【Elasticsearch】flattened`类型在查询嵌套数组时可能返回不准确结果的情况
好的!为了更清楚地说明`flattened`类型在查询嵌套数组时可能返回不准确结果的情况,我们可以通过一个具体的例子来展示。这个例子将展示如何在文档中没有完全匹配的嵌套对象时,`flattened`类型仍然可能返回该文档。
示例文档结构
假设你有以下文档结构,其中`addresses`是一个嵌套数组:
```json
PUT /my_index/_doc/1
{
"user": {
"id": 1,
"name": "John Doe",
"addresses": [
{
"street": "123 Main St",
"city": "Anytown",
"state": "NY" // 注意这里 state 是 NY,而不是 CA
},
{
"street": "456 Elm St",
"city": "Othertown",
"state": "CA" // 注意这里 city 是 Othertown,而不是 Anytown
}
]
}
}
```
在这个文档中,`addresses`数组包含两个地址对象:
1. 第一个地址对象的`city`是`"Anytown"`,但`state`是`"NY"`。
2. 第二个地址对象的`state`是`"CA"`,但`city`是`"Othertown"`。
查询示例
假设你希望查询所有`city`为`"Anytown"`且`state`为`"CA"`的地址。如果`addresses`字段被定义为`flattened`类型,你可能会写出以下查询:
```json
GET /my_index/_search
{
"query": {
"bool": {
"must": [
{
"term": {
"user.addresses.city": {
"value": "Anytown"
}
}
},
{
"term": {
"user.addresses.state": {
"value": "CA"
}
}
}
]
}
}
}
```
查询结果
由于`flattened`类型会将嵌套结构展开为多个字段路径,Elasticsearch 无法保证`city`和`state`属于同一个嵌套对象。因此,查询可能会返回不准确的结果。
在上面的例子中,`flattened`类型会将`addresses`展开为以下字段路径:
```json
{
"user.addresses.street.0": "123 Main St",
"user.addresses.city.0": "Anytown",
"user.addresses.state.0": "NY",
"user.addresses.street.1": "456 Elm St",
"user.addresses.city.1": "Othertown",
"user.addresses.state.1": "CA"
}
```
当你执行查询时,Elasticsearch 会分别匹配`city`和`state`,但无法保证它们属于同一个嵌套对象。因此,查询可能会返回包含以下内容的文档:
```json
{
"hits": {
"total": {
"value": 1,
"relation": "eq"
},
"max_score": 1.0,
"hits": [
{
"_index": "my_index",
"_type": "_doc",
"_id": "1",
"_score": 1.0,
"_source": {
"user": {
"id": 1,
"name": "John Doe",
"addresses": [
{
"street": "123 Main St",
"city": "Anytown",
"state": "NY"
},
{
"street": "456 Elm St",
"city": "Othertown",
"state": "CA"
}
]
}
}
}
]
}
}
```
问题解释
尽管文档中没有完全匹配`city`为`"Anytown"`且`state`为`"CA"`的地址对象,但查询仍然返回了该文档。这是因为`flattened`类型无法保证`city`和`state`属于同一个嵌套对象。具体来说:
• 第一个地址对象的`city`是`"Anytown"`,但`state`是`"NY"`。
• 第二个地址对象的`state`是`"CA"`,但`city`是`"Othertown"`。
由于`flattened`类型将这些字段路径展开后,Elasticsearch 会分别匹配`city`和`state`,而不会检查它们是否属于同一个嵌套对象。因此,只要文档中存在满足条件的字段路径,即使这些字段路径不属于同一个嵌套对象,查询也会返回该文档。
