nlf loss 学习笔记
目录
数据集:
3d 投影到2d 继续求loss
reconstruct_absolute
1. 功能概述
2. 参数详解
3. 两种重建模式对比
数据集:
agora3 | 5264/5264 [00:00<00:00, 143146.78it/s]
behave 37736/37736 [00:00<00:00, 76669.67it/s]
mads 32649/32649 [00:00<00:00, 32823.97it/s]
coco 38592/38592 [00:00<00:00, 150037.89it/s]
densepose_coco.pkl 29586/29586 [00:00<00:00, 143833.04it/s]
3d 投影到2d 继续求loss
compute_loss_with_3d_gt
def compute_loss_with_3d_gt(self, inps, preds):losses = EasyDict()if inps.point_validity is None:inps.point_validity = tf.ones_like(preds.coords3d_abs[..., 0], dtype=tf.bool)diff = inps.coords3d_true - preds.coords3d_abs# CENTER-RELATIVE 3D LOSS# We now compute a "center-relative" error, which is either root-relative# (if there is a root joint present), or mean-relative (i.e. the mean is subtracted).meanrel_diff = tfu3d.center_relative_pose(diff, joint_validity_mask=inps.point_validity, center_is_mean=True)# root_index is a [batch_size] int tensor that holds which one is the root# diff is [batch_size, joint_cound, 3]# we now need to select the root joint from each batch elementif inps.root_index.shape.ndims == 0:inps.root_index = tf.fill(tf.shape(diff)[:1], inps.root_index)# diff has shape N,P,3 for batch, point, coord# and root_index has shape N# and we want to select the root joint from each batch elementsanitized_root_index = tf.where(inps.root_index == -1, tf.zeros_like(inps.root_index), inps.root_index)root_diff = tf.expand_dims(tf.gather_nd(diff, tf.stack([tf.range(tf.shape(diff)[0]), sanitized_root_index], axis=1)), axis=1)rootrel_diff = diff - root_diff# Some elements of the batch do not have a root joint, which is marked as -1 as root_index.center_relative_diff = tf.where(inps.root_index[:, tf.newaxis, tf.newaxis] == -1, meanrel_diff, rootrel_diff)losses.loss3d = tfu.reduce_mean_masked(self.my_norm(center_relative_diff, preds.uncert), inps.point_validity)# ABSOLUTE 3D LOSS (camera-space)absdiff = tf.abs(diff)# Since the depth error will naturally scale linearly with distance, we scale the z-error# down to the level that we would get if the person was 5 m away.scale_factor_for_far = tf.minimum(np.float32(1), 5 / tf.abs(inps.coords3d_true[..., 2:]))absdiff_scaled = tf.concat([absdiff[..., :2], absdiff[..., 2:] * scale_factor_for_far], axis=-1)# There are numerical difficulties for points too close to the camera, so we only# apply the absolute loss for points at least 30 cm away from the camera.is_far_enough = inps.coords3d_true[..., 2] > 0.3is_valid_and_far_enough = tf.logical_and(inps.point_validity, is_far_enough)# To make things simpler, we estimate one uncertainty and automatically# apply a factor of 4 to get the uncertainty for the absolute prediction# this is just an approximation, but it works well enough.# The uncertainty does not need to be perfect, it merely serves as a# self-gating mechanism, and the actual value of it is less important# compared to the relative values between different points.losses.loss3d_abs = tfu.reduce_mean_masked(self.my_norm(absdiff_scaled, preds.uncert * 4.),is_valid_and_far_enough)# 2D PROJECTION LOSS (pixel-space)# We also compute a loss in pixel space to encourage good image-alignment in the model.coords2d_pred = tfu3d.project_pose(preds.coords3d_abs, inps.intrinsics)coords2d_true = tfu3d.project_pose(inps.coords3d_true, inps.intrinsics)# Balance factor which considers the 2D image size equivalent to the 3D box size of the# volumetric heatmap. This is just a factor to get a rough ballpark.