DAY 23 训练
DAY 23 训练
- DAY23 机器学习管道 pipeline
- 基础概念
- 转换器(Transformer)
- 估计器(Estimator)
- 管道(Pipeline)
- 代码演示
- 没有 pipeline 的代码
- pipeline 的代码教学
- 导入库和数据加载
- 分离特征和标签,划分数据集
- 定义预处理步骤
- 构建完整 pipeline
- 使用 Pipeline 进行训练和评估
- 总结
DAY23 机器学习管道 pipeline
在机器学习领域,“管道”(pipeline)是一个至关重要的概念。它为我们提供了一种高效且结构化的方式来组织和执行机器学习工作流程。今天,我将带领大家一起深入理解机器学习管道的概念和应用,并通过代码演示如何构建一个完整的机器学习管道。
基础概念
转换器(Transformer)
转换器是用于对数据进行预处理和特征提取的 estimator。它实现了 transform 方法,用于对数据进行预处理和特征提取。常见的转换器包括数据缩放器(如 StandardScaler、MinMaxScaler)、特征选择器(如 SelectKBest、PCA)、特征提取器(如 CountVectorizer、TF-IDFVectorizer)等。
from sklearn.preprocessing import StandardScaler# 初始化转换器
scaler = StandardScaler()# 学习训练数据的缩放规则
scaler.fit(X_train)# 应用规则到训练数据和测试数据
X_train_scaled = scaler.transform(X_train)
X_test_scaled = scaler.transform(X_test)
估计器(Estimator)
估计器是实现机器学习算法的对象或类。它用于拟合(fit)数据并进行预测(predict)。常见的估计器包括分类器(classifier)、回归器(regresser)、聚类器(clusterer)。
from sklearn.linear_model import LinearRegression# 创建一个回归器
model = LinearRegression()# 在训练集上训练模型
model.fit(X_train_scaled, y_train)# 对测试集进行预测
y_pred = model.predict(X_test_scaled)
管道(Pipeline)
管道是一种将多个转换器和估计器按顺序连接在一起的机制,可以构建一个完整的数据处理和模型训练流程。在管道机制中,可以使用 Pipeline 类来组织和连接不同的转换器和估计器。
from sklearn.pipeline import Pipeline# 构建一个简单的管道
pipeline = Pipeline([('scaler', StandardScaler()), # 数据标准化('classifier', RandomForestClassifier()) # 分类器
])# 在训练集上训练管道
pipeline.fit(X_train, y_train)# 在测试集上进行预测
y_pred = pipeline.predict(X_test)
代码演示
没有 pipeline 的代码
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
import seaborn as sns
import warnings
warnings.filterwarnings("ignore")# 设置中文字体(解决中文显示问题)
plt.rcParams['font.sans-serif'] = ['SimHei']
plt.rcParams['axes.unicode_minus'] = Falsedata = pd.read_csv('data.csv')# 先筛选字符串变量
discrete_features = data.select_dtypes(include=['object']).columns.tolist()# Home Ownership 标签编码
home_ownership_mapping = {'Own Home': 1,'Rent': 2,'Have Mortgage': 3,'Home Mortgage': 4
}
data['Home Ownership'] = data['Home Ownership'].map(home_ownership_mapping)# Years in current job 标签编码
years_in_job_mapping = {'< 1 year': 1,'1 year': 2,'2 years': 3,'3 years': 4,'4 years': 5,'5 years': 6,'6 years': 7,'7 years': 8,'8 years': 9,'9 years': 10,'10+ years': 11
}
data['Years in current job'] = data['Years in current job'].map(years_in_job_mapping)# Purpose 独热编码
data = pd.get_dummies(data, columns=['Purpose'])
data2 = pd.read_csv("data.csv")
list_final = []
for i in data.columns:if i not in data2.columns:list_final.append(i)
for i in list_final:data[i] = data[i].astype(int)# Term 0 - 1 映射
term_mapping = {'Short Term': 0,'Long Term': 1
}
data['Term'] = data['Term'].map(term_mapping)
data.rename(columns={'Term': 'Long Term'}, inplace=True)continuous_features = data.select_dtypes(include=['int64', 'float64']).columns.tolist()# 连续特征用中位数补全
for feature in continuous_features:mode_value = data[feature].mode()[0]data[feature].fillna(mode_value, inplace=True)from sklearn.model_selection import train_test_split
X = data.drop(['Credit Default'], axis=1)
y = data['Credit Default']
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)from sklearn.ensemble import RandomForestClassifier
from sklearn.metrics import accuracy_score, precision_score, recall_score, f1_score
from sklearn.metrics import classification_report, confusion_matrix
import warnings
warnings.filterwarnings("ignore")# --- 1. 默认参数的随机森林 ---
print("--- 1. 默认参数随机森林 (训练集 -> 测试集) ---")
import time
start_time = time.time()
rf_model = RandomForestClassifier(random_state=42)
