Elasticsearch索引全生命周期管理指南之一
#作者:猎人
文章目录
- 一、索引常规操作
- 二、索引mapping和别名管理
一、索引常规操作
索引数据特点:
索引中的数据随着时间,持续不断增长
按照时间序列划分索引的好处&挑战:
按照时间进行划分索引,会使得管理更加简单。例如,完整删除一个索引,性能比 delete by query 好。
如何进行自动化管理,减少人工操作。从Hot 移动到 Warm。定期关闭或者删除索引。
1、创建索引
(1)创建索引的语法
用settings给这个索引在创建时可以添加一些设置,还有可以初始化一些type的mapping
curl -XPUT 'http://elasticsearch02:9200/twitter?pretty' -d '
{"settings" : {"index" : {"number_of_shards" : 3, "number_of_replicas" : 2 }},"mappings" : {"type1" : {"properties" : {"field1" : { "type" : "text" }}}}
}'
(2)索引创建返回消息的解释
默认索引创建命令会在每个primary shard的副本开始进行复制以后,或者是请求超时以后,返回一个响应消息,类似下面这样的。其中acknowledged表明了这个索引有没有创建成功,shards_acknowledged表明了每个primary shard有没有足够数量的replica开始进行复制了。有可能这两个参数会为false,但是索引依然可以创建成功。因为这些参数仅仅是表明在请求超时之前,那两个行为有没有成功,也有可能请求超时,在超时前都没成功,但是超时后在es server端还是都执行了。如果acknoledged是false,那么就可能是超时了,此时接受到响应消息的时候,cluster state都还没变更,没有加入新创建的index,但是也许之后还是会创建这个index。如果shards_acknowledged是false,那么可能在primary shard进行副本copy之前,就timeout了,但是此时也许index创建成功了,而且cluster state已经加入了新创建的index。
{"acknowledged": true,"shards_acknowledged": true
}
2、删除索引
curl -XDELETE ‘http://elasticsearch02:9200/twitter?pretty’
删除索引中的一个type
3、查询索引设置信息
curl -XGET ‘http://elasticsearch02:9200/twitter?pretty’
4、打开/关闭索引
curl -XPOST 'http://elasticsearch02:9200/twitter/_close?pretty'
curl -XPOST 'http://elasticsearch02:9200/twitter/_open?pretty'
curl -XPUT 'http://elasticsearch02:9200/twitter/type1/1?pretty' -d '
{"field1": "1"
}
’
如果关闭了一个索引之后,那么这个索引是不会带来任何的性能开销了,只要保留这个索引的元数据即可,然后对这个索引的读写操作都不会成功。一个关闭的索引可以接着再打开,打开以后会进行shard recovery过程。
比如在做一些运维操作的时候,现在要对某一个索引做一些配置,运维操作,修改一些设置,关闭索引,不允许写入,成功以后再打开索引。
5、压缩索引
shrink命令可以将一个已有的索引压缩成一个新的索引,同时primary shard会更少。因为以前提到过,primary shard因为涉及到document的hash路由问题,所以是不允许修改的。但是如果要减少index的primary shard,可以用shrink命令来压缩index。但是压缩后的shard数量必须可以被原来的shard数量整除。举例来说,一个有8个primary shard的index可以被压缩成4个,2个,或者1个primary shard的index。
压缩索引,是这样啊,如果你的索引中本来比如是要保留7天的数据,那么给了10个shard,但是现在需求变了,这个索引只要保留3天的数据就可以了,那么数据量变小了,就不需要10个shard了,就可以做shrink操作,5个shard。
shrink命令的工作流程如下:
(1)首先,它会创建一个跟source index的定义一样的target index,但是唯一的变化就是primary shard变成了指定的数量
(2)接着它会将source index的segment file直接用hard-link的方式连接到target index的segment file,如果操作系统不支持hard-link,那么就会将source index的segment file都拷贝到target index的data dir中,会很耗时。如果用hard-link会很快
(3)最后,会将target index进行shard recovery恢复
如果要shrink index,那么这个index必须先被标记为read only,而且这个index的每个shard的某一个copy,可以是primary或者是replica,都必须被复制到一个节点上去。默认情况下,index的每个shard有可能在不同机器上的,比如说,index有5个shard,shard0和shard1在机器1上,shard2、shard3在机器2上,shard4在机器3上。现在还得把shard0,shard1,shard2,shard3,shard4全部拷贝到一个同一个机器上去,但是可以是shard0的replica shard。而且每个primary shard都必须存在。可以通过下面的命令来完成。其中index.routing.allocation.require._name必须是某个node的名称,这个都是可以自己设置的。
curl -XPUT 'http://elasticsearch02:9200/twitter/_settings?pretty' -d '
{"settings": {"index.routing.allocation.require._name": "node-elasticsearch-02", "index.blocks.write": true }
}'
这个命令会花费一点时间将source index每个shard的一个copy都复制到指定的node上去,可以通过GET _cat/recovery?v命令来追踪这个过程的进度。
等上面的shard copy relocate过程结束之后,就可以shrink一个index,用下面的命令即可:POST my_source_index/_shrink/my_target_index。如果target index被添加进了cluster state之后,这个命令就会立即返回,不是等待shrink过程完成之后才返回的。当然还可以用下面的命令来shrink的时候修改target index的设置,在settings里就可以设置target index的primary shard的数量。
curl -XPOST 'http://elasticsearch02:9200/twitter/_shrink/twitter_shrinked?pretty' -d '
