Spring Batch学习,和Spring Cloud Stream区别
Spring Batch学习,和Spring Cloud Stream区别
- 1. 使用Spring Initializr创建项目
- 2. 使用步骤构建作业(Chunk 模式)
- 🧩 场景说明
- 🧰 1. 示例目录结构
- 📄 2. 创建输入文件(`users.csv`)
- 🧱 3. 创建实体类(`User.java`)
- 🔄 4. 编写处理器(`UserItemProcessor.java`)
- ⚙️ 5. Job 配置(`ChunkJobConfig.java`)
- 🚀 6. 启动类(`BatchDemoApplication.java`)
- 📄 7. 配置文件(`application.yml`)
- ✅ 8. 启动后输出示例
- 🎓 小结
- 3. 添加容错功能(retry、skip)
- 🎯 场景目标
- 🧱 修改点概览
- 🧩 1. 修改 `UserItemProcessor.java`,模拟失败逻辑
- 🛠️ 2. 修改 `chunkStep()`:添加容错配置
- 📄 3. 示例 CSV 文件(`users.csv`)
- ✅ 4. 启动后控制台输出示例
- 🔎 总结关键 API
- 4. 多步骤 Job 示例(多个 Step 串联)
- 🎯 模块目标
- 🗂 项目结构说明(在原基础上新增)
- 📄 1. 创建 Tasklet 步骤:通知任务(`NotificationTasklet.java`)
- ⚙️ 2. 多步骤 Job 配置(`MultiStepJobConfig.java`)
- ✅ 3. 控制台输出预期
- 🧠 关键知识点
- 5. 定时调度执行 Spring Batch Job
- 📦 添加定时任务类(`ScheduledJobLauncher.java`)
- ✅ 注意:
- 🔧 开启定时任务功能(`BatchDemoApplication.java`)
- 🛠 示例控制台输出(每 30 秒一次)
- 🎓 小结
- 6. Spring Cloud Stream和Spring Batch区别
- 🧠 一句话总结
- 🔍 核心区别详解
参考文章: Building a Batch Application with Spring Batch - Spring Academy
1. 使用Spring Initializr创建项目
[~/exercises] $ curl -o 'billing-job.zip' 'https://start.spring.io/starter.zip?type=gradle-project&language=java&dependencies=batch%2Cpostgresql&name=Billing+Job&groupId=example&artifactId=billing-job&description=Billing+job+for+Spring+Cellular&packaging=jar&packageName=example.billingjob&javaVersion=17' && unzip -d 'billing-job' 'billing-job.zip'
cd billing-job
查看目录
[~/exercises/billing-job] $ tree .
.
├── HELP.md
├── mvnw
├── mvnw.cmd
├── pom.xml
└── src├── main│ ├── java│ │ └── example│ │ └── billingjob│ │ └── BillingJobApplication.java│ └── resources│ └── application.properties└── test└── java└── example└── billingjob└── BillingJobApplicationTests.java11 directories, 8 files
创建配置文件
package example.billingjob;import org.springframework.context.annotation.Configuration;@Configuration
public class BillingJobConfiguration {// TODO add job definition here
}
[~/exercises] $ docker ps
CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES
c711e7873371 postgres:14.1-alpine "docker-entrypoint.s…" 20 minutes ago Up 20 minutes 127.0.0.1:5432->5432/tcp postgres
[~/exercises] $
连接数据库创建表
[~/exercises] $ docker exec -it postgres psql -U postgres
psql (14.1)
Type "help" for help.
postgres=#
CREATE TABLE BATCH_JOB_INSTANCE (JOB_INSTANCE_ID BIGINT NOT NULL PRIMARY KEY ,VERSION BIGINT ,JOB_NAME VARCHAR(100) NOT NULL,JOB_KEY VARCHAR(32) NOT NULL,constraint JOB_INST_UN unique (JOB_NAME, JOB_KEY)
) ;
CREATE TABLE BATCH_JOB_EXECUTION (JOB_EXECUTION_ID BIGINT NOT NULL PRIMARY KEY ,VERSION BIGINT ,JOB_INSTANCE_ID BIGINT NOT NULL,CREATE_TIME TIMESTAMP NOT NULL,START_TIME TIMESTAMP DEFAULT NULL ,END_TIME TIMESTAMP DEFAULT NULL ,STATUS VARCHAR(10) ,EXIT_CODE VARCHAR(2500) ,EXIT_MESSAGE VARCHAR(2500) ,LAST_UPDATED TIMESTAMP,constraint JOB_INST_EXEC_FK foreign key (JOB_INSTANCE_ID)references BATCH_JOB_INSTANCE(JOB_INSTANCE_ID)
) ;
CREATE TABLE BATCH_JOB_EXECUTION_PARAMS (JOB_EXECUTION_ID BIGINT NOT NULL ,PARAMETER_NAME VARCHAR(100) NOT NULL ,PARAMETER_TYPE VARCHAR(100) NOT NULL ,PARAMETER_VALUE VARCHAR(2500) ,IDENTIFYING CHAR(1) NOT NULL ,constraint JOB_EXEC_PARAMS_FK foreign key (JOB_EXECUTION_ID)references BATCH_JOB_EXECUTION(JOB_EXECUTION_ID)
) ;
CREATE TABLE BATCH_STEP_EXECUTION (STEP_EXECUTION_ID BIGINT NOT NULL PRIMARY KEY ,VERSION BIGINT NOT NULL,STEP_NAME VARCHAR(100) NOT NULL,JOB_EXECUTION_ID BIGINT NOT NULL,CREATE_TIME TIMESTAMP NOT NULL,START_TIME TIMESTAMP DEFAULT NULL ,END_TIME TIMESTAMP DEFAULT NULL ,STATUS VARCHAR(10) ,COMMIT_COUNT BIGINT ,READ_COUNT BIGINT ,FILTER_COUNT BIGINT ,WRITE_COUNT BIGINT ,READ_SKIP_COUNT BIGINT ,WRITE_SKIP_COUNT BIGINT ,PROCESS_SKIP_COUNT BIGINT ,ROLLBACK_COUNT BIGINT ,EXIT_CODE VARCHAR(2500) ,EXIT_MESSAGE VARCHAR(2500) ,LAST_UPDATED TIMESTAMP,constraint JOB_EXEC_STEP_FK foreign key (JOB_EXECUTION_ID)references BATCH_JOB_EXECUTION(JOB_EXECUTION_ID)
) ;
CREATE TABLE BATCH_STEP_EXECUTION_CONTEXT (STEP_EXECUTION_ID BIGINT NOT NULL PRIMARY KEY,SHORT_CONTEXT VARCHAR(2500) NOT NULL,SERIALIZED_CONTEXT TEXT ,constraint STEP_EXEC_CTX_FK foreign key (STEP_EXECUTION_ID)references BATCH_STEP_EXECUTION(STEP_EXECUTION_ID)
) ;
CREATE TABLE BATCH_JOB_EXECUTION_CONTEXT (JOB_EXECUTION_ID BIGINT NOT NULL PRIMARY KEY,SHORT_CONTEXT VARCHAR(2500) NOT NULL,SERIALIZED_CONTEXT TEXT ,constraint JOB_EXEC_CTX_FK foreign key (JOB_EXECUTION_ID)references BATCH_JOB_EXECUTION(JOB_EXECUTION_ID)
) ;
CREATE SEQUENCE BATCH_STEP_EXECUTION_SEQ MAXVALUE 9223372036854775807 NO CYCLE;
CREATE SEQUENCE BATCH_JOB_EXECUTION_SEQ MAXVALUE 9223372036854775807 NO CYCLE;
