ISBI 2012 EM 神经元结构分割数据集复现UNet
一些笔记在代码的注释中
因为使用的数据集比较简单,所以没有使用模型可视化和调试的内容,只是简单的数据集预处理和模型的搭建以及训练。
# 1. PyTorch 基础模块
import torch # 张量操作
import torch.nn as nn # 构建神经网络模块(如Conv2d, Module等)
import torch.nn.functional as F # 函数式API(如激活函数、卷积等)
import torch.optim as optim # 优化器(如Adam, SGD)
from torch.utils.data import Dataset, DataLoader # 数据加载
# 2. 图像处理和增强
import torchvision.transforms as transforms # 常用图像变换方法(ToTensor, Normalize等)
import torchvision.transforms.functional as TF # 具体变换函数(hflip, vflip等)
# 3. 读取医学图像文件(TIFF格式)
import tifffile # tif文件读取函数 tifffile.imread()
# 4. 其他辅助模块
import numpy as np # 数组和矩阵操作
import random # 随机数生成
import os
import zipfile
import requests
import matplotlib.pyplot as plt# 数据路径
data_dir = "D:\python\Pytorch"# 读取训练图像和标签
train_image_stack = tifffile.imread(os.path.join(data_dir, "train-volume.tif"))
train_label_stack = tifffile.imread(os.path.join(data_dir, "train-labels.tif"))print("图像 shape:", train_image_stack.shape) # (30, 512, 512)
print("标签 shape:", train_label_stack.shape) # (30, 512, 512)#数据集加载
class ISBIDataset(Dataset):def __init__(self,images,masks,patch_size=128,augment=True):##augment=True 这个参数通常用于控制**数据增强(data augmentation)**功能是否开启。self.images = imagesself.masks = masksself.patch_size = patch_sizeself.augment = True#作用:初始化 Dataset 对象,完成数据路径、预处理操作等的准备工作。你可以在这里加载数据列表、设置变换(transform)等。def __len__(self):return len(self.images)*10 #将一张图片分为10个patch 输出的数据的总数#作用:返回整个数据集的样本数量。DataLoader 会调用它来知道数据集有多大,从而决定迭代次数。def __getitem__(self, idx):img_idx = idx % len(self.images) #上面把一张图片分为10个patch 这里是把每10个patch的样本编码表示为同一图片image = self.images[img_idx]mask = self.masks[img_idx]#作用:根据给定的索引,返回对应的数据样本(例如图像和标签)。DataLoader 通过索引调用它,取出单个样本进行训练或推理。#数据预处理
#随即裁剪patch# 随机裁剪 patchi = random.randint(0, image.shape[0] - self.patch_size)j = random.randint(0, image.shape[1] - self.patch_size)image_patch = image[i:i + self.patch_size, j:j + self.patch_size]mask_patch = mask[i:i + self.patch_size, j:j + self.patch_size]# 转为 tensor 并归一化image_patch = torch.from_numpy(image_patch).float().unsqueeze(0) / 255.0 # (1, H, W)mask_patch = torch.from_numpy(mask_patch).float().unsqueeze(0) / 255.0mask_patch = (mask_patch > 0.5).float() # 转为0/1标签# 数据增强(水平/垂直翻转)if self.augment:if random.random() > 0.5:image_patch = TF.hflip(image_patch)mask_patch = TF.hflip(mask_patch)if random.random() > 0.5:image_patch = TF.vflip(image_patch)mask_patch = TF.vflip(mask_patch)return image_patch, mask_patch
#在面对不同的数据集时,都要根据数据集的文档或者特征使用不同的数据预处理的方法
# 创建训练数据集和 DataLoader
train_dataset = ISBIDataset(train_image_stack, train_label_stack, patch_size=128, augment=True)#这里的augment参数 是指数据增强又没有开启
train_loader = DataLoader(train_dataset, batch_size=8, shuffle=True)# 测试一下 DataLoader
for img, mask in train_loader:print("图像 shape:", img.shape) # [8, 1, 128, 128]print("掩码 shape:", mask.shape) # [8, 1, 128, 128]break#卷积模块