{"settings": {"index.number_of_replicas": 1,"index.number_of_shards": 1, "index.codec": "best_compression" }
}
’
当然也是需要监控整个shrink的过程的,用GET _cat/recovery?v即可。
6、rollover index
rollover命令可以将一个alias重置到一个新的索引上去,如果已经存在的index被认为太大或者数据太旧了。这个命令可以接收一个alias名称,还有一系列的condition。如果索引满足了condition,那么就会创建一个新的index,同时alias会指向那个新的index。比如下面的命令。举例有一个logs-0000001索引,给了一个别名是logs_write,然后发起了一个rollover的命令,如果logs_write别名之前指向的那个index,也就是logs-0000001,创建了超过7天,或者里面的document已经超过了1000个了,然后就会创建一个logs-000002的索引,同时logs_write别名会指向新的索引。
也可以写一个shell脚本,每天0:00的时候就执行以下rollover命令,此时就判断,如果说之前的索引已经存在了超过1天了,那么此时就创建一个新的索引出来,同时将别名指向新的索引。自动去滚动创建新的索引,保持每个索引就只有一个小时,一天,七天,三天,一周,一个月。
类似用es来做日志平台,就可能分布式电商平台,可能订单系统的日志,单独的一个索引,要求的是保留最近3天的日志就可以了。交易系统的日志,是单独的一个索引,要求的是保留最近30天的日志。
curl -XPUT 'http://elasticsearch02:9200/logs-000001?pretty' -d '
{"aliases": {"logs_write": {}}
}'# Add > 1000 documents to logs-000001curl -XPUT 'http://elasticsearch02:9200/logs-000001/data/1?pretty' -d '
{"userid": 1,"page": 1
}'
curl -XPUT 'http://elasticsearch02:9200/logs-000001/data/2?pretty' -d '
{"userid": 2,"page": 2
}'
curl -XPUT 'http://elasticsearch02:9200/logs-000001/data/3?pretty' -d '
{"userid": 3,"page": 3
}'curl -XPOST 'http://elasticsearch02:9200/logs_write/_rollover?pretty' -d '
{"conditions": {"max_age": "1d","max_docs": 3}
}'{"acknowledged": true,"shards_acknowledged": true,"old_index": "logs-000001","new_index": "logs-000002","rolled_over": true, "dry_run": false, "conditions": { "[max_age: 7d]": false,"[max_docs: 1000]": true}
}
这个过程常见于网站用户行为日志数据,比如按天来自动切分索引,写个脚本定时去执行rollover,就会自动不断创建新的索引,但是别名永远是一个,对于外部的使用者来说,用的都是最新数据的索引。
比如用es做网站的实时用户行为分析,要求的是一个索引只要保留当日的数据就可以了,那么就可以用这个rollover的策略,确保每个索引都是包含当日的最新数据的。老的数据,就变成别的索引了,此时可以写一个shell脚本,删除旧的数据,这样的话,es里就保留当前最新的数据就可以了。也可以根据你的需求,就保留最近7天的数据,但是最新一天的数据在一个索引中,供分析查询使用。
默认情况下,如果已经存在的那个索引是用-符号加上一个数字结尾的,比如说logs-000001,那么新索引的名称就会是自动给那个数字加1,比如logs-000002,自动就是给一个6位的数字,而且会自动补零。但是我们也可以自己指定要的新的索引名称,比如下面这样:
POST /my_alias/_rollover/my_new_index_name
{"conditions": {"max_age": "7d","max_docs": 1000}
}
可以将rollover命令和date日期结合起来使用,比如下面的例子,先创建了一个logs-2016.10.31-1格式的索引。接着每次如果成功rollover了,那么如果是在当天rollover了多次,那就是当天的日期,末尾的数字递增。如果是隔天才rollover,会自动变更日期,同时维护末尾的数字序号。
PUT /%3Clogs-%7Bnow%2Fd%7D-1%3E
{"aliases": {"logs_write": {}}
}PUT logs_write/log/1
{"message": "a dummy log"
}POST logs_write/_refresh# Wait for a day to passPOST /logs_write/_rollover
{"conditions": {"max_docs": "1"}
}
当然,还可以在rollover的时候,给新的index进行新的设置:
POST /logs_write/_rollover
{"conditions" : {"max_age": "7d","max_docs": 1000},"settings": {"index.number_of_shards": 2}
}
二、索引mapping和别名管理
1、mapping管理
put mapping命令可以让我们给一个已有的索引添加一个新的type,或者修改一个type,比如给某个type加一些字段
下面这个命令是在创建索引的时候,直接跟着创建一个type
curl -XPUT ‘http://elasticsearch02:9200/twitter?pretty’ -d ’
{
“mappings”: {
“tweet”: {
“properties”: {
“message”: {
“type”: “text”
}
}
}
}
}’
下面这个命令是给一个已有的索引添加一个type
curl -XPUT 'http://elasticsearch02:9200/twitter/_mapping/user?pretty' -d '
{"properties": {"name": {"type": "text"}}
}'
下面这个命令是给一个已有的type添加一个field
curl -XPUT 'http://elasticsearch02:9200/twitter/_mapping/tweet?pretty' -d '
{"properties": {"user_name": {"type": "text"}}
}'
curl -XGET ‘http://elasticsearch02:9200/twitter/_mapping/tweet?pretty’,上面这行命令可查看某个type的mapping映射信息
