使用 Whisper 生成视频字幕:从提取音频到批量处理
生成视频字幕是许多视频处理任务的核心需求。本文将指导你使用 OpenAI 的 Whisper 模型为视频文件(如电视剧《Normal People》或电影《花样年华》)生成字幕(SRT 格式)。我们将从提取音频开始,逐步实现字幕生成,并提供一个 Python 脚本实现批量处理。此外,我们还将探讨如何处理非英语音频(如中文)并优化字幕质量。
前提条件
在开始之前,请确保安装以下工具:
1. FFmpeg:用于从视频提取音频。
- 安装:
- Windows:下载 FFmpeg 并添加到系统路径。
- macOS:
brew install ffmpeg - Linux:
sudo apt-get install ffmpeg(Ubuntu/Debian)或sudo dnf install ffmpeg(Fedora)
2. Python 3.8+:用于运行脚本和 Whisper。
- 安装 Python:python.org。
3. Whisper:OpenAI 的语音转文字模型。
- 通过 pip 安装:
pip install openai-whisper
4. uv(可选):用于管理 Python 项目环境。
- 安装:
pip install uv
5. 视频文件:准备 MP4 或 MKV 格式的视频文件(如《Normal People》或《花样年华》)。
步骤 1:提取音频
第一步是从视频文件中提取音频。我们使用 FFmpeg 将视频的音频流保存为 AAC 格式。
示例命令
为《Normal People》第1季第1集提取音频:
ffmpeg -i /path/to/Normal.People.S01E01.mp4 -vn -acodec copy /path/to/audio/Normal.People.S01E01.aac-i:输入视频文件路径。-vn:禁用视频流(仅提取音频)。-acodec copy:直接复制音频流,不重新编码,保持原始质量。- 输出:保存为
/path/to/audio/Normal.People.S01E01.aac。
注意事项
- 确保输出目录(如
/path/to/audio/)存在。 - 替换
/path/to/为实际文件路径。
步骤 2:生成字幕
使用 Whisper 模型将音频文件转换为 SRT 格式的字幕文件。Whisper 支持多种模型(如 tiny、base、small、medium、large 和 turbo),turbo 速度快,适合快速测试。
示例命令
为提取的音频生成字幕:
whisper /path/to/audio/Normal.People.S01E01.aac --model turbo --output_format srt --output_dir /path/to/generated_subs/--model turbo:使用 turbo 模型(快速但可能牺牲精度)。--output_format srt:输出 SRT 格式字幕。--output_dir:指定字幕输出目录。- 输出:生成
/path/to/generated_subs/Normal.People.S01E01.srt。
示例输出
生成的前几条字幕可能如下:
1
00:00:00,000 --> 00:00:24,000
It's a simple game. You have 15 players. Give one of them the ball.
Get it into the net. 2
00:00:24,000 --> 00:00:26,000
Very simple. Isn't it? 步骤 3:批量处理脚本
手动为多个视频生成字幕效率低下。以下 Python 脚本自动处理目录中的所有视频文件,提取音频并生成字幕。
完整脚本
import os
import subprocess
import argparse defextract_audio(input_dir, output_dir): """Extract audio from video files in input_dir and save to output_dir."""ifnot os.path.exists(output_dir): os.makedirs(output_dir) for filename in os.listdir(input_dir): if filename.endswith(('.mp4', '.mkv')): input_path = os.path.join(input_dir, filename) audio_filename = os.path.splitext(filename)[0] + '.aac'output_path = os.path.join(output_dir, audio_filename) command = [ 'ffmpeg', '-i', input_path, '-vn', '-acodec', 'copy', output_path ] print(f"Extracting audio: {command}") try: subprocess.run(command, check=True) except subprocess.CalledProcessError as e: print(f"Error extracting audio from {filename}: {e}") defgenerate_subtitles(input_dir, output_dir): """Generate subtitles for audio files using Whisper."""ifnot os.path.exists(output_dir): os.makedirs(output_dir) for