pytorch小记(二十二):全面解读 PyTorch 的 `torch.cumprod`——累积乘积详解与实战示例
pytorch小记(二十二):全面解读 PyTorch 的 `torch.cumprod`——累积乘积详解与实战示例
- 一、函数签名与参数说明
- 二、基础用法
- 1. 一维张量累积乘积
- 2. 二维张量按行/按列累积
- 三、`dtype` 参数:避免整数溢出与提升精度
- 四、典型应用场景
- 1. 几何序列生成
- 2. 概率分布的累积乘积
- 3. 模型门控或权重衰减
- 五、进阶示例:预分配 `out` 张量
- 六、小结
在深度学习与科学计算中,往往需要沿某个维度追踪“前面所有元素的乘积”,比如几何序列计算、概率分布构建、模型门控/权重衰减等场景。PyTorch 提供的 torch.cumprod 函数可以一行代码搞定这一需求。本文将从函数签名、参数含义、基础用法,到进阶示例、典型应用场景,为你带来最全面的讲解,并附上丰富示例助你快速上手。
一、函数签名与参数说明
torch.cumprod(input: Tensor,dim: int,*,dtype: Optional[torch.dtype] = None,out: Optional[Tensor] = None
) → Tensor
input:任意维度的输入张量。dim:指定沿哪个维度做累积乘积(0表示第一个维度,以此类推)。dtype(可选):输出张量的数据类型。如果原张量为整数且会溢出,可通过将其提升到更宽数据类型来避免溢出。out(可选):预先分配好的张量,用于存储输出,避免额外内存分配。
二、基础用法
1. 一维张量累积乘积
import torchx = torch.tensor([1, 2, 3, 4])
y = torch.cumprod(x, dim=0)
print(y) # tensor([ 1, 2, 6, 24])
y[0] = 1y[1] = 1 * 2 = 2y[2] = 1 * 2 * 3 = 6y[3] = 1 * 2 * 3 * 4 = 24
2. 二维张量按行/按列累积
x2 = torch.tensor([[1, 2, 3],[4, 5, 6]])
# 沿行(dim=1)累积
row_prod = torch.cumprod(x2, dim=1)
print(row_prod)
# tensor([[ 1, 2, 6],
# [ 4, 20, 120]])# 沿列(dim=0)累积
col_prod = torch.cumprod(x2, dim=0)
print(col_prod)
# tensor([[1, 2, 3],
# [4, 10, 18]])
三、dtype 参数:避免整数溢出与提升精度
当 input 为大整数且乘积超出类型范围时,会导致溢出。此时可指定更宽的数据类型:
x_int = torch.tensor([1000, 1000, 1000], dtype=torch.int32)
# 默认 int32 会溢出
print(torch.cumprod(x_int, dim=0))
# tensor([1000, -727, -728], dtype=torch.int32)# 改为 int64 避免溢出
print(torch.cumprod(x_int, dim=0, dtype=torch.int64))
# tensor([ 1000, 1000000, 1000000000])
四、典型应用场景
1. 几何序列生成
几何序列 a , a r , a r 2 , … a, ar, ar^2, … a,ar,ar2,… 可用累积乘积实现:
a, r, n = 2.0, 0.5, 5
ratios = torch.full((n,), r) # [r, r, r, r, r]
geom = a * torch.cumprod(ratios, dim=0)
print(geom)
# tensor([1.0000, 0.5000, 0.2500, 0.1250, 0.0625])
2. 概率分布的累积乘积
在构建离散分布的乘积模型时,用累乘来得到联合概率:
probs = torch.tensor([0.2, 0.3, 0.5])
# 标准化(确保和为1)
probs = probs / probs.sum()
# 获取依次乘积(注意:乘积非累加,因此并非 CDF)
joint = torch.cumprod(probs, dim=0)
print(joint)
# tensor([0.2000, 0.0600, 0.0300])
3. 模型门控或权重衰减
在 RNN、Transformer 等模型中,若需要对前 n 层或时间步做指数衰减,可用累积乘积计算衰减系数:
decay_rates = torch.linspace(0.9, 0.5, steps=4) # 每层不同衰减率
coeffs = torch.cumprod(decay_rates, dim=0) # 累积得到层间总衰减
print(coeffs)
# tensor([0.9000, 0.7200, 0.5040, 0.2520])
五、进阶示例:预分配 out 张量
为了在高性能场景下避免额外内存分配,可以先分配好输出张量,再将结果写入:
x = torch.arange(1, 1001, dtype=torch.float32)
out = torch.empty_like(x)
torch.cumprod(x, dim=0, out=out)
print(out[:5]) # tensor([1., 2., 6., 24., 120.])
