RAG数据处理:PDF/HTML
RAG而言用户输入的数据通常是各种各样文档,本文主要采用langchain实现PDF/HTML文档的处理方法
PDF文档解析
PDF文档很常见格式,但内部结构常常较复杂:
- 复杂的版式布局
- 多样的元素(段落、表格、公式、图片等)
- 文本流无法直接获取
- 特殊元素如页眉页脚、侧边栏
主流分为两类:
- 基于规则匹配(实战不常用,效果差)
技巧:转md
在实际应用中,我们经常会遇到这样的情况:
- PDF文档中的数学公式在导入知识库过程中变成乱码
- 解析过程极慢,特别是对于包含大量公式的长文档
几乎所有主流大模型都原生支持Markdown格式,它们的输出也多采用Markdown,因此我们可以考虑选择将pdf识别前转为md格式。现在主流方法采用MinerU(star33k)
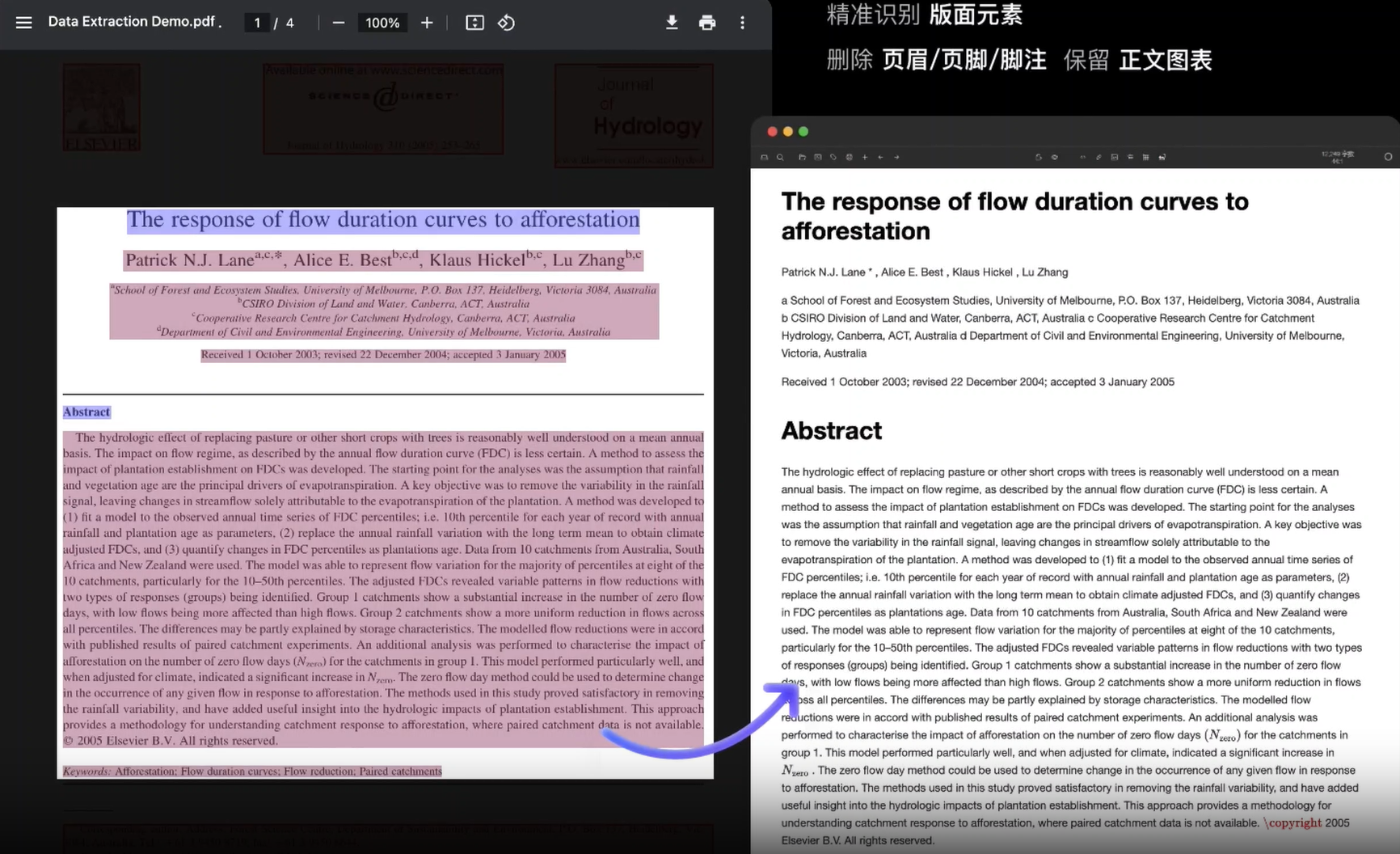
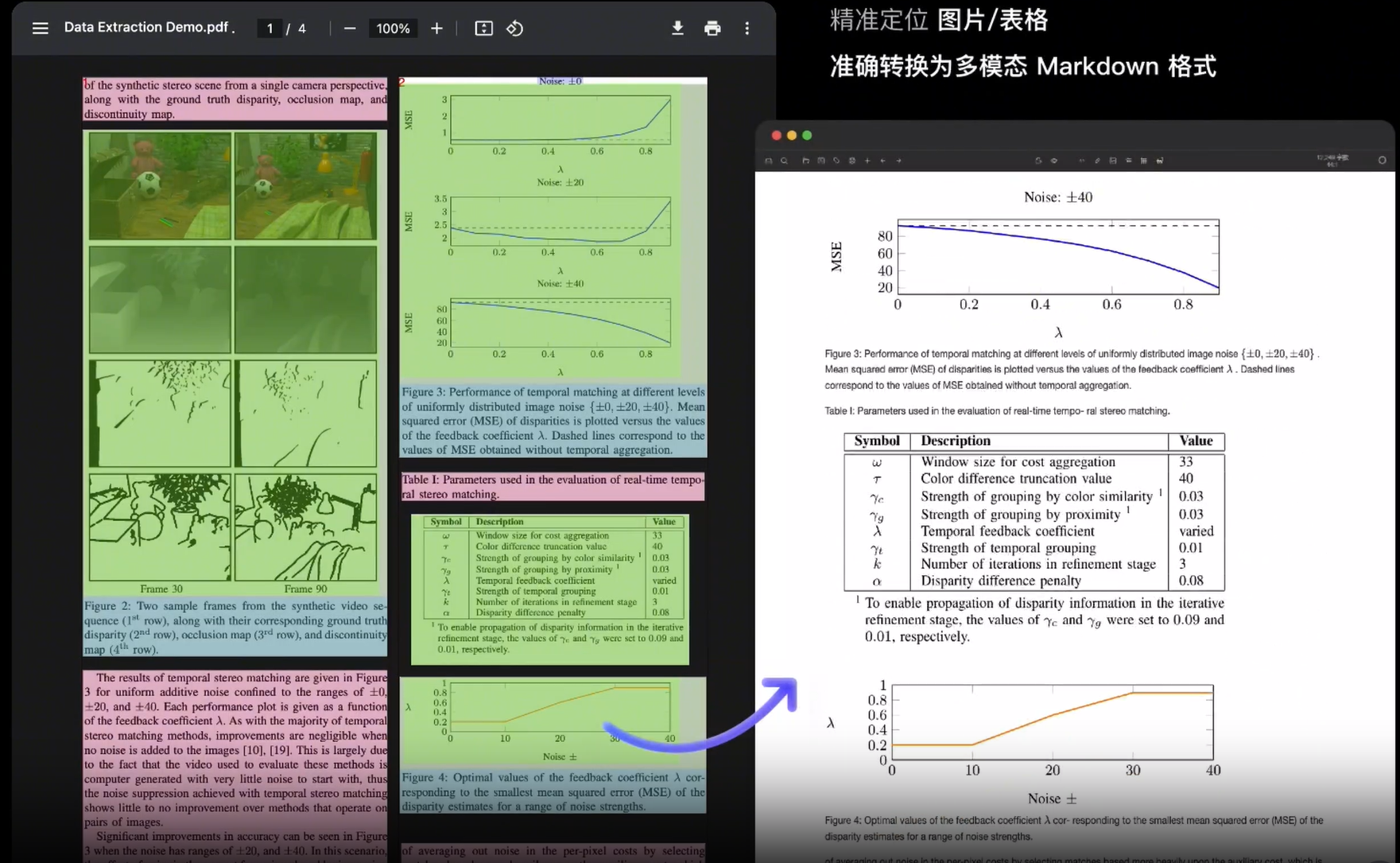
常规电子版解析
pdfplumber 对中文支持较好,且在表格解析方面表现优秀,但对双拦文本的解析能力较差;pdfminer 和 PyMuPDF 对中文支持良好,但表格解析效果较弱;PyPDF2 对英文支持较好,但中文支持较差;papermage集成了pdfminer 和其他工具,特引适合处理论文场景。开发者可以根据实际业务场景的测试结果选择合适的工具odfplumber 或 pdfminer 都是兰不错的选择。
-
PyMuPDF (fitz):功能强大的PDF解析库,支持文本提取、表格识别和版面分析。
-
LangChain中的解析器:
- PyMuPDFLoader:基于PyMuPDF的封装,可提取文本和图片
-
基于机器视觉的解析工具:
- 深度学习方案:如百度飞桨的PP-Structure、上海AI实验室的MADU
- 商业解决方案:如PDFPlumber、LlamaIndex的LlamaParse
代码示例
# 使用LangChain的PyMuPDFLoader
from langchain.document_loaders import PyMuPDFLoaderloader = PyMuPDFLoader("example.pdf")
documents = loader.load()# 直接使用PyMuPDF进行高级解析
import fitz # PyMuPDF# 打开PDF
doc = fitz.open("example.pdf")# 提取所有文本(按页)
for page_num, page in enumerate(doc):text = page.get_text()print(f"页面 {page_num + 1}:\n{text}\n")# 提取表格
for page_num, page in enumerate(doc):tables = page.find_tables()for i, table in enumerate(tables):# 转换为pandas DataFramedf = table.to_pandas()print(f"页面 {page_num + 1}, 表格 {i + 1}:\n{df}\n")# 提取图片
for page_num, page in enumerate(doc):image_list = page.get_images(full=True)for img_index, img in enumerate(image_list):xref = img[0] # 图片的xref(引用号)image = doc.extract_image(xref)# 可以保存图片或进行进一步处理print(f"页面 {page_num + 1}, 图片 {img_index + 1}: {image['ext']}")
含图片电子版解析
基于深度学习匹配
比规则匹配有更好的效果
Layout-parser、Pp-StructureV2、PDF-Extract-Kit、pix2text、MinerU、 marker
HTML文档解析
HTML是网页的标准标记语言,包含文本、图片、视频等多种内容,通过不同标签组织。
常用解析工具
-
Beautiful Soup:Python中最常用的HTML解析库,能通过标签和CSS选择器精确提取内容。
-
LangChain中的解析器:
- WebBaseLoader:结合urllib和Beautiful Soup,先下载HTML再解析
- BSHTMLLoader:直接解析本地HTML文件
代码示例
# 使用LangChain的WebBaseLoader解析网页
from langchain.document_loaders import WebBaseLoaderloader = WebBaseLoader("https://example.com")
documents = loader.load()# 使用Beautiful Soup定制解析
from bs4 import BeautifulSoup
import requestsresponse = requests.get("https://example.com")
soup = BeautifulSoup(response.text, "html.parser")# 提取所有代码块
