Python训练打卡Day22
复习日:
1.标准化数据(聚类前通常需要标准化)
scaler = StandardScaler()
X_scaled = scaler.fit_transform(X)StandardScaler() :这部分代码调用了 StandardScaler 类的构造函数。在Python中,当你在类名后面加上括号时,就相当于调用了这个类的构造函数,构造函数会创建并初始化一个新的对象。
scaler = ... :这部分代码把调用构造函数后创建的新对象赋值给变量 scaler 。之后,你就可以使用 scaler 这个变量来访问 StandardScaler 类定义的属性和方法。
2.k_range = range(2, 11) # 测试 k 从 2 到 10:为什么不是2到11呢?
Python 里 range() 函数的特性是左闭右开区间,也就是说,它会包含起始值,但不包含结束值。
3.plt.subplot(2, 2, 2)
用 matplotlib.pyplot 模块的 subplot() 函数来创建一个子图。 subplot() 函数的参数解释如下:
- 第一个参数 2 :表示将图形窗口在垂直方向上划分为 2 行。
- 第二个参数 2 :表示将图形窗口在水平方向上划分为 2 列。
- 第三个参数 2 :表示当前要创建和操作的子图编号,编号从左到右、从上到下依次递增。在这个例子中, 2 表示选择第二个子图(即第一行的第二个位置)。
4.奇异值分解(SVD)
输入为矩阵A,尺寸为m*n,可以不是方阵,经过SVD后得到三个矩阵、
和
:
左奇异向量矩阵: 是一个
的正交矩阵,列向量是矩阵
的特征向量。
- 作用:表示原始矩阵 在行空间(样本空间)中的主方向或基向量。简单来说,$U$ 的列向量描述了数据在行维度上的“模式”或“结构”。
- 应用:在降维中, 的前几列可以用来投影数据到低维空间,保留主要信息(如在图像处理中提取主要特征)。
奇异值矩阵:
- 是一个 的对角矩阵,对角线上的值是奇异值(singular values),按降序排列,非负。
- 作用:奇异值表示原始矩阵 在每个主方向上的“重要性”或“能量”。较大的奇异值对应更重要的特征,较小的奇异值对应噪声或次要信息。
- 应用:通过选择前个较大的奇异值,可以实现降维,丢弃不重要的信息(如数据压缩、去噪)。
右奇异向量矩阵的转置:
- 是 的转置,
是一个
的正交矩阵,列向量是矩阵
的特征向量。
- 作用:表示原始矩阵 在列空间(特征空间)中的主方向或基向量。简单来说,
的列向量描述了数据在列维度上的“模式”或“结构”。
- 应用:类似,
的前几列可以用来投影数据到低维空间,提取主要特征。
简单来说、
和
提供了数据的核心结构信息,帮助我们在保留主要信息的同时简化数据处理。
奇异值分解(SVD)后,原始矩阵被分解为
,这种分解是等价的,意味着通过
、
和
的乘积可以完全重构原始矩阵
,没有任何信息损失。
但在实际应用中,我们通常不需要保留所有的奇异值和对应的向量,而是可以通过筛选规则选择排序靠前的奇异值及其对应的向量来实现降维或数据压缩。以下是这个过程的核心思想:
1. 奇异值的排序:
- 在 矩阵中,奇异值(对角线上的值)是按降序排列的。靠前的奇异值通常较大,代表了数据中最重要的信息或主要变化方向;靠后的奇异值较小,代表次要信息或噪声。
- 奇异值的大小反映了对应向量对原始矩阵 的贡献程度。
2. 筛选规则:
- 我们可以根据需求选择保留前个奇异值(
是一个小于原始矩阵秩的数),并丢弃剩余的较小奇异值。
- 常见的筛选规则包括:
- 固定数量:直接选择前 个奇异值(例如,前 10 个)。
- 累计方差贡献率:计算奇异值的平方(代表方差),选择累计方差贡献率达到某个阈值(如 95%)的前 个奇异值。
- 奇异值下降幅度:观察奇异值下降的“拐点”,在下降明显变缓的地方截断。
3. 降维与近似:
- 保留前 个奇异值后,我们只取
矩阵的前
列(记为
,尺寸为
)、
矩阵的前
个奇异值(记为
,尺寸为
)、以及 $V^T$ 矩阵的前
行(记为
,尺寸为
)。
- 近似矩阵为 ,这个矩阵是原始矩阵
的低秩近似,保留了主要信息,丢弃了次要信息或噪声。
- 这种方法在降维(如主成分分析 PCA)、图像压缩、推荐系统等领域非常常用。
4. 对应的向量:
- $U$ 的列向量和 $V$ 的列向量分别对应左右奇异向量。保留前 个奇异值时,
的列向量代表数据在行空间中的主要方向,
的列向量代表数据在列空间中的主要方向。
- 这些向量与奇异值一起,构成了数据的主要“模式”或“结构”。
总结:SVD 分解后原始矩阵是等价的,但通过筛选排序靠前的奇异值和对应的向量,我们可以实现降维,保留数据的主要信息,同时减少计算量和噪声影响。这种方法是许多降维算法(如 PCA)和数据处理技术的基础。
import numpy as np
from sklearn.model_selection import train_test_split
from sklearn.linear_model import LogisticRegression
from sklearn.metrics import accuracy_score# 设置随机种子以便结果可重复
np.random.seed(42)# 模拟数据:1000 个样本,50 个特征
n_samples = 1000
