leetcode - 滑动窗口问题集
目录
前言
题1 长度最小的子数组:
思考:
参考代码1:
参考代码2:
题2 无重复字符的最长子串:
思考:
参考代码1:
参考代码2:
题3 最大连续1的个数 III:
思考:
参考代码:
题4 将 x 减到 0 的最小操作数:
思考:
参考代码:
题5 水果成篮:
思考;
参考代码1:
参考代码2:
参考代码3:
题6 找到字符串中所有字母异位词:
思考:
参考代码1:
参考代码2:
题 7 串联所有单词的子串:
思考:
参考代码:
题8 最小覆盖子串 :
思考:
参考代码1:
参考代码2:
总结
前言
路漫漫其修远兮,吾将上下而求索;
以下是滑窗口问题leetcode 集,大家可以先自己做做看:
- 209. 长度最小的子数组
- 3. 无重复字符的最长子串
- 1004. 最大连续1的个数 III
- 1658. 将 x 减到 0 的最小操作数
- 904. 水果成篮
- 438. 找到字符串中所有字母异位词
- 30. 串联所有单词的子串
- 76. 最小覆盖子串
题1 长度最小的子数组:
209. 长度最小的子数组 - 力扣(LeetCode)
题干:
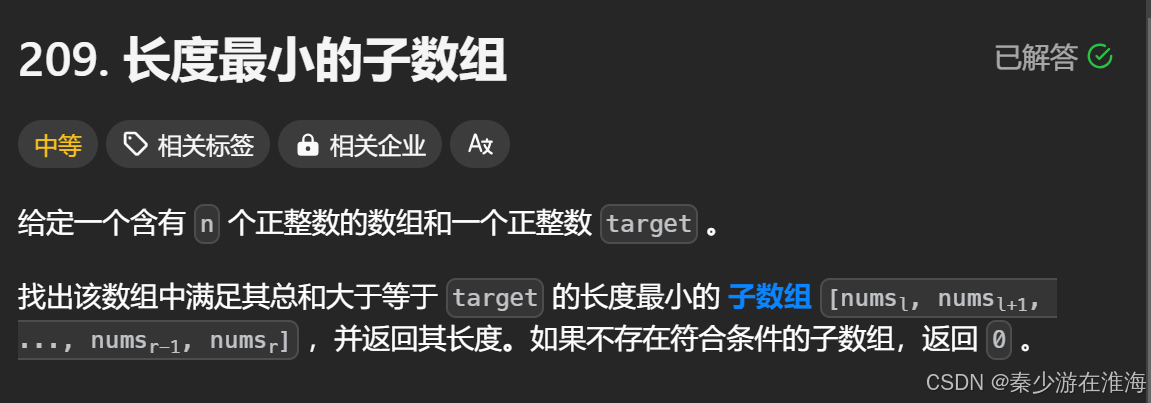
数据范围:
例子:

思考:
子数组:连续的数据
解法一:暴力枚举出所有子数组的情况,然后将其中的数据相加判断和是否大于target ;
这样的话,时间复杂度为O(N^3),并且本题的数据量不少,单纯地用暴力解决一定会超时;可以在暴力解法的基础上进行优化吗?无非就是在优化枚举所有子数组,计算该子数组的和这两点上进行优化;
由于数组中的数据均是正整数,正整数做加法有这样的性质:加的数越多,和就越大(利用了数据的单调性);
和前一篇“双指针题集”有相同之处,此处也可以利用数据的单调性来优化枚举所有子数组,而且还顺便可以优化计算其和:
- 假设我们两个指针(假设为left right, 这两个指针是同向走的)指向的区间中的数据为sum ,当sum 刚好大于target 的时候,可以再用一个变量记录此时子数组的长度;此时sum 已经大于target 了,那么可以让left++ ,减去前面较小的数看sum 是否还大于target ,如果还大于left 可以继续++,如果小于了就让right ++;(整体思路很像双指针)
稍微粗略的分析觉得可行之后,我们可以更加细节地分析:
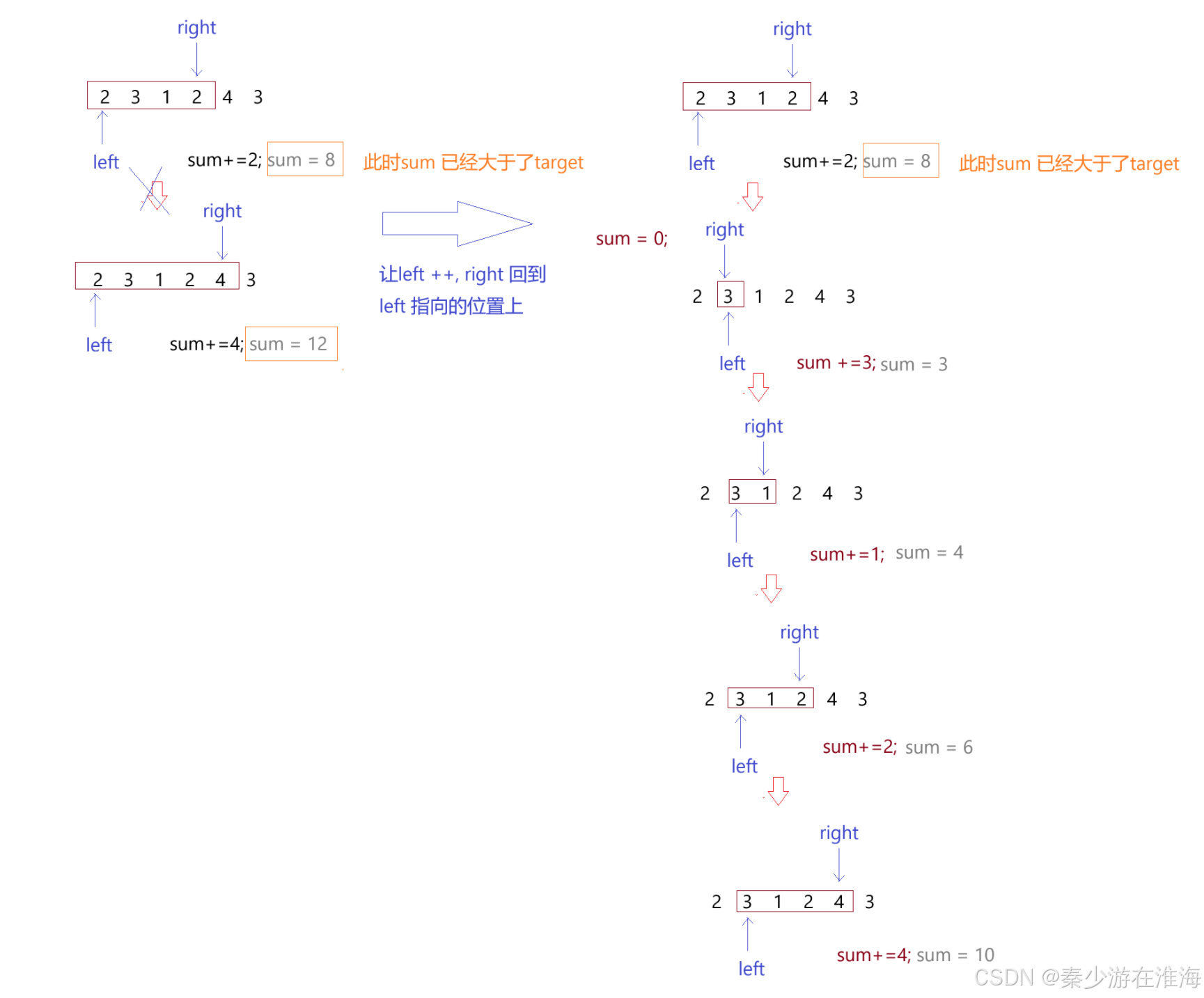
优化计算子数字的和:固定左区间,再定义一个变量来一直计算,这样就不用每遇到一个区间就从头到尾依次计算,图解如下:(下图的target 为 7)

当sum 已经大于target 的时候,此时left 和 right 的区间就已经为较小子数组长度下的和,right 也没有必要继续向前走了;
优化:当sum 已经大于target 的时候,让变量记录一下该子数组的长度,然后让left ++ ,再让right 回到left 指向的位置上,如下:
倘若当我们找到一个符合要求的区间之后让left 自增,然后再让right 指向left 指向的字符,那么就会需要将sum 置为0,然后一个一个地再遍历,计算该子数组中数据中的和;时间复杂度为O(N^2);实际上,还可以继续优化:当left 和 right 指向的区间中的数据和大于target 的时候,left ++ ,但是right 并不回到left 指向的位置处,而是让right 不动,sum 减去left 之前所指向的数据,再判断sum 和 target 的大小关系,如果sum 还是大于target ,left 继续++ ,sum 再减去left 之前所指向的数,然后再判断sum 和 target 的大小关系……如果sum小于target ,right 就++……优化二如下图:
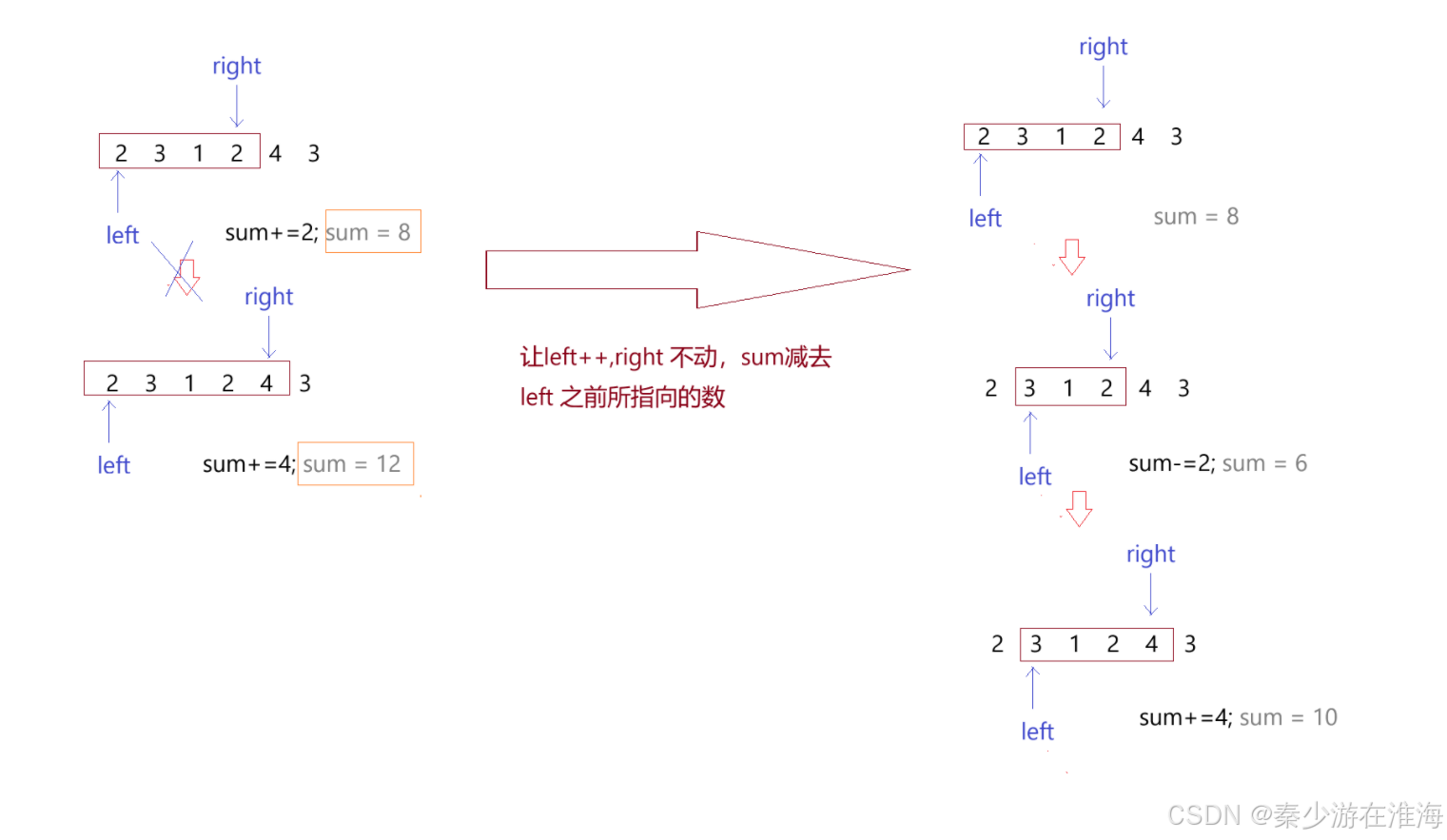
对于优化2的操作,本质上就是滑动窗口的理念,即利用单调性,并且使用同向双指针;利用滑动窗口一般是来维护一个区间;
思路总结:
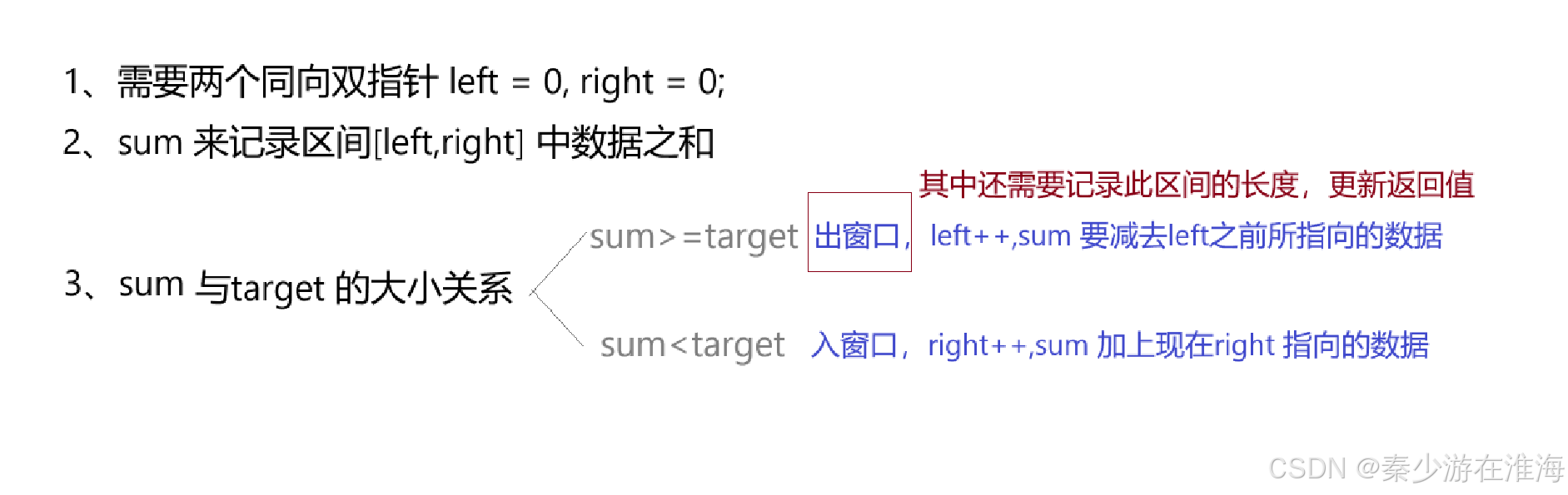
按照上面的思路写代码,我们会发现:

在出窗口的位置要写成循环:
参考代码1:
(while 循环版本)
int minSubArrayLen(int target, vector<int>& nums) {int n = nums.size();//单调性 + 同向双指针int left = 0, right = 0;int sum = 0, retlen = INT_MAX;while(right < n){//当sum 小于target 就入窗口sum+=nums[right];while(sum >= target){//此时sum >= target ,满足题干条件,可以更新结果,并且出窗口retlen = min(retlen , right-left+1);sum-=nums[left++];}right++;}return retlen==INT_MAX?0:retlen;}Q:为什么right++ 放在出窗口后面?不应该是先入窗口然后再出窗口吗?
- 最初left == right 的时候(left ==0 , right == 0),实际上是将第一个数入窗口,相当于right天然地就已经自增了;所以将right++,放在最后,每次right向后走一步就入窗口,是合理的;
基于此,我们还可以写成for 循环版本的:
参考代码2:
(for 循环版本)
int minSubArrayLen(int target, vector<int>& nums) {int n = nums.size();//单调性 + 同向双指针int sum = 0, retlen = INT_MAX;for(int left = 0, right = 0;right <n;right++){//当sum 小于target 就入窗口sum+=nums[right];//更新数据 + 出窗口 while(sum >= target){//此时sum >= target ,满足题干条件,可以更新结果,并且出窗口retlen = min(retlen , right-left+1);sum-=nums[left++];}}return retlen==INT_MAX?0:retlen;}题2 无重复字符的最长子串:
3. 无重复字符的最长子串 - 力扣(LeetCode)
题干:
数据范围:

例子:

思考:
子串:连续的字符构成的串
要求:不重复的最长子串
解法一:暴力解法
列举出所有的子串的情况,再判断这每一个子串是否是不重复的子串,然后找到一个最长的就可以了;其中枚举所有子串的情况:固定每一个有可能的起始位置,然后依次向后扩展,直到扩展到不能再扩展为止;而判断这个子串是否重复:利用哈希表;
即暴力解法就是:暴力枚举 + 哈希表判断;
此处就不演示暴力解法是否能通过,我们需要做的是能否在暴力解法的基础上进行优化:这道题其实和上一道题有异曲同工之妙,只不过上一道题出窗口的条件是:当sum >= target, 而本题出窗口的条件:窗口[left,right] 之中有重复的字符,图解如下:
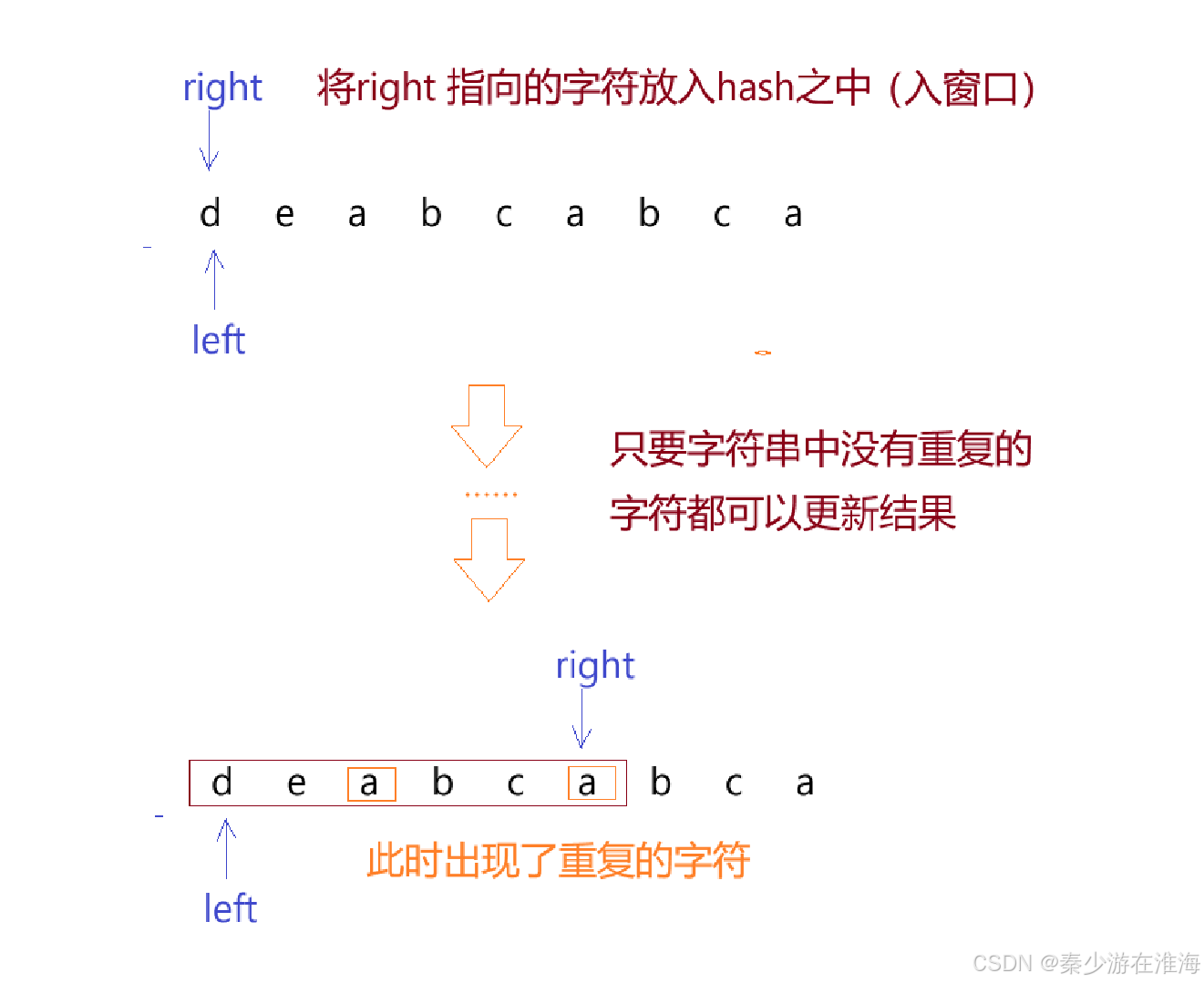
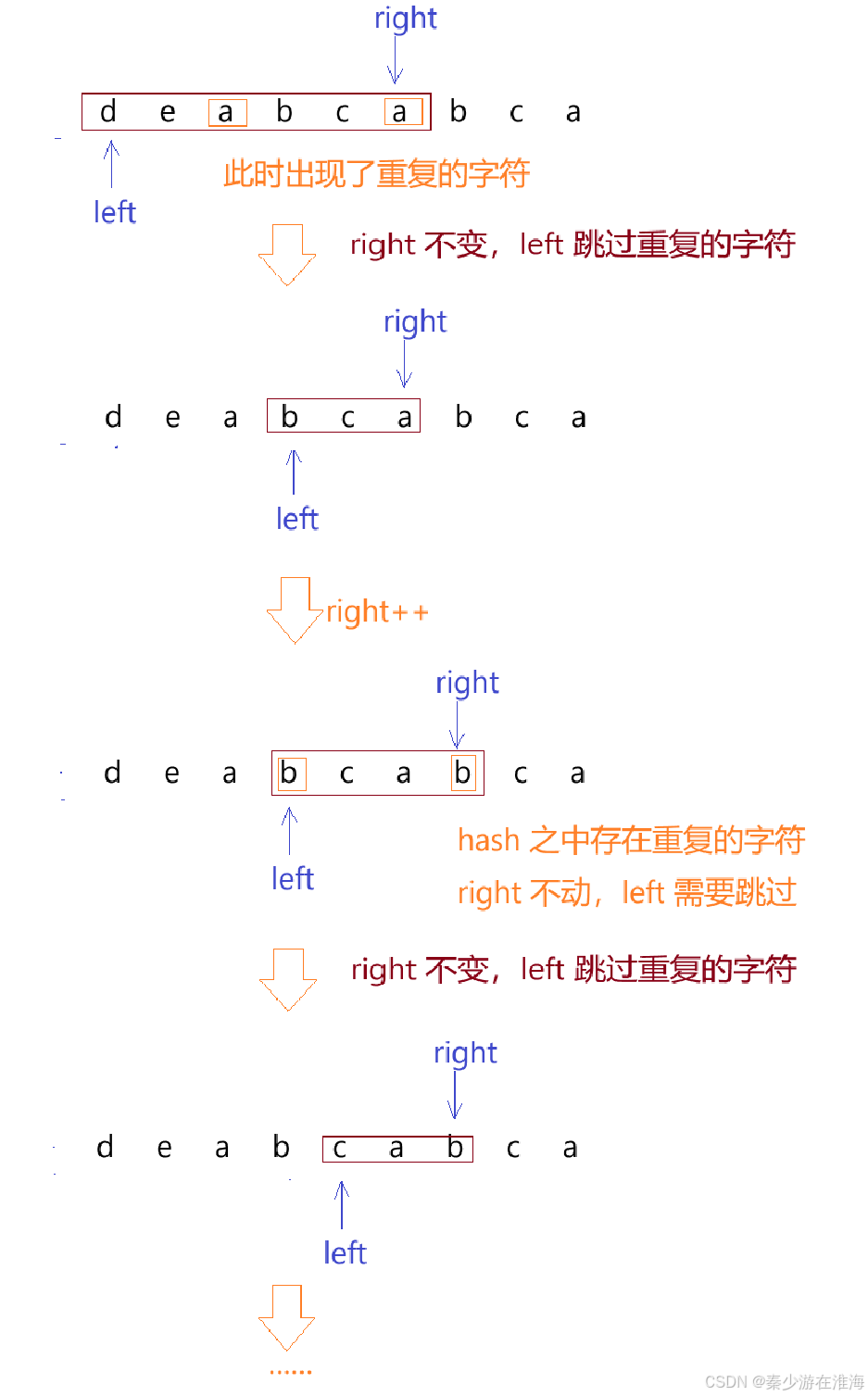
我们需要想清楚的是,当hash 之中出现了重复的字符的时候我们要怎么做?
方法一:根据暴力枚举的想法,left ++,然后right 指向left 指向的位置;
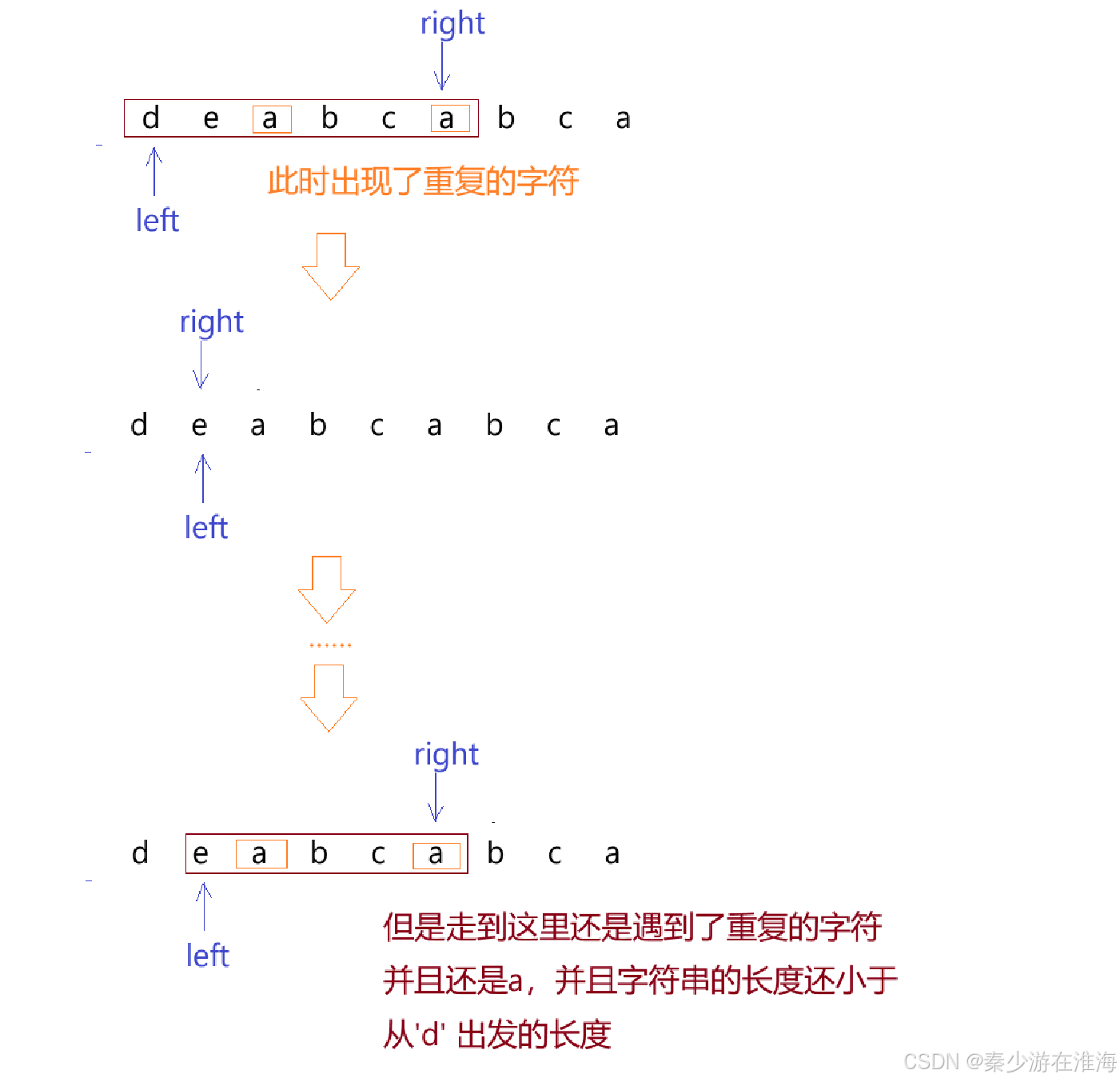
显然这种方式处理出现重复的字符的情况,不仅会有无效情况的加入,还要清空hash表重新记录,时间复杂度仍是O(N^2)
方法二:既然从方法一我们已经得知,当遇到重复的字符时,left++,right 回到left 指向的位置,还是没有解决重复字符的问题,只有越过这个重复的字符才能从根源上解决问题;
如何越过呢?
- left一直向前走,每走一步都要判断hash 之中是否还存在重复的字符,直到hash 之中没有重复的字符了,left 才停止向前走,此时出窗口结束,并且需要更新结果,图解如下:
参考代码1:
int lengthOfLongestSubstring(string s) {int n = s.size(),retlen = INT_MIN;//同向双指针 + hash判断窗口中是否有重复的数据unordered_map<char,int> hash;for(int left = 0 , right = 0;right < n;right++){//入窗口if(hash[s[right]] == 0) hash[s[right]] = 1;else{hash[s[right]]++;//出窗口while(hash[s[right]]==2){hash[s[left++]]--;}} //更新结果 - 走到这里就意味着没有重复字符retlen = max(retlen , right-left+1);}return retlen==INT_MIN?0:retlen;}由于题干说了字符串s 由英文字母、数字、符号和空格组成,所以在实现hash 的时候可以不用容器unordered_map ,可以使用128大小的整形数组,用下标来映射字符;参考代码2换成while 循环来实现,并且可以优化其代码逻辑,right 指向的字符每要入一次都要检查,那么同一个字符出现的个数最大为2,可以直接入窗口,然后再判断出窗口,走到了此处,此时窗口[left,right] 中的字符一定不会重复,所以可以更新数据,如下:
参考代码2:
int lengthOfLongestSubstring(string s) {int n = s.size(),retlen = INT_MIN;//同向双指针 + hash判断窗口中是否有重复的数据//可以使用大小为128的字符数组来实现hashint hash[128] ={0};int left = 0 , right = 0;while(right < n){//入窗口hash[s[right]]++;//判断 - 出窗口while(hash[s[right]]==2){hash[s[left++]]--;}//更新结果 - 走到这里就意味着没有重复字符retlen = max(retlen , right-left+1);right++;}return retlen==INT_MIN?0:retlen;}这两个参考代码的时间复杂度均为O(N);
题3 最大连续1的个数 III:
1004. 最大连续1的个数 III - 力扣(LeetCode)
题干:

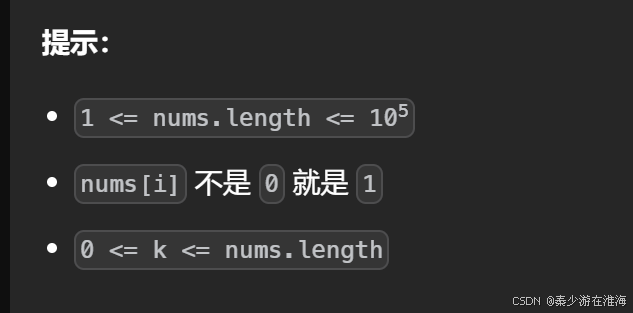
数据范围:
例子:

思考:
题干意思就是一个数组中只有0和1,可以将k个0变成1,求连续1的最长连续长度;
那么首先想到的肯定是暴力解法,枚举出所有的子数组,然后将子数组中k个0全部变为1,再求最长的子数组的长度;即枚举 + 判断,经过前面两道题的练习不难想到,想要高效地枚举,可以利用同向双指针来解决;而至于判断窗口中将k 个0变为1能否构成全1,可以借助于窗口的总数与数据个数的关系,例如:假设窗口中的数据有5个,k为3,那么该窗口中的数据总和的范围为[2,5] ,即[n-k,n] 一旦不在这个范围就一定不能构成连续1的子数组;那这样的话,时间复杂度依旧是O(N^2),因为没有实质性地解决枚举的消耗高的问题,需要砍掉一些可能性来降低时间复杂度;那么就得从k 入手,当窗口中的0的个数大于k个的时候,出窗口,图解如下:


思路总结:

参考代码:
int longestOnes(vector<int>& nums, int k) {int n = nums.size(),count = 0, retlen = INT_MIN;//同向双指针 + 一个变量来记录窗口中0的个数for(int left =0 , right = 0; right < n;right++){//入窗口if(nums[right]==0) count++;while(count>k){if(nums[left]==0) count--;left++;}//此时窗口中0的个数一定合法,可以更新数据retlen = max(right-left+1, retlen);}return retlen;//因为数组中至少有一个数据,所以不用判断retlen 是否会为INT_MIN}可以再简洁该代码,如下:
int longestOnes(vector<int>& nums, int k) {int n = nums.size(),retlen = INT_MIN;//同向双指针 + 一个变量来记录窗口中0的个数for(int left =0 , right = 0,count = 0; right < n;right++){//入窗口if(nums[right]==0) count++;while(count>k)if(nums[left++]==0) count--;//此时窗口中0的个数一定合法,可以更新数据retlen = max(right-left+1, retlen);}return retlen;//因为数组中至少有一个数据,所以不用判断retlen 是否会为INT_MIN}题4 将 x 减到 0 的最小操作数:
1658. 将 x 减到 0 的最小操作数 - 力扣(LeetCode)
题干:

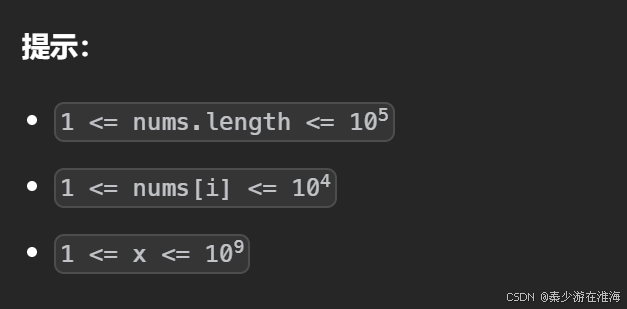
数据范围:
例子:

思考:
从nums 的最左边或者最右边选择一个数据,让x 减去,求让x 减为0的最少选数次数;
我们先来思考一下如何才可以让x减去一些数之后值为0?
- 显然这些数相加要为x。
那么最少的操作次数呢?
- 用最少的数相加为x;
那么每次只能选最左边或者最右边的数据该如何解决呢?
- 首先我们想到的是在左右两边均设置一个指针,一个一个地试。
但是选这个数的时候我们怎么知道这个数合不合适呢?
显然这是非常矛盾的;画图再分析一下:
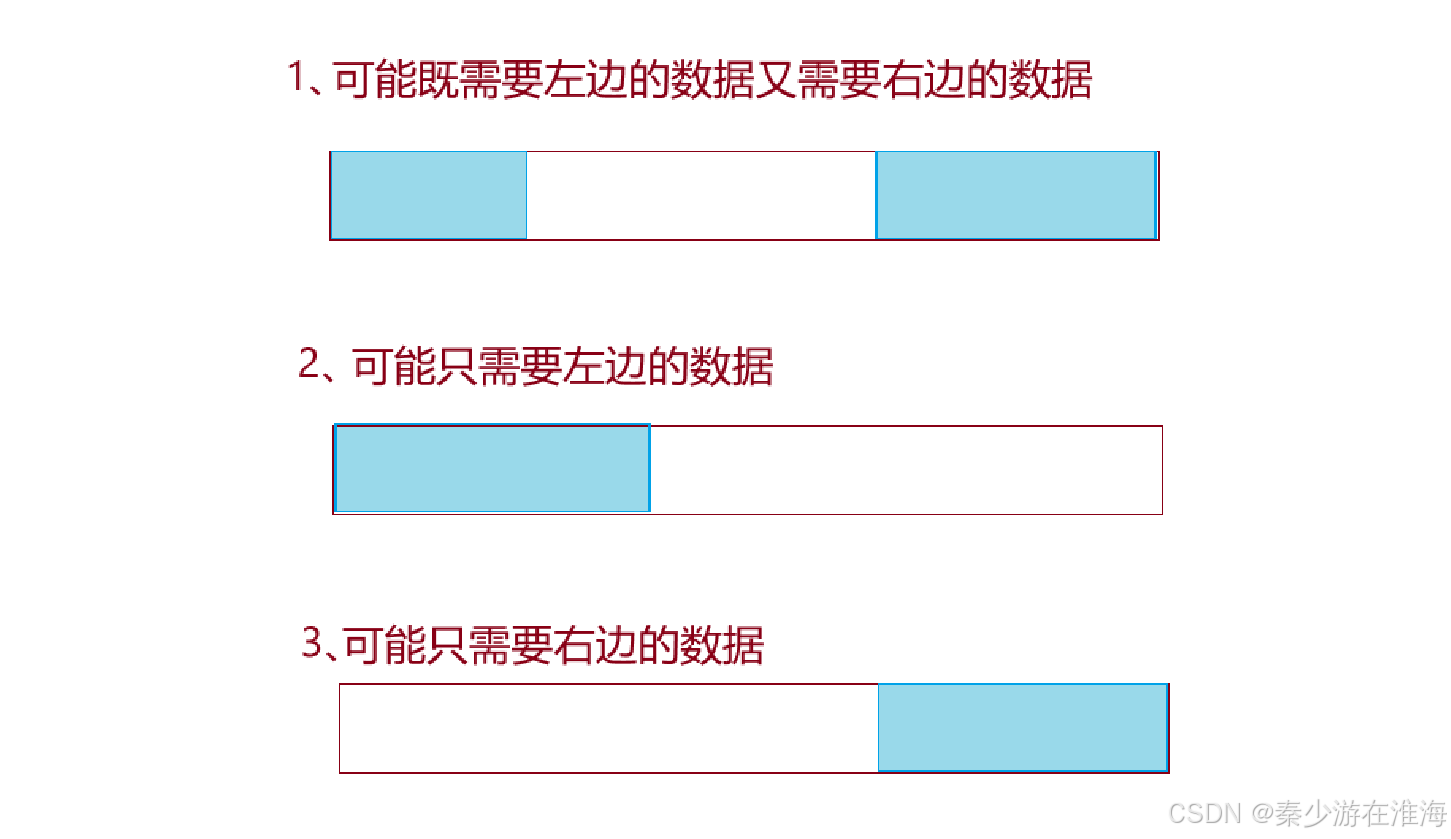
所得到的结果无非就是这三种情况中的一个,其共同点都是需要蓝色区域中的数据相加和为x ,并且求该区域中数据的最少个数,那么空白区域中数据的和为 sum-x ,则反过来就是求空白区域的最多数据个数;
而,空白区域无论在哪一个情况下均是连续的区域,我们是否可以将题干中的意思进行转换?换一个角度解决问题?
题干转换:找出nums中最长的和为(sum-x) 的子数组的长度;
解法一:暴力解法 + 计算和
枚举出所有子数组的情况,并计算其和是否等于 (sum-x) ,并且求出最长的和为 (sum-x)的 子数组的长度;
解法一一定是首先就能想到的解法,但是经过前面三道题的训练,应该可以敏感地感知,此处还可以用同向双指针进行优化,即解法二;
解法二:根据暴力解法进行优化
由题干中的信息可以知道,nums 中的数据均为正整数,所以数据就已经有了天然的单调性-> 数据的个数越多,其和越大;可以利用同向双指针来解决,假设同向双指针为left ,right ,范围[left,right] 中的数据总和为sum ,当sum > target 的时候,就要减少窗口中的数据个数来以此减小sum,即在left 窗口,出窗口可能会多次操作,故而应该用循环解决;当sum < target ,应该增加窗口中的数据个数来增大sum ,所以从right 处入窗口;当sum == target 的时候,就是我们的目标情况,此时需要更新数据;其中target 在本题中为nums 的总和减去x;
思路总结:
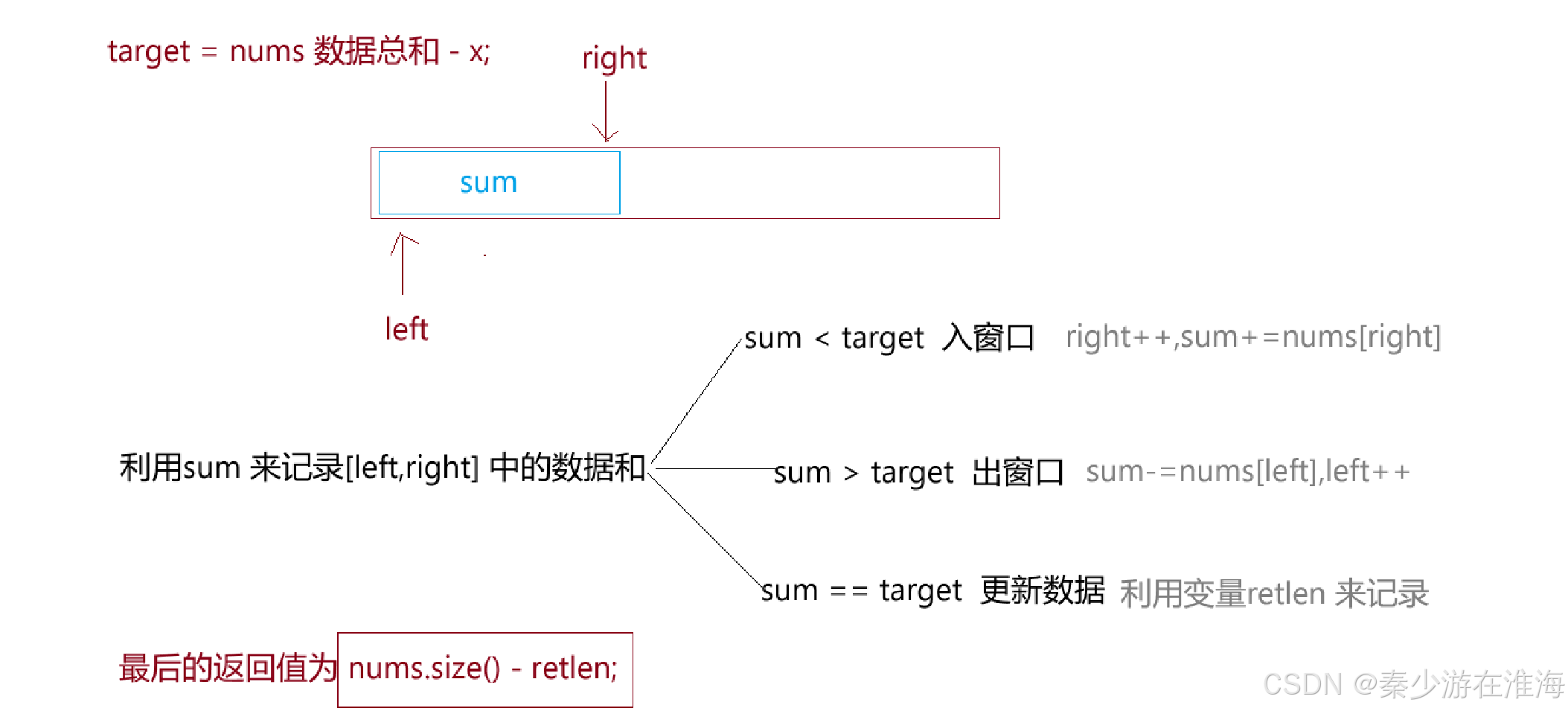
还有一个细节的地方,如果题干所要求的x 本身就大于nums 中的数据总和,那么是一定在nums 中找不到数据相加结果为x , 直接返回-1即可;
参考代码:
int minOperations(vector<int>& nums, int x) {//转换题意:t:nums总和-x ,寻找和为t 的最多数据个数的子数组int sumnums = 0, n = nums.size();for(auto e: nums) sumnums+=e;int target = sumnums - x;//如果x大于nums中左右数据的总和是一定找到不的;if(target < 0) return -1;int left = 0, right = 0, sum = 0 , retlen = INT_MIN;//同向双指针while(right < n){//入窗口sum += nums[right];//判断sum 与 target 的大小关系,决定是否要出窗口while(sum > target){sum-=nums[left++];}//如果sum == target 就更新数据if(sum == target) retlen = max(retlen , right-left+1);right++;}//retlen 可能还是为INT_MIN,就说明没有找到if(retlen == INT_MIN) return -1;else return n - retlen;}题5 水果成篮:
904. 水果成篮 - 力扣(LeetCode)
题干:

数据范围:
例子:

思考;
题干的意思可以提炼为:从正整数数组nums的任意一个位置开始,向右连续地选数,只能选两种数,求最多地数据个数,窗口[left,right] 中只能有两种数字;
注:此处的nums 表示题干中的数组fruits,用nums 来解释比较好理解,下文的阐述中也是用nums 代表 fruits 来阐述的;
解法一:暴力解法:
枚举出所有的子数组,判断该子数组中是否只存在两种数字,并且求满足条件的最长的子数组长度;枚举就不用多说,固定一个位置挨个枚举即可;如何判断一个区间中的数据种类?利用哈希表来解决;根据数据范围可以得知,数组nums 中最大的数值为99999,可以是开辟大小为100001的数组当作哈希表,也可以利用容器unordered_map 来解决;
看到连续的子数组的题目,我们肯定可以联想到为可以利用同向双指针来解决,从暴力解法上进行优化;
解法二:同向双指针 - 滑动窗口
需要利用变量kinds统计窗口中的数据种类,当kinds 小于等于2 的时候继续入窗口,当kinds大于2的时候出窗口,kinds 合法的时候就要更新数据;其实很像本博文中的题2 无重复字符的最长子串,只不过两个判断出窗口时的条件不同;
此处就不赘述了,思想真的一模一样;
参考代码1:
int totalFruit(vector<int>& fruits) {int n= fruits.size();//hashunordered_map<int,int> hash;int left = 0, right = 0, retlen = INT_MIN, kinds = 0;while(right < n){//入窗口hash[fruits[right]]++;if(hash[fruits[right]] == 1) kinds++;//判断是否要出窗口while(kinds>2){hash[fruits[left]]--;if(hash[fruits[left]]==0) kinds--;left++;}//到了此处的kinds一定合法,更新数据retlen = max(retlen , right - left +1);right++;}//因为fruits 中至少有一个数,直接范围即可不用进行判断return retlen;}实际上我们利用unordered_map容器来实现哈希表就可以不使用变量来记录窗口中的数据种类,直接使用接口函数 size() 、erase() 等来实现就可以了,如下:
参考代码2:
int totalFruit(vector<int>& fruits) {int n= fruits.size();//hashunordered_map<int,int> hash;int left = 0, right = 0, retlen = INT_MIN;while(right < n){//入窗口hash[fruits[right]]++;//判断是否要出窗口while(hash.size()>2){hash[fruits[left]]--;if(hash[fruits[left]]==0) hash.erase(fruits[left]);left++;}//到了此处的kinds一定合法,更新数据retlen = max(retlen , right - left +1);right++;}//因为fruits 中至少有一个数,直接范围即可不用进行判断return retlen;}实际上在unordered_map 中频繁地插入、删除,效率十分低下,可以这么说,参考代码2的效率没有参考代码1 的高,此处还有一种写法,就是hash 用数组来实现,用空间换时间,直接开辟大小为100001的空间,最终代码与参考代码1如出一辙,只不过是hash 实现的不同罢了;
参考代码3:
int totalFruit(vector<int>& fruits) {int n= fruits.size();//hashint hash[100001] = {0};int left = 0, right = 0, retlen = INT_MIN, kinds = 0;while(right < n){//入窗口hash[fruits[right]]++;if(hash[fruits[right]] == 1) kinds++;//判断是否要出窗口while(kinds>2){hash[fruits[left]]--;if(hash[fruits[left]]==0) kinds--;left++;}//到了此处的kinds一定合法,更新数据retlen = max(retlen , right - left +1);right++;}//因为fruits 中至少有一个数,直接范围即可不用进行判断return retlen;}题6 找到字符串中所有字母异位词:
438. 找到字符串中所有字母异位词 - 力扣(LeetCode)
题干:
数据范围:
例子:

思考:
即在字符串s 中找有字符串p 中字符构成的子串,返回首字母的下标;
Q:如何判断两个字符串是否为”异位词“?
eg: s1 = "aabac" , s2="abaca"
方法一:先为这两个字符串排序,然后利用两个指针对其内容进行一一比对;时间复杂度为O(Nlogn+N),如下:

方法二:不考虑每个字符串中的字符的顺序怎么样,只是判断这两个字符串中的字符种类与个数是否相同即可,如下:
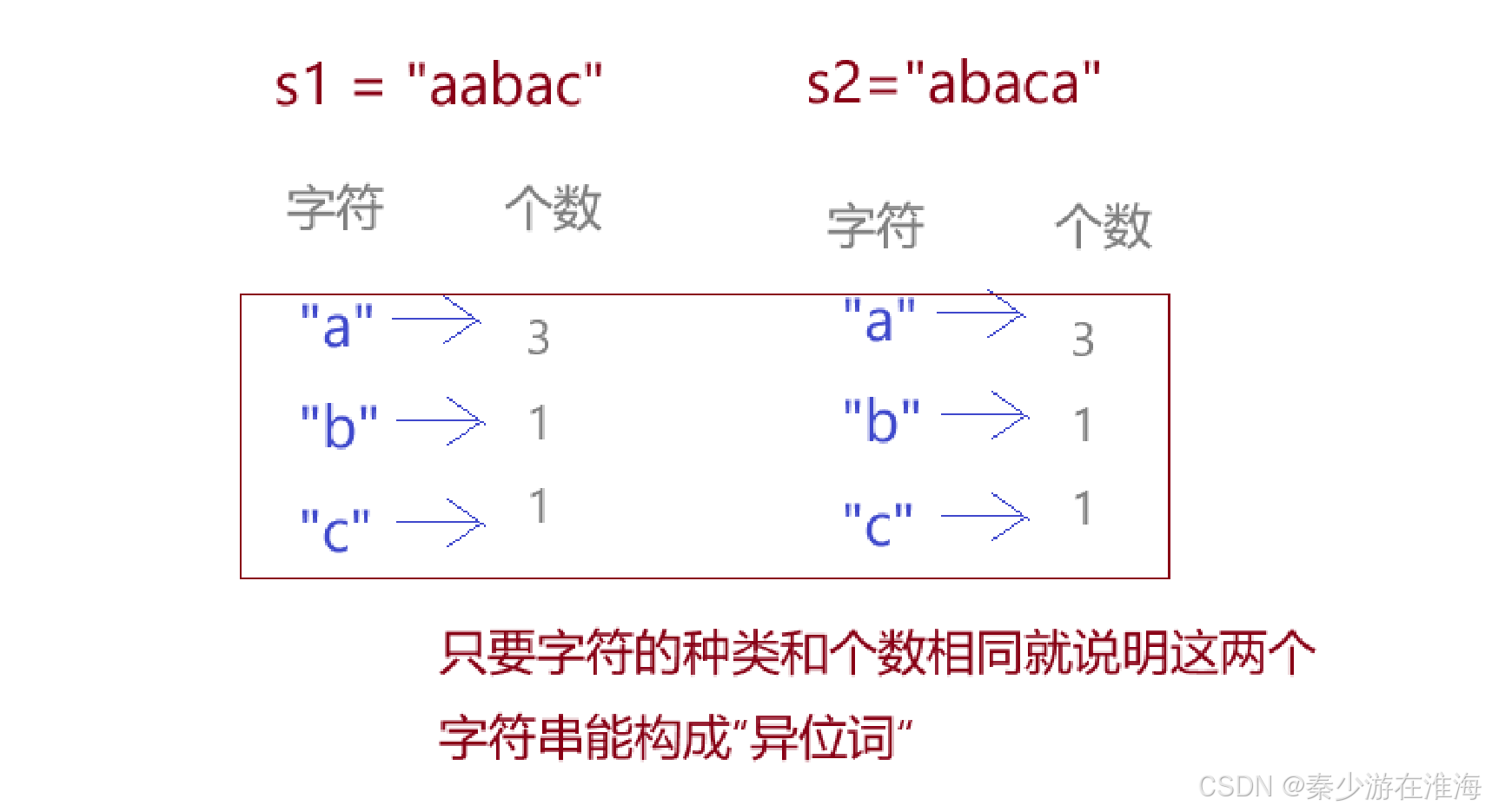
而至于如何判断,我们可以借助于哈希表来实现;
解法一:暴力解法
暴力枚举出字符串s 中所有子串的情况,然后利用hash表来判断列举出来的子串是否与字符串p构成”异位词“;
创建两个哈希表 hash1 与 hash2 , 先将字符串p 中的字符放入hash2 之中,然后再将列举出来的子串放入hash1 之中,最后再比较hash1 与 hash2是否相等即可;相等的,便可以将该子串的首字符下标放入返回的数组之中;
我们现在思考的是能否在暴力解法的基础上进行优化?首先是枚举出所有的子串,实际上有些子串根本就没有枚举的必要,例如已知这个子串中出现了非字符串p 中的字符;基于这点,如果哈希表是用容器unordered_map 实现的话,就可以使用接口函数 count() 来查找hash2 中是否有这个字符;而维护一段连续的区域,我们不难想到会使用同向双指针来解决;
解法二:同向双指针 + hash
Q:如何比较两个哈希表是否相同?
因为题干说了字符串中的字符全为小写字符,所以还可以使用大小为26 的数组来实现hash;
解决方法一:直接比较,若哈希表用数组实现的话,比较26次就可以了;
如若哈希表用unordered_map 实现的话,就需要设置一个变量来统计窗口中有效数据的个数,并且在统计的时候还需要结合hash2与hash1 字符的个数来实现;那么同样的,再增加一个变量记录窗口中有效数据的个数就可以了;
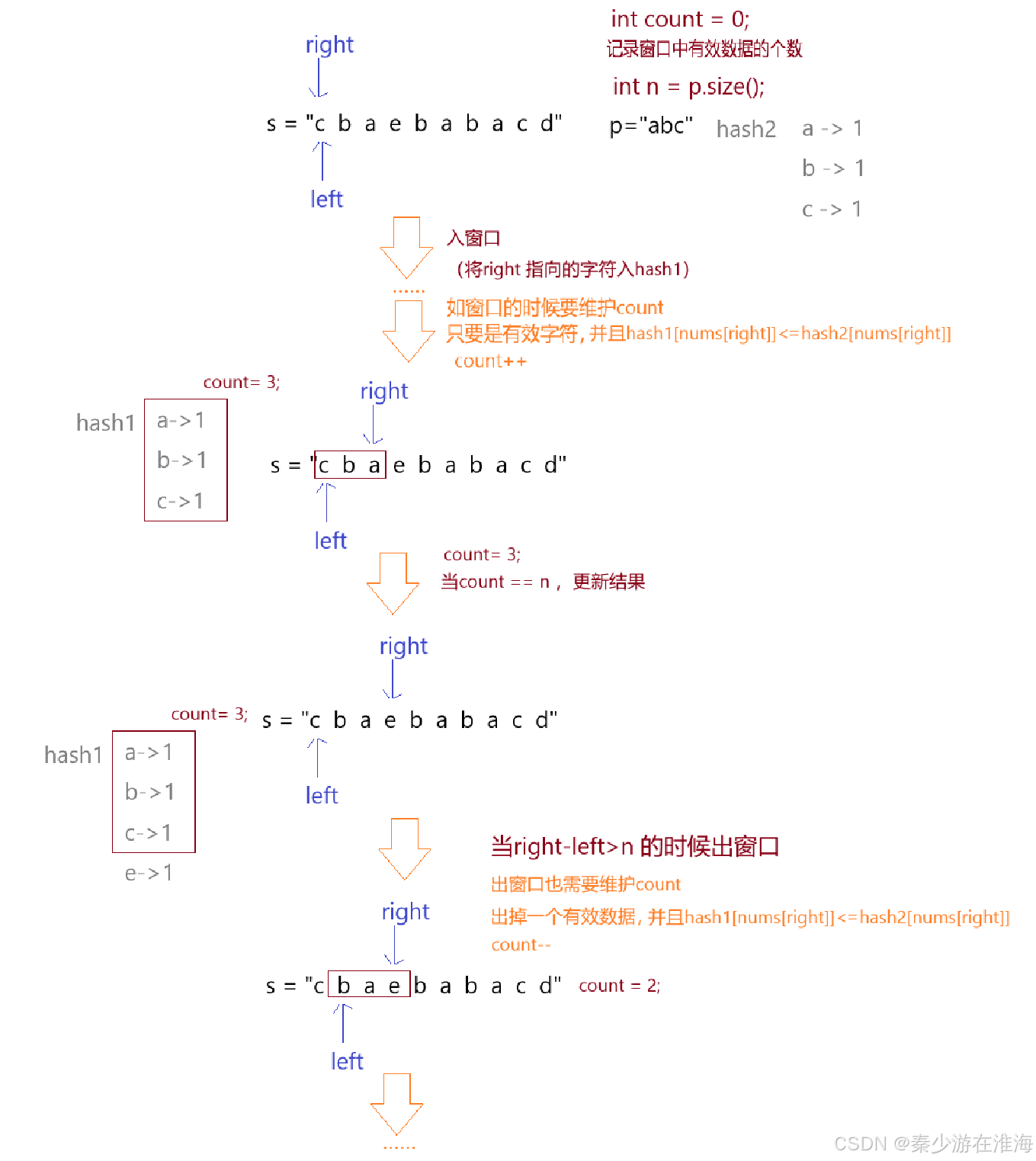
思路总结:

参考代码1:
vector<int> findAnagrams(string s, string p) {int m = s.size(), n = p.size();unordered_map<char , int> hash1,hash2;//将字符串p 中的字符均放入hash表中for(auto e : p) hash2[e]++;int left = 0, right = 0, count = 0;vector<int> ret;while(right < m){//入窗口char in = s[right];hash1[in]++;if(hash2.count(in) && hash1[in] <= hash2[in]) count++;//判断是否要出窗口//因为一定只会执行一次,所以可以写成if 判断语句if(right - left + 1 > n){char out = s[left];//维护countif(hash2.count(out) && hash1[out] <= hash2[out]) count--;hash1[out]--;left++;}//更新结果 - 窗口中的数一定是小于等于n 的if(count == n) ret.push_back(left);right++;}return ret;}如果用变量记录有效数据个数的,还可以用数组实现的hash代替unordered_map ,但是需要注意下标的映射关系,如下:
参考代码2:
vector<int> findAnagrams(string s, string p) {int m = s.size(), n = p.size();int hash1[26] = {0};int hash2[26] = {0};//将字符串p 中的字符均放入hash表中for(auto e : p) hash2[e - 'a']++;int left = 0, right = 0, count = 0;vector<int> ret;while(right < m){//入窗口char in = s[right];hash1[in - 'a']++;if(hash1[in - 'a'] <= hash2[in - 'a']) count++;//判断是否要出窗口//因为一定只会执行一次,所以可以写成if 判断语句if(right - left + 1 > n){char out = s[left];//维护countif( hash1[out - 'a'] <= hash2[out - 'a']) count--;hash1[out - 'a']--;left++;}//更新结果 - 窗口中的数一定是小于等于n 的if(count == n) ret.push_back(left);right++;}return ret;}还可以对代码进行简化,如下:
vector<int> findAnagrams(string s, string p) {int m = s.size(), n = p.size();int hash1[26] = {0};int hash2[26] = {0};//将字符串p 中的字符均放入hash表中for(auto e : p) hash2[e - 'a']++;int left = 0, right = 0, count = 0;vector<int> ret;while(right < m){//入窗口char in = s[right];if( ++ hash1[in - 'a'] <= hash2[in - 'a']) count++;//判断是否要出窗口//因为一定只会执行一次,所以可以写成if 判断语句if(right - left + 1 > n){char out = s[left++];//维护countif( hash1[out - 'a']-- <= hash2[out - 'a']) count--;}//更新结果 - 窗口中的数一定是小于等于n 的if(count == n) ret.push_back(left);right++;}return ret;}题 7 串联所有单词的子串:
30. 串联所有单词的子串 - 力扣(LeetCode)
题干:

数据范围:
例子:

思考:
结合题干我们可以得知,s 中的字符均是words 中所有字符串以任意顺序拼接而成的;其实这道题跟上一道题很像,只不过上道题是处理字符,而本题是处理字符串;
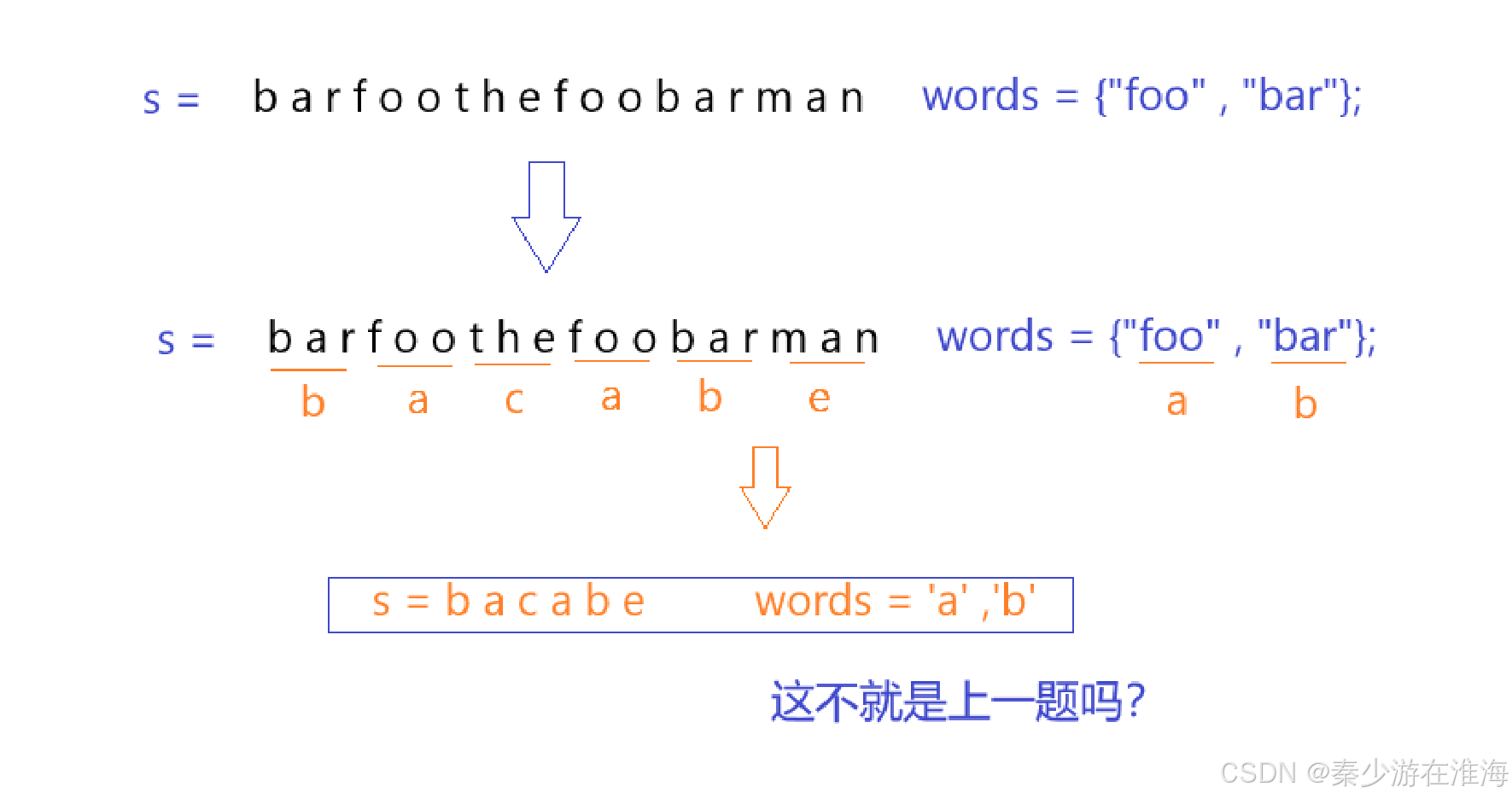
可见本题和上一题的思路大差不差,不过是在细节层面有所区别;
解法:同向双指针 + 哈希表
在上题中,因为是对字符进行操作,所以其中的哈希表可以用数组实现也可以用容器unordered_map 来实现哈希表,但是本题中是要对字符串进行处理,所以哈希表最好就不要使用数组实现,而是用容器unordered_map 来实现;
因为words 中的字符串的长度都一样,而每一次移动需要指向下一个字符串,也就是说同向双指针的移动不能是一个位置一个位置地移动,而其一次移动地距离由words 中字符串的长度决定;算法逻辑跟上一题如出一辙,此处就不再过多赘述;
还需要注意的是,s 字符串中的划分不会像我们上图那样words 中的字符串长度为多长其余的单词也为多长,此处为了不漏,需要在外层再套一个循环:从哪个位置开始向后找,由words 中字符串的长度决定;
参考代码:
vector<int> findSubstring(string s, vector<string>& words) {int n = s.size() , m = words.size() , len = words[0].size();vector<int> ret;unordered_map<string,int> hash1;for(auto&e: words) hash1[e]++;//执行m次for(int i = 0; i<len;i++){int left = i, right = i , count = 0;unordered_map<string,int> hash2;//滑动窗口while(right <= n - len)//此处是一个细节{//入窗口string in = s.substr(right , len);hash2[in]++;//维护countif(hash1.count(in) && hash2[in] <= hash1[in]) count++;//判断 - 出窗口if(right-left+1 > m*len) {string out = s.substr(left , len);//出窗口前维护countif(hash1.count(out) && hash2[out] <= hash1[out]) count--;hash2[out]--;left+=len;}//更新数据if(count == m) ret.push_back(left);right+=len;}}return ret;}题8 最小覆盖子串 :
76. 最小覆盖子串 - 力扣(LeetCode)
题干:
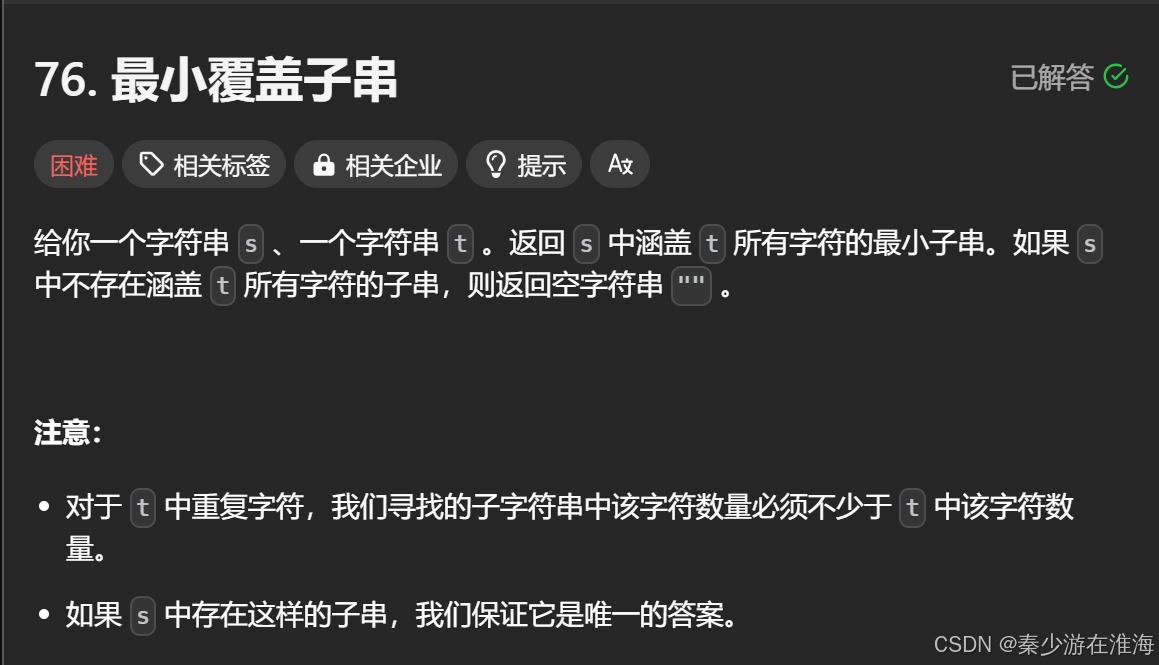
数据范围:

例子:

思考:
本题跟题6也很相似,只不过本题求的是当窗口中均包含了 t 中的字符的时候,窗口中的最小长度,并且返回窗口中的字符;此处可以用两个变量来记录,一个记录窗口中字符串的最小长度,一个来记录最小长度的内容或者是一个记录窗口中字符串最小长度的起始下标,一个记录窗口中字符串的最小长度;
如何才能让窗口中的字符个数最小?当然窗口的最左边和最右边都是所要求的字符(t 中的字符),那么这就是出窗口的判断,判断left 指向的是否是t 中的字符;同样地,与题6相似,需要用到hash 表来统计窗口中、t 中的字符,并且需要一个变量来维护窗口中有效字符的个数;
完整逻辑讲解:
解法一:暴力解法+哈希表
枚举出所有子串的情况,然后后找到符合题干的最短的子串返回即可;同样的,想要知道枚举出来的子串是否覆盖t 中的字符,与题6一样,需要借助于哈希表来实现;
我们需要优化暴力枚举的过程:
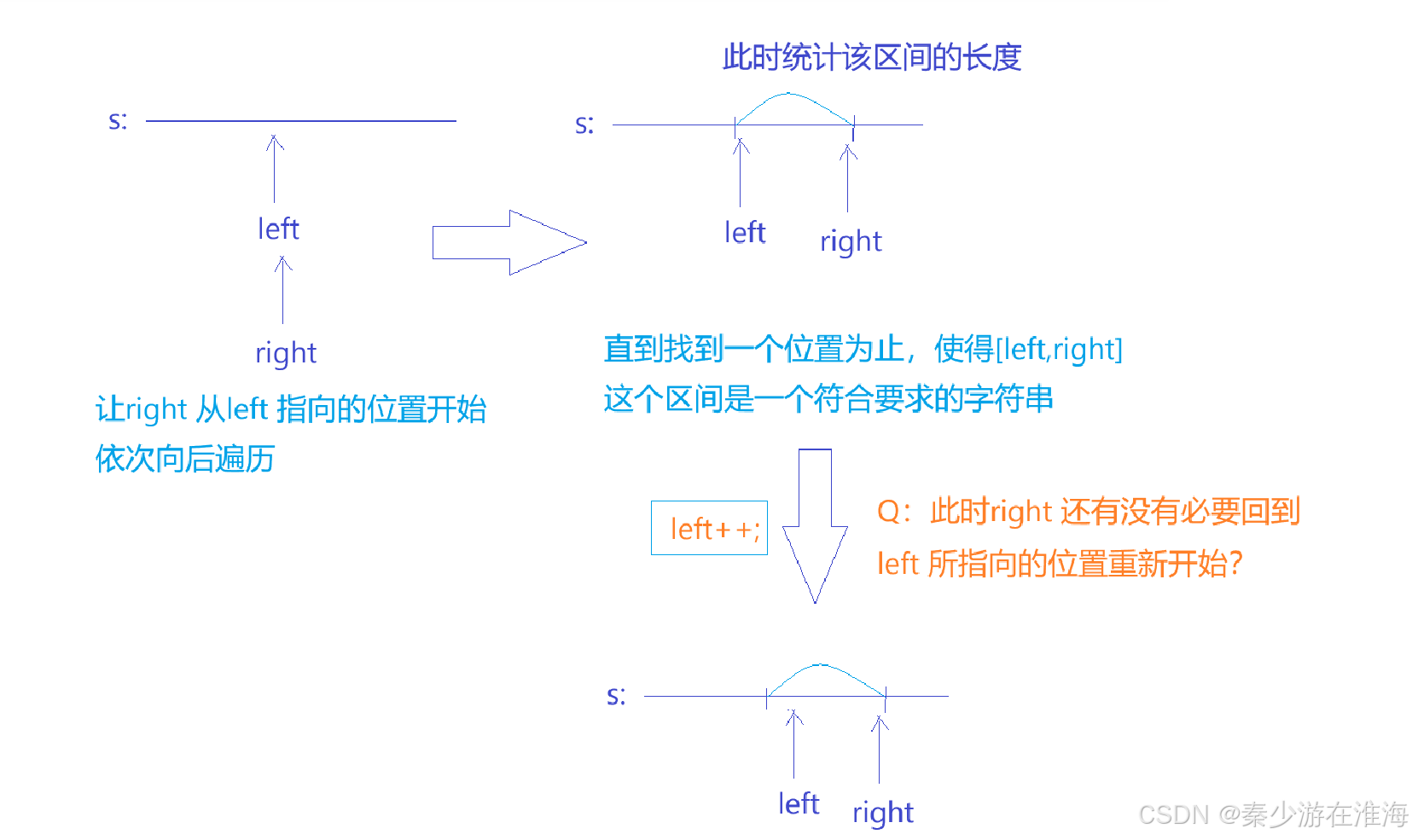
我们定义了两个指针left right , right 进行查找,当区间[left,right] 中的字符串符合题干规定的时候,就可以计算此区间的长度;然后left ++,right 回到left 指向的地方,right 继续往后找……这是暴力枚举的做法;我们需要思考的是,right 是否有必要重新回到left 指向的地方?
没必要;因为我们需要维护[left,right] 之中包含所有t 中的字符就行了;所以我们就需要讨论,left自增之后,[left,right] 中的情况,如下:

显然,此处的优化就是用滑动窗口来解决;在实现代码之前,我们需要弄清楚,入窗口、出窗口、更新数据如何操作;
解法二:同向双指针(滑动窗口) + 哈希表
因为s 与 t 中的字符全为英文字符,所以我们哈希表的实现可以是用 大小为128 的数组实现,也可以是用容器unordered_map 来实现;
首先是要将 t 中的字符全部放入hash1 之中,然后是入窗口,将right 指向的字符放入hash2 之中。按照前面几道题的做题逻辑,此时我们应该判断是否要出窗口。如何出窗口呢?当[left,right] 区间中给的字符符合要求,暴力枚举的思想是:left++,right 回到left 指向的地方;但是符合要求了不统计就直接left++?显然本题就需要先更新数据然后再判断是否要出窗口;
还需要注意的一个点是,想要判断hash2 中是否都有hsah1 中的字符与个数时,无论是用数组实现的哈希表还是利用容器unordered_map 实现的哈希表均要一个遍历比较,有点消耗效率;此处可以参考前几道题用过的策略来进行优化:利用变量来记录[left,right] 中有效数据的个数;
思路总结:

参考代码1:
此处使用unordered_map 实现的
string minWindow(string s, string t) {int n = s.size() , m = t.size();unordered_map<char , int> hash1,hash2;for(auto ch : t) hash1[ch]++;int left = 0, right = 0, count = 0 , retlen = INT_MAX, begin = -1;while(right < n){//入窗口char in = s[right];hash2[in]++;//统计窗口中有效数据的个数if(hash1[in] && hash2[in] <= hash1[in]) count++;//更新数据while(count == m){int len = right - left +1;if(len < retlen){retlen = len;begin = left;}char out = s[left];//维护countif(hash1[out] && hash2[out]<=hash1[out]) count--;hash2[out]--;left++;}right++;}if(begin == -1) return "";//直接返回空字符串return s.substr(begin , retlen);}参考代码2:
代码二的哈希表就用数组实现并且简化代码的书写:
string minWindow(string s, string t) {int n = s.size() , m = t.size();int hash1[128] = {0};int hash2[128] = {0};for(auto ch : t) hash1[ch]++;int left = 0, right = 0, count = 0 , retlen = INT_MAX, begin = -1;while(right < n){//入窗口char in = s[right];//统计窗口中有效数据的个数if(hash1[in] && ++hash2[in] <= hash1[in]) count++;//更新数据while(count == m){int len = right - left +1;if(len < retlen){retlen = len;begin = left;}char out = s[left++];//维护countif(hash1[out] && hash2[out]-- <= hash1[out]) count--;}right++;}if(begin == -1) return "";//直接返回空字符串return s.substr(begin , retlen);}总结
既然看到这里了,那就把这些题再做一遍吧~
- 209. 长度最小的子数组
- 3. 无重复字符的最长子串
- 1004. 最大连续1的个数 III
- 1658. 将 x 减到 0 的最小操作数
- 904. 水果成篮
- 438. 找到字符串中所有字母异位词
- 30. 串联所有单词的子串
- 76. 最小覆盖子串
滑动窗口,无非就是利用两个同向双指针,根据题干的要求设置入窗口的条件、出窗口的条件以及什么时候更新结果;需要注意的是,更新结果的地方是不确定的,可能是在入窗口后更新结果,也有可能是在出窗口之后才更新结果,需要根据具体的题意定夺;
相关文章:
leetcode - 滑动窗口问题集
目录 前言 题1 长度最小的子数组: 思考: 参考代码1: 参考代码2: 题2 无重复字符的最长子串: 思考: 参考代码1: 参考代码2: 题3 最大连续1的个数 III: 思考&am…...
一分钟在Cherry Studio和VSCode集成火山引擎veimagex-mcp
MCP的出现打通了AI模型和外部数据库、网页API等资源,成倍提升工作效率。近期火山引擎团队推出了 MCP Server SDK: veimagex-mcp。本文介绍如何在Cherry Studio 和VSCode平台集成 veimagex-mcp。 什么是MCP MCP(Model Context Protocol&…...

Tomcat与纯 Java Socket 实现远程通信的区别
Servlet 容器(如 Tomcat) 是一个管理 Servlet 生命周期的运行环境,主要功能包括: 协议解析:自动处理 HTTP 请求/响应的底层协议(如报文头解析、状态码生成); 线程…...

为什么企业建站或独立站选用WordPress
与大多数组织相比,企业业务更需要保持可扩展和可靠的网络存在,以保持竞争力。为此,许多大型企业的 IT 领导者历来寻求昂贵的网络解决方案,这些方案需要签订专有支持合同来保证质量。不过,还有另一种方法。WordPress问世…...

镜头内常见的马达类型(私人笔记)
① 螺杆式马达 驱动来源:机身内马达。镜头尾部有一个接收“螺杆”的接口,通过机械传动带动镜头对焦组。缺点:慢、吵、不能用于无机身马达的相机。✅ 典型镜头:尼康 AF、AF-D 系列;美能达老镜头。尼康传统的AF镜头通过…...

docker-compose——安装mysql8
一、编写Dockerfile FROM mysql:8.0.39 ENV TZAsia/Shanghai RUN ln -sf /usr/share/zoneinfo/$TZ /etc/localtime && echo $TZ > /etc/timezone二、编写docker-compose.yml version : 3.8services:zaomeng-mysql:build:context: ./mysqlimage: mysql:8.0.39conta…...

从代码学习深度学习 - 语义分割和数据集 PyTorch版
文章目录 前言什么是语义分割?图像分割和实例分割Pascal VOC2012 语义分割数据集Pascal VOC2012 语义分割数据集介绍基本信息语义分割部分特点数据格式评价指标应用价值数据集获取使用提示辅助工具代码 (`utils_for_huitu.py`)读取数据预处理数据自定义语义分割数据集类读取数…...

4G物联网模块实现废气处理全流程数据可视化监控配置
一、项目背景 随着工业化进程的加速,工业废气的排放对环境造成了严重影响,废气处理厂应运而生。然而,废气处理厂中的设备众多且分散,传统的人工巡检和数据记录方式效率低下,难以及时发现问题。为了实现对废气处理设备…...

深圳SMT贴片加工厂制造流程解析
内容概要 作为大湾区电子制造产业链的重要节点,深圳SMT贴片加工厂凭借精密的生产体系与技术创新,构建了涵盖12道核心工序的标准化流程。从PCB基板的来料检验开始,通过全自动贴片机的高精度元件定位、SPI三维锡膏检测、智能温控回流焊接等关键…...

电商平台如何做好DDoS 攻防战?
一、新型 DDoS 攻击技术演进分析 1.1 电商平台面临的四类攻击范式 graph LR A[DDoS攻击] --> B{网络层} A --> C{应用层} B --> D[CLDAP反射攻击<br>峰值达3.5Tbps] B --> E[QUIC协议洪水攻击] C --> F[API CC攻击<br>精准打击抢购接口] C -->…...

Spark处理过程-转换算子
大家前面的课程,我们学习了Spark RDD的基础知识,知道了如何去创建RDD,那spark中具体有哪些rdd,它们有什么特点呢? 我们这节课来学习。 (一)RDD的处理过程 Spark使用Scala语言实现了RDD的API,程…...

【计算机视觉】OpenCV实战项目:Athlete-Pose-Detection 运动员姿态检测系统:基于OpenCV的实时运动分析技术
运动员姿态检测系统:基于OpenCV的实时运动分析技术 1. 项目概述1.1 技术背景1.2 项目特点 2. 技术架构与算法原理2.1 系统架构2.2 核心算法2.3 模型选择 3. 项目部署与运行指南3.1 环境准备硬件要求软件依赖 3.2 项目配置3.3 运行项目基本运行模式高级参数 4. 常见问…...

Java 性能调优全解析:从设计模式到 JVM 的 7 大核心方向实践
引言 在高并发、低延迟的技术场景中,Java 性能优化需要系统化的方法论支撑。本文基于7 大核心优化方向(复用优化、计算优化、结果集优化、资源冲突优化、算法优化、高效实现、JVM 优化),结合权威框架与真实案例,构建从…...

为什么要选择七彩喜数字康养平台?加盟后有何优势?
一.七彩喜数字康养平台 1.技术领先性 七彩喜依托“端-网-云-脑”四层技术架构,整合毫米波雷达、AI算法引擎、区块链等前沿技术,解决传统养老的隐私泄露、设备孤岛等痛点。 比如非接触式健康监测系统通过毫米波雷达实现跌倒检测准确率&#…...

【计算机视觉】OpenCV实战项目:基于OpenCV的车牌识别系统深度解析
基于OpenCV的车牌识别系统深度解析 1. 项目概述2. 技术原理与算法设计2.1 图像预处理1) 自适应光照补偿2) 边缘增强 2.2 车牌定位1) 颜色空间筛选2) 形态学操作3) 轮廓分析 2.3 字符分割1) 投影分析2) 连通域筛选 2.4 字符识别 3. 实战部署指南3.1 环境配置3.2 项目代码解析 4.…...
鸿蒙接入flutter环境变量配置windows-命令行或者手动配置-到项目的创建-运行demo项目
鸿蒙接入flutter环境变量配置 参考官网 下载flutter git clone https://gitcode.com/openharmony-sig/flutter_flutter.git git checkout -b dev origin/dev # 国内镜像 export PUB_HOSTED_URLhttps://pub.flutter-io.cn export FLUTTER_STORAGE_BASE_URLhttps://storage.fl…...
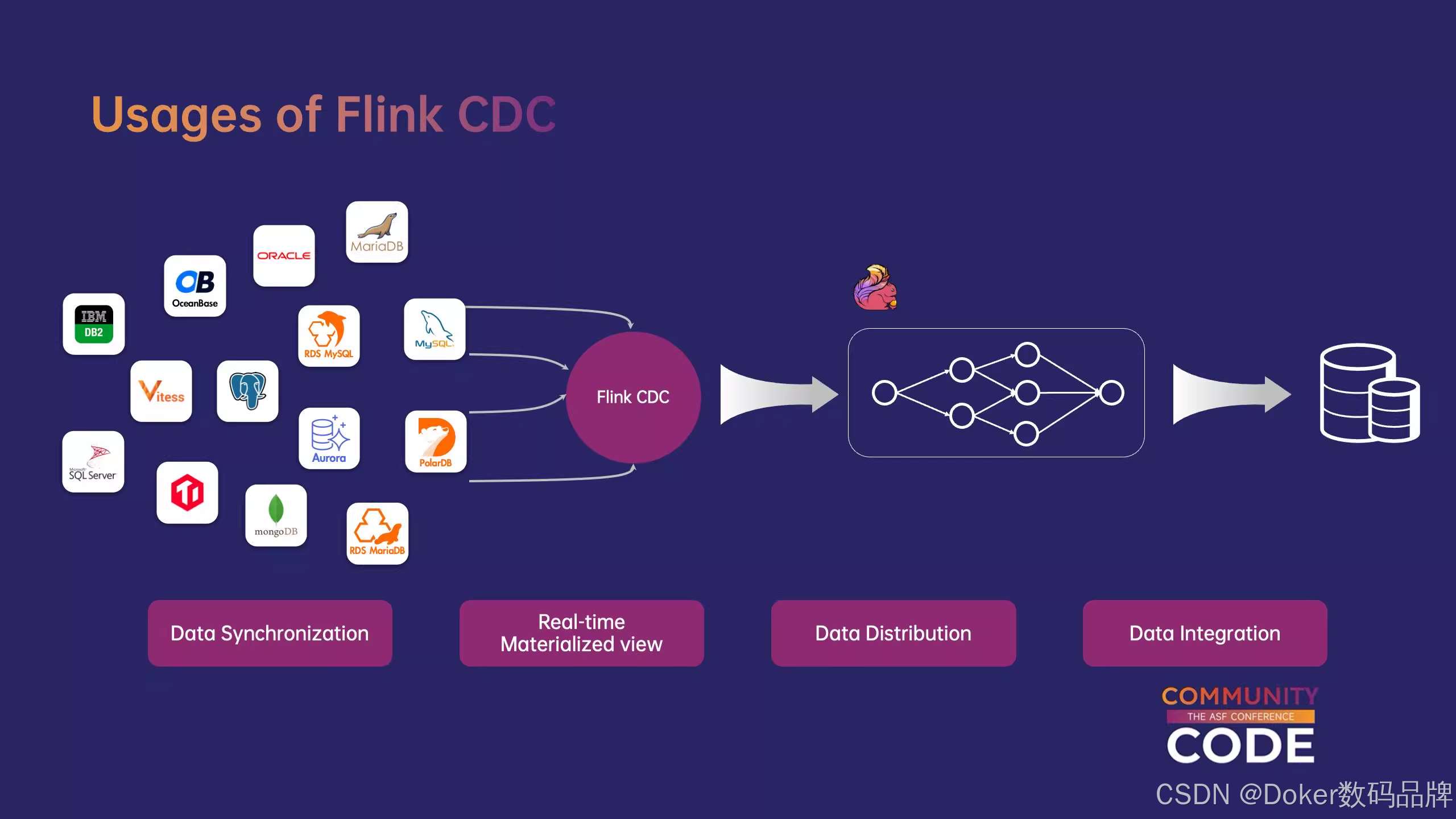
Flink CDC—实时数据集成框架
Flink CDC 是一个基于流的数据集成工具,旨在为用户提供一套功能更加全面的编程接口(API),它基于数据库日志的 CDC(变更数据捕获)技术实现了统一的增量和全量数据读取。 该工具使得用户能够以 YAML 配置文件…...