code_blocks = soup.find_all("div", class_="highlight")
for block in code_blocks:print(block.get_text())# 提取所有标题和段落
content = []
for heading in soup.find_all(["h1", "h2", "h3"]):content.append({"type": "heading", "text": heading.get_text()})# 获取标题后的段落for p in heading.find_next_siblings("p"):if p.find_next(["h1", "h2", "h3"]) == p:breakcontent.append({"type": "paragraph", "text": p.get_text()})
进阶技巧
对于复杂的HTML页面,可以考虑以下策略:
- 使用CSS选择器精确定位元素
- 识别并过滤导航栏、广告等无关内容
- 保留文档结构(标题层级关系)
- 特殊处理表格、代码块等结构化内容
基于深度学习的通用文档解析:以DeepDoc为例
传统的解析方法各有局限,近年来基于深度学习的文档解析技术取得了突破性进展。DeepDoc(来自RapidocAI)是一个典型代表,它采用机器视觉方式解析文档。
DeepDoc的工作流程
- 文档转图像:将PDF等文档转换为图像
- OCR文本识别:识别图像中的文本内容
- 布局分析:使用专门模型识别文档布局结构
- 表格识别与解析:使用TSR(Table Structure Recognition)模型解析表格
- 内容整合:将识别的各部分内容整合成结构化数据
代码示例
# 使用DeepDoc进行文档解析
from rapidocr import RapidOCR
from deepdoc import LayoutAnalyzer, TableStructureRecognizer# 初始化模型
ocr = RapidOCR()
layout_analyzer = LayoutAnalyzer()
table_recognizer = TableStructureRecognizer()# 文档OCR
image_path = "document.png" # 可以是PDF转换的图像
ocr_result = ocr.recognize(image_path)
texts, positions = ocr_result# 布局分析
layout_result = layout_analyzer.analyze(image_path)
# 识别出的布局元素:标题、段落、表格、图片等
elements = layout_result["elements"]# 处理识别到的表格
for element in elements:if element["type"] == "table":table_image = element["image"]# 表格结构识别table_result = table_recognizer.recognize(table_image)# 表格数据可转换为CSV或DataFrametable_data = table_result["data"]# 整合所有内容
document_content = []
for element in sorted(elements, key=lambda x: x["position"]):if element["type"] == "title":document_content.append({"type": "title", "text": element["text"]})elif element["type"] == "paragraph":document_content.append({"type": "paragraph", "text": element["text"]})elif element["type"] == "table":document_content.append({"type": "table", "data": element["table_data"]})# 其他类型元素...
DeepDoc的优势
- 多格式支持:可处理PDF、Word、Excel、PPT、HTML等多种格式
- 结构保留:准确识别文档的层次结构和布局
- 表格处理:精确解析复杂表格,包括合并单元格
- 图像处理:可提取和关联文档中的图像内容
- 多语言支持:支持中英文等多种语言的文档解析
通用文档解析:Unstructured库
对于需要处理多种文档格式但又不想为每种格式单独编写解析代码的场景,Unstructured库提供了统一的解决方案。
Unstructured的工作原理
Unstructured可自动识别文件格式,并调用相应的解析器提取内容,支持多种常见文档格式。
代码示例
from unstructured.partition.auto import partition# 自动识别文件格式并解析
elements = partition("document.pdf") # 也可以是docx, pptx, html等# 提取所有文本元素