filename in os.listdir(input_dir): if filename.endswith('.aac'): input_path = os.path.join(input_dir, filename) command = [ 'whisper', input_path, '--model', 'turbo', '--output_format', 'srt', '--output_dir', output_dir ] print(f"Generating subtitles: {command}") try: subprocess.run(command, check=True) except subprocess.CalledProcessError as e: print(f"Error generating subtitles for {filename}: {e}") if __name__ == "__main__": parser = argparse.ArgumentParser(description="Extract audio and generate subtitles.") parser.add_argument("input_dir", help="Directory containing video files.") parser.add_argument("audio_dir", help="Directory to save extracted audio files.") parser.add_argument("subtitle_dir", help="Directory to save generated subtitles.") args = parser.parse_args() extract_audio(args.input_dir, args.audio_dir) generate_subtitles(args.audio_dir, args.subtitle_dir) 使用方法
- 保存脚本为
generate_subtitles.py。 - 运行脚本,指定目录路径:
python generate_subtitles.py /path/to/videos /path/to/audio /path/to/generated_subs 步骤 4:优化字幕质量
生成的字幕可能存在以下问题,我们提供优化方法:
问题 1:时间戳不准确
- 解决方法:
- 使用
--max_line_width 50和--max_line_count 2限制字幕长度。 - 后处理调整时间戳(示例代码):
- 使用
import pysrt
subs = pysrt.open('subtitles.srt')
for sub in subs: if sub.start.seconds < 18: sub.shift(seconds=18)
subs.save('adjusted_subtitles.srt') 问题 2:字幕过长
- 解决方法:
- 使用 NLTK 分句(示例代码):
import nltk
nltk.download('punkt')
from nltk.tokenize import sent_tokenize def split_long_subtitle(text): return sent_tokenize(text) long_text = "It's a simple game. You have 15 players. Give one of them the ball."
sentences = split_long_subtitle(long_text) # 输出:['It's a simple game.', 'You have 15 players.', ...] 问题 3:标点不一致
- 解决方法:
- 使用
--append_punctuations ".,!?"参数。 - 使用 spaCy 后处理添加标点(示例代码):
- 使用
import spacy
nlp = spacy.load("en_core_web_sm")
text = "It's a simple game You have 15 players"
doc = nlp(text)
punctuated_text = " ".join(token.text_with_ws for token in doc) # 输出:It's a simple game. You have 15 players. 步骤 5:处理非英语音频(如中文)
示例命令
生成中文字幕并翻译为英文:
whisper /path/to/In.the.Mood.for.Love.mp4 --model large --output_format srt --output_dir /path/to/generated_subs --language zh --task transcribe 优化建议
- 使用 large 模型:非英语音频需更高精度。
- 指定方言:如粤语使用
--language yue。 - 预处理音频:降噪命令示例:
ffmpeg -i input.mp4 -af "afftdn" -vn -acodec copy output.aac 注意事项
- 性能考虑:large 模型需更多计算资源。
- 文件格式:确保兼容 MP4、MKV、AAC 等格式。
- 调试:使用
--verbose查看详细日志。
总结
通过 FFmpeg 和 Whisper,可以轻松为视频生成高质量字幕。批量处理脚本自动化了提取音频和生成字幕的过程,优化时间戳、字幕长度和标点的方法进一步提升了字幕质量。对于非英语音频(如中文),使用 large 模型、预处理音频和分离转录翻译是关键。
相关文章:

使用 Whisper 生成视频字幕:从提取音频到批量处理
生成视频字幕是许多视频处理任务的核心需求。本文将指导你使用 OpenAI 的 Whisper 模型为视频文件(如电视剧《Normal People》或电影《花样年华》)生成字幕(SRT 格式)。我们将从提取音频开始,逐步实现字幕生成…...
Axure难点解决分享:垂直菜单展开与收回(4大核心问题与专家级解决方案)
亲爱的小伙伴,在您浏览之前,烦请关注一下,在此深表感谢!如有帮助请订阅专栏! Axure产品经理精品视频课已登录CSDN可点击学习https://edu.csdn.net/course/detail/40420 课程主题:垂直菜单展开与收回 主要内容:超长菜单实现、展开与收回bug解释、Axure9版本限制等问题解…...
Linux:网络层的重要协议或技术
一、DNS DNS(Domain Name System)是一整套从域名映射到IP的系统 1.1 DNS的背景 TCP/IP中使用IP地址和端口号来确定网络上的一台主机的一个程序. 但是IP地址不方便记忆. 于是人们发明了一种叫主机名的东西, 是一个字符串, 并且使用hosts文件来描述主机名和IP地址的关系. 最初,…...

【Hadoop 实战】Yarn 模式上传 HDFS 卡顿时 “No Route to Host“ 错误深度解析与解决方案
🌟 飞哥带你攻克 Hadoop 网络通信难题 大家好,我是小飞!最近在大数据集群运维中遇到一个典型问题:使用 Yarn 模式向 HDFS 上传大文件时进度条卡住不动,查看日志发现关键报错: No Route to Host from BigDat…...

JAVA请求vllm的api服务报错Unsupported upgrade request、 Invalid HTTP request received.
环境: vllm 0.8.5 java 17 Qwen3-32B-FP8 问题描述: JAVA请求vllm的api服务报错Unsupported upgrade request、 Invalid HTTP request received. WARNING: Unsupported upgrade request. INFO: - "POST /v1/chat/completions HTTP/1.1&…...
基于 CSS Grid 的网页,拆解页面整体布局结构
通过以下示例拆解网页整体布局结构: 一、基础结构(HTML骨架) <!DOCTYPE html> <html lang"zh-CN"> <head><meta charset"UTF-8"><meta http-equiv"X-UA-Compatible" content"…...
的概念梳理)
华为云Astro轻应用创建业务对象(BO)的概念梳理
目录 一、业务对象(BO)是什么?——【详细概念解释】 二、形象理解业务对象(BO) 🍱 类比方式: 📦 举个具体例子:以做一个“智能烟雾报警系统”应用 三、为什么使用BO很重要? 四、小结: 一、业务对象(BO)是什么?——【详细概念解释】 在华为云Astro轻应用…...

利用systemd启动部署在服务器上的web应用
0.背景 系统环境: Ubuntu 22.04 web应用情况: 前后端分类,前端采用react,后端采用fastapi 1.具体配置 1.1 前端配置 开发态运行(启动命令是npm run dev),创建systemd服务文件 sudo nano /etc/systemd/…...

ArkUI Tab组件开发深度解析与应用指南
ArkUI Tab组件开发深度解析与应用指南 一、组件架构与核心能力 ArkUI的Tabs组件采用分层设计结构,由TabBar(导航栏)和TabContent(内容区)构成,支持底部、顶部、侧边三种导航布局模式。组件具备以下核心特…...
psotgresql18 源码编译安装
环境: 系统:centos7.9 数据库:postgresql18beta1 #PostgreSQL 18 已转向 DocBook XML 构建体系(SGML 未来将被弃用)。需要安装 XML 工具链,如下: yum install -y docbook5-style-xsl libxsl…...

虚幻引擎5-Unreal Engine笔记之Pawn与胶囊体的关系
虚幻引擎5-Unreal Engine笔记之Pawn与胶囊体的关系 code review! 文章目录 虚幻引擎5-Unreal Engine笔记之Pawn与胶囊体的关系1. 什么是Pawn?2. 什么是胶囊体(Capsule Component)?3. Pawn与胶囊体的具体关系(1&#x…...

python创建flask项目
好的,我会为你提供一个使用 Flask、pg8000 和 Pandas 构建的后台基本框架,用于手机理财产品 App 的报表分析接口。这个框架将包含异常处理、模块化的结构以支持多人协作,以及交易分析和收益分析的示例接口。 项目结构: financial_report_ap…...