# It could be tuned further.scale_2d = 1 / FLAGS.proc_side * FLAGS.box_size_m# We only use the 2D loss for points that are in front of the camera and aren't# very far out of the field of view. It's not a problem that the point is outside# to a certain extent, because this will provide training signal to move points which# are outside the image, toward the image border. Therefore those point predictions# will gather up near the border and we can mask them out when doing the absolute# reconstruction.is_in_fov_pred = tf.logical_and(tfu3d.is_within_fov(coords2d_pred, border_factor=-20 * (FLAGS.proc_side / 256)),preds.coords3d_abs[..., 2] > 0.001)is_near_fov_true = tf.logical_and(tfu3d.is_within_fov(coords2d_true, border_factor=-20 * (FLAGS.proc_side / 256)),inps.coords3d_true[..., 2] > 0.001)losses.loss2d = tfu.reduce_mean_masked(self.my_norm((coords2d_true - coords2d_pred) * scale_2d, preds.uncert),tf.logical_and(is_valid_and_far_enough,tf.logical_and(is_in_fov_pred, is_near_fov_true)))return losses, tf.add_n([losses.loss3d,losses.loss2d,FLAGS.absloss_factor * self.stop_grad_before_step(losses.loss3d_abs, FLAGS.absloss_start_step)])reconstruct_absolute
def adjusted_train_counter(self):return self.train_counter // FLAGS.grad_accum_stepsdef reconstruct_absolute(self, head2d, head3d, intrinsics, mix_3d_inside_fov, point_validity_mask=None):return tf.cond(self.adjusted_train_counter() < 500,lambda: tfu3d.reconstruct_absolute(head2d, head3d, intrinsics, mix_3d_inside_fov=mix_3d_inside_fov,weak_perspective=True, point_validity_mask=point_validity_mask,border_factor1=1, border_factor2=0.55, mix_based_on_3d=False),lambda: tfu3d.reconstruct_absolute(head2d, head3d, intrinsics, mix_3d_inside_fov=mix_3d_inside_fov,weak_perspective=False, point_validity_mask=point_validity_mask,border_factor1=1, border_factor2=0.55, mix_based_on_3d=False))1. 功能概述
该函数根据当前训练步数(adjusted_train_counter)选择两种不同的 3D重建策略:
-
训练初期(前500步):使用 弱透视投影(Weak Perspective Projection) 模型,简化计算以稳定训练。
-
训练后期(500步之后):切换为 更精确的投影模型(可能是全透视投影),提升重建精度。
2. 参数详解
| 参数 | 类型/范围 | 说明 |
|---|---|---|
head2d | Tensor | 网络预测的2D坐标(像素空间) |
head3d | Tensor | 网络预测的3D坐标(相对于根关节的偏移量,可能未对齐绝对坐标系) |
intrinsics | Tensor | 相机内参矩阵(用于从3D到2D的投影) |
mix_3d_inside_fov | Float [0,1] | 控制视场内(FOV)点使用3D预测的权重(与2D反投影结果混合) |
point_validity_mask | Tensor (bool) | 标记哪些点是有效的(如过滤掉遮挡点或离群点) |
weak_perspective | bool | 是否使用弱透视投影(True:忽略深度变化;False:使用完整透视投影) |
border_factor1/2 | float | 控制视场边缘的扩展范围(用于判断点是否在图像边界内) |
mix_based_on_3d | bool | 混合策略是否基于3D坐标(若为False,可能基于2D置信度) |
3. 两种重建模式对比
| 特性 | 训练初期(weak_perspective=True) | 训练后期(weak_perspective=False) |
|---|---|---|
| 投影模型 | 弱透视投影(假设物体深度变化可忽略) | 完整透视投影(考虑深度变化) |
| 计算复杂度 | 低(适合训练初期快速收敛) | 高(适合精细优化) |
| 适用场景 | 初始阶段姿态大致对齐 | 需要高精度重建(如关节细节优化) |
| 稳定性 | 对噪声和初始值更鲁棒 | 依赖准确的初始预测 |
相关文章:

nlf loss 学习笔记
目录 数据集: 3d 投影到2d 继续求loss reconstruct_absolute 1. 功能概述 2. 参数详解 3. 两种重建模式对比 数据集: agora3 | 5264/5264 [00:00<00:00, 143146.78it/s] behave 37736/37736 [00:00<00:00, 76669.67it/s] mads 32649/3264…...
【Redis】零碎知识点(易忘 / 易错)总结回顾
一、Redis 是一种基于键值对(key-value)的 NoSQL 数据库 二、Redis 会将所有数据都存放在内存中,所以它的读写性能非常惊人 Redis 还可以将内存的数据利用快照和日志的形式保存到硬盘上,这样在发生类似断电或者机器故障时…...