class DoubleConv(nn.Module):def __init__(self, in_channels, out_channels):super(DoubleConv, self).__init__()self.conv1 = nn.Conv2d(in_channels, out_channels, kernel_size=3, padding=1)self.conv2 = nn.Conv2d(out_channels, out_channels, kernel_size=3, padding=1)self.relu = nn.ReLU(inplace=True) # 一般设置inplace=True节省内存def forward(self, x):x = self.relu(self.conv1(x))x = self.relu(self.conv2(x))return x
#每个卷积模块都是由 两层(conv+relu)组成的 方便后面使用#UNet模型核心模块
class UNet(nn.Module):def __init__(self,in_channels=1,out_channels=1):super(UNet,self).__init__()#编码器部分#连续的卷积块(Conv + ReLU + Conv + ReLU)#每个卷积块后接池化层(MaxPool)进行下采样,提取特征并降低分辨率self.down1 = DoubleConv(in_channels=1, out_channels=64)self.pool1 = nn.MaxPool2d(kernel_size=2)#池化层self.down2 = DoubleConv(64, 128)self.pool2 = nn.MaxPool2d(2)self.down3 = DoubleConv(128, 256)self.pool3 = nn.MaxPool2d(2)self.down4 = DoubleConv(256, 512)self.pool4 = nn.MaxPool2d(2)# 瓶颈层# 起到信息压缩 + 表征增强的作用# 这个位置的特征图最小(尺寸最小,语义最强)# 为解码器提供最深的上下文信息,提升分割准确性self.bottleneck = DoubleConv(512,1024)#解码器部分#使用反卷积(TransposedConv)或插值上采样#拼接对应编码器层的特征图(skipconnection)#卷积块提取融合特征self.up1 = nn.ConvTranspose2d(1024, 512, kernel_size=2, stride=2)self.dec1 = DoubleConv(1024, 512) # 拼接后通道是 512 + 512self.up2 = nn.ConvTranspose2d(512, 256, kernel_size=2, stride=2)self.dec2 = DoubleConv(512, 256)self.up3 = nn.ConvTranspose2d(256, 128, kernel_size=2, stride=2)self.dec3 = DoubleConv(256, 128)self.up4 = nn.ConvTranspose2d(128, 64, kernel_size=2, stride=2)self.dec4 = DoubleConv(128, 64)#最终卷积层1x1卷积输出预测掩码self.final = nn.Conv2d(64, out_channels, kernel_size=1)#模型的前向传播部分def forward(self,x):x1 = self.down1(x)x2 = self.down2(self.pool1(x1))x3 = self.down3(self.pool1(x2))x4 = self.down4(self.pool1(x3))x5 = self.bottleneck(self.pool1(x4))#实现跳跃连接的部分d1 = self.up1(x5) # 上采样 1024 -> 512d1 = torch.cat([d1, x4], dim=1) # 拼接编码器对应层(跳跃连接)d1 = self.dec1(d1) # -> 输出 512d2 = self.up2(d1) # 512 -> 256d2 = torch.cat([d2, x3], dim=1) #将对应的卷积层进行跳跃连接d2 = self.dec2(d2)d3 = self.up3(d2) # 256 -> 128d3 = torch.cat([d3, x2], dim=1)d3 = self.dec3(d3)d4 = self.up4(d3) # 128 -> 64d4 = torch.cat([d4, x1], dim=1)d4 = self.dec4(d4)out = self.final(d4)return out
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
model = UNet(in_channels=1,out_channels=1).to(device) #定义模型criterion = nn.BCEWithLogitsLoss() #损失函数
optimizer = torch.optim.Adam(model.parameters(),lr = 1e-4) #优化器#对单个训练计划的定义
def train_one_epoch(model,dataloader,optimizer,criterion,device):model.train()total_loss = 0.0for images,masks in dataloader:images = images.to(device)masks = masks.to(device)outputs = model(images)loss = criterion(outputs,masks)optimizer.zero_grad()loss.backward()optimizer.step()total_loss +=loss.item()*images.size(0)avg_loss = total_loss / len(dataloader.dataset)return avg_lossnum_epochs = 20 # 你可以根据数据大小调整for epoch in range(num_epochs):train_loss = train_one_epoch(model, train_loader, optimizer, criterion, device)print(f"Epoch [{epoch+1}/{num_epochs}], Train Loss: {train_loss:.4f}")
相关文章:

ISBI 2012 EM 神经元结构分割数据集复现UNet
一些笔记在代码的注释中 因为使用的数据集比较简单,所以没有使用模型可视化和调试的内容,只是简单的数据集预处理和模型的搭建以及训练。 # 1. PyTorch 基础模块 import torch # 张量操作 import torch.nn as nn # 构建神经网…...

Java视频流RTMP/RTSP协议解析与实战代码
在Java中实现视频直播的输入流处理,通常需要结合网络编程、多媒体处理库以及流媒体协议(如RTMP、HLS、RTSP等)。以下是实现视频直播输入流的关键步骤和技术要点: 1. 视频直播输入流的核心组件 网络输入流:通过Socket或…...
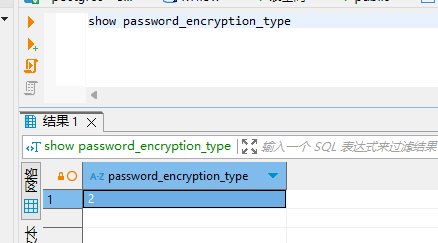
springboot连接高斯数据库(GaussDB)踩坑指南
1. 用户密码加密类型与gsjdbc4版本不兼容问题 我的数据库,设置的加密类型(password_encryption_type)是2, 直接使用gsjdbc4.jar连接数据库报错。 org.postgresql.util.PSQLException: Invalid or unsupported by client SCRAM mechanisms 后使用gsjdb…...
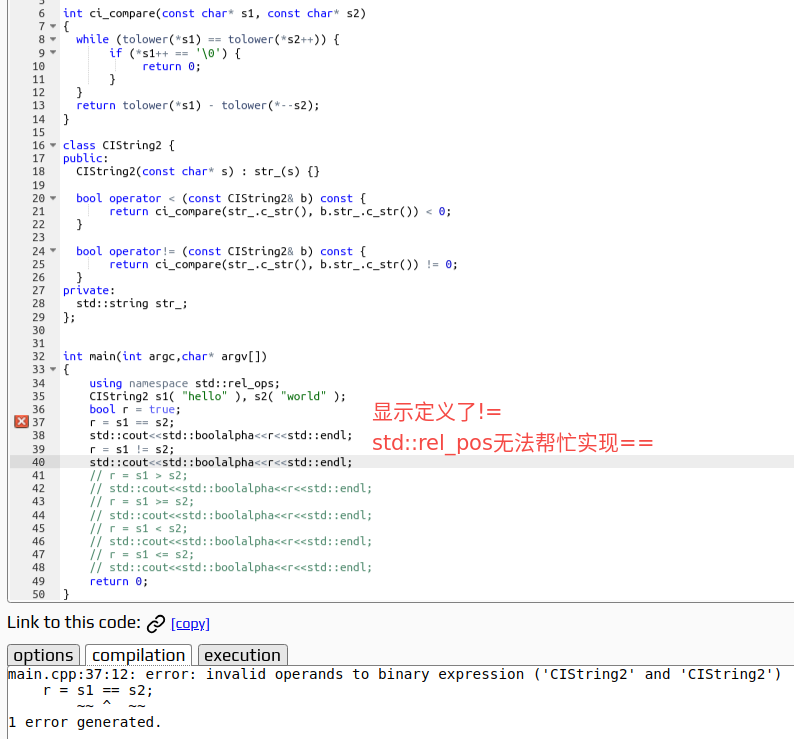
c++20引入的三路比较操作符<=>
目录 一、简介 二、三向比较的返回类型 2.1 std::strong_ordering 2.2 std::weak_ordering 2.3 std::partial_ordering 三、对基础类型的支持 四、自动生成的比较运算符函数 4.1 std::rel_ops的作用 4.2 使用<> 五、兼容他旧代码 一、简介 c20引入了三路比较操…...
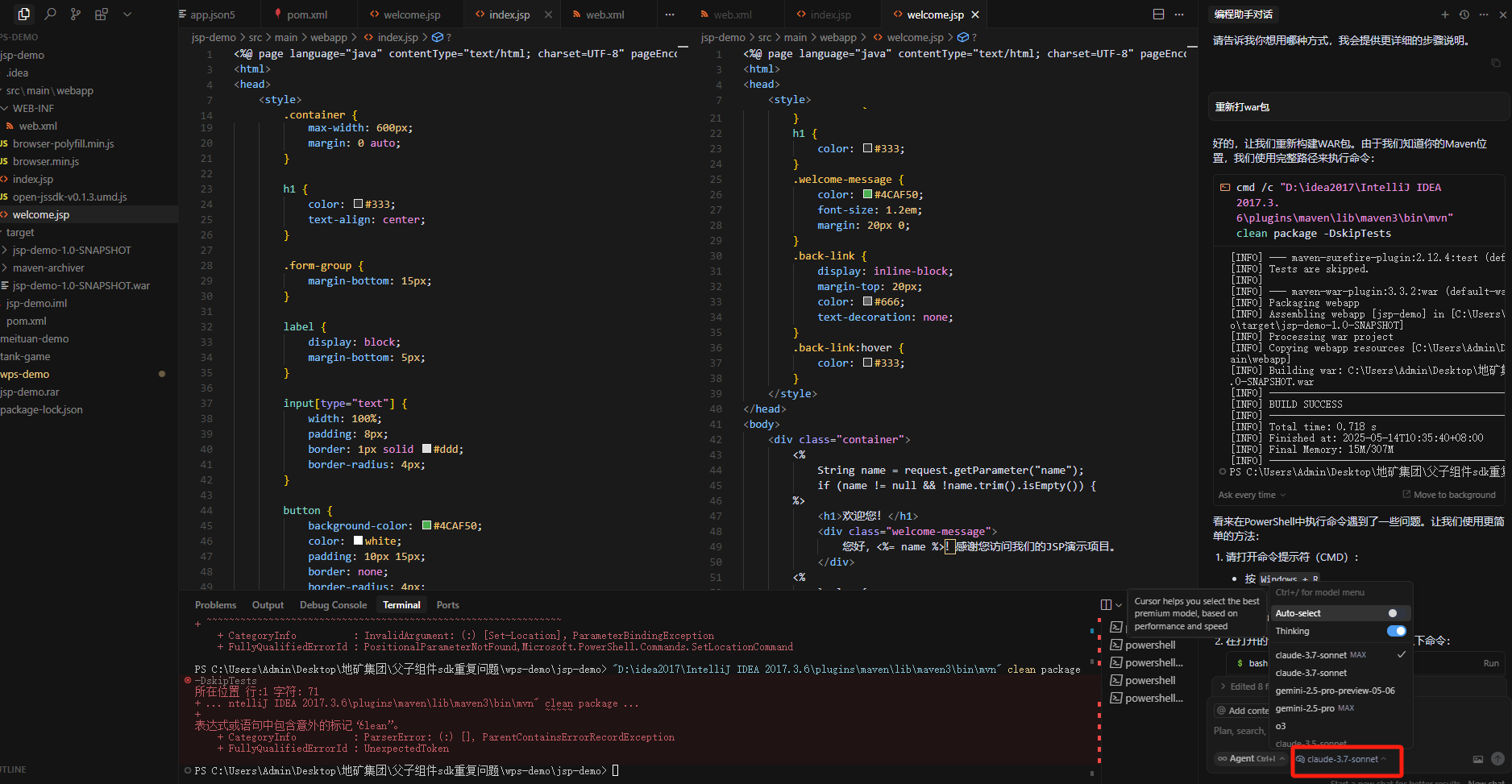
Cursor开发酒店管理系统
目录: 1、后端代码初始化2、使用Cursor打开spingboot项目3、前端代码初始化4、切换其他大模型5、Curosr无限续杯 1、后端代码初始化 找一个目录,使用idea在这个目录下新建springboot的项目。 2、使用Cursor打开spingboot项目 在根目录下新建.cursor文件…...

