自然语言处理入门级项目——文本分类
文章目录
- 前言
- 1.数据预处理
- 1.1数据集介绍
- 1.2数据集抽取
- 1.3划分数据集
- 1.4数据清洗
- 1.5数据保存
- 2.样本的向量化表征
- 2.1词汇表
- 2.2向量化
- 2.3自定义数据集
- 2.4备注
- 结语
前言
本篇博客主要介绍自然语言处理领域中一个项目案例——文本分类,具体而言就是判断评价属于积极还是消极的模型,选用的模型属于最简单的单层感知机模型。
1.数据预处理
1.1数据集介绍
本项目数据集来源:2015年,Yelp 举办了一场竞赛,要求参与者根据点评预测一家餐厅的评级。该数据集分为 56 万个训练样本和3.8万个测试样本。共计两个类别,分别代表该评价属于积极还是消极。这里以训练集为例,进行介绍展示:
import pandas as pdtrain_reviews=pd.read_csv('data/yelp/raw_train.csv',header=None,names=['rating','review'])
train_reviews,train_reviews.rating.value_counts()
运行结果:
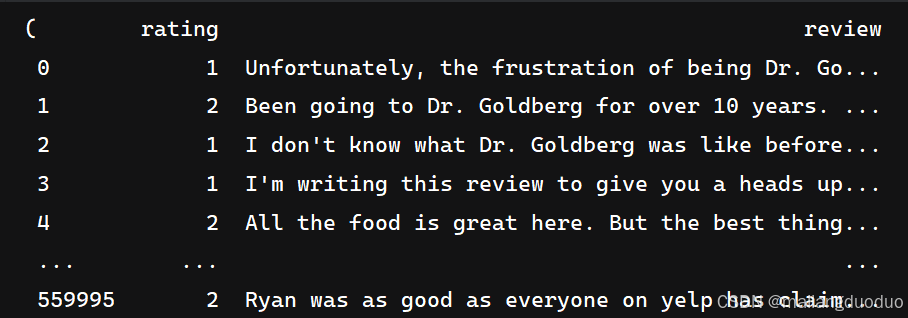
共计两个类别,同时类别数量相等,因此不需要进行类平衡操作。因为当前数据集过大,因此这里对数据集进行抽取。
1.2数据集抽取
首先,将两个类别的数据分别使用两个列表进行保存。代码如下:
import collectionsby_rating = collections.defaultdict(list)
for _, row in train_reviews.iterrows():by_rating[row.rating].append(row.to_dict())运行查看:
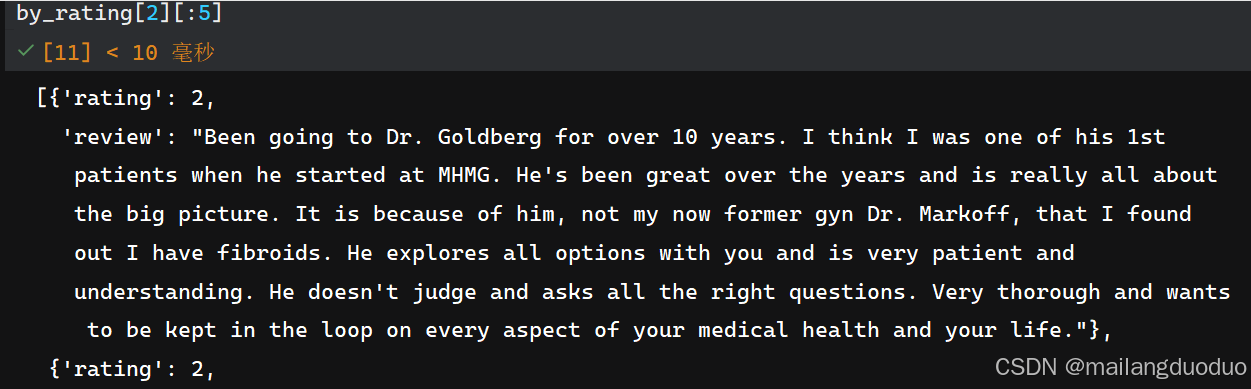
共计两个类别,分别存储在by_rating[1]和by_rating[2]对于的列表中。
接着选择合适的比例将数据从相应的类别中抽取出来,这里选择的比例为0.01,具体代码如下:
review_subset = []
for _, item_list in sorted(by_rating.items()):n_total = len(item_list)n_subset = int(0.01 * n_total)review_subset.extend(item_list[:n_subset])
为了可视化方便,这里将抽取后的子集转化为DataFrame数据格式,具体代码如下:
review_subset = pd.DataFrame(review_subset)
review_subset.head(),review_subset.shape
运行结果:
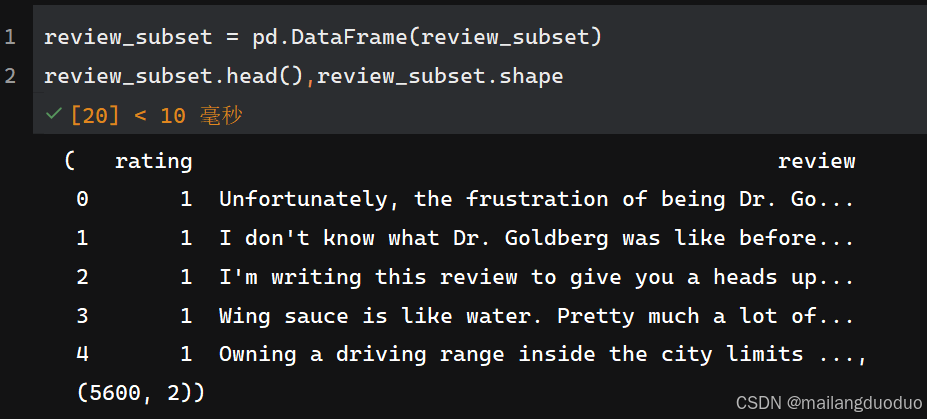
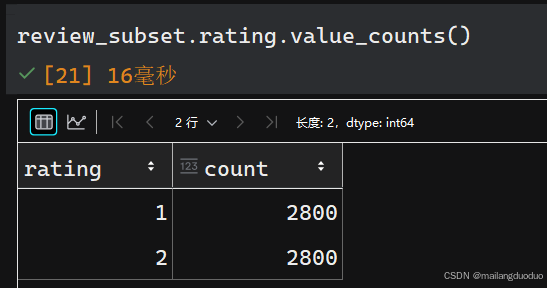
共计两个类别,每个类别均有2800条数据。
1.3划分数据集
首先,将两个类别的数据分别使用两个列表进行保存。代码如下:
by_rating = collections.defaultdict(list)
for _, row in review_subset.iterrows():by_rating[row.rating].append(row.to_dict())因为该过程包括了打乱顺序,为了保证结果的可重复性,因此设置了随机种子。这里划分的训练集:验证集:测试集=0.70:0.15:0.15,同时为了区分数据,增加了一个属性split,该属性共有三种取值,分别代表训练集、验证集、测试集。
import numpy as npfinal_list = []
np.random.seed(1000)for _, item_list in sorted(by_rating.items()):np.random.shuffle(item_list)n_total = len(item_list)n_train = int(0.7 * n_total)n_val = int(0.15 * n_total)n_test = int(0.15 * n_total)for item in item_list[:n_train]:item['split'] = 'train'for item in item_list[n_train:n_train+n_val]:item['split'] = 'val'for item in item_list[n_train+n_val:n_train+n_val+n_test]:item['split'] = 'test'final_list.extend(item_list)
同理为了可视化方便,将其转化为DataFrame类型,代码如下:
final_reviews = pd.DataFrame(final_list)
final_reviews.head()
运行结果:
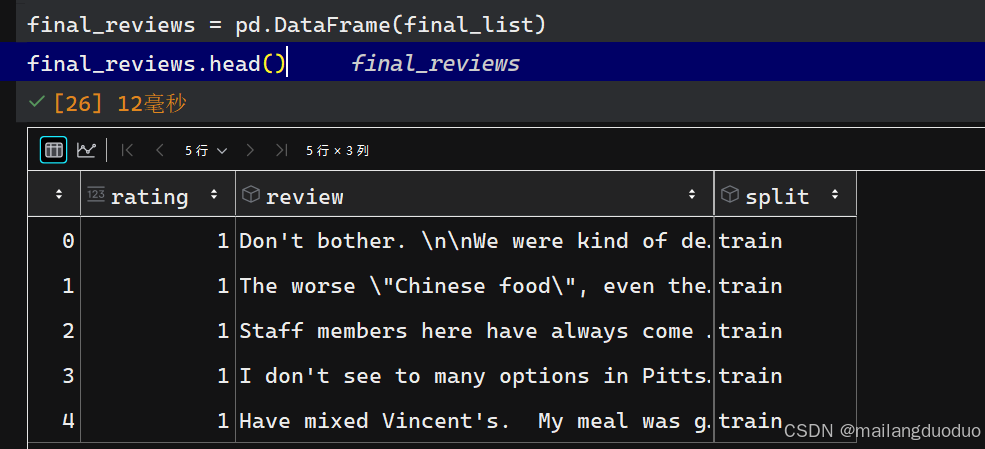
从上述结果可以看到,每条数据中还是有很多无意义的字符,如\,因此希望将其过滤掉,这就需要对数据进行清洗。
1.4数据清洗
这里为了将无意义的字符去除掉,自然就会想到正则表达式,用于匹配指定格式的字符串。具体操作代码如下:
import redef preprocess_text(text):text = text.lower()text = re.sub(r"([.,!?])", r" \1 ", text)text = re.sub(r"[^a-zA-Z.,!?]+", r" ", text)return textfinal_reviews.review = final_reviews.review.apply(preprocess_text)
这里对上述代码进行解释:
\1:指的是被匹配的字符,该段代码的功能是将匹配到的标点符号前后均加一个空格。- 第二个正则表达式:将除表示的字母及标点符号,其他符号均使用空格替代。
运行结果:
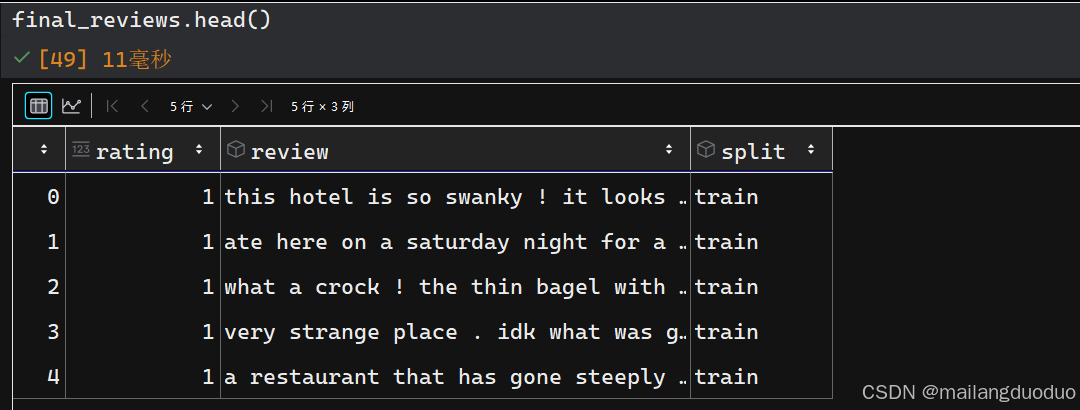
这里为了更好的展示数据,将rating属性做了更改,替换为negative和positive,
代码如下:
final_reviews['rating'] = final_reviews.rating.apply({1: 'negative', 2: 'positive'}.get)
final_reviews.head()
运行结果:
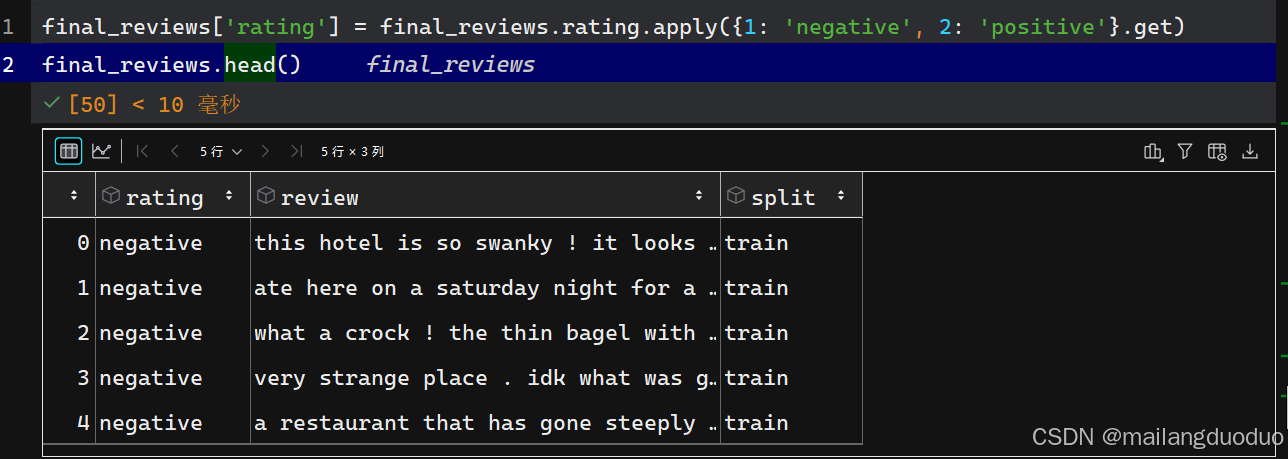
1.5数据保存
至此数据预处理基本完成,这里将处理好的数据进行保存。