基于three.js 全景图片或视频开源库Photo Sphere Viewer
Photo Sphere Viewer 是一个基于 JavaScript 的开源库,专门用于在网页上展示 360 全景图片或视频。它提供了丰富的交互功能,允许用户通过鼠标、触摸屏或陀螺仪来浏览全景内容,适用于旅游、房地产、虚拟现实、教育等多个领域。 主要特点 多种…...

LangPDF: Empowering Your PDFs with Intelligent Language Processing
LangPDF: Empowering Your PDFs with Intelligent Language Processing Unlock Global Communication: AI-Powered PDF Translation and Beyond In an interconnected world, seamless multilingual document management is not just an advantage—it’s a necessity. LangP…...

OpenVLA (2) 机器人环境和环境数据
文章目录 [TOC](文章目录) 前言1 BridgeData V21.1 概述1.2 硬件环境 2 数据集2.1 场景与结构2.2 数据结构2.2.1 images02.2.2 obs_dict.pkl2.2.3 policy_out.pkl 3 close question3.1 英伟达环境3.2 LIBERO 环境更适合仿真3.3 4090 运行问题 前言 按照笔者之前的行业经验, 数…...
代码复现5——VLMaps
项目地址 1 Setup # 拉取VLMaps仓库,成功运行后会在主目录生成文件夹vlmapsgit clone https://github.com/vlmaps/vlmaps.git#通过 conda 创建虚拟环境conda create -n vlmaps python=3.8 -yconda activate vlmaps #激活环境cd vlmaps # 切换到项目文件下bash install.ba…...
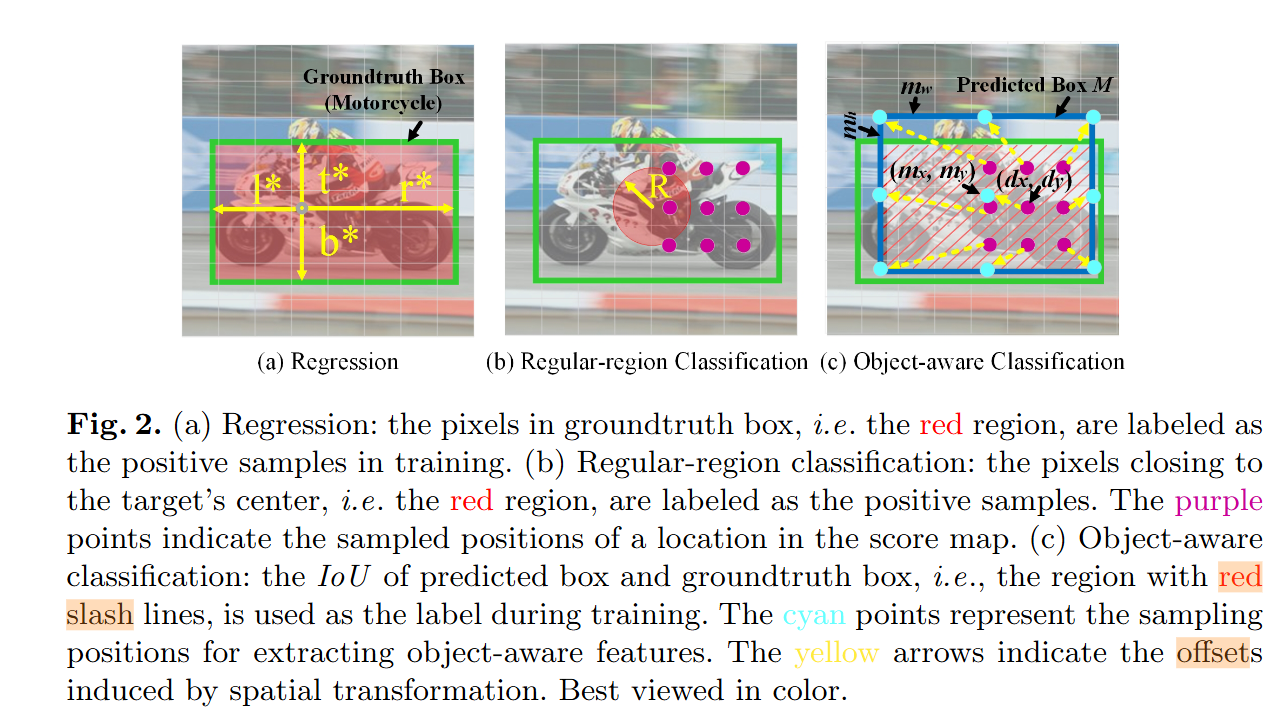
Ocean: Object-aware Anchor-free Tracking
领域:Object tracking It aims to infer the location of an arbitrary target in a video sequence, given only its location in the first frame 问题/现象: Anchor-based Siamese trackers have achieved remarkable advancements in accuracy, yet…...

