25、DeepSeek-R1论文笔记
DeepSeek-R1论文笔记
- 1、研究背景与核心目标
- 2、核心模型与技术路线
- 3、蒸馏技术与小模型优化
- 4、训练过程简介
- 5、COT思维链(Chain of Thought)
- 6、强化学习算法(GRPO)
- 7、冷启动
- **1. 冷启动的目的**
- **2. 冷启动的实现步骤**
- **3. 冷启动的作用**
- **典型应用场景**
- 汇总
- 一、核心模型与技术路线
- 二、蒸馏技术与小模型优化
- 三、实验与性能对比
- 四、研究贡献与开源
- 五、局限与未来方向
- 关键问题
- 1. **DeepSeek-R1与DeepSeek-R1-Zero的核心区别是什么?**
- 2. **蒸馏技术在DeepSeek-R1研究中的核心价值是什么?**
- 3. **DeepSeek-R1在数学推理任务上的性能如何超越同类模型?**
DeepSeek-R1
• 标题:DeepSeek-R1: Incentivizing Reasoning Capability in LLMs via Reinforcement Learning
• 时间:2025年1月
• 链接:arXiv:2501.12948
• 突破:基于DeepSeek-V3-Base,通过多阶段强化学习训练(RL)显著提升逻辑推理能力,支持思维链(CoT)和过程透明化输出。
1、研究背景与核心目标
-
大语言模型的推理能力提升
近年来,LLM在推理任务上的性能提升显著,OpenAI的o1系列通过思维链(CoT)扩展实现了数学、编码等任务的突破,但如何通过高效方法激发模型的推理能力仍需探索。- 传统方法依赖大量监督数据,而本文探索**纯强化学习(RL)**路径,无需监督微调(SFT)即可提升推理能力。
-
核心目标
- 验证纯RL能否驱动LLM自然涌现推理能力(如自我验证、长链推理)。
- 解决纯RL模型的局限性(如语言混合、可读性差),通过多阶段训练提升实用性。
- 将大模型推理能力迁移至小模型,推动模型轻量化。
2、核心模型与技术路线
-
DeepSeek-R1-Zero
- 纯强化学习训练:基于DeepSeek-V3-Base,使用GRPO算法,无监督微调(SFT),通过规则奖励(准确性+格式)引导推理过程。
- 能力涌现:自然发展出自我验证、反思、长链推理(CoT)等行为,AIME 2024 Pass@1从15.6%提升至71.0%,多数投票达86.7%,接近OpenAI-o1-0912。
- 局限性:语言混合、可读性差,需进一步优化。
-
DeepSeek-R1
- 多阶段训练:
- 冷启动阶段:使用数千条长CoT数据微调,提升可读性和初始推理能力。
- 推理导向RL:引入语言一致性奖励,解决语言混合问题。
- 拒绝采样与SFT:收集60万推理数据+20万非推理数据(写作、事实QA等),优化通用能力。
- 全场景RL:结合规则奖励(推理任务)和神经奖励(通用任务),对齐人类偏好。
- 性能突破:AIME 2024 Pass@1 79.8%(超越o1-1217的79.2%),MATH-500 97.3%(对标o1-1217的96.4%),Codeforces评级2029(超越96.3%人类选手)。
- 多阶段训练:
3、蒸馏技术与小模型优化
- 蒸馏策略:以DeepSeek-R1为教师模型,生成80万训练数据,微调Qwen和Llama系列模型,仅用SFT阶段(无RL)。
- 关键成果:
- 14B蒸馏模型:AIME 2024 Pass@1 69.7%,远超QwQ-32B-Preview的50.0%。
- 32B/70B模型:MATH-500 94.3%、LiveCodeBench 57.2%,刷新密集模型推理性能纪录。
4、训练过程简介
zero:cot+grpo
R1:冷启动+cot+grpo


5、COT思维链(Chain of Thought)
COT详细原理参考:CoT论文笔记
2022 年 Google 论文《Chain-of-Thought Prompting Elicits Reasoning in Large Language Models》中首次提出,通过让大模型逐步参与将一个复杂问题分解为一步一步的子问题并依次进行求解的过程可以显著提升大模型的性能。而这些推理的中间步骤就被称为思维链(Chain of Thought)。
思维链提示(CoT Prompting),在少样本提示中加入自然语言推理步骤(如“先计算…再相加…”),将问题分解为中间步骤,引导模型生成连贯推理路径。
-
示例:标准提示仅给“问题-答案”,思维链提示增加“问题-推理步骤-答案”(如)。
-
区别于传统的 Prompt 从输入直接到输出的映射 <input——>output> 的方式,CoT 完成了从输入到思维链再到输出的映射,即 <input——>reasoning chain——>output>。如果将使用 CoT 的 Prompt 进行分解,可以更加详细的观察到 CoT 的工作流程。
-
示例对比(传统 vs. CoT)
-
传统提示
问题:1个书架有3层,每层放5本书,共有多少本书? 答案:15本 -
CoT 提示
问题:1个书架有3层,每层放5本书,共有多少本书? 推理: 1. 每层5本书,3层的总书数 = 5 × 3 2. 5 × 3 = 15 答案:15本
-
关键类型
-
零样本思维链(Zero-Shot CoT)
无需示例,仅通过提示词(如“请分步骤思考”)触发模型生成思维链。适用于快速引导模型进行推理。 -
少样本思维链(Few-Shot CoT)
提供少量带思维链的示例,让模型模仿示例结构进行推理。例如,先给出几个问题及其分解步骤,再让模型处理新问题。