text_elements = [el for el in elements if hasattr(el, "text")]
for element in text_elements:print(element.text)# 根据元素类型处理
from unstructured.partition.html import partition_html
from unstructured.chunking.title import chunk_by_title# HTML特定解析
html_elements = partition_html("document.html")# 按标题分块
chunks = chunk_by_title(elements)
for chunk in chunks:print(f"标题: {chunk.title}")print(f"内容: {chunk.text}")
构建文档处理管道
在实际的RAG系统中,我们通常需要构建完整的文档处理管道,将解析、清洗、分块等步骤串联起来。
完整处理流程示例
import os
from typing import List, Dict, Any
from langchain.document_loaders import PyMuPDFLoader, WebBaseLoader, UnstructuredExcelLoader
from langchain.text_splitter import RecursiveCharacterTextSplitterdef process_document(file_path: str) -> List[Dict[str, Any]]:"""处理各种格式的文档,返回标准化的文档块"""# 根据文件扩展名选择合适的加载器ext = os.path.splitext(file_path)[1].lower()if ext == ".pdf":loader = PyMuPDFLoader(file_path)elif ext == ".html" or ext == ".htm":# 假设是本地HTML文件with open(file_path, "r", encoding="utf-8") as f:content = f.read()loader = WebBaseLoader(file_path)elif ext in [".xlsx", ".xls"]:loader = UnstructuredExcelLoader(file_path)else:# 对于其他格式,使用Unstructuredfrom langchain.document_loaders import UnstructuredFileLoaderloader = UnstructuredFileLoader(file_path)# 加载文档documents = loader.load()# 文本清洗(去除多余空格、特殊字符等)cleaned_documents = []for doc in documents:text = doc.page_content# 基本清洗text = text.replace("\n\n", " ").replace("\t", " ")text = ' '.join(text.split()) # 规范化空格# 更新文档doc.page_content = textcleaned_documents.append(doc)# 文本分块text_splitter = RecursiveCharacterTextSplitter(chunk_size=1000,chunk_overlap=200,separators=["\n\n", "\n", ". ", " ", ""])chunks = text_splitter.split_documents(cleaned_documents)# 转换为标准格式processed_chunks = []for chunk in chunks:processed_chunks.append({"text": chunk.page_content,"metadata": chunk.metadata,"source": file_path,"chunk_id": f"{os.path.basename(file_path)}_{chunks.index(chunk)}"})return processed_chunks# 使用示例
pdf_chunks = process_document("example.pdf")
html_chunks = process_document("example.html")
excel_chunks = process_document("example.xlsx")# 合并所有文档的处理结果
all_chunks = pdf_chunks + html_chunks + excel_chunks# 现在可以将这些块用于向量化和索引
相关文章:
RAG数据处理:PDF/HTML
RAG而言用户输入的数据通常是各种各样文档,本文主要采用langchain实现PDF/HTML文档的处理方法 PDF文档解析 PDF文档很常见格式,但内部结构常常较复杂: 复杂的版式布局多样的元素(段落、表格、公式、图片等)文本流无…...