curl -XGET ‘http://elasticsearch02:9200/twitter/_mapping/tweet/field/message?pretty’,这行命令可以看某个type的某个field的映射信息
mapping管理是运维中,索引管理中,很基础的一块。生产环境中索引应考虑禁止 Dynamic IndexMapping,避免过多字段导致 Cluster State占用过多。禁止索引自动创建的功能,创建时必须提供Mapping 或通过Index Template 进行设定。
2、索引别名管理
curl -XPOST 'http://elasticsearch02:9200/_aliases?pretty' -d '
{"actions" : [{ "add" : { "index" : "twitter", "alias" : "twitter_prod" } }]
}'curl -XPOST 'http://elasticsearch02:9200/_aliases?pretty' -d '
{"actions" : [{ "remove" : { "index" : "twitter", "alias" : "twitter_prod" } }]
}'POST /_aliases
{"actions" : [{ "remove" : { "index" : "test1", "alias" : "alias1" } },{ "add" : { "index" : "test2", "alias" : "alias1" } }]
}POST /_aliases
{"actions" : [{ "add" : { "indices" : ["test1", "test2"], "alias" : "alias1" } }]
}
上面是给某个index添加和删除alias的命令,还有重命名alias的命令(先删除再添加),包括将一个alias绑定多个index
POST /_aliases
{"actions" : [{"add" : {"index" : "test1","alias" : "alias2","filter" : { "term" : { "user" : "kimchy" } }}}]
}
DELETE /logs_20162801/_alias/current_day
GET /_alias/2016
索引别名是说可以将一个索引别名底层挂载多个索引,比如说7天的数据。索引别名常常和之前讲解的那个rollover结合起来,为了性能和管理方便,每天的数据都rollover出来一个索引,但是在对数据分析的时候,比如有一个索引access-log,指向了当日最新的数据,用来计算实时数据的; 有一个索引access-log-7days,指向了7天的7个索引,可以让我们进行一些周数据的统计和分析。
3、index settings管理
curl -XPUT 'http://elasticsearch02:9200/twitter/_settings?pretty' -d '
{"index" : {"number_of_replicas" : 1}
}'curl -XGET 'http://elasticsearch02:9200/twitter/_settings?pretty'
经常可能要对index做一些settings的调整,常常和之前的index open和close结合起来
4、index template管理
什么是Index Template
Index Templates - 帮助你设定 Mappings 和 Settings,并按照一定的规则自动匹配到新创建的索引之上。模版仅在一个索引被新创建时,才会产生作用。修改模版不会影响已创建的索引。你可以设定多个索引模版,这些设置会被“merge”在一起。你可以指定“order”的数值,控制“merging”的过程。
Index Template 的工作方式:
当一个索引被新创建时
应用 Elasticsearch 默认的 settings 和 mappings
应用 order 数值低的 Index Template 中的设定
应用 order 高的 Index Template 中的设定,之前的设定会被覆盖0
应用创建索引时,用户所指定的 Settings 和 Mappings,并覆盖之前模版中的设定
Demo:
创建 2个Index Templates
查看 根据名字查看 Template。
查看所有 templates,template/*
创建一个临时索引,查看replica和数据类型推断
将索引名字设为能Index Template 匹配时,查看所生成的 ndex 的 mappings 和 Settings
什么是 Dynamic Template:
根据 Elasticsearch 识别的数据类型,结合字段名称,来动态设定字段类型
所有的字符串类型都设定成 Keyword,或者关闭 keyword 字段
is 开头的字段都设置成 boolean
long_开头的都设置成 long 类型
Dynamic Template:
Dynamic Tempate 是定义在在某个索引的 Mapping 中
Template有一个名称
匹配规则是一个数组
为匹配到字段设置 Mapping
可以定义一些index template,这样template会自动应用到新创建的索引上去。template中可以包含settings和mappings,还可以包含一个pattern,决定了template会被应用到哪些index上。而且template仅仅在index创建的时候会被应用,修改template,是不会对已有的index产生影响的。
curl -XPUT 'http://elasticsearch02:9200/_template/template_access_log?pretty' -d '
{"template": "access-log-*","settings": {"number_of_shards": 2},"mappings": {"log": {"_source": {"enabled": false},"properties": {"host_name": {"type": "keyword"},"created_at": {"type": "date","format": "EEE MMM dd HH:mm:ss Z YYYY"}}}},"aliases" : {"access-log" : {}}
}'
curl -XDELETE ‘http://elasticsearch02:9200/_template/template_access_log?pretty’
curl -XGET ‘http://elasticsearch02:9200/_template/template_access_log?pretty’
curl -XPUT ‘http://elasticsearch02:9200/access-log-01?pretty’
curl -XGET ‘http://elasticsearch02:9200/access-log-01?pretty’
index template,可能是这样子的,就是你可能会经常创建不同的索引,比如说商品,分成了多种,每个商品种类的数据都很大,可能就是说,一个商品种类一个索引,但是每个商品索引的设置是差不多的,所以干脆可以搞一个商品索引模板,然后每次新建一个商品种类索引,直接绑定到模板,引用相关的设置
相关文章:

Elasticsearch索引全生命周期管理指南之一
#作者:猎人 文章目录 一、索引常规操作二、索引mapping和别名管理 一、索引常规操作 索引数据特点: 索引中的数据随着时间,持续不断增长 按照时间序列划分索引的好处&挑战: 按照时间进行划分索引,会使得管理更加…...

STM32F407VET6的HAL库使用CRC校验的思路
CRC校验在数据传输快,且量大的时候使用。 步骤实现: CubeMX配置 c // 在CubeMX中启用CRC模块 // AHB总线时钟自动启用 HAL库代码 c // 初始化(main函数中) CRC_HandleTypeDef hcrc; hcrc.Instance CRC; hcrc.Init.Default…...

【Manim】使用manim画一个高斯分布的动画
1 Manim例子一 最近接触到manim,觉得挺有趣的,来玩一玩把。如下是一个使用manim画的高斯分布的动画。 from manim import * import numpy as npclass GaussianDistribution(Scene):def construct(self):# 创建坐标系axes Axes(x_range[-4, 4, 1],y_ra…...

elementUI 循环出来的表单,怎么做表单校验?
数据结构如下: diversionParamList: [ { length: null, positionNumber: null, value: null, } ] 思路:可根据 index 动态绑定 :props 属性值,校验规则写在:rules <div class"config-item" v-for"(item, index) in form.…...

Leetcode76覆盖最小子串
覆盖最小子串 代码来自b站左程云 class Solution {public String minWindow(String str, String tar) {char[] s str.toCharArray();char[] t tar.toCharArray();int[] cnt new int[256];for (char cha : t) { cnt[cha]--;}int len Integer.MAX_VALUE;int debt t.length…...

