Day11-苍穹外卖(数据统计篇)
前言:
今天写day11的内容,主要讲了四个统计接口的制作。看起来内容较多,其实代码逻辑都是相似的,这里我们过一遍。
今日所学:
- Apache ECharts
- 营业额统计
- 用户统计
- 订单统计
- 销量排行统计
1. Apache ECharts
1.1 介绍
Apache ECharts 是一个功能强大、易于使用的数据可视化工具,适用于多种场景下的数据展示需求。通过简单的配置和灵活的定制,用户可以快速生成美观且交互性强的图表,提升数据分析和展示的效果。
总结:
Apache ECharts 是一个前端数据可视化库,适用于Web端的数据展示和分析
我们后端需要做的,就是提供符合格式要求的动态数据,然后响应给前端来展示图表。
1.2 使用流程:
1.下载echarts.js
这边黑马的资料中给我们准备好了
2.在前端的代码中引用
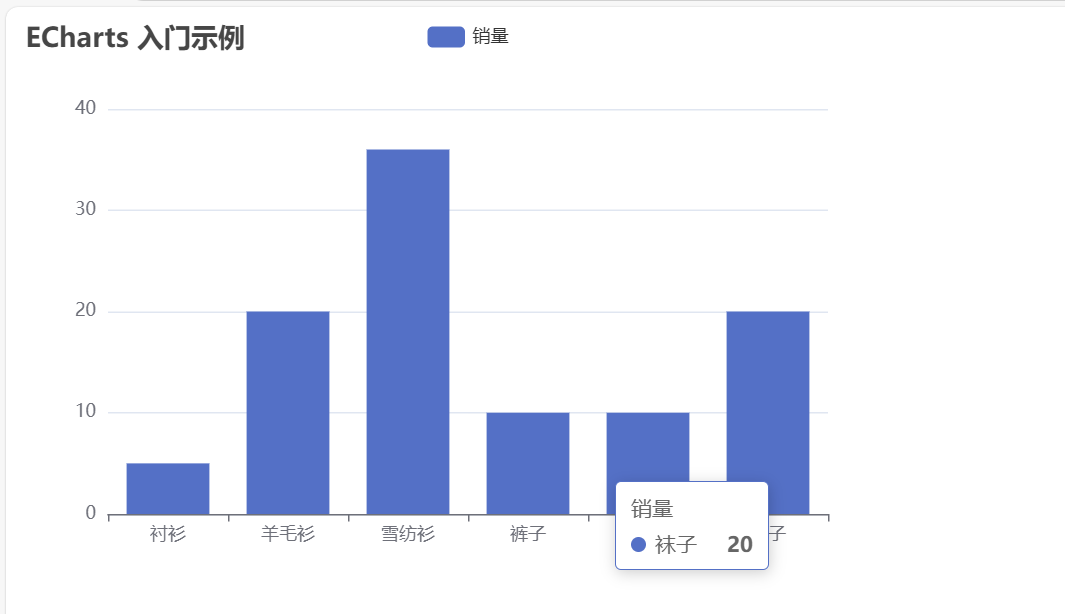
打开echartsDemo.html文件代码,可以看到已成功引入了echarts.js

运行这个html文件
2.营业额统计
需求分析
业务规则:
1.营业额指的是订单状态为完成的订单金额合计
2.X轴表示日期,Y轴表示营业额
3. 根据时间选择区间,展示每天的营业额数据
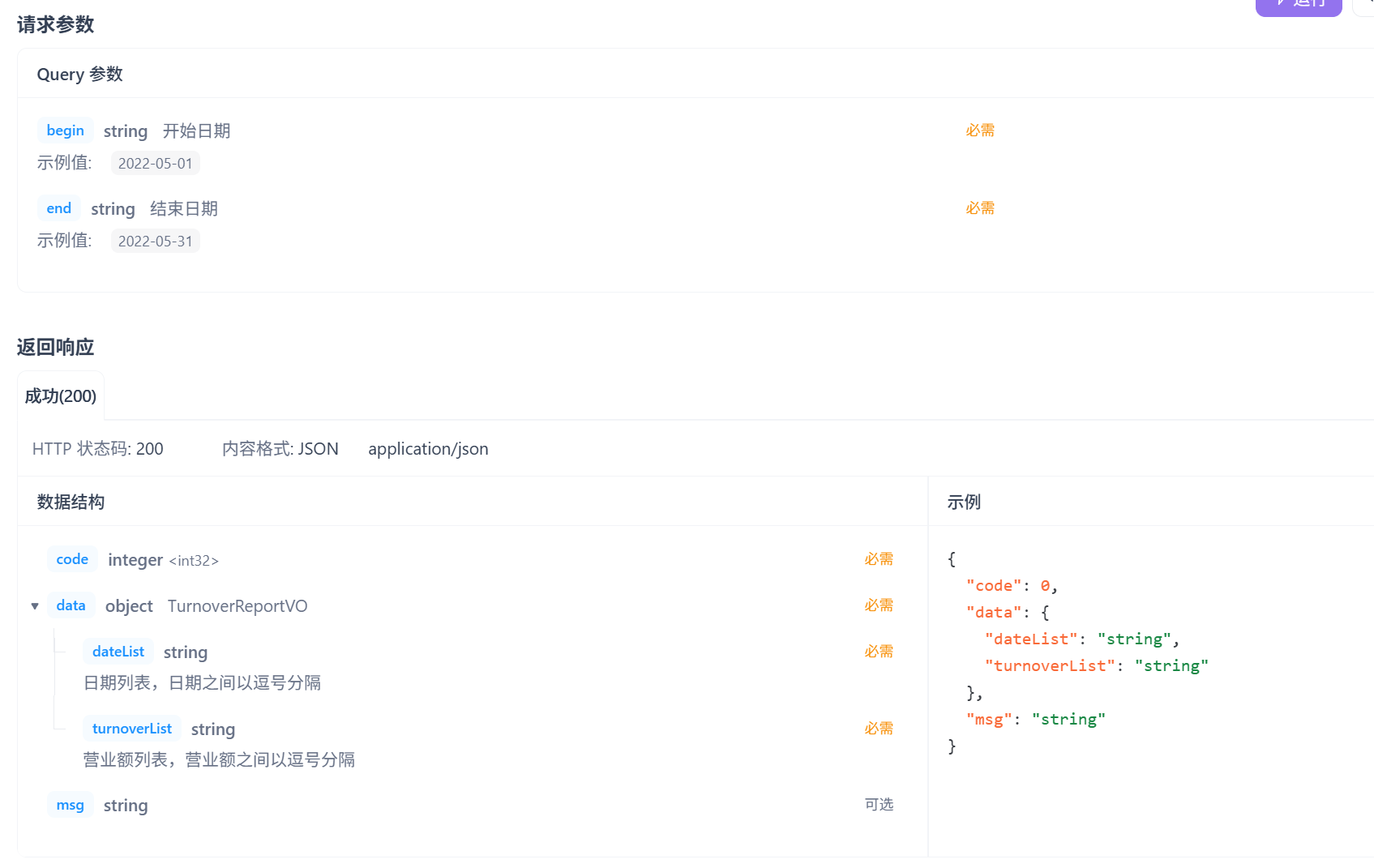
请求参数是开始时间和结束时间,这里注意传给前端的dataList和turnoverList都要是String类型的数据
代码展示
Controller层:

这里注意begin,end是LocalData变量,传入的时候要指定时间格式
service层:
这里具体的代码逻辑是:
1.先是定义两个arrayList容器用于后续储存每日的日期还有相应的营业额
2.while循环储存从开始(begin)到结束(end)的每一天日期数据
3.将每一天的日期数据(LocalData变量)转换成(LocalDataTime变量),分别取极小值(00:00:00)和极大值(23:59:5999)
4.调用Ordermapper,执行如下SQL语句:
select sum(amount) from Orders where order_time > beginTime(一天的极小值) and order_time < endTime(一天的极大值) and status = 5(已完成)
注意下这里传给mapper的数据是由map储存的
/*** 指定时间内的营业额* @param begin* @param end* @return*/
@Override
public TurnoverReportVO turnoverStatistics(LocalDate begin, LocalDate end) {// 用于储存begin,end范围内每天的日期List<LocalDate> dateList = new ArrayList<>();List<Double> turnoverList = new ArrayList<>();dateList.add(begin);while(!begin.equals(end)) {// 指定日期的后一天begin = begin.plusDays(1);dateList.add(begin);}for (LocalDate date : dateList) {LocalDateTime beginTime = LocalDateTime.of(date, LocalTime.MIN);LocalDateTime endTime = LocalDateTime.of(date, LocalTime.MAX);Map map = new HashMap();map.put("beginTime", beginTime);map.put("endTime", endTime);map.put("status", Orders.COMPLETED);Double amount = orderMapper.getSumBymap(map);amount = amount == null ? 0.0 : amount;turnoverList.add(amount);}return TurnoverReportVO.builder().turnoverList(StringUtils.join(turnoverList, ",")).dateList(StringUtils.join(dateList, ",")).build();
}
mapper层:
<select id="getSumBymap" resultType="java.lang.Double">select sum(amount) from orders<where><if test="begin != null">and order_time > #{beginTime}</if><if test="end != null">and order_time < #{endTime}</if><if test="status != null">and status = #{status}</if></where>
</select>
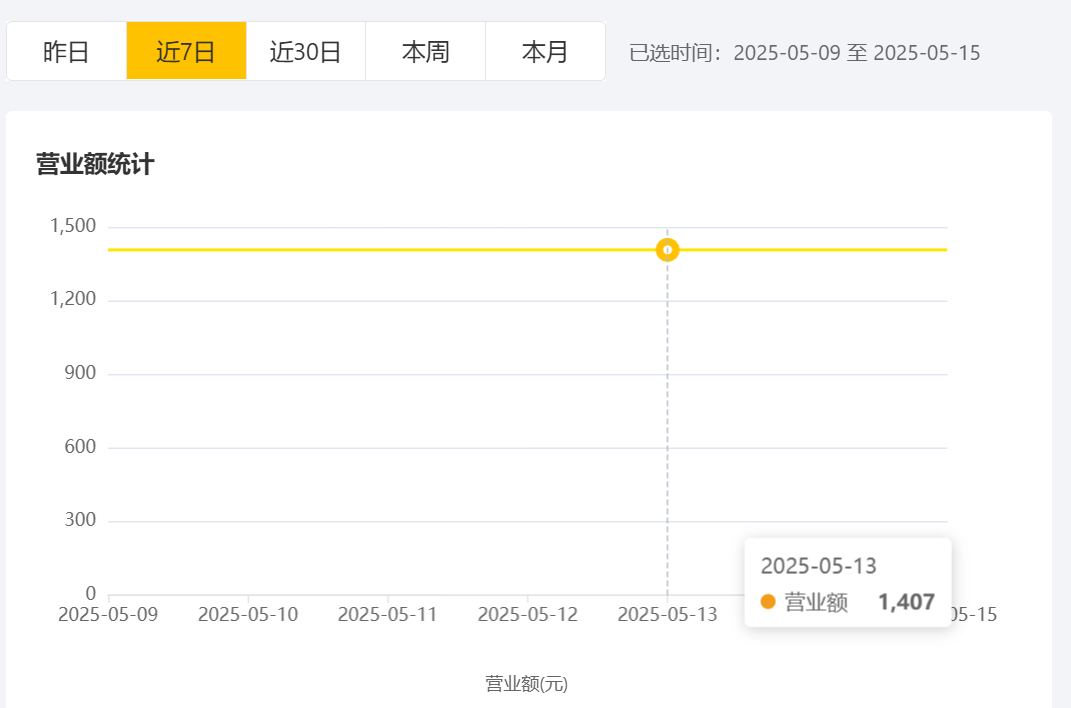
运行展示:
问题
这里我遇到的问题是几个:
1.路径写错了(写成另一个接口的了),导致前端图表一直展示不出来,改了挺久的