final_reviews.to_csv('data/yelp/reviews_with_splits_lite_new.csv', index=False)
在输入模型前,总不能是一个句子吧,因此需要将每个样本中的review表示为向量化。
2.样本的向量化表征
2.1词汇表
这里定义了一个 Vocabulary 类,用于处理文本并提取词汇表,以实现单词和索引之间的映射。具体代码如下:
class Vocabulary(object):"""处理文本并提取词汇表,以实现单词和索引之间的映射"""def __init__(self, token_to_idx=None, add_unk=True, unk_token="<UNK>"):"""参数:token_to_idx (dict): 一个已有的单词到索引的映射字典add_unk (bool): 指示是否添加未知词(UNK)标记unk_token (str): 要添加到词汇表中的未知词标记"""if token_to_idx is None:token_to_idx = {}self._token_to_idx = token_to_idxself._idx_to_token = {idx: token for token, idx in self._token_to_idx.items()}self._add_unk = add_unkself._unk_token = unk_tokenself.unk_index = -1if add_unk:self.unk_index = self.add_token(unk_token) def to_serializable(self):"""返回一个可序列化的字典"""return {'token_to_idx': self._token_to_idx, 'add_unk': self._add_unk, 'unk_token': self._unk_token}@classmethoddef from_serializable(cls, contents):"""从一个序列化的字典实例化 Vocabulary 类"""return cls(**contents)def add_token(self, token):"""根据传入的单词更新映射字典。参数:token (str): 要添加到词汇表中的单词返回:index (int): 该单词对应的整数索引"""if token in self._token_to_idx:index = self._token_to_idx[token]else:index = len(self._token_to_idx)self._token_to_idx[token] = indexself._idx_to_token[index] = tokenreturn indexdef add_many(self, tokens):"""向词汇表中添加一组单词参数:tokens (list): 一个字符串单词列表返回:indices (list): 一个与这些单词对应的索引列表"""return [self.add_token(token) for token in tokens]def lookup_token(self, token):"""查找与单词关联的索引,若单词不存在则返回未知词索引。参数:token (str): 要查找的单词返回:index (int): 该单词对应的索引注意:`unk_index` 需要 >=0(即已添加到词汇表中)才能启用未知词功能"""if self.unk_index >= 0:return self._token_to_idx.get(token, self.unk_index)else:return self._token_to_idx[token]def lookup_index(self, index):"""返回与索引关联的单词参数: index (int): 要查找的索引返回:token (str): 该索引对应的单词异常:KeyError: 若索引不在词汇表中"""if index not in self._idx_to_token:raise KeyError("索引 (%d) 不在词汇表中" % index)return self._idx_to_token[index]def __str__(self):"""返回表示词汇表大小的字符串"""return "<Vocabulary(size=%d)>" % len(self)def __len__(self):"""返回词汇表中单词的数量"""return len(self._token_to_idx)
这里对该类中方法体做以下解释:
__init__构造方法:若token_to_idx为 None,则初始化为空字典。_idx_to_token是索引到单词的映射字典,通过_token_to_idx反转得到。若add_unk为 True,则调用add_token 方法添加未知词标记,并记录其索引。to_serializable 方法:返回一个字典,包含_token_to_idx、_add_unk和_unk_token,可用于序列化存储。from_serializable: 是类方法,接收一个序列化的字典,通过解包字典参数创建 Vocabulary 类的实例。add_token 方法:用于向词汇表中添加单个单词。若单词已存在,返回其索引;否则,分配一个新索引并更新两个映射字典。add_many 方法:用于批量添加单词列表,返回每个单词对应的索引列表。lookup_token 方法:根据单词查找对应的索引。若单词不存在且unk_index大于等于 0,则返回 unk_index;否则,返回单词的索引。lookup_index 方法:根据索引查找对应的单词。若索引不存在,抛出 KeyError 异常。__str__ 方法返回一个字符串,显示词汇表的大小。__len__ 方法:返回词汇表中单词的数量。
2.2向量化
此处定义了 ReviewVectorizer 类,其作用是协调词汇表(Vocabulary)并将其投入使用,主要负责把文本评论转换为可用于模型训练的向量表示。具体代码如下:
class ReviewVectorizer(object):""" 协调词汇表并将其投入使用的向量化器 """def __init__(self, review_vocab, rating_vocab):"""参数:review_vocab (Vocabulary): 将单词映射为整数的词汇表rating_vocab (Vocabulary): 将类别标签映射为整数的词汇表"""self.review_vocab = review_vocabself.rating_vocab = rating_vocabdef vectorize(self, review):"""为评论创建一个压缩的独热编码向量参数:review (str): 评论文本返回:one_hot (np.ndarray): 压缩后的独热编码向量"""# 初始化一个长度为词汇表大小的全零向量one_hot = np.zeros(len(self.review_vocab), dtype=np.float32)# 遍历评论中的每个单词for token in review.split(" "):# 若单词不是标点符号if token not in string.punctuation:# 将向量中对应单词索引的位置置为 1one_hot[self.review_vocab.lookup_token(token)] = 1return one_hot@classmethoddef from_dataframe(cls, review_df, cutoff=25):"""从数据集的 DataFrame 实例化向量化器参数:review_df (pandas.DataFrame): 评论数据集cutoff (int): 基于词频过滤的阈值参数返回:ReviewVectorizer 类的一个实例"""# 创建评论词汇表,添加未知词标记review_vocab = Vocabulary(add_unk=True)# 创建评分词汇表,不添加未知词标记rating_vocab = Vocabulary(add_unk=False)# 添加评分标签到评分词汇表for rating in sorted(set(review_df.rating)):rating_vocab.add_token(rating)# 统计词频,若词频超过阈值则添加到评论词汇表word_counts = Counter()for review in review_df.review:for word in review.split(" "):if word not in string.punctuation:word_counts[word] += 1for word, count in word_counts.items():if count > cutoff:review_vocab.add_token(word)return cls(review_vocab, rating_vocab)@classmethoddef from_serializable(cls, contents):"""从可序列化的字典实例化 ReviewVectorizer参数:contents (dict): 可序列化的字典返回:ReviewVectorizer 类的一个实例"""# 从可序列化字典中恢复评论词汇表review_vocab = Vocabulary.from_serializable(contents['review_vocab'])# 从可序列化字典中恢复评分词汇表rating_vocab = Vocabulary.from_serializable(contents['rating_vocab'])return cls(review_vocab=review_vocab, rating_vocab=rating_vocab)def to_serializable(self):"""创建用于缓存的可序列化字典返回:contents (dict): 可序列化的字典"""return {'review_vocab': self.review_vocab.to_serializable(),'rating_vocab': self.rating_vocab.to_serializable()}
这里对该类中方法体做以下解释:
__init__方法:类的构造方法,接收两个 Vocabulary 类的实例:
review_vocab:将评论中的单词映射为整数。
rating_vocab:将评论的评分标签映射为整数。vectorize 方法:将输入的评论文本转换为压缩的独热编码向量。具体操作为:
首先创建一个长度为词汇表大小的全零向量 one_hot。
遍历评论中的每个单词,若该单词不是标点符号,则将向量中对应单词索引的位置置为 1。
最后返回处理好的独热编码向量。from_dataframe类方法:用于从包含评论数据的 DataFrame 中实例化ReviewVectorizer。具体操作为:
创建两个Vocabulary实例,review_vocab添加未知词标记,rating_vocab不添加。
遍历数据框中的评分列,将所有唯一评分添加到 rating_vocab 中。
统计评论中每个非标点单词的出现频率,将出现次数超过 cutoff 的单词添加到 review_vocab 中。
最后返回 ReviewVectorizer 类的实例。from_serializable 方法:从一个可序列化的字典中实例化ReviewVectorizer。
从字典中提取review_vocab和rating_vocab对应的序列化数据,分别创建 Vocabulary 实例。
最后返回 ReviewVectorizer 类的实例。to_serializable 方法:创建一个可序列化的字典,用于缓存 ReviewVectorizer 的状态。调用 review_vocab 和 rating_vocab 的 to_serializable 方法,将结果存储在字典中并返回。
2.3自定义数据集
该数据集继承Dataset,具体代码如下:
class ReviewDataset(Dataset):def __init__(self, review_df, vectorizer):"""参数:review_df (pandas.DataFrame): 数据集vectorizer (ReviewVectorizer): 从数据集中实例化的向量化器"""self.review_df = review_dfself._vectorizer = vectorizer# 从数据集中筛选出训练集数据self.train_df = self.review_df[self.review_df.split=='train']# 训练集数据的数量self.train_size = len(self.train_df)# 从数据集中筛选出验证集数据self.val_df = self.review_df[self.review_df.split=='val']# 验证集数据的数量self.validation_size = len(self.val_df)# 从数据集中筛选出测试集数据self.test_df = self.review_df[self.review_df.split=='test']# 测试集数据的数量self.test_size = len(self.test_df)# 用于根据数据集划分名称查找对应数据和数据数量的字典self._lookup_dict = {'train': (self.train_df, self.train_size),'val': (self.val_df, self.validation_size),'test': (self.test_df, self.test_size)}# 默认设置当前使用的数据集为训练集self.set_split('train')@classmethoddef load_dataset_and_make_vectorizer(cls, review_csv):"""从文件加载数据集并从头创建一个新的向量化器参数:review_csv (str): 数据集文件的路径返回:ReviewDataset 类的一个实例"""review_df = pd.read_csv(review_csv)# 从数据集中筛选出训练集数据train_review_df = review_df[review_df.split=='train']return cls(review_df, ReviewVectorizer.from_dataframe(train_review_df))@classmethoddef load_dataset_and_load_vectorizer(cls, review_csv, vectorizer_filepath):"""加载数据集和对应的向量化器。用于向量化器已被缓存以便重复使用的情况参数:review_csv (str): 数据集文件的路径vectorizer_filepath (str): 保存的向量化器文件的路径返回:ReviewDataset 类的一个实例"""review_df = pd.read_csv(review_csv)vectorizer = cls.load_vectorizer_only(vectorizer_filepath)return cls(review_df, vectorizer)@staticmethoddef load_vectorizer_only(vectorizer_filepath):"""一个静态方法,用于从文件加载向量化器参数:vectorizer_filepath (str): 序列化的向量化器文件的路径返回:ReviewVectorizer 类的一个实例"""with open(vectorizer_filepath) as fp:return ReviewVectorizer.from_serializable(json.load(fp))def save_vectorizer(self, vectorizer_filepath):"""使用 JSON 将向量化器保存到磁盘参数:vectorizer_filepath (str): 保存向量化器的文件路径"""with open(vectorizer_filepath, "w") as fp:json.dump(self._vectorizer.to_serializable(), fp)def get_vectorizer(self):"""返回向量化器"""return self._vectorizerdef set_split(self, split="train"):"""根据数据框中的一列选择数据集中的划分参数:split (str): "train", "val", 或 "test" 之一"""self._target_split = splitself._target_df, self._target_size = self._lookup_dict[split]def __len__(self):"""返回当前所选数据集划分的数据数量"""return self._target_sizedef __getitem__(self, index):"""PyTorch 数据集的主要入口方法参数:index (int): 数据点的索引返回:一个字典,包含数据点的特征 (x_data) 和标签 (y_target)"""row = self._target_df.iloc[index]# 将评论文本转换为向量review_vector = \self._vectorizer.vectorize(row.review)# 获取评分对应的索引rating_index = \self._vectorizer.rating_vocab.lookup_token(row.rating)return {'x_data': review_vector,'y_target': rating_index}def get_num_batches(self, batch_size):"""根据给定的批次大小,返回数据集中的批次数量参数:batch_size (int): 批次大小返回:数据集中的批次数量"""return len(self) // batch_sizedef generate_batches(dataset, batch_size, shuffle=True,drop_last=True, device="cpu"):"""一个生成器函数,封装了 PyTorch 的 DataLoader。它将确保每个张量都位于正确的设备上。"""dataloader = DataLoader(dataset=dataset, batch_size=batch_size,shuffle=shuffle, drop_last=drop_last)for data_dict in dataloader:out_data_dict = {}for name, tensor in data_dict.items():out_data_dict[name] = data_dict[name].to(device)yield out_data_dict这里不对代码进行解释了,关键部分已添加注释。
2.4备注
上述代码可能过长,导致难以理解,其实就是一个向量化表征的思想。上述采用的思想就是基于词频统计的,将整个训练集上的每条评论数据使用split(" ")分开形成若干个token,统计这些token出现的次数,将频次大于cutoff=25的token加入到词汇表中,并分配一个编码,其实就是索引。样本中的每条评论数据应该怎么表征呢,其实就是一个基于上述创建的词汇表的独热编码,因此是一个向量。
至此样本的向量化表征到此结束。接着就到定义模型,进行训练了。
结语
为了避免博客内容过长,这里就先到此结束,后续将接着上述内容进行阐述!同时本项目也是博主接触的第一个NLP领域的项目,如有不足,请批评指正!!!
备注:本案例代码参考本校《自然语言处理》课程实验中老师提供的参考代码
相关文章:
自然语言处理入门级项目——文本分类
文章目录 前言1.数据预处理1.1数据集介绍1.2数据集抽取1.3划分数据集1.4数据清洗1.5数据保存 2.样本的向量化表征2.1词汇表2.2向量化2.3自定义数据集2.4备注 结语 前言 本篇博客主要介绍自然语言处理领域中一个项目案例——文本分类,具体而言就是判断评价属于积极还…...