机器学习 day04
文章目录 前言一、线性回归的基本概念二、损失函数三、最小二乘法 前言 通过今天的学习,我掌握了机器学习中的线性回归的相关基本概念,包括损失函数的概念,最小二乘法的理论与算法实现。 一、线性回归的基本概念 要理解什么是线性回归&…...

蓝牙耳机什么牌子好?倍思值得冲不?
最近总被问“蓝牙耳机什么牌子好”,作为踩过无数坑的资深耳机党,必须安利刚入手的倍思M2s Pro主动降噪蓝牙耳机!降噪、音质、颜值全都在线,性价比直接拉满。 -52dB降噪,通勤摸鱼神器 第一次开降噪就被惊到!…...

机器学习-人与机器生数据的区分模型测试-数据处理 - 续
这里继续 机器学习-人与机器生数据的区分模型测试-数据处理1的内容 查看数据 中1的情况 #查看数据1的分布情况 one_ratio_list [] for col in data.columns:if col city or col target or col city2: # 跳过第一列continueelse:one_ratio data[col].mean() # 计算1值占…...
ESP系列单片机选择指南:结合实际场景的最优选择方案
前言 在物联网(IoT)快速发展的今天,ESP系列单片机凭借其优异的无线连接能力和丰富的功能特性,已成为智能家居、智慧农业、工业自动化等领域的首选方案。本文将深入分析各款ESP芯片的特点,结合典型应用场景,帮助开发者做出最优选择…...

特斯拉虚拟电厂:能源互联网时代的分布式革命
在双碳目标与能源转型的双重驱动下,特斯拉虚拟电厂(Virtual Power Plant, VPP)通过数字孪生技术与能源系统的深度融合,重构了传统电力系统的运行范式。本文从系统架构、工程实践、技术挑战三个维度,深度解析这一颠覆性…...
openjdk17 c++源码垃圾回收之安全点结束,唤醒线程)
jvm安全点(三)openjdk17 c++源码垃圾回收之安全点结束,唤醒线程
1. VMThread::inner_execute() - 触发安全点 cpp 复制 void VMThread::inner_execute(VM_Operation* op) { if (op->evaluate_at_safepoint()) { SafepointSynchronize::begin(); // 进入安全点,阻塞所有线程 // ...执行GC等操作... SafepointSynchronize::…...

Python OOP核心技巧:如何正确选择实例方法、类方法和静态方法
Python方法类型全解析:实例方法、类方法与静态方法的使用场景 一、三种方法的基本区别二、访问能力对比表三、何时使用实例方法使用实例方法的核心场景:具体应用场景:1. 操作实例属性2. 对象间交互3. 实现特定实例的行为 四、何时使用类方法使…...
【Linux笔记】nfs网络文件系统与autofs(nfsdata、autofs、autofs.conf、auto.master)
一、nfs概念 NFS(Network File System,网络文件系统) 是一种由 Sun Microsystems 于1984年开发的分布式文件系统协议,允许用户通过网络访问远程计算机上的文件,就像访问本地文件一样。它广泛应用于 Unix/Linux 系统&a…...
博客打卡-求解流水线调度
题目如下: 有n个作业(编号为1~n)要在由两台机器M1和M2组成的流水线上完成加工。每个作业加工的顺序都是先在M1上加工,然后在M2上加工。M1和M2加工作业i所需的时间分别为ai和bi(1≤i≤n)。 流水…...

基于React的高德地图api教程006:两点之间距离测量
文章目录 6、距离测量6.1 两点之间距离测量6.1.1 两点距离测量按钮6.1.2 点击地图添加点6.1.3 测量两点之间距离并画线6.2 测量过程显示两点之间预览线6.3 绘制完毕6.4 显示清除按钮6.5 代码下载6.06、距离测量 6.1 两点之间距离测量 6.1.1 两点距离测量按钮 实现代码: re…...

