Redis——底层数据结构
SDS(simple dynamic string):

优点:
- O1时间获取长度(char *需要ON)
- 快速计算剩余空间(alloc-len),拼接时根据所需空间自动扩容,避免缓存区溢出(char *容易溢出)
- 使用字节数组存储二进制数据,可存储图片、视频等数据,且不会因为特殊字符“\0”意外中断字符串(char *默认末尾存储“\0”,可能导致意外中断)
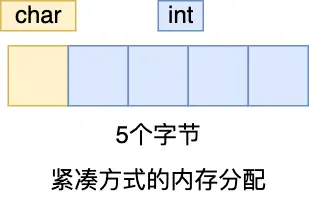
- flags:分为sdshdr5、sdshdr8、sdshdr16、sdshdr32和sdshdr64,用于定义len和alloc的类型,统一为uint16_t(对应sdshdr16)或uint32_t,灵活保存不同大小的字符串,节省内存空间。同时使用了编译优化,取消字节对齐式的内存分配(浪费多余内存),使用紧凑方式的内存分配。

双向链表:
原双向链表结构:
typedef struct listNode {//前置节点struct listNode *prev;//后置节点struct listNode *next;//节点的值void *value;
} listNode;二次包装:
typedef struct list {//链表头节点listNode *head;//链表尾节点listNode *tail;//节点值复制函数void *(*dup)(void *ptr);//节点值释放函数void (*free)(void *ptr);//节点值比较函数int (*match)(void *ptr, void *key);//链表节点数量unsigned long len;
} list;优点:
- 双向链表,获取某个节点的前后节点都只需要O1时间
- 增加头尾指针,快速定位表头表尾
- 保存了链表长度,O1时间获取链表大小
- 函数和值都使用void*指针,可以指向任意类型数据,因此链表节点可以保存任意不同类型的值
缺陷:
内存不连续,无法利用CPU缓存,每个节点都是一个结构体,内存开销较大。
哈希表:
概述:
Redis采用了链式哈希(拉链法)来解决哈希冲突,这与Java中的hashMap是相似的。
哈希表的底层其实是数组,通过计算对象的哈希值对数组长度取余来确定索引位置,可以在O1的时间获取数据。
哈希表结构:
typedef struct dictht {//哈希表数组dictEntry **table;//哈希表大小unsigned long size; //哈希表大小掩码,用于计算索引值unsigned long sizemask;//该哈希表已有的节点数量unsigned long used;
} dictht;dictEntry是哈希数组,数组的每个元素是指向一个哈希表节点(dictEntry)的指针
哈希表节点结构:
typedef struct dictEntry {//键值对中的键void *key;//键值对中的值union {void *val;uint64_t u64;int64_t s64;double d;} v;//指向下一个哈希表节点,形成链表struct dictEntry *next;
} dictEntry;特色:
dictEntry结构中的值实际上是一个联合体,可以存储浮点数,无符号或有符合整数,然后是对应值的地址。这样做的好处是可以节省内存空间,因为简单的数据类型可以直接存储值而无需再存放地址。
rehash(本质上类似于数组的自动扩容):
拉链法解决哈希冲突有局限性,链表过长时查询性能就会下降。实际Redis使用哈希表时,定义了一个dict结构体,并在里面定义了两个哈希表。
typedef struct dict {…//两个Hash表,交替使用,用于rehash操作dictht ht[2]; …
} dict;正常服务时,插入数据都会写入到哈希表1中,哈希表2此时没有分配空间。
随着数据增多,触发rehash操作:
- 给哈希表2分配空间,一般是哈希表1的两倍大小
- 哈希表1数据迁移到表2
- 释放表1空间,并将哈希表2设为表1,并创建新的空白表2,为下次rehash做准备
迁移过程中,若表1的数据量非常大,可能会涉及大量的数据拷贝,进而导致Redis阻塞。
因此Redis采用了渐进式rehash:
- 给表2分配空间
- rehash期间,每次哈希表元素进行查找或更新时,Redis除了进行这些操作外,还会顺序将表1中该索引位置上的所有key-value迁移到表2上。
- 随着客户端发起的操作请求数量变多,最终某个时间点表1的节点会全部迁移到表2中,变成空表。
- 且rehash期间,查找操作会先到表1查找再到表2查找。另外,新增操作直接在哈希表2中进行,保证表1的键值对数量只会减少。
rehash的触发条件:

- 当负载因子大于等于1,且没有进行bgsave或bgrewiteaof命令时(也就是没有执行RDB快照或AOF重写时),就会进行rehash操作。
- 当负载因子大于等于5时,说明哈希冲突已经非常严重了,无论有没有再进行RDB快照或AOF重写,都会强制进行rehash操作。
整数集合
整数集合是set对象的底层实现,若一个set对象只包含整数,且数量不大时,就会使用整数集合。
结构设计:
本质上是一块连续内存空间,定义如下:
typedef struct intset {uint32_t encoding; // 编码类型(INTSET_ENC_INT16/32/64)uint32_t length; // 元素数量int8_t contents[]; // 实际类型由 encoding 决定
} intset;保存元素的容器是类型为int8_t的contents数组,但实际上,int8_t只是占位符,数组保存的值的类型是encoding的属性值,不同类型的contents数组大小也不同。
- 若encoding属性值是INTSET_ENC_INT16,那么contents就是一个int16_t类型的数组
- 若encoding属性值是INTSET_ENC_INT32,那么contents就是一个int32_t类型的数组
- 若encoding属性值是INTSET_ENC_INT64,那么contents就是一个int64_t类型的数组
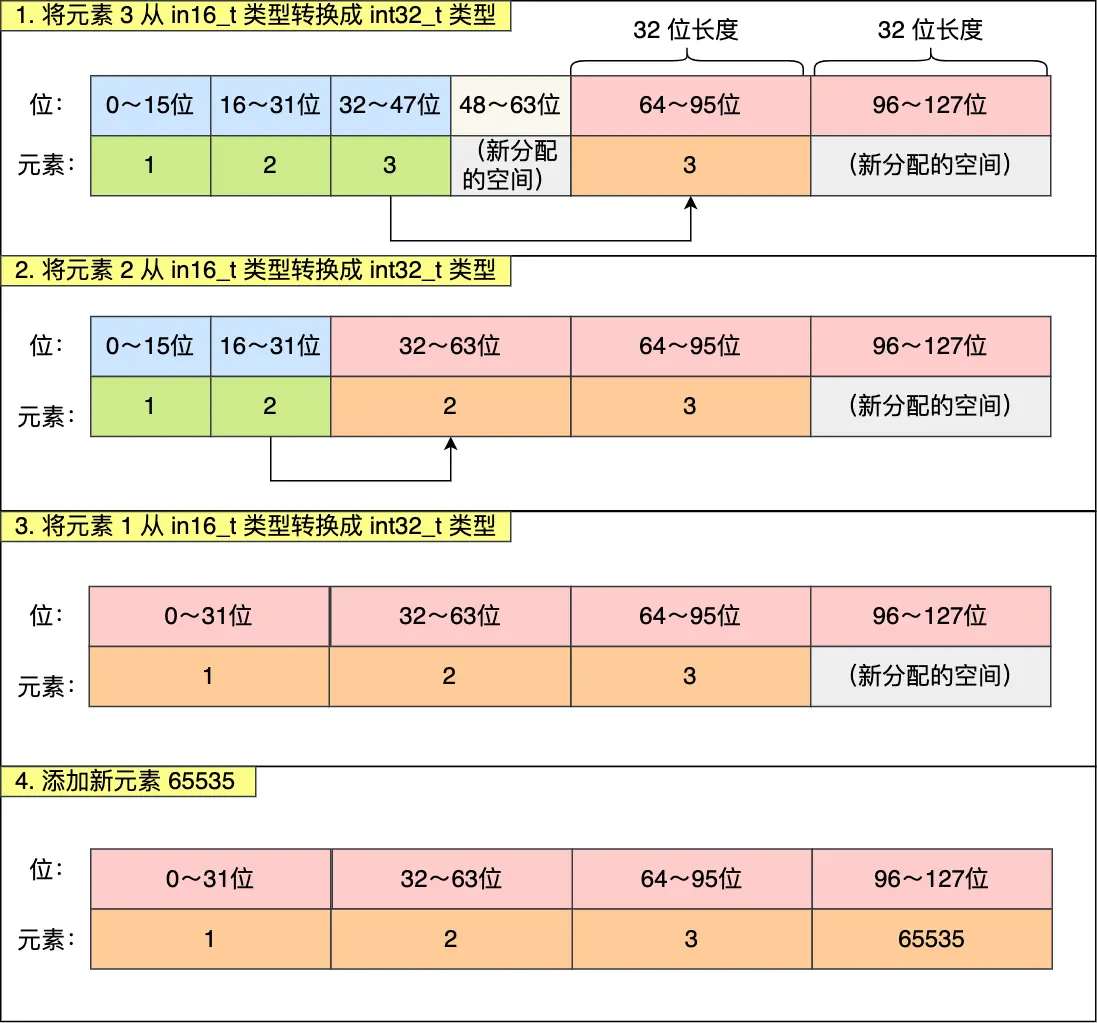
升级操作:
添加到整数集合的新元素类型比现有元素类型都要长时,整数集合会进行升级:
按新的类型扩展contents数组的空间大小
将新元素加入到整数集合里
升级过程中维持集合的有序性
特点:
动态升级可按需存储数据,节省内存
不支持降级操作,会一直保持升级后的状态
跳表:
只有Zset对象底层用到了跳表,支持平均OlogN的节点查找
zset有两个数据结构:跳表和哈希表。既能进行高效范围查询,又能进行高效单点查询
typedef struct zset {dict *dict;zskiplist *zsl;
} zset;结构设计:
在链表基础上改造为多层的有序链表
层级为3的跳表示例:
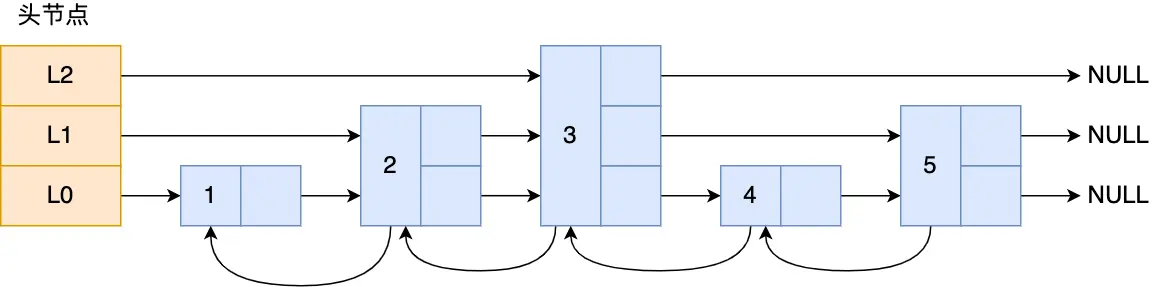
例如我们要查找节点4的数据,使用链表需要遍历四次,但使用跳表只需要遍历两次,查找过程就是在不同层级上根据元素的权重进行遍历直到定位数据。
跳表节点结构:
typedef struct zskiplistNode {//Zset 对象的元素值sds ele;//元素权重值double score;//后向指针struct zskiplistNode *backward;//节点的level数组,保存每层上的前向指针和跨度struct zskiplistLevel {struct zskiplistNode *forward;unsigned long span;} level[];
} zskiplistNode;跳表底层结构:
typedef struct zskiplist {//跳表的头尾节点,便于在O(1)时间复杂度内访问跳表的头节点和尾节点struct zskiplistNode *header, *tail;//跳表长度,便于在O(1)时间复杂度获取跳表节点的数量unsigned long length;//跳表的最大层数,便于在O(1)时间复杂度获取跳表中层高最大的那个节点的层数量int level;
} zskiplist;查询过程:
- 如果当前节点的权重小于要查找的权重,访问该层下一个节点
- 如果当前节点的权重等于要查找的权重,比较对应的SDS类型数据,若小于则访问该层下一个节点
- 若上面两个条件都不满足,或下一个节点为空,则沿着当前节点的下一层指针继续查找
查询过程示例:

如果要查找「元素:abcd,权重:4」的节点,查找的过程是这样的:
- 先从头节点的最高层开始,L2 指向了「元素:abc,权重:3」节点,这个节点的权重比要查找节点的小,所以要访问该层上的下一个节点;
- 但是该层的下一个节点是空节点( leve[2]指向的是空节点),于是就会跳到「元素:abc,权重:3」节点的下一层去找,也就是 leve[1];
- 「元素:abc,权重:3」节点的 leve[1] 的下一个指针指向了「元素:abcde,权重:4」的节点,然后将其和要查找的节点比较。虽然「元素:abcde,权重:4」的节点的权重和要查找的权重相同,但是当前节点的 SDS 类型数据「大于」要查找的数据,所以会继续跳到「元素:abc,权重:3」节点的下一层去找,也就是 leve[0];
- 「元素:abc,权重:3」节点的 leve[0] 的下一个指针指向了「元素:abcd,权重:4」的节点,该节点正是要查找的节点,查询结束
跳表节点层数设置:
跳表相邻节点数量最理想的比例是2:1,查找复杂度可以降低到OlogN
维持手段:
- 采用新增或删除节点来维持比例会带来额外开销,所以Redis使用概率生成来决定每个节点的层数
- 跳表创建节点时,会生成0到1的随机数,若随机数小于0.25,则该节点层数增加一层,然后继续生成随机数,直到结果大于0.25结束。
- 层数越高,概率越低,层高大小限制为64,创建跳表时,会根据层高限制创建所有头节点
为什么使用跳表而不用平衡树?
- 内存占用上:跳表使用的内存更少。平衡树每个节点包含两个指针,而跳表平均只有1.33个指针(概率为25%的情况下)
- 范围查找时:跳表操作更简单。平衡树找到指定范围的小值后,还需要中序遍历寻找其他不超过大值的节点。而跳表只需要找到最小值后对第1层链表进行遍历即可。
- 算法实现难度上:跳表实现更加简单。平衡树的插入删除操作可能引发子树的调整。而跳表只需要修改相邻节点的指针,与链表类似。
压缩列表:
结构设计:
连续内存块组成的顺序数组结构,类似于数组。Redis7.0后被完全废除
时间复杂度为On