2.StringUtils包导错了
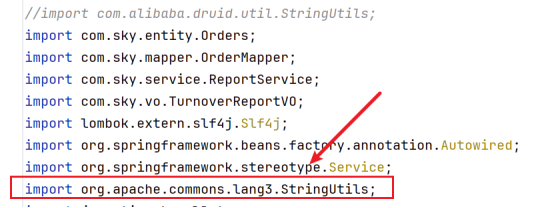
这里要注意导入的是我标注的那个包,而不是我最上面注释掉的那个
3.这里要注意要写的是Double,而不是double.Double是包装类,是一种类,存在null值,而double是一种基本数据类型,是不存在null值的
3.用户统计
需求分析
业务规则:
- 基于可视化报表的折线图展示用户数据,X轴为日期,Y轴为用户数
- 根据时间选择区间,展示每天的用户总量和新增用户量数据
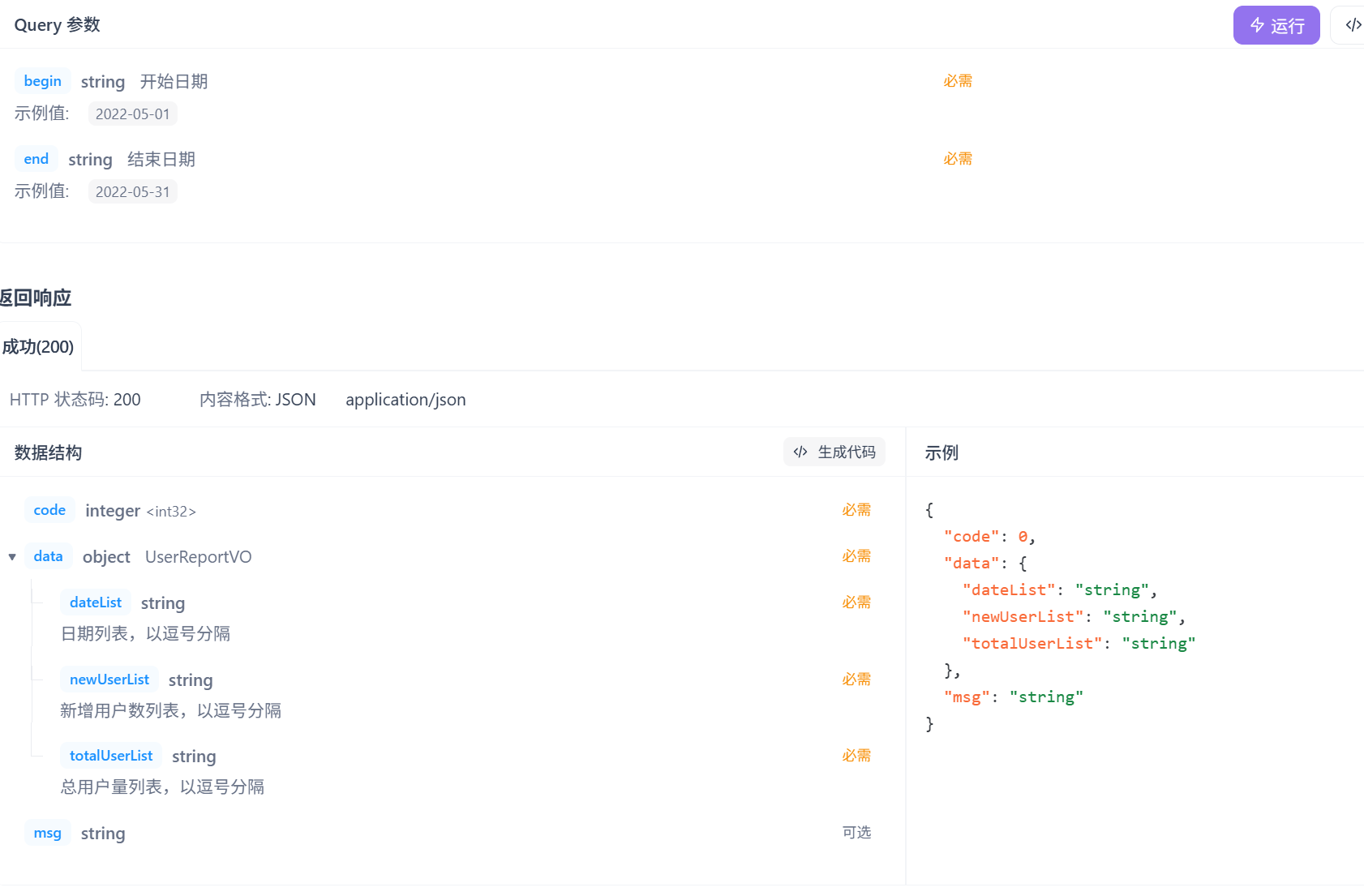
这里的传入参数和返回数据跟营业额统计格式上基本是一致的:传入开始日期和结束日期,
返回数据也都是要String类型的
代码展示:
Controller层:
@ApiOperation("用户统计")
@GetMapping("/userStatistics")
public Result<UserReportVO> userStatistics(@DateTimeFormat(pattern = "yyyy-MM-dd") LocalDate begin,@DateTimeFormat(pattern = "yyyy-MM-dd") LocalDate end){UserReportVO userReportVO = reportService.userStatistics(begin, end);return Result.success(userReportVO);
}
这里同样注意传入的LocalData类型的数据要用@DataTimeFormat规定时间格式
Service层:
具体逻辑:
1.定义三个ArrayList格式的数据,分别用于储存每一天的时间,每一天的用户总量,每一天的用户增量
2.while循环得到开始日期到结束日期之间每天的日期
3..将每一天的日期数据(LocalData变量)转换成(LocalDataTime变量),分别取极小值(00:00:00)和极大值(23:59:5999)
4.调用mapper,执行相应的语句,得到每一天的用户总量和用户新增量
这里注意用户总量只要查询endTime就行了,用户新增量再查询beginTime和endTime之间创建的用户,具体SQL执行逻辑:
select count(id) from user where create_time < endTime and create_time > beginTime(求用户新增量的时间再传入相应参数)
mapper参数还是由map传入
/*** 用户统计* @param begin* @param end* @return*/
@Override
public UserReportVO userStatistics(LocalDate begin, LocalDate end) {List<LocalDate> dateList = new ArrayList<>();dateList.add(begin);while(!begin.equals(end)) {begin = begin.plusDays(1);dateList.add(begin);}List<Integer> totalUserList = new ArrayList<>();List<Integer> newUserList = new ArrayList<>();for(LocalDate date : dateList) {LocalDateTime beginTime = LocalDateTime.of(date, LocalTime.MIN);LocalDateTime endTime = LocalDateTime.of(date, LocalTime.MAX);Map map = new HashMap();map.put("endTime", endTime);Integer userNum = userMapper.countByMap(map);map.put("beginTime", beginTime);Integer newUserNum = userMapper.countByMap(map);userNum = userNum == null ? 0 : userNum;totalUserList.add(userNum);newUserList.add(newUserNum);}return UserReportVO.builder().dateList(StringUtils.join(dateList,",")).totalUserList(StringUtils.join(totalUserList, ",")).newUserList(StringUtils.join(newUserList, ",")).build();
}
mapper层
<select id="countByMap" resultType="java.lang.Integer">select count(id) from user<where><if test="beginTime != null">and create_time > #{beginTime}</if><if test="beginTime != null">and create_time < #{endTime}</if></where>
</select>
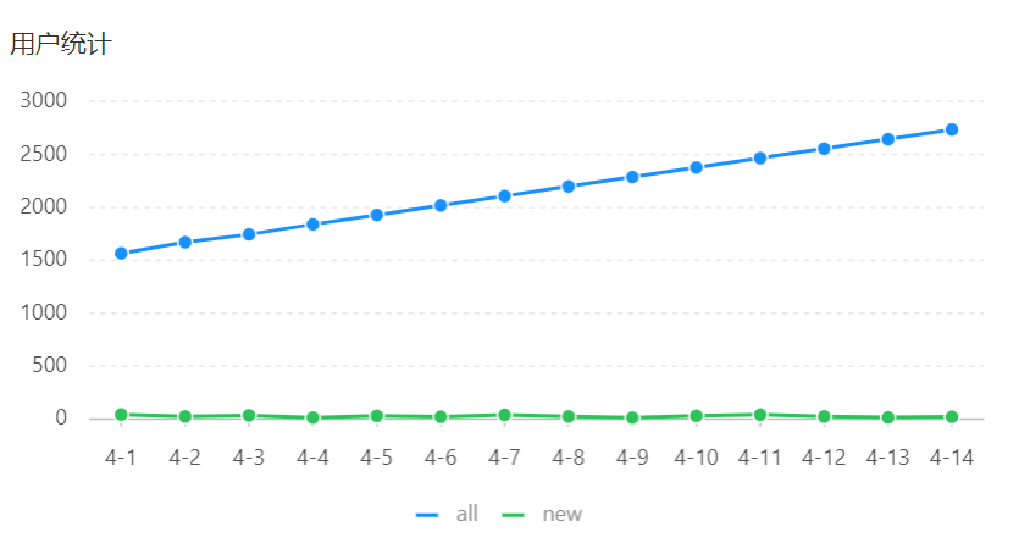
运行展示:
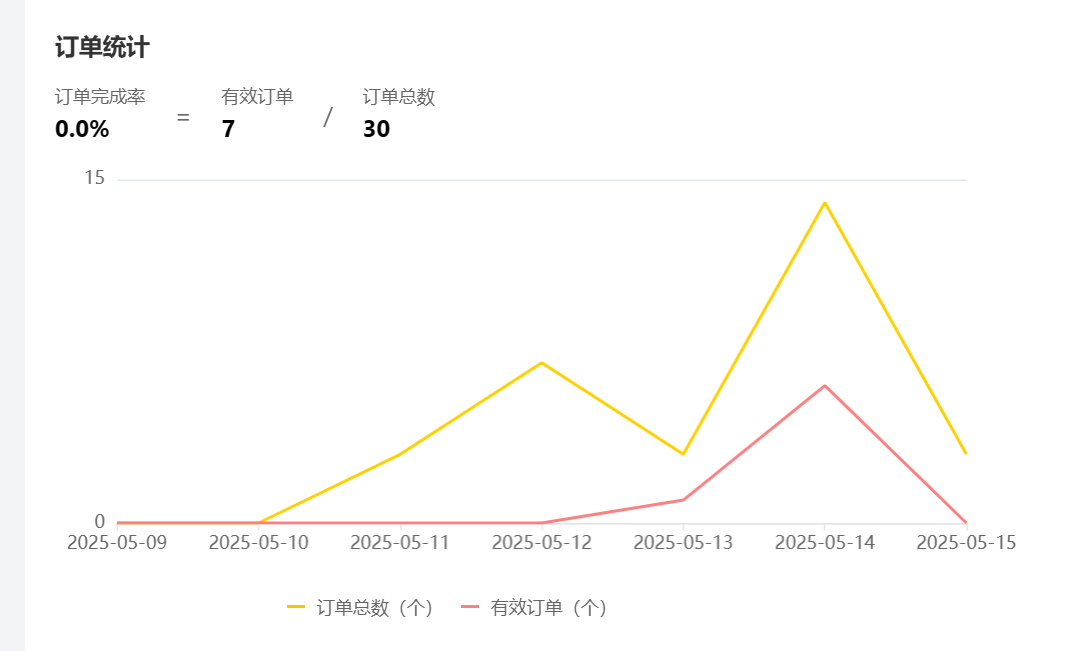
4.订单统计
需求分析
业务规则:
- 有效订单指状态为 “已完成” 的订单
- 基于可视化报表的折线图展示订单数据,X轴为日期,Y轴为订单数量
- 根据时间选择区间,展示每天的订单总数和有效订单数
- 展示所选时间区间内的有效订单数、总订单数、订单完成率,订单完成率 = 有效订单数 / 总订单数 * 100%
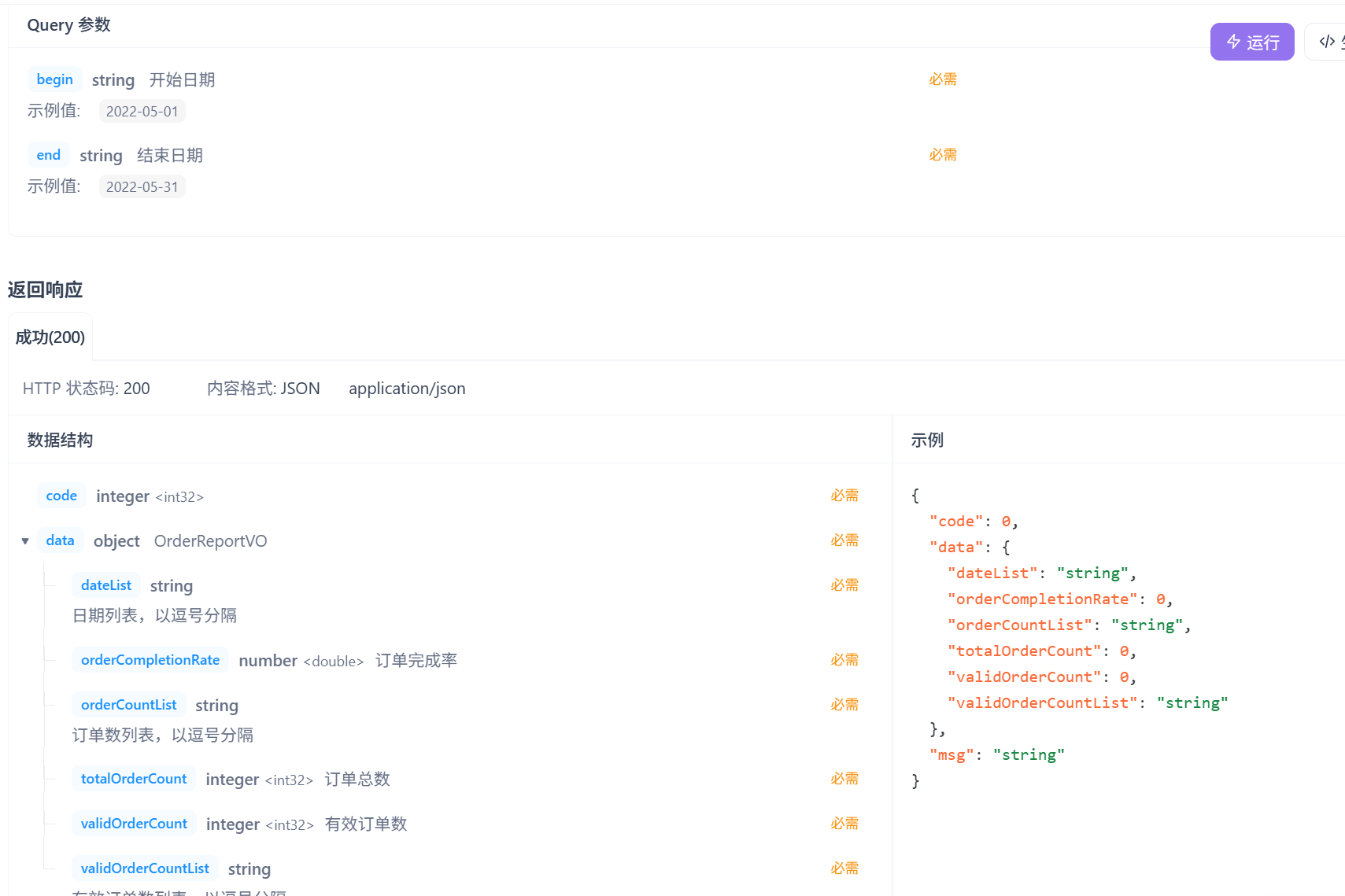
