【嵌入模型与向量数据库】
目录
一、什么是向量?
二、为什么需要向量数据库?
三、向量数据库的特点
四、常见的向量数据库产品
FAISS 支持的索引类型 vs 相似度
五、常见向量相似度方法对比
六、应该用哪种
七、向量数据库的核心逻辑
🔍 示例任务:查找与这句话最相似的一句话
八、图示:向量空间中的相似度搜索
九、实际案例:文本语义检索
十、实际案例:图像搜索
十一、总结图:向量数据库流程
十二、 faiss向量数据代码用例
说明
文件结构
documents.txt
main.py(简化版)
运行结果

向量数据库(Vector Database)是一种专门用于存储、管理和检索高维向量数据的数据库系统。它的核心作用是实现相似度搜索(Similarity Search),即在海量数据中快速找到“最相似”的数据项。
一、什么是向量?
在机器学习和人工智能中,向量是一种用来表示数据的数学结构。比如:
-
一张图片可以被编码成一个128维的向量。
-
一段文本可以通过模型(如BERT)转换成768维的向量。
-
用户的兴趣或商品的特征也可以表示为向量。
这些向量通常来源于神经网络模型,称为“嵌入向量(embedding)”。
二、为什么需要向量数据库?
传统数据库适合处理结构化数据(如数字、字符串等),而不适合处理向量的“相似性检索”。向量数据库的优势在于可以支持如下需求:
-
检索与某段文本语义相似的内容(如ChatGPT的知识搜索)
-
找到与用户行为相似的商品或视频(推荐系统)
-
查找长相相似的人脸图像(图像识别)
-
在安全监控中匹配相似的车牌或目标(目标识别)
三、向量数据库的特点
| 特点 | 描述 |
|---|---|
| 高维向量支持 | 支持数十到上千维的向量存储与计算 |
| 相似度检索 | 支持基于余弦相似度、欧氏距离、点积等方式的Top-K搜索 |
| 近似最近邻搜索(ANN) | 使用高效算法(如 HNSW、IVF、PQ)实现“近似而快速”的搜索 |
| 可扩展性 | 能够处理上亿甚至上百亿条向量数据 |
| 多模态支持 | 支持图像、文本、音频等多种模态的向量嵌入 |
四、常见的向量数据库产品
| 名称 | 特点 |
|---|---|
| FAISS(Meta) | 高性能向量搜索库,适合本地使用 |
| Milvus | 开源,分布式,支持亿级向量,适合工业部署 |
| Weaviate | 支持文本搜索和语义索引,内置向量生成 |
| Pinecone | 云原生,面向生产级应用 |
| Qdrant | 支持高效过滤器和payload数据的检索 |
FAISS 支持的索引类型 vs 相似度
| FAISS 索引类型 | 支持相似度方式 | 是否需归一化 |
|---|---|---|
IndexFlatL2 | 欧氏距离 | ❌ 否 |
IndexFlatIP | 内积(近似余弦) | ✅ 是(手动) |
IndexFlatCosine | ✅ 余弦相似度 | ✅ 自动归一化(新版本才支持) |
- FAISS: Meta 开源的向量检索引擎 https://github.com/facebookresearch/faiss
- Pinecone: 商用向量数据库,只有云服务 The vector database to build knowledgeable AI | Pinecone
- Milvus: 开源向量数据库,同时有云服务 Milvus | High-Performance Vector Database Built for Scale
- Weaviate: 开源向量数据库,同时有云服务 The AI-native database developers love | Weaviate
- Qdrant: 开源向量数据库,同时有云服务 Qdrant - Vector Database - Qdrant
- PGVector: Postgres 的开源向量检索引擎 https://github.com/pgvector/pgvector
- RediSearch: Redis 的开源向量检索引擎 https://github.com/RediSearch/RediSearch
- ElasticSearch 也支持向量检索 Elasticsearch vector search - highly relevant, lightning fast search | Elastic
五、常见向量相似度方法对比
| 方法名称 | 公式(向量 A 和 B) | 取值范围 | 越小越相似? | 特点说明 |
|---|---|---|---|---|
| 欧氏距离 (L2) | [0, +∞) | ✅ 是 | 距离越小越相似。对向量长度敏感。 | |
| 余弦相似度 | [-1, 1] | ❌ 否 | 越接近 1 越相似。方向相近即可,不管长度。 | |
| 内积 (dot product) | 任意实数 | ❌ 否 | 通常需要归一化后使用,变成余弦相似度。 |
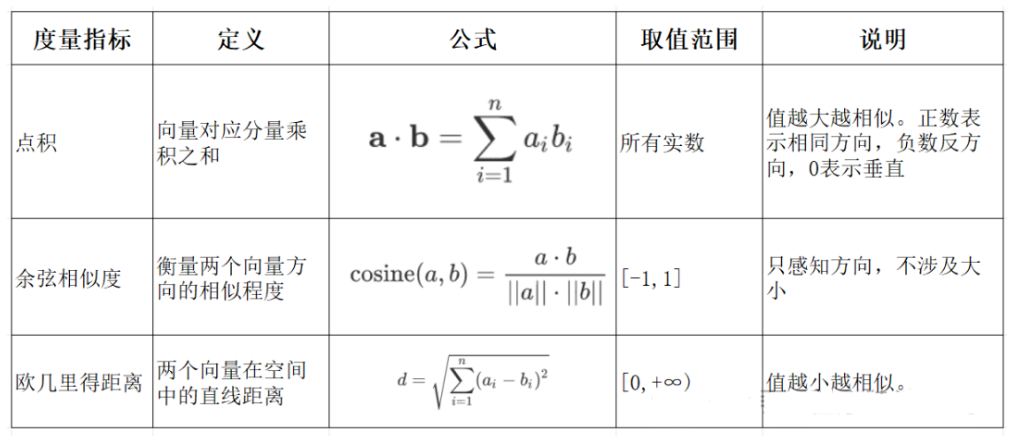
六、应该用哪种
| 场景 | 推荐相似度类型 | 理由 |
|---|---|---|
| 文本检索 / 语义搜索 | 余弦相似度 or 内积(需归一化) | 语义相似的句子方向一致,即便长度不同也应视为相似。 |
| 数值空间距离计算 | 欧氏距离(L2) | 更注重“几何距离”本身。 |
| 图像、传感器数据 | L2 / 内积 | 嵌入空间常是连续向量域,L2 更合适。 |
代码示例
import numpy as np# 假设有两个向量
vec1 = np.array([0.1, 0.3, 0.5])
vec2 = np.array([0.2, 0.1, 0.7])# 欧氏距离
euclidean = np.linalg.norm(vec1 - vec2)# 曼哈顿距离
manhattan = np.sum(np.abs(vec1 - vec2))# 余弦相似度
cosine = np.dot(vec1, vec2) / (np.linalg.norm(vec1) * np.linalg.norm(vec2))print(f"欧氏距离: {euclidean:.4f}")
print(f"曼哈顿距离: {manhattan:.4f}")
print(f"余弦相似度: {cosine:.4f}")
运行结果
欧氏距离: 0.3000
曼哈顿距离: 0.5000
余弦相似度: 0.9201
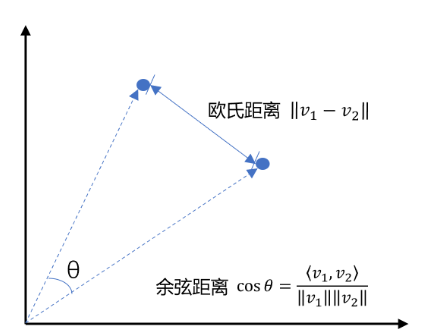
七、向量数据库的核心逻辑
🔍 示例任务:查找与这句话最相似的一句话
🟢 查询语句:
“我今天想去看电影。”
被模型(如 BERT)转换成一个 768 维向量:
[0.12, -0.34, 0.56, ..., 0.87]
🗂 向量数据库中预存了大量句子的向量,比如:
| 原始句子 | 向量表示(768维) |
|---|---|
| “晚上看个电影放松一下吧。” | [0.13, -0.33, 0.57, ..., 0.88] |
| “我今天不太想出门。” | [0.01, -0.55, 0.24, ..., 0.39] |
| “今天天气很好。” | [0.45, 0.22, 0.18, ..., 0.72] |
📌 向量数据库通过余弦相似度等算法,找出最相似的向量(Top-K),再返回对应的句子。
八、图示:向量空间中的相似度搜索
想象每个句子被映射到一个三维空间中的点(实际是高维空间):