四个额外字段:
- zlbytes:记录压缩列表占用的内存字节数
- zltail:记录压缩列表尾部节点的偏移量
- zllen:记录压缩列表包含的节点数量
- zlend:位于表尾,标记结束点,固定值0xFF(255)
每个键或值都作为一个独立的 entry 节点存储,节点结构包含:
prevlen:记录前一个节点的长度(用于逆向遍历)。encoding:标识当前节点的数据类型(字符串或整数)及长度。content:存储实际的键或值数据
插入数据时,根据数据结构和类型进行不同空间大小的分配,节省内存
连锁更新:
新增或修改元素时,若空间不足,压缩列表占用的内存空间就需要重新分配。插入元素较大时,可能会导致后续元素的prevlen占用空间全部发生变化,从而引起连锁更新(后面元素的prevlen的记录量本来为1字节,但新元素大小超过了254字节,需要用5字节来存储,而当前元素扩容后,后续的元素也要相应扩容,直到所有元素扩容完成)。
缺陷:
虽然压缩列表紧凑型的内存布局能节省内存开销,但元素过大会导致内存重新分配,甚至连锁更新。影响压缩列表的访问性能,所以压缩列表只适合保存节点数量不多的场景。
后续引入的quicklist类型和listpack类型就是在保持节省内存的优势的同时解决压缩列表的连锁更新的问题。
quicklist:
3.0前,List对象底层是双向链表或压缩链表。后来底层改为quicklist实现。quicklist实质上就是双向链表+压缩链表的组合:quicklist是一个双向链表,节点存储的是压缩列表。
解决连锁更新的办法:
quicklist通过控制每个节点中压缩列表的大小或者元素个数来规避连锁更新的问题。因为压缩列表元素越少越小,连锁更新带来的影响就越小。
结构设计:
typedef struct quicklist {//quicklist的链表头quicklistNode *head; //quicklist的链表头//quicklist的链表尾quicklistNode *tail; //所有压缩列表中的总元素个数unsigned long count;//quicklistNodes的个数unsigned long len; ...
} quicklist;节点结构设计:
typedef struct quicklistNode {//前一个quicklistNodestruct quicklistNode *prev; //前一个quicklistNode//下一个quicklistNodestruct quicklistNode *next; //后一个quicklistNode//quicklistNode指向的压缩列表unsigned char *zl; //压缩列表的的字节大小unsigned int sz; //压缩列表的元素个数unsigned int count : 16; //ziplist中的元素个数 ....
} quicklistNode;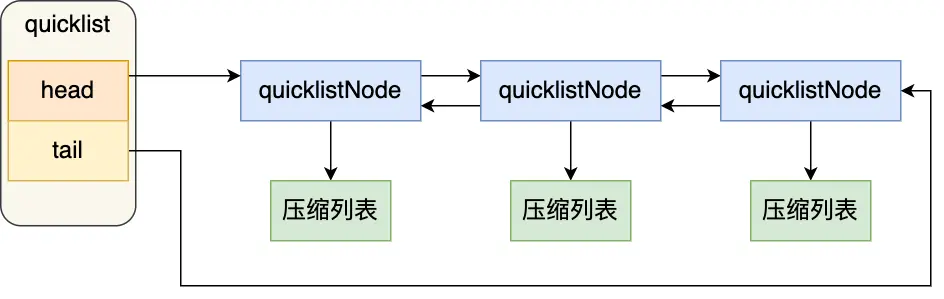
添加元素时,会先检查插入位置的压缩列表是否能容纳该元素,如果能容纳就直接保存到该压缩列表,否则才新增节点和压缩列表。
本质上连锁更新是没有解决的,只是通过控制压缩列表的大小来尽量减少连锁更新的性能损耗
listpack:
采用了很多压缩列表的优秀设计,例如还是用连续空间来紧凑存储数据,并且为节省内存开销,listpack节点采用不同的编码方式保存不同大小的数据。
结构设计:

节点结构:
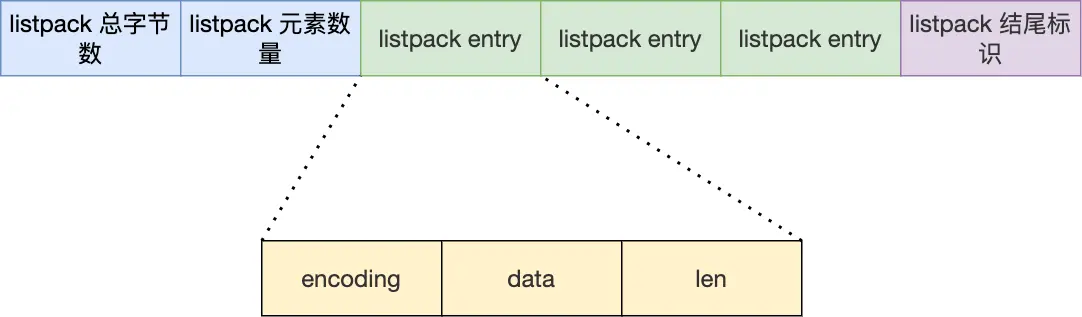
- backlen:encoding+data的总长度
- encoding:该元素的编码类型,对不同长度的整数和字符串进行编码
- data:实际存放的数据
可以发现,listpack移除了prevlen字段,只记录当前节点的长度,当我们向listpack加入新元素时,不会影响其他节点的内存空间,从而避免了压缩列表的连锁更新问题。
相关文章:
Redis——底层数据结构
SDS(simple dynamic string): 优点: O1时间获取长度(char *需要ON)快速计算剩余空间(alloc-len),拼接时根据所需空间自动扩容,避免缓存区溢出(ch…...

ChatGPT 能“记住上文”的原因
原因如下 你把对话历史传给了它 每次调用 OpenAI 接口时,都会把之前的对话作为参数传入(messages 列表),模型“看见”了之前你说了什么。 它没有长期记忆 它不会自动记住你是谁或你说过什么,除非你手动保存历史并再次…...