跟上两个接口传入参数返回数据格式上是一致的,请求参数是开始时间和结束时间,传给前端的orderCountList和validOrderCountList都要是String类型的数据
代码展示
Controller层
/*** 订单统计接口* @param begin* @param end* @return*/
@ApiOperation("订单统计接口")
@GetMapping("/ordersStatistics")
public Result<OrderReportVO> orderStatistics(@DateTimeFormat(pattern = "yyyy-MM-dd") LocalDate begin,@DateTimeFormat(pattern = "yyyy-MM-dd") LocalDate end
){log.info("订单统计接口{},{}", begin, end);OrderReportVO orderReportVO = reportService.orderStatistics(begin, end);return Result.success(orderReportVO);
}
这里注意begin,end是LocalData变量,传入的时候要指定时间格式
service层
具体执行逻辑:
1.先是定义三个arrayList容器,分别用于储存每日的日期,每日的订单数,以及有效订单数
2.再定义两个total(Integer),用来统计订单总数和有效订单总数
3.while循环储存从开始(begin)到结束(end)的每一天日期数据
4.将每一天的日期数据(LocalData变量)转换成(LocalDataTime变量),分别取极小值(00:00:00)和极大值(23:59:5999)
4.调用Ordermapper,执行如下SQL语句:
select count(id) from Orders where order_time > beginTime(一天的极小值) and order_time < endTime(一天的极大值) and status = 5(已完成->当统计有效订单再传入相应参数)
每统计一天的,加入相应的容器和总数中
注意下这里传给mapper的数据是由map储存的
/*** 订单统计* @param begin* @param end* @return*/
@Override
public OrderReportVO orderStatistics(LocalDate begin, LocalDate end) {List<LocalDate> dateList = new ArrayList<>();dateList.add(begin);while(!begin.equals(end)) {begin = begin.plusDays(1);dateList.add(begin);}List<Integer> orderCountList = new ArrayList<>();Integer totalOrderCount = 0;List<Integer> vaildOrderCountList = new ArrayList<>();Integer VaildOrderCount = 0;for(LocalDate date : dateList) {LocalDateTime beginTime = LocalDateTime.of(date, LocalTime.MIN);LocalDateTime endTime = LocalDateTime.of(date, LocalTime.MAX);Map map = new HashMap();map.put("beginTime", beginTime);map.put("endTime", endTime);Integer orderCount = orderMapper.CountByMap(map);orderCountList.add(orderCount);totalOrderCount += orderCount;map.put("status",Orders.COMPLETED);Integer vaildCount = orderMapper.CountByMap(map);vaildOrderCountList.add(vaildCount);VaildOrderCount += vaildCount;}return OrderReportVO.builder().orderCountList(StringUtils.join(orderCountList, ",")).totalOrderCount(totalOrderCount).validOrderCount(VaildOrderCount).validOrderCountList(StringUtils.join(vaildOrderCountList, ",")).dateList(StringUtils.join(dateList,",")).build();
}
mapper层
<select id="CountByMap" resultType="java.lang.Integer">select count(id) from orders<where><if test="beginTime != null">and order_time > #{beginTime}</if><if test="endTime != null">and order_time < #{endTime}</if><if test="status != null">and status = #{status}</if></where>
</select>
运行展示:
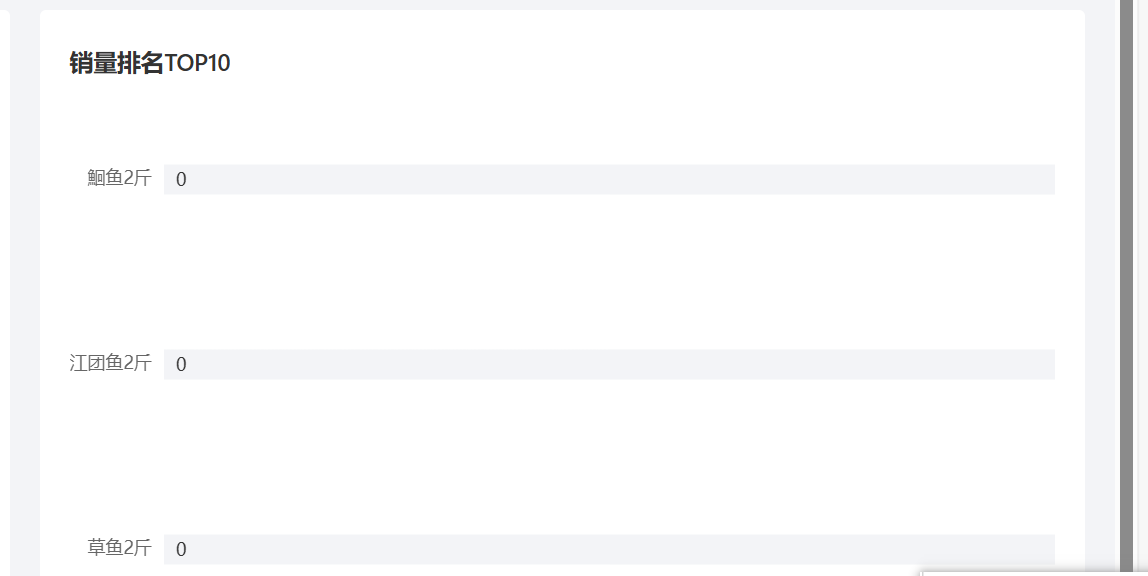
5. 销量排行统计
需求分析:
业务规则:
- 根据时间选择区间,展示销量前10的商品(包括菜品和套餐)
- 基于可视化报表的柱状图降序展示商品销量
- 此处的销量为商品销售的份数
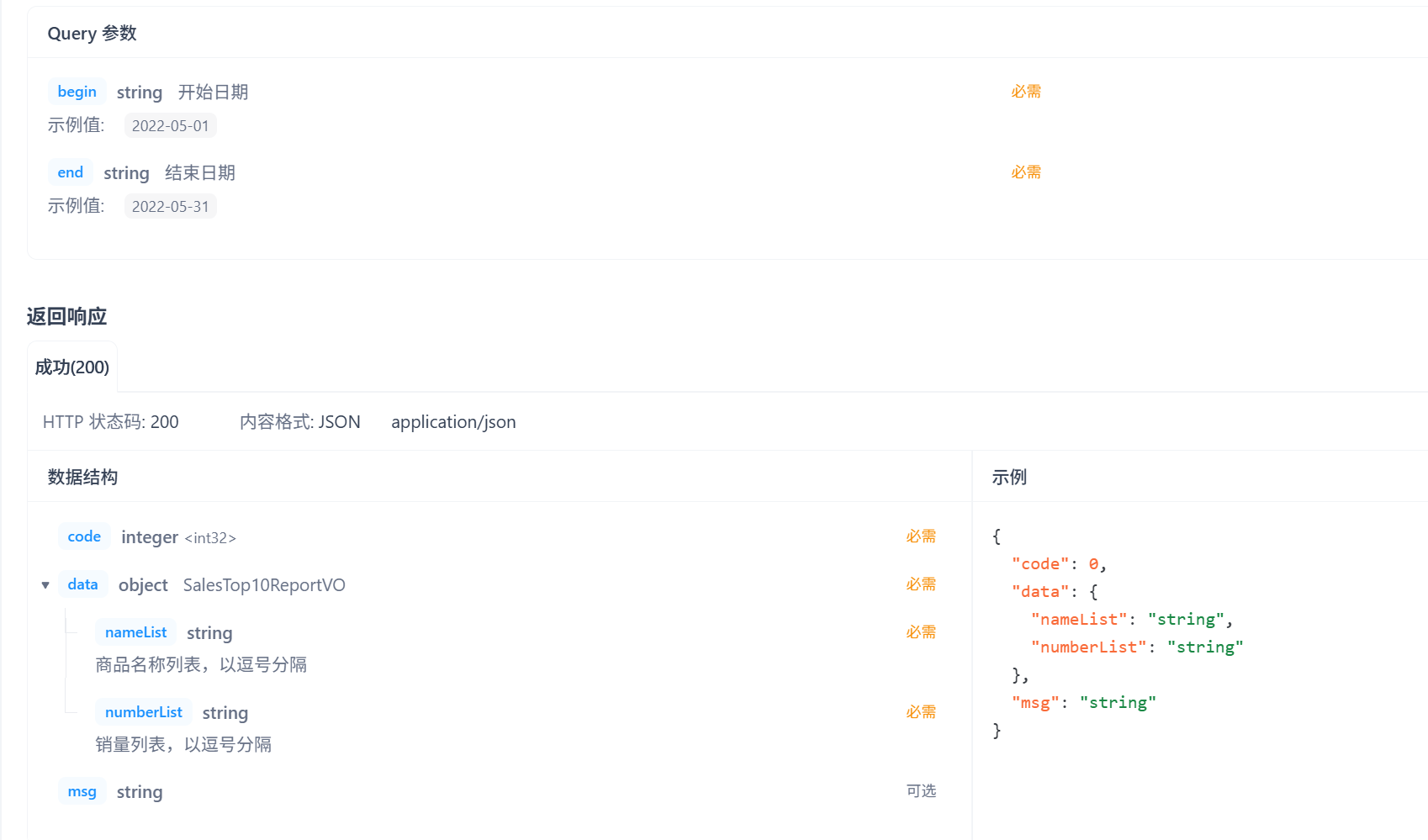
请求参数是开始时间和结束时间,这里注意传给前端的nameList和numberList都要是String类型的数据