计算机网络(1)——概述
1.计算机网络基本概念 1.1 什么是计算机网络 计算机网络的产生背景 在计算机网络出现之前,计算机之间都是相互独立的,每台计算机只能访问自身存储的数据,无法与其他计算机进行数据交换和资源共享。这种独立的计算机系统存在诸多局限性&#…...

刘家祎双剧收官见证蜕变,诠释多面人生
近期,两部风格迥异的剧集迎来收官时刻,而青年演员刘家祎在《我家的医生》与《无尽的尽头》中的精彩演绎,无疑成为观众热议的焦点。从温暖治愈的医疗日常到冷峻深刻的少年救赎,他以极具张力的表演,展现出令人惊叹的可塑…...
Axure制作可视化大屏动态滚动列表教程
在可视化大屏设计中,动态滚动列表是一种常见且实用的展示方式,能够有效地展示大量信息。本文将详细介绍如何使用Axure制作一个动态滚动的列表展示模块。 一、准备工作 打开Axure软件:确保你已经安装并打开了Axure RP软件。创建新项目&#x…...
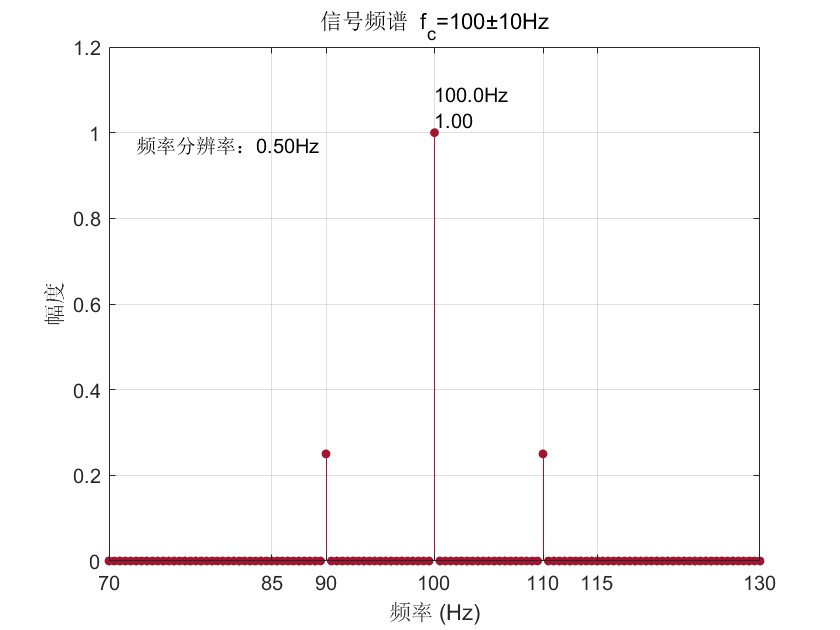
MATLAB实现振幅调制(AM调制信号)
AM调制是通信专业非常重要的一个知识点。今天我们使用MATLAB编程实现AM调制。 我们实现输入一个载波信号的频率与调制信号的频率后,再输入调幅度,得到已调信号的波形与包络信号的波形,再使用FFT算法分析出已调信号的频谱图。 源代码&#x…...
)
LLM-Based Agent综述及其框架学习(五)
文章目录 摘要Abstract1. 引言2. 文本输出3. 工具的使用3.1 理解工具3.2 学会使用工具3.3 制作自给自足的工具3.4 工具可以扩展LLM-Based Agent的行动空间3.5 总结 4. 具身动作5. 学习智能体框架5.1 CrewAI学习进度5.2 LangGraph学习进度5.3 MCP学习进度 参考总结 摘要 本文围绕…...

6.1.1图的基本概念
基本概念 图: 顶点集边集 顶点集:所有顶点的集合,不能为空(因为图是顶点集和边集组成,其中一个顶点集不能为空,则图肯定不为空) 边集:所有边的集合,边是由顶点集中的2…...
Linux面试题集合(6)
创建多级目录或者同级目录 mkdir -p 文件名/文件名/文件名 mkdir -p 文件名 文件名 文件名 Linux创建一个文件 touch 文件名 DOS命令创建文件 echo 内容>文件名(创建一个有内容的文件) echo >文件名(创建一个没有内容的文件)…...

