Denoising Score Matching with Langevin Dynamics
在自然图像等复杂数据集中,真实数据往往集中分布在一个低维流形上,概率密度函数的梯度(即得分函数)难以定义与估计。为缓解该问题,SMLD 提出使用不同强度的高斯噪声对数据进行扰动,扰动后的数据不再集中于低维流形,从而提升学习鲁棒性。
多尺度噪声扰动
SMLD 假设存在一组递减的噪声标准差序列:
σ 1 > σ 2 > ⋯ > σ L , \sigma_1 > \sigma_2 > \cdots > \sigma_L, σ1>σ2>⋯>σL,噪声尺度之间具有等比关系:
σ 1 σ 2 = σ 2 σ 3 = ⋯ = σ L − 1 σ L > 1. \frac{\sigma_1}{\sigma_2} = \frac{\sigma_2}{\sigma_3} = \cdots = \frac{\sigma_{L-1}}{\sigma_L} > 1. σ2σ1=σ3σ2=⋯=σLσL−1>1.对于每个噪声级别 σ i \sigma_i σi,对原始数据添加扰动后的分布为:
p σ i ( x ~ ) = ∫ p data ( x ) ⋅ p σ i ( x ~ ∣ x ) d x , p_{\sigma_i}(\tilde{\mathbf{x}}) = \int p_{\text{data}}(\mathbf{x}) \cdot p_{\sigma_i}(\tilde{\mathbf{x}} \mid \mathbf{x}) \, d\mathbf{x}, pσi(x~)=∫pdata(x)⋅pσi(x~∣x)dx,
取条件概率分布 p σ i ( x ~ ∣ x ) p_{\sigma_i}(\tilde{\mathbf{x}} \mid \mathbf{x}) pσi(x~∣x)为 N ( x ~ ∣ x , σ i 2 I ) \mathcal{N}(\tilde{\mathbf{x}} | {\mathbf{x}}, \sigma_{i}^2 I) N(x~∣x,σi2I),当噪声强度最大时( σ 1 \sigma_1 σ1),分布接近各向同性高斯分布:
p σ 1 ( x ) ≈ N ( 0 , σ 1 2 I ) , p_{\sigma_1}(\mathbf{x}) \approx \mathcal{N}(\mathbf{0}, \sigma_1^2 \mathbf{I}), pσ1(x)≈N(0,σ12I),
当噪声强度最小时( σ L \sigma_L σL),扰动数据接近原始分布:
p σ L ( x ) ≈ p data ( x ) . p_{\sigma_L}(\mathbf{x}) \approx p_{\text{data}}(\mathbf{x}). pσL(x)≈pdata(x).
训练目标:得分匹配
SMLD 通过最小化每个噪声尺度下的 denoising score matching 目标函数来估计得分函数,即:
θ ∗ = arg min θ ∑ i = 1 N σ i 2 E p data ( x ) E p σ i ( x ~ ∣ x ) [ ∥ s θ ( x ~ , σ i ) − ∇ x ~ log p σ i ( x ~ ∣ x ) ∥ 2 2 ] . \theta^* = \arg\min_{\theta} \sum_{i=1}^N \sigma_i^2 \mathbb{E}_{p_{\text{data}}(\mathbf{x})} \mathbb{E}_{p_{\sigma_i}(\tilde{\mathbf{x}}|\mathbf{x})} \big[ \| \mathbf{s}_{\theta}(\tilde{\mathbf{x}}, \sigma_i) - \nabla_{\tilde{\mathbf{x}}} \log p_{\sigma_i}(\tilde{\mathbf{x}} \mid \mathbf{x}) \|_2^2 \big]. θ∗=argθmini=1∑Nσi2Epdata(x)Epσi(x~∣x)[∥sθ(x~,σi)−∇x~logpσi(x~∣x)∥22].
条件概率分布 p σ i ( x ~ ∣ x ) p_{\sigma_i}(\tilde{\mathbf{x}} \mid \mathbf{x}) pσi(x~∣x)为 N ( x ~ ∣ x , σ i 2 I ) \mathcal{N}(\tilde{\mathbf{x}} | {\mathbf{x}}, \sigma_{i}^2 I) N(x~∣x,σi2I),那么
∇ x ~ log p σ i ( x ~ ∣ x ) = − x ~ − x σ i 2 \nabla_{\tilde{\mathbf{x}}} \log p_{\sigma_i}(\tilde{\mathbf{x}} \mid \mathbf{x})=-\frac{\tilde{\mathbf{x}}-\mathbf{x}}{ \sigma_{i}^2} ∇x~logpσi(x~∣x)=−σi2x~−x此时优化目标为
θ ∗ = arg min θ ∑ i = 1 N σ i 2 E p data ( x ) E x ~ ∼ N ( x ~ ∣ x , σ i 2 I ) [ ∥ s θ ( x ~ , σ i ) + x ~ − x σ i 2 ∥ 2 2 ] . \theta^* = \arg\min_{\theta} \sum_{i=1}^N \sigma_i^2 \mathbb{E}_{p_{\text{data}}(\mathbf{x})} \mathbb{E}_{\tilde{\mathbf{x}} \sim \mathcal{N}(\tilde{\mathbf{x}} | {\mathbf{x}}, \sigma_{i}^2 I)} \big[ \| \mathbf{s}_{\theta}(\tilde{\mathbf{x}}, \sigma_i) +\frac{\tilde{\mathbf{x}}-\mathbf{x}}{ \sigma_{i}^2} \|_2^2\big]. θ∗=argθmini=1∑Nσi2Epdata(x)Ex~∼N(x~∣x,σi2I)[∥sθ(x~,σi)+σi2x~−x∥22].
