第9讲、深入理解Scaled Dot-Product Attention
Scaled Dot-Product Attention是Transformer架构的核心组件,也是现代深度学习中最重要的注意力机制之一。本文将从原理、实现和应用三个方面深入剖析这一机制。
1. 基本原理
Scaled Dot-Product Attention的本质是一种加权求和机制,通过计算查询(Query)与键(Key)的相似度来确定对值(Value)的关注程度。其数学表达式为:
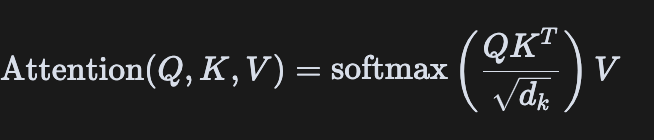
这个公式包含几个关键步骤:
- 计算相似度:通过点积(dot product)计算Query和Key的相似度,得到注意力分数(attention scores)
- 缩放(Scaling):将点积结果除以 d k \sqrt{d_k} dk进行缩放,其中 d k d_k dk是Key的维度
- 应用Mask(可选):在某些情况下(如自回归生成)需要遮盖未来信息
- Softmax归一化:将注意力分数通过softmax转换为概率分布
- 加权求和:用这些概率对Value进行加权求和
2. 为什么需要缩放(Scaling)?
缩放是Scaled Dot-Product Attention区别于普通Dot-Product Attention的关键。当输入的维度 d k d_k dk较大时,点积的方差也会变大,导致softmax函数梯度变得极小(梯度消失问题)。通过除以 d k \sqrt{d_k} dk,可以将方差控制在合理范围内。
假设Query和Key的各个分量是均值为0、方差为1的独立随机变量,则它们点积的方差为 d k d_k dk。通过除以 d k \sqrt{d_k} dk,可以将方差归一化为1。
3. 代码实现解析
让我们看看PyTorch中Scaled Dot-Product Attention的典型实现:
def scaled_dot_product_attention(query, key, value, mask=None, dropout=None):# 获取key的维度d_k = query.size(-1)# 计算注意力分数并缩放scores = torch.matmul(query, key.transpose(-2, -1)) / math.sqrt(d_k)# 应用mask(如果提供)if mask is not None:scores = scores.masked_fill(mask == 0, float('-inf'))# 应用softmax得到注意力权重attn = F.softmax(scores, dim=-1)# 应用dropout(如果提供)if dropout is not None:attn = dropout(attn)# 加权求和return torch.matmul(attn, value), attn
这个函数接受query、key、value三个张量作为输入,可选的mask用于遮盖某些位置,dropout用于正则化。
4. 张量维度分析
假设输入的形状为:
- Query: [batch_size, seq_len_q, d_k]
- Key: [batch_size, seq_len_k, d_k]
- Value: [batch_size, seq_len_k, d_v]
计算过程中各步骤的维度变化:
- Key转置后: [batch_size, d_k, seq_len_k]
- Query与Key的点积: [batch_size, seq_len_q, seq_len_k]
- Softmax后的注意力权重: [batch_size, seq_len_q, seq_len_k]
- 最终输出: [batch_size, seq_len_q, d_v]
5. 在Multi-Head Attention中的应用
Scaled Dot-Product Attention是Multi-Head Attention的基础。在Multi-Head Attention中,我们将输入投影到多个子空间,在每个子空间独立计算注意力,然后将结果合并:
class MultiHeadAttention(nn.Module):def __init__(self, h, d_model, dropout=0.1):super().__init__()assert d_model % h == 0self.d_k = d_model // hself.h = hself.linears = clones(nn.Linear(d_model, d_model), 4)self.attn = Noneself.dropout = nn.Dropout(dropout)def forward(self, query, key, value, mask=None):if mask is not None:mask = mask.unsqueeze(1)nbatches = query.size(0)# 1) 投影并分割成多头query, key, value = [l(x).view(nbatches, -1, self.h, self.d_k).transpose(1, 2)for l, x in zip(self.linears, (query, key, value))]# 2) 应用注意力机制x, self.attn = scaled_dot_product_attention(query, key, value, mask, self.dropout)# 3) 合并多头结果x = x.transpose(1, 2).contiguous().view(nbatches, -1, self.h * self.d_k)return self.linears[-1](x)
6. 实际应用场景
Scaled Dot-Product Attention在多种场景下表现出色:
- 自然语言处理:捕捉句子中词与词之间的依赖关系
- 计算机视觉:关注图像中的重要区域
- 推荐系统:建模用户与物品之间的交互
- 语音处理:捕捉音频信号中的时序依赖
7. 优势与局限性
优势:
- 计算效率高(可以通过矩阵乘法并行计算)
- 能够捕捉长距离依赖关系
- 模型可解释性强(可以可视化注意力权重)
局限性:
- 计算复杂度为O(n²),对于长序列计算开销大
- 没有考虑位置信息(需要额外的位置编码)
- 对于某些任务,可能需要结合CNN等结构以捕捉局部特征
8. 总结
Scaled Dot-Product Attention是现代深度学习中的关键创新,通过简单而优雅的设计实现了强大的表达能力。它不仅是Transformer架构的核心,也启发了众多后续工作,如Performer、Linformer等对注意力机制的改进。理解这一机制对于掌握现代深度学习模型至关重要。
通过缩放点积、应用softmax和加权求和这三个简单步骤,Scaled Dot-Product Attention成功地让模型"关注"输入中的重要部分,这也是它能在各种任务中取得卓越表现的关键所在。
##9、Scaled Dot-Product Attention应用案例
敬请关注下一篇
相关文章:
第9讲、深入理解Scaled Dot-Product Attention
Scaled Dot-Product Attention是Transformer架构的核心组件,也是现代深度学习中最重要的注意力机制之一。本文将从原理、实现和应用三个方面深入剖析这一机制。 1. 基本原理 Scaled Dot-Product Attention的本质是一种加权求和机制,通过计算查询(Query…...