时间筛掉了不够坚定的东西
2025年5月17日,16~25℃,还好 待办: 《高等数学1》重修考试 《高等数学2》备课 《物理[2]》备课 《高等数学2》取消考试资格学生名单 《物理[2]》取消考试资格名单 职称申报材料 2024年税务申报 5月24日、25日监考报名 遇见:敲了一…...

Python集合运算:从基础到进阶全解析
Python基础:集合运算进阶 文章目录 Python基础:集合运算进阶一、知识点详解1.1 集合运算(运算符 vs 方法)1.2 集合运算符优先级1.3 集合关系判断方法1.4 方法对比 二、说明示例2.1 权限管理系统2.2 数据去重与差异分析2.3 数学运算…...
openjdk17 c++源码垃圾回收安全点信号函数处理线程阻塞)
jvm安全点(二)openjdk17 c++源码垃圾回收安全点信号函数处理线程阻塞
1. 信号处理与桩代码(Stub) 当线程访问安全点轮询页(Polling Page)时: 触发 SIGSEGV 信号:访问只读的轮询页会引发 SIGSEGV 异常。信号处理函数:pd_hotspot_signal_handl…...
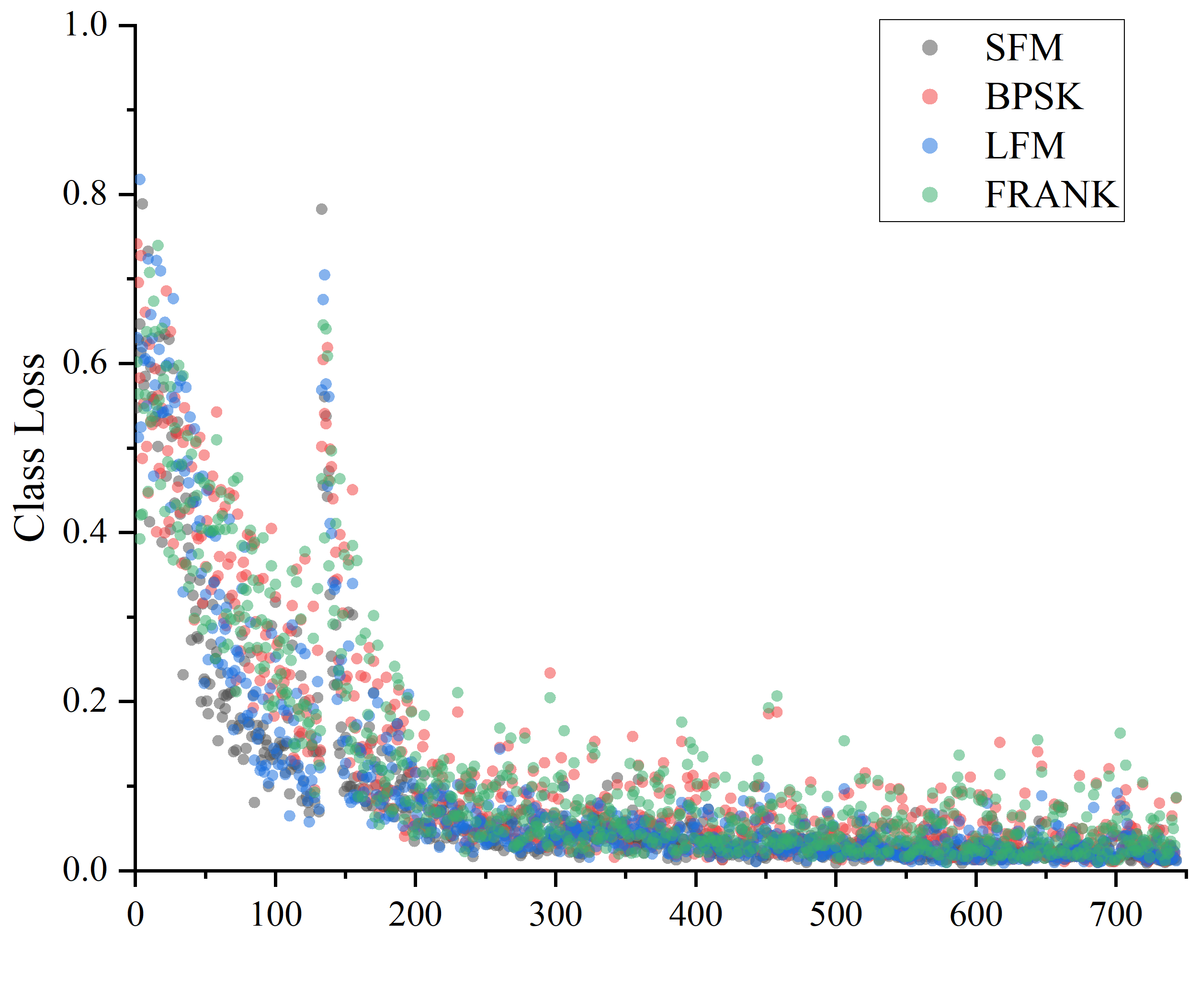
YOLOv7训练时4个类别只出2个类别
正常是4个类别: 但是YOLOv7训练完后预测总是只有两个类别: 而且都是LFM和SFM 我一开始检查了下特征图大小,如果输入是640*640的话,三个尺度特征图是80*80,40*40,20*20;如果输入是416*416的话,三个尺度特征…...
