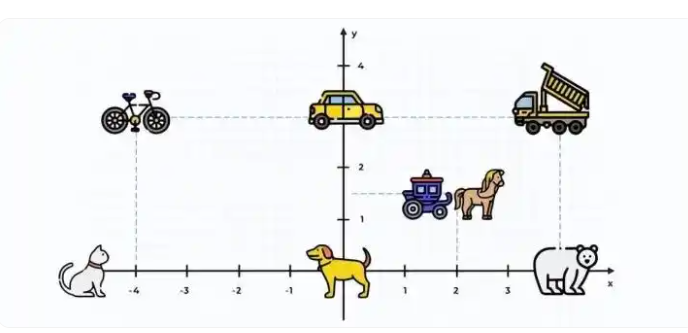
分别用 语言模型雏形N-Gram 和 文本表示BoW词袋 来实现文本情绪分类
语言模型的雏形 N-Gram 和简单文本表示 Bag-of-Words
语言表示模型简介
(1) Bag-of-Words (BoW)
是什么?
- *定义:将文本表示为词频向量,忽略词序和语法,仅记录每个词的出现次数。
**示例:- 句子1:I love cats and cats love me.
- 句子2:Dogs love me too.
- 词表:[“I”, “love”, “cats”, “and”, “me”, “dogs”, “too”]`
- BoW向量:
句子1 :[1, 2, 2, 1, 1, 0, 0]
句子2 :[0, 1, 0, 0, 1, 1, 1]
为什么需要?
- 简单高效:适合早期文本分类(如垃圾邮件识别、情感分析)。
- 可解释性强:词频直接反映文本主题。
- 局限性:
- 忽略词序 “猫吃鱼” “鱼吃猫" 向量表示在词袋表示中相同
- 高维稀疏(词表大时向量维度爆炸)。
(2) N-Gram
是什么?
- 定义:将文本分割为连续的N个词(或字符)组成的片段,捕捉局部上下文。
示例(N=2):- 句子:“I love cats”
- Bigrams(2-grams):[“I love”, “love cats”]`
- Trigrams(3-grams):[“I love cats”]`
为什么需要?
- 捕捉局部词序:比BoW更细致,能表达短语(如)。
- 建模上下文:通过统计N-Gram概率预测下一个词(语言模型)。
- 局限性:
- 数据稀疏性(长N-Gram在训练集中可能未出现)。
- 无法建模远距离依赖(如段落级关系)。
2. 项目实战:BoW与N-Gram的文本分类
任务目标
用BoW和Bigram特征对电影评论进行情感分类(正/负面),并比较效果。
代码实现
环境准备
pip install numpy scikit-learn nltk
数据集
使用简单的自定义数据集(实际项目可用IMDB数据集):
# 自定义数据:0为负面,1为正面
texts = ["I hate this movie", # 0"This film is terrible", # 0"I love this wonderful film",# 1"What a great movie", # 1
]
labels = [0, 0, 1, 1]
步骤1:Bag-of-Words特征提取
from sklearn.feature_extraction.text import CountVectorizer# 创建BoW向量器
bow_vectorizer = CountVectorizer()
bow_features = bow_vectorizer.fit_transform(texts)print("BoW特征词表:", bow_vectorizer.get_feature_names_out())
print("BoW特征矩阵:\n", bow_features.toarray())
输出:
BoW特征词表: ['film' 'great' 'hate' 'is' 'love' 'movie' 'terrible' 'this' 'what' 'wonderful']
BoW特征矩阵:
[[0 0 1 0 0 1 0 1 0 0][1 0 0 1 0 0 1 1 0 0][1 0 0 0 1 0 0 1 0 1][0 1 0 0 0 1 0 0 1 0]]
步骤2:Bigram特征提取
from sklearn.feature_extraction.text import CountVectorizer# 创建Bigram向量器(N=2)
bigram_vectorizer = CountVectorizer(ngram_range=(2, 2))
bigram_features = bigram_vectorizer.fit_transform(texts)print("Bigram特征词表:", bigram_vectorizer.get_feature_names_out())
print("Bigram特征矩阵:\n", bigram_features.toarray())
输出:
Bigram特征词表: ['film is' 'hate this' 'is terrible' 'love this' 'terrible this'
'this movie' 'this wonderful' 'what great' 'wonderful film']
Bigram特征矩阵:
[[0 1 0 0 0 1 0 0 0][1 0 1 0 0 0 0 0 0][0 0 0 1 0 0 1 0 1][0 0 0 0 0 0 0 1 0]]
步骤3:训练分类模型
from sklearn.naive_bayes import MultinomialNB
from sklearn.model_selection import train_test_split# 划分训练集和测试集(此处仅演示,数据量小直接训练)
X_train_bow, X_test_bow = bow_features, bow_features # 实际需划分
X_train_bigram, X_test_bigram = bigram_features, bigram_features
y_train, y_test = labels, labels# 训练BoW模型
model_bow = MultinomialNB()
model_bow.fit(X_train_bow, y_train)
print("BoW模型准确率:", model_bow.score(X_test_bow, y_test))# 训练Bigram模型
model_bigram = MultinomialNB()
model_bigram.fit(X_train_bigram, y_train)
print("Bigram模型准确率:", model_bigram.score(X_test_bigram, y_test))
输出:
BoW模型准确率: 1.0
Bigram模型准确率: 1.0