n_features = 50
X = np.random.randn(n_samples, n_features) * 10 # 随机生成特征数据
y = (X[:, 0] + X[:, 1] > 0).astype(int) # 模拟二分类标签# 划分训练集和测试集
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
print(f"训练集形状: {X_train.shape}")
print(f"测试集形状: {X_test.shape}")# 对训练集进行 SVD 分解
U_train, sigma_train, Vt_train = np.linalg.svd(X_train, full_matrices=False)
print(f"Vt_train 矩阵形状: {Vt_train.shape}")# 选择保留的奇异值数量 k
k = 10
Vt_k = Vt_train[:k, :] # 保留前 k 行,形状为 (k, 50)
print(f"保留 k={k} 后的 Vt_k 矩阵形状: {Vt_k.shape}")# 降维训练集:X_train_reduced = X_train @ Vt_k.T
X_train_reduced = X_train @ Vt_k.T
print(f"降维后训练集形状: {X_train_reduced.shape}")# 使用相同的 Vt_k 对测试集进行降维:X_test_reduced = X_test @ Vt_k.T
X_test_reduced = X_test @ Vt_k.T
print(f"降维后测试集形状: {X_test_reduced.shape}")# 训练模型(以逻辑回归为例)
model = LogisticRegression(random_state=42)
model.fit(X_train_reduced, y_train)# 预测并评估
y_pred = model.predict(X_test_reduced)
accuracy = accuracy_score(y_test, y_pred)
print(f"测试集准确率: {accuracy}")# 计算训练集的近似误差(可选,仅用于评估降维效果)
X_train_approx = U_train[:, :k] @ np.diag(sigma_train[:k]) @ Vt_k
error = np.linalg.norm(X_train - X_train_approx, 'fro') / np.linalg.norm(X_train, 'fro')
print(f"训练集近似误差 (Frobenius 范数相对误差): {error}")实际操作过程中的注意事项:
#1. 标准化数据:在进行 SVD 之前,通常需要对数据进行标准化(均值为 0,方差为 1),以避免某些特征的量纲差异对降维结果的影响。可以使用 `sklearn.preprocessing.StandardScaler`。from sklearn.preprocessing import StandardScalerscaler = StandardScaler()X_train_scaled = scaler.fit_transform(X_train)X_test_scaled = scaler.transform(X_test)
# 注意:`scaler` 必须在训练集上 `fit`,然后对测试集只用 `transform`,以避免数据泄漏。#2. 选择合适的 k:可以通过累计方差贡献率(explained variance ratio)选择 k,通常选择解释 90%-95% 方差的 k值。代码中可以计算:explained_variance_ratio = np.cumsum(sigma_train**2) / np.sum(sigma_train**2)print(f"前 {k} 个奇异值的累计方差贡献率: {explained_variance_ratio[k-1]}")#3. 使用 sklearn 的 TruncatedSVD:`sklearn` 提供了 `TruncatedSVD` 类,专门用于高效降维,尤其适合大规模数据。它直接计算前 k个奇异值和向量,避免完整 SVD 的计算开销。from sklearn.decomposition import TruncatedSVDsvd = TruncatedSVD(n_components=k, random_state=42)X_train_reduced = svd.fit_transform(X_train)X_test_reduced = svd.transform(X_test)print(f"累计方差贡献率: {sum(svd.explained_variance_ratio_)}")@浙大疏锦行
相关文章:
Python训练打卡Day22
复习日: 1.标准化数据(聚类前通常需要标准化) scaler StandardScaler() X_scaled scaler.fit_transform(X) StandardScaler() :这部分代码调用了 StandardScaler 类的构造函数。在Python中,当你在类名后面加上括号…...

