤其是矩阵乘法(GEMM)、自注意力(Self-Attention)、矩阵向量乘法(GEMV)和逐元素计算,对LLM服务的整体性能至关重要。尽管针对GEMM和GEMV的优化已广泛开展,但在LLM服务场景中,针对自注意力的性能研究仍较为缺乏。将自注意力拆解为三个阶段:预填充(prefill)、解码(decode)和追加(append),分析这三个阶段在单请求和批处理场景下的性能瓶颈,并提出应对方案。这些思路已整合到FlashInfer中——一个基于Apache 2.0许可证开源的LLM服务加速库。
FlashInfer概述
FlashInfer由华盛顿大学、卡内基梅隆大学和OctoAI的研究人员自2023年夏季起开发,提供PyTorch API用于快速原型设计,以及无依赖的纯头文件C++ API以便集成到LLM服务系统。相较现有库,它具备以下独特优势:
- 全场景注意力核:实现覆盖LLM服务所有常见场景的高性能注意力核,包括单请求和批处理版本的预填充、解码、追加核,支持多种键值缓存(KV-Cache)格式(填充张量、不规则张量、页表)。
- 优化的共享前缀批解码:通过级联技术提升共享前缀批解码性能,在长提示(32768 tokens)和大批次(256)场景下,相比基线vLLM的PageAttention实现最高可达31倍加速(详见另一篇博客)。
- 压缩/量化KV-Cache加速:针对分组查询注意力(Grouped-Query Attention)、融合RoPE注意力(Fused-RoPE Attention)和量化注意力进行优化,在A100和H100上,Grouped-Query Attention相比vLLM实现最高2-3倍加速。
FlashInfer已被MLC-LLM(CUDA后端)、Punica和sglang等LLM服务系统采用。
MLC-LLM(CUDA 后端)、Punica 和 sglang 的介绍:
1. MLC-LLM(CUDA 后端)
MLC-LLM 是一个 跨平台高性能 LLM 推理框架,核心目标是通过编译优化技术,让大语言模型(如 LLaMA、Mistral、Qwen 等)能够在 多种硬件平台(包括 CUDA GPU、ARM 芯片、Web 浏览器等)上高效运行。其 CUDA 后端是针对 NVIDIA GPU 的深度优化版本,具备以下特点:
编译优化:基于 Apache TVM 编译栈,将模型计算图转换为高度优化的 CUDA 内核,显著提升推理速度。
跨平台支持:除 CUDA 外,还支持 WebGPU(通过 WebLLM)、iPhone 等本地环境,实现“一次编译,多端运行”。
低延迟与高吞吐量:针对在线服务场景优化,支持动态批处理和显存管理,适合实时对话、API 推理等高并发需求。
模型兼容性:原生支持 Hugging Face 模型格式,兼容主流量化技术(如 GPTQ、AWQ),并在 2025 年新增对 Qwen3 等模型的支持。
企业级部署:如金融交易、智能客服等需低延迟和高吞吐的场景。
边缘设备:在消费级 GPU(如 RTX 3060)或 ARM 芯片上实现轻量化推理。
多模态任务:与视觉模型结合,支持图像-文本联合生成(如 LLaMA-Vision)。
已被集成到 sglang 等框架中,用于加速复杂 LLM 程序的执行。
提供 OpenAI 兼容 API,便于快速迁移现有应用。
2. Punica
Punica 是一个 开源的 LLM 多模型服务框架,专为 LoRA 微调模型设计,旨在简化多模型部署和调用流程。其核心目标是为多个经过 LoRA 技术微调的模型提供 统一的 API 接口,降低企业级应用的开发成本。
多模型管理:支持同时加载和服务多个 LoRA 微调模型,动态切换推理配置。
性能优化:通过显存复用和计算图优化,提升多模型并行推理的效率,尤其适用于需频繁切换模型的场景(如 A/B 测试)。
低代码集成:提供 Python API 和 RESTful 接口,开发者可快速将多个微调模型整合到现有系统中。
兼容性:支持主流 LoRA 工具(如 Hugging Face PEFT),并与 vLLM、MLC-LLM 等框架协同工作。
垂直领域定制:在金融、医疗等领域,同时部署多个针对不同任务的 LoRA 模型(如情感分析、实体识别)。
模型迭代管理:通过 Punica 统一管理模型版本,无缝切换新旧版本,减少运维复杂度。
轻量级部署:适用于中小型企业,无需复杂分布式架构即可实现多模型服务。
目前主要聚焦于 LoRA 模型,对其他微调技术(如 IA³、QLoRA)的支持有限。
高并发场景下的吞吐量优化仍依赖底层框架(如 vLLM)的支持。
3. sglang
sglang 是一个 结构化语言模型程序执行框架,专为复杂 LLM 任务设计,通过 前端 DSL 和后端优化的协同设计,显著提升多轮对话、逻辑推理、多模态交互等场景的效率。
前端 DSL:嵌入 Python 的领域特定语言,提供 gen(生成)、select(选择)、fork(并行)等原语,简化多调用工作流的编程复杂度。例如,可直接在代码中定义 JSON 约束、多分支逻辑,避免手动处理字符串和 API 调用。
后端运行时优化:
RadixAttention:通过基数树结构自动复用 KV 缓存,减少冗余计算。例如,在多轮对话中,共享前缀的 KV 缓存可被自动识别并复用,吞吐量最高提升 6.4 倍。