🧲 目标是:找到距离查询点最近的几个点 —— 这就是向量数据库做的事!
九、实际案例:文本语义检索
你构建了一个问答系统,用户输入:
“怎么注册公司的营业执照?”
系统会将这个问题转为向量,然后在知识库中查找语义最接近的答案,比如:
-
“如何办理工商注册?”
-
“注册公司需要准备哪些资料?”
-
“去哪个地方办营业执照?”
向量数据库会返回这些“语义相似”的文本,而不只是关键词匹配。
🧠 这就是语义搜索 vs 关键词搜索的区别。
十、实际案例:图像搜索
你上传一张猫的照片,系统会在数据库中返回类似的图片:
-
🐱 颜色相近的猫
-
🐈 姿势相似的猫
-
🐾 背景相近的猫图
原因是:图像也可以转成向量,向量数据库进行相似度查找。
十一、总结图:向量数据库流程
原始数据(文本/图片/音频)↓向量模型生成 embedding↓向量入库(Milvus, FAISS, Pinecone等)↓用户输入查询 → 同样转换成向量↓在向量空间中找最近的K个邻居(ANN)↓返回原始内容(文本、图片、视频等)
十二、 faiss向量数据代码用例
说明
1、选用向量模型:阿里百炼的文本向量模型(text-embedding-v1);
2、运行条件:需要有百炼控制台的APIkey;
3、查看(选择)其它向量模型:百炼控制台;
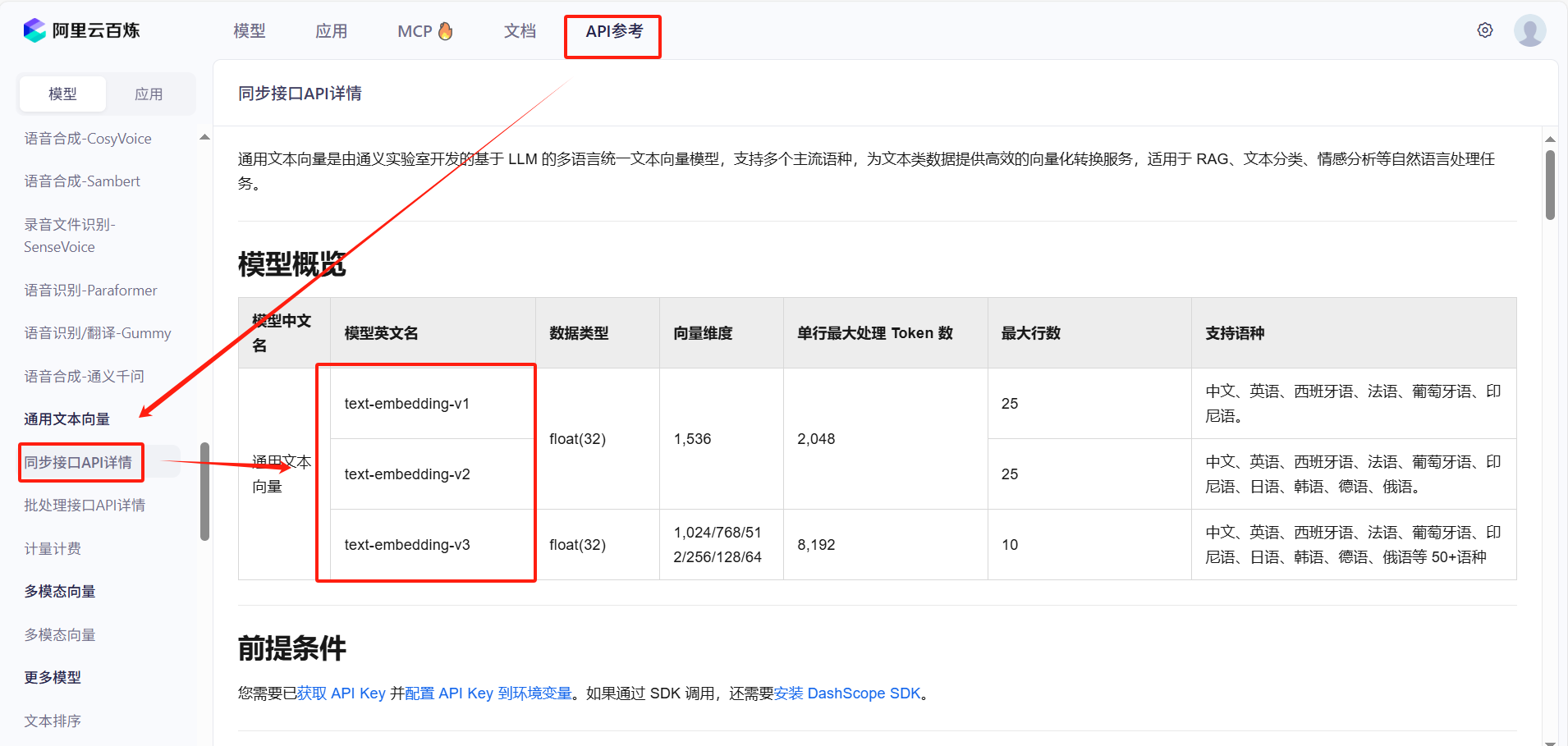
该图是百炼提供的3种文本向量模型
文件结构
semantic_search_demo/
├── main.py # 主程序
├── documents.txt # 示例语料库(你要搜索的内容)
├── requirements.txt # 依赖库
documents.txt
这个作为知识库示例
注册公司需要准备身份证、注册地址、公司章程等材料。
营业执照由工商局颁发,需要填写申请表。
税务登记是注册公司的后续步骤。
开公司银行账户需要营业执照和法人身份证。
你可以在线申请营业执照。
main.py(简化版)
import faiss
import dashscope
import os
import numpy as np
from tqdm import tqdm# 设置 API KEY(你也可以改为用环境变量)
dashscope.api_key = os.getenv("DASHSCOPE_API_KEY")# 获取当前脚本所在目录的绝对路径
BASE_DIR = os.path.dirname(os.path.abspath(__file__))
DOC_PATH = os.path.join(BASE_DIR, "documents.txt")# 载入文档
if not os.path.exists(DOC_PATH):raise FileNotFoundError(f"未找到文件:{DOC_PATH}")with open(DOC_PATH, "r", encoding="utf-8") as f:docs = [line.strip() for line in f.readlines() if line.strip()]# 使用阿里百炼嵌入模型
def get_embedding(text):rsp = dashscope.TextEmbedding.call(model="text-embedding-v1",input=text)if rsp.status_code == 200:return rsp.output['embeddings'][0]['embedding']else:raise ValueError(f"❌ 嵌入失败: {rsp.message}")# 生成文档向量
print("🔍 正在生成文档向量...")
doc_embeddings = [get_embedding(doc) for doc in tqdm(docs)]# 建立 FAISS 索引
dim = len(doc_embeddings[0])
index = faiss.IndexFlatL2(dim)
index.add(np.array(doc_embeddings).astype("float32"))# 查询函数
def search(query, top_k=3):q_embedding = get_embedding(query)D, I = index.search(np.array([q_embedding]).astype("float32"), top_k)return [(docs[i], D[0][j]) for j, i in enumerate(I[0])]# 主循环
if __name__ == "__main__":while True:q = input("\n请输入查询(输入 'exit' 退出):\n> ")if q.lower() == "exit":breakresults = search(q)print("\n🔍 最相似的段落:")for i, (text, score) in enumerate(results):print(f"{i+1}. {text} (距离:{score:.4f})")
运行结果
🔍 正在生成文档向量...
100%|█████████████████████████████████████| 5/5 [00:09<00:00, 1.90s/it]请输入查询(输入 'exit' 退出):
> 一个公司的创建需要具备什么条件🔍 最相似的段落:
1. 注册公司需要准备身份证、注册地址、公司章程等材料。 (距离:6633.3623)
2. 开公司银行账户需要营业执照和法人身份证。 (距离:8122.5732)
3. 营业执照由工商局颁发,需要填写申请表。 (距离:9337.1758)请输入查询(输入 'exit' 退出):
> 三里屯怎么走🔍 最相似的段落:
1. 注册公司需要准备身份证、注册地址、公司章程等材料。 (距离:15391.9512)
2. 税务登记是注册公司的后续步骤。 (距离:15656.2275)
3. 你可以在线申请营业执照。 (距离:16183.6201)请输入查询(输入 'exit' 退出):
> 注册公司需要准备什么材料🔍 最相似的段落:
1. 注册公司需要准备身份证、注册地址、公司章程等材料。 (距离:1627.7302)
2. 营业执照由工商局颁发,需要填写申请表。 (距离:5437.8076)
3. 开公司银行账户需要营业执照和法人身份证。 (距离:5667.3779)
main.py(优化版)
import faiss
import os
import numpy as np
from tqdm import tqdm
import dashscope
from dotenv import load_dotenv# 加载 .env 文件中的 API Key
load_dotenv()
dashscope.api_key = os.getenv("DASHSCOPE_API_KEY")# 获取当前脚本所在目录的路径
BASE_DIR = os.path.dirname(os.path.abspath(__file__))
DOC_PATH = os.path.join(BASE_DIR, "documents.txt")# 载入文档
if not os.path.exists(DOC_PATH):raise FileNotFoundError(f"未找到文件:{DOC_PATH}")with open(DOC_PATH, "r", encoding="utf-8") as f:docs = [line.strip() for line in f.readlines() if line.strip()]# 获取阿里百炼的向量
def get_embedding(text):rsp = dashscope.TextEmbedding.call(model="text-embedding-v1", # 阿里模型名input=text,)return rsp.output["embeddings"][0]["embedding"]# 向量归一化函数
def normalize(vec):norm = np.linalg.norm(vec)return vec / norm if norm > 0 else vec# 生成文档向量
print("🔍 正在生成文档向量...")
doc_embeddings = [normalize(get_embedding(doc)) for doc in tqdm(docs)]# 建立 FAISS 余弦相似度索引(内积模式)
dim = len(doc_embeddings[0])
index = faiss.IndexFlatIP(dim)
index.add(np.array(doc_embeddings).astype("float32"))# 计算欧几里得距离(欧式距离)
def euclidean_distance(vec1, vec2):return float(np.linalg.norm(np.array(vec1) - np.array(vec2)))# 查询函数:使用余弦相似度
def search(query, top_k=3):q_embedding = normalize(get_embedding(query))similarities = []for doc, doc_emb in zip(docs, doc_embeddings):# 计算余弦相似度cosine_sim = float(np.dot(q_embedding, doc_emb))# 计算欧几里得距离dist = euclidean_distance(q_embedding, doc_emb)similarities.append((doc, cosine_sim, dist, doc_emb))# 按余弦相似度排序similarities.sort(key=lambda x: x[1], reverse=True)top_results = similarities[:top_k]print("\n🔍 查询向量:")print(np.round(q_embedding, 4).tolist())print("\n📊 相似文档向量、余弦相似度 & 欧式距离:")for i, (doc, sim, dist, vec) in enumerate(top_results):print(f"\n{i+1}. 文本内容:{doc}")print(f" 文档向量:{np.round(vec, 4).tolist()}")print(f" 余弦相似度:{sim:.4f}")print(f" 欧式距离:{dist:.4f}")return [(doc, sim, dist) for doc, sim, dist, _ in top_results]# 主循环