nosqlbooster pojie NoSQLBooster for MongoDB
测过可用,注意 asar的安装使用报错改用 npx asar extract app.asar app 路径 C:\Users{computerName}\AppData\Local\Programs\nosqlbooster4mongo\resources npm install asar -g asar extract app.asar app 打开shared\lmCore.js 修改MAX_TRIAL_DAYS3000 修改…...

基于 Flink 的实时推荐系统:从协同过滤到多模态语义理解
基于 Flink 的实时推荐系统:从协同过滤到多模态语义理解 嘿,各位技术小伙伴们!在这个信息爆炸的时代,你是不是常常惊叹于各大平台仿佛能 “读懂你的心”,精准推送你感兴趣的内容呢?今天,小编就…...

【HBase整合Hive】HBase-1.4.8整合Hive-2.3.3过程
HBase-1.4.8整合Hive-2.3.3过程 一、摘要二、整合过程三、注意事项 一、摘要 HBase集成Hive,由Hive来编写SQL语句操作HBase有以下好处: 简化操作:Hive提供了类SQL的查询语言HiveQL,对于熟悉SQL的用户来说,无需学习HBas…...

图像对比度调整(局域拉普拉斯滤波)
一、背景介绍 之前刷对比度相关调整算法,找到效果不错,使用局域拉普拉斯做图像对比度调整,尝试复现和整理了下相关代码。 二、实现流程 1、基本原理 对输入图像进行高斯金字塔拆分,对每层的每个像素都针对性处理,生产…...

如何在本地打包 StarRocks 发行版
字数 615,阅读大约需 4 分钟 最近我们在使用 StarRocks 的时候碰到了一些小问题: • 重启物化视图的时候会导致视图全量刷新,大量消耗资源。- 修复 PR:https://github.com/StarRocks/starrocks/pull/57371• excluded_refresh_tab…...

git使用的DLL错误
安装好git windows客户端打开git bash提示 Error: Could not fork child process: Resource temporarily unavailable (-1). DLL rebasing may be required; see ‘rebaseall / rebase –help’. 提示 MINGW64的DLL链接有问题,其实是Windows的安全中心限制了&…...