如何利用大模型对文章进行分段,提高向量搜索的准确性?
利用大模型对文章进行分段以提高向量搜索准确性,需结合文本语义理解、分块策略优化以及向量表示技术。以下是系统性的解决方案: 一、分块策略的核心原则 语义完整性优先 分块需确保每个文本单元在语义上独立且完整。研究表明,当分块内容保持单一主题时,向量嵌入的语义表征能…...

一发入魂:极简解决 SwiftUI 复杂视图未能正确刷新的问题(上)
概述 各位似秃非秃小码农们都知道,在 SwiftUI 中视图是状态的函数,这意味着状态的改变会导致界面被刷新。 但是,对于有些复杂布局的 SwiftUI 视图来说,它们的界面并不能直接映射到对应的状态上去。这就会造成一个问题࿱…...

深入理解 Dijkstra 算法:原理、实现与优化
算法核心思想 Dijkstra算法采用贪心策略,其核心思想可以概括为: 初始化:设置起点到自身的距离为0,到其他所有点的距离为无穷大 迭代处理: 从未处理的顶点中选择当前距离起点最近的顶点 标记该顶点为已处理 通过该顶…...

Postman中https和http的区别是什么?
作为每天与API打交道的测试工程师,理解HTTP与HTTPS的区别不仅关乎协议本身,更直接影响测试方案设计。本文将用测试视角揭示二者在Postman中的关键差异,并分享实战排查技巧。 一、协议层本质差异(测试工程师需要知道的底层原理) 1. 安全传输机制对比 特性HTTPHTTPS加密方…...
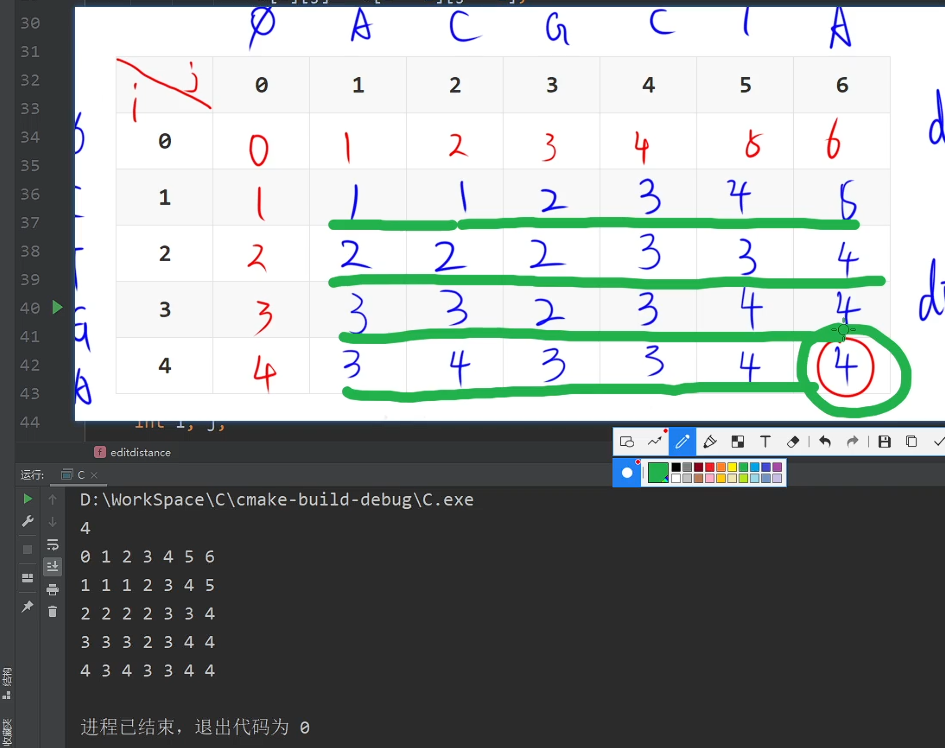
软件设计师-下午题-试题4(15分)
目录 1 回溯法 1.1 N皇后问题 1.1.1 非递归求解N皇后问题 1.1.2 递归求解N皇后问题 1.2 真题 2 分治法 2.1 真题 3 动态规划法 3.1 0-1背包问题 3.2 真题 1 回溯法 1.1 N皇后问题 上图Q4与Q2在同一列且与Q1在同一斜线,先回溯到上一个皇后改变Q3皇后的位置…...