# 自定义数据:0为负面,1为正面
texts = ["I hate this movie", # 0"This film is terrible", # 0"I love this wonderful film",# 1"What a great movie", # 1"I dislike this film", # 0"This movie is amazing", # 1"I enjoy this film", # 1"This film is awful", # 0 "I adore this movie", # 1"This film is fantastic", # 1"I loathe this movie", # 0"This movie is boring", # 0"I appreciate this film", # 1"This film is dreadful", # 0"I cherish this movie", # 1"This film is mediocre", # 0"I detest this movie", # 0"This film is superb", # 1"I value this film", # 1"This movie is subpar", # 0"I respect this film", # 1"This film is excellent", # 1"I abhor this movie", # 0"This film is lackluster", # 0"I admire this film", # 1"This movie is unsatisfactory", # 0"I relish this film", # 1"This film is remarkable", # 1"I scorn this movie", # 0"This film is outstanding", # 1"I disapprove of this film", # 0"This movie is unremarkable", # 0"I treasure this film", # 1"This film is commendable", # 1"I find this movie distasteful", # 0"This film is praiseworthy", # 1"I think this movie is substandard", # 0"This film is noteworthy", # 1"I consider this movie to be poor", # 0"This film is exceptional", # 1"I feel this movie is inadequate", # 0"This film is extraordinary", # 1"I regard this movie as unsatisfactory", # 0"This film is phenomenal", # 1"I perceive this movie as disappointing", # 0"This film is stellar", # 1"I think this movie is mediocre" # 0
]
labels = [0, 0, 1, 1, 0, 1, 1, 0, 1, 1, 0, 0, 1, 0, 1,0, 0, 1,1, 0,1, 1, 0, 0, 1, 0, 1, 1, 0, 1, 0, 0, 1, 1, 0,1, 0, 1,0,1,0,1,0,1,0,1,0]
print("文本数据:", len(texts), "条")
print("label:", len(labels), "条")
# 导入所需库
from sklearn.feature_extraction.text import CountVectorizer
# 创建BoW向量器
bow_vectorizer = CountVectorizer()
bow_features = bow_vectorizer.fit_transform(texts)print("BoW特征词表:", bow_vectorizer.get_feature_names_out())
print("BoW特征矩阵:\n", bow_features.toarray())# 创建Bigram向量器(N=2)
bigram_vectorizer = CountVectorizer(ngram_range=(2, 2))
bigram_features = bigram_vectorizer.fit_transform(texts)print("Bigram特征词表:", bigram_vectorizer.get_feature_names_out())
print("Bigram特征矩阵:\n", bigram_features.toarray())from sklearn.naive_bayes import MultinomialNB
from sklearn.model_selection import train_test_split# 划分训练集和测试集(此处仅演示,数据量小直接训练)
train_test_split = 0.8
train_len = int(len(texts) * train_test_split)X_train_bow, X_test_bow = bow_features[:train_len], bow_features[train_len:] # 实际需划分
X_train_bigram, X_test_bigram = bigram_features[:train_len], bigram_features[train_len:]
y_train, y_test = labels[:train_len], labels[train_len:]# 训练BoW模型
model_bow = MultinomialNB()
model_bow.fit(X_train_bow, y_train)
print("BoW模型准确率:", model_bow.score(X_test_bow, y_test))# 训练Bigram模型
model_bigram = MultinomialNB()
model_bigram.fit(X_train_bigram, y_train)
print("Bigram模型准确率:", model_bigram.score(X_test_bigram, y_test))3. 项目扩展与思考
(1) 分析结果
- BoW:通过单个词区分情感(如
<font style="color:rgba(0, 0, 0, 0.9);">"hate"</font>表示负面,<font style="color:rgba(0, 0, 0, 0.9);">"love"</font>表示正面)。 - Bigram:捕捉短语(如
<font style="color:rgba(0, 0, 0, 0.9);">"terrible this"</font>可能加强负面判断)。
(2) 改进方向
- 尝试更大的N(如Trigrams),观察是否过拟合。
- 使用TF-IDF代替词频,降低常见词的权重。
- 在真实数据集(如IMDB) 上测试效果。
4. 关键总结
- BoW:简单高效,适合基线模型,但忽略上下文。
- N-Gram:捕捉局部词序,但需权衡N的大小和稀疏性问题。
- 现代应用:两者仍用于轻量级任务(如快速原型),但深度模型(如RNN、Transformer)在复杂任务中更优。
相关文章:
分别用 语言模型雏形N-Gram 和 文本表示BoW词袋 来实现文本情绪分类
语言模型的雏形 N-Gram 和简单文本表示 Bag-of-Words 语言表示模型简介 (1) Bag-of-Words (BoW) 是什么? *定义:将文本表示为词频向量,忽略词序和语法,仅记录每个词的出现次数。 **示例: 句子1:I love …...