压缩有限状态机:加速结构化输出解码(如 JSON),一次解码多个 token,降低延迟。
多模态支持:原生集成视觉模型(如 BLIP-2),支持图像-文本联合生成。
高性能推理:在 NVIDIA A100/H100 上,相比 vLLM 实现 2-5 倍吞吐量提升,尤其适合高并发结构化查询(如金融数据解析、医疗报告生成)。
复杂任务流程:代理控制、思维链推理、检索增强生成(RAG)等需多步骤交互的场景。
结构化输出需求:如 JSON 生成、表格提取,通过约束解码保证输出格式合规。
多模态交互:同时处理图像和文本数据,适用于工业质检、智能教育等领域。
与 FlashInfer 深度集成,优化量化 KV 缓存和 RoPE 融合的推理性能。
兼容 OpenAI API,支持无缝迁移现有应用。
对比
| 框架 | 核心定位 | 技术亮点 | 典型场景 |
|---|---|---|---|
| MLC-LLM | 跨平台推理引擎 | 编译优化、多硬件支持、低延迟 | 企业级部署、边缘设备、多模态 |
| Punica | 多模型服务框架(LoRA 专用) | 统一 API、显存复用、低代码集成 | 垂直领域定制、模型迭代管理 |
| sglang | 结构化 LLM 程序执行框架 | 前端 DSL、RadixAttention、多模态支持 | 复杂任务流程、高并发结构化查询 |
LLM服务中的注意力阶段
LLM服务包含三个通用阶段:
- 预填充(Prefill):注意力在KV-Cache与所有查询之间计算,填充完整的注意力图(受因果掩码约束)。
- 解码(Decode):模型逐token生成,仅在KV-Cache与单个查询间计算注意力,每次填充注意力图的一行。
- 追加(Append):在KV-Cache与新追加的token查询间计算注意力,形成梯形区域的注意力图。该阶段在推测解码中尤为重要——草稿模型生成候选token序列后,大模型通过追加注意力计算决定是否接受,同时将候选token添加到KV-Cache。
影响注意力计算效率的关键因素是查询长度( l q l_q lq),它决定了操作是计算密集型还是IO密集型。注意力的操作强度(每字节内存流量的操作数)为 O ( 1 1 / l q + 1 / l k v ) O\left(\frac{1}{1/l_q + 1/l_{kv}} \right) O(1/lq+1/lkv1),其中 l k v l_{kv} lkv为KV-Cache长度:
- 解码阶段: l q = 1 l_q=1 lq=1,操作强度接近 O ( 1 ) O(1) O(1),完全受限于GPU内存带宽(IO密集型)。
- 预填充/追加阶段:操作强度约为 O ( l q ) O(l_q) O(lq),当 l q l_q lq较大时为计算密集型,较小时为IO密集型。
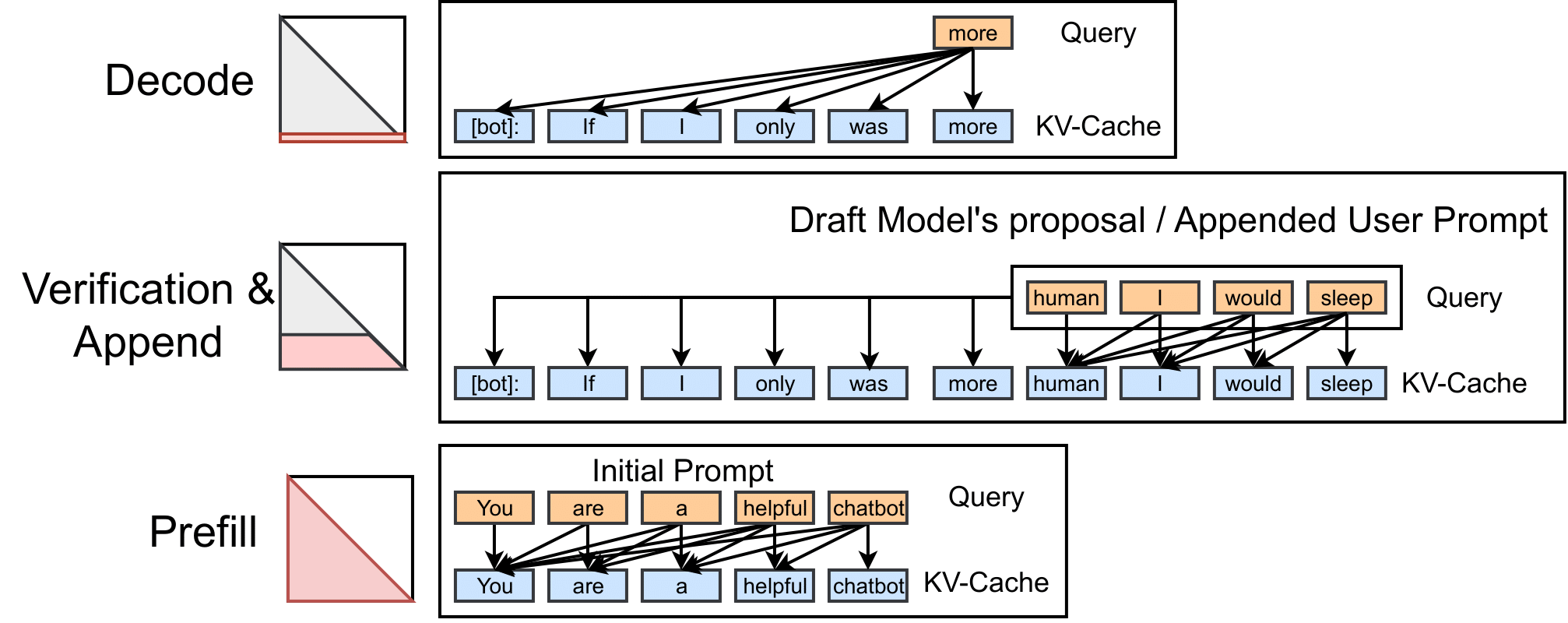
(图1:注意力计算示意图。解码注意力每次填充一行,预填充填充完整注意力图,追加填充梯形区域。)

图2:注意力算子的屋顶线模型(数据来自A100 PCIe 80GB)。解码注意力受限于峰值带宽(IO瓶颈),预填充受限于峰值计算性能(计算瓶颈),追加注意力在短查询时为IO密集型,长查询时为计算密集型。)
单请求与批处理服务
LLM服务主要有两种模式:
- 批处理:将多个用户请求合并并行处理以提升吞吐量,但注意力核的操作强度与批大小无关——批解码注意力的操作强度仍为 O ( 1 ) O(1) O(1),仍受限于IO。
- 单请求:直接处理单个用户请求,需针对低操作强度场景(如解码阶段)优化内存访问效率。
FlashInfer的核心优化
FlashInfer在以下方面实现创新,支持多阶段、多KV-Cache格式的高效注意力计算:
1. 全场景注意力核支持
- 实现单请求/批处理版本的FlashAttention,覆盖预填充、解码、追加三个阶段,支持不规则张量、页表等KV-Cache格式。
- 针对页表KV-Cache实现预填充/追加核(现有库未支持),适用于推测解码等复杂场景。
2. 压缩/量化KV-Cache优化
- 分组查询注意力(GQA):通过减少键值头数降低内存流量,操作强度随查询头数与键值头数的比值提升。FlashInfer利用预填充核(张量核心)优化GQA的解码阶段,在A100/H100上相比vLLM实现2-3倍加速。
- 融合RoPE注意力:针对需动态修剪KV-Cache的场景(如StreamingLLM),将RoPE位置编码融合到注意力核中,直接在计算时动态应用,避免修剪后旧编码失效的问题,开销可忽略。
- 量化注意力:支持4位/8位低精度核,压缩比接近线性加速(4位约4倍,8位约2倍),平衡精度与效率。
3. 页表KV-Cache优化
针对LightLLM、sglang等系统采用的单页大小页表结构,FlashInfer通过在GPU共享内存预取页索引,消除页大小对核性能的影响,提升复杂场景下的缓存管理效率。
底层优化基石
1. 技术互补:分层协作的技术栈
FlashInfer:底层优化基石
- 定位:提供高性能的 GPU 注意力内核(如 FlashAttention、PageAttention、量化注意力等),专注于自注意力计算的底层优化。