数据库blog1_信息(数据)的处理与效率提升
🌿信息的处理 🍂实际中离不开信息处理 ● 解决问题的建模 任何对问题的处理都可以看作数据的输入、处理、输出。 eg.一个项目中,用户点击信息由前端接收传递到后端处理后返回结果eg.面对一个问题,我们在搜集信息后做出处理与分析…...
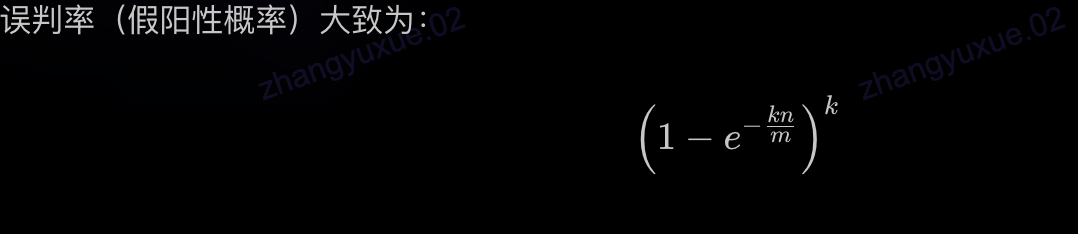
布隆过滤器介绍及其在大数据场景的应用
目录 布隆过滤器(Bloom Filter)介绍一、布隆过滤器的基本原理插入元素过程:查询元素过程: 二、布隆过滤器的特点三、误判率计算四、举例说明五、总结 Python版的简单布隆过滤器实现示例一、简单布隆过滤器Python示例二、布隆过滤器…...

Ansys 计算刚柔耦合矩阵系数
Ansys 计算刚柔耦合系数矩阵 文章目录 Ansys 计算刚柔耦合系数矩阵卫星的刚柔耦合动力学模型采用 ANSYS 的 APDL 语言的计算方法系统转动惯量的求解方法参考文献 卫星的刚柔耦合动力学模型 柔性航天器的刚柔耦合动力学模型可以表示为 m v ˙ B t r a n η F J ω ˙ ω J…...
)
微服务八股(自用)
微服务 SpringCloud 注册中心:Eureka 负载均衡:Ribbon 远程调用:Feign 服务熔断:Hystrix 网关:Gateway/Zuul Alibaba 配置中心:Nacos 负载均衡:Ribbon 服务调用:Feign 服务…...