Elasticsearch倒排索引核心原理面试题
倒排索引核心原理面试题 🚀 目录 基础概念性能优化应用场景数据结构设计问题排查扩展思考基础概念 🔍 面试题1:基础概念 题目:Elasticsearch/Lucene的倒排索引(Inverted Index)是如何工作的?请描述从关键词搜索到返回文档的完整流程。 👉 查看参考答案 倒排索引…...

区块链blog1__合作与信任
🍂我们的世界 🌿不是孤立的,而是网络化的 如果是单独孤立的系统,无需共识,而我们的社会是网络结构,即结点间不是孤立的 🌿网络化的原因 而目前并未发现这样的理想孤立系统,即现实中…...
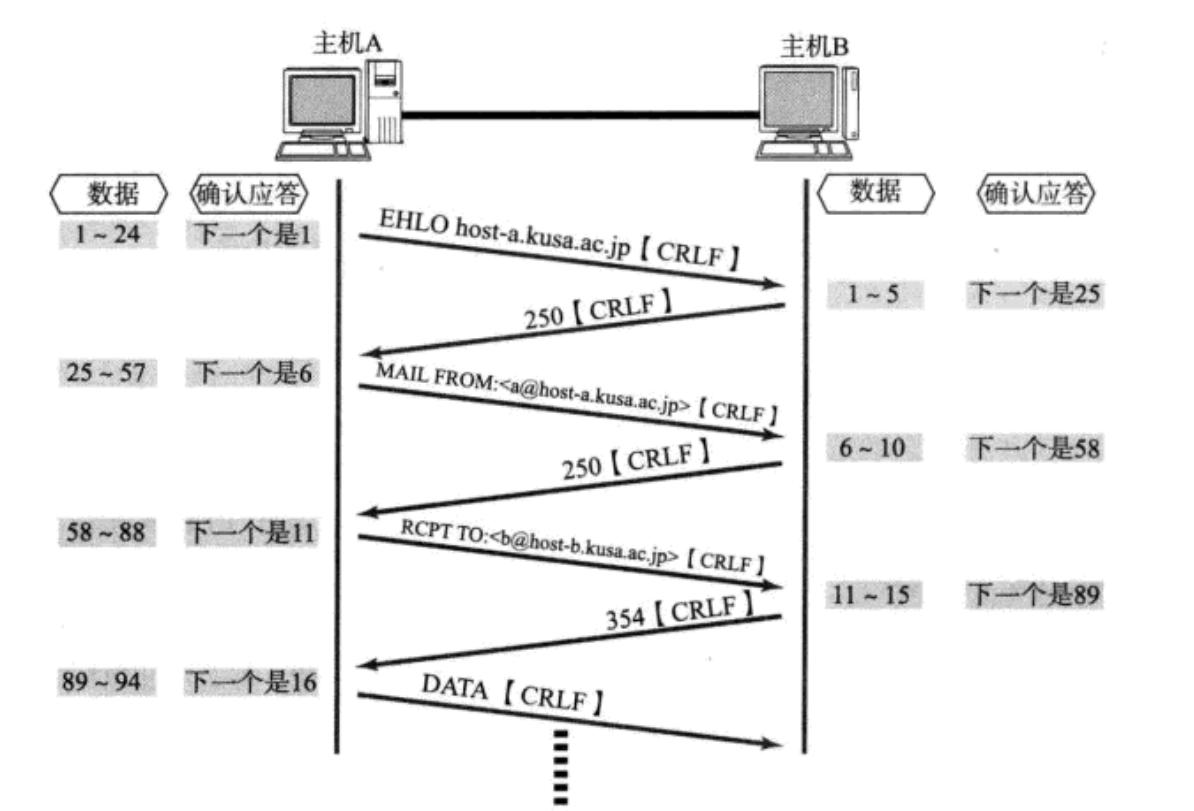
从数据包到可靠性:UDP/TCP协议的工作原理分析
之前我们已经使用udp/tcp的相关接口写了一些简单的客户端与服务端代码。也了解了协议是什么,包括自定义协议和知名协议比如http/https和ssh等。现在我们再回到传输层,对udp和tcp这两传输层巨头协议做更深一步的分析。 一.UDP UDP相关内容很简单…...