if __name__ == "__main__":while True:q = input("\n请输入查询(输入 'exit' 退出):\n> ")if q.lower() == "exit":breakresults = search(q)print("\n🔍 最相似的段落(按余弦相似度降序):")for i, (text, sim, dist) in enumerate(results):print(f"{i+1}. {text} (余弦相似度:{sim:.4f},欧式距离:{dist:.4f})")运行结果
🔍 正在生成文档向量...
100%|█████████████████████████████████████████████████████████████████████████████████████████████████████| 5/5 [00:12<00:00, 2.59s/it]请输入查询(输入 'exit' 退出):
> 你好🔍 查询向量:
[0.0026, -0.0312, 0.0114, 0.0236, -0.0029, 0.0034, 0.0251, -0.0333, -0.0135, 0.0028, -0.0288, 0.0582, 0.0263, -0.0033, 0.0137, -0.0047, -0.0317, 0.016, -0.0047, 0.0211, -0.0313, -0.0203, 0.0066, -0.0228, 0.0292, -0.0183, 0.0028, 0.0084, -0.0164, 0.0071... ]📊 相似文档向量、余弦相似度 & 欧式距离:
1. 文本内容:你可以在线申请营业执照。
文档向量:[0.0312, 0.0475, 0.0324, 0.0472, -0.0346, 0.0171, -0.0325, 0.028, -0.0763, -0.0216, -0.0158, 0.0121, -0.0084, -0.0194, 0.0368, -0.0105, 0.0095, -0.0155, 0.0385, 0.013, -0.0147, 0.001, 0.0547, 0.0259, 0.0132, 0.0262, -0.0585, 0.0146, -0.0198, 0.016, ... ]
余弦相似度:0.1997
欧式距离:1.26522. 文本内容:注册公司需要准备身份证、注册地址、公司章程等材料。
文档向量:[0.0006, 0.0363, 0.0236, 0.0462, -0.0021, 0.0076, -0.0199, 0.027, -0.0587, -0.0176, -0.0289, -0.0134, 0.0296, -0.0566, 0.0102, -0.006, 0.0052, -0.0242, 0.0255, -0.046, -0.0065, 0.0107, 0.0173, 0.0214, -0.0075, 0.0027, -0.0233, -0.014, -0.0467, 0.0144, ]余弦相似度:0.1473
欧式距离:1.30593. 文本内容:开公司银行账户需要营业执照和法人身份证。
文档向量:[0.0007, 0.0148, 0.107, 0.009, -0.0025, 0.0103, -0.0273, 0.0553, -0.0794, -0.0432, -0.0285, -0.0105, 0.0291, -0.0292, 0.0212, -0.0296, 0.0196, -0.0294, 0.0092, -0.0325, 0.0117, -0.0071, -0.0013, 0.0267, -0.0065, 0.0112, -0.044, 0.0127, -0.0102...]
余弦相似度:0.1357
欧式距离:1.3148🔍 最相似的段落(按余弦相似度降序):
1. 你可以在线申请营业执照。 (余弦相似度:0.1997,欧式距离:1.2652)
2. 注册公司需要准备身份证、注册地址、公司章程等材料。 (余弦相似度:0.1473,欧式距离:1.3059)
3. 开公司银行账户需要营业执照和法人身份证。 (余弦相似度:0.1357,欧式距离:1.3148)
相关文章:
【嵌入模型与向量数据库】
目录 一、什么是向量? 二、为什么需要向量数据库? 三、向量数据库的特点 四、常见的向量数据库产品 FAISS 支持的索引类型 vs 相似度 五、常见向量相似度方法对比 六、应该用哪种 七、向量数据库的核心逻辑 🔍 示例任务:…...
【东枫科技】使用LabVIEW进行NVIDIA CUDA GPU 开发
文章目录 工具包 CuLab - LabVIEW 的 GPU 工具包特性和功能功能亮点类似 LabVIEW 的 GPU 代码开发支持的功能数值类型和维数开发系统要求授权售价 工具包 CuLab - LabVIEW 的 GPU 工具包 CuLab 是一款非常直观易用的 LabVIEW 工具包,旨在加速 Nvidia GPU 上的计算密…...
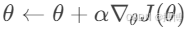
基于策略的强化学习方法之策略梯度(Policy Gradient)详解
在前文中,我们已经深入探讨了Q-Learning、SARSA、DQN这三种基于值函数的强化学习方法。这些方法通过学习状态值函数或动作值函数来做出决策,从而实现智能体与环境的交互。 策略梯度是一种强化学习算法,它直接对策略进行建模和优化,…...