指定elf文件dwarf 版本以及查看dwarf版本号
背景: 在实际项目开发过程中,为了让低版本的CANape 工具识别elf 文件,需要在编译elf文件时,指定dwarf的版本。 使用方法: 需要再CMakeLists.txt中指定dwarf 版本 add_compile_options(-g -gdwarf-2) #-gdwarf-4 验…...
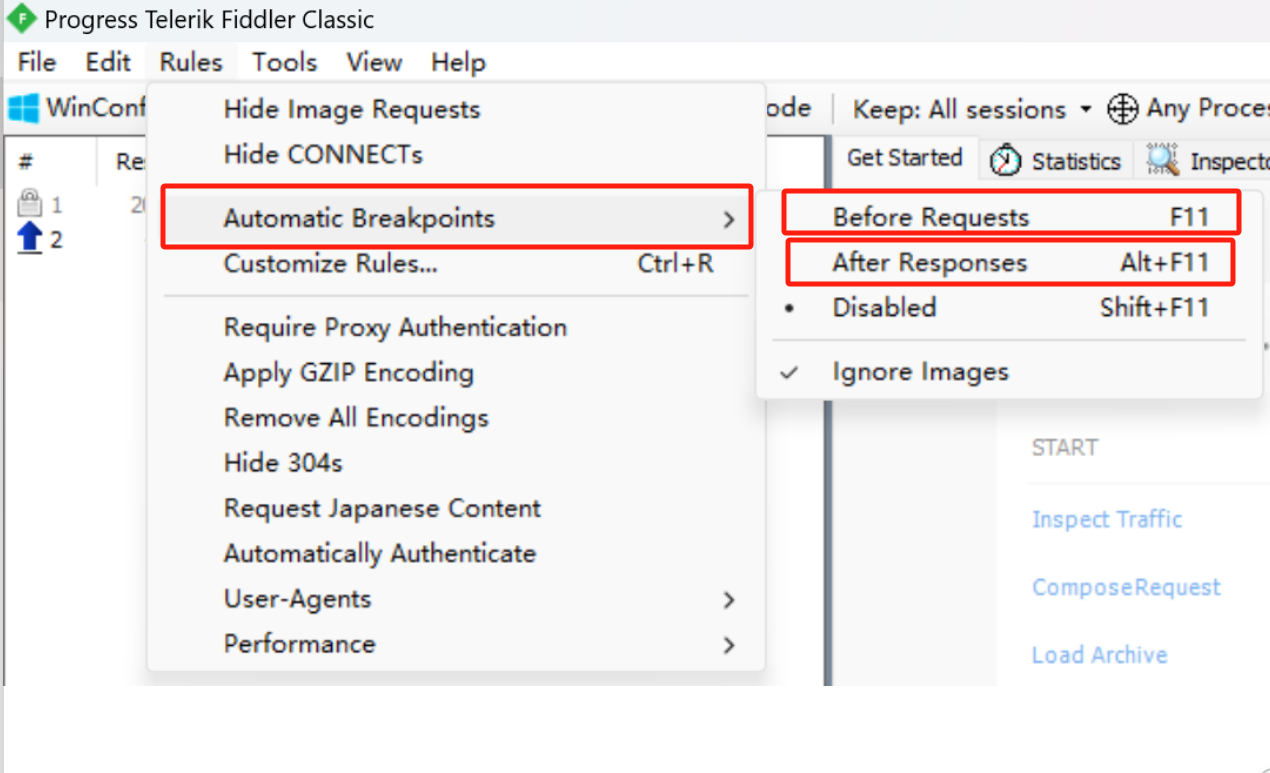
Fidder基本操作
1.抓取https请求 Fidder默认不能抓取https请求,我们必须通过相应的设置才能抓取https请求 1.选择tools下的option 2.选择https选项,并且勾选下面的选项 3.点击Actions导出信任证书到桌面(expert root certificate to desktop) 4.在浏览器中添加对应的证…...
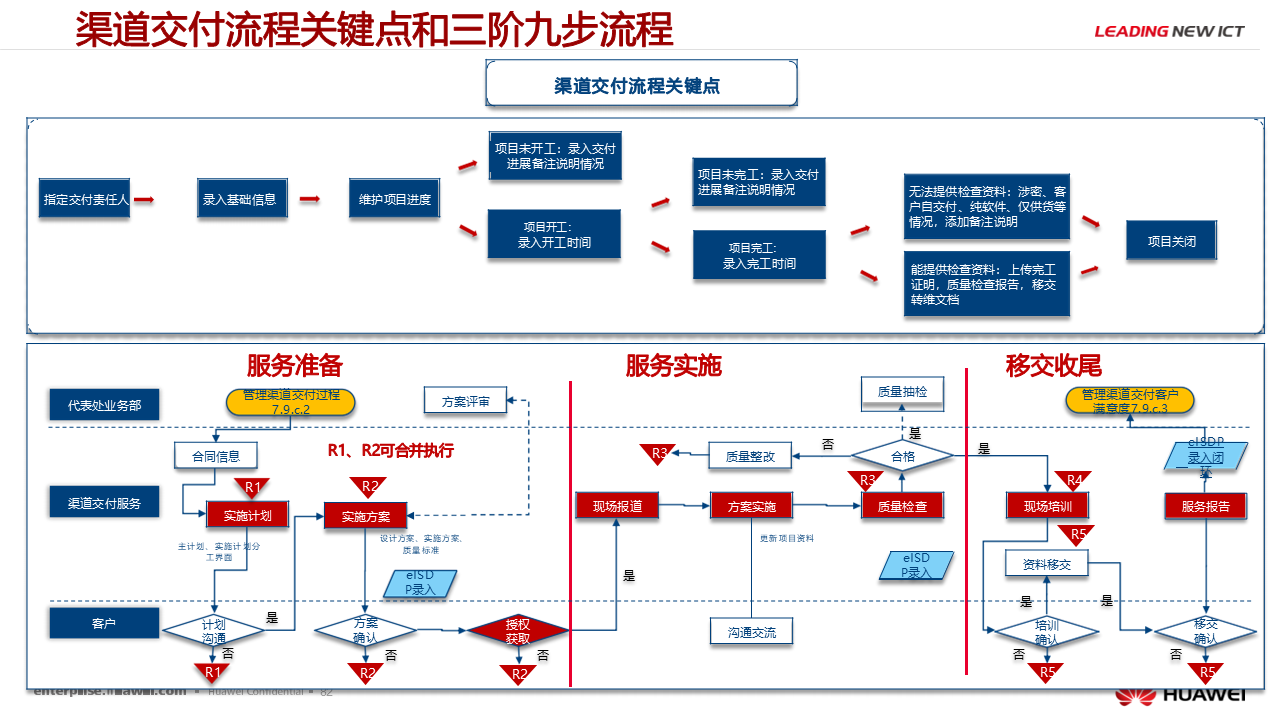
项目管理进阶:精读 78页华为项目管理高级培训教材【附全文阅读】
本文概述了华为项目管理(高级)课程的学习目标及学习方法。学习该课程后,学员应能: 1. **深刻理解项目管理**:掌握项目管理的基本概念与方法,构建项目管理思维框架。 2. **应用IBEST理念**:结合I…...
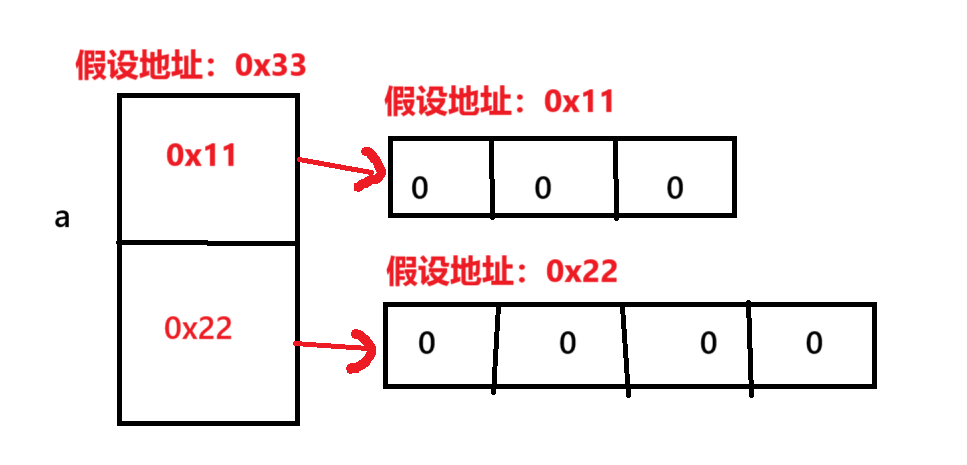
[Java] 方法和数组
目录 1. 方法 1.2 什么是方法 1.2 方法的定义 1.3 方法的调用 1.4 方法的重载 1.5 递归 2. 一维数组 2.1 什么是数组 2.2 数组的创建 2.3 数组的初始化 2.4 遍历数组 2.5 引用数据类型 2.6 关于null 2.7 数组转字符串 2.8 数组元素的查找 2.9 数组的排序 2.10…...