CREATE SEQUENCE BATCH_JOB_SEQ MAXVALUE 9223372036854775807 NO CYCLE;
检查创建的表
postgres=# \dList of relationsSchema | Name | Type | Owner
--------+------------------------------+----------+----------public | batch_job_execution | table | postgrespublic | batch_job_execution_context | table | postgrespublic | batch_job_execution_params | table | postgrespublic | batch_job_execution_seq | sequence | postgrespublic | batch_job_instance | table | postgrespublic | batch_job_seq | sequence | postgrespublic | batch_step_execution | table | postgrespublic | batch_step_execution_context | table | postgrespublic | batch_step_execution_seq | sequence | postgres
(9 rows)
postgres=#
修改配置billing-job/src/main/resources/application.properties
spring.datasource.url=jdbc:postgresql://localhost:5432/postgres
spring.datasource.username=postgres
spring.datasource.password=postgres
2. 使用步骤构建作业(Chunk 模式)
很好!下面是 Spring Batch 模块 2:使用步骤构建作业(Chunk 模式) 的完整示例,模拟一个典型的「读取 → 处理 → 写入」的场景。
🧩 场景说明
我们将读取一个 CSV 文件中的用户信息(users.csv),处理数据(将用户名转为大写),然后将处理结果打印出来(模拟写入数据库)。
🧰 1. 示例目录结构
src/
├── main/
│ ├── java/
│ │ └── com/example/batch/
│ │ ├── BatchDemoApplication.java
│ │ ├── config/ChunkJobConfig.java
│ │ ├── model/User.java
│ │ ├── processor/UserItemProcessor.java
│ ├── resources/
│ ├── users.csv
│ └── application.yml
📄 2. 创建输入文件(users.csv)
id,name
1,alice
2,bob
3,charlie
🧱 3. 创建实体类(User.java)
public class User {private Long id;private String name;// 构造方法、getter/setterpublic User() {}public User(Long id, String name) {this.id = id;this.name = name;}public Long getId() { return id; }public void setId(Long id) { this.id = id; }public String getName() { return name; }public void setName(String name) { this.name = name; }@Overridepublic String toString() {return "User{id=" + id + ", name='" + name + "'}";}
}
🔄 4. 编写处理器(UserItemProcessor.java)
@Component
public class UserItemProcessor implements ItemProcessor<User, User> {@Overridepublic User process(User user) {user.setName(user.getName().toUpperCase());return user;}
}
⚙️ 5. Job 配置(ChunkJobConfig.java)
@Configuration
@EnableBatchProcessing
public class ChunkJobConfig {@Autowiredprivate JobBuilderFactory jobBuilderFactory;@Autowiredprivate StepBuilderFactory stepBuilderFactory;@Autowiredprivate UserItemProcessor processor;// 读取器:从 CSV 文件中读取数据@Beanpublic FlatFileItemReader<User> reader() {return new FlatFileItemReaderBuilder<User>().name("userItemReader").resource(new ClassPathResource("users.csv")).delimited().names("id", "name").fieldSetMapper(fieldSet -> new User(fieldSet.readLong("id"),fieldSet.readString("name"))).linesToSkip(1) // 跳过标题行.build();}// 写入器:将处理后的数据打印到控制台(模拟写数据库)@Beanpublic ItemWriter<User> writer() {return users -> {System.out.println("📥 写入数据:");users.forEach(System.out::println);};}@Beanpublic Step chunkStep() {return stepBuilderFactory.get("chunkStep").<User, User>chunk(2) // 每2个为一个块处理.reader(reader()).processor(processor).writer(writer()).build();}@Beanpublic Job chunkJob() {return jobBuilderFactory.get("chunkJob").start(chunkStep()).build();}
}
🚀 6. 启动类(BatchDemoApplication.java)
@SpringBootApplication
public class BatchDemoApplication {public static void main(String[] args) {SpringApplication.run(BatchDemoApplication.class, args);}
}
📄 7. 配置文件(application.yml)
spring:batch:job:enabled: truedatasource:url: jdbc:h2:mem:testdbdriver-class-name: org.h2.Driverusername: sapassword:h2:console:enabled: true
✅ 8. 启动后输出示例
📥 写入数据:
User{id=1, name='ALICE'}
User{id=2, name='BOB'}
📥 写入数据:
User{id=3, name='CHARLIE'}
🎓 小结
| 部件 | 作用 |
|---|---|
ItemReader | 读取数据源(CSV) |
ItemProcessor | 转换数据(小写转大写) |
ItemWriter | 输出结果(控制台) |
chunk(n) | 每 n 条数据为一个事务处理块 |
3. 添加容错功能(retry、skip)
🎯 场景目标
在上一个示例基础上,模拟某些数据处理失败 的情况,并配置:
- ✅ 自动重试指定异常(如最多重试 2 次)
- ✅ 跳过指定异常(跳过错误记录继续执行)
🧱 修改点概览
| 部分 | 修改 |
|---|---|
processor | 模拟处理过程中抛异常 |
chunkStep() | 添加 .faultTolerant()、.retry()、.skip() 配置 |
| 控制台输出 | 可看到错误被捕获、重试、跳过后的行为 |
🧩 1. 修改 UserItemProcessor.java,模拟失败逻辑
@Component
public class UserItemProcessor implements ItemProcessor<User, User> {@Overridepublic User process(User user) throws Exception {// 模拟用户 id 为 2 的处理会失败if (user.getId() == 2) {System.out.println("❌ 模拟处理异常:用户 " + user.getName());throw new IllegalArgumentException("处理用户失败!");}user.setName(user.getName().toUpperCase());return user;}
}
🛠️ 2. 修改 chunkStep():添加容错配置
@Bean
public Step chunkStep() {return stepBuilderFactory.get("chunkStep").<User, User>chunk(2).reader(reader()).processor(processor).writer(writer()).faultTolerant() // 开启容错模式.retry(IllegalArgumentException.class) // 指定重试异常.retryLimit(2) // 最多重试 2 次.skip(IllegalArgumentException.class) // 如果还失败则跳过.skipLimit(5) // 最多跳过 5 个.build();