1.Redis-key的基本命令
(一)Redis的基本类型 String,List,Set,Hash,Zset 三种特殊类型:geospatial(地理空间数据)、hyperloglog[基数估算(去重计数)]、bitmaps(位图&…...

JavaScript 中级进阶技巧之map函数
作为一名初级 JavaScript 开发者,你可能已经熟悉了基础语法、变量和简单的循环。但要从初级迈向中级,掌握一些高效、优雅的编码技巧是关键。其中,map 函数是中级开发者常用的工具,它不仅能简化代码,还能提升代码的可读…...

PROFIBUS DP转ModbusTCP网关模块于污水处理系统的成功应用案例解读
在当今的工业生产领域,众多企业在生产过程中会产生大量工业废水。若这些废水未经处理直接排放,将会引发严重的工业污染问题。因此,借助科技手段对污水进行有效处理显得尤为重要。在一个污水处理系统中,往往包含来自不同厂家、不同…...

Java实现桶排序算法
1. 桶排序原理图解 桶排序是一种基于分桶思想的非比较排序算法,适用于数据分布较为均匀的场景。其核心思想是将数据分散到有限数量的“桶”中,每个桶再分别进行排序(通常使用插入排序或其他简单的排序算法)。以下是桶排序的步骤&a…...

《Effective Python》第2章 字符串和切片操作——深入理解 Python 中 __repr__ 与 __str__
引言 本文基于学习《Effective Python》第三版 Chapter 2: Strings and Slicing 中的 Item 12: Understand the Difference Between repr and str When Printing Objects 后的总结与延伸。在 Python 中,__repr__ 和 __str__ 是两个与对象打印密切相关的魔术方法&am…...
电脑开机提示按f1原因分析及解决方法(6种解决方法)
经常有网友问到一个问题,我电脑开机后提示按f1怎么解决?不管理是台式电脑,还是笔记本,都有可能会遇到开机需要按F1,才能进入系统的问题,引起这个问题的原因比较多,今天小编在这里给大家列举了比较常见的几种电脑开机提示按f1的解决方法。 电脑开机提示按f1原因分析及解决…...
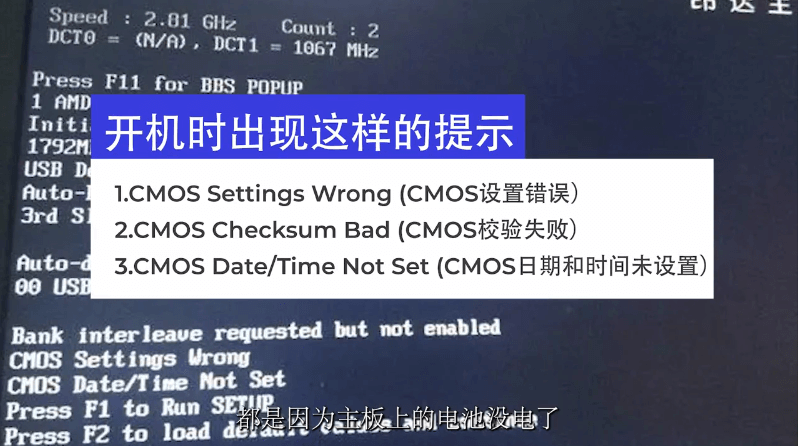
复现:DemoGen 用于数据高效视觉运动策略学习的 合成演示生成 (RSS) 2025
https://github.com/TEA-Lab/DemoGen?tabreadme-ov-file 复现步骤很简单,按照readme配置好conda环境即可运行。 运行: cd demo_generation bash run_gen_demo.sh 等待生成: 查看data文件夹...