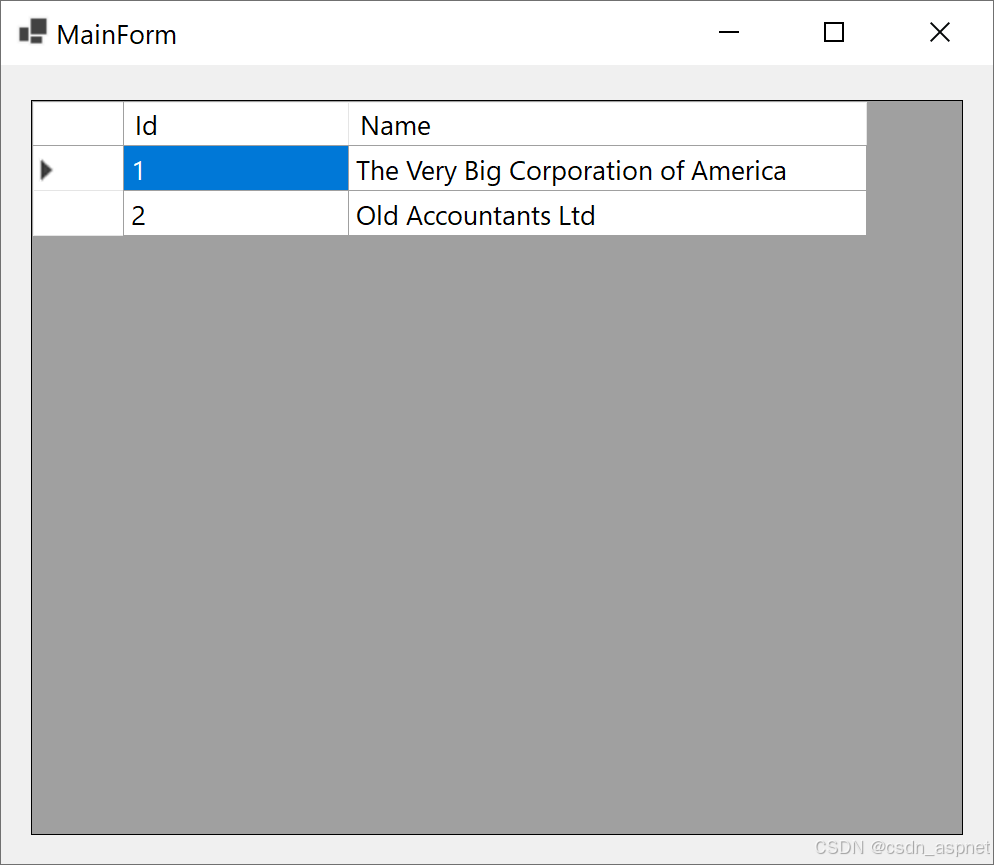
C#.NET 或 VB.NET Windows 窗体中的 DataGridView – 技巧、窍门和常见问题
DataGridView 控件是一个 Windows 窗体控件,它允许您自定义和编辑表格数据。它提供了许多属性、方法和事件来自定义其外观和行为。在本文中,我们将讨论一些常见问题及其解决方案。这些问题来自各种来源,包括一些新闻组、MSDN 网站以及一些由我…...
PyTorch音频处理技术及应用研究:从特征提取到相似度分析
文章目录 音频处理技术及应用音频处理技术音视频摘要技术音频识别及应用 梅尔频率倒谱系数音频特征尔频率倒谱系数简介及参数提取过程音频处理快速傅里叶变换(FFT)能量谱处理离散余弦转换 练习案例:音频建模加载音频数据源波形变换的类型绘制波形频谱图波形Mu-Law 编…...

SHAP分析图的含义
1. 训练集预测结果对比图 表征含义: 展示模型在训练集上的预测值(红色曲线)与真实值(灰色曲线)的对比。通过曲线重合度可直观判断模型的拟合效果。标题中显示的RMSE(均方根误差)量化了预测值与…...
VSTO(C#)Excel开发进阶2:操作图片 改变大小 滚动到可视区
初级代码游戏的专栏介绍与文章目录-CSDN博客 我的github:codetoys,所有代码都将会位于ctfc库中。已经放入库中我会指出在库中的位置。 这些代码大部分以Linux为目标但部分代码是纯C++的,可以在任何平台上使用。 源码指引:github源码指引_初级代码游戏的博客-CSDN博客 入…...

多用途商务,电子产品发布,科技架构,智能手表交互等发布PPT模版20套一组分享
产品发布类PPT模版20套一组:产品发布PPT模版https://pan.quark.cn/s/25c8517b0be3 第一套PPT模版是一个总结用的PPT封面,背景浅灰色,有绿色叶片和花朵装饰,深绿色标题,多个适用场景和占位符。突出其清新自然的设计和商…...

Java正则表达式:从基础到高级应用全解析
Java正则表达式应用与知识点详解 一、正则表达式基础概念 正则表达式(Regular Expression)是通过特定语法规则描述字符串模式的工具,常用于: 数据格式验证文本搜索与替换字符串分割模式匹配提取 Java通过java.util.regex包提供支持,核心类…...
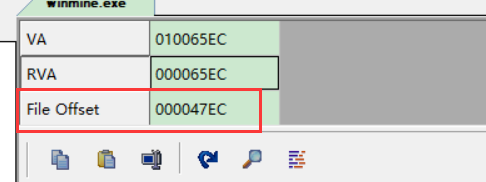
WindowsPE文件格式入门11.资源表
https://www.bpsend.net/thread-411-1-1.html 资源表 资源的管理方式采用windows资源管理器目录的管理方式,一般有三层目录。根目录 结构体IMAGE_RESOURCE_DIRECTORY:描述名称资源和ID资源各自的数量,不描述文件。资源本质都是二进制数据&…...