六、小结
-
功能:
torch.cumprod沿指定维度计算输入张量的累计乘积,返回新张量。 -
关键参数:
dim:累积轴;dtype:避免整数溢出/提升精度;out:预分配输出提高性能。
-
常见应用:
- 几何序列生成;
- 概率分布乘积;
- 模型门控/权重衰减;
- 其它需要“前缀乘积”场景。
相关文章:
:全面解读 PyTorch 的 `torch.cumprod`——累积乘积详解与实战示例)
pytorch小记(二十二):全面解读 PyTorch 的 `torch.cumprod`——累积乘积详解与实战示例
pytorch小记(二十二):全面解读 PyTorch 的 torch.cumprod——累积乘积详解与实战示例 一、函数签名与参数说明二、基础用法1. 一维张量累积乘积2. 二维张量按行/按列累积 三、dtype 参数:避免整数溢出与提升精度四、典…...
TTS:F5-TTS 带有 ConvNeXt V2 的扩散变换器
1,项目简介 F5-TTS 于英文生成领域表现卓越,发音标准程度在本次评测软件中独占鳌头。再者,官方预设的多角色生成模式独具匠心,能够配置多个角色,一次性为多角色、多情绪生成对话式语音,别出心裁。 最低配置…...
基本概念)
强化学习笔记(一)基本概念
文章目录 1. 强化学习 (Reinforcement Learning, RL) 概述1.1 与监督学习 (Supervised Learning, SL) 的对比监督学习的特点:强化学习的特点: 2. 核心概念与术语2.1 策略 (Policy, π)2.2 价值函数 (Value Function)2.3 模型 (Model)2.4 回报 (Return, G)2.5 其他重要术语 3. 标…...

大型语言模型中的QKV与多头注意力机制解析
每周跟踪AI热点新闻动向和震撼发展 想要探索生成式人工智能的前沿进展吗?订阅我们的简报,深入解析最新的技术突破、实际应用案例和未来的趋势。与全球数同行一同,从行业内部的深度分析和实用指南中受益。不要错过这个机会,成为AI领…...
基于地图的数据可视化:解锁地理数据的真正价值
目录 一、基于地图的数据可视化概述 (一)定义与内涵 (二)重要性与意义 二、基于地图的数据可视化的实现方式 (一)数据收集与整理 (二)选择合适的可视化工具 (三&a…...

利用自适应双向对比重建网络与精细通道注意机制实现图像去雾化技术的PyTorch代码解析
利用自适应双向对比重建网络与精细通道注意机制实现图像去雾化技术的PyTorch代码解析 漫谈图像去雾化的挑战 在计算机视觉领域,图像复原一直是研究热点。其中,图像去雾化技术尤其具有实际应用价值。然而,复杂的气象条件和多种因素干扰使得这…...
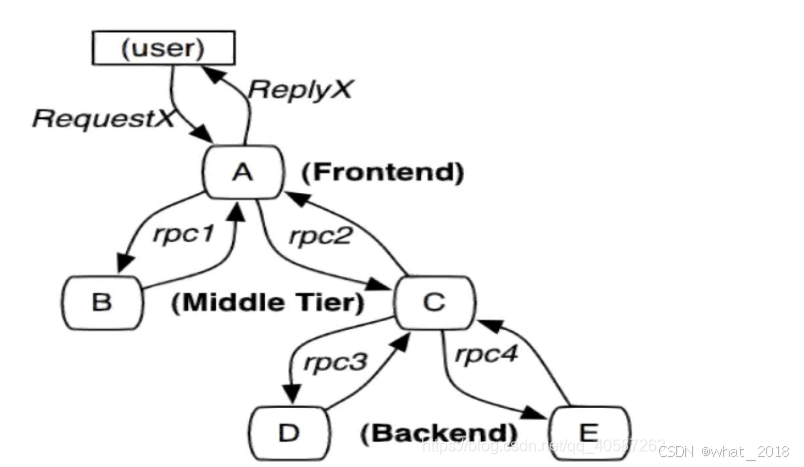
分布式链路跟踪
目录 链路追踪简介 基本概念 基于代理(Agent)的链路跟踪 基于 SDK 的链路跟踪 基于日志的链路跟踪 SkyWalking Sleuth ZipKin 链路追踪简介 分布式链路追踪是一种监控和分析分布式系统中请求流动的方法。它能够记录和分析一个请求在系统中经历的每…...