Nginx核心功能及同类产品对比
Nginx 作为一款高性能的 Web 服务器和反向代理工具,凭借其独特的架构设计和丰富的功能,成为互联网基础设施中不可或缺的组件。以下是其核心功能及与同类产品(如 HAProxy、LVS)的对比优势: 一、Nginx 核心功能 高性能架…...
本地部署firecrawl的两种方式,自托管和源码部署
网上资料很多 AI爬虫黑科技 firecrawl本地部署-CSDN博客 源码部署 前提条件本地安装py,node.js环境,嫌弃麻烦直接使用第二种 使用git或下载压缩包 git clone https://github.com/mendableai/firecrawl.git 设置环境参数 cd /firecrawl/apps/api 复制环境参数 …...
2023年12月中国电子学会青少年软件编程(Python)等级考试试卷(六级)答案 + 解析
青少年软件编程(Python)等级考试试卷(六级) 分数:100 题数:38 一、单选题(共25题,共50分) 1. 运行以下程序,输出的结果是?( ) class A(): …...
)
spark:map 和 flatMap 的区别(Scala)
场景设定 假设有一个包含句子的 RDD: scala val rdd sc.parallelize(List("Hello World", "Hi Spark")) 目标是:将每个句子拆分成单词。 1. 用 map 的效果 代码示例 scala val resultMap rdd.map(sentence > sentence…...
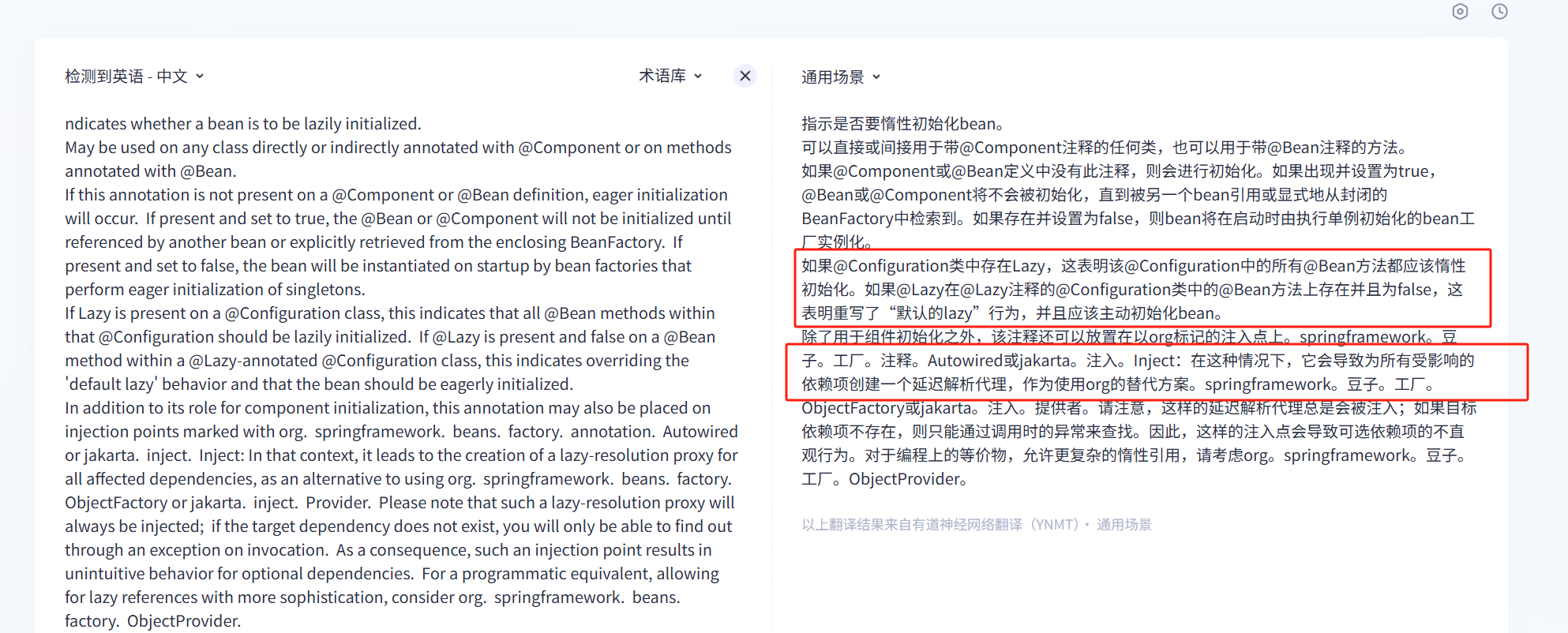
Spring @Lazy注解详解
文章目录 Lazy注解主要作用工作原理使用方法注意事项总结 Lazy注解主要作用 首先,让我们看看Lazy注解的源码,截图如下: 源码注释翻译如下 通过源码,我们可以看到:Lazy注解是一个标记注解,用于标记 bean会…...

关于推送后台的webapi demo
文章目录 目录 系列文章目录 文章目录 前言 一、如何实现推送的思考 二、使用步骤 1.引入库 2.连接方法 3. 发送数据 4.结束时发的消息 5.相关的类 总结 前言 手机app一般都有接收消息推送的功能,比如美团app 点的外卖订单推送,那么对于后台如何将消息推…...

中国品牌日 | 以科技创新为引领,激光院“风采”品牌建设结硕果
品牌,作为企业不可或缺的隐形财富,在当今竞争激烈的市场环境中,其构建与强化已成为推动企业持续繁荣的关键基石。为了更好地保护自主研发产品,激光院激光公司于2020年3月7日正式注册“风采”商标,创建拥有自主知识产权…...
GNU Screen 曝多漏洞:本地提权与终端劫持风险浮现
SUSE安全团队全面审计发现,广泛使用的终端复用工具GNU Screen存在一系列严重漏洞,包括可导致本地提权至root权限的缺陷。这些问题同时影响最新的Screen 5.0.0版本和更普遍部署的Screen 4.9.x版本,具体影响范围取决于发行版配置。 尽管GNU Sc…...

05.three官方示例+编辑器+AI快速学习three.js webgl - animation - skinning - ik
本实例主要讲解内容 这个Three.js示例展示了**反向运动学(Inverse Kinematics, IK)**在3D角色动画中的应用。通过加载一个角色模型,演示了如何使用IK技术实现自然的肢体运动控制,如手部抓取物体的动作。 核心技术包括: CCD反向运动学求解器…...