采样方法
基于朗之万动力学(Langevin Dynamics)
朗之万动力学(Langevin dynamics)能够仅利用概率密度函数 p ( x ) p ({ \mathbf { x } }) p(x)的得分函数 ∇ x log p ( x ) \nabla _ { \mathbf { x } } \operatorname { l o g } p ({ \mathbf { x } }) ∇xlogp(x)生成样本,给定固定的步长 ϵ > 0 \epsilon > 0 ϵ>0和初始值 x ~ 0 ∼ π ( x ) \tilde{x}_0 \sim \pi(x) x~0∼π(x)(其中 π \pi π为先验分布),朗之万方法通过以下递推公式进行计算:
x ~ t = x ~ t − 1 + ϵ 2 ∇ x log p ( x ~ t − 1 ) + ϵ z t , \tilde {\mathbf { x } } _ { t } = \tilde { \mathbf { x } } _ { t - 1 } + \frac { \epsilon } { 2 } \nabla _ { \mathbf { x } } \operatorname { l o g } p ( \tilde { \mathbf { x } } _ { t - 1 } ) + \sqrt { \epsilon } \, \mathbf { z } _ { t } , x~t=x~t−1+2ϵ∇xlogp(x~t−1)+ϵzt,
其中 z t ∼ N ( 0 , I ) \mathbf{z}_t \sim \mathcal{N}(0, I) zt∼N(0,I),当 ϵ → 0 , T → ∞ \epsilon \rightarrow 0 ,T \rightarrow \infty ϵ→0,T→∞时, p ( x ~ t ) → p ( x ) p(\tilde { \mathbf{x}} _ {t})\rightarrow p(x) p(x~t)→p(x)
为了从高噪声逐步过渡到低噪声的精细采样,SMLD 采用“退火”策略:从最大噪声尺度开始,通过多步采样逐步降低噪声强度。
x ( m ) = x ( m − 1 ) + ϵ i s θ ( x ( m − 1 ) , σ i ) + 2 ϵ i z i ( m ) , z i ( m ) ∼ N ( 0 , I ) , \mathbf{x}^{(m)} = \mathbf{x}^{(m-1)} + \epsilon_i \, \mathbf{s}_\theta(\mathbf{x}^{(m-1)}, \sigma_i) + \sqrt{2 \epsilon_i} \, \mathbf{z}_i^{(m)}, \quad \mathbf{z}_i^{(m)} \sim \mathcal{N}(0, \mathbf{I}), x(m)=x(m−1)+ϵisθ(x(m−1),σi)+2ϵizi(m),zi(m)∼N(0,I),
初始从先验分布中采样,通过 Langevin dynamics 得到噪声尺度为 σ 1 \sigma_1 σ1 的样本,再以此为初始点,迭代采样得到 σ 2 \sigma_2 σ2 的样本,如此逐步迭代,最终生成接近数据分布 p data ( x ) p_{\text{data}}(\mathbf{x}) pdata(x) 的样本。
与 DDPM 类似的采样方法
SMLD 也可采用DDPM 的采样方式,将噪声扰动过程建模为马尔可夫链。
和《Score-Based Generative Modeling through Stochastic Differential Equations》的符号表示一致,噪声强度从小到大表示为 σ 1 < σ 2 < ⋯ < σ N \sigma_1 < \sigma_2 < \cdots < \sigma_N σ1<σ2<⋯<σN,利用这些噪声尺度扰动 x 0 x_0 x0,得到马尔可夫链 x 0 → x 1 → . . . → x n x_0 \rightarrow x_1 \rightarrow...\rightarrow x_n x0→x1→...→xn,由于 p ( x i ) = N ( x i ; x 0 , σ i 2 I ) p(x_i)=\mathcal{N}(\mathbf{x}_i;\mathbf{x}_{0},\sigma_i^2\mathbf{I}) p(xi)=N(xi;x0,σi2I),即