使用`nested`类型的正确结果
如果`addresses`字段被定义为`nested`类型,查询会正确地返回没有匹配结果的情况:
```json
PUT /my_index
{
"mappings": {
"properties": {
"user": {
"properties": {
"id": { "type": "integer" },
"name": { "type": "text" },
"addresses": { "type": "nested" }
}
}
}
}
}
```
查询:
```json
GET /my_index/_search
{
"query": {
"nested": {
"path": "user.addresses",
"query": {
"bool": {
"must": [
{
"term": {
"user.addresses.city": {
"value": "Anytown"
}
}
},
{
"term": {
"user.addresses.state": {
"value": "CA"
}
}
}
]
}
}
}
}
}
```
返回结果:
```json
{
"hits": {
"total": {
"value": 0,
"relation": "eq"
},
"max_score": null,
"hits": []
}
}
```
`nested`类型会正确地检查每个嵌套对象的完整性,因此不会返回不匹配的文档。
总结
• `flattened`类型的限制:`flattened`类型会将嵌套结构展开为多个字段路径,无法保证这些字段属于同一个嵌套对象。因此,在查询时可能会返回不准确的结果。
• `nested`类型的优势:`nested`类型可以保持嵌套对象的完整性,支持复杂的嵌套查询,能够精确匹配嵌套结构。
希望这个例子清楚地展示了`flattened`类型在查询嵌套数组时可能返回不准确结果的情况。
这里`flattened`类型在处理嵌套对象时出现不准确结果的问题,主要是因为嵌套对象是列表(数组)结构。当嵌套对象是数组时,`flattened`类型会将数组中的每个对象展开为多个字段路径,而这些字段路径之间没有关联关系,因此无法保证它们属于同一个嵌套对象。
为什么`flattened`类型在数组结构中会出现问题?
当嵌套对象是数组时,`flattened`类型会将数组中的每个对象的字段路径展开为独立的字段。例如,假设你有以下文档结构:
```json
{
"user": {
"id": 1,
"name": "John Doe",
"addresses": [
{
"street": "123 Main St",
"city": "Anytown",
"state": "NY"
},
{
"street": "456 Elm St",
"city": "Othertown",
"state": "CA"
}
]
}
}
```
如果`addresses`字段被定义为`flattened`类型,Elasticsearch 会将`addresses`展开为以下字段路径:
```json
{
"user.addresses.street.0": "123 Main St",
"user.addresses.city.0": "Anytown",
"user.addresses.state.0": "NY",
"user.addresses.street.1": "456 Elm St",
"user.addresses.city.1": "Othertown",
"user.addresses.state.1": "CA"
}
```
当你执行查询时,Elasticsearch 会分别匹配这些字段路径,但无法保证它们属于同一个嵌套对象。因此,查询可能会返回不准确的结果。
示例:`flattened`类型在数组结构中的问题
假设你希望查询所有`city`为`"Anytown"`且`state`为`"CA"`的地址。如果`addresses`字段被定义为`flattened`类型,你可能会写出以下查询:
```json
GET /my_index/_search
{
"query": {
"bool": {
"must": [
{
"term": {
"user.addresses.city": {
"value": "Anytown"
}
}
},
{
"term": {
"user.addresses.state": {
"value": "CA"
}
}
}
]
}
}
}
```