如图所示,一个完整的包含 CoT 的 Prompt 往往由指令(Instruction),逻辑依据(Rationale),示例(Exemplars)三部分组成。一般而言指令用于描述问题并且告知大模型的输出格式,逻辑依据即指 CoT 的中间推理过程,可以包含问题的解决方案、中间推理步骤以及与问题相关的任何外部知识,而示例则指以少样本的方式为大模型提供输入输出对的基本格式,每一个示例都包含:问题,推理过程与答案。
以是否包含示例为区分,可以将 CoT 分为 Zero-Shot-CoT 与 Few-Shot-CoT,在上图中,Zero-Shot-CoT 不添加示例而仅仅在指令中添加一行经典的“Let’s think step by step”,就可以“唤醒”大模型的推理能力。而 Few-Shot-Cot 则在示例中详细描述了“解题步骤”,让大模型照猫画虎得到推理能力。
提示词工程框架( 链式提示Chain):其他提示词工程框架,思维链CoT主要是线性的,多个推理步骤连成一个链条。在思维链基础上,又衍生出ToT、GoT、PoT等多种推理模式。这些和CoT一样都属于提示词工程的范畴。CoT、ToT、GoT、PoT等提示词工程框架大幅提升了大模型的推理能力,让我们能够使用大模型解决更多复杂问题,提升了大模型的可解释性和可控性,为大模型应用的拓展奠定了基础。
参考:
https://blog.csdn.net/kaka0722ww/article/details/147950677
https://www.zhihu.com/tardis/zm/art/670907685?source_id=1005
6、强化学习算法(GRPO)
详细GRPO原理参考:DeepSeekMath论文笔记
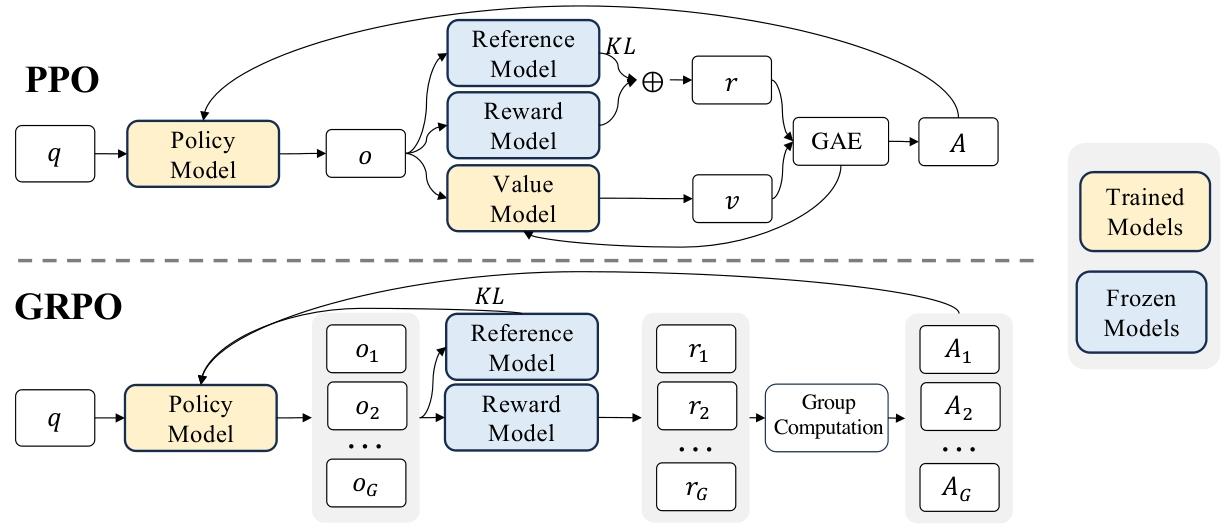
2.2.1 强化学习算法
群组相对策略优化 为降低强化学习的训练成本,我们采用群组相对策略优化(GRPO)算法(Shao等人,2024)。该算法无需与策略模型规模相当的评论家模型,而是通过群组分数估计基线。具体来说,对于每个问题𝑞,GRPO从旧策略𝜋𝜃𝑜𝑙𝑑中采样一组输出{𝑜1, 𝑜2, · · · , 𝑜𝐺},然后通过最大化以下目标函数优化策略模型𝜋𝜃:
J GRPO ( θ ) = E [ q ∼ P ( Q ) , { o i } i = 1 G ∼ π θ old ( O ∣ q ) ] 1 G ∑ i = 1 G ( min ( π θ ( o i ∣ q ) π θ old ( o i ∣ q ) A i , clip ( π θ ( o i ∣ q ) π θ old ( o i ∣ q ) , 1 − ε , 1 + ε ) A i ) − β D KL ( π θ ∣ ∣ π ref ) ) , ( 1 ) J_{\text{GRPO}}(\theta) = \mathbb{E}\left[ q \sim P(Q), \{o_i\}_{i=1}^G \sim \pi_{\theta^{\text{old}}}(O|q) \right] \frac{1}{G} \sum_{i=1}^G \left( \min\left( \frac{\pi_\theta(o_i|q)}{\pi_{\theta^{\text{old}}}(o_i|q)} A_i, \text{clip}\left( \frac{\pi_\theta(o_i|q)}{\pi_{\theta^{\text{old}}}(o_i|q)}, 1 - \varepsilon, 1 + \varepsilon \right) A_i \right) - \beta D_{\text{KL}}(\pi_\theta || \pi_{\text{ref}}) \right), \quad (1) JGRPO(θ)=E[q∼P(Q),{oi}i=1G∼πθold(O∣q)]G1i=1∑G(min(πθold(oi∣q)πθ(oi∣q)Ai,clip(πθold(oi∣q)πθ(oi∣q),1−ε,1+ε)Ai)−βDKL(πθ∣∣πref)),(1)
D KL ( π θ ∣ ∣ π ref ) = π ref ( o i ∣ q ) ( π θ ( o i ∣ q ) π ref ( o i ∣ q ) − log π θ ( o i ∣ q ) π ref ( o i ∣ q ) − 1 ) , ( 2 ) D_{\text{KL}}(\pi_\theta || \pi_{\text{ref}}) = \pi_{\text{ref}}(o_i|q) \left( \frac{\pi_\theta(o_i|q)}{\pi_{\text{ref}}(o_i|q)} - \log \frac{\pi_\theta(o_i|q)}{\pi_{\text{ref}}(o_i|q)} - 1 \right), \quad (2) DKL(πθ∣∣πref)=πref(oi∣q)(πref(oi∣q)πθ(oi∣q)−logπref(oi∣q)πθ(oi∣q)−1),(2)
其中,𝜀和𝛽为超参数,𝐴𝑖为优势函数,通过每组输出对应的奖励集合{𝑟1, 𝑟2, . . . , 𝑟𝐺}计算得到:
A i = r i − mean ( { r 1 , r 2 , ⋅ ⋅ ⋅ , r G } ) std ( { r 1 , r 2 , ⋅ ⋅ ⋅ , r G } ) . ( 3 ) A_i = \frac{r_i - \text{mean}(\{r_1, r_2, · · · , r_G\})}{\text{std}(\{r_1, r_2, · · · , r_G\})}. \quad (3) Ai=std({r1,r2,⋅⋅⋅,rG})ri−mean({r1,r2,⋅⋅⋅,rG}).(3)