2025B难题练习
1.启动多任务排序 拓扑排序 每次选入度为0的点 对每次选的点进行排序 package mainimport ("bufio""fmt""os""slices""strings" )func main() {scanner : bufio.NewScanner(os.Stdin)scanner.Scan()text : scanner.Text()…...
双向长短期记忆网络-BiLSTM
5月14日复盘 二、BiLSTM 1. 概述 双向长短期记忆网络(Bi-directional Long Short-Term Memory,BiLSTM)是一种扩展自长短期记忆网络(LSTM)的结构,旨在解决传统 LSTM 模型只能考虑到过去信息的问题。BiLST…...
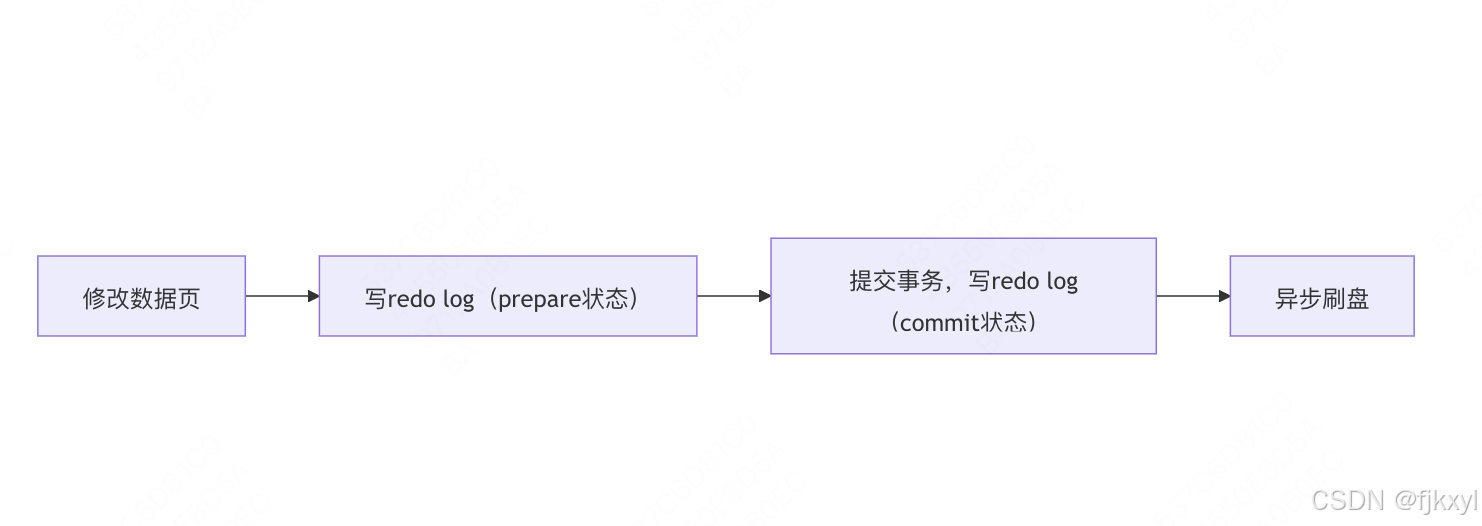
MySQL UPDATE 执行流程全解析
引言 当你在 MySQL 中执行一条 UPDATE 语句时,背后隐藏着一套精密的协作机制。从解析器到存储引擎,从锁管理到 WAL 日志,每个环节都直接影响数据一致性和性能。 本文将通过 Mermaid 流程图 和 时序图,完整还原 UPDATE 语句的执行…...
亚马逊云科技:开启数字化转型的无限可能
在数字技术蓬勃发展的今天,云计算早已突破单纯技术工具的范畴,成为驱动企业创新、引领行业变革的核心力量。亚马逊云科技凭借前瞻性的战略布局与持续的技术深耕,在全球云计算领域树立起行业标杆,为企业和个人用户提供全方位、高品…...