- 角色:作为基础库被 vLLM 和 sglang 集成,为两者提供核心计算能力。例如:
vLLM 的 PageAttention 内核部分依赖 FlashInfer 的优化技术。
sglang 直接复用 FlashInfer 的 CUDA 内核,结合自身 RadixAttention 技术实现 KV 缓存高效重用。
针对量化、压缩 KV 缓存(如 Grouped-Query Attention、Fused-RoPE)的优化,显著提升推理效率,尤其在 A100/H100 等 GPU 上实现 2-3 倍加速。
vLLM:高性能批处理引擎
- 定位:专注于高吞吐量的批处理推理,通过 PagedAttention 技术优化内存管理,适用于单轮生成场景(如 API 服务)。
- 与 FlashInfer 的关系:
- 技术依赖:部分优化(如 GQA)可能采用 FlashInfer 的内核,但 vLLM 仍以自主开发的 PageAttention 为核心。
- 竞争与互补:在通用批处理场景中,vLLM 的性能与 FlashInfer 优化后的 sglang 接近,但在复杂任务(如多轮对话)中,sglang 更具优势。
sglang:复杂任务执行框架
- 定位:通过前端 DSL 和后端优化(如 RadixAttention、压缩有限状态机),支持多轮对话、结构化输出(如 JSON)、多模态交互等复杂任务。
- 与 FlashInfer 的关系:
- 深度集成:直接调用 FlashInfer 的注意力内核,结合自身调度器实现更高吞吐量。
- 场景扩展:利用 FlashInfer 的量化和压缩优化,支持更高效的 KV 缓存管理,尤其在推测解码等场景中表现突出。
- 与 vLLM 的关系:
- 技术继承:sglang 团队部分成员来自 vLLM 原班人马,继承了 vLLM 的部分设计思想(如动态批处理),但更专注于复杂任务的优化。
- 场景分工:vLLM 适合高吞吐单轮推理,sglang 擅长多轮对话和结构化输出,两者在不同场景下形成互补。
底层优化关键方向
在系统、框架或软件栈中,为上层功能提供核心性能支撑的基础优化技术或组件。这些底层技术是整个架构的“根基”,其设计和实现直接决定了上层应用的效率、稳定性和可扩展性。
这些底层技术看似不直接面向用户,但却是上层框架实现高性能的前提:
无底层优化,则上层功能无法高效落地*:例如,若没有高效的Decode核函数,即使上层支持千万级Token处理,单Token生成延迟也会极高;
跨框架通用性*:底层优化(如内存管理、硬件适配)可被多个上层框架复用。
例如FlashInfer中的“核心组件*:针对三种注意力阶段的专用核函数、KV-Cache格式无关的优化、量化/分组注意力的高效实现;为上层LLM Serving系统提供“高性能引擎”,使其能在复杂场景(如推测解码、动态Token处理)下保持低延迟和高吞吐量。
底层优化主要指以下关键方向
1. 核心计算原语的优化
- 注意力机制(Self-Attention)的高效实现:如将注意力分解为Prefill、Decode、Append三个阶段,针对每个阶段的计算特性(计算密集型 vs. IO密集型)设计专用核函数(Kernel)。例如:
- Decode阶段(单Query)因计算量小,优化重点是减少内存访问开销(IO-bound);
- Prefill阶段(批量Query)则利用GPU张量核心(Tensor Core)加速矩阵运算(计算密集型)。
- 基础线性代数操作(GEMM/GEMV)的优化:这些操作是Transformer的核心,底层优化(如融合计算、数据布局调整)直接影响整体吞吐量。
2. 内存与数据管理优化
- KV-Cache格式适配:支持多种KV-Cache格式(Padded Tensor、Ragged Tensor、Page Table),针对不同场景(如稀疏解码、动态Token处理)优化内存访问模式,减少碎片和带宽浪费。
- 量化与压缩技术:如4-bit/8-bit量化KV-Cache,在降低内存占用的同时保持计算效率,是底层优化的关键手段(如FlashInfer的量化注意力核函数)。
3. 硬件特性适配
- GPU专用优化:针对A100/H100等GPU的架构特性(如低非张量核心性能、高带宽内存)设计算法,例如:
- 利用张量核心加速Grouped-Query Attention(GQA),避免传统实现的计算瓶颈;
- 预取页索引到共享内存,优化PageAttention的访存效率。
4. 基础架构与算法创新
- 融合技术:如将RoPE位置编码融合到注意力核函数中(Fused-RoPE),避免中间数据读写开销;
- 批处理策略:优化共享前缀批解码(Cascading Batch Decoding),提升长序列场景下的并行效率。
相关文章:
FlashInfer - 介绍 LLM服务加速库 地基的一块石头
FlashInfer - 介绍 LLM服务加速库 地基的一块石头 flyfish 大型语言模型服务中的注意力机制 大型语言模型服务(LLM Serving)迅速成为重要的工作负载。Transformer中的算子效率——尤其是矩阵乘法(GEMM)、自注意力(S…...