《隐私计算:数据安全与隐私保护的新希望》
一、引言 在数字化时代,数据已成为企业和组织的核心资产。然而,数据的收集、存储和使用过程中面临着诸多隐私和安全挑战。隐私计算作为一种新兴技术,旨在解决数据隐私保护和数据共享之间的矛盾。本文将深入探讨隐私计算的基本概念、技术原理、…...
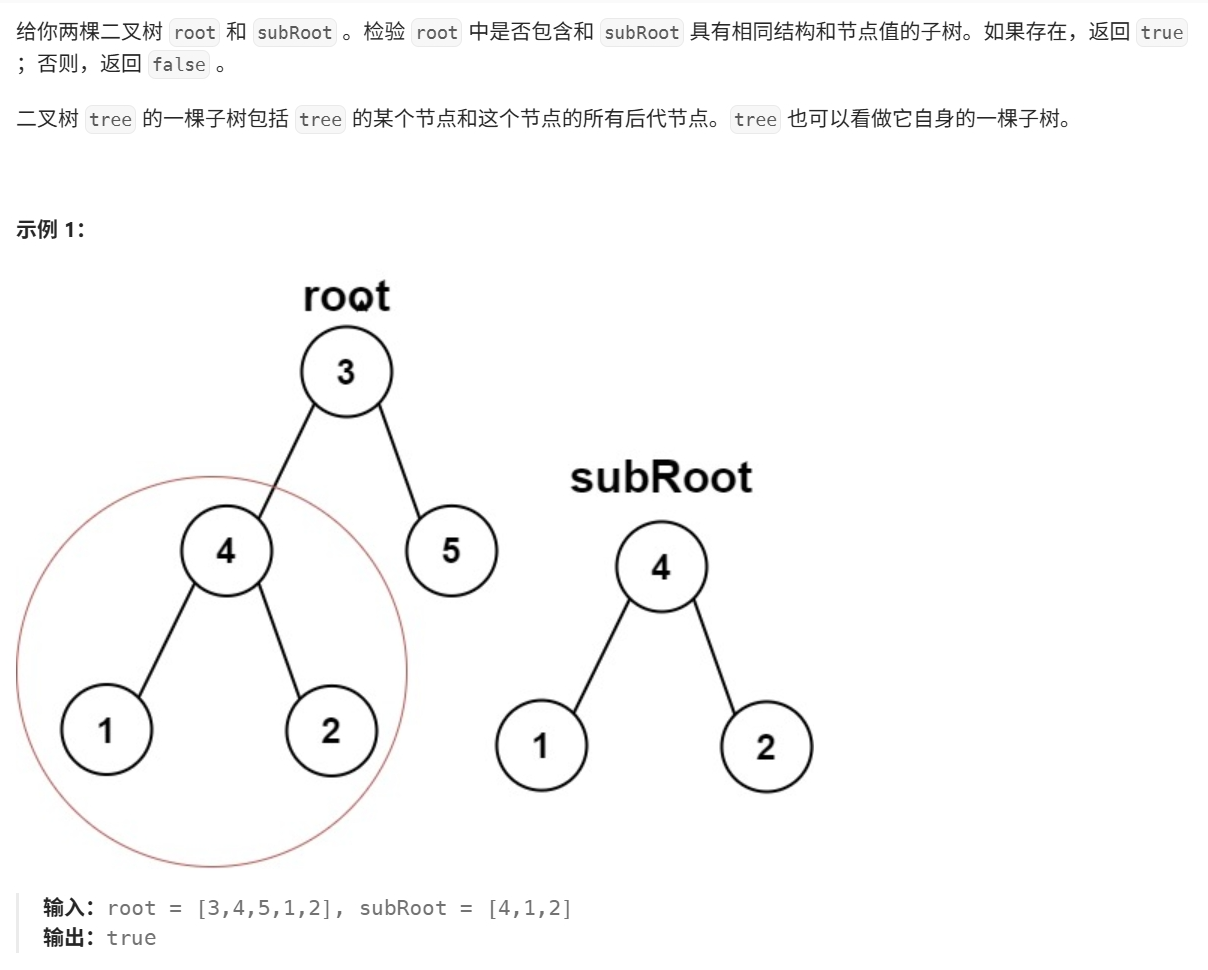
leetcode二叉树相关题目复习(C语言版)
目录 1.单值二叉树 2.相同的树 3.对称二叉树 4.二叉树的前序遍历 5.另一颗树的子树 1.单值二叉树 思路1: 判断根节点、左节点与右节点的值是否相等,因为正向判断(即判断三值相等返回true)比较麻烦(不能根节点满足…...
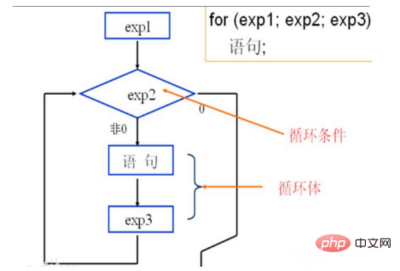
第十九次博客打卡
今天学习的内容是Java中的常见循环。 在 Java 中,常见的循环结构主要有以下几种:for 循环、while 循环、do-while 循环以及增强型 for 循环(也称为 for-each 循环)。 1. for 循环 for 循环是一种非常灵活的循环结构,…...