Cold Diffusion: Inverting Arbitrary Image Transforms Without Noise论文阅读
冷扩散:无需噪声的任意图像变换反转 摘要 标准扩散模型通常涉及两个核心步骤:图像降质 (添加高斯噪声)和图像恢复 (去噪操作)。本文发现,扩散模型的生成能力并不强烈依赖于噪声的选择…...

2025认证杯数学建模第二阶段C题:化工厂生产流程的预测和控制,思路+模型+代码
2025认证杯数学建模第二阶段思路模型代码,详细内容见文末名片 一、探秘化工世界:问题背景大揭秘 在 2025 年 “认证杯”数学中国数学建模网络挑战赛第二阶段 C 题中,我们一头扎进了神秘又复杂的化工厂生产流程预测与控制领域。想象一下&…...

物联网驱动的共享充电站系统:智能充电的实现原理与技术解析!
随着新能源汽车的快速普及,共享充电站系统作为其核心基础设施,正通过物联网技术的深度赋能,实现从“传统充电”到“智能充电”的跨越式升级。本文将从系统架构、核心技术、优化策略及实际案例等角度,解析物联网如何驱动共享充电站…...
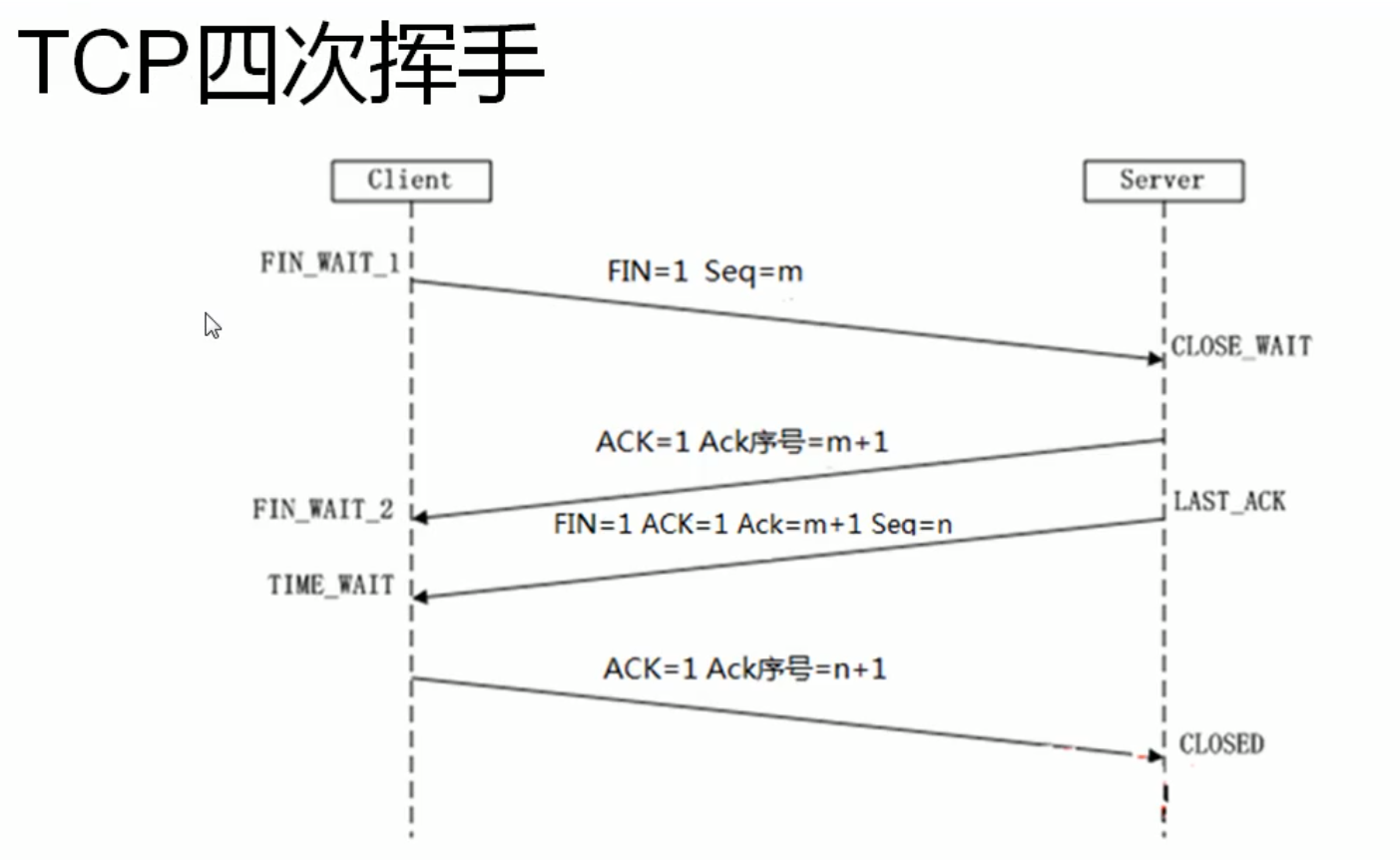
嵌软面试每日一阅----通信协议篇(二)之TCP
一. TCP和UDP的区别 可靠性 TCP:✅ 可靠传输(三次握手 重传机制) UDP:❌ 不可靠(可能丢包) 连接方式 TCP:面向连接(需建立/断开连接) UDP:无连接࿰…...
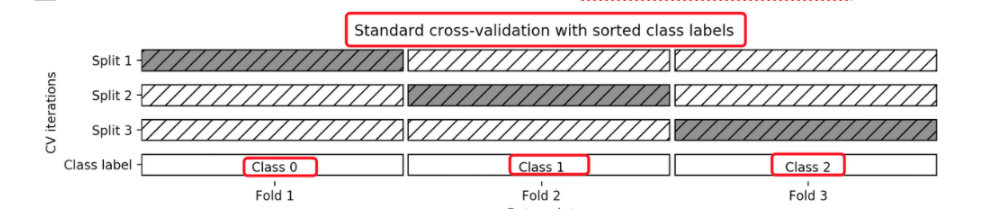
机器学习 --- 模型选择与调优
机器学习 — 模型选择与调优 文章目录 机器学习 --- 模型选择与调优一,交叉验证1.1 保留交叉验证HoldOut1.2 K-折交叉验证(K-fold)1.3 分层k-折交叉验证Stratified k-fold 二,超参数搜索三,鸢尾花数据集示例四,现实世界数据集示例…...
《Python星球日记》 第58天:Transformer 与 BERT
名人说:路漫漫其修远兮,吾将上下而求索。—— 屈原《离骚》 创作者:Code_流苏(CSDN)(一个喜欢古诗词和编程的Coder😊) 目录 一、引言一、Transformer 架构简介1. 自注意力机制(Self-Attention)工作原理2. 多头注意力与位置编码多头注意力机制位置编码二、BERT 的结构…...