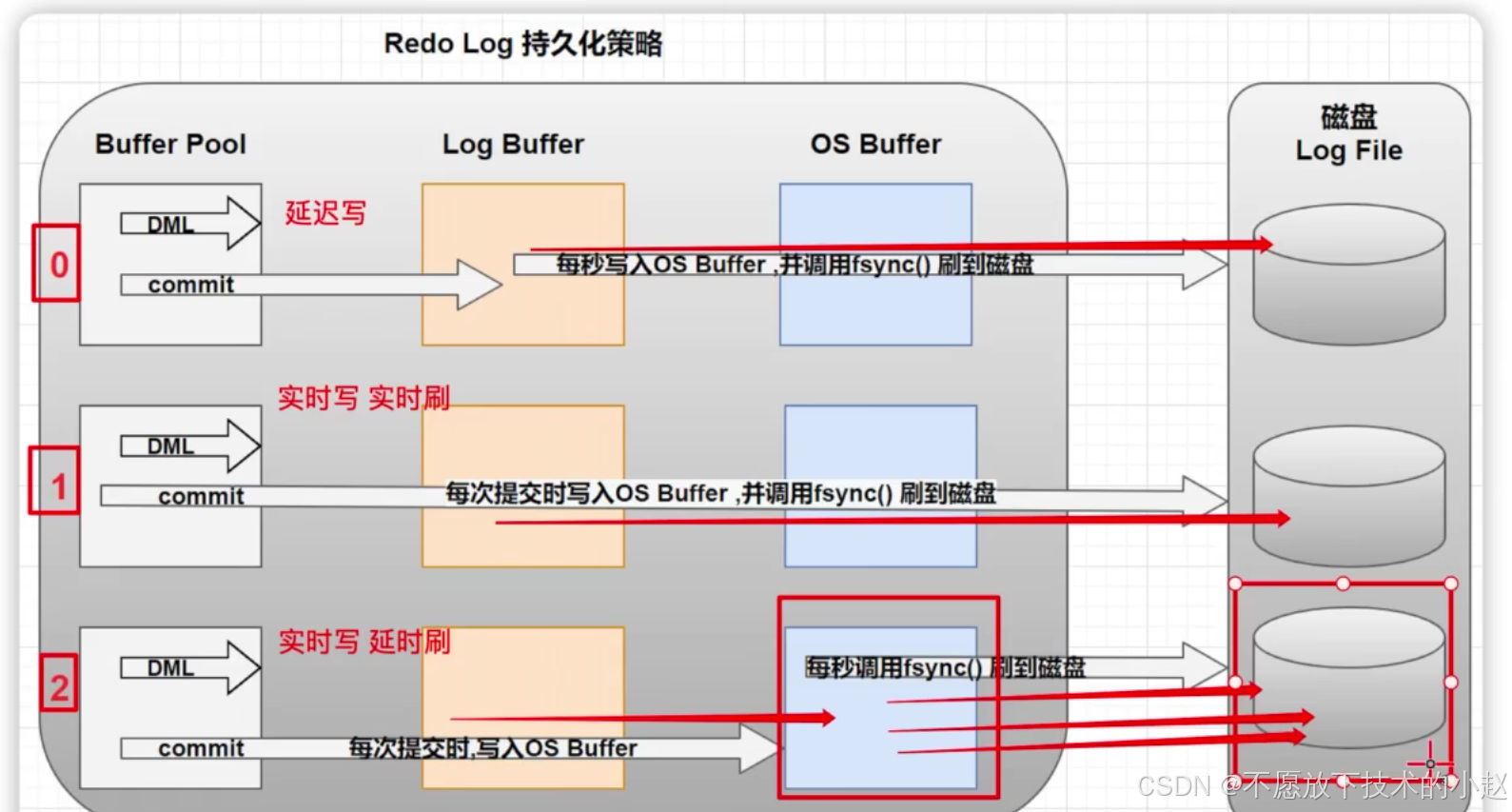
MySQL 学习(七)undo log、redo log、bin log 的作用以及持久化机制
目录 一、前言二、三大日志的概念、作用、存储位置2.1 bin log 二进制执行日志2.2 undo log 事务回滚日志2.3 redo log 快速恢复日志 三、补充说明3.1 补充:为什么使用 buffer pool 而不直接修改磁盘中的数据?3.2 补充:同为操作数据变更的日志…...

vue中,created和mounted两个钩子之间调用时差值受什么影响
在 Vue 中,created 和 mounted 是两个生命周期钩子,它们之间的调用时差主要受以下几个因素影响: 🟢 1. 模板复杂度与渲染耗时(最主要因素) mounted 的触发时间是在组件的 DOM 被挂载之后(也就是…...
)
16S18S_OTU分析(3)
OTU的定义 OTU:操作分类单元是在系统发生学研究或群体遗传学研究中,为了便于进行分析,人为给某一个分类单元(如品系、种、属、分组等)设置的同一标志。目的:OTU用于将相似的序列归为一类,以便于…...

电机的导程和脉冲之间的关系
文章目录 导程计算关系相互影响关系 在电机相关领域中,导程通常是针对直线电机或带有丝杠等传动机构的电机系统而言的。 导程 导程是指丝杠或类似传动部件旋转一周时,与其相连的运动部件在轴向方向上移动的距离。例如,在一个由电机驱动丝杠来…...
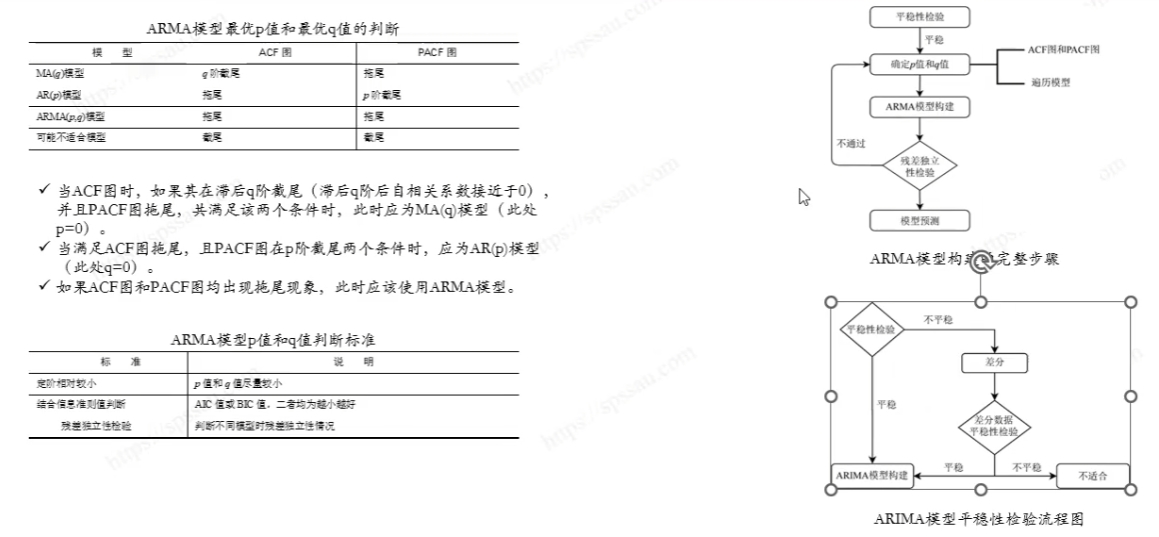
时间序列预测建模的完整流程以及数据分析【学习记录】
文章目录 1.时间序列建模的完整流程2. 模型选取的和数据集2.1.ARIMA模型2.2.数据集介绍 3.时间序列建模3.1.数据获取3.2.处理数据中的异常值3.2.1.Nan值3.2.2.异常值的检测和处理(Z-Score方法) 3.3.离散度3.4.Z-Score3.4.1.概述3.4.2.公式3.4.3.Z-Score与…...

Flink和Spark的选型
在Flink和Spark的选型中,需要综合考虑多个技术维度和业务需求,以下是在项目中会重点评估的因素及实际案例说明: 一、核心选型因素 处理模式与延迟要求 Flink:基于事件驱动的流处理优先架构,支持毫秒级低延迟、高吞吐的…...