7、冷启动


冷启动(Cold Start)
在DeepSeek-R1的训练流程中,冷启动是一个关键阶段,旨在通过少量高质量数据为模型提供初步的推理能力,为后续强化学习(RL)奠定基础。以下是其核心内容:
AI 冷启动是指人工智能系统在初始阶段因缺乏足够数据或历史信息导致的性能瓶颈问题,常见于推荐系统、大模型训练、提示词优化等场景。以下是基于多领域研究的综合解析:
AI模型训练的冷启动问题
-
数据匮乏的挑战
• 问题:模型初期因数据不足导致推理能力弱,生成结果混乱或重复。
• 解决方案:
• 冷启动数据(Cold-start Data):
◦ 高质量微调:用少量人工筛选的推理数据(如数学题详细步骤)对模型进行初步训练,提供“入门指南”。
◦ 数据来源:从大型模型生成(如ChatGPT)、现有模型输出筛选、人工优化等方式获取。 -
多阶段训练策略
• 阶段1:冷启动微调:用冷启动数据优化模型基础推理能力,提升生成结果的可读性和逻辑性。
• 阶段2:强化学习(RL):通过奖励机制(如答案准确度、格式规范性)动态调整模型参数,优化推理策略。
• 阶段3:多场景优化:结合拒绝采样(筛选高质量输出)和监督微调(SFT),扩展模型在专业领域(如金融、医学)的适用性。
三、提示词与上下文冷启动
-
提示词冷启动策略
• 知识初始化:利用领域知识库初始化模型参数,指导模型生成更符合任务需求的回答。
• 动态调整:根据模型表现实时调整学习率和任务权重,例如在复杂任务中增加上下文信息权重。 -
上下文信息利用
• 时间/场景适配:结合用户当前环境(如工作日早晨推荐新闻,周末推荐娱乐内容)提升推荐相关性。
• 多模态数据融合:整合文本、图像、社交网络等多源数据,丰富冷启动阶段的特征提取。
1. 冷启动的目的
• 解决DeepSeek-R1-Zero的局限性:
直接从基础模型启动RL(如DeepSeek-R1-Zero)会导致生成内容可读性差、语言混杂(如中英文混合)。
• 引导模型生成结构化推理链:
通过冷启动数据,教会模型以“思考过程→答案”的格式输出,提升可读性和逻辑性。
2. 冷启动的实现步骤
(1) 数据收集
• 来源:
• 模型生成:用基础模型(DeepSeek-V3-Base)通过few-shot提示生成长链推理(CoT)数据。
• 人工修正:对模型生成的答案进行筛选和润色,确保可读性。
• 外部数据:少量开源数学、编程问题的高质量解答。
• 格式要求:
强制要求模型将推理过程放在<reasoning>标签内,答案放在<answer>标签内,例如:
<reasoning>设方程√(a−√(a+x))=x,首先平方两边...</reasoning>
<answer>\boxed{2a-1}</answer>
(2) 监督微调(SFT)
• 数据规模:数千条(远少于传统SFT的百万级数据)。
• 训练目标:让模型学会:
• 生成清晰的推理步骤。
• 遵守指定输出格式。
• 避免语言混杂(如中英文混合)。
3. 冷启动的作用
• 提升可读性:
通过结构化标签和人工修正,生成内容更符合人类阅读习惯。
• 加速RL收敛:
冷启动后的模型已具备基础推理能力,RL阶段更易优化策略。
• 缓解语言混合问题:
强制输出格式和语言一致性奖励(如中文或英文占比)减少混杂。
典型应用场景
-
推荐系统
- 新用户注册时,通过引导式问卷(主动学习)或热门内容(规则策略)完成冷启动,随后逐步切换至个性化推荐。
- 案例:TikTok对新用户先推送泛领域热门视频,再根据前几个视频的互动数据快速建模兴趣标签。
-
自然语言处理(NLP)
- 新领域对话系统冷启动:用预训练语言模型(如LLaMA)结合少量领域数据微调,快速适应垂直场景(如法律咨询、金融客服)。
-
计算机视觉(CV)
- 新类别图像识别:通过迁移学习加载ImageNet预训练模型,再用少量新类别样本微调,解决“新物体冷启动”问题。
-
医疗AI
- 罕见病诊断冷启动:利用元学习快速适配新病例,或通过合成医学影像数据增强模型泛化能力。
汇总
一、核心模型与技术路线
-
DeepSeek-R1-Zero
- 纯强化学习训练:基于DeepSeek-V3-Base,使用GRPO算法,无监督微调(SFT),通过规则奖励(准确性+格式)引导推理过程。
- 能力涌现:自然发展出自我验证、反思、长链推理(CoT)等行为,AIME 2024 Pass@1从15.6%提升至71.0%,多数投票达86.7%,接近OpenAI-o1-0912。
- 局限性:语言混合、可读性差,需进一步优化。
-
DeepSeek-R1
- 多阶段训练:
- 冷启动阶段:使用数千条长CoT数据微调,提升可读性和初始推理能力。
- 推理导向RL:引入语言一致性奖励,解决语言混合问题。
- 拒绝采样与SFT:收集60万推理数据+20万非推理数据(写作、事实QA等),优化通用能力。
- 全场景RL:结合规则奖励(推理任务)和神经奖励(通用任务),对齐人类偏好。
- 性能突破:AIME 2024 Pass@1 79.8%(超越o1-1217的79.2%),MATH-500 97.3%(对标o1-1217的96.4%),Codeforces评级2029(超越96.3%人类选手)。
- 多阶段训练:
二、蒸馏技术与小模型优化
- 蒸馏策略:以DeepSeek-R1为教师模型,生成80万训练数据,微调Qwen和Llama系列模型,仅用SFT阶段(无RL)。
- 关键成果:
- 14B蒸馏模型:AIME 2024 Pass@1 69.7%,远超QwQ-32B-Preview的50.0%。
- 32B/70B模型:MATH-500 94.3%、LiveCodeBench 57.2%,刷新密集模型推理性能纪录。
三、实验与性能对比
| 任务/模型 | DeepSeek-R1 | OpenAI-o1-1217 | DeepSeek-R1-Zero | DeepSeek-V3 |
|---|---|---|---|---|
| AIME 2024 (Pass@1) | 79.8% | 79.2% | 71.0% | 39.2% |
| MATH-500 (Pass@1) | 97.3% | 96.4% | 86.7% | 90.2% |
| Codeforces (评级) | 2029 | - | 1444 | 1134 |
| MMLU (Pass@1) | 90.8% | 91.8% | - | 88.5% |
四、研究贡献与开源
- 方法论创新:
- 首次证明纯RL可激发LLM推理能力,无需监督微调(SFT)。
- 提出“冷启动数据+多阶段RL”框架,平衡推理能力与用户友好性。
- 开源资源:
- 开放DeepSeek-R1/Zero及6个蒸馏模型(1.5B、7B、8B、14B、32B、70B),基于Qwen和Llama。
五、局限与未来方向
- 当前局限:
- 语言混合问题(中英文混杂),多语言支持不足。
- 工程任务(如代码生成)数据有限,性能待提升。
- 对提示格式敏感,少样本提示可能降低性能。
- 未来方向:
- 探索长CoT在函数调用、多轮对话中的应用。
- 优化多语言一致性,解决非中英查询的推理语言偏好问题。
- 引入异步评估,提升软件任务的RL训练效率。
关键问题
1. DeepSeek-R1与DeepSeek-R1-Zero的核心区别是什么?
答案:DeepSeek-R1-Zero采用纯强化学习训练,无需监督微调(SFT),依赖规则奖励自然涌现推理能力,但存在语言混合和可读性问题;DeepSeek-R1在此基础上引入冷启动数据(数千条长CoT示例)进行初始微调,并通过多阶段训练(SFT+RL交替)优化可读性、语言一致性和通用能力,最终性能更接近OpenAI-o1-1217。
2. 蒸馏技术在DeepSeek-R1研究中的核心价值是什么?
答案:蒸馏技术将大模型的推理模式迁移至小模型,使小模型在保持高效的同时获得强大推理能力。例如,DeepSeek-R1-Distill-Qwen-14B在AIME 2024上的Pass@1为69.7%,远超同规模的QwQ-32B-Preview(50.0%);32B蒸馏模型在MATH-500上达94.3%,接近o1-mini的90.0%。该技术证明大模型推理模式对小模型优化至关重要,且蒸馏比直接对小模型进行RL更高效经济。
3. DeepSeek-R1在数学推理任务上的性能如何超越同类模型?
答案:DeepSeek-R1在AIME 2024上的Pass@1为79.8%,略超OpenAI-o1-1217的79.2%;MATH-500达97.3%,与o1-1217持平(96.4%)。其优势源于强化学习对长链推理的优化(如自动扩展思考步骤、自我验证),以及冷启动数据和多阶段训练对推理过程可读性和准确性的提升。此外,规则奖励模型确保了数学问题答案的格式正确性(如公式框输出),减少了因格式错误导致的失分。
相关文章:
25、DeepSeek-R1论文笔记
DeepSeek-R1论文笔记 1、研究背景与核心目标2、核心模型与技术路线3、蒸馏技术与小模型优化4、训练过程简介5、COT思维链(Chain of Thought)6、强化学习算法(GRPO)7、冷启动**1. 冷启动的目的****2. 冷启动的实现步骤****3. 冷启动…...