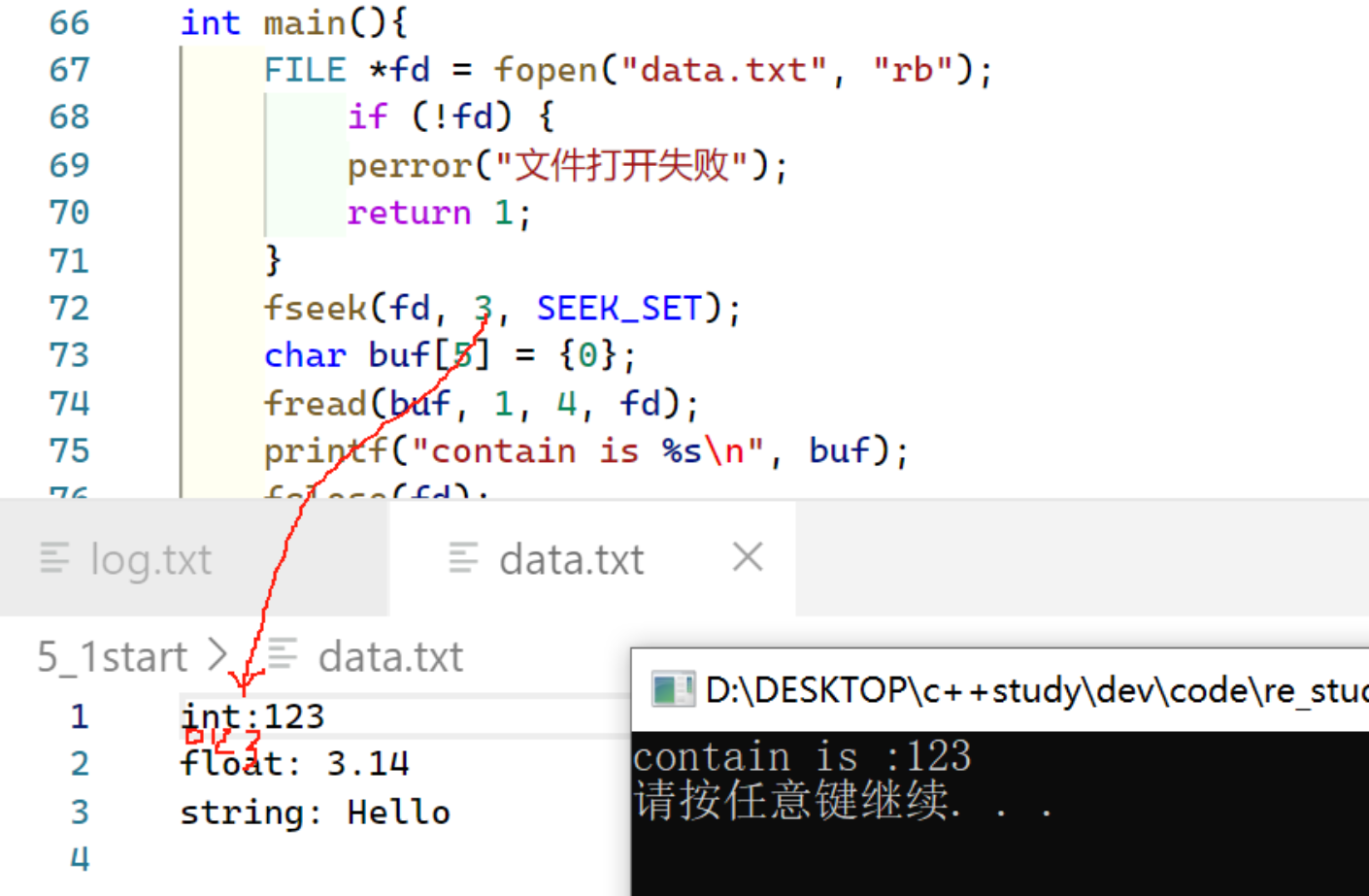
C语言标准I/O与Linux系统调用的文件操作
01. 标准库函数与系统调用对比 系统调用标准I/O库open/read/write/closefopen/fread/fwrite/fclose文件描述符(fd)文件指针(FILE*)无缓冲,直接系统调用自动缓冲管理每次操作触发系统调用减少系统调用次数<fcntl.h> <unistd.h><stdio.h> 系统调用…...

【MYSQL】笔记
📚 博主的专栏 🐧 Linux | 🖥️ C | 📊 数据结构 | 💡C 算法 | 🅒 C 语言 | 🌐 计算机网络 在ubuntu中,改配置文件: sudo nano /etc/mysql/mysql.conf.d/mysq…...