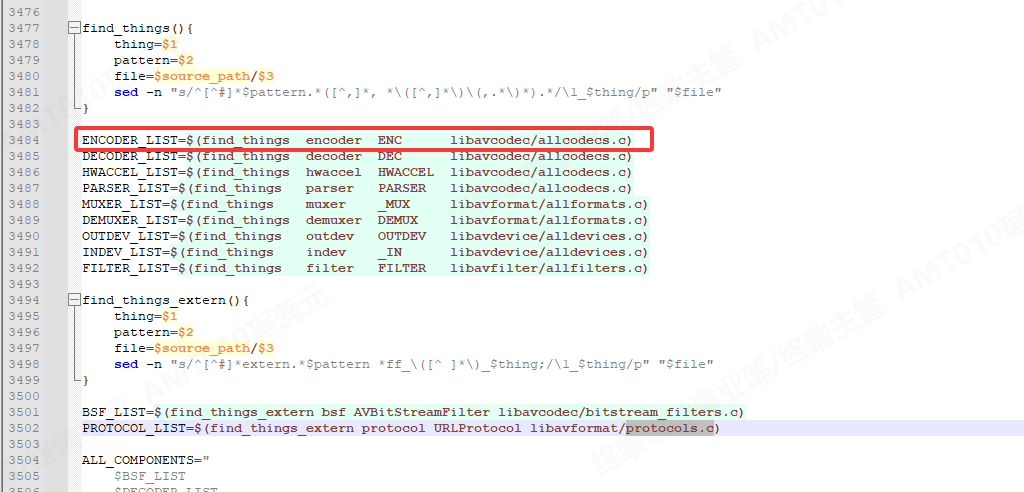
FFmpeg3.4 libavcodec协议框架增加新的decode协议
查看ffmepg下面的configure文件发现,config.h文件;解码协议的配置是通过libavcodec/allcodecs.c文件,通过查找DEC关键字生成的。 1、在libavcodec/allcodecs.c 新增REGISTER_ENCODER(MYCODE, mycode); REGISTER_ENCODER(VP8_VAAPI, vp8_vaapi); …...

无人机数据处理与特征提取技术分析!
一、运行逻辑 1. 数据采集与预处理 多传感器融合:集成摄像头、LiDAR、IMU、GPS等传感器,通过硬件时间戳或PPS信号实现数据同步,确保时空一致性。 边缘预处理:在无人机端进行数据压缩(如JPEG、H.265)…...
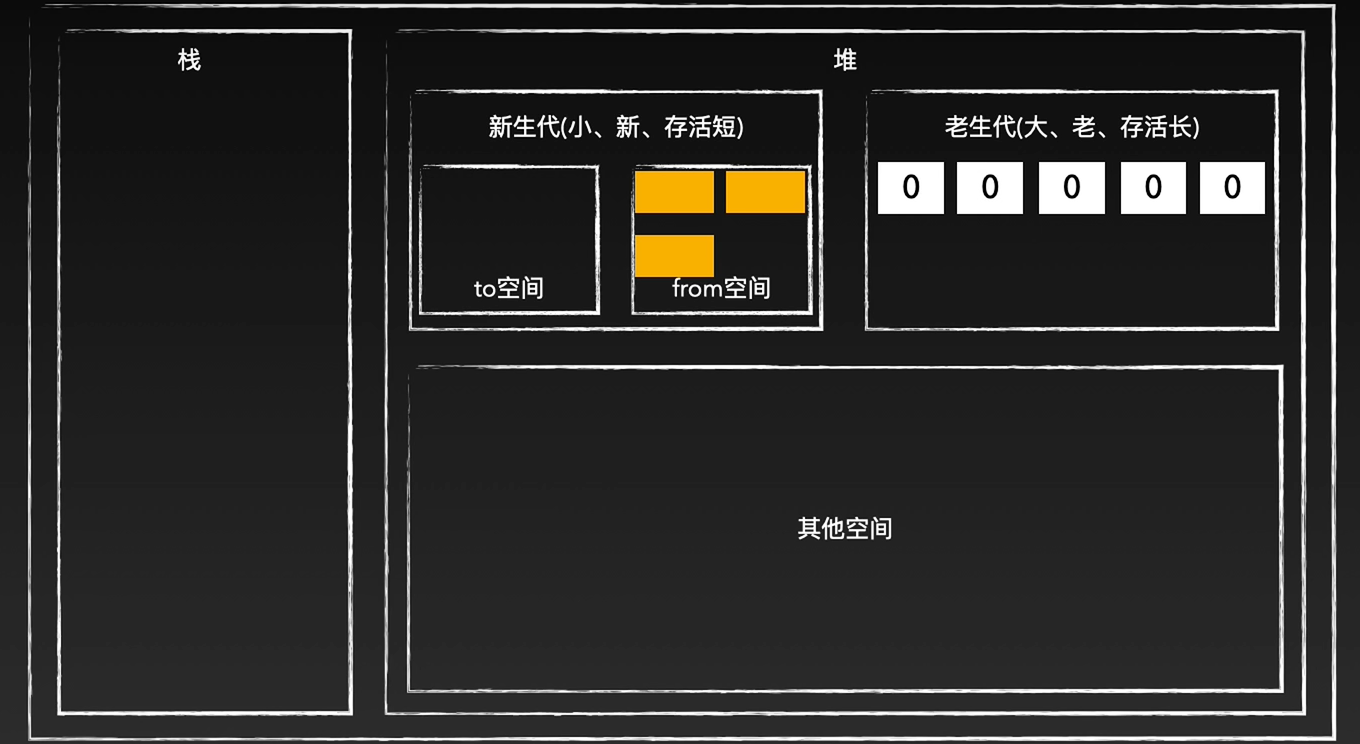
前端面试宝典---js垃圾回收机制
什么是垃圾回收 垃圾回收是指一种自动内存管理机制,当声明一个变量时,会在内存中开辟一块内存空间用于存放这个变量。当这个变量被使用过后,可能再也不需要它了,此时垃圾回收器会自动检测并回收这些不再使用的内存空间。垃圾回收…...