Gartner《How to Leverage Lakehouse Design in Your DataStrategy》学习心得
一、背景 随着数据量的爆炸式增长和数据类型复杂性的不断提高,企业面临着构建高效、灵活且经济的数据存储与处理架构的挑战。湖仓一体(Lakehouse)作为一种新兴的数据架构设计方法,融合了数据仓库和数据湖的优势,为这一挑战提供了创新的解决方案。Gartner发布了《How to L…...

【实测有效】Edge浏览器打开部分pdf文件显示空白
问题现象 Edge浏览器打开部分pdf文件显示空白或显示异常。 问题原因 部分pdf文件与edge浏览器存在兼容性问题,打开显示异常。 解决办法 法1:修改edge配置 打开edge浏览器&#x…...

RJ连接器的未来:它还会是网络连接的主流标准吗?
RJ连接器作为以太网接口的代表,自20世纪以来在计算机网络、通信设备、安防系统等领域中占据了核心地位。以RJ45为代表的RJ连接器,凭借其结构稳定、信号传输可靠、成本低廉等优势,在有线网络布线领域被广泛采用。然而,在无线网络不…...

Redis持久化机制详解:保障数据安全的关键策略
在现代应用开发中,Redis作为高性能的内存数据库被广泛使用。然而,内存的易失性特性使得持久化成为Redis设计中的关键环节。本文将全面剖析Redis的持久化机制,包括RDB、AOF以及混合持久化模式,帮助开发者根据业务需求选择最适合的持…...
:备份MySQL数据库表)
shell脚本练习(6):备份MySQL数据库表
一、脚本编写 编写脚本如下: #!/bin/bash# 系统数据库 SYS_DB"information_schema|mysql|performance_schema|sys"# 需要备份的数据库 DBmysql -N -e "show databases" | egrep -v $SYS_DBfor i in $DB;do# 备份的路径BAK_PATH"/server/…...