Vue环境下数据导出PDF的全面指南
文章目录 1. 前言2. 原生浏览器打印方案2.1 使用window.print()实现2.2 使用CSS Paged Media模块 3. 常用第三方库方案3.1 使用jsPDF3.2 使用html2canvas jsPDF3.3 使用pdfmake3.4 使用vue-pdf 4. 服务器端导出方案4.1 前端请求服务器生成PDF4.2 使用无头浏览器生成PDF 5. 方法…...
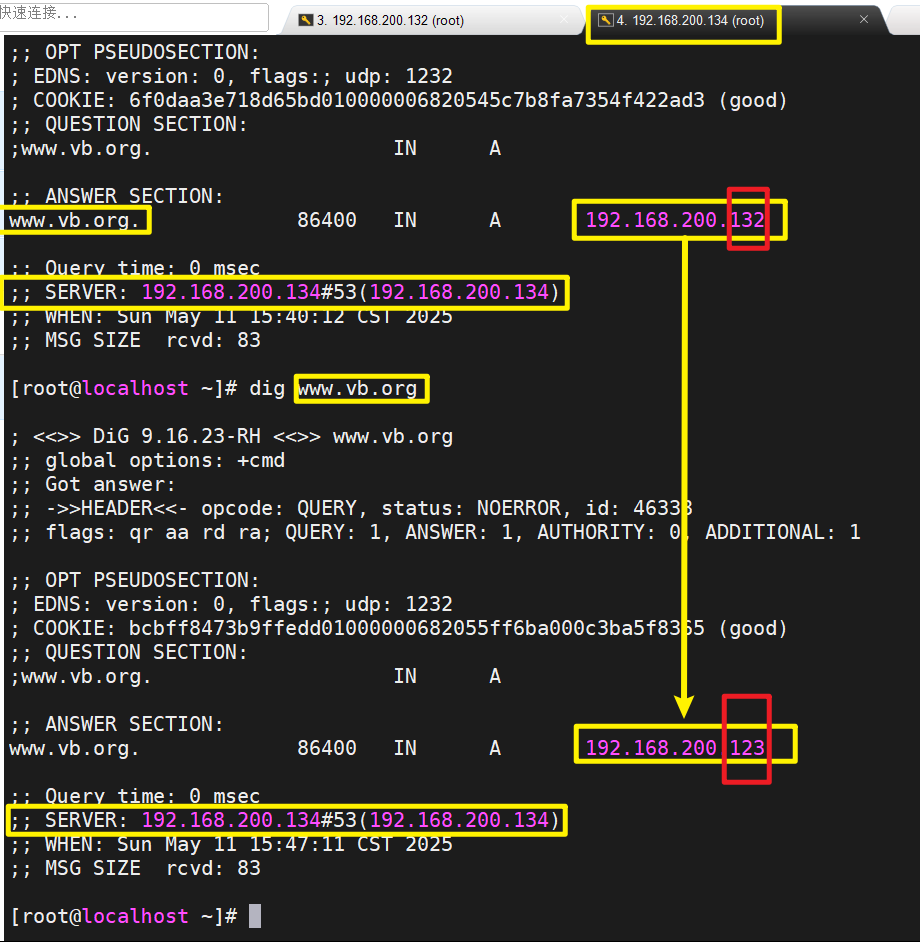
Linux中的DNS的安装与配置
DNS简介 DNS(DomainNameSystem)是互联网上的一项服务,它作为将域名和IP地址相互映射的一个分布式数据库,能够使人更方便的访问互联网。 DNS使用的是53端口 通常DNS是以UDP这个较快速的数据传输协议来查询的,但是没有查…...

linux服务器与时间服务器同步时间
内网部署服务器,需要同步时间 使用系统内置的systemctl-timesyncd进行时间同步 1.编辑配置文件 sudo nano /etc/systemd/timesyncd.conf修改添加内容入下 [Time] NTP10.100.13.198 FallbackNTP#说明 #NTP10.100.13.198:你的主 NTP 时间服务器 IP #Fall…...
【数据结构篇】排序1(插入排序与选择排序)
注:本文以排升序为例 常见的排序算法: 目录: 一 直接插入排序: 1.1 基本思想: 1.2 代码: 1.3 复杂度: 二 希尔排序(直接插入排序的优化): 2.1 基本思想…...
《Linux服务与安全管理》| DNS服务器安装和配置
《Linux服务与安全管理》| DNS服务器安装和配置 目录 《Linux服务与安全管理》| DNS服务器安装和配置 第一步:使用dnf命令安装BIND服务 第二步:查看服务器server01的网络配置 第三步:配置全局配置文件 第四步:修改bind的区域…...