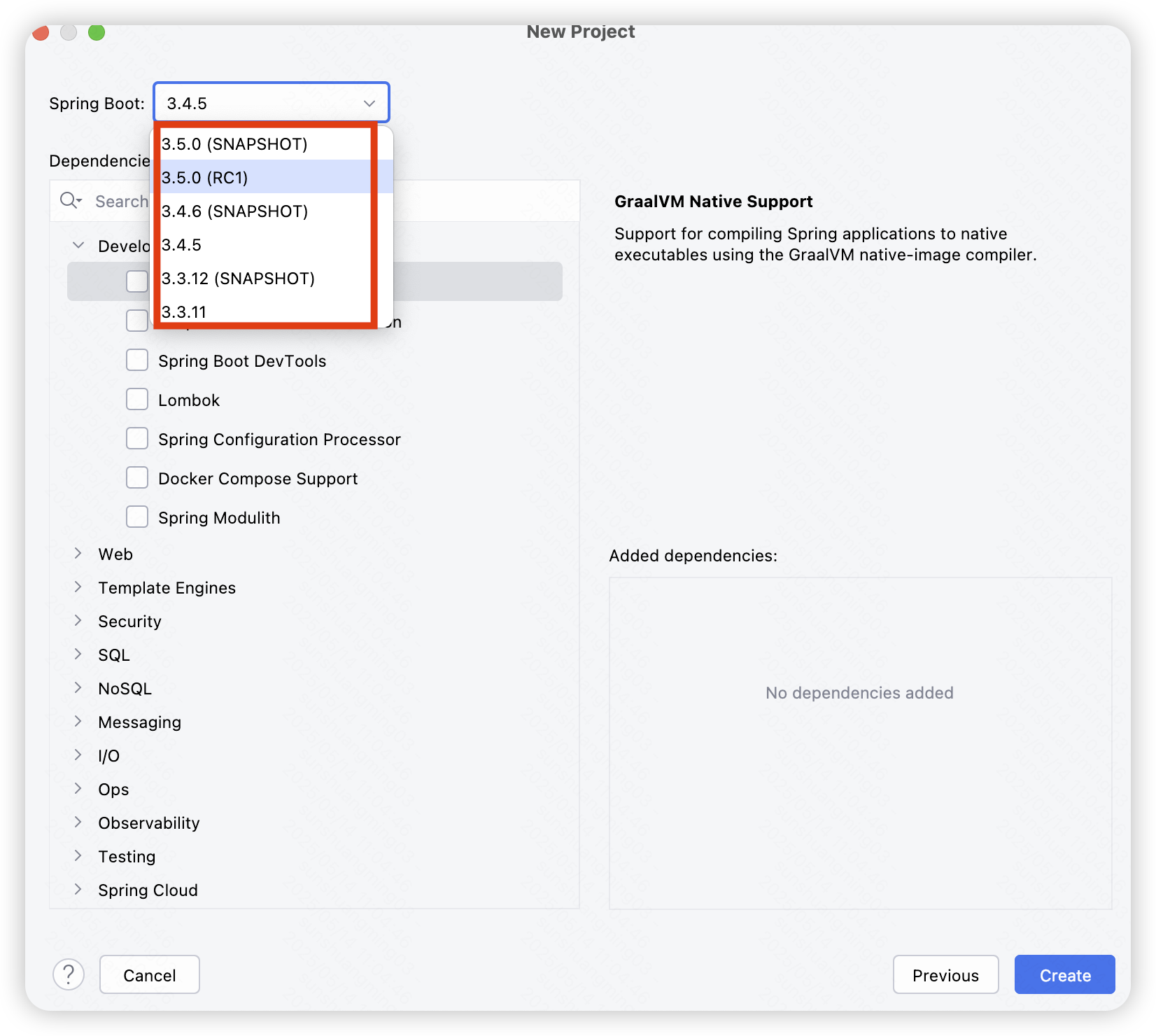
IDEA 新建 SpringBoot 项目时,没有高版本 SpringBoot 可选
环境描述 IDEA 2025.1.1JDK17Maven 3.9.9 问题描述 IDEA 新建 SpringBoot 项目时,没有高版本 SpringBoot 可选,可以看到此时的最高版本为 3.0.2: 问题分析 返回上一步,可以发现 Spring Initializr 的服务地址为阿里云&#…...
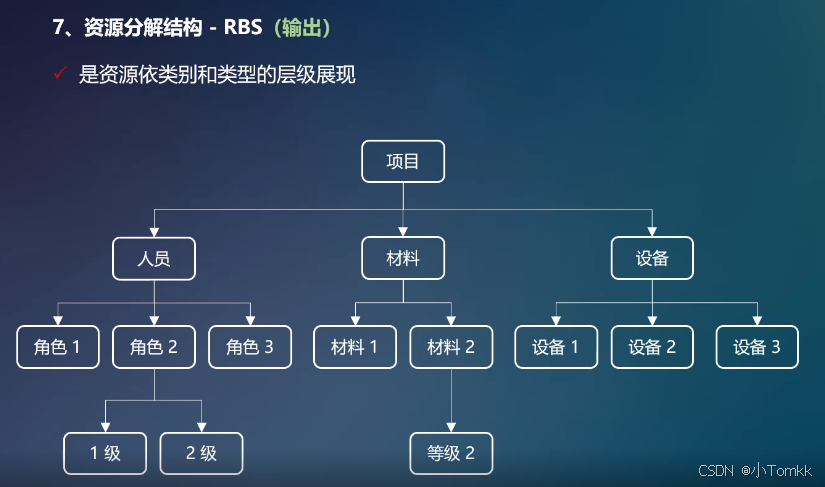
2025年PMP 学习十三 第9章 项目资源管理(9.1,9.2)
2025年PMP 学习十三 第9章 项目资源管理(9.1,9.2) 序号过程过程组9.1规划资源管理规划9.2估算活动资源规划9.3获取资源执行9.4建设团队执行9.5管理团队执行9.6控制资源监控 文章目录 2025年PMP 学习十三 第9章 项目资源管理(9.1,9.2…...

动态规划问题 -- 多状态模型(删除并获得点数)
目录 动态规划分析问题五步曲题目概述预处理阶段 代码编写 动态规划分析问题五步曲 不清楚动态规划分析问题是哪关键的五步的少年们可以移步到 链接: 动态规划算法基础 这篇文章非常详细的介绍了动态规划算法是如何分析和解决问题的 题目概述 链接: 删除并获得点数 预处理阶段…...