rf_model.fit(X_train, y_train)
rf_pred = rf_model.predict(X_test)
end_time = time.time()print(f"训练与预测耗时: {end_time - start_time:.4f} 秒")
print("\n默认随机森林 在测试集上的分类报告:")
print(classification_report(y_test, rf_pred))
print("默认随机森林 在测试集上的混淆矩阵:")
print(confusion_matrix(y_test, rf_pred))
pipeline 的代码教学
导入库和数据加载
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
import seaborn as sns
import time
import warningswarnings.filterwarnings("ignore")plt.rcParams['font.sans-serif'] = ['SimHei']
plt.rcParams['axes.unicode_minus'] = Falsefrom sklearn.pipeline import Pipeline
from sklearn.compose import ColumnTransformer
from sklearn.preprocessing import OrdinalEncoder, OneHotEncoder, StandardScaler
from sklearn.impute import SimpleImputerfrom sklearn.ensemble import RandomForestClassifier
from sklearn.metrics import classification_report, confusion_matrix
from sklearn.model_selection import train_test_splitdata = pd.read_csv('data.csv')print("原始数据加载完成,形状为:", data.shape)
分离特征和标签,划分数据集
y = data['Credit Default']
X = data.drop(['Credit Default'], axis=1)print("\n特征和标签分离完成。")
print("特征 X 的形状:", X.shape)
print("标签 y 的形状:", y.shape)X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)print("\n数据集划分完成 (预处理之前)。")
print("X_train 形状:", X_train.shape)
print("X_test 形状:", X_test.shape)
print("y_train 形状:", y_train.shape)
print("y_test 形状:", y_test.shape)
定义预处理步骤
object_cols = X.select_dtypes(include=['object']).columns.tolist()
numeric_cols = X.select_dtypes(exclude=['object']).columns.tolist()ordinal_features = ['Home Ownership', 'Years in current job', 'Term']
ordinal_categories = [['Own Home', 'Rent', 'Have Mortgage', 'Home Mortgage'],['< 1 year', '1 year', '2 years', '3 years', '4 years', '5 years', '6 years', '7 years', '8 years', '9 years', '10+ years'],['Short Term', 'Long Term']
]ordinal_transformer = Pipeline(steps=[('imputer', SimpleImputer(strategy='most_frequent')),('encoder', OrdinalEncoder(categories=ordinal_categories, handle_unknown='use_encoded_value', unknown_value=-1))
])nominal_features = ['Purpose']nominal_transformer = Pipeline(steps=[('imputer', SimpleImputer(strategy='most_frequent')),('onehot', OneHotEncoder(handle_unknown='ignore', sparse_output=False))
])continuous_features = [f for f in X.columns if f not in ordinal_features + nominal_features]continuous_transformer = Pipeline(steps=[('imputer', SimpleImputer(strategy='most_frequent')),('scaler', StandardScaler())
])preprocessor = ColumnTransformer(transformers=[('ordinal', ordinal_transformer, ordinal_features),('nominal', nominal_transformer, nominal_features),('continuous', continuous_transformer, continuous_features)],remainder='passthrough'
)print("\nColumnTransformer (预处理器) 定义完成。")
构建完整 pipeline
pipeline = Pipeline(steps=[('preprocessor', preprocessor),('classifier', RandomForestClassifier(random_state=42))
])print("\n完整的 Pipeline 定义完成。")
使用 Pipeline 进行训练和评估
print("\n--- 1. 默认参数随机森林 (训练集 -> 测试集) ---")
start_time = time.time()pipeline.fit(X_train, y_train)pipeline_pred = pipeline.predict(X_test)end_time = time.time()print(f"训练与预测耗时: {end_time - start_time:.4f} 秒")print("\n默认随机森林 在测试集上的分类报告:")
print(classification_report(y_test, pipeline_pred))
print("默认随机森林 在测试集上的混淆矩阵:")
print(confusion_matrix(y_test, pipeline_pred))
总结
通过使用 pipeline,我们可以将整个机器学习工作流程封装成一个简洁的流程,提高代码的可读性和可维护性。同时,pipeline 还可以帮助我们防止数据泄露,简化超参数调优,提高模型的性能和稳定性。
在实际项目中,我们可以使用 pipeline 来构建复杂的机器学习工作流,提高我们的工作效率。希望今天的分享能够帮助大家更好地理解和使用机器学习管道。
@浙大疏锦行
相关文章:

DAY 23 训练
DAY 23 训练 DAY23 机器学习管道 pipeline基础概念转换器(Transformer)估计器(Estimator) 管道(Pipeline)代码演示没有 pipeline 的代码pipeline 的代码教学导入库和数据加载分离特征和标签,划分…...

wordcount程序
### 在 IntelliJ IDEA 中编写和运行 Spark WordCount 程序 要使用 IntelliJ IDEA 编写并运行 Spark 的 WordCount 程序,需按照以下流程逐步完成环境配置、代码编写以及任务提交。 --- #### 1. **安装与配置 IntelliJ IDEA** 确保已正确安装 IntelliJ IDEA&#x…...
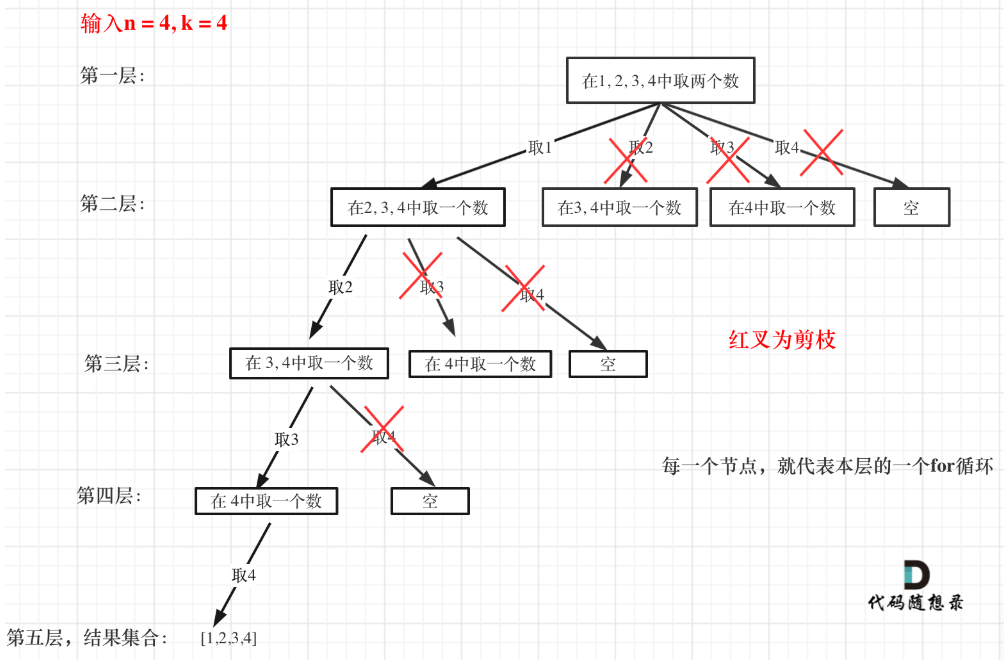
回溯法理论基础 LeetCode 77. 组合 LeetCode 216.组合总和III LeetCode 17.电话号码的字母组合
目录 回溯法理论基础 回溯法 回溯法的效率 用回溯法解决的问题 如何理解回溯法 回溯法模板 LeetCode 77. 组合 回溯算法的剪枝操作 LeetCode 216.组合总和III LeetCode 17.电话号码的字母组合 回溯法理论基础 回溯法 回溯法也可以叫做回溯搜索法,它是一…...
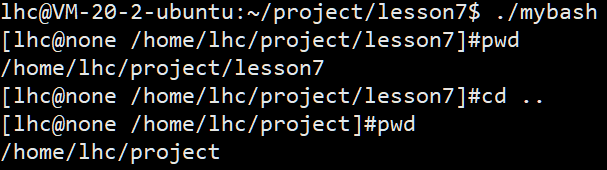
【进程控制二】进程替换和bash解释器
【进程控制二】进程替换 1.exec系列接口2.execl系列2.1execl接口2.2execlp接口2.3execle 3.execv系列3.1execv3.2总结 4.实现一个bash解释器4.1内建命令 通过fork创建的子进程,会继承父进程的代码和数据,因此本质上还是在执行父进程的代码 进程替换可以将…...

线性回归策略
一种基于ATR(平均真实范围)、线性回归和布林带的交易策略。以下是对该策略的全面总结和分析: 交易逻辑思路 1. 过滤条件: - 集合竞价过滤:在每个交易日的开盘阶段,过滤掉集合竞价产生的异常数据。 - 价格异常过滤:排除当天开盘价与最高价或最低价相同的情况,这…...

Linux下的c/c++开发之操作Redis数据库
C/C 操作 Redis 的常用库 在 C/C 开发中操作 Redis 有多种方式,最主流的选择是使用第三方客户端库。由于 Redis 官方本身是使用 C 编写的,提供的 API 非常适合 C/C 调用。常见的 Redis C/C 客户端库包括: hiredis:官方推荐的轻量…...