【CanMV K230】AI_CUBE1.4
《k230-AI 最近小伙伴有做模型的需求。所以我重新捡起来了。正好把之前没测过的测一下。 这次我们用的是全新版本。AICUBE1.4.dotnet环境9.0 注意AICUBE训练模型对硬件有所要求。最好使用独立显卡。 有小伙伴说集显也可以。emmmm可以试试哈 集显显存2G很勉强了。 我们依然用…...

vscode 默认环境路径
目录 1.下面放在项目根目录上: 2.settings.json内容: 自定义conda环境断点调试 启动默认参数: 1.下面放在项目根目录上: .vscode/settings.json 2.settings.json内容: {"python.analysis.extraPaths"…...
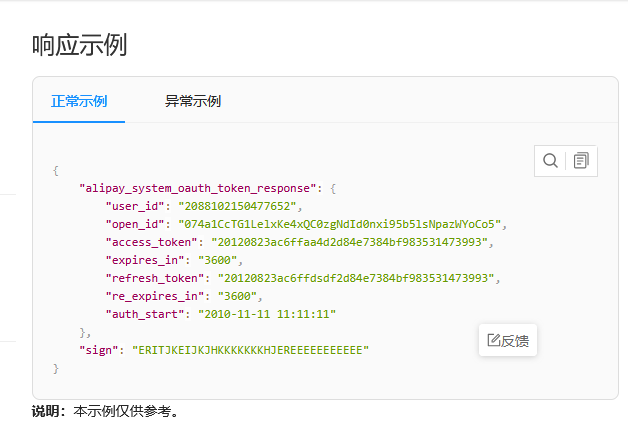
支付宝授权登录
支付宝授权登录 一、场景 支付宝小程序登录,获取用户userId 二、注册支付宝开发者账号 1、支付宝开放平台 2、点击右上角–控制台,创建小程序 3、按照步骤完善信息,生成密钥时会用到的工具 4、生成的密钥,要保管好ÿ…...

Fabric 服务端插件开发简述与聊天事件监听转发
原文链接:Fabric 服务端插件开发简述与聊天事件监听转发 < Ping通途说 0. 引言 以前写过Spigot的插件,非常简单,仅需调用官方封装好的Event类即可。但Fabric这边在开发时由于官方文档和现有互联网资料来看,可能会具有一定的误…...

认识Docker/安装Docker
一、认识Docker Docker的定义 Docker 是一个开源的应用容器引擎,允许开发者将应用及其依赖打包到一个轻量级、可移植的容器中。容器化技术使得应用可以在任何支持 Docker 的环境中运行,确保环境一致性。 Docker的核心组件 Docker Engine:负责…...
电商物流管理优化:从网络重构到成本管控的全链路解析
大家好,我是沛哥儿。作为电商行业,我始终认为物流是电商体验的“最后一公里”,更是成本控制的核心战场。随着行业竞争加剧,如何通过物流网络优化实现降本增效,已成为电商企业的必修课。本文将从物流网络的各个环节切入…...

Unity:延迟执行函数:Invoke()
目录 Unity 中的 Invoke() 方法详解 什么是 Invoke()? 基本使用方法 使用要点 延伸功能 ❗️Invoke 的局限与注意事项 在Unity中,延迟执行函数是游戏逻辑中常见的需求,比如: 延迟切换场景 延迟播放音效或动画 给玩家时间…...

移植RTOS,发现任务栈溢出怎么办?
目录 1、硬件检测方法 2、软件检测方法 3、预防堆栈溢出 4、处理堆栈溢出 在嵌入式系统中,RTOS通过管理多个任务来满足严格的时序要求。任务堆栈管理是RTOS开发中的关键环节,尤其是在将RTOS移植到新硬件平台时。堆栈溢出是嵌入式开发中常见的错误&am…...

k8s部署实战-springboot应用部署
在 Kubernetes 上部署 SpringBoot 应用实战指南 前言 本文将详细介绍如何将一个 SpringBoot 应用部署到 Kubernetes 集群中,包括制作镜像、编写部署文件、创建服务等完整步骤。 准备工作 1. 示例 SpringBoot 应用 假设我们有一个简单的 SpringBoot 应用,提供 REST API 服…...

【设计模式】- 结构型模式
代理模式 给目标对象提供一个代理以控制对该对象的访问。外界如果需要访问目标对象,需要去访问代理对象。 分类: 静态代理:代理类在编译时期生成动态代理:代理类在java运行时生成 JDK代理CGLib代理 【主要角色】: 抽…...
 中)
《Vuejs设计与实现》第 5 章(非原始值响应式方案) 中
目录 5.4 合理触发响应 5.5 浅响应与深响应 5.6 只读和浅只读 5.4 合理触发响应 为了合理触发响应,我们需要处理一些问题。 首先,当值没有变化时,我们不应该触发响应: const obj = { foo: 1 } const p = new Proxy(obj, { /* ... */ })effect(() => {console.log(p…...