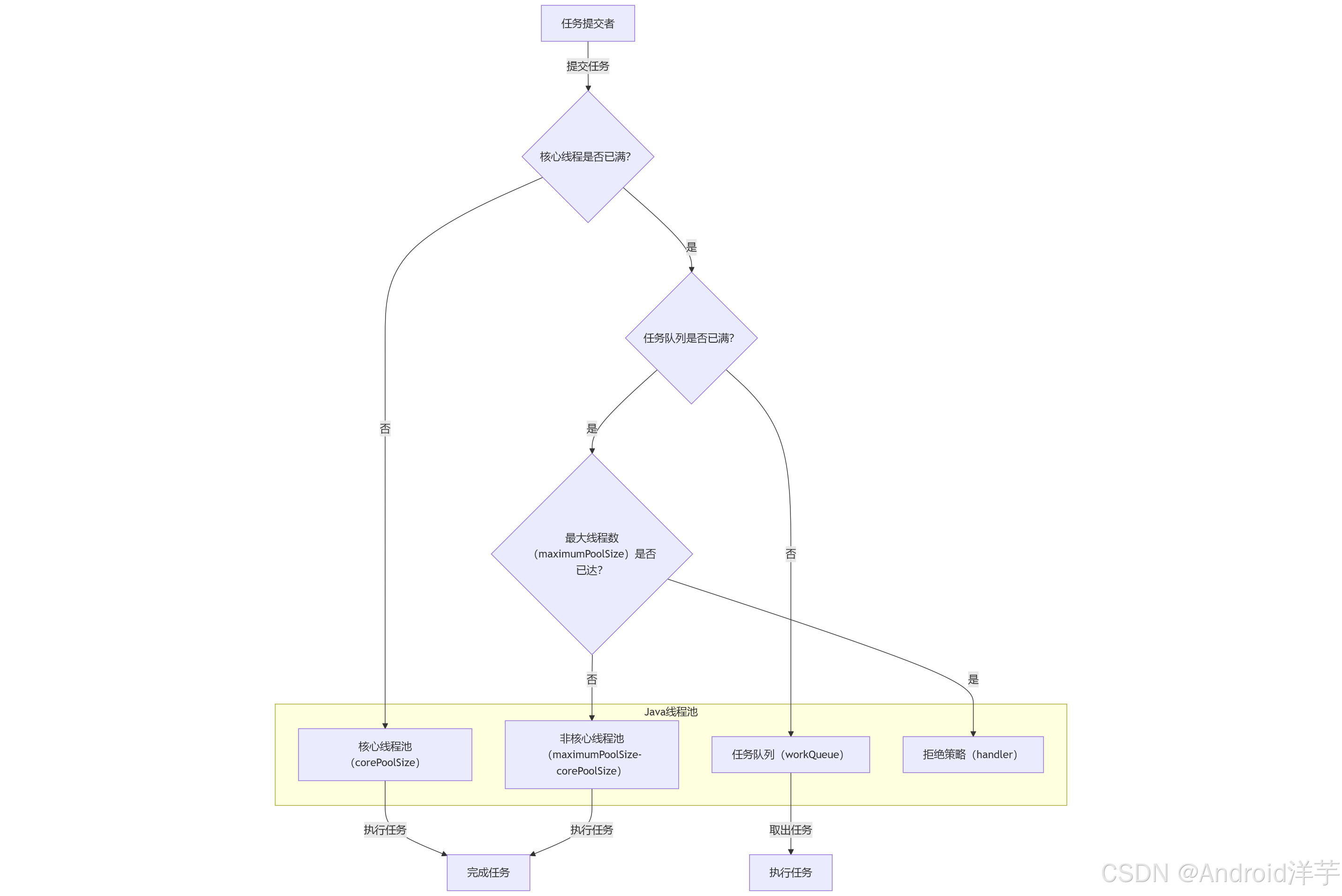
线程池核心线程永续机制:从源码到实战的深度解析
简介 源管理的基石,其核心线程为何不会超时销毁一直是开发者关注的焦点。核心线程的永续机制不仅确保了系统的稳定响应,还避免了频繁创建和销毁线程带来的性能损耗。本文将从源码层面深入剖析线程池核心线程的存活原理,同时结合企业级实战案例,展示如何正确配置和管理线程…...
DS新论文解读(2)
上一章忘了说论文名字了,是上图这个名字 我们继续,上一章阅读地址: dsv3新论文解读(1) 这论文剩下部分值得说的我觉得主要就是他们Infra通信的设计 先看一个图 这个是一个标准的h800 8卡with 8cx7 nic的图…...
html文件cdn一键下载并替换
业务场景: AI生成的html文件,通常会使用多个cdn资源、手动替换or下载太过麻烦、如下py程序为此而生,指定html目录自动下载并替换~ import os import requests from bs4 import BeautifulSoup from urllib.parse import urlparse import has…...

react路由中Suspense的介绍
好的,我们来详细解释一下这个 AppRouter 组件的代码。 这个组件是一个在现代 React 应用中非常常见的模式,特别是在使用 React Router v6 进行路由管理和结合代码分割(Code Splitting)来优化性能时。 JavaScript const AppRout…...
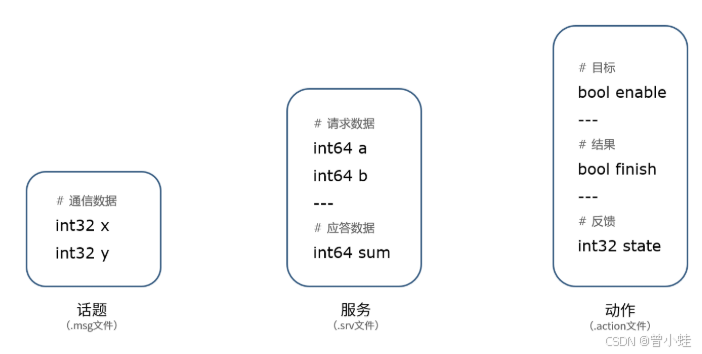
【ROS2】 核心概念6——通信接口语法(Interfaces)
古月21讲/2.6_通信接口 官方文档:Interfaces — ROS 2 Documentation: Humble documentation 官方接口代码实战:https://docs.ros.org/en/humble/Tutorials/Beginner-Client-Libraries/Single-Package-Define-And-Use-Interface.html ROS 2使用简化的描…...

matlab官方免费下载安装超详细教程2025最新matlab安装教程(MATLAB R2024b)
文章目录 准备工作MATLAB R2024b 安装包获取详细安装步骤1. 文件准备2. 启动安装程序3. 配置安装选项4. 选择许可证文件5. 设置安装位置6. 选择组件7. 开始安装8. 完成辅助设置 常见问题解决启动失败问题 结语 准备工作 本教程将帮助你快速掌握MATLAB R2024b的安装技巧&#x…...