Bitmap、Roaring Bitmap、HyperLogLog对比介绍
一、Bitmap(位图)概述 Bitmap 是一种用位(bit)来表示集合元素是否存在的数据结构。每个位代表一个元素的状态(0或1),非常节省空间且支持快速集合操作。 常见Bitmap类型: 普通Bitmap 最简单的位数组,适合元素范围固定且不稀疏的场景。例如,元素范围是0~1000,用1001…...
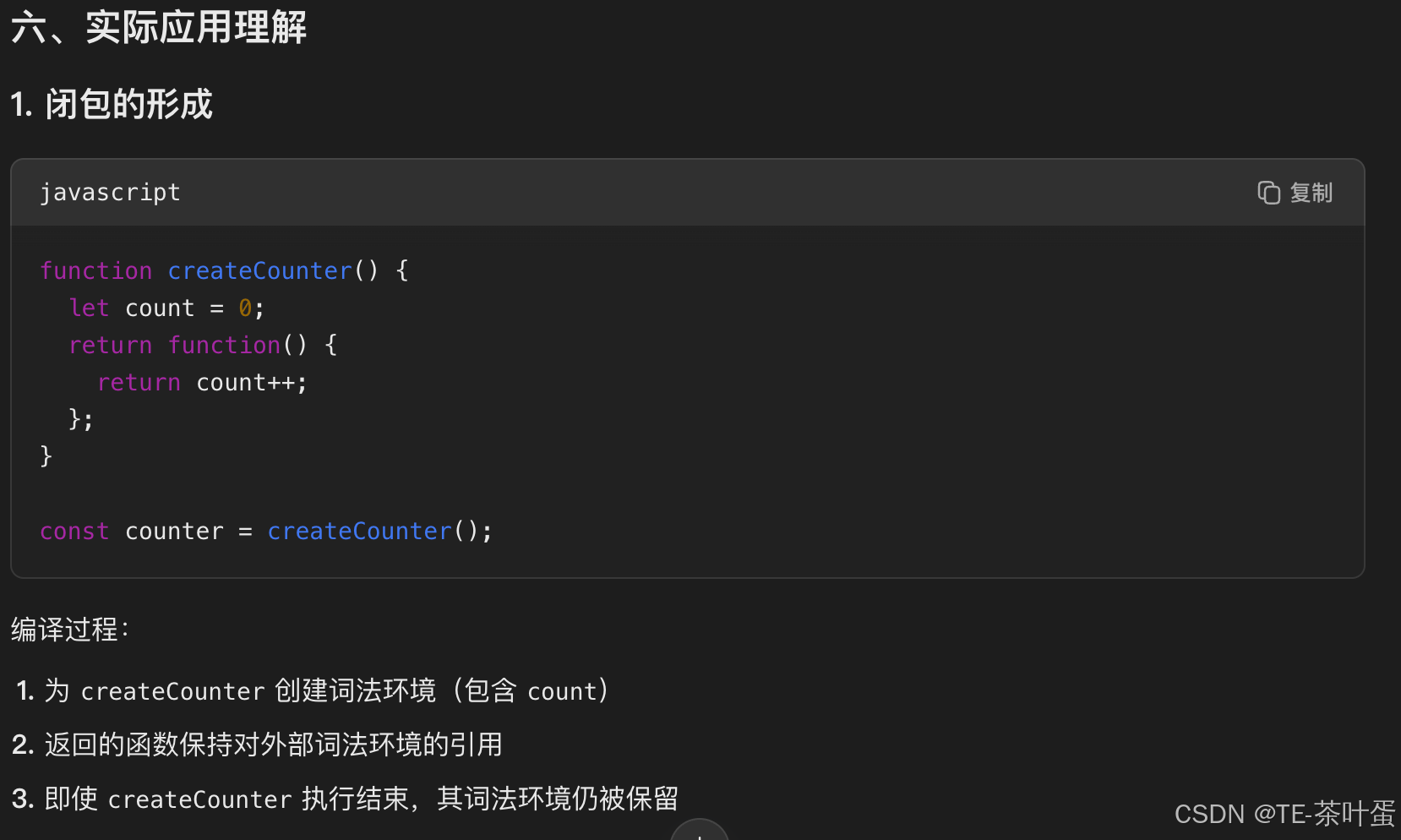
JavaScript 的编译与执行原理
文章目录 前言🧠 一、JavaScript 编译与执行过程1. 编译阶段(发生在代码执行前)✅ 1.1 词法分析(Lexical Analysis)✅ 1.2 语法分析(Parsing)✅ 1.3 语义分析与生成执行上下文 🧰 二…...