2900. 最长相邻不相等子序列 I
2900. 最长相邻不相等子序列 I class Solution:def getLongestSubsequence(self, words: List[str], groups: List[int]) -> List[str]:n len(groups) # 获取 groups 列表的长度ans [] # 初始化一个空列表,用于存储结果for i, g in enumerate(groups): # 遍…...
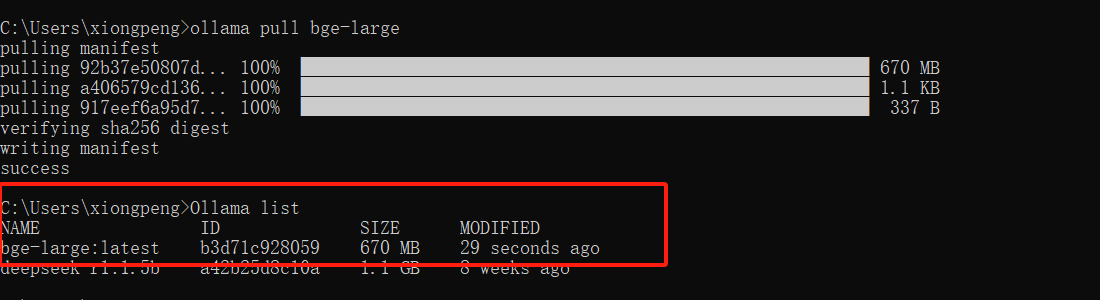
AGI大模型(15):向量检索之调用ollama向量数据库
这里介绍将向量模型下载到本地,这里使用ollama,现在本地安装ollama,这里就不过多结束了。直接从下载开始。 1 下载模型 首先搜索模型,这里使用bge-large模型,你可以根据自己的需要修改。 点击进入,复制命令到命令行工具中执行。 安装后查看: 2 代码实现 先下载ollama…...

Python网络请求利器:urllib库深度解析
一、urllib库概述 urllib是Python内置的HTTP请求库,无需额外安装即可使用。它由四个核心模块构成: urllib.request:发起HTTP请求的核心模块urllib.error:处理请求异常(如404、超时等)…...

什么是Agentic AI(代理型人工智能)?
什么是Agentic AI(代理型人工智能)? 一、概述 Agentic AI(代理型人工智能)是一类具备自主决策、目标导向性与持续行动能力的人工智能系统。与传统AI系统依赖外部输入和显式命令不同,Agentic AI在设定目标…...
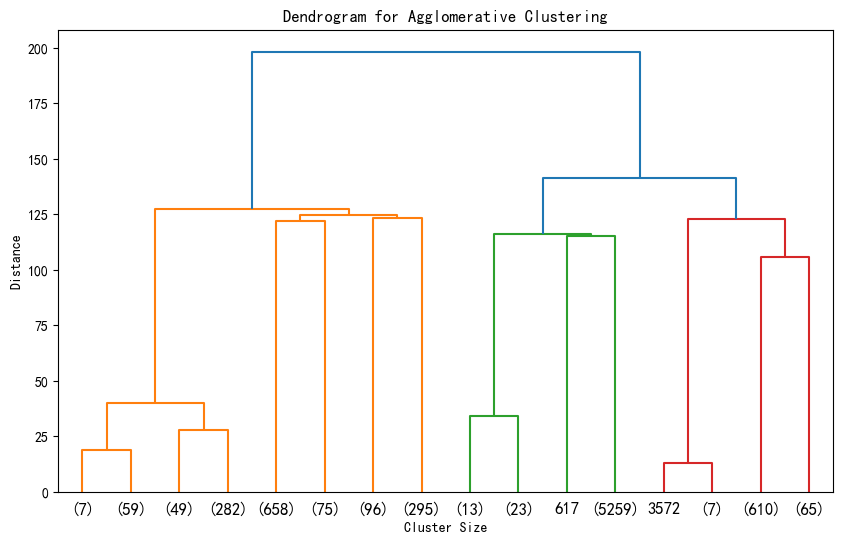
day 17 无监督学习之聚类算法
一、聚类流程 1. 利用聚类发现数据模式 无监督算法中的聚类,目的就是将数据点划分成不同的组或 “簇”,使得同一簇内的数据点相似度较高,而不同簇的数据点相似度较低,从而发现数据中隐藏的模式。 2. 对聚类后的类别特征进行可视…...