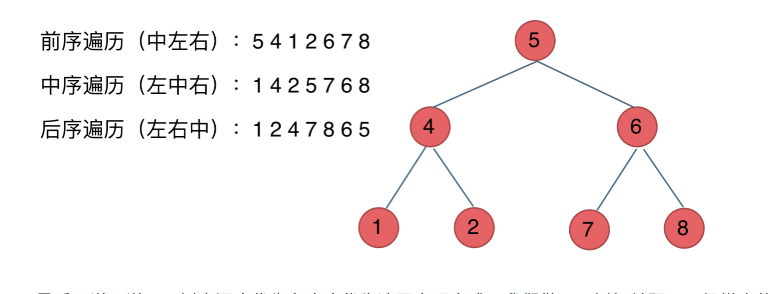
刷leetcodehot100返航版--二叉树
二叉树理论基础 二叉树的种类 满二叉树和完全二叉树,二叉树搜索树 满二叉树 如果一棵二叉树只有度为0的结点和度为2的结点,并且度为0的结点在同一层上,则这棵二叉树为满二叉树。 节点个数2^n-1【n为树的深度】 完全二叉树 在完全二叉树…...

chmod 777含义:
1.chmod 777 的含义及其在文件权限中的作用 chmod 777 是一种用于修改 Unix 和 Linux 系统中文件或目录权限的命令。它赋予指定文件或目录的所有用户(文件所有者、所属组成员以及其他用户)完全的访问权限,即 读取 (Read)、写入 (Write) 和 执…...
:混合检索之混合搜索)
AGI大模型(21):混合检索之混合搜索
为了执行混合搜索,我们结合了 BM25 和密集检索的结果。每种方法的分数均经过标准化和加权以获得最佳总体结果 1 代码 先编写 BM25搜索的代码,再编写密集检索的代码,最后进行混合。 from rank_bm25 import BM25Okapi from nltk.tokenize import word_tokenize import jieb…...

双重差分模型学习笔记4(理论)
【DID最全总结】90分钟带你速通双重差分!_哔哩哔哩_bilibili 目录 总结:双重差分法(DID)在社会科学中的应用:理论、发展与前沿分析 一、DID的基本原理与核心思想 二、经典DID:标准模型与应用案例 三、…...

Mysql 8.0.32 union all 创建视图后中文模糊查询失效
记录问题,最近在使用union all聚合了三张表的数据,创建视图作为查询主表,发现字段值为中文的筛选无法生效.......... sql示例: CREATE OR REPLACE VIEW test_view AS SELECTid,name,location_address AS address,type,"1" AS data_type,COALESCE ( update_time, cr…...
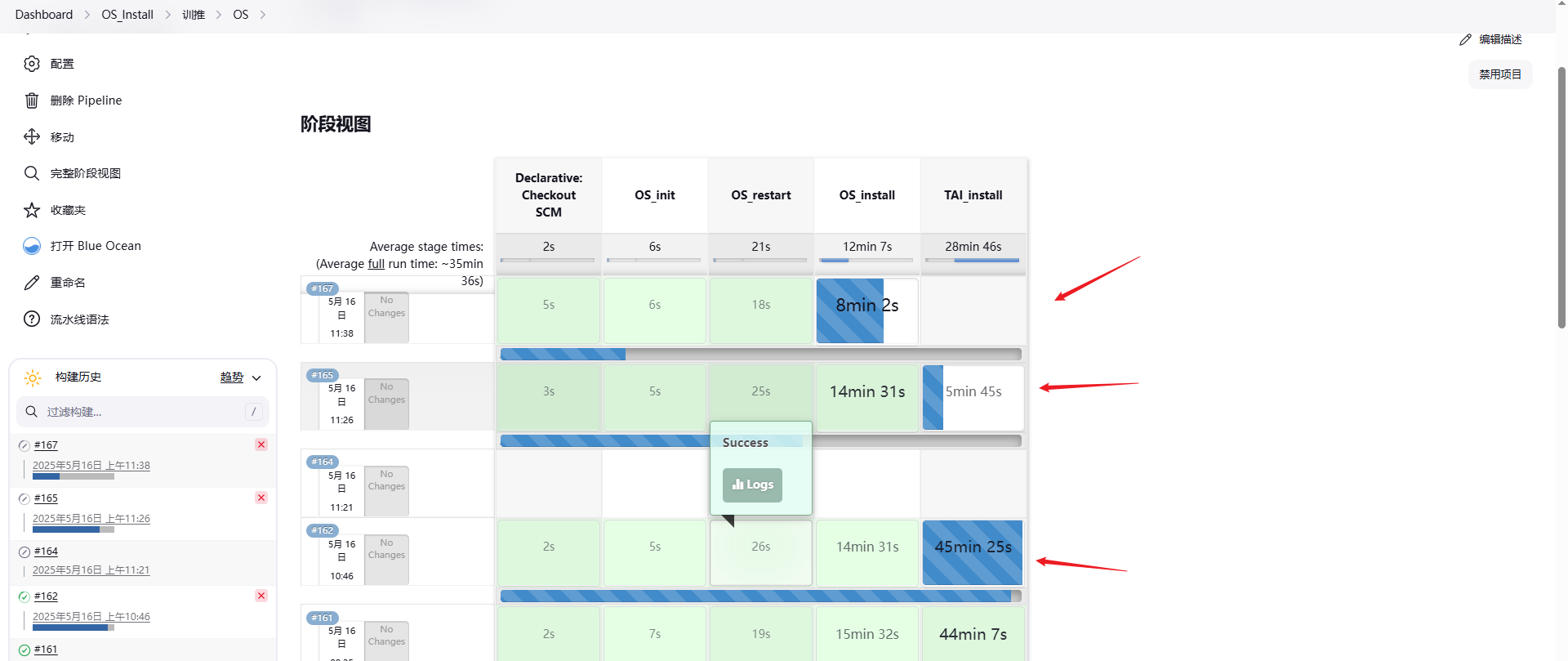
Jenkins 执行器(Executor)如何调整限制?