fastapi项目中数据流转架构设计规范
一、数据库层设计 1.1 ORM模型定义 class SysUser(Base):__table_args__ {"mysql_engine": "InnoDB","comment": "用户表"}id: Mapped[int] mapped_column(Integer, primary_keyTrue, autoincrementTrue, comment"用户ID&quo…...
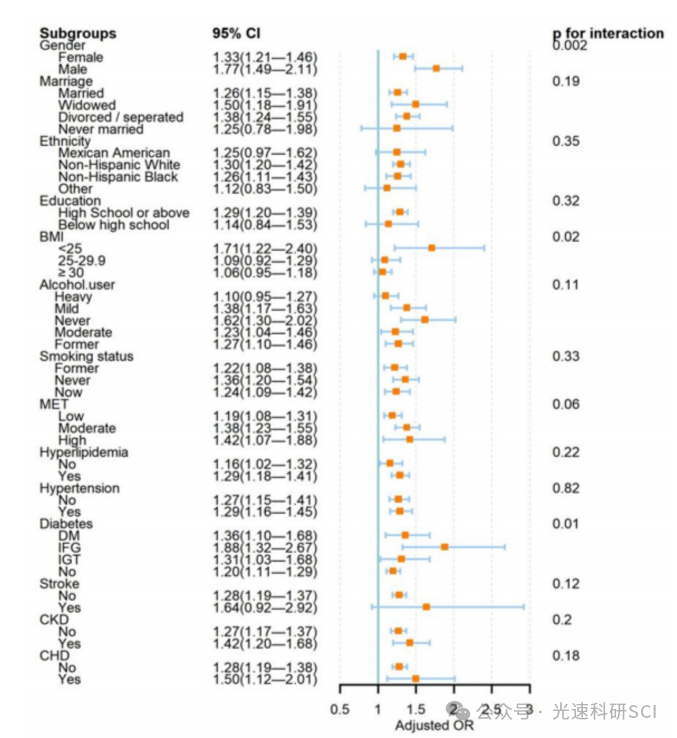
NHANES指标推荐:FMI
文章题目:Exploring the relationship between fat mass index and metabolic syndrome among cancer patients in the U.S: An NHANES analysis DOI:10.1038/s41598-025-90792-9 中文标题:探索美国癌症患者脂肪量指数与代谢综合征之间的关系…...
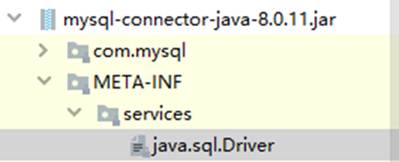
【JDBC】JDBC常见错误处理方法及驱动的加载
MySQL8中数据库连接的四个参数有两个发生了变化 String driver "com.mysql.cj.jdbc.Driver"; String url "jdbc:mysql://127.0.0.1:3306/mydb?useSSLfalse&useUnicodetrue&characterEncodingutf8&serverTimezoneAsia/Shanghai"; 或者Strin…...

React中useState中更新是同步的还是异步的?
文章目录 前言一、useState 的基本用法二、useState 的更新机制1. 内部状态管理2. 状态初始化3. 状态更新 三、useState 的更新频率与异步行为1. 异步更新与批量更新2. 为什么需要异步更新? 四、如何正确处理 useState 的更新1. 使用回调函数形式的更新2. 理解异步更…...