《Python星球日记》 第68天:BERT 与预训练模型
名人说:路漫漫其修远兮,吾将上下而求索。—— 屈原《离骚》 创作者:Code_流苏(CSDN)(一个喜欢古诗词和编程的Coder😊) 目录 一、BERT模型基础1. 什么是BERT?2. BERT 的结构3.预训练和微调对比二、BERT 的预训练任务1. 掩码语言模型 (MLM)2. 下一句预测 (NSP)三、微调 …...
)
Spring 集成 SM4(国密对称加密)
Spring 集成 SM4(国密对称加密)算法 主要用于保护敏感数据,如身份证、手机号、密码等。 下面是完整集成步骤(含工具类 使用示例),采用 Java 实现(可用于 Spring Boot)。 一、依赖引…...
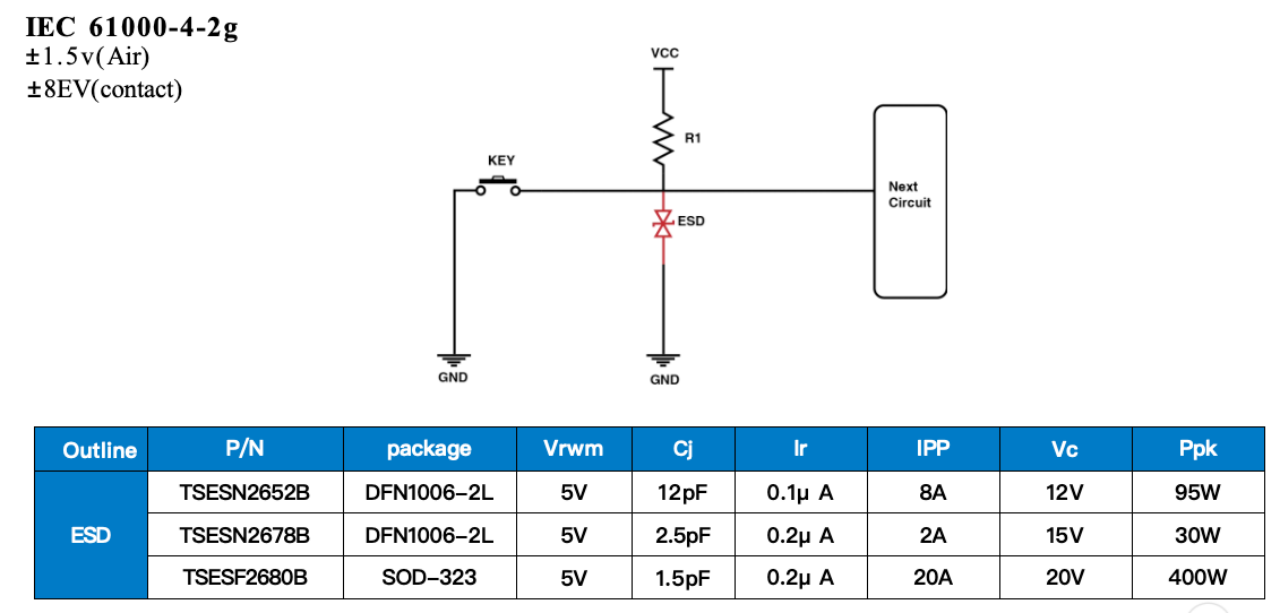
时源芯微| KY键盘接口静电浪涌防护方案
KY键盘接口静电浪涌防护方案通过集成ESD保护元件、电阻和连接键,形成了一道有效的防护屏障。当键盘接口受到静电放电或其他浪涌冲击时,该方案能够迅速将过电压和过电流引导至地,从而保护后续电路免受损害。 ESD保护元件是方案中的核心部分&a…...

CodeBuddy编程新范式
不会写?不想写? 腾讯推出的CodeBuddy彻底解放双手。 示例 以下是我对CodeBuddy的一个小体验。 我只用一行文字对CodeBuddy说明了一下我的需求,剩下的全部就交给了CodeBuddy,我需要做的就是验收结果即可。 1.首先CodeBuddy会对任…...