计算机视觉与深度学习 | 激光雷达 vs. RTK+摄像头:谁是智能割草机器人的最优选择?
激光雷达 vs. RTK+摄像头 一、技术原理与核心优势对比二、实际应用中的性能差异三、行业趋势与创新方向四、场景化选择建议五、未来展望激光雷达与RTK+摄像头是智能割草机器人领域两种主流技术路线,各有其适用场景与优劣势。结合行业最新动态与技术演进,以下从多个维度对比分…...
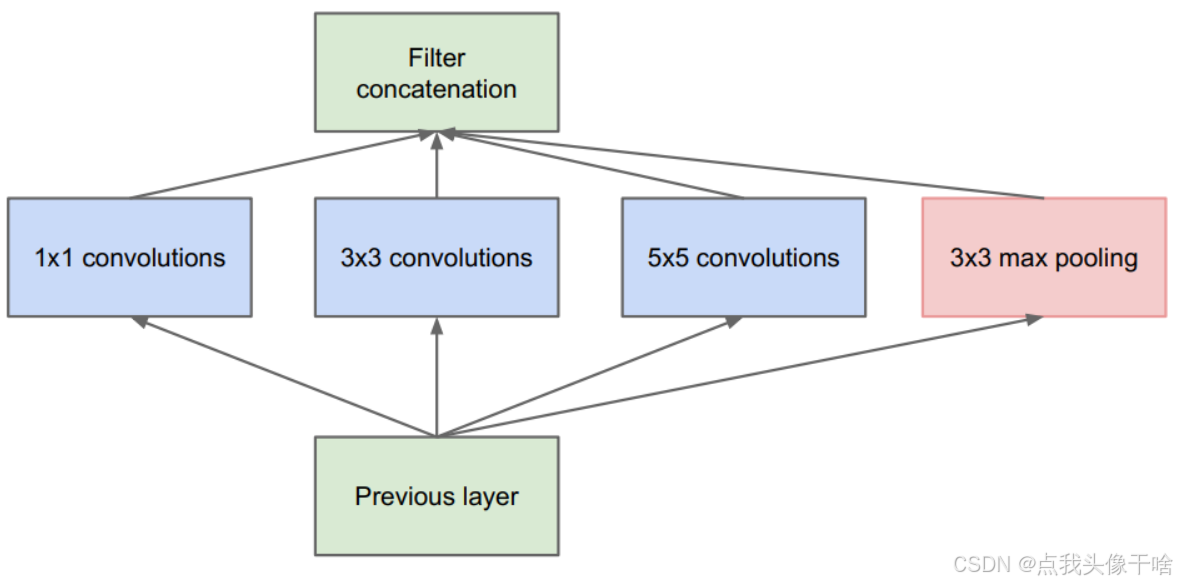
第29节:现代CNN架构-Inception系列模型
引言 Inception系列模型是卷积神经网络(CNN)发展历程中的重要里程碑,由Google研究人员提出并不断演进。这一系列模型通过创新的架构设计,在保持计算效率的同时显著提升了图像识别任务的性能。从最初的Inception v1到最新的Inception-ResNet,每一代Inception模型都引入了突破…...

【深度学习】将本地工程上传到Colab运行的方法
1、将本地工程(压缩包)上传到一个新的colab窗口:如下图中的 2.zip,如果工程中有数据集,可以删除掉。 2、解压压缩包。 !unzip /content/2.zip -d /content/2 如果解压出了不必要的文件夹可以递归删除: #…...
RabbitMQ 中的六大工作模式介绍与使用
文章目录 简单队列(Simple Queue)模式配置类定义消费者定义发送消息测试消费 工作队列(Work Queues)模式配置类定义消费者定义发送消息测试消费负载均衡调优 发布/订阅(Publish/Subscribe)模式配置类定义消…...
Android HttpAPI通信问题(已解决)
使用ClearTextTraffic是Android中一项重要的网络设置,它控制了应用程序是否允许在不使用HTTPS加密的情况下访问网络。在默认情况下,usescleartexttraffic的值为true,这意味着应用程序可以通过普通的HTTP协议进行网络通信。然而,这样的设置可能会引发一些安全问题,本文将对…...
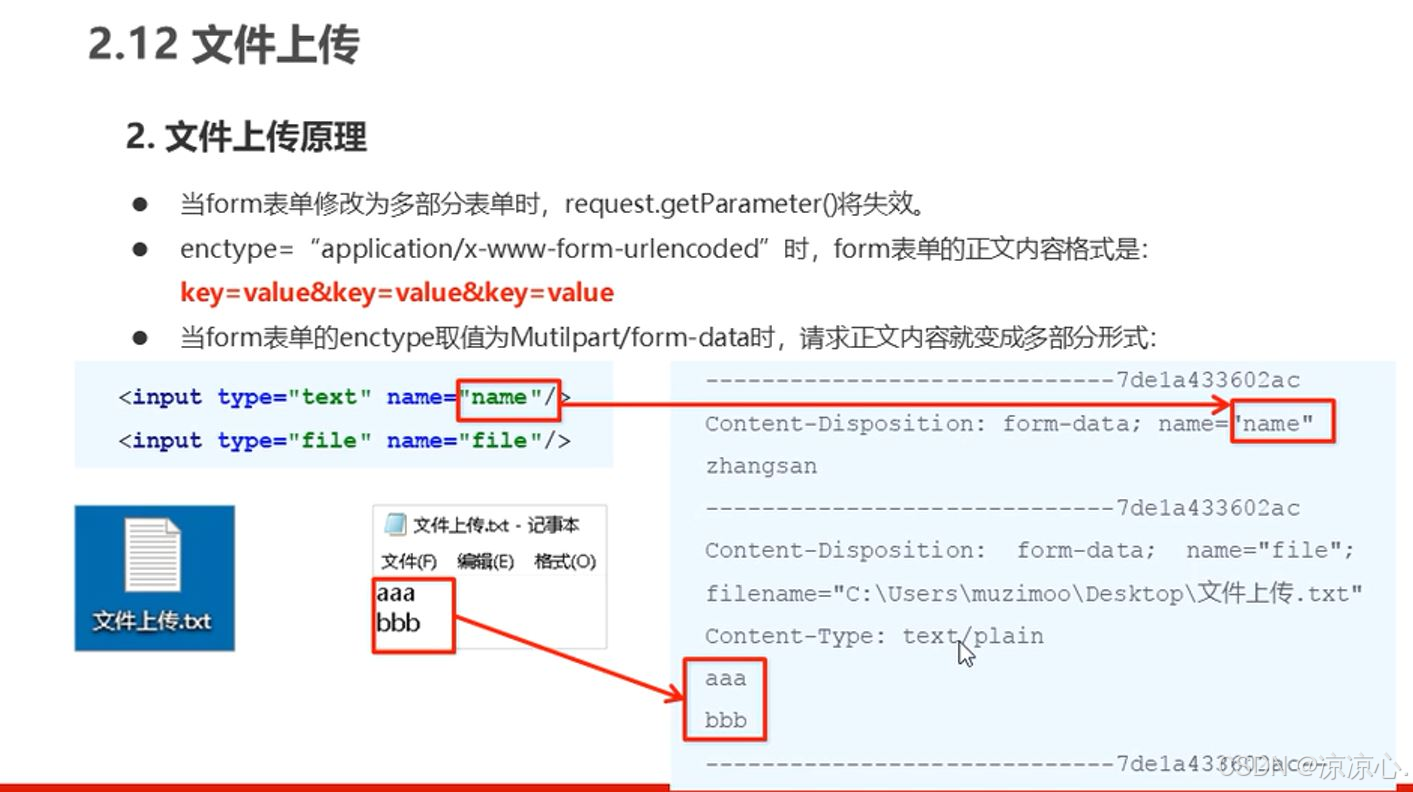
【SSM-SpringMVC(二)】Spring接入Web环境!本篇开始研究SpringMVC的使用!SpringMVC数据响应和获取请求数据
SpringMVC的数据响应方式 页面跳转 直接返回字符串通过ModelAndView对象返回 回写数据 直接返回字符串返回对象或集合 页面跳转: 返回字符串方式 直接返回字符串:此种方式会将返回的字符串与视图解析器的前后缀拼接后跳转 RequestMapping("/con&…...
docker安装mysql8, 字符集,SQL大小写规范,sql_mode
一、Docker安装MySQL 使用Docker安装MySQL,命令如下 docker run -d \-p 3306:3306 \-v mysql_conf:/etc/mysql/conf.d \-v mysql_data:/var/lib/mysql \--name mysql \--restartalways \--privileged \-e MYSQL_ROOT_PASSWORD1234 \mysql:8.0.30参数解释 🐳 dock…...