微软家各种copilot的AI产品:Github copilot、Microsoft copilot
背景 大家可能听到很多copilot,比如 Github Copilot,Microsoft Copilot、Microsoft 365 Copilot,有什么区别 Github Copilot:有网页版、有插件(idea、vscode等的插件),都是面向于程序员的。Mi…...
)
KL散度 (Kullback-Leibler Divergence)
KL散度,也称为相对熵 (Relative Entropy),是信息论中一个核心概念,用于衡量两个概率分布之间的差异。给定两个概率分布 P ( x ) P(x) P(x) 和 Q ( x ) Q(x) Q(x)(对于离散随机变量)或 p ( x ) p(x) p(x) 和 q ( x …...

深入解析:java.sql.SQLException: No operations allowed after statement closed 报错
在 Java 应用程序开发过程中,尤其是涉及数据库交互时,开发者常常会遇到各种各样的异常。其中,java.sql.SQLException: No operations allowed after statement closed是一个较为常见且容易令人困惑的错误。本文将深入剖析这一报错,…...

DAY 23 训练
DAY 23 训练 DAY23 机器学习管道 pipeline基础概念转换器(Transformer)估计器(Estimator) 管道(Pipeline)代码演示没有 pipeline 的代码pipeline 的代码教学导入库和数据加载分离特征和标签,划分…...

wordcount程序
### 在 IntelliJ IDEA 中编写和运行 Spark WordCount 程序 要使用 IntelliJ IDEA 编写并运行 Spark 的 WordCount 程序,需按照以下流程逐步完成环境配置、代码编写以及任务提交。 --- #### 1. **安装与配置 IntelliJ IDEA** 确保已正确安装 IntelliJ IDEA&#x…...
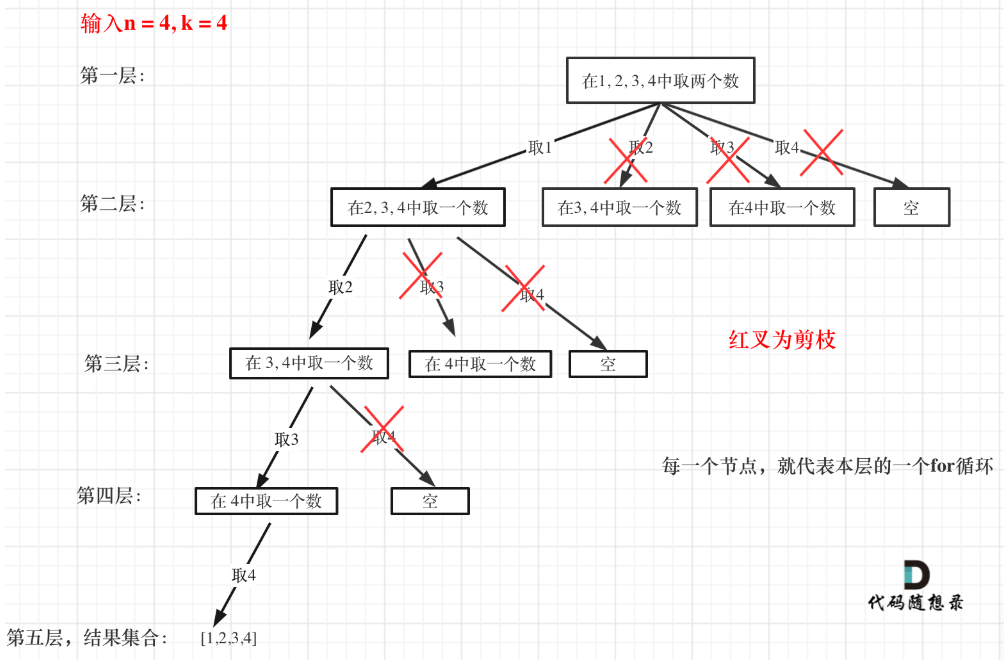
回溯法理论基础 LeetCode 77. 组合 LeetCode 216.组合总和III LeetCode 17.电话号码的字母组合
目录 回溯法理论基础 回溯法 回溯法的效率 用回溯法解决的问题 如何理解回溯法 回溯法模板 LeetCode 77. 组合 回溯算法的剪枝操作 LeetCode 216.组合总和III LeetCode 17.电话号码的字母组合 回溯法理论基础 回溯法 回溯法也可以叫做回溯搜索法,它是一…...
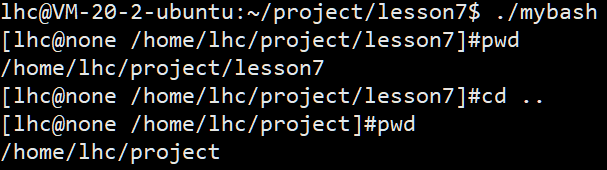
【进程控制二】进程替换和bash解释器
【进程控制二】进程替换 1.exec系列接口2.execl系列2.1execl接口2.2execlp接口2.3execle 3.execv系列3.1execv3.2总结 4.实现一个bash解释器4.1内建命令 通过fork创建的子进程,会继承父进程的代码和数据,因此本质上还是在执行父进程的代码 进程替换可以将…...