【Pandas】pandas DataFrame describe
Pandas2.2 DataFrame Computations descriptive stats 方法描述DataFrame.abs()用于返回 DataFrame 中每个元素的绝对值DataFrame.all([axis, bool_only, skipna])用于判断 DataFrame 中是否所有元素在指定轴上都为 TrueDataFrame.any(*[, axis, bool_only, skipna])用于判断…...

机器人示教操作
机器人基础操作 **ES机器人试教操作知识** **1. 视角移动** **1.1 基础模式** - 关节轴控制:通过关节1至关节6实现单轴正反转移动 - 直线移动:通过X/Y/Z坐标轴沿指定方向直线移动 - 旋转移动:通过RX/RY/RZ坐标轴绕指定轴旋转 **1.2 步进模式…...
浅聊一下数据库的索引优化
背景 这里的索引说的是关系数据库(MSSQL)中的索引。 本篇不是纯技术性的内容,只是聊一次性能调优的经历,包含到一些粗浅的实现和验证手段,所以,大神忽略即可。 额…对了,笔者对数据库的优化手段…...

山东大学软件学院软件工程计算机图形学复习笔记(2025)
写在前面: 现在是考完试的第二天,考试的内容还是有一部分没有复习到的…… 根据三角形的3个顶点坐标和内部某点坐标D,写出点D的基于面积的权重坐标Bresenham的算法描述与改进策略(这里ppt上很不清晰)以及直线反走样的…...

【Docker】Docker Compose方式搭建分布式内存数据库(Redis)集群
文章目录 开发环境开发流程运行效果Docker Desktop桌面中的Redis结点启动图Redis结点1的打印日志情况图 配置代码命令行启动配置文件: README.md删除集群信息新建数据目录本地Redis的结点的域名,并添加到/etc/hosts文件的末尾域名映射启动集群结点创建集群关闭集群结点 redis-c…...

如何在 Bash 中使用 =~ 操作符 ?
在 Bash 脚本世界中,有各种操作符可供我们使用,使我们能够操作、比较和测试数据。其中一个操作符是 ~ 操作符。这个操作符经常被忽视,但功能非常强大,它为我们提供了一种使用正则表达式匹配字符串模式的方法。 ~ 操作符语法 语法…...

科学养生指南:打造健康生活
在快节奏的现代生活中,健康养生成为人们关注的焦点。科学养生无需复杂理论,掌握以下几个关键要素,就能为身体构筑坚实的健康防线。 合理饮食是健康的基础。世界卫生组织建议,每天应摄入至少 5 份蔬菜和水果,保证维生…...

华为OD机试真题——单词接龙(首字母接龙)(2025A卷:100分)Java/python/JavaScript/C/C++/GO最佳实现
2025 A卷 100分 题型 本专栏内全部题目均提供Java、python、JavaScript、C、C++、GO六种语言的最佳实现方式; 并且每种语言均涵盖详细的问题分析、解题思路、代码实现、代码详解、3个测试用例以及综合分析; 本文收录于专栏:《2025华为OD真题目录+全流程解析+备考攻略+经验分…...

React构建组件
React构建组件 React 组件构建方式详解 React 组件的构建方式随着版本迭代不断演进,目前主要有 函数组件 和 类组件 两种核心模式,并衍生出多种高级组件设计模式。以下是完整的构建方式指南: 文章目录 React构建组件React 组件构建方式详解…...
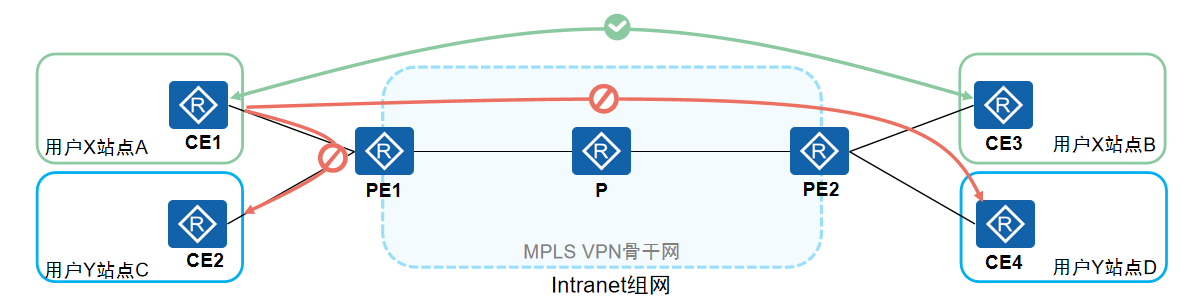
计算机网络-MPLS VPN基础概念
前面几篇文章我们学习了MPLS的标签转发原理,有静态标签分发和LDP动态标签协议,可以实现LSR设备基于标签实现数据高效转发。现在开始学习MPLS在企业实际应用的场景-MPLS VPN。 一、MPLS VPN概念 MPLS(多协议标签交换)位于TCP/IP协…...

基于TouchSocket实现WebSocket自定义OpCode扩展协议
基于TouchSocket实现WebSocket自定义OpCode扩展协议 前言一、WebSocket OpCode规范速览二、实现示例:协同编辑光标同步1. 客户端发送实现2. 服务端接收处理 三、应用场景分析1. 实时协作系统2. 物联网控制协议3. 游戏实时交互 四、协议设计建议1. 帧结构优化2. 性能…...