}
📄 3. 示例 CSV 文件(users.csv)
id,name
1,alice
2,bob <-- 模拟失败
3,charlie
✅ 4. 启动后控制台输出示例
👉 正在读取用户数据...
📥 写入数据:
User{id=1, name='ALICE'}
❌ 模拟处理异常:用户 bob
⚠️ 重试第1次...
❌ 模拟处理异常:用户 bob
⚠️ 重试第2次...
❌ 模拟处理异常:用户 bob
⚠️ 达到重试次数限制,跳过该用户📥 写入数据:
User{id=3, name='CHARLIE'}
你将看到:
- 用户
bob被处理时故意失败 - 自动重试 2 次
- 重试仍失败 → 被跳过
- Job 正常完成,未中断!
🔎 总结关键 API
| 方法 | 含义 |
|---|---|
.faultTolerant() | 启用容错处理 |
.retry(Exception.class) | 出现该异常时会自动重试 |
.retryLimit(n) | 最大重试次数 |
.skip(Exception.class) | 如果重试仍失败,可以跳过 |
.skipLimit(n) | 最大跳过条数,超过就 fail |
4. 多步骤 Job 示例(多个 Step 串联)
🎯 模块目标
我们将构建一个包含多个 Step 的 Job:
- Step 1:打印 Job 启动信息
- Step 2:执行 chunk 处理逻辑(读取、处理、写入用户)
- Step 3:清理任务或发送通知(模拟)
🗂 项目结构说明(在原基础上新增)
├── config/
│ └── MultiStepJobConfig.java <-- 新增:多个步骤的 Job 配置
├── service/
│ └── NotificationTasklet.java <-- 新增:通知步骤
📄 1. 创建 Tasklet 步骤:通知任务(NotificationTasklet.java)
@Component
public class NotificationTasklet implements Tasklet {@Overridepublic RepeatStatus execute(StepContribution contribution, ChunkContext chunkContext) {System.out.println("📣 所有用户处理完成,发送通知!");return RepeatStatus.FINISHED;}
}
⚙️ 2. 多步骤 Job 配置(MultiStepJobConfig.java)
@Configuration
public class MultiStepJobConfig {@Autowired private JobBuilderFactory jobBuilderFactory;@Autowired private StepBuilderFactory stepBuilderFactory;@Autowired private FlatFileItemReader<User> reader;@Autowired private ItemProcessor<User, User> processor;@Autowired private ItemWriter<User> writer;@Autowired private NotificationTasklet notificationTasklet;@Beanpublic Step startStep() {return stepBuilderFactory.get("startStep").tasklet((contribution, context) -> {System.out.println("🚀 Job 开始执行!");return RepeatStatus.FINISHED;}).build();}@Beanpublic Step chunkStep() {return stepBuilderFactory.get("chunkStep").<User, User>chunk(2).reader(reader).processor(processor).writer(writer).faultTolerant().retry(IllegalArgumentException.class).retryLimit(2).skip(IllegalArgumentException.class).skipLimit(5).build();}@Beanpublic Step notifyStep() {return stepBuilderFactory.get("notifyStep").tasklet(notificationTasklet).build();}@Beanpublic Job multiStepJob() {return jobBuilderFactory.get("multiStepJob").start(startStep()).next(chunkStep()).next(notifyStep()).build();}
}
✅ 3. 控制台输出预期
🚀 Job 开始执行!
📥 写入数据:
User{id=1, name='ALICE'}
❌ 模拟处理异常:用户 bob
⚠️ 重试中...
📥 写入数据:
User{id=3, name='CHARLIE'}
📣 所有用户处理完成,发送通知!
🧠 关键知识点
| 概念 | 说明 |
|---|---|
| 多个 Step | 使用 .start().next().next() 串联 |
| Tasklet Step | 适合执行单个逻辑(如日志、通知) |
| Chunk Step | 适合批量数据处理 |
| JobBuilder | 构建包含多个 Step 的流程 |
5. 定时调度执行 Spring Batch Job
📦 添加定时任务类(ScheduledJobLauncher.java)
@Component
public class ScheduledJobLauncher {@Autowiredprivate JobLauncher jobLauncher;@Autowired@Qualifier("multiStepJob") // 使用我们前面定义的 Jobprivate Job job;@Scheduled(fixedRate = 30000) // 每 30 秒触发一次public void runJob() {try {JobParameters params = new JobParametersBuilder().addLong("timestamp", System.currentTimeMillis()) // 保证每次唯一.toJobParameters();System.out.println("⏰ 定时任务启动 Job...");jobLauncher.run(job, params);} catch (Exception e) {System.err.println("❌ Job 启动失败:" + e.getMessage());}}
}
✅ 注意:
Spring Batch 的 Job 每次执行都需要唯一参数(否则不会重复执行),因此我们加了:
.addLong("timestamp", System.currentTimeMillis())
🔧 开启定时任务功能(BatchDemoApplication.java)
@SpringBootApplication
@EnableScheduling // 启用定时任务功能
public class BatchDemoApplication {public static void main(String[] args) {SpringApplication.run(BatchDemoApplication.class, args);}
}
🛠 示例控制台输出(每 30 秒一次)
⏰ 定时任务启动 Job...
🚀 Job 开始执行!
📥 写入数据:
User{id=1, name='ALICE'}
❌ 模拟处理异常:用户 bob
📥 写入数据:
User{id=3, name='CHARLIE'}
📣 所有用户处理完成,发送通知!
🎓 小结
| 组件 | 功能 |
|---|---|
@Scheduled | 每隔一段时间自动触发 Job |
JobLauncher | 手动执行指定 Job |
JobParametersBuilder | 创建 Job 参数,确保唯一性 |
@EnableScheduling | 启用定时任务功能 |
6. Spring Cloud Stream和Spring Batch区别
🧠 一句话总结
| 框架 | 关注点 | 用于什么 |
|---|---|---|
| Spring Cloud Stream | 实时消息流处理 | 处理从消息队列(如 Kafka、RabbitMQ)中来的事件流 |
| Spring Batch | 批量任务处理 | 处理大量结构化数据的离线批处理任务,如夜间账单 |
🔍 核心区别详解
| 特性 / 区别点 | Spring Cloud Stream | Spring Batch |
|---|---|---|
| 💡 处理模式 | 异步、实时流式处理(事件驱动) | 同步、批量处理(定时或手动触发) |
| 🕘 适用场景 | IoT 数据流、订单事件、消息队列消费者、微服务事件链路 | 日终结算、数据库导入导出、文件解析、大规模数据迁移 |
| 🔌 输入来源 | Kafka、RabbitMQ、Pulsar 等消息中间件 | 数据库、CSV、XML、REST 接口等 |
| 🔄 输出目标 | 下游队列或服务 | 数据库、文件、API |
| 🧱 组成模型 | Supplier、Function、Consumer | Step、Job、ItemReader、ItemProcessor、ItemWriter |
| 💥 故障处理 | 支持 Retry、DLQ、分区等 | 支持跳过、重试、事务、Job Restart |
| 🛠️ 持久化状态 | 一般无状态,靠中间件保证可靠传递 | 有状态,支持 Job Execution 状态保存(如重启恢复) |
| 🧪 测试/调试 | 流处理链可拆解为小函数,易于集成测试 | Job 参数可控制执行,适合验证数据处理逻辑 |
| 🧰 配置方式 | application.yml(通道绑定) | XML/Java DSL 配置 Job、Step、Reader 等 |
相关文章:

Spring Batch学习,和Spring Cloud Stream区别
Spring Batch学习,和Spring Cloud Stream区别 1. 使用Spring Initializr创建项目2. 使用步骤构建作业(Chunk 模式)🧩 场景说明🧰 1. 示例目录结构📄 2. 创建输入文件(users.csv)&…...

【技术原理】Linux 文件时间属性详解:Access、Modify、Change 的区别与联系
在 Linux 系统中,每个文件都有三个核心时间属性:Access Time (atime)、Modify Time (mtime) 和 Change Time (ctime)。它们分别记录文件不同维度的变更信息,以下是具体区别与联系: 一、定义与触发条件 时间属性定义触发条件示例A…...

k8s之LoadBalancer Service 解析
Kubernetes LoadBalancer Service 解析:IP与端口详解 服务类型与IP解析 Service 是 Kubernetes 中的资源类型,用来将一组 Pod 的应用作为网络服务公开。每个 Pod 都有自己的 IP,但是这个 IP 的生命周期与 Pod 生命周期一致,也就…...

Vue3项目使用ElDrawer后select方法不生效
Vue3 项目中 ElDrawer 内 ElSelect 下拉框 z-index 失效问题分析与解决方案 问题描述问题分析解决方案结论 问题描述 在 Vue3 项目中使用 Element Plus 的 ElDrawer 组件时,当在抽屉内部使用 ElSelect 组件,发现下拉选择框(dropdownÿ…...
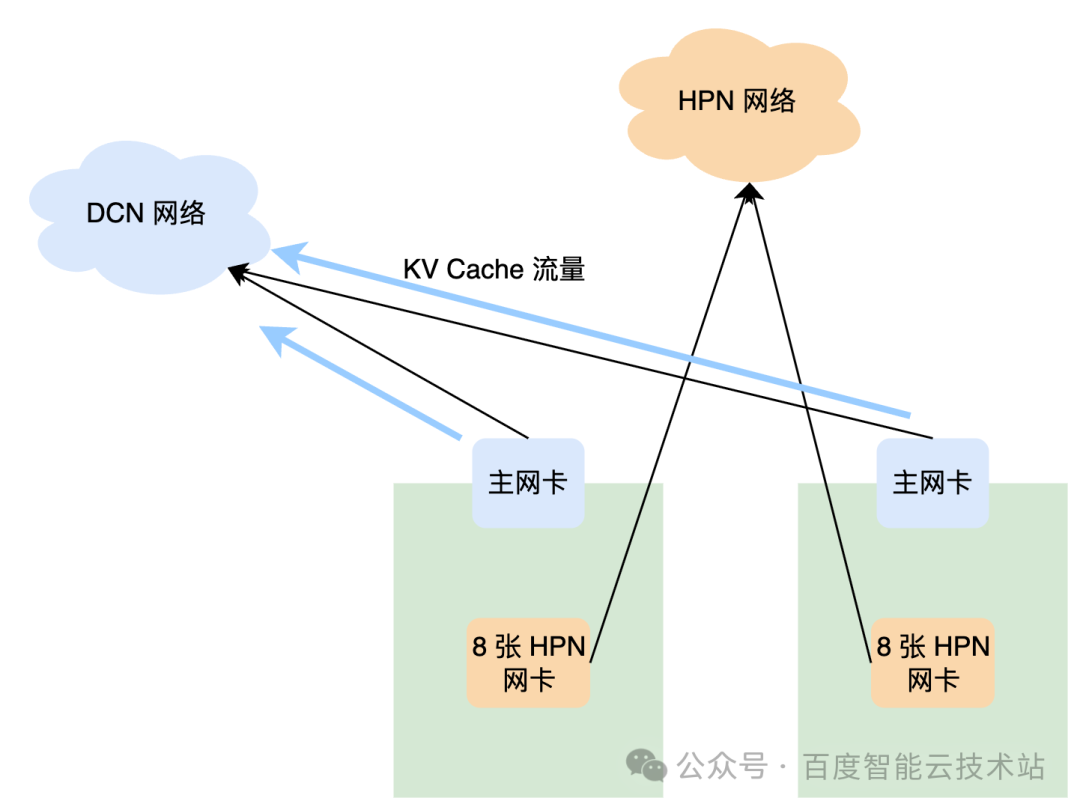
PD 分离推理的加速大招,百度智能云网络基础设施和通信组件的优化实践
为了适应 PD 分离式推理部署架构,百度智能云从物理网络层面的「4us 端到端低时延」HPN 集群建设,到网络流量层面的设备配置和管理,再到通信组件和算子层面的优化,显著提升了上层推理服务的整体性能。 百度智能云在大规模 PD 分离…...
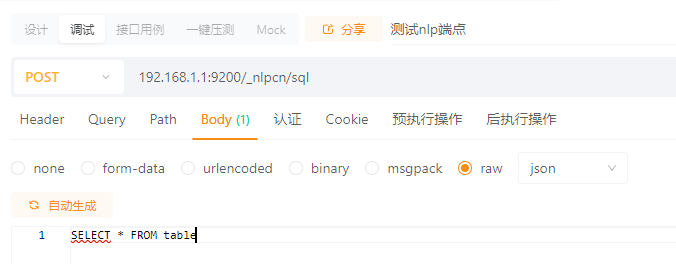
