PR-2021
推荐深蓝学院的《深度神经网络加速:cuDNN 与 TensorRT》,课程面向就业,细致讲解CUDA运算的理论支撑与实践,学完可以系统化掌握CUDA基础编程知识以及TensorRT实战,并且能够利用GPU开发高性能、高并发的软件系统,感兴趣可以直接看看链接:深蓝学院《深度神经网络加速:cuDNN 与 TensorRT》

2. 核心思想分析
论文提出了一种基于通道注意力机制和空间图卷积网络的单幅图像超分辨率(Single Image Super-Resolution, SISR)模型,称为 CASGCN(Channel Attention and Spatial Graph Convolutional Network)。其核心思想是通过结合通道注意力机制和空间图卷积网络,增强网络对图像特征的表达能力,解决传统卷积神经网络(CNN)在捕捉全局自相似性和空间相关性方面的局限性。
- 通道注意力机制:通过对不同通道的特征进行加权,突出重要特征,抑制次要特征,从而提高特征提取的针对性。
- 空间图卷积网络:利用图结构建模图像像素之间的全局空间相关性,突破传统CNN固定感受野的限制,捕捉图像中的非局部自相似性。
- 多尺度特征提取:通过预处理模块提取不同尺度的特征,增强模型对复杂纹理和结构的适应能力。
- 全局融合策略:通过融合多个CASG模块的中间输出,保留长期信息,提高重建质量。
论文强调通过动态生成的邻接矩阵(基于Gram矩阵)实现全局感受野,而无需额外参数,降低计算复杂度,同时结合残差学习和全局融合策略,进一步提升性能。
3. 目标函数分析
论文的目标函数旨在最小化重建图像 I S R I_{SR} ISR 与高分辨率真实图像 I H R I_{HR} IHR 之间的差异,采用 L1损失函数,其数学表达式如下:
min θ L ( θ ) = 1 N ∑ i = 1 N ∥ F CASGCN ( I L R i ; θ ) − I H R i ∥ 1 \min_{\theta} L(\theta) = \frac{1}{N} \sum_{i=1}^{N} \left\| \mathcal{F}_{\text{CASGCN}}(I_{LR}^i; \theta) - I_{HR}^i \right\|_1 θminL(θ)=N1i=1∑N FCASGCN(ILRi;θ)−IHRi 1
-
符号说明:
- θ \theta θ:网络参数集合。
- N N N:训练样本数量。
- I L R i I_{LR}^i ILRi:第 i i i 个低分辨率输入图像。
- I H R i I_{HR}^i IHRi:对应的第 i i i 个高分辨率真实图像。
- F CASGCN \mathcal{F}_{\text{CASGCN}} FCASGCN:CASGCN网络的映射函数,从低分辨率图像生成超分辨率图像。
- ∥ ⋅ ∥ 1 \left\| \cdot \right\|_1 ∥⋅∥1:L1范数,表示像素级绝对误差。
-
选择L1损失的理由:
- L1损失相比L2损失更能减少模糊效应,生成更锐利的图像。
- L1损失对异常值不敏感,训练更稳定。
- 论文提到,L1损失在先前工作中(如EDSR、RDN)已被证明有效,因此沿用此损失函数以保持一致性。
4. 目标函数的优化过程
优化过程通过最小化上述L1损失函数来更新网络参数 θ \theta θ,具体步骤如下:
-
优化器:
- 使用 ADAM优化器,参数设置为 β 1 = 0.9 \beta_1 = 0.9 β1=0.9, β 2 = 0.999 \beta_2 = 0.999 β2=0.999, ϵ = 1 0 − 8 \epsilon = 10^{-8} ϵ=10−8。
- ADAM通过自适应地调整学习率,加速梯度下降收敛,适合深层神经网络的优化。
-
学习率策略:
- 初始学习率设为 1 0 − 4 10^{-4} 10−4。
- 每 2 × 1 0 5 2 \times 10^5 2×105 次迭代,学习率减半,以逐步细化参数更新。
- 这种学习率衰减策略有助于模型在早期快速收敛,后期稳定优化。
-
训练设置:
- 数据增强:对800张训练图像进行随机旋转(90°、180°、270°)和水平翻转,增加数据多样性。
- 批量处理:每个训练批次包含16个大小为 32 × 32 32 \times 32 32×32 的低分辨率彩色图像块。
- 迭代次数:通过多次迭代(具体次数未明确,但提到200个epoch用于消融实验),优化网络参数。
-
实现平台:
- 使用 PyTorch 框架,运行在 Titan V GPU 上,确保高效计算。
-
几何自集成(Geometric Self-ensemble):
- 在测试阶段,采用自集成策略,通过对输入图像进行8种几何变换(翻转和旋转),生成多个增强输入,分别通过网络预测后逆变换并融合结果,进一步提升性能。
优化过程的核心是通过梯度下降迭代更新网络参数,使L1损失最小化,从而提高重建图像的质量。残差学习和全局融合策略的引入进一步缓解了深层网络的训练难度,增强了梯度传播。
5. 主要贡献点
论文的主要贡献点包括以下几个方面:
-
提出CASGCN模型:
- 设计了一种新颖的通道注意力与空间图卷积网络(CASGCN),通过结合通道注意力机制和图卷积网络,增强特征表达能力,捕捉全局自相似性。
-
开发CASG模块:
- 提出通道注意力与空间图(CASG)模块,包含通道注意力单元(CA)和空间感知图单元(SG)。
- 通道注意力单元通过加权机制突出重要特征;空间图单元通过图卷积层建模空间相关性。
- 动态生成邻接矩阵(基于Gram矩阵),无需额外参数即可实现全局感受野。
-
多尺度特征提取与全局融合:
- 引入预处理模块,通过不同卷积核(3×3、5×5)提取多尺度特征。
- 采用全局融合策略,融合多个CASG模块的中间输出,保留长期信息。
-
优异的实验表现:
- 在多个标准数据集(如Set5、Set14、BSD100、Urban100、Manga109)上,CASGCN在双三次(BI)和模糊降采样(BD)退化模型下均表现出色,优于或媲美现有最先进方法。
- 特别是在大尺度因子(如×8)下,CASGCN+表现最佳,显示出强大的细节恢复能力。
-
模型效率:
- 与其他高性能模型(如RDN、RCAN)相比,CASGCN参数量更少,性能更高,实现了性能与模型大小的良好权衡。
6. 实验结果分析
实验在多个标准数据集上进行,评估指标包括 PSNR(峰值信噪比)和 SSIM(结构相似性),测试了双三次(BI)和模糊降采样(BD)两种退化模型。以下是关键结果的总结:
6.1 双三次(BI)退化模型
- 数据集:Set5、Set14、BSD100、Urban100、Manga109。
- 比较方法:包括SRCNN、FSRCNN、MemNet、DBPN、EDSR、RDN、NLRN、RCAN、HDRN、RFANet。
- 结果:
- CASGCN和CASGCN+(自集成版本)在所有尺度(×2、×3、×4、×8)上均表现优异,PSNR和SSIM值达到最佳或次佳。
- 尤其在×8尺度下,CASGCN+显著优于其他方法,表明其在恢复高倍率超分辨率图像细节方面的优势。
- 例如,在Manga109数据集上,CASGCN+在×8尺度下PSNR达到23.48,优于其他方法的23.16–23.40(表3)。
6.2 模糊降采样(BD)退化模型
- 数据集:与BI模型相同,尺度为×3。
- 比较方法:SPMSR、SRCNN、FSRCNN、VDSR、IRCNN、SRMD、RDN、RCAN、RFANet。
- 结果:
- CASGCN+在大多数数据集上PSNR和SSIM值最高,显示出对复杂退化场景的适应性。