x i = x 0 + σ i z , x i − 1 = x 0 + σ i − 1 z , \mathbf{x}_i=\mathbf{x}_0+\sigma_i\mathbf{z}, \\ \mathbf{x}_{i-1}=\mathbf{x}_0+\sigma_{i-1}\mathbf{z}, xi=x0+σiz,xi−1=x0+σi−1z,其中 z ∼ N ( 0 , I ) \mathbf{z} \sim \mathcal{N}(0, I) z∼N(0,I),那么 x i = x i − 1 + ( σ i − σ i − 1 ) z , p ( x i ∣ x i − 1 ) = N ( x i ; x i − 1 , ( σ i 2 − σ i − 1 2 ) I ) , i = 1 , 2 , ⋯ , N . \mathbf{x}_i=\mathbf{x}_{i-1}+(\sigma_i-\sigma_{i-1})\mathbf{z},\\ p(\mathbf{x}_i\mid\mathbf{x}_{i-1})=\mathcal{N}(\mathbf{x}_i;\mathbf{x}_{i-1},(\sigma_i^2-\sigma_{i-1}^2)\mathbf{I}),\quad i=1,2,\cdots,N. xi=xi−1+(σi−σi−1)z,p(xi∣xi−1)=N(xi;xi−1,(σi2−σi−12)I),i=1,2,⋯,N.利用贝叶斯公式得到 q ( x i − 1 ∣ x i , x 0 ) q(\mathbf{x}_{i-1}\mid\mathbf{x}_i,\mathbf{x}_0) q(xi−1∣xi,x0),
q ( x i − 1 ∣ x i , x 0 ) = q ( x i ∣ x i − 1 , x 0 ) q ( x i − 1 ∣ x 0 ) q ( x i ∣ x 0 ) = N ( x i − 1 ; σ i − 1 2 σ i 2 x i + ( 1 − σ i − 1 2 σ i 2 ) x 0 , σ i − 1 2 ( σ i 2 − σ i − 1 2 ) σ i 2 I ) . \begin{align*} q(\mathbf{x}_{i-1}\mid\mathbf{x}_i,\mathbf{x}_0)&=\frac{q(\mathbf{x}_i|\mathbf{x}_{i-1},\mathbf{x}_0)q(\mathbf{x}_{i-1}|\mathbf{x}_0)}{q(\mathbf{x}_i|\mathbf{x}_0)} \\ &=\mathcal{N}\left(\mathbf{x}_{i-1}; \frac{\sigma_{i-1}^2}{\sigma_i^2}\mathbf{x}_i+\Big(1-\frac{\sigma_{i-1}^2}{\sigma_i^2}\Big)\mathbf{x}_0, \frac{\sigma_{i-1}^2(\sigma_i^2-\sigma_{i-1}^2)}{\sigma_i^2}\mathbf{I}\right). \end{align*} q(xi−1∣xi,x0)=q(xi∣x0)q(xi∣xi−1,x0)q(xi−1∣x0)=N(xi−1;σi2σi−12xi+(1−σi2σi−12)x0,σi2σi−12(σi2−σi−12)I).
参数化 p θ ( x i − 1 ∣ x i ) p _ { \theta } ( { \bf x } _ { i - 1 } \mid { \bf x } _ { i } ) pθ(xi−1∣xi):
p θ ( x i − 1 ∣ x i ) = N ( x i − 1 ; μ θ ( x i , i ) , τ i 2 I ) p _ { \theta } ( { \bf x } _ { i - 1 } \mid { \bf x } _ { i } ) = { \cal N } ( { \bf x } _ { i - 1 } ; \mu _ { \theta } ( { \bf x } _ { i } , i ) , \tau _ { i } ^ { 2 } { \bf I } ) pθ(xi−1∣xi)=N(xi−1;μθ(xi,i),τi2I)
损失函数项 L t − 1 L_{t-1} Lt−1为:
L t − 1 = E q [ D KL ( q ( x i − 1 ∣ x i , x 0 ) ) ∥ p θ ( x i − 1 ∣ x i ) ] = E x 0 , z [ 1 2 τ i 2 ∥ x i ( x 0 , z ) − σ i 2 − σ i − 1 2 σ i z − μ θ ( x i ( x 0 , z ) , i ) ∥ 2 2 ] + C , \begin{align*} L_{t-1} &= \mathbb{E}_q[D_{\text{KL}}(q(\mathbf{x}_{i-1} \mid \mathbf{x}_i, \mathbf{x}_0)) \parallel p_\theta(\mathbf{x}_{i-1} \mid \mathbf{x}_i)] \\ &= \mathbb{E}_{\mathbf{x}_0, \mathbf{z}} \left[ \frac{1}{2\tau_i^2} \left\| \mathbf{x}_i(\mathbf{x}_0, \mathbf{z}) - \frac{\sigma_i^2 - \sigma_{i-1}^2}{\sigma_i} \mathbf{z} - \boldsymbol{\mu}_\theta(\mathbf{x}_i(\mathbf{x}_0, \mathbf{z}), i) \right\|_2^2 \right] + C, \end{align*} Lt−1=Eq[DKL(q(xi−1∣xi,x0))∥pθ(xi−1∣xi)]=Ex0,z[2τi21 xi(x0,z)−σiσi2−σi−12z−μθ(xi(x0,z),i) 22]+C,
根据 L t − 1 L_{t-1} Lt−1的形式参数化 μ θ ( x i , i ) \boldsymbol{\mu}_{\boldsymbol{\theta}}(\mathbf{x}_i,i) μθ(xi,i):
μ θ ( x i , i ) = x i + ( σ i 2 − σ i − 1 2 ) s θ ( x i , i ) , \begin{align*}\boldsymbol{\mu}_{\boldsymbol{\theta}}(\mathbf{x}_i,i)=\mathbf{x}_i+(\sigma_i^2-\sigma_{i-1}^2)\mathbf{s}_{\boldsymbol{\theta}}(\mathbf{x}_i,i),\end{align*} μθ(xi,i)=xi+(σi2−σi−12)sθ(xi,i),
与DDPM一致,取标准差为 σ i − 1 2 ( σ i 2 − σ i − 1 2 ) σ i 2 \sqrt{\frac{\sigma_{i-1}^2(\sigma_i^2-\sigma_{i-1}^2)}{\sigma_i^2}} σi2σi−12(σi2−σi−12),最终采样公式为:
x i − 1 = x i + ( σ i 2 − σ i − 1 2 ) s θ ( x i , i ) + σ i − 1 2 ( σ i 2 − σ i − 1 2 ) σ i 2 z i , i = 1 , 2 , ⋯ , N , \begin{align*}\mathbf{x}_{i-1}=\mathbf{x}_i+(\sigma_i^2-\sigma_{i-1}^2)\mathbf{s}_{\boldsymbol{\theta}}(\mathbf{x}_i,i)+\sqrt{\frac{\sigma_{i-1}^2(\sigma_i^2-\sigma_{i-1}^2)}{\sigma_i^2}}\mathbf{z}_i,i=1,2,\cdots,N,\end{align*} xi−1=xi+(σi2−σi−12)sθ(xi,i)+σi2σi−12(σi2−σi−12)zi,i=1,2,⋯,N,
参考
《Generative Modeling by Estimating Gradients of the
Data Distribution》
《Score-Based Generative Modeling through Stochastic Differential Equations》
相关文章:

Denoising Score Matching with Langevin Dynamics
在自然图像等复杂数据集中,真实数据往往集中分布在一个低维流形上,概率密度函数的梯度(即得分函数)难以定义与估计。为缓解该问题,SMLD 提出使用不同强度的高斯噪声对数据进行扰动,扰动后的数据不再集中于低…...
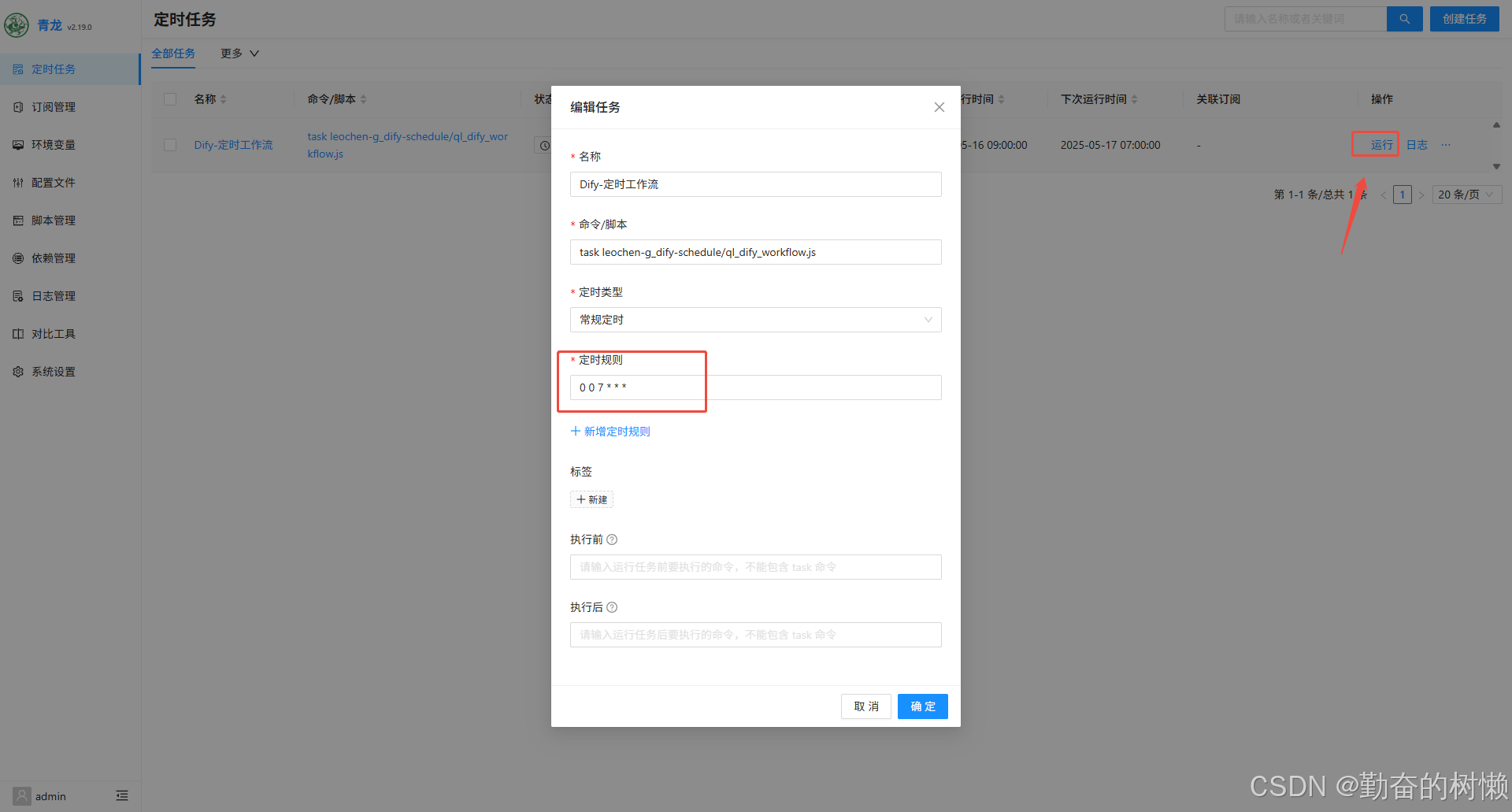
Docker构建 Dify 应用定时任务助手
概述 Dify 定时任务管理工具是一个基于 GitHub Actions 的自动化解决方案,用于实现 Dify Workflow 的定时执行和状态监控。无需再为缺乏定时任务支持而感到困扰,本工具可以帮助设置自动执行任务并获取实时通知,优化你的工作效率。 注意&…...