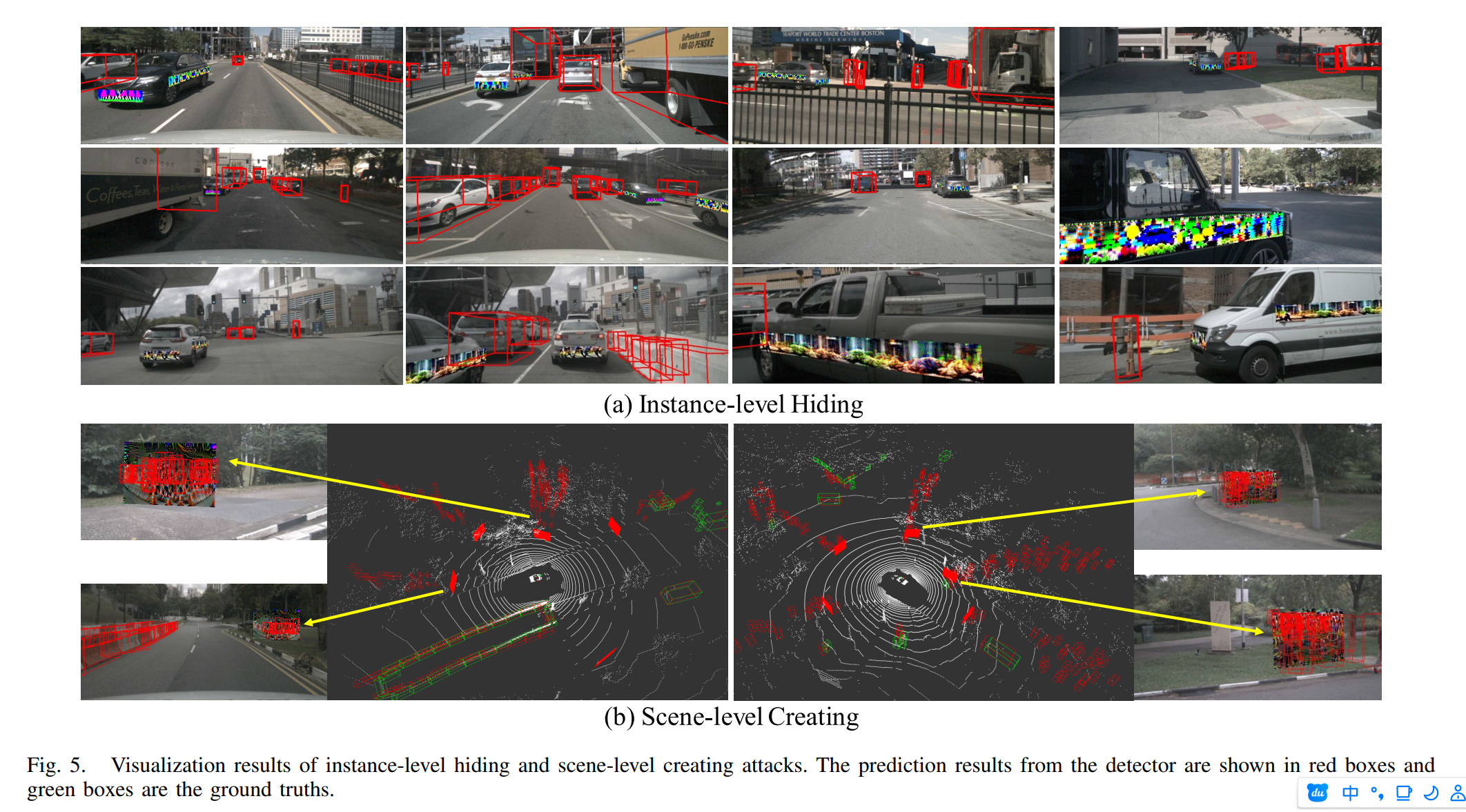
【论文阅读】针对BEV感知的攻击
Understanding the Robustness of 3D Object Detection with Bird’s-Eye-View Representations in Autonomous Driving 这篇文章是发表在CVPR上的一篇文章,针对基于BEV的目标检测算法进行了两类可靠性分析,即恶劣自然条件以及敌对攻击。同时也提出了一…...