官方 Elasticsearch SQL NLPChina Elasticsearch SQL
官方的可以在kibana 控制台上进行查询: POST /_sql { “query”: “SELECT client_ip, status FROM logs-2024-05 WHERE status 500” } NLPChina Elasticsearch SQL就无法以在kibana 控制台上进行查询,但是可以使用postman接口进行查询:...
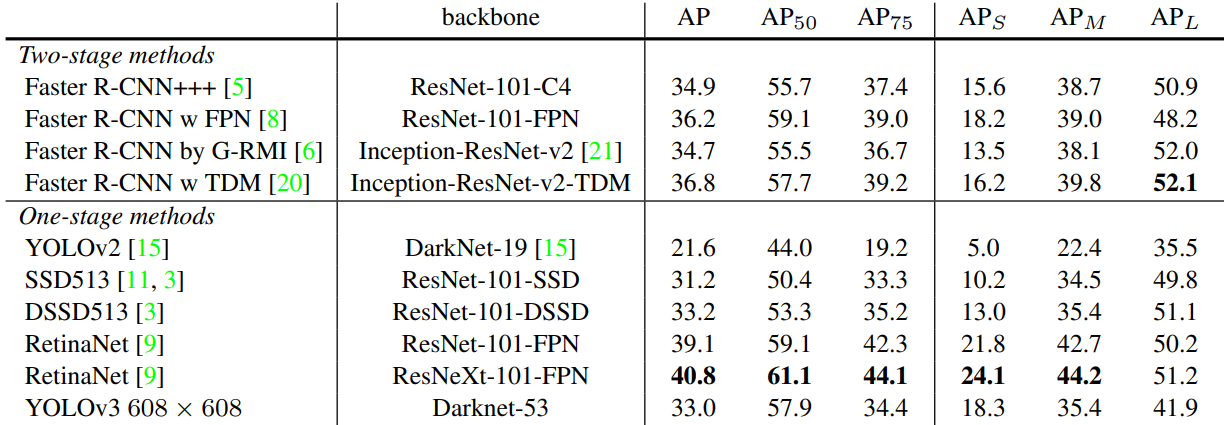
5月16日复盘-目标检测开端
5月16日复盘 一、图像处理之目标检测 1. 目标检测认知 Object Detection,是指在给定的图像或视频中检测出目标物体在图像中的位置和大小,并进行分类或识别等相关任务。 目标检测将目标的分割和识别合二为一。 What、Where 2. 使用场景 目标检测用于…...

读取toml, 合并,生成新文件
依次读取三个TOML文件并合并,后续文件覆盖之前的值,最终将结果写入新文件 import toml def deep_update(base_dict, update_dict): """ 递归合并字典,后续字典的值覆盖前者[6] """ for key, …...

mathematics-2024《Graph Convolutional Network for Image Restoration: A Survey》
推荐深蓝学院的《深度神经网络加速:cuDNN 与 TensorRT》,课程面向就业,细致讲解CUDA运算的理论支撑与实践,学完可以系统化掌握CUDA基础编程知识以及TensorRT实战,并且能够利用GPU开发高性能、高并发的软件系统…...
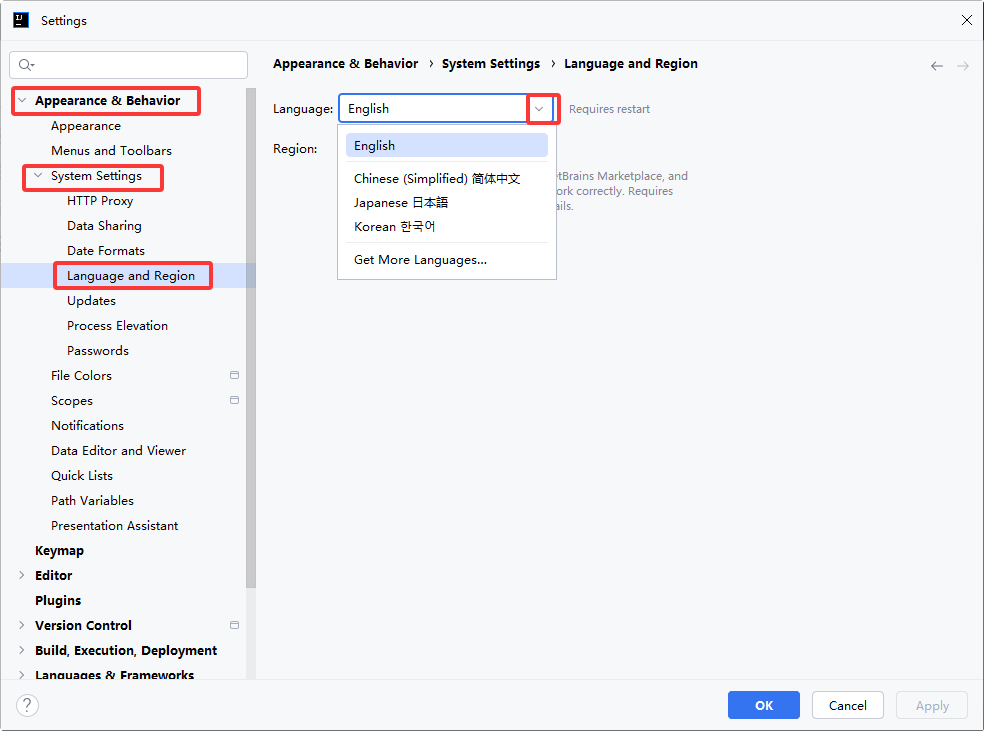
IDEA怎么汉化idea中文改回英文版
第一步:点击左上角的File,然后选择Setting 第二步:Setting页面选择 Appearance & Behavior,然后展开System Settings,然后选择 Language and Region,进行修改 我操作的是2024年的版本 File->Settings -> Ap…...