大疆无人机自主飞行解决方案局限性及增强解决方案-AIBOX:特色行业无人机巡检解决方案
大疆无人机自主飞行解决方案局限性及增强解决方案-AIBOX:特色行业无人机巡检解决方案 大疆无人机是低空行业无人机最具性价比的产品,尤其是大疆机场3的推出,以及持续自身产品升级迭代,包括司空2、大疆智图以及大疆智运等专业软件和…...

医学影像系统性能优化与调试技术:深度剖析与实践指南
🧑 博主简介:CSDN博客专家、CSDN平台优质创作者,高级开发工程师,数学专业,10年以上C/C, C#, Java等多种编程语言开发经验,拥有高级工程师证书;擅长C/C、C#等开发语言,熟悉Java常用开…...

day 25
*被遗忘的一集 程序:二进制文件,文件存储在磁盘中,例如/usr/bin/目录下 进程:进程是已启动的可执行程序的运行实例。 *进程和程序并不是一一对应的关系,相同的程序运行在不同的数据集上就是不同的进程 *进程还具有并…...
吉客云数据集成到金蝶云星空的最佳实践
吉客云数据集成到金蝶云星空的技术案例分享 在本次技术案例中,我们将探讨如何通过仓库方案-I0132,将吉客云的数据高效集成到金蝶云星空。此方案旨在解决企业在数据对接过程中遇到的多种技术挑战,包括数据吞吐量、实时监控、异常处理和数据格…...

【Spark】-- DAG 和宽窄依赖的核心
目录 Spark DAG 和宽窄依赖的核心 一、什么是 DAG? 示例:WordCount 程序的 DAG 二、宽依赖与窄依赖 1. 窄依赖 2. 宽依赖 三、DAG 与宽窄依赖的性能优化 1. 减少 Shuffle 操作 2. 合理划分 Stage 3. 使用缓存机制 四、实际案例分析:同行车判断 五、总结 Spark D…...

原生的 XMLHttpRequest 和基于 jQuery 的 $.ajax 方法的异同之处以及使用场景
近期参与一个项目的开发,发现项目中的ajax请求有两种不同的写法,查询了下两种写法的异同之处以及使用场景。 下面将从以下两段简单代码进行异同之处的分析及使用场景的介绍: // 写法一: var xhr new XMLHttpRequest(); xhr.open…...

快速选择算法:优化大数据中的 Top-K 问题
在处理海量数据时,经常会遇到这样的需求:找出数据中最大的前 K 个数,而不必对整个数据集进行排序。这种场景下,快速选择算法(Quickselect)就成了一个非常高效的解决方案。本文将通过一个 C 实现的快速选择算…...

使用Frp搭建内网穿透,外网也可以访问本地电脑。
一、准备 1、服务器:需要一台外网可以访问的服务器,不在乎配置,宽带好就行。我用的是linux服务器。(一般买一个1核1g的云服务器就行),因为配置高的服务器贵,所以这是个择中办法。 2、客户端&a…...

【RabbitMQ】消息丢失问题排查与解决
RabbitMQ 消息丢失是一个常见的问题,可能发生在消息的生产、传输、消费或 Broker 端等多个环节。消息丢失的常见原因及对应的解决方案: 一、消息丢失的常见原因 1. 生产端(Producer)原因 (1) 消息未持久化 原因:生产…...

电子电路:被动电子元件都有哪些?
在电子电路中,被动元件(Passive Components)是指不需要外部电源即可工作且不具备信号放大或能量控制能力的元件。它们主要通过消耗、存储或传递能量来调节电路的电流、电压、频率等特性。以下是常见的被动元件及其核心作用: 一、基础被动元件 1. 电阻(Resistor) 功能:限…...
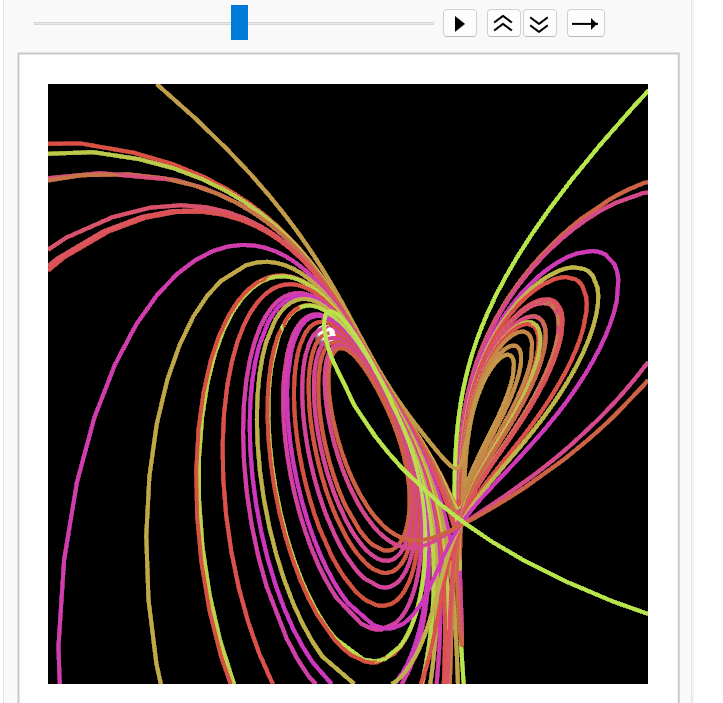
使用Mathematica制作Lorenz吸引子的轨道追踪视频
Lorenz奇异吸引子是混沌理论中最早被发现和研究的吸引子之一,它由Edward Lorenz在1963年研究确定性非周期流时提出。Lorenz吸引子以其独特的"蝴蝶"形状而闻名,是混沌系统和非线性动力学的经典例子。 L NDSolveValue[{x[t] -3 (x[t] - y[t]),…...