【NLP】34. 数据专题:如何打造高质量训练数据集
构建大语言模型的秘密武器:如何打造高质量训练数据集? 在大语言模型(LLM)如 GPT、BERT、T5 爆发式发展的背后,我们常常关注模型架构的演化,却忽视了一个更基础也更关键的问题:训练数据从哪里来…...
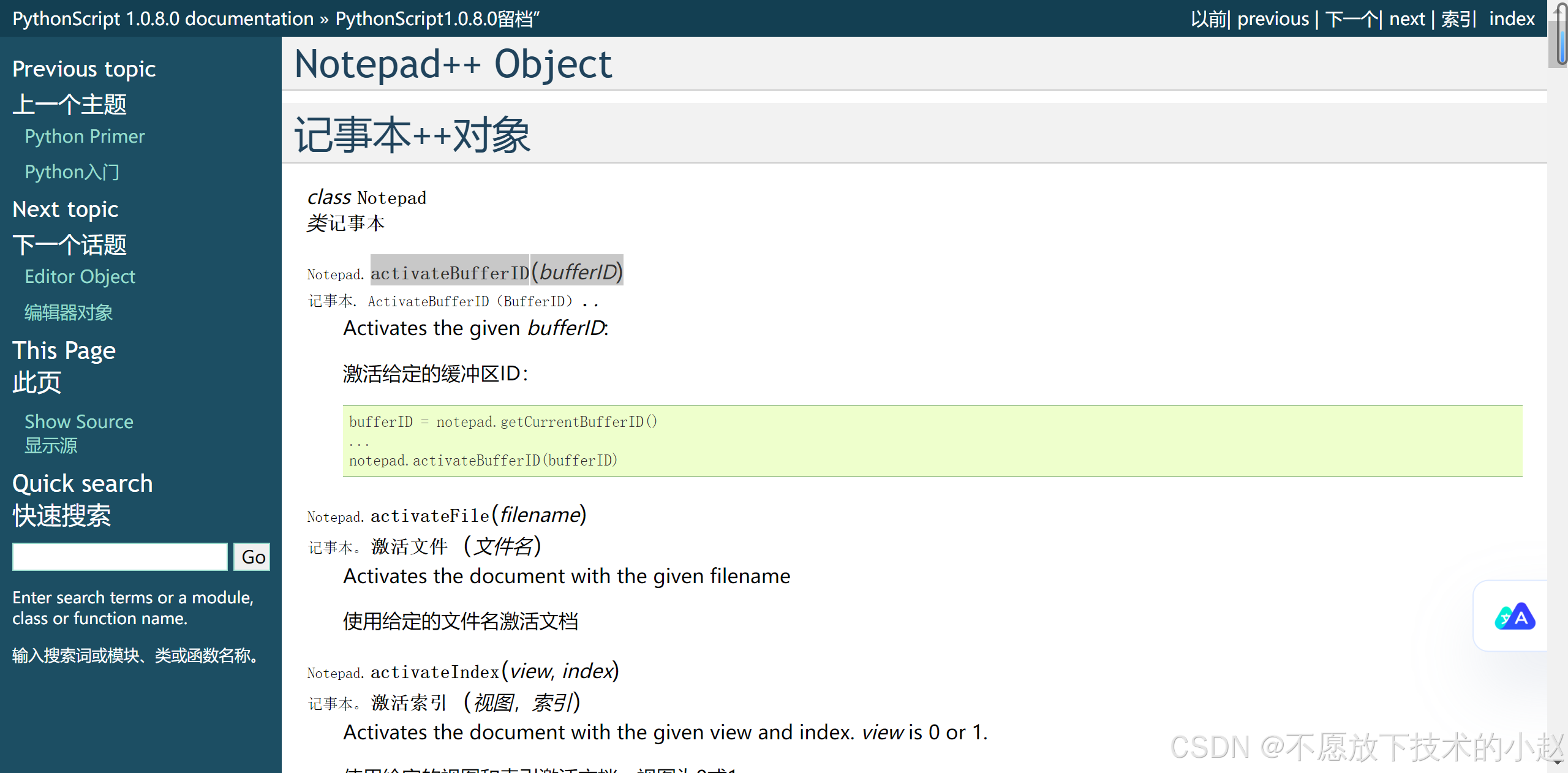
Notepad++ 学习(三)使用python插件编写脚本:实现跳转指定标签页(自主研发)
目录 一、先看成果二、安装Python Script插件三、配置Python脚本四、使用脚本跳转标签页方法一:通过菜单运行方法二:设置快捷键(推荐) 五、注意事项六、进阶使用 官网地址: https://notepad-plus-plus.org/Python Scri…...