电力杆塔安全监测解决方案
一、方案背景 在台风、滑坡等自然灾害出现时,极易产生倒杆、断杆、杆塔倾斜、塔基滑动等致使杆塔失稳的状况,进而引发导线断线、线路跳闸等事故,给电网的安全稳定运行造成影响。可借助在铁塔上装设的传感器,能够感知铁塔的工作状态…...
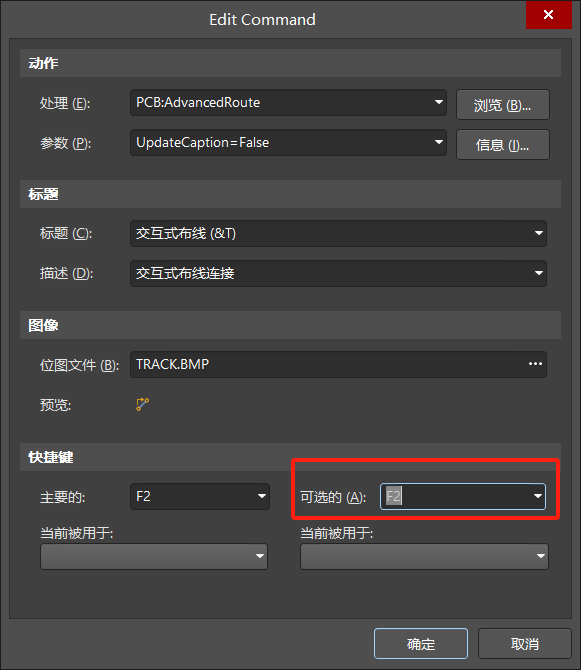
AD 常用系统快捷键
(1) L: 打开层设置开关选项(在元件移动状态下,按下“L”键换层) (2) S: 打开选择,如SL(线选)、SI(框选)、SE(滑动选择) (3) J: 跳转,如JC(跳转到元件)、JN(跳转到网络) (4) CtrlQ: 英寸和毫米相互切换。 (5) Delete: 删除已被选择的对象 E…...

今日行情明日机会——20250516
上证缩量收阴线,小盘股表现相对更好,上涨的个股大于下跌的,日线已到前期压力位附近,注意风险。 深证缩量收假阳线,临近日线周期上涨末端,注意风险。 2025年5月16日涨停股行业方向分析 机器人概念&#x…...
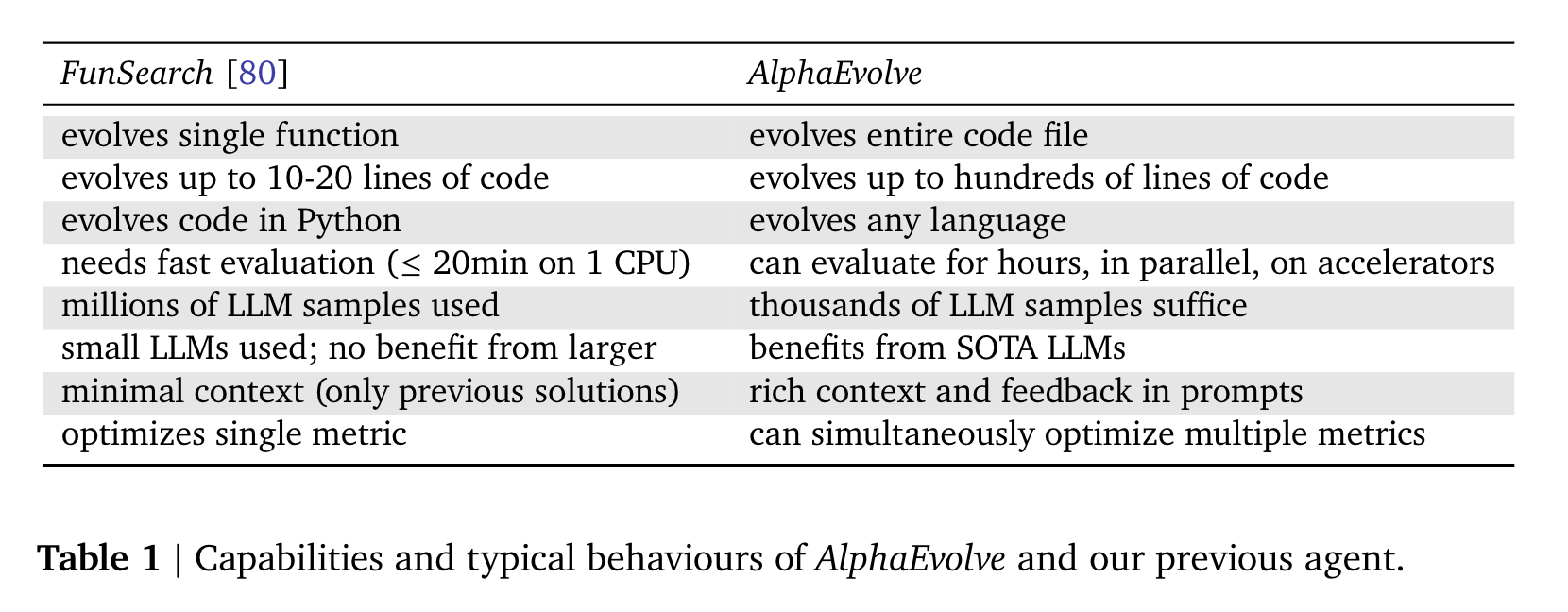
AlphaEvolve:LLM驱动的算法进化革命与科学发现新范式
AlphaEvolve:LLM驱动的算法进化革命与科学发现新范式 本文聚焦Google DeepMind最新发布的AlphaEvolve,探讨其如何通过LLM与进化算法的结合,在数学难题突破、计算基础设施优化等领域实现革命性进展。从48次乘法优化44矩阵相乘到数据中心资源利…...