rk3576 gstreamer opencv
安装gstreamer rk3588使用gstreamer推流_rk3588 gstreamer-CSDN博客 rk3588使用gstreamer推流_rk3588 gstreamer-CSDN博客 Installing on Linux sudo apt-get install libgstreamer1.0-dev libgstreamer-plugins-base1.0-dev libgstreamer-plugins-bad1.0-dev gstreamer1.0-pl…...
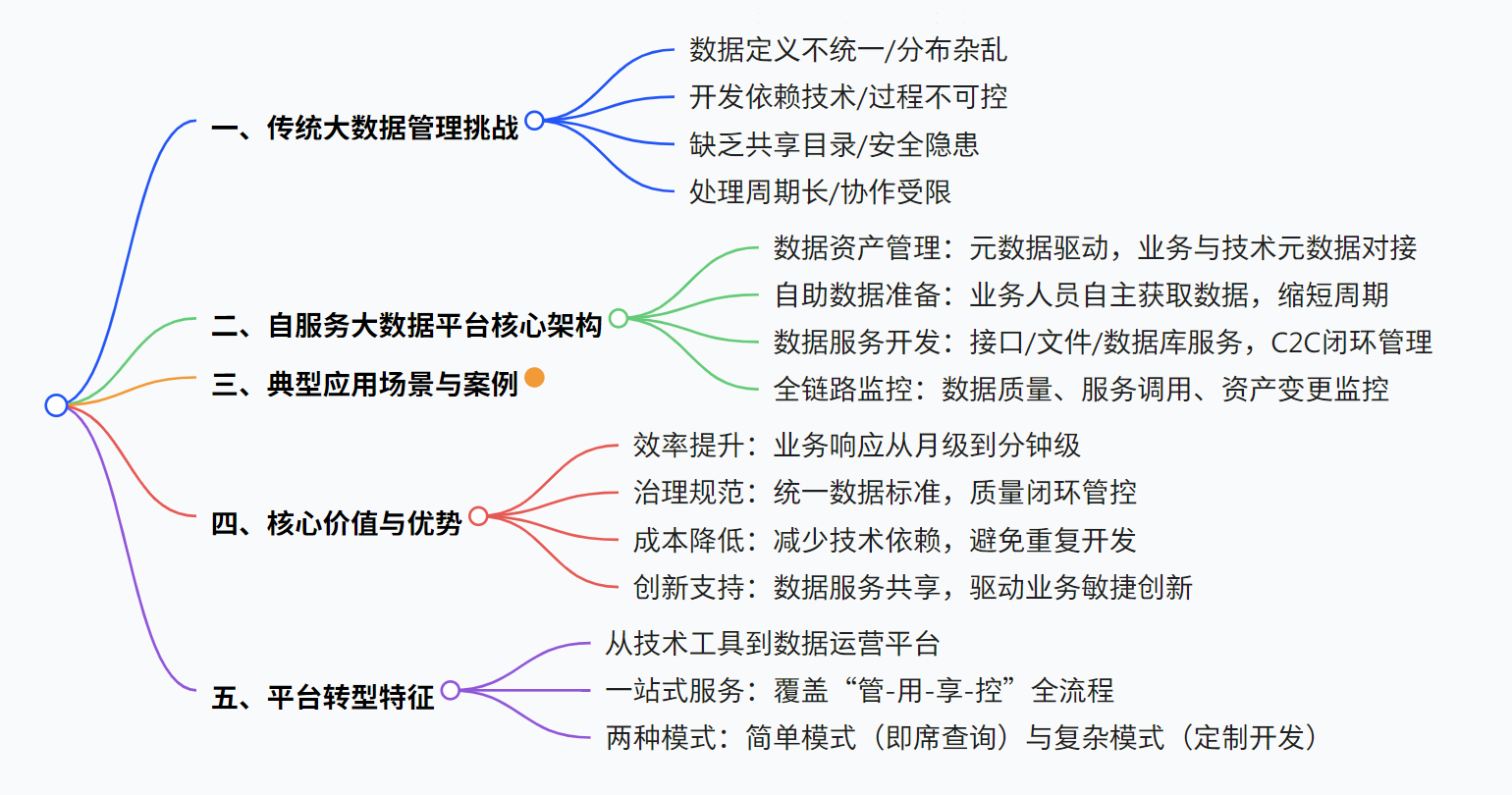
数据服务共享平台方案
该文档聚焦数据服务共享平台方案,指出传统大数据管理存在数据定义不统一、开发困难、共享不足等挑战,提出通过自服务大数据平台实现数据 “采、存、管、用” 全流程优化,涵盖数据资产管理、自助数据准备、服务开发与共享、全链路监控等功能,并通过国家电网、东方航空、政府…...
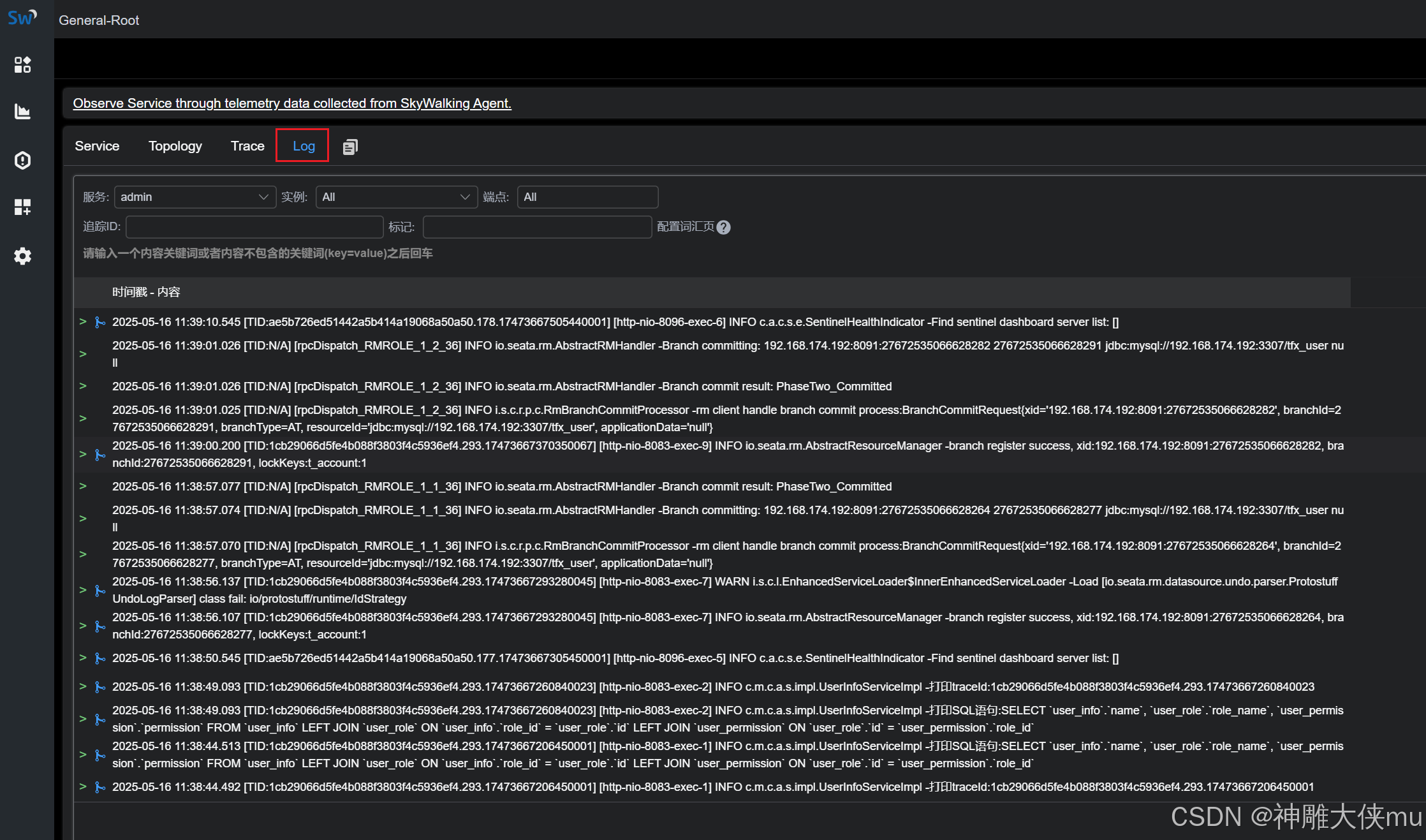
skywalking使用教程
skywalking使用教程 一、介绍 skywalking 1.1 概念 skywalking是分布式系统的应用程序性能监视工具,专为微服务、云原生架构和基于容器(Docker、K8s、Mesos)架构而设计。SkyWalking 是观察性分析平台和应用性能管理系统,提供分布…...

C 语 言 - - - 简 易 通 讯 录
C 语 言 - - - 简 易 通 讯 录 代 码 全 貌 与 功 能 介 绍通 讯 录 的 功 能 说 明通 讯 录 效 果 展 示代 码 详 解contact.hcontact.ctest.c 总 结 💻作 者 简 介:曾 与 你 一 样 迷 茫,现 以 经 验 助 你 入 门 C 语 言 💡个 …...

大模型MCP之UV安装使用
1.Windows安装 1.1 pip安装 pip install uv -i https://pypi.tuna.tsinghua.edu.cn/simple如果需要centos安装pip sudo yum install python3-pipCentOS 8开始使用dnf作为包管理器: sudo dnf install python3-pip对于基于Debian的系统(如Ubuntu&#…...