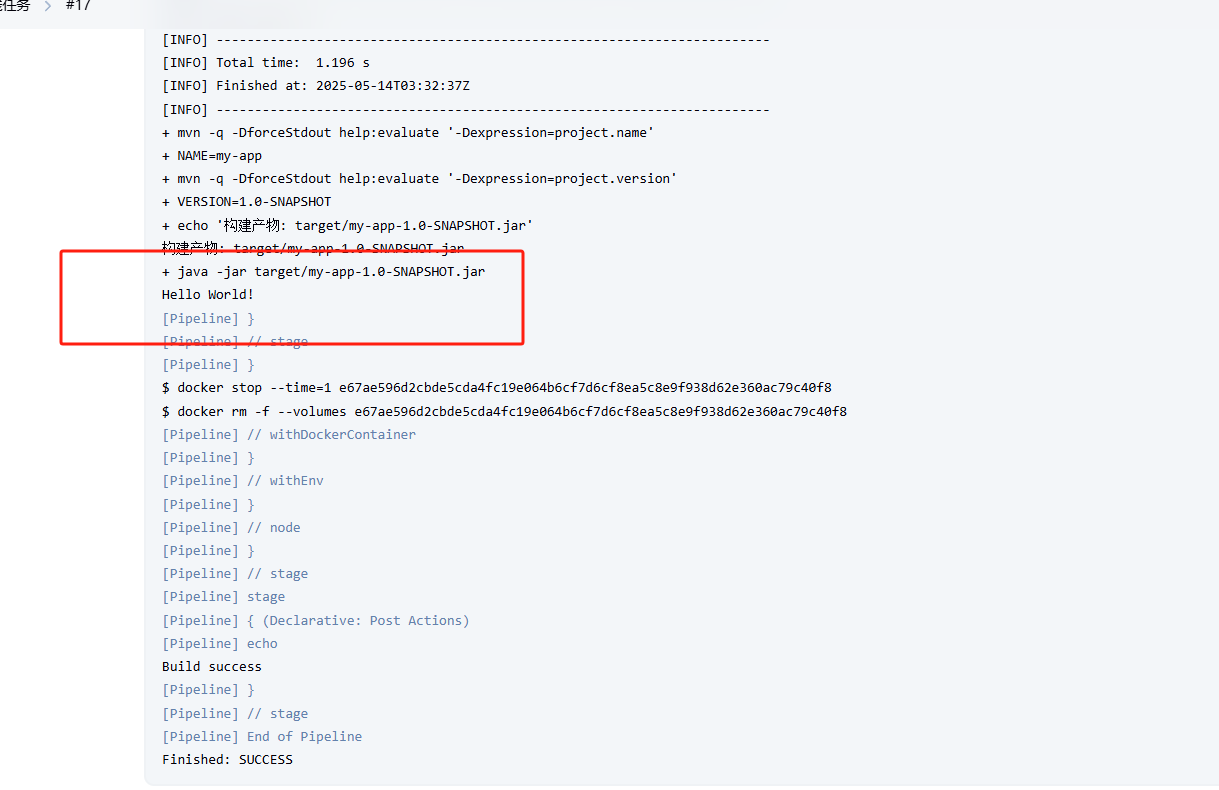
Jenkins里构建一个简单流水线
前情提要:传送门,我在虚拟机里装了一个Ubuntu,然后在docker里装了一个Jenkins及GitLab! 点击这里下载或fork一个简单的Java项目用于学习Jenkins! 目标:修改代码后,上传到git,在在Jenkins流水线里…...
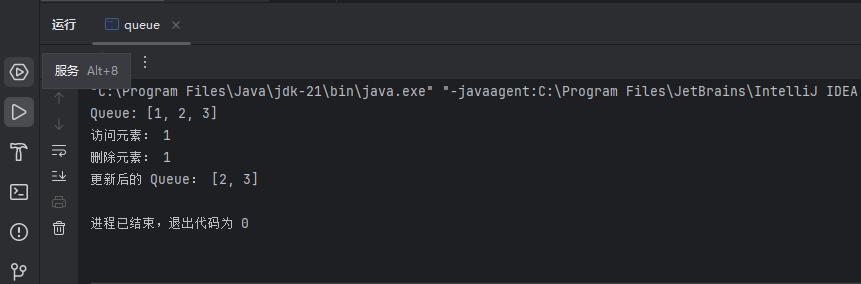
Java Queue 接口实现
Date: 2025.05.14 20:46:38 author: lijianzhan Java中的Queue接口是位于java.util包中,它是一个用于表示队列的接口。队列是一种先进先出(First-In-First-Out, 简称为FIFO)的数据结构,其中元素被添加到队列的尾部,并从…...

华为0507机试
题目二 建设基站 有一棵二叉树,每个节点上都住了一户居民。现在要给这棵树上的居民建设基站,每个基站只能覆盖她所在与相邻的节点,请问信号覆盖这棵树最少需要建设多少个基站 #include <bits/stdc.h> using namespace std;const int …...

OpenEvidence AI临床决策支持工具平台研究报告
平台概述 OpenEvidence是一个专为医疗专业人士设计的临床决策支持工具,旨在通过整合各类临床计算器和先进的人工智能技术,提高医生的诊疗决策效率和准确性。作为一款综合性医疗平台,OpenEvidence将复杂的医学计算流程简化,同时提供个性化的临床建议,使医生能够更快、更准…...
`RotationTransition` 是 Flutter 中的一个动画组件,用于实现旋转动画效果
RotationTransition 是 Flutter 中的一个动画组件,用于实现旋转动画效果。它允许你对子组件进行动态的旋转变换,从而实现平滑的动画效果。RotationTransition 通常与 AnimationController 和 Tween 一起使用,以控制动画的开始、结束和过渡效果…...
)
Android多媒体——媒体start流程分析(十三)
当多媒体的数据源准备好,并且完成调用准备结束流程后,接下来就开始是调用 start() 方法开始播放媒体了。这里我们就来分析一下媒体开始播放的整个流程。 一、媒体播放流程 对于媒体播放流程的 Java 层和 JNI 层与前面的示例基本相同,这里不再重复展示了,我们直接从 mediap…...
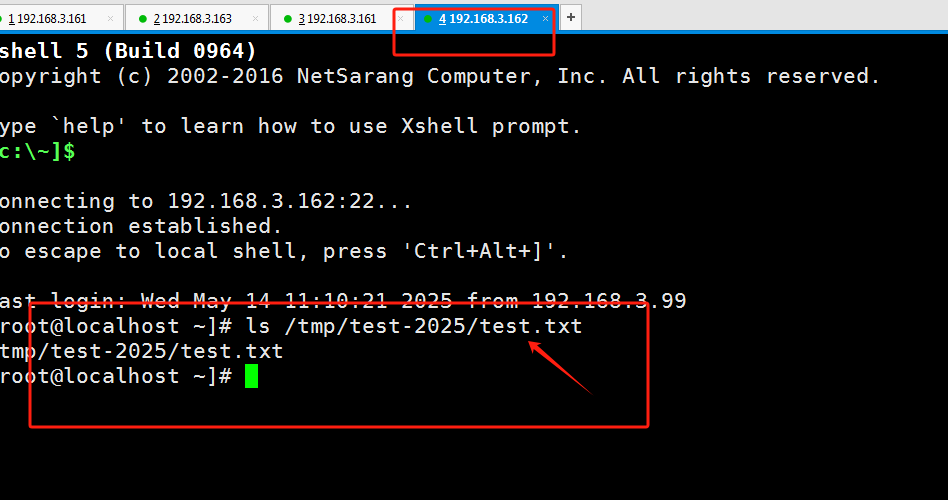
如何远程执行脚本不留痕迹
通常我们在做远程维护的时候,会有这么一个需求,就是我想在远程主机执行一个脚本,但是这个脚本我又不想保留在远程主机上,那么有人就说了,那就复制过去再登录远程执行不就行了吗?嗯嗯,但是这还不…...