深度学习模型基本框架
简介: 归纳了一套基本框架,以帮助使用者快速创建新的模型,同时有paddlepaddle版本和pytorch版本的,它们虽有差别,但是对于初级使用者,只是两种不同但是很相近的语法而已。都采用paddle平台作为载体来存项目…...

[Java][Leetcode middle] 134. 加油站
方法一,自己想的,超时 双重循环 从第一个点开始循环尝试, 如果最终能走到终点,说明可行。 public int canCompleteCircuit(int[] gas, int[] cost) {int res -1;int n gas.length;int remainGas;int j;for (int i 0; i < …...
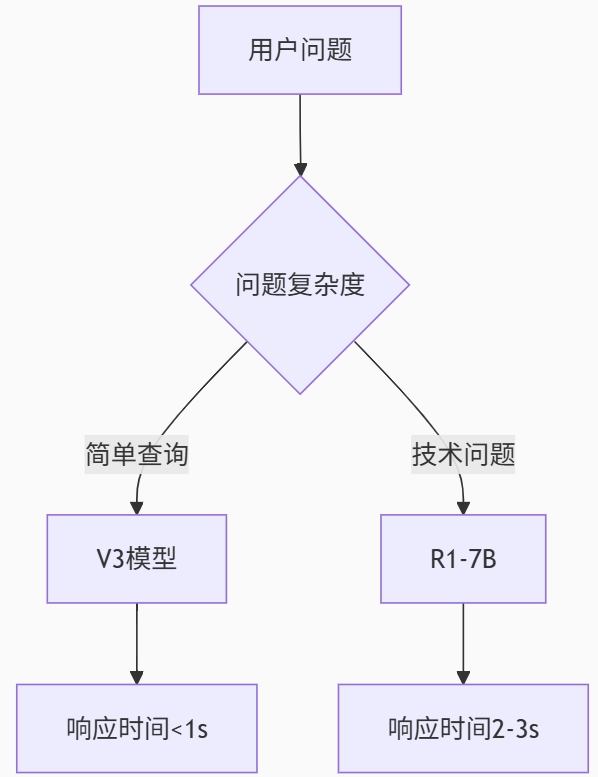
DeepSeek 大模型部署全指南:常见问题、优化策略与实战解决方案
DeepSeek 作为当前最热门的开源大模型之一,其强大的语义理解和生成能力吸引了大量开发者和企业关注。然而在实际部署过程中,无论是本地运行还是云端服务,用户往往会遇到各种技术挑战。本文将全面剖析 DeepSeek 部署中的常见问题,提…...

嵌入式培训之数据结构学习(五)栈与队列
一、栈 (一)栈的基本概念 1、栈的定义: 注:线性表中的栈在堆区(因为是malloc来的);系统中的栈区存储局部变量、函数形参、函数返回值地址。 2、栈顶和栈底: 允许插入和删除的一端…...

RabbitMQ--进阶篇
RabbitMQ 客户端整合Spring Boot 添加相关的依赖 <dependency><groupId>org.springframework.boot</groupId><artifactId>spring-boot-starter-amqp</artifactId> </dependency> 编写配置文件,配置RabbitMQ的服务信息 spri…...
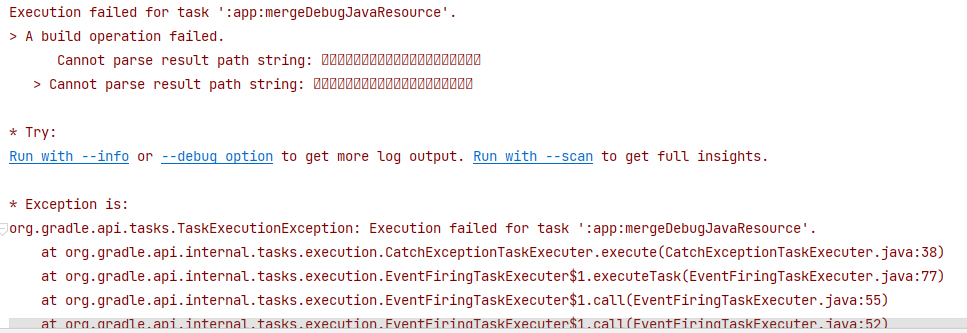
Android Studio报错Cannot parse result path string:
前言 最近在写个小Demo,参考郭霖的《第一行代码》,学习DrawerLayout和NavigationView,不知咋地,突然报错Cannot parse result path string:xxxxxxxxxxxxx 反正百度,问ai都找不到答案,报错信息是完全看不懂…...