目录 现象原因解决 现象 Jenkins 构建时,提示如下: 此刻的心情正如上图中的小老头,火冒三丈,但是不要急,因为每一次错误,都是系统中某个环节在说‘我撑不住了’。 原因 其实是上图的提示表示 Jenkins 当…...

Android 中 权限分类及申请方式
在 Android 中,权限被分为几个不同的类别,每个类别有不同的申请和管理方式。 一、 普通权限(Normal Permissions) 普通权限通常不会对用户隐私或设备安全造成太大风险。这些权限在应用安装时自动授予,无需用户在运行时手动授权。 android.permission.INTERNETandroid.pe…...
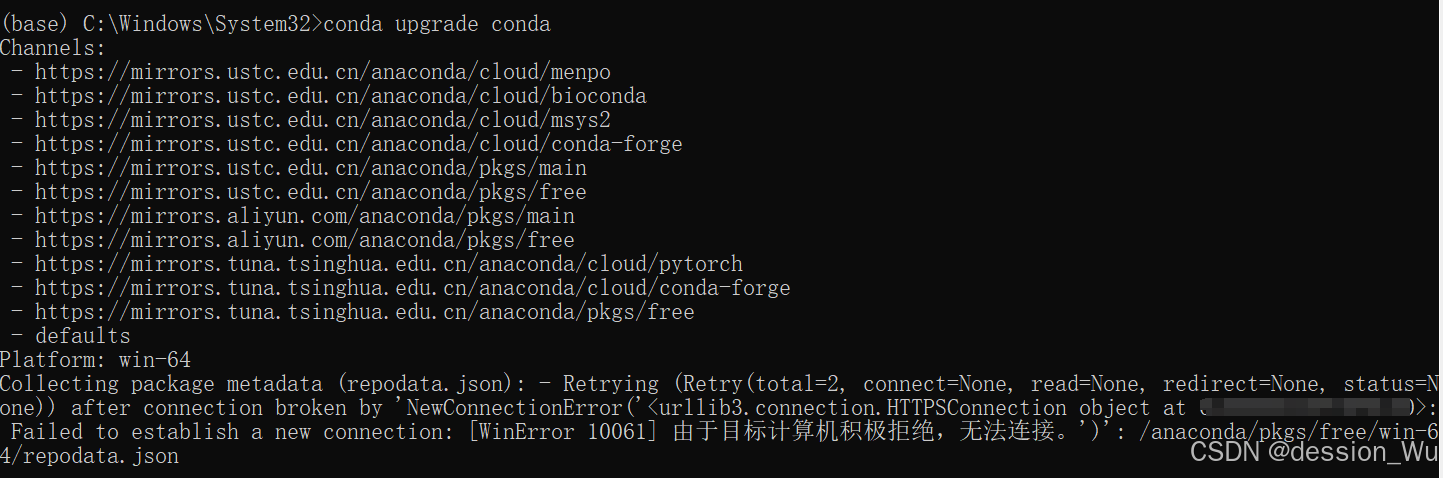
编程错题集系列(一)
编程错题集系列(一) 人生海海,山山而川。 谨以此系列作为自己一路的见证。本期重点:明明已经安装相关库,但在PyCharm中无法调用 最大的概率是未配置合适的解释器,也就是你的书放在B房间,你在A…...