由于`flattened`类型将数组中的每个对象的字段路径展开为独立的字段,Elasticsearch 会分别匹配`city`和`state`,但无法保证它们属于同一个嵌套对象。因此,查询可能会返回包含以下内容的文档:
```json
{
"hits": {
"total": {
"value": 1,
"relation": "eq"
},
"max_score": 1.0,
"hits": [
{
"_index": "my_index",
"_type": "_doc",
"_id": "1",
"_score": 1.0,
"_source": {
"user": {
"id": 1,
"name": "John Doe",
"addresses": [
{
"street": "123 Main St",
"city": "Anytown",
"state": "NY"
},
{
"street": "456 Elm St",
"city": "Othertown",
"state": "CA"
}
]
}
}
}
]
}
}
```
尽管文档中没有完全匹配`city`为`"Anytown"`且`state`为`"CA"`的地址对象,但查询仍然返回了该文档。这是因为`flattened`类型无法保证`city`和`state`属于同一个嵌套对象。
如果嵌套对象不是数组结构呢?
如果嵌套对象不是数组结构,`flattened`类型通常不会出现这种问题。例如,假设你有以下文档结构:
```json
{
"user": {
"id": 1,
"name": "John Doe",
"address": {
"street": "123 Main St",
"city": "Anytown",
"state": "CA"
}
}
}
```
在这种情况下,`address`是一个嵌套对象,而不是数组。如果`address`字段被定义为`flattened`类型,Elasticsearch 会将`address`展开为以下字段路径:
```json
{
"user.address.street": "123 Main St",
"user.address.city": "Anytown",
"user.address.state": "CA"
}
```
当你执行查询时,Elasticsearch 会匹配这些字段路径,而这些字段路径属于同一个嵌套对象,因此不会出现不准确的结果。
示例:`flattened`类型在非数组结构中的表现
假设你希望查询所有`city`为`"Anytown"`且`state`为`"CA"`的地址。如果`address`字段被定义为`flattened`类型,你可能会写出以下查询:
```json
GET /my_index/_search
{
"query": {
"bool": {
"must": [
{
"term": {
"user.address.city": {
"value": "Anytown"
}
}
},
{
"term": {
"user.address.state": {
"value": "CA"
}
}
}
]
}
}
}
```
返回结果:
```json
{
"hits": {
"total": {
"value": 1,
"relation": "eq"
},
"max_score": 1.0,
"hits": [
{
"_index": "my_index",
"_type": "_doc",
"_id": "1",
"_score": 1.0,
"_source": {
"user": {
"id": 1,
"name": "John Doe",
"address": {
"street": "123 Main St",
"city": "Anytown",
"state": "CA"
}
}
}
}
]
}
}
```
在这种情况下,`flattened`类型可以正确匹配`city`和`state`,因为它们属于同一个嵌套对象。
总结
• `flattened`类型在数组结构中的问题:
• 当嵌套对象是数组时,`flattened`类型会将数组中的每个对象的字段路径展开为独立的字段。
• Elasticsearch 无法保证这些字段路径属于同一个嵌套对象,因此查询可能会返回不准确的结果。
• `flattened`类型在非数组结构中的表现:
• 当嵌套对象不是数组时,`flattened`类型可以正确匹配字段路径,因为这些字段路径属于同一个嵌套对象。
• 查询结果通常是准确的。
因此,`flattened`类型在处理嵌套数组时需要特别小心,而`nested`类型在这种场景下通常是更好的选择,因为它可以保持嵌套对象的完整性并支持复杂的嵌套查询。
相关文章:

【Elasticsearch】flattened`类型在查询嵌套数组时可能返回不准确结果的情况
好的!为了更清楚地说明flattened类型在查询嵌套数组时可能返回不准确结果的情况,我们可以通过一个具体的例子来展示。这个例子将展示如何在文档中没有完全匹配的嵌套对象时,flattened类型仍然可能返回该文档。 示例文档结构 假设你有以下文…...

Mysql、Oracle、Sql Server、达梦之间sql的差异
1:分页查询 Sql Server: <bind name"startRow" value"(page - 1) * limit 1"/> <bind name"endRow" value"page * limit"/> SELECT *FROM (SELECT ROW_NUMBER() OVER (<if test"sortZd!…...
记录算法笔记(2025.5.15)将有序数组转换为二叉搜索树
给你一个整数数组 nums ,其中元素已经按 升序 排列,请你将其转换为一棵 平衡 二叉搜索树。 示例 1: 输入:nums [-10,-3,0,5,9] 输出:[0,-3,9,-10,null,5] 解释:[0,-10,5,null,-3,null,9] 也将被视为正确…...

数学复习笔记 11
前言 向量开始。 矩阵的秩 k 阶子式。从这个概念开始复习。考虑 k 阶子式是否为零,具体是多少我们不在乎,我们只在乎 k 阶子式是否为零。把一套资料复习好就好了。 秩的计算 初等变换秩不发生改变。要么初等变换,要么行列式。用行列式需…...
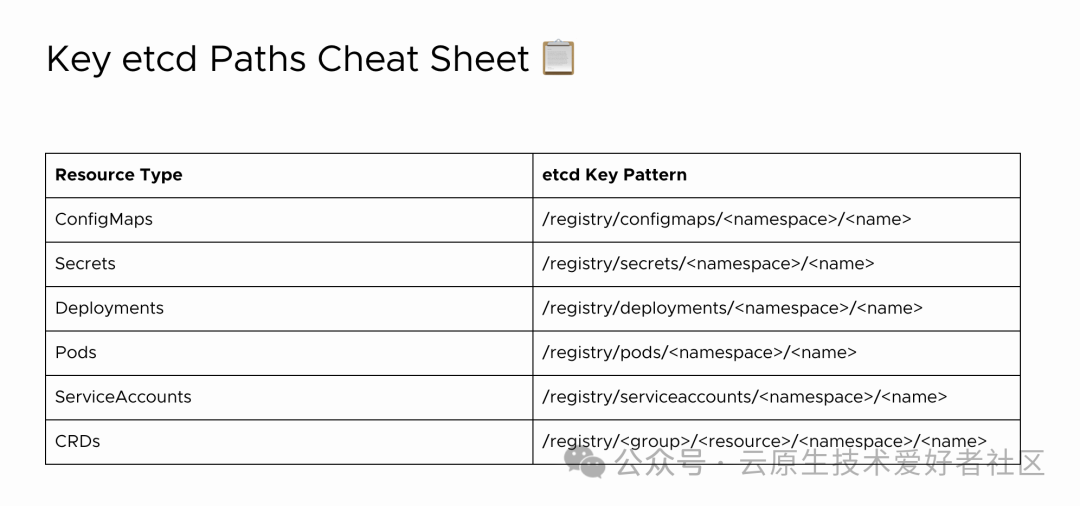
Kubernetes 运维操作手册:从 etcd 快照进行精确恢复
1 5 步实现 etcd 精确恢复 将快照恢复到本地 etcd 数据目录。使用恢复的数据启动本地 etcd 实例。使用 etcdctl 查询特定键(例如,ConfigMap)。使用 auger 解码以提取干净的 YAML。使用 kubectl 申请恢复到您的实时集群。 本指南将指导您从 et…...
云轴科技ZStack官网上线Support AI,智能助手助力高效技术支持
5月16日,云轴科技ZStack在官网(www.zstack.io)正式上线ZStack Support AI智能助手。该系统是ZStack应用人工智能于技术支持服务领域的重要创新,基于自研ZStack AIOS平台智塔及LLMOPS技术打造。 ZStack Support AI定位为智能客服&…...