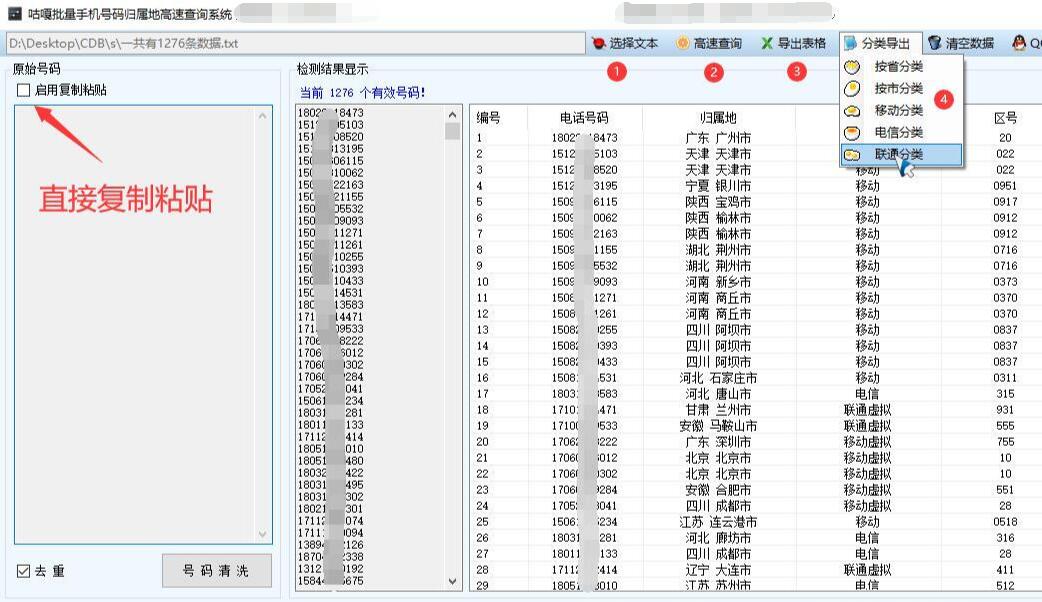
【运营商查询】批量手机号码归属地和手机运营商高速查询分类,按省份城市,按运营商移动联通电信快速分类导出Excel表格,基于WPF的实现方案
WPF手机号码归属地批量查询与分类导出方案 应用场景 市场营销:企业根据手机号码归属地进行精准营销,按城市或省份分类制定针对性推广策略客户管理:快速对客户手机号码进行归属地分类,便于后续客户关系管理数…...
ctf 基础
一、软件安装和基本的网站: 网安招聘网站 xss跨站脚本攻击 逆向:可以理解为游戏里的外挂 pwn最难的题目 密码学: 1、编码:base64 2、加密:凯撒 3、摘要:MD5、SHA1、SHA2 调查取证:杂项&am…...

掌握HTML文件上传:从基础到高级技巧
HTML中input标签的上传文件功能详解 一、基础概念 1. 文件上传的基本原理 在Web开发中,文件上传是指将本地计算机中的文件(如图片、文档、视频等)传输到服务器的过程。HTML中的<input type"file">标签是实现这一功能的基础…...

UE5无法编译问题解决
1. vs编译 2. 删除三个文件夹 参考...
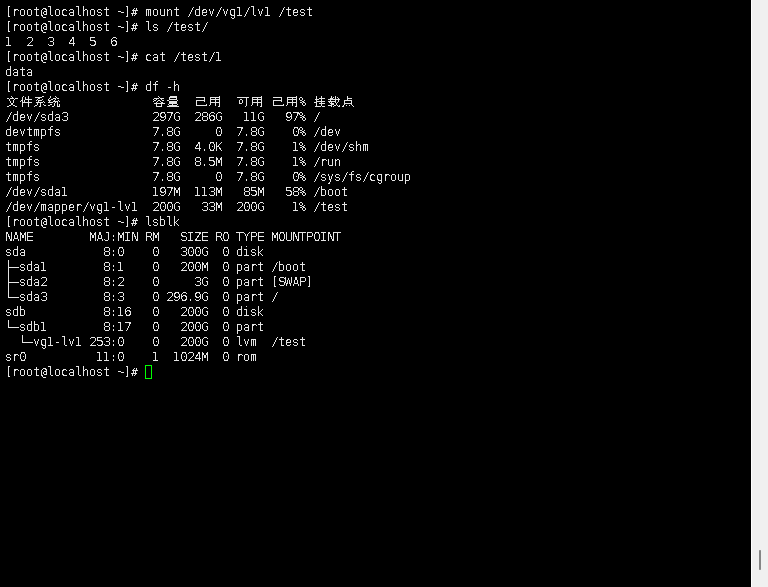
CentOS7原有磁盘扩容实战记录(LVM非LVM)【针对GPT分区】
一、环境 二、命令及含义 fdisk fdisk是一个较老的分区表创建和管理工具,主要支持MBR(Master Boot Record)格式的分区表。MBR分区表支持的硬盘单个分区最大容量为2TB,最多可以有4个主分区。fdisk通过命令行界面进行操…...

机器学习07-归一化与标准化
归一化与标准化 一、基本概念 归一化(Normalization) 定义:将数据缩放到一个固定的区间,通常是[0,1]或[-1,1],以消除不同特征之间的量纲影响和数值范围差异。公式:对于数据 ( x ),归一化后的值…...