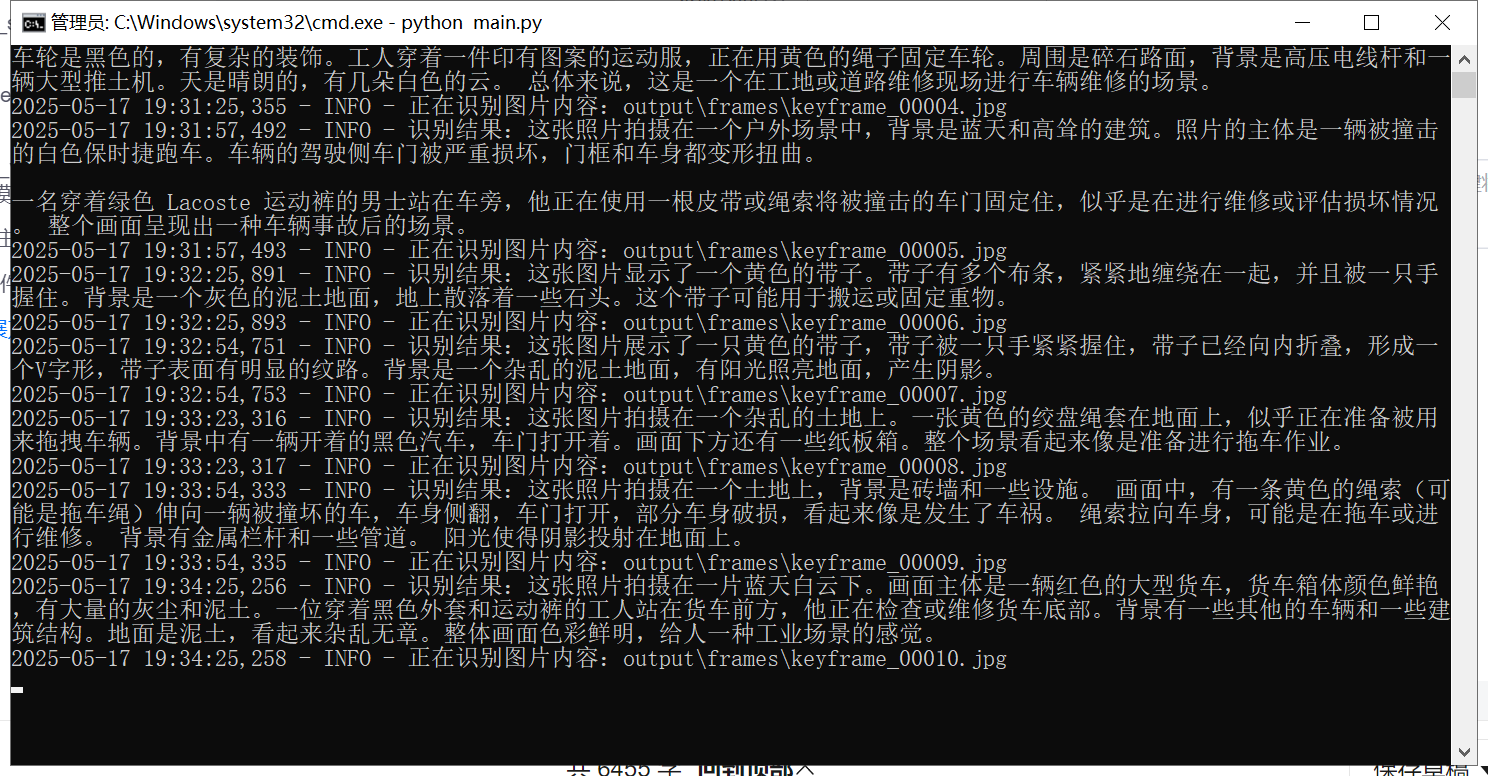
【原创】基于视觉大模型gemma-3-4b实现短视频自动识别内容并生成解说文案
📦 一、整体功能定位 这是一个用于从原始视频自动生成短视频解说内容的自动化工具,包含: 视频抽帧(可基于画面变化提取关键帧) 多模态图像识别(每帧图片理解) 文案生成(大模型生成…...
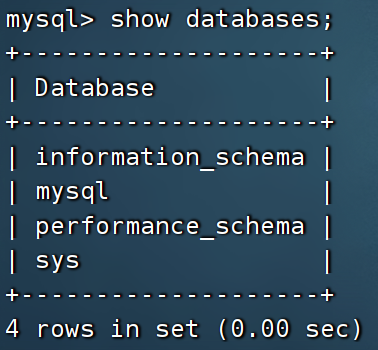
Spark(32)SparkSQL操作Mysql
(一)准备mysql环境 我们计划在hadoop001这台设备上安装mysql服务器,(当然也可以重新使用一台全新的虚拟机)。 以下是具体步骤: 使用finalshell连接hadoop001.查看是否已安装MySQL。命令是: rpm -qa|grep ma…...