ArcGIS+InVEST+RUSLE:水土流失模拟与流域管理的高效解决方案;水土保持专题地图制作
在全球生态与环境面临严峻挑战的当下,水土流失问题已然成为制约可持续发展的重要因素之一。水土流失不仅影响土地资源的可持续利用,还对生态环境、农业生产以及区域经济发展带来深远影响。因此,科学、精准地模拟与评估水土流失状况࿰…...
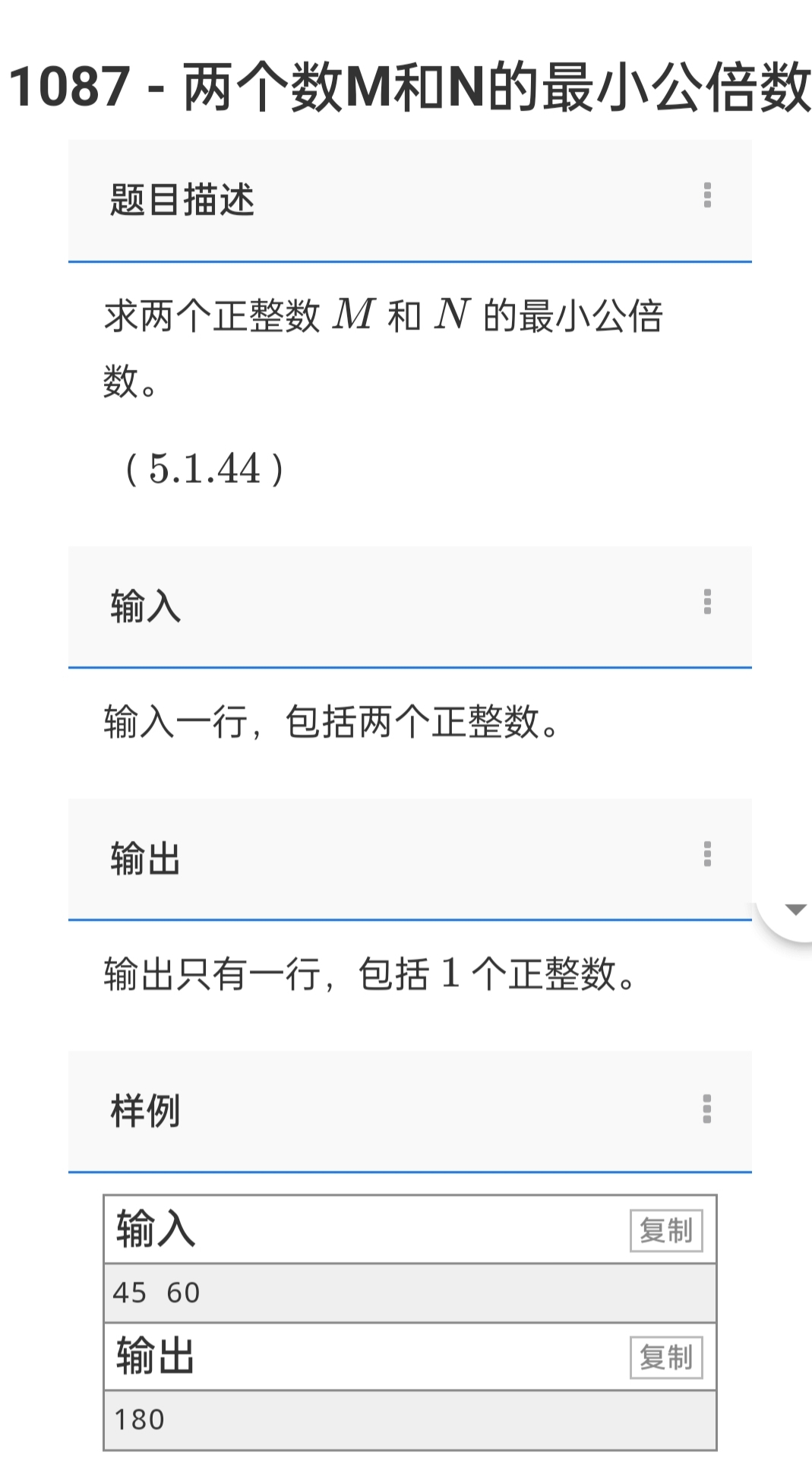
小刚说C语言刷题—1088求两个数M和N的最大公约数
1.题目描述 求两个正整数 M 和 N 的最大公约数(M,N都在长整型范围内) .输入 输入一行,包括两个正整数。 输出 输出只有一行,包括1个正整数。 样例 输入 45 60 输出 15 2.参考代码(C语言版) #include <stdio.h> …...

【LLIE专题】基于码本先验与生成式归一化流的低光照图像增强新方法
GLARE: Low Light Image Enhancement via Generative Latent Feature based Codebook Retrieval(2024,ECCV) 专题介绍一、研究背景二、GLARE方法阶段一:正常光照代码本学习(Normal-Light Codebook Learning)…...

[MySQL数据库] SQL优化
🌸个人主页:https://blog.csdn.net/2301_80050796?spm1000.2115.3001.5343 🏵️热门专栏: 🧊 Java基本语法(97平均质量分)https://blog.csdn.net/2301_80050796/category_12615970.html?spm1001.2014.3001.5482 🍕 Collection与…...
)
AWS VPC 核心笔记(小白向)
AWS VPC 核心笔记(小白向) 一、核心组成:VPC 云上的“私有网络” 组件名类比说明VPC小区你在 AWS 上自定义的私有网络范围子网(Subnet)小区里的楼子网是 VPC 的一个切分区域,决定资源的网络分布ÿ…...

召回11:地理位置召回、作者召回、缓存召回
GeoHash 召回 属于地理位置召回,用户可能对附近发生的事情感兴趣。GeoHash 是一种对经纬度的编码,地图上每个单位矩形的 GeoHash 的前几位是相同的,GeoHash 编码截取前几位后,将相同编码发布的内容按时间顺序(先是时间…...