- 视觉结果(图8)表明,CASGCN能有效减少模糊伪影,恢复更锐利的边缘,优于基于插值输入的方法。
6.3 消融实验
- 预处理模块:与残差块、稠密块、Inception模块相比,预处理模块在Set14数据集上PSNR更高(如×2尺度下34.02 vs. 33.87–33.93,表1)。
- CASG模块:通道注意力与图卷积的并行组合优于单独使用或非局部块(表2)。
- 全局融合:添加预处理模块、CASG模块和全局融合后,PSNR逐步提升,验证了各组件的有效性(表3)。
6.4 模型大小比较
- CASGCN参数量少于RDN和RCAN,但性能更高(图9),在Set5数据集上×3尺度下PSNR达到34.22,优于MemNet、DBPN、NLRN。
6.5 视觉效果
- 在BI退化模型下(图7),CASGCN恢复的细节更丰富,例如在Urban100的“img067”图像中恢复了更多纹理细节。
- 在BD退化模型下(图8),CASGCN减少了模糊伪影,边缘更清晰,显示出对复杂退化的鲁棒性。
7. 算法实现过程详细解释
CASGCN的实现过程可以分为网络结构设计、前向传播、训练和测试四个部分,以下逐一详细说明。
7.1 网络结构
CASGCN由三个主要部分组成(图2):
-
预处理模块:
- 输入低分辨率图像 I L R I_{LR} ILR,通过标准卷积层生成初始特征图 H 0 H_0 H0:
H 0 = F 0 ( I L R ) H_0 = \mathcal{F}_0(I_{LR}) H0=F0(ILR) - 预处理模块采用双分支结构,分别使用3×3和5×5卷积核提取不同尺度特征,类似Inception架构:
H pre = F pre ( H 0 ) H_{\text{pre}} = \mathcal{F}_{\text{pre}}(H_0) Hpre=Fpre(H0) - 两个分支的特征通过共享信息,增强多尺度特征表达。
- 输入低分辨率图像 I L R I_{LR} ILR,通过标准卷积层生成初始特征图 H 0 H_0 H0:
-
CASG模块:
- 由 N N N 个CASG块堆叠组成,每个CASG块包含通道注意力单元(CA)和空间感知图单元(SG)。
- 通道注意力单元:
- 采用类似SE块的结构,通过全局平均池化压缩空间维度,生成通道描述符。
- 使用全连接层和Sigmoid激活函数生成通道权重,重新缩放特征图:
H CA = σ ( W 2 ⋅ ReLU ( W 1 ⋅ GAP ( H ) ) ) ⋅ H H_{\text{CA}} = \sigma(W_2 \cdot \text{ReLU}(W_1 \cdot \text{GAP}(H))) \cdot H HCA=σ(W2⋅ReLU(W1⋅GAP(H)))⋅H
其中 GAP \text{GAP} GAP 为全局平均池化, W 1 W_1 W1、 W 2 W_2 W2 为全连接层参数, σ \sigma σ 为Sigmoid函数。
- 空间感知图单元:
- 将特征图视为图结构,节点为像素,边由邻接矩阵定义。
- 动态计算邻接矩阵 A A A,使用Gram矩阵捕捉特征间的空间相关性:
A = softmax ( H T H ) A = \text{softmax}(H^T H) A=softmax(HTH)
其中 H H H 为展平后的特征图, softmax \text{softmax} softmax 归一化相关性。 - 图卷积操作更新节点特征:
H SG = A ⋅ H ⋅ W H_{\text{SG}} = A \cdot H \cdot W HSG=A⋅H⋅W
其中 W W W 为可学习的权重矩阵。
- CA和SG单元的输出并行融合,形成CASG块输出:
H CASG = Concat ( H CA , H SG ) H_{\text{CASG}} = \text{Concat}(H_{\text{CA}}, H_{\text{SG}}) HCASG=Concat(HCA,HSG) - 采用残差学习缓解训练难度:
H L R = F CASG ( H pre ) + H 0 H_{LR} = \mathcal{F}_{\text{CASG}}(H_{\text{pre}}) + H_0 HLR=FCASG(Hpre)+H0
-
上采样模块:
- 使用子像素卷积或转置卷积将 H L R H_{LR} HLR 上采样至目标分辨率:
I S R = F up ( H L R ) I_{SR} = \mathcal{F}_{\text{up}}(H_{LR}) ISR=Fup(HLR)
- 使用子像素卷积或转置卷积将 H L R H_{LR} HLR 上采样至目标分辨率:
-
全局融合:
- 多个CASG块的中间输出通过拼接融合,保留长期信息:
H fusion = Concat ( H 1 , H 2 , … , H N ) H_{\text{fusion}} = \text{Concat}(H_1, H_2, \ldots, H_N) Hfusion=Concat(H1,H2,…,HN)
- 多个CASG块的中间输出通过拼接融合,保留长期信息:
7.2 前向传播
- 输入 I L R I_{LR} ILR,通过预处理模块生成 H pre H_{\text{pre}} Hpre。
- H pre H_{\text{pre}} Hpre 依次通过 N N N 个CASG块,每个块计算通道注意力和空间图卷积,融合后输出 H L R H_{LR} HLR。
- H L R H_{LR} HLR 通过上采样模块生成超分辨率图像 I S R I_{SR} ISR。
- 计算 I S R I_{SR} ISR 与 I H R I_{HR} IHR 的L1损失,驱动网络优化。
7.3 训练
- 数据准备:使用800张图像,增强后生成 32 × 32 32 \times 32 32×32 的LR图像块。
- 优化:通过ADAM优化器最小化L1损失,学习率从 1 0 − 4 10^{-4} 10−4 逐步衰减。
- 实现细节:使用PyTorch在Titan V GPU上训练,批大小为16。
7.4 测试
- 自集成:对测试图像应用8种几何变换,生成增强输入,分别预测后逆变换并平均。
- 评估:在标准数据集上计算PSNR和SSIM,比较视觉质量。
8. 总结
这篇论文通过提出CASGCN模型,结合通道注意力机制和空间图卷积网络,显著提升了单幅图像超分辨率的性能。其核心在于动态邻接矩阵、多尺度特征提取和全局融合策略,有效捕捉全局自相似性和通道重要性。实验结果验证了其在BI和BD退化模型下的优越性,尤其在大尺度因子下表现突出。算法实现清晰,训练和测试过程高效,模型在性能和参数量之间取得了良好平衡,为SISR领域提供了新的研究思路。
相关文章:
PR-2021
推荐深蓝学院的《深度神经网络加速:cuDNN 与 TensorRT》,课程面向就业,细致讲解CUDA运算的理论支撑与实践,学完可以系统化掌握CUDA基础编程知识以及TensorRT实战,并且能够利用GPU开发高性能、高并发的软件系统…...
和 Anaconda 的不同)
CMD(Command Prompt)和 Anaconda 的不同
CMD(Command Prompt)和 Anaconda 是两种不同的工具,它们在功能和用途上有明显的区别: CMD(Command Prompt) 定义:CMD 是 Windows 操作系统自带的一个命令行界面工具。 主要用途: 文件…...
)
软考 系统架构设计师系列知识点之杂项集萃(60)
接前一篇文章:软考 系统架构设计师系列知识点之杂项集萃(59) 第97题 在面向对象设计中,()可以实现界面控制、外部接口和环境隔离。()作为完成用例业务的责任承担者,协调…...