多尺度对比度调整
一、背景介绍 受到了前面锐化算法实现的启发,对高频层做增强是锐化,那么对中低频一起做增强,就应该能有局域对比度增强效果。 直接暴力实现了个基本版本,确实有对比度增强效果。然后搜了下关键字,还真找到了已经有人这…...
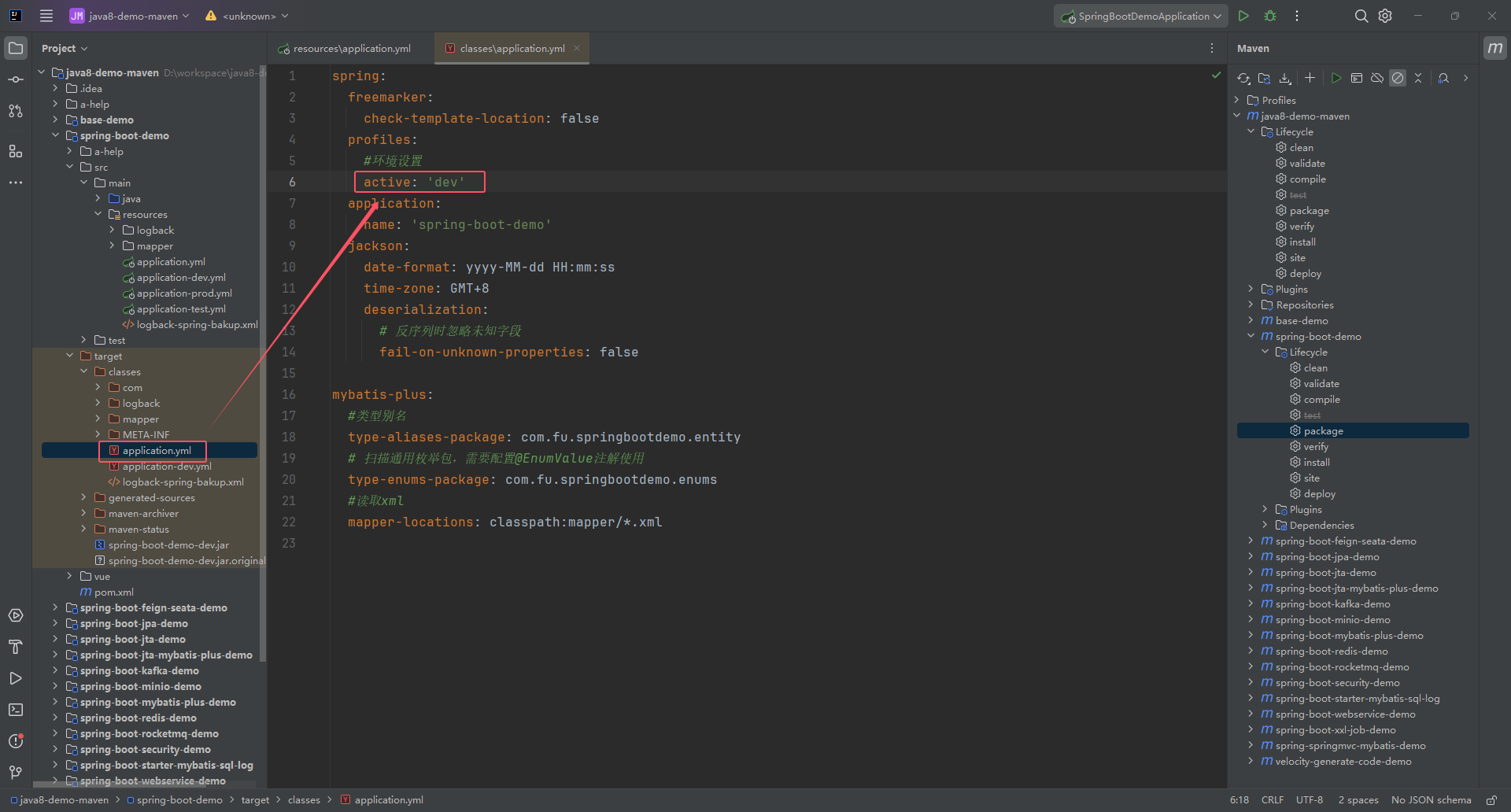
解决IDEA Maven编译时@spring.profiles.active@没有替换成具体环境变量的问题
如果不加filtering true,编译后的文件还是 spring.profiles.active 编译前的application.yml 编译后的application.yml【环境变量没有改变】 解决方案 找到 SpringBoot 启动类所在的pom.xml,在 resources 增加 filtering true,然后重新…...
)
博客系统技术需求文档(基于 Flask)
以下内容是AI基于要求生成的技术文档,仅供参考~ 🧱 一、系统架构设计概览 层级 内容 前端层 HTML Jinja2 模板引擎,集成 Markdown 编辑器、代码高亮 后端层 Flask 框架,RESTful 风格,Jinja2 渲染 数据库 SQLi…...