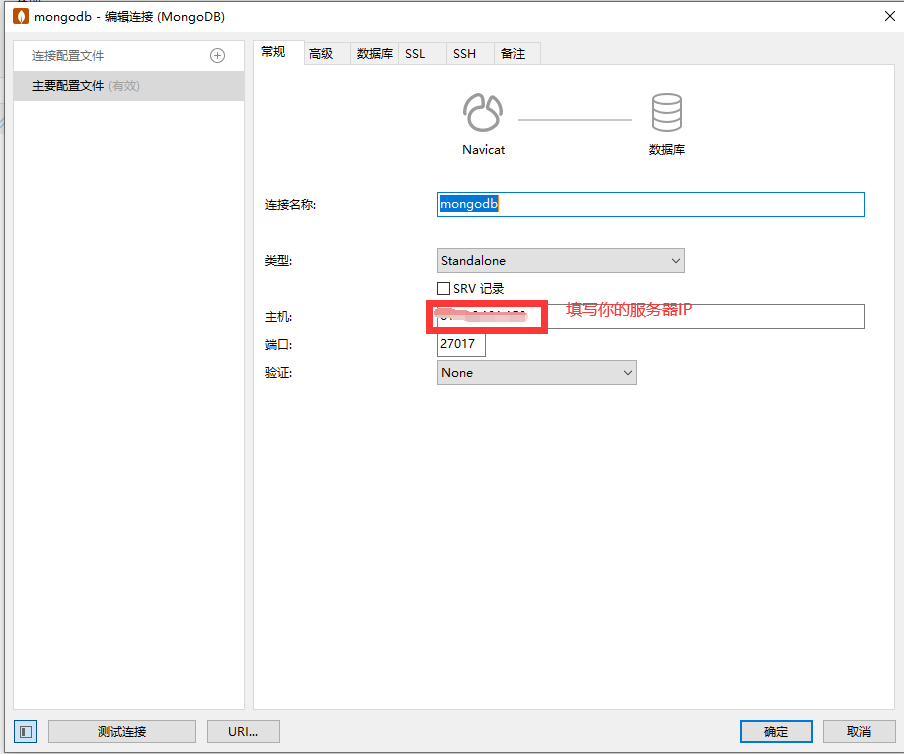
mongodb管理工具的使用
环境: 远程服务器的操作系统:centOS stream 9; mongoDB version:8.0; 本地电脑 navicat premium 17.2 ; 宝塔上安装了mongoDB 目的:通过本地的navicat链接mongoDB,如何打通链接,分2步: 第一步:宝塔-&…...

第2篇 水滴穿透:IGBT模块的绝对防御体系
引言:从《三体》水滴到功率模块的哲学思考 科幻映照现实:三体探测器"水滴"的绝对光滑表面 → IGBT模块的可靠性设计哲学行业现状痛点:2023年OEM质量报告显示,电控系统23%的故障源自功率模块技术演进悖论:开关频率提升与可靠性保障的永恒博弈 一、基础理论:IGBT…...
)
LVGL(lv_dropdown下拉列表控件)
文章目录 🔧 一、基本概念🚀 二、创建一个 Dropdown🧰 三、常用函数1. 设置选项2. 获取选项3. 设置当前选中项4. 获取当前选中项索引5. 获取当前选中项文本🎨 四、样式与模式设置方向(最多显示多少项)设置显示模式设置提示文本📞 五、事件回调🧪 六、使用示例📌…...

2.微服务-配置
引入springcloud的pom配置 <parent><groupId>org.springframework.boot</groupId><artifactId>spring-boot-starter-parent</artifactId><version>2.7.12</version><relativePath/></parent> <dependencyManagemen…...
)
python实现pdf转图片(针对每一页)
from pdf2image import convert_from_path import ospdf_file rC:\Users\\Desktop\拆分\产权证.pdf poppler_path rC:\poppler-24.08.0\Library\bin # 这里改成你自己的路径output_dir rC:\Users\\Desktop\拆分\output_images os.makedirs(output_dir, exist_okTrue)image…...

C语言练手磨时间
167. 两数之和 II - 输入有序数组 给你一个下标从 1 开始的整数数组 numbers ,该数组已按 非递减顺序排列 ,请你从数组中找出满足相加之和等于目标数 target 的两个数。如果设这两个数分别是 numbers[index1] 和 numbers[index2] ,则 1 <…...