matlab求矩阵的逆、行列式、秩、转置
inv - 计算矩阵的逆 用途:计算一个可逆矩阵的逆矩阵。 D [1, 2; 3, 4]; % 定义一个2x2矩阵 D_inv inv(D); % 计算矩阵D的逆 disp(D_inv);det - 计算矩阵的行列式 用途:计算方阵的行列式。 E [1, 2; 3, 4]; determinant det(E); % 计算行列式 disp…...
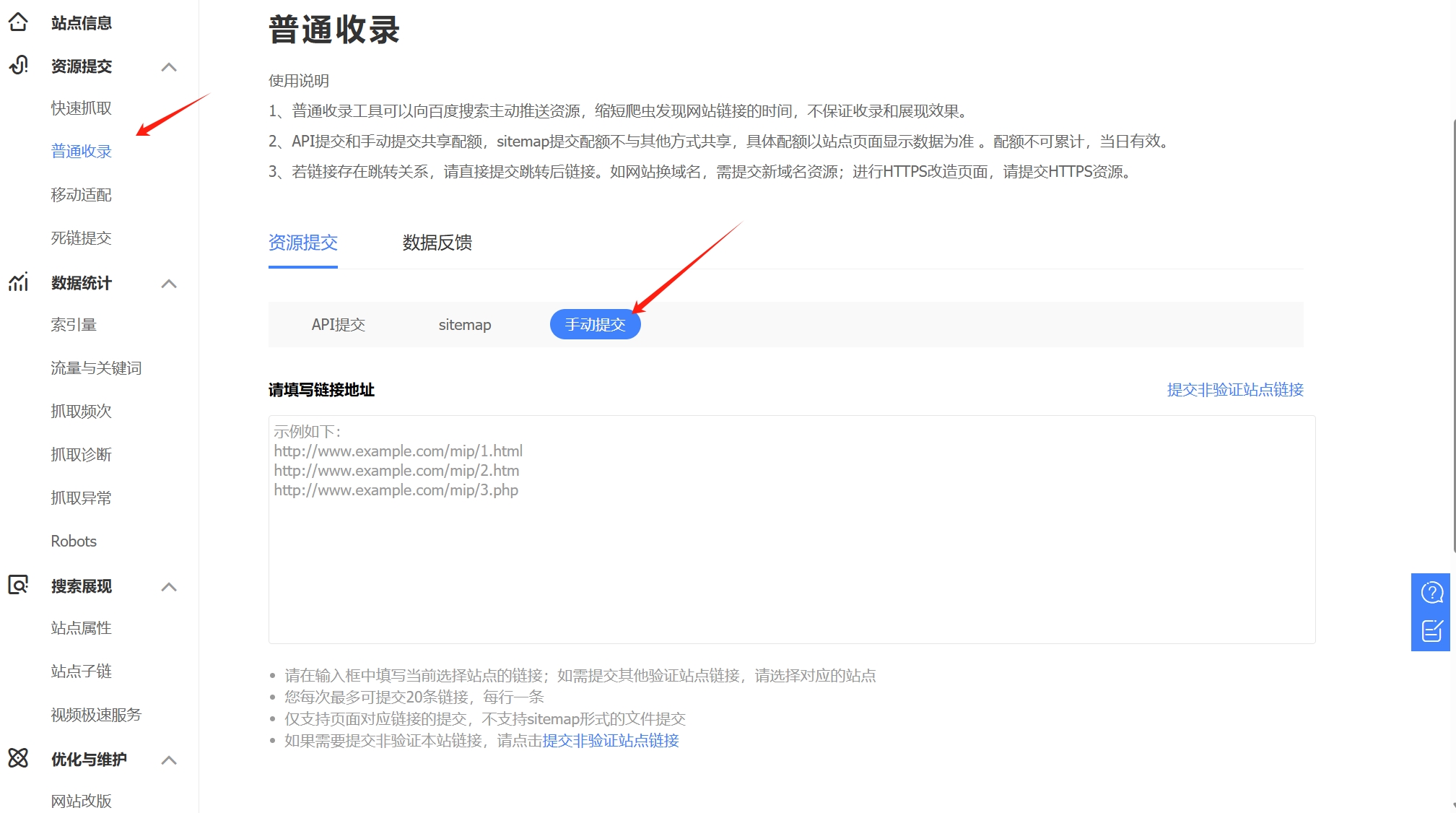
关于网站提交搜索引擎
发布于Eucalyptus-blog 一、前言 将网站提交给搜索引擎是为了让搜索引擎更早地了解、索引和显示您的网站内容。以下是一些提交网站给搜索引擎的理由: 提高可见性:通过将您的网站提交给搜索引擎,可以提高您的网站在搜索结果中出现的机会。当用…...
)
计算机视觉与深度学习 | Python实现EMD-SSA-VMD-LSTM-Attention时间序列预测(完整源码和数据)
EMD-SSA-VMD-LSTM-Attention 一、完整代码实现二、代码结构解析三、关键数学公式四、参数调优建议五、性能优化方向六、工业部署建议 以下是用Python实现EMD-SSA-VMD-LSTM-Attention时间序列预测的完整解决方案。该方案结合了四层信号分解技术与注意力增强的深度学习模型&#…...