UE5中制作动态数字Decal
在进行城市道路编辑时,经常需要绘制人行道、交通标志、停车线等路面元素。如果能够使用具有动态修改功能的 Decal(贴花),将大大提升编辑效率和灵活性。接下来讲解如何制作。 1.首先准备一张包含所需元素的Texture,这里…...
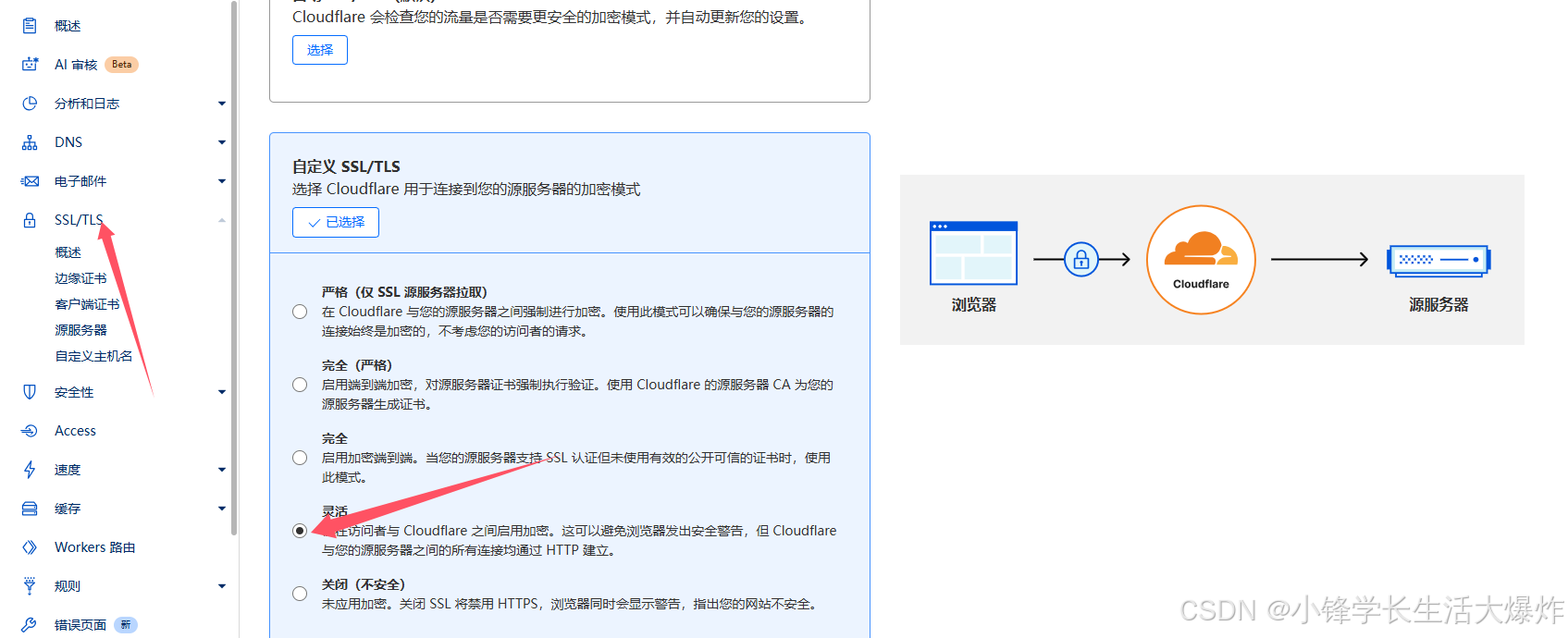
【踩坑】修复Cloudflare的Origin Rules端口重定向不生效
转载请注明出处:小锋学长生活大爆炸[xfxuezhagn.cn] 如果本文帮助到了你,欢迎[点赞、收藏、关注]哦~ 网上没人说,目前我是通过以下两种方式成功将二级域名映射到指定端口的。关于如何映射,网上教程很多,这里只说不生效…...

2025 年十大网络安全预测
随着我们逐步迈向 2026 年,网络安全领域正处于一个关键的转折点,技术创新与数字威胁以前所未有的复杂态势交织在一起。 地缘政治环境进一步加剧了这些网络安全挑战,国际犯罪组织利用先进的技术能力来追求战略目标。 人工智能在这一不断演变…...

JS手写代码篇---手写 instanceof 方法
2、手写 instanceof 方法 instancecof用于检测一个对象是否是某个构造函数的实例。它通常用于检查对象的类型,尤其是在处理继承关系时。 eg: const arr [1,2,3,4,5]console.log(arr instanceof Array); // trueconsole.log(arr instanceof Object); // true那这是…...

STM32硬件I2C驱动OLED屏幕
本文基于STM32硬件I2C驱动SSD1306 OLED屏幕,提供完整的代码实现及关键注意事项,适用于128x32或128x64分辨率屏幕。代码通过模块化设计,支持显示字符、数字、汉字及位图,并优化了显存刷新机制。 零、完整代码 完整代码: 1&#x…...