Vim编辑器命令模式操作指南
Vim 的命令模式(即 Normal 模式)是 Vim 的核心操作模式,用于执行文本编辑、导航、搜索、保存等操作。以下是命令模式下的常用操作总结: 1. 模式切换 进入命令模式:在任何模式下按 Esc 键(可能需要多次按&a…...
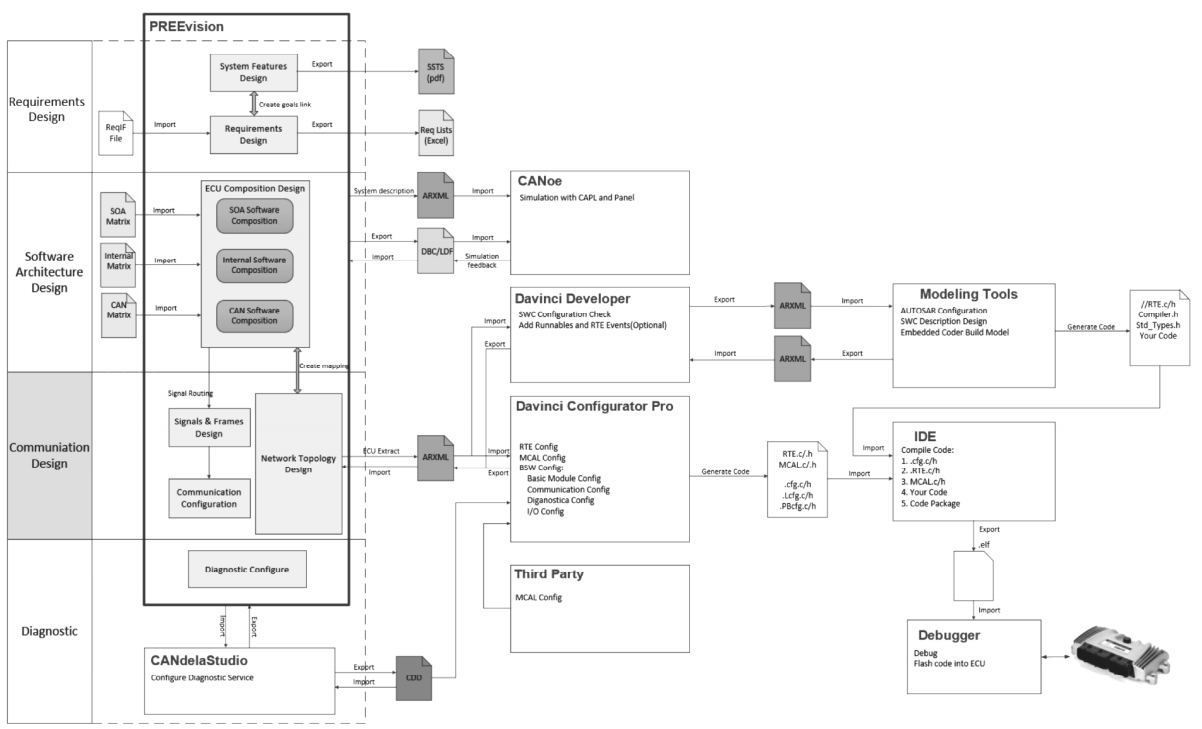
车载以太网驱动智能化:域控架构设计与开发实践
title: 车载以太网驱动专用车智能化:域控架构设计与开发实践 date: 2023-12-01 categories: 新能源汽车 tags: [车载以太网, 电子电气架构, 域控架构, 专用车智能化, SOME/IP, AUTOSAR] 引言:专用车智能化转型的挑战与机遇 专用车作为城市建设与工业运输…...
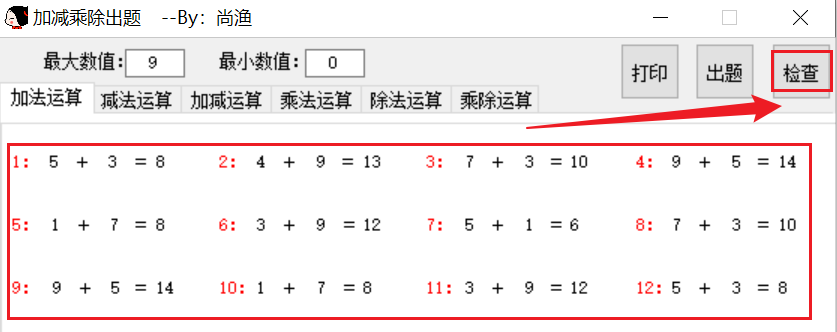
如何利用技术手段提升小学数学练习效率
在日常辅导孩子数学作业的过程中,我发现了一款比较实用的练习题生成工具。这个工具的安装包仅1.8MB大小,但基本能满足小学阶段的数学练习需求。 主要功能特点: 参数化出题 可自由设置数字范围(如10以内、100以内) 支…...

C# DataGrid功能总览
目录 前言一、DataGrid基础功能1.DataGrid基础属性2.DataGridTextColumn属性3.DataGridTemplateColumn属性4.表DataGrid点击单元格或行时弹出两个按钮 二、其他功能1.表行DataGrid出现斑马纹效果2.表行DataGrid字体、行背景标红 前言 最近所实现的功能里,表DataGri…...
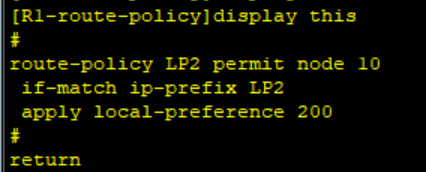
BGP路由策略 基础实验
要求: 1.使用Preva1策略,确保R4通过R2到达192.168.10.0/24 2.用AS_Path策略,确保R4通过R3到达192.168.11.0/24 3.配置MED策略,确保R4通过R3到达192.168.12.0/24 4.使用Local Preference策略,确保R1通过R2到达192.168.1.0/24 …...
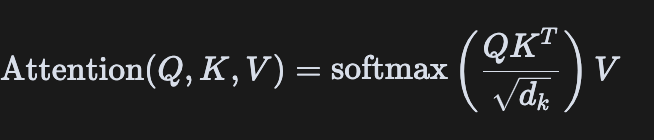
第9讲、深入理解Scaled Dot-Product Attention
Scaled Dot-Product Attention是Transformer架构的核心组件,也是现代深度学习中最重要的注意力机制之一。本文将从原理、实现和应用三个方面深入剖析这一机制。 1. 基本原理 Scaled Dot-Product Attention的本质是一种加权求和机制,通过计算查询(Query…...