代码展示:
controller层
/*** 销量排行展示* @param begin* @param end* @return*/
@ApiOperation("销量排名展示")
@GetMapping("/top10")
public Result<SalesTop10ReportVO> salesTop10Statistics(@DateTimeFormat(pattern = "yyyy-MM-dd") LocalDate begin,@DateTimeFormat(pattern = "yyyy-MM-dd") LocalDate end
){log.info("销量排名展示{},{}", begin,end);SalesTop10ReportVO salesTop10ReportVO = reportService.top10(begin, end);return Result.success(salesTop10ReportVO);
}
这里注意begin,end是LocalData变量,传入的时候要指定时间格式
service层:
具体实现逻辑:
1.这里我们项目有一个专门封装了菜品名称和菜品销量的dto(GoodsSalesDTO),所以我们不用专门再创建容器去记录数据
2.因为销量统计是统计我们这一整段时间(从begin到end)的菜品销量,所以不用在遍历每一天的订单数据
3.将LocalDate变量数据转换成LocalDataTime,求得这一段时间的极小值和极大值
4.调用ordermapper,因为涉及到订单(orders)的下单时间和订单详情(order_detail)的菜品数据,所以这里我采用join进行连接查询,具体SQL语句为:
select od.name as name , coount(od.name) as number from orders o join order_detail od
on od.order_id = o.id
where status = 5(查看已下单的数据) and order_time > beginTime and order_time < endTime
group by name order by name desc limit 0, 10(查询销量前十的菜品)
5.得到相应的数据后使用stream流进行遍历,最后用StringUtils.join连接起来
/*** 销量统计* @param begin* @param end* @return*/
@Override
public SalesTop10ReportVO top10(LocalDate begin, LocalDate end) {LocalDateTime beginTime = LocalDateTime.of(begin, LocalTime.MIN);LocalDateTime endTime = LocalDateTime.of(end, LocalTime.MAX);List<GoodsSalesDTO> goodsSalesDTOList = orderMapper.getByNameNum(beginTime, endTime);String nameList = StringUtils.join(goodsSalesDTOList.stream().map(GoodsSalesDTO::getName).collect(Collectors.toList()), ",");String numList = StringUtils.join(goodsSalesDTOList.stream().map(GoodsSalesDTO::getNumber).collect(Collectors.toList()), ",");return SalesTop10ReportVO.builder().nameList(nameList).numberList(numList).build();
}
mapper层
<select id="getByNameNum" resultType="com.sky.dto.GoodsSalesDTO">select od.name as name, sum(od.name) as number from orders o join order_detail odon o.id = od.order_idand o.status = 5<where><if test="beginTime != null">and order_time > #{beginTime}</if><if test="endTime != null">and order_time < #{endTime}</if></where>group by nameorder by number desclimit 0, 10
</select>
运行展示:
最后:
今天的分享就到这里。如果我的内容对你有帮助,请点赞,评论,收藏。创作不易,大家的支持就是我坚持下去的动力!(๑`・ᴗ・´๑)
相关文章:
Day11-苍穹外卖(数据统计篇)
前言: 今天写day11的内容,主要讲了四个统计接口的制作。看起来内容较多,其实代码逻辑都是相似的,这里我们过一遍。 今日所学: Apache ECharts营业额统计用户统计订单统计销量排行统计 1. Apache ECharts 1.1 介绍 A…...
Tomcat简述介绍
文章目录 Web服务器Tomcat的作用Tomcat分析目录结构 Web服务器 Web服务器的作用是接收客户端的请求,给客户端作出响应。 知名Java Web服务器 Tomcat(Apache):用来开发学习使用;免费,开源JBoss࿰…...
《从零开始:Spring Cloud Eureka 配置与服务注册全流程》
关于Eureka的学习,主要学习如何搭建Eureka,将order-service和product-service都注册到Eureka。 1.为什么使用Eureka? 我在实现一个查询订单功能时,希望可以根据订单中productId去获取对应商品的详细信息,但是产品服务和订单服…...