二进制与十进制互转的方法
附言: 在计算机科学和数字系统中,二进制和十进制是最常见的两种数制。二进制是计算机内部数据存储和处理的基础,而十进制则是我们日常生活中最常用的数制。因此,掌握二进制与十进制之间的转换方法对于计算机学习者和相关领域的从业者来说至关…...

05、基础入门-SpringBoot-HelloWorld
05、基础入门-SpringBoot-HelloWorld ## 一、Spring Boot 简介 **Spring Boot** 是一个用于简化 **Spring** 应用初始搭建和开发的框架,旨在让开发者快速启动项目并减少配置文件。 ### 主要特点 - **简化配置**:采用“约定优于配置”的原则,减…...

LeetCode 153. 寻找旋转排序数组中的最小值:二分查找法详解及高频疑问解析
文章目录 问题描述算法思路:二分查找法关键步骤 代码实现代码解释高频疑问解答1. 为什么循环条件是 left < right 而不是 left < right?2. 为什么比较 nums[mid] > nums[right] 而不是 nums[left] < nums[mid]?3. 为什么 right …...

基于QT(C++)OOP 实现(界面)酒店预订与管理系统
酒店预订与管理系统 1 系统功能设计 酒店预订是旅游出行的重要环节,而酒店预订与管理系统中的管理与信息透明是酒店预订业务的关键问题所在,能够方便地查询酒店信息进行付款退款以及用户之间的交流对于酒店预订行业提高服务质量具有重要的意义。 针对…...
?)
人工智能100问☞第25问:什么是循环神经网络(RNN)?
目录 一、通俗解释 二、专业解析 三、权威参考 循环神经网络(RNN)是一种通过“记忆”序列中历史信息来处理时序数据的神经网络,可捕捉前后数据的关联性,擅长处理语言、语音等序列化任务。 一、通俗解释 想象你在和朋友聊天,每说一句话都会根据之前的对话内容调整语气…...
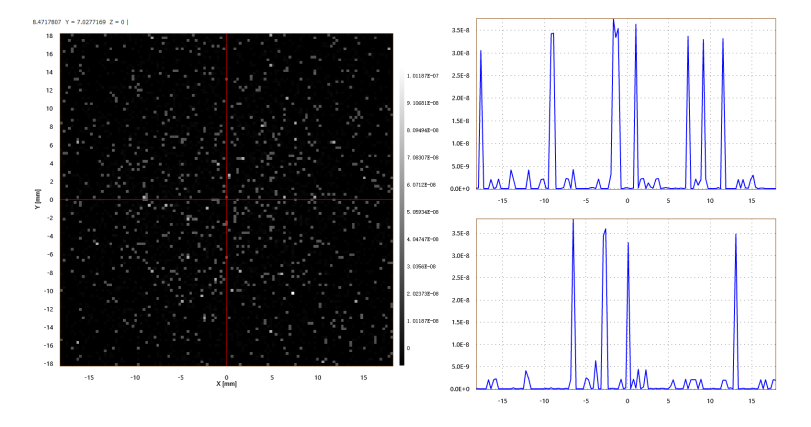
机械元件杂散光难以把控?OAS 软件案例深度解析
机械元件的杂散光分析 简介 在光学系统设计与工程实践中,机械元件的杂散光问题对系统性能有着不容忽视的影响。杂散光会降低光学系统的信噪比、图像对比度,甚至导致系统功能失效。因此,准确分析机械元件杂散光并采取有效抑制措施,…...