jQuery知识框架
一、jQuery 基础 核心概念 $ 或 jQuery:全局函数,用于选择元素或创建DOM对象。 链式调用:多数方法返回jQuery对象,支持连续操作。 文档就绪事件: $(document).ready(function() { /* 代码 */ }); // 简写 $(function…...

java加强 -File
File类的对象可以代表文件/文件夹,并可以调用其提供的方法对象文件进行操作。 File对象既可以代表文件,也可以代表文件夹。 创建File对象,获取某个文件的信息 语法: File 对象名 new File("需要访问文件的绝对路径&…...

c# 倒序方法
在C#中,有几种方法可以对List进行倒序排列: 1. 使用List的Reverse()方法(原地反转) List<int> numbers new List<int> { 1, 2, 3, 4, 5 };numbers.Reverse(); // 直接修改原列表// 结果:5, 4, 3, 2, 1 …...
))
每日c/c++题 备战蓝桥杯(P2241 统计方形(数据加强版))
洛谷P2241 统计方形(数据加强版)题解 题目描述 给定一个 n m n \times m nm 的方格棋盘,要求统计其中包含的正方形数量和长方形数量(不包含正方形)。输入为两个正整数 n n n 和 m m m,输出两个整数分…...
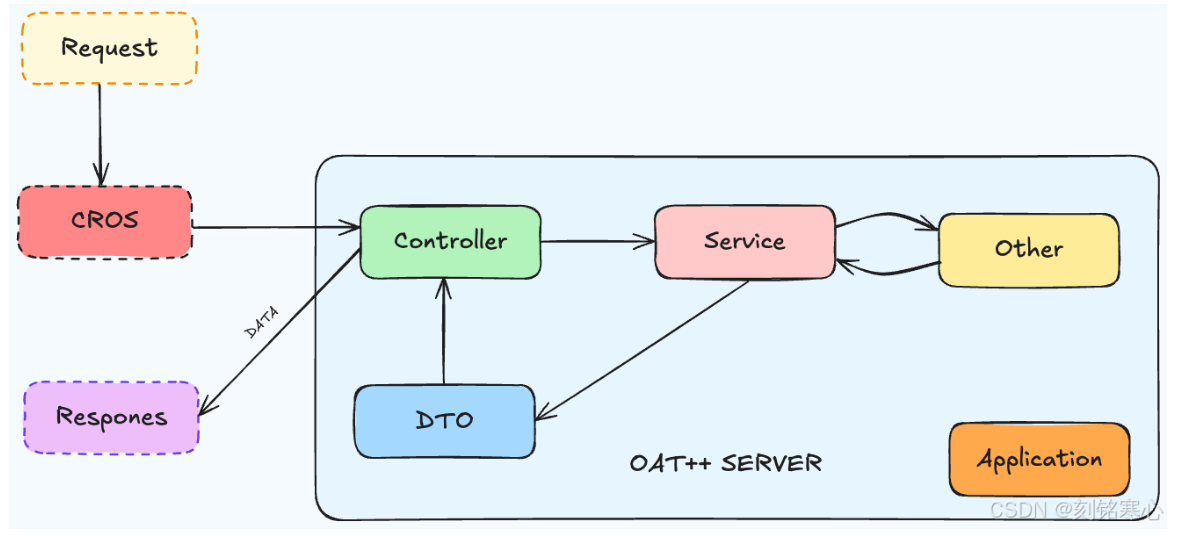
Ota++框架学习
一:框架结构 这是一幅展现 Web 应用程序架构的示意图,以下是对图中各部分的详细解释: 外部交互部分 Request(请求):位于架构图的左上角,用黄色虚线框表示 。代表来自客户端(如浏览器…...
Chrome安装最新vue-devtool插件
本vue-devtool版本是官方的 v7.6.8版本,兼容性好、功能齐全且稳定。 操作步骤: 方法一: 打开谷歌浏览器 --> 右上角三个点 --> 扩展程序 --> 管理扩展程序 --> 加载已解压的扩展程序, 然后选择解压后的文件夹即可。…...

Android锁
引言 🔒 在 Android 应用的开发过程中,随着业务需求的复杂度不断提升,多线程并发场景层出不穷。为了保证数据一致性与线程安全,锁(Lock)成为了不可或缺的工具。本篇博客将深入剖析 Android 中常用的锁机制…...

bfs-最小步数问题
最小步长模型 特征: 主要是解决权值为1且状态为字符串类型的最短路问题,实质上是有向图的最短路问题,可以简化为bfs求最短路问题。 代表题目: acwing 845 八数码问题: 八数码题中由于每次交换的状态是由x进行上下左右…...

sqlalchemy库详细使用
SQLAlchemy 是 Python 中最强大、最受欢迎的 ORM(对象关系映射)库,它允许你使用 Python 对象来操作数据库,而不需要直接编写 SQL 语句。同时,它也提供了对底层 SQL 的完全控制能力,适用于从简单脚本到大型企…...
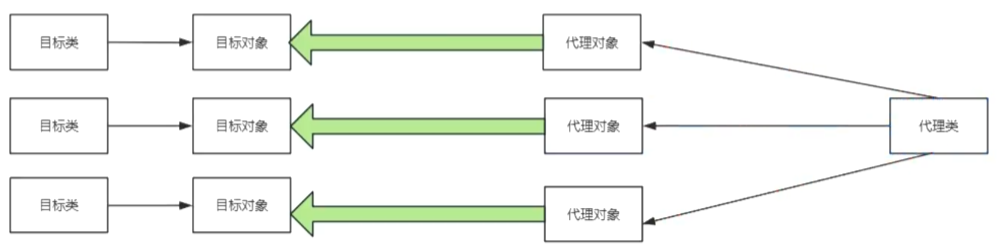
java----------->代理模式
目录 什么是代理模式? 为什么会有代理模式? 怎么写代理模式? 实现代理模式总共需要三步: 什么是代理模式? 代理模式:给目标对象提供一个代理对象,并且由代理对象控制目标对象的引用 代理就是…...