线性回归策略
一种基于ATR(平均真实范围)、线性回归和布林带的交易策略。以下是对该策略的全面总结和分析: 交易逻辑思路 1. 过滤条件: - 集合竞价过滤:在每个交易日的开盘阶段,过滤掉集合竞价产生的异常数据。 - 价格异常过滤:排除当天开盘价与最高价或最低价相同的情况,这…...

Linux下的c/c++开发之操作Redis数据库
C/C 操作 Redis 的常用库 在 C/C 开发中操作 Redis 有多种方式,最主流的选择是使用第三方客户端库。由于 Redis 官方本身是使用 C 编写的,提供的 API 非常适合 C/C 调用。常见的 Redis C/C 客户端库包括: hiredis:官方推荐的轻量…...

Bitmap、Roaring Bitmap、HyperLogLog对比介绍
一、Bitmap(位图)概述 Bitmap 是一种用位(bit)来表示集合元素是否存在的数据结构。每个位代表一个元素的状态(0或1),非常节省空间且支持快速集合操作。 常见Bitmap类型: 普通Bitmap 最简单的位数组,适合元素范围固定且不稀疏的场景。例如,元素范围是0~1000,用1001…...
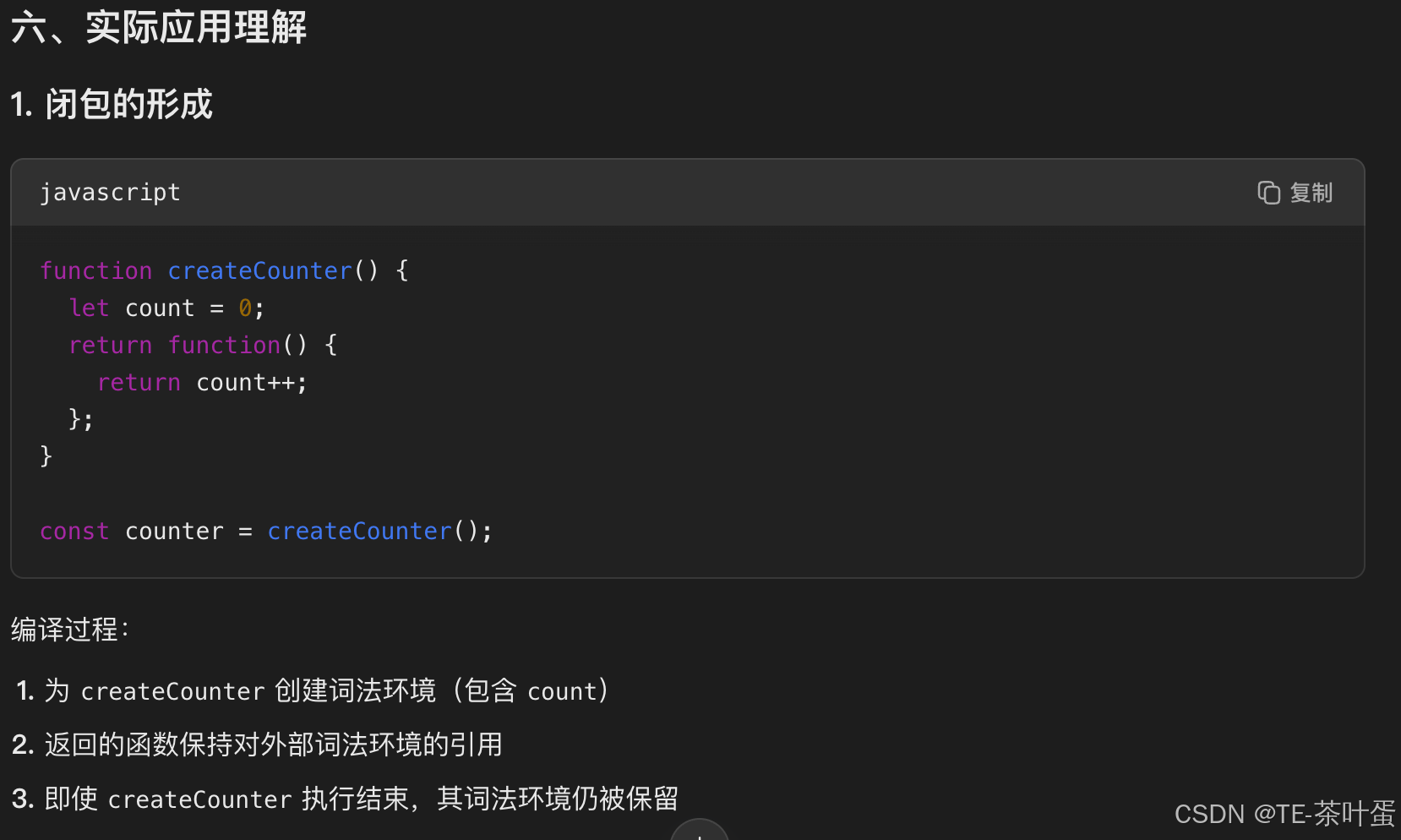
JavaScript 的编译与执行原理
文章目录 前言🧠 一、JavaScript 编译与执行过程1. 编译阶段(发生在代码执行前)✅ 1.1 词法分析(Lexical Analysis)✅ 1.2 语法分析(Parsing)✅ 1.3 语义分析与生成执行上下文 🧰 二…...