深入解析VPN技术原理:安全网络的护航者
在当今信息化迅速发展的时代,虚拟私人网络(VPN)技术成为了我们在互联网时代保护隐私和数据安全的重要工具。VPN通过为用户与网络之间建立一条加密的安全通道,确保了通讯的私密性与完整性。本文将深入解析VPN的技术原理、工作机制以…...
:前端框架性能优化深度解析)
JavaScript性能优化实战(10):前端框架性能优化深度解析
引言 React、Vue、Angular等框架虽然提供了强大的抽象和开发效率,但不恰当的使用方式会导致严重的性能问题,针对这些问题,本文将深入探讨前端框架性能优化的核心技术和最佳实践。 React性能优化核心技术 React通过虚拟DOM和高效的渲染机制提供了出色的性能,但当应用规模…...
 VS (LINQ) 性能比拼 ——c#)
(for 循环) VS (LINQ) 性能比拼 ——c#
在大多数情况下,for 循环的原始性能会优于 LINQ,尤其是在处理简单遍历、数据筛选或属性提取等场景时。这是由两者的实现机制和抽象层次决定的。以下是具体分析: 一、for 循环与 LINQ 的性能差异原因 1. 抽象层次与执行机制 for 循环&#…...

《Spring Boot 4.0新特性深度解析》
Spring Boot 4.0的发布标志着Java生态向云原生与开发效能革命的全面迈进。作为企业级应用开发的事实标准框架,此次升级在运行时性能、云原生支持、开发者体验及生态兼容性四大维度实现突破性创新。本文深度解析其核心技术特性,涵盖GraalVM原生镜像支持、…...
的可能原因有哪些?如何从数据或训练层面缓解?)
【大模型面试每日一题】Day 20:大模型出现“幻觉”(Hallucination)的可能原因有哪些?如何从数据或训练层面缓解?
【大模型面试每日一题】Day 20:大模型出现“幻觉”(Hallucination)的可能原因有哪些?如何从数据或训练层面缓解? 📌 题目重现 🌟🌟 面试官:大模型出现“幻觉”…...

简单图像自适应亮度对比度调整
一、背景介绍 继续在刷对比度调整相关算法,偶然间发现了这个简单的亮度/对比度自适应调整算法,做个简单笔记记录。也许后面用得到。 二、自适应亮度调整 1、基本原理 方法来自论文:Adaptive Local Tone Mapping Based on Retinex for High Dynamic Ran…...

CompletableFuture统计任务
ApiOperation(value "首页统计")GetMapping("/statistics")public UnifyResponse<List<BusinessStatisticsVO>> statistics() throws Exception {StatisticsPermissionQuery permissionQuery getPermission();ThreadPoolExecutor executor …...

neo4j框架:ubuntu系统中neo4j安装与使用教程
在使用图数据库的时候,经常需要用到neo4j这一图数据库处理框架。本文详细介绍了neo4j安装使用过程中的问题与解决方法。 一、安装neo4j 在安装好了ubuntu系统、docker仓库和java的前提下 在ubuntu系统命令行依次输入如下命令: # 安装依赖库 sudo apt-…...

ECPF 简介
ECPF(Embedded CPU Function,嵌入式CPU功能)是NVIDIA BlueField DPU特有的一种功能类型,和PF(Physical Function,物理功能)、VF(Virtual Function,虚拟功能)密…...

eSwitch manager 简介
eSwitch manager 的定义和作用 eSwitch manager 通常指的是能够配置和管理 eSwitch(嵌入式交换机)的实体或接口。在 NVIDIA/Mellanox 的网络架构中,Physical Function(PF)在 switchdev 模式下充当 eSwitch manager&am…...
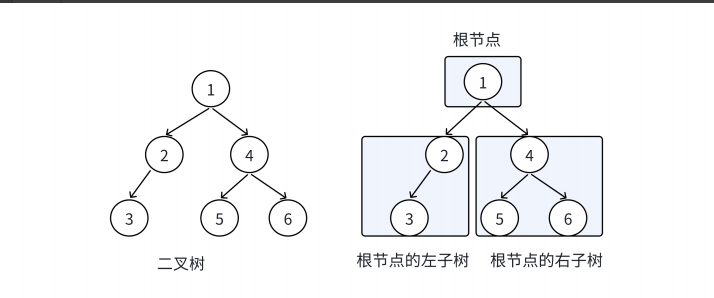
深入理解二叉树:遍历、存储与算法实现
在之前的博客系列中,我们系统地探讨了多种线性表数据结构,包括顺序表、栈和队列等经典结构,并通过代码实现了它们的核心功能。从今天开始,我们将开启一个全新的数据结构篇章——树结构。与之前讨论的线性结构不同,树形…...