紫外相机工作原理及可应用范围
紫外相机是一种利用紫外线(UV)波段进行成像的设备,紫外线可用于机器视觉应用中,以检测使用可见光无法检测到的特征,工业上使用最常见的紫外波长是365nm和395nm。紫外相机通常用于高分辨率视频显微镜、电晕检测、半导体…...
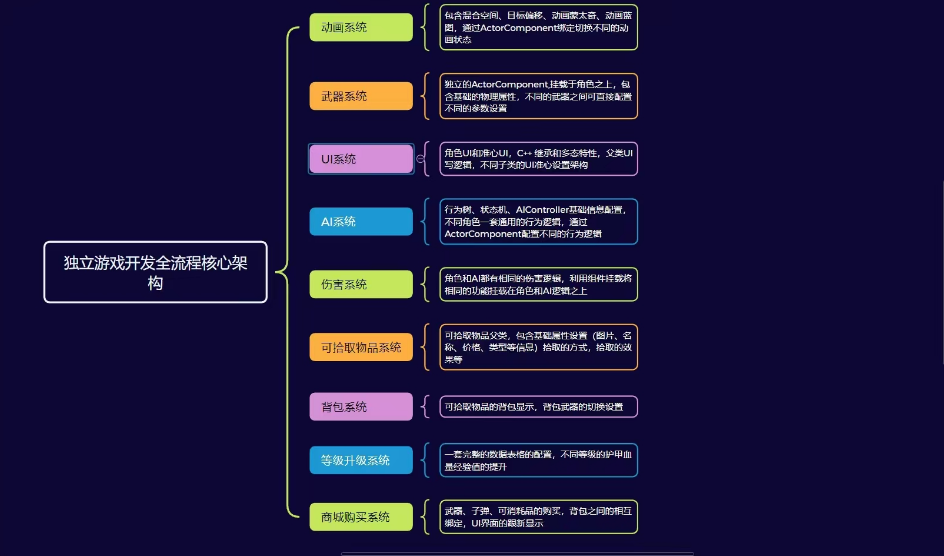
【虚幻引擎】UE5独立游戏开发全流程(商业级架构)
本套课程我将会讲解一下知识 1.虚幻引擎的常用功能节点、模块包含但不限于动画模块、UI模块、AI模块、碰撞模块、伤害模块、背包模块、准心模块、武器模块、可拾取物品模块、死亡等模块。 2.整个游戏的设计思路(游戏架构),本套教程讲解了如…...
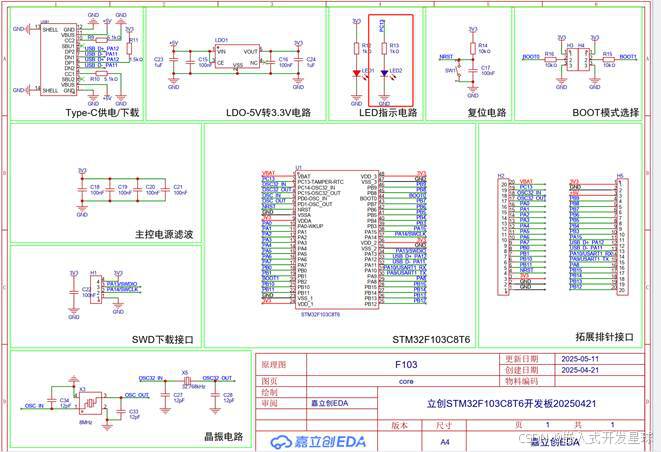
嵌入式单片机中STM32F1演示寄存器控制方法
该文以STM32F103C8T6为示例,演示如何使用操作寄存器的方法点亮(关闭LED灯),并讲解了如何调试,以及使用宏定义。 第一:操作寄存器点亮LED灯。 (1)首先我们的目的是操作板子上的LED2灯,对其实现点亮和关闭操作。打开STM32F103C8T6的原理图,找到LED2的位置。 可以看到…...
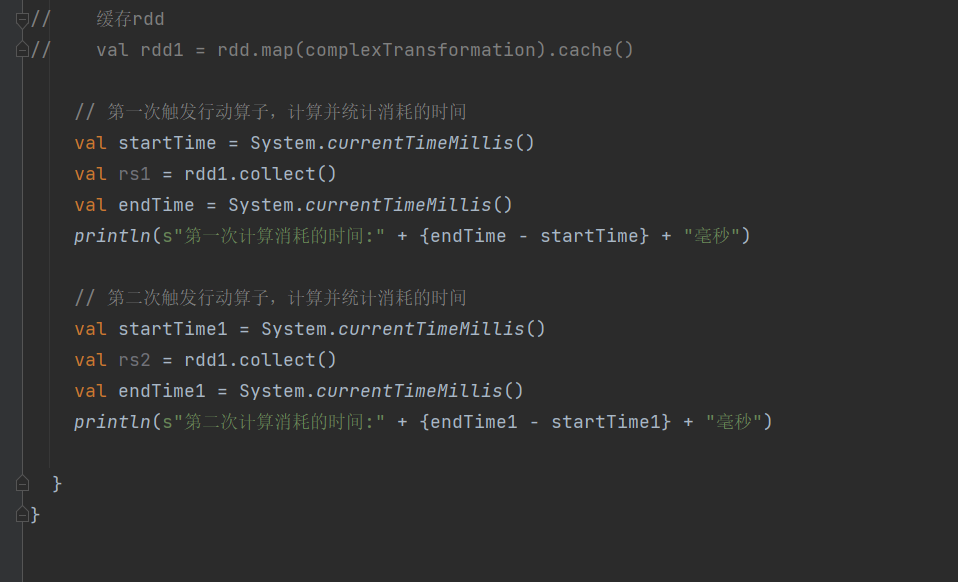
spark-cache模式
一、RDD持久化 1.什么时候该使用持久化(缓存) 2. RDD cache & persist 缓存 3. RDD CheckPoint 检查点 4. cache & persist & checkpoint 的特点和区别 特点 区别 二、cache & persist 的持久化级别及策略选择 Spark的几种持久化…...