【Linux系列】bash_profile 与 zshrc 的编辑与加载
💝💝💝欢迎来到我的博客,很高兴能够在这里和您见面!希望您在这里可以感受到一份轻松愉快的氛围,不仅可以获得有趣的内容和知识,也可以畅所欲言、分享您的想法和见解。 推荐:kwan 的首页,持续学…...

Spring Boot中的拦截器!
每次用户请求到达Spring Boot服务端,你是否需要重复写日志、权限检查或请求格式化代码?这些繁琐的“前置后置”工作让人头疼!好在,Spring Boot拦截器如同一道智能关卡,统一处理请求的横切逻辑,让代码优雅又…...
基于 Spring Boot 瑞吉外卖系统开发(十五)
基于 Spring Boot 瑞吉外卖系统开发(十五) 前台用户登录 在登录页面输入验证码,单击“登录”按钮,页面会携带输入的手机号和验证码向“/user/login”发起请求。 定义UserMapper接口 Mapper public interface UserMapper exte…...

计算机网络笔记(二十三)——4.5IPv6
4.5.1IPv6的基本首部 IPv6 的基本首部相对于 IPv4 进行了重大简化和优化,固定长度为 40 字节,大幅提升了路由器的处理效率。以下是各字段的详细说明: IPv6 基本首部字段组成 字段名位数作用描述版本 (Version)4 bits固定值为 6,…...

推荐一个Winform开源的UI工具包
从零学习构建一个完整的系统 推荐一个开源、免费的适合.NET WinForms 控件的套件。 项目简介 Krypton是一套开源的.Net组件,用于快速构建具有丰富UI交互的WinForms应用程序。 丰富的UI控件,提供了48个基础控件,如按钮、文本框、标签、下拉…...
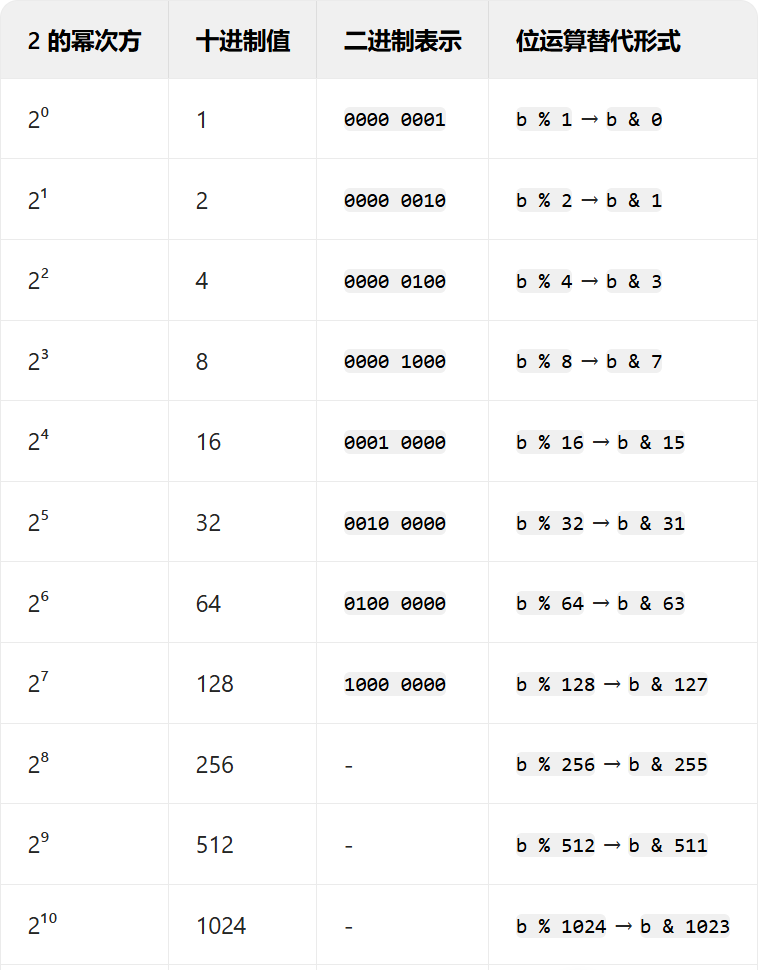
位与运算
只有当除数是 2 的幂次方(如 2、4、8、16...)时,取模运算才可以转换为位运算。 int b 19;int a1 b % 16; // 传统取模运算int a2 b & 15; // 位运算替代取模printf("b %d\n", b);printf("b %% 8 %d\n",…...

算法备案如何判断自己的产品是否具备舆论属性
判断互联网产品是否具备舆论属性或社会动员能力,需要结合《具备舆论属性或社会动员能力的互联网信息服务安全评估规定》法规及实际功能、用户规模、信息传播方式等综合因素判定。 一、舆论属性判断标准 (1)服务功能与形式 信息交互功能&am…...

AR禁毒:科技赋能,筑牢防毒新防线
过去,传统禁毒宣传教育方式对普及禁毒知识、提高禁毒意识意义重大。但随着时代和社会环境变化,其困境逐渐显现。传统宣传方式单一,主要依靠讲座、发传单、办展览。讲座形式枯燥,对青少年吸引力不足;发传单易被丢弃&…...

趣味编程:四叶草
概述:在万千三叶草中寻觅,只为那一抹独特的四叶草之绿,它象征着幸运与希望。本篇博客主要介绍四叶草的绘制。 1. 效果展示 绘制四叶草的过程是一个动态的过程,因此博客中所展示的为绘制完成的四叶草。 2. 源码展示 #define _CR…...
详解)
访问者模式(Visitor Pattern)详解
文章目录 1. 访问者模式概述1.1 定义1.2 基本思想2. 访问者模式的结构3. 访问者模式的UML类图4. 访问者模式的工作原理5. Java实现示例5.1 基本实现示例5.2 访问者模式处理复杂对象层次结构5.3 访问者模式在文件系统中的应用6. 访问者模式的优缺点6.1 优点6.2 缺点7. 访问者模式…...