18.中介者模式:思考与解读
原文地址:中介者模式:思考与解读 更多内容请关注:深入思考与解读设计模式 引言 在软件开发中,尤其是处理多个对象交互时,你是否遇到过一个问题:当多个对象需要互相通信时,系统变得复杂,难以管…...
flutter 配置 安卓、Ios启动图
android 配置启动图 launch_background.xml <?xml version"1.0" encoding"utf-8"?> <!-- Modify this file to customize your launch splash screen --> <layer-list xmlns:android"http://schemas.android.com/apk/res/android&…...
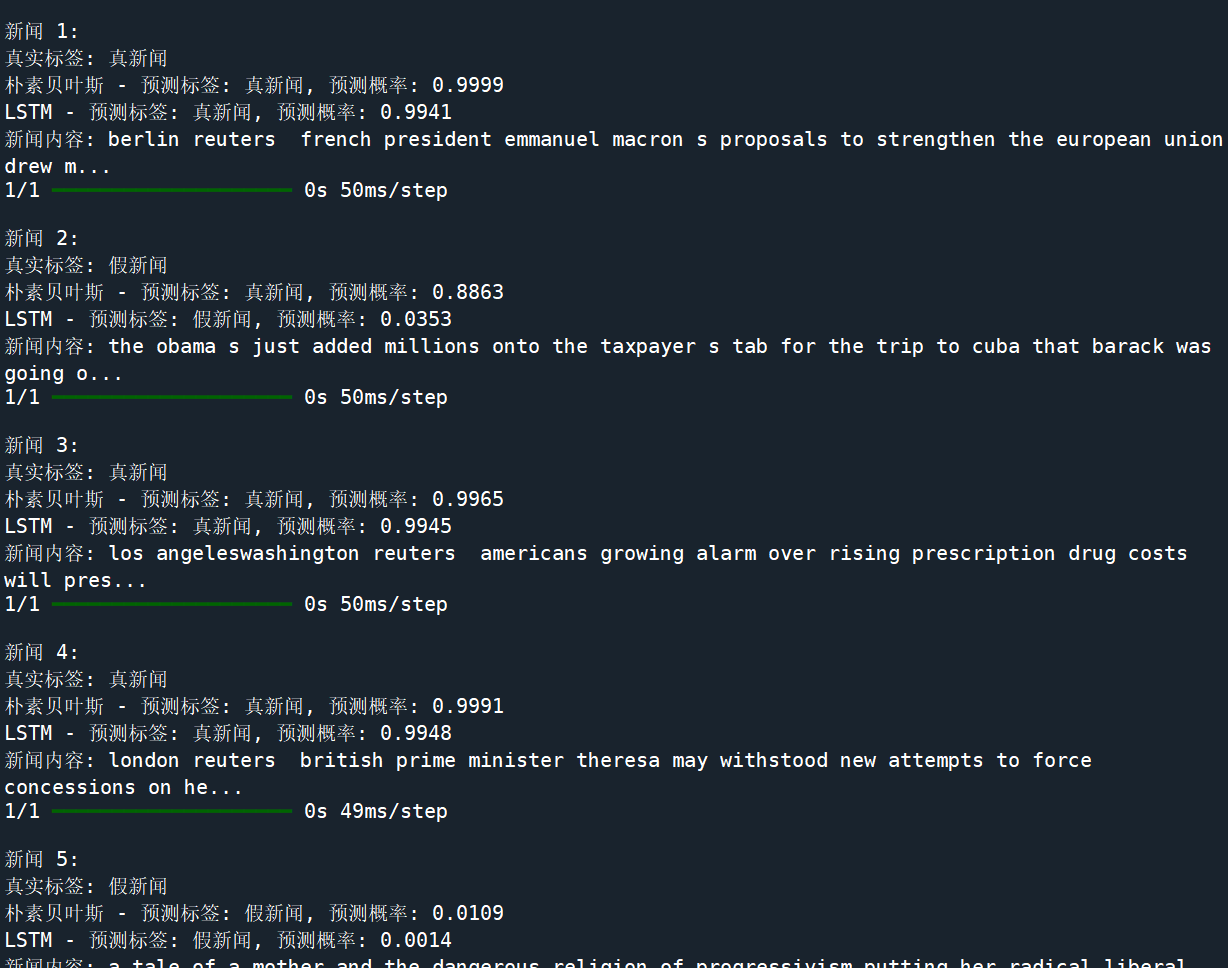
基于朴素贝叶斯与 LSTM 的假新闻检测模型对比分析
一、引言 在信息爆炸的时代,假新闻的传播对社会产生了诸多负面影响。如何快速、准确地识别假新闻成为了重要的研究课题。本文将对比传统机器学习算法(朴素贝叶斯)与深度学习模型(LSTM)在假新闻检测任务中的性能表现&am…...