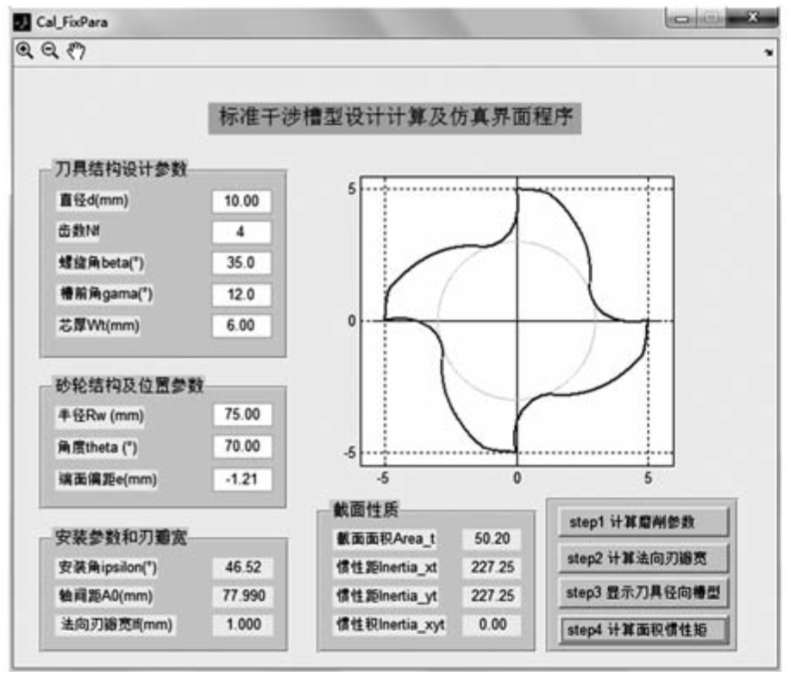
基于 Python 的界面程序复现:标准干涉槽型设计计算及仿真
基于 Python 的界面程序复现:标准干涉槽型设计计算及仿真 在工业设计与制造领域,刀具的设计与优化是提高生产效率和产品质量的关键环节之一。本文将介绍如何使用 Python 复现一个用于标准干涉槽型设计计算及仿真的界面程序,旨在帮助工程师和…...
c++成员函数返回类对象引用和直接返回类对象的区别
c成员函数返回类对象引用和直接返回类对象的区别 成员函数直接返回类对象(返回临时对象,对象拷贝) #include <iostream> class MyInt { public:int value;//构造函数explicit MyInt(int v0) : value(v){}//加法操作,返回对象副本&…...
:混合检索之rank_bm25库来实现词法搜索)
AGI大模型(20):混合检索之rank_bm25库来实现词法搜索
1 混合检索简介 混合搜索结合了两种检索信息的方法 词法搜索 (BM25) :这种传统方法根据精确的关键字匹配来检索文档。例如,如果您搜索“cat on the mat”,它将找到包含这些确切单词的文档。 基于嵌入的搜索(密集检索) :这种较新的方法通过比较文档的语义来检索文档。查…...
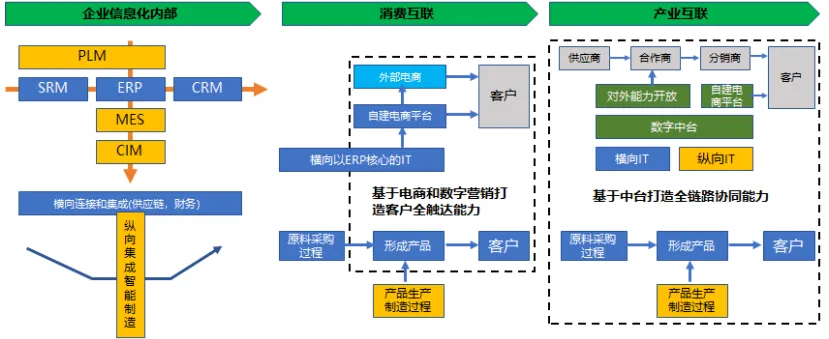
数字化转型- 数字化转型路线和推进
数字化转型三个阶段 百度百科给出的企业的数字化转型包括信息化、数字化、数智化三个阶段 信息化是将企业在生产经营过程中产生的业务信息进行记录、储存和管理,通过电子终端呈现,便于信息的传播与沟通。数字化通过打通各个系统的互联互通,…...

字体样式集合
根据您提供的字体样式列表,以下是分类整理后的完整字体样式名称(不含数量统计): 基础样式 • Regular • Normal • Plain • Medium • Bold • Black • Light • Thin • Heavy • Ultra • Extra • Semi • Hai…...