记参加一次数学建模
题目请到全国大学生数学建模竞赛下载查看。 注:过程更新了很多文件,所有这里贴上的有些内容不是最新的(而是草稿)。 注:我们队伍并没有获奖,文章内容仅供一乐。 从这次比赛,给出以下赛前建议 …...

TC8:SOMEIP_ETS_029-030
SOMEIP_ETS_029: echoUINT8Array16Bitlength 目的 检查当method echoUINT8Array16BitLength的参数中长度字段为16bit时,SOME/IP协议层是否能对参数进行序列化和反序列化。 对于可变长度的数组而言,必须用长度字段表示数组长度。否则接收方无法判断有效数据。 SOMEIP_ETS_02…...

PYTHON训练营DAY27
装饰器 编写一个装饰器 logger,在函数执行前后打印日志信息(如函数名、参数、返回值) logger def multiply(a, b):return a * bmultiply(2, 3) # 输出: # 开始执行函数 multiply,参数: (2, 3), {} # 函数 multiply 执行完毕&a…...

Maven使用详解:Maven的概述(二)
一、核心定义与功能 Maven是由Apache软件基金会开发的开源项目管理工具,专为Java项目设计,主要用于自动化构建、依赖管理和项目标准化。其核心功能包括: 依赖管理:通过pom.xml文件声明依赖库,自动从中央仓库下载并管…...

printspoofer的RPC调用接口的简单代码
🧠 问题背景:为什么不能“啥都不导库”就直接调用 RPC 接口? 因为: 你想调用的是 RPC 接口函数,比如 RpcRemoteFindFirstPrinterChangeNotificationEx; 它不是像 MessageBox() 那样的普通 API,…...

刻录光盘--和炸铁路,tarjan
https://www.luogu.com.cn/problem/P2835 多做多看多想,一切都会水到渠成 受欢迎的牛--tarjan缩点图论出度-CSDN博客 #include<bits/stdc.h> using namespace std; #define N 100011 typedef long long ll; typedef pair<ll,int> pii; int n,m; ve…...
新型智慧园区技术架构深度解析:数字孪生与零碳科技的融合实践
🏭在杭州亚运村零碳园区,光伏板与氢燃料大巴构成的能源网络,正通过数字孪生技术实现智能调度。这不仅是格力电器与龙源电力在新能源领域的创新实践,更是智慧园区4.0时代的标杆案例。当AI算法开始接管能源调度,当BIM建模…...
详解)
lo(Loopback 接口)详解
lo(Loopback 接口)详解 lo 是 Loopback(环回)接口,它是一个虚拟网络接口,主要用于 本地通信,不依赖物理网卡。所有操作系统(包括 Linux、Windows、macOS)默认都会创建 l…...

duxapp 2025-03-29 更新 编译结束的复制逻辑等
CLI copy 文件夹内的内容支持全量复制优化小程序配置文件合并逻辑(更新后建议将 project.config.json 文件从git的追踪中移除)新增 copy.build.complete 文件夹的复制逻辑,会在程序编译结束之后将文件复制到指定位置 (模块和用户…...

《构建社交应用的安全结界:双框架对接审核API的底层逻辑与实践》
用户生成内容如潮水般涌来。从日常的生活分享,到激烈的观点碰撞,这些内容赋予社交应用活力,也带来管理难题。虚假信息、暴力言论、侵权内容等不良信息,如同潜藏的暗礁,威胁着社交平台的健康生态。内容审核机制…...