【LeetCode 热题 100】搜索插入位置 / 搜索旋转排序数组 / 寻找旋转排序数组中的最小值
⭐️个人主页:小羊 ⭐️所属专栏:LeetCode 热题 100 很荣幸您能阅读我的文章,诚请评论指点,欢迎欢迎 ~ 目录 搜索插入位置搜索二维矩阵在排序数组中查找元素的第一个和最后一个位置搜索旋转排序数组寻找旋转排序数组中的最小值…...
副业小程序YUERGS,从开发到变现
文章目录 我为什么写这个小程序网站转小程序有什么坑有什么推广渠道个人开发者如何变现简单介绍YUERGS小程序给独立开发者一点小建议 我为什么写这个小程序 关注我的粉丝应该知道,我在硕士阶段就已经掌握了小程序开发技能,并写了一个名为“约球online”…...
)
计算机视觉与深度学习 | Python实现EMD-VMD-LSTM时间序列预测(完整源码和数据)
EMD-VMD-LSTM 一、完整代码实现二、代码结构解析三、关键参数说明四、性能优化建议五、工业部署方案以下是用Python实现EMD-VMD-LSTM时间序列预测的完整代码,结合经验模态分解(EMD)、变分模态分解(VMD)与LSTM深度学习模型,适用于复杂非平稳信号的预测任务。代码包含数据生…...
基于LLM合成高质量情感数据,提升情感分类能力!!
摘要:大多数用于情感分析的数据集缺乏意见表达的上下文,而上下文对于理解情绪往往至关重要,并且这些数据集主要局限于几种情绪类别。像 GPT-4 这样的基础大型语言模型(Foundation Large Language Models,LLMsÿ…...
网络检测工具InternetTest v8.9.1.2504 单文件版,支持一键查询IP/DNS、WIFI密码信息
—————【下 载 地 址】——————— 【本章下载一】:https://drive.uc.cn/s/295e068b79314 【本章下载二】:https://pan.xunlei.com/s/VOQDXguH0DYPxrql5y2zlkhTA1?pwdg2nx# 【百款黑科技】:https://ucnygalh6wle.feishu.cn/wiki/…...

SpringBoot中使用Flux实现流式返回的技术总结
背景 近期在使用deepseek/openai等网页和APP时,发现大模型在思考和回复时,内容是一点点的显示出来的,于是好奇他们的实现方式。经调研和使用开发者工具抓取请求,每次聊天会向后台发送一个http请求,而这个接口跟普通接…...

【网络编程】十、详解 UDP 协议
文章目录 Ⅰ. 传输层概述1、进程之间的通信2、再谈端口号端口号的引出五元组标识一个通信端口号范围划分常见的知名端口号查看知名端口号协议号 VS 端口号 3、两个问题一个端口号是否可以被多个进程绑定?一个进程是否可以绑定多个端口号? 4、部分常见指令…...

从零开始理解Jetty:轻量级Java服务器的入门指南
目录 一、Jetty是什么?先看一个生活比喻 二、5分钟快速入门:搭建你的第一个Jetty服务 步骤1:Maven依赖配置 步骤2:编写简易Servlet(厨房厨师) 步骤3:组装服务器(餐厅开业准备&am…...