游戏引擎学习第289天:将视觉表现与实体类型解耦
回顾并为今天的工作设定基调 我们正在继续昨天对代码所做的改动。我们已经完成了“脑代码(brain code)”的概念,它本质上是一种为实体构建的自组织控制器结构。现在我们要做的是把旧的控制逻辑迁移到这个新的结构中,并进一步测试…...
【Linux网络】ARP协议
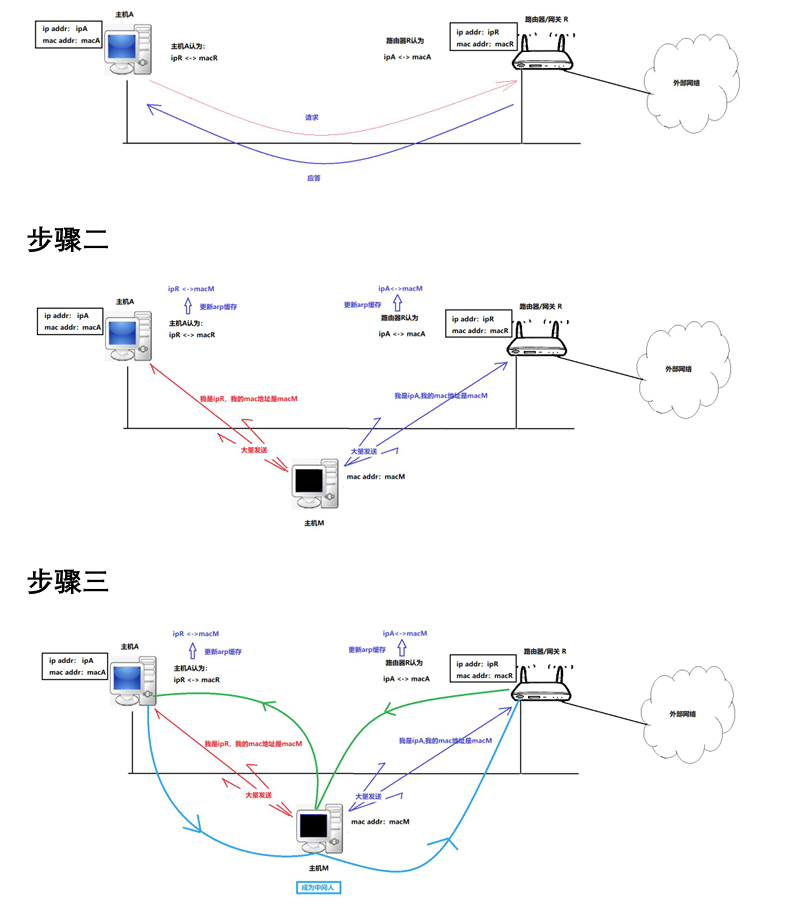
ARP协议 虽然我们在这里介绍 ARP 协议,但是需要强调,ARP 不是一个单纯的数据链路层的协议,而是一个介于数据链路层和网络层之间的协议。 ARP数据报的格式 字段长度(字节)说明硬件类型2网络类型(如以太网为…...
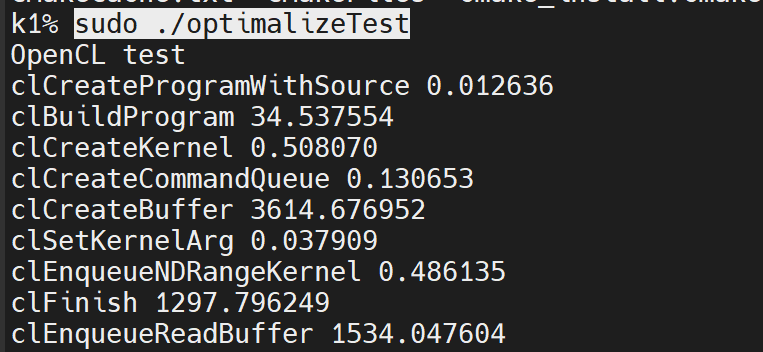
MUSE Pi Pro 开发板 Imagination GPU 利用 OpenCL 测试
视频讲解: MUSE Pi Pro 开发板 Imagination GPU 利用 OpenCL 测试 继续玩MUSE Pi