Stable Diffusion 学习笔记02
模型下载网站: 1,LiblibAI-哩布哩布AI - 中国领先的AI创作平台 2,Civitai: The Home of Open-Source Generative AI 模型的安装: 将下载的sd模型放置在sd1.5的文件内即可,重启客户端可用。 外挂VAE模型:…...

python:pymysql概念、基本操作和注入问题讲解
python:pymysql分享目录 一、概念二、数据准备三、安装pymysql四、pymysql使用(一)使用步骤(二)查询操作(三)增(四)改(五)删 五、关于pymysql注入…...

Scala语言基础与函数式编程详解
Scala语言基础与函数式编程详解 本文系统梳理Scala语言基础、函数式编程核心、集合与迭代器、模式匹配、隐式机制、泛型与Spark实战,并对每个重要专业术语进行简明解释,配合实用记忆口诀与典型代码片段,助你高效学习和应用Scala。 目录 Scal…...

类的加载过程详解
类的加载过程详解 Java类的加载过程分为加载(Loading)、链接(Linking) 和 初始化(Initialization) 三个阶段。其中链接又分为验证(Verification)、准备(Preparation&…...
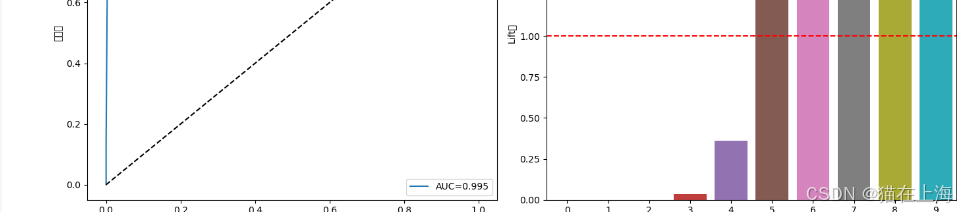
机器学习-人与机器生数据的区分模型测试 - 模型融合与检验
模型融合 # 先用普通Pipeline训练 from sklearn.pipeline import Pipeline#from sklearn2pmml.pipeline import PMMLPipeline train_pipe Pipeline([(scaler, StandardScaler()),(ensemble, VotingClassifier(estimators[(rf, RandomForestClassifier(n_estimators200, max_de…...
机器学习 day03
文章目录 前言一、特征降维1.特征选择2.主成分分析(PCA) 二、KNN算法三、模型的保存与加载 前言 通过今天的学习,我掌握了机器学习中的特征降维的概念以及用法,KNN算法的基本原理及用法,模型的保存和加载 一、特征降维…...

《社交应用动态表情:RN与Flutter实战解码》
React Native依托于JavaScript和React,为动态表情的实现开辟了一条独特的道路。其核心优势在于对原生模块的便捷调用,这为动态表情的展示和交互提供了强大支持。在社交应用中,当用户点击发送动态表情时,React Native能够迅速调用相…...
嵌入式软件--stm32 DAY 6 USART串口通讯(下)
1.寄存器轮询_收发字符串 通过寄存器轮询方式实现了收发单个字节之后,我们趁热打铁,争上游,进阶到字符串。字符串就是多个字符。很明显可以循环收发单个字节实现。 然后就是接收字符串。如果接受单个字符的函数放在while里,它也可…...

问题处理——在ROS2(humble)+Gazebo+rqt下,无法显示仿真无人机的相机图像
文章目录 前言一、问题展示二、解决方法:1.下载对应版本的PX42.下载对应版本的Gazebo3.启动 总结 前言 在ROS2的环境下,进行无人机仿真的过程中,有时需要调取无人机的相机图像信息,但是使用rqt,却发现相机图像无法显示…...
容器化与云原生)
69、微服务保姆教程(十二)容器化与云原生
容器化与云原生 在微服务架构中,容器化和云原生技术是将应用程序部署到生产环境的核心技术。通过容器化技术,可以将应用程序及其依赖项打包成一个容器镜像,确保在任何环境中都能一致运行。而云原生技术则通过自动化的容器编排系统(如 Kubernetes),实现应用的动态扩展、自…...
朱老师,3518e系列,第六季
第一节:概述。 首先是 将 他写好的 rtsp 源码上传,用于分析。 已经拷贝完。 第二节: h264 编码概念。 编解码 可以用cpu, 也可以用 bsp cpu 编解码的效果不好。做控制比较好。 h264 由 VCL, NAL 组成。 NAL 关心的是 压缩…...