如何备考GRE?
1.引言 GRE和雅思不太相同,首先GRE是美国人的考试,思维方式和很多细节和英系雅思不一样。所以底层逻辑上我觉得有点区别。 难度方面,我感觉GRE不容易考低分,但考高分较难。雅思就不一样了不仅上限难突破,下限还容易6…...
Linux复习笔记(六)shell编程
遇到的问题,都有解决方案,希望我的博客能为你提供一点帮助。 三、shell编程简明教程 一、Shell基础概念 1. Shell的作用 是用户与Linux内核交互的桥梁,既是命令解释器,也是一种脚本语言。运行机制:用户输入…...

Unity 拖尾烟尘效果及参数展示
亮点:在移动特效过后 ,粒子会顺着惯性继续向前移动一小段距离。 以unity-URP管线为例,下图是Particle System参数分享: Start Color参数: UnityEditor.GradientWrapperJSON:{"gradient":{"serialized…...
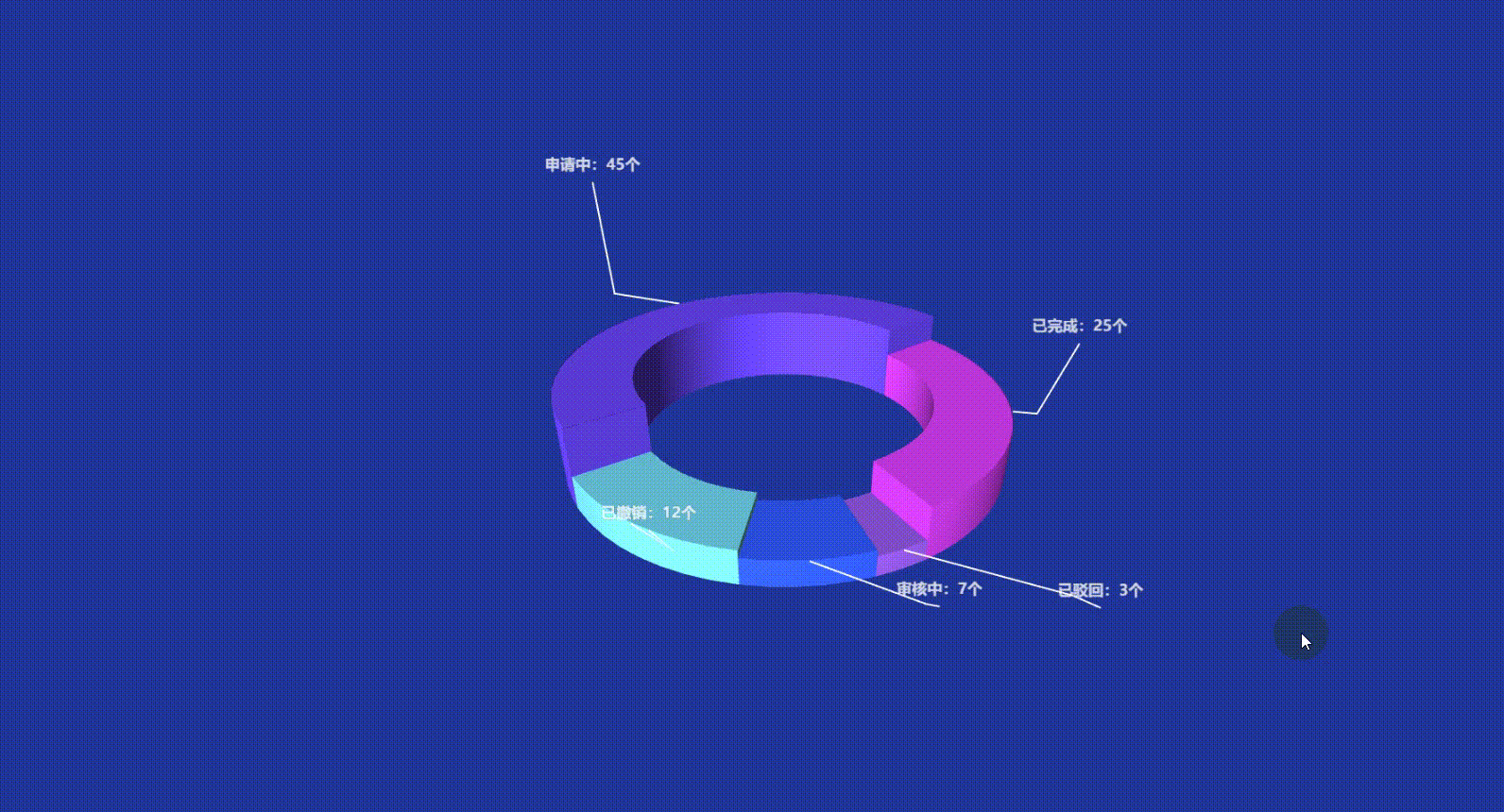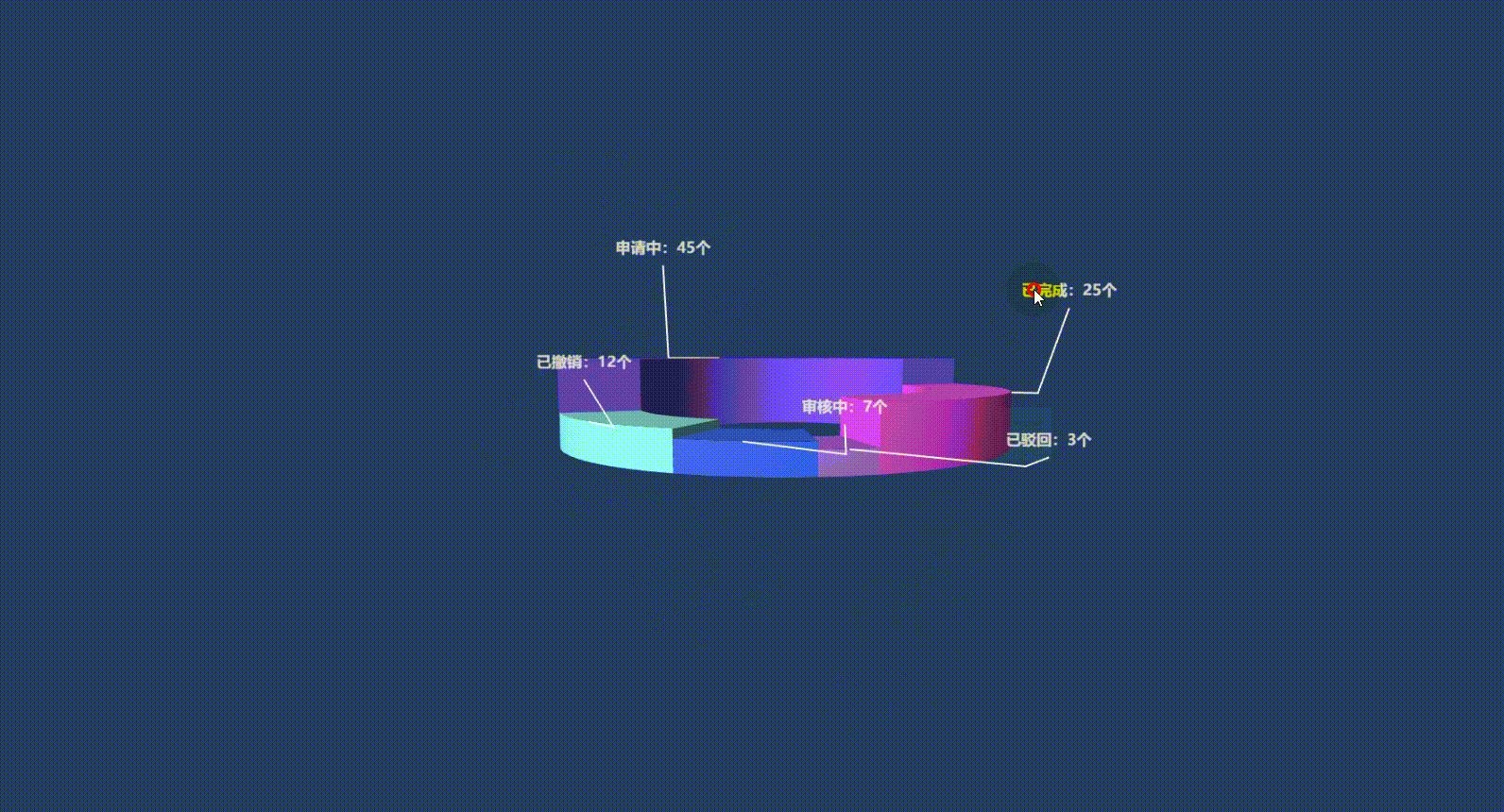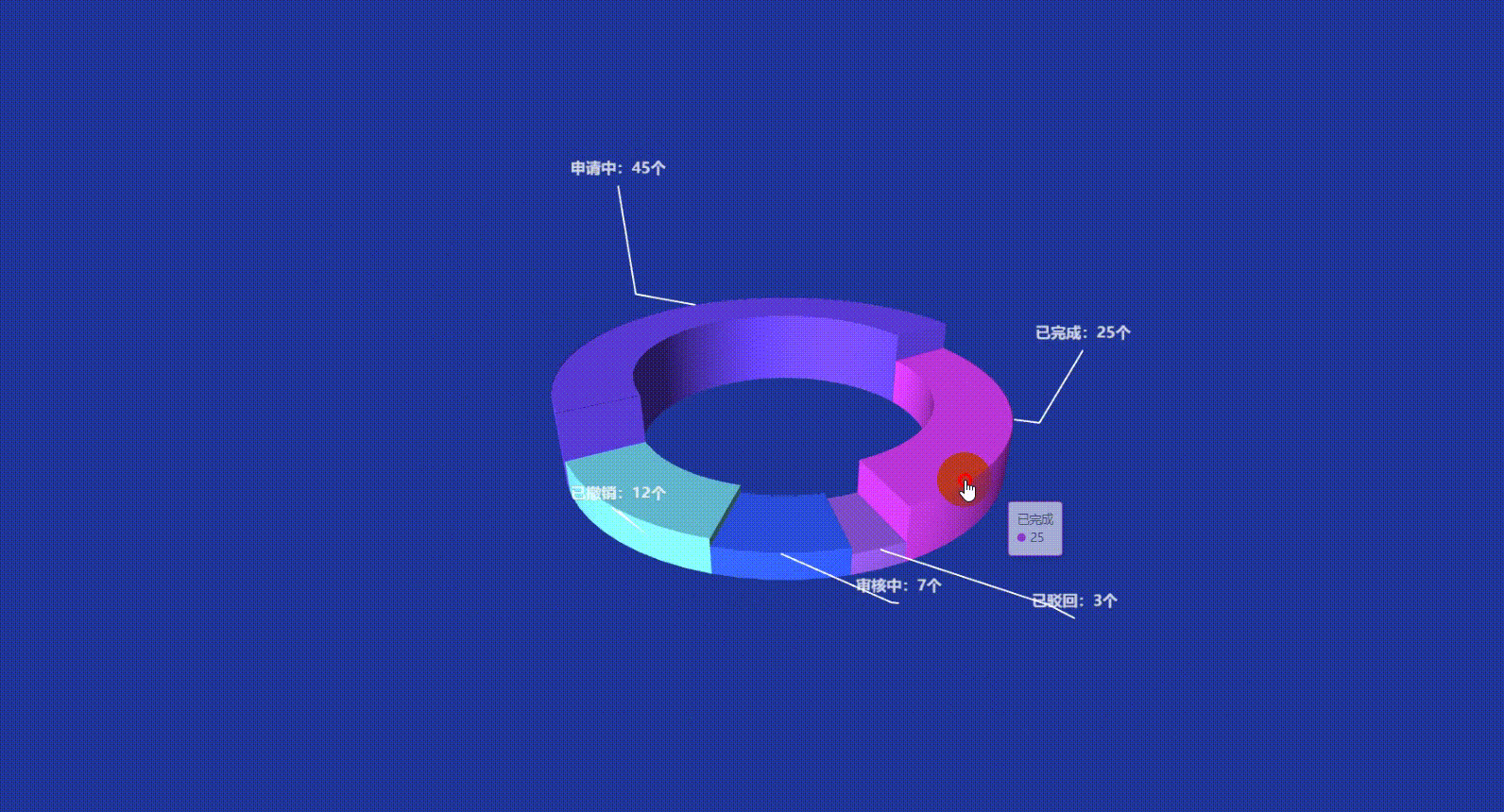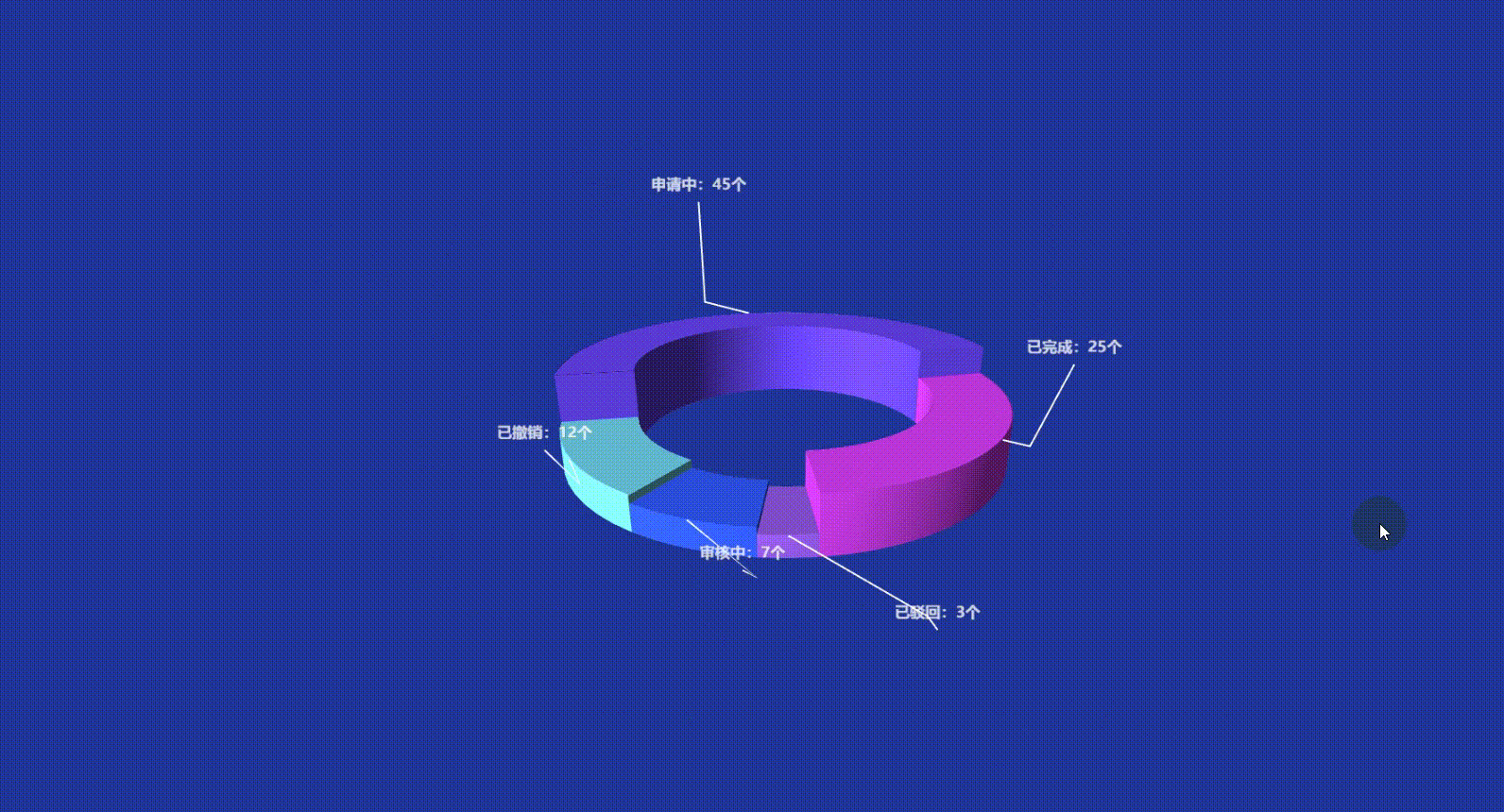
Vue3 Echarts 3D饼图(3D环形图)实现讲解附带源码
文章目录 前言一、准备工作1. 所需工具2. 引入依赖方式一:CDN 快速引入方式二:npm 本地安装(推荐) 二、实现原理解析三、echarts-gl 3D插件 使用回顾grid3D 常用通用属性:series 常用通用属性:surface&…...
Kafka快速安装与使用
引言 这篇文章是一篇Ubuntu(Linux)环境下的Kafka安装与使用教程,通过本文,你可以非常快速搭建一个kafka的小单元进行日常开发与调测。 安装步骤 下载与解压安装 首先我们需要下载一下Kafka,这里笔者采用wget指令: wget https:…...