IP68防水Type-C连接器实测:水下1米浸泡72小时的生存挑战
IP68防水Type-C连接器正成为户外设备、水下仪器和高端消费电子的核心组件。其宣称的“1米水深防护”是否真能抵御长时间浸泡?我们通过极限实测,将三款主流品牌IP68防水Type-C连接器沉入1米盐水(模拟海水浓度)中持续72小时…...
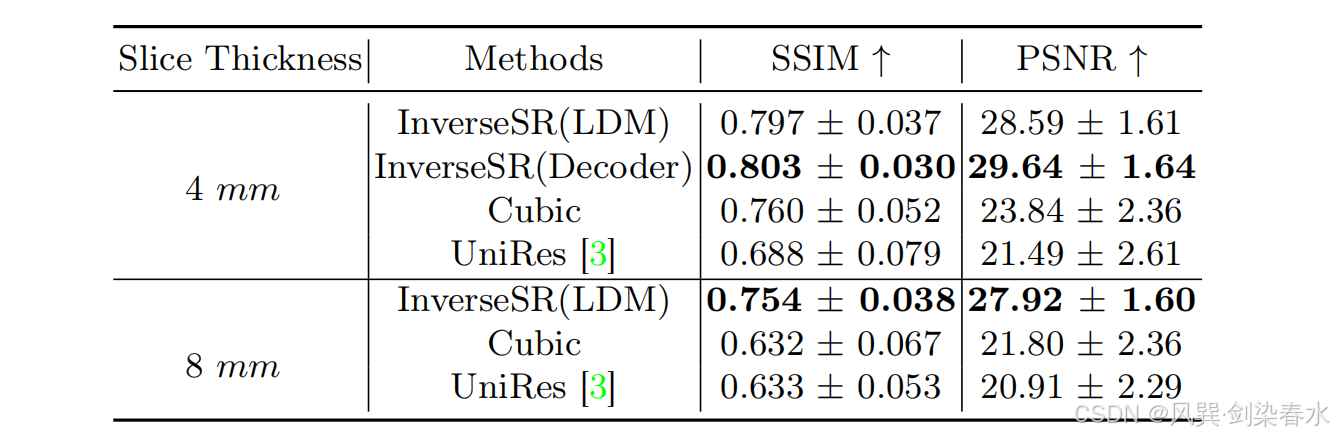
【技术追踪】InverseSR:使用潜在扩散模型进行三维脑部 MRI 超分辨率重建(MICCAI-2023)
LDM 实现三维超分辨率~ 论文:InverseSR: 3D Brain MRI Super-Resolution Using a Latent Diffusion Model 代码:https://github.com/BioMedAI-UCSC/InverseSR 0、摘要 从研究级医疗机构获得的高分辨率(HR)MRI 扫描能够提供关于成像…...
-变量)
React学习(二)-变量
也是很无聊,竟然写这玩意,毕竟不是学术研究,普通工作没那么多概念性东西,会用就行╮(╯▽╰)╭ 在React中,变量是用于存储和管理数据的基本单位。根据其用途和生命周期,React中的变量可以分为以下几类: 1. 状态变量(State) 用途:用于存储组件的内部状态,状态变化会触…...

list重点接口及模拟实现
list功能介绍 c中list是使用双向链表实现的一个容器,这个容器可以实现。插入,删除等的操作。与vector相比,vector适合尾插和尾删(vector的实现是使用了动态数组的方式。在进行头删和头插的时候后面的数据会进行挪动,时…...
基础知识④)
【自然语言处理与大模型】大模型(LLM)基础知识④
(1)微调主要用来干什么? 微调目前最主要用在定制模型的自我认知和改变模型对话风格。模型能力的适配与强化只是辅助。 定制模型的自我认知:通过微调可以调整模型对自我身份、角色功能的重新认知,使其回答更加符合自定义…...
:分布式架构与微服务)
系统架构设计(九):分布式架构与微服务
基础定义 架构类型定义分布式架构指将系统部署在多个服务器节点上,通过网络协作完成整体功能。强调物理上的分布与任务协作。微服务架构一种分布式架构模式,将系统按照业务维度拆分为多个小型自治服务,每个服务可独立开发、部署、伸缩。 核…...