Python3 简易DNS服务器实现
使用Python3开发一个简单的DNS服务器,支持配置资源记录(RR),并能通过dig命令进行查询。 让自己理解DNS原理 实现方案 我们将使用socketserver和dnslib库来构建这个DNS服务器。dnslib库能帮助我们处理DNS协议的复杂细节。 1. 安装依赖 首先确保安装了d…...

【Win32 API】 lstrcmpA()
作用 比较两个字符字符串(比较区分大小写)。 lstrcmp 函数通过从第一个字符开始检查,若相等,则检查下一个,直到找到不相等或到达字符串的末尾。 函数 int lstrcmpA(LPCSTR lpString1, LPCSTR lpString2); 参数 lpStr…...
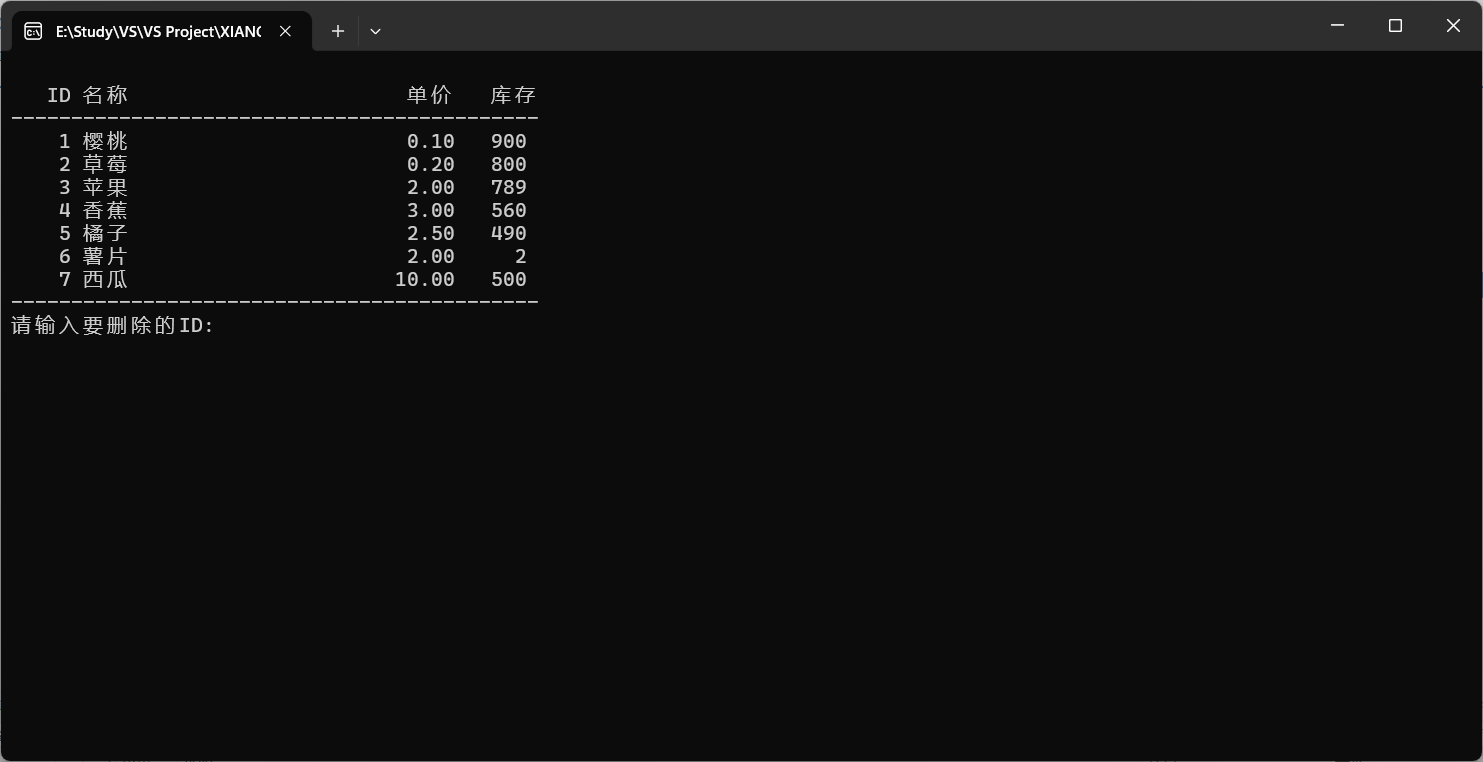
(C语言)超市管理系统 (正式版)(指针)(数据结构)(清屏操作)(文件读写)
目录 前言: 源代码: product.h product.c fileio.h fileio.c main.c 代码解析: 一、程序结构概述 二、product.c 函数详解 1. 初始化商品列表 Init_products 2. 添加商品 add_product 3. 显示商品 display_products 4. 修改商品 mo…...
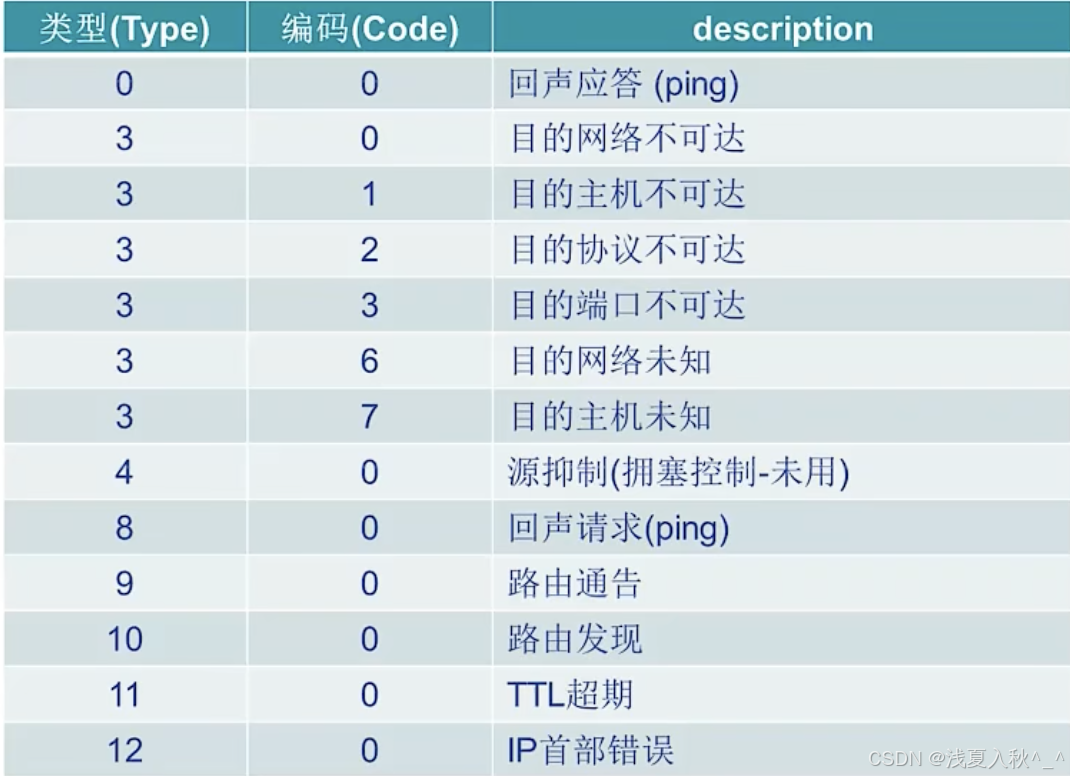
NAT转换和ICMP
NAT nat原理示意 nat实现 ICMP ICMP支持主机或路由器: 差错或异常报告网络探寻 2类icmp报文: 差错报告报文(5种) 目的不可达源抑制--拥塞控制超时&超期--TTL超时参数问题--问题报文丢弃重定向--不应该由这个路由器转发&a…...