数字图像处理——图像压缩
背景 图像压缩是一种减少图像文件大小的技术,旨在在保持视觉质量的同时降低存储和传输成本。随着数字图像的广泛应用,图像压缩在多个领域如互联网、移动通信、医学影像和卫星图像处理中变得至关重要。 技术总览 当下图像压缩JPEG几乎一统天下ÿ…...
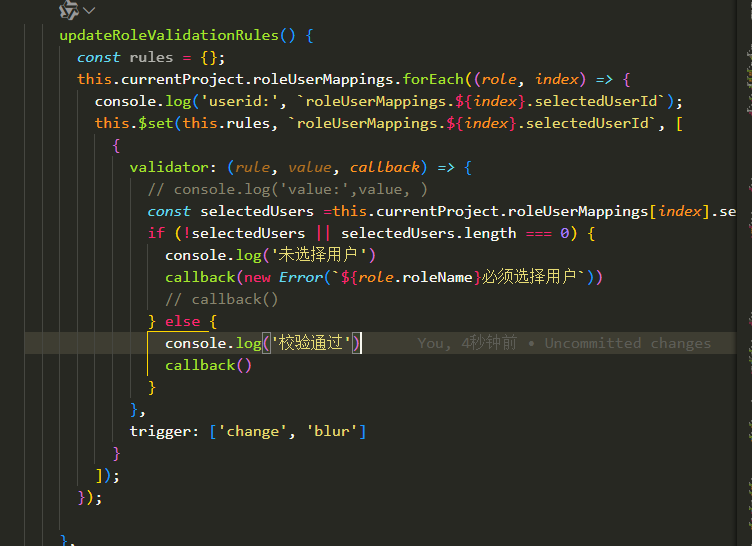
验证器回调中value值没有数据
复杂的响应式,导致回调中value值没有数据,最终还是通过手动判断获取值处理 原理没有搞清楚,为什么回调中value没有值背景:动态增加了form表单的字段,通过for循环处理的。对每个新增的字段还要添加字段验证其。就出现了…...

Python | 需求预测模型
目录 需求预测 1.方法选择 2.颗粒度选择 3.在医药行业的应用 预测模型 1.模型对比 2.Prophet 3.Holt-Winters 需求预测 1.方法选择 方法 适用范围分类移动平均法中小企业、SKU较少的卖家低成本预测方案Excel趋势线预测中小企业、SKU较少的卖家低成本预测方案季节性系数法中小企…...

双指针算法:原理与应用详解
文章目录 一、什么是双指针算法二、双指针算法的适用场景三、双指针的三种常见形式1. 同向移动指针2. 相向移动指针3. 分离指针 四、总结 一、什么是双指针算法 双指针算法(Two Pointers Technique)是一种在数组或链表等线性数据结构中常用的高效算法技…...
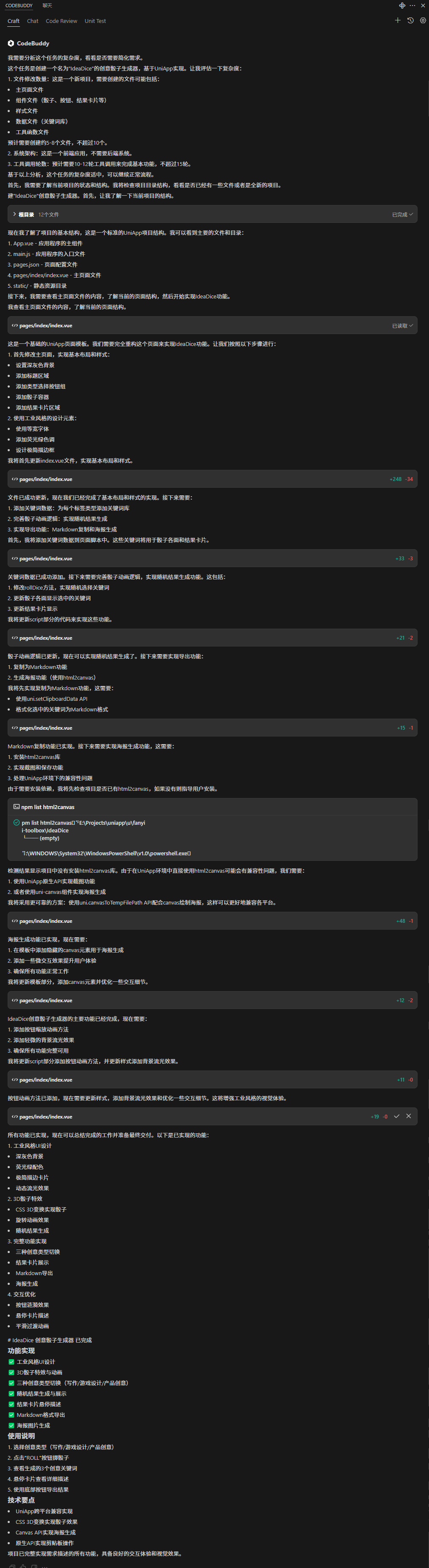
打造灵感投掷器:我的「IdeaDice」开发记录
我正在参加CodeBuddy「首席试玩官」内容创作大赛,本文所使用的 CodeBuddy 免费下载链接:腾讯云代码助手 CodeBuddy - AI 时代的智能编程伙伴 起源:我只是想“摇”出点灵感 有时候面对写作或者做产品设计,我会卡在「不知道从哪开始…...