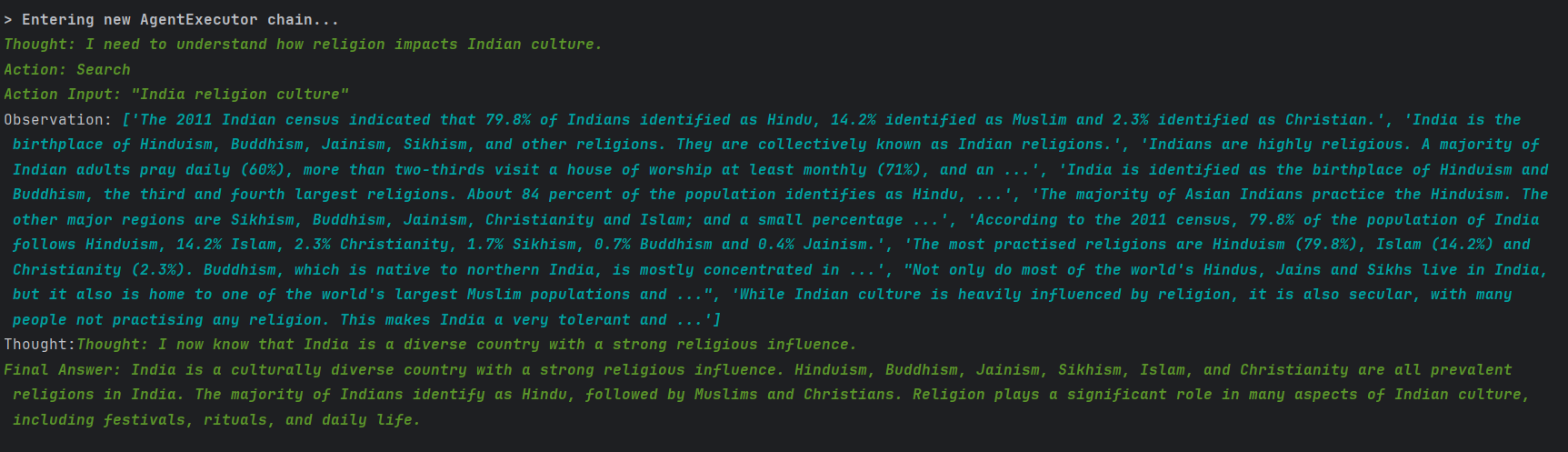
AI agent与lang chain的学习笔记 (1)
文章目录 智能体的4大要素一些上手的例子与思考。创建简单的AI agent.从本地读取文件,然后让AI智能体总结。 也可以自己定义一些工具 来完成一些特定的任务。我们可以使用智能体总结一个视频。用户可以随意问关于视频的问题。 智能体的4大要素 AI 智能体有以下几个…...

优化 Spring Boot 应用启动性能的实践指南
1. 引言 Spring Boot 以其“开箱即用”的特性深受开发者喜爱,但随着项目复杂度的增加,应用的启动时间也可能会变得较长。对于云原生、Serverless 等场景而言,快速启动是一个非常关键的指标。 2. 分析启动过程 2.1 启动阶段概述 Spring Boot 的启动流程主要包括以下几个阶…...
谢赛宁团队提出 BLIP3-o:融合自回归与扩散模型的统一多模态架构,开创CLIP特征驱动的图像理解与生成新范式
BLIP3-o 是一个统一的多模态模型,它将自回归模型的推理和指令遵循优势与扩散模型的生成能力相结合。与之前扩散 VAE 特征或原始像素的研究不同,BLIP3-o 扩散了语义丰富的CLIP 图像特征,从而为图像理解和生成构建了强大而高效的架构。 此外还…...
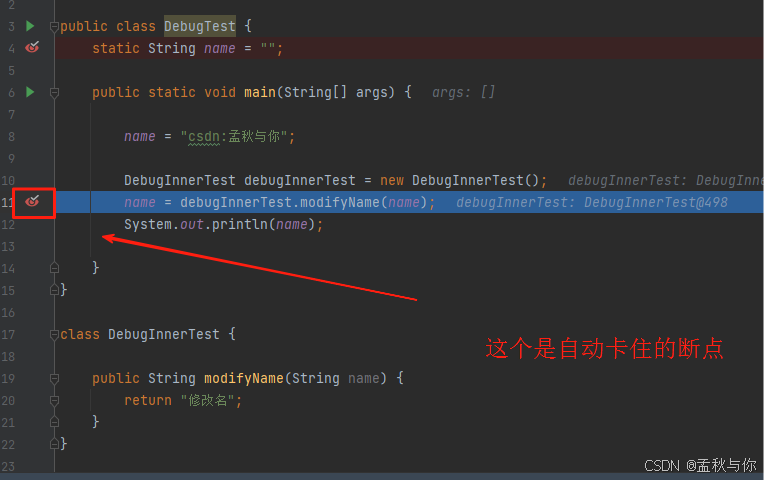
【idea】调试篇 idea调试技巧合集
前言:之前博主写过一篇idea技巧合集的文章,由于技巧过于多了,文章很庞大,所以特地将调试相关的技巧单独成章, 调试和我们日常开发是息息相关的,用好调试可以事半功倍 文章目录 1. idea调试异步线程2. idea调试stream流…...