Java EE初阶——wait 和 notify
1. 线程饥饿 线程饥饿是指一个或多个线程因长期无法获取所需资源(如锁,CPU时间等)而持续处于等待状态,导致其任务无法推进的现象。 典型场景 优先级抢占: 在支持线程优先级的系统中,高优先级线程可能持续…...
RPA vs. 传统浏览器自动化:效率与灵活性的终极较量
1. 引言 在数字化转型的大潮下,企业和开发者对浏览器自动化的需求日益增长。无论是网页数据抓取、自动化测试,还是用户行为模拟,浏览器自动化已经成为提升效率的关键工具。然而,面对越来越严格的反自动化检测、复杂的 Web 结构和…...

Flask框架深度解析:蓝图、上下文机制与Jinja2模板引擎实战
Flask作为Python最流行的轻量级Web框架之一,以其简洁、灵活和高度可扩展的特性赢得了广大开发者的青睐。本文将深入探讨Flask框架的三大核心特性:蓝图(Blueprint)模块化开发、上下文(Context)管理机制以及Jinja2模板引擎的高级用法。无论你是Flask初学者…...
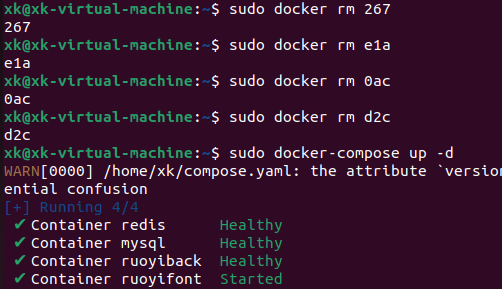
docker 快速部署若依项目
1、首先创建一个自定义网络,作用是使连接到该网络的容器能够通过容器名称进行通信,无需使用复杂的IP地址配置,方便了容器化应用中各个服务之间的交互。 sudo docker network create ruoyi 2、创建一个文件夹,创建compose.yml文件…...

polarctf-web-[rce1]
考点: (1)RCE(exec函数) (2)空格绕过 (3)执行函数(exec函数) (4)闭合(ping命令闭合) 题目来源:Polarctf-web-[rce1] 解题: 这段代码实现了一个简单的 Ping 测试工具,用户可以通过表单提交一个 IP 地址,服务器会执…...