LeetCode --- 156双周赛
题目列表 3541. 找到频率最高的元音和辅音 3542. 将所有元素变为 0 的最少操作次数 3543. K 条边路径的最大边权和 3544. 子树反转和 一、找到频率最高的元音和辅音 分别统计元音和辅音的出现次数最大值,然后相加即可,代码如下 // C class Solution {…...

模型量化AWQ和GPTQ哪种效果好?
环境: AWQ GPTQ 问题描述: 模型量化AWQ和GPTQ哪种效果好? 解决方案: 关于AWQ(Adaptive Weight Quantization)和GPTQ(Generative Pre-trained Transformer Quantization)这两种量化方法的…...
npm 报错 gyp verb `which` failed Error: not found: python2 解决方案
一、背景 npm 安装依赖报如下错: gyp verb check python checking for Python executable "python2" in the PATH gyp verb which failed Error: not found: python2 一眼看过去都觉得是Python环境问题,其实并不是你python环境问题…...
初识Linux · IP协议· 下
目录 前言: 内网IP和公网IP 内网IP 公网IP 路由 前言: 前文我们介绍了IP协议的协议头,通过源码等方式我们理解了IP协议中的字段,比如8位协议,比如通过环回问题引出的8位最大生存时间,比如8位协议&…...

5.27本日总结
一、英语 复习list2list29 二、数学 学习14讲部分内容 三、408 学习计组1.2内容 四、总结 高数和计网明天结束当前章节,计网内容学完之后主要学习计组和操作系统 五、明日计划 英语:复习lsit3list28,完成07年第二篇阅读 数学&#…...

JavaScript基础-创建对象的三种方式
在JavaScript中,对象是构建复杂数据结构和实现面向对象编程的核心。掌握如何创建对象对于每个开发者来说都是必不可少的技能。本文将介绍创建JavaScript对象的三种主要方式:对象字面量、构造函数以及类(ES6引入),并探讨…...

JAVA的常见API文档(上)
游戏打包 注意API文档中的方法不需要记忆!! 了解之后如果需要可以查询API文档 对Math的方法总结: 运用刚学的Math方法加快代码的运行效率 可以减少循环次数 找规律: 发现因子有规律: 必定一个大于平方根,…...

JavaScript 中的 for...in 和 for...of 循环详解
在 JavaScript 中,for...in 和 for...of 是两种常用的循环结构,但它们有着不同的用途和行为。很多初学者容易混淆这两者,本文将详细解析它们的区别、适用场景以及注意事项。 目录 for…in 循环 基本用法遍历对象属性注意事项 for…of 循环 …...

AtCoder AT_abc406_c [ABC406C] ~
前言 除了 A 题,唯一一道一遍过的题。 题目大意 我们定义满足以下所有条件的一个长度为 N N N 的序列 A ( A 1 , A 2 , … , A N ) A(A_1,A_2,\dots,A_N) A(A1,A2,…,AN) 为波浪序列: N ≥ 4 N\ge4 N≥4(其实满足后面就必须满足这…...
Spark,连接MySQL数据库,添加数据,读取数据
连接数据库 可以看到shell中我们读取出的数据 在IDEA中打代码如果能输出跟shell中一样的结果即证明连接成功 【出错反思】 像我前面出错的原因就是在打代码时将密码输入错误 添加数据 读取数据就是在上面代码中一起展示了,这里我就不单独说了...