Android minSdk从21升级24后SO库异常
问题 minSdk从21调整到24后: java.nio.file.NoSuchFileException: /data/app/~~Z9s2NfuDdclOUwUBLKnk0A/com.rs.unity- Bg31QvFwF4qsCwv2XCqT-w/split_config.arm64_v8a.apkjava.nio.file.NoSuchFileException: /data/app/~~Z9s2NfuDdclOUwUBLKnk0A/com.rs.unity-…...
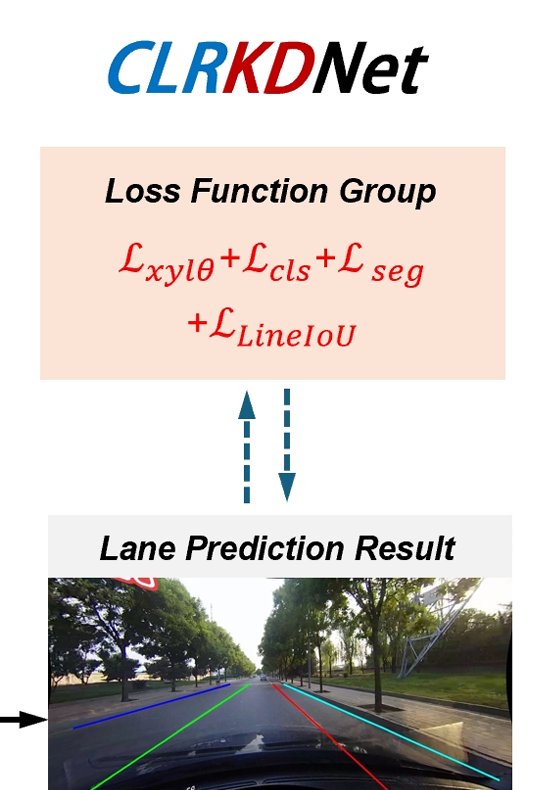
车道线检测----CLRKDNet
今天的最后一篇 车道线检测系列结束 CLRKDNet:通过知识蒸馏加速车道检测 摘要:道路车道是智能车辆视觉感知系统的重要组成部分,在安全导航中发挥着关键作用。在车道检测任务中,平衡精度与实时性能至关重要,但现有方法…...
从技术视角解构 Solana Meme 币生态
在高吞吐、高并发的 Solana 网络上,一类轻量化、高热度的代币形式正在爆发式增长——Meme Token(迷因代币)。尽管起源于社群文化,但其技术实现并非“玩笑”,而是一整套构建于 Solana Runtime 与 Token Extensions 之上…...

智能接处警系统:以秒级联动响应重塑应急处置效能
随着我国能源、化工、航空等关键行业的快速发展,传统消防管理模式已难以满足高效应急响应的需求。国家能源局、应急管理部、民航总局均出台专项规定,对消防站建设提出更高要求,在此背景下,智能接处警系统正是应对这些挑战的核…...

OpenCV直方图与直方图均衡化
一、图像直方图基础 1. 什么是图像直方图? 图像直方图是图像处理中最基本且重要的统计工具之一,它用图形化的方式表示图像中像素强度的分布情况。对于数字图像,直方图描述了每个可能的像素强度值(0-255)在图像中出现…...

7-15 计算圆周率
π131352!3573!⋯357⋯(2n1)n!⋯ 输入格式: 输入在一行中给出小于1的阈值。 输出格式: 在一行中输出满足阈值条件的近似圆周率,输出到小数点后6位。 输入样例: 0.01输出样例: 3.132157 我的代码 #i…...

Mosaic数据增强技术
Mosaic 数据增强技术是一种在计算机视觉领域广泛应用的数据增强方法。下面是Mosaic 数据增强技术原理的详细介绍 一、原理 Mosaic 数据增强是将多张图像(通常是 4 张)按照一定的规则拼接在一起,形成一张新的图像。在拼接过程中,会…...

GpuGeek 网络加速:破解 AI 开发中的 “最后一公里” 瓶颈
摘要: 网络延迟在AI开发中常被忽视,却严重影响效率。GpuGeek通过技术创新,提供学术资源访问和跨国数据交互的加速服务,助力开发者突破瓶颈。 目录 一、引言:当算力不再稀缺,网络瓶颈如何破局? …...

Sigmoid与Softmax:从二分类到多分类的深度解析
Sigmoid与Softmax:从二分类到多分类的深度解析 联系 函数性质:二者都是非线性函数 ,也都是指数归一化函数,可将输入值映射为0到1之间的实数 ,都能把输出转化成概率分布的形式,在神经网络中常作为激活函数使用。Softmax是Sigmoid的推广:从功能角度看,Softmax函数可视为…...