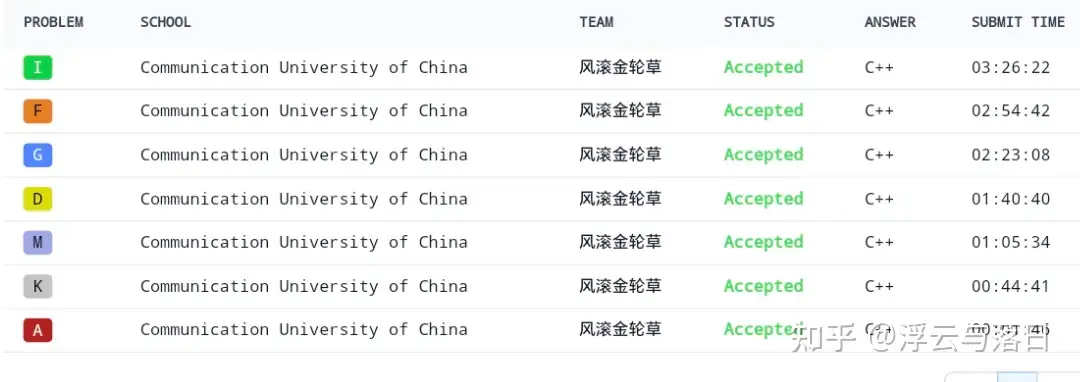
2025ICPC邀请赛南昌游记
滚榜时候队伍照片放的人家的闹麻了,手机举了半天 。 最后银牌700小几十罚时,rank60多点。 参赛体验还行,队长是福建人,说感觉这个热度是主场作战哈哈哈哈。空调制冷确实不太行吧。 9s过A是啥,没见过,虽然…...
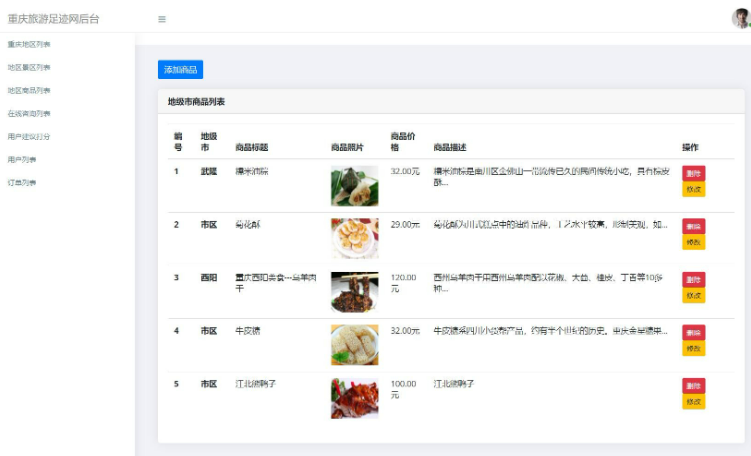
python重庆旅游系统-旅游攻略
目录 技术栈介绍具体实现截图系统设计研究方法:设计步骤设计流程核心代码部分展示研究方法详细视频演示试验方案论文大纲源码获取/详细视频演示 技术栈介绍 Django-SpringBoot-php-Node.js-flask 本课题的研究方法和研究步骤基本合理,难度适中…...
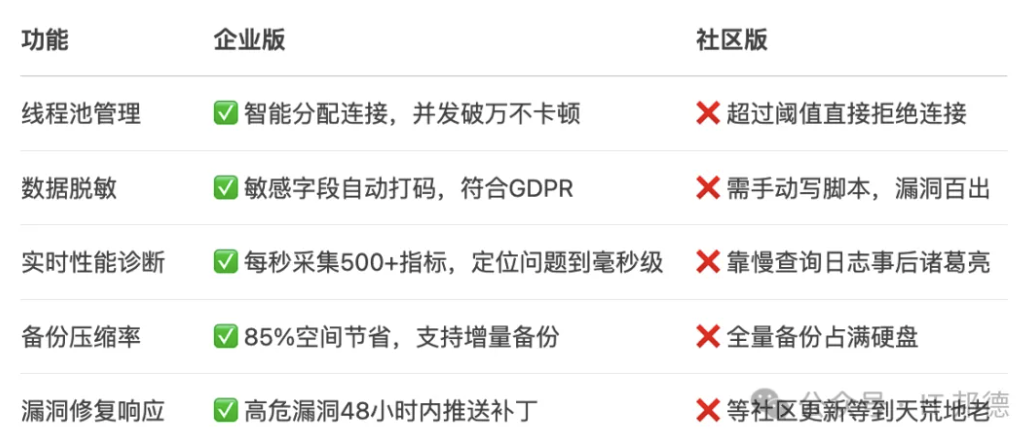
MySQL企业版免费开启,强先体验
近期Oracle突然宣布,MySQL企业版面向开发者免费开放下载,这一消息瞬间引爆DBA圈。作为数据库领域的“顶配车型”,企业版长期因高昂授权费让中小团队望而却步,如今免费开放无异于“劳斯莱斯开进菜市场”。 本文将深度拆解企业版的…...