【AI News | 20250515】每日AI进展
AI Repos 1、helix-db 专用于RAG以及AI应用的一款高性能图向量数据库:HelixDB,比Neo4j快1000倍,比TigerGraph快100倍,向量搜索性能和Qdrant相当。原生支持图形和矢量数据类型,比较适合RAG和AI应用,像知识图…...
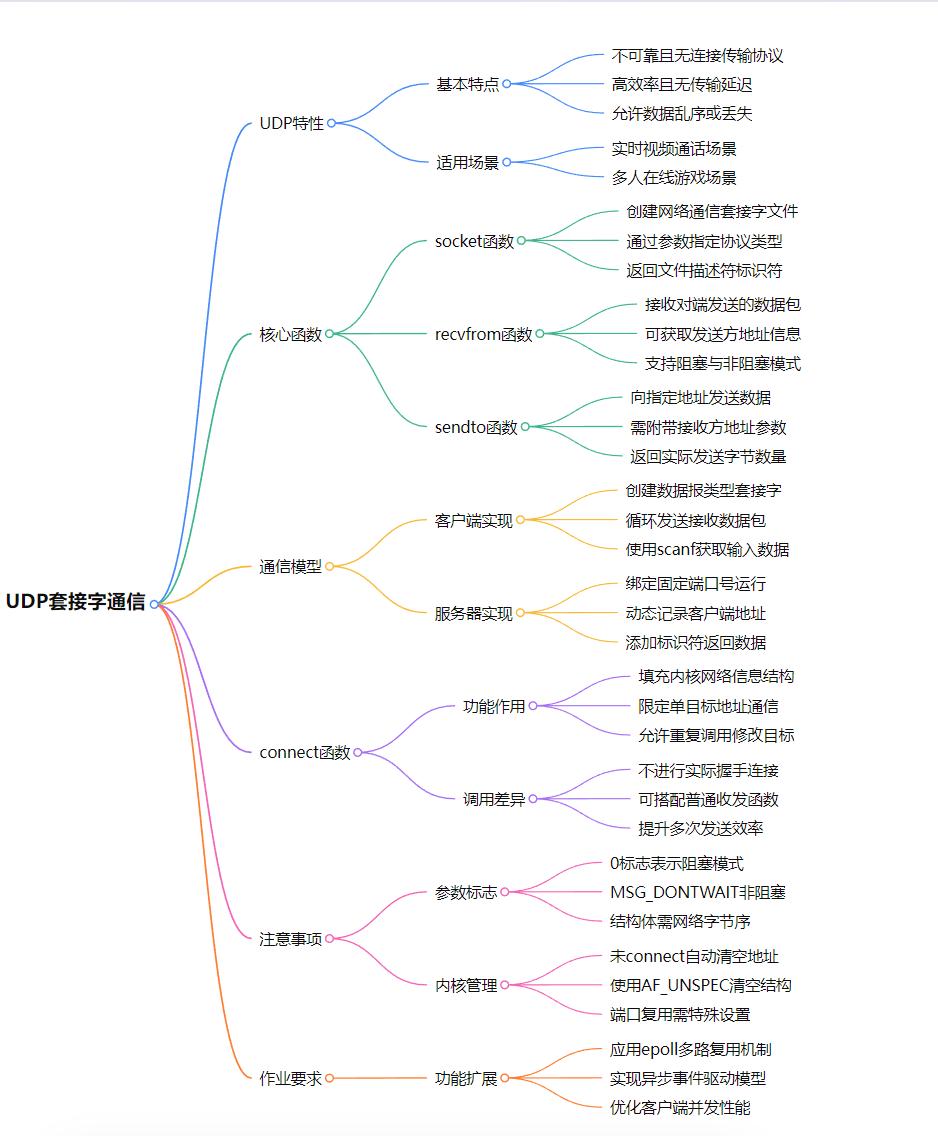
网络编程epoll和udp
# epoll模型核心要点## 1. epoll核心概念### 1.1 高效IO多路复用- 监视列表与激活列表分离- 内核使用红黑树存储描述符- 边缘触发模式(EPOLLET)支持### 1.2 事件触发机制- **水平触发(LT)**:- 默认模式,类似select/poll- 数据未读完持续触发事件- **边缘…...

elementUI如何动态增减表单项
设置prop的字段::prop"configs.${i}.platform" <template><el-dialogtitle"编辑配置":close-on-click-modal"false":before-close"beforeClose":visible.sync"visible"v-if"visible"class&q…...
【iOS】源码阅读(四)——isa与类关联的原理
文章目录 前言OC对象本质探索clang探索对象本质objc_setProperty源码探索 cls与类的关联原理为什么说bits与cls为互斥关系isa的类型isa_t原理探索isa与类的关联 总结 前言 本篇文章主要是笔者在学习和理解类与isa的关联关系时所写的笔记。 OC对象本质探索 在学习和理解类与isa…...

sql server 2019 将单用户状态修改为多用户状态
记录两种将单用户状态修改为多用户状态,我曾经成功过的方法,供参考 第一种方法 USE master; GO -- 终止所有活动连接 DECLARE kill_connections NVARCHAR(MAX) ; SELECT kill_connections KILL CAST(session_id AS NVARCHAR(10)) ; FROM sys.dm_ex…...