Linux容器技术详解
容器技术基础 什么是容器 容器是一种轻量级的虚拟化技术,它将应用程序及其依赖(库、二进制文件、配置文件等)打包在一个独立的单元中,可以在任何支持容器运行时的环境中一致地运行。 Docker官网:https://www.docker…...
【EDA软件】【联合Modelsim仿真使用方法】
背景 业界EDA工具仿真功能是必备的,例如Vivado自带仿真工具,且无需联合外部仿真工具,例如MoodelSim。 FUXI工具仿真功能需要联合Modelsim,才能实现仿真功能。 方法一:FUXI联合ModelSim 1 添加testbench文件 新建to…...

STM32 __main
STM32开发中__main与用户main()函数的本质区别及工作机制 在STM32开发中,__main和用户定义的main()函数是启动过程中的两个关键节点,分别承担运行时初始化和用户程序入口的职责。以下是它们的核心差异及协作机制: 一、定义与层级差异 __ma…...
【离散化 线段树】P3740 [HAOI2014] 贴海报|普及+
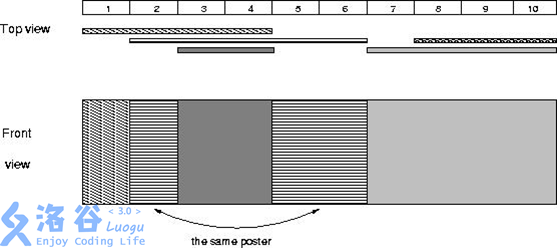
本文涉及知识点 C线段树 [HAOI2014] 贴海报 题目描述 Bytetown 城市要进行市长竞选,所有的选民可以畅所欲言地对竞选市长的候选人发表言论。为了统一管理,城市委员会为选民准备了一个张贴海报的 electoral 墙。 张贴规则如下: electoral…...

Python训练营打卡Day28
浙大疏锦行 DAY 28 类的定义和方法 知识点回顾: 1.类的定义 2.pass占位语句 3.类的初始化方法 4.类的普通方法 5.类的继承:属性的继承、方法的继承 作业 题目1:定义圆(Circle)类 要求: 1.包含属性&#x…...

MODBUS RTU通信协议详解与调试指南
一、MODBUS RTU简介 MODBUS RTU(Remote Terminal Unit)是一种基于串行通信(RS-485/RS-232)的工业标准协议,采用二进制数据格式,具有高效、可靠的特点,广泛应用于PLC、传感器、变频器等工业设备…...
CSP 2024 提高级第一轮(CSP-S 2024)单选题解析
单选题解析 第 1 题 在 Linux 系统中,如果你想显示当前工作目录的路径,应该使用哪个命令?(A) A. pwd B. cd C. ls D. echo 解析:Linux 系统中,pwd命令可以显示当前工作目录的路径。pwd&#x…...