Redis的持久化:RDB和AOF机制
概述 Redis 提供 RDB 和 AOF 两种持久化机制,它们在数据安全性、性能、恢复速度等方面有显著差异。 为什么要进行持久化?如果是大数据量的恢复,会有下述的影响 会对数据库带来巨大的压力,数据库的性能不如Redis。导致程序响应慢…...
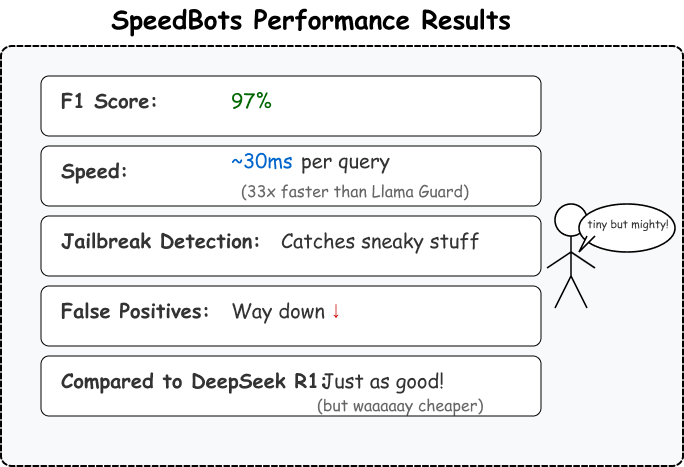
微调ModernBERT为大型语言模型打造高效“过滤器”
ModernBERT(2024 年 12 月)是最近发布的小型语言模型,由 Answer.AI、LightOn 和 HuggingFace 共同开发。它利用了现代优化技术,如用于 8,192 token 上下文窗口的 RoPE 和 GeGLU layers,在保持效率的同时提升性能。jina…...

数据库查询中的分页实现:Page对象与Pageable接口详解
文章目录 前言1. 分页查询的核心概念1.1 Page对象1.2 Pageable接口2. 实现代码详解2.1 实体类定义2.2 Repository接口定义2.3 服务层实现2.4 控制器层实现3. 关键点解析3.1 Pageable对象的创建3.2 Page对象的常用方法3.4 错误用法示例4.完整示例输出4.1 基本分页查询输出4.2 条…...
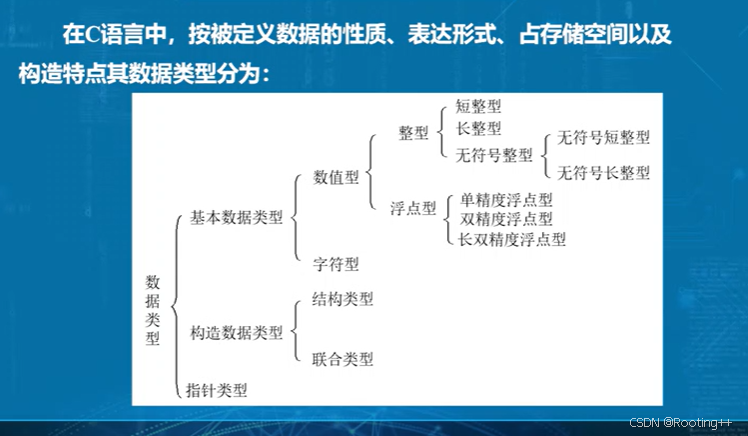
各大编程语言基本语法区别
1:语言特点 函数式语言和面向对象语言的区别:函数式用函数直接进行操作,面向对象用object.method()进行操作;如:len() <=> object.length() C 语言:1)C 语言可以像汇编语言一样对位、字节和地址进行操作;2)有函数原型;3)具有大量的数值类型;4)函数是C语言…...

云计算中的虚拟化:成本节省、可扩展性与灾难恢复的完美结合
云计算中虚拟化的 4 大优势 1. 成本效益 从本质上讲,虚拟化最大限度地减少了硬件蔓延。团队可以将多个虚拟机整合到单个物理主机上,而不是为每个工作负载部署单独的服务器。这大大减少了前期硬件投资和持续维护。 结果如何?更低的功耗、更低…...
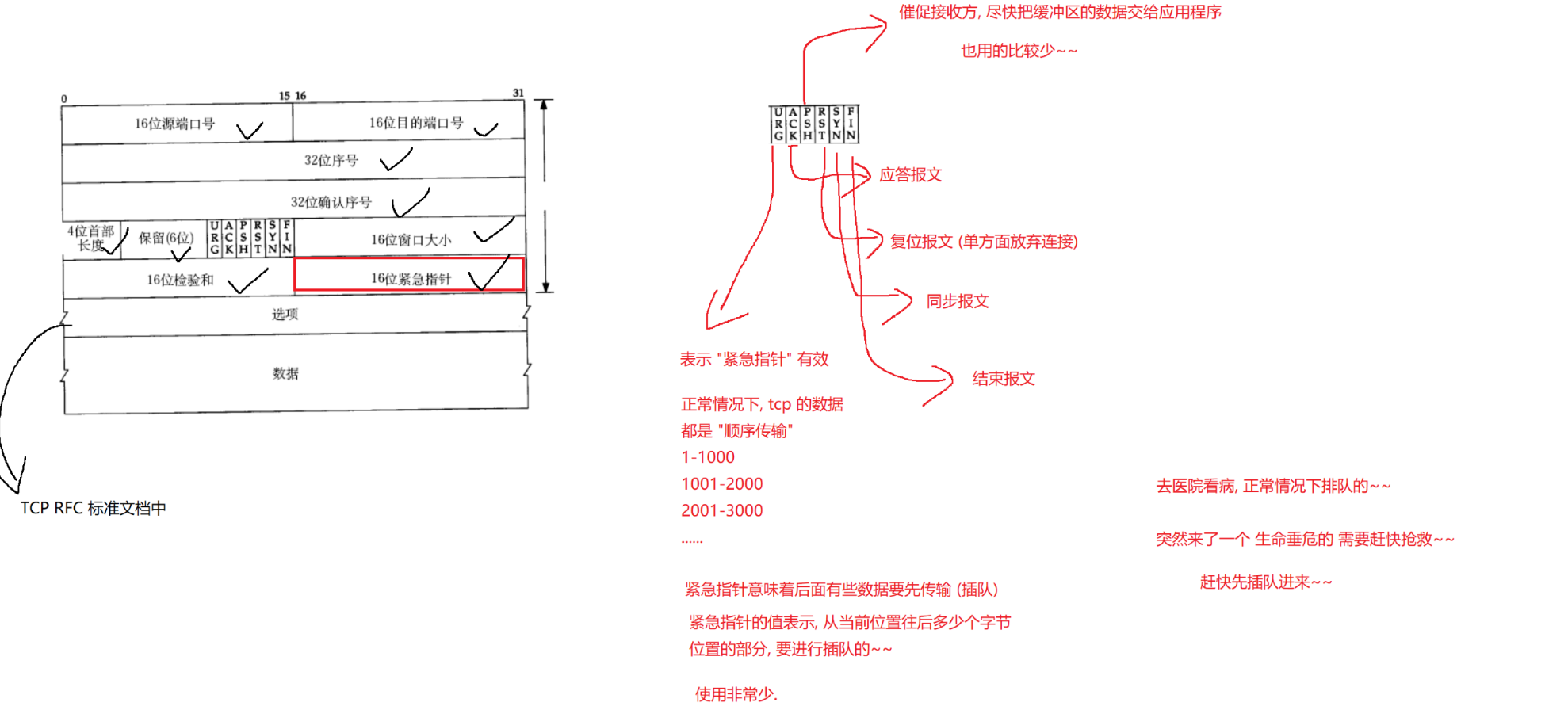
【Java ee初阶】网络原理
TCP协议 1.确认应答 实现可靠传输的核心机制 2.超时重传 实现可靠传输的核心机制 3.连接管理 网络部分最高频的面试题 4.滑动窗口 提高传输效率的机制 5.流量控制 依据接收方的处理能力,限制发送方的发送速度。 6.拥塞控制 依据传输链路的处理能力,…...
是什么?)
MongoDB 的核心概念(文档、集合、数据库、BSON)是什么?
MongoDB 是一个面向文档的数据库,它的核心概念与传统的关系型数据库(RDBMS)有所不同。以下是它的四个主要核心概念: 文档 (Document) 定义: 文档是 MongoDB 中的基本数据单元。它类似于关系型数据库中的一行记录&#…...

Spring 事件监听机制的使用
文章目录 1. 创建自定义事件2. 发布事件3. 监听事件4. 异步事件 1. 创建自定义事件 事件可以是任意对象(Spring 4.2支持POJO),或继承ApplicationEvent(旧版)。 // 自定义事件(POJO形式,无需继…...
awesome-digital-human本地部署及配置:打造高情绪价值互动指南
在数字化交互的浪潮中,awesome-digital-human-live2d项目为我们打开了本地数字人互动的大门。结合 dify 聊天 api,并借鉴 coze 夸夸机器人的设计思路,能为用户带来充满情绪价值的交互体验。本文将详细介绍其本地部署步骤、dify 配置方法及情绪…...

WebSocket与Socket.IO实现简易客服聊天系统全解析
WebSocket结合Socket.IO实现简易客服聊天系统全解析 一、技术选型对比 技术优点缺点适用场景原生WebSocket浏览器原生支持,性能好API较底层,需手动处理断线重连等逻辑简单实时应用Socket.IO自动重连,房间管理,兼容性好体积较大&…...
:[macOS 64bit App开发]: 获取macOS App的Bundle路径信息.)
[原创](现代Delphi 12指南):[macOS 64bit App开发]: 获取macOS App的Bundle路径信息.
[作者] 常用网名: 猪头三 出生日期: 1981.XX.XX 企鹅交流: 643439947 个人网站: 80x86汇编小站 编程生涯: 2001年~至今[共24年] 职业生涯: 22年 开发语言: C/C++、80x86ASM、Object Pascal、Objective-C、C#、R、Python、PHP、Perl、 开发工具: Visual Studio、Delphi、XCode、…...

C++取时间戳窗口
应用场景 防止接口在指定的时间内重复调用,比如 10 秒内不能重复调用。 函数实现 #include <chrono>/// brief 计算当前时间戳所属时间窗口的起始点(对齐到 Window 秒的整数倍) /// param Window 时间窗口长度(单位&…...

第26节:卷积神经网络(CNN)-数据增强技术(PyTorch)
1. 引言 在深度学习领域,数据增强(Data Augmentation)是提升卷积神经网络(CNN)性能的关键技术之一。通过人为地扩展训练数据集,数据增强能够有效提高模型的泛化能力,防止过拟合,特别是在训练数据有限的情况下。本文将全面介绍PyTorch框架下的数据增强技术,包括基本原理、…...