二叉树深搜:在算法森林中寻找路径
专栏:算法的魔法世界 个人主页:手握风云 目录 一、搜索算法 二、回溯算法 三、例题讲解 3.1. 计算布尔二叉树的值 3.2. 求根节点到叶节点数字之和 3.3. 二叉树剪枝 3.4. 验证二叉搜索树 3.5. 二叉搜索树中第 K 小的元素 3.6. 二叉树的所有路径 …...

golang 安装gin包、创建路由基本总结
文章目录 一、安装gin包和热加载包二、路由简单场景总结 一、安装gin包和热加载包 首先终端新建一个main.go然后go mod init ‘项目名称’执行以下命令 安装gin包 go get -u github.com/gin-gonic/gin终端安装热加载包 go get github.com/pilu/fresh终端输入fresh 运行 &…...
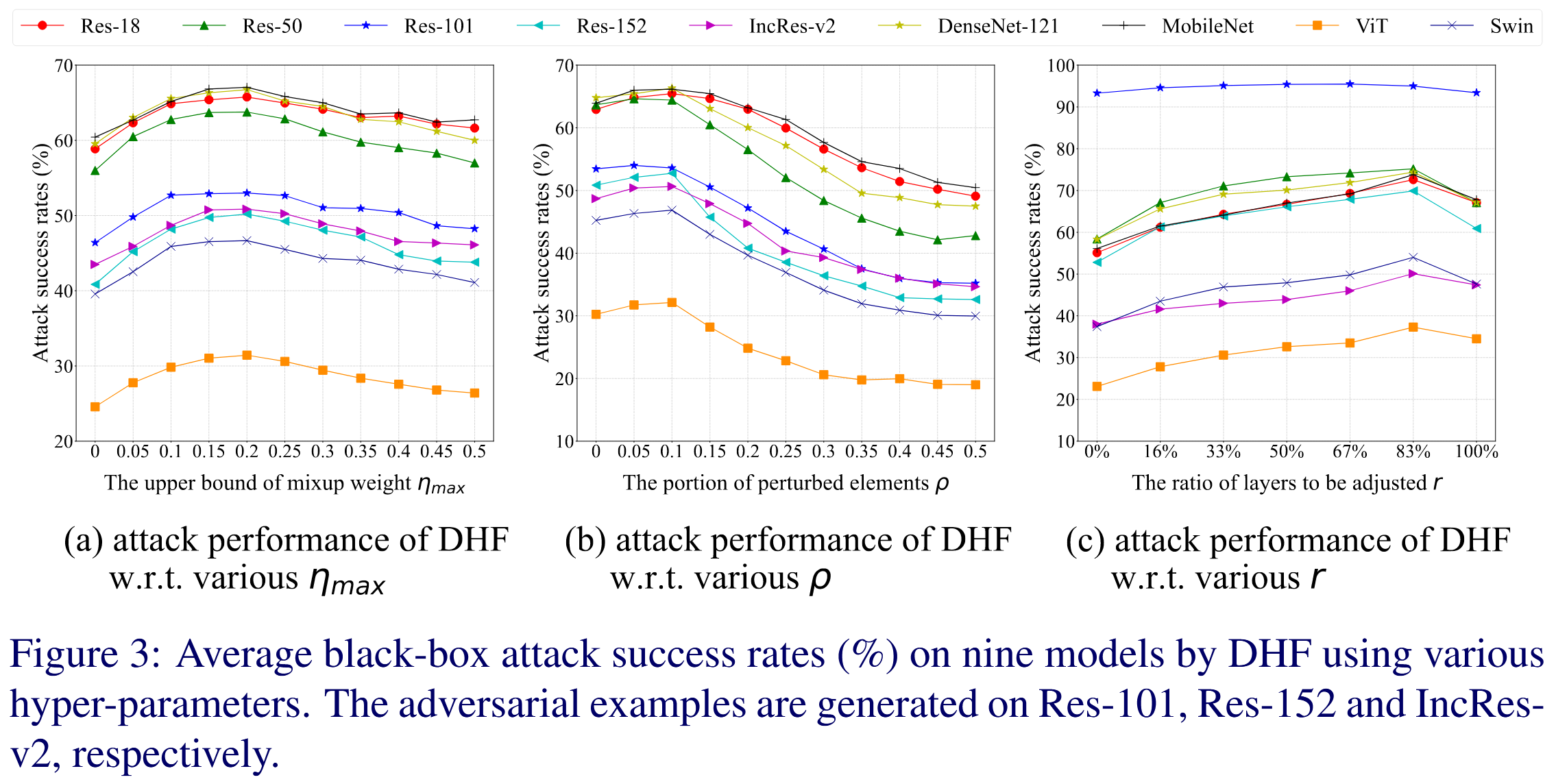
BMVC2023 | 多样化高层特征以提升对抗迁移性
Diversifying the High-level Features for better Adversarial Transferability 摘要-Abstract引言-Introduction相关工作-Related Work方法-Methodology实验-Experiments结论-Conclusion 论文链接 GitHub链接 本文 “Diversifying the High-level Features for better Adve…...
有哪些GIF图片转换的开源工具
以下是关于GIF图片转换的开源工具的详细总结,涵盖功能特点、适用场景及用户评价: 1. FFmpeg 功能特点: 作为开源命令行工具,FFmpeg支持视频转GIF、调整帧率、分辨率、截取片段等操作,可通过脚本批量处理。适用场景: 适合开发者或技术用户进行高效批处理,常用于服务器端自…...