Executors类详解
Executors类详解 Executors 是Java中用于快速创建线程池的工具类,提供了一系列工厂方法,简化了 ThreadPoolExecutor 和 ScheduledThreadPoolExecutor 的配置。以下是其核心方法、实现原理及使用注意事项: 1. 常用线程池工厂方法 (1) newFixedThreadPool 作用:创建固定大小…...
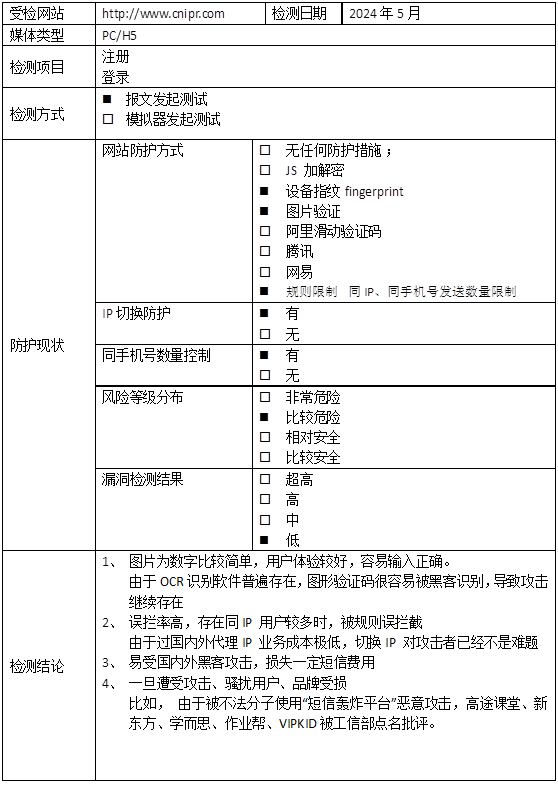
【专利信息服务平台-注册/登录安全分析报告】
前言 由于网站注册入口容易被黑客攻击,存在如下安全问题: 暴力破解密码,造成用户信息泄露短信盗刷的安全问题,影响业务及导致用户投诉带来经济损失,尤其是后付费客户,风险巨大,造成亏损无底洞…...