Pro,今天看下比较关注的gpu这块,从opencl看起,安装clinfo指令 sudo apt install clinfo 可以看到这颗GPU是Imagination的 一般嵌入式中gpu都和hos…...
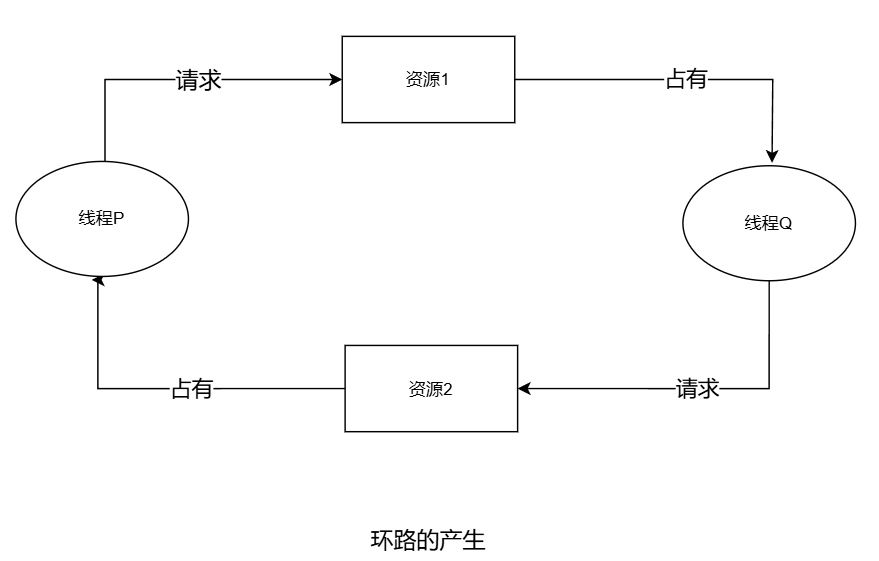
多线程与线程互斥
我们初步学习完线程之后,就要来试着写一写多线程了。在写之前,我们需要继续来学习一个线程接口——叫做线程分离。 默认情况下,新创建的线程是joinable的,线程退出后,需要对其进行pthread_join操作,否则无法…...

使用Spring Boot和Spring Security构建安全的RESTful API
使用Spring Boot和Spring Security构建安全的RESTful API 引言 在现代Web开发中,安全性是构建应用程序时不可忽视的重要方面。本文将介绍如何使用Spring Boot和Spring Security框架构建一个安全的RESTful API,并结合JWT(JSON Web Token&…...