如何保证RabbitMQ消息的顺序性?
保证RabbitMQ消息的顺序性是一个常见的需求,尤其是在处理需要严格顺序的消息时。然而,默认情况下,RabbitMQ不保证消息的全局顺序,因为消息可能会通过不同的路径(例如不同的网络连接或线程)到达队列…...

FPGA学习知识(汇总)
1. wire与reg理解,阻塞与非阻塞 2. 时序取值,时钟触发沿向左看 3. ip核/setup debug 添加 ila 一、ila使用小技巧 二、同步复位、异步复位和异步复位同步释放 设计复位设计,尽量使用 异步复位同步释放;尽管该方法仍然对毛刺敏感…...

c语言 写一个五子棋
c语言 IsWin判赢 display 画 10 x 10 的棋盘 判断落子的坐标是否已有棋子 判断落子坐标范围是否超出范围 // 五子棋 #include <stdio.h> #include <stdlib.h>// 画棋盘 10 x 10的棋盘,len为行数 void display(char map[][10], int len) {system(&q…...
Redisson分布式锁-锁的可重入、可重试、WatchDog超时续约、multLock联锁(一文全讲透,超详细!!!)
本文涉及到使用Redis实现基础分布式锁以及Lua脚本的内容,如有需要可以先参考博主的上一篇文章:Redis实现-优惠卷秒杀(基础版本) 一、功能介绍 (1)前面分布式锁存在的问题 在JDK当中就存在一种可重入锁ReentrantLock,可重入指的是在同一线…...

Python爬虫实战:研究源码还原技术,实现逆向解密
1. 引言 在网络爬虫技术实际应用中,目标网站常采用各种加密手段保护数据传输和业务逻辑。传统逆向解密方法依赖人工分析和调试,效率低下且易出错。随着 Web 应用复杂度提升,特别是 JavaScript 混淆技术广泛应用,传统方法面临更大挑战。 本文提出基于源码还原的逆向解密方法…...
)
WordPress Relevanssi插件时间型SQL注入漏洞(CVE-2025-4396)
免责声明 本文档所述漏洞详情及复现方法仅限用于合法授权的安全研究和学术教育用途。任何个人或组织不得利用本文内容从事未经许可的渗透测试、网络攻击或其他违法行为。使用者应确保其行为符合相关法律法规,并取得目标系统的明确授权。 对于因不当使用本文信息而造成的任何直…...

Adobe Illustrator学习备忘
1.移动画板:需按住空格键加鼠标一块才能拖动 2.放大缩小画板:按住Alt键加鼠标滚轮 3.撤回:CtrlZ 4.钢笔练习网站:The Bzier Game...

C#中的dynamic与var:看似相似却迥然不同
在C#编程的世界里,var和dynamic这两个关键字常常让初学者感到困惑。它们看起来都在定义变量时省略了显式类型声明,但实际上它们的工作方式和应用场景有着天壤之别。今天,让我们一起揭开这两个关键字的神秘面纱。 var:编译时的类型…...

求职困境:开发、AI、运维、自动化
文章目录 问:我的技术栈是web全栈(js,css,html,react,typscript),C开发,python开发,音视频图像开发,神经网络深度学习开发,运维&#…...

语言模型:AM-Thinking-v1 能和大参数语言模型媲美的 32B 单卡推理模型
介绍 a-m-team 是北科 (Ke.com) 的一个内部团队,致力于探索 AGI 技术。这是一个专注于增强推理能力的 32B 密集语言模型。 a-m-team / AM-Thinking-v1 是其旗下的一个语言模型,采用低成本的方式能实现和大参数模型媲美。 DeepSe…...
ChatGPT:OpenAI Codex—一款基于云的软件工程 AI 代理,赋能 ChatGPT,革新软件开发模式
ChatGPT:OpenAI Codex—一款基于云的软件工程 AI 代理,赋能 ChatGPT,革新软件开发模式 导读:2025年5月16日,OpenAI 发布了 Codex,一个基于云的软件工程 AI 代理,它集成在 ChatGPT 中,…...

docker compose up -d 是一个用于 通过 Docker Compose 在后台启动多容器应用 的命令
docker compose 表示调用 Docker Compose 工具,用于管理基于 YAML 文件定义的多容器应用。 up 核心指令,作用是根据 docker-compose.yml 文件中的配置,创建并启动所有定义的服务、网络、卷等资源。 如果容器未创建,会先构建镜像&…...

智能视觉检测技术:制造业质量管控的“隐形守护者”
在工业4.0浪潮的推动下,制造业正经历一场以智能化为核心的变革。传统人工质检模式因效率低、误差率高、成本高昂等问题,逐渐难以满足现代生产对高精度、高速度的需求。智能视觉检测技术作为人工智能与机器视觉融合的产物,正成为制造业质量管控…...
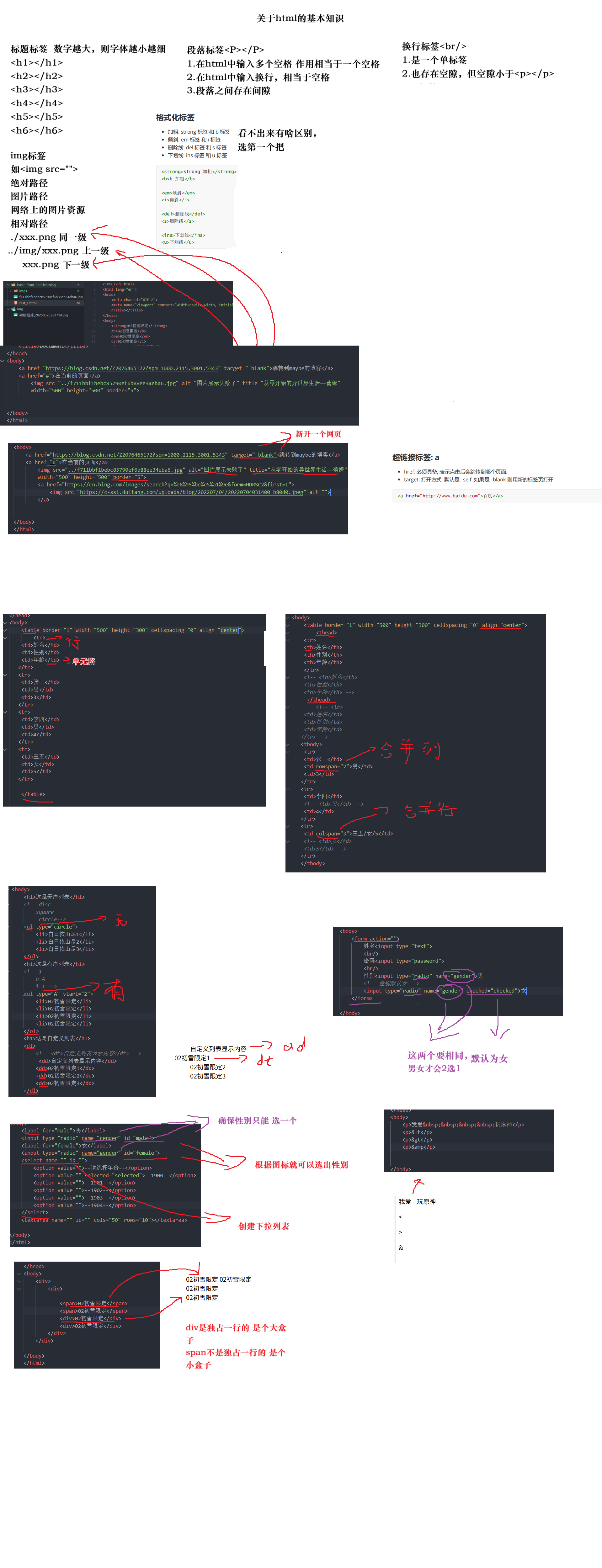
利用html制作简历网页和求职信息网页
前言 大家好,我是maybe。今天下午初步学习了html的基础知识。做了两个小网页,一个网页是简历网页,一个网页是求职信息填写网页。跟大家分享一波~ 说明:我不打算上传图片。所以如果有朋友按照我的代码运行网页,会出现一个没有图片…...