2025B难题练习
1.启动多任务排序 拓扑排序 每次选入度为0的点 对每次选的点进行排序 package mainimport ("bufio""fmt""os""slices""strings" )func main() {scanner : bufio.NewScanner(os.Stdin)scanner.Scan()text : scanner.Text()…...
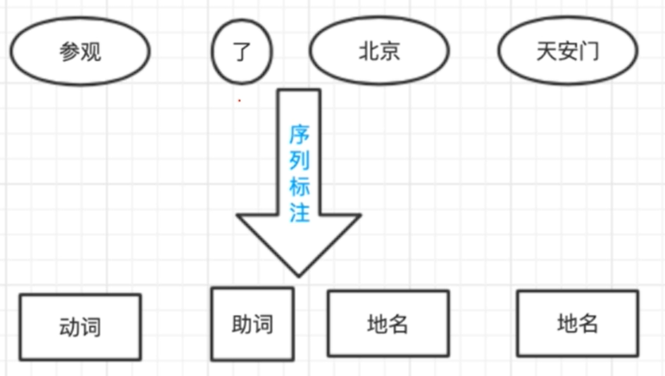
双向长短期记忆网络-BiLSTM
5月14日复盘 二、BiLSTM 1. 概述 双向长短期记忆网络(Bi-directional Long Short-Term Memory,BiLSTM)是一种扩展自长短期记忆网络(LSTM)的结构,旨在解决传统 LSTM 模型只能考虑到过去信息的问题。BiLST…...
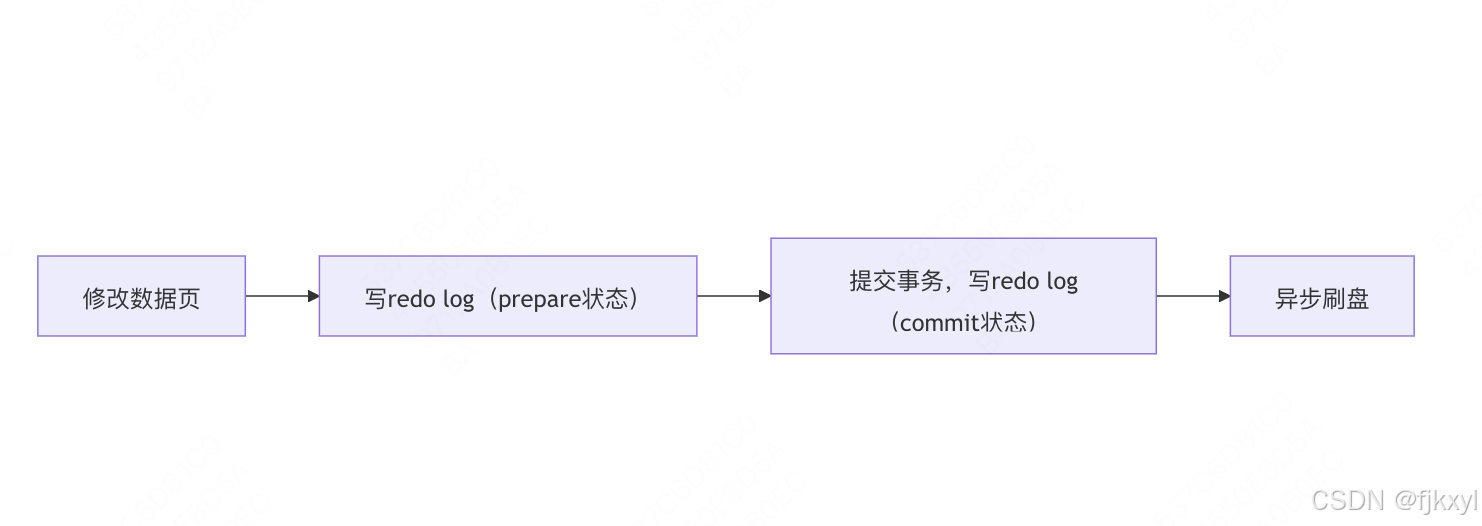
MySQL UPDATE 执行流程全解析
引言 当你在 MySQL 中执行一条 UPDATE 语句时,背后隐藏着一套精密的协作机制。从解析器到存储引擎,从锁管理到 WAL 日志,每个环节都直接影响数据一致性和性能。 本文将通过 Mermaid 流程图 和 时序图,完整还原 UPDATE 语句的执行…...
亚马逊云科技:开启数字化转型的无限可能
在数字技术蓬勃发展的今天,云计算早已突破单纯技术工具的范畴,成为驱动企业创新、引领行业变革的核心力量。亚马逊云科技凭借前瞻性的战略布局与持续的技术深耕,在全球云计算领域树立起行业标杆,为企业和个人用户提供全方位、高品…...