uniapp引入七鱼客服微信小程序SDK
小程序引入七鱼sdk 1.微信公众平台引入2.代码引入3.在pagesQiyu.vue初始化企业appKey4.跳转打开七鱼客服 1.微信公众平台引入 账号设置->第三方设置->添加插件->搜索 QIYUSDK ->添加 2.代码引入 在分包中引入插件 "subPackages": [{"root":…...

uniapp 常用 UI 组件库
1. uView UI 特点: 组件丰富:提供覆盖按钮、表单、图标、表格、导航、图表等场景的内置组件。跨平台支持:兼容 App、H5、小程序等多端。高度可定制:支持主题定制,组件样式灵活。实用工具类:提供时间、数组操…...
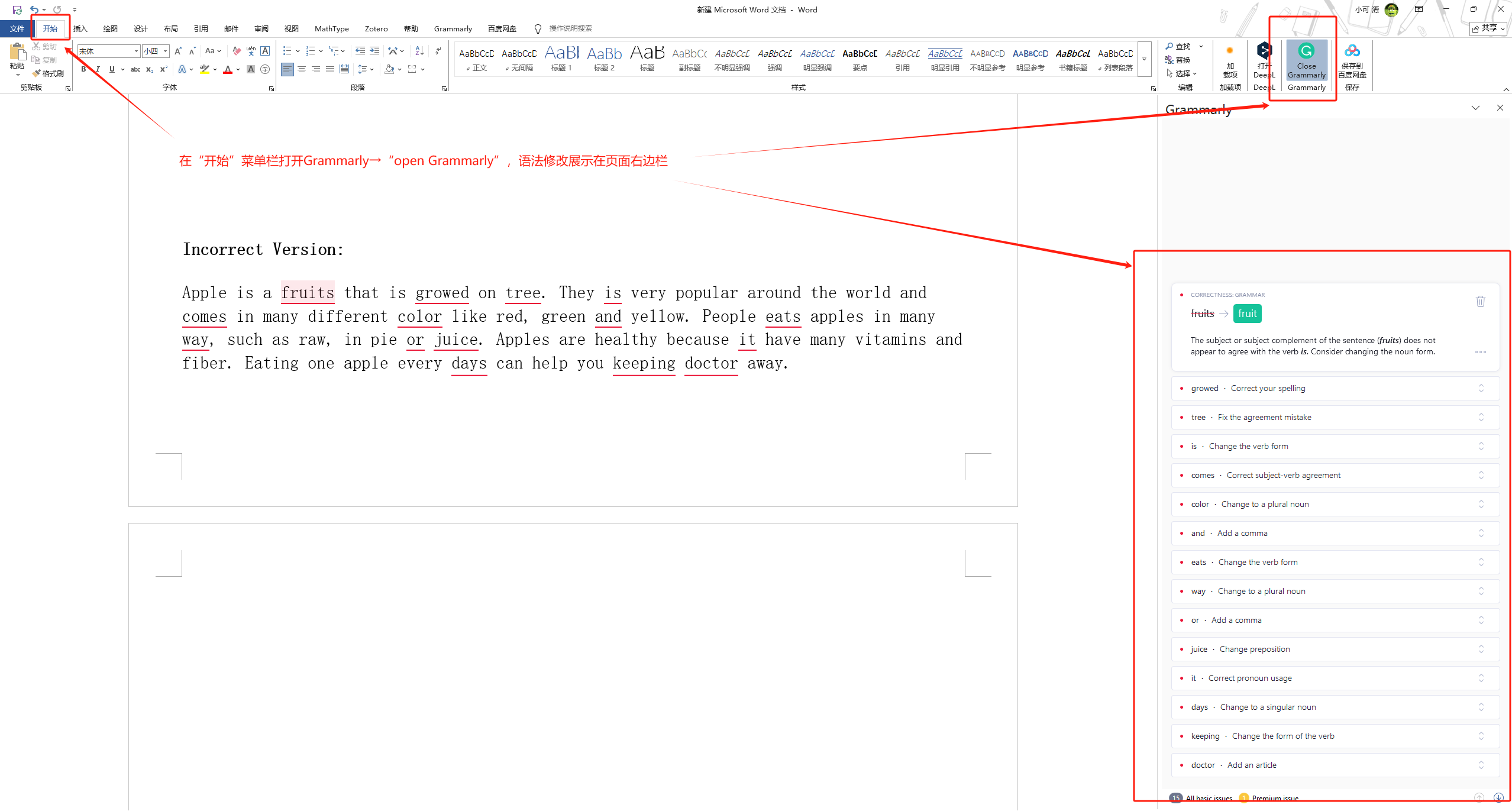
SCI写作开挂!把Grammarly语法修订嵌入word
详细分享如何把Grammarly嵌入Word,实现英文写作时的实时语法校改。 ①进入Grammarly官网 ②点击右上角的“Get Grammarly Its free”会直接跳转到注册或者登录界面,如果还没有账号先注册。 ③注册或登录后进入这个页面,点击“Support”。 ④…...