容器编排利器-k8s入门指南
Kubernetes(K8s)入门指南:容器编排利器 什么是 Kubernetes? Kubernetes(常简称为K8s)是一个开源的容器编排平台,由 Google 开源并交由云原生计算基金会(CNCF)管理。它可以帮助我们自动化部署、扩展和管理容器化应用程序。 为什么需要 Kubernetes? 在微服务架构盛行的今…...
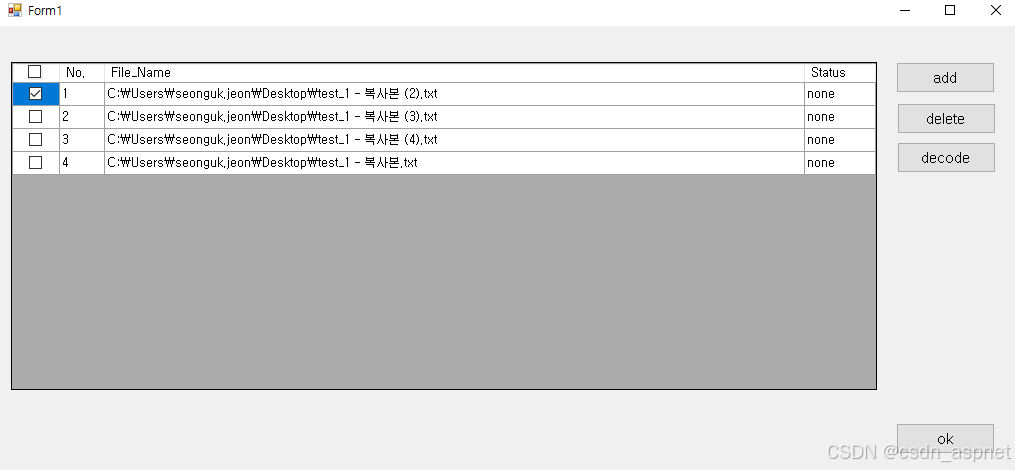
C# DataGridView 选中所有复选框
问题描述 在程序中尝试选中所有复选框,但出现错误。如果单击顶部的完整选中/释放复选框,同时选中包含复选框的列,则选定区域不会改变。该如何解决? 上面的图片是点击完整版本之后的。 下面是本文的测试代码,函数 dat…...

C#学习第23天:面向对象设计模式
什么是设计模式? 定义:设计模式是软件开发中反复出现的特定问题的解决方案。它们提供了问题的抽象描述和解决方案。目的:通过提供成熟的解决方案,设计模式可以加快开发速度并提高代码质量。 常见的设计模式 设计模式通常分为三大…...

LineBasicMaterial
LineBasicMaterial 描述 用于绘制纯色线条的基础材质,支持颜色、线宽和纹理映射。常用于THREE.Line或THREE.LineSegments几何体。 构造函数 (Constructor) 构造函数参数描述LineBasicMaterial(parameters?: Object)parameters定义材质外观的对象,可…...
AB Download Manager v1.5.8 开源免费下载工具
下载文件是我们日常工作和生活中经常进行的操作。面对动辄数十GB的4K影片、设计素材包或开发工具,传统浏览器的单线程下载如同"涓涓细流",非常影响我们的效率和体验。 那么,一款高效且易用的下载工具至关重要。今天就让我们解锁这…...

react-native中createContext的使用
在 React Native 中,createContext 是一个非常强大的工具,用于在组件树中共享状态,避免了逐层传递 props 的繁琐。以下是对 createContext 的详细解释以及一个完整的示例。 详细解释 createContext 是 React 提供的一个函数,用于…...
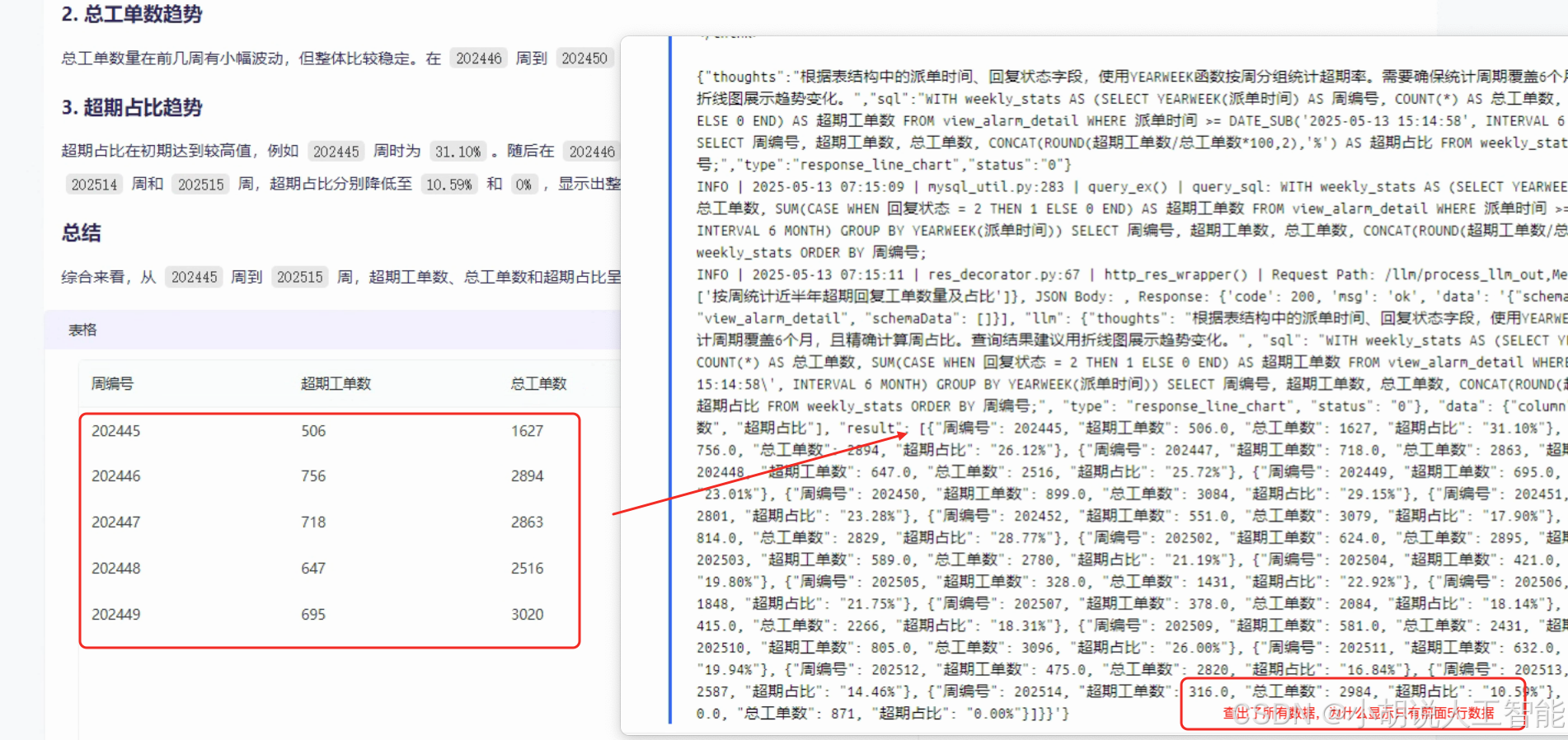
深度剖析:Dify+Sanic+Vue+ECharts 搭建 Text2SQL 项目 sanic-web 的 Debug 实战
目录 项目背景介绍sanic-web Dify\_service handle\_think\_tag报错NoneType问题描述debug Dify调用不成功,一直转圈圈问题描述debug 前端markdown格式只显示前5页问题描述debug1. 修改代码2.重新构建1.1.3镜像3.更新sanic-web/docker/docker-compose.yaml4. 重新部…...