Problem E: List练习
1.题目描述 运用List完成下面的要求: 1) 创建一个List,在List中增加三个工人,基本信息如下: 姓名 年龄 工资 Tom 18 3000 Peter 25 3500 Mark 22 3200 2) 插入一个工人,信息为:姓名:Robert࿰…...

卷积神经网络进阶:转置卷积与棋盘效应详解
【内容摘要】 本文深入解析卷积神经网络中的转置卷积(反卷积)技术,重点阐述标准卷积与转置卷积的计算过程、转置卷积的上采样作用,以及其常见问题——棋盘效应的产生原因与解决方法,为图像分割、超分辨率等任务提供理论…...
重塑 Android 工程效能:2000 字终极实践指南)
用 Kotlin 脚本(KTS)重塑 Android 工程效能:2000 字终极实践指南
一、KTS 核心优势解码 1.1 类型安全革命 对比 Groovy 的动态类型缺陷,KTS 的静态类型系统能在 编译期拦截 90% 的配置错误: // Groovy 的危险操作(运行时才会报错) dependencies {implementation "com.squareup.retrofit:…...

2025年5月13日第一轮
1.百词斩 2.安全状态和死锁 3.银行家算法和状态图 4.Vue运行 5.英语听力 6.词汇 7.英语 长篇:数学竞赛 8.数学 间断点类型和数量 The rapid development of artificial intelligence has led to widerspareasd concreasns about job displacemant.As AI technology conti…...

HarmonyOs开发之———使用HTTP访问网络资源
谢谢关注!! 前言:上一篇文章主要介绍HarmonyOs开发之———Video组件的使用:HarmonyOs开发之———Video组件的使用_华为 video标签查看-CSDN博客 HarmonyOS 网络开发入门:使用 HTTP 访问网络资源 HarmonyOS 作为新一代智能终端…...
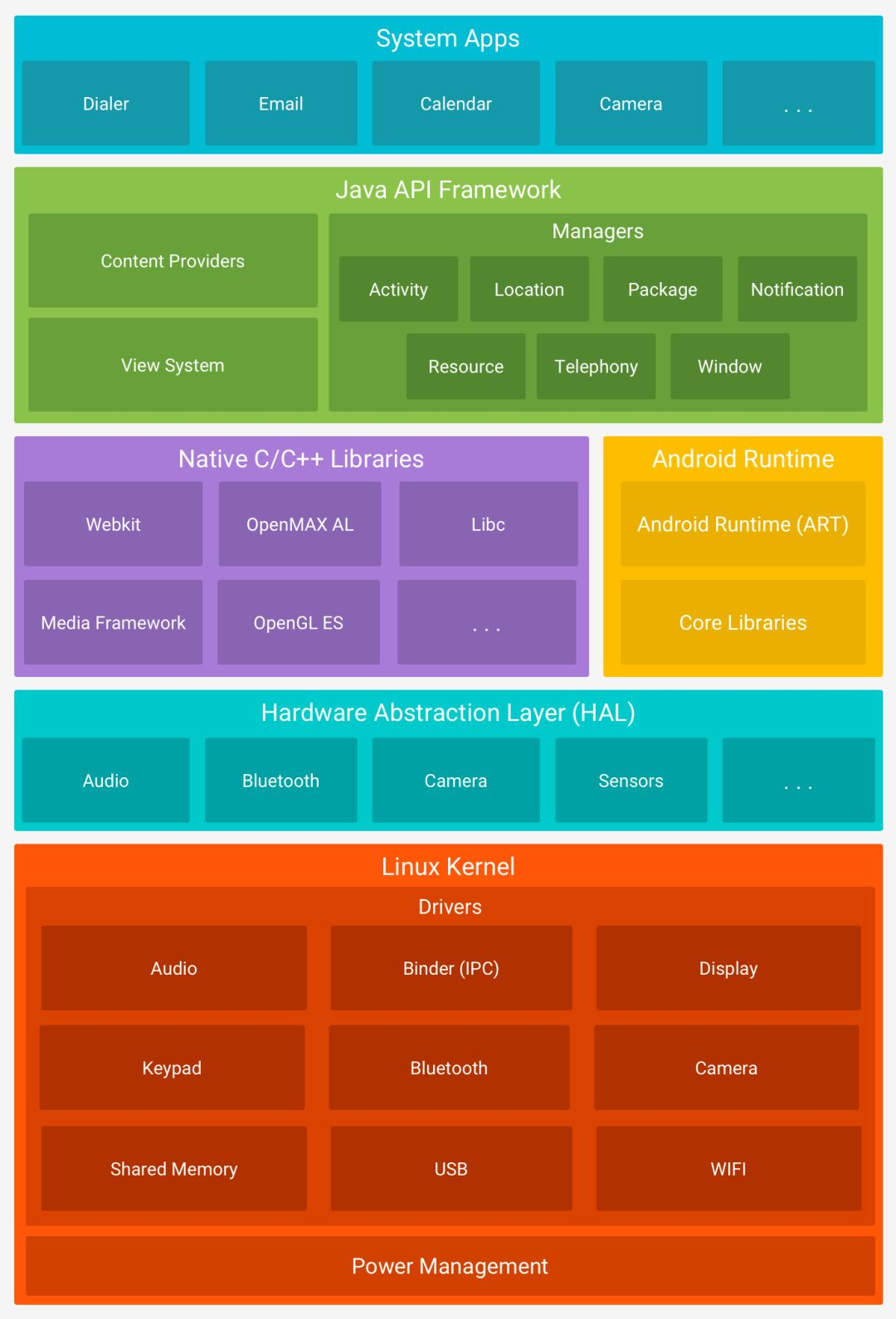
小结:Android系统架构
https://developer.android.com/topic/architecture?hlzh-cn Android系统的架构,分为四个主要层次:应用程序层、应用框架层、库和运行时层以及Linux内核层。: 1. 应用程序层(Applications) 功能:这一层包…...

单物理机上部署多个TaskManager与调优 Flink 集群
单物理机上如何高效部署与调优 Flink 集群 一、硬件环境概述 单物理机,4CPU,16G 内存,旨在充分利用硬件资源,部署 Apache Flink 集群,实现高效的分布式流处理任务。 二、Flink 集群配置 (一)配置文件说明 进入$FLINK_HOME/conf目录。备份原始配置文件:cp flink-con…...
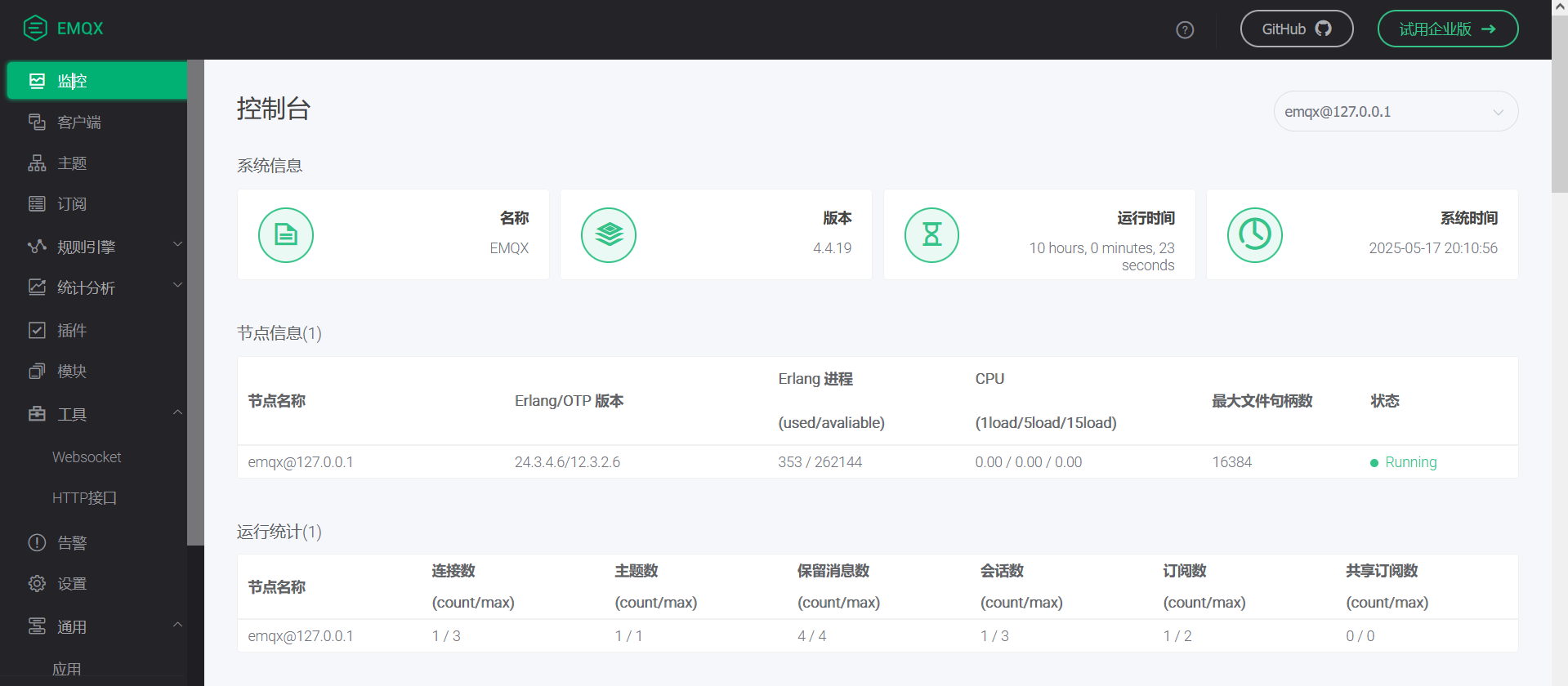
基于C#的MQTT通信实战:从EMQX搭建到发布订阅全解析
MQTT(Message Queueing Telemetry Transport) 消息队列遥测传输,在物联网领域应用的很广泛,它是基于Publish/Subscribe模式,具有简单易用,支持QoS,传输效率高的特点。 它被设计用于低带宽,不稳定或高延迟的…...

VUE3_ref和useTemplateRef获取组件实例,ref获取dom对象
旧写法 ref的字符串需要跟js中ref定义的变量名称一样 类型丢失,无法获取到ref定义的title类型 <template><div><h1 ref"title">Hello Vue3.5</h1></div> </template><script setup>import { ref, onMounted } …...
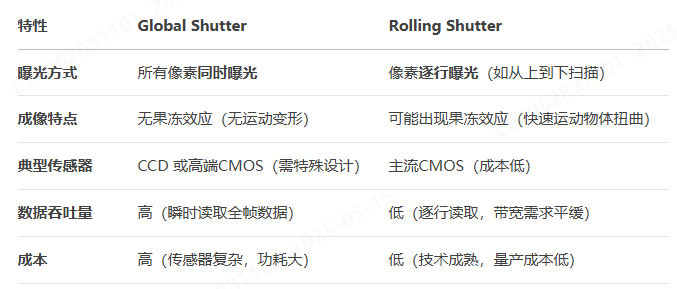
ISP中拖影问题的处理
有时候会出现如下的阴影问题该如何处理呢?本文将提供几个思路。 1、降低曝光时间 如果曝光时间过大,会统计整个曝光时间内的图像信息,就会导致拖影的产生,这个时候可以考虑降低一下曝光时间。 2、时域降噪过大 只要明白时域降噪…...

C++.备考知识点
C++备考知识点 1. 循环结构与等差数列求和1.1 逐天累加实现方法1.2 等差数列求和公式优化2.1 数字转字符串方法2.2 首尾字符交换实现2.3 去除前导零技巧3.1 异或运算基本性质3.2 找出出现奇数次的数问题分析示例代码输出结果扩展应用4.1 字符位移量计算问题分析示例代码输出结果…...

SQLMesh 模型管理指南:从创建到验证的全流程解析
本文全面介绍SQLMesh这一现代化数据转换工具的核心功能,重点讲解模型创建、编辑、验证和删除的全生命周期管理方法。通过具体示例和最佳实践,帮助数据工程师掌握SQLMesh的高效工作流程,包括增量模型配置、变更影响评估、安全回滚机制等关键操…...
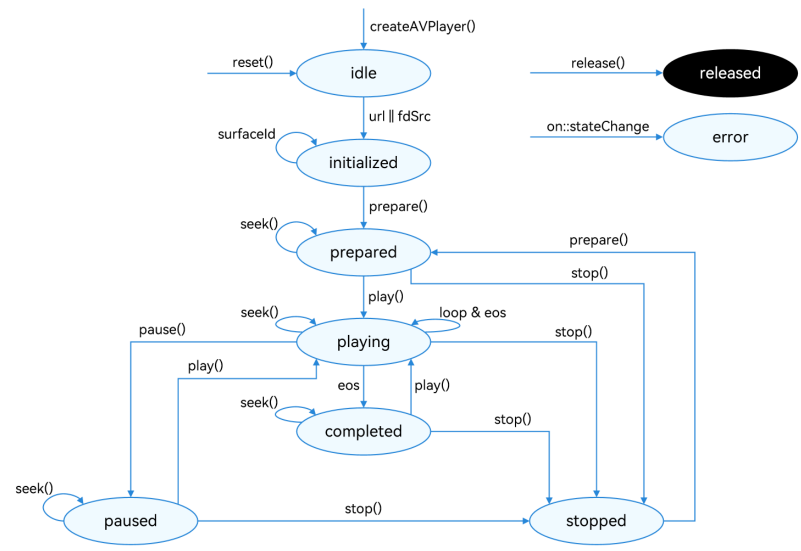
HarmonyOS AVPlayer 音频播放器
鸿蒙文档中心:使用AVPlayer播放视频(ArkTS)文档中心https://developer.huawei.com/consumer/cn/doc/harmonyos-guides/video-playback 这张图描述的是 HarmonyOS AVPlayer 音频播放器的状态流转过程,展示了 AVPlayer 在不同状态之间的切换条件和关键操作…...