架构思维:通用架构模式_系统监控的设计
文章目录 引言什么是监控三大常见监控类型1. 次数监控2. 性能监控3. 可用率监控 落地监控1. 服务入口2. 服务内部3. 服务依赖 监控时间间隔的取舍小结 引言 架构思维:通用架构模式_从设计到代码构建稳如磐石的系统 架构思维:通用架构模式_稳如老狗的SDK…...

Laravel 参数验证工具
Laravel 提供了内置的参数验证工具,可以让你定义参数需满足的规则,程序自动进行验证。如果验证成功,程序继续运行;如果失败,则自动返回响应并显示失败原因。 具体实现方式如下: 1. 创建自定义请求类 你可…...

InfluxDB 2.7 连续查询实战指南:Task 替代方案详解
InfluxDB 2.7 引入了 Task 功能,作为连续查询(CQ)的现代替代方案。本文详细介绍了如何使用 Task 实现传统 CQ 的功能,包括语法解析、示例代码、参数对比以及典型应用场景。通过实际案例和最佳实践,帮助开发者高效迁移并…...
【SpringBoot】从零开始全面解析SpringMVC (二)
本篇博客给大家带来的是SpringBoot的知识点, 本篇是SpringBoot入门, 介绍SpringMVC相关知识. 🐎文章专栏: JavaEE进阶 🚀若有问题 评论区见 👉gitee链接: 薯条不要番茄酱 ❤ 欢迎大家点赞 评论 收藏 分享 如果你不知道分享给谁,那就分享给薯条…...

蒟蒻编程日志
ORZ (用于记录你这个“人”是不是真的,也就是说CSDN的流量是否属合适) 2025/4/14 21:25 开坑 前言 2024/10/26:CSP-J 260pts,CSP-S 45pts。 2025/3/1:%你赛 180pts rk34 寄!这就是不认真的…...
git克隆github项目到本地的三种方式
本文旨在使用git工具将别人发布在github上的项目保存到本地 1.安装git,创建github账户,并使用ssh关联自己的github账号和git,具体教程可以参照下面两篇文章: Github入门教程,适合新手学习(非常详细&#…...