数据备份与恢复方案
数据备份与恢复方案 一.背景 为确保公司信息安全,防止关键数据丢失,应对突发事件,特制定全面的数据备份与恢复方案。该方案将对公司的各类文件资料进行分级管理,并针对不同级别的数据设定相应的备份策略和恢复流程。 二…...

Redis+Caffeine构造多级缓存
一、背景 项目中对性能要求极高,因此使用多级缓存,最终方案决定是RedisCaffeine。其中Redis作为二级缓存,Caffeine作为一级本地缓存。 二、Caffeine简单介绍 Caffeine是一款基于Java 8的高性能、灵活的本地缓存库。它提供了近乎最佳的命中…...

docker(四)使用篇二:docker 镜像
在上一章中,我们介绍了 docker 镜像仓库,本文就来介绍 docker 镜像。 一、什么是镜像 docker 镜像本质上是一个 read-only 只读文件, 这个文件包含了文件系统、源码、库文件、依赖、工具等一些运行 application 所必须的文件。 我们可以把…...

ms-swift 代码推理数据集
目前想要对SFT微调后的模型进行测试,看官方文档ms-swift中有eval的教程,但是从介绍来看,eval使用的是modelscope的评测内容。 评测 SWIFT支持了eval(评测)能力,用于对原始模型和训练后的模型给出标准化…...
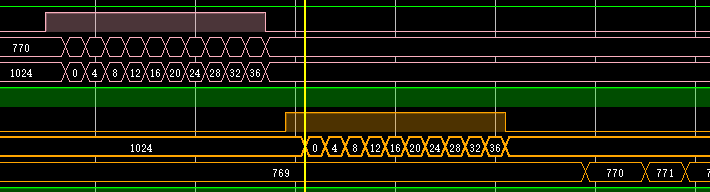
AXI4总线协议 ------ AXI_LITE协议
一、AXI 相关知识介绍 https://download.csdn.net/download/mvpkuku/90841873 AXI_LITE 选出部分重点,详细文档见上面链接。 1.AXI4 协议类型 2.握手机制 二、AXI_LITE 协议的实现 1. AXI_LITE 通道及各通道端口功能介绍 2.实现思路及框架 2.1 总体框架 2.2 …...

DATE_FORMAT可以接收date类型,也可以接收String类型!
DATE_FORMAT 是 SQL 函数,主要用于将日期/时间类型的字段按照指定格式转换成字符串。在 MyBatis 的 XML 动态 SQL 中,你看到的这段代码是为了比较数据库中的日期字段和传入参数的日期值,但会忽略时间部分,只比较年月日。 代码解释…...
Ubuntu24.04 安装 5080显卡驱动以及cuda
前言 之前使用Ubuntu22.04版本一直报错,然后换了24.04版本才能正常安装 一. 配置基础环境 Linux系统进行环境开发环境配置-CSDN博客 二. 安装显卡驱动 1.安装驱动 按以下步骤来: sudo apt update && sudo apt upgrade -y#下载最新内核并安装 sudo add…...

华三H3C交换机配置NTP时钟步骤 示例
现场1台H3C 5110交换机 版本:Comware Software, Version 5.20.99, Release 1105 当前没有指定NTP, <H3C-5110>dis ntp-service status Clock status: unsynchronizedClock stratum: 16Reference clock ID: noneNominal frequency: 100.0000 HzAc…...
)
RKNN开发环境搭建(ubuntu22.04)
以下情况在RV1106G3的平台上验证正常。 1、conda安装 1)conda --version//确认是否安装 2)创建一个安装目录,进行下一步 3)wget https://mirrors.tuna.tsinghua.edu.cn/anaconda/miniconda/Miniconda3-4.6.14-Linux-x…...