Gartner《How to Leverage Lakehouse Design in Your DataStrategy》学习心得
一、背景 随着数据量的爆炸式增长和数据类型复杂性的不断提高,企业面临着构建高效、灵活且经济的数据存储与处理架构的挑战。湖仓一体(Lakehouse)作为一种新兴的数据架构设计方法,融合了数据仓库和数据湖的优势,为这一挑战提供了创新的解决方案。Gartner发布了《How to L…...

【实测有效】Edge浏览器打开部分pdf文件显示空白
问题现象 Edge浏览器打开部分pdf文件显示空白或显示异常。 问题原因 部分pdf文件与edge浏览器存在兼容性问题,打开显示异常。 解决办法 法1:修改edge配置 打开edge浏览器&#x…...

RJ连接器的未来:它还会是网络连接的主流标准吗?
RJ连接器作为以太网接口的代表,自20世纪以来在计算机网络、通信设备、安防系统等领域中占据了核心地位。以RJ45为代表的RJ连接器,凭借其结构稳定、信号传输可靠、成本低廉等优势,在有线网络布线领域被广泛采用。然而,在无线网络不…...

Redis持久化机制详解:保障数据安全的关键策略
在现代应用开发中,Redis作为高性能的内存数据库被广泛使用。然而,内存的易失性特性使得持久化成为Redis设计中的关键环节。本文将全面剖析Redis的持久化机制,包括RDB、AOF以及混合持久化模式,帮助开发者根据业务需求选择最适合的持…...
:备份MySQL数据库表)
shell脚本练习(6):备份MySQL数据库表
一、脚本编写 编写脚本如下: #!/bin/bash# 系统数据库 SYS_DB"information_schema|mysql|performance_schema|sys"# 需要备份的数据库 DBmysql -N -e "show databases" | egrep -v $SYS_DBfor i in $DB;do# 备份的路径BAK_PATH"/server/…...

深度学习模型基本框架
简介: 归纳了一套基本框架,以帮助使用者快速创建新的模型,同时有paddlepaddle版本和pytorch版本的,它们虽有差别,但是对于初级使用者,只是两种不同但是很相近的语法而已。都采用paddle平台作为载体来存项目…...

[Java][Leetcode middle] 134. 加油站
方法一,自己想的,超时 双重循环 从第一个点开始循环尝试, 如果最终能走到终点,说明可行。 public int canCompleteCircuit(int[] gas, int[] cost) {int res -1;int n gas.length;int remainGas;int j;for (int i 0; i < …...
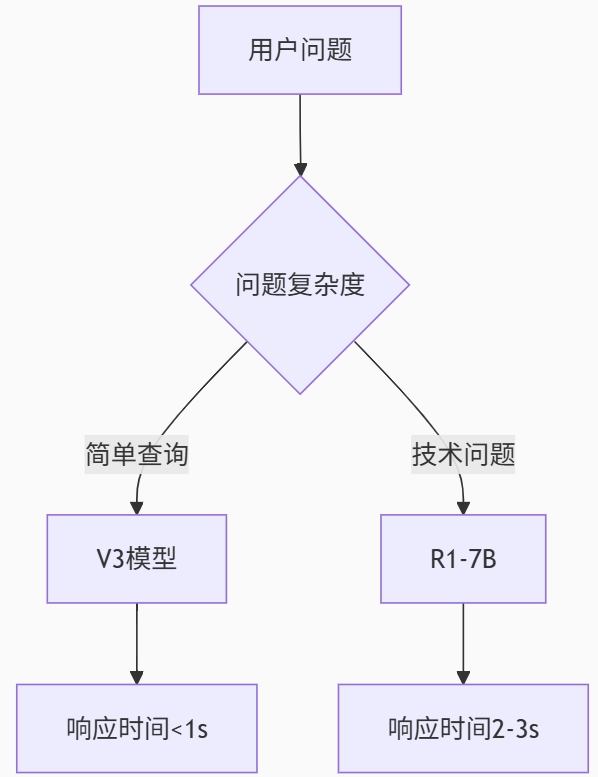
DeepSeek 大模型部署全指南:常见问题、优化策略与实战解决方案
DeepSeek 作为当前最热门的开源大模型之一,其强大的语义理解和生成能力吸引了大量开发者和企业关注。然而在实际部署过程中,无论是本地运行还是云端服务,用户往往会遇到各种技术挑战。本文将全面剖析 DeepSeek 部署中的常见问题,提…...