六、绘制图片
文章目录 1.创建一个红色图片2.加载bmp图片3.加载png、jpg图片 前面的几个示例,我们已经展示过如果在Linux系统下使用xlib接口向窗口中绘制文本、线、矩形;并设置文本、线条的颜色。并利用xlib提供的接口结合事件处理机制完成了一个自绘按钮控件功能。有…...
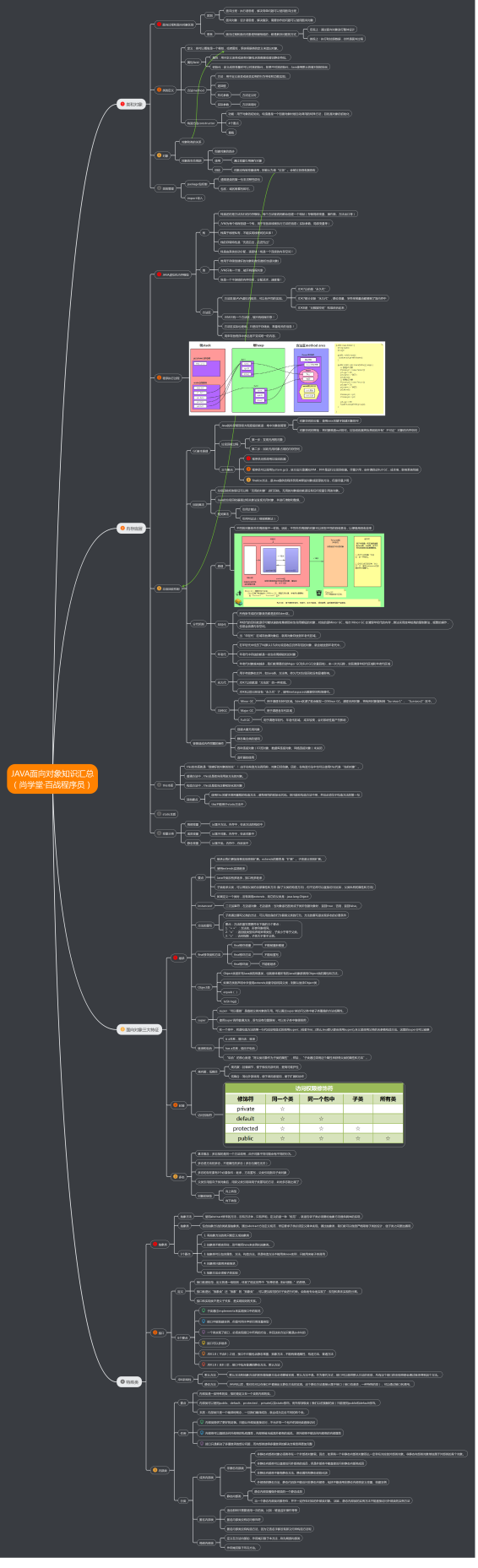
Java 面向对象详解和JVM底层内存分析
先关注、点赞再看、人生灿烂!!!(谢谢) 神速熟悉面向对象 表格结构和类结构 我们在现实生活中,思考问题、发现问题、处理问题,往往都会用“表格”作为工具。实际上,“表格思维”就是…...
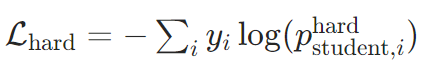
深度学习---知识蒸馏(Knowledge Distillation, KD)
一、知识蒸馏的本质与起源 定义: 知识蒸馏是一种模型压缩与迁移技术,通过将复杂高性能的教师模型(Teacher Model)所学的“知识”迁移到轻量级的学生模型(Student Model),使学生模型在参数量和计…...
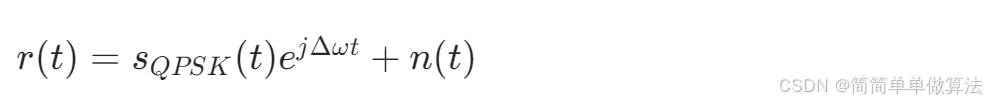
基于CNN卷积神经网络的带频偏QPSK调制信号检测识别算法matlab仿真
目录 1.算法运行效果图预览 2.算法运行软件版本 3.部分核心程序 4.算法理论概述 5.算法完整程序工程 1.算法运行效果图预览 (完整程序运行后无水印) 2.算法运行软件版本 matlab2024b 3.部分核心程序 (完整版代码包含详细中文注释和操作步骤视频)…...
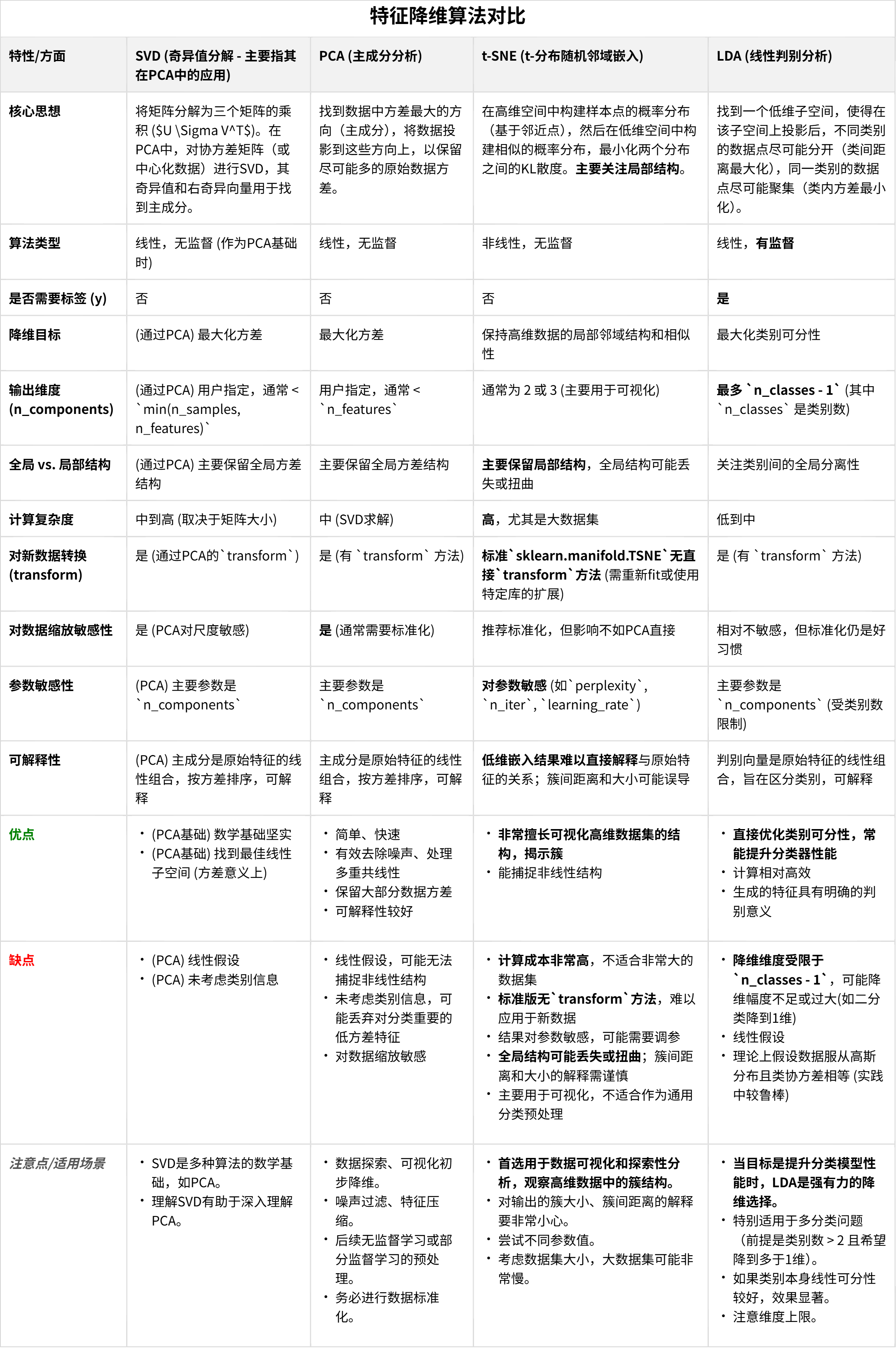
【DAY21】 常见的降维算法
内容来自浙大疏锦行python打卡训练营 浙大疏锦行 目录 PCA主成分分析 t-sne降维 线性判别分析 (Linear Discriminant Analysis, LDA) 作业: 什么时候用到降维 降维的主要应用场景 知识点回顾: PCA主成分分析t-sne降维LDA线性判别 通常情况下,…...