网络世界的“百变身份“:动态IP让连接更自由
深夜的程序调试 凌晨两点,我盯着电脑屏幕上的报错信息:"Connection timed out"。这是本周第三次测试服务器响应时被拒绝访问了——只因为之前同一个IP地址尝试登录太过频繁。正在改代码的朋友小王凑过来看了眼:"老兄&…...
Linux基础开发工具大全
目录 软件包管理器 1>软件包 2>软件生态 3>yum操作 a.查看软件包 b.安装软件 c.卸载软件 4>知识点 vim编辑器 1>基本概念 2>基本操作 3>正常模式命令集 a.模式切换 b.移动光标 c.删除 d.复制 e.替换 f.撤销 g.更改 4>底行模式命令…...

【C/C++】C++中引用类型私有成员的设计与应用
文章目录 C中引用类型私有成员的设计与应用核心意义典型使用场景1. 依赖注入(Dependency Injection)2. 避免拷贝开销3. 实现不可变设计4. 接口约束 注意事项1. 生命周期管理2. 构造函数的强制性3. 不可重新绑定4. 与多态的结合 对比指针的优缺点总结 C中…...
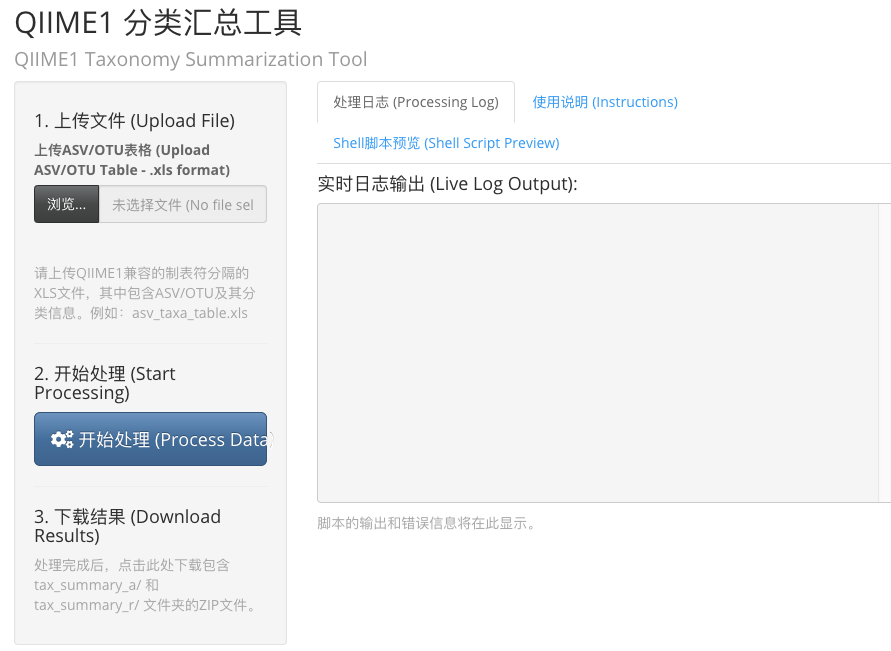
网页工具-OTU/ASV表格物种分类汇总工具
AI辅助下开发了个工具,功能如下,分享给大家: 基于Shiny开发的用户友好型网页应用,专为微生物组数据分析设计。该工具能够自动处理OTU/ASV_taxa表格(支持XLS/XLSX/TSV/CSV格式),通过调用QIIME1&a…...

存储器上如何存储1和0
在计算机存储器中,数据最终以**二进制形式(0和1)**存储,这是由硬件特性和电子电路的物理特性决定的。以下是具体存储方式的详细解析: 一、存储的物理基础:半导体电路与电平信号 计算机存储器(…...

2025第三届盘古初赛(计算机部分)
前言 比赛的时候时间不对,打一会干一会,导致比赛时候思路都跟不上,赛后简单复现一下,希望大家批批一下 计算机取证 1、分析贾韦码计算机检材,计算机系统Build版本为?【标准格式:19000】 183…...
【源码级开发】Qwen3接入MCP,企业级智能体开发实战!
Qwen3接入MCP智能体开发实战(上) 一、MCP技术与Qwen3原生MCP能力介绍 1.智能体开发核心技术—MCP 1.1 Function calling技术回顾 如何快速开发一款智能体应用,最关键的技术难点就在于如何让大模型高效稳定的接入一些外部工具。而在MCP技术…...

文本数据词汇级增强
import nltkfrom nltk.corpus import wordnetfrom nltk.tokenize import word_tokenizeimport random# nltk.download(wordnet)# nltk.download(punkt)def get_synonyms(word):"""获取单词的同义词列表"""synonyms []for syn in wordnet.synset…...