深入理解 this 指向与作用域解析
引言 JavaScript 中的 this 关键字的灵活性既是强大特性也是常见困惑源。理解 this 的行为对于编写可维护的代码至关重要,但其动态特性也会让我们感到困惑。 与大多数编程语言不同,JavaScript 的 this 不指向函数本身,也不指向函数的词法作…...

EtherCAT转EtherNet/IP解决方案-泗博网关CEI-382
一、应用场景 在智能制造快速发展的背景下,工业自动化领域对设备间通信提出了更高要求,需要同时满足实时性、可靠性和灵活性的需求。EtherCAT 与 EtherNet/IP 作为工业通信领域的两大核心协议,各自在不同应用场景中发挥着关键作用。EtherCAT …...

子查询对多层join优化记录
需求背景 查询某个用户是否具有某个角色 表 CREATE TABLE mdm_platform_role_user (ID bigint NOT NULL AUTO_INCREMENT,ROLE_ID varchar(100) CHARACTER SET utf8 COLLATE utf8_general_ci DEFAULT NULL,USER_ID varchar(100) CHARACTER SET utf8 COLLATE utf8_general_ci …...
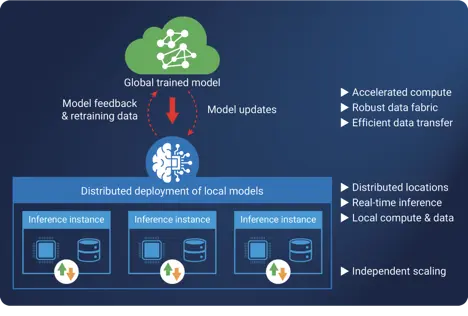
分布式AI推理的成功之道
随着AI模型逐渐成为企业运营的核心支柱,实时推理已成为推动这一转型的关键引擎。市场对即时、可决策的AI洞察需求激增,而AI代理——正迅速成为推理技术的前沿——即将迎来爆发式普及。德勤预测,到2027年,超半数采用生成式AI的企业…...

随笔:hhhhh
第一题 ∫ − ∞ ∞ x e x − e x d x ∫ 0 ∞ ln t ⋅ e ln t − t ⋅ 1 t d t ∫ 0 ∞ ln t ⋅ e − t ⋅ 1 t ⋅ t d t ∫ 0 ∞ ln t ⋅ e − t d t ψ ( 1 ) − γ \begin{align*} \int_{-\infty}^{\infty}xe^{x-e^x}\text{d}x&\int_{0}^{\infty}…...

PR-2021
推荐深蓝学院的《深度神经网络加速:cuDNN 与 TensorRT》,课程面向就业,细致讲解CUDA运算的理论支撑与实践,学完可以系统化掌握CUDA基础编程知识以及TensorRT实战,并且能够利用GPU开发高性能、高并发的软件系统…...
和 Anaconda 的不同)
CMD(Command Prompt)和 Anaconda 的不同
CMD(Command Prompt)和 Anaconda 是两种不同的工具,它们在功能和用途上有明显的区别: CMD(Command Prompt) 定义:CMD 是 Windows 操作系统自带的一个命令行界面工具。 主要用途: 文件…...
)
软考 系统架构设计师系列知识点之杂项集萃(60)
接前一篇文章:软考 系统架构设计师系列知识点之杂项集萃(59) 第97题 在面向对象设计中,()可以实现界面控制、外部接口和环境隔离。()作为完成用例业务的责任承担者,协调…...

如何备考GRE?
1.引言 GRE和雅思不太相同,首先GRE是美国人的考试,思维方式和很多细节和英系雅思不一样。所以底层逻辑上我觉得有点区别。 难度方面,我感觉GRE不容易考低分,但考高分较难。雅思就不一样了不仅上限难突破,下限还容易6…...