FastMCP v2:构建MCP服务器和客户端的Python利器
FastMCP v2:构建MCP服务器和客户端的Python利器 引言 在人工智能与大语言模型(LLMs)的应用场景中,如何高效地构建服务器和客户端以实现数据交互与功能调用是关键问题。Model Context Protocol (MCP) 为此提供了一种标准…...

一个WordPress连续登录失败的问题排查
文章目录 1. 问题背景2. 解决方案搜索3. 问题定位4. 排查过程5. 清理空间6. 处理结果7. 后续优化 1. 问题背景 登录请求URL: Request URL: https://www.xxxxxx.com/wp-login.php 返回的响应头信息是: location: https://www.xxxxxx.com/wp-admin/ 证明登录成功。 接下来浏览器…...
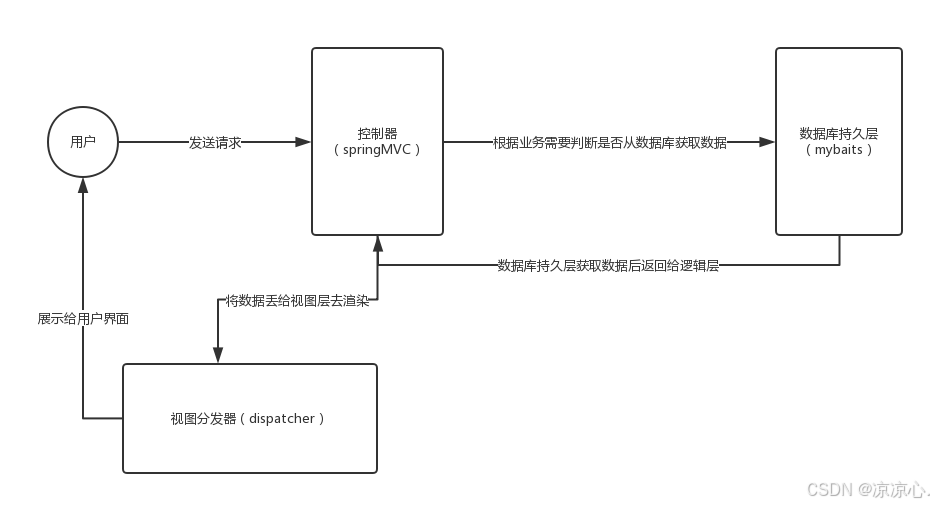
【SSM-SSM整合】将Spring、SpringMVC、Mybatis三者进行整合;本文阐述了几个核心原理知识点,附带对应的源码以及描述解析
SSM整合的基础jar包 需要创建的层级: controller层 该层下需要创建对应的控制器Servlet POJO文件夹 该层下需要创建与数据库对应的POJO类 mapper层 该层下需要创建Mapper的接口实现 service层 该层下需要创建业务层的接口及其接口实现 需要创建的配置文件&#x…...

Go语言超时控制方案全解析:基于goroutine的优雅实现
一、引言 在构建高可靠的后端服务时,超时控制就像是守护系统稳定性的"安全阀",它确保当某些操作无法在预期时间内完成时,系统能够及时止损并释放资源。想象一下,如果没有超时控制,一个简单的数据库查询卡住…...