matlab多项式
1. 多项式表示 多项式用行向量表示,按降幂排列系数。例如,多项式 3x22x1 表示为 [3 2 1]。 2. 创建多项式 直接输入系数:如 p [1 -3 3 -1] 表示 x3−3x23x−1。由根创建:使用 poly 函数。例如,根为 [1, 1, 1]&…...
?)
Sprnig MVC 如何统一异常处理 (Exception Handling)?
主要有以下几种方式来实现统一异常处理,其中 ControllerAdvice (或 RestControllerAdvice) 结合 ExceptionHandler 是最常用的方式。 1. ExceptionHandler 注解 作用: 用于标记一个方法,该方法将处理在同一个 Controller 类中抛出的特定类型…...
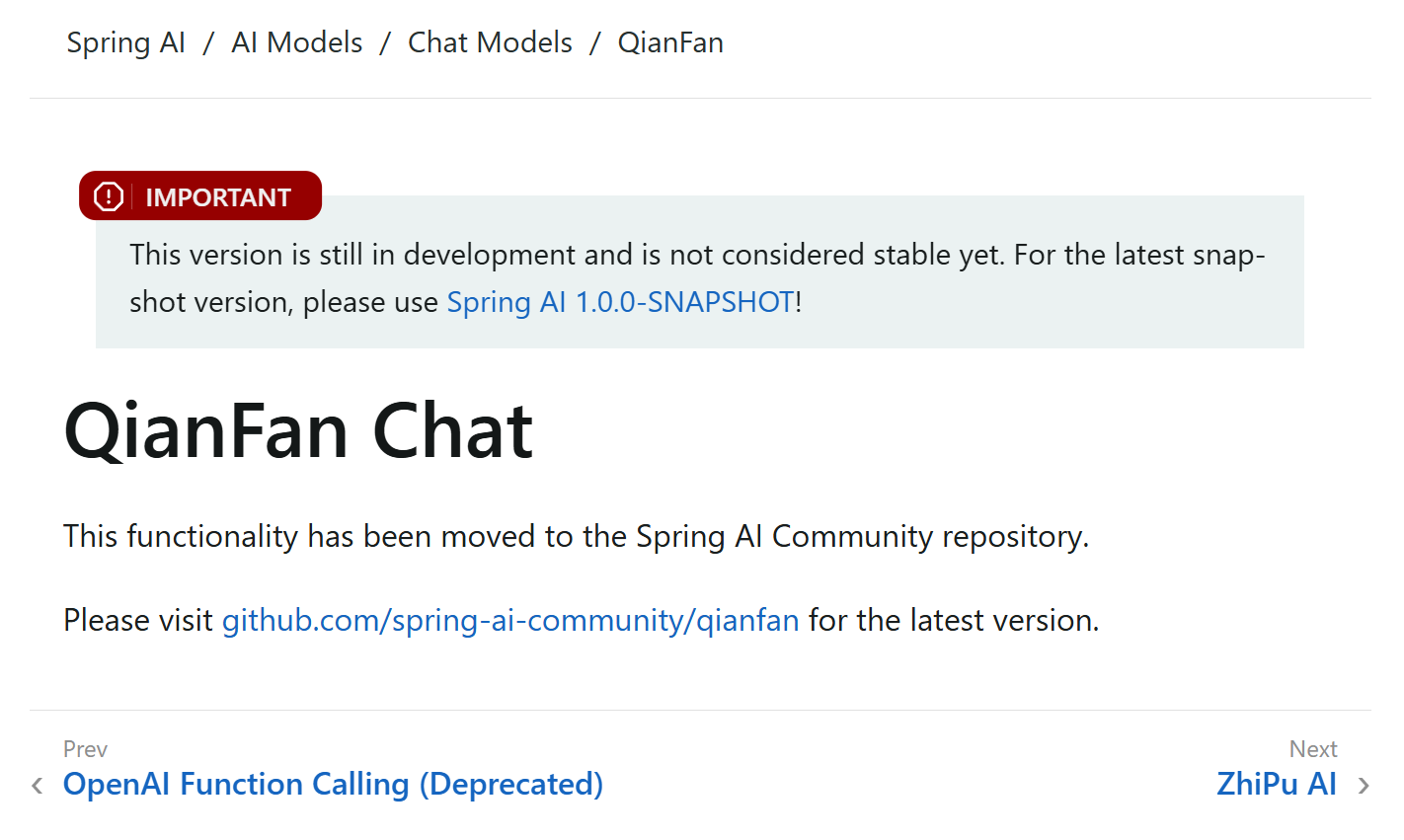
SpringAI-RC1正式发布:移除千帆大模型!
续 Spring AI M8 版本之后(5.1 发布),前几日 Spring AI 悄悄的发布了最新版 Spring AI 1.0.0 RC1(5.13 发布),此版本也将是 GA(Generally Available,正式版)发布前的最后…...
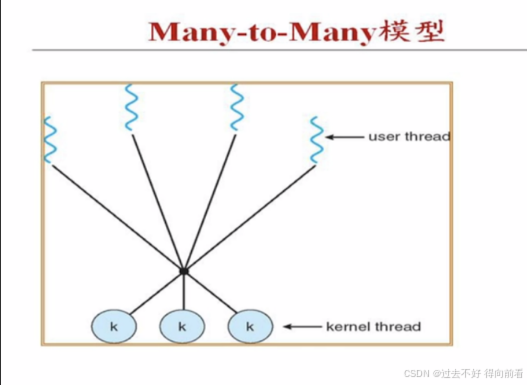
操作系统之进程和线程听课笔记
计算机的上电运行就是构建进程树,进程调度就是在进程树节点进程进行切换 进程间通信的好处 经典模型 生产者和消费者 进程和线程的区别 线程引入带来的问题线程的优势 由于unix70年代产生,90年代有线程,当时数据库系统操作需要线程,操作系统没有来得及重造,出现了用户态线…...

【vue】封装接口,全局字典,表格表头及使用
一、封装接口(API请求) 1. 创建axios实例 // src/utils/request.js import axios from axiosconst service axios.create({baseURL: process.env.VUE_APP_BASE_API,timeout: 10000 })// 请求拦截器 service.interceptors.request.use(config > {co…...

深入解析ZAB协议:ZooKeeper的分布式一致性核心
引言 在分布式系统中,如何高效、可靠地实现多节点间的数据一致性是核心挑战之一。ZAB协议(ZooKeeper Atomic Broadcast)作为 ZooKeeper的核心算法,被广泛应用于分布式协调服务(如Kafka、HBase、Dubbo等)。…...

COMSOL随机参数化表面流体流动模拟
基于粗糙度表面的裂隙流研究对于理解地下水的流动、污染物传输以及与之相关的地质灾害(如滑坡)等方面具有重要意义。本研究通过蒙特卡洛方法生成随机表面形貌,并利用COMSOL Multiphysics对随机参数化表面的微尺度流体流动进行模拟。 参数化…...

大模型笔记-“训练”和“推理”概念
在大模型(如Transformer类模型、LLM)的资源管理和开发流程中,“训练”和“推理”是两个核心概念,分别对应模型的构建和实际应用阶段: 训练是模型的“学习过程”,需要大量资源和时间。推理是模型的“应用过…...