PostGIS实现栅格数据入库-raster2pgsql
raster2pgsql使用与最佳实践 一、工具概述 raster2pgsql是PostGIS提供的命令行工具,用于将GDAL支持的栅格格式(如GeoTIFF、JPEG、PNG等)导入PostgreSQL数据库,支持批量加载、分块切片、创建空间索引及金字塔概览,是栅格数据入库的核心工具。 二、核心功能与典型用法 1…...
校园社区小程序源码解析
基于ThinkPHP、FastAdmin和UniApp开发的校园社区小程序源码,旨在为校园内的学生和教职员工提供一个便捷的在线交流和服务平台。 该小程序前端采用UniApp进行开发,具有良好的跨平台兼容性,可以轻松发布到iOS和Android平台。同时,后…...
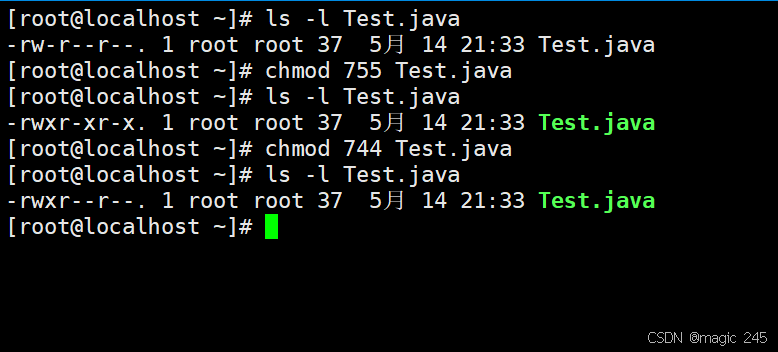
第6章:文件权限
一、文件权限概述 Linux为了保证系统中每个文件的安全,引入了文件权限机制。针对于系统中的每一个文件Linux都可以提供精确的权限控制。它可以做到不同的用户对同一个文件具有不同的操作权利。而通常这个权利包括以下3个: 读的权利(Read&…...

使用 Python 连接 Oracle 23ai 数据库完整指南
方法一:使用 oracledb 官方驱动(推荐) Oracle 官方维护的 oracledb 驱动(原 cx_Oracle)是最新推荐方案,支持 Thin/Thick 两种模式。 1. 环境准备 pip install oracledb2. 完整示例代码 import oracledb import getpass from typing import Unionclass Oracle23aiConn…...

C语言| 指针变量的定义
C语言| 指针的优点-CSDN博客 * 表示“指向”,为了说明指针变量和它所指向的变量之间的联系。 int * i;//表示指针变量i里面存放的地址,所指向的存储单元里的【数据】。 【指针变量的定义】 C语言规定所有变量,在使用前必须先定…...

HTML 中的 input 标签详解
HTML 中的 input 标签详解 一、基础概念 1. 定义与作用 HTML 中的 <input> 标签是表单元素的核心组件,用于创建各种用户输入字段。作为一个空标签(没有闭合标签),它通过 type 属性来决定呈现何种输入控件,是实…...

Python 在自动驾驶数据标签中的应用:如何让 AI 读懂道路?
Python 在自动驾驶数据标签中的应用:如何让 AI 读懂道路? 在自动驾驶系统中,数据就是生命线。不管是摄像头、激光雷达还是雷达传感器,这些设备每天都能产生 海量数据,但如果这些数据没有被正确标注,它们对 AI 来说毫无意义。那么,如何让自动驾驶系统准确理解道路环境呢…...