学习51单片机02
吐血了,板子今天才到,下午才刚开始学的,生气了,害我笔记都断更了一天。。。。 紧接上文...... 如何将HEX程序烧写到程序? Tips:HEX 文件是一种常用于单片机等嵌入式系统的文件格式,它包含了程序的机器码…...
麒麟服务器操作系统安装 MySQL 8 实战指南
往期好文连接:统信UOS/麒麟KYLINOS安装JDBC驱动包 Hello,大家好啊,今天给大家带来一篇麒麟服务器操作系统上安装 MySQL 8 的文章,欢迎大家分享点赞,点个在看和关注吧!MySQL 作为主流开源数据库之一&#x…...
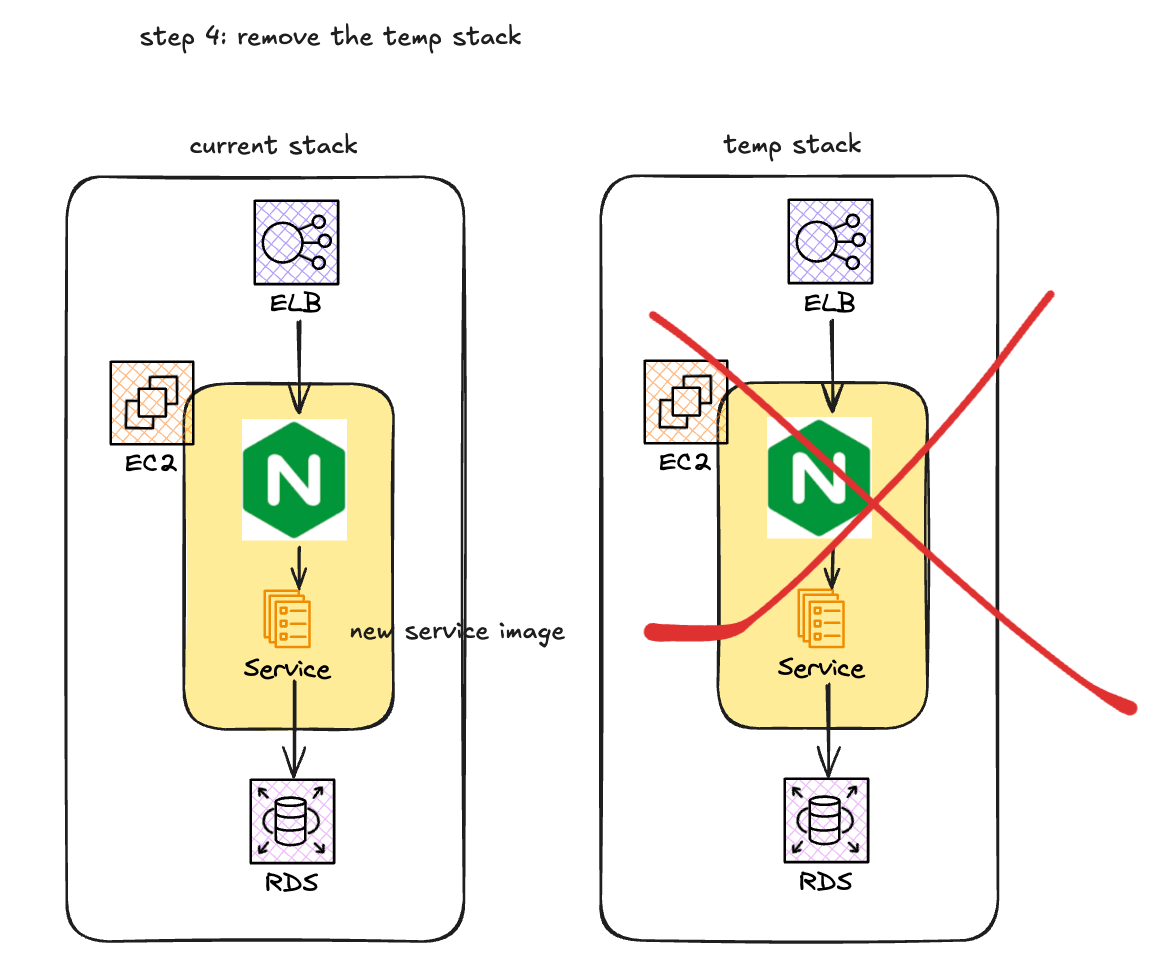
AWS EC2 微服务 金丝雀发布(Canary Release)方案
为什么需要实现金丝雀发布? 在当前项目的工程实践中, 已经有了充分的单元测试, 预发布环境测试, 但是还是会在线上环境出现非预期的情况, 导致线上事故, 因此, 为了提升服务质量, 需要线上能够有一个预验证的机制. 如何实现金丝雀发布? 使用AWS code deploy方案 AWS code…...

力扣-78.子集
给你一个整数数组 nums ,数组中的元素 互不相同 。返回该数组所有可能的子集(幂集)。 解集 不能 包含重复的子集。你可以按 任意顺序 返回解集。 class Solution {List<List<Integer>> res new ArrayList<>();List<I…...