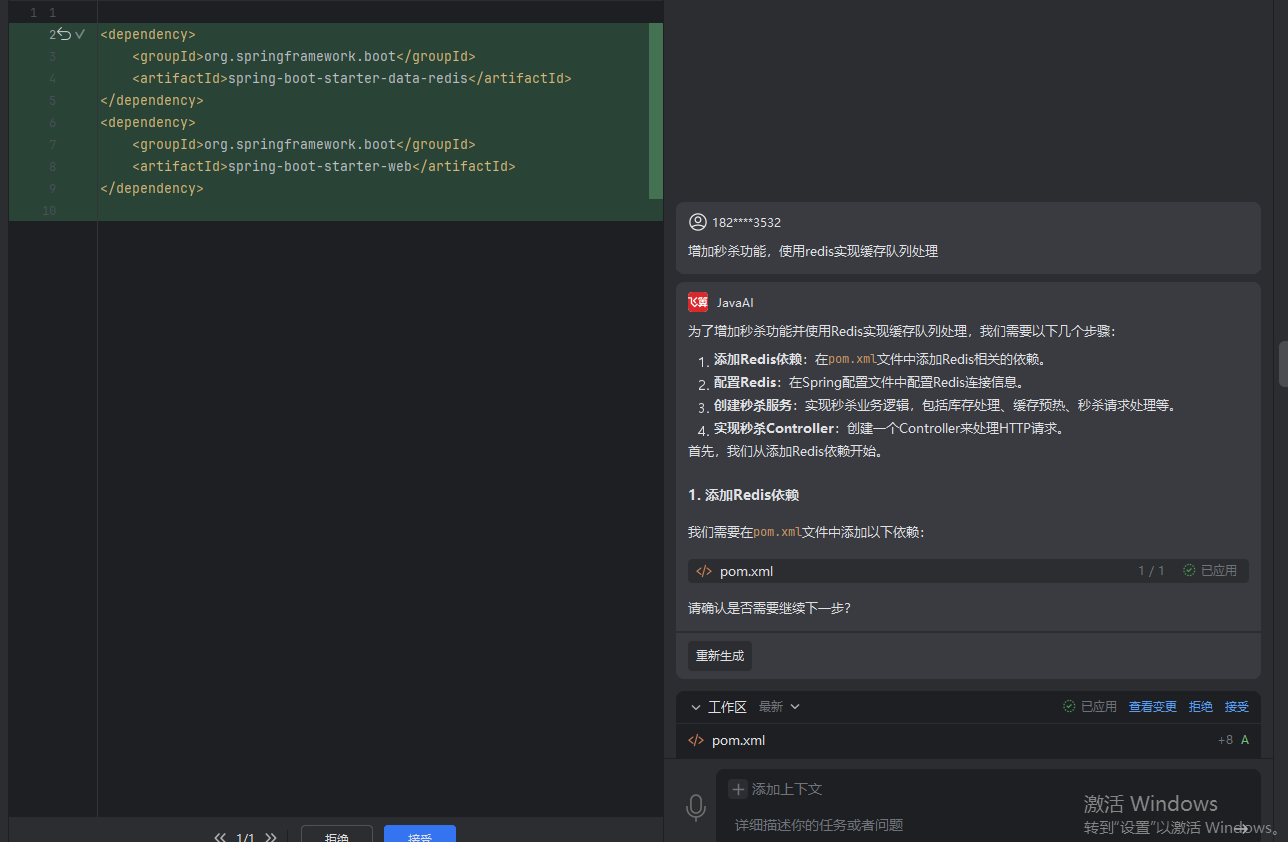
Java 框架配置自动化:告别冗长的 XML 与 YAML 文件
在 Java 开发领域,框架的使用极大地提升了开发效率和系统的稳定性。然而,传统框架配置中冗长的 XML 与 YAML 文件,却成为开发者的一大困扰。这些配置文件不仅书写繁琐,容易出现语法错误,而且在项目规模扩大时ÿ…...
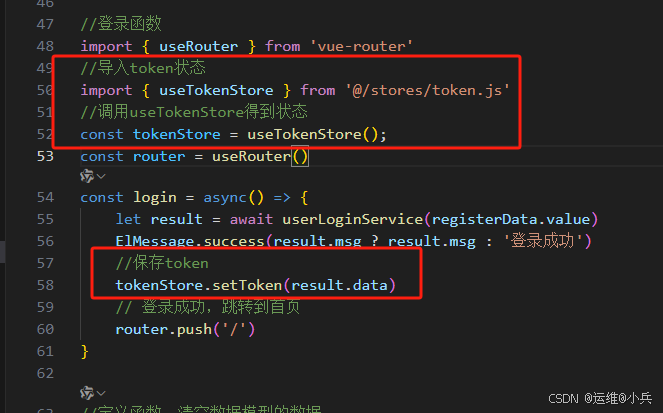
vue使用Pinia实现不同页面共享token
文章目录 一、概述二、使用步骤安装pinia在vue应用实例中使用pinia在src/stores/token.js中定义store在组件中使用store登录成功后,将token保存pinia中向后端API发起请求时,携带从pinia中获取的token 三、参考资料 一、概述 Pinia是Vue的专属状态管理库…...