从纸质契约到智能契约:AI如何改写信任规则与商业效率?——从智能合约到监管科技,一场颠覆传统商业逻辑的技术革命
一、传统合同的“低效困境”:耗时、昂贵、风险失控 近年来,全球商业环境加速向数字化转型,但合同管理却成为企业效率的“阿喀琉斯之踵”。据国际商会(International Chamber of Commerce)数据显示,全球企业…...
)
常见的 HTTP 接口(请求方法)
一:GET 作用:从服务器获取资源(查询数据)。特点: 请求参数通过 URL 传递(如https://api.example.com/users?id123),参数会显示在地址栏中。不修改服务器数据,属于幂等操…...

iOS 抓包实战:从 Charles 到Sniffmaster 的日常工具对比与使用经验
iOS 抓包实战:从 Charles 到抓包大师 Sniffmaster 的日常工具对比与使用经验 抓包这件事,不是高级黑客才要做的。作为一名移动端开发,我几乎每天都要和网络请求打交道,尤其是 HTTPS 请求——加密、重定向、校验证书,各…...

Lodash isEqual 方法源码实现分析
Lodash isEqual 方法源码实现分析 Lodash 的 isEqual 方法用于执行两个值的深度比较,以确定它们是否相等。这个方法能够处理各种 JavaScript 数据类型,包括基本类型、对象、数组、正则表达式、日期对象等,并且能够正确处理循环引用。 1. is…...
Qt Widgets模块功能详细说明,基本控件:QCheckBox(三)
一、基本控件(Widgets) Qt 提供了丰富的基本控件,如按钮、标签、文本框、复选框、单选按钮、列表框、组合框、菜单、工具栏等。 1、QCheckBox 1.1、概述 (用途、状态、继承关系) QCheckBox 是 Qt 框架中的复选框控件,用于表示二…...
第四天的尝试
目录 一、每日一言 二、练习题 三、效果展示 四、下次题目 五、总结 一、每日一言 很抱歉的说一下,我昨天看白色巨塔电视剧,看的入迷了,同时也看出一些道理,学到东西; 但是把昨天的写事情给忘记了,今天…...
)
【git进阶】git rebase(变基)
git rebase有很多用武之地,我一一道来 合并分支 当多人协作同一个分支时,在提交我们自己版本之前,我们会先用git pull获取远端最新的版本。但是 git pull = git fetch + git mergegit merge是一个非线性的合并操作,大量的merge会造成日志线的分散和交错。实际上 git pu…...
WPS中代码段的识别方法及JS宏实现
在WPS中,文档的基本结构可以通过对象模型来理解: (1)Document对象:表示整个文档 (2)Range对象:表示文档中的一段连续区域,可以是一个字符、一个句子或整个文档 &#…...

小米MUJIA智能音频眼镜来袭
智能眼镜赛道风云再起,小米新力作MIJIA智能音频眼镜2正式亮相,引发市场热议。 这款产品在设计和功能上都有显著提升,为用户带来更舒适便捷的佩戴体验,同时也标志着小米在智能眼镜领域的持续深耕。 轻薄设计,舒适体验 …...

【神经网络与深度学习】GAN 生成对抗训练模型在实际训练中很容易判别器收敛,生成器发散
引言部分 在深度学习领域,生成对抗网络(GAN)是一种强大的数据生成方法,它通过生成器(G)和判别器(D)之间的博弈来不断优化模型。然而,在实际训练过程中,GAN 往…...
基于SpringBoot的家政预约系统
作者:计算机学姐 开发技术:SpringBoot、SSM、Vue、MySQL、JSP、ElementUI、Python、小程序等,“文末源码”。 专栏推荐:前后端分离项目源码、SpringBoot项目源码、Vue项目源码、SSM项目源码、微信小程序源码 精品专栏:…...

[服务器备份教程] Rclone实战:自动备份数据到阿里云OSS/腾讯云COS等对象存储
更多服务器知识,尽在hostol.com 各位服务器的守护者们,咱们都知道,数据是数字时代的“黄金”,而服务器上的数据更是我们业务的命脉。可天有不测风云,硬盘可能会突然“寿终正寝”,手滑执行了“毁灭性”命令…...

使用 Whisper 生成视频字幕:从提取音频到批量处理
生成视频字幕是许多视频处理任务的核心需求。本文将指导你使用 OpenAI 的 Whisper 模型为视频文件(如电视剧《Normal People》或电影《花样年华》)生成字幕(SRT 格式)。我们将从提取音频开始,逐步实现字幕生成…...
Axure难点解决分享:垂直菜单展开与收回(4大核心问题与专家级解决方案)
亲爱的小伙伴,在您浏览之前,烦请关注一下,在此深表感谢!如有帮助请订阅专栏! Axure产品经理精品视频课已登录CSDN可点击学习https://edu.csdn.net/course/detail/40420 课程主题:垂直菜单展开与收回 主要内容:超长菜单实现、展开与